

Spatio-Temporal Transformer Recommender: Next Location Recommendation with Attention Mechanism by Mining the Spatio-Temporal Relationship between Visited Locations

Abstract
:1. Introduction
- We propose a multi-layer Spatio-Temporal attention model for the next location recommendation by mining the spatio-temporal relationship between visited locations (STTF-Recommender for short), including multi-layer Transformer aggregation and an attention matcher.
- We exploit the Transformer aggregation layer for processing sequence data, which can directly compute the correlation of two visits in a parallel way, and better capture long-term preferences in sequence data so that the patterns of non-adjacent locations and non-contiguous visits in LBSNs can be better discovered.
- We develop an attention matcher based on the attention mechanism by updating representations of check-in to match the most plausible candidate locations.
- We further explore the regularity of spatio-temporal in LBSN by constructing different aggregation modules to make a personalized recommendation. Consequently, the accuracy of recommendations can be further improved.
- We evaluate the performance of our model on two real data sets, including NYC [8] and Gowalla [9]. The results show that our model improves by at least 13.75% in the mean value of the Recall index at different scales compared with the state-of-the-art models and outperforms the best baseline by 4% in the Recall rate.
2. Related Works
2.1. Sequential Recommendation
2.2. Next POI Recommendation
3. Preliminaries
3.1. User Trajectory
3.2. Definition of Problem Mobility Prediction
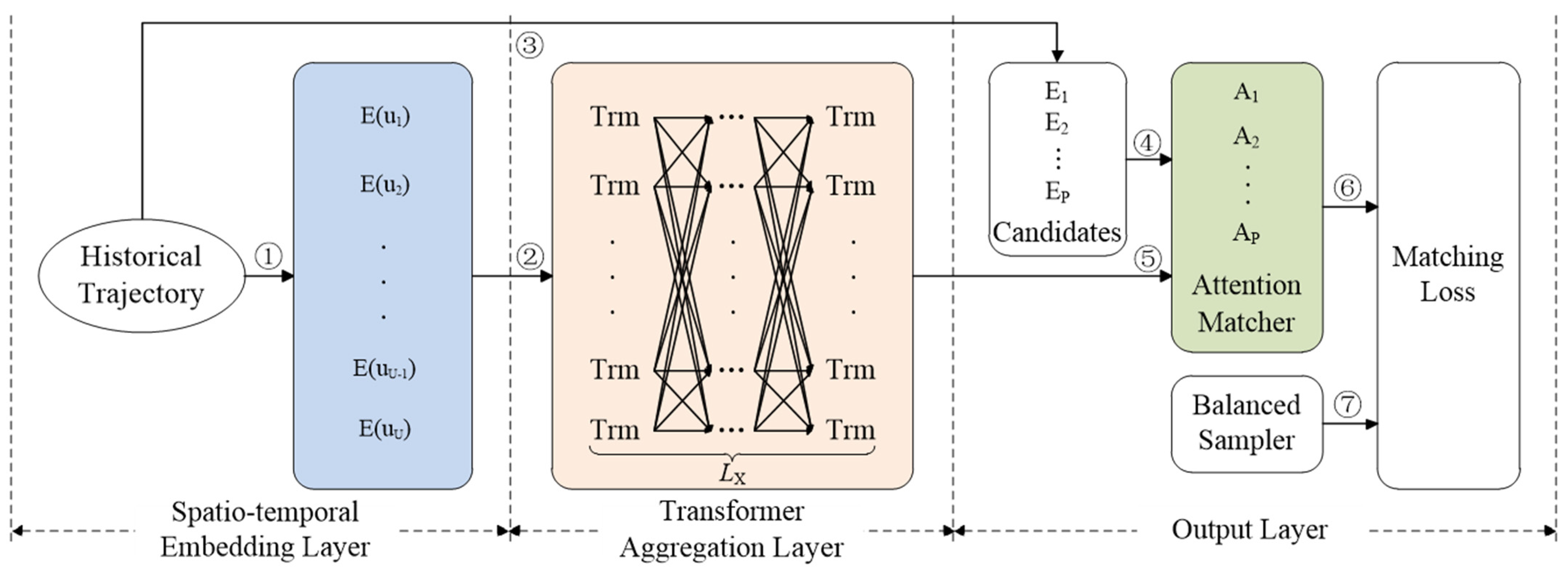
4. The STTF-Recommender Model
4.1. Spatio-Temporal Embedding Layer
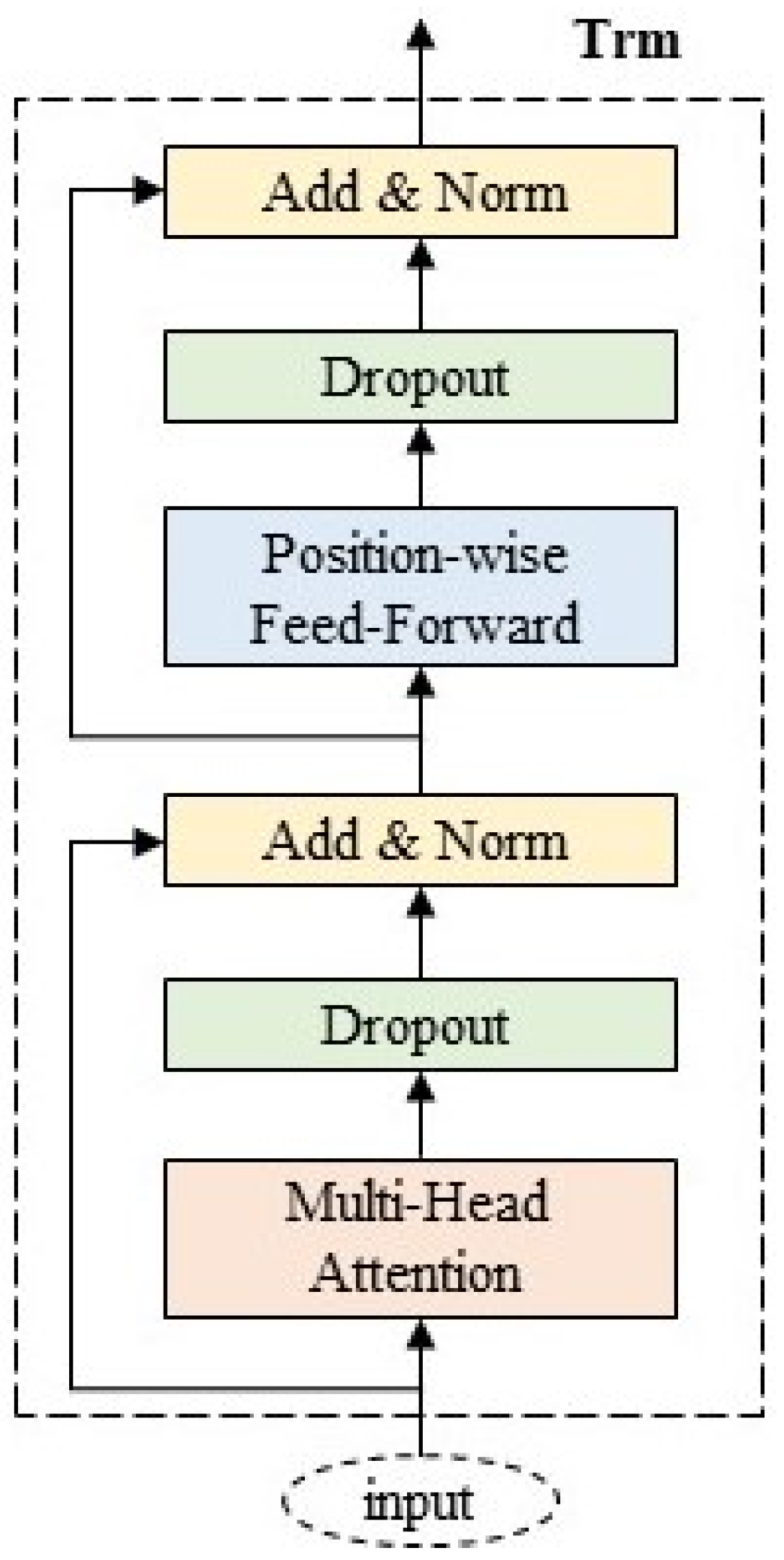
4.2. Transformer Aggregation Layer
4.3. Output Layer
5. Performance Evaluation
5.1. Experiment
5.1.1. Datasets
5.1.2. Baseline Models
- STRNN [9]: A RNN model with invariance, which incorporates spatio-temporal features among consecutive visits.
- LSTPM [7]: A model based on LSTM. It uses two LSTMS to capture users’ long- and short-term preferences and uses geographic extended RNN to simulate discontinuous geographic relationships among POIS.
- DeepMove [10]: A prediction model that uses GRU to deal with short-term dependence and attention to capture historical activities.
- STAN [8]: A model using a self-attention mechanism to deal with spatio-temporal data relation.
5.1.3. Evaluation Method
5.2. Results
5.3. Ablation Study
- STTF-R used recurrent layers as the aggregation layer, which only can model consecutive activities in the user’s check-in sequence while it cannot learn the features of discrete visits.
- STTF-A only used a self-attention as the aggregation layer, which can capture long-term dependency and assign different weights to each visit within the trajectory.
- STTF-M adopted the multi-head self-attention, which mapped the input to different subspaces through a random initialization to capture the dependencies from different representation subspaces.
- STTF-S used a single-layer transformer, which added Position-wise Feed-Forward Network over the STTF-M as the aggregation layer.
- STTF-T stacked three transformer layers, which investigated whether more transformer layers can further improve the recommendation performance.
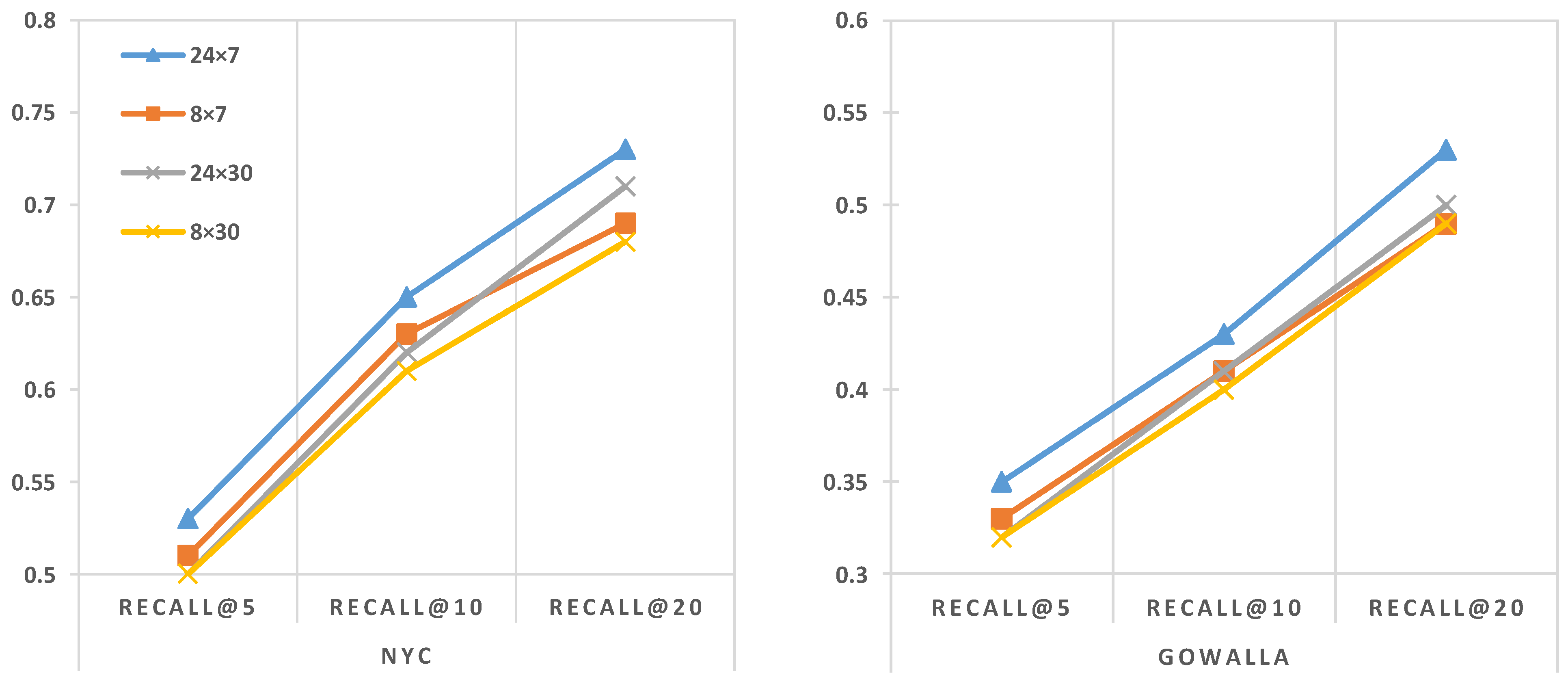
5.4. The Impact of Different Time Scale
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Huang, Q.; Wong, D.W.S. Activity patterns, socioeconomic status and urban spatial structure: What can social media data tell us? Int. J. Geogr. Inf. Sci. 2016, 30, 1873–1898. [Google Scholar] [CrossRef]
- Xu, S.; Fu, X.; Cao, J.; Liu, B.; Wang, Z. Survey on user location prediction based on geo-social networking data. World Wide Web 2020, 23, 1621–1664. [Google Scholar] [CrossRef]
- Islam, A.; Mohammad, M.M.; Das, S.S.S.; Ali, M.E. A survey on deep learning based Point-of-Interest (POI) recommendations. Neurocomputing 2021, 472, 306–325. [Google Scholar] [CrossRef]
- Zou, Z.; Xie, X.; Sha, C. Mining User Behavior and Similarity in Location-Based Social Networks. In Proceedings of the 2015 Seventh International Symposium on Parallel Architectures, Algorithms and Programming (PAAP), Nanjing, China, 12–14 December 2015; pp. 167–171. [Google Scholar] [CrossRef]
- Wang, S.; Cao, J.; Yu, P.S. Deep Learning for Spatio-Temporal Data Mining: A Survey. IEEE Trans. Knowl. Data Eng. 2020, 34, 3681–3700. [Google Scholar] [CrossRef]
- Yang, X.; Guo, Y.; Liu, Y.; Steck, H. A survey of collaborative filtering based social recommender systems. Comput. Commun. 2014, 41, 1–10. [Google Scholar] [CrossRef]
- Sun, K.; Qian, T.; Chen, T.; Liang, Y.; Nguyen, Q.V.H.; Yin, H. Where to Go Next: Modeling Long- and Short-Term User Preferences for Point-of-Interest Recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 214–221. [Google Scholar] [CrossRef]
- Luo, Y.; Liu, Q.; Liu, Z. STAN: Spatio-Temporal Attention Network for Next Location Recommendation. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; Volume 2021, pp. 2177–2185. [Google Scholar] [CrossRef]
- Liu, Q.; Wu, S.; Wang, L.; Tan, T. Predicting the Next Location: A Recurrent Model with Spatial and Temporal Contexts. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2021; Volume 30, pp. 194–200. [Google Scholar] [CrossRef]
- Feng, J.; Li, Y.; Zhang, C.; Sun, F.; Meng, F.; Guo, A.; Jin, D. Deepmove: Predicting Human Mobility with Attentional Recurrent Networks. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; Volume 2, pp. 1459–1468. [Google Scholar]
- Sun, F.; Liu, J.; Wu, J.; Pei, C.; Lin, X.; Ou, W.; Jiang, P. BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2019; Volume 30. [Google Scholar]
- Shani, G.; Heckerman, D.; Brafman, R.I. An MDP-based recommender system. J. Mach. Learn. Res. 2005, 6. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Schmidt-Thieme, L. Factorizing personalized Markov chains for next-basket recommen-dation. In Proceedings of the 19th International World Wide Web Conference, Raleigh, NC, USA, 26–30 April 2010. [Google Scholar]
- He, R.; Kang, W.-C.; McAuley, J. Translation-based Recommendation. In Proceedings of the Translation-Based Recommendation, Como, Italy, 27–31 August 2017; ACM: New York, NY, USA, 2017; pp. 161–169. [Google Scholar]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Hidasi, B.; Karatzoglou, A.; Baltrunas, L.; Tikk, D. Session-based recommendations with recurrent neural networks. arXiv 2016, arXiv:1511.06939. [Google Scholar]
- Donkers, T.; Loepp, B.; Ziegler, J. Sequential User-based Recurrent Neural Network Recommendations. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017; pp. 152–160. [Google Scholar] [CrossRef]
- Li, J.; Wang, Y.; McAuley, J. Time Interval Aware Self-Attention for Sequential Recommendation. In Proceedings of the Thirteenth ACM International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020. [Google Scholar] [CrossRef] [Green Version]
- Noulas, A.; Scellato, S.; Mascolo, C.; Pontil, M. Exploiting semantic annotations for clustering geographic areas and users in location-based social networks. AAAI Work.-Tech. Rep. 2011, WS-11-02, 32–35. [Google Scholar]
- He, J.; Li, X.; Liao, L.; Wang, M. Inferring continuous latent preference on transition intervals for next point-of-interest recommendation. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Proceedings, Part II 18; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; Volume 11052 LNAI. [Google Scholar]
- Liu, W.; Wang, Z.J.; Yao, B.; Nie, M.; Wang, J.; Mao, R.; Yin, J. Geographical relevance model for long tail point-of-interest recommendation. In Lecture Notes in Comput-er Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2018; Volume 10827 LNCS. [Google Scholar]
- Baral, R.; Iyengar, S.S.; Zhu, X.; Li, T.; Sniatala, P. HiRecS: A Hierarchical Contextual Location Recommendation System. IEEE Trans. Comput. Soc. Syst. 2019, 6, 1020–1037. [Google Scholar] [CrossRef]
- Huang, Q.; Li, Z.; Li, J.; Chang, C. Mining frequent trajectory patterns from online footprints. In Proceedings of the 7th ACM SIGSPATIAL International Workshop on GeoStreaming, San Francisco, CA, USA, 31 October 2016; pp. 1–7. [Google Scholar]
- Li, J.; Liu, G.; Yan, C.; Jiang, C. Lori: A learning-to-rank-based integration method of location recommendation. IEEE Trans. Comput. Soc. Syst. 2019, 6, 430–440. [Google Scholar] [CrossRef]
- Yang, D.; Fankhauser, B.; Rosso, P.; Cudre-Mauroux, P. Location Prediction over Sparse User Mobility Traces Using RNNs. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 11–17 July 2020; pp. 2184–2190. [Google Scholar] [CrossRef]
- Halder, S.; Lim, K.H.; Chan, J.; Zhang, X. Transformer-based multi-task learning for queuing time aware next POI rec-ommendation. In Pacific-Asia Conference on Knowledge Discovery and Data Mining: 25th Pacific-Asia Conference, PAKDD 2021, Virtual Event, 11–14 May 2021; Springer International Publishing: Cham, Switzerland, 2021; pp. 510–523. [Google Scholar]
- Li, R.; Shen, Y.; Zhu, Y. Next Point-of-Interest Recommendation with Temporal and Multi-level Context Attention. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 1110–1115. [Google Scholar] [CrossRef]
- Qin, Y.; Song, D.; Chen, H.; Cheng, W.; Jiang, G.; Cottrell, G.W. A dual-stage attention-based recurrent neural network for time series prediction. IJCAI 2017, 2627–2633. [Google Scholar]
- Liu, T.; Liao, J.; Wu, Z.; Wang, Y.; Wang, J. Exploiting geographical-temporal awareness attention for next point-of-interest recommendation. Neurocomputing 2020, 400, 227–237. [Google Scholar] [CrossRef]
- Liu, T.; Liao, J.; Wu, Z.; Wang, Y.; Wang, J. A Geographical-Temporal Awareness Hierarchical Attention Network for Next Point-of-Interest Recommendation. In Proceedings of the International Conference on Multimedia Retrieval, Ottawa, ON, Canada, 10–13 June 2019; pp. 7–15. [Google Scholar] [CrossRef]
- Liu, C.H.; Wang, Y.; Piao, C.; Dai, Z.; Yuan, Y.; Wang, G.; Wu, D. Timeaware location prediction by convolutional area-of-interest modeling and memory-augmented attentive lstm. IEEE Trans. Knowl. Data Eng. 2020, 34, 2472–2484. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
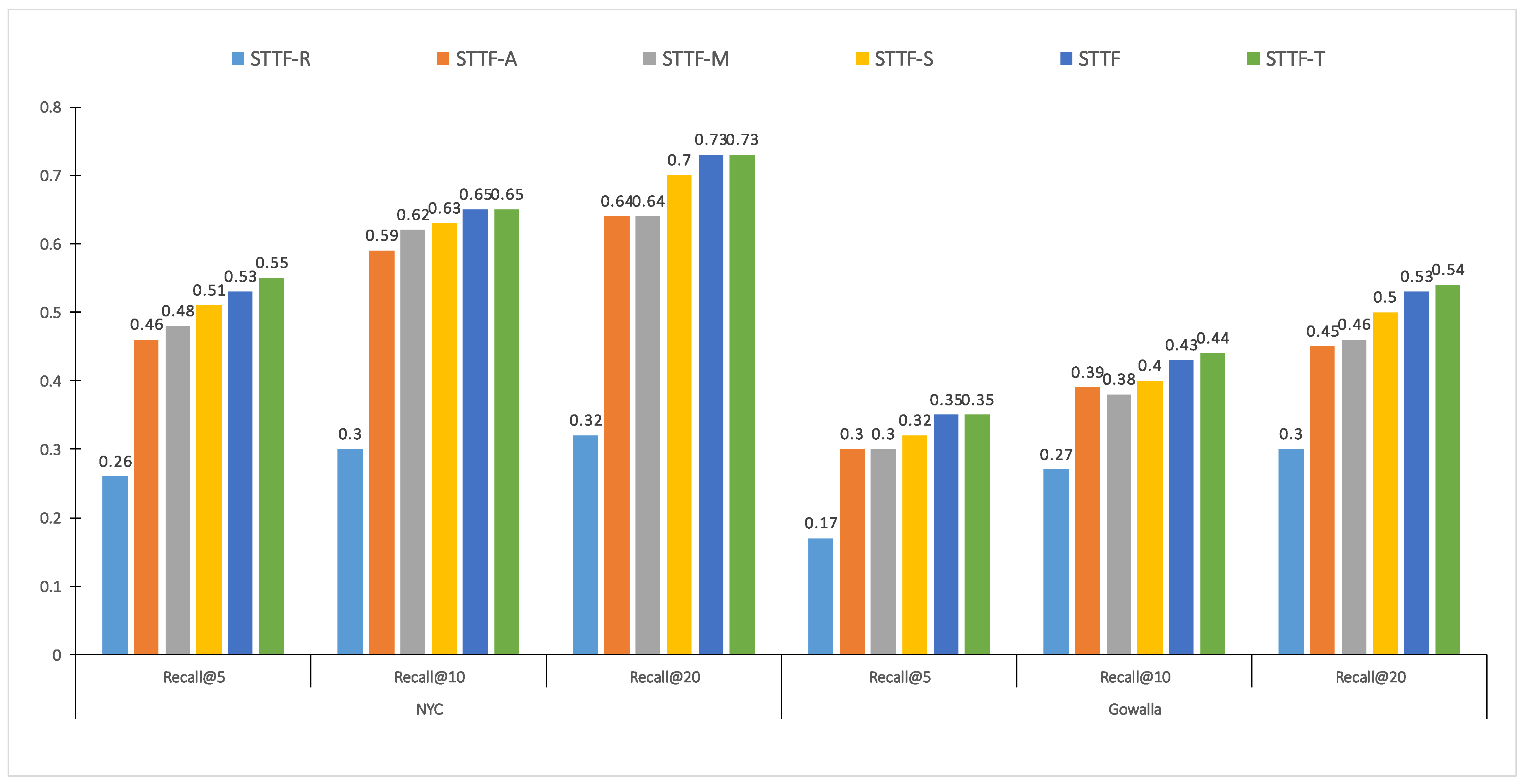{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| User | |
| Location of Check-in | |
| Time of Check-in | |
| Check-in , which is represented as a tuple | |
| trajectories sequence of | |
| The dense vectors of | |
| , | Set of , |
| , | A random layer, and number of layers |
| Hidden representations of visit in the layer | |
| A matrix of stacks | |
| , , | Query, keys, values [12] |
| Number of head | |
| Projection matrices of each head, | |
| Projections matrices for | |
| , | The probability set that each candidate location becomes the next location for user |
| Dataset | User | POIs | Check-Ins |
|---|---|---|---|
| Gowalla | 10,162 | 24,250 | 456,988 |
| NYC | 1064 | 5136 | 147,939 |
| Gowalla | NYC | |||
|---|---|---|---|---|
| Recall@5 | Recall@10 | Recall@5 | Recall@10 | |
| STRNN [9] | 0.16 | 0.25 | 0.24 | 0.28 |
| LSTPM [7] | 0.20 | 0.27 | 0.27 | 0.35 |
| DeepMove [10] | 0.19 | 0.26 | 0.32 | 0.40 |
| STAN [8] | 0.30 | 0.39 | 0.46 | 0.59 |
| STTF-Recommender | 0.35 | 0.43 | 0.53 | 0.65 |
| Improvement | 13.75% | 13.75% | 20.75% | 24.5% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, S.; Huang, Q.; Zou, Z. Spatio-Temporal Transformer Recommender: Next Location Recommendation with Attention Mechanism by Mining the Spatio-Temporal Relationship between Visited Locations. ISPRS Int. J. Geo-Inf. 2023, 12, 79. https://doi.org/10.3390/ijgi12020079
Xu S, Huang Q, Zou Z. Spatio-Temporal Transformer Recommender: Next Location Recommendation with Attention Mechanism by Mining the Spatio-Temporal Relationship between Visited Locations. ISPRS International Journal of Geo-Information. 2023; 12(2):79. https://doi.org/10.3390/ijgi12020079
Chicago/Turabian StyleXu, Shuqiang, Qunying Huang, and Zhiqiang Zou. 2023. "Spatio-Temporal Transformer Recommender: Next Location Recommendation with Attention Mechanism by Mining the Spatio-Temporal Relationship between Visited Locations" ISPRS International Journal of Geo-Information 12, no. 2: 79. https://doi.org/10.3390/ijgi12020079