


A Flexible Code Review Framework for Combining Defect Detection and Review Comments
 , ,
, ,
Abstract
:1. Introduction
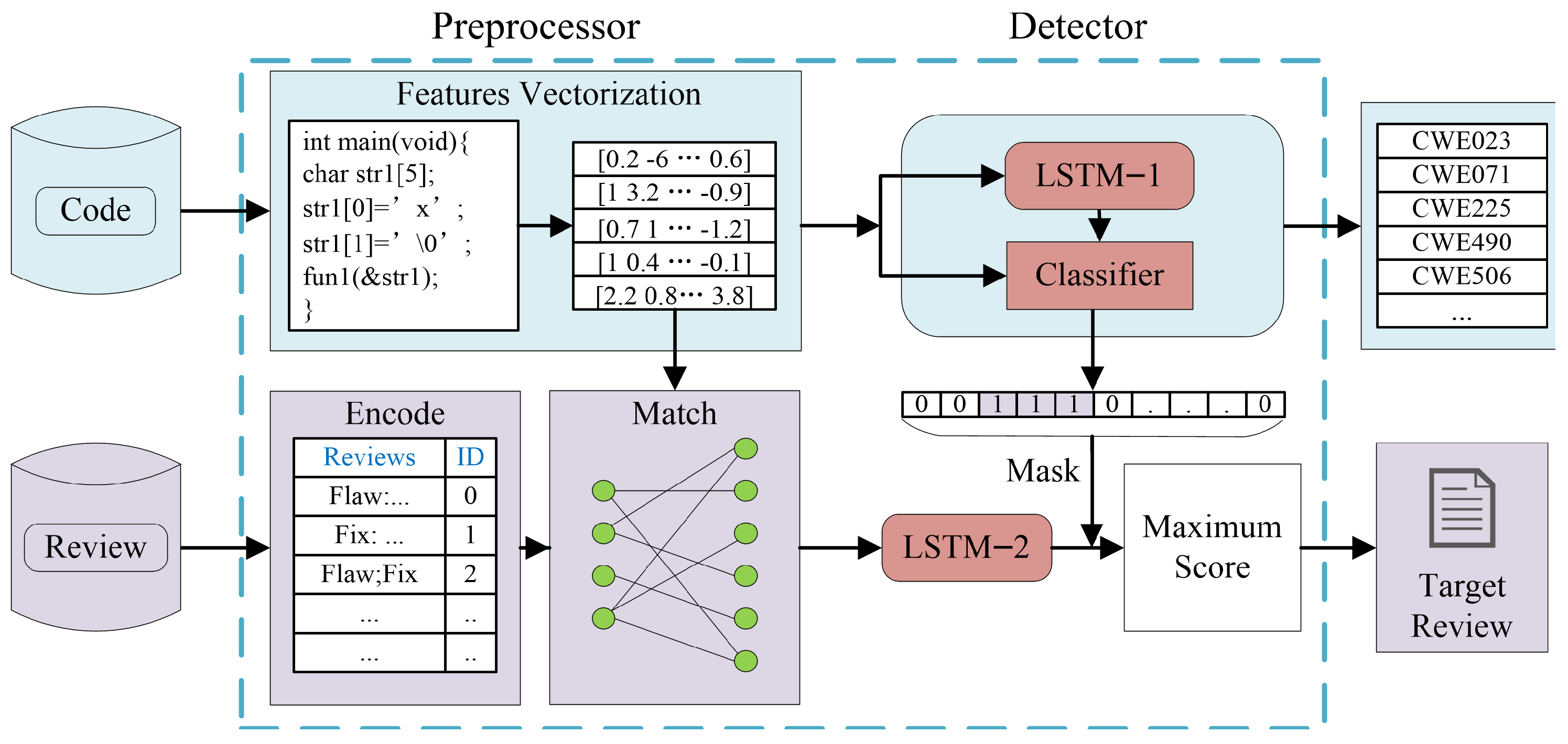
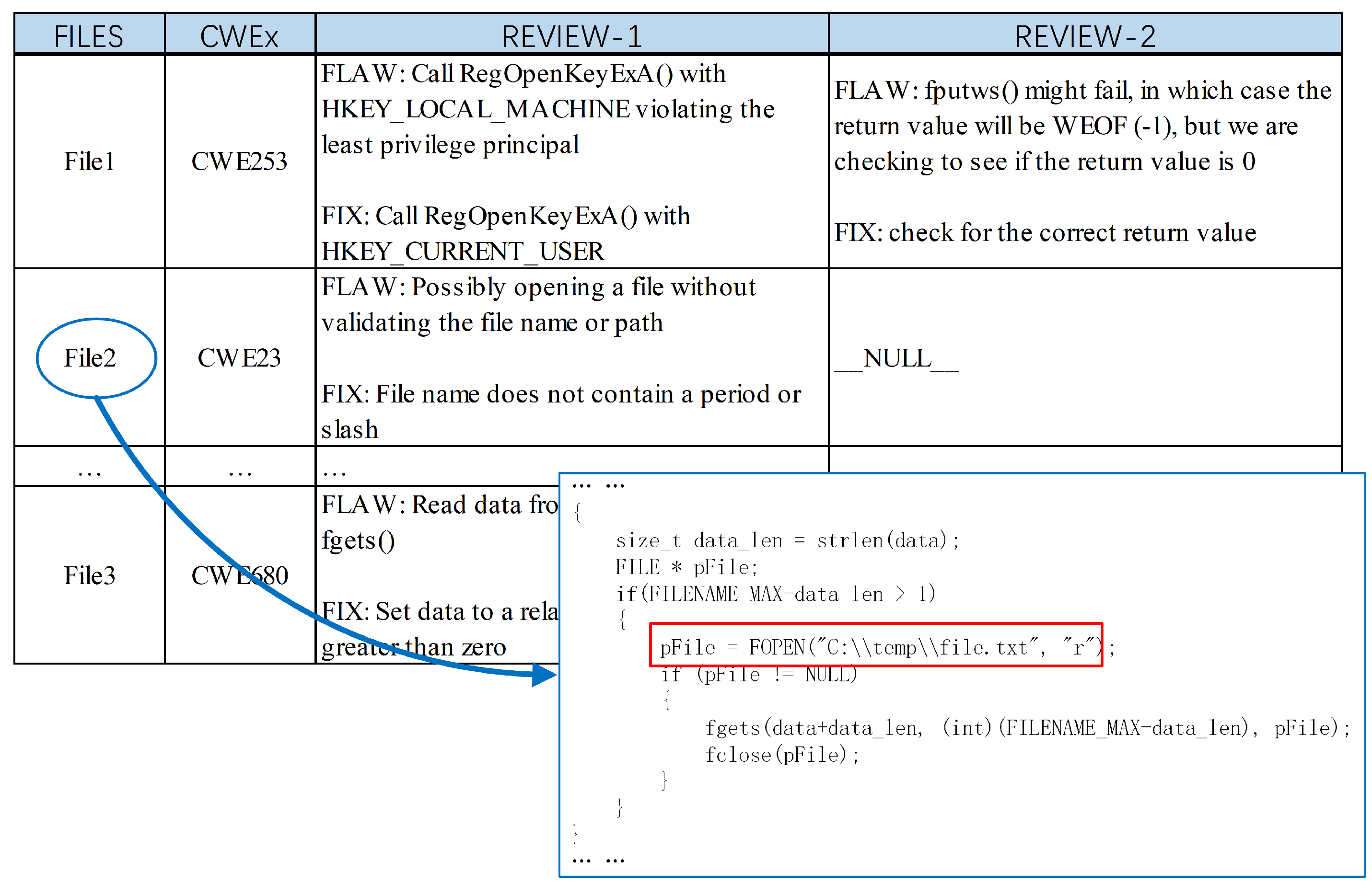
- We propose a high-precision and flexible framework, Deep Reviewer. For the first time, the framework associates can detect defect types with corresponding pre-edited review comments, which allows reviewers and programmers to easily make corrections to detected defects, thereby improving the efficiency of the code review process.
- In the preprocessor part of Deep Reviewer, we propose a code-slicing method called D2U flow. It extracts the life cycle of a variable that is complete and free of running conflicts from Definition-to-Usage. D2U flow avoids the problems caused by different branch statements appearing in the same slice. At the cost of consuming more offline computational resources, shorter slices are obtained, resulting in more accurate defect localization results. In the detector part, we designed a depth model called twin LSTM. It can correlate two kinds of outputs, i.e., code defect types and review comments.
- We evaluate the performance on a large-scale database SARD. We compare the proposed method with state-of-the-art approaches. The results demonstrate the apparent advantages of the proposed method over previous work.
2. Related Work
3. Preprocessor
3.1. D2U Flow
3.1.1. Basic Ideas
3.1.2. Code Slicing Method
| Algorithm 1 D2U flow. |
| Input: source code C; |
Output: slice vector S
|
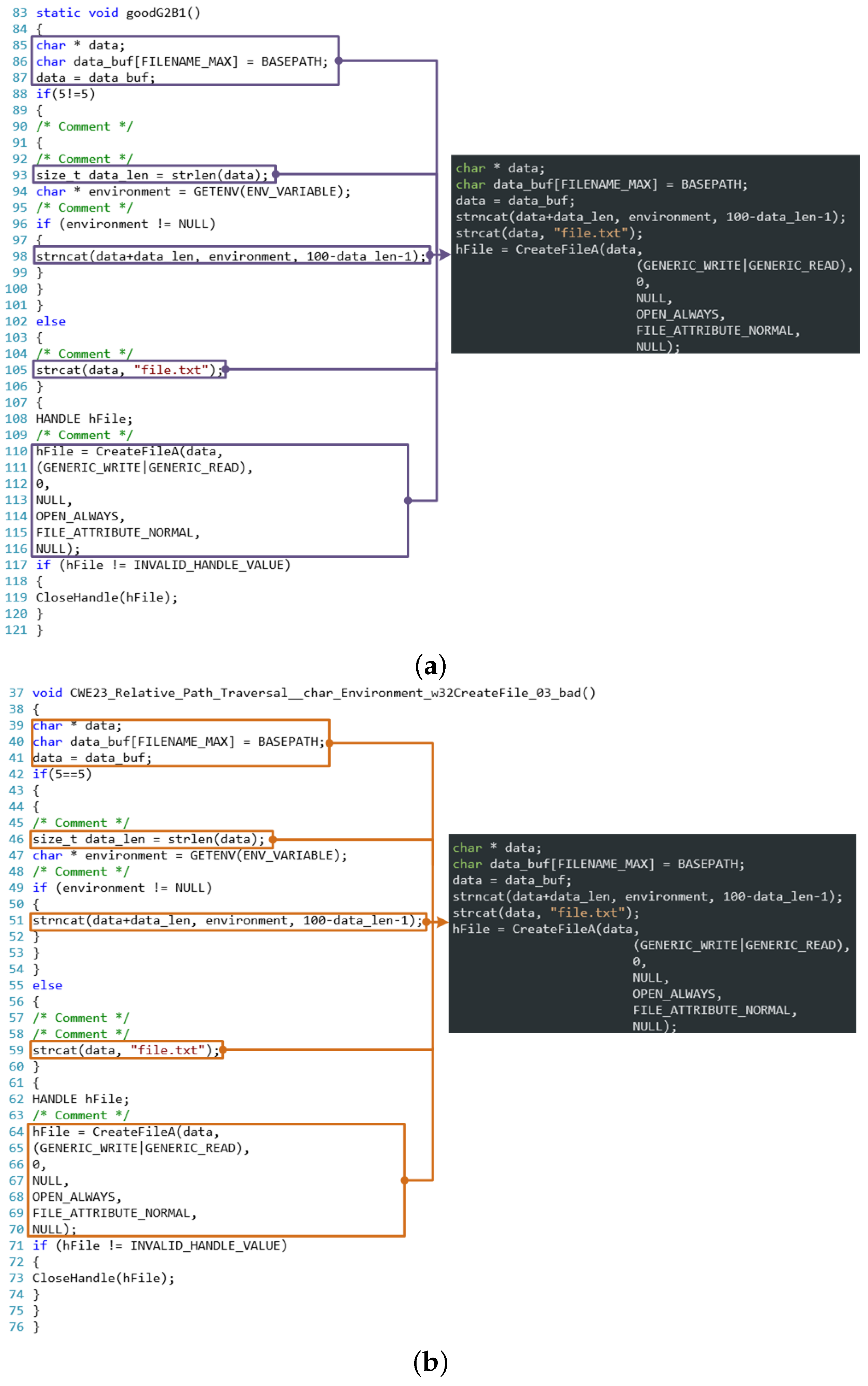
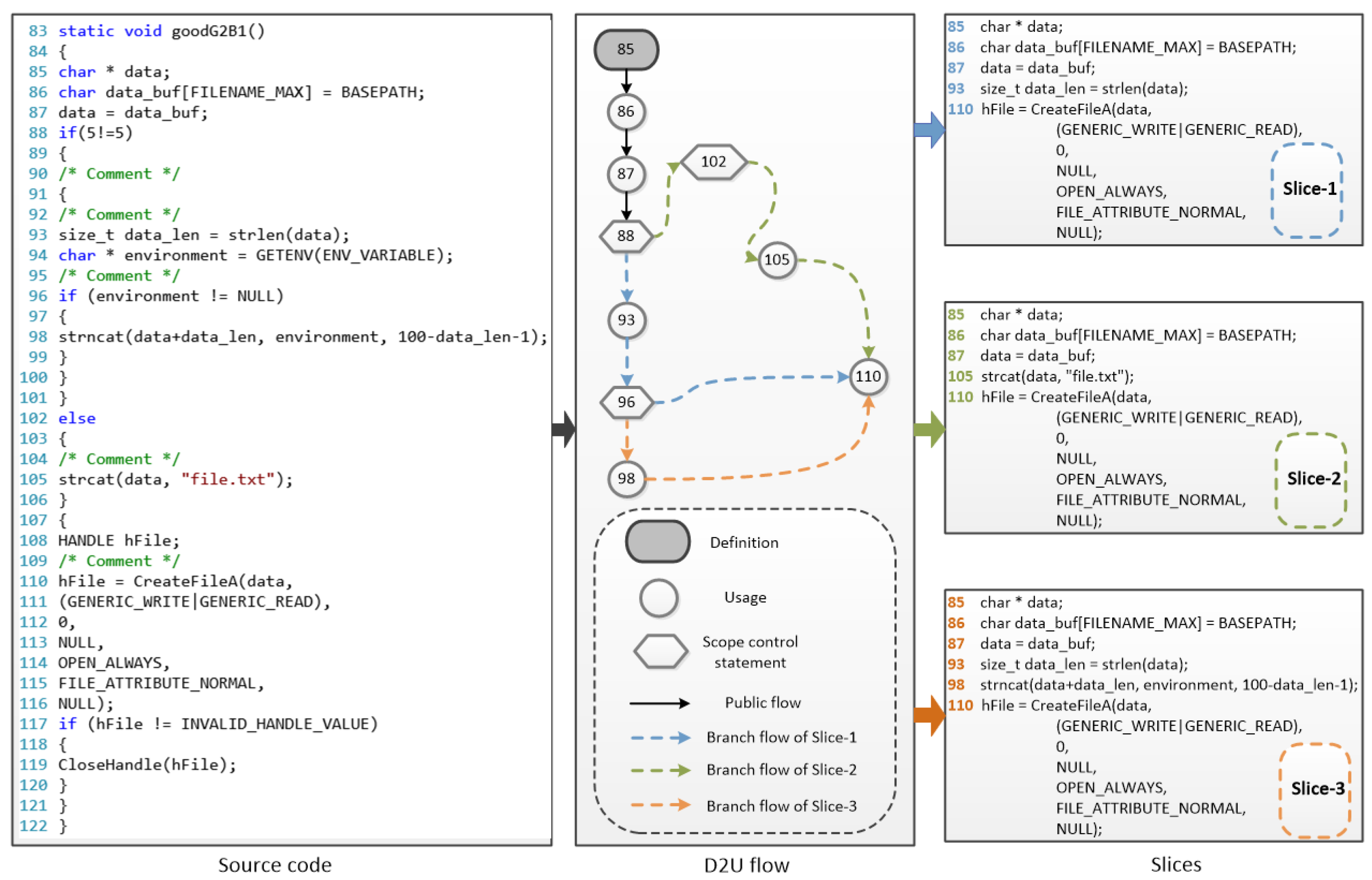
- Step I.1: Find the definition of char * data in line 85, and pick its usages in lines 86 and 87 as public usages. After this step, there is a candidate slice .
- Step I.2: Obtain the branch usage in line 93, contained in a local scope with the keyword if in line 88. After this step, there is a global slice S and a local slice .
- Step I.3: Obtain the branch usage in line 98, contained in another local scope with keyword if in line 96. After this step, there is a global slice S and two local slices: and .
- Step I.4: Obtain the branch usage in line 105, contained in the local scope with keyword else in line 102. After this step, there is a global slice S and three local slices: , , and .
- Step I.5: Find the public usage in line 110 without a local scope. Insert local slices into S to make three global slices , , . Then, add line 110 into these slices.
- Step I.6: Complete the source code search and output the slice vector , as shown in Figure 3.
3.1.3. Slice Labeling
- Since slice-level detection does not use the original labels in the database during the training phase but needs relabel slices, it solves the problem that the same content slices are labeled as different types, thus improving the accuracy of slice labeling and the objectivity of the test results based on the slices.
- Compared with previous work in Ref. [9], for the same database, since D2U flow splits data flow according to the execution conditions. It will obtain more slices, but the average slice length is shorter. Considering that a defective statement is contextualized, it has not been possible to implement statement-level detection so far, i.e., we cannot determine whether a single statement is defective by itself. Therefore, shorter slices indicate that D2U flow can provide more accurate defect localization.
3.2. Feature Representation
3.3. Binding of Review Comments to Defective Samples
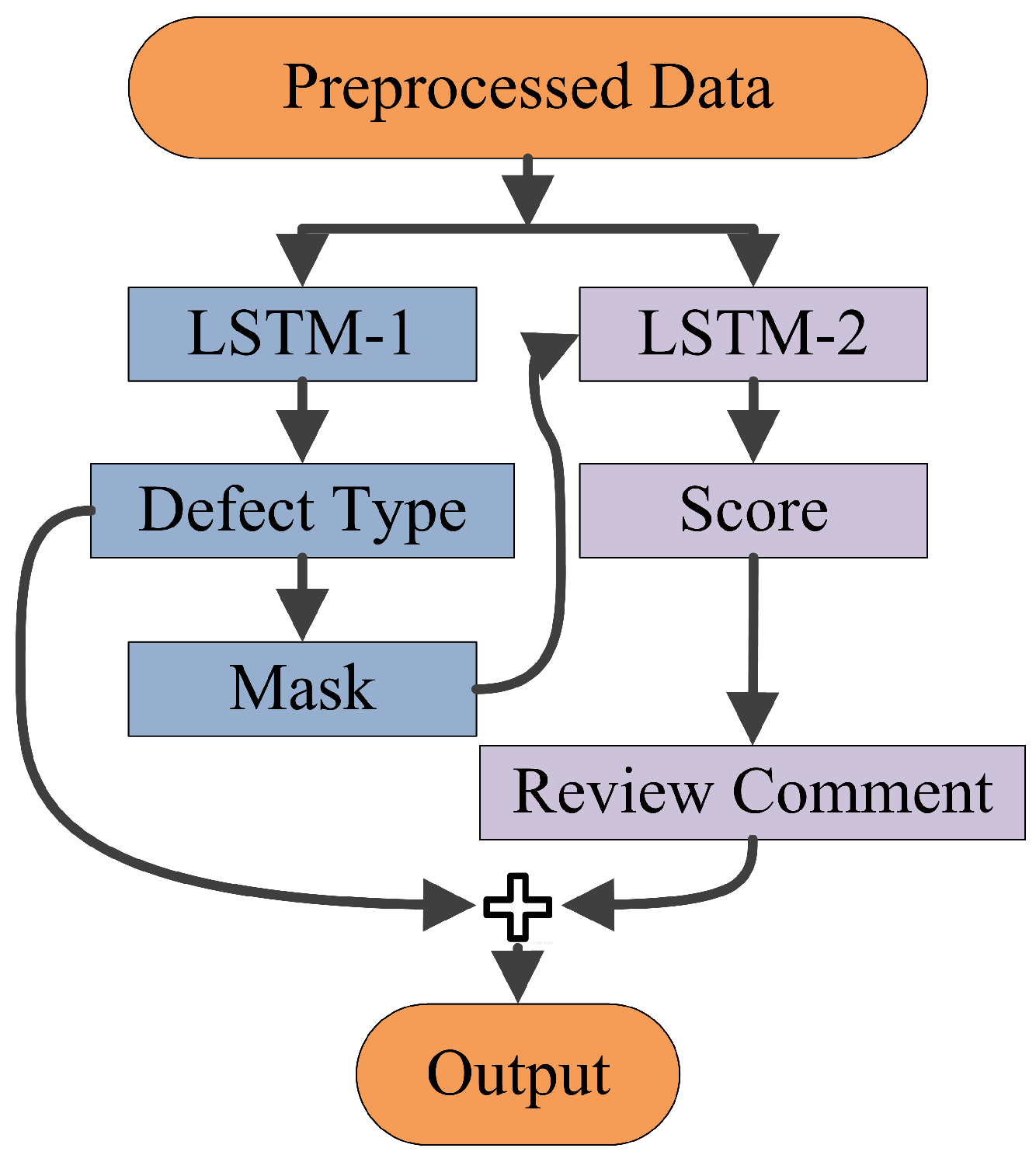
4. Detector Based on Twin LSTM
4.1. Twin LSTM Structure
4.2. Detector Workflow
- If the text similarity of the code is used to train and discriminate the defect types, it tends to cause overfitting of the detection model and focuses the model’s attention on the surface text features rather than the mechanism of defect generation.
- The higher the textual similarity of two pieces of code, the more similar their details are and the more similar the causes of the defects are, within a limited range of comparison, provided that they clearly have the same defect type. Therefore, the more similar the review comments are for them.
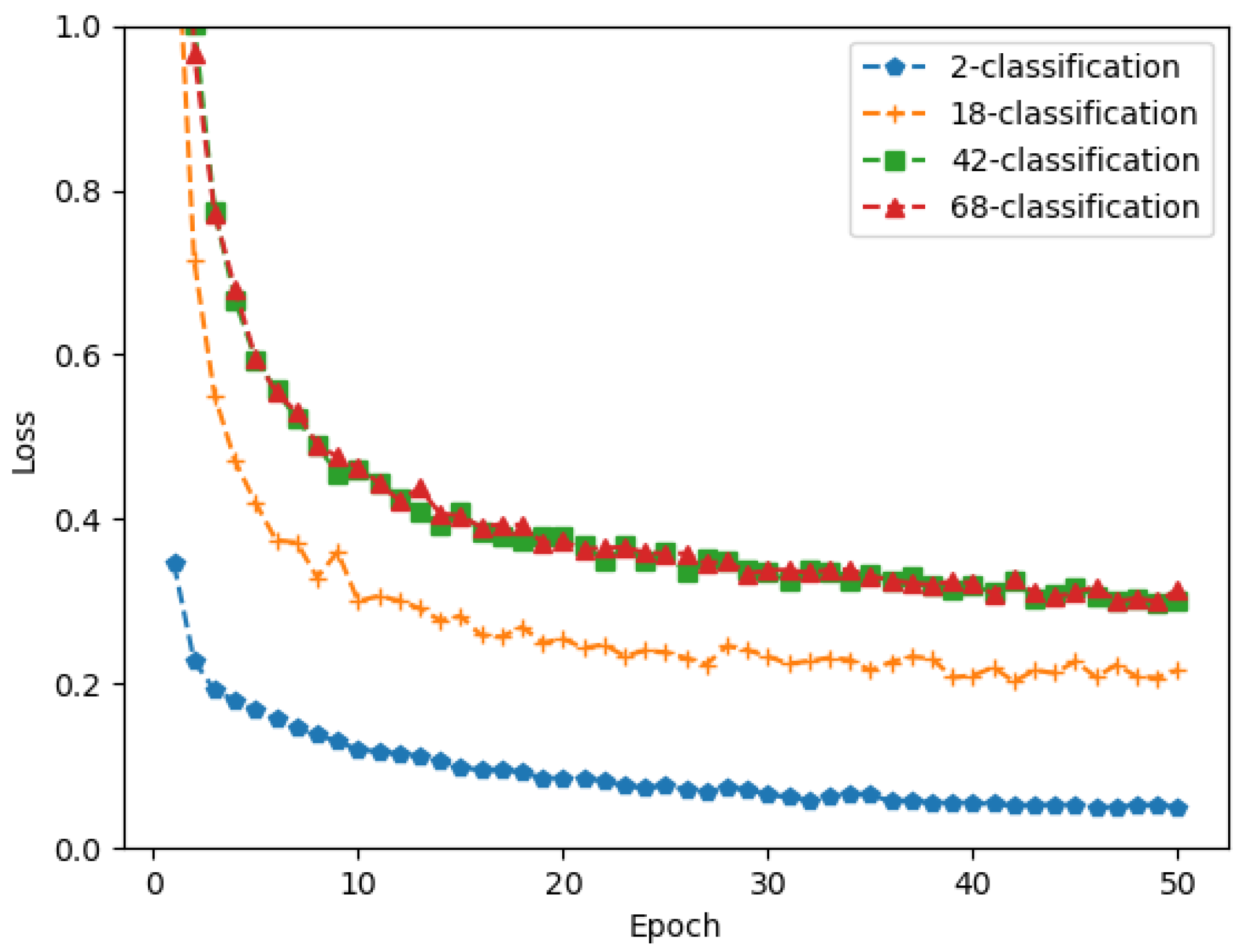
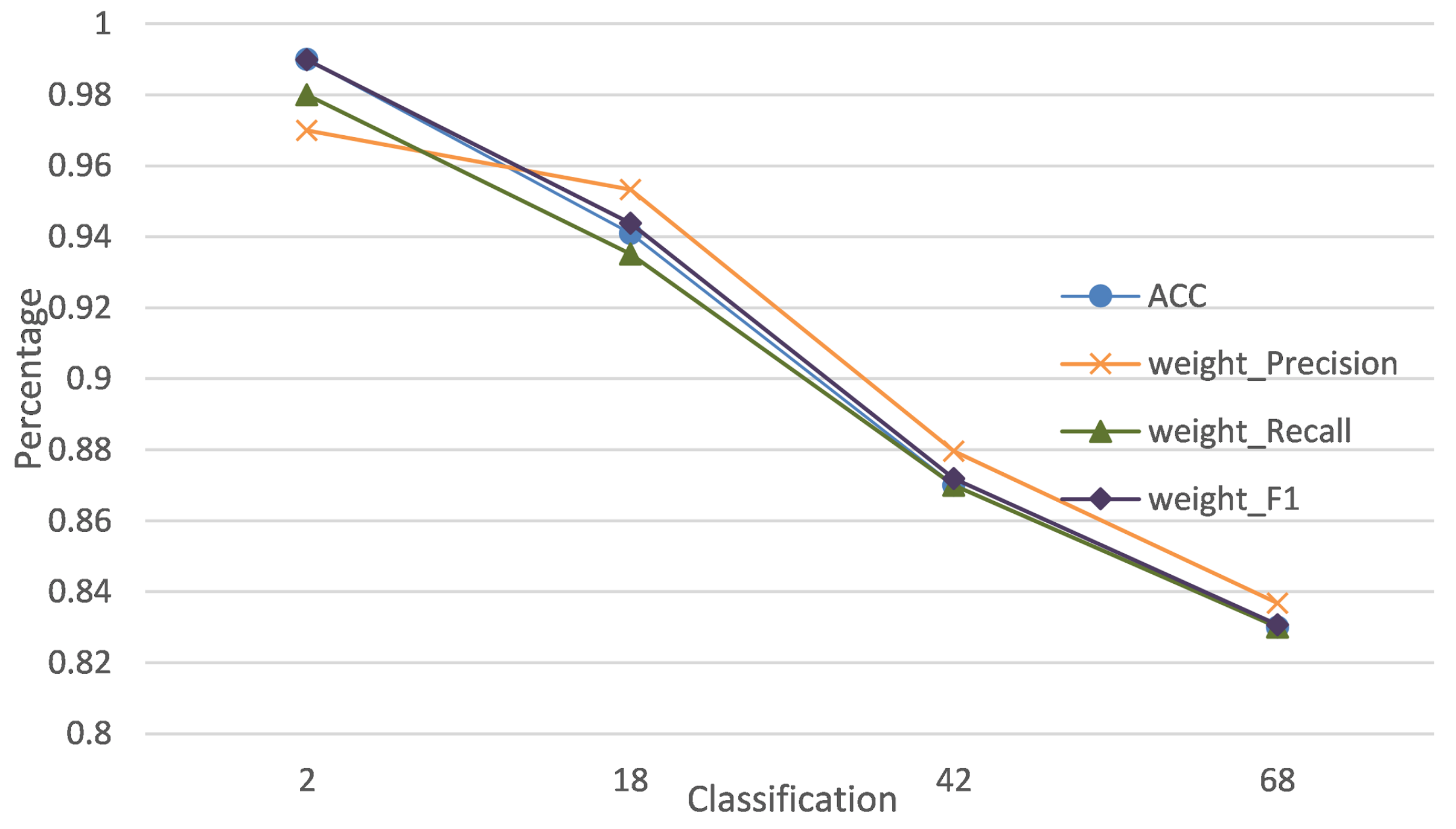
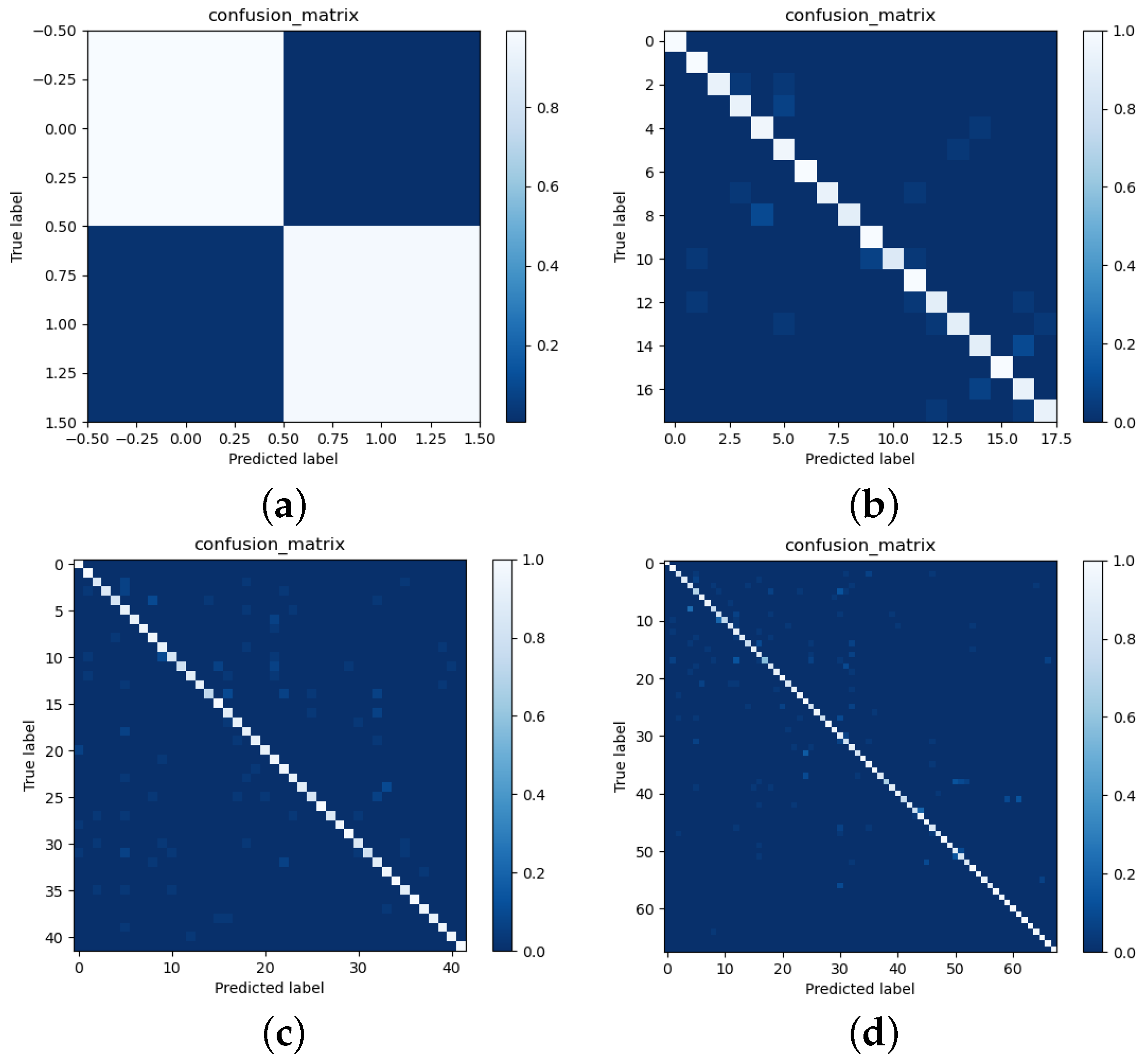
5. Experimental Results
5.1. Performance Indicators
- ACC: It measures the proportion of correctly detected among all samples and can be calculated using Equation (1).
- MCC: MCC is the abbreviation of Matthews correlation coefficient. The true-class and predicted-class are considered two binary variables, and their correlation coefficients are calculated as Equation (2). A prediction will yield a high score only if it obtains good results in all four confusion matrix classes (TP, TN, FN, and FP).
- Macro Average: Assuming that there are common L classes, each class is given the same weight, which characterizes the overall accuracy performance of the database, including the following indicators.: It is the precision of truly defective samples among the detected (or claimed) defective samples. can be calculated using Equation (3).: It is the recall value within Marco. It refers to the proportion of samples that are predicted to be positive in a true positive class. can be calculated using Equation (4).Then, we obtain the final Macro F1 calculation as follows:
- Weight Average: Unlike the Marco average, the weight average gives different weights for each class based on the amount of data it contains, so that classes with smaller amounts of data are not overlooked. This method includes the following indicators, in which the parameter refers to the normalized weights, indicating the percentage of sample size in ith class.
5.2. Comparisons and Analysis
5.2.1. Binary Classification Task
5.2.2. Multi Classification Task
5.2.3. Review Comment Output
5.2.4. Analysis and Discussion
- Although the proposed framework innovatively outputs defect categories and review comments jointly, we are unable to quantitatively evaluate the compliance of the output review comments, which somewhat reduces the objectivity of the conclusions.
- As the backbone, LSTM is a relatively outdated neural network model. Although our selection is based on experiments compared with other state-of-the-art methods, there may be a better model as the backbone of the detector.
- Although the proposed approach is theoretically applicable to other programming languages, we have not been able to conduct relevant experiments to verify it due to the lack of training data. This is the next step in our research direction: adapting the preprocessor to achieve support for different programming languages.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lions, J.L.; Lennart Lübeck, L. ARIANE 5 Failure-Full Report; European Space Agency: Paris, France, 1996. [Google Scholar]
- Sadowski, C.; Söderberg, E.; Church, L.; Sipko, M.; Bacchelli, A. Modern Code Review: A Case Study at Google. In Proceedings of the IEEE/ACM 40th International Conference on Software Engineering: Software Engineering in Practice Track (ICSE-SEIP), Gothenburg, Sweden, 27 May–3 June 2018; pp. 181–190. [Google Scholar]
- Heckman, S.; Williams, L. A systematic literature review of actionable alert identification techniques for automated static code analysis. Inf. Softw. Technol. 2011, 53, 363–387. [Google Scholar] [CrossRef]
- Zhioua, Z.; Short, S.; Roudier, Y. Static code analysis for software security verification: Problems and approaches. In Proceedings of the 38th International Computer Software and Applications Conference Workshops, Vasteras, Sweden, 21–25 July 2014; pp. 102–109. [Google Scholar]
- Muske, T.; Serebrenik, A. Survey of Approaches for Postprocessing of Static Analysis Alarms. ACM Comput. Surv. (CSUR) 2022, 55, 1–39. [Google Scholar] [CrossRef]
- FlawFinder. 2018. Available online: www.dwheeler.com/flawfinder (accessed on 5 May 2022).
- Li, Z.; Zou, D.; Xu, S.; Ou, X.; Jin, H.; Wang, S.; Deng, Z.; Zhong, Y. Vuldeepecker: A deep learning-based system for vulnerability detection. arXiv 2018, arXiv:1801.01681. [Google Scholar]
- Zou, D.; Wang, S.; Xu, S.; Li, Z.; Jin, H. μVulDeePecker: A Deep Learning-Based System for Multiclass Vulnerability Detection. IEEE Trans. Dependable Secur. Comput. 2021, 18, 2224–2236. [Google Scholar] [CrossRef]
- Li, Z.; Zou, D.; Xu, S.; Jin, H.; Zhu, Y.; Chen, Z. SySeVR: A Framework for Using Deep Learning to Detect Software Vulnerabilities. IEEE Trans. Dependable Secur. Comput. 2022, 19, 2244–2258. [Google Scholar] [CrossRef]
- Liu, S.; Lin, G.; Han, Q.L.; Wen, S.; Zhang, J.; Xiang, Y. DeepBalance: Deep-Learning and Fuzzy Oversampling for Vulnerability Detection. IEEE Trans. Fuzzy Syst. 2020, 28, 1329–1343. [Google Scholar] [CrossRef]
- Rough Audit Tool for Security. 2014. Available online: code.google.com/archive/p/rough-auditing-tool-for-security (accessed on 5 May 2022).
- Checkmarx. 2014. Available online: www.checkmarx.com/ (accessed on 5 May 2022).
- Yamaguchi, F. Pattern-based methods for vulnerability discovery. It-Inf. Technol. 2017, 59, 101–106. [Google Scholar] [CrossRef]
- Lin, G.; Xiao, W.; Zhang, J.; Xiang, Y. Deep learning-based vulnerable function detection: A benchmark. In Proceedings of the International Conference on Information and Communications Security, Beijing, China, 15–17 December 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 219–232. [Google Scholar]
- Wu, F.; Wang, J.; Liu, J.; Wang, W. Vulnerability detection with deep learning. In Proceedings of the 3rd International Conference on Computer and Communications (ICCC), Chengdu, China, 13–16 December 2017; pp. 1298–1302. [Google Scholar] [CrossRef]
- Fidalgo, A.; Medeiros, I.; Antunes, P.; Neves, N. Towards a Deep Learning Model for Vulnerability Detection on Web Application Variants. In Proceedings of the International Conference on Software Testing, Verification and Validation Workshops (ICSTW), Porto, Portugal, 24–28 October 2020; pp. 465–476. [Google Scholar] [CrossRef]
- Wartschinski, L.; Noller, Y.; Vogel, T.; Kehrer, T.; Grunske, L. VUDENC: Vulnerability Detection with Deep Learning on a Natural Codebase for Python. Inf. Softw. Technol. 2022, 144, 106809. [Google Scholar] [CrossRef]
- Cao, S.; Sun, X.; Bo, L.; Wei, Y.; Li, B. BGNN4VD: Constructing Bidirectional Graph Neural-Network for Vulnerability Detection. Inf. Softw. Technol. 2021, 136, 106576. [Google Scholar] [CrossRef]
- Grieco, G.; Grinblat, G.L.; Uzal, L.; Rawat, S.; Feist, J.; Mounier, L. Toward large-scale vulnerability discovery using machine learning. In Proceedings of the 6th ACM Conference on Data and Application Security and Privacy, New Orleans, LA, USA, 9–11 March 2016; pp. 85–96. [Google Scholar]
- Moshtari, S.; Sami, A. Evaluating and comparing complexity, coupling and a new proposed set of coupling metrics in cross-project vulnerability prediction. In Proceedings of the 31st Annual ACM Symposium on Applied Computing, Pisa, Italy, 4–8 April 2016; pp. 1415–1421. [Google Scholar]
- Yamaguchi, F.; Lottmann, M.; Rieck, K. Generalized vulnerability extrapolation using abstract syntax trees. In Proceedings of the 28th Annual Computer Security Applications Conference, Orlando, FL, USA, 3–7 December 2012; pp. 359–368. [Google Scholar]
- Hin, D.; Kan, A.; Chen, H.; Babar, M.A. LineVD: Statement-level Vulnerability Detection using Graph Neural Networks. arXiv 2022, arXiv:2203.05181. [Google Scholar]
- Li, Y.; Wang, S.; Nguyen, T.N. Vulnerability detection with fine-grained interpretations. In Proceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Athens, Greece, 23–28 August 2021; pp. 292–303. [Google Scholar]
- Wang, X.; Guan, Z.; Xin, W.; Wang, J. Source code defect detection using deep convolutional neural networks. J. Tsinghua Univ. Technol. 2021, 61, 1267–1272. [Google Scholar]
- Noonan, R.E. An algorithm for generating abstract syntax trees. Comput. Lang. 1985, 10, 225–236. [Google Scholar] [CrossRef]
- Ferrante, J.; Ottenstein, K.J.; Warren, J.D. The program dependence graph and its use in optimization. ACM Trans. Program. Lang. Syst. (TOPLAS) 1987, 9, 319–349. [Google Scholar] [CrossRef]
- NIST. SARD Database. 2020. Available online: www.nist.gov/itl/ssd/software-quality-group/samate/software-assurance-reference-dataset-sard (accessed on 5 May 2022).
- Bayer, U.; Moser, A.; Kruegel, C.; Kirda, E. Dynamic analysis of malicious code. J. Comput. Virol. 2006, 2, 67–77. [Google Scholar] [CrossRef]
- Ball, T. The concept of dynamic analysis. ACM SIGSOFT Softw. Eng. Notes 1999, 24, 216–234. [Google Scholar] [CrossRef]
- Schütte, J.; Fedler, R.; Titze, D. Condroid: Targeted dynamic analysis of android applications. In Proceedings of the 29th International Conference on Advanced Information Networking and Applications, Gwangju, Republic of Korea, 24–27 March 2015; pp. 571–578. [Google Scholar]
- Muhammad, P.F.; Kusumaningrum, R.; Wibowo, A. Sentiment Analysis Using Word2vec And Long Short-Term Memory (LSTM) For Indonesian Hotel Reviews. Procedia Comput. Sci.f 2021, 179, 728–735. [Google Scholar] [CrossRef]
- Adipradana, R.; Nayoga, B.P.; Suryadi, R.; Suhartono, D. Hoax analyzer for Indonesian news using RNNs with fasttext and glove embeddings. Bull. Electr. Eng. Inform. 2021, 10, 2130–2136. [Google Scholar] [CrossRef]
- CWE. 2023. Available online: http://cwe.mitre.org/ (accessed on 5 May 2022).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Dynamic Analysis | Static Analysis | |
|---|---|---|---|
| Text Rule Based | Machine Learning Based | ||
| Full Coverage | ✕ | ✓ | ✓ |
| Rule Dependence | ✓ | ✓ | ✕ |
| Code Instrumentation | ✓ | ✕ | ✕ |
| Method | R | P | ACC | F1 |
|---|---|---|---|---|
| SySeVR | 94.15 | 93.35 | 93.32 | 93.39 |
| TextCNN | 93.30 | 94.15 | 93.03 | 93.41 |
| Proposed | 98.68 | 98.87 | 98.68 | 98.67 |
| Method | Macro | Weight | MCC | ACC | ||||
|---|---|---|---|---|---|---|---|---|
| R | P | F1 | R | P | F1 | |||
| TextCNN | 90.75 | 83.11 | 86.30 | 93.03 | 94.15 | 93.39 | 73.46 | 93.03 |
| SySeVR | 87.24 | 85.47 | 86.32 | 93.62 | 93.80 | 93.70 | 72,69 | 93.62 |
| Proposed | 98.67 | 98.68 | 98.67 | 98.67 | 98.68 | 98.67 | 97.34 | 98.67 |
| Method | Macro | Weight | MCC | ACC | ||||
|---|---|---|---|---|---|---|---|---|
| R | P | F1 | R | P | F1 | |||
| TextCNN | 47.61 | 62.73 | 51.68 | 92.22 | 91.24 | 91.38 | 58.10 | 93.03 |
| SySeVR | 47.14 | 47.20 | 51.10 | 92.61 | 91.56 | 91.70 | 60.32 | 92.61 |
| Proposed | 94.81 | 95.07 | 94.83 | 98.66 | 98.68 | 98.67 | 97.25 | 96.27 |
| Method | Macro | Weight | MCC | ACC | ||||
|---|---|---|---|---|---|---|---|---|
| R | P | F1 | R | P | F1 | |||
| TextCNN | 58.45 | 67.47 | 60.70 | 92.68 | 92.70 | 92.52 | 61.29 | 92.68 |
| SySeVR | 42.22 | 64.50 | 48.12 | 92.82 | 91.93 | 91.97 | 58.40 | 92.82 |
| Proposed | 91.21 | 91.64 | 90.97 | 95.22 | 95.76 | 95.26 | 95.22 | 95.22 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Dong, L.; Li, H.-C.; Yao, X.-P.; Wang, P.; Yao, S. A Flexible Code Review Framework for Combining Defect Detection and Review Comments. Aerospace 2023, 10, 465. https://doi.org/10.3390/aerospace10050465
Chen X, Dong L, Li H-C, Yao X-P, Wang P, Yao S. A Flexible Code Review Framework for Combining Defect Detection and Review Comments. Aerospace. 2023; 10(5):465. https://doi.org/10.3390/aerospace10050465
Chicago/Turabian StyleChen, Xi, Lei Dong, Hong-Chang Li, Xin-Peng Yao, Peng Wang, and Shuang Yao. 2023. "A Flexible Code Review Framework for Combining Defect Detection and Review Comments" Aerospace 10, no. 5: 465. https://doi.org/10.3390/aerospace10050465