
On the Bayesian Mixture of Generalized Linear Models with Gamma-Distributed Responses


Abstract
:1. Introduction
2. Materials and Methods
3. Bayesian Approach for the Finite Mixture of GLMs
3.1. Bayesian Framework for Inference
3.2. Bayesian-MCMC Approach
| Algorithm 1: the Gibbs sampler for estimating the finite mixture of the log-link gamma GLMs. |
| A. Determining the initial values for parameters . |
| B. Setting s = s + 1. |
| , |
| where |
| with |
| , |
| . |
| through the Equation (20), |
| , |
| where |
| , |
| is given by (16): for |
| . |
| 3. from the Equation (21), |
| , |
| where |
| . |
| 4. from the full-conditional posterior distribution (22), |
| , |
| , |
| , |
| , |
| where |
| , |
| is given by (17): for |
| . |
| 5. Repeating B sampling steps 1 to 4 until the convergence for all parameters is achieved. |
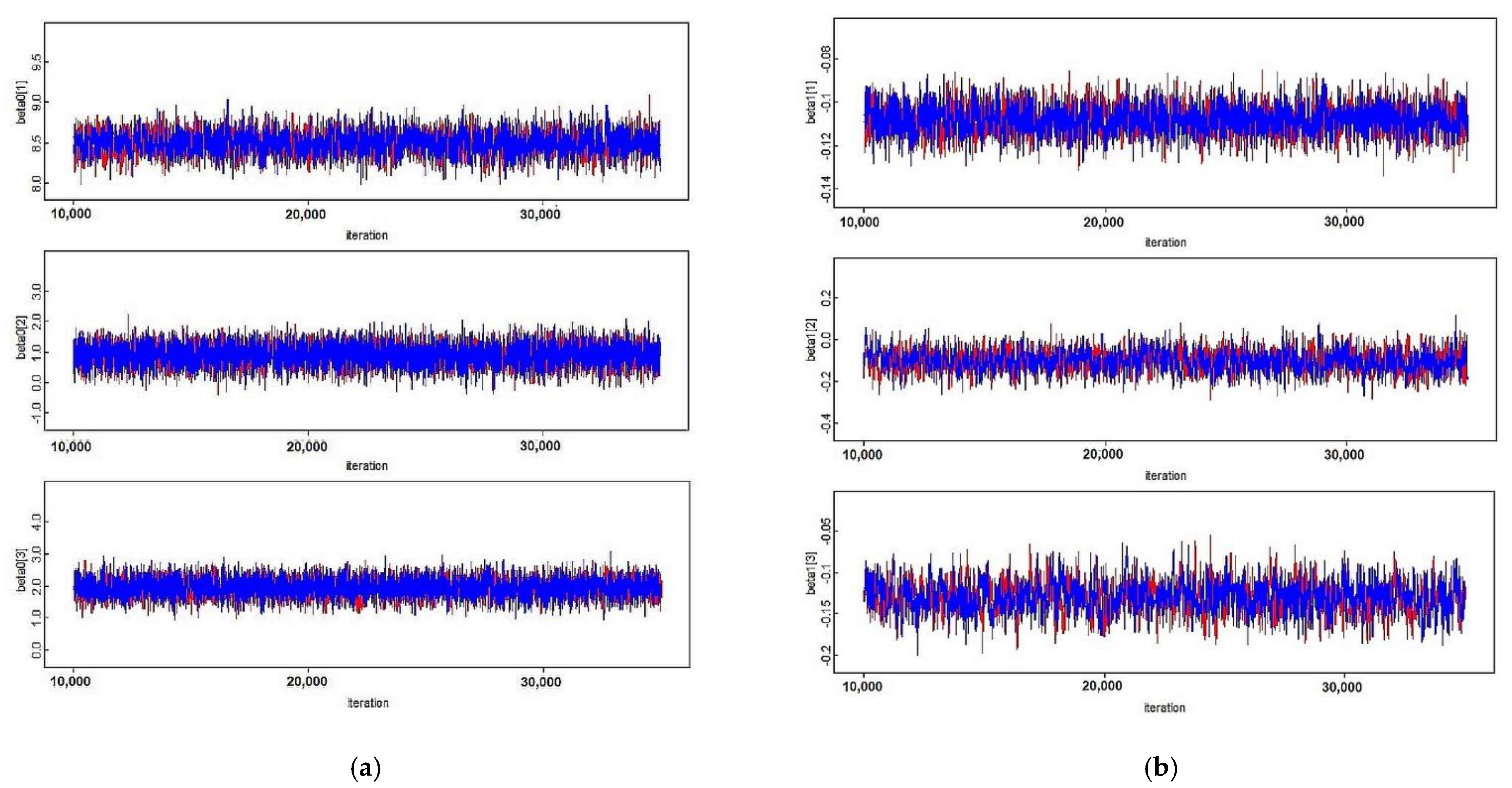
3.3. Convergence Diagnostics
3.4. Model Selection
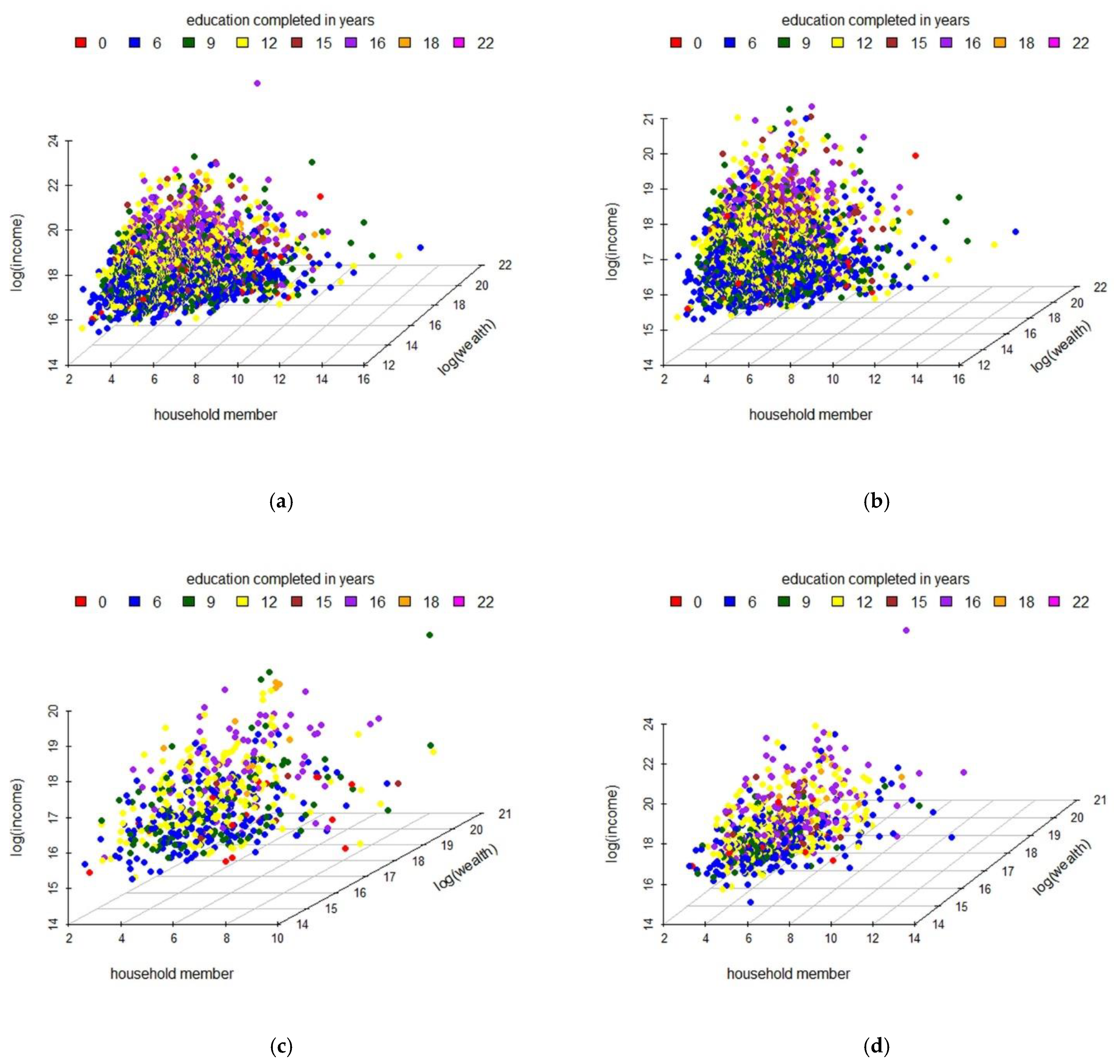
4. Real Data Applications
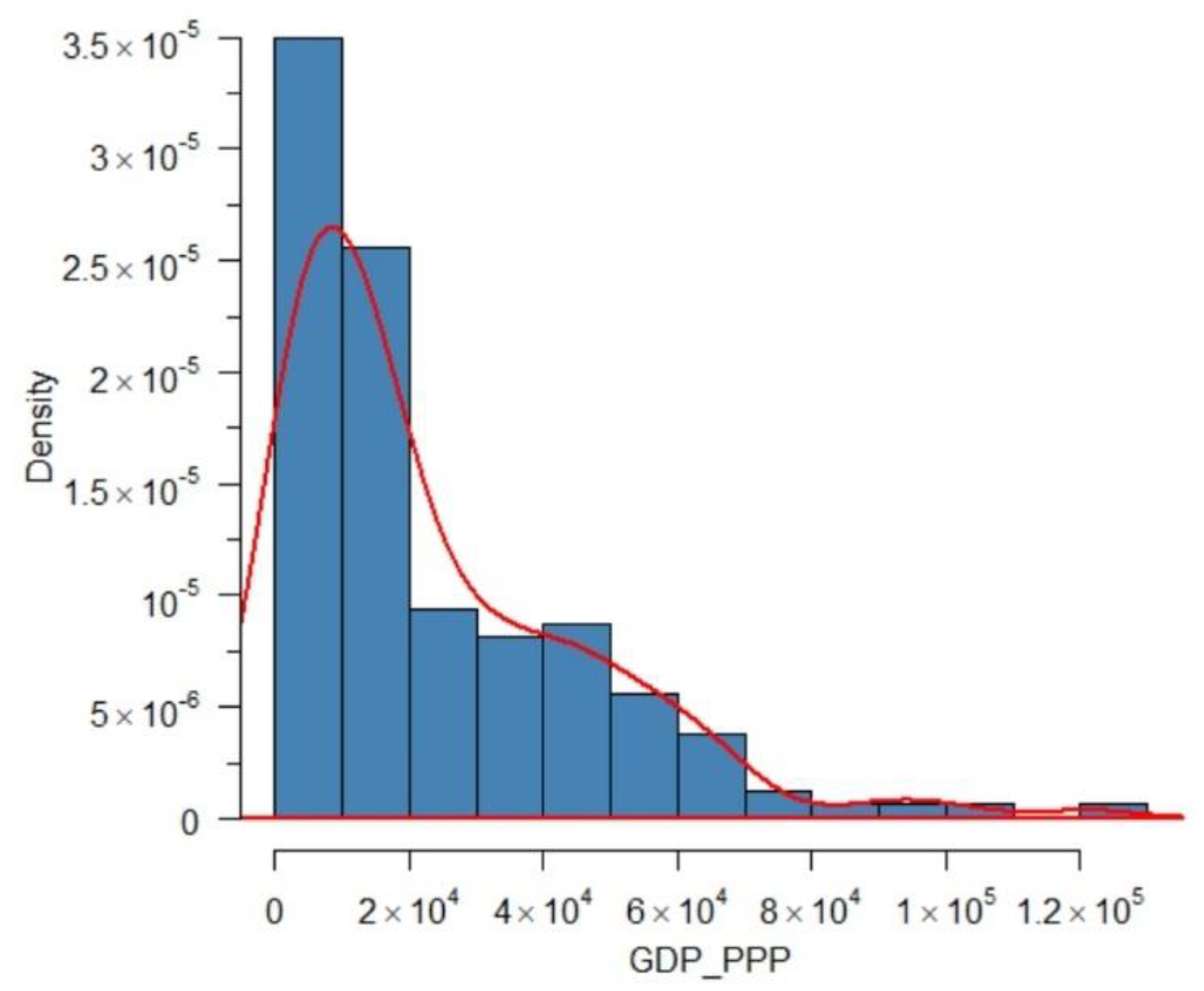
4.1. Modeling GDP_PPP
4.1.1. Data Description
4.1.2. Estimated Parameters
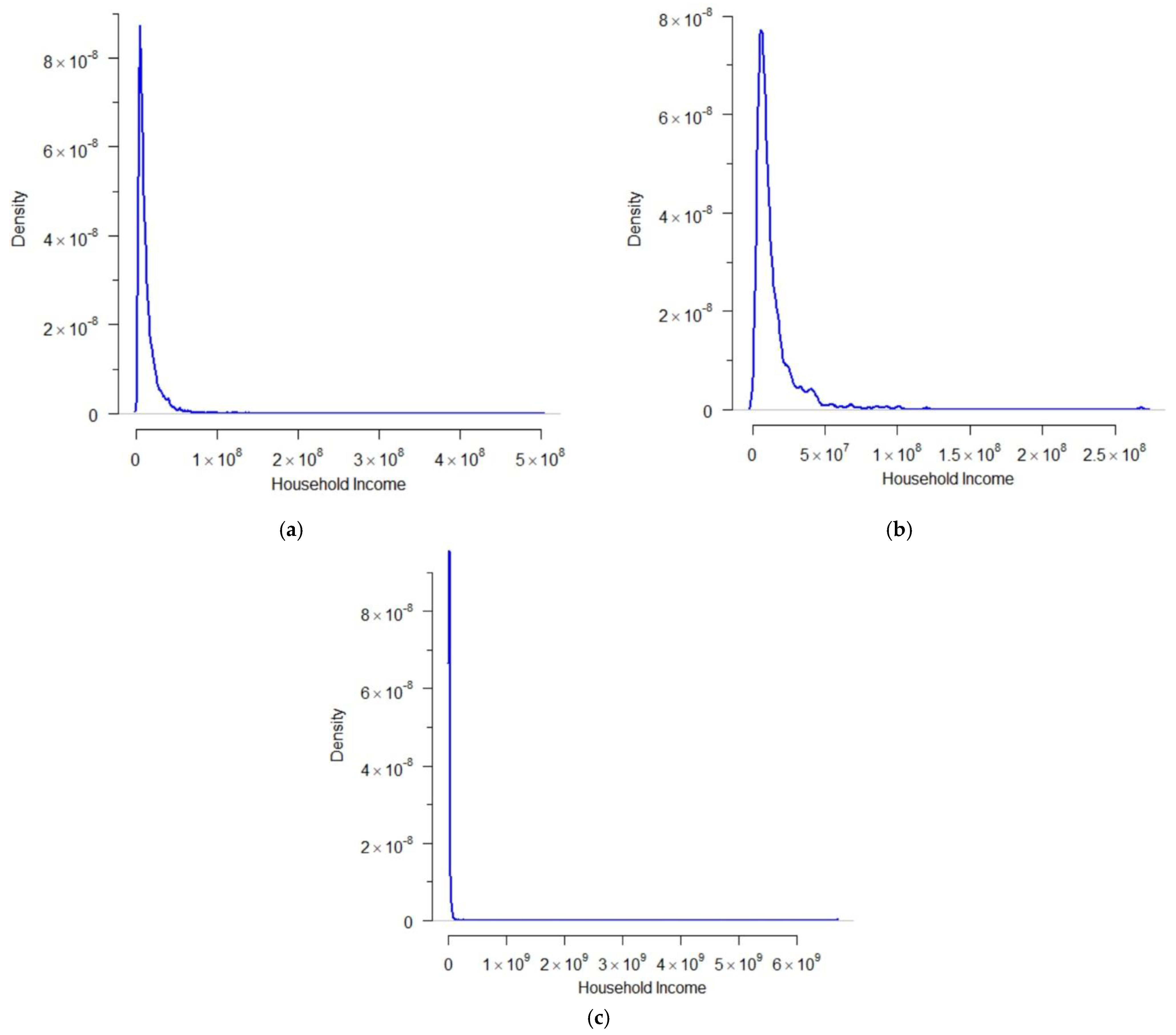
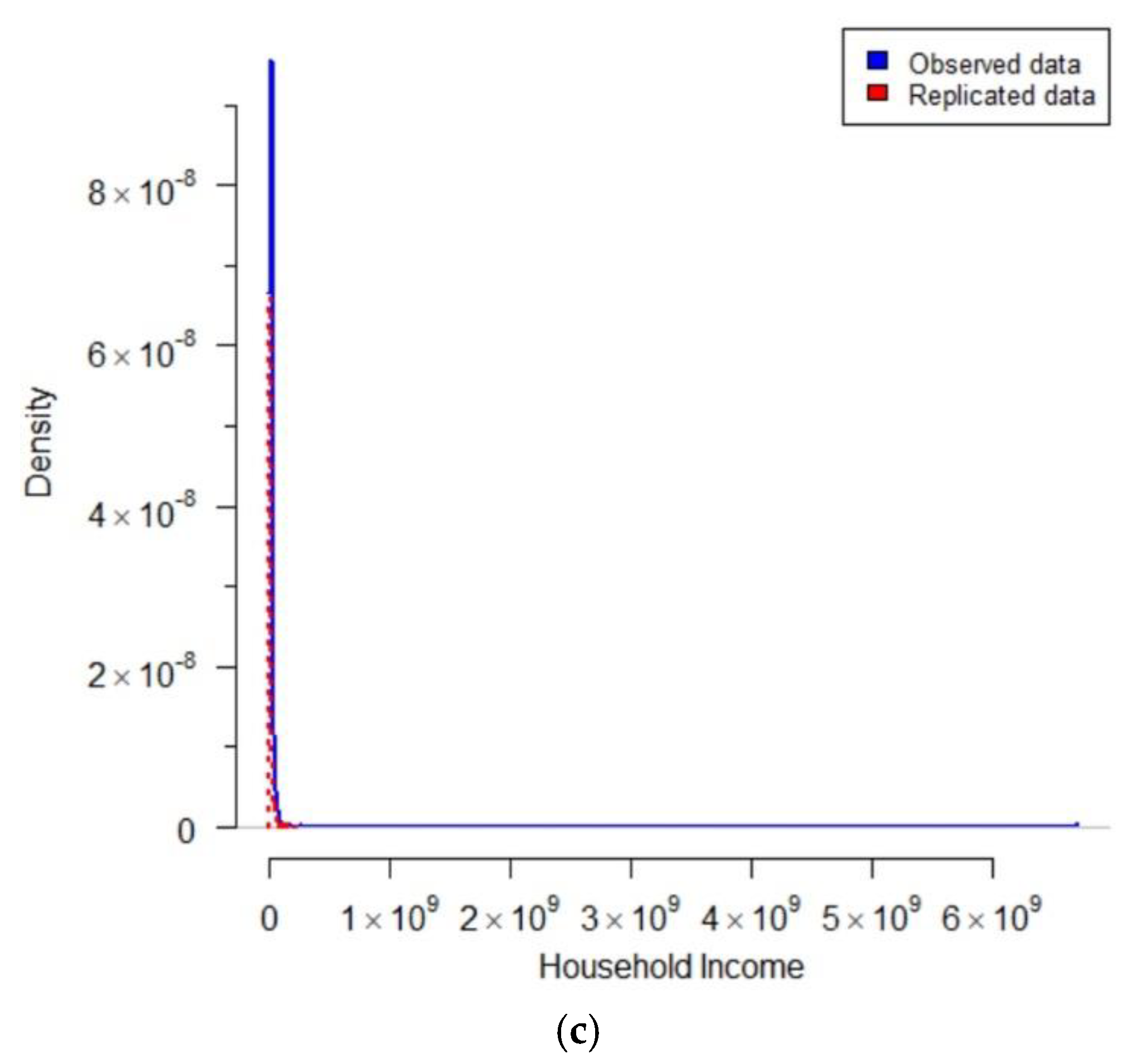
4.2. Modeling Household Income
4.2.1. Data Description
4.2.2. Estimated Parameters
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Groups | Country | ||||||
|---|---|---|---|---|---|---|---|
| Low | Afghanistan | Uganda | Cent. African | Chad | Congo, Dem. | Guinea | Gambia |
| Ethiopia | Guinea-Bissau | Haiti | Togo | Sudan | Malawi | Sierra Leone | |
| Rwanda | Mali | Madagascar | Tajikistan | Liberia | Burkina Faso | ||
| Lower- middle | Albania | Algeria | Bangladesh | Benin | Bolivia | Cabo Verde | Cameroon |
| Comoros | Congo, Rep. | Cote d’Ivoire | Djibouti | Egypt | El Salvador | Eswatini | |
| Ghana | Honduras | India | Kenya | Kyrgyz | Lao PDR | Lesotho | |
| Mauritania | Moldova | Mongolia | Morocco | Myanmar | Nepal | Nicaragua | |
| Nigeria | Pakistan | Philippines | Sao Tome Pr. | Senegal | Sri Lanka | Tanzania | |
| Timor-Leste | Tunisia | Ukraine | Uzbekistan | Vietnam | Zambia | Zimbabwe | |
| Upper- middle | Angola | Argentina | Armenia | Azerbaijan | Belarus | Bosnia | Brazil |
| Bulgaria | China | Colombia | Costa Rica | Dominica | Dominican | Ecuador | |
| Eq. Guinea | Gabon | Georgia | Grenada | Guatemala | Guyana | Indonesia | |
| Iran | Iraq | Jamaica | Jordan | Kazakhstan | Lebanon | Libya | |
| Malaysia | Maldives | Mexico | Montenegro | Namibia | N. Macedonia | Paraguay | |
| Peru | Russian Fed. | Serbia | South Africa | St. Lucia | St. Vincent G | Suriname | |
| Thailand | Turkey | ||||||
| High | Australia | Austria | Bahamas, The | Bahrain | Barbados | Belgium | Brunei Dar. |
| Germany | Chile | Croatia | Cyprus | Czech | Denmark | Luxembourg | |
| Finland | Spain | Canada | Uruguay | Hong Kong | Hungary | Iceland | |
| Ireland | Israel | Italy | Japan | Korea, Rep. | Kuwait | Latvia | |
| Lithuania | Estonia | Seychelles | Mauritius | Netherlands | New Zealand | Norway | |
| Oman | Panama | Poland | Portugal | Qatar | Romania | Saudi Arabia | |
| Malta | Singapore | Slovak Rep. | Slovenia | France | Sweden | Switzerland | |
| Trinidad and Tobago | United Arab Emirates | United Kingdom | United States | Greece | |||
References
- Alisjahbana, Arminda. 2011. Masterplan Percepatan Dan Perluasan Pembangunan Ekonomi Indonesia 2011–2025. Paper presented at the Work Meeting for Acceleration and Expansion of Indonesia Economic Development, Bogor, Indonesia, February 21–22. [Google Scholar]
- Causa, Orsetta, Sonia Araujo, Agnès Cavaciuti, Nicolas Ruiz, and Zuzana Smidova. 2014. Economic Growth from the Household Perspective: GDP and Income Distribution Developments across OECD Countries. April. Available online: https://www.oecd-ilibrary.org/economics/economic-growth-from-the-household-perspective_5jz5m89dh0nt-en (accessed on 3 March 2020).
- Chotikapanich, Duangkamon, William E. Griffiths, D. S. Prasada Rao, and Vicar Valencia. 2012. Global Income Distributions and Inequality, 1993 and 2000: Incorporating Country-Level Inequality Modeled with Beta Distributions. The Review of Economics and Statistics 94: 52–73. [Google Scholar] [CrossRef]
- Coordinating Ministry for Economic Affairs. 2011. Master Plan: Acceleration and Expansion of Indonesia Economic Development, 2011–2025; Jakarta: Ministry of National Development Planning/National Development Planning Agency.
- Corrales, Marta Lucia, and Edilberto Cepeda-Cuervo. 2019. A Bayesian Approach to Mixed Gamma Regression Models. Revista Colombiana de Estadística 42: 81–99. [Google Scholar] [CrossRef]
- Cowell, Frank A., and Emmanuel Flachaire. 2015. Chapter 6—Statistical Methods for Distributional Analysis. In Handbook of Income Distribution. Edited by Anthony B. Atkinson and François Bourguignon. Amsterdam: Elsevier, vol. 2, pp. 359–465. [Google Scholar] [CrossRef] [Green Version]
- Cowles, Mary Kathryn, and Bradley P. Carlin. 1996. Markov Chain Monte Carlo Convergence Diagnostics: A Comparative Review. Journal of the American Statistical Association 91: 883–904. [Google Scholar] [CrossRef]
- Diebolt, Jean, and Christian P. Robert. 1994. Estimation of Finite Mixture Distributions Through Bayesian Sampling. Journal of the Royal Statistical Society: Series B (Methodological) 56: 363–75. [Google Scholar] [CrossRef]
- Faraway, Julian J. 2016. Extending the Linear Model with R: Generalized Linear, Mixed Effects and Nonparametric Regression Models, 2nd ed. New York: Chapman and Hall/CRC. [Google Scholar] [CrossRef]
- Frühwirth-Schnatter, Sylvia. 2006. Finite Mixture and Markov Switching Models. New York: Springer Science & Business Media. [Google Scholar]
- Fu, Luyang, and Richard B. Moncher. 2004. Severity Distributions for GLMs: Gamma or Lognormal? Evidence from Monte Carlo Simulations. In Casualty Actuarial Society Discussion Paper Program. Arlington: Casualty Actuarial Society, pp. 149–230. [Google Scholar]
- Garrido, Liliana, and Edilberto Cepeda. 2012. Mixture of Distributions in the Biparametric Exponential Family: A Bayesian Approach. Communications in Statistics-Simulation and Computation 41: 355–75. [Google Scholar] [CrossRef]
- Garrido, Liliana, and Edilberto C. Cuervo. 2014. Heteroscedastic Weibull-Normal Mixture Models: A Bayesian Approach. Communications in Statistics-Theory and Methods 43: 249–65. [Google Scholar] [CrossRef]
- Gelman, Andrew, Aleks Jakulin, Maria Grazia Pittau, and Yu-Sung Su. 2008. A Weakly Informative Default Prior Distribution for Logistic and Other Regression Models. The Annals of Applied Statistics 2: 1360–83. [Google Scholar] [CrossRef]
- Gelman, Andrew, and Kenneth Shirley. 2011. Inference from Simulations and Monitoring Convergence. In Handbook of Markov Chain Monte Carlo. Boca Raton: CRC Press. [Google Scholar] [CrossRef]
- Gelman, Andrew, Daniel Simpson, and Michael Betancourt. 2017. The Prior Can Often Only Be Understood in the Context of the Likelihood. Entropy 19: 555. [Google Scholar] [CrossRef] [Green Version]
- Gelman, Andrew, Jessica Hwang, and Aki Vehtari. 2014. Understanding Predictive Information Criteria for Bayesian Models. Statistics and Computing 24: 997–1016. [Google Scholar] [CrossRef]
- Gelman, Andrew, John B. Carlin, Hal S. Stern, David B. Dunson, Aki Vehtari, and Donald B. Rubin. 2013. Bayesian Data Analysis, 3rd ed. New York: Chapman and Hall/CRC. [Google Scholar] [CrossRef]
- Goudie, Robert J. B., Rebecca M. Turner, Daniela De Angelis, and Andrew Thomas. 2020. MultiBUGS: A Parallel Implementation of the BUGS Modeling Framework for Faster Bayesian Inference. Journal of Statistical Software 95: 1–20. [Google Scholar] [CrossRef]
- Grün, Bettina, and Friedrich Leisch. 2008. Finite Mixtures of Generalized Linear Regression Models. In Recent Advances in Linear Models and Related Areas: Essays in Honour of Helge Toutenburg. Edited by Shalabh and Christian Heumann. Heidelberg: Physica-Verlag HD, pp. 205–30. [Google Scholar] [CrossRef] [Green Version]
- Hubert, Mia, and Ellen Vandervieren. 2008. An Adjusted Boxplot for Skewed Distributions. Computational Statistics & Data Analysis 52: 5186–5201. [Google Scholar] [CrossRef]
- Hurn, Merrilee, Ana Justel, and Christian P. Robert. 2003. Estimating Mixtures of Regressions. Journal of Computational and Graphical Statistics 12: 55–79. [Google Scholar] [CrossRef]
- Iriawan, Nur, Kartika Fithriasari, Brodjol S. S. Ulama, Irwan Susanto, Wahyuni Suryaningtyas, and Anindya A. Pravitasari. 2019. On the Markov Chain Monte Carlo Convergence Diagnostic of Bayesian Bernoulli Mixture Regression Model for Bidikmisi Scholarship Classification. In Proceedings of the Third International Conference on Computing, Mathematics and Statistics (ICMS2017). Edited by Liew-Kee Kor, Abd-Razak Ahmad, Zanariah Idrus and Kamarul Ariffin Mansor. Singapore: Springer, pp. 397–403. [Google Scholar] [CrossRef]
- Iriawan, Nur, Kartika Fithriasari, Brodjol S. S. Ulama, Wahyuni Suryaningtyas, Irwan Susanto, and Anindya A. Pravitasari. 2018. Bayesian Bernoulli Mixture Regression Model for Bidikmisi Scholarship Classification. Jurnal Ilmu Komputer Dan Informasi 11: 67–76. [Google Scholar] [CrossRef]
- Klebanov, Lev B., and Irina Volchenkova. 2019. Outliers and the Ostensibly Heavy Tails. Mathematical Methods of Statistics 28: 74–81. [Google Scholar] [CrossRef]
- Lemoine, Nathan P. 2019. Moving beyond Noninformative Priors: Why and How to Choose Weakly Informative Priors in Bayesian Analyses. Oikos 128: 912–28. [Google Scholar] [CrossRef] [Green Version]
- Lenk, Peter J., and Wayne S. DeSarbo. 2000. Bayesian Inference for Finite Mixtures of Generalized Linear Models with Random Effects. Psychometrika 65: 93–119. [Google Scholar] [CrossRef] [Green Version]
- Lopera, Liliana Garrido, Edilberto Cepeda-Cuervo, and Jorge Alberto Achcar. 2011. Heteroscedastic Normal–Exponential Mixture Models: Bayesian and Classical Approaches. Applied Mathematics and Computation 218: 3635–48. [Google Scholar] [CrossRef]
- Lunn, David, Christopher Jackson, Nicky Best, Andrew Thomas, and David Spiegelhalter. 2013. The BUGS Book. In A Practical Introduction to Bayesian Analysis. London: Chapman Hall. [Google Scholar]
- Myers, Raymond H., Douglas C. Montgomery, G. Geoffrey Vining, and Timothy J. Robinson. 2012. Generalized Linear Models: With Applications in Engineering and the Sciences. Hoboken: John Wiley & Sons, vol. 791. [Google Scholar]
- Park, Byung-Jung, and Dominique Lord. 2009. Application of Finite Mixture Models for Vehicle Crash Data Analysis. Accident Analysis & Prevention 41: 683–91. [Google Scholar] [CrossRef] [Green Version]
- Plummer, Martyn, Nicky Best, Kate Cowles, and Karen Vines. 2006. CODA: Convergence Diagnosis and Output Analysis for MCMC. R News 6: 7–11. [Google Scholar]
- Rufo, Maria J., Jacinto Martín, and Carlos J. Pérez. 2006. Bayesian Analysis of Finite Mixture Models of Distributions from Exponential Families. Computational Statistics 21: 621–37. [Google Scholar] [CrossRef]
- Solikhah, Arifatus, Heri Kuswanto, Nur Iriawan, and Kartika Fithriasari. 2021. Fisher’s z Distribution-Based Mixture Autoregressive Model. Econometrics 9: 27. [Google Scholar] [CrossRef]
- Stiglitz, Joseph. 2015. 8. Inequality and Economic Growth. The Political Quarterly 86: 134–55. [Google Scholar] [CrossRef]
- Strauss, John, Firman Witoelar, and Bondan Sikoki. 2016. The Fifth Wave of the Indonesia Family Life Survey: Overview and Field Report. Santa Monica: RAND. [Google Scholar]
- Suryaningtyas, Wahyuni, Nur Iriawan, Kartika Fithriasari, Brodjol Sutija Suprih Ulama, Irwan Susanto, and Anindya Apriliyanti Pravitasari. 2018. On the Bernoulli Mixture Model for Bidikmisi Scholarship Classification with Bayesian MCMC. Journal of Physics: Conference Series 1090: 012072. [Google Scholar] [CrossRef]
- Susanto, Irwan, Nur Iriawan, Heri Kuswanto, and Suhartono. 2019. Bayesian Inference for the Finite Gamma Mixture Model of Income Distribution. Journal of Physics: Conference Series 1217: 012077. [Google Scholar] [CrossRef]
- Tatarinova, Tatiana, and Alan Schumitzky. 2015. Nonlinear Mixture Models: A Bayesian Approach. Singapore: World Scientific. [Google Scholar]
- Transparency.org. 2021. 2019-CPI. Available online: https://www.transparency.org/en/cpi/2019 (accessed on 6 January 2021).
- Watanabe, Sumio. 2010. Asymptotic Equivalence of Bayes Cross Validation and Widely Applicable Information Criterion in Singular Learning Theory. Journal of Machine Learning Research 11: 3571–94. [Google Scholar]
- Wedel, Michel, and Wagner A. Kamakura. 2000. Market Segmentation: Conceptual and Methodological Foundations, 2nd ed. International Series in Quantitative Marketing; New York: Springer. [Google Scholar] [CrossRef]
- Wesner, Jeff S., David L. Swanson, Mark D. Dixon, Daniel A. Soluk, Danielle J. Quist, Lisa A. Yager, Jerry W. Warmbold, Erika Oddy, and Tyler C. Seidel. 2020. Loss of Potential Aquatic-Terrestrial Subsidies Along the Missouri River Floodplain. Ecosystems 23: 111–23. [Google Scholar] [CrossRef]
- Wicaksono, Eko, Hidayat Amir, and Anda Nugroho. 2017. The Sources of Income Inequality in Indonesia: A Regression-Based Inequality Decomposition. Tokyo: Asian Development Bank. Available online: https://www.adb.org/publications/sources-income-inequality-indonesia (accessed on 6 March 2020).
- Wiper, Michael, David Rios Insua, and Fabrizio Ruggeri. 2001. Mixtures of Gamma Distributions with Applications. Journal of Computational and Graphical Statistics 10: 440–54. [Google Scholar] [CrossRef]
- World Bank Open Data. 2021. World Bank Open Data|Data. Available online: https://data.worldbank.org/ (accessed on 11 January 2021).
- World Bank Open Data. 2022. World Bank Open Data|Data. Available online: https://data.worldbank.org/indicator/NY.GDP.PCAP.PP.CD (accessed on 22 February 2022).
- World Bank. 2020. Purchasing Power Parities and the Size of World Economies: Results from the 2017 International Comparison Program. Washington, DC: World Bank. [Google Scholar] [CrossRef]
- World Bank. 2021a. New World Bank Country Classifications by Income Level: 2020–2021. World Bank Blogs. Available online: https://blogs.worldbank.org/opendata/new-world-bank-country-classifications-income-level-2020-2021 (accessed on 11 January 2021).
- World Bank. 2021b. Purchasing Power Parities for Policy Making: A Visual Guide to Using Data from the International Comparison Program. Washington, DC: World Bank. Available online: https://openknowledge.worldbank.org/handle/10986/35736 (accessed on 11 November 2021).













| Data | p-Value | Significant Statistical DISTRIBUTION | |
|---|---|---|---|
| Kolmogorov-Smirnov Test | Chi Squared Test | ||
| whole data | 0.5419 | 0.1989 | Gamma(1.06, 21,722) |
| first group | 0.8673 | 0.8839 | Gamma(7.52, 286.48) |
| second group | 0.5166 | 0.8310 | Gamma(3.97, 1750.3) |
| third group | 0.9198 | 0.6462 | Gamma(9.73, 1733.4) |
| fourth group | 0.9507 | 0.7565 | Gamma(5.90, 8259.4) |
| Mixture Component | Estimated Parameter | Estimated Value | 95% Posterior Credible Interval | PSRF | Prior Distribution | |
|---|---|---|---|---|---|---|
| Lower | Upper | |||||
| First | 4.7110 | 2.3760 | 8.1820 | 1 | ||
| 0.1279 | 0.0813 | 0.1830 | 1 | |||
| 6.0850 | 4.8980 | 7.1260 | 1 | |||
| 0.1373 | 0.0365 | 0.2532 | 1 | |||
| 0.0179 | −0.004 | 0.0455 | 1 | |||
| Second | 4.8840 | 3.0920 | 7.2460 | 1 | ||
| 0.2621 | 0.1977 | 0.3315 | 1 | |||
| 6.4750 | 5.5900 | 7.2510 | 1 | |||
| 0.1354 | 0.0811 | 0.1918 | 1 | |||
| 0.0314 | 0.0109 | 0.0545 | 1 | |||
| Third | 7.500 | 4.7750 | 11.030 | 1 | ||
| 0.2742 | 0.2087 | 0.3488 | 1 | |||
| 8.913 | 8.2900 | 9.4530 | 1 | |||
| 0.0391 | 0.0003 | 0.0787 | 1 | |||
| 0.0106 | 0.0005 | 0.0214 | 1 | |||
| Fourth | 7.4700 | 4.8990 | 10.790 | 1 | ||
| 0.3358 | 0.2650 | 0.4103 | 1 | |||
| 9.0980 | 8.3280 | 9.4530 | 1.01 | |||
| 0.0220 | −0.029 | 0.0768 | 1 | |||
| 0.0221 | 0.0154 | 0.0295 | 1.01 | |||
| Mixture Component | Estimated Parameter | Estimated Value | 95% Posterior Credible Interval | PSRF | Prior Distribution | |
|---|---|---|---|---|---|---|
| Lower | Upper | |||||
| First | 1043 | 820.1 | 1347 | 1 | ||
| 0.2139 | 0.154 | 0.2799 | 1 | |||
| 1180 | 40.68 | 2391 | 1 | |||
| 102.2 | −17.68 | 218.5 | 1 | |||
| 23.82 | −5.616 | 53.78 | 1 | |||
| Second | 3573 | 2917 | 4403 | 1 | ||
| 0.3357 | 0.2661 | 0.4097 | 1 | |||
| 3059 | 1489 | 4665 | 1 | |||
| 311.9 | 163 | 458.4 | 1 | |||
| 108.3 | 64.75 | 151.2 | 1 | |||
| 7644 | 6762 | 7990 | 1 | |||
| 0.2008 | 0.1429 | 0.2648 | 1 | |||
| Third | 4344 | 2515 | 6160 | 1 | ||
| 418.1 | 241.2 | 594 | 1 | |||
| 188.4 | 138 | 238.6 | 1 | |||
| 7963 | 7864 | 7999 | 1 | |||
| 0.2496 | 0.1868 | 0.3183 | 1 | |||
| Fourth | 6617 | 4760 | 8490 | 1 | ||
| 627.4 | 444 | 809 | 1 | |||
| 467.7 | 428.1 | 508 | 1 | |||
| Estimated Parameter | Estimated Value | 95% Posterior Credible Interval | PSRF | Prior Distribution | |
|---|---|---|---|---|---|
| Lower | Upper | ||||
| 2.2160 | 1.7990 | 2.6990 | 1 | ||
| 7.1270 | 6.6560 | 7.5760 | 1 | ||
| 0.0798 | 0.0356 | 0.1251 | 1 | ||
| 0.0413 | 0.0353 | 0.0471 | 1 | ||
| Fitted Model | WAIC |
|---|---|
| Bayesian mixture of the log-link gamma GLMs | 3231 |
| Bayesian mixture of linear regression | 3341 |
| Bayesian gamma regression | 3411 |
| Estimated Parameter and Coefficient | Estimated Value | 95% Posterior Credible Interval | Markov Chain Error | PSRF | |
|---|---|---|---|---|---|
| Lower | Upper | ||||
| 2.2740 | 2.1820 | 2.3670 | 0.0002 | 1 | |
| 0.5182 | 0.4701 | 0.5688 | 0.0001 | 1 | |
| 1.6270 | 1.4690 | 1.7910 | 0.0004 | 1 | |
| 0.7693 | 0.7581 | 0.7804 | 0.0000 | 1 | |
| 0.1058 | 0.0978 | 0.114 | 0.0000 | 1 | |
| 0.1249 | 0.1164 | 0.1338 | 0.0000 | 1 | |
| 8.4930 | 8.2150 | 8.7630 | 0.0029 | 1 | |
| 0.8892 | 0.2691 | 1.5140 | 0.0034 | 1 | |
| 1.9470 | 1.4240 | 2.4710 | 0.0032 | 1 | |
| −0.1080 | −0.1205 | −0.0953 | 0.0001 | 1 | |
| −0.1013 | −0.1993 | −0.0035 | 0.0012 | 1 | |
| −0.1298 | −0.1657 | −0.0926 | 0.0005 | 1 | |
| 0.0321 | 0.0262 | 0.0379 | 0.0000 | 1 | |
| 0.1679 | 0.1315 | 0.2014 | 0.0004 | 1 | |
| 0.0172 | 0.0013 | 0.0332 | 0.0001 | 1 | |
| 0.4710 | 0.4539 | 0.4889 | 0.0001 | 1 | |
| 0.8904 | 0.8375 | 0.9452 | 0.0005 | 1 | |
| 0.8685 | 0.8319 | 0.9049 | 0.0003 | 1 | |
| Estimated Parameter and Coefficient | Estimated Value | 95% Posterior Credible Interval | Markov Chain Error | PSRF | |
|---|---|---|---|---|---|
| Lower | Upper | ||||
| 1.3920 | 1.3440 | 1.4400 | 0.0001 | 1 | |
| 7.6290 | 7.3250 | 7.9360 | 0.0030 | 1 | |
| −0.1092 | −0.1241 | −0.0941 | 0.0001 | 1 | |
| 0.0539 | 0.0472 | 0.0608 | 0.0000 | 1 | |
| 0.5178 | 0.4976 | 0.5375 | 0.0002 | 1 | |
| Fitted Model | WAIC |
|---|---|
| Bayesian mixture of the log-link gamma GLMs | 192,200 |
| Bayesian gamma regression | infinity |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Susanto, I.; Iriawan, N.; Kuswanto, H. On the Bayesian Mixture of Generalized Linear Models with Gamma-Distributed Responses. Econometrics 2022, 10, 32. https://doi.org/10.3390/econometrics10040032
Susanto I, Iriawan N, Kuswanto H. On the Bayesian Mixture of Generalized Linear Models with Gamma-Distributed Responses. Econometrics. 2022; 10(4):32. https://doi.org/10.3390/econometrics10040032
Chicago/Turabian StyleSusanto, Irwan, Nur Iriawan, and Heri Kuswanto. 2022. "On the Bayesian Mixture of Generalized Linear Models with Gamma-Distributed Responses" Econometrics 10, no. 4: 32. https://doi.org/10.3390/econometrics10040032