
On the Proper Computation of the Hausman Test Statistic in Standard Linear Panel Data Models: Some Clarifications and New Results


Abstract
:1. Introduction
2. Motivation
2.1. Notation
2.2. Motivating Examples
2.2.1. Motivating Example 1: Gasoline
2.2.2. Motivating Example 2: Airline
2.2.3. Motivating Example 3: Wage determination
3. The Two Versions of the Hausman Test Statistic
3.1. The Original Hausman Test Specification in a Balanced Panel Data Model
3.2. Two Estimation Procedures
3.2.1. Approach 1: The (Direct) FGLS Approach
3.2.2. Approach 2: The Quasi-Demeaning Approach
3.3. Comparing the Two Versions
3.3.1. Two Statistics
“Note that the elements of and its standard errors are simply calculated given the estimates and of and their standarderrors, making sure to adjust to use the fixed effects estimate of ”.
3.3.2. Main Results
- is a symmetric positive definite (SPD) matrix. It follows that is a positive-definite quadratic form.
- can be either a symmetric positive or a negative definite matrix or even an indefinite matrix depending on specific conditions holding for h. As a consequence, can be of either sign (and even of indeterminate sign a priori) depending on the values taken by h. Specifically, we have:
- (a)
- is a symmetric positive definite (SPD) matrix iff . In this case, is a positive-definite quadratic form
- (b)
- is a symmetric negative definite (SND) matrix iff . In this case, is a negative-definite quadratic form
- (c)
- is indefinite iff . In this case, can be of either sign, which is indeterminate a priori.
- If is SPD, the relevant comparison relies upon the magnitude . We have whenever
- If is SND, it necessarily follows that .
3.3.3. Back to the Case Studies
3.4. What about h?
3.4.1. Determinants
- The first category is related to the structure of the data at hand, i.e., the Between and Within components of the (empirical) covariance matrix of the explanatory variables. They are captured by the matrices and , which influence the structure of (and therefore the magnitude of its eigenvalues).
- The second category is linked to the correlation between the individual effects and the regressors contained in , which determines the extent of the (asymptotic as well as finite sample) bias for (with respect to ). This affects the gap between (that is unbiased) and and therefore the value of .
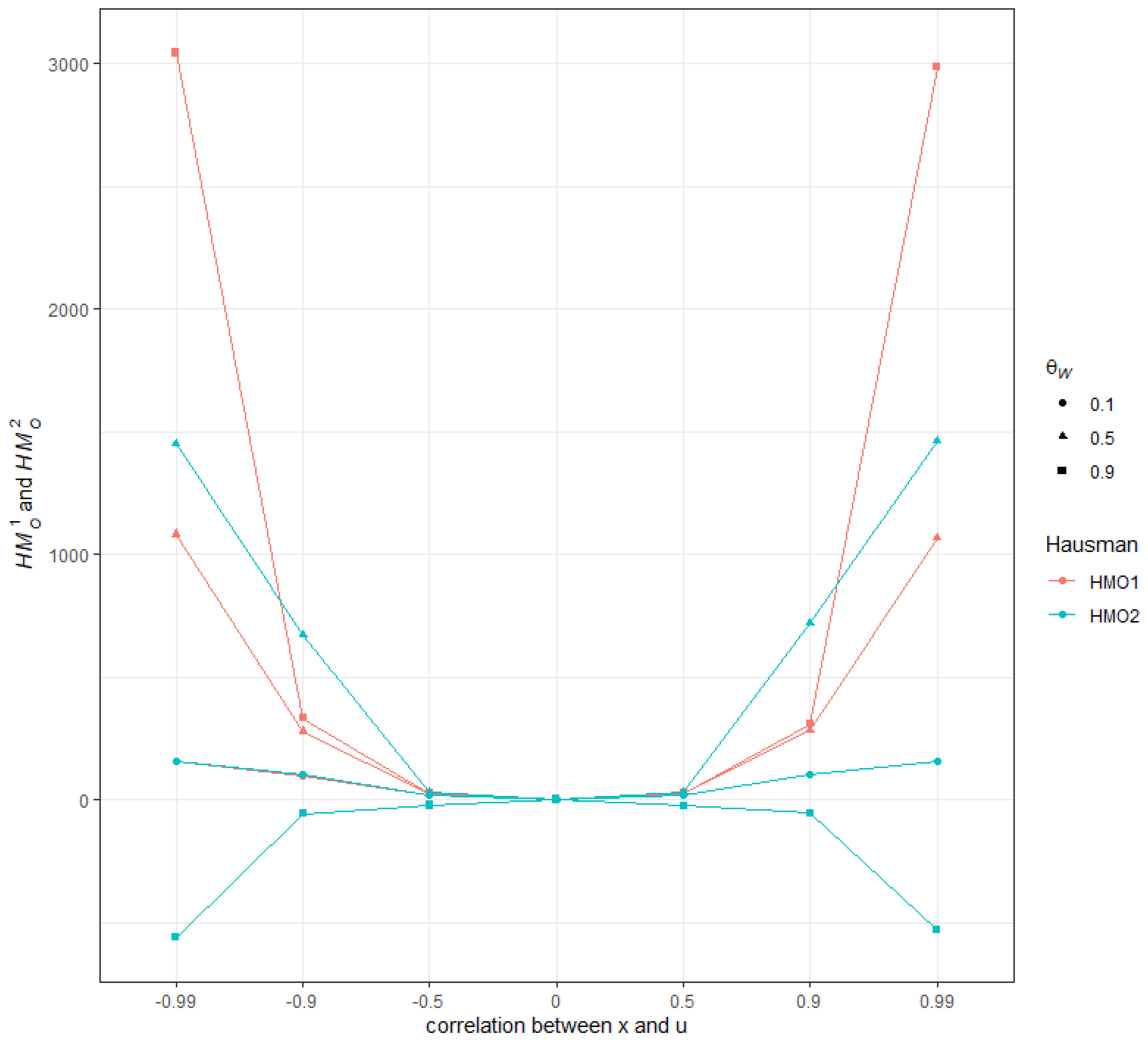
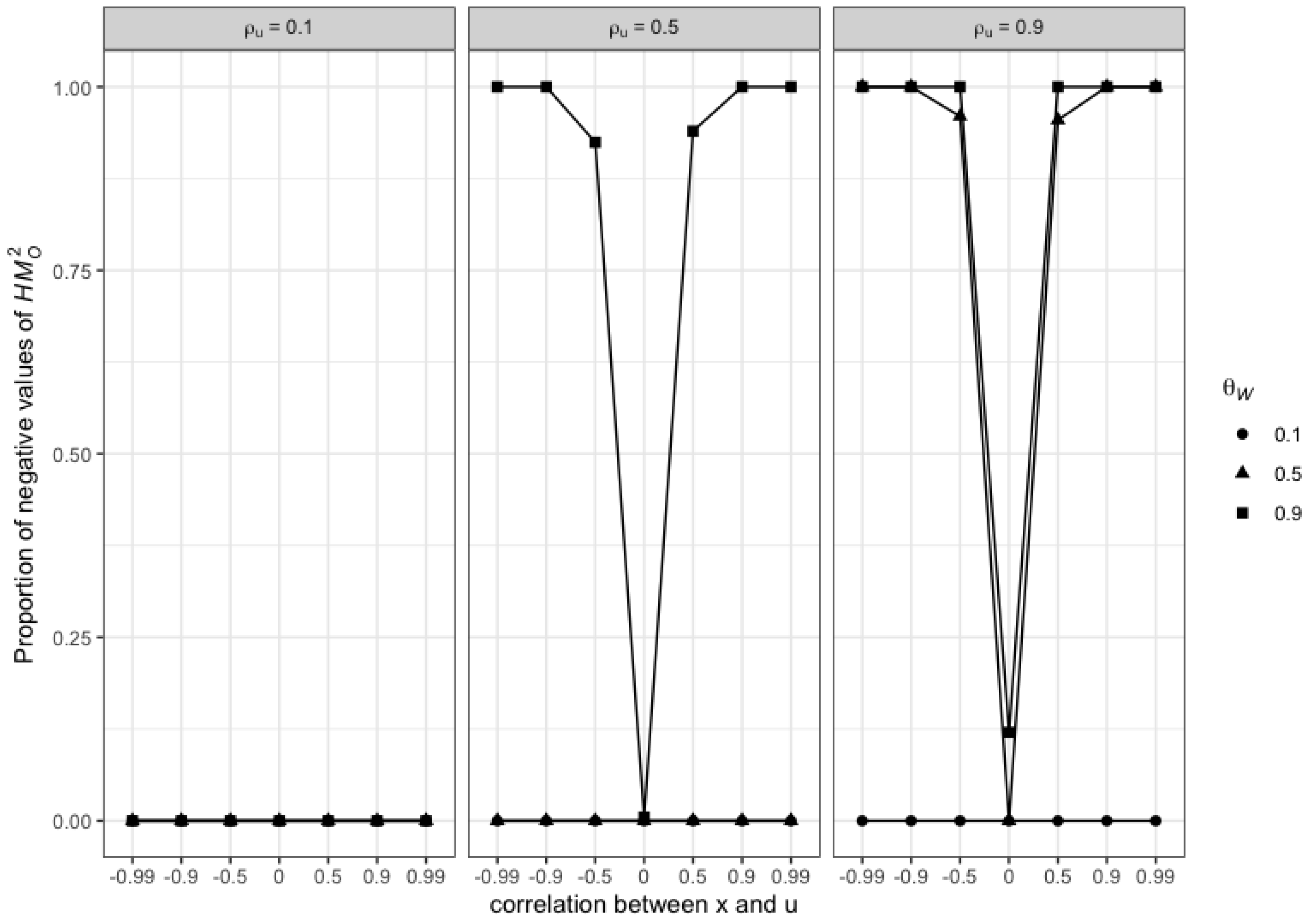
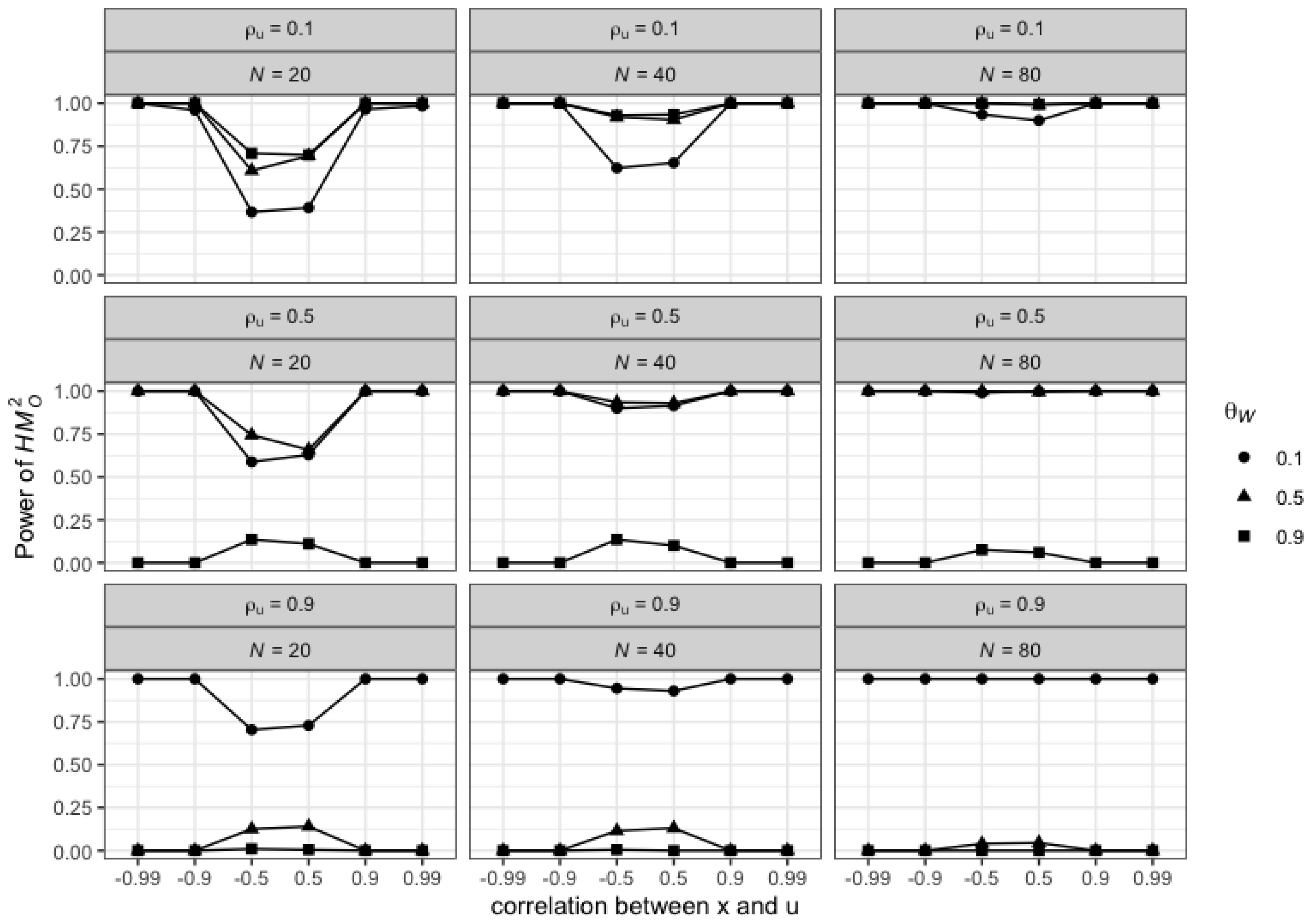
3.4.2. Illustrations in the Single Regressor Case
Preliminary Results
Design of Simulations
Results of the Simulations
4. The Implementation of the Hausman Test in Standard Econometric Software Packages for Panel Data: A Brief Review and Discussion
4.1. Review
- STATA programming commands for the estimation of the random-effects panel data models (xtreg with the re option) rely on the specification of the quasi-demeaned model in (8). As a consequence, the random effects parameter estimates as well as its “conventional” covariance matrix estimate are provided as standard outputs of the OLS regression performed on that model. In particular, the vce(conventional) - default - command yields the (asymptotic) covariance matrix estimate based on the standard variance estimator for OLS regression. This corresponds to with, accordingly, used for the residual variance estimate. The default version of the command for implementing the standard Hausman test (the hausman command) corresponds accordingly to .
- The R PLM package developed by Croissant and Millo (2008) allows estimating a wide range of panel data models with R software. Regarding the random-effects specification, the estimation process can be implemented via the plm function, whose model argument takes the random option. Croissant and Millo (2008) point out that it could have been possible to program the computation of the covariance matrix estimator for directly from the formula (11), “once the variance components have been estimated and hence the covariance matrix of errors”. However, to limit the computational costs associated with the inversion of the () matrix () or () and the related memory limits to store it, plm resorts to the specification and estimation of the quasi-demeaning estimator (8). Then, the coefficients’ covariance matrix estimator is readily calculated by applying the standard OLS formulas which, in the R language, go through the vcov() command.The phtest command computes the Hausman test in plm. Its main arguments are the two-panel model objects that underlie the comparison (ex. model = within and model = random). The corresponding estimates of the asymptotic covariances matrices provided under both models are thus used to compute the Hausman statistic corresponding to .
- EViews estimates the random effects models using feasible GLS. The first step refers to the estimation of the covariance matrix for the composite error formed by the effects and the idiosyncratic disturbance. The EViews 9 User’s Guide II notes “Once the component variances have been estimated, we form an estimator of the composite residual covariance, and then GLS transform the dependent and regressor data”. As for the computation of the FGLS estimate, Eviews uses the quasi-demeaned model specification and proceeds on this basis. However, the calculation of the related coefficients’ covariance matrix is based on the direct application of the formula (11) and thus corresponds to . The procedure for the Hausman test then corresponds to .
- MATLAB provides estimation methods for the standard fixed (Within), between, and random effects models with the the panel data toolbox. Panel data models are estimated using the panel(·) function with the options argument set to re for the random effects model specification. The random effects FGLS estimates are based on the quasi-demeaned model and the asymptotic variance-covariance matrix for statistical inference is accordingly provided by (see Equation (18) in Alvarez et al. (2017)). Then, hausmantest computes the Hausman test where the input of the hausmantest function requires the output structures of the two estimations to be compared. Accordingly, the statistics that are computed correspond to .
- GAUSS: The GAUSS Times Serie∞s MT 3.0 TSMT provides a fixed effects and random effects models (TSCS) package that can be implemented through the tsmt library and the one-in-all tscsFit procedure. Another possibility is to use the pdlib GAUSS library and the randomEffects procedure in it. Both procedures implement the quasi-demeaning transformation on the original dataset and apply the standard OLS estimator on the transformed data so as to form the FGLS estimate. The covariance matrix estimate comes as a direct by-product of the OLS outcome so that is used. The Hausman test provided in the tscsFit procedure is implemented accordingly and corresponds to .
- SAS (SAS ETS 13.2) provides estimation methods for the standard fixed (Within), between, and random effects models in the balanced and unbalanced cases with the PANEL procedure toolbox. Standard panel data models are estimated using the PROC PANEL command with the MODEL statement specifying the regression model and the assumptions for the error structure. Specifically, FIXONE and RANONE must be used to specify the fixed-effect and the random-effect models, respectively (in the cross-sectional one-way case). In the latter case, various methods (but not the Swamy-Arora approach) are proposed to estimate, in the first stage, the variance components (through the VCOMP = option). It is explicitly indicated that the random effects FGLS estimates are then based, in the balanced case, on these variance components estimates through the quasi-demeaning approach, where ‘the random effects is then the result of simple OLS on the transformed data’ (see SAS ETS 13.2 User Manual (2014), p. 1417). The estimator for the asymptotic variance-covariance matrix is thus provided by . The Hausman statistic is automatically generated and reported as a conventional F statistic, with the statistic computed as .
4.2. Discussion
- Use the quasi-demeaning estimator to compute the RE estimator for and .
- Use and (within regression) to compute h.
- Rearranging (21), obtain from h as: .
- Implement the Hausman test on the basis of
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Hausman Test Statistics
Appendix A.1. Matrix Conditions
Appendix A.2. Applications
- We first note that and are two symmetric (real valued) matrices. This comes from the definition of which is computed as the sum of two symmetric matrices, .
- Note and . By construction R and are two real positive symmetric definite matrices (this is because and that R can be written as which is the inverse of the sum of two symmetric positive definite matrices).We then deduce from Lemma1 that can be diagonalised and that there exists a non singular matrix P such that:As is SPD (given that is itself SPD), this ensures that the spectrum of is only composed of strictly positive elements.
- Let and . By construction, R and are again two real symmetric positive matrices. We deduce from Lemma1 that can be diagonalised and that there exists a non singular matrix P such that:
- Noticing that , then, on the basis of the results above, we can write as:Then, let denote a non-null vector, and setting , we obtain the spectral decomposition of as:Since we know that is SPD, we obtain from the latter decomposition that . which implies that .
- Further, noticing that and proceeding as for above, we can write as:Let denote a non-null vector, and setting , we obtain the spectral decomposition of as:From this spectral decomposition, we conclude that
- –
- will be SPD if and only if , that is, if and only if is fulfilled.
- –
- will be SND if and only if , that is, if and only if is fulfilled.
- If is SPD, the relevant comparison can be built on the magnitude . The former can be written as:with .Thus, whenever is SPD or SND. Given the definition of , and since is SPD, this, in turn, depends on whether is SPD or SND.Then, observe that .As is SPD, it follows that whether is SPD or SND depends on whether .
- If is SND, the relevant comparison is between and , and can be built on . The former magnitude can be written as:where and .Thus, whenever is SPD or SND. Given the definition of , and as is SPD (since is SND), this, in turn, depends on whether is SND or SPD.Then, observe that .Proceeding as for above, we can write as:Note by a non-null vector, and setting , we obtain the spectral decomposition of as:From this spectral decomposition, we conclude that:
- –
- will be SPD if and only if , that is, if and only if .
- –
- Conversely, will be SND if and only if , that is, if and only if .

{kind=link}
{kind=link}
{kind=link}
| ( is SPD and ) | ||
| ( and sign of a priori indefinite) | ||
| indefinite | ||
| ( is SND and ) | ||
| indefinite | ||
Appendix B. Relation between Within Residuals and Quasi-Demeaned Residuals
Appendix C. Simulations in the Single Regressor Case
Appendix C.1. Generating u it and x it
- First, we draw N pairs for the random vector in the bivariate normal distribution with: , ; and .
- Second, for each , we draw T pairs for the random vector in the bivariate normal distribution with with and .
Appendix C.2. Shaping the Experiment
Appendix C.3. ANCOVA Results
| Dependent Variable: | ||||
|---|---|---|---|---|
| Mean (1) | Mean (2) | Median (3) | Median (4) | |
| (ref = 20) | −24.158 | 134.826 ** | −24.132 | 136.294 ** |
| (37.475) | (56.029) | (36.677) | (55.435) | |
| (ref = 20) | −72.354 * | 405.306 *** | −72.281 ** | 409.057 *** |
| (37.475) | (56.029) | (36.677) | (55.435) | |
| (ref = 20) | 63.206 *** | 111.042 *** | 60.953 *** | 110.473 *** |
| (16.759) | (25.057) | (16.402) | (24.791) | |
| (ref = 20) | 126.892 *** | 306.754 *** | 122.040 *** | 303.316 *** |
| (16.759) | (25.057) | (16.402) | (24.791) | |
| (ref = 0.01) | 0.039 | −1.105 | 0.322 | −0.300 |
| (16.759) | (25.057) | (16.402) | (24.791) | |
| (ref = 0.01) | 0.277 | 2.784 | 0.803 | −0.171 |
| (16.759) | (25.057) | (16.402) | (24.791) | |
| (ref = 0.1) | 90.452 *** | −18.134 | 83.656 *** | −16.453 |
| (29.028) | (43.400) | (28.410) | (42.940) | |
| (ref = 0.1) | 184.362 *** | −35.323 | 167.161 *** | −30.374 |
| (29.028) | (43.400) | (28.410) | (42.940) | |
| (ref = 0) | 1083.156 *** | 640.633 *** | 1057.507 *** | 643.296 *** |
| (25.600) | (38.275) | (25.055) | (37.869) | |
| (ref = 0) | 147.213 *** | 214.549 *** | 141.792 *** | 202.157 *** |
| (25.600) | (38.275) | (25.055) | (37.869) | |
| (ref = 0) | 13.481 | 14.882 | 12.514 | 5.921 |
| (25.600) | (38.275) | (25.055) | (37.869) | |
| (ref = 0) | 13.436 | 3.664 | 12.469 | 5.878 |
| (25.600) | (38.275) | (25.055) | (37.869) | |
| (ref = 0) | 147.237 *** | 215.027 *** | 141.974 *** | 201.985 *** |
| (25.600) | (38.275) | (25.055) | (37.869) | |
| (ref = 0) | 1083.935 *** | 641.078 *** | 1058.341 *** | 643.762 *** |
| (25.600) | (38.275) | (25.055) | (37.869) | |
| (ref = 0.01) | −0.265 | 3.723 | 0.343 | 0.056 |
| (16.759) | (25.057) | (16.402) | (24.791) | |
| (ref = 0.01) | 0.400 | 0.780 | 1.234 | −0.119 |
| (16.759) | (25.057) | (16.402) | (24.791) | |
| (ref = 0.1) | 90.544 *** | −20.710 | 83.885 *** | −15.796 |
| (29.028) | (43.400) | (28.410) | (42.940) | |
| (ref = 0.1) | 184.478 *** | −31.878 | 167.171 *** | −29.092 |
| (29.028) | (43.400) | (28.410) | (42.940) | |
| : | 86.977 ** | −16.080 | 87.205 ** | −15.864 |
| (41.052) | (61.376) | (40.177) | (60.726) | |
| : | 261.702 *** | −41.165 | 262.250 *** | −48.630 |
| (41.052) | (61.376) | (40.177) | (60.726) | |
| : | 175.791 *** | −27.656 | 176.433 *** | −30.434 |
| (41.052) | (61.376) | (40.177) | (60.726) | |
| : | 525.795 *** | −89.808 | 526.255 *** | −92.123 |
| (41.052) | (61.376) | (40.177) | (60.726) | |
| : | 86.826 ** | −13.059 | 86.837 ** | −16.015 |
| (41.052) | (61.376) | (40.177) | (60.726) | |
| : | 261.064 *** | −45.820 | 261.054 *** | −48.512 |
| (41.052) | (61.376) | (40.177) | (60.726) | |
| : | 175.736 *** | −30.548 | 176.043 *** | −31.087 |
| (41.052) | (61.376) | (40.177) | (60.726) | |
| : | 526.388 *** | −84.972 | 526.704 *** | −92.531 |
| (41.052) | (61.376) | (40.177) | (60.726) | |
| Constant | −446.938 *** | −246.347 *** | −430.229 *** | −246.886 *** |
| (35.552) | (53.154) | (34.795) | (52.590) | |
| Observations | 5103 | 5103 | 5103 | 5103 |
| R2 | 0.580 | 0.165 | 0.579 | 0.169 |
| Adjusted R2 | 0.578 | 0.161 | 0.577 | 0.165 |
| Residual Std. Error (df = 5076) | 488.758 | 730.740 | 478.346 | 722.994 |
| F Statistic (df = 26; 5076) | 269.238 *** | 38.691 *** | 268.675 *** | 39.743 *** |


Appendix D. Regression Outcomes in the Single Regressor Case for the Motivating Example 2 [Airline]
| Specification | Intercept | ||
|---|---|---|---|
| Within specification | Coef. | − | |
| Std Err. | − | ||
| Between specification | Coef. | ||
| Std Err. | |||
| Random effect specification | Coef. | ||
| Std Err. 1 | |||
| Std Err. 2 | |||
| h | |||
| Within variance | |||
| Between variance | |||
| Within variance/Total variance (in %) | |||
| Between variance/Total variance (in %) |
| 1 | |
| 2 | In particular, this issue is generally not addressed in the leading textbooks in panel data econometrics. An exception is Wooldridge (2010), (chp. 10, pp. 289–90), but he merely mentions the possibility of obtaining a non-positive definite covariance matrix if different estimates of the error term variance are used, suggesting a way out, which we further discuss below. |
| 3 | See Nerlove (1971) and Fuller and Battese (1973), for an original exposition of the transformed, quasi-demeaned model and the related approach. |
| 4 | Schreiber (2008) also considers a panel data framework as an illustration for the asymptotic results and highlights cases where the matrix is not SPD in a context where the error term variance estimates differ. He does not, however, focus on the comparison of the different estimation approaches in the random effects model and their implications for the computation of the Hausman test statistic, as we do. |
| 5 | We assume in what follows that there is no time-invariant regressor in , so that it is possible to compute the -estimator with the Within transformation of (see below). |
| 6 | See the initial study by Baltagi and Griffin (1973). The dataset is available at: https://www.wiley.com/legacy/wileychi/baltagi/datasets.html, accessed on 2 May 2023. |
| 7 | Interestingly, in an updated version of his textbook, Baltagi (2021) modified the presentation of the Gasoline case study compared to the one provided in 2005 and presented here. In this update, there is no more disconnection between the two versions of the statistic, and only one version is considered, . While, in both presentations, the estimations are drawn from the STATA software package, the second presentation benefits from the use of the sigmaless option command that fixes the computation of the estimator for the idiosyncratic component of the error term. See infra in Section 4.2. |
| 8 | The original study is from Greene (1999). The dataset is available at: http://pages.stern.nyu.edu/~wgreene/Text/tables/tablelist5.htm, accessed on 2 May 2023. |
| 9 | The dataset is available at: http://pages.stern.nyu.edu/~wgreene/Text/Edition7/tablelist8new.htm, accessed on 2 May 2023. |
| 10 | A typical -observation for is given by where and . A similar transformation is applied for each of the components of , hence the quasi-demeaning expression for the transformed model that is obtained in that way. |
| 11 | Indeed, , which is equivalent to (4) given the definition of , and . |
| 12 | Given the definition of those matrices, this replacement relies on the use of consistent estimators for the variance components, i.e., , and/or . For a discussion about these variance component estimators, see, among others, Amemiya (1971); Fuller and Battese (1974); Maddala (1971); Nerlove (1971); Swamy and Arora (1972); Wallace and Hussain (1969). |
| 13 | In particular, we assume that (resp. ) is a consistent estimator for (resp. ). See Wooldridge (2010) for a discussion on these conditions. |
| 14 | The estimator for is usually computed from the sum of the squares of the OLS regression residuals, , for the Between (transformed) regression model with . (Swamy-Arora approach), see infra. |
| 15 | It can be easily checked that the two approaches give rise to the same (RE) estimator for the parameters, and . |
| 16 | The emphasis is added by us. The notation used by Hausman for the fixed-effects estimate of corresponds to our . |
| 17 | The intra-class coefficient drives the value of . It can be shown, indeed, that: . |
| 18 | Note that this estimator is also used to compute and in turn , which makes it fully, logically consistent with respect to the FGLS regression model framework. |
| 19 | This is, e.g., recommended by Cameron and Trivedi (2009), p. 360. |
| 20 | We thank both referees for having highlighted those approaches and suggested to account for them in this discussion subsection. |
| 21 | In this case, indeed, . |
| 22 | Baltagi and Liu show in (Baltagi and Liu 2007) that the Hausman test can be obtained equivalently from other artificial regressions, involving the use of the set of Between-transformed regressor variables, , or even the set of the initial regressor variables, . They also discuss the case where the auxiliary regression can accommodate the presence of potentially endogenous regressors. With respect to the issue of weak instruments in this context, see also (Staiger and Stock 1997). |
| 23 | Take two symmetric matrices A and B. We denote by the property according to which is a positive definite matrix (what we can also write as ). |
| 24 | If A and B are two symmetric positive definite matrices and are non-singular, then . |
| 25 | As a reminder, note that . |
References
- Alvarez, Inmaculada C., Javier Barbero, and José L. Zofío. 2017. A Panel Data Toolbox for MATLAB. Journal of Statistical Software 76: 1–17. [Google Scholar] [CrossRef]
- Amemiya, Takeshi. 1971. The Estimation of the Variances in a Variance-Components Model. International Economic Review 12: 1–13. [Google Scholar] [CrossRef]
- Arellano, Manuel. 1993. On the testing of correlated effects with panel data. Journal of Econometrics 59: 87–97. [Google Scholar] [CrossRef]
- Axler, Sheldon. 2014. Linear Algebra Done Right. New York: Springer. [Google Scholar]
- Baltagi, Badi H. 2005. Econometric Analysis of Panel Data, 3rd ed. Chichester and Hoboken: J. Wiley & Sons. [Google Scholar]
- Baltagi, Badi H. 2021. Econometric Analysis of Panel Data, 6th ed. Springer texts in Business and Economics. Cham: Springer. [Google Scholar] [CrossRef]
- Baltagi, Badi H., and James M. Griffin. 1973. Gasoline demand in the oecd: An application of pooling and testing procedures. European Economic Review 22: 626–32. [Google Scholar] [CrossRef]
- Baltagi, Badi H., and Long Liu. 2007. Alternative ways of obtaining Hausman’s test using artificial regressions. Statistics & Probability Letters 77: 1413–17. [Google Scholar] [CrossRef]
- Baum, Christopher F., Mark E. Schaffer, and Steven Stillman. 2003. Instrumental Variables and GMM: Estimation and Testing. The Stata Journal: Promoting Communications on Statistics and Stata 3: 1–31. [Google Scholar] [CrossRef]
- Cameron, Adrian Colin, and Pravin K. Trivedi. 2009. Microeconometrics Using Stata. College Station: Stata Press. [Google Scholar]
- Cornwell, Christopher, and Peter Rupert. 2008. Efficient estimation with panel data: An empirical comparison of instrumental variable estimators. Journal of Applied Econometrics 3: 149–55. [Google Scholar]
- Croissant, Yves, and Giovanni Millo. 2008. Panel Data Econometrics in R: The plm Package. Journal of Statistical Software 27: 1–43. [Google Scholar] [CrossRef]
- Fuller, Wayne A., and George E. Battese. 1973. Transformations for Estimation of Linear Models with Nested-Error Structure. Journal of the American Statistical Association 68: 626–32. [Google Scholar] [CrossRef]
- Fuller, Wayne A., and George E. Battese. 1974. Estimation of linear models with crossed-error structure. Journal of Econometrics 2: 67–78. [Google Scholar] [CrossRef]
- Greene, William. 1999. Frontier Production Functions. In Handbook of Applied Econometrics Volume II: Microeconomics. Edited by Pesaran M. Hashem and Schmidt Peter. Oxford: Blackwell Publishing Ltd., pp. 75–153. [Google Scholar] [CrossRef]
- Greene, William. 2000. Econometric Analysis, 4th ed. Upper Saddle River: Prentice Hall Internat. [Google Scholar]
- Greene, William. 2012. Econometric Analysis, 7th ed. Pearson Series in Economics; Boston and Munich: Pearson. [Google Scholar]
- Hausman, Jerry A. 1978. Specification Tests in Econometrics. Econometrica 46: 1251–71. [Google Scholar] [CrossRef]
- Hausman, Jerry A., and William E. Taylor. 1981. Panel data and unobservable individual effects. Econometrica 49: 1377–98. [Google Scholar]
- Hayashi, Fumio. 2000. Econometrics. Princeton: Princeton University Press. [Google Scholar]
- Holly, Alberto. 1982. A Remark on Hausman’s Specification Test. Econometrica 50: 749–60. [Google Scholar] [CrossRef]
- Maddala, Gangadharrao Soundalyara. 1971. The Use of Variance Components Models in Pooling Cross-Section and Time Series Data. Econometrica 39: 341–57. [Google Scholar]
- Mundlak, Yair. 1978. On the pooling of time series and cross section data. Econometrics 46: 69–85. [Google Scholar]
- Nerlove, Marc. 1971. A Note on Error Components Models. Econometrica 39: 383–96. [Google Scholar] [CrossRef]
- Schreiber, Sven. 2008. The Hausman Test Statistic Can Be Negative even Asymptotically. Jahrbücher für Nationalökonomie und Statistik 228: 394–405. [Google Scholar] [CrossRef]
- Staiger, Douglas, and James H. Stock. 1997. Instrumental Variables Regression with Weak Instruments. Econometrica 65: 557–86. [Google Scholar] [CrossRef]
- Swamy, Paravastu Aananta Venkata Bhattandha, and Swarnjit S. Arora. 1972. The Exact Finite Sample Properties of the Estimators of Coefficients in the Error Components Regression Models. Econometrica 40: 261–75. [Google Scholar] [CrossRef]
- Wallace, T. Dudley, and Ashiq Hussain. 1969. The Use of Error Components Models in Combining Cross Section with Time Series Data. Econometrica 37: 55. [Google Scholar] [CrossRef]
- White, Halbert. 1982. Maximum Likelihood Estimation of Misspecified Models. Econometrica 50: 1–25. [Google Scholar] [CrossRef]
- Wooldridge, Jeffrey M. 2010. Econometric Analysis of Cross Section and Panel Data, 2nd ed. Cambridge, MA: MIT Press. [Google Scholar]

| Specification | Intercept | ||||
|---|---|---|---|---|---|
| Within/fixed effects | Coef. | − | |||
| Std Err. | − | ||||
| Between | Coef. | ||||
| Std Err. | |||||
| Random effects | Coef. | ||||
| Std Err._1 | |||||
| Std Err._2 | |||||
| h | |||||
| Within variance | |||||
| Between variance | |||||
| With. var. share (in %) | |||||
| Betw. var. share (in %) |
| Specification | Intercept | ||||
|---|---|---|---|---|---|
| Within | Coef. | − | |||
| Std Err. | − | ||||
| Between | Coef. | ||||
| Std Err. | |||||
| Random effects | Coef. | ||||
| Std Err._1 | |||||
| Std Err._2 | |||||
| h | |||||
| Within variance | |||||
| Between variance | |||||
| With. var. share (in %) | |||||
| Betw. var. share (in %) |
| Specification | Intercept | |||
|---|---|---|---|---|
| Within | Coef. | − | ||
| Std Err. | − | |||
| Between | Coef. | |||
| Std Err. | ||||
| Random effects | Coef. | |||
| Std Err._1 | ||||
| Std Err._2 | ||||
| h | ||||
| Within variance (1) | ||||
| Between variance (2) | ||||
| With. var. share (in %) | ||||
| Betw. var. share (in %) |
| Specification | Intercept | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Within | Coef. | − | |||||||||
| Std Err. | − | ||||||||||
| Between | Coef. | ||||||||||
| Std Err. | |||||||||||
| Random effects | Coef. | ||||||||||
| Std Err._1 | |||||||||||
| Std Err._2 | |||||||||||
| h | |||||||||||
| Within variance (1) | 4 | ||||||||||
| Between variance (2) | |||||||||||
| With. var. share (in %) | |||||||||||
| Betw. var. share (in %) |
| ( is SPD and ) | ||
| ( and sign of a priori indefinite) | ||
| indefinite | ||
| ( is SND and ) | ||
| negative definite | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Le Gallo, J.; Sénégas, M.-A. On the Proper Computation of the Hausman Test Statistic in Standard Linear Panel Data Models: Some Clarifications and New Results. Econometrics 2023, 11, 25. https://doi.org/10.3390/econometrics11040025
Le Gallo J, Sénégas M-A. On the Proper Computation of the Hausman Test Statistic in Standard Linear Panel Data Models: Some Clarifications and New Results. Econometrics. 2023; 11(4):25. https://doi.org/10.3390/econometrics11040025
Chicago/Turabian StyleLe Gallo, Julie, and Marc-Alexandre Sénégas. 2023. "On the Proper Computation of the Hausman Test Statistic in Standard Linear Panel Data Models: Some Clarifications and New Results" Econometrics 11, no. 4: 25. https://doi.org/10.3390/econometrics11040025