
Target Localization Method Based on Image Degradation Suppression and Multi-Similarity Fusion in Low-Illumination Environments
 ,
,
Abstract
:1. Introduction
- (1)
- Aiming at the problem that localization accuracy is reduced or even unable to be located due to the local feature loss of images, the NEALMF image degradation suppression method is proposed, thus providing sufficient feature points for feature matching in visual localization by enhancing image quality.
- (2)
- To address the problem of poor localization accuracy caused by existing similarity retrieval methods, the VLMSF method is constructed, thereby accurately determining the location information of the target by improving the accuracy of feature matching.
2. Related Works
2.1. Image Enhancement
2.2. Visual Localization Based on Image Retrieval
3. Framework of the Proposed Method NEALMF
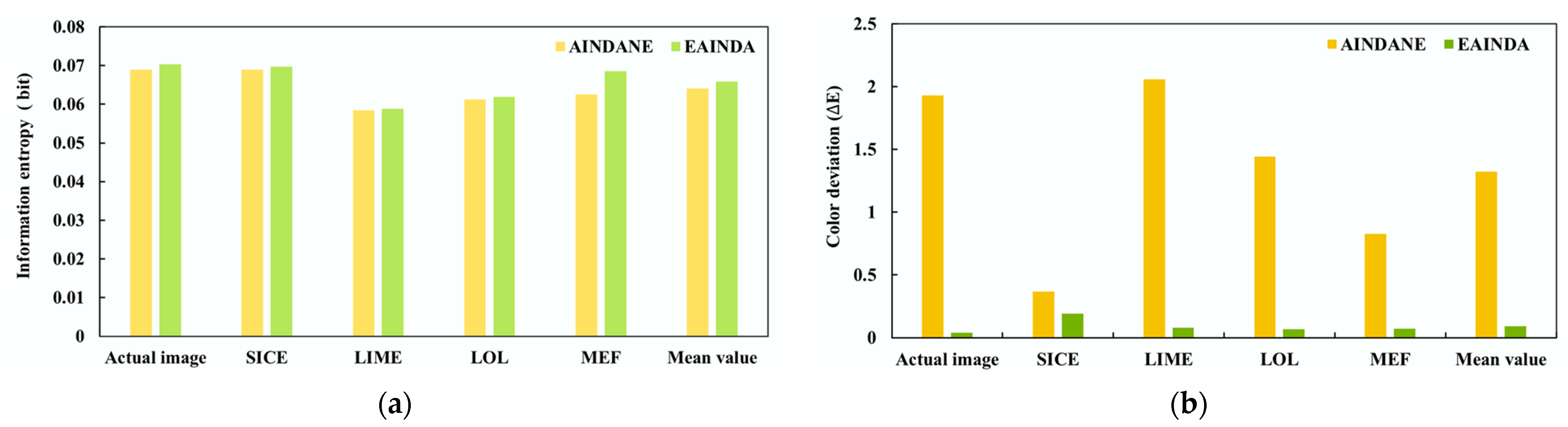
3.1. Low-Illumination Image Enhancement Based on the EAINDA
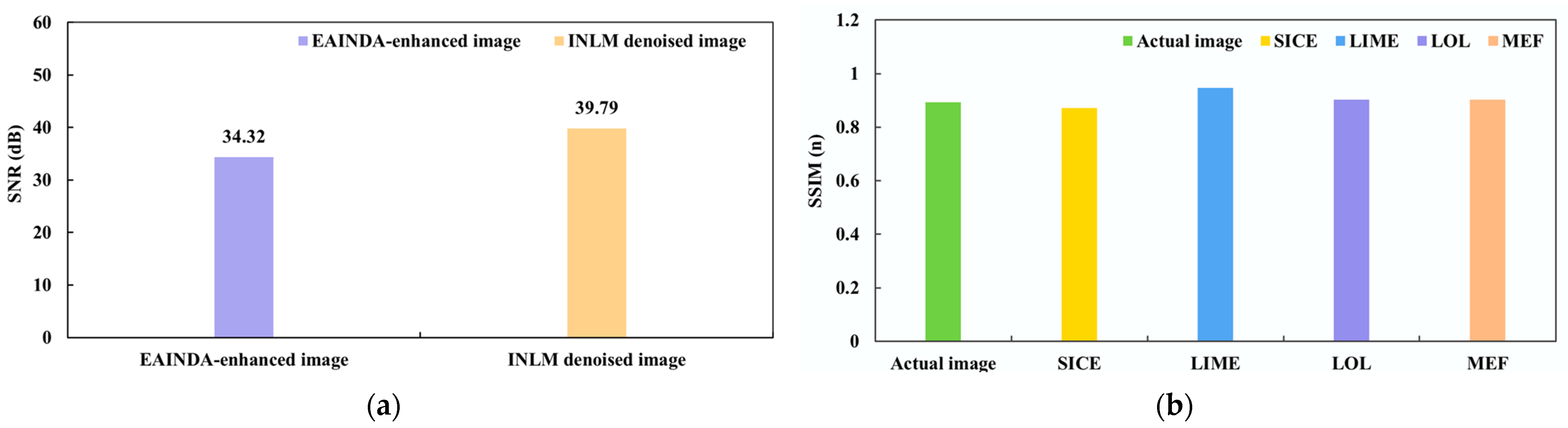
3.2. Experiment and Result Analysis of the EAINDA Method
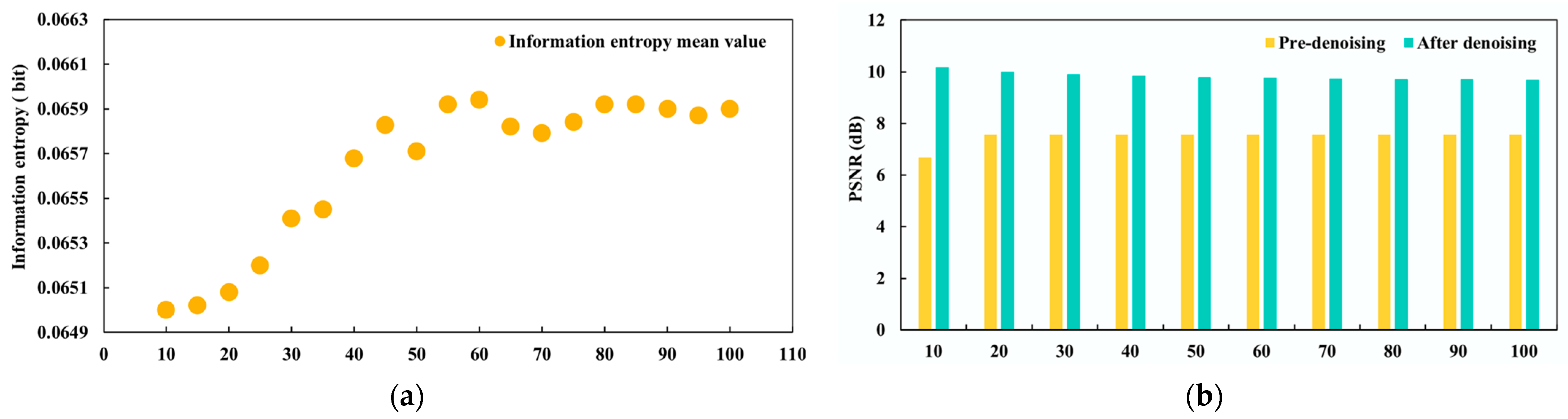
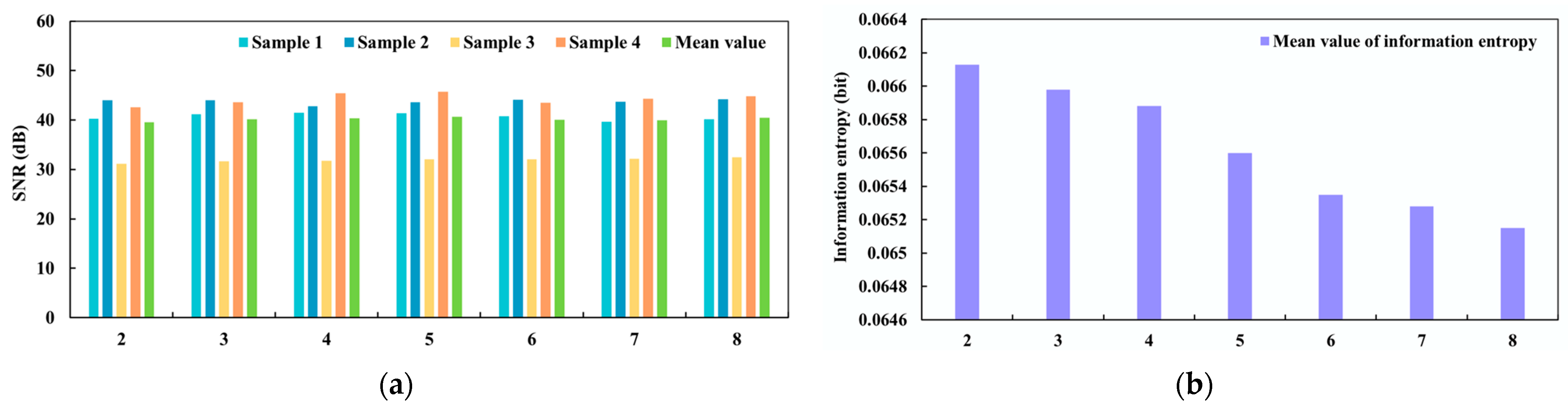
3.3. Low-Illumination Image Denoising Based on INLM
3.3.1. Primary Denoising Based on IGLPF
3.3.2. Secondary Denoising Based on TGNLM
3.3.3. Evaluation of Denoising Effect Based on INLM
3.4. Sharpness Enhancement Based on Unsharp Mask
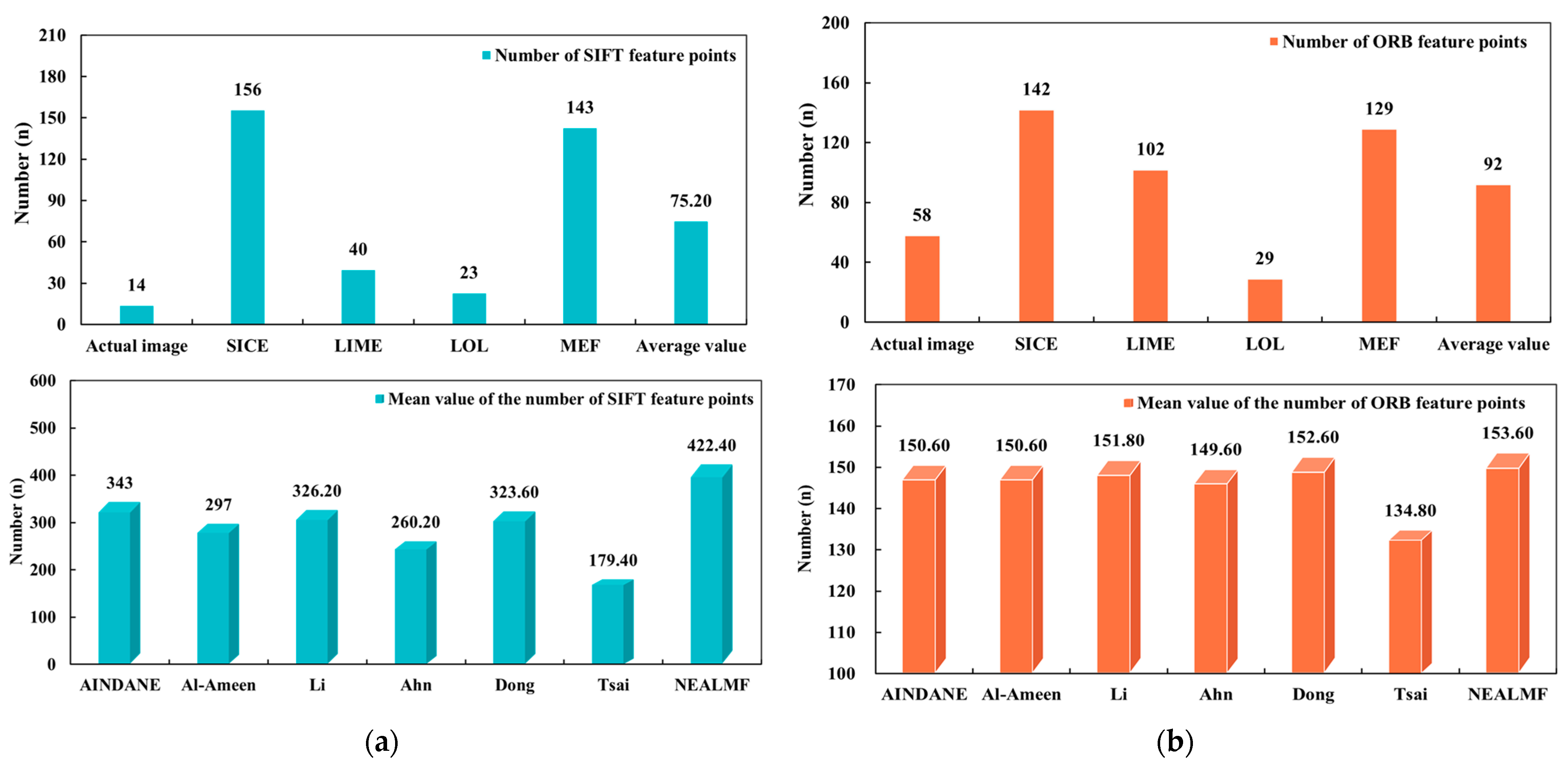
3.5. Experiment and Result Analysis of NEALMF Method
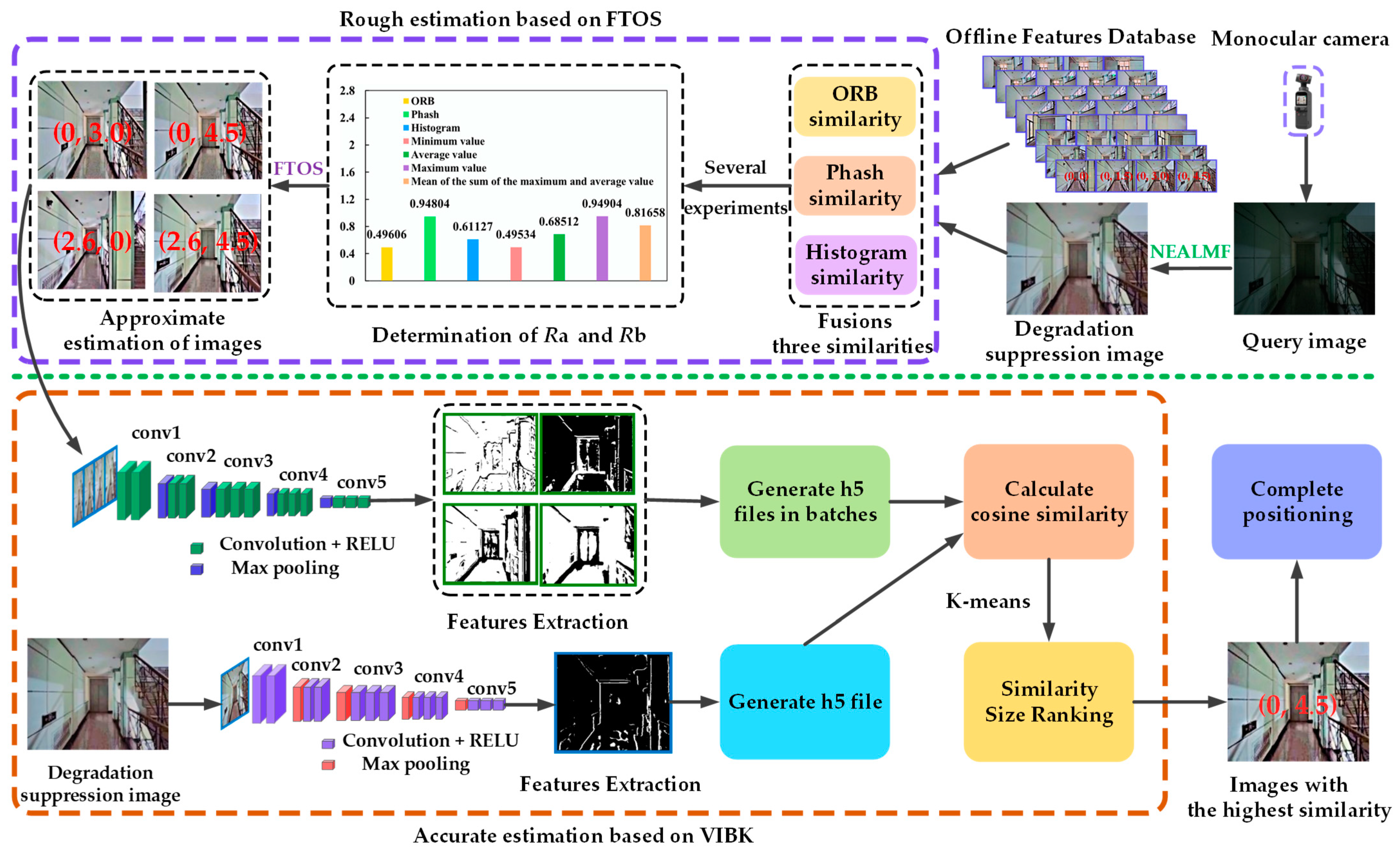
4. Framework of the Proposed Positioning Method VLMSF
| Algorithm 1 VLMSF |
| Input: unpositioned image Iq, offline feature database image Id, fusion threshold Ra, final similarity threshold Rb; Output: geographical position of the image to be positioned (x, y); Begin: 1. Iq is preprocessed by the NEALMF to obtain Ii; 2. The similarity Rc of Ii and Id by the FTOS method; 3. If Rc Rb or Rc Ra, then obtain rough images Is (s = 1,2,3...); 4. If S = 1, then obtain the most similar image Is; 5. Else S > 1, obtain the most similar image Is to Ii by using the VIBK; 6. End If 7. The location information (x,y) of Iq is the coordinate information carried by Is; End |
4.1. Visual Localization Based on Multi-Similarity Fusions
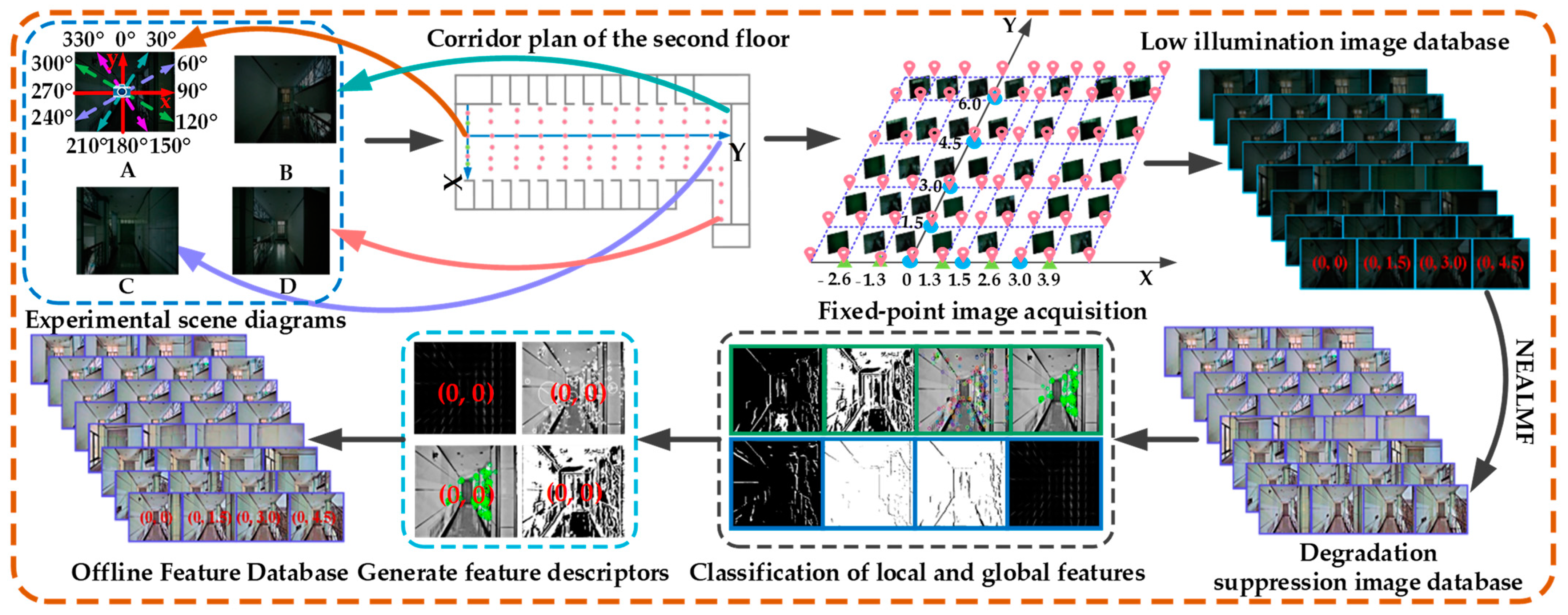
4.2. Construction of the Offline Feature Database
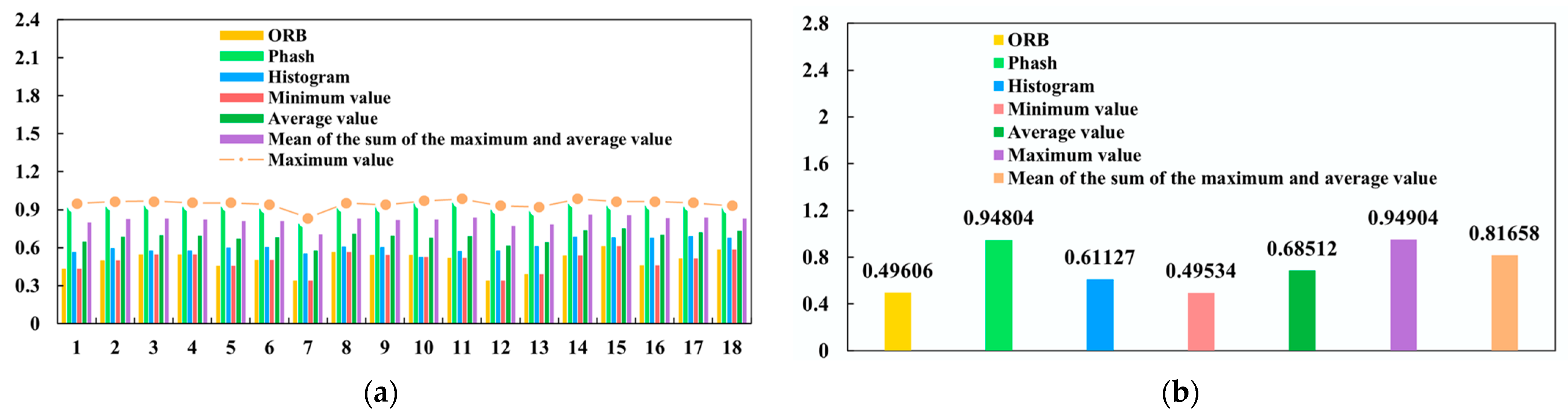
4.3. Similarity Calculation Based on the VLMSF
- (1)
- For the two selected images, if the maximum similarity calculated by the three similarity algorithms is greater than or equal to the fusion threshold, the maximum value is the similarity Ra after the fusion algorithm. Otherwise, the minimum value of similarity calculated by the three algorithms is taken as the subsequent similarity Ra of the fusion algorithm.
- (2)
- Define the final threshold as Rb. If Ra reaches the final threshold, the two images are considered to be very similar.
4.4. Location Estimation Based on the VLMSF
5. Simulation and Analysis of the Proposed Method VLMSF
5.1. Visual Positioning Effects of Different Types for Low-Illumination Images
5.2. Simulation and Result Analysis of Different Vision Methods
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pinem, M.; Zardika, A.; Siregar, Y. Location Misplacement Analysis on Global Positioning System. In Proceedings of the 2020 4rd International Conference on Electrical, Telecommunication and Computer Engineering (ELTICOM), Medan, Indonesia, 3–4 September 2020; pp. 246–249. [Google Scholar]
- Li, F.; Tu, R.; Hong, J.; Zhang, S.; Zhang, P.; Lu, X. Combined positioning algorithm based on BeiDou navigation satellite system and raw 5G observations. Measurement 2022, 190, 110763. [Google Scholar] [CrossRef]
- Agarwal, S.; Lazarus, S.B.; Savvaris, A. Monocular vision based navigation and localisation in indoor environments. IFAC Proc. Vol. 2012, 45, 97–102. [Google Scholar] [CrossRef]
- Tan, S.F.; Isa, N.A.M. Exposure based multi-histogram equalization contrast enhancement for non-uniform illumination images. IEEE Access 2019, 7, 70842–70861. [Google Scholar] [CrossRef]
- Gu, K.; Zhai, G.; Liu, M.; Min, X.; Yang, X.; Zhang, W. Brightness preserving video contrast enhancement using S-shaped transfer function. In Proceedings of the 2013 Visual Communications and Image Processing (VCIP), Kuching, Malaysia, 17–20 November 2013; pp. 1–6. [Google Scholar]
- Tian, H.; Cai, M.; Guan, T.; Hu, Y. Low-light image enhancement method using retinex method based on YCbCr color space. Acta Photonica Sin. 2020, 49, 173–184. [Google Scholar]
- Guo, X.; Li, Y.; Ling, H. LIME: Low-light image enhancement via illumination map estimation. IEEE Trans. Image Process. 2016, 26, 982–993. [Google Scholar] [CrossRef] [PubMed]
- Ying, Z.; Li, G.; Gao, W. A bio-inspired multi-exposure fusion framework for low-light image enhancement. arXiv 2017, arXiv:1711.00591. [Google Scholar]
- Li, Y. Research and Implementation of Low Illumination image Enhancement Algorithm Based on Retinex Theory. Master’s Thesis, Xidian University, Xi’an, China, 2018. [Google Scholar]
- Ahn, H.; Keum, B.; Kim, D.; Lee, H.S. Adaptive local tone mapping based on retinex for high dynamic range images. In Proceedings of the 2013 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 11–14 January 2013; pp. 153–156. [Google Scholar]
- Sun, Y.; Zhao, Z.; Jiang, D.; Tong, X.; Tao, B.; Jiang, G.; Kong, J.; Yun, J.; Liu, Y.; Liu, X.; et al. Low-illumination image enhancement algorithm based on improved multi-scale Retinex and ABC algorithm optimization. Front. Bioeng. Biotechnol. 2022, 10, 865820. [Google Scholar] [CrossRef] [PubMed]
- Al-Ameen, Z. Nighttime image enhancement using a new illumination boost algorithm. IET Image Process. 2019, 13, 1314–1320. [Google Scholar] [CrossRef]
- Noyel, G.; Jourlin, M. Functional Asplund metrics for pattern matching, robust to variable lighting conditions. arXiv 2019, arXiv:1909.01585. [Google Scholar] [CrossRef]
- Dong, X.; Pang, Y.; Wen, J. Fast efficient algorithm for enhancement of low lighting video. In ACM SIGGRAPH 2010 Posters; Association for Computing Machinery: New York, NY, USA, 2010; p. 1. [Google Scholar]
- Tsai, C.M. Adaptive local power-law transformation for color image enhancement. Appl. Math. Inf. Sci. 2013, 7, 2019. [Google Scholar] [CrossRef] [Green Version]
- Cheng, R.; Hu, W.; Chen, H.; Fang, Y.; Wang, K.; Xu, Z.; Bai, J. Hierarchical visual localization for visually impaired people using multimodal images. Expert Syst. Appl. 2021, 165, 113743. [Google Scholar] [CrossRef]
- Toft, C.; Stenborg, E.; Hammarstrand, L.; Brynte, L.; Pollefeys, M.; Sattler, T.; Kahl, F. Semantic match consistency for long-term visual localization. In Proceedings of the European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2018; pp. 383–399. [Google Scholar]
- Feng, G.; Jiang, Z.; Tan, X.; Cheng, F. Hierarchical Clustering-Based Image Retrieval for Indoor Visual Localization. Electronics 2022, 11, 3609. [Google Scholar] [CrossRef]
- Weinzaepfel, P.; Csurka, G.; Cabon, Y.; Humenberger, M. Visual localization by learning objects-of-interest dense match regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5634–5643. [Google Scholar]
- Yu, S.; Jiang, Z. Visual tracking via perceptual image hash from a mobile robot. In Proceedings of the 2015 IEEE International Conference on Information and Automation, Lijiang, China, 8–10 August 2015; pp. 1612–1616. [Google Scholar]
- Bi, J.; Zhen, J.; Wang, Y.; Liu, X. Improved KNN indoor positioning method with Gaussian function fixed weight. Bull. Surv. Mapp. 2017, 06, 9–12+35. [Google Scholar]
- Tao, L.; Asari, V. An integrated neighborhood dependent approach for nonlinear enhancement of color images. In Proceedings of the International Conference on Information Technology: Coding and Computing, Las Vegas, NV, USA, 5–7 April 2004; Proceedings. ITCC 2004. IEEE: Washington, DC, USA, 2004; Volume 2, pp. 138–139. [Google Scholar]
- Xu, X.; Cai, Y.; Liu, C.; Jia, K.; Shen, L. Color deviation detection and color correction method based on image analysis. Meas. Control. Technol. 2008, 27, 10–12. [Google Scholar]
- Zhang, X. Center pixel weight based on Wiener filter for non-local means image denoising. Optik 2021, 244, 167557. [Google Scholar] [CrossRef]
- Xu, P.; Chen, B.; Zhang, J.; Xue, L.; Zhu, L. A new HSI denoising method via interpolated block matching 3D and guided filter. PeerJ 2021, 9, e11642. [Google Scholar] [CrossRef] [PubMed]
- Liu, G.H.; Wei, Z. Image retrieval using the fused perceptual color histogram. Comput. Intell. Neurosci. 2020, 2020, 8876480. [Google Scholar] [CrossRef] [PubMed]
- Yin, Y. Research on Image Similarity Retrieval Algorithm Based on Perceptual Hashing. Master’s Thesis, Kunming University of Science and Technology, Kunming, China, 2020. [Google Scholar]
- Liu, X.; Huang, H.; Hu, B. Indoor Visual Positioning Method Based on Image Features. Sens. Mater. 2022, 34, 337. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, Y.; Bi, J.; Cao, H. An indoor positioning method based on image gray histogram similarity calculation. Bull. Surv. Mapp. 2018, 4, 63–67. [Google Scholar]
- Manzo, M. Graph-based image matching for indoor localization. Mach. Learn. Knowl. Extr. 2019, 1, 46. [Google Scholar] [CrossRef] [Green Version]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Different Image Datasets | Actual Image | SICE | LIME | LOL | MEF |
|---|---|---|---|---|---|
| Original images |  |  |  |  |  |
| AINDANE |  |  |  |  |  |
| EAINDA |  |  |  |  |  |
| Different Image Datasets | Actual Image | SICE | LIME | LOL | MEF | Mean Value |
|---|---|---|---|---|---|---|
| Before | 41.72 | 48.44 | 59.16 | 42.17 | 62.37 | 50.77 |
| After | 50.63 | 58.28 | 73.33 | 50.98 | 73.75 | 61.39 |
| Different Image Datasets | Actual Image | SICE | LIME | LOL | MEF |
|---|---|---|---|---|---|
| Original Images |  |  |  |  |  |
| AINDANE |  |  |  |  |  |
| Al-Ameen |  |  |  |  |  |
| Li |  |  |  |  |  |
| Ahn |  |  |  |  |  |
| Dong |  |  |  |  |  |
| Tsai |  |  |  |  |  |
| NEALMF |  |  |  |  |  |
| Location Information | Correct Location Information | Estimated Location Information |
|---|---|---|
| Global low-luminance images | (3.90, 6.00) | (1.30, 6.00) |
| Local low-luminance images | (30.00, 24.00) | (31.50, 2.40) |
| Types of Low-Illumination Images | Global Low-Luminance Images | Local Low-Luminance Images |
|---|---|---|
| Positioning accuracy/% | 96.88% | 96.88% |
| Total positioning error/m | 2.60 | 1.50 |
| Average positioning error/m | 0.08 | 0.05 |
| No. | Actual Position | Calculated Results | Location Error/m | Deviation Angle/° |
|---|---|---|---|---|
| 1 | (3.9, 6.0) | (1.3, 6.0) | 2.60 | 0 |
| 2 | (3.9, 1.5) | (−2.6, 3.0) | 6.67 | 12.99 |
| 3 | (30, 24.0) | (31.5, 24.0) | 1.50 | 0 |
| 4 | (10.5, 25.5) | (10.5, 21.0) | 4.50 | 0 |
| Each Phase Method in the NEALMF | EAINDA | INLM | USM | Total Time |
|---|---|---|---|---|
| Average preprocessing time/ms | 14.00 | 86.00 | 4.00 | 104.00 |
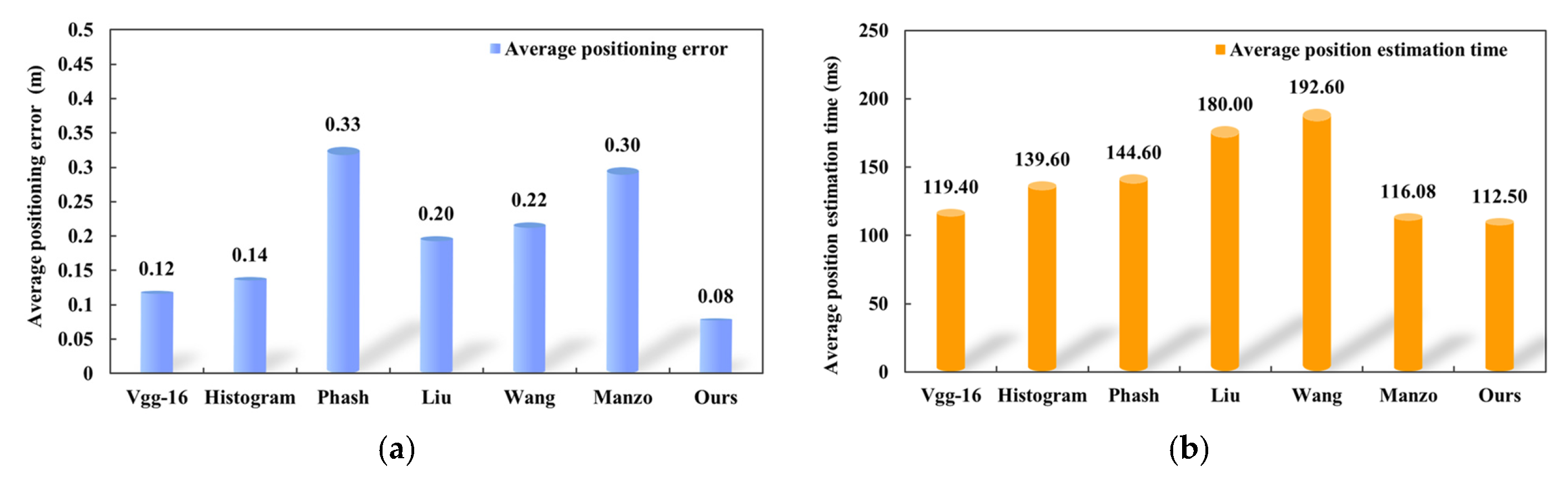
| Method | Vgg-16 | Histogram | Phash | Liu | Wang | Manzo | Ours |
|---|---|---|---|---|---|---|---|
| Total deviation angle/° | 72.03 | 84.56 | 62.08 | 84.52 | 77.00 | 83.82 | 12.99 |
| Total positioning error/m | 20.82 | 24.31 | 60.06 | 35.94 | 39.67 | 54.26 | 15.27 |
| Average deviation angle/° | 0.40 | 0.47 | 0.34 | 0.47 | 0.43 | 0.47 | 0.07 |
| Average positioning error/m | 0.12 | 0.14 | 0.33 | 0.20 | 0.22 | 0.30 | 0.08 |
| Average position estimation time/ms | 119.40 | 139.60 | 144.60 | 180.00 | 192.60 | 116.08 | 112.50 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, H.; Qin, D.; Yang, J.; Bie, H.; Yan, M.; Zhang, G.; Ma, L. Target Localization Method Based on Image Degradation Suppression and Multi-Similarity Fusion in Low-Illumination Environments. ISPRS Int. J. Geo-Inf. 2023, 12, 300. https://doi.org/10.3390/ijgi12080300
Tang H, Qin D, Yang J, Bie H, Yan M, Zhang G, Ma L. Target Localization Method Based on Image Degradation Suppression and Multi-Similarity Fusion in Low-Illumination Environments. ISPRS International Journal of Geo-Information. 2023; 12(8):300. https://doi.org/10.3390/ijgi12080300
Chicago/Turabian StyleTang, Huapeng, Danyang Qin, Jiaqiang Yang, Haoze Bie, Mengying Yan, Gengxin Zhang, and Lin Ma. 2023. "Target Localization Method Based on Image Degradation Suppression and Multi-Similarity Fusion in Low-Illumination Environments" ISPRS International Journal of Geo-Information 12, no. 8: 300. https://doi.org/10.3390/ijgi12080300