
Multi-Omics Integration for the Design of Novel Therapies and the Identification of Novel Biomarkers

Abstract
:1. Introduction
2. Main Text
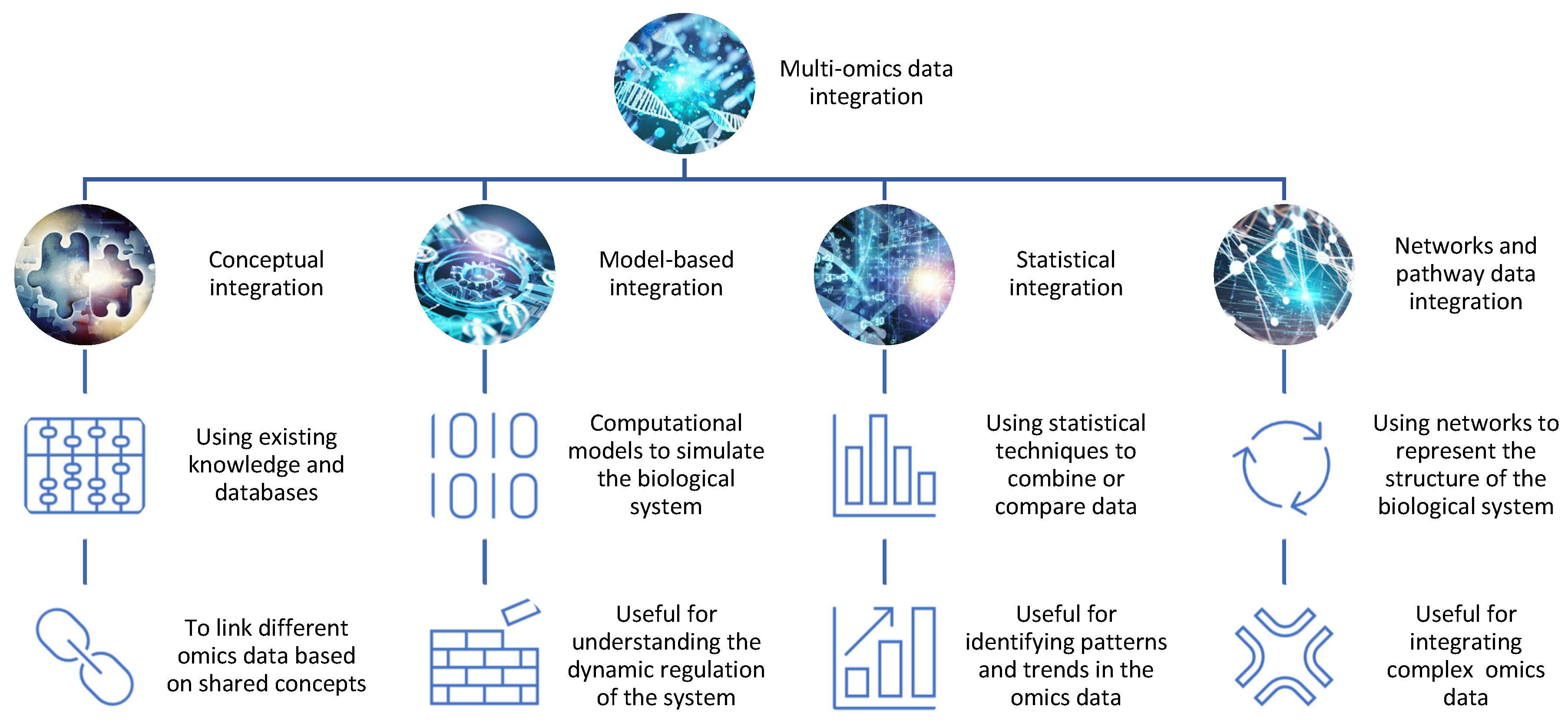
2.1. Different Approaches for Multi-Omics Data Integration
- −
- Conceptual integration: This method involves using existing knowledge and databases to link different omics data based on shared concepts or entities, such as genes, proteins, pathways, or diseases. For example, one can use gene ontology (GO) terms or pathway databases to annotate and compare different omics data sets and identify common or specific biological functions or processes [7]. This method is useful for generating hypotheses and exploring associations between different omics data, but it may not capture the complexity and dynamics of the biological system. Open-source pipelines such as STATegra [8] or OmicsON [9] have recently demonstrated an enhanced capacity of the framework to detect specific features overlapping between the compared omics sets;
- −
- Statistical integration: This method involves using statistical techniques to combine or compare different omics data based on quantitative measures, such as correlation, regression, clustering, or classification [10]. For example, one can use correlation analysis to identify co-expressed genes or proteins across different omics data sets or use regression analysis to model the relationship between gene expression and drug response [11]. This method is useful for identifying patterns and trends in the omics data, but it may not account for the causal or mechanistic relationships between the omics data;
- −
- Model-based integration: This method involves using mathematical or computational models to simulate or predict the behavior of the biological system based on different omics data [12]. For example, one can use network models to represent the interactions between genes and proteins in different omics datasets or use pharmacokinetic/pharmacodynamic (PK/PD) models to describe the absorption, distribution, metabolism, and excretion (ADME) of drugs in different tissues or organs [13]. This method is useful for understanding the dynamics and regulation of the biological system, but it may require a lot of prior knowledge and assumptions about the system parameters and structure;
- −
- Networks and pathway data integration: This method involves using networks or pathways to represent the structure and function of the biological system based on different omics data. Networks are graphical representations of the nodes (e.g., genes, proteins) and interactions in the system, while pathways are collections of related biological processes or events that occur in a specific order or context [14]. For example, one can use protein–protein interaction (PPI) networks to visualize the physical interactions between proteins in different omics data sets or use metabolic pathways to illustrate the biochemical reactions involved in drug metabolism [15]. This method is useful for integrating multiple types of omics data at different levels of granularity and complexity, but it may not capture the temporal or spatial aspects of the system.
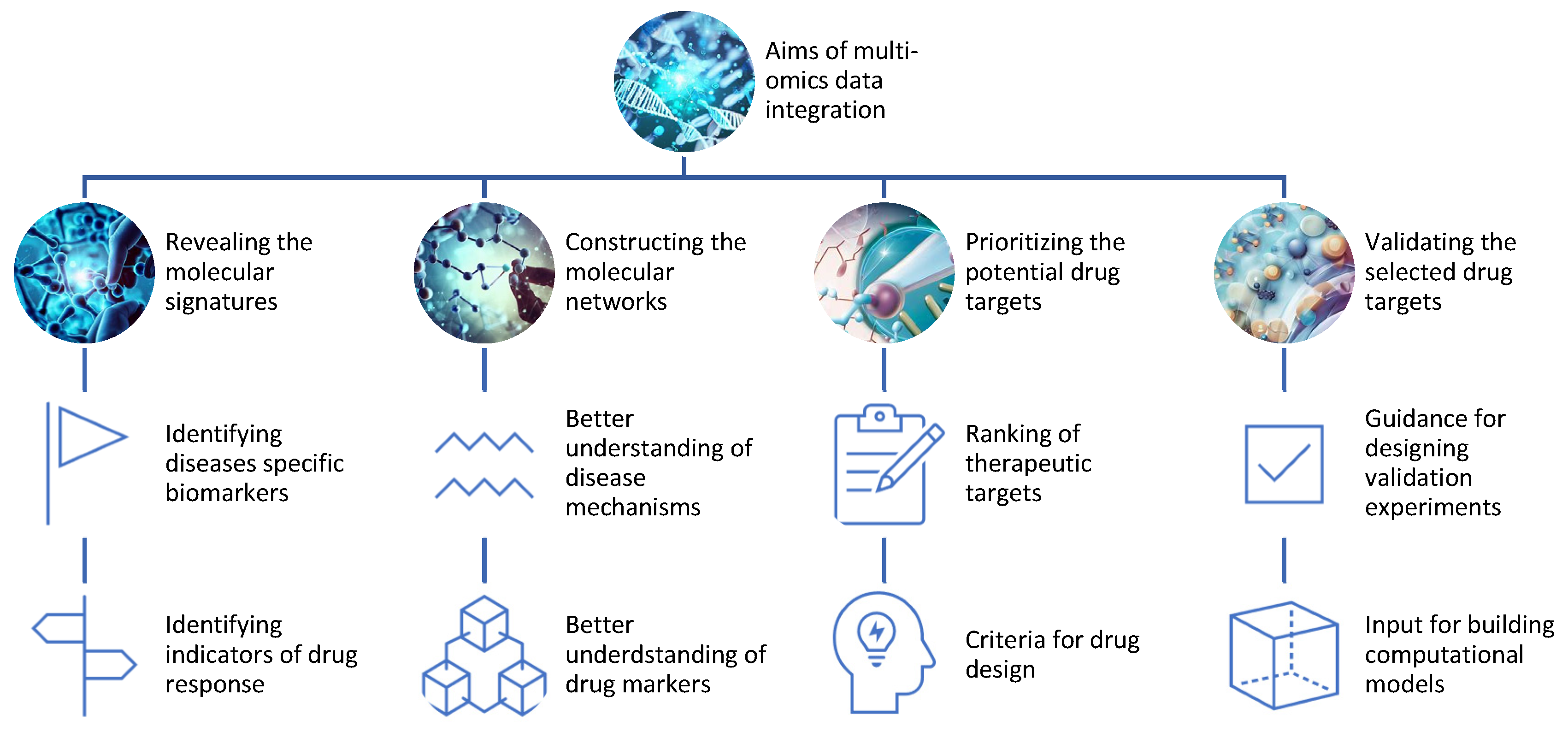
2.2. Aims of Multi-Omics Analyses
- −
- Revealing the molecular signatures or profiles of diseases and drug responses using omics data from different levels of biological molecules [16]. For example, multi-omics can identify the genes, proteins, metabolites, and epigenetic marks that are differentially expressed or regulated in diseased versus healthy samples or individuals, or in responsive versus non-responsive samples or individuals to a given drug;
- −
- Constructing the molecular networks or pathways of diseases and drug responses using omics data from different levels of biological molecules [17]. For example, multi-omics can infer the interactions or relationships among genes, proteins, metabolites, and epigenetic marks that are involved in disease mechanisms or drug mechanisms of action;
- −
- Prioritizing the potential drug targets based on their relevance or importance to diseases and drug responses using omics data from different levels of biological molecules [18]. For example, multi-omics can rank genes, proteins, metabolites, and epigenetic marks based on their differential expression or regulation, network centrality, functional annotation, disease association, drug association, or other criteria;
- −
- Validating the selected drug targets using experimental methods or computational models that can test the effects of modulating the drug targets on diseases and drug responses. For example, multi-omics can provide guidance for designing experiments such as knockdowns, overexpressions, mutations, inhibitors, activators, or combinations thereof for the drug targets [19]. Alternatively, multi-omics can provide input for building computational models such as PK/PD models, systems pharmacology models, or machine learning models that can simulate the effects of modulating the drug targets [20].
- −
- Characterizing the inter-individual variability of drug responses using omics data from different levels of biological molecules [21]. For example, multi-omics can identify the genetic variants (e.g., single nucleotide polymorphisms (SNPs), copy number variations (CNVs), insertions/deletions (indels)), gene expression levels (e.g., mRNA levels), protein expression levels (e.g., protein levels), metabolite levels, and epigenetic modifications (e.g., DNA methylation levels) that influence how different individuals respond to a given drug;
- −
- Classifying the subtypes or groups of individuals with similar drug responses using omics data from different levels of biological molecules [22]. For example, multi-omics can cluster individuals based on their molecular signatures or profiles of drug responses into responders versus non-responders, sensitive versus resistant, or toxic versus non-toxic groups;
- −
- Predicting the optimal drug responses for individual patients using omics data from different levels of biological molecules [23]. For example, multi-omics can use machine learning methods such as SVMs, random forests, or neural networks to build predictive models that can estimate the efficacy, safety, toxicity, adverse effects, resistance, sensitivity, dosage, and duration of drug responses.
- −
- A study used multi-omics data from post-mortem brain samples to clarify the roles of risk-factor genes in complex diseases such as autism spectrum disorder (ASD) and Parkinson’s disease. The study integrated genomic, transcriptomic, epigenomic, and proteomic data to identify gene expression changes, DNA methylation patterns, and protein-protein interactions associated with ASD and Parkinson’s disease [24]. The study also revealed novel molecular pathways and potential therapeutic targets for these diseases;
- −
- A study that explained how to use multi-omics data from microbial metagenomes to investigate the interactions between plants, animals, and their microbiomes [25]. Another study integrated genomic, transcriptomic, proteomic, and metabolomic data from different host tissues and microbial communities to understand how the microbiome influences the host physiology, metabolism, immunity, and behavior [26];
- −
- Another example of multi-omics studies in cancer research is a work where authors used multi-omics data from tumor-infiltrating immune cells to develop a deep learning framework for predicting survival and drug response in breast cancer patients. Genomic, transcriptomic, proteomic, and epigenomic data were successfully integrated to identify the molecular signatures and profiles of immune cells in the tumor microenvironment [27];
- −
- Another example is a research article that describes the use of multi-omics in studying the molecular mechanisms and therapeutic targets of meningioma, a type of benign brain tumor. The authors used multi-omics data from human meningioma samples and cell lines to identify the functional roles of two genes, TRAF7 and KLF4, that are frequently mutated in meningioma [28]. The article demonstrates how multi-omics can provide novel insights into the molecular basis of diseases and drug responses, identify new biomarkers and therapeutic targets, predict and optimize individualized treatments, and design and engineer novel biological systems.

{kind=link}
{kind=link}
| Title of the Article and Reference | Type of Data | Approach Used for Integration |
|---|---|---|
| An integrated multi-omics approach identifies epigenetic alterations associated with Alzheimer’s disease [24] | Transcriptomics, epigenomic, Chip-seq | GO analysis of genes, comparison to published data |
| Loss-of-function mutations in TRAF7 and KLF4 cooperatively activate RAS-like GTPase signaling and promote meningioma development [28] | Ubiquitome, proteome, interactome (ViroTrap) and transcriptome | Ingenuity Pathway analysis and network visualization using EnrichmentMap Cytoscape |
| Single-cell multi-omic integration compares and contrasts features of brain cell identity [29] | Single-cell RNA-seq and DNA methylation profiles | LIGER, an algorithm that delineates shared and dataset-specific features of cell identity |
| Multi-omics resolves a sharp disease-state shift between mild and moderate COVID-19 [30] | Proteome, single-cell Secretome (Isoplexis), Metabolome, single-cell RNA-seq | Cross-omic network analysis, and enrichment analysis using GSEA |
| Multi-omics delineation of cytokine-induced endothelial inflammatory states [31] | Secretome, proteome, phosphoproteome, transcriptome | Co-expression analysis was performed using the WGCNA, pathway analysis using clusterPofiler/WikiPathways |
| Multi-omics integration at single-cell resolution using bayesian networks: a case study in hepatocellular carcinoma [32] | Single-cell RNA-seq and copy number alterations | Bayesian networks |
| Spatial heterogeneity of infiltrating T cells in high-grade serous ovarian cancer revealed by multi-omics analysis [33] | Single-cell RNA-seq and whole genome sequencing, immunophenotyping (FACs), bulk RNA-seq analyses for immune cell infiltration | Gaussian Mixture Models |
| Computational integration of HSV-1 multi-omics data [34] | Ribosome profiling, RNA-seq, ATAC-seq | ContextMap2 which allows parallel mapping of RNA-seq reads against multiple genomes (host and microbial) |
| A “multi-omics” analysis of blood-brain barrier and synaptic dysfunction in APOE4 mice [35] | Single-nucleus RNA-sequencing, phosphoproteome proteome, interactome | Pathways analysis using FindMarkers, phosphorylated substrate to kinase network generation using Biogrid data |
| Multiomics signatures of type 1 diabetes with and without albuminuria [36] | Proteomics, lipidomics, metabolomics | Integration using MOFA, mapping using EggNog and KEGG databases |
2.3. Different Types of Proteomics Data That Can Be Used for Multi-Omics Analyses
3. Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
References
- Vahabi, N.; Michailidis, G. Unsupervised Multi-Omics Data Integration Methods: A Comprehensive Review. Front. Genet. 2022, 13, 854752. [Google Scholar] [CrossRef] [PubMed]
- Baietti, M.F.; Sewduth, R.N. Novel Therapeutic Approaches Targeting Post-Translational Modifications in Lung Cancer. Pharmaceutics 2023, 15, 206. [Google Scholar] [CrossRef] [PubMed]
- Beger, R.D.; Dunn, W.; Schmidt, M.A.; Gross, S.S.; Kirwan, J.A.; Cascante, M.; Brennan, L.; Wishart, D.S.; Oresic, M.; Hankemeier, T.; et al. For “Precision Medicine and Pharmacometabolomics Task Group”-Metabolomics Society Initiative. Metabolomics enables precision medicine: “A White Paper, Community Perspective”. Metabolomics 2016, 12, 149. [Google Scholar] [CrossRef] [PubMed]
- Athieniti, E.; Spyrou, G.M. A guide to multi-omics data collection and integration for translational medicine. Comput. Struct. Biotechnol. J. 2022, 21, 134–149. [Google Scholar] [CrossRef]
- Graw, S.; Chappell, K.; Washam, C.L.; Gies, A.; Bird, J.; Robeson, M.S., 2nd; Byrum, S.D. Multi-omics data integration considerations and study design for biological systems and disease. Mol. Omics 2021, 17, 170–185. [Google Scholar] [CrossRef] [PubMed]
- Paananen, J.; Fortino, V. An omics perspective on drug target discovery platforms. Brief. Bioinform. 2020, 21, 1937–1953. [Google Scholar] [CrossRef]
- Adossa, N.; Khan, S.; Rytkönen, K.T.; Elo, L.L. Computational strategies for single-cell multi-omics integration. Comput. Struct. Biotechnol. J. 2021, 19, 2588–2596. [Google Scholar] [CrossRef]
- Planell, N.; Lagani, V.; Sebastian-Leon, P.; van der Kloet, F.; Ewing, E.; Karathanasis, N.; Urdangarin, A.; Arozarena, I.; Jagodic, M.; Tsamardinos, I.; et al. STATegra: Multi-Omics Data Integration—A Conceptual Scheme with a Bioinformatics Pipeline. Front. Genet. 2021, 12, 620453. [Google Scholar] [CrossRef]
- Turek, C.; Wróbel, S.; Piwowar, M. OmicsON—Integration of omics data with molecular networks and statistical procedures. PLoS ONE 2020, 15, e0235398. [Google Scholar] [CrossRef]
- Gu, Z.; El Bouhaddani, S.; Pei, J.; Houwing-Duistermaat, J.; Uh, H.W. Statistical integration of two omics datasets using GO2PLS. BMC Bioinform. 2021, 22, 131. [Google Scholar] [CrossRef]
- Argelaguet, R.; Velten, B.; Arnol, D.; Dietrich, S.; Zenz, T.; Marioni, J.C.; Buettner, F.; Huber, W.; Stegle, O. Multi-Omics Factor Analysis-a framework for unsupervised integration of multi-omics data sets. Mol. Syst. Biol. 2018, 14, e8124. [Google Scholar] [CrossRef]
- ElKarami, B.; Alkhateeb, A.; Qattous, H.; Alshomali, L.; Shahrrava, B. Multi-omics Data Integration Model Based on UMAP Embedding and Convolutional Neural Network. Cancer Inform. 2022, 21, 11769351221124205. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Ma, J.; Leng, L.; Han, M.; Li, M.; He, F.; Zhu, Y. MoGCN: A Multi-Omics Integration Method Based on Graph Convolutional Network for Cancer Subtype Analysis. Front. Genet. 2022, 13, 806842. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.Y.; Mei, X.Y. Prediction of drug sensitivity based on multi-omics data using deep learning and similarity network fusion approaches. Front. Bioeng. Biotechnol. 2023, 11, 1156372. [Google Scholar] [CrossRef] [PubMed]
- Zhou, G.; Li, S.; Xia, J. Network-Based Approaches for Multi-omics Integration. Methods Mol. Biol. 2020, 2104, 469–487. [Google Scholar]
- Kreitmaier, P.; Katsoula, G.; Zeggini, E. Insights from multi-omics integration in complex disease primary tissues. Trends Genet. 2023, 39, 46–58. [Google Scholar] [CrossRef]
- Doran, S.; Arif, M.; Lam, S.; Bayraktar, A.; Turkez, H.; Uhlen, M.; Boren, J.; Mardinoglu, A. Multi-omics approaches for revealing the complexity of cardiovascular disease. Brief Bioinform. 2021, 22, bbab061. [Google Scholar] [CrossRef]
- Doherty, L.M.; Mills, C.E.; Boswell, S.A.; Liu, X.; Hoyt, C.T.; Gyori, B.; Buhrlage, S.J.; Sorger, P.K. Integrating multi-omics data reveals function and therapeutic potential of deubiquitinating enzymes. eLife 2022, 11, e72879. [Google Scholar] [CrossRef]
- Li, K.; Du, Y.; Li, L.; Wei, D.Q. Bioinformatics Approaches for Anti-cancer Drug Discovery. Curr. Drug Targets 2020, 21, 3–17. [Google Scholar] [CrossRef]
- Béal, J.; Pantolini, L.; Noël, V.; Barillot, E.; Calzone, L. Personalized logical models to investigate cancer response to BRAF treatments in melanomas and colorectal cancers. PLoS Comput. Biol. 2021, 17, e1007900. [Google Scholar] [CrossRef]
- Allesøe, R.L.; Lundgaard, A.T.; Medina, R.H.; Aguayo-Orozco, A.; Johansen, J.; Nissen, J.N.; Brorsson, C.; Mazzoni, G.; Niu, L.; Biel, J.H.; et al. Discovery of drug-omics associations in type 2 diabetes with generative deep-learning models. Nat. Biotechnol. 2023, 41, 399–408. [Google Scholar] [CrossRef] [PubMed]
- Gallego-Paüls, M.; Hernández-Ferrer, C.; Bustamante, M.; Basagaña, X.; Barrera-Gómez, J.; Lau, C.-H.E.; Siskos, A.P.; Vives-Usano, M.; Ruiz-Arenas, C.; Wright, J.; et al. Variability of multi-omics profiles in a population-based child cohort. BMC Med. 2021, 19, 166. [Google Scholar] [CrossRef] [PubMed]
- Sammut, S.J.; Crispin-Ortuzar, M.; Chin, S.F.; Provenzano, E.; Bardwell, H.A.; Ma, W.; Cope, W.; Dariush, A.; Dawson, S.-J.; Abraham, J.E.; et al. Multi-omic machine learning predictor of breast cancer therapy response. Nature 2022, 601, 623–629. [Google Scholar] [CrossRef] [PubMed]
- Nativio, R.; Lan, Y.; Donahue, G.; Sidoli, S.; Berson, A.; Srinivasan, A.R.; Shcherbakova, O.; Amlie-Wolf, A.; Nie, J.; Cui, X.; et al. An integrated multi-omics approach identifies epigenetic alterations associated with Alzheimer’s disease. Nat. Genet. 2020, 52, 1024–1035. [Google Scholar] [CrossRef] [PubMed]
- Heintz-Buschart, A.; Westerhuis, J.A. A beginner’s guide to integrating multi-omics data from microbial communities. Biochemist 2022, 44, 23–29. [Google Scholar] [CrossRef]
- Gutleben, J.; Chaib De Mares, M.; Van Elsas, J.D.; Smidt, H.; Overmann, J.; Sipkema, D. The multi-omics promise in context: From sequence to microbial isolate. Crit. Rev. Microbiol. 2018, 44, 212–229. [Google Scholar] [CrossRef]
- Finotello, F.; Eduati, F. Multi-Omics Profiling of the Tumor Microenvironment: Paving the Way to Precision Immuno-Oncology. Front. Oncol. 2018, 8, 430. [Google Scholar] [CrossRef]
- Najm, P.; Zhao, P.; Steklov, M.; Sewduth, R.N.; Baietti, M.F.; Pandolfi, S.; Criem, N.; Lechat, B.; Maia, T.M.; Van Haver, D.; et al. Loss-of-Function Mutations in TRAF7 and KLF4 Cooperatively Activate RAS-Like GTPase Signaling and Promote Meningioma Development. Cancer Res. 2021, 81, 4218–4229. [Google Scholar] [CrossRef]
- Welch, J.D.; Kozareva, V.; Ferreira, A.; Vanderburg, C.; Martin, C.; Macosko, E.Z. Single-Cell Multi-omic Integration Compares and Contrasts Features of Brain Cell Identity. Cell 2019, 177, 1873–1887.e17. [Google Scholar] [CrossRef]
- Su, Y.; Chen, D.; Yuan, D.; Lausted, C.; Choi, J.; Dai, C.L.; Voillet, V.; Duvvuri, V.R.; Scherler, K.; Troisch, P.; et al. Multi-Omics Resolves a Sharp Disease-State Shift between Mild and Moderate, COVID-19. Cell 2020, 183, 1479–1495.e20. [Google Scholar] [CrossRef]
- Groten, S.A.; Smit, E.R.; Janssen, E.F.J.; van den Eshof, B.L.; van Alphen, F.P.J.; van der Zwaan, C.; Meijer, A.B.; Hoogendijk, A.J.; van den Biggelaar, M. Multi-omics delineation of cytokine-induced endothelial inflammatory states. Commun. Biol. 2023, 6, 525. [Google Scholar] [CrossRef] [PubMed]
- Jihad, M.; Yet, İ. Multiomics Integration at Single-Cell Resolution Using Bayesian Networks: A Case Study in Hepatocellular Carcinoma. OMICS 2023, 27, 24–33. [Google Scholar] [CrossRef] [PubMed]
- Yang, B.; Li, X.; Zhang, W.; Fan, J.; Zhou, Y.; Li, W.; Yin, J.; Yang, X.; Guo, E.; Li, X.; et al. Spatial heterogeneity of infiltrating T cells in high-grade serous ovarian cancer revealed by multi-omics analysis. Cell Rep. Med. 2022, 3, 100856. [Google Scholar] [CrossRef]
- Friedel, C.C. Computational Integration of HSV-1 Multi-omics Data. Methods Mol. Biol. 2023, 2610, 31–48. [Google Scholar] [PubMed]
- Barisano, G.; Kisler, K.; Wilkinson, B.; Nikolakopoulou, A.M.; Sagare, A.P.; Wang, Y.; Gilliam, W.; Huuskonen, M.T.; Hung, S.-T.; Ichida, J.K.; et al. A “multi-omics” analysis of blood-brain barrier and synaptic dysfunction in APOE4 mice. J. Exp. Med. 2022, 219, e20221137. [Google Scholar] [CrossRef]
- Clos-Garcia, M.; Ahluwalia, T.S.; Winther, S.A.; Henriksen, P.; Ali, M.; Fan, Y.; Stankevic, E.; Lyu, L.; Vogt, J.K.; Hansen, T.; et al. Multiomics signatures of type 1 diabetes with and without albuminuria. Front. Endocrinol. 2022, 13, 1015557. [Google Scholar] [CrossRef]
- Rao, P.K.; Li, Q. Protein turnover in mycobacterial proteomics. Molecules 2009, 14, 3237–3258. [Google Scholar] [CrossRef]
- Sewduth, R.N.; Baietti, M.F.; Sablina, A.A. Cracking the Monoubiquitin Code of Genetic Diseases. Int. J. Mol. Sci. 2020, 21, 3036. [Google Scholar] [CrossRef]
- Bludau, I.; Aebersold, R. Proteomic and interactomic insights into the molecular basis of cell functional diversity. Nat. Rev. Mol. Cell Biol. 2020, 21, 327–340. [Google Scholar] [CrossRef]
- Gerritsen, J.S.; White, F.M. Phosphoproteomics: A valuable tool for uncovering molecular signaling in cancer cells. Expert Rev. Proteomics 2021, 18, 661–674. [Google Scholar] [CrossRef]
- Tate, J.G.; Bamford, S.; Jubb, H.C.; Sondka, Z.; Beare, D.M.; Bindal, N.; Boutselakis, H.; Cole, C.G.; Creatore, C.; Dawson, E.; et al. COSMIC: The Catalogue of Somatic Mutations in Cancer. Nucleic Acids Res. 2019, 47, D941–D947. [Google Scholar] [CrossRef]
- Blum, A.; Wang, P.; Zenklusen, J.C. SnapShot: TCGA-Analyzed Tumors. Cell 2018, 173, 530. [Google Scholar] [CrossRef] [PubMed]
- Vasaikar, S.V.; Straub, P.; Wang, J.; Zhang, B. LinkedOmics: Analyzing multi-omics data within and across 32 cancer types. Nucleic Acids Res. 2018, 46, D956–D963. [Google Scholar] [CrossRef] [PubMed]
- Kwon, Y.W.; Jo, H.S.; Bae, S.; Seo, Y.; Song, P.; Song, M.; Yoon, J.H. Application of Proteomics in Cancer: Recent Trends and Approaches for Biomarkers Discovery. Front. Med. 2021, 8, 747333. [Google Scholar] [CrossRef] [PubMed]
- Savage, S.R.; Zhang, B. Using phosphoproteomics data to understand cellular signaling: A comprehensive guide to bioinformatics resources. Clin. Proteom. 2020, 17, 27. [Google Scholar] [CrossRef]
- Das, T.; Andrieux, G.; Ahmed, M.; Chakraborty, S. Integration of Online Omics-Data Resources for Cancer Research. Front. Genet. 2020, 11, 578345. [Google Scholar] [CrossRef]
- Swatek, K.; Komander, D. Ubiquitin modifications. Cell Res. 2016, 26, 399–422. [Google Scholar] [CrossRef] [PubMed]
- Sewduth, R.N.; Jaspard-Vinassa, B.; Peghaire, C.; Guillabert, A.; Franzl, N.; Larrieu-Lahargue, F.; Moreau, C.; Fruttiger, M.; Dufourcq, P.; Couffinhal, T.; et al. The ubiquitin ligase PDZRN3 is required for vascular morphogenesis through Wnt/planar cell polarity signalling. Nat. Commun. 2014, 5, 4832. [Google Scholar] [CrossRef]
- Du, T.; Song, Y.; Ray, A.; Wan, X.; Yao, Y.; Samur, M.K.; Shen, C.; Penailillo, J.; Sewastianik, T.; Tai, Y.T.; et al. Ubiquitin receptor PSMD4/Rpn10 is a novel therapeutic target in multiple myeloma. Blood 2023, 141, 2599–2614. [Google Scholar] [CrossRef]
- Buneeva, O.; Medvedev, A. Atypical Ubiquitination and Parkinson’s Disease. Int. J. Mol. Sci. 2022, 23, 3705. [Google Scholar] [CrossRef]
- Schmid, A.W.; Fauvet, B.; Moniatte, M.; Lashuel, H.A. Alpha-synuclein post-translational modifications as potential biomarkers for Parkinson disease and other synucleinopathies. Mol. Cell Proteomics 2013, 12, 3543–3558. [Google Scholar] [CrossRef]
- Sewduth, R.N.; Pandolfi, S.; Steklov, M.; Sheryazdanova, A.; Zhao, P.; Criem, N.; Baietti, M.F.; Lechat, B.; Quarck, R.; Impens, F.; et al. The Noonan Syndrome Gene Lztr1 Controls Cardiovascular Function by Regulating Vesicular Trafficking. Circ. Res. 2020, 126, 1379–1393. [Google Scholar] [CrossRef] [PubMed]
- Shajahan, A.; Heiss, C.; Ishihara, M.; Azadi, P. Glycomic and glycoproteomic analysis of glycoproteins—A tutorial. Anal. Bioanal. Chem. 2017, 409, 4483–4505. [Google Scholar] [CrossRef] [PubMed]
- Van Scherpenzeel, M.; Willems, E.; Lefeber, D.J. Clinical diagnostics and therapy monitoring in the congenital disorders of glycosylation. Glycoconj. J. 2016, 33, 345–358. [Google Scholar] [CrossRef]
- Guo, J.; Chai, X.; Mei, Y.; Du, J.; Du, H.; Shi, H.; Zhu, J.-K.; Zhang, H. Acetylproteomics analyses reveal critical features of lysine-ε-acetylation in Arabidopsis and a role of 14-3-3 protein acetylation in alkaline response. Stress Biol. 2022, 2, 1. [Google Scholar] [CrossRef] [PubMed]
- Pei, J.; Harakalova, M.; Treibel, T.A.; Lumbers, R.T.; Boukens, B.J.; Efimov, I.R.; van Dinter, J.T.; González, A.; López, B.; El Azzouzi, H.; et al. H3K27ac acetylome signatures reveal the epigenomic reorganization in remodeled non-failing human hearts. Clin. Epigenetics 2020, 12, 106. [Google Scholar] [CrossRef] [PubMed]
- Whitson, J.A.; Johnson, R.; Wang, L.; Bammler, T.K.; Imai, S.-I.; Zhang, H.; Fredrickson, J.; Latorre-Esteves, E.; Bitto, A.; MacCoss, M.J.; et al. Age-related disruption of the proteome and acetylome in mouse hearts is associated with loss of function and attenuated by elamipretide (SS-31) and nicotinamide mononucleotide (NMN) treatment. GeroScience 2022, 44, 1621–1639. [Google Scholar] [CrossRef] [PubMed]
- Menche, J.; Sharma, A.; Kitsak, M.; Ghiassian, S.D.; Vidal, M.; Loscalzo, J.; Barabási, A.L. Disease networks. Uncovering disease-disease relationships through the incomplete interactome. Science 2015, 347, 1257601. [Google Scholar] [CrossRef]
- Tracy, T.E.; Madero-Pérez, J.; Swaney, D.L.; Chang, T.S.; Moritz, M.; Konrad, C.; Ward, M.E.; Stevenson, E.; Hüttenhain, R.; Kauwe, G.; et al. Tau interactome maps synaptic and mitochondrial processes associated with neurodegeneration. Cell 2022, 185, 712–728.e14. [Google Scholar] [CrossRef]
- Sewduth, R.N.; Kovacic, H.; Jaspard-Vinassa, B.; Jecko, V.; Wavasseur, T.; Fritsch, N.; Pernot, M.; Jeaningros, S.; Roux, E.; Dufourcq, P.; et al. PDZRN3 destabilizes endothelial cell-cell junctions through a PKCζ-containing polarity complex to increase vascular permeability. Sci. Signal. 2017, 10, eaag3209. [Google Scholar] [CrossRef]
- Sidhaye, J.; Trepte, P.; Sepke, N.; Novatchkova, M.; Schutzbier, M.; Dürnberger, G.; MechtlerJürgen, G.; Knoblich, A. Integrated transcriptome and proteome analysis reveals posttranscriptional regulation of ribosomal genes in human brain organoids. eLife 2023, 12, e85135. [Google Scholar] [CrossRef] [PubMed]
- Schwartz, G.W.; Petrovic, J.; Zhou, Y.; Faryabi, R.B. Differential Integration of Transcriptome and Proteome Identifies Pan-Cancer Prognostic Biomarkers. Front. Genet. 2018, 9, 205. [Google Scholar] [CrossRef] [PubMed]
- Riku, L.; Sampsa, H. CNAmet: An R package for integrating copy number, methylation and expression data. Bioinformatics 2011, 11, 887–888. [Google Scholar]
- Baietti, M.F.; Zhao, P.; Crowther, J.; Sewduth, R.N.; De Troyer, L.; Debiec-Rychter, M.; Sablina, A.A. Loss of 9p21 Regulatory Hub Promotes Kidney Cancer Progression by Upregulating, H.O.XB13. Mol. Cancer Res. 2021, 19, 979–990. [Google Scholar] [CrossRef] [PubMed]
- Shave, S.; Dawson, J.C.; Athar, A.M.; Nguyen, C.Q.; Kasprowicz, R.; Carragher, N.O. Phenonaut: Multiomics data integration for phenotypic space exploration. Bioinformatics 2023, 39, btad143. [Google Scholar] [CrossRef] [PubMed]
- Subramanian, I.; Verma, S.; Kumar, S.; Jere, A.; Anamika, K. Multi-omics Data Integration, Interpretation, and Its Application. Bioinform. Biol. Insights 2020, 14, 1177932219899051. [Google Scholar] [CrossRef]
- Ningh, K. Methodologies of Multi-Omics Data Integration and Data Mining, Translational Bioinformatics; Springer: Berlin/Heidelberg, Germany, 2023; Volume 19. [Google Scholar]


| Cancer Type | Genome [41] | Transcriptome [42] | Methylome | Proteome [43] | Other CPTAC Data [43] |
|---|---|---|---|---|---|
| Acute Myeloid Leukemia | COSMIC | TCGA | TCGA | - | |
| Adrenocortical Carcinoma | COSMIC | TCGA | TCGA | - | |
| Bladder Carcinoma | COSMIC | TCGA | - | - | |
| Breast Carcinoma | COSMIC | TCGA | TCGA | CPTAC | Acetylome |
| Cervical Carcinoma | COSMIC | TCGA | TCGA | - | |
| Cholangiocarcinoma | COSMIC | TCGA | - | - | |
| Colorectal Adenocarcinoma | COSMIC | TCGA | - | CPTAC | |
| Esophageal Carcinoma | COSMIC | TCGA | - | - | |
| Gastric Adenocarcinoma | COSMIC | TCGA | - | - | |
| Glioblastoma | COSMIC | TCGA | - | CPTAC | Acetylome, Phosphoproteome, Proteome |
| Head and Neck Squamous Cell Carcinoma | COSMIC | TCGA | - | CPTAC | Phosphoproteome, Proteome |
| Hepatocellular Carcinoma | COSMIC | TCGA | - | - | Phosphoproteome, Proteome |
| Chromophobe Renal Cell Carcinoma | COSMIC | TCGA | - | - | |
| Clear Cell Renal Cell Carcinoma | COSMIC | TCGA | TCGA | - | |
| Papillary Renal Cell Carcinoma | COSMIC | TCGA | - | - | |
| Lung Adenocarcinoma | COSMIC | TCGA | TCGA | CPTAC | Phosphoproteome, Acetylome |
| Lung Squamous Cell Carcinoma | COSMIC | TCGA | TCGA | CPTAC | Ubiquitinome, Phosphoproteome |
| Mesothelioma | COSMIC | TCGA | - | - | |
| Ovarian Serous Adenocarcinoma | COSMIC | TCGA | TCGA | CPTAC | Glycoproteome, Phosphoproteome, Proteome |
| Pancreatic Ductal Adenocarcinoma | COSMIC | TCGA | - | CPTAC | |
| Paraganglioma and Pheochromocytoma | COSMIC | TCGA | - | - | |
| Prostate Adenocarcinoma | COSMIC | TCGA | - | - | |
| Sarcoma | COSMIC | TCGA | - | - | |
| Skin Cutaneous Melanoma | COSMIC | TCGA | - | - | |
| Testicular Germ Cell Cancer | COSMIC | TCGA | - | - | |
| Thymoma | COSMIC | TCGA | - | - | |
| Thyroid Papillary Carcinoma | COSMIC | TCGA | - | - | |
| Uterine Carcinosarcoma | COSMIC | TCGA | - | - | |
| Uterine Endo-metrioid Carcinoma | COSMIC | TCGA | TCGA | - | - |
| Uveal Melanoma | COSMIC | TCGA |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ivanisevic, T.; Sewduth, R.N. Multi-Omics Integration for the Design of Novel Therapies and the Identification of Novel Biomarkers. Proteomes 2023, 11, 34. https://doi.org/10.3390/proteomes11040034
Ivanisevic T, Sewduth RN. Multi-Omics Integration for the Design of Novel Therapies and the Identification of Novel Biomarkers. Proteomes. 2023; 11(4):34. https://doi.org/10.3390/proteomes11040034
Chicago/Turabian StyleIvanisevic, Tonci, and Raj N. Sewduth. 2023. "Multi-Omics Integration for the Design of Novel Therapies and the Identification of Novel Biomarkers" Proteomes 11, no. 4: 34. https://doi.org/10.3390/proteomes11040034