
When It Counts—Econometric Identification of the Basic Factor Model Based on GLT Structures

Abstract
:1. Introduction
2. The Basic Factor Model
2.1. Model Definition
2.2. Loading Matrices with a Simple Structure
2.3. A Brief Review of Identification When the Number of Factors Is Known
2.4. Conditions Resolving Rotational Invariance
2.5. Conditions for Variance Identification
3. Solving Rotational Invariance through GLT Structures
3.1. Ordered and Unordered GLT Structures
3.2. Rotation into GLT
- (a)
- There exists an equivalent unique representation of β involving an ordered GLT structure Λ,where is a rotation matrix. Λ is called the GLT representation of β;
- (b)
- To compute from β, first find the smallest row index such that the th row of β is not fully zero. Next, in an iterative manner, given indices for , find the smallest row index such that , …, and together form a linearly independent set of vectors. After the last iteration, the rows , …, form an invertible matrix . Then, is the ‘Q’ part of the QR-decomposition of .3
3.3. Simple GLT Structures
4. Variance Identification for Simple GLT Structures
4.1. Counting Rules for Variance Identification
- (a)
- If δ violates the counting rule , then the extended row-deletion property is violated for all simple structures generated by δ;
- (b)
- If δ satisfies the counting rule , then the extended row-deletion property holds for all simple structures except for a set of measure 0.
- (a)
- If a binary matrix δ of size satisfies the 3579 counting rule, i.e., every column of δ has at least three non-zero elements, every pair of columns at least five, and, more generally, every possible combination of columns has at least non-zero elements, then variance identification is given for all simple unordered GLT structures except for a set of measure 0; i.e., for any other factor decomposition of the marginal covariance matrix , where is an unordered GLT matrix, it follows that , i.e., , and .
- (b)
- If a binary matrix δ of size violates the 3579 counting rule, then for all , the row-deletion property AR does not hold.
- (c)
- For , , and , condition is both sufficient and necessary for variance identification.
4.2. Variance Identification in Practice
5. Identification in Exploratory Factor Analysis
5.1. Exploratory Factor Analysis
5.2. “Revealing the Truth” in an Overfitting EFA Model
5.3. Identifying Irrelevant Variables
6. Identifying the Number of Factors in Sparse Bayesian Factor Analysis
6.1. Sparse Bayesian Factor Analysis
6.2. MCMC Estimation
6.3. Identifying the Number of Factors
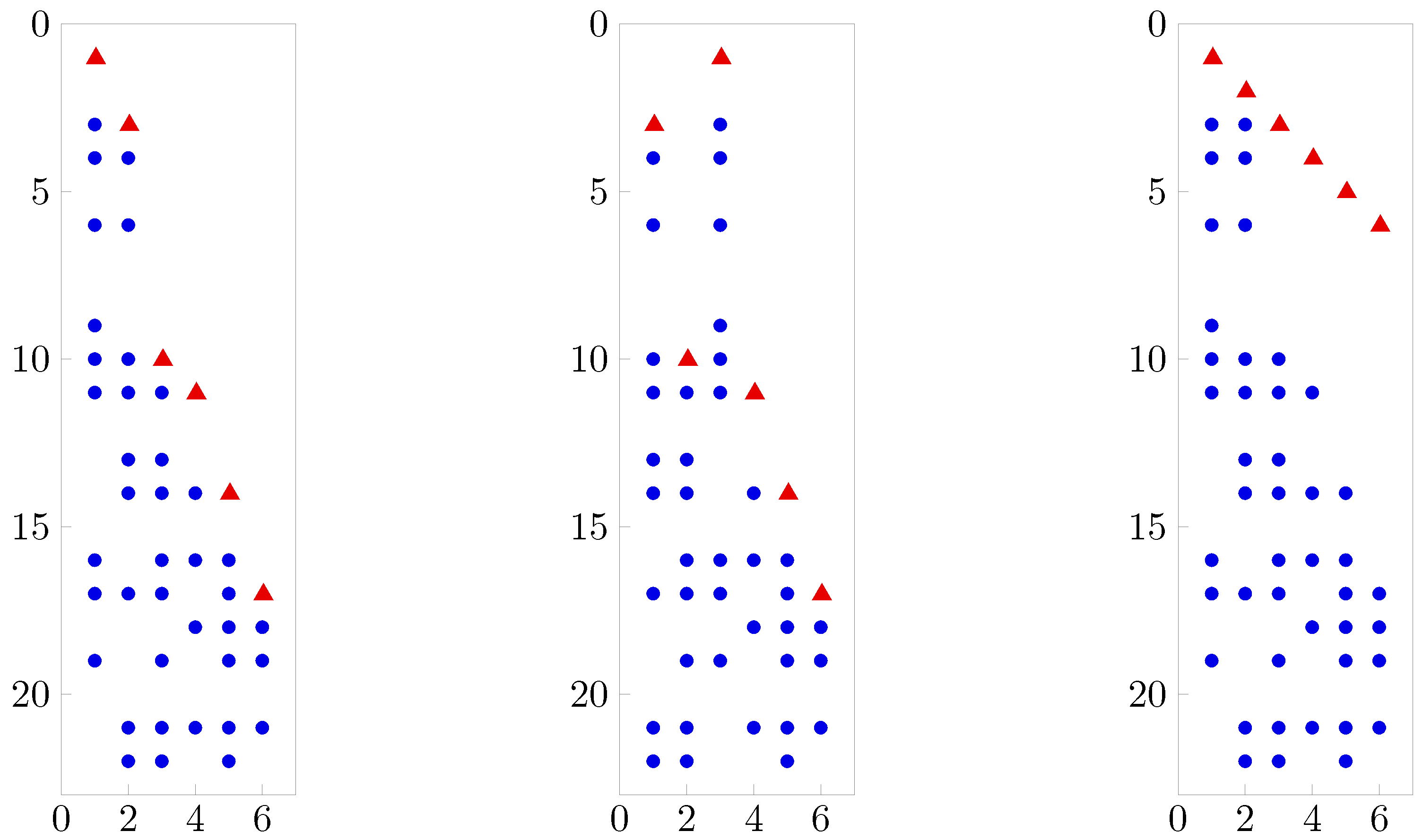
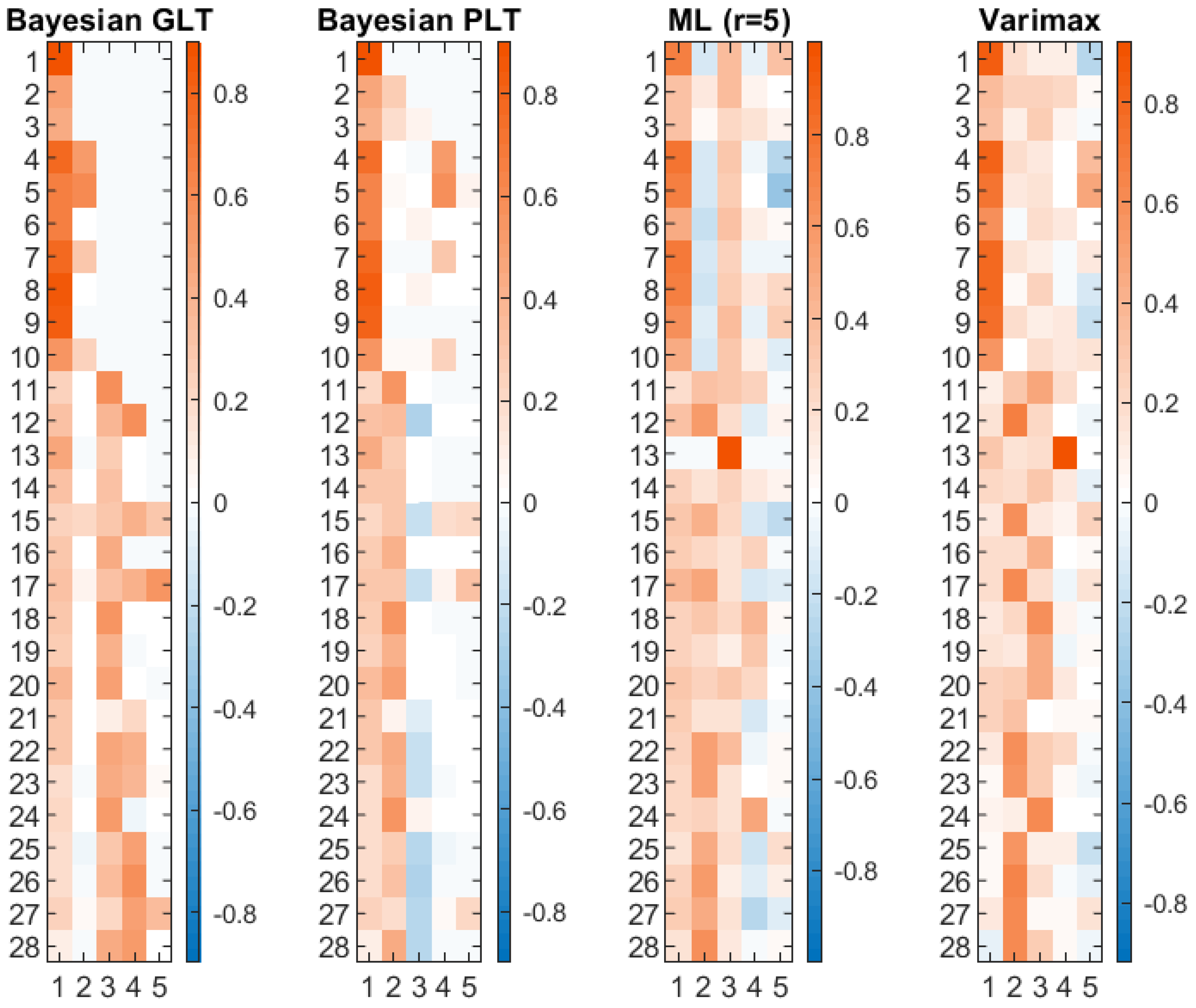
7. Illustrative Applications
7.1. An Illustrative Simulation Study
7.2. A Real Data Example

8. Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
- (a)
- holds for δ if holds for every submatrix of columns of δ;
- (b)
- If holds for δ and arbitrary rows are deleted from δ, then the remaining matrix satisfies ;
- (c)
- If holds for δ and some or all zero rows are removed from δ, then also holds for the remaining matrix.
| 1 | The sign condition on is needed to avoid sign switching, since loading matrices can be constructed, which differ from by a sign switch in a subset of columns, but yield the same cross-covariance matrix (see also Section 3). Without sign conditions, would not be identified. However, any other sign condition, such as , could be applied. |
| 2 | Our use of the term “pivot” is inspired by the concept of pivot columns in a row reduced echelon form (RREF), which is the result of Gauss–Jordan elimination. In particular, if is in RREF, then pivot rows of are the pivot columns of . For more details, see, e.g., Anton and Rorres (2013). |
| 3 | The pivot rows thus coincide with the pivot columns of the row reduced echelon form (RREF) of . |
| 4 | Their algorithm for the efficient verification of is implemented in R and MATLAB. The computer code is publicly available at https://github.com/hdarjus/sparvaride (accessed on 31 October 2023) and, respectively, https://github.com/hdarjus/sparvaride-matlab (accessed on 31 October 2023). |
| 5 | Note that the non-spurious columns of form an unordered GLT structure, while is GLT. |
| 6 | Evidently, zero columns (if any) in a posterior draw of can be ignored, since . |
| 7 | It should be noted that Dirac-spike-and-slab priors such as (29) are useful in this regard, since they are able to identify the exact zeros in the columns corresponding to spurious factors. Under continuous shrinkage priors *(see, e.g., Bhattacharya and Dunson (2011); Ročková and George (2017)), how to identify and remove spurious factors is not straightforward. |
| 8 | This algorithm is designed for inference in EFA models under the GLT condition, but can be easily extended to models with unconstrained loading matrices . |
| 9 | See Frühwirth-Schnatter et al. (2023) for a case study involving additional industry sectors. |
| 10 | These computation were carried out using the function factoran in MATLAB. |
References
- Anderson, Brian David Outram, Manfred Deistler, Elisabeth Felsenstein, Bernd Funovits, Lukas Koelbl, and Mohsen Zamani. 2016. Multivariate AR systems and mixed frequency data: G-identifiability and estimation. Econometric Theory 32: 793–826. [Google Scholar] [CrossRef]
- Anderson, Theodore Wilbur. 2003. An Introduction to Multivariate Statistical Analysis, 3rd ed. Chichester: Wiley. [Google Scholar]
- Anderson, Theodore Wilbur, and Herman Rubin. 1956. Statistical inference in factor analysis. Paper presented at Third Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, December 26–31; Volume V, pp. 111–50. [Google Scholar]
- Anton, Howard, and Chris Rorres. 2013. Elementary Linear Algebra, 11th ed. Hoboken: Wiley Global Education. [Google Scholar]
- Aßmann, Christian, Jens Boysen-Hogrefe, and Markus Pape. 2016. Bayesian analysis of static and dynamic factor models: An ex-post approach toward the rotation problem. Journal of Econometrics 192: 190–206. [Google Scholar] [CrossRef]
- Bai, Jushan, and Serena Ng. 2002. Determining the number of factors in approximate factor models. Econometrica 70: 191–221. [Google Scholar] [CrossRef]
- Bai, Jushan, and Serena Ng. 2013. Principal components estimation and identification of static factors. Journal of Econometrics 176: 18–29. [Google Scholar] [CrossRef]
- Bartholomew, David John. 1987. Latent Variable Models and Factor Analysis. London: Charles Griffin. [Google Scholar]
- Bekker, Paul A. 1989. Identification in restricted factor models and the evaluation of rank conditions. Journal of Econometrics 41: 5–16. [Google Scholar] [CrossRef]
- Bhattacharya, Anirban, and David Brian Dunson. 2011. Sparse Bayesian infinite factor models. Biometrika 98: 291–306. [Google Scholar] [CrossRef]
- Boivin, Jean, and Serena Ng. 2006. Are more data always better for factor analysis? Journal of Econometrics 132: 169–94. [Google Scholar] [CrossRef]
- Carvalho, Carlos M., Jeffrey Chang, Joseph E. Lucas, Joseph R. Nevins, Quanli Wang, and Mike West. 2008. High-dimensional sparse factor modeling: Applications in gene expression genomics. Journal of the American Statistical Association 103: 1438–56. [Google Scholar] [CrossRef]
- Chan, Joshua, Roberto Leon-Gonzalez, and Rodney W. Strachan. 2018. Invariant inference and efficient computation in the static factor model. Journal of the American Statistical Association 113: 819–28. [Google Scholar] [CrossRef]
- Conti, Gabriella, Sylvia Frühwirth-Schnatter, James Joseph Heckman, and Rémi Piatek. 2014. Bayesian exploratory factor analysis. Journal of Econometrics 183: 31–57. [Google Scholar] [CrossRef]
- Fan, Jianqing, Yingying Fan, and Jinchi Lv. 2008. High dimensional covariance matrix estimation using a factor model. Journal of Econometrics 147: 186–97. [Google Scholar] [CrossRef]
- Forni, Mario, Domenico Giannone, Marco Lippi, and Lucrezia Reichlin. 2009. Opening the black box: Structural factor models with large cross sections. Econometric Theory 25: 1319–47. [Google Scholar] [CrossRef]
- Frühwirth-Schnatter, Sylvia. 2023. Generalized cumulative shrinkage process priors with applications to sparse Bayesian factor analysis. Philosophical Transactions of the Royal Society A. forthcoming. [Google Scholar] [CrossRef] [PubMed]
- Frühwirth-Schnatter, Sylvia, and Hedibert F. Lopes. 2018. Sparse Bayesian factor analysis when the number of factors is unknown. arXiv arXiv:1804.04231. [Google Scholar]
- Frühwirth-Schnatter, Sylvia, Darjus Hosszejni, and Hedibert Freitas Lopes. 2023. Sparse Bayesian factor analysis when the number of factors is unknown. arXiv arXiv:2301.06459. [Google Scholar]
- Geweke, John Frederick, and Guofu Zhou. 1996. Measuring the pricing error of the arbitrage pricing theory. Review of Financial Studies 9: 557–87. [Google Scholar] [CrossRef]
- Geweke, John Frederick, and Kenneth James Singleton. 1980. Interpreting the likelihood ratio statistic in factor models when sample size is small. Journal of the American Statistical Association 75: 133–37. [Google Scholar] [CrossRef]
- Golub, Gene H., and Charles F. Van Loan. 2013. Matrix Computations, 4th ed. Baltimore: Johns Hopkins University Press. [Google Scholar]
- Hayashi, Kentaro, and George A. Marcoulides. 2006. Examining identification issues in factor analysis. Structural Equation Modeling 13: 631–45. [Google Scholar] [CrossRef]
- Hosszejni, Darjus, and Sylvia Frühwirth-Schnatter. 2022. Cover it up! Bipartite graphs uncover identifiability in sparse factor analysis. arXiv arXiv:2211.00671. [Google Scholar]
- Jöreskog, Karl Gustav. 1969. A general approach to confirmatory maximum likelihood factor analysis. Psychometrika 34: 183–202. [Google Scholar]
- Kastner, Gregor. 2019. Sparse Bayesian time-varying covariance estimation in many dimensions. Journal of Econometrics 210: 98–115. [Google Scholar] [CrossRef]
- Kaufmann, Sylvia, and Christian Schumacher. 2017. Identifying relevant and irrelevant variables in sparse factor models. Journal of Applied Econometrics 32: 1123–44. [Google Scholar] [CrossRef]
- Kaufmann, Sylvia, and Christian Schumacher. 2019. Bayesian estimation of sparse dynamic factor models with order-independent and ex-post identification. Journal of Econometrics 210: 116–34. [Google Scholar] [CrossRef]
- Koopmans, Tjalling Charles, and Olav Reiersøl. 1950. The identification of structural characteristics. The Annals of Mathematical Statistics 21: 165–81. [Google Scholar] [CrossRef]
- Ledoit, Olivier, and Michael Wolf. 2020. The power of (non-)linear shrinking: A review and guide to covariance matrix estimation. Journal of Financial Econometrics 20: 187–218. [Google Scholar] [CrossRef]
- Lee, Sik-Yum, and Xin-Yuan Song. 2002. Bayesian selection on the number of factors in a factor analysis model. Behaviormetrika 29: 23–39. [Google Scholar] [CrossRef]
- Legramanti, Sirio, Daniele Durante, and David B. Dunson. 2020. Bayesian cumulative shrinkage for infinite factorizations. Biometrika 107: 745–52. [Google Scholar] [CrossRef]
- Lopes, Hedibert Freitas, and Mike West. 2004. Bayesian model assessment in factor analysis. Statistica Sinica 14: 41–67. [Google Scholar]
- Magnus, Jan R., and Heinz Neudecker. 2019. Matrix Differential Calculus with Applications in Statistics and Econometrics. Hoboken: John Wiley & Sons. [Google Scholar]
- Neudecker, Heinz 1990. On the identification of restricted factor loading matrices: An alternative condition. Journal of Mathematical Psychology 34: 237–41. [CrossRef]
- Ohn, Ilsang, and Yongdai Kim. 2022. Posterior consistency of factor dimensionality in high-dimensional sparse factor models. Bayesian Analysis 17: 491–514. [Google Scholar] [CrossRef]
- Owen, Art B., and Jingshu Wang. 2016. Bi-cross-validation for factor analysis. Statistical Science 31: 119–39. [Google Scholar] [CrossRef]
- Reiersøl, Olav. 1950. On the identifiability of parameters in Thurstone’s multiple factor analysis. Psychometrika 15: 121–49. [Google Scholar] [CrossRef] [PubMed]
- Ročková, Veronika, and Edward I. George. 2017. Fast Bayesian factor analysis via automatic rotation to sparsity. Journal of the American Statistical Association 111: 1608–22. [Google Scholar] [CrossRef]
- Sato, Manabu. 1992. A study of an identification problem and substitute use of principal component analysis in factor analysis. Hiroshima Mathematical Journal 22: 479–524. [Google Scholar] [CrossRef]
- Teh, Yee Whye, Dilan Görür, and Zoubin Ghahramani. 2007. Stick-breaking construction for the Indian buffet process. Paper presented at Eleventh International Conference on Artificial Intelligence and Statistics, Proceedings of Machine Learning Research (PMLR), San Juan, Puerto Rico, March 21–24; Edited by Marina Meila and Xiaotong Shen. vol. 2, pp. 556–63. [Google Scholar]
- Thurstone, Louis Leon. 1935. The Vectors of Mind. Chicago: University of Chicago. [Google Scholar]
- Thurstone, Louis Leon. 1947. Multiple Factor Analysis. Chicago: University of Chicago. [Google Scholar]
- Tumura, Yosiro, and Manabu Sato. 1980. On the identification in factor analysis. TRU Mathematics 16: 121–31. [Google Scholar]
- West, Mike. 2003. Bayesian factor regression models in the “large p, small n” paradigm. In Bayesian Statistics 7. Edited by José Miguel Bernardo, María Jesús Bayarri, James Orvis Berger, Alexander Philip Dawid, David Heckerman, Adrian Frederick Melhuish Smith and Mike West. Oxford: Oxford University Press, pp. 733–42. [Google Scholar]
- Williams, Benjamin. 2020. Identification of the linear factor model. Econometric Reviews 39: 92–109. [Google Scholar] [CrossRef]
- Zhao, Shiwen, Chuan Gao, Sayan Mukherjee, and Barbara E. Engelhardt. 2016. Bayesian group factor analysis with structured sparsity. Journal of Machine Learning Research 17: 1–47. [Google Scholar]


{kind=link}
{kind=link}
| Scenario | Prior | Med (QR) | Med (QR) | Med (QR) | Med (QR) | |
|---|---|---|---|---|---|---|
| Dedic | GLT | 1PB | 97.0 (91.5, 98.3) | 5 (5, 5) | 0.90 (0.94, 0.99) | 0.018 (0.014, 0.030) |
| 2PB | 97.6 (87.7, 98.9) | 5 (5, 5) | 0.99 (0.83, 1.00) | 0.019 (0.016, 0.027) | ||
| EFA | 1PB | - | 5 (5, 6) | 0.66 (0.09, 0.79) | 0.020 (0.015, 0.026) | |
| 2PB | - | 5 (5, 6) | 0.69 (0.36, 0.80) | 0.019 (0.014, 0.024) | ||
| EFA-V | 1PB | 80.3 (49.8, 87.0) | 5 (5, 6) | 0.81 (0.17, 0.91) | 0.020 (0.015, 0.026) | |
| 2PB | 82.6 (63.4, 87.9) | 5 (5, 6) | 0.84 (0.53, 0.92) | 0.019 (0.014, 0.024) | ||
| Block | GLT | 1PB | 96.5 (39.4, 98.9) | 5 (5, 5) | 0.99 (0.28, 0.99) | 0.12 (0.08, 0.18) |
| 2PB | 98.7 (61.9, 99.4) | 5 (5, 5) | 0.99 (0.54, 1.00) | 0.10 (0.08, 0.14) | ||
| EFA | 1PB | - | 5 (4, 5) | 0.78 (0.22, 0.88) | 0.14 (0.11, 0.20) | |
| 2PB | - | 5 (4, 5) | 0.79 (0.08, 0.89) | 0.12 (0.08, 0.24) | ||
| EFA-V | 1PB | 87.0 (55.0, 91.5) | 5 (4, 5) | 0.89 (0.09, 0.96) | 0.14 (0.11, 0.20) | |
| 2PB | 85.9 (28.3, 90.4) | 5 (4, 5) | 0.92 (0.03, 0.97) | 0.12 (0.08, 0.24) | ||
| Dense | GLT | 1PB | 95.7 (84.6, 98.6) | 5 (5, 5) | 0.98 (0.92, 0.99) | 0.67 (0.44, 1.12) |
| 2PB | 99.4 (90.8, 99.8) | 5 (5, 5) | 0.99 (0.93, 1.00) | 0.68 (0.51, 1.18) | ||
| EFA | 1PB | - | 5 (5, 6) | 0.76 (0.43, 0.85) | 0.54 (0.39, 0.76) | |
| 2PB | - | 5 (5, 5) | 0.80 (0.66, 0.91) | 0.59 (0.43, 0.90) | ||
| EFA-V | 1PB | 84.4 (76.0, 90.2) | 5 (5, 6) | 0.89 (0.57, 0.95) | 0.54 (0.39, 0.76) | |
| 2PB | 89.7 (80.4, 93.9) | 5 (5, 5) | 0.93 (0.77, 0.98) | 0.59 (0.43, 0.90) | ||
| r | 0–3 | 4 | 5 | 6 | 7 | 8 | 9–13 |
|---|---|---|---|---|---|---|---|
| 0 | 0.28 | 0.45 | 0.25 | 0.02 | 0.001 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Frühwirth-Schnatter, S.; Hosszejni, D.; Lopes, H.F. When It Counts—Econometric Identification of the Basic Factor Model Based on GLT Structures. Econometrics 2023, 11, 26. https://doi.org/10.3390/econometrics11040026
Frühwirth-Schnatter S, Hosszejni D, Lopes HF. When It Counts—Econometric Identification of the Basic Factor Model Based on GLT Structures. Econometrics. 2023; 11(4):26. https://doi.org/10.3390/econometrics11040026
Chicago/Turabian StyleFrühwirth-Schnatter, Sylvia, Darjus Hosszejni, and Hedibert Freitas Lopes. 2023. "When It Counts—Econometric Identification of the Basic Factor Model Based on GLT Structures" Econometrics 11, no. 4: 26. https://doi.org/10.3390/econometrics11040026