
Detecting and Quantifying Structural Breaks in Climate
Abstract
:1. Introduction
2. Methodologies for Detecting Structural Breaks
2.1. Impulse Indicator Saturation
- Estimate the model, including impulse indicator dummies for the first half of the sample, as represented by Figure 2a. That estimation is equivalent to estimating the model over the second half of the sample, ignoring the first half. Drop all statistically insignificant impulse indicator dummies and retain the statistically significant dummies (Figure 2b).
2.2. Extensions
3. Background
4. Data
4.1. Palmer Drought Severity Index
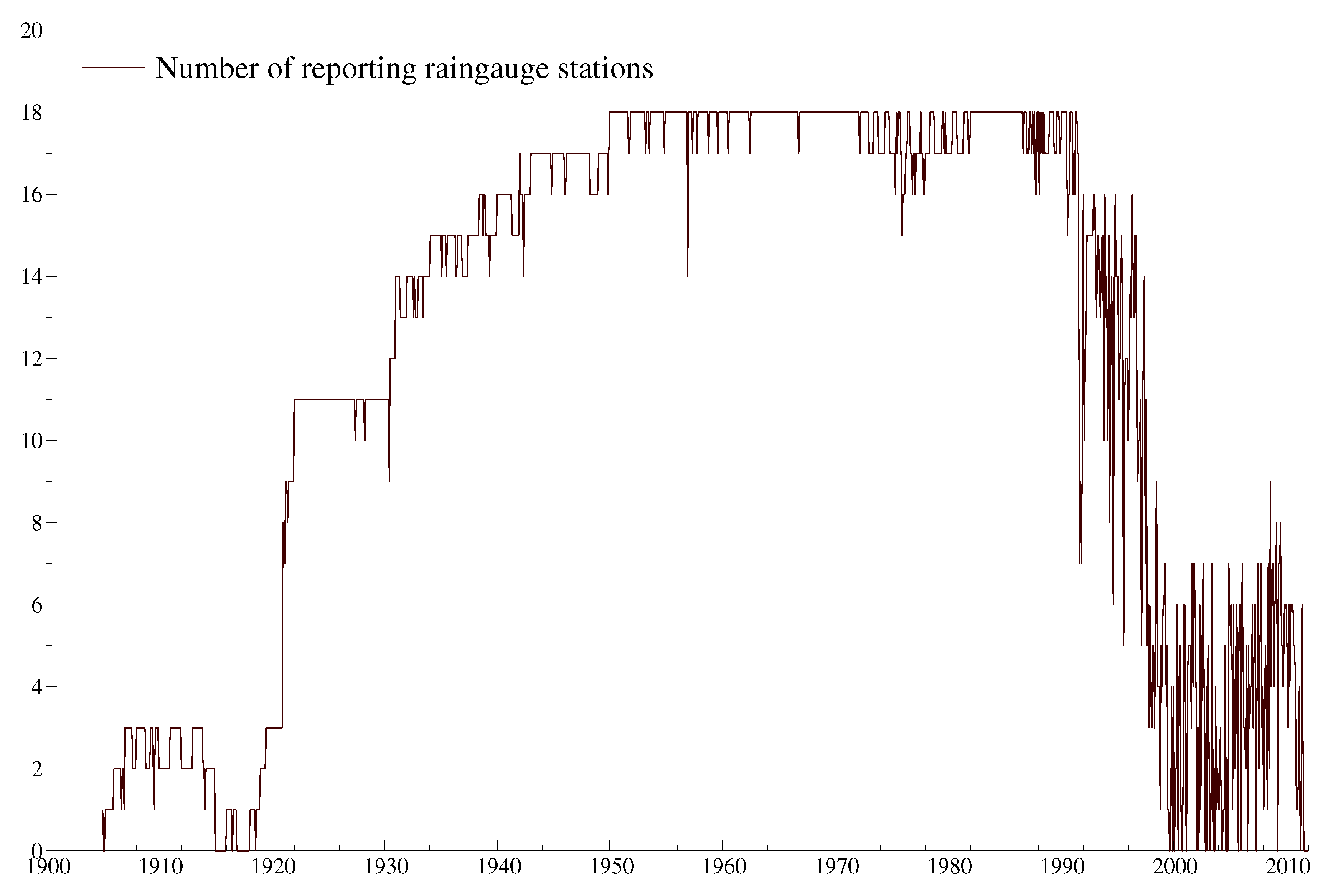
4.2. Rainfall Data
4.3. Remarks
5. Empirical Analysis
6. Remarks
Article 4.8 contains a specific commitment of financial assistance for “… [c]ountries with areas liable to drought and desertification …”. For such assistance, the decline in Mauritanian food production since 1970 can be reasonably attributed to the decline in rainfall. Put somewhat differently, a “date” is needed to establish the start of these impacts. A country may have a case for UNFCCC-based assistance if it can establish a reasonable benchmark for the decline in local food production. For Mauritania, the detected structural break in 1970 of the distribution of precipitation may serve as a plausible claim. That is, the adverse consequences of climate change and subsequent decline in food production could be “dated” to have started around 1970; and financial assistance could be based on this evidence. Additionally, at the 2015 UNFCCC Conference of the Parties (COP 21), 195 countries (Mauritania included) adopted the Paris Agreement on greenhouse gas emissions, mitigation, and financing from 2020. That agreement went into effect on November 4, 2016, shortly before the COP 22 in Marrakesh. More recently, the COP 27 in Sharm el-Sheikh approved a loss and damage fund to assist certain countries adversely affected by climate change.Cooperate in preparing for adaptation to the impacts of climate change; develop and elaborate appropriate and integrated plans for coastal zone management, water resources and agriculture, and for the protection and rehabilitation of areas, particularly in Africa, affected by drought and desertification, as well as floods …
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Aldy, Joseph E., Matthew J. Kotchen, Robert N. Stavins, and James H. Stock. 2021. Keep climate policy focused on the social cost of carbon. Science 373: 850–52. [Google Scholar] [CrossRef] [PubMed]
- Andrews, Donald W. K. 1993. Tests for parameter instability and structural change with unknown change point. Econometrica 61: 821–56. [Google Scholar] [CrossRef] [Green Version]
- Bai, Jushan, and Pierre Perron. 1998. Estimating and testing linear models with multiple structural changes. Econometrica 66: 47–78. [Google Scholar] [CrossRef] [Green Version]
- Baiardi, Donatella, and Claudio Morana. 2021. Climate change awareness: Empirical evidence for the European Union. Energy Economics 96: 105163. [Google Scholar] [CrossRef]
- Baltagi, Badi H. 1995. Econometric Analysis of Panel Data. Chichester: John Wiley and Sons. [Google Scholar]
- Bergamelli, Michele, and Giovanni Urga. 2014. Detecting Multiple Structural Breaks: Dummy Saturation vs. Sequential Bootstrapping. With an Application to the Fisher Relationship for US. CEA@Cass Working Paper Series no. WP–CEA–03–2014. London: Cass Business School. [Google Scholar]
- Campos, Julia, Neil R. Ericsson, and David F. Hendry, eds. 2005a. General-to-Specific Modelling. Vols. I and II, Cheltenham: Edward Elgar. [Google Scholar]
- Campos, Julia, Neil R. Ericsson, and David F. Hendry. 2005b. Introduction: General-to-Specific Modelling. In General-to-Specific Modelling. Edited by Julia Campos, Neil R. Ericsson and David F. Hendry. Cheltenham: Edward Elgar, vol. I, pp. xi–xci. [Google Scholar]
- Castle, Jennifer L., and David F. Hendry. 2019. Modelling Our Changing World. Cham: Palgrave Macmillan. [Google Scholar]
- Castle, Jennifer L., and David F. Hendry. 2020a. Climate econometrics: An overview. Foundations and Trends in Econometrics 10: 145–322. [Google Scholar] [CrossRef]
- Castle, Jennifer L., and David F. Hendry. 2020b. Identifying the Causal Role of CO2 during the Ice Ages. Discussion Paper no. 898. Oxford: Department of Economics, University of Oxford. [Google Scholar]
- Castle, Jennifer L., Michael P. Clements, and David F. Hendry. 2013. Forecasting by factors, by variables, by both or neither? Journal of Econometrics 177: 305–19. [Google Scholar] [CrossRef]
- Castle, Jennifer L., Jurgen A. Doornik, and David F. Hendry. 2012. Model selection when there are multiple breaks. Journal of Econometrics 169: 239–46. [Google Scholar] [CrossRef] [Green Version]
- Castle, Jennifer L., Jurgen A. Doornik, and David F. Hendry. 2020. Medium-Term Forecasting of the Coronavirus Pandemic. Draft. Oxford: Nuffield College, University of Oxford. [Google Scholar]
- Castle, Jennifer L., Jurgen A. Doornik, David F. Hendry, and Felix Pretis. 2015. Detecting location shifts during model selection by step-indicator saturation. Econometrics 3: 240–64. [Google Scholar] [CrossRef] [Green Version]
- Castle, Jennifer L., Nicholas W. P. Fawcett, and David F. Hendry. 2010. Forecasting with equilibrium-correction models during structural breaks. Journal of Econometrics 158: 25–36. [Google Scholar] [CrossRef] [Green Version]
- CERN. 2012. CERN Experiments Observe Particle Consistent with Long-sought Higgs Boson. CERN Press Release. Available online: http://press.cern/press-releases/2012/07/cern-experiments-observe-particle-consistent-long-sought-higgs-boson (accessed on 8 November 2022).
- Chow, Gregory C. 1960. Tests of equality between sets of coefficients in two linear regressions. Econometrica 28: 591–605. [Google Scholar] [CrossRef] [Green Version]
- Coumou, Dim, and Stefan Rahmstorf. 2012. A decade of weather extremes. Nature Climate Change 2: 491–96. [Google Scholar] [CrossRef]
- Craioveanu, Mihaela, and Eric Hillebrand. 2012. Level changes in volatility models. Annals of Finance 8: 277–308. [Google Scholar] [CrossRef]
- Dai, Aiguo, Kevin E. Trenberth, and Taotao Qian. 2004. A global dataset of Palmer drought severity index for 1870–2002: Relationship with soil moisture and effects of surface warming. Journal of Hydrometeorology 5: 1117–30. [Google Scholar] [CrossRef] [Green Version]
- Dai, Aiguo, Peter J. Lamb, Kevin E. Trenberth, Mike Hulme, Philip D. Jones, and Pingping Xie. 2004. The recent Sahel drought is real. International Journal of Climatology 24: 1323–31. [Google Scholar] [CrossRef]
- Demarée, G. R. 1990. An indication of climatic change as seen from the rainfall data of a Mauritanian station. Theoretical and Applied Climatology 42: 139–47. [Google Scholar] [CrossRef]
- Doan, Thomas A. 2007. RATS Version 7: User’s Guide and Reference Manual. 2 vols. Evanston: Estima. [Google Scholar]
- Doornik, Jurgen A. 2008. Encompassing and automatic model selection. Oxford Bulletin of Economics and Statistics 70: 915–25. [Google Scholar] [CrossRef]
- Doornik, Jurgen A. 2009. Autometrics. In The Methodology and Practice of Econometrics: A Festschrift in Honour of David F. Hendry. Edited by Jennifer L. Castle and Neil Shephard. Oxford: Oxford University Press, chp. 4. pp. 88–121. [Google Scholar]
- Doornik, Jurgen A., and David F. Hendry. 2018. PcGive 15. 3 vols. Richmond: Timberlake Consultants Ltd. [Google Scholar]
- Dore, Mohammed H. I. 2005. Climate change and changes in global precipitation patterns: What do we know? Environment International 31: 1167–81. [Google Scholar] [CrossRef]
- Dore, Mohammed H. I., and Jean-François Lamarche. 2006. Estimating baselines for climate change for less developed countries: The case of the Sahel. Climate Policy 6: 231–40. [Google Scholar] [CrossRef]
- Elliott, Wayne, Winston Moore, and Shernnel Thompson. 2012. Climate change and Atlantic storm activity. Paper presented at the International Symposium on Forecasting, Boston, MA, USA, June 25. [Google Scholar]
- Ericsson, Neil R. 2011a. Improving Global Vector Autoregressions. Draft. Washington, DC: Board of Governors of the Federal Reserve System. [Google Scholar]
- Ericsson, Neil R. 2011b. Justifying empirical macro-econometric evidence in practice. Invited presentation at the online conference Communications with Economists: Current and Future Trends commemorating the 25th Anniversary of the Journal of Economic Surveys, 16–18 November 2011. Available online: https://joesonlineconference.files.wordpress.com/2011/11/hendry-commentary-ericsson.pdf (accessed on 8 November 2022).
- Ericsson, Neil R. 2012. Detecting Crises, Jumps, and Changes in Regime. Draft. Washington, DC: Board of Governors of the Federal Reserve System. [Google Scholar]
- Ericsson, Neil R. 2016. Eliciting GDP forecasts from the FOMC’s minutes around the financial crisis. International Journal of Forecasting 32: 571–83. [Google Scholar] [CrossRef] [Green Version]
- Ericsson, Neil R. 2017a. How biased are U.S. government forecasts of the federal debt? International Journal of Forecasting 33: 543–59. [Google Scholar] [CrossRef]
- Ericsson, Neil R. 2017b. Interpreting estimates of forecast bias. International Journal of Forecasting 33: 563–68. [Google Scholar] [CrossRef]
- Ericsson, Neil R., and Erica L. Reisman. 2012. Evaluating a global vector autoregression for forecasting. International Advances in Economic Research 18: 247–58. [Google Scholar] [CrossRef]
- Ericsson, Neil R., David F. Hendry, and Kevin M. Prestwich. 1998. The demand for broad money in the United Kingdom, 1878–1993. Scandinavian Journal of Economics 100: 289–324, With discussion. [Google Scholar] [CrossRef]
- Fisher, Ronald A. 1922. The goodness of fit of regression formulae, and the distribution of regression coefficients. Journal of the Royal Statistical Society 85: 597–612. [Google Scholar] [CrossRef]
- Gamber, Edward N., and Jeffrey P. Liebner. 2017. Comment on ‘How biased are US government forecasts of the federal debt?’. International Journal of Forecasting 33: 560–62. [Google Scholar] [CrossRef]
- Grassi, Stefano, Eric Hillebrand, and Daniel Ventosa-Santaularia. 2013. The statistical relation of sea-level and temperature revisited. Dynamics of Atmospheres and Oceans 64: 1–9. [Google Scholar] [CrossRef] [Green Version]
- Handloff, Robert E., ed. 1990. Mauritania: A Country Study, 2nd ed. Washington, DC: Federal Research Division, Library of Congress. [Google Scholar]
- Hansen, Bruce E. 1992. Testing for parameter instability in linear models. Journal of Policy Modeling 14: 517–33. [Google Scholar] [CrossRef]
- Hendry, David F. 1999. An econometric analysis of US food expenditure, 1931–1989. In Methodology and Tacit Knowledge: Two Experiments in Econometrics. Edited by Jan R. Magnus and Mary S. Morgan. Chichester: John Wiley and Sons, chp. 17. pp. 341–61. [Google Scholar]
- Hendry, David F. 2011. Climate change: Lessons for our future from the distant past. In The Political Economy of the Environment: An Interdisciplinary Approach. Edited by Simon Dietz, Jonathan Michie and Christine Oughton. Abington: Routledge, chp. 2. pp. 19–43. [Google Scholar]
- Hendry, David F. 2015. Introductory Macro-econometrics: A New Approach. London: Timberlake Consultants Ltd. [Google Scholar]
- Hendry, David F. 2020. First In, First Out: Econometric Modelling of UK Annual CO2 Emissions, 1860–2017. Economics Discussion Paper no. 2020–W02. Oxford: Nuffield College, University of Oxford. [Google Scholar]
- Hendry, David F., and Jurgen A. Doornik. 2014. Empirical Model Discovery and Theory Evaluation: Automatic Selection Methods in Econometrics. Cambridge: MIT Press. [Google Scholar]
- Hendry, David F., and Søren Johansen. 2015. Model discovery and Trygve Haavelmo’s legacy. Econometric Theory 31: 93–114. [Google Scholar] [CrossRef] [Green Version]
- Hendry, David F., and Hans-Martin Krolzig. 1999. Improving on ‘Data mining reconsidered’ by K. D. Hoover and S. J. Perez. Econometrics Journal 2: 202–19. [Google Scholar] [CrossRef]
- Hendry, David F., and Hans-Martin Krolzig. 2001. Automatic Econometric Model Selection Using PcGets 1.0. London: Timberlake Consultants Press. [Google Scholar]
- Hendry, David F., and Hans-Martin Krolzig. 2005. The properties of automatic Gets modelling. Economic Journal 115: C32–C61. [Google Scholar] [CrossRef]
- Hendry, David F., and Feliz Pretis. 2013. Anthropogenic influences on atmospheric CO2. In Handbook on Energy and Climate Change. Edited by Roger Fouquet. Cheltenham: Edward Elgar, chp. 12. pp. 287–326. [Google Scholar]
- Hendry, David F., and Jean-François Richard. 1982. On the formulation of empirical models in dynamic econometrics. Journal of Econometrics 20: 3–33. [Google Scholar] [CrossRef]
- Hendry, David F., and Jean-François Richard. 1983. The econometric analysis of economic time series. International Statistical Review 51: 111–148, With discussion. [Google Scholar] [CrossRef]
- Hendry, David F., and Carlos Santos. 2010. An automatic test of super exogeneity. In Volatility and Time Series Econometrics: Essays in Honor of Robert F. Engle. Edited by Tim Bollerslev, Jeffrey R. Russell and Mark W. Watson. Oxford: Oxford University Press, chp. 12. pp. 164–93. [Google Scholar]
- Hendry, David F., Søren Johansen, and Carlos Santos. 2008. Automatic selection of indicators in a fully saturated regression. Computational Statistics 23: 317–35, 337–39. [Google Scholar] [CrossRef] [Green Version]
- Hillebrand, Eric, Felix Pretis, and Tommaso Proietti. 2020. Special issue: Econometric models of climate change. Journal of Econometrics, 214. [Google Scholar]
- Hillebrand, Eric, Søren Johansen, and Torben Schmith. 2020. Data revisions and the statistical relation of global mean sea level and surface temperature. Econometrics 8: 19. [Google Scholar] [CrossRef]
- Hoover, Kevin D., and Stephen J. Perez. 1999. Data mining reconsidered: Encompassing and the general-to-specific approach to specification search. Econometrics Journal 2: 167–91, With discussion. [Google Scholar] [CrossRef]
- Hoover, Kevin D., and Stephen J. Perez. 2004. Truth and robustness in cross-country growth regressions. Oxford Bulletin of Economics and Statistics 66: 765–98. [Google Scholar] [CrossRef] [Green Version]
- Hulme, Mike. 1996. Recent climatic change in the world’s drylands. Geophysical Research Letters 23: 61–64. [Google Scholar] [CrossRef]
- Hulme, Mike, Timothy J. Osborn, and Timothy C. Johns. 1998. Precipitation sensitivity to global warming: Comparison of observations with HadCM2 simulations. Geophysical Research Letters 25: 3379–82. [Google Scholar] [CrossRef]
- IHS Global Inc. 2022. EViews Version 12. Irvine: IHS Global Inc. Available online: www.eviews.com (accessed on 8 November 2022).
- Jackson, Luke P., Katarina Juselius, Andrew B. Martinez, and Felix Pretis. 2021. Modeling the Interconnectivity of Non-Stationary Polar Ice Sheets. Working Paper. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3912725 (accessed on 8 November 2022).
- Johansen, Søren, and Bent Nielsen. 2009. An analysis of the indicator saturation estimator as a robust regression estimator. In The Methodology and Practice of Econometrics: A Festschrift in Honour of David F. Hendry. Edited by Jennifer L. Castle and Neil Shephard. Oxford: Oxford University Press, chp. 1. pp. 1–36. [Google Scholar]
- Johansen, Søren, and Bent Nielsen. 2013. Outlier detection in regression using an iterated one-step approximation to the Huber-skip estimator. Econometrics 1: 53–70. [Google Scholar] [CrossRef] [Green Version]
- Johansen, Søren, and Bent Nielsen. 2016. Asymptotic theory of outlier detection algorithms for linear time series regression models. Scandinavian Journal of Statistics 43: 321–81, With discussion and rejoinder. [Google Scholar] [CrossRef]
- Jones, Philip D., and Mike Hulme. 1996. Calculating regional climatic time series for temperature and precipitation: Methods and illustrations. International Journal of Climatology 16: 361–77. [Google Scholar] [CrossRef]
- Krolzig, Hans-Martin, and David F. Hendry. 2001. Computer automation of general-to-specific model selection procedures. Journal of Economic Dynamics and Control 25: 831–66. [Google Scholar] [CrossRef] [Green Version]
- Lamb, Evelyn. 2012. 5 sigma what’s that? Scientific American. Observations. Available online: https://blogs.scientificamerican.com/observations/five-sigmawhats-that/ (accessed on 8 November 2022).
- Marczak, Martyna, and Tommaso Proietti. 2016. Outlier detection in structural time series models: The indicator saturation approach. International Journal of Forecasting 32: 180–202. [Google Scholar] [CrossRef] [Green Version]
- Martinez, Andrew B. 2020. Forecast accuracy matters for hurricane damage. Econometrics 8: 18. [Google Scholar] [CrossRef]
- McShane, Blakeley B., and Abraham J. Wyner. 2011. A statistical analysis of multiple temperature proxies: Are reconstructions of surface temperatures over the last 1000 years reliable? Annals of Applied Statistics 5: 5–123, With discussion and rejoinder. [Google Scholar]
- Morana, Claudio. 2020. Special topic: Econometric analysis of climate change. Econometrics, 8. [Google Scholar]
- Morana, Claudio, and Giacomo Sbrana. 2019. Climate change implications for the catastrophe bonds market: An empirical analysis. Economic Modelling 81: 274–94. [Google Scholar] [CrossRef]
- Murray-Lee, Maggie. 1988. Mauritania: Expansion of the Desert. New York: UNICEF. Available online: http://www.country-data.com/cgi-bin/query/r-8508.html (accessed on 8 November 2022).
- Mwale, Davidson, Thian Yew Gan, and Samuel S. P. Shen. 2004. A new analysis on variability and predictability of seasonal rainfall of Central Southern Africa. International Journal of Climatology 24: 1509–30. [Google Scholar] [CrossRef]
- National Center for Atmospheric Research. 2022. Climate Data: Palmer Drought Severity Index (PDSI). Boulder: UCAR. Available online: climatedataguide.ucar.edu/climate-data/palmer-drought-severity-index-pdsi (accessed on 8 November 2022).
- Nicholson, S. E., B. Some, and B. Kane. 2000. An analysis of recent rainfall conditions in West Africa, including the rainy seasons of the 1997 El Niño and the 1998 La Niña years. Journal of Climate 13: 2628–40. [Google Scholar] [CrossRef]
- Nielsen, Bent, and Matthias Qian. 2022. Asymptotic Properties of the Gauge of Step-Indicator Saturation. Draft. Oxford: Nuffield College, University of Oxford. [Google Scholar]
- Nouaceur, Zeineddine, and Ovidiu Murarescu. 2020. Rainfall variability and trend analysis of rainfall in West Africa (Senegal, Mauritania, Burkina Faso). Water 12: 1754. [Google Scholar] [CrossRef]
- Ntale, Henry K., and Thian Yew Gan. 2003. Drought indices and their application to East Africa. International Journal of Climatology 23: 1335–57. [Google Scholar] [CrossRef]
- Nyblom, Jukka. 1989. Testing for the constancy of parameters over time. Journal of the American Statistical Association 84: 223–30. [Google Scholar] [CrossRef]
- Palmer, Wayne C. 1965. Meteorolgical Drought. Research Paper no. 45. Washington, DC: Office of Climatology, U.S. Weather Bureau, U.S. Department of Commerce. Available online: www.droughtmanagement.info/literature/USWB_Meteorological_Drought_1965.pdf (accessed on 8 November 2022).
- Peterson, Thomas C., and Russell S. Vose. 1997. An overview of the global historical climatology network temperature database. Bulletin of the American Meteorological Society 78: 2837–49. [Google Scholar] [CrossRef]
- Phillips, Peter C. B. 2020. Dynamic panel modeling of climate change. Econometrics 8: 30. [Google Scholar] [CrossRef]
- Plackett, R. L. 1950. Some theorems in least squares. Biometrika 37: 149–57. [Google Scholar] [CrossRef]
- Pretis, Felix. 2020. Econometric modelling of climate systems: The equivalence of energy balance models and cointegrated vector autoregressions. Journal of Econometrics 214: 256–73. [Google Scholar] [CrossRef]
- Pretis, Felix, J. James Reade, and Genaro Sucarrat. 2018. Automated general-to-specific (GETS) regression modeling and indicator saturation for outliers and structural breaks. Journal of Statistical Software 86: 44. [Google Scholar] [CrossRef]
- Pretis, Felix, Lea Schneider, Jason E. Smerdon, and David F. Hendry. 2016. Detecting volcanic eruptions in temperature reconstructions by designed break-indicator saturation. Journal of Economic Surveys 30: 403–29. [Google Scholar] [CrossRef]
- Proietti, Tommaso, and Eric Hillebrand. 2017. Seasonal changes in Central England temperatures. Journal of the Royal Statistical Society, Series A 180: 769–91. [Google Scholar] [CrossRef]
- Rojas, Oscar, Yanyun Li, and Renato Cumani. 2014. Understanding the Drought Impact of El Nino on the Global Agricultural Areas: An Assessment Using FAO’s Agricultural Stress Index (ASI). Rome: Food and Agriculture Organization of the United Nations. [Google Scholar]
- United Nations. 1992. United Nations Framework Convention on Climate Change. New York: United Nations. [Google Scholar]
- United Nations Development Programme. 2015. Human Development Report 2015. New York: United Nations. [Google Scholar]
- White, Halbert. 1990. A consistent model selection procedure based on m-testing. In Modelling Economic Series: Readings in Econometric Methodology. Edited by Clive W. J. Granger. Oxford: Oxford University Press, chp. 16. pp. 369–83. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Focus of Test Statistic | References |
|---|---|
| Covariance equality | Fisher (1922) |
| Recursive estimates | Plackett (1950) |
| Forecast errors | Chow (1960) |
| Single unknown breakpoint in regression coefficients | Nyblom (1989); Andrews (1993), Hansen (1992) |
| Multiple unknown breakpoints in the intercept | Bai and Perron (1998) |
| Arbitrary unknown impulse breaks (impulse indicator saturation) | Hendry (1999), Hendry et al. (2008), Johansen and Nielsen (2009) |
| Arbitrary unknown step breaks (step indicator saturation) | Castle et al. (2015) |
| Step, trend, and coefficient breaks (super saturation, ultra saturation, and multi-saturation) | Ericsson (2011b) |
| Station’s Location | Sample Period | Number of Observations | Average Monthly Rainfall (mm) | Maximum Monthly Rainfall (mm) | Standard Deviation of Monthly Rainfall (mm) |
|---|---|---|---|---|---|
| Aioun el Atrouss | 1946–2011 | 673 | 20.4 | 245 | 37.9 |
| Akjoujt | 1931–2011 | 749 | 7.0 | 131 | 17.2 |
| Aleg | 1921–1997 | 918 | 20.6 | 290 | 40.8 |
| Atar | 1921–2009 | 907 | 7.0 | 121 | 15.3 |
| Bir Moghrein | 1942–2003 | 622 | 3.3 | 74 | 10.0 |
| Boghe | 1919–1997 | 941 | 23.7 | 310 | 44.0 |
| Boutilimit | 1921–2009 | 944 | 13.6 | 200 | 28.5 |
| Chinguetti | 1931–1997 | 774 | 4.4 | 99 | 10.4 |
| F’Derik | 1938–1997 | 685 | 4.2 | 117 | 11.9 |
| Kaedi | 1905–1997 | 956 | 31.2 | 364 | 56.4 |
| Kiffa | 1922–2011 | 944 | 25.5 | 325 | 47.6 |
| Moudjeria | 1911–1997 | 955 | 16.7 | 229 | 34.2 |
| Nema | 1922–2011 | 963 | 21.1 | 205 | 35.8 |
| Nouadhibou | 1906–2011 | 1137 | 1.8 | 83 | 5.8 |
| Nouakchott | 1930–2011 | 845 | 9.7 | 191 | 23.7 |
| Rosso | 1934–2011 | 754 | 21.9 | 498 | 45.9 |
| Tichitt | 1921–1997 | 826 | 6.4 | 102 | 14.2 |
| Tidjikja | 1907–2011 | 980 | 10.8 | 173 | 22.7 |
| Model Description | ||||
|---|---|---|---|---|
| Regressor or Diagnostic Statistic | Baseline AR(2) | Baseline AR(2), with Forecasts for 1971–1997 | AR(2) with IIS (1%) | AR(2) with Super Satur-ation (1%) |
| Estimation Sample | 1921–1997 | 1921–1970 | 1921–1997 | 1921–1997 |
| Intercept | 81.1 (20.6) | 201.5 (40.1) | 78.7 (18.9) | 191.8 (25.6) |
| 0.37 (0.12) | −0.08 (0.15) | 0.44 (0.11) | 0.11 (0.10) | |
| 0.12 (0.11) | −0.02 (0.15) | 0.05 (0.10) | −0.16 (0.10) | |
| — | — | 129.1 (42.4) | 104.8 (37.1) | |
| — | — | 115.4 (43.0) | — | |
| — | — | — | −72.6 (12.7) | |
| — | — | — | 68.9 (20.7) | |
| AR(2) statistic | 1.59 [0.2118] F(2,72) | 2.30 [0.1121] F(2,45) | 0.96 [0.3884] F(2,70) | 0.40 [0.6735] F(2,69) |
| ARCH(1) statistic | 0.01 [0.9437] F(1,75) | 0.02 [0.9003] F(1,48) | 0.50 [0.4812] F(1,75) | 0.15 [0.6988] F(1,75) |
| Normality statistic | 1.30 [0.5218] (2) | 0.75 [0.6860] (2) | 0.87 [0.6481] (2) | 0.27 [0.8738] (2) |
| Heteroscedasticity statistic #1 | 2.48 [0.0511] F(4,72) | 1.63 [0.1843] F(4,45) | 1.29 [0.2824] F(4,70) | 1.74 [0.1254] F(6,69) |
| Heteroscedasticity statistic #2 | 2.70 [0.0273] F(5,71) | 1.86 [0.1214] F(5,44) | 1.21 [0.3126] F(5,69) | 1.52 [0.1758] F(7,68) |
| RESET statistic | 0.78 [0.4633] F(2,72) | 0.29 [0.7520] F(2,45) | 0.97 [0.3858] F(2,70) | 0.84 [0.4361] F(2,69) |
| Number of Breaks | Schwarz | LWZ | F(m) | F(m ∣ m − 1) |
|---|---|---|---|---|
| 0 | 7.77 | 7.90 | — | — |
| 1 | <7.59> | <7.84> | 9.96 | 9.96 |
| 2 | 7.65 | 8.03 | 6.61 | 2.60 |
| 3 | 7.73 | 8.24 | 5.34 | 2.14 |
| 4 | 7.77 | 8.42 | 5.00 | 2.72 |
| 5 | 7.82 | 8.60 | 4.78 | 2.46 |
| 6 | 7.86 | 8.78 | 4.73 | 2.58 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ericsson, N.R.; Dore, M.H.I.; Butt, H. Detecting and Quantifying Structural Breaks in Climate. Econometrics 2022, 10, 33. https://doi.org/10.3390/econometrics10040033
Ericsson NR, Dore MHI, Butt H. Detecting and Quantifying Structural Breaks in Climate. Econometrics. 2022; 10(4):33. https://doi.org/10.3390/econometrics10040033
Chicago/Turabian StyleEricsson, Neil R., Mohammed H. I. Dore, and Hassan Butt. 2022. "Detecting and Quantifying Structural Breaks in Climate" Econometrics 10, no. 4: 33. https://doi.org/10.3390/econometrics10040033