1. Introduction
With the increasing maturity of autonomous driving, the safety of pedestrians, as the main participants in traffic, has become more of a concern and is one of the core issues of autonomous driving technology. The accurate prediction of pedestrian trajectory can provide a basis for the vehicle’s controller to plan vehicle movement in an adversarial environment and reliably achieve collision avoidance or emergency braking [
1,
2,
3,
4]. However, predicting the trajectory of pedestrians in intelligent transportation systems accurately is very challenging. The fact that pedestrian movements are not only influenced by the surrounding pedestrians and environment but also depend on the social habits of individuals makes it very difficult to model pedestrian trajectory prediction [
5].
In recent years, several deep learning models have been designed to predict pedestrian trajectories, including recurrent neural networks (RNN) [
6], generative adversarial networks (GAN) [
7], and graph-based models [
8]. Among them, long short-term memory networks (LSTM) are widely used because of their great advantages in solving time series problems and the temporal nature of pedestrian trajectories. In “Social-LSTM” [
9], deep learning models and social power were combined in pedestrian trajectory prediction for the first time, which improved the accuracy of pedestrian trajectory prediction to a certain extent. However, the computation of the model is large and the real-time performance is too poor to calculate the state of all pedestrians in the scene [
8]. In addition, Strat [
10], SoPhie [
11], and other related works [
7,
12,
13,
14,
15,
16] also utilized LSTM to model the complex interactions among pedestrians. Later, Matteo Lisotto et al. proposed a new pooling layer to improve the model. The introduction of Generative Adversarial Networks (GAN) can improve the performance of the model to some extent [
11]. For example, the Social-GAN model [
7] proposed by Agrim et al. first extracts pedestrian features using an encoder, and then, uses a decoder to process the pedestrian features to generate multiple pedestrian prediction trajectories. This solved the problem of previous models only being able to predict one trajectory.
With the rapid development of spatio-temporal graphs, graph convolutional neural networks (GCNs) have provided new ideas for pedestrian trajectory prediction [
17,
18]. An increasing number of pedestrian trajectory [
19,
20] prediction models adopt the spatio-temporal graph approach, i.e., modeling pedestrian interactions in both spatial and temporal dimensions. To predict pedestrian trajectories more accurately with fewer parameters, Mohamed et al. proposed the Social-STGCNN framework [
21], in which he modeled pedestrian trajectories as spatio-temporal graphs, with pedestrians as vertices and interaction forces among pedestrians as edges, to construct weight matrices. This method improves computational speed and prediction accuracy compared the original method.
Although there have been some achievements in pedestrian trajectory prediction, there are still some deficiencies. Most of the proposed pedestrian trajectory prediction methods extract features with equal consideration of trajectory coordinate information and timing change information [
22,
23,
24]. In addition, most of the models [
25,
26,
27,
28] do not take into account redundant information that affects the accuracy of the predicted trajectory.
To deal with the above problems, we propose a graph convolutional neural network trajectory prediction model based on prior awareness and information fusion. Based on the original trajectory, features are extracted from coordinate information and temporal information, and weighted pedestrian historical trajectory information is fused to improve the validity of the trajectory data. Secondly, the spatial interaction between pedestrians is divided into multiple modes, and interaction fusion processing is performed separately, to better represent the clustering effect in the pedestrian group. Additionally, a graph convolution interaction model is proposed to reduce the influence of redundant information generated in the process of pedestrian spatial interaction on trajectory prediction.
2. Information Fusion Graph Convolutional Network for Trajectory Forecasting
2.1. Problem Description for Trajectory Prediction
The pedestrian trajectory prediction task can be represented as predicting the future trajectory of a pedestrian for
p time steps by learning potential movement rules for the observed locations of given pedestrians (N) over time. The trajectory sequence is defined as:
where
denotes the position of the
i-th pedestrian at the
t-th time step, and the number of pedestrians
.
The purpose of the trajectory prediction model is to predict the future trajectory of the
i-th pedestrian from the observed location of the input. The mapping relationship between observation and prediction is defined as (2):
where
is the observation time,
denotes the
t-th observation location,
is the prediction time, and
denotes the
t-th prediction location.
Meanwhile, we define the spatio-temporal map of pedestrian trajectories as
, which represents the relative positions of pedestrians at
t-th the time step of a scene.
where
is the set of vertices of the graph
, and
is the set of edges within the graph
which is expressed as
.
= 1 if
and
are connected; otherwise,
= 0. To better model the strength of the interaction of two nodes, we follow the kernel function
, the setting of the weighted adjacency matrix
of Social-STGCNN [
21], and propose an optimization model to improve
. We will present the details of
later in
Section 2.4. View-Direction Graph.
2.2. Weighting Module of Temporal Information
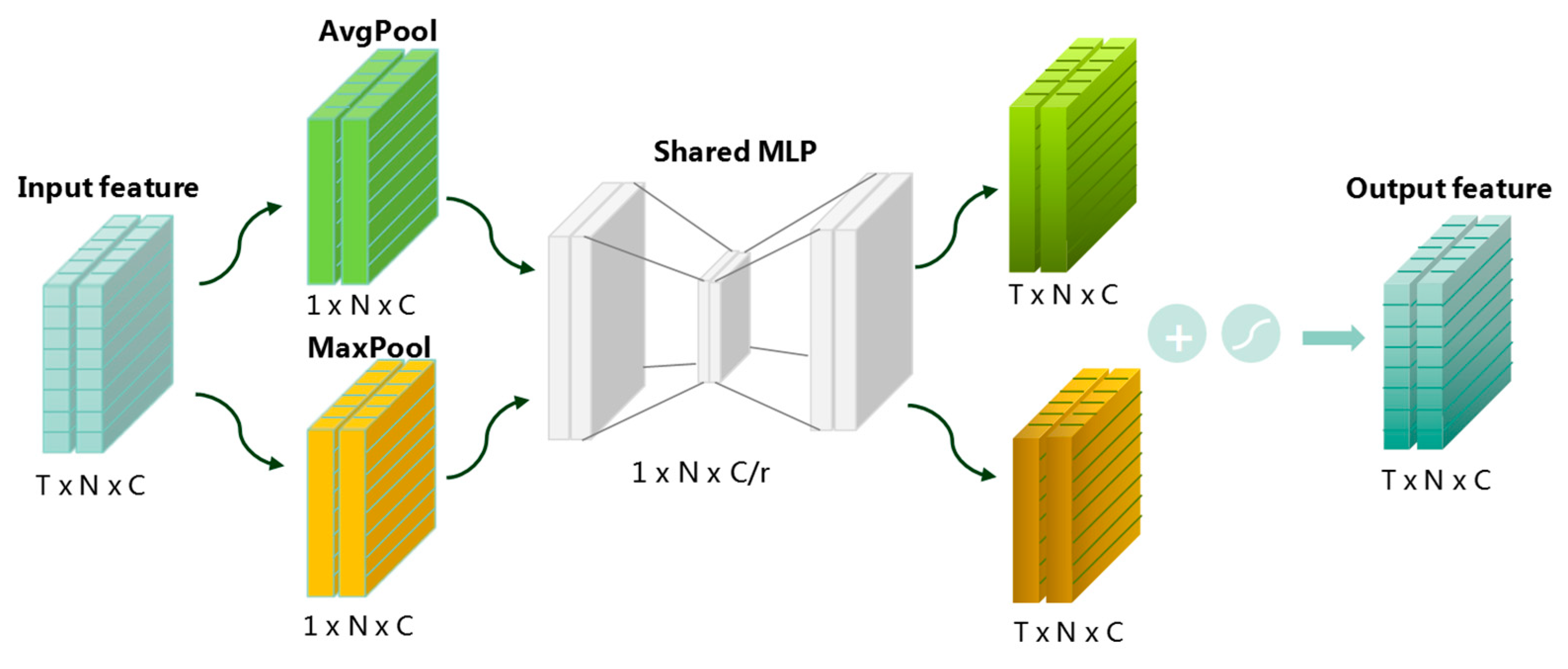
When predicting the next period based on the existing observation information, if the same weight is given to the pedestrian trajectory coordinates, it will cause insufficient attention to one coordinate direction, and excessive attention to the other coordinate direction. Then, it cannot effectively explore the motion characteristics of pedestrians in different orientations. Similarly, for each moment in the observation time , each moment has a different degree of influence and importance for the subsequent trajectory prediction; for example, when a pedestrian makes an unconventional movement such as a turn or a stop, the importance of the input for prediction varies from one observation moment to another. Therefore, the weighting module of temporal information (TIW) proposed in this paper is no longer in the previous form, but fully extracts the information of pedestrian trajectory coordinates and each moment in the observed time , fuses them separately, and assigns different weights to the historical trajectory information of the pedestrian.
The temporal information weighting module first integrates the pedestrian trajectory data into a matrix as the input to the module.
As shown in
Figure 1, N is the number of pedestrians, T is the total length of the observation time, and C includes information on the x and y coordinates of the pedestrians. Then, the pedestrian trajectory information is input into the convolutional network to operate on the pedestrian historical time-series trajectory; the trajectory information between the observation periods is given different weights by convolution, and then, superimposed with the pedestrian trajectory information to obtain the pedestrian trajectory information after module processing. The structure of the temporal information weighting module is as follows.
The model in this paper obtains the output by fusing the weighted information of the location of the i-th pedestrian at each moment in the period .
The first step of the weighted fusion of temporal information is to extract temporal features from the trajectory information of the
i-th pedestrian in period
, assign different weights to the position information
x and
y at each moment
, and then, sum up with the corresponding original coordinate information in the corresponding moment to obtain the output result
, as shown in (4):
where σ denotes the sigmoid function,
, and
. The shared network consists of a multi-layer perceptron (MLP) whose weights
and
are shared, and the ReLU activation function, followed by
.
2.3. Spatial Interaction Module of Multi-Pedestrians
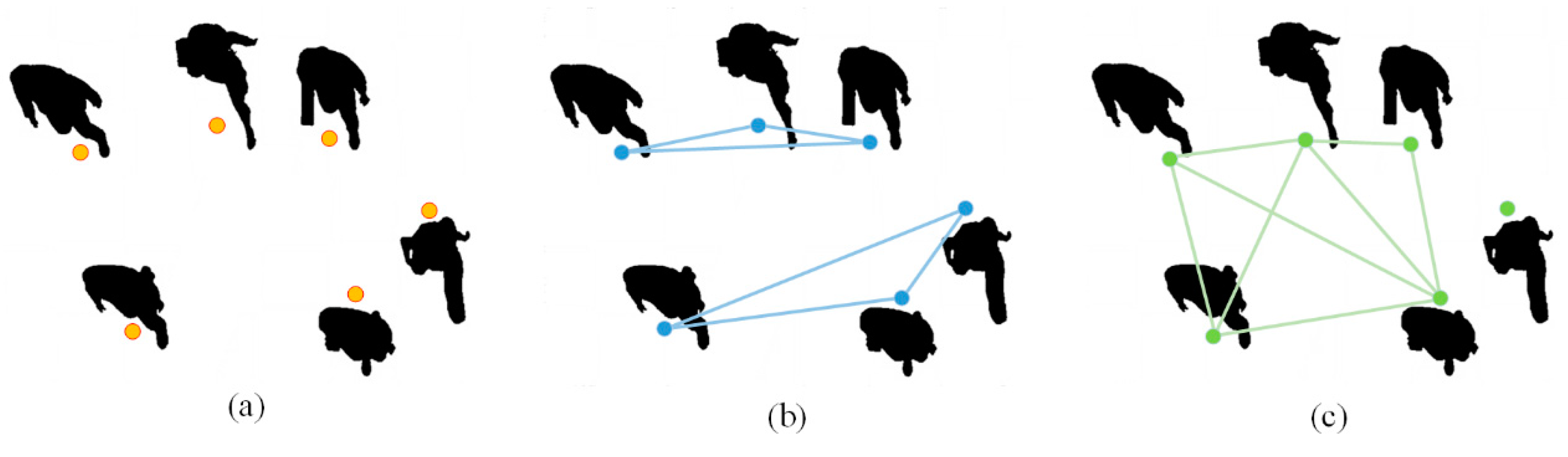
Although it is quite advanced to integrate the spatial interaction information of pedestrians into existing models, integrating spatial interaction information among all pedestrians at one time will lead to redundant information. This paper addresses this problem by proposing a spatial interaction module for multi-pedestrians. The statistical analysis of pedestrian aggregation and the number of mainstream clusters is performed through the ETH [
29] and UCY [
30] datasets, and this paper combines the analysis results to classify the pedestrian spatial interaction into three types of aggregate according to the number of pedestrians, as shown in
Figure 2. In the first category (a), each pedestrian is considered independently as an aggregate, and the influence between the aggregates is considered; in the second category (b), three people are considered as an aggregate and only the interaction between these three people is considered as a case of small-scale aggregated interaction; in the third category (c), five people are considered as an aggregate, and only the interaction between these five pedestrians is considered as a case of large-scale aggregated interaction. The reason we chose the three types of aggregate above is explained in detail in the ablation test in the Ablation Experiments part of
Section 3. At the same time, this paper uses a convolution calculation formula (5) to set the number of pedestrians in the aggregate (1, 3, and 5).
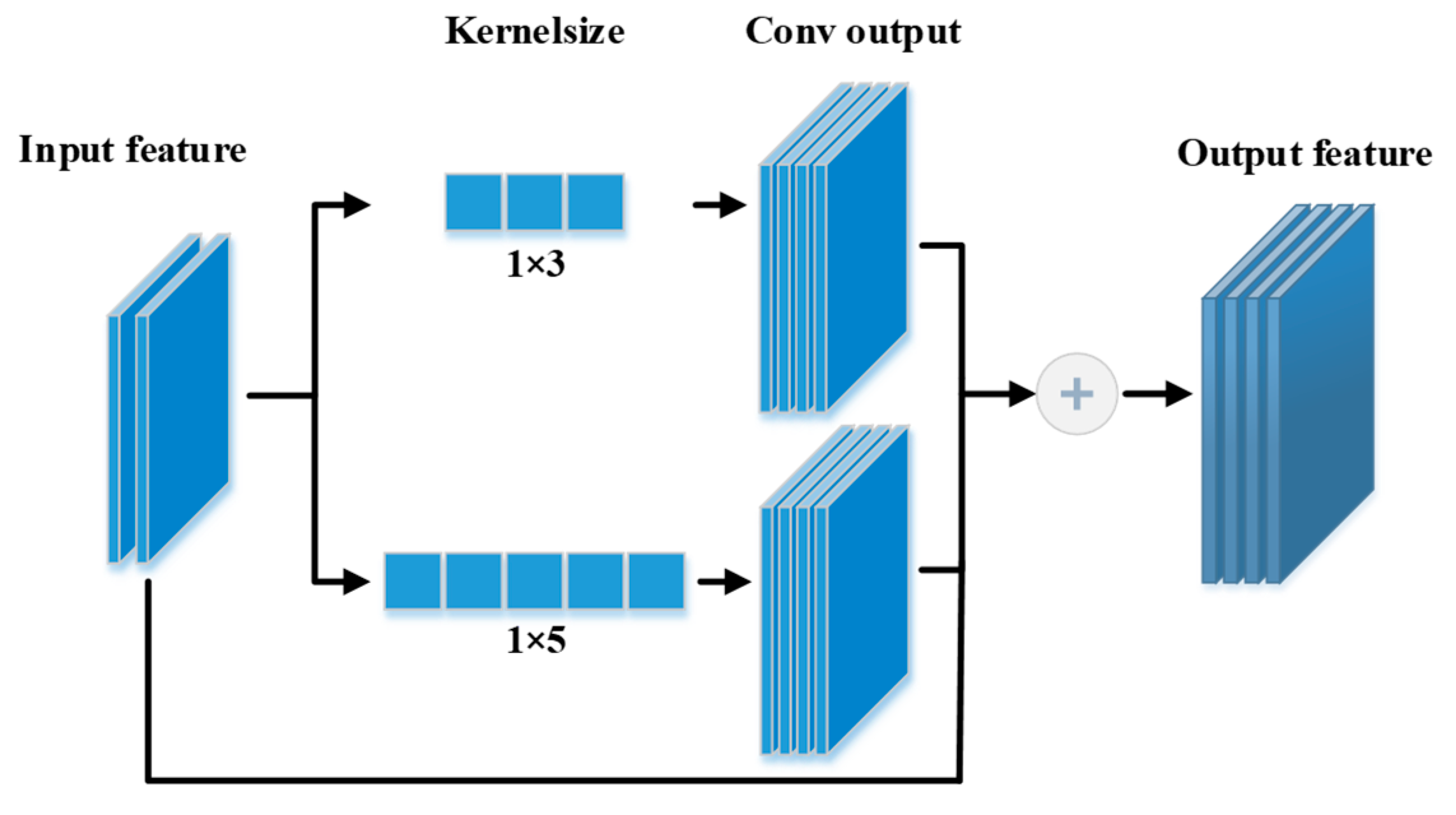
With the spatial interaction module of multi-pedestrians (M-PSI), the model in this paper can effectively obtain interaction information between pedestrians in multiple aggregation situations. By superimposing the interaction information between pedestrians in multiple different modes, the impact of redundant interaction information generated by the network on future trajectory prediction is reduced. The aim of the implementation of the method in this thesis is to obtain the same dimensional information by convolving the pedestrian feature information in different ways, and then, superimposing the information with the input pedestrian features. The structure uses multiple convolutional kernels of different sizes to achieve the extraction of interaction information between pedestrians in the convolution. According to the convolution formula, the output in the pedestrian number dimension is shown in (5):
Num represents the number of pedestrians, kernel size represents the size of the convolution kernel in the pedestrian number dimension, padding represents padding, stride represents the step size, and Nums represents the output after convolution.
As shown in
Figure 3, the spatial interaction module of multi-pedestrians in this paper is a three-level module with a two-dimensional convolution. To ensure that no redundant time-dimensional interactions are generated, the sizes of the convolution kernels are set to 1 × 3 and 1 × 5, respectively, and the original input information is superimposed and fused with the convolution output to obtain the output information.
Additionally, by filling the number of pedestrians dimensionally, the convolution is carried out properly and the consistency of the convolution output is guaranteed. This ensures that the spatial interaction information of pedestrians at the corresponding moment is extracted efficiently, and no temporal interaction is generated, which is implemented in (6).
where
is the parameter of 1 × 3 convolution,
is the parameter of 1 × 5 convolution,
is the output of single-person interaction,
is the output of three-person interaction, and
is the output of five-person interaction.
is the output of multimodal
i-th pedestrian space interaction.
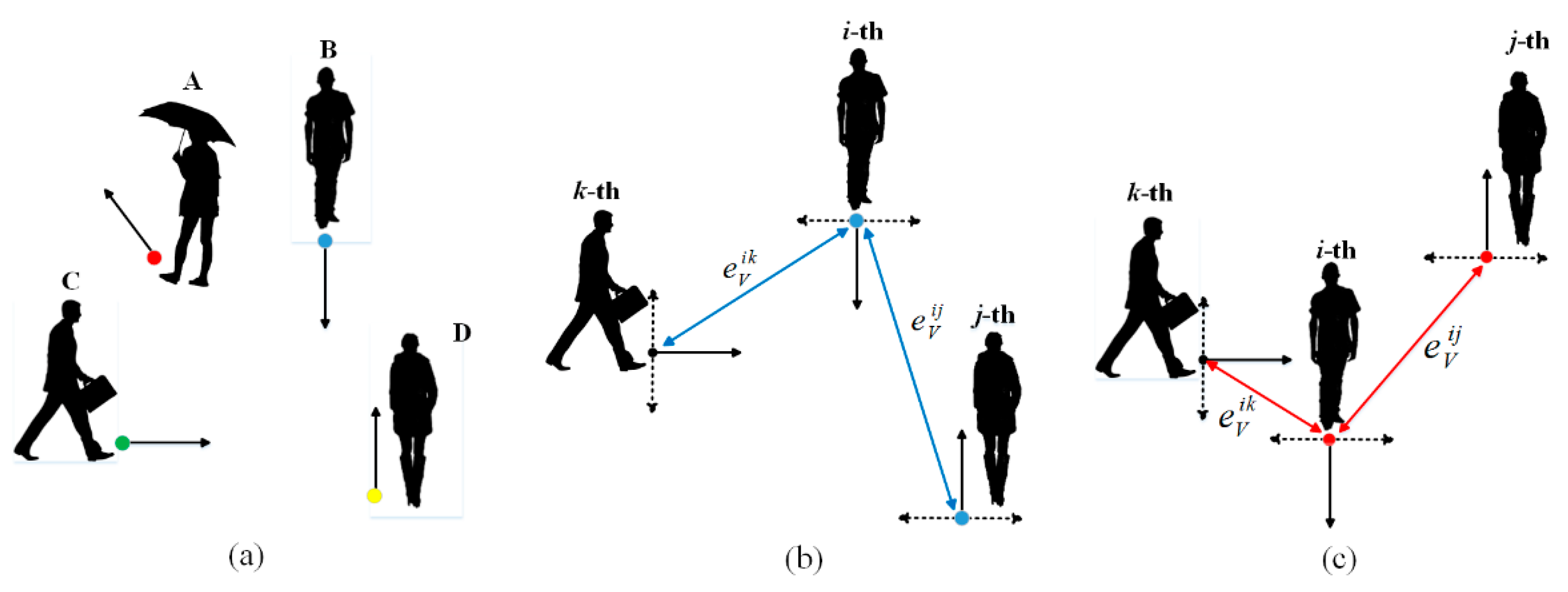
2.4. View-Direction Graph
Intuitively, a pedestrian’s movement behavior is significantly influenced by other pedestrians in his or her field of view. For example, while walking, we are always aware of pedestrians within our field of view. As shown in
Figure 4a, pedestrian A cannot see any pedestrians, so her motion is not influenced by other pedestrians. However, since she appears in the field of view of pedestrians B, C, and D, her behavior may affect their future movements. Inspired by this situation, we construct a View Graph (VG) of the pedestrian’s field of view based on the horizontal view of the pedestrian. In the model, we assume that the pedestrian moves forward along the observation trajectory and that the pedestrian’s field of view is set to be a sector with a tensor angle of π. The parallels of the pedestrian’s field of view coincide with his/her direction of motion. For simplicity, we set the field of view of the pedestrian to π, which we can see in
Figure 4b.
The View Graph is defined as
. If the
j-th pedestrian is in the view of the
i-th pedestrian,
= 1 if
and
are connected; otherwise,
= 0, in which
is weighted by the kernel function and defined as follows.
where
indicates the direction of motion of the
i-th pedestrian. We illustrate the topology of the VG further in
Figure 4.
Figure 4b shows that since the angle between the
i-th pedestrian and the
j-th pedestrian is smaller than π/2, they influence each other, so
is not 0; however, if the angle between the
i-th pedestrian and the
j-th pedestrian is greater than π/2 in
Figure 4c, they have entered blind spots in each other’s vision; thus,
= 0.
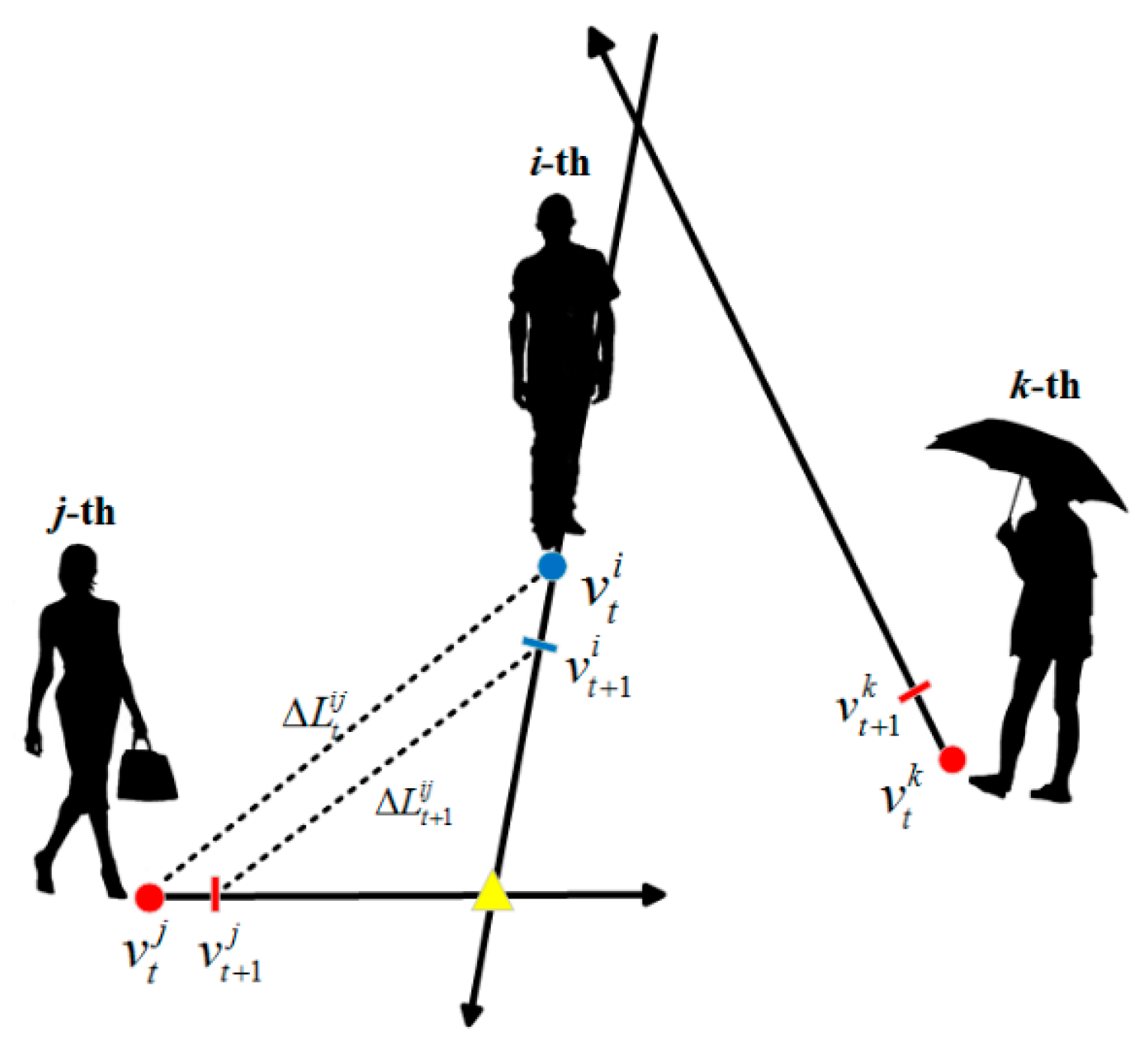
The VG presented in the previous section utilizes only the location information of pedestrians. In crowded situations, we also need to be aware of pedestrians who may be in potential conflict. In this section, we propose a Direction Graph (DG)
, where
, and the impact of conflicts between pedestrians is described by determining the direction of their movement. If the movement directions of two pedestrians intersect, we can assume that they have a potential collision risk.
Figure 5 shows that the possibility of collision exists between the
i-th and
j-th pedestrians. The impact between them satisfies the following constraint.
where
represents the spatial distance between the
i-th pedestrian and
j-th pedestrian at time
t, i.e.,
.
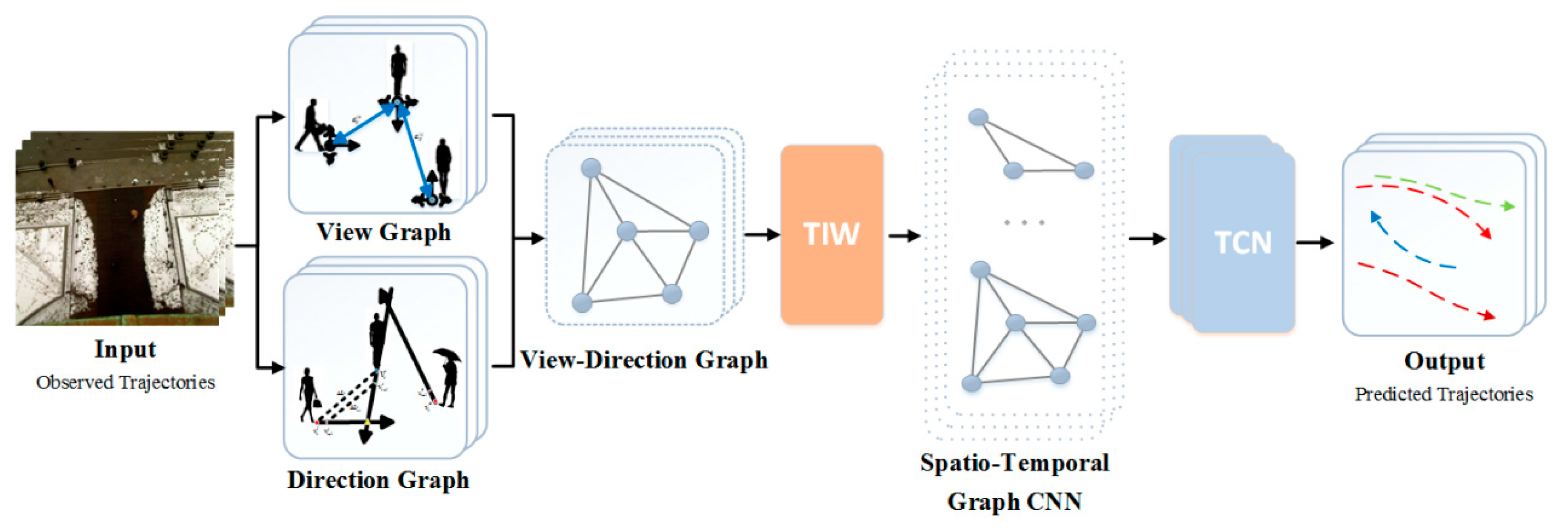
2.5. View-Direction Graph Convolutional Neural Network
In this subsection, we propose a View-Direction graph (V-DG) convolutional neural network framework for trajectory prediction. The framework of our proposed method is shown in
Figure 6, and consists of three main components, i.e., topological graph fusion, graph convolution, and temporal convolution. We use a multilayer perceptron (MLP) to fuse the pedestrian interaction information in VG and DG to form a unified topological graph structure. If we assume that there are N pedestrians in the scene at time t, we can construct weighted adjacency matrices of all edges in VG and DG according to (6) and (7), respectively. Then, we stack them onto a tensor of
and use MLP to adaptively fuse the weighted edges. Finally, we obtain the weighted adjacency matrix
, which fuses the features of VG and DG. The matrix fusion process is performed as follows:
where the input size of the graph fusion module is
and the output size is
.
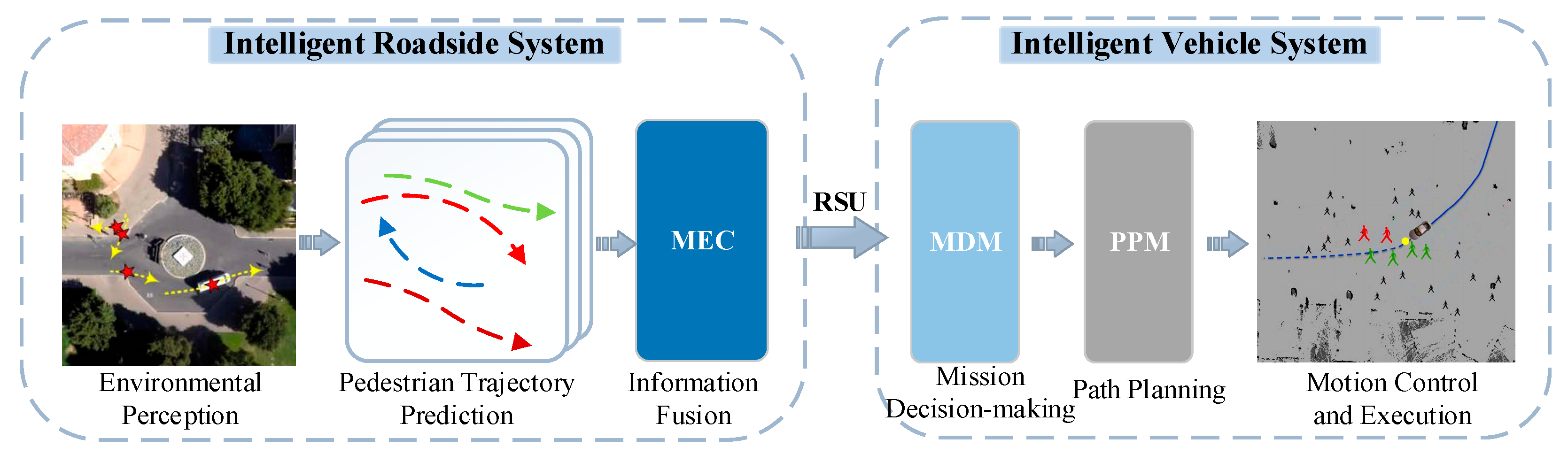
2.6. Autonomous Driving Obstacle Avoidance System
To better apply the pedestrian trajectory prediction model proposed in this paper, in this section, we design an autonomous driving obstacle avoidance system based on pedestrian trajectory prediction, which is shown in
Figure 7. The system consists of two parts: the intelligent roadside system and the intelligent vehicle system. Firstly, the intelligent roadside system performs image acquisition through the roadside camera for pedestrian trajectory prediction and sends the information to multi-access edge computing (MEC) for information fusion; then, it transmits the processed roadside data to the intelligent vehicle system through the roadside unit (RSU). The system performs subsequent mission decision-making, path planning, and motion control execution. With the above two subsystems, we can achieve active obstacle avoidance for autonomous driving. Meanwhile, because our proposed pedestrian trajectory prediction model has a fast inference speed, which we will introduce in detail later, this autonomous driving obstacle avoidance system can achieve faster responses in real-time to road emergencies.
3. Experiments
3.1. Datasets and Evaluation metrics
The model we propose is trained on two pedestrian trajectory prediction datasets: the ETH and the UCY. The ETH contains two scenarios (ETH and HOTEL), and the UCY contains three scenarios (ZARA1, ZARA2, and UNIV). These datasets contain the real motion trajectories of a total of 1536 pedestrians, implying a wide variety of pedestrian interactions and challenging social behaviors. In the experiments on the datasets, this paper uses four datasets to train the model, and then, tests it on the remaining one dataset. In the evaluation phase, the model predicts the later 4.8 s pedestrian trajectories by observing the first 3.2 s pedestrian trajectories.
Following our previous work, we compare this model with existing models, and, as with existing methods, we use two error metrics to evaluate and express the performance of the proposed method.
Average displacement error (
ADE): This is obtained by calculating the average Euclidean distance between the predicted trajectory and the true trajectory for each pedestrian in all prediction time steps, and a smaller value indicates a better prediction.
ADE is defined as follows.
Final Displacement Error (
FDE): This is obtained by calculating the average Euclidean distance between the predicted trajectory and the true trajectory for each pedestrian’s position in the final prediction time step, and a smaller value indicates a better prediction.
FDE is defined as follows.
We compare our proposed model with eleven recently proposed models in terms of both ADE and FDE, mainly including the following: Social-LSTM [
9]: A neural network-based algorithm for pedestrian trajectory prediction that uses an LSTM model and a social pool model to learn the sequence characteristics and social behavior of pedestrians, respectively; Social-GAN [
7]: a GAN-based method for multimodal pedestrian trajectory generation; PIF [
31]: a multi-task LSTM model using visual features and interactive features; SoPhie [
11]: a model that employs an attentional GAN to consider physical constraints and social concerns; SR-LSTM [
13]: a state refinement method for extracting the social features of pedestrian trajectories; STSGN [
32]: an LSTM approach for the graph-attention-based modeling of pedestrian social interactions; CGNS [
33]: a conditional generation network based on the GRU model; Social-BiGAT [
34]: a bicycle-GAN multimodal path and pedestrian social interaction model with a GAT module; TPNSTA [
24]: a pedestrian pyramid network trajectory prediction model with spatio-temporal attention; Social-STGCNN [
21]: a social spatio-temporal graph convolutional neural network for human trajectory prediction; and Trajectron++ [
35]: a CVAE-based model that incorporates agent dynamics and semantic maps.
3.2. Model Construction and Training Setup
The model in this paper includes a V-DG information fusion module, a temporal information weighting module, a spatial interaction module of multi-pedestrians, and a temporal convolutional network module consisting of four TCN layers. Experiments on the number of module stacks verify that a spatial interaction module of multi-pedestrians and a stack of four TCN layers work best for pedestrian trajectory prediction. The training batch size is set to 128. The activation function used for the model in this paper is PReLU, and stochastic gradient descent (SGD) is used to train the model 250 times. The initial learning rate is 0.01, and the learning efficiency changes to 0.002 after another 150 times. The experiments in this paper are conducted under the same hardware conditions; the experimental computer uses an Intel Core i7-10875k CPU @2.3 GHz with 8 cores and 16 threads, and the graphics card is an NVIDIA 2060 Max-Q GPU with 6 GB video memory.
3.3. Quantitative Analysis
Model comparison: In this subsection, we compare the model we propose, At-VD-GCN, with the eight methods that have been mentioned above.
Table 1 shows the experimental results obtained for each model in five scenarios included in the two datasets, and the average results for each pedestrian trajectory prediction method are given in the last column, with the red values in the table representing the best results and the blue values representing the second best results. Based on the experimental results, we can analyze and draw the following conclusions.
We can visually see that our proposed model achieves the best or second-best results for each scenario of the test datasets. Furthermore, our proposed method, At-VD-GCN, achieves the best performance on both the average ADE and FDE results, resulting in a prediction performance improvement of at least 6%/16% or more.
Compared with the base model, Social-STGCNN, our algorithm outperforms Social-STGCNN on all datasets, improving the prediction performance by about 32% and 38% on the average ADE and FDE results, respectively. This validates that the information fusion graph convolutional network we propose describing pedestrian interactions indeed helps to improve social interactions and make them more relevant and accurate.
When no scene information is in consideration, our method, At-VD-GCN, still predicts better than those methods that utilize scene features, such as [
11,
31,
34]. This suggests that the prediction performance of At-VD-GCN can be further improved by incorporating the background information of the scene in which the pedestrian is located.
3.3.1. Inference Speed and Model Size
The size of the model we propose is 6.16 K parameters, which is less than that of the Social-STGCNN. A comparison of the model parameters and inference time between our model and the models available for public use is shown in the following table, where the inference time is the average of some single inference steps, and the lower the inference time, the better. The reason for these results in this model is that the model uses only convolutional neural networks, which overcomes the two major limitations of recursive architecture and the aggregation mechanism.
Table 2 shows a comparison table of each model parameter and inference speeds, where our model inference times are the results of tests using the edge device NVIDIA Jetson TX2.
3.3.2. Ablation Experiments
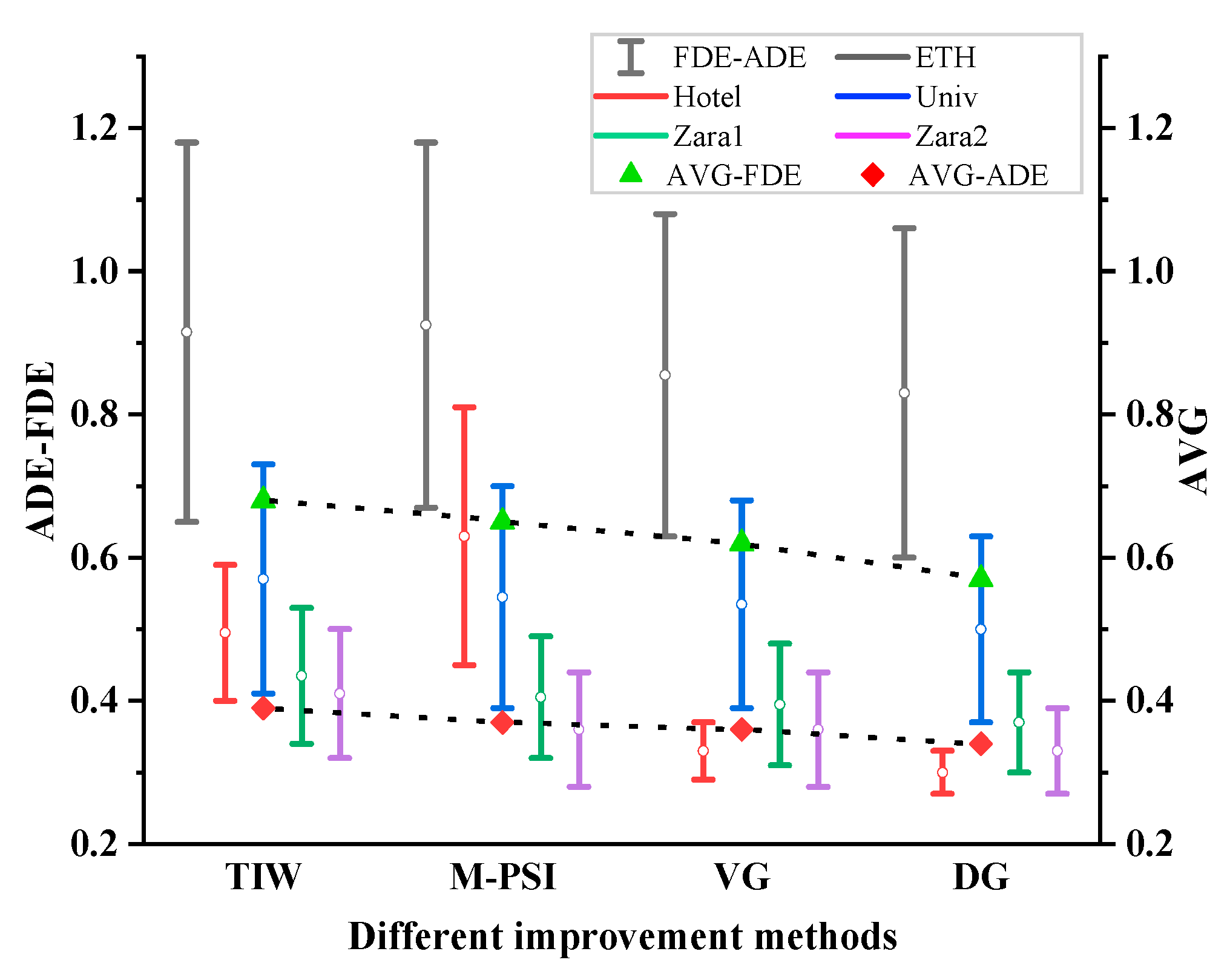
To further analyze the impacts of different improvement methods on the performance of the Social-STGCNN algorithm, four sets of experiments are designed to analyze the different improvement methods. In these experiments, ADE and FDE are used as evaluation metrics for the experiments, as shown in
Table 3, where “√” indicates that the improvement method is introduced in the model and “×” indicates that the method is not introduced in the model. The effects of different improvement methods on the datasets for ETH and UCY are shown in
Figure 8, and it can be seen that all the improvement methods proposed in this paper can improve the prediction accuracy to some extent.
To ensure that the spatial interaction module of multi-pedestrians (M-PSI) that we propose can express the influence between multiple individuals, we focus on the distribution of pedestrian groups in the ETH and UCY datasets. An ablation experiment, which includes a total number of pedestrians from 1 to 7, is carried out. As shown in
Table 4, it can be seen that the number of pedestrians is set to 1, 3, and 5, and the results of trajectory prediction are superior to those of the other cases. Therefore, to optimize the interaction effect between pedestrians, we designed the M-PSI module to analyze the weighted fusion of the three scenarios to obtain more accurate pedestrian interaction information.
3.4. Qualitative Analysis
In the quantitative analysis section, it is shown that the model proposed in this paper outperforms the previous level in ADE/FDE metrics. Now, we qualitatively analyze why the temporal information weighting module of this paper’s model improves the effectiveness of trajectory information; how the spatial interaction module of pedestrian assemblies can better achieve the information extraction of pedestrian aggregation situations; and how the View-Direction graph information fusion module reduces redundant information and describes the pedestrian interaction situation more accurately.
When pedestrians walk, they may turn left or right, accelerate or decelerate, and stop due to various road conditions, in addition to walking straight in a certain direction. Simply giving the same weight to the information at each observation moment will affect the validity of the information. In this paper, the temporal information weighting module gives different weights to the trajectory information of the pedestrian observation phase at each moment, so that the model can focus on the coordinate information of an important moment. As shown in the trajectory comparison in
Figure 9, the model in this paper gives more weight to the coordinate information of the important moments of the trajectory by considering the historical trajectory information of the observation phase, and the predicted pedestrian trajectory is more consistent with the real trajectory.
When groups of two or more people walk together, they are usually spatially close to each other and have similar movement speeds and walking directions, which are defined as pedestrian aggregates in the spatial interaction module of multi-pedestrians. In
Figure 10, the walking routes of pedestrians C, D, and E are parallel to each other. From
Figure 10a, it can be seen that although the predicted trajectory results obtained based on Social-STGCNN can maintain the tightness of the group, there is great deviation from the real trajectory on the ground. In contrast, the prediction results of our model, At-VD-GCN, in
Figure 10b show that C, D, and E as an aggregate of pedestrians will keep walking parallel to each other, and the predicted trajectories have much less deviation from the ground truth trajectories. This is because the model in this paper fully considers the interaction and influence of pedestrians within different pedestrian aggregates, which reduces the influence of redundant information when interacting in large-scale pedestrian scenarios and makes the predicted pedestrian trajectories more accurate.
4. Conclusions
In this paper, we showed that a graph-based spatio-temporal setup for pedestrian trajectory prediction improves previous methods in several key aspects, including prediction error, computational time, and number of parameters. By applying the View-Direction graph to describe the social interaction between pedestrians and weighting the pedestrian trajectory with temporal information, At-VD-GCN outperforms state-of-the-art models when applied to a number of publicly available datasets. We also qualitatively analyzed the performance of At-VD-GCN under situations such as collision avoidance, parallel walking, and individuals meeting in groups. In these situations, At-VD-GCN tends to provide more realistic path forecasts than several other reported methods. Furthermore, At-VD-GCN is also efficient computationally, and its inference speed is increased compared to previous models. In the future, we intend to extend At-VD-GCN to multi-modal settings that involve other moving objects, including bicycles, cars, and pedestrians.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}