

Hybrid Prediction Model Based on Decomposed and Synthesized COVID-19 Cumulative Confirmed Data

Abstract
:1. Introduction
1.1. Literature Review
1.2. Contributions of This Paper
- Currently, COVID-19 predictions are mostly univariate. This paper builds a new predictive dataset by incorporating policy factors.
- Existing hybrid models for COVID-19 prediction are mainly based on component combinations, while methods based on data processing have just begun to emerge. Aiming at the defects of EMD and its optimization algorithms such as EEMD, CEEMDAN, etc., this paper proposes a VMD method for decomposing COVID data.
- The VMD method has certain defects, namely, the key parameters K and α need to be preset based on experience. Aiming at this problem, this paper proposes a PSO–VMD method, which realizes the adaptive value of K and α.
- The AdaBoost algorithm is proposed to enhance the LSTM, which finally improves the prediction accuracy to a certain extent.
- The effectiveness of the method is verified and tested using the epidemic data from Hubei Province and Hebei Province.
2. Materials and Methods
2.1. Variational Mode Decomposition (VMD)
2.2. LSTM
2.3. VMD Optimized by PSO
2.4. AdaBoost–LSTM
2.5. Final Model
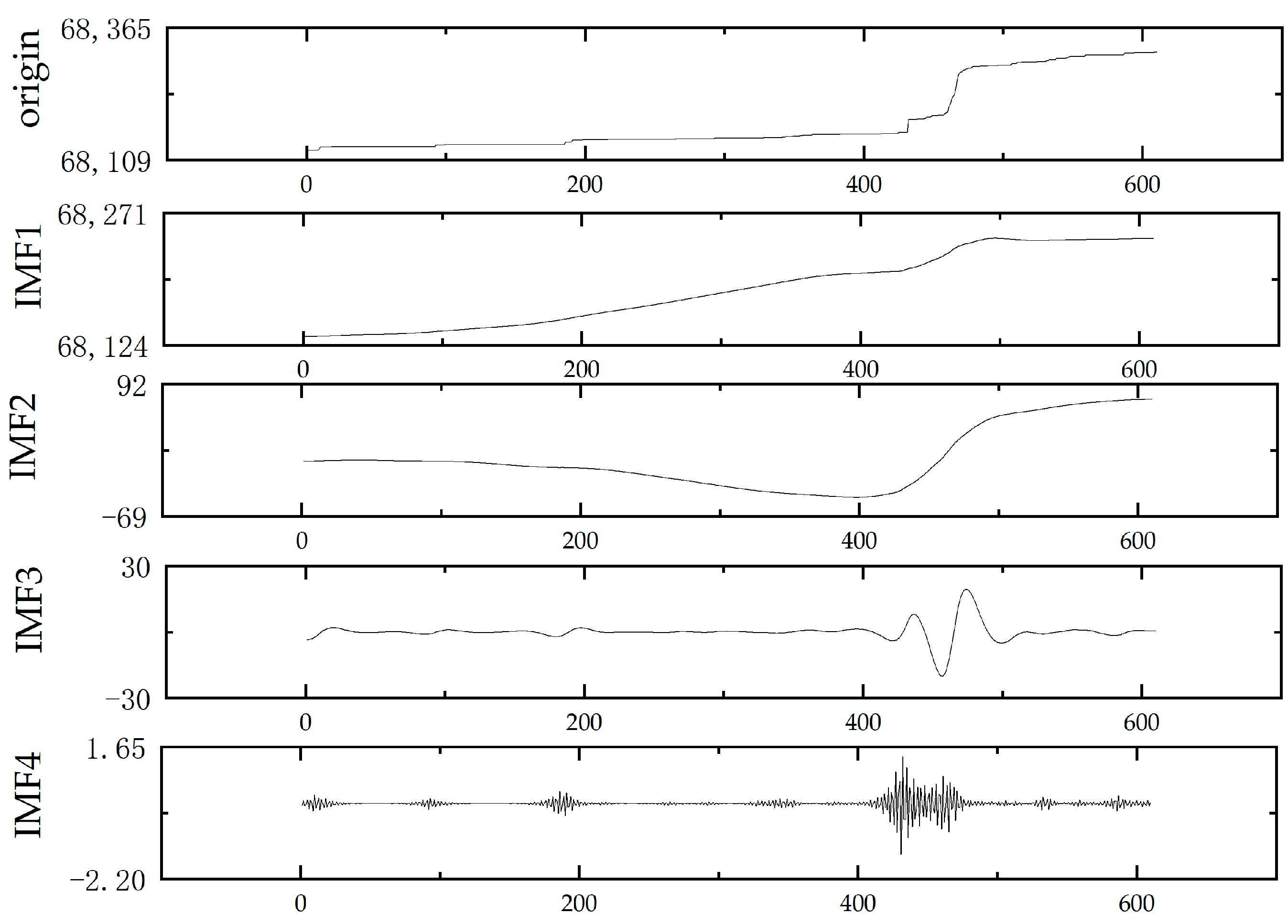
2.6. Date Modeling
2.6.1. Data Sources and Experimental Environment
2.6.2. Evaluating Indicator
3. Results
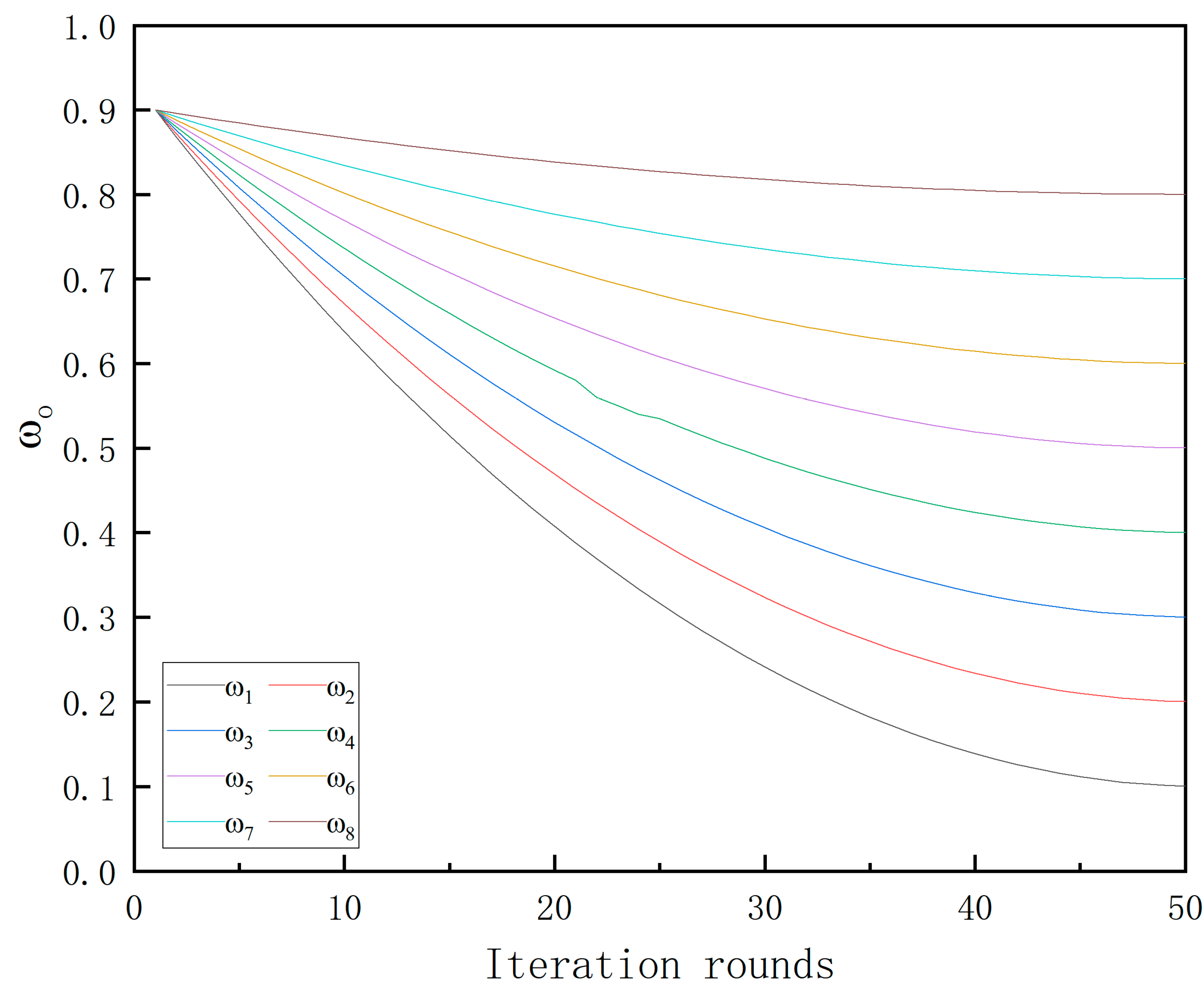
3.1. The Experiment of PSO–VMD
3.2. Forecasting Results
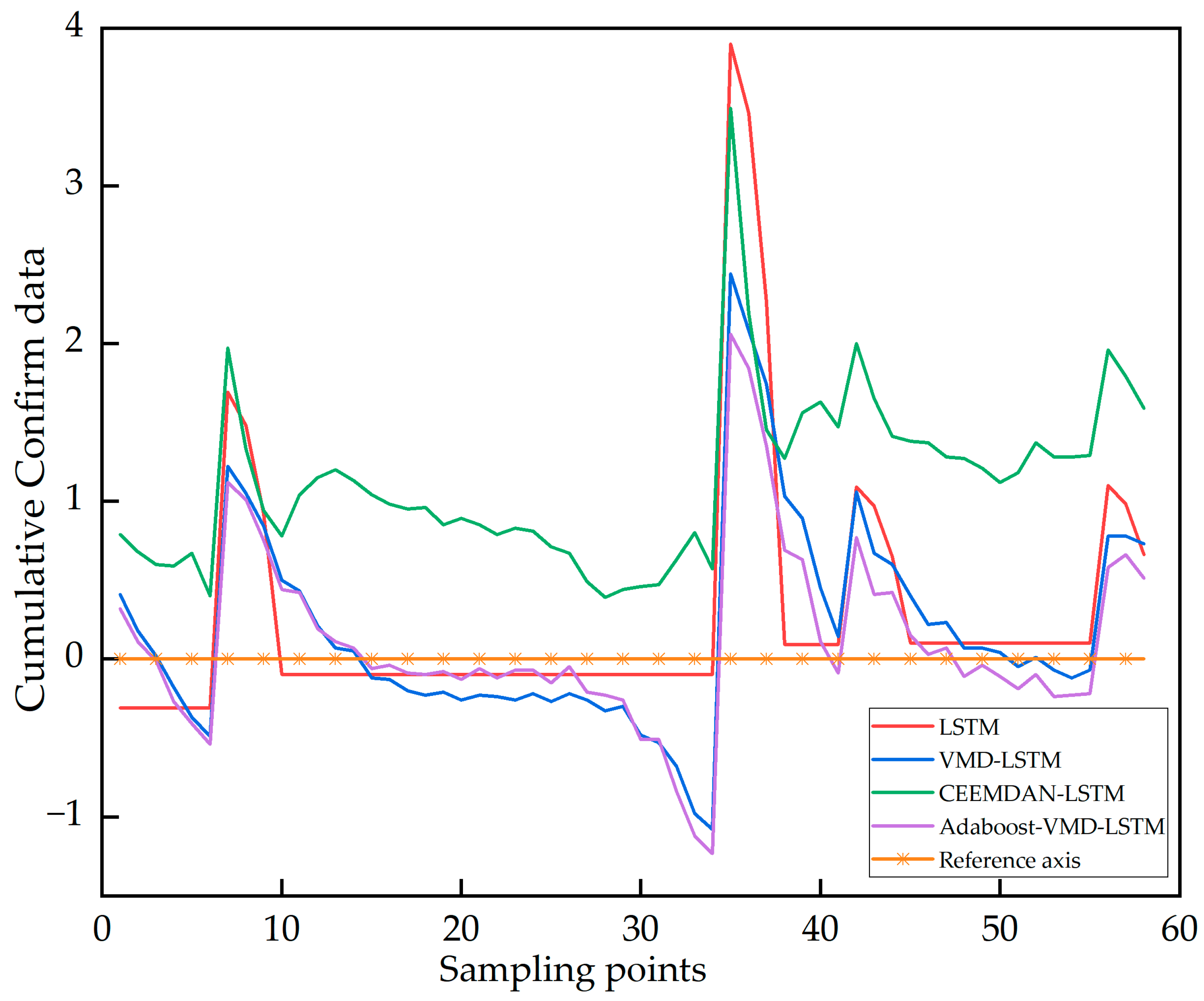
3.2.1. Prediction Based on Hubei Cumulative Confirmed Data
- The hybrid prediction model optimized by PSO–VMD demonstrates superior performance compared to the undecomposed model. This highlights the advantages of employing VMD decomposition in prediction.
- The RMSE, MAE and MAPE of the hybrid model VMD–AdaBoost–LSTM are lower than those of the other three models. The prediction result of VMD–AdaBoost–LSTM is the best among all models. Hence, the utilization of the VMD method contributes to improved prediction accuracy.
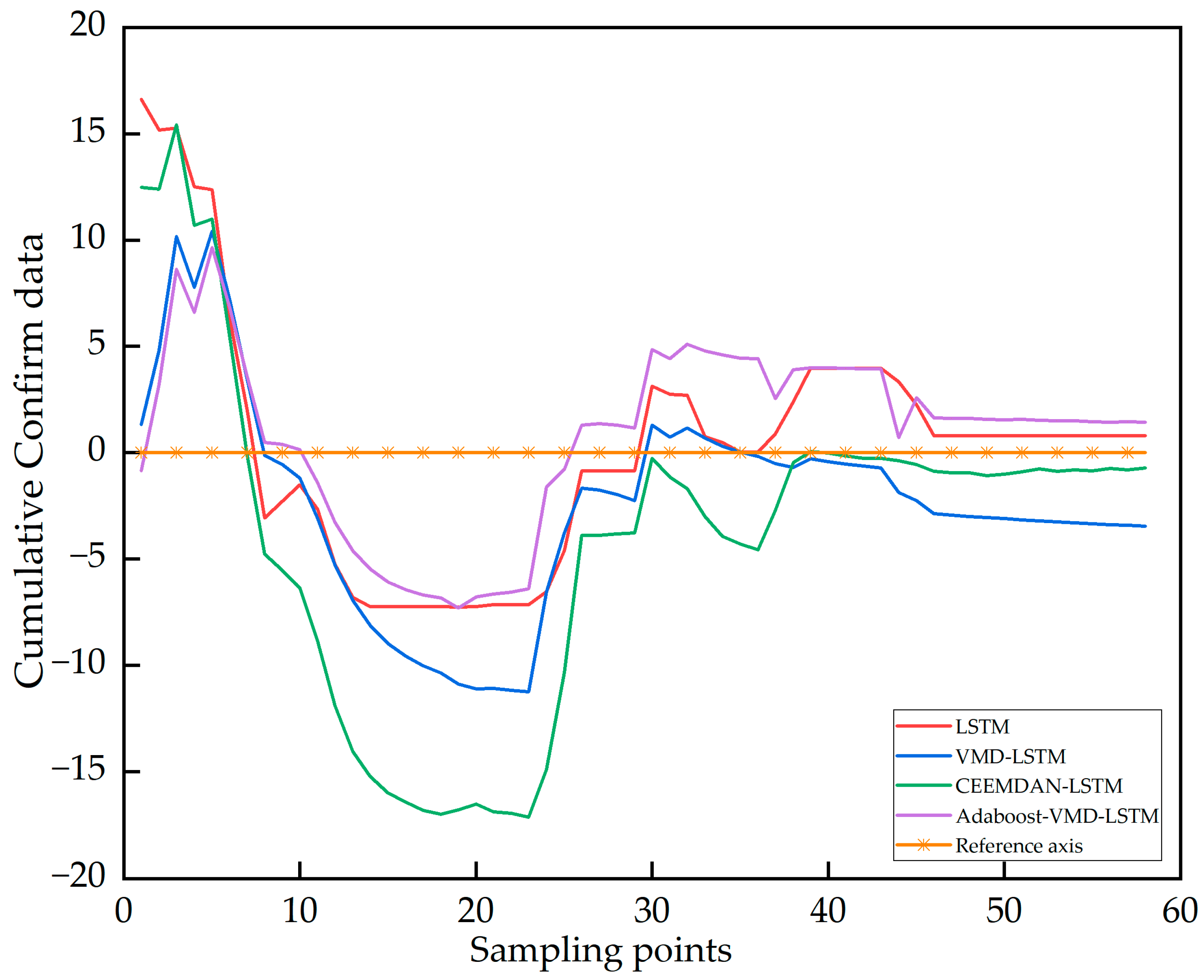
3.2.2. Prediction Based on Hebei Cumulative Confirmed Data
4. Discussion
- The selection of models used to predict IMF components after VMD decomposition is limited, indicating the need to explore other models so as to optimize prediction accuracy;
- Due to the limited amount of epidemic data available, there is a possibility that the neural network’s prediction accuracy could be affected;
- The growth of the epidemic is related to various factors, such as surrounding environment-related policies and population movement, but this paper only obtained factors related to containment policies. Therefore, the consideration of other factors is not comprehensive enough.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gnanvi, J.E.; Salako, K.V.; Kotanmi, G.B.; Kakaï, R.G. On the reliability of predictions on COVID-19 dynamics: A systematic and critical review of modelling techniques. Infect. Dis. Model. 2021, 6, 258–272. [Google Scholar] [CrossRef] [PubMed]
- Zoabi, Y.; Deri-Rozov, S.; Shomron, N. Machine learning-based prediction of COVID-19 diagnosis based on symptoms. NPJ Digit. Med. 2021, 4, 3. [Google Scholar] [CrossRef] [PubMed]
- Alenezi, M.N.; Al-Anzi, F.S.; Alabdulrazzaq, H. Building a sensible SIR estimation model for COVID-19 outspread in Kuwait. Alex. Eng. J. 2021, 60, 3161–3175. [Google Scholar] [CrossRef]
- Moein, S.; Nickaeen, N.; Roointan, A.; Borhani, N.; Heidary, Z.; Javanmard, S.H.; Ghaisari, J.; Gheisari, Y. Inefficiency of SIR models in forecasting COVID-19 epidemic: A case study of Isfahan. Sci. Rep. 2021, 11, 4725. [Google Scholar] [CrossRef]
- Cooper, I.; Mondal, A.; Antonopoulos, C.G. A SIR model assumption for the spread of COVID-19 in different communities. Chaos Solitons Fractals 2020, 139, 110057. [Google Scholar] [CrossRef]
- He, S.; Peng, Y.; Sun, K. SEIR modeling of the COVID-19 and its dynamics. Nonlinear Dyn. 2020, 101, 1667–1680. [Google Scholar] [CrossRef]
- Annas, S.; Pratama, M.I.; Rifandi, M.; Sanusi, W.; Side, S. Stability analysis and numerical simulation of SEIR model for pandemic COVID-19 spread in Indonesia. Chaos Solitons Fractals 2020, 139, 110072. [Google Scholar] [CrossRef]
- Rǎdulescu, A.; Williams, C.; Cavanagh, K. Management strategies in a SEIR-type model of COVID 19 community spread. Sci. Rep. 2020, 10, 21256. [Google Scholar] [CrossRef]
- Ren, X.; Weisel, C.P.; Georgopoulos, P.G. Modeling effects of spatial heterogeneities and layered exposure interventions on the spread of COVID-19 across New Jersey. Int. J. Environ. Res. Public Health 2021, 18, 11950. [Google Scholar] [CrossRef]
- Rustam, F.; Reshi, A.A.; Mehmood, A.; Ullah, S.; On, B.W.; Aslam, W.; Choi, G.S. COVID-19 future forecasting using supervised machine learning models. IEEE Access 2020, 8, 101489–101499. [Google Scholar] [CrossRef]
- Ballı, S. Data analysis of COVID-19 pandemic and short-term cumulative case forecasting using machine learning time series methods. Chaos Solitons Fractals 2021, 142, 110512. [Google Scholar] [CrossRef] [PubMed]
- Chimmula, V.K.R.; Zhang, L. Time series forecasting of COVID-19 transmission in Canada using LSTM networks. Chaos Solitons Fractals 2020, 135, 109864. [Google Scholar] [CrossRef] [PubMed]
- Chandra, R.; Jain, A.; Chauhan, D.S. Deep learning via LSTM models for COVID-19 infection forecasting in India. PLoS ONE 2022, 17, e0262708. [Google Scholar] [CrossRef] [PubMed]
- Shahin, A.I.; Almotairi, S. A deep learning BiLSTM encoding-decoding model for COVID-19 pandemic spread forecasting. Fractal Fract. 2021, 5, 175. [Google Scholar] [CrossRef]
- Alabdulrazzaq, H.; Alenezi, M.N.; Rawajfih, Y.; Alghannam, B.A.; Al-Hassan, A.A.; Al-Anzi, F.S. On the accuracy of ARIMA based prediction of COVID-19 spread. Results Phys. 2021, 27, 104509. [Google Scholar] [CrossRef]
- Alzahrani, S.I.; Aljamaan, I.A.; Al-Fakih, E.A. Forecasting the spread of the COVID-19 pandemic in Saudi Arabia using ARIMA prediction model under current public health interventions. J. Infect. Public Health 2020, 13, 914–919. [Google Scholar] [CrossRef]
- Delli Compagni, R.; Cheng, Z.; Russo, S.; Van Boeckel, T.P. A hybrid Neural Network-SEIR model for forecasting intensive care occupancy in Switzerland during COVID-19 epidemics. PLoS ONE 2022, 17, e0263789. [Google Scholar] [CrossRef]
- Singh, S.; Parmar, K.S.; Kumar, J.; Makkhan, S.J.S. Development of new hybrid model of discrete wavelet decomposition and autoregressive integrated moving average (ARIMA) models in application to one month forecast the casualties cases of COVID-19. Chaos Solitons Fractals 2020, 135, 109866. [Google Scholar] [CrossRef]
- Liu, S.; Wan, Y.; Yang, W.; Tan, A.; Jian, J.; Lei, X. A Hybrid Model for Coronavirus Disease 2019 Forecasting Based on Ensemble Empirical Mode Decomposition and Deep Learning. Int. J. Environ. Res. Public Health 2022, 20, 617. [Google Scholar] [CrossRef]
- Yuan, F.; Che, J. An ensemble multi-step M-RMLSSVR model based on VMD and two-group strategy for day-ahead short-term load forecasting. Knowl.-Based Syst. 2022, 252, 109440. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, Y.; Kong, C.; Chen, B. A new prediction method based on VMD-PRBF-ARMA-E model considering wind speed characteristic. Energy Convers. Manag. 2020, 203, 112254. [Google Scholar] [CrossRef]
- Jin, Z.; He, D.; Wei, Z. Intelligent fault diagnosis of train axle box bearing based on parameter optimization VMD and improved DBN. Eng. Appl. Artif. Intell. 2022, 110, 104713. [Google Scholar] [CrossRef]
- Chinazzi, M.; Davis, J.T.; Ajelli, M.; Gioannini, C.; Litvinova, M.; Merler, S.; Piontti, Y.; Pastore, A.; Mu, K.; Rossi, L.; et al. The effect of travel restrictions on the spread of the 2019 novel coronavirus (COVID-19) outbreak. Science 2020, 368, 395–400. [Google Scholar] [CrossRef] [PubMed]
- Pei, S.; Kandula, S.; Shaman, J. Differential effects of intervention timing on COVID-19 spread in the United States. Sci. Adv. 2020, 6, eabd6370. [Google Scholar] [CrossRef]
- Li, G.; Chen, K.; Yang, H. A new hybrid prediction model of cumulative COVID-19 confirmed data. Process Saf. Environ. Prot. 2022, 157, 1–19. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational mode decomposition. IEEE Trans. Signal Process. 2013, 62, 531–544. [Google Scholar] [CrossRef]
- Nikparvar, B.; Rahman, M.M.; Hatami, F.; Thill, J.C. Spatio-temporal prediction of the COVID-19 pandemic in US counties: Modeling with a deep LSTM neural network. Sci. Rep. 2021, 11, 21715. [Google Scholar] [CrossRef]
- Zhang, Y.; Pan, G. A hybrid prediction model for forecasting wind energy resources. Environ. Sci. Pollut. Res. 2020, 27, 19428–19446. [Google Scholar] [CrossRef]
- Zhao, Y.; Fan, Y.; Li, H.; Gao, X. Rolling bearing composite fault diagnosis method based on EEMD fusion feature. J. Mech. Sci. Technol. 2022, 36, 4563–4570. [Google Scholar] [CrossRef]
- Busari, G.A.; Lim, D.H. Crude oil price prediction: A comparison between AdaBoost-LSTM and AdaBoost-GRU for improving forecasting performance. Comput. Chem. Eng. 2021, 155, 107513. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.-C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proceedings of the Royal Society of London. Ser. A Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Explain |
|---|---|
| C1_School closing | Record school suspensions |
| C2_Workplace closing | Record the closure of public places |
| C3_Cancel public events | Record the development of public events |
| C4_Restrictions on gatherings | Record party restrictions |
| C5_Close public transport | Record whether public transport is closed |
| C6_Stay at home requirements | Record whether home isolation is imposed |
| C7_Restrictions on internal movement | Record restrictions on internal mobility between cities/regions |
| Variable | Value |
|---|---|
| population | 30 |
| Tmax | 50 |
| acceleration constant | 2 |
| boundary | K ∈ [2, 12], α ∈ [10, 5000] |
| Model | R2 | RMSE | MAE | MAPE |
|---|---|---|---|---|
| LSTM | 0.89 | 0.8740 | 0.43069 | 0.00063 |
| CEEMDAN–LSTM | 0.79 | 1.2474 | 1.12655 | 0.00165 |
| VMD–LSTM | 0.93 | 0.6911 | 0.48259 | 0.00071 |
| VMD–AdaBoost–LSTM | 0.95 | 0.5979 | 0.40190 | 0.00059 |
| Method | Parameters | Values |
|---|---|---|
| LSTM | Layer | 2 |
| Neurons | 64 | |
| Learning rate | 0.01 | |
| Batchsize | 32 | |
| Epoch | 50 | |
| VMD–LSTM | Layer | 3 |
| Neurons | 128 | |
| Learning rate | 0.001 | |
| Batchsize | 32 | |
| Epoch | 60 | |
| CEEMDAN–LSTM | Layer | 2 |
| Neurons | 256 | |
| Learning rate | 0.002 | |
| Batchsize | 64 | |
| Epoch | 50 | |
| VMD–AdaBoost–LSTM | Layer | 3 |
| Neurons | 128 | |
| Learning rate | 0.001 | |
| Batchsize | 32 | |
| Epoch | 100 | |
| Number of base learners | 5 |
| Model | R2 | RMSE | MAE | MAPE |
|---|---|---|---|---|
| LSTM | 0.83 | 5.7447 | 4.0963 | 0.2844 |
| CEEMDAN–LSTM | 0.61 | 8.85517 | 6.21707 | 0.43007 |
| VMD–LSTM | 0.84 | 5.46402 | 4.08121 | 0.28175 |
| VMD–AdaBoost–LSTM | 0.91 | 4.2436 | 3.52603 | 0.24323 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xia, Z.; Duan, G.; Xu, T. Hybrid Prediction Model Based on Decomposed and Synthesized COVID-19 Cumulative Confirmed Data. ISPRS Int. J. Geo-Inf. 2023, 12, 215. https://doi.org/10.3390/ijgi12060215
Xia Z, Duan G, Xu T. Hybrid Prediction Model Based on Decomposed and Synthesized COVID-19 Cumulative Confirmed Data. ISPRS International Journal of Geo-Information. 2023; 12(6):215. https://doi.org/10.3390/ijgi12060215
Chicago/Turabian StyleXia, Zongyou, Gonghao Duan, and Ting Xu. 2023. "Hybrid Prediction Model Based on Decomposed and Synthesized COVID-19 Cumulative Confirmed Data" ISPRS International Journal of Geo-Information 12, no. 6: 215. https://doi.org/10.3390/ijgi12060215