
Measuring COVID-19 Vulnerability for Northeast Brazilian Municipalities: Social, Economic, and Demographic Factors Based on Multiple Criteria and Spatial Analysis

 ,
,
Abstract
:1. Introduction
2. Theoretical Review
3. Data and Methods
3.1. Data Treatment
3.2. Variable Exploration
3.3. Multiple-Criteria Decision Model
- ClLow—low vulnerability
- ClModerate—moderate vulnerability
- ClHigh—high vulnerability
3.4. Spatial Inference
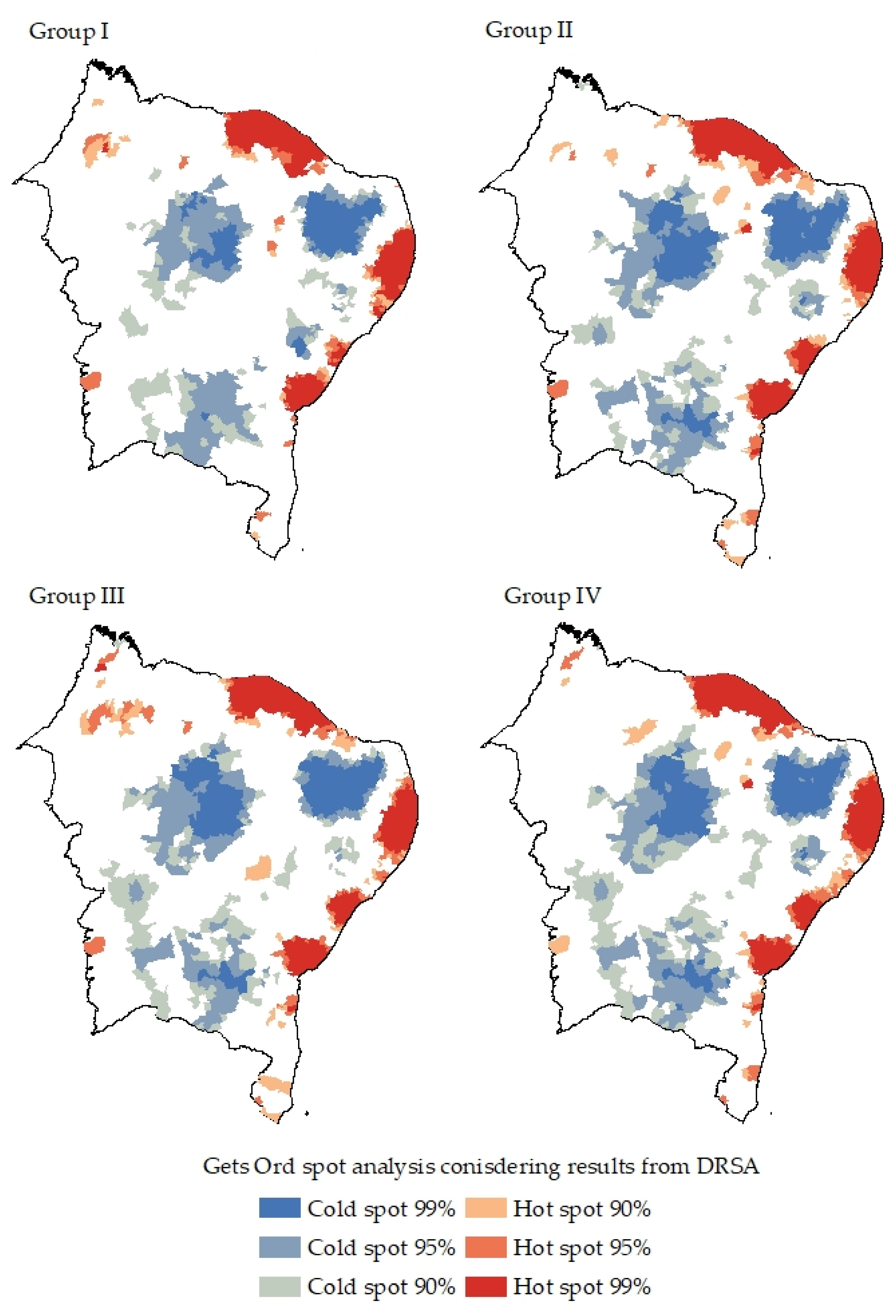
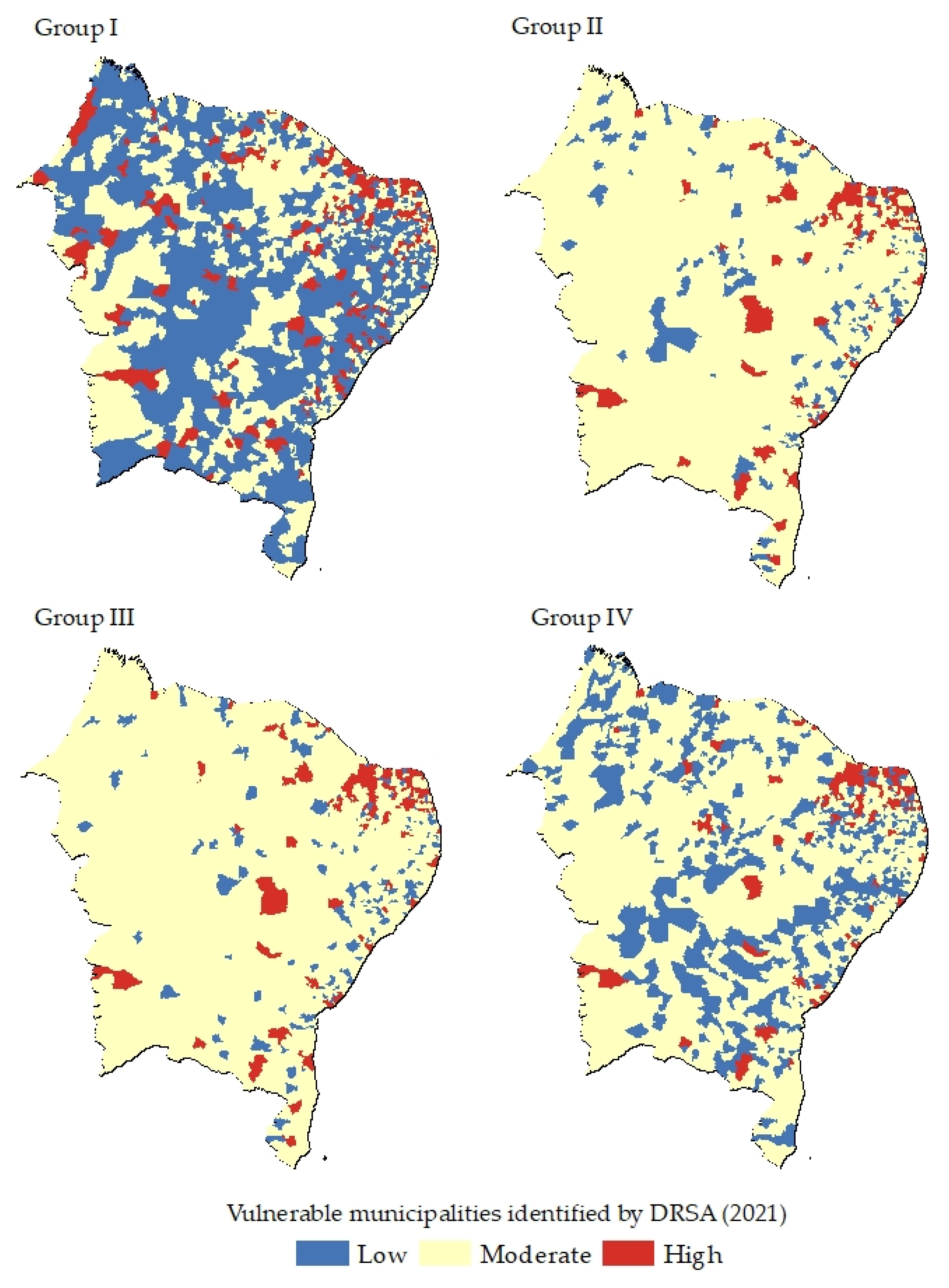
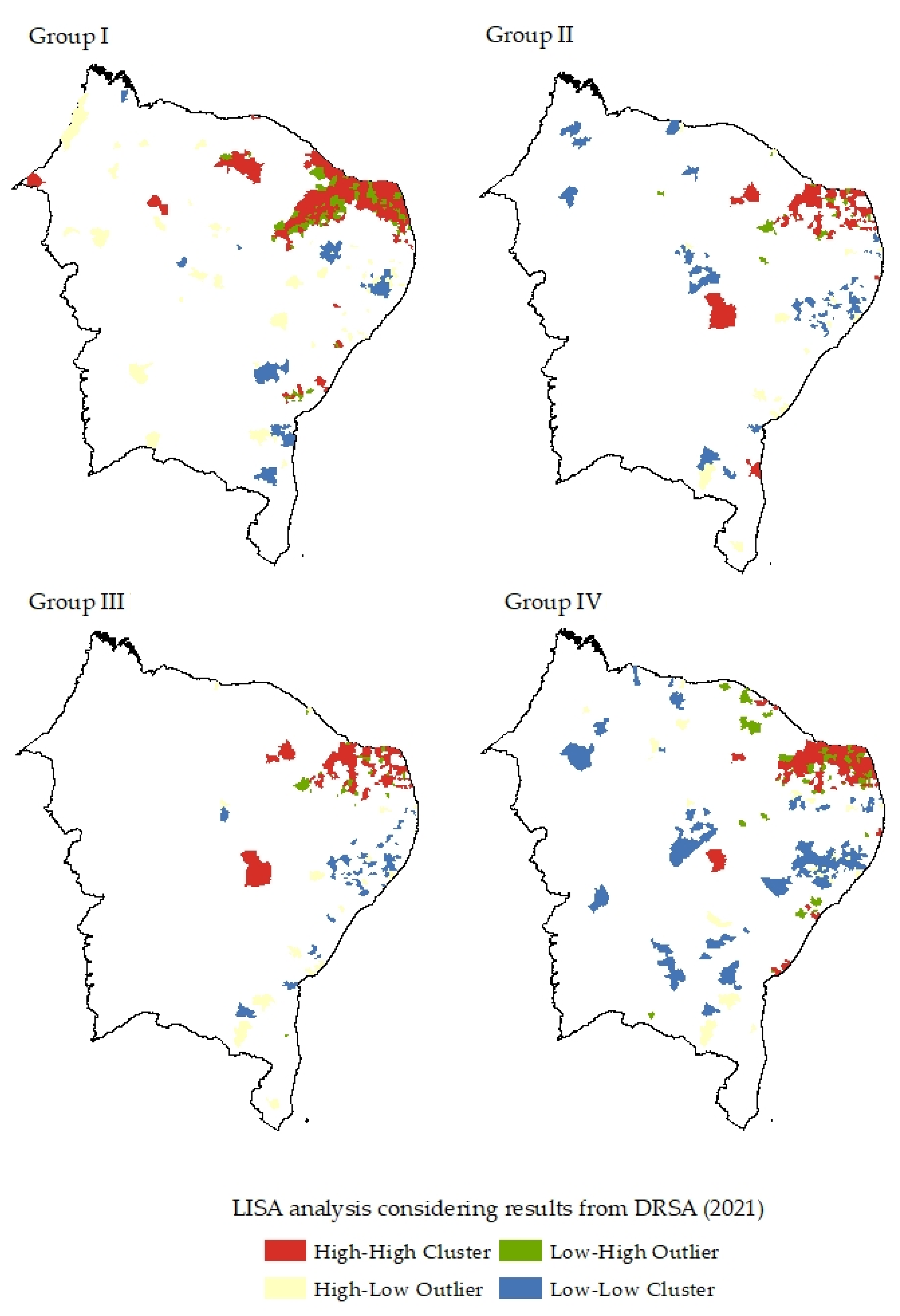
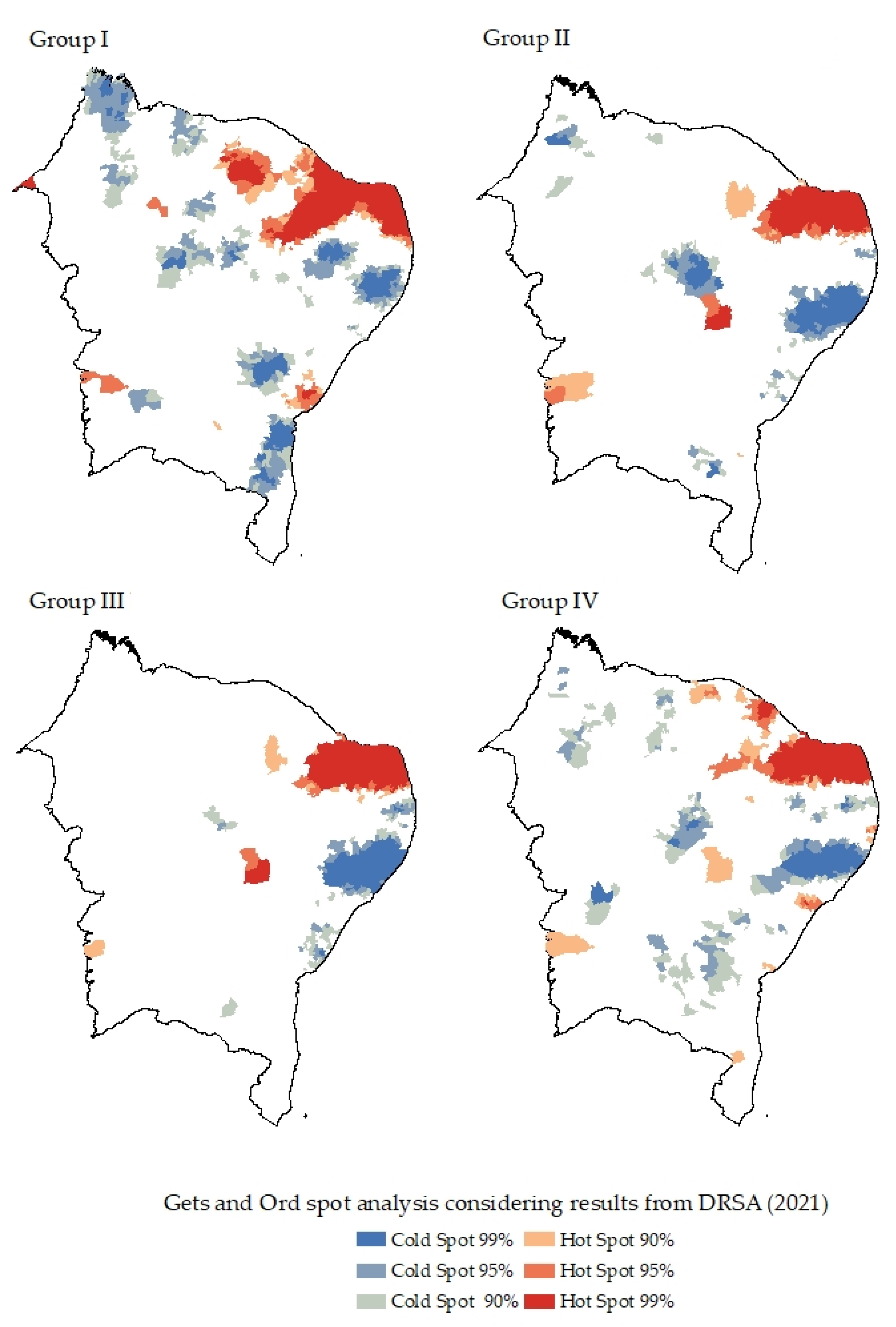
4. Results
5. Discussion and Final Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guan, W.; Ni, Z.; Hu, Y.; Liang, W.; Ou, C.; He, J.; Liu, L.; Shan, H.; Lei, C.; Hui, D.; et al. Clinical Characteristics of Coronavirus Disease 2019 in China. N. Engl. J. Med. 2020, 382, 1708–1720. [Google Scholar] [CrossRef] [PubMed]
- Zhou, P.; Yang, X.L.; Wang, X.G.; Hu, B.; Zhang, L.; Zhang, W.; Si, H.R.; Zhu, Y.; Li, B.; Huang, C.L.; et al. Pneumonia outbreak associated with a new coronavirus of probable bat origin. Nature 2020, 579, 270–273. [Google Scholar] [CrossRef] [PubMed]
- Gorayeb, A.; de Oliveira Santos, J.; da Cunha, H.G.; da Silva, R.B.; de Souza, W.F.; Mesquita, R.D.; da Silva Libério, L.; de Sousa Silva, F.D.; do Nascimento, S.L.; Mota, C.M.; et al. Volunteered Geographic Information Generates New Spatial Understandings of COVID-19 in Fortaleza. J. Lat. Am. Geogr. 2020, 19, 260–271. [Google Scholar] [CrossRef]
- Coelho, F.C.; Lana, R.M.; Cruz, O.G.; Villela, D.A.; Bastos, L.S.; Pastore y Piontti, A.; Davis, J.T.; Vespignani, A.; Codeço, C.T.; Gomes, M.F. Assessing the spread of COVID-19 in Brazil: Mobility, morbidity and social vulnerability. PLoS ONE 2020, 15, e0238214. [Google Scholar] [CrossRef] [PubMed]
- COVID-19 Dashboard by the Center of Systems Science and Engineering (CSSE) at Johns Hopkins University (HUI). Coronavirus Resrouce Center = Johns Hopkins University & Medicine. [Online]. Available online: https://coronavirus.jhu.edu/map.html (accessed on 25 March 2022).
- Freitas, C.M.; Silva, I.V.M.; Cidade, N.C. COVID-19 as a global disaster: Challenges to risk governance and social vulnerability Brazil. Rev. Ambiente Soc. 2020, 23, 1–12. [Google Scholar] [CrossRef]
- Ribeiro, H.V.; Sunahara, A.A.; Sutton, J.; Perc, M.; Hanley, Q.S. City size and the spreading of COVID-19 in Brazil. PLoS ONE 2020, 15, e0239699. [Google Scholar] [CrossRef]
- Braga, J.U.; Ramos, N.A.; Ferreira, A.F.; Lacerda, V.M.; Freire, R.M.C.; Bertoncini, B.V. Propensity for COVID-19 severe among the populations of the neighborhoods of Fortaleza, Brazil, in 2020. BMC Public Health 2020, 20, 1486. [Google Scholar] [CrossRef]
- Marson, F.A.L. COVID-19-6 milion cases worldwide and an overview of the diagnosis in Brazil: A tragedy to be announced. Diagn. Microbiol. Infect. Dis. 2020, 98, 115113. [Google Scholar] [CrossRef]
- Nepomuceno, T.C.C.; Silva, W.M.N.; Nepomuceno, K.T.C.; Barros, I.K.B. A DEA-Based Complexity of Needs Approach for Hospital Beds Evacuation during the COVID-19 Outbreak. J. Healthc. Eng. 2020, 2020, 8857553. [Google Scholar] [CrossRef]
- Ferraz, F.D.; Mariano, E.B.; Manzine, P.R.; Moralles, H.F.; Morceiro, P.C.; Torres, B.G.; de Almeida, M.R.; Soares de Mello, J.C.; Rebelatto, D.A.D.N. COVID Health Structure Index: The vulnerability of Brazilian Microregions. Soc. Indic. Res. 2021, 159, 197–215. [Google Scholar] [CrossRef]
- Huang, Q.; Jackson, S.; Derakhshan, S.; Lee, L.; Pham, E.; Jackson, A.; Cutter, S.L. Urban-rural differences in COVID-19 exposures and outcomes in the South: A preliminary analysis of South Carolina. PLoS ONE 2020, 16, e0246548. [Google Scholar] [CrossRef] [PubMed]
- Markovc, R.; Sterk, M.; Marhl, M.; Perc, M.; Gosak, M. Socio-demographic and health factors drive the epidemic progression and should guide vaccination strategies for best COVID-19 containment. Results Phys. 2021, 26, 104433. [Google Scholar] [CrossRef] [PubMed]
- McMahon, T.; Chan, A.; Havlin, S.; Gallos, L.K. Spatial correlations in geographical spreading of COVID-19 in the United States. Sci. Rep. 2022, 12, 699. [Google Scholar] [CrossRef] [PubMed]
- Khavarian-Garmsir, A.; Sharifi, A.; Moradpour, N. Are high-density districts more vulnerable to the COVID-9 pandemic? Sustain. Cities Soc. 2021, 70, 102911. [Google Scholar] [CrossRef]
- Nicolelis, M.; Raimundo, R.L.G.; Peixoto, P.S.; Andre, C.S. The impact of super-spreader cities, highways, and intensive care availability in the early stges of the COVID19 epidemic in Brazil. Sci. Rep. 2021, 11, 13001. [Google Scholar] [CrossRef]
- Scarpone, C.; Brinkmann, S.T.; Grobe, T.; Sonnenwald, D.; Fuchs, M.; Walker, B.B. A multimethod approach for county-scale geospatial analysis of emerging infectious diseases: A cross-sectional case study of COVID-19 incidence in Germany. Int. J. Health Geogr. 2020, 19, 32. [Google Scholar] [CrossRef]
- Han, Y.; Yang, L.; Jia, K.; Li, J.; Feng, S.; Chen, W.; Zhao, W.; Pereira, P. Spatial distribution characteristics of the CVODI-19 pandemic in Beijing and its relationship with environmental factors. Sci. Total Environ. 2021, 761, 144257. [Google Scholar] [CrossRef]
- Fall, E.S.; Abdalla, E.; Quansah, J.; Franklin, M.J.; Whaley-Omidire, W. County-level assessment of vulnerability to COVID-19 in Alabama. ISPRS Int. J. Geo-Inf. 2022, 11, 320. [Google Scholar] [CrossRef]
- Sharma, S.N.; Basu, S.; Sharma, P. Sociodemographic determinants of the adoption of a contact tracing application during the COVID-19 epidemic in Delhi, India. Health Policy Technol. 2021, 10, 100496. [Google Scholar] [CrossRef]
- Andersen, L.M.; Harden, S.R.; Sugg, M.M.; Runkle, J.D.; Lundquist, T.E. Analyzing the spatial determinants of local COVID-19 transmission in the United States. Sci. Total Environ. 2021, 754, 142396. [Google Scholar] [CrossRef]
- Ma, J.; Zhu, H.; Li, P.; Liu, C.; Li, F.; Luo, Z.; Zhang, M.; Li, L. Spatial patterns of the spread of the COVID-19 in Singapore and the influencing factors. ISPRS Int. J. Geo-Inf. 2022, 11, 152. [Google Scholar] [CrossRef]
- Penha, M.E.R. The pandemic and its ethno-spatial disparities: Considerations from Salvador, Bahia, Brasil. J. Lat. Am. Cult. Stud. 2020, 29, 325–331. [Google Scholar] [CrossRef]
- Maciel, J.A.C.; Castro-Silva, I.I.; Farias, M.R. Analise inicial da correlação espacial entre a incidência de COVID-19 e o desenvolvimento humano nos municípios do estado do Ceará no Brasil. Rev. Bras. De Epidemiol. 2020, 23, e200057. [Google Scholar] [CrossRef] [PubMed]
- Paula, D.P.; Medeiros, D.H.; Barros, E.L.; Guerra, R.G.; Santos, J.D.; Lima, J.S.; Monteiro, R.M. Diffusion of COVID-19 in the Northern Metropolis in Northeast Brail: Territorial dynamics and risks associated with Social Vulnerability. Soc. Nat. 2020, 32, 639–656. [Google Scholar] [CrossRef]
- Souza, A.P.G.; Mota, C.M.M.; Rosa, A.G.F.; Figueiredo, C.J.J.; Candeias, A.L.B. A spatial-temporal analysis at the early stages of the COVID-19 pandemic and its determinants: The case of Recife neighborhoods, Brazil. PLoS ONE 2022, 17, e0268538. [Google Scholar] [CrossRef]
- Natividade, M.D.S.; Bernardes, K.; Pereira, M.; Miranda, S.S.; Bertoldo, J.; Teixeira, M.D.G.; Livramento, H.L.; Aragão, E. Social distancing and living conditions in the pandemic COVID-19 in Salvador-Bahia, Brazil. Ciênc. Saúde Coletiva 2020, 25, 3385–3392. [Google Scholar] [CrossRef]
- Silva, A.P.S.C.; Maia, L.T.S.; Souza, W.V. Severe acute respiratory syndrome in Pernambuco: Comparison of patterns before and during the COVID-19 pandemic. Ciênc. Saúde Coletiva 2020, 25, 4141–4150. [Google Scholar] [CrossRef]
- Brito, P.L.; Kuffer, M.; Koeva, M.; Pedrassoli, J.C.; Wang, J.; Costa, F.; Freitas, A.D. The spatial dimension of COVID-19: The potential of earth observation data in support of slum communities with evidence from Brazil. ISPRS Int. J. Geo-Inf. 2020, 9, 557. [Google Scholar] [CrossRef]
- Tang, I.W.; Vieira, V.M.; Shearer, E. Effect of socioeconomic factors during the early COVID-19 pandemic: A spatial analysis. BMC Public Health 2022, 22, 1212. [Google Scholar] [CrossRef]
- Ramírez, I.J.; Lee, J. COVID-19 emergence and social and health determinants in Colorado: A rapid spatial analysis. Int. J. Environ. Res. Public Health 2020, 17, 3856. [Google Scholar] [CrossRef]
- Mota, C.M.M.; Figueiredo, C.J.J.; Pereira, D.V.S. Identifying areas vulnerable to homicide using multiple criteria analysis and spatial analysis. Omega 2021, 100, 102211. [Google Scholar] [CrossRef]
- Gao, Z.; Jiang, Y.; He, J.; Wu, J.; Xu, J.; Christakos, G. An AHP-based regional COVID-19 vulnerability model and its application in China. Model. Earth Syst. Environ. 2022, 8, 2525–2538. [Google Scholar] [CrossRef] [PubMed]
- Malakar, S. Geospatial modelling of COVID-19 vulnerability using an integrated fuzzy MCDM approach: A case study of West Bengal, India. Model. Earth Syst. Environ. 2021, 27, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Yetim, B.Y.; Sönmez, S.; Konca, M.; Ilgun, M. Prioritization of the policies and practices applied in Turkey to fight against COVID-19 through AHP technique. Saúde Soc. 2021, 30, 1–11. [Google Scholar] [CrossRef]
- Sarkar, S.K. COVID-19 susceptibility mapping using multicriteria evaluation. Disaster Med. Public Health Prep. 2021, 14, 521–537. [Google Scholar] [CrossRef] [PubMed]
- Brazilian Institute of Geography and Statistics. IBGE Cidades IBGE. 2020. Available online: https://cidades.ibge.gov.br/ (accessed on 21 January 2021).
- Getis, A.; Ord, J.K. The Analysis of Spatial Association by Use of Distance Statistics. Geogr. Anal. 1992, 24, 189–206. [Google Scholar] [CrossRef]
- Greco, S.; Matarazzo, B.; Slowinski, R. Rough sets methodology for sorting problems in presence of multiple attributes and criteria. Eur. J. Oper. Res. 2002, 138, 247–259. [Google Scholar] [CrossRef]
- Alvarez, P.A.; Ishizaka, A.; Martínez, L. Multiple-criteria decision making sorting methods: Survey. Expert Syst. Appl. 2021, 183, 115368. [Google Scholar] [CrossRef]
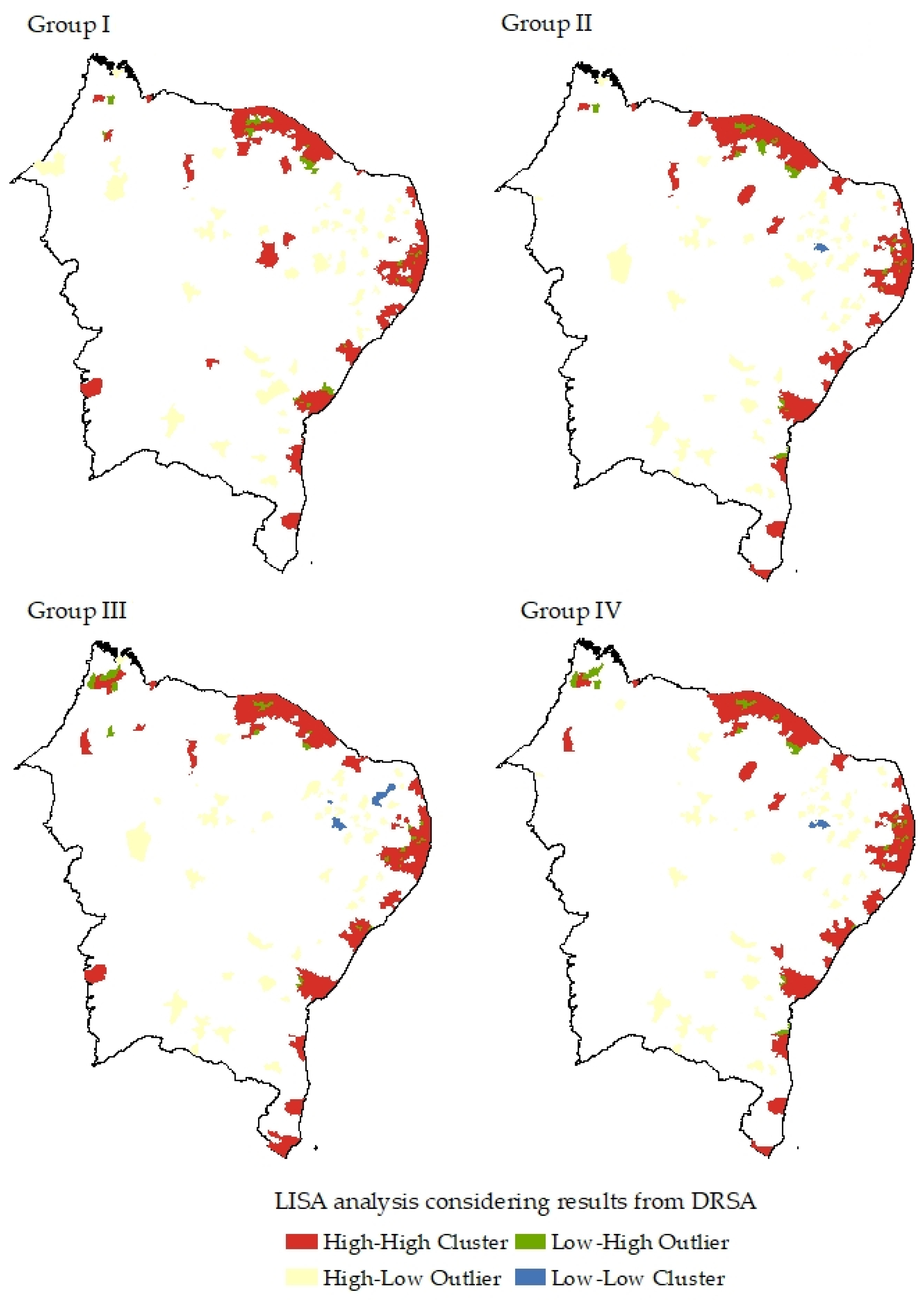
- Anselin, L. Local Indicators of Spatial Association–LISA. Geogr. Anal. 1995, 27, 93–115. [Google Scholar] [CrossRef]
- Brasil, P.; Medeiros, P. NetStRes–Model for Operation of Non-Strategic Reservoirs for irrigation in drylands: Model descrition and application to a semiarid basin. Water Resour. Manag. 2020, 34, 195–210. [Google Scholar] [CrossRef]
- Haguenauer, H.G.M.; Silva, G.D.P.; Sharqawy, M.H.; Neto, A.S.; Viana, D.B.; de Freitas, M.A.V. Current and future opportunities for renewable integrated desalination systems in the Brazilian semiarid region. Desalination Water Treat. 2019, 166, 279–295. [Google Scholar] [CrossRef]
- Cavalcanti, C.A.; Lima, J.P.R. The northeastern semi-arid: Recent evolution of both the economy and the industrial sector. Rev. Econômica Do Nordeste 2019, 50, 69–88. [Google Scholar]
- Schkade, D.A.; Kahneman, D. Does living in California make people happy? a focusing illusion in judgments of life satisfaction. Psychol. Sci. 1998, 9, 340–346. [Google Scholar] [CrossRef]
- Mocnik, F.; Raposo, P.; Feringa, W.; Raak, M.; Köbben, B. Epidemics and pandemics in maps-tha case of COVID-19. J. Maps 2020, 16, 144–152. [Google Scholar] [CrossRef]
- Eryando, T.; Sipahutar, T.; Rahardiantoro, S. The risk distribution of COVID-19 in Indonesia: A spatial analysis. Asia Pac. J. Public Health 2020, 32, 450–452. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Objective | Approaches | Factors | Spatial Units | Findings | References |
|---|---|---|---|---|---|
| COVID index to verify capability of hospital structures to deal with COVID-19 | Data envelopment analysis (DEA) approach | Respirators Intensive care units (ICU) Hospital beds Physicians Nurses | Microregional administrative units | Patterns of socioeconomics inequalities | [11] |
| Comparison of SARS before and during COVID-19 | Logistic regression model | Municipal human development index Proportion of population vulnerable to poverty Proportion of extremely poor Presence of federal highways | Macroregional health offices Municipalities | High population density and urban mobility are the factors that most contribute to the spread of COVID-19 | [28] |
| Identify data gaps in large slum communities, considering socio-economic, demographic, and physical variables | Earth observation (EO) (satellites images) | Population Buildings Road and pathway types Local markets Health facilities | Pixels | Provides guidelines on which locals need further investigation via EO and gathers procedures to support COVID-19 responses | [29] |
| Trends in analyses of social distancing and living conditions based on the social distancing index and living conditions index of municipalities | Aggregated score | Distribution of residents by per-capita monthly income Proportion of black people Schooling rate Households connected to regular water supply network | Neighborhood | Social distancing measures must consider the place; the most vulnerable neighborhoods are weak at responding to the pandemic | [27] |
| Identify most vulnerable areas, considering risk of arrival cases and local transmission | Probabilistic models and multivariate cluster analysis | Population per age group Infant mortality Life expectancy GINI index | Microregional administrative units | Several microregional administrative units considered as vulnerable | [4] |
| Employ additive models into spatial patterns considering factors such as race/ethnicity, service occupation, and household size | Generalized additive models and Poisson framework | Race/ethnicity, service occupation household size, cases, and hospitalizations | Cities | Percent minority, average household size, and percent service industry keep positive association with COVID-19 risk | [30] |
| Explore spatial patterns (initial stages) of COVID-19 cases with social determinants | Density spatial analysis and statistical correlation | COVID-19 incidence, asthma cases, per capt income, education, housing, multiple unit structures | Counties | Greatest number of cases associated with senior living facilities, cases in places with high population density and asthma hospitalization | [31] |
| Variable | Description |
|---|---|
| Pop_estim | Absolute population in estimated values per municipality |
| Peop_ocup | Percentage of total population that are currently employed ([number of employed individuals in the municipality/total population of the municipality × 100) (2019) |
| Income_m | Average monthly income of formal workers (2019) BRL USD |
| Pop_ocu | Number of employed people in the municipality (%) (2019) |
| Income_prop | Percentage of population with nominal monthly income per capita of up to 1/2 minimum wage: [Population residing in permanent private households with monthly income of up to 1/2 minimum wage/Total population residing in permanent private households] × 100 (2010) |
| Esco_1 | Absolute number of schools that offer basic education in the municipality (2020) |
| Escol_2 | Absolute number of schools offering secondary education in the municipality (2020) |
| MHDI | Municipal human development index, based on the following dimensions: income, education, and health (2010) |
| GPD | Gross domestic product (2018) |
| Schollar_prop | [Population residing in the municipality aged 6 to 14 years old enrolled in regular education/Total population residing in the municipality aged 6 to 14 years old] × 100 (2010) |
| SUS | Establishments that offer basic health services and are part of the Unified Health System [Sistema Único de Saúde] (2009). |
| Sewage | [Total resident population in permanent private households with sewage system belonging to the general network and septic tank/Total resident population in permanent private households] × 100 (2010) |
| Area | Total area of the municipality based on rural areas, urban areas, urban core, rural core, and urban areas with high densities of buildings |
| Area1 | Total area of the municipality based on urban core, rural core, urban areas with high densities of buildings, and urban areas with low densities of buildings |
| Area2 | Total area of the municipality based on urban core and urban areas with high densities of buildings |
| Den | Population density: [Absolute population in estimated values by municipality/Area] |
| Den 1 | Population density1: [Absolute population in estimated values by municipality/Area2] |
| Den 2 | Population density2: [Absolute population in estimated values by municipality/Area3] |
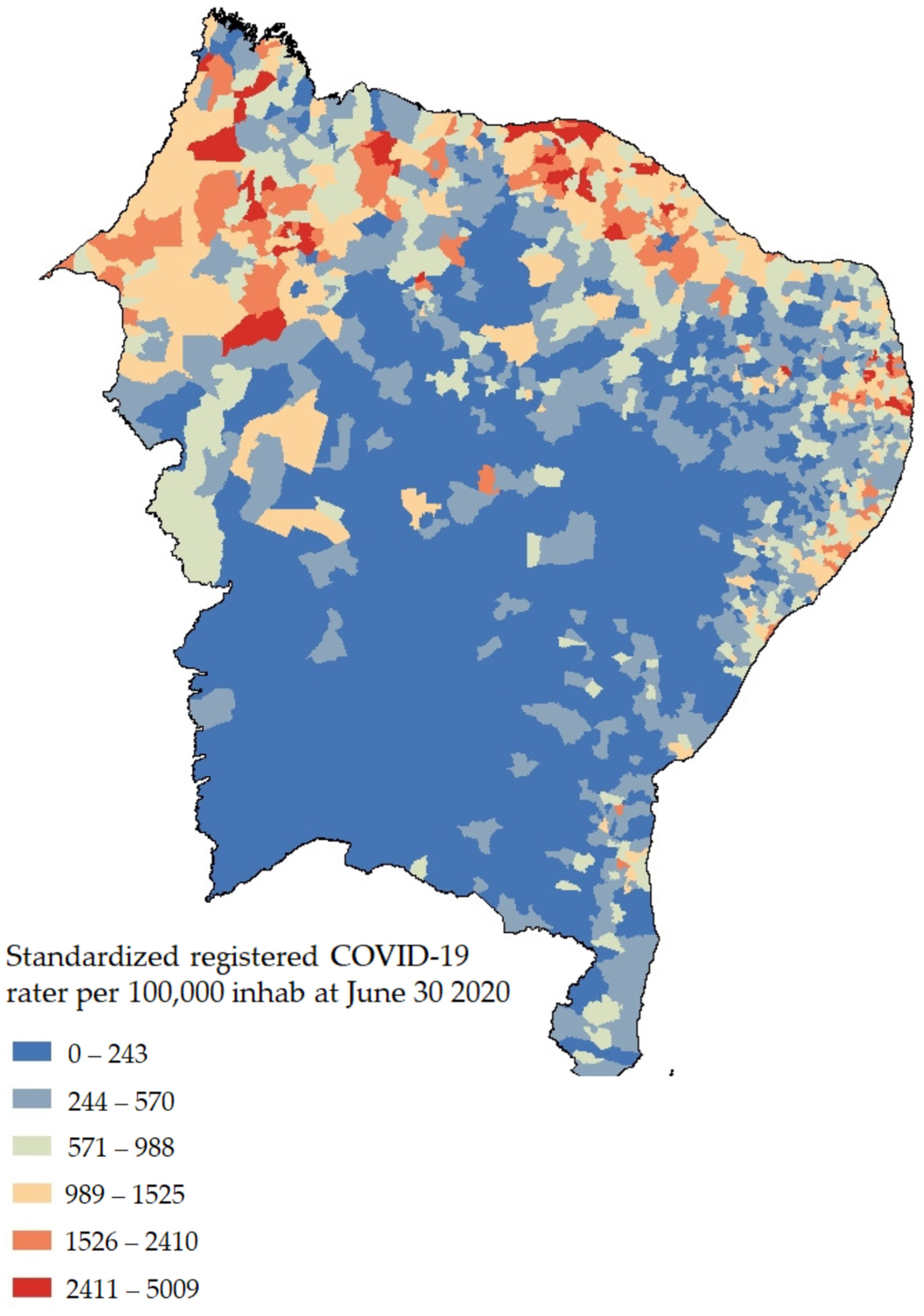
| COVID-19 registers | Daily COVID-19 cases included as attribute feature |
| Variable | Group I | Group II | Group III | Group IV |
|---|---|---|---|---|
| Pop_estim | ** | ** | ** | |
| Peop_ocup | ** | ** | ** | |
| Income_m | ** | ** | ||
| Pop_ocu | ** | ** | ** | |
| Income_prop | ** | ** | ||
| Esco_1 | ** | |||
| Esco_2 | ** | |||
| MHDI | ** | ** | ** | ** |
| GPD | ** | ** | ** | ** |
| Schollar_prop | ** | |||
| SUS | ** | |||
| Sewage | ** | |||
| Area | ** | ** | ** | ** |
| Area1 | ** | ** | ** | ** |
| Area2 | ** | ** | ** | ** |
| Den | ** | ** | ** | ** |
| Den1 | ** | ** | ** | ** |
| Den2 | ** | ** | ** | ** |
| Day_1 (06/24)—2020 | ** | ** | ** | ** |
| Day_2 (06/27)—2020 | ** | ** | ** | ** |
| Day_3 (06/30)—2020 | ** | ** | ** | ** |
| Variable | Mean | Min | Max | SD |
|---|---|---|---|---|
| Pop_estim | 31,813 | 1246 | 2,872,347 | 119,072 |
| Peop_ocup | 5295 | 59 | 849,711 | 37,919 |
| Income_m | 1.80 | 0.80 | 6.50 | 0.37 |
| Pop_ocu | 8.94% | 1.00% | 79.40% | 5.59% |
| Income_prop | 51.54% | 22.70% | 64.10% | 4.84% |
| Esco_1 | 28 | 1 | 1173 | 53 |
| Esco_2 | 4 | 0 | 307 | 14 |
| MHDI | 0.591 | 0.443 | 0.788 | 0.043 |
| GPD | 11,207.52 | 3285.04 | 253,895.58 | 11,181.27 |
| Schollar_prop | 97% | 81% | 100% | 2% |
| SUS | 12 | 1 | 367 | 19 |
| Sewage | 25.37% | 0.00% | 97.30% | 22.09% |
| Area | 865.20 | 18.61 | 15,634.33 | 1355.32 |
| Area1 | 12.73 | 0.18 | 421.88 | 29.89 |
| Area2 | 6.66 | 0.06 | 293.36 | 17.67 |
| Den | 98.27 | 0.84 | 9503.20 | 456.85 |
| Den1 | 3681.23 | 202.18 | 39,399.11 | 2930.72 |
| Den2 | 6357.30 | 281.86 | 122,002.24 | 6861.10 |
| Date (DD-MM) | 15-03 | 30-03 | 15-04 | 30-04 | 15-05 | 30-05 | 15-06 | 30-06 |
|---|---|---|---|---|---|---|---|---|
| Moran’s index | 0.000152 | 0.000012 | 0.000470 | 0.001537 | 0.002523 | 0.004999 | 0.006344 | 0.006194 |
| z-score | 0.583468 | 0.649571 | 0.954859 | 1.726499 | 2.568552 | 4.373238 | 5.183223 | 4.957213 |
| p-value | 0.559579 | 0.515969 | 0.339649 | 0.084258 | 0.010212 | 0.000012 | 0.000 | 0.0000 |
| Model | Random | Random | Random | Clustered | Clustered | Clustered | Clustered | Clustered |
| Group | OLS | ||
|---|---|---|---|
| Adjusted R2 | AICc | p-Value | |
| Group I | 0.95 | 26,186.30 | 0.0000 |
| Group II | 0.93 | 26,366.51 | 0.0000 |
| Group III | 0.93 | 26,450.05 | 0.0000 |
| Group IV | 0.051 | 28,178.83 | 0.0000 |
| Group | Reducts | Core | Quality |
|---|---|---|---|
| Group I | 4 | Esco, sewage, area, den | 0.989 |
| Group II | 4 | Pro_ocup, MHDI, area, den, den1, c3006 | 0.901 |
| Group III | 7 | Income_m, MHDI, area, den, den1, c3006 | 0.917 |
| Group IV | 1 | Peop_ocup, MHDI, GPD, area, den, den1, den2, c2406, c3006 | 0.901 |
| Group | Rules | |
|---|---|---|
| Group I | IF pop_estim >= 42,130.0 AND esco <= 0.926 THEN At Least 3 IF sewage <= 0.377 AND area >= 567.78 AND den >= 68.225369 THEN At Least 3 IF Income_m >= 1.7 AND c3006 >= 8.0 THEN At Least 2 IF pop_estim >= 28,933 AND esco <= 0.959 THEN At Least 2 IF ocup_mei >= 0.539 AND den <= 17.578066 THEN At Most 1 IF Peop_ocup <= 463.0 AND den <= 30.431274 THEN At Most 1 IF mhdi <= 0.548 AND c2706 <= 9 THEN At Most 2 IF Peop_ocup <= 862.0 AND c2706 <= 0 THEN At Most 2 | C: 90.05 I: 9.95 |
| Group II | IF area >= 270.752 AND c2706 >= 50.0 AND c3006 >= 20.0 THEN At Least 3 IF area >= 842.106 AND c3006 >= 22 THEN At Least 3 IF den >= 124.146236 AND den2 <= 10,760.08 THEN At Least 2 IF pop_estim >= 28,933.0 AND mhdi >= 0.592 AND den >= 88.545652 THEN At Least 2 IF pib <= 51,697.69 AND den <= 13.66 THEN At Most 1 IF pro_ocup <= 0.054 AND c2706 <= 2 THEN At Most 1 IF mhdi <= 0.534 THEN At Most 2 IF area2 <= 1.88 AND c3006 <= 7 THEN At Most 2 | C: 90.05 I: 9.95 |
| Group III | IF area >= 270.752 AND c2706 >= 50 AND c3006 >= 20 THEN At Least 3 IF area >= 755.59 AND c2706 >= 37 THEN At Least 3 IF pib >= 25,892.88 AND den >= 19.24 THEN At Least 2 IF area2 >= 4.24 AND c2406 >= 7 THEN At Least 2 IF Peop_ocup <= 421 AND pib <= 7434.96 THEN At Most 1 IF Income_m <= 1.7 AND den <= 19.593458 AND den2 >= 16,998.68 THEN At Most 1 IF den <= 17.57 AND c2406 <= 14 THEN At Most 2 IF mhdi <= 0.548 AND c2706 <= 9 THEN At Most 2 | C: 88.40 I: 11.60 |
| Group IV | IF area >= 270.752 AND c2706 >= 50 AND c3006 >= 20 THEN At Least 3 IF area >= 385.583 AND c2406 >= 16 AND c3006 >= 24 THEN At Least 3 IF den1 <= 493.20 THEN At Least 2 IF den >= 124.14 AND den2 <= 10,760.08 THEN At Least 2 IF mhdi <= 0.534 AND pib <= 6811.66 THEN At Most 1 IF pib <= 11,566.03 AND den <= 19.59 AND den2 >= 16,998.68 THEN At Most 1 IF den1 >= 7400.67 THEN At Most 2 IF area2 <= 2.17 AND den <= 73.11 AND c3006 <= 2 THEN At Most 2 | C: 89.50 I: 10.50 |
| Group | Reducts | Core | Quality |
|---|---|---|---|
| Group I | 1 | Income_m, pro_ocup, ocup_mei, MHDI, pib, esco, sewage, area, den, den1, den2, c2206, c2606 | 0.872 |
| Group II | 1 | Pro_ocup, odhm, pib, area, den, den1, den2, c2206, c2406, c2606 | 0.739 |
| Group III | 1 | Income_m, prop_ocup, ocup_mei, MHDI, pib, area, den, den1, den2, c2206, c2406, c2606 | 0.789 |
| Group IV | 1 | Mhdi, pib, area, den, den1, den2, c2206, c2406, c2606 | 0.722 |
| Group I | Group II | Group III | Group IV | |||||
|---|---|---|---|---|---|---|---|---|
| Year | 2020 | 2021 | 2020 | 2021 | 2020 | 2021 | 2020 | 2021 |
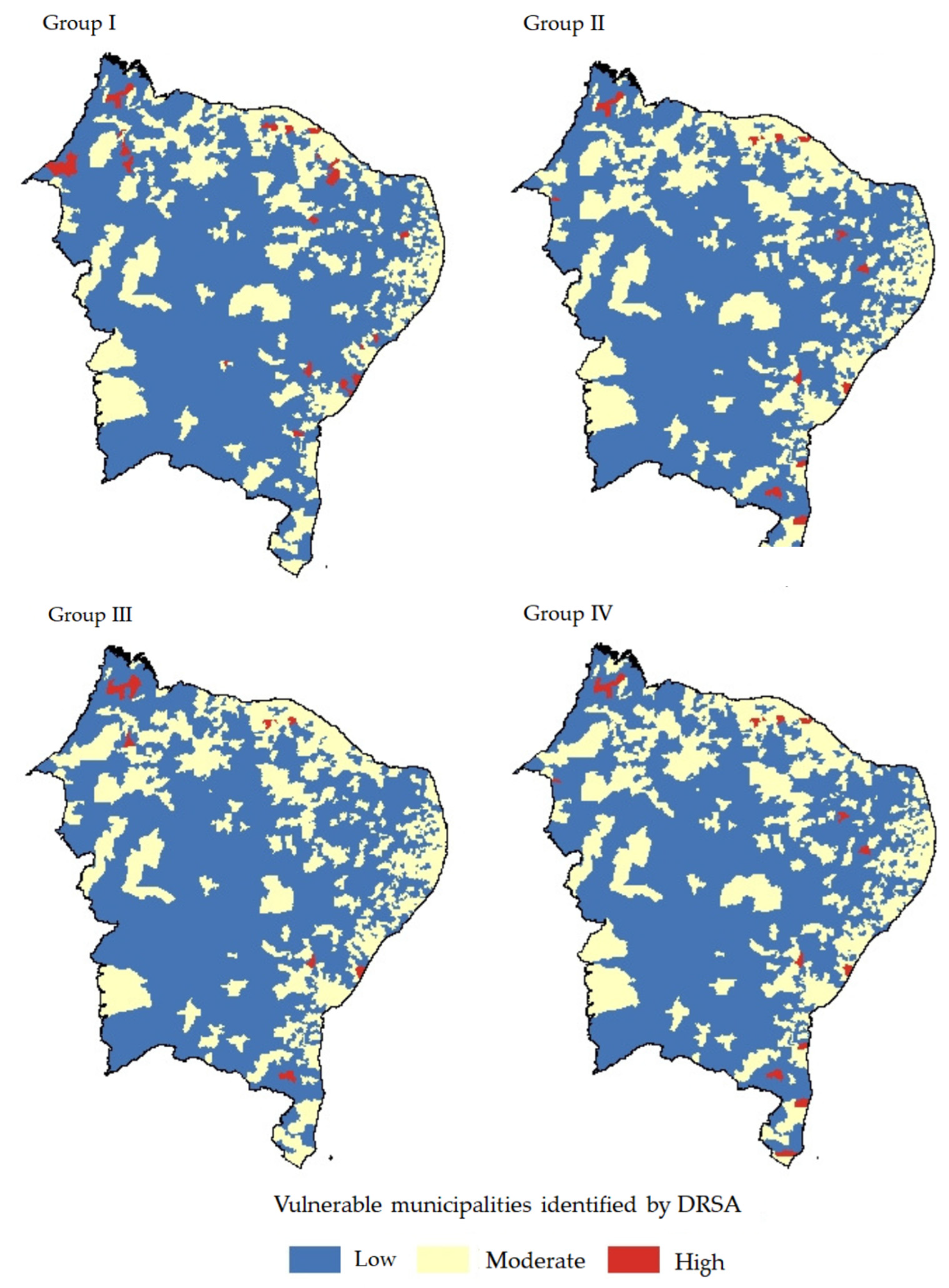
| High | 22 | 209 | 15 | 104 | 11 | 109 | 16 | 100 |
| Moderate | 461 | 549 | 554 | 1532 | 561 | 1537 | 578 | 1149 |
| Low | 1311 | 1035 | 1225 | 544 | 1222 | 147 | 1200 | 544 |
| Groups | 2020 | 2021 |
|---|---|---|
| Group I | #62 Den, den1, den2, pop_ocup, GPD, MHDI, sewage, Schollar_prop, Esco_1, area, June days 2020 (24; 27; 30) | #96 MHDI, den1, den2, income_m, peop_ocup, area, sewage, June days 2021 (22; 24; 26) |
| Group II | #58 Den, den1, MHDI, area, GPD, income_prop, pop_estim, June days 2020 (24; 27; 30) | #50 Area, pop_ocup, MHDI, GPD, den, den1, den2, June days 2021 (22; 24) |
| Group III | #56 Area, den1, den2, MHDI, peop_ocup, MDHI, June days 2020 (24; 27) | #52 Area, income_m, MHDI, den2, income_prop, GPD, income_m, June days 2021 (22; 24) |
| Group IV | #56 Sewage, income_m, area, pop_ocup, den, den2, GPD, income_prop, MHDI, June days 2020 (24; 27) | #47 Area, den1, den2, GPD, MHDI, June days 2021 (24; 22) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Figueiredo, C.J.J.d.; de Miranda Mota, C.M.; de Araújo, K.G.D.; Rosa, A.G.F.; de Souza, A.P.G. Measuring COVID-19 Vulnerability for Northeast Brazilian Municipalities: Social, Economic, and Demographic Factors Based on Multiple Criteria and Spatial Analysis. ISPRS Int. J. Geo-Inf. 2022, 11, 449. https://doi.org/10.3390/ijgi11080449
Figueiredo CJJd, de Miranda Mota CM, de Araújo KGD, Rosa AGF, de Souza APG. Measuring COVID-19 Vulnerability for Northeast Brazilian Municipalities: Social, Economic, and Demographic Factors Based on Multiple Criteria and Spatial Analysis. ISPRS International Journal of Geo-Information. 2022; 11(8):449. https://doi.org/10.3390/ijgi11080449
Chicago/Turabian StyleFigueiredo, Ciro José Jardim de, Caroline Maria de Miranda Mota, Kaliane Gabriele Dias de Araújo, Amanda Gadelha Ferreira Rosa, and Arthur Pimentel Gomes de Souza. 2022. "Measuring COVID-19 Vulnerability for Northeast Brazilian Municipalities: Social, Economic, and Demographic Factors Based on Multiple Criteria and Spatial Analysis" ISPRS International Journal of Geo-Information 11, no. 8: 449. https://doi.org/10.3390/ijgi11080449