

A High-Resolution Spatial Distribution-Based Integration Machine Learning Algorithm for Urban Fire Risk Assessment: A Case Study in Chengdu, China

Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Urban Spatial Distribution Characteristics
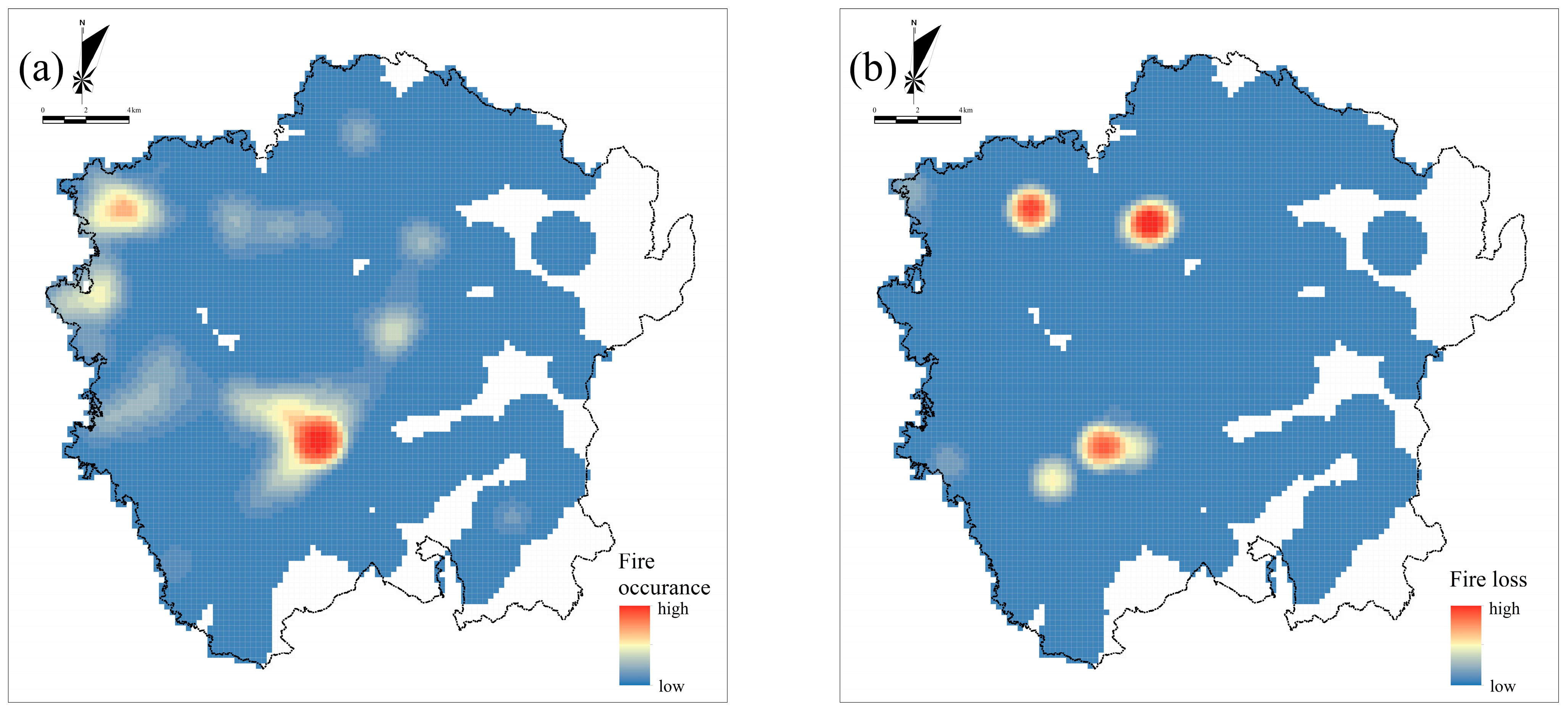
2.3. Fire Dataset
2.4. Methods
2.4.1. Indicator Selection Models
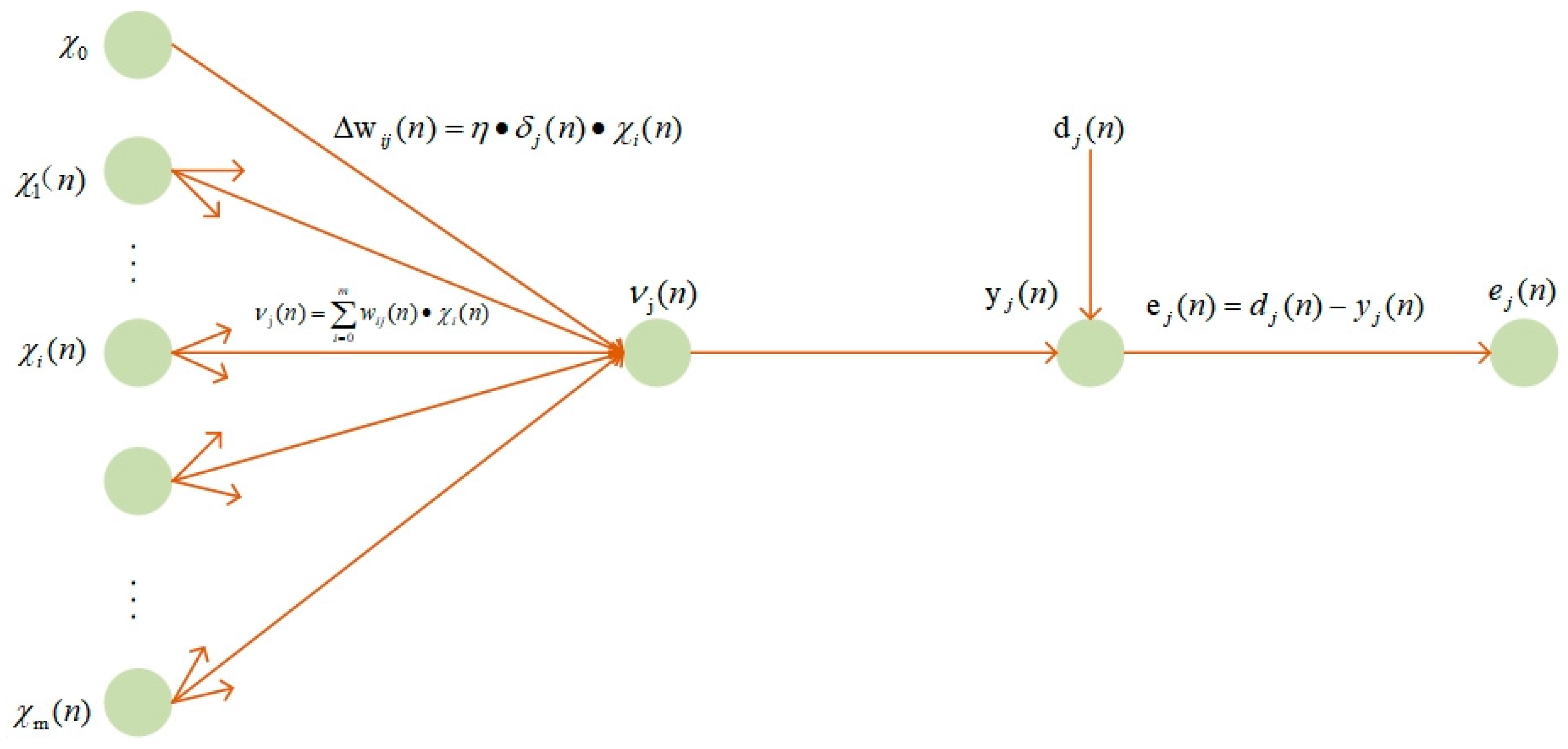
2.4.2. Fire Risk Assessment Models
3. Results
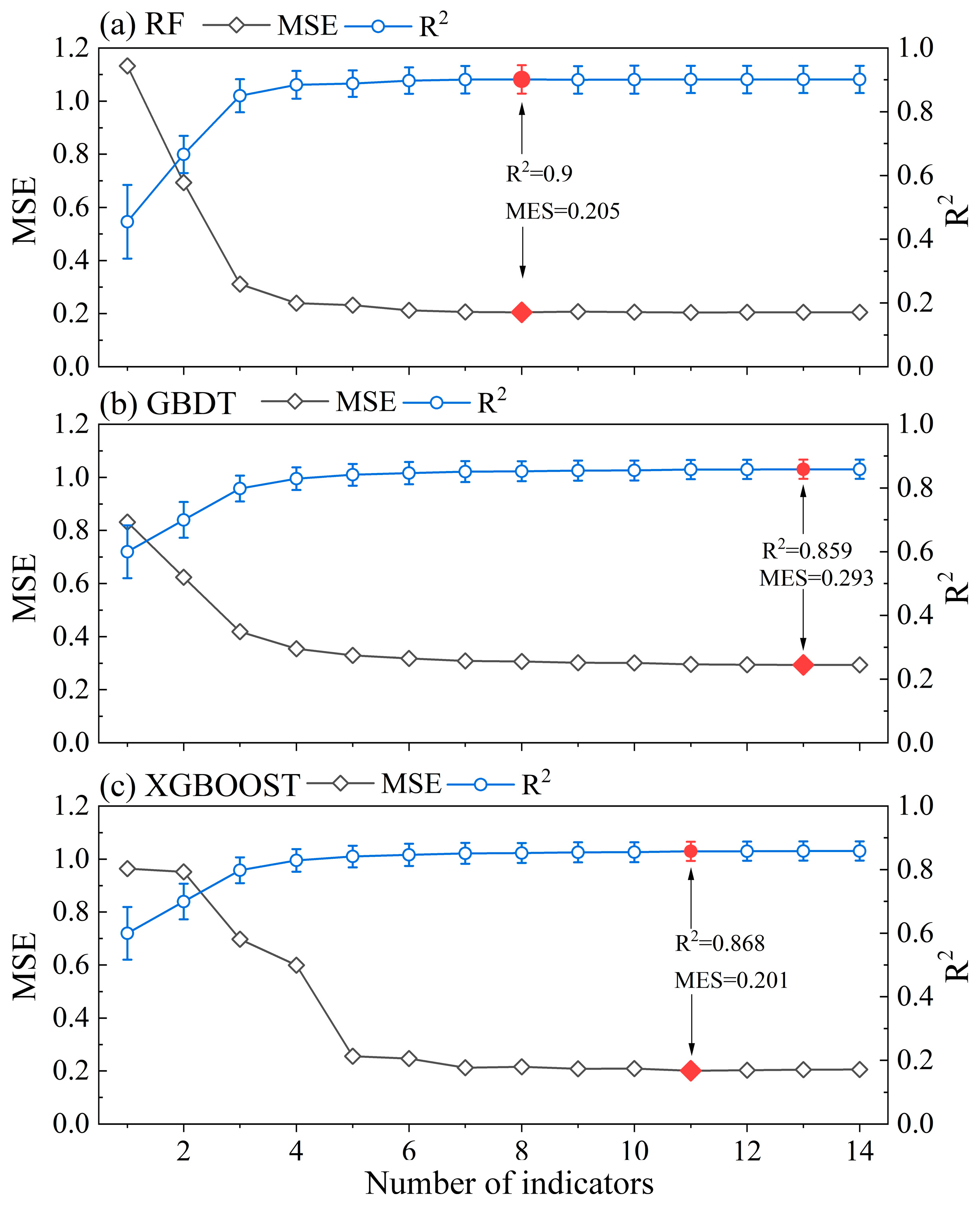
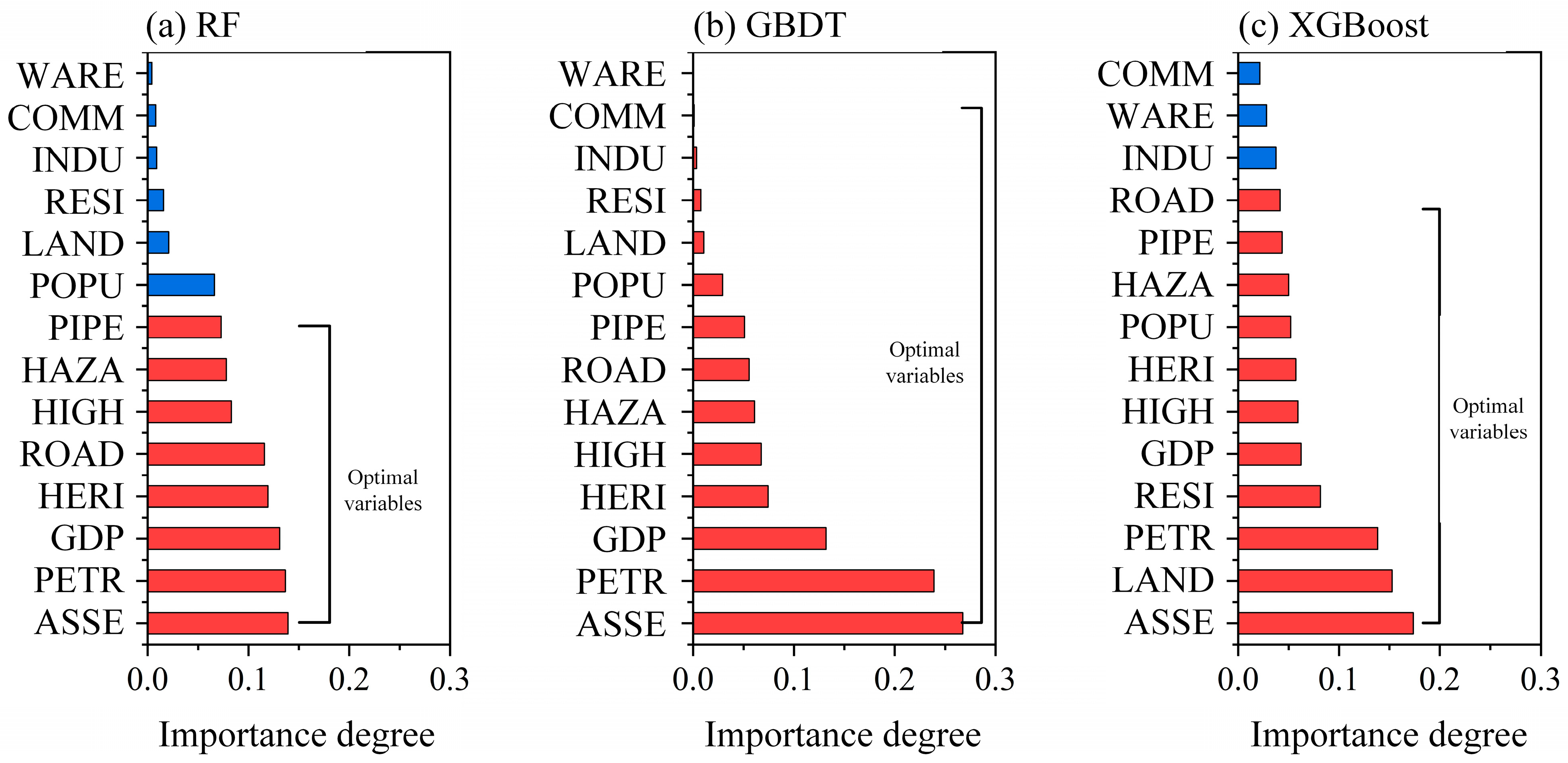
3.1. Indicator Selection
3.2. Indicators Multicollinearity Test
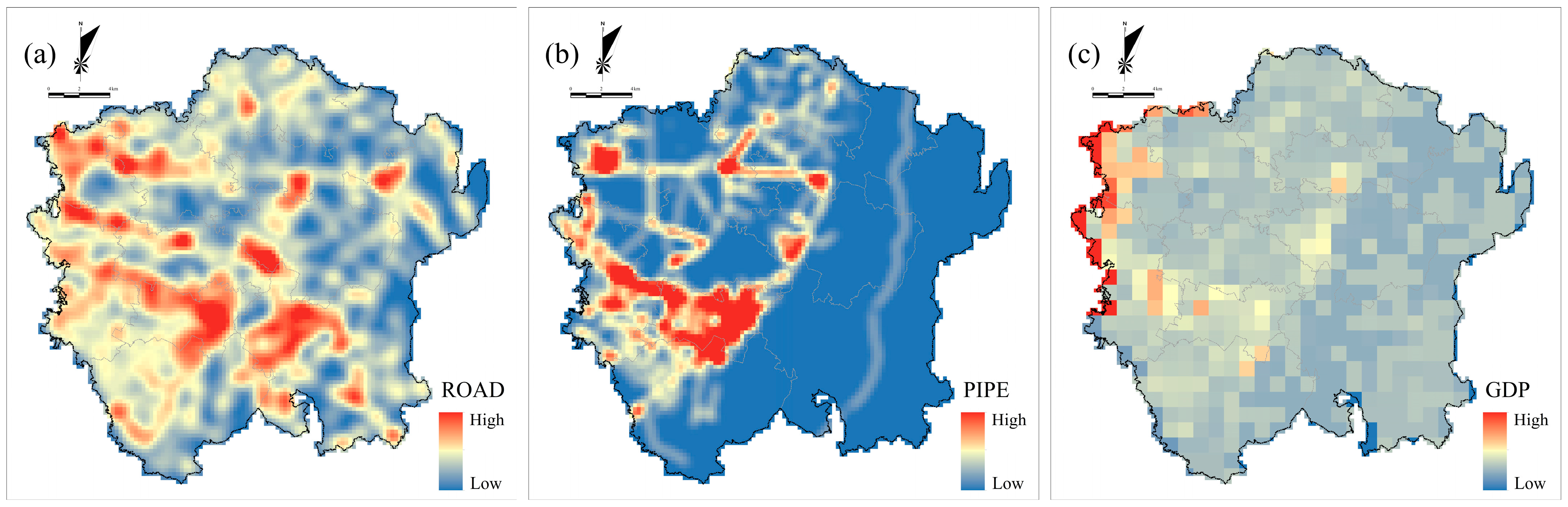
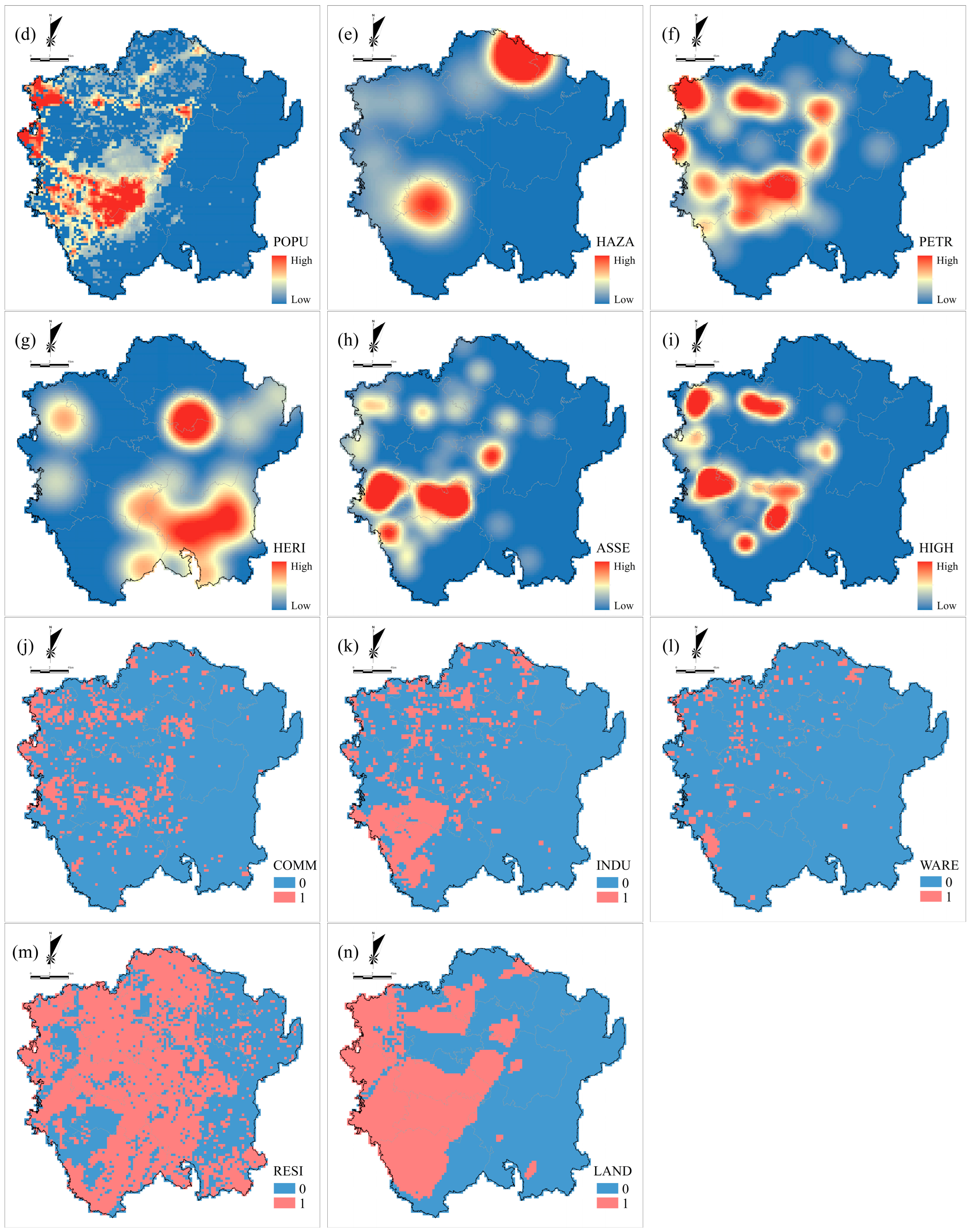
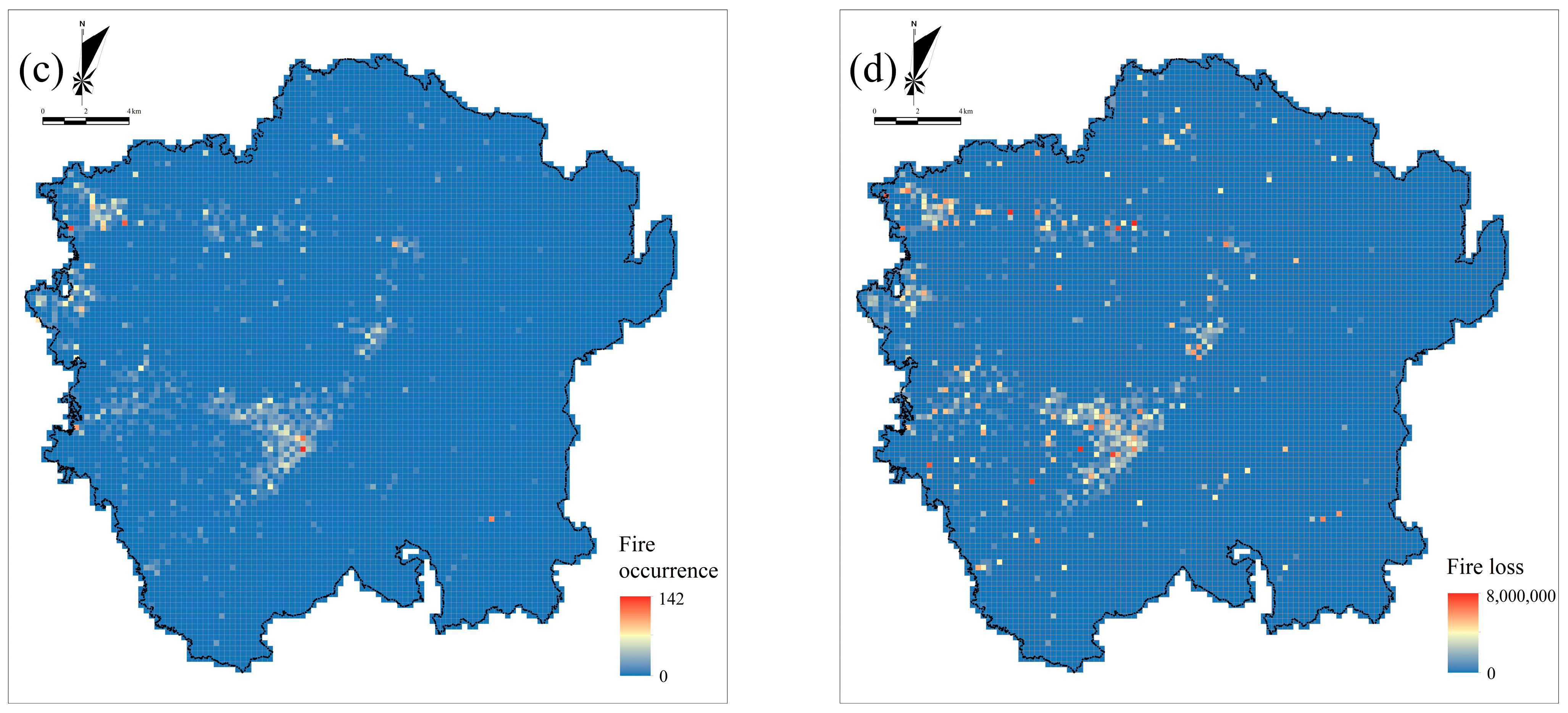
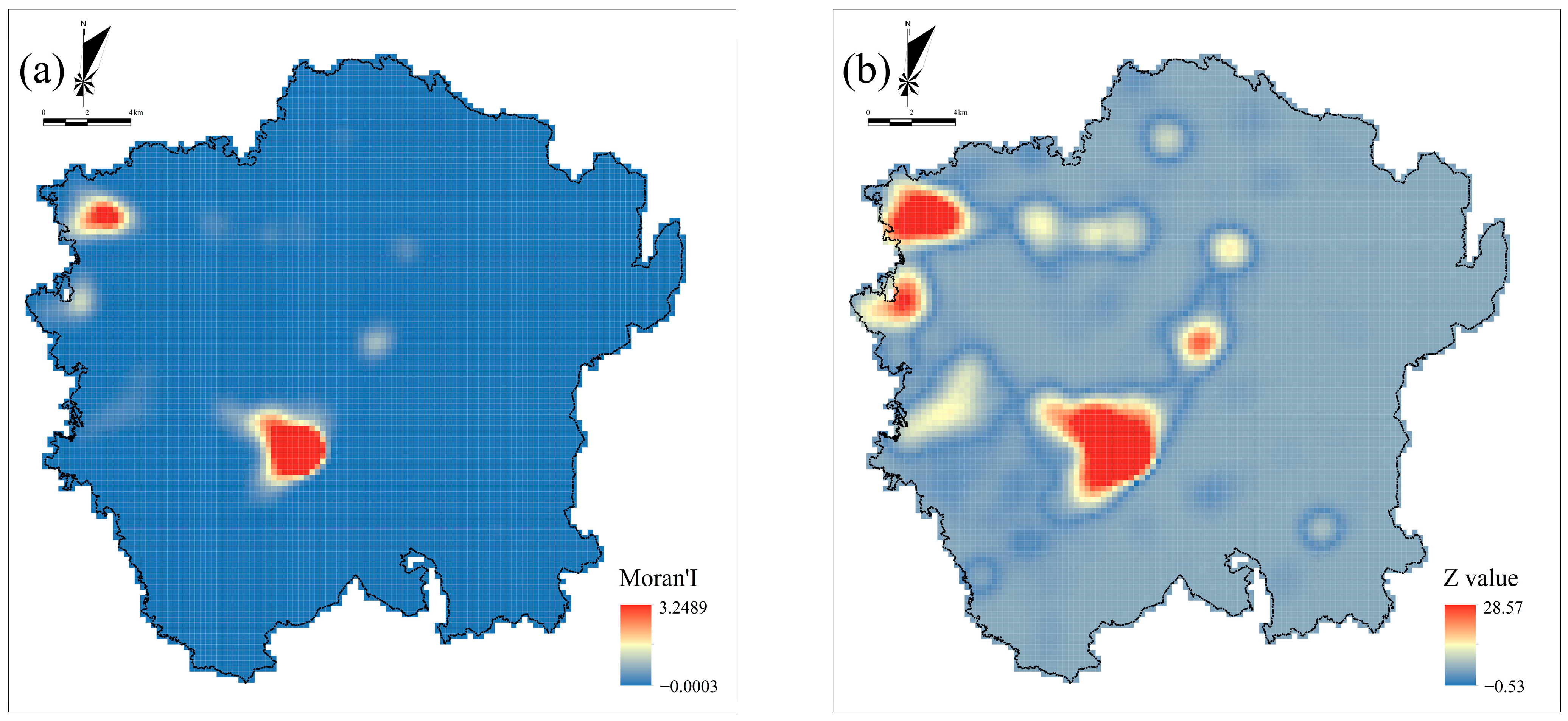
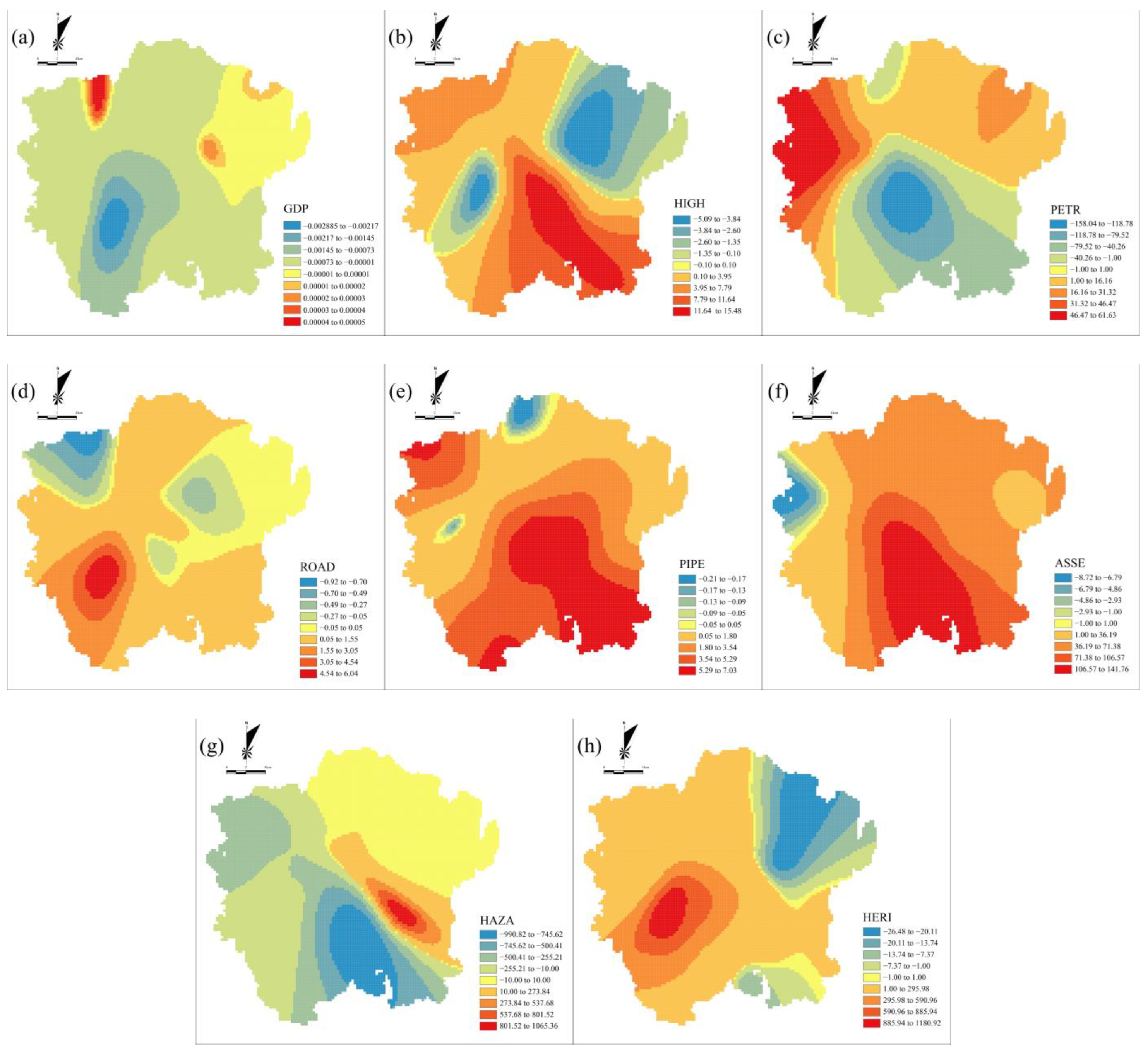
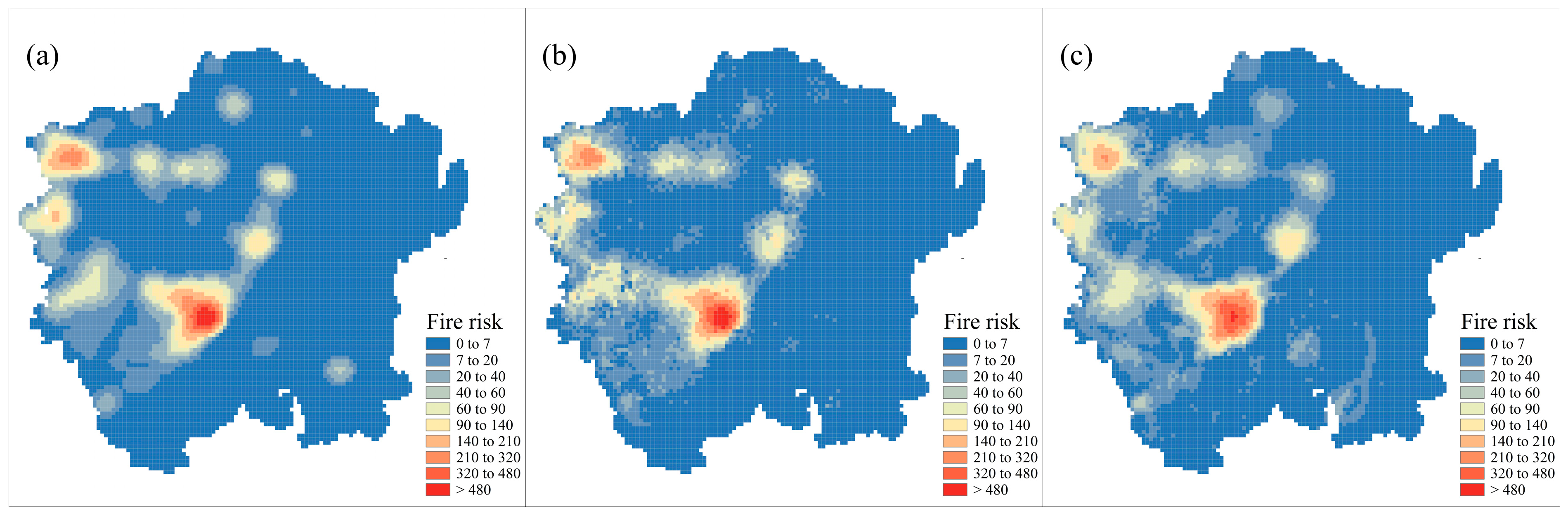
3.3. Spatial Patterns of Indicators and Fire Risk
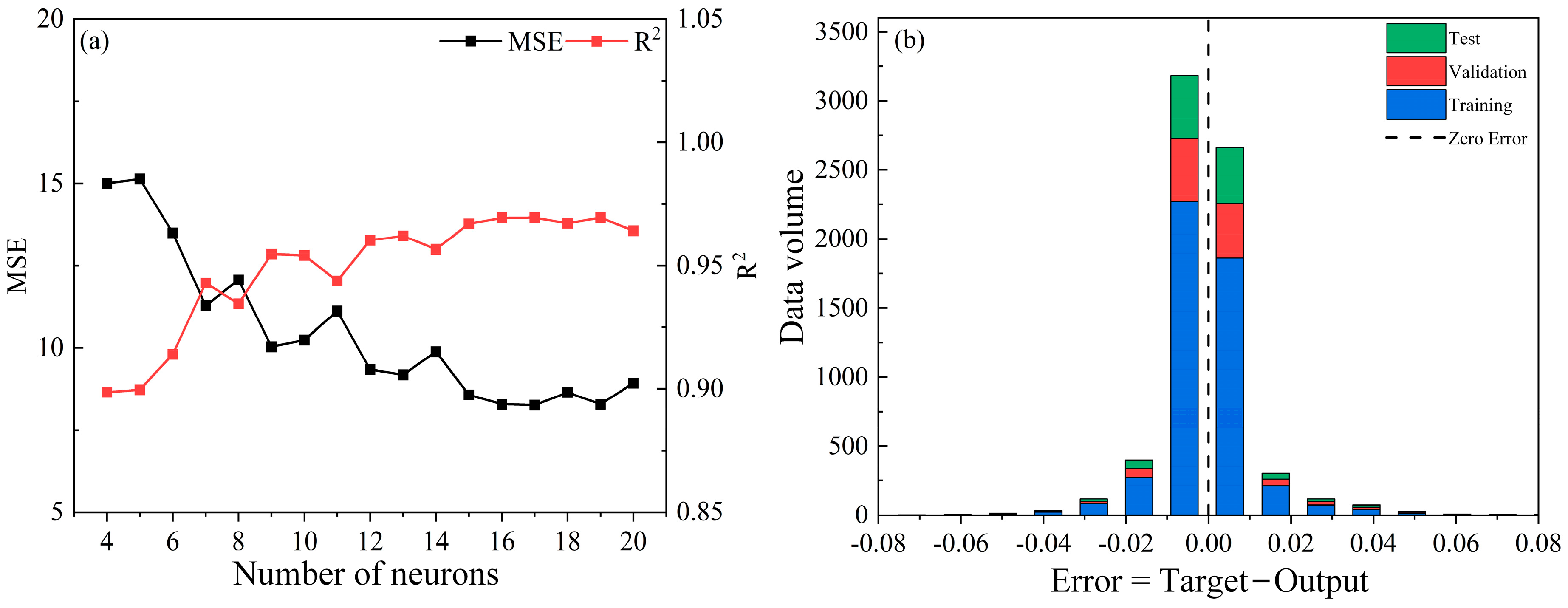
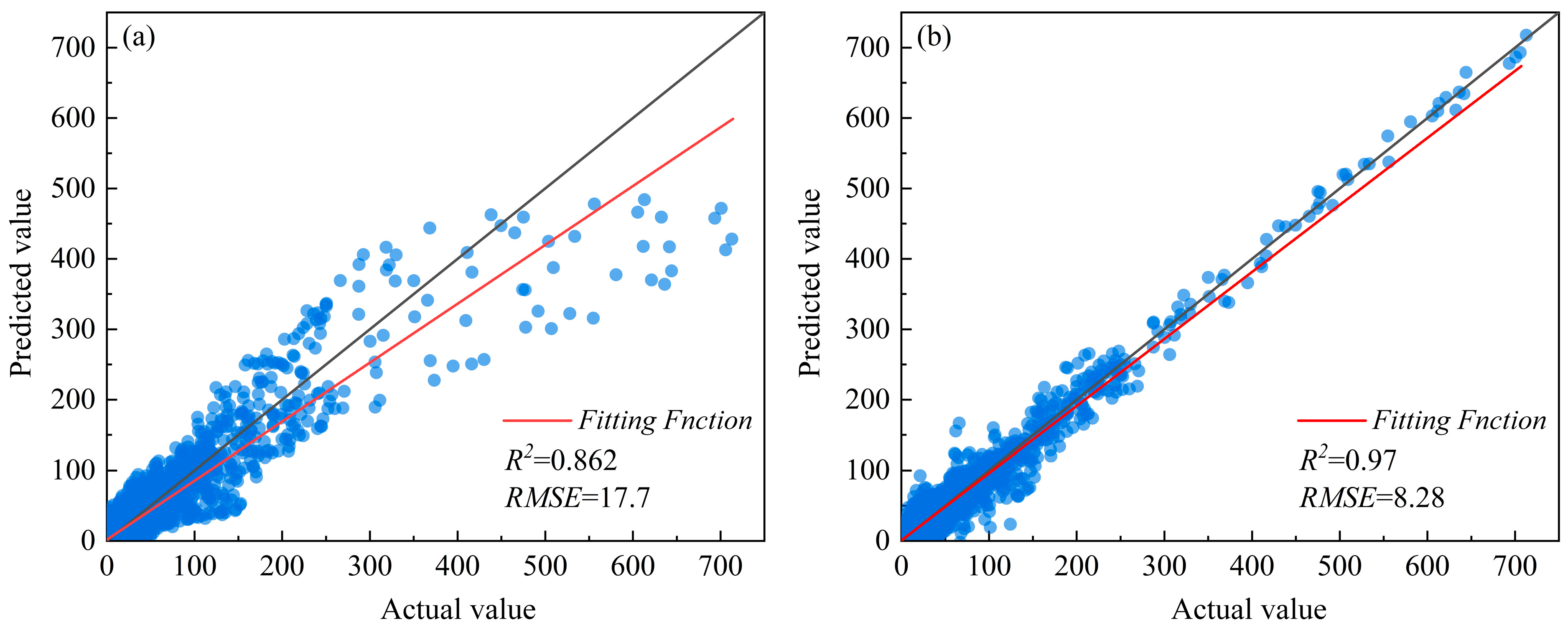
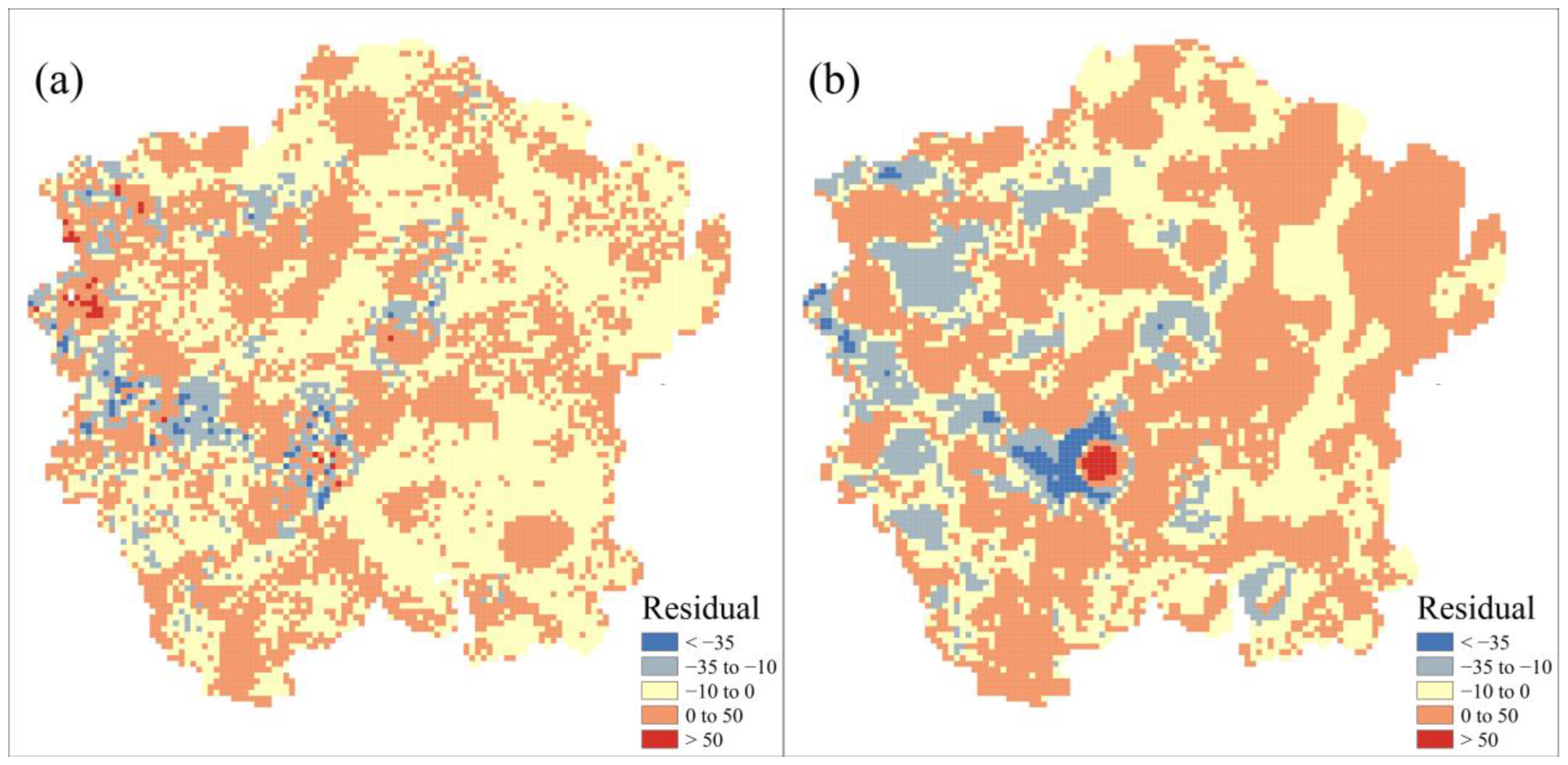
3.4. Comparison of BPNN and GWR Fire Risk Assessment Model
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Firefighters Responded to a Record Number of Calls in 2021, Fighting 745,000 Fires. Available online: https://www.119.gov.cn/gk/sjtj/2022/26442.shtml (accessed on 14 July 2022).
- Rohde, D.; Corcoran, J.; Chhetri, P. Spatial forecasting of residential urban fires: A Bayesian approach. Comput. Environ. Urban Syst. 2010, 34, 58–69. [Google Scholar] [CrossRef]
- Granda, S.; Ferreira, T.M. Assessing Vulnerability and Fire Risk in Old Urban Areas: Application to the Historical Centre of Guimarães. Fire Technol. 2018, 55, 105–127. [Google Scholar] [CrossRef]
- Masoumi, Z.; John van, L.G.; Maleki, J. Fire Risk Assessment in Dense Urban Areas Using Information Fusion Techniques. ISPRS Int. J. Geo-Inf. 2019, 8, 579. [Google Scholar] [CrossRef]
- Silva, D.; Rodrigues, H.; Ferreira, T.M. Assessment and Mitigation of the Fire Vulnerability and Risk in the Historic City Centre of Aveiro, Portugal. Fire 2022, 5, 173. [Google Scholar] [CrossRef]
- Chhetri, P.; Corcoran, J.; Stimson, R.J.; Inbakaran, R. Modelling Potential Socio-economic Determinants of Building Fires in South East Queensland. Geogr. Res. 2010, 48, 75–85. [Google Scholar] [CrossRef]
- Wuschke, K.; Clare, J.; Garis, L. Temporal and geographic clustering of residential structure fires: A theoretical platform for targeted fire prevention. Fire Saf. J. 2013, 62, 3–12. [Google Scholar] [CrossRef]
- Vasiliauskas, D.; Beconytė, G. Spatial Analysis of Fires in Vilnius City in 2010–2012. Geod. Cartogr. 2015, 41, 25–30. [Google Scholar] [CrossRef]
- Song, C.; Kwan, M.-P.; Song, W.; Zhu, J. A Comparison between Spatial Econometric Models and Random Forest for Modeling Fire Occurrence. Sustainability 2017, 9, 819. [Google Scholar] [CrossRef]
- Zhang, X.; Yao, J.; Sila-Nowicka, K.; Jin, Y. Urban Fire Dynamics and Its Association with Urban Growth: Evidence from Nanjing, China. ISPRS Int. J. Geo-Inf. 2020, 9, 218. [Google Scholar] [CrossRef]
- Chen, Y.; Wu, G.; Chen, Y.; Xia, Z. Spatial Location Optimization of Fire Stations with Traffic Status and Urban Functional Areas. Appl. Spat. Anal. Policy 2023, 16, 771–788. [Google Scholar] [CrossRef]
- Jin, G.; Wang, Q.; Zhu, C.; Feng, Y.; Huang, J.; Hu, X. Urban Fire Situation Forecasting: Deep sequence learning with spatio-temporal dynamics. Appl. Soft Comput. 2020, 97, 106730. [Google Scholar] [CrossRef]
- Rahman Tishi, T.; Islam, I. Urban fire occurrences in the Dhaka Metropolitan Area. GeoJournal 2018, 84, 1417–1427. [Google Scholar] [CrossRef]
- Wang, K.; Yuan, Y.; Chen, M.; Wang, D. A POIs based method for determining spatial distribution of urban fire risk. Process Saf. Environ. Prot. 2021, 154, 447–457. [Google Scholar] [CrossRef]
- Orusa, T.; Viani, A.; Moyo, B.; Cammareri, D.; Borgogno-Mondino, E. Risk Assessment of Rising Temperatures Using Landsat 4–9 LST Time Series and Meta® Population Dataset: An Application in Aosta Valley, NW Italy. Remote Sens. 2023, 15, 2348. [Google Scholar] [CrossRef]
- Kumar, V.; Jana, A.; Ramamritham, K. A decision framework to assess urban fire vulnerability in cities of developing nations: Empirical evidence from Mumbai. Geocarto Int. 2020, 37, 543–559. [Google Scholar] [CrossRef]
- Bernardini, G.; Quagliarini, E.; D’Orazio, M. Towards creating a combined database for earthquake pedestrians’ evacuation models. Saf. Sci. 2016, 82, 77–94. [Google Scholar] [CrossRef]
- Tomar, S.K.; Kaur, A.; Dangi, H.K. Impact of Spatial–Temporal Variations on Fire Vulnerability: A Case Study of the South-West Division of Delhi, India. In Risk Analysis XI; WIT Press: Southampton, UK, 2018; pp. 273–282. [Google Scholar]
- Turner, S.L.; Johnson, R.D.; Weightman, A.L.; Rodgers, S.E.; Arthur, G.; Bailey, R.; Lyons, R.A. Risk factors associated with unintentional house fire incidents, injuries and deaths in high-income countries: A systematic review. Inj. Prev. 2017, 23, 131–137. [Google Scholar] [CrossRef] [PubMed]
- Tomar, S.; Kaur, A.; Sarma, K.; Dangi, H. Fire risk assessment and fire hazard zonation mapping using GIS in South-West division of Delhi. J. Adv. Res. Appl. 2018, 5, 213–220. [Google Scholar]
- Hastie, C.; Searle, R. Socio-economic and demographic predictors of accidental dwelling fire rates. Fire Saf. J. 2016, 84, 50–56. [Google Scholar] [CrossRef]
- Parente, J.; Pereira, M.G.; Amraoui, M.; Tedim, F. Negligent and intentional fires in Portugal: Spatial distribution characterization. Sci. Total Environ. 2018, 624, 424–437. [Google Scholar] [CrossRef] [PubMed]
- Aven, T.; Guikema, S. Whose uncertainty assessments (probability distributions) does a risk assessment report: The analysts’ or the experts’? Reliab. Eng. Syst. Saf. 2011, 96, 1257–1262. [Google Scholar] [CrossRef]
- Gehandler, J.; Ingason, H.; Lönnermark, A.; Frantzich, H.; Strömgren, M. Performance-based design of road tunnel fire safety: Proposal of new Swedish framework. Case Stud. Fire Saf. 2014, 1, 18–28. [Google Scholar] [CrossRef]
- Dong, Y.; Frangopol, D.M. Probabilistic ship collision risk and sustainability assessment considering risk attitudes. Struct. Saf. 2015, 53, 75–84. [Google Scholar] [CrossRef]
- Chen, J.; Wang, X.; Yu, Y.; Yuan, X.; Quan, X.; Huang, H. Improved Prediction of Forest Fire Risk in Central and Northern China by a Time-Decaying Precipitation Model. Forests 2022, 13, 480. [Google Scholar] [CrossRef]
- McCarty, J.; Francis, R.; Fain, J.; Haynes, K. Wildfire Risk Models for Western Greenland: Geostatistical Considerations. In EGU General Assembly Conference Abstracts, Proceedings of the 22nd EGU General Assembly, Online, 4–8 May 2020; EDU: Munich, Germany, 2020; p. 12660. [Google Scholar]
- Hegde, J.; Rokseth, B. Applications of machine learning methods for engineering risk assessment—A review. Saf. Sci. 2020, 122, 104492. [Google Scholar] [CrossRef]
- Guha, S.; Jana, R.K.; Sanyal, M.K. Artificial neural network approaches for disaster management: A literature review. Int. J. Disaster Risk Reduct. 2022, 81, 103276. [Google Scholar] [CrossRef]
- Xiong, J.; Sun, M.; Zhang, H.; Cheng, W.; Yang, Y.; Sun, M.; Cao, Y.; Wang, J. Application of the Levenburg–Marquardt back propagation neural network approach for landslide risk assessments. Nat. Hazards Earth Syst. Sci. 2019, 19, 629–653. [Google Scholar] [CrossRef]
- Li, S.; Bi, F.; Chen, W.; Miao, X.; Liu, J.; Tang, C. An Improved Information Security Risk Assessments Method for Cyber-Physical-Social Computing and Networking. IEEE Access 2018, 6, 10311–10319. [Google Scholar] [CrossRef]
- Wu, Y.; Li, X.; Liu, Q.; Tong, G. The Analysis of Credit Risks in Agricultural Supply Chain Finance Assessment Model Based on Genetic Algorithm and Backpropagation Neural Network. Comput. Econ. 2021, 60, 1269–1292. [Google Scholar] [CrossRef]
- Feng, Y.; Souri, A. Bank Green Credit Risk Assessment and Management by Mobile Computing and Machine Learning Neural Network under the Efficient Wireless Communication. Wirel. Commun. Mob. Comput. 2022, 2022, 3444317. [Google Scholar] [CrossRef]
- Ting, L.; Man, Z.; Yuhan, J.; Sha, S.; Yiqiong, J.; Minzan, L. Management of CO2 in a tomato greenhouse using WSN and BPNN techniques. Int. J. Agric. Biol. Eng. 2015, 8, 43–51. [Google Scholar]
- Bistinas, I.; Oom, D.; Sa, A.C.; Harrison, S.P.; Prentice, I.C.; Pereira, J.M. Relationships between human population density and burned area at continental and global scales. PLoS ONE 2013, 8, e81188. [Google Scholar] [CrossRef] [PubMed]
- Jennings, C.R. Social and economic characteristics as determinants of residential fire risk in urban neighborhoods: A review of the literature. Fire Saf. J. 2013, 62, 13–19. [Google Scholar] [CrossRef]
- Sarvia, F.; De Petris, S.; Borgogno-Mondino, E. Exploring Climate Change Effects on Vegetation Phenology by MOD13Q1 Data: The Piemonte Region Case Study in the Period 2001–2019. Agronomy 2021, 11, 555. [Google Scholar] [CrossRef]
- Orusa, T.; Cammareri, D.; Borgogno Mondino, E.B. A Possible Land Cover EAGLE Approach to Overcome Remote Sensing Limitations in the Alps Based on Sentinel-1 and Sentinel-2: The Case of Aosta Valley (NW Italy). Remote Sens. 2022, 15, 178. [Google Scholar] [CrossRef]
- Rausand, M. Risk Assessment: Theory, Methods, and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2013; Volume 115. [Google Scholar]
- Yoe, C. Principles of Risk Analysis: Decision Making under Uncertainty; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Matellini, D.B.; Wall, A.D.; Jenkinson, I.D.; Wang, J.; Pritchard, R. Modelling dwelling fire development and occupancy escape using Bayesian network. Reliab. Eng. Syst. Saf. 2013, 114, 75–91. [Google Scholar] [CrossRef]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; Routledge: Abingdon, UK, 2018. [Google Scholar]
- Oliveira, S.; Oehler, F.; San-Miguel-Ayanz, J.; Camia, A.; Pereira, J.M.C. Modeling spatial patterns of fire occurrence in Mediterranean Europe using Multiple Regression and Random Forest. For. Ecol. Manag. 2012, 275, 117–129. [Google Scholar] [CrossRef]
- Lee, S.; Kim, J.-C.; Jung, H.-S.; Lee, M.J.; Lee, S. Spatial prediction of flood susceptibility using random-forest and boosted-tree models in Seoul metropolitan city, Korea. Geomat. Nat. Hazards Risk 2017, 8, 1185–1203. [Google Scholar] [CrossRef]
- Čeh, M.; Kilibarda, M.; Lisec, A.; Bajat, B. Estimating the Performance of Random Forest versus Multiple Regression for Predicting Prices of the Apartments. ISPRS Int. J. Geo-Inf. 2018, 7, 168. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, R.; Ma, Q.; Wang, Y.; Wang, Q.; Huang, Z.; Huang, L. A feature selection and multi-model fusion-based approach of predicting air quality. ISA Trans. 2020, 100, 210–220. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks and Learning Machines; Pearson: Upper Saddle River, NJ, USA, 2009; Volume 3. [Google Scholar]
- Foster, S.A.; Gorr, W.L.J.M.S. An adaptive filter for estimating spatially-varying parameters: Application to modeling police hours spent in response to calls for service. Manag. Sci. 1986, 32, 878–889. [Google Scholar] [CrossRef]
- Brunsdon, C.; Fotheringham, A.S.; Charlton, M.E. Geographically weighted regression: A method for exploring spatial nonstationarity. Geogr. Anal. 1996, 28, 281–298. [Google Scholar] [CrossRef]
- Fotheringham, A.S.; Charlton, M.E.; Brunsdon, C.J.E. Geographically weighted regression: A natural evolution of the expansion method for spatial data analysis. Environ. Plan. A 1998, 30, 1905–1927. [Google Scholar] [CrossRef]
- Buyantuyev, A.; Wu, J. Urban heat islands and landscape heterogeneity: Linking spatiotemporal variations in surface temperatures to land-cover and socioeconomic patterns. Landsc. Ecol. 2009, 25, 17–33. [Google Scholar] [CrossRef]
- Anselin, L. The Moran Scatterplot as an ESDA Tool to Assess Local Instability in Spatial Association; Regional Research Institute, West Virginia University: Morgantown, WV, USA, 1993. [Google Scholar]
- Kanaroglou, P.S.; Adams, M.D.; De Luca, P.F.; Corr, D.; Sohel, N. Estimation of sulfur dioxide air pollution concentrations with a spatial autoregressive model. Atmos. Environ. 2013, 79, 421–427. [Google Scholar] [CrossRef]
- Baller, R.D.; Anselin, L.; Messner, S.F.; Deane, G.; Hawkins, D.F.J.C. Structural covariates of US county homicide rates: Incorporating spatial effects. Criminology 2001, 39, 561–588. [Google Scholar] [CrossRef]
- Dong, L.; Liang, H. Spatial analysis on China’s regional air pollutants and CO2 emissions: Emission pattern and regional disparity. Atmos. Environ. 2014, 92, 280–291. [Google Scholar] [CrossRef]
- Xie, L.; Zhang, R.; Zhan, J.; Li, S.; Shama, A.; Zhan, R.; Wang, T.; Lv, J.; Bao, X.; Wu, R. Wildfire Risk Assessment in Liangshan Prefecture, China Based on An Integration Machine Learning Algorithm. Remote Sens. 2022, 14, 4592. [Google Scholar] [CrossRef]
- Guo, J.; Lu, L.; Dong, Y.; Huang, W.; Zhang, B.; Du, B.; Ding, C.; Ye, H.; Wang, K.; Huang, Y.; et al. Spatiotemporal Distribution and Main Influencing Factors of Grasshopper Potential Habitats in Two Steppe Types of Inner Mongolia, China. Remote Sens. 2023, 15, 866. [Google Scholar] [CrossRef]
- Shah-Heydari Pour, A.; Pahlavani, P.; Bigdeli, B. Providing the Fire Risk Map in Forest Area Using a Geographically Weighted Regression Model with Gaussin Kernel and Modis Images, a Case Study: Golestan Province. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, XLII-4/W4, 477–481. [Google Scholar] [CrossRef]
- Jafari Goldarag, Y.; Mohammadzadeh, A.; Ardakani, A.S. Fire Risk Assessment Using Neural Network and Logistic Regression. J. Indian Soc. Remote Sens. 2016, 44, 885–894. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indicator | Data Sources | Abbreviation | Unit | Value |
|---|---|---|---|---|
| Road | https://www.openstreetmap.org/ (accessed on 14 July 2022) | ROAD | km/km2 | Numerical |
| Gas pipeline | Bureau of Economy and Information Technology | PIPE | km/km2 | Numerical |
| GDP | Resource and Environment Science and Data Center | GDP | 1/km2 | Numerical |
| Population | https://hub.worldpop.org/geodata/summary?id=49730 (accessed on 14 July 2022) | POPU | 1/km2 | Numerical |
| Hazardous chemical enterprises | Fire and Rescue Administration | HAZA | 1/km2 | Numerical |
| Petrol and charging stations | Amap | PETR | 1/km2 | Numerical |
| Cultural Heritage Protection Unit | Bureau of Culture, Sports and Tourism | HERI | 1/km2 | Numerical |
| Assembly occupancies 1 | Amap | ASSE | 1/km2 | Numerical |
| High-rise building | Fire and Rescue Administration | HIGH | 1/km2 | Numerical |
| Commercial service zone | Bureau of Natural Resources and Planning | COMM | — | Binary |
| Industrial zone | Bureau of Natural Resources and Planning | INDU | — | Binary |
| Warehouse zone | Bureau of Natural Resources and Planning | WARE | — | Binary |
| Residential zone | Bureau of Natural Resources and Planning | RESI | — | Binary |
| Land development intensity | Bureau of Natural Resources and Planning | LAND | — | Binary |
| Parameter | Parameter Tuning | Optimal Setting |
|---|---|---|
| Activation functions | Logsig, tansig, ReLU | tansig |
| Transfer functions | Logsig, tansig, purelin | purelin |
| Number of neurons in hidden layer | [4, 20] | 19 |
| Training functions | Traingd, traingdm, traingda, traingdx, trainrp, traincgb, trainscg, trainlm | traincgb |
| Learning Rate | 0.05, 0.06, 0.07, 0.08, 0.09, 0.1 | 0.05 |
| Momentum parameters | 0.5, 0.6, 0.7, 0.8, 0.9 | 0.9 |
| Indicator | VIF | Indicator | VIF |
|---|---|---|---|
| ROAD | 1.56 | HIGH | 1.9 |
| PIPE | 2.87 | HERI | 1.19 |
| GDP | 1.2 | PETR | 2.77 |
| ASSE | 2.61 | HAZA | 1.18 |
| Variable | Minimum | Maximum | Average |
|---|---|---|---|
| ROAD | −0.91597 | 6.035046 | 0.630819 |
| GDP | −0.00289 | 0.00005 | −0.00038 |
| PIPE | −0.20668 | 7.034545 | 3.139437 |
| ASSE | −8.72046 | 141.7564 | 60.52752 |
| HAZA | −990.822 | 1065.363 | −178.216 |
| PETR | −158.038 | 61.62599 | −14.656 |
| HIGH | −5.08626 | 15.4803 | 3.095104 |
| HERI | −26.4821 | 1180.921 | 159.7819 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hao, Y.; Li, M.; Wang, J.; Li, X.; Chen, J. A High-Resolution Spatial Distribution-Based Integration Machine Learning Algorithm for Urban Fire Risk Assessment: A Case Study in Chengdu, China. ISPRS Int. J. Geo-Inf. 2023, 12, 404. https://doi.org/10.3390/ijgi12100404
Hao Y, Li M, Wang J, Li X, Chen J. A High-Resolution Spatial Distribution-Based Integration Machine Learning Algorithm for Urban Fire Risk Assessment: A Case Study in Chengdu, China. ISPRS International Journal of Geo-Information. 2023; 12(10):404. https://doi.org/10.3390/ijgi12100404
Chicago/Turabian StyleHao, Yulu, Mengdi Li, Jianyu Wang, Xiangyu Li, and Junmin Chen. 2023. "A High-Resolution Spatial Distribution-Based Integration Machine Learning Algorithm for Urban Fire Risk Assessment: A Case Study in Chengdu, China" ISPRS International Journal of Geo-Information 12, no. 10: 404. https://doi.org/10.3390/ijgi12100404