
A Deep Transfer Learning Toponym Extraction and Geospatial Clustering Framework for Investigating Scenic Spots as Cognitive Regions
 , , , ,
, , , ,
Abstract
:1. Introduction
2. Related work
2.1. Toponym Entity Recognition in Web Text
2.2. Vague Region Perception
3. Methodology
3.1. Overall Architecture
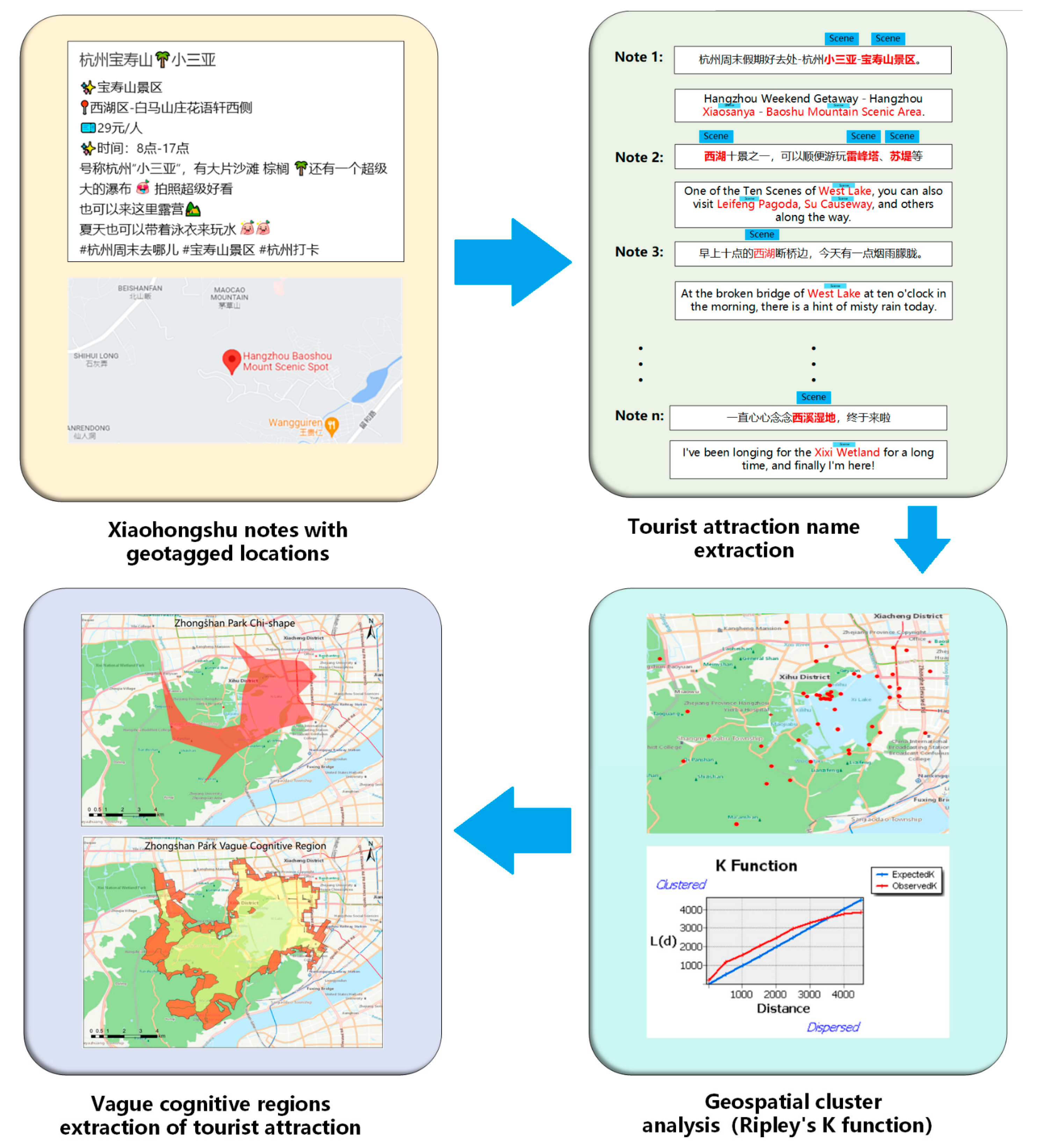
3.2. Tourist Attraction Name Extraction
3.3. Delineating Vague Cognitive Boundaries of Tourist Attraction Regions
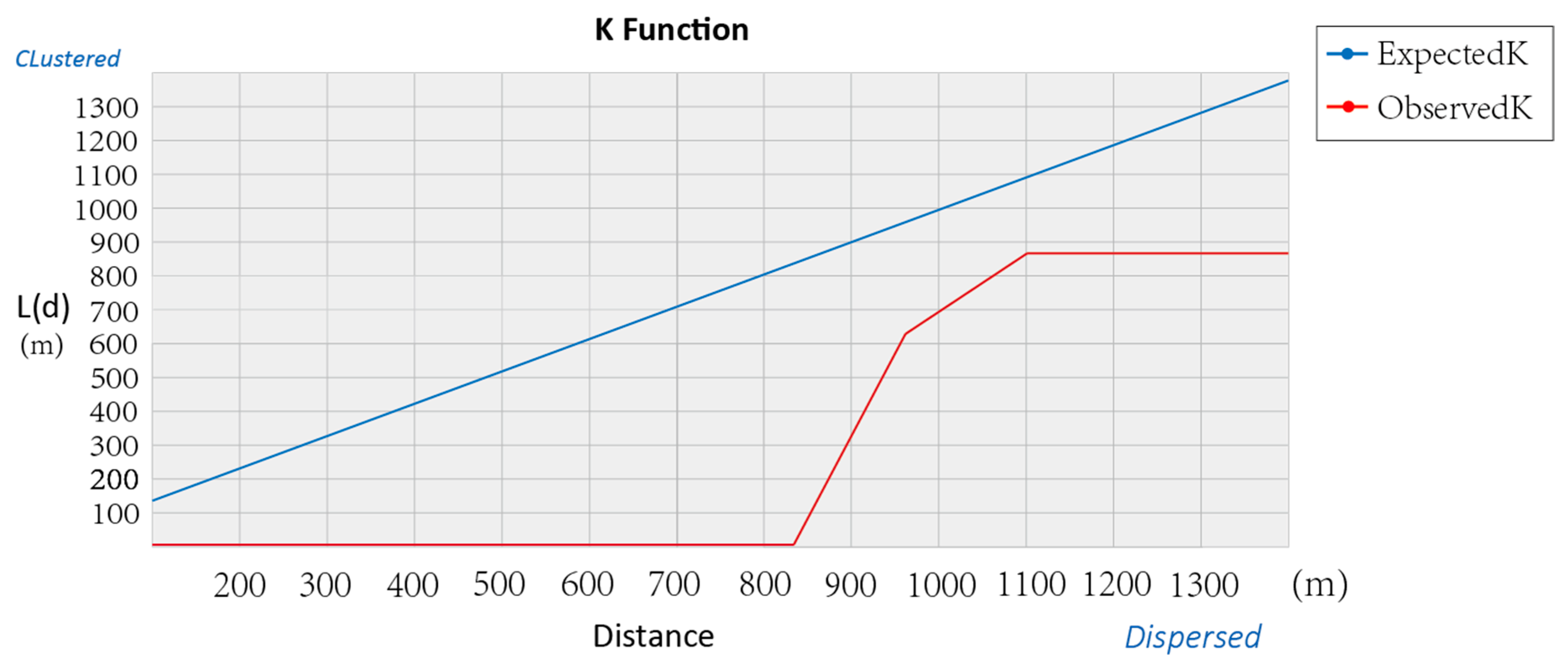
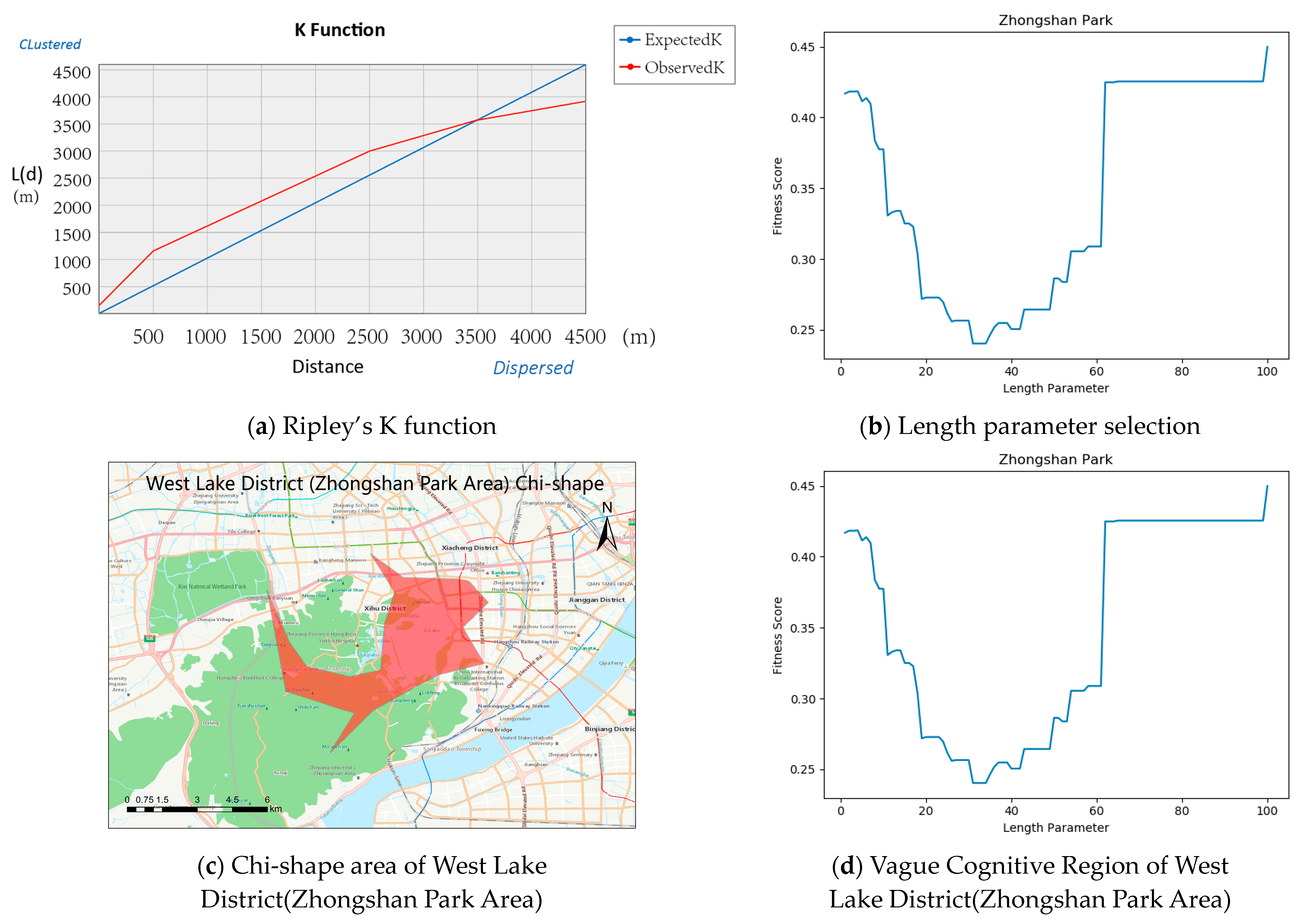
3.3.1. Geospatial Clustering Analysis
3.3.2. Extracting Vague Cognitive Zones of Tourist Attractions
- (1)
- Generate Delaunay triangulation based on the input tourist attraction name point set.
- (2)
- Remove the longest external edge from the Delaunay triangulation, as long as the external boundary meets the following conditions:
- The length of the edge is longer than the length parameter;
- The remaining edges after removing the edge form a simple polygon.
- (3)
- Repeat step (2) as long as there are edges that meet the removal conditions.
- (4)
- Return the polygon formed by the remaining external edges of the Delaunay triangulation (Duckham and Kulik et al., 2008).
4. Experimental Results and Discussion
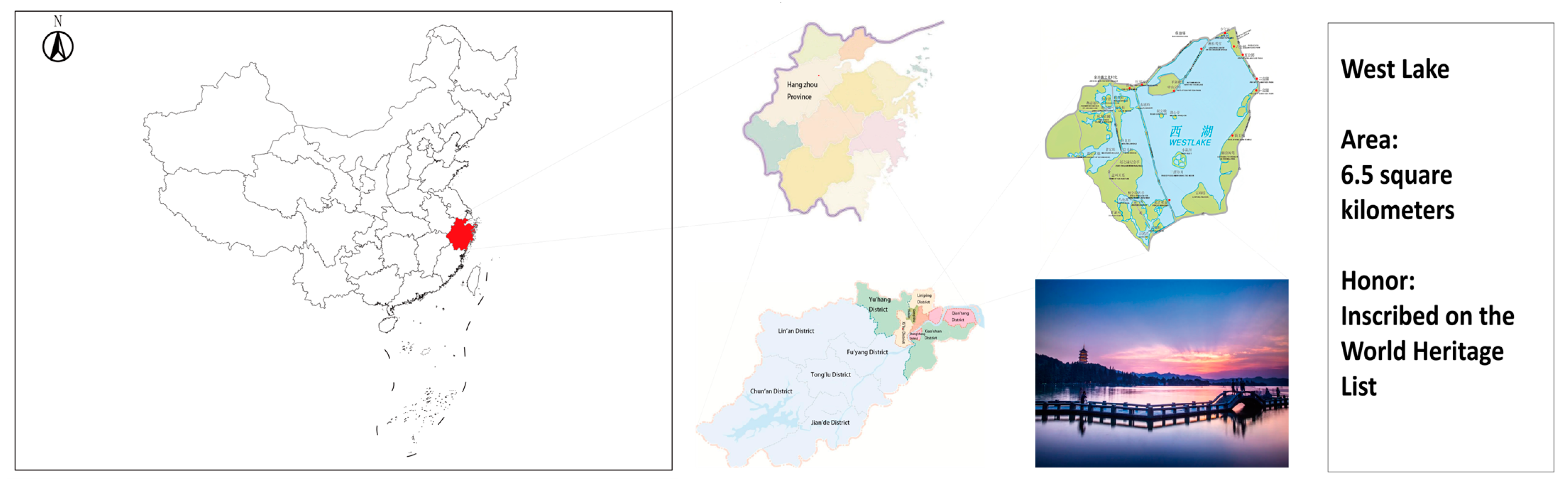
4.1. Dataset
4.2. Tourist Attraction Name Extraction and Multi-Distance Spatial Clustering
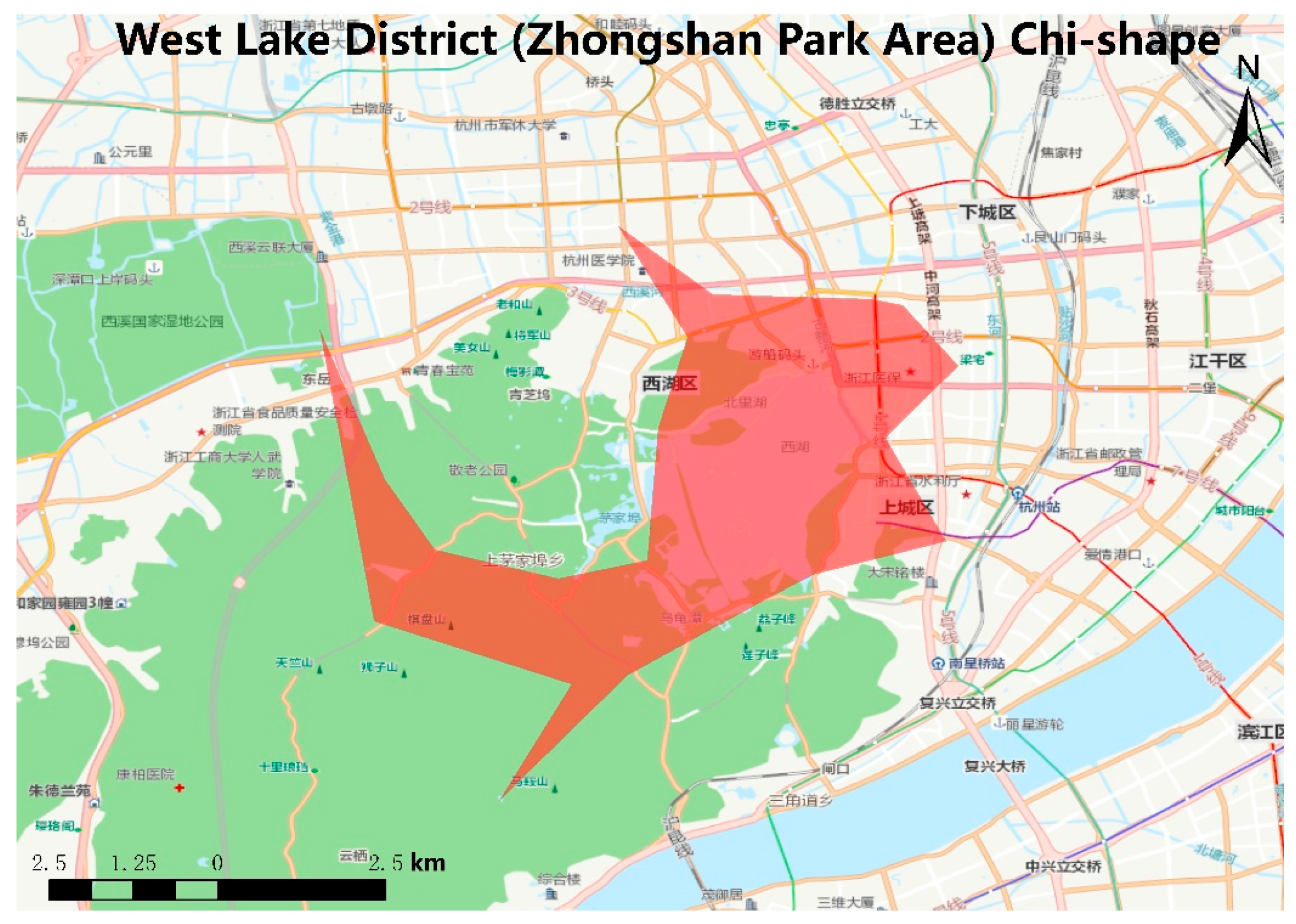
4.3. Generating Chi-Shape Regions Using the Chi-Shape Algorithm
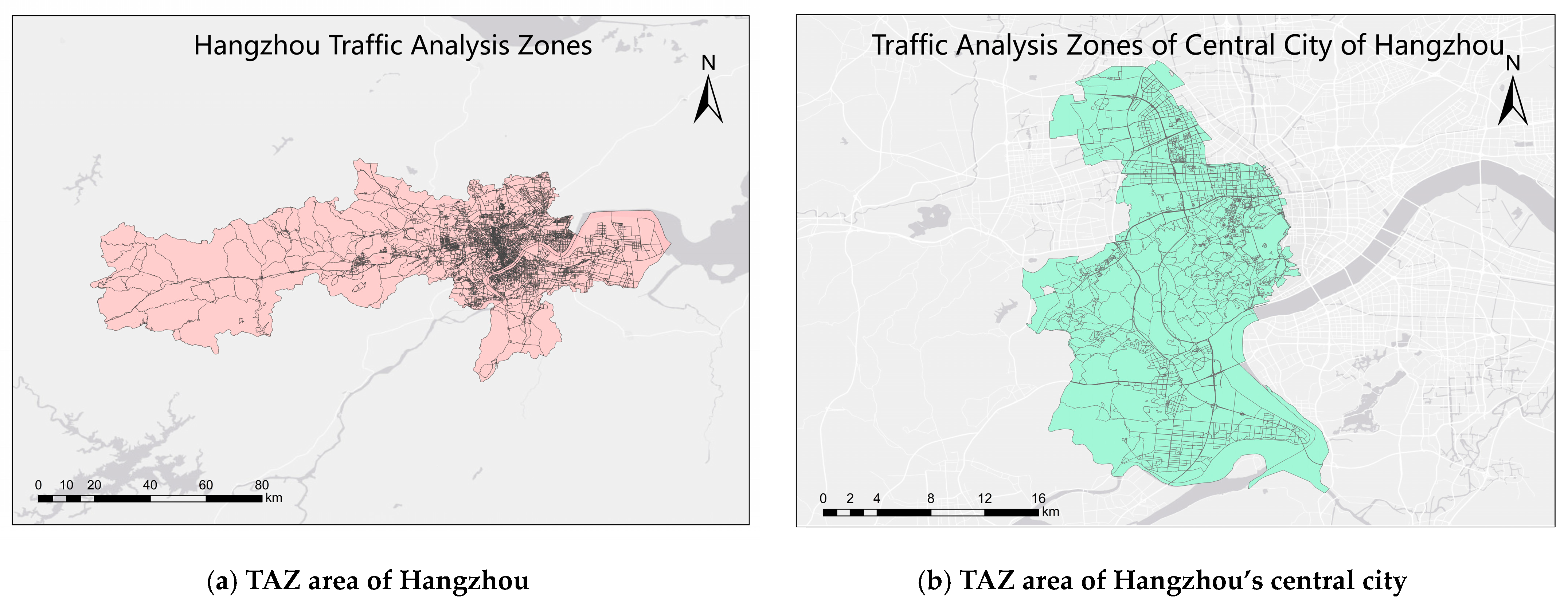
4.4. Intersection of Chi-Shape Regions and TAZ Regions
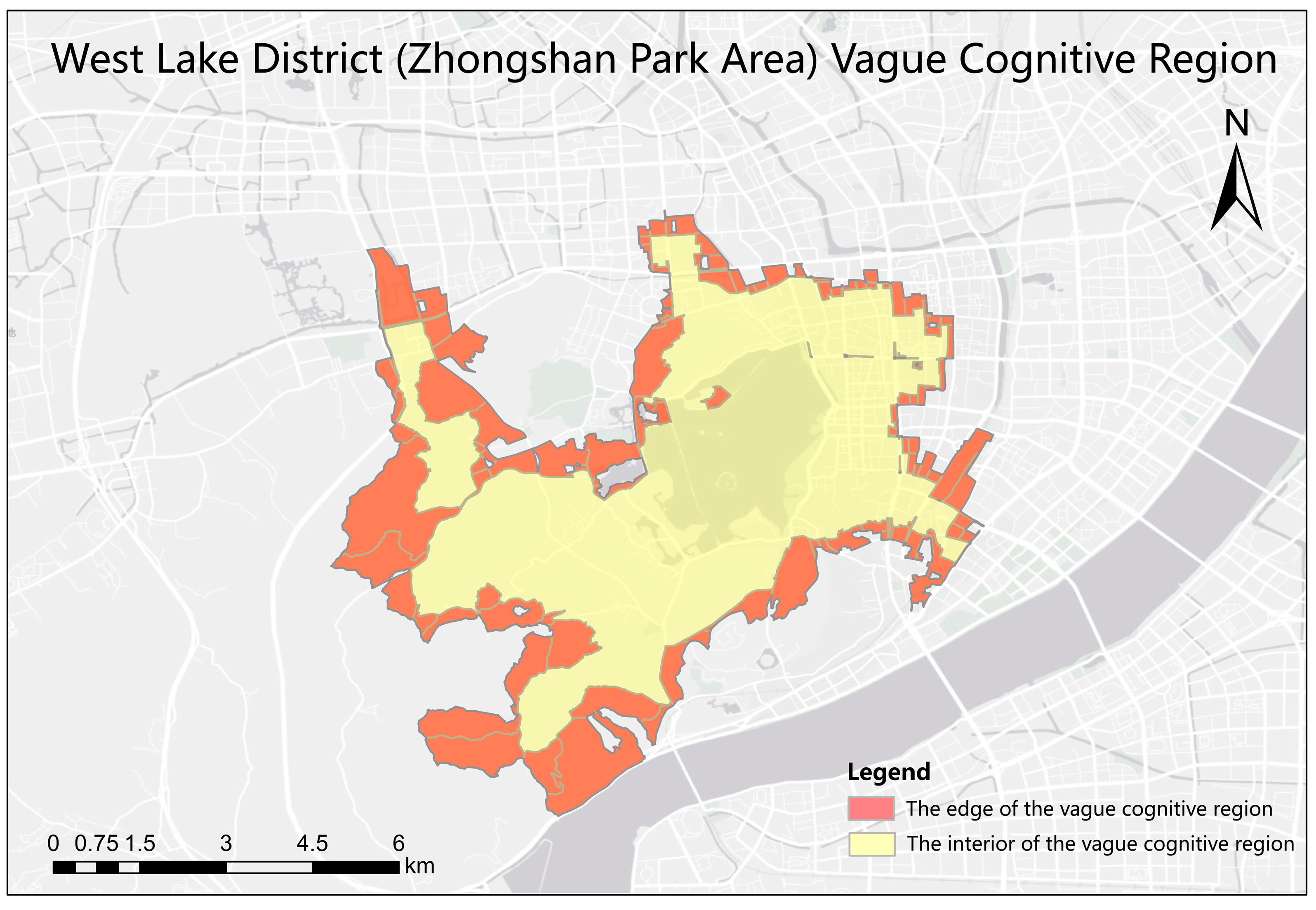
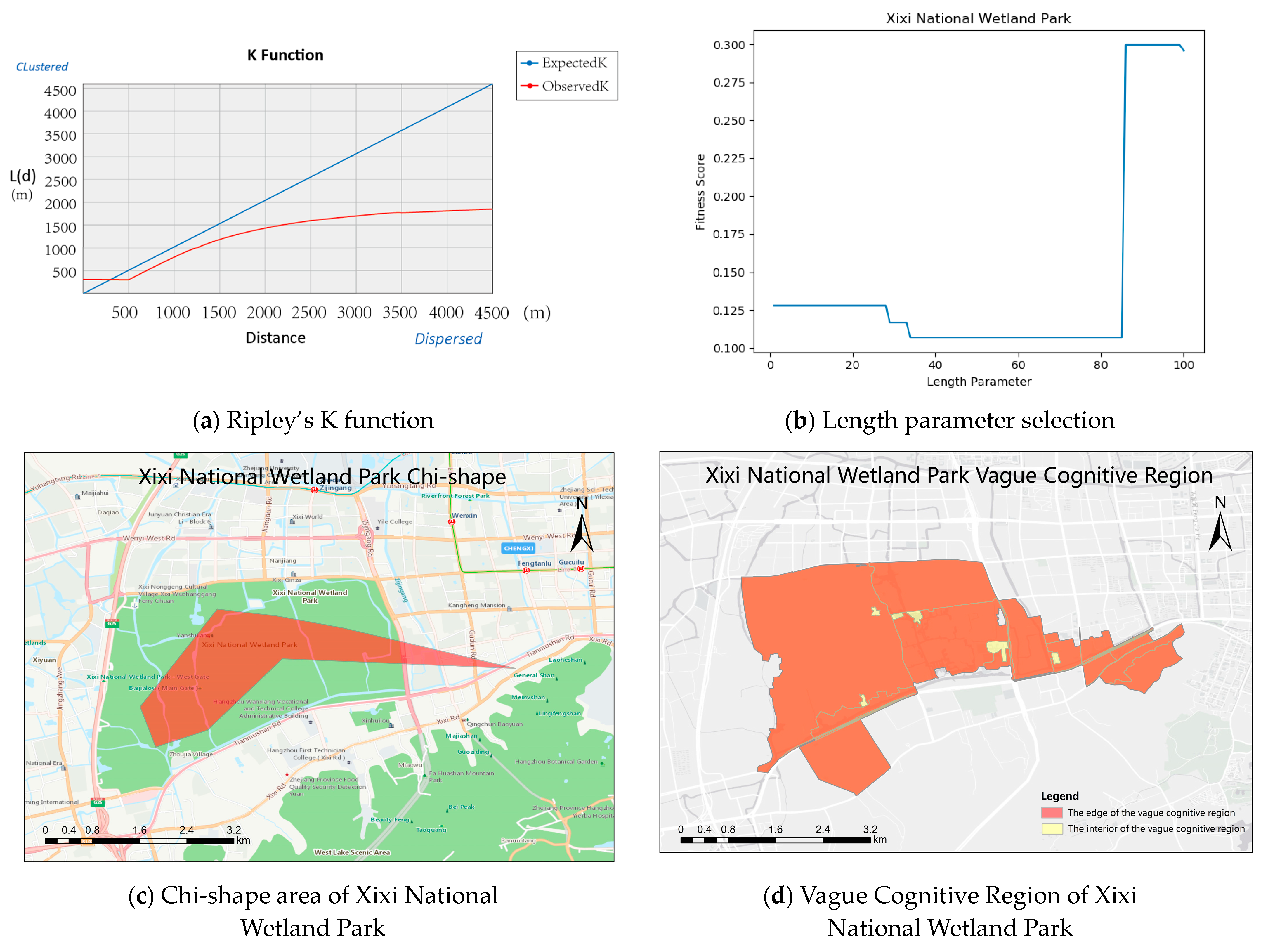
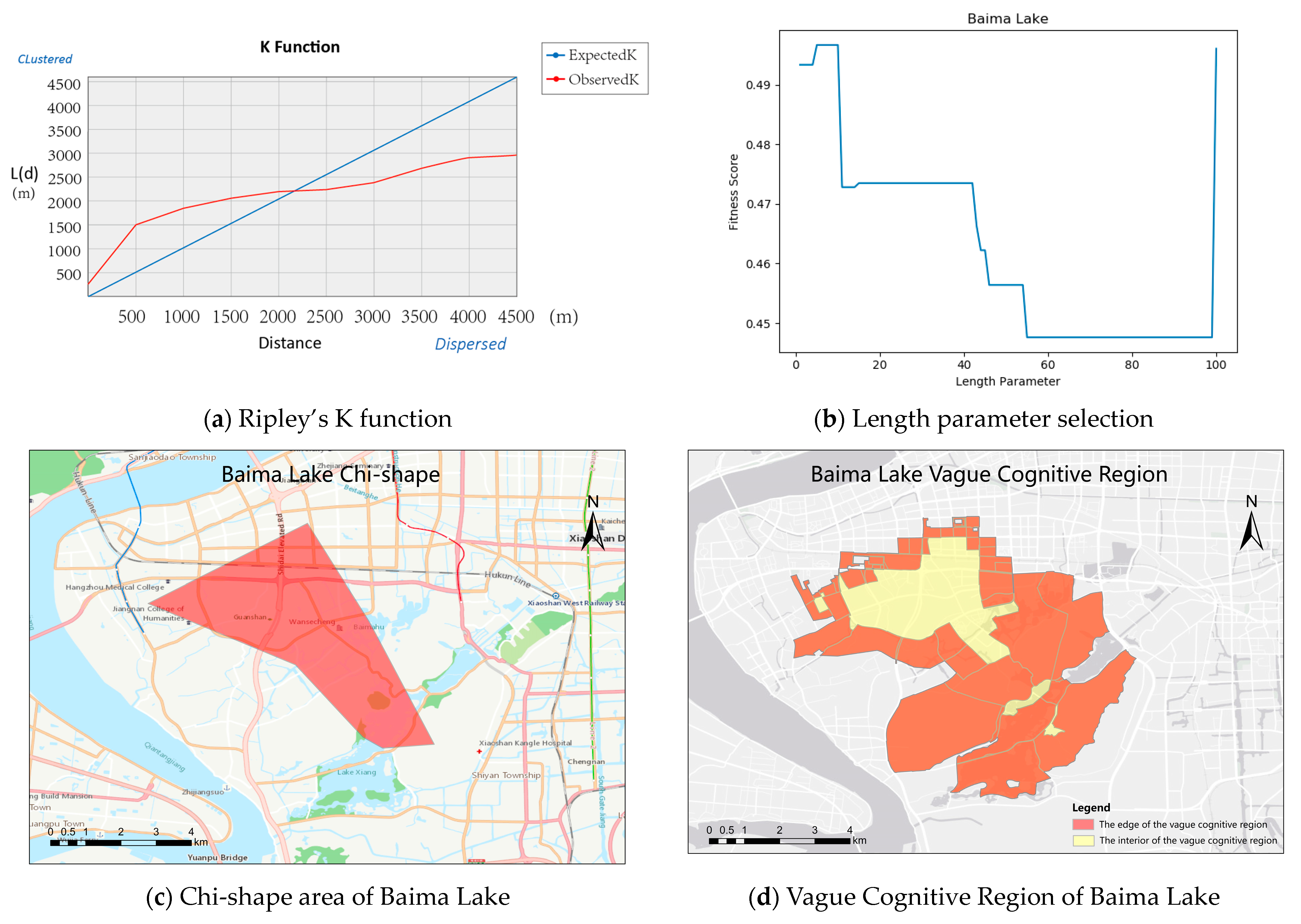
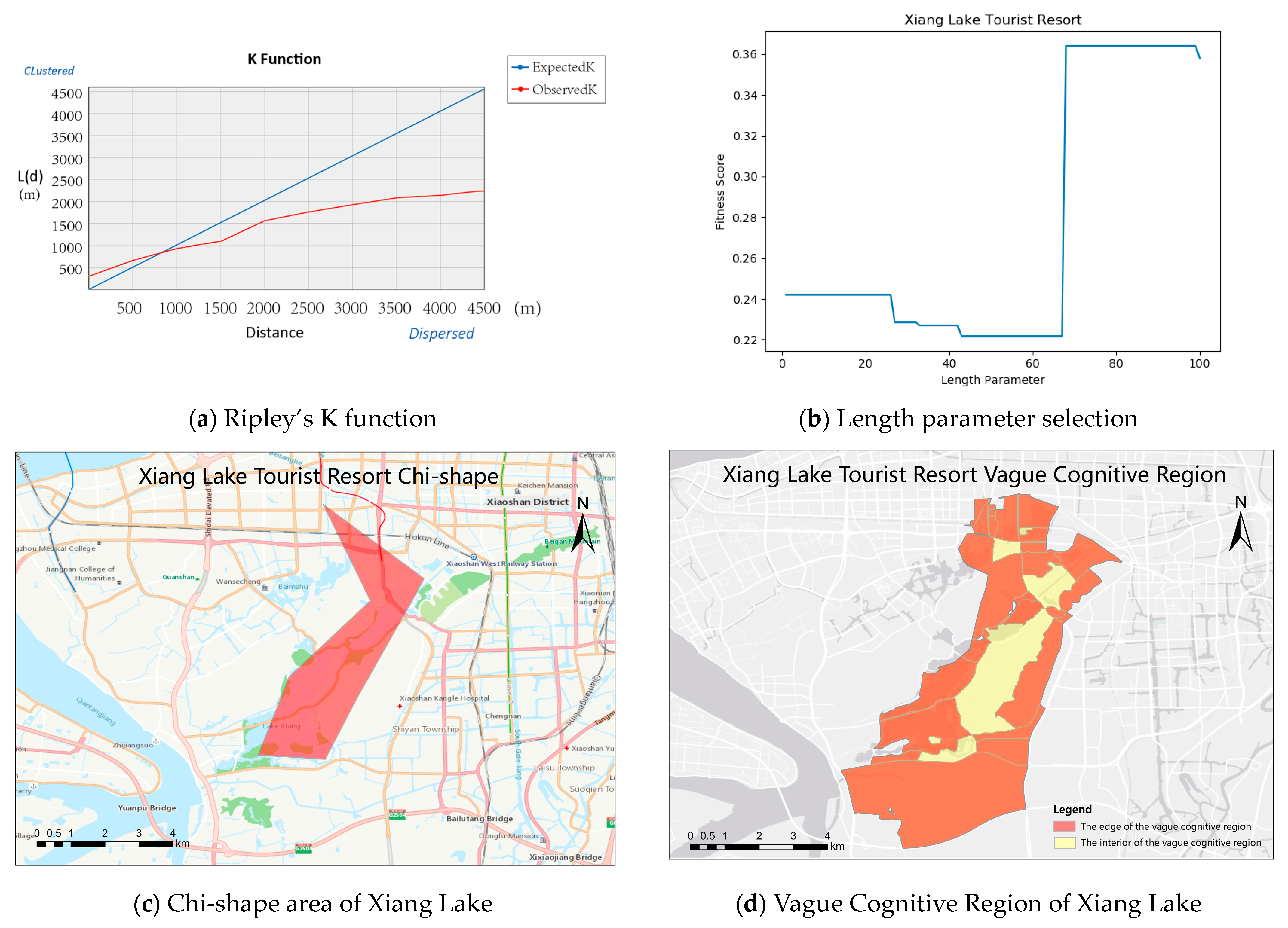
4.5. Experimental Results and Analysis of Vague Block Extraction in Different Scenic Regions
4.6. Experiment Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rather, R.A.H.L.; Rasoolimanesh, S.M. First-time versus repeat tourism customer engagement, experience, and value cocreation: An empirical investigation. J. Travel Res. 2022, 61, 549–564. [Google Scholar] [CrossRef]
- Trupp, A.; Pratt, S.; Stephenson, M.L.; Matatolu, I.; Gibson, D. Representing and evaluating the travel motivations of Pacific islanders. Int. J. Tour. Res. 2022, 24, 653–666. [Google Scholar] [CrossRef]
- Jauhari, A.A.D.R. Analysis of Clusters Number Effect Based on K-Means Method for Tourist Attractions Segmentation. In Journal of Physics: Conference Series; IOP Publishing: Tokyo, Japan, 2022; Volume 2406, p. 012024. [Google Scholar]
- Shabani, A.; Keshavarz, H. Media Literacy and Social Media Information. Glob. Knowl. Mem. Commun. 2022, 71, 413–431. [Google Scholar] [CrossRef]
- Niu, H.; Silva, E.A. Understanding temporal and spatial patterns of urban activities across demographic groups through geotagged social media data. Comput. Environ. Urban Syst. 2023, 100, 101934. [Google Scholar] [CrossRef]
- Akdeniz, E.; Borschewski, K.; Breuer, J.; Voronin, Y. Sharing social media data: The role of past experiences, attitudes, Sharing social media data: The role of past experiences, attitudes, norms, and perceived behavioral control. Front. Big Data 2023, 5, 971974. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, X.; Huang, Q.; Gao, S.; Xia, J. Activity knowledge discovery: Detecting collective and individual activities with digital footprints and open source geographic data. Comput. Environ. Urban Syst. 2021, 85, 101551. [Google Scholar] [CrossRef]
- Zhang, C.; Xu, L.; Yan, Z.; Wu, S. A GloVe-Based POI Type Embedding Model for Extracting and Identifying Urban Functional Regions. ISPRS Int. J. Geo-Inf. 2021, 10, 372. [Google Scholar] [CrossRef]
- Jones, C.B.; Purves, R.S.; Clough, P.D.; Joho, H. Modelling vague places with knowledge from the Web. Int. J. Geogr. Inf. Sci. 2008, 22, 1045–1065. [Google Scholar] [CrossRef]
- Clough, P.; Pasley, R. Images and perceptions of neighbourhood extents. In Proceedings of the 6th Workshop on Geographic Information Retrieval, Zurich, Switzerland, 18–19 February 2010. [Google Scholar]
- Montello, D.R.; Goodchild, M.F.; Gottsegen, J.; Fohl, P. Where’s downtown? Behavioral methods for determining referents of vague spatial queries. Spat. Cogn. Comput. 2003, 3, 185–204. [Google Scholar]
- Leidner, J.L.; Lieberman, M.D. Detecting geographical references in the form of place names and associated spatial natural language. Sigspatial Spec. 2011, 3, 5–11. [Google Scholar] [CrossRef]
- Medway, D.; Warnaby, G. What’s in a name? Place branding and toponymic commodification. Env. Plann A 2014, 46, 153–167. [Google Scholar] [CrossRef]
- Zhang, W.; Gelernter, J. Geocoding location expressions in Twitter messages: A preference learning method. J. Spat. Inf. Sci. 2014, 9, 37–70. [Google Scholar]
- De Bruijn, J.A.; de Moel, H.; Jongman, B.; de Ruiter, M.C.; Wagemaker, J.; Aerts, J.C. A global database of historic and real-time flood events based on social media. Sci. Data 2019, 6, 311. [Google Scholar] [CrossRef] [PubMed]
- McKenzie, G.; Liu, Z.; Hu, Y.; Lee, M. Identifying urban neighborhood names through user-contributed online property listings. ISPRS Int. J. Geo-Inf. 2018, 7, 388. [Google Scholar] [CrossRef]
- Lai, J.; Lansley, G.; Haworth, J.; Cheng, T. A name-led approach to profile urban places based on geotagged Twitter data. Trans. GIS 2020, 24, 858–879. [Google Scholar] [CrossRef]
- Hu, Y.; Mao, H.; McKenzie, G. A natural language processing and geospatial clustering framework for harvesting local place names from geotagged housing advertisements. Int. J. Geogr. Inf. Sci. 2019, 33, 714–738. [Google Scholar] [CrossRef]
- Karimzadeh, M.; Pezanowski, S.; MacEachren, A.M.; Wallgrün, J.O. GeoTxt: A scalable geoparsing system for unstructured text geolocation. Trans. GIS 2019, 23, 118–136. [Google Scholar] [CrossRef]
- Won, M.; Murrieta-Flores, P.; Martins, B. ensemble named entity recognition (ner): Evaluating ner Tools in the identification of Place names in historical corpora. Front. Digit. Humanit. 2018, 5, 2. [Google Scholar] [CrossRef]
- Aldana-Bobadilla, E.; Molina-Villegas, A.; Lopez-Arevalo, I.; Reyes-Palacios, S.; Muñiz-Sanchez, V.; Arreola-Trapala, J. Adaptive Geoparsing Method for Toponym Recognition and Resolution in Unstructured Text. Remote Sens. 2020, 12, 3041. [Google Scholar] [CrossRef]
- Davari, M.; Kosseim, L.; Bui, T.D. Toponym Identification in Epidemiology Articles-A Deep Learning Approach. arXiv 2019, arXiv:1904.11018. [Google Scholar]
- Molina-Villegas, A.; Muñiz-Sanchez, V.; Arreola-Trapala, J.; Alcántara, F. Geographic Named Entity Recognition and Disambiguation in Mexican News using word embeddings. Expert Syst. Appl. 2021, 176, 114855. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, X.; Ye, P.; Du, M. Deep belief networks based toponym recognition for Chinese text. ISPRS Int. J. Geo-Inf. 2018, 7, 217. [Google Scholar] [CrossRef]
- Hu, X.; Al-Olimat, H.S.; Kersten, J.; Wiegmann, M.; Klan, F.; Sun, Y.; Fan, H. GazPNE: Annotation-free deep learning for place name extraction from microblogs leveraging gazetteer and synthetic data by rules. Int. J. Geogr. Inf. Sci. 2022, 36, 310–337. [Google Scholar] [CrossRef]
- Wang, J.; Hu, Y.; Joseph, K. NeuroTPR: A neuro-net toponym recognition model for extracting locations from social media messages. Trans. GIS 2020, 24, 719–735. [Google Scholar] [CrossRef]
- Cadorel, L.; Blanchi, A.; Tettamanzi, A.G. Geospatial Knowledge in Housing Advertisements: Capturing and Extracting Spatial Information from Text. In Proceedings of the 11th on Knowledge Capture Conference, Virtual, 2–3 December 2021. [Google Scholar]
- Kew, T.; Shaitarova, A.; Meraner, I.; Goldzycher, J.; Clematide, S.; Volk, M. Geotagging a Diachronic Corpus of Alpine Texts: Comparing Distinct Approaches to Toponym Recognition. In Proceedings of the Workshop on Language Technology for Digital Historical Archives in Conjuction with RANLP, Varna, Bulgaria, 5 September 2019. [Google Scholar]
- Liu, H.; Qiu, Q.; Wu, L.; Li, W.; Wang, B.; Zhou, Y. Few-shot learning for name entity recognition in geological text based on GeoBERT. Earth Sci. Inform. 2022, 15, 979–991. [Google Scholar] [CrossRef]
- Ma, K.; Tan, Y.; Xie, Z.; Qiu, Q.; Chen, S. Chinese toponym recognition with variant neural structures from social media messages based on BERT methods. J. Geogr. Syst. 2022, 24, 143–169. [Google Scholar] [CrossRef]
- Qiu, Q.; Xie, Z.; Wang, S.; Zhu, Y.; Lv, H.; Sun, K. ChineseTR: A weakly supervised toponym recognition architecture based on automatic training data generator and deep neural network. Trans. GIS 2022, 26, 1256–1279. [Google Scholar] [CrossRef]
- Xu, L.; Du, Z.; Mao, R.; Zhang, F.; Liu, R. GSAM: A deep neural network model for extracting computational representations of Chinese addresses fused with geospatial feature. Comput. Environ. Urban Syst. 2020, 81, 101473. [Google Scholar] [CrossRef]
- Gao, S.; Janowicz, K.; Montello, D.R.; Hu, Y.; Yang, J.-A.; McKenzie, G.; Ju, Y.; Gong, L.; Adams, B.; Yan, B. A data-synthesis-driven method for detecting and extracting vague cognitive regions. Int. J. Geogr. Inf. Sci. 2017, 31, 1245–1271. [Google Scholar] [CrossRef]
- Brindley, P.; Goulding, J.; Wilson, M.L. Generating vague neighbourhoods through data mining of passive web data. Int. J. Geogr. Inf. Sci. 2018, 32, 498–523. [Google Scholar] [CrossRef]
- Montello, D.R.; Friedman, A.; Phillips, D.W. Vague cognitive regions in geography and geographic information science. Int. J. Geogr. Inf. Sci. 2014, 28, 1802–1820. [Google Scholar] [CrossRef]
- Chen, M.; Arribas-Bel, D.; Singleton, A. Understanding the dynamics of urban regions of interest through volunteered geographic information. J. Geogr. Syst. 2019, 21, 89–109. [Google Scholar] [CrossRef]
- Akdag, F.; Eick, C.F.; Chen, G. Creating polygon models for spatial clusters. In Foundations of Intelligent Systems, In Proceedings of the 21st International Symposium, ISMIS 2014, Roskilde, Denmark, 25–27 June 2014; Springer International Publishing: Cham, Switzerland, 2014. [Google Scholar]
- Liu, K.; Qiu, P.; Gao, S.; Lu, F.; Jiang, J.; Yin, L. Investigating urban metro stations as cognitive places in cities using points of interest. Cities 2020, 97, 102561. [Google Scholar] [CrossRef]
- Cai, M.; Hong, L.; Xiong, C. Data-driven traffic zone division in smart city: Framework and technology. Sustain. Energy Technol. Assess. 2022, 52, 102251. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, Z.; Liang, T. Assessing urban travel patterns: An analysis of traffic analysis zone-based mobility patterns. Sustainability 2019, 11, 5452. [Google Scholar] [CrossRef]
- Shao, H.; Zhang, Y.; Li, W. Extraction and analysis of city’s tourism districts based on social media data. Comput. Environ. Urban Syst. 2017, 65, 66–78. [Google Scholar] [CrossRef]
- Xu, L.; Mao, R.; Zhang, C.; Wang, Y.; Zheng, X.; Xue, X.; Xia, F. Deep Transfer Learning Model for Semantic Address Matching. Appl. Sci. 2022, 12, 10110. [Google Scholar] [CrossRef]
- Peng, X.; Huang, Z. A novel popular tourist attraction discovering approach based on geo-tagged social media big data. ISPRS Int. J. Geo-Inf. 2017, 6, 216. [Google Scholar] [CrossRef]
- Devkota, B.; Miyazaki, H.; Witayangkurn, A.; Kim, S.M. Using volunteered geographic information and nighttime light remote sensing data to identify tourism regions of interest. Sustainability 2019, 11, 4718. [Google Scholar] [CrossRef]
- Devkota, B.; Miyazaki, H.; Pahari, N. Utilizing User Generated Contents to Describe Tourism Regions of Interest. In Proceedings of the 2019 First International Conference on Smart Technology & Urban Development (STUD), Chiang Mai, Thailand, 13–14 December 2019. [Google Scholar]
- Karayazi, S.S.; Dane, G.; Vries, B.D. Utilizing urban geospatial data to Understand heritage attractiveness in Amsterdam. ISPRS Int. J. Geo-Inf. 2021, 10, 198. [Google Scholar] [CrossRef]
- Maeda, T.N.; Yoshida, M.; Toriumi, F.; Ohashi, H. Extraction of tourist destinations and comparative analysis of preferences between foreign tourists and domestic tourists on the basis of geotagged social media data. ISPRS Int. J. Geo-Inf. 2018, 7, 99. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Kan, Z.; Kwan, M.P.; Tang, L. Ripley’s K-function for network-constrained flow data. Geogr. Anal. 2021, 54, 769–788. [Google Scholar] [CrossRef]
- Shakiba, M.; Lake, L.W.; Gale, J.F.; Pyrcz, M.J. Multiscale spatial analysis of fracture arrangement and pattern reconstruction using Ripley’s K-function. J. Struct. Geol. 2022, 155, 104531. [Google Scholar] [CrossRef]
- Duckham, M.; Kulik, L.; Worboys, M.; Galton, A. Efficient generation of simple polygons for characterizing the shape of a set of points in the plane. Pattern Recogn. 2008, 41, 3224–3236. [Google Scholar] [CrossRef]
- Hu, Y.; Gao, S.; Janowicz, K.; Yu, B.; Li, W.; Prasad, S. Extracting and understanding urban regions of interest using geotagged photos. Comput. Environ. Urban Syst. 2015, 54, 240–254. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Original Note Title | English Translation of the Note Title | Original Note Content | English Translation of the Note Content | Latitude/ Longitude |
|---|---|---|---|---|
| 你喝过西湖十景吗?无法抗拒的西湖元素? | Have you ever tried the “Ten Scenes of West Lake”? The irresistible elements of West Lake? | 苏堤春晓、断桥残雪、满陇桂雨…这家店竟然以西湖十景命名咖啡在杭州 没有人会拒绝西湖吧-这家创意咖啡店藏在嘉里中心旁边的居民楼下 | Su Causeway in Spring, Snow on the Broken Bridge, Osmanthus Rain at Manjuelong...This café in Hangzhou is named after the ten scenic spots of West Lake. Who could refuse West Lake? This creative coffee shop is hidden under a residential building next to Kerry Center. | 30.2613902 120.162644 |
| Statistical Items | Statistical Values |
|---|---|
| Maximum length of the notes | 2169 |
| Minimum length of the notes | 1 |
| Average length of the notes | 325.087 |
| Original Text | English Translation | Original Label | English Label |
|---|---|---|---|
| 过一个月,青山湖的水上森林将会出现期待已久的红杉林,上帝仿佛在这里打翻了调色盘,小伙伴们记得来打卡哦 | In another month, the long-awaited redwood forest will appear in the water forest of Qing Shan Lake. It’s as if God spilled his paint palette here. Friends, remember to come and take a photo! | ‘scene’: {‘青山湖’: [6,8], ’水上森林’: [10,13], ‘红杉林’: [23,25]} | ‘scene’: {‘Qing Shan Lake’: [6,8], ’water forest’: [10,13], ‘redwood forest‘: [23,25]} |
| Methods | RoBERTa+BiLSTM+CRF | BERT+BiLSTM+CRF | RoBERTa+CRF | RoBERTa+Softmax | BiLSTM+CRF | CRF | RNN+CRF | Fully Connected CRF | |
|---|---|---|---|---|---|---|---|---|---|
| Metric | |||||||||
| Precision before filtering | 0.5668 | 0.6032 | 0.5008 | 0.5426 | 0.3510 | 0.3519 | 0.3405 | 0.3333 | |
| Recall before Filtering | 0.7510 | 0.3638 | 0.6245 | 0.5817 | 0.3093 | 0.1662 | 0.2782 | 0.1751 | |
| F1 before filtering | 0.6460 | 0.4539 | 0.5558 | 0.5615 | 0.3289 | 0.2258 | 0.3062 | 0.2296 | |
| Precision after filtering | 0.7371 | 0.7578 | 0.7468 | 0.7541 | 0.6062 | 0.5019 | 0.7111 | 0.6641 | |
| Recall after filtering | 0.6926 | 0.3288 | 0.5739 | 0.5370 | 0.2665 | 0.0711 | 0.2490 | 0.1654 | |
| F1 after filtering | 0.7141 | 0.4586 | 0.6491 | 0.6273 | 0.3703 | 0.1245 | 0.3689 | 0.2647 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Zhang, Y.; Zhang, J.; Yao, J.; Liu, H.; He, T.; Zheng, X.; Xue, X.; Xu, L.; Yang, J.; et al. A Deep Transfer Learning Toponym Extraction and Geospatial Clustering Framework for Investigating Scenic Spots as Cognitive Regions. ISPRS Int. J. Geo-Inf. 2023, 12, 196. https://doi.org/10.3390/ijgi12050196
Zhang C, Zhang Y, Zhang J, Yao J, Liu H, He T, Zheng X, Xue X, Xu L, Yang J, et al. A Deep Transfer Learning Toponym Extraction and Geospatial Clustering Framework for Investigating Scenic Spots as Cognitive Regions. ISPRS International Journal of Geo-Information. 2023; 12(5):196. https://doi.org/10.3390/ijgi12050196
Chicago/Turabian StyleZhang, Chengkun, Yiran Zhang, Jiajun Zhang, Junwei Yao, Hongjiu Liu, Tao He, Xinyu Zheng, Xingyu Xue, Liang Xu, Jing Yang, and et al. 2023. "A Deep Transfer Learning Toponym Extraction and Geospatial Clustering Framework for Investigating Scenic Spots as Cognitive Regions" ISPRS International Journal of Geo-Information 12, no. 5: 196. https://doi.org/10.3390/ijgi12050196