
Querying Similar Multi-Dimensional Time Series with a Spatial Database

Abstract
:1. Introduction
2. Related Work
2.1. Similarity Measures
2.2. Indexing Methods
2.2.1. Indexing One-Dimensional Time Series
2.2.2. Indexing Multi-Dimensional Time Series
3. Methodology
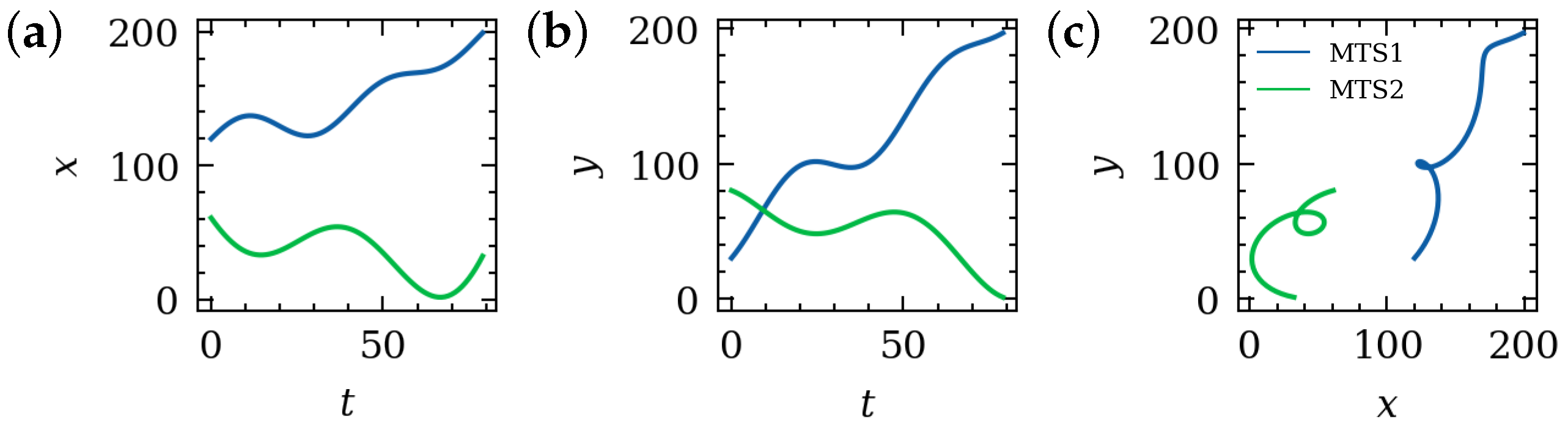
3.1. Association between Time Series and Spatial Objects
3.1.1. Conversion from Time Series to Spatial Objects
3.1.2. Temporal Features and Its Spatial Counterparts
3.2. Similar Time Series Search in Spatial Database
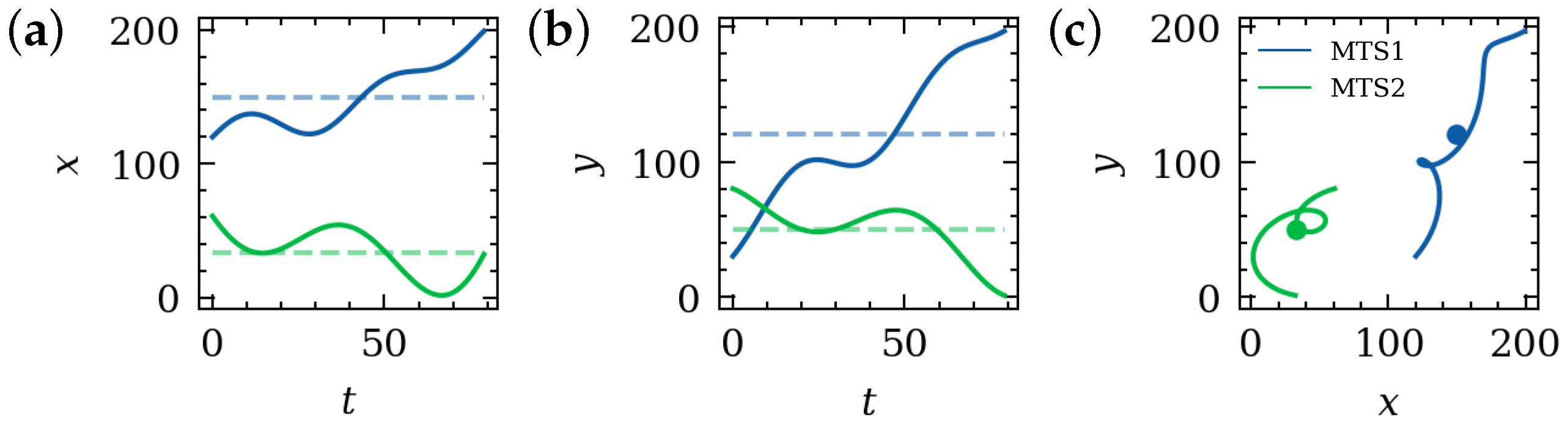
3.2.1. Top-k Search for Strictly Similar Time Series
3.2.2. Top-k Search for Time Series with Similar Trend
4. Experiments and Evaluations
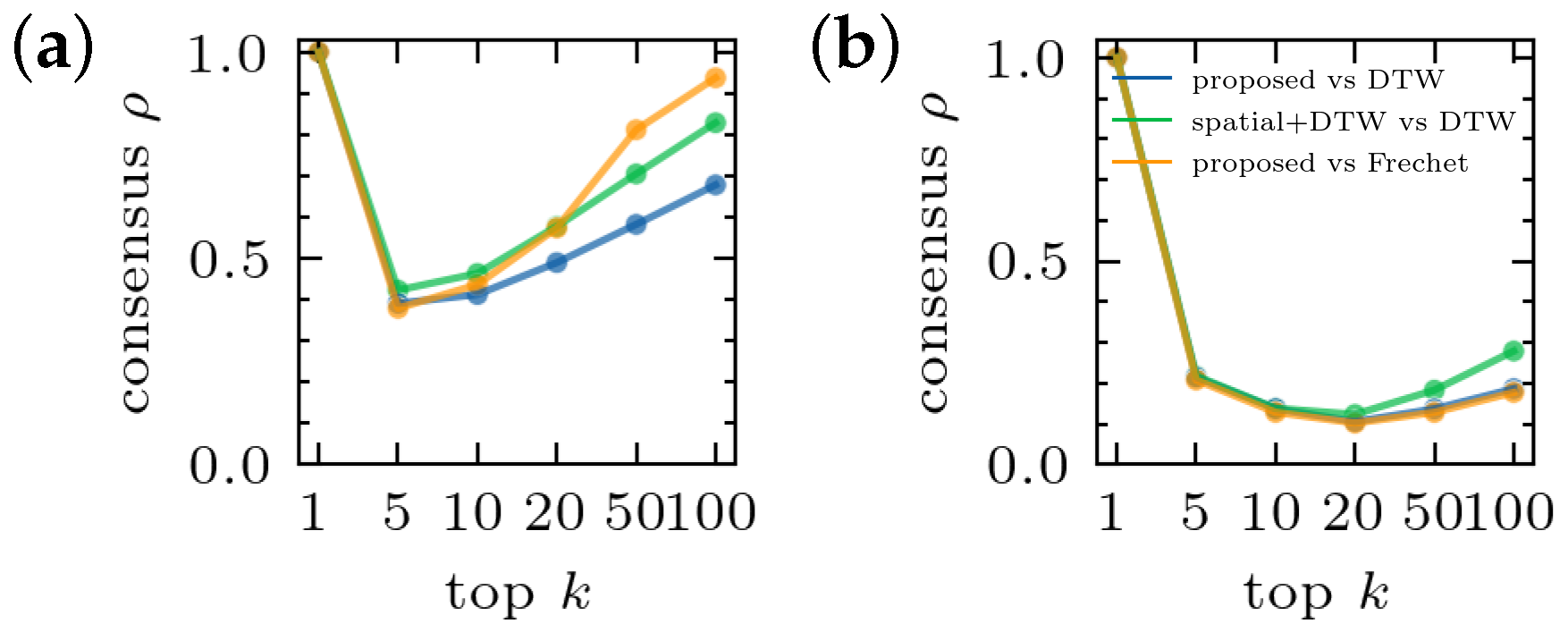
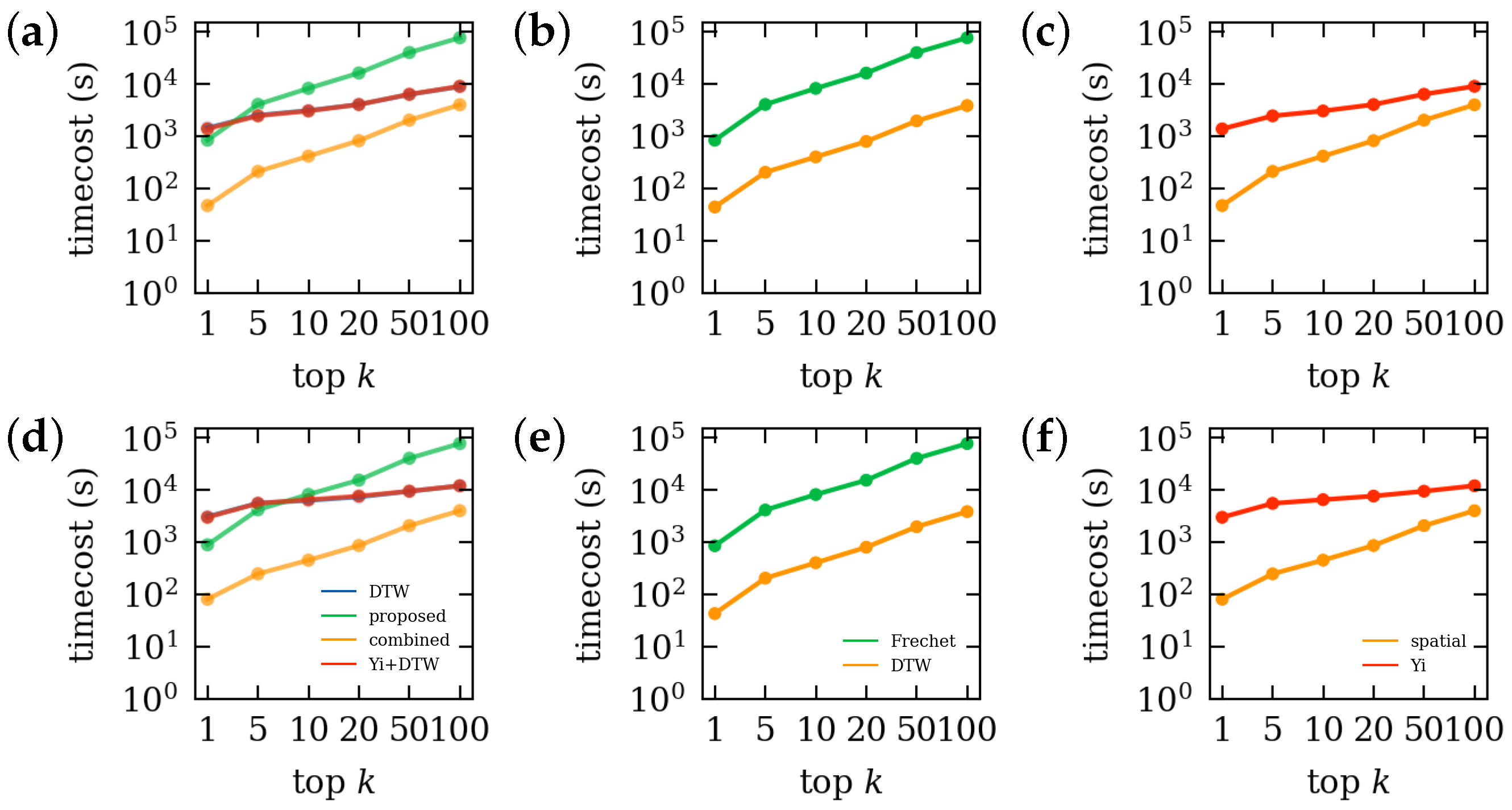
4.1. Performance of the Proposed Method
4.2. In-Depth Evaluation on “Beijingdynamics” Dataset
4.2.1. Comparison from a Stepwise Perspective
4.2.2. Comparison from a Spatial Perspective
5. Discussion
5.1. Trade-Off between Information Loss and Search Efficiency
5.2. Extension of Build-In Functions in Spatial Database
5.3. Scalability of the Proposed Method
5.4. Similarity Search of Spatial Trajectories
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| DTW | Dynamic Time Warping |
| LCSS | Longest Common Subsequence |
| GEMINI | Generic Multimedia Indexing |
| MBR | Minimum Bounding Rectangle |
| TAZ | Traffic Analysis Zone |
References
- Lu, Y.; Liu, Y. Pervasive location acquisition technologies: Opportunities and challenges for geospatial studies. Comput. Environ. Urban Syst. 2012, 36, 105–108. [Google Scholar] [CrossRef]
- Guo, H. Big Earth data: A new frontier in Earth and information sciences. Big Earth Data 2017, 1, 4–20. [Google Scholar] [CrossRef]
- Shasha, D.E. Tuning Time Series Queries in Finance: Case Studies and Recommendations. IEEE Data Eng. Bull. 1999, 22, 40–46. [Google Scholar]
- Zarnowitz, V.; Ozyildirim, A. Time series decomposition and measurement of business cycles, trends and growth cycles. J. Monet. Econ. 2006, 53, 1717–1739. [Google Scholar] [CrossRef]
- Miller, J.W. A multivariate time-series examination of motor carrier safety behaviors. J. Bus. Logist. 2017, 38, 266–289. [Google Scholar] [CrossRef]
- Wild, D. Short-term forecasting based on a transformation and classification of traffic volume time series. Int. J. Forecast. 1997, 13, 63–72. [Google Scholar] [CrossRef]
- Bellazzi, R.; Ferrazzi, F.; Sacchi, L. Predictive data mining in clinical medicine: A focus on selected methods and applications. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 1, 416–430. [Google Scholar] [CrossRef]
- Duchon, C.; Hale, R. Time Series Analysis in Meteorology and Climatology: An Introduction; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Pan, D.; Shen, J.Y. Similarity discovery techniques in temporal data mining. J. Softw. 2007, 18, 246–258. [Google Scholar] [CrossRef]
- Shekhar, S.; Xiong, H. Encyclopedia of GIS; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Ismail Fawaz, H.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Deep learning for time series classification: A review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar] [CrossRef]
- Blázquez-García, A.; Conde, A.; Mori, U.; Lozano, J.A. A review on outlier/anomaly detection in time series data. ACM Comput. Surv. (CSUR) 2021, 54, 56. [Google Scholar] [CrossRef]
- Fu, T.C. A review on time series data mining. Eng. Appl. Artif. Intell. 2011, 24, 164–181. [Google Scholar] [CrossRef]
- Tiano, D.; Bonifati, A.; Ng, R. FeatTS: Feature-based Time Series Clustering. In Proceedings of the International Conference on Management of Data, Shaanxi, China, 20–25 June 2021; pp. 2784–2788. [Google Scholar]
- Kumar, N.; Lolla, V.N.; Keogh, E.; Lonardi, S.; Ratanamahatana, C.A.; Wei, L. Time-series bitmaps: A practical visualization tool for working with large time series databases. In Proceedings of the SIAM International Conference on Data Mining, SIAM, Newport Beach, CA, USA, 21–23 April 2005; pp. 531–535. [Google Scholar]
- Lacasa, L.; Luque, B.; Ballesteros, F.; Luque, J.; Nuno, J.C. From time series to complex networks: The visibility graph. Proc. Natl. Acad. Sci. USA 2008, 105, 4972–4975. [Google Scholar] [CrossRef] [PubMed]
- Schäfer, P. Scalable time series classification. Data Min. Knowl. Discov. 2016, 30, 1273–1298. [Google Scholar] [CrossRef]
- Rodrigues, J.; Liu, H.; Folgado, D.; Belo, D.; Schultz, T.; Gamboa, H. Feature-based information retrieval of multimodal biosignals with a self-similarity matrix: Focus on automatic segmentation. Biosensors 2022, 12, 1182. [Google Scholar] [CrossRef] [PubMed]
- Hatami, N.; Gavet, Y.; Debayle, J. Classification of time-series images using deep convolutional neural networks. In Proceedings of the Tenth International Conference on Machine Vision (ICMV 2017), Vienna, Austria, 13–15 November 2017; SPIE: San Jose, CA, USA, 2018; Volume 10696, pp. 242–249. [Google Scholar]
- Keogh, E.; Wei, L.; Xi, X.; Lee, S.H.; Vlachos, M. LB_Keogh supports exact indexing of shapes under rotation invariance with arbitrary representations and distance measures. In Proceedings of the 32nd International Conference on Very Large Data Bases, COEX, Seoul, Republic of Korea, 12–15 September 2006; Citeseer: Berkeley, CA, USA, 2006; pp. 882–893. [Google Scholar]
- Xing, X.; Yuan, Y.; Huang, Z.; Peng, X.; Zhao, P.; Liu, Y. Flow trace: A novel representation of intra-urban movement dynamics. Comput. Environ. Urban Syst. 2022, 96, 101832. [Google Scholar] [CrossRef]
- Yagoubi, D.E.; Akbarinia, R.; Masseglia, F.; Palpanas, T. Massively distributed time series indexing and querying. IEEE Trans. Knowl. Data Eng. 2018, 32, 108–120. [Google Scholar] [CrossRef]
- Mueen, A.; Keogh, E. Extracting optimal performance from dynamic time warping. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 2129–2130. [Google Scholar]
- Pratt, K.B.; Fink, E. Search for patterns in compressed time series. Int. J. Image Graph. 2002, 2, 89–106. [Google Scholar] [CrossRef]
- Huang, H.; Shi, Z.Z.; Zheng, Z. Similarity search based on shape k-d tree for multidimensional time sequences. J. Softw. 2006, 17, 2048–2056. [Google Scholar] [CrossRef]
- Keogh, E.; Chakrabarti, K.; Pazzani, M.; Mehrotra, S. Dimensionality reduction for fast similarity search in large time series databases. Knowl. Inf. Syst. 2001, 3, 263–286. [Google Scholar] [CrossRef]
- Keogh, E.; Ratanamahatana, C.A. Exact indexing of dynamic time warping. Knowl. Inf. Syst. 2005, 7, 358–386. [Google Scholar] [CrossRef]
- Echihabi, K.; Zoumpatianos, K.; Palpanas, T.; Benbrahim, H. Return of the lernaean hydra: Experimental evaluation of data series approximate similarity search. arXiv 2020, arXiv:2006.11459. [Google Scholar] [CrossRef]
- Handhika, T.; Murni; Lestari, D.P.; Sari, I. Multivariate time series classification analysis: State-of-the-art and future challenges. IOP Conf. Ser. Mater. Sci. Eng. 2019, 536, 012003. [Google Scholar] [CrossRef]
- Yang, K.; Shahabi, C. A multilevel distance-based index structure for multivariate time series. In Proceedings of the 12th International Symposium on Temporal Representation and Reasoning (TIME’05), Burlington, VT, USA, 23–25 June 2005; IEEE: New York, NY, USA, 2005; pp. 65–73. [Google Scholar]
- Li, H. Distance measure with improved lower bound for multivariate time series. Phys. A Stat. Mech. Its Appl. 2017, 468, 622–637. [Google Scholar] [CrossRef]
- Papapetrou, P.; Athitsos, V.; Potamias, M.; Kollios, G.; Gunopulos, D. Embedding-based subsequence matching in time-series databases. ACM Trans. Database Syst. (TODS) 2011, 36, 1–39. [Google Scholar] [CrossRef]
- Aßfalg, J.; Kriegel, H.P.; Kröger, P.; Kunath, P.; Pryakhin, A.; Renz, M. Similarity search on time series based on threshold queries. In Proceedings of the International Conference on Extending Database Technology, Munich, Germany, 26–31 March 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 276–294. [Google Scholar]
- Levchenko, O.; Kolev, B.; Yagoubi, D.E.; Akbarinia, R.; Masseglia, F.; Palpanas, T.; Shasha, D.; Valduriez, P. BestNeighbor: Efficient evaluation of kNN queries on large time series databases. Knowl. Inf. Syst. 2021, 63, 349–378. [Google Scholar] [CrossRef]
- Folgado, D.; Barandas, M.; Antunes, M.; Nunes, M.L.; Liu, H.; Hartmann, Y.; Schultz, T.; Gamboa, H. TSSEARCH: Time series subsequence search library. SoftwareX 2022, 18, 101049. [Google Scholar] [CrossRef]
- Ten Holt, G.A.; Reinders, M.J.; Hendriks, E.A. Multi-dimensional dynamic time warping for gesture recognition. In Proceedings of the Thirteenth Annual Conference of the Advanced School for Computing and Imaging, Heijen, The Netherlands, 13–15 June 2007; Volume 300, pp. 158–165. [Google Scholar]
- Vlachos, M.; Hadjieleftheriou, M.; Gunopulos, D.; Keogh, E. Indexing multi-dimensional time-series with support for multiple distance measures. In Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–27 August 2003; pp. 216–225. [Google Scholar]
- Salvador, S.; Chan, P. Toward accurate dynamic time warping in linear time and space. Intell. Data Anal. 2007, 11, 561–580. [Google Scholar] [CrossRef]
- Geler, Z.; Kurbalija, V.; Ivanović, M.; Radovanović, M. Elastic distances for time-series classification: Itakura versus Sakoe-Chiba constraints. Knowl. Inf. Syst. 2022, 64, 2797–2832. [Google Scholar] [CrossRef]
- Vlachos, M.; Hadjieleftheriou, M.; Gunopulos, D.; Keogh, E. Indexing multidimensional time-series. VLDB J. 2006, 15, 1–20. [Google Scholar] [CrossRef]
- Wu, L.; Cheng, X.; Kang, C.; Zhu, D.; Huang, Z.; Liu, Y. A framework for mixed-use decomposition based on temporal activity signatures extracted from big geo-data. Int. J. Digit. Earth 2020, 13, 708–726. [Google Scholar] [CrossRef]
- Toole, J.L.; Ulm, M.; González, M.C.; Bauer, D. Inferring land use from mobile phone activity. In Proceedings of the ACM SIGKDD International Workshop on Urban Computing, Beijing, China, 12 August 2012; pp. 1–8. [Google Scholar]
- Liu, Y.; Wang, F.; Xiao, Y.; Gao, S. Urban land uses and traffic ‘source-sink areas’: Evidence from GPS-enabled taxi data in Shanghai. Landsc. Urban Plan. 2012, 106, 73–87. [Google Scholar] [CrossRef]
- Agrawal, R.; Faloutsos, C.; Swami, A. Efficient similarity search in sequence databases. In Proceedings of the International Conference on Foundations of Data Organization and Algorithms, Chicago, IL, USA, 13–15 October 1993; Springer: Berlin/Heidelberg, Germany, 1993; pp. 69–84. [Google Scholar]
- Wu, Y.L.; Agrawal, D.; El Abbadi, A. A comparison of DFT and DWT based similarity search in time-series databases. In Proceedings of the 9th International Conference on Information and Knowledge Management, Washington, DC, USA, 6–11 November 2000; pp. 488–495. [Google Scholar]
- Chan, K.P.; Fu, A.W.C. Efficient time series matching by wavelets. In Proceedings of the 15th International Conference on Data Engineering, Sydney, Australia, 23–26 March 1999; IEEE: New York, NY, USA, 1999; pp. 126–133. [Google Scholar]
- Batista, L.V.; Melcher, E.U.K.; Carvalho, L.C. Compression of ECG signals by optimized quantization of discrete cosine transform coefficients. Med. Eng. Phys. 2001, 23, 127–134. [Google Scholar] [CrossRef]
- Cai, Y.; Ng, R. Indexing spatio-temporal trajectories with chebyshev polynomials. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Paris, France, 13–18 June 2004; pp. 599–610. [Google Scholar]
- Beckmann, N.; Kriegel, H.P.; Schneider, R.; Seeger, B. The R*-tree: An efficient and robust access method for points and rectangles. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Atlantic City, NJ, USA, 23–25 May 1990; pp. 322–331. [Google Scholar]
- Indyk, P.; Motwani, R. Approximate nearest neighbors: Towards removing the curse of dimensionality. In Proceedings of the Thirtieth Annual ACM Symposium on Theory of Computing, Dallas, TX, USA, 24–26 May 1998; pp. 604–613. [Google Scholar]
- Lin, K.I.; Jagadish, H.V.; Faloutsos, C. The TV-tree: An index structure for high-dimensional data. VLDB J. 1994, 3, 517–542. [Google Scholar] [CrossRef]
- Berchtold, S.; Keim, D.A.; Kriegel, H.P. The X-tree: An index structure for high-dimensional data. In Proceedings of the Very Large Data Bases, Mumbai, India, 3–6 September 1996; pp. 28–39. [Google Scholar]
- Wang, Y.; Wang, P.; Pei, J.; Wang, W.; Huang, S. A data-adaptive and dynamic segmentation index for whole matching on time series. Proc. VLDB Endow. 2013, 6, 793–804. [Google Scholar] [CrossRef]
- Zoumpatianos, K.; Idreos, S.; Palpanas, T. Indexing for interactive exploration of big data series. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Snowbird, UT, USA, 22–27 June 2014; pp. 1555–1566. [Google Scholar]
- Faloutsos, C.; Ranganathan, M.; Manolopoulos, Y. Fast subsequence matching in time-series databases. Acm SIGMOD Rec. 1994, 23, 419–429. [Google Scholar] [CrossRef]
- Yi, B.K.; Jagadish, H.V.; Faloutsos, C. Efficient retrieval of similar time sequences under time warping. In Proceedings of the 14th International Conference on Data Engineering, Orlando, FL, USA, 23–27 February 1998; IEEE: New York, NY, USA, 1998; pp. 201–208. [Google Scholar]
- Kim, S.W.; Park, S.; Chu, W.W. An index-based approach for similarity search supporting time warping in large sequence databases. In Proceedings of the 17th International Conference on Data Engineering, Heidelberg, Germany, 2–6 April 2001; IEEE: New York, NY, USA, 2001; pp. 607–614. [Google Scholar]
- Gong, X.; Xiong, Y.; Huang, W.; Chen, L.; Lu, Q.; Hu, Y. Fast similarity search of multi-dimensional time series via segment rotation. In Proceedings of the International Conference on Database Systems for Advanced Applications, Hanoi, Vietnam, 20–23 April 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 108–124. [Google Scholar]
- Lv, Q.; Josephson, W.; Wang, Z.; Charikar, M.; Li, K. Multi-probe LSH: Efficient indexing for high-dimensional similarity search. In Proceedings of the 33rd International Conference on Very large Data Bases, Vienna, Austria, 23–27 September 2007; Citeseer: Berkeley, CA, USA, 2007; pp. 950–961. [Google Scholar]
- Lian, X.; Chen, L.; Wang, B. Approximate similarity search over multiple stream time series. In Proceedings of the International Conference on Database Systems for Advanced Applications, Busan, Republic of Korea, 15–18 April 2012; Springer: Berlin/Heidelberg, Germany, 2007; pp. 962–968. [Google Scholar]
- Tang, C.L.; Dong, J.Q. Similarity query of time series sub-sequences based on LSH. Chin. J. Comput. 2012, 35, 2228–2236. [Google Scholar] [CrossRef]
- Gan, J.; Feng, J.; Fang, Q.; Ng, W. Locality-sensitive hashing scheme based on dynamic collision counting. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Scottsdale, AZ, USA, 20–24 May 2012; pp. 541–552. [Google Scholar]
- Yoon, H.; Yang, K.; Shahabi, C. Feature subset selection and feature ranking for multivariate time series. IEEE Trans. Knowl. Data Eng. 2005, 17, 1186–1198. [Google Scholar] [CrossRef]
- Yang, K.; Shahabi, C. An efficient k nearest neighbor search for multivariate time series. Inf. Comput. 2007, 205, 65–98. [Google Scholar] [CrossRef]
- Wang, J.; Zhu, Y.; Li, S.; Wan, D.; Zhang, P. Multivariate time series similarity searching. Sci. World J. 2014, 2014, 851017. [Google Scholar] [CrossRef]
- Lee, S.L.; Chun, S.J.; Kim, D.H.; Lee, J.H.; Chung, C.W. Similarity search for multidimensional data sequences. In Proceedings of the 16th International Conference on Data Engineering (Cat. No. 00CB37073), San Diego, CA, USA, 29 February–3 March 2000; IEEE: New York, NY, USA, 2000; pp. 599–608. [Google Scholar]
- Berchtold, S.; Böhm, C.; Kriegal, H.P. The pyramid-technique: Towards breaking the curse of dimensionality. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Seattle, DC, USA, 1–4 June 1998; pp. 142–153. [Google Scholar]
- Kale, D.C.; Gong, D.; Che, Z.; Liu, Y.; Medioni, G.; Wetzel, R.; Ross, P. An examination of multivariate time series hashing with applications to health care. In Proceedings of the IEEE International Conference on Data Mining, Shenzhen, China, 14–17 December 2014; IEEE: New York, NY, USA, 2014; pp. 260–269. [Google Scholar]
- Yu, C.; Luo, L.; Chan, L.L.H.; Rakthanmanon, T.; Nutanong, S. A fast LSH-based similarity search method for multivariate time series. Inf. Sci. 2019, 476, 337–356. [Google Scholar] [CrossRef]
- Lin, B.; Su, J. One way distance: For shape based similarity search of moving object trajectories. GeoInformatica 2008, 12, 117–142. [Google Scholar] [CrossRef]
- Chen, J.; Wang, R.; Liu, L.; Song, J. Clustering of trajectories based on Hausdorff distance. In Proceedings of the International Conference on Electronics, Communications and Control (ICECC), Ningbo, China, 9–11 September 2011; IEEE: New York, NY, USA, 2011; pp. 1940–1944. [Google Scholar]
- Kucuk, A.; Hamdi, S.M.; Aydin, B.; Schuh, M.A.; Angryk, R.A. Pg-trajectory: A postgresql/postgis based data model for spatiotemporal trajectories. In Proceedings of the IEEE International Conferences on Big Data and Cloud Computing (BDCloud), Social Computing and Networking (SocialCom), Sustainable Computing and Communications (SustainCom)(BDCloud-SocialCom-SustainCom), Atlanta, GA, USA, 8–10 October 2016; IEEE: New York, NY, USA, 2016; pp. 81–88. [Google Scholar]
- Rakthanmanon, T.; Campana, B.; Mueen, A.; Batista, G.; Westover, B.; Zhu, Q.; Zakaria, J.; Keogh, E. Searching and mining trillions of time series subsequences under dynamic time warping. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 262–270. [Google Scholar]
- Dau, H.A.; Bagnall, A.; Kamgar, K.; Yeh, C.C.M.; Zhu, Y.; Gharghabi, S.; Ratanamahatana, C.A.; Keogh, E. The UCR time series archive. IEEE/CAA J. Autom. Sin. 2019, 6, 1293–1305. [Google Scholar] [CrossRef]
- Zhao, X.; Huang, X.; Qiao, J.; Kang, R.; Li, N.; Wang, J. A spatio-temporal index based on skew spatial coding and r-tree. J. Comput. Res. Dev. 2019, 56, 666–676. [Google Scholar]
- Toohey, K.; Duckham, M. Trajectory similarity measures. SIGSPATIAL Spec. 2015, 7, 43–50. [Google Scholar] [CrossRef]
- Chen, L.; Özsu, M.T.; Oria, V. Robust and fast similarity search for moving object trajectories. In Proceedings of the ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 14–16 June 2005; SIGMOD ’05. pp. 491–502. [Google Scholar] [CrossRef]
- Yuan, Y.; Raubal, M. Measuring similarity of mobile phone user trajectories—A Spatio-temporal Edit Distance method. Int. J. Geogr. Inf. Sci. 2014, 28, 496–520. [Google Scholar] [CrossRef]
- Xie, D.; Li, F.; Phillips, J.M. Distributed trajectory similarity search. Proc. VLDB Endow. 2017, 10, 1478–1489. [Google Scholar] [CrossRef]
- Besse, P.C.; Guillouet, B.; Loubes, J.M.; Royer, F. Review and perspective for distance-based clustering of vehicle trajectories. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3306–3317. [Google Scholar] [CrossRef]
- Pelekis, N.; Kopanakis, I.; Marketos, G.; Ntoutsi, I.; Andrienko, G.; Theodoridis, Y. Similarity search in trajectory databases. In Proceedings of the 14th International Symposium on Temporal Representation and Reasoning (TIME’07), Virtual Conference, 7–9 November 2022; pp. 129–140. [Google Scholar] [CrossRef]
- Luo, C.; Dan, T.; Li, Y.; Meng, X.; Li, G. Why-not questions about spatial temporal top-k trajectory similarity search. Knowl.-Based Syst. 2021, 231, 107407. [Google Scholar] [CrossRef]
- Tiakas, E.; Papadopoulos, A.N.; Nanopoulos, A.; Manolopoulos, Y.; Stojanovic, D.; Djordjevic-Kajan, S. Trajectory similarity search in spatial networks. In Proceedings of the 10th International Database Engineering and Applications Symposium, Delhi, India, 11–14 December 2006; IDEAS ’06. pp. 185–192. [Google Scholar] [CrossRef]
- Chen, L.; Gao, Y.; Zheng, B.; Jensen, C.S.; Yang, H.; Yang, K. Pivot-based metric indexing. Proc. VLDB Endow. 2017, 10, 1058–1069. [Google Scholar] [CrossRef]
- Li, X.; Zhao, K.; Cong, G.; Jensen, C.S.; Wei, W. Deep representation learning for trajectory similarity computation. In Proceedings of the IEEE 34th International Conference on Data Engineering (ICDE), Paris, France, 16–19 April 2018; pp. 617–628. [Google Scholar] [CrossRef]
- Tedjopurnomo, D.A.; Li, X.; Bao, Z.; Cong, G.; Choudhury, F.; Qin, A.K. Similar trajectory search with spatio-temporal deep representation learning. ACM Trans. Intell. Syst. Technol. 2021, 12, 1–26. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | l | d | Description | |
|---|---|---|---|---|
| CharacterTrajectories | 1422 | 182 | 3 | Handwriting character trajectories captured using a WACOM tablet. Each instance is a 3-dimensional pen tip velocity trajectory. |
| EthanolConcentration | 261 | 1751 | 3 | Raw spectra taken of water-and-ethanol solutions with different concentrations. The wavelength range of the recorded spectra is from 226 nm to 1101.5 nm, with a sampling interval of 0.5 nm. |
| Libras | 180 | 45 | 2 | Hand movement represented as a bi-dimensional curve performed by the hand in a period of time. The curves were obtained from videos of hand movements. |
| PenDigits | 7494 | 8 | 2 | Handwritten digit instances made up of the x and y coordinates of the pen traced across a digital screen. |
| BeijingDynamics | 1107 | 1116 | 2 | Hourly variation of in/outflow of each traffic analysis zone in Beijing. The data are derived from signaling records between 1 July 2018 to 31 August 2018 provided by China Unicom. |
| Name | Indicator | Strict Similarity | Trend Similarity | ||||
|---|---|---|---|---|---|---|---|
| 1% | 5% | 10% | 1% | 5% | 10% | ||
| CharacterTrajectories | 0.384 | 0.458 | 0.452 | 0.113 | 0.180 | 0.229 | |
| 1.844 | 0.434 | 0.255 | 1.701 | 0.443 | 0.255 | ||
| EthanolConcentration | 0.654 | 0.598 | 0.663 | 0.500 | 0.192 | 0.188 | |
| 0.349 | 0.140 | 0.106 | 0.476 | 0.158 | 0.115 | ||
| Libras | 1.000 | 0.463 | 0.454 | 1.000 | 0.222 | 0.228 | |
| 8.887 | 1.509 | 0.776 | 7.944 | 1.499 | 0.790 | ||
| PenDigits | 0.197 | 0.380 | 0.479 | 0.057 | 0.161 | 0.259 | |
| 8.958 | 2.474 | 1.358 | 2.933 | 1.778 | 1.200 | ||
| BeijingDynamics | 0.435 | 0.608 | 0.688 | 0.114 | 0.133 | 0.192 | |
| 0.358 | 0.152 | 0.110 | 0.711 | 0.211 | 0.165 | ||
Temple of Heaven | Sanlitun | |||
|---|---|---|---|---|
| DTW | Proposed | DTW | Proposed | Random |
 |  |  |  |  |
| Name | Scale Factor | Strict Similarity | Trend Similarity | ||
|---|---|---|---|---|---|
| CharacterTrajectories | 0.1 | 0.526 | 10.642 | 0.635 | 1.388 |
| 0.5 | 0.409 | 2.711 | 0.788 | 0.466 | |
| 1.0 | 0.392 | 1.559 | 0.673 | 0.246 | |
| EthanolConcentration | 0.1 | 0.105 | 5.433 | 0.500 | 2.247 |
| 0.5 | 0.123 | 2.586 | 0.500 | 0.585 | |
| 1.0 | 0.116 | 1.494 | 0.500 | 0.368 | |
| Name | Scale Factor | Strict Similarity | Trend Similarity | ||
|---|---|---|---|---|---|
| CharacterTrajectories | 0.1 | 0.477 | 0.284 | 0.750 | 0.085 |
| 0.5 | 0.478 | 0.869 | 0.673 | 0.175 | |
| 1.0 | 0.392 | 1.559 | 0.673 | 0.246 | |
| EthanolConcentration | 0.1 | 0.273 | 0.286 | 0.615 | 0.090 |
| 0.5 | 0.154 | 0.911 | 0.500 | 0.245 | |
| 1.0 | 0.116 | 1.494 | 0.500 | 0.368 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Kang, C.; Xing, X. Querying Similar Multi-Dimensional Time Series with a Spatial Database. ISPRS Int. J. Geo-Inf. 2023, 12, 179. https://doi.org/10.3390/ijgi12040179
Liu Z, Kang C, Xing X. Querying Similar Multi-Dimensional Time Series with a Spatial Database. ISPRS International Journal of Geo-Information. 2023; 12(4):179. https://doi.org/10.3390/ijgi12040179
Chicago/Turabian StyleLiu, Zheren, Chaogui Kang, and Xiaoyue Xing. 2023. "Querying Similar Multi-Dimensional Time Series with a Spatial Database" ISPRS International Journal of Geo-Information 12, no. 4: 179. https://doi.org/10.3390/ijgi12040179