
Spatial Prediction of COVID-19 Pandemic Dynamics in the United States
 , ,
, , {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
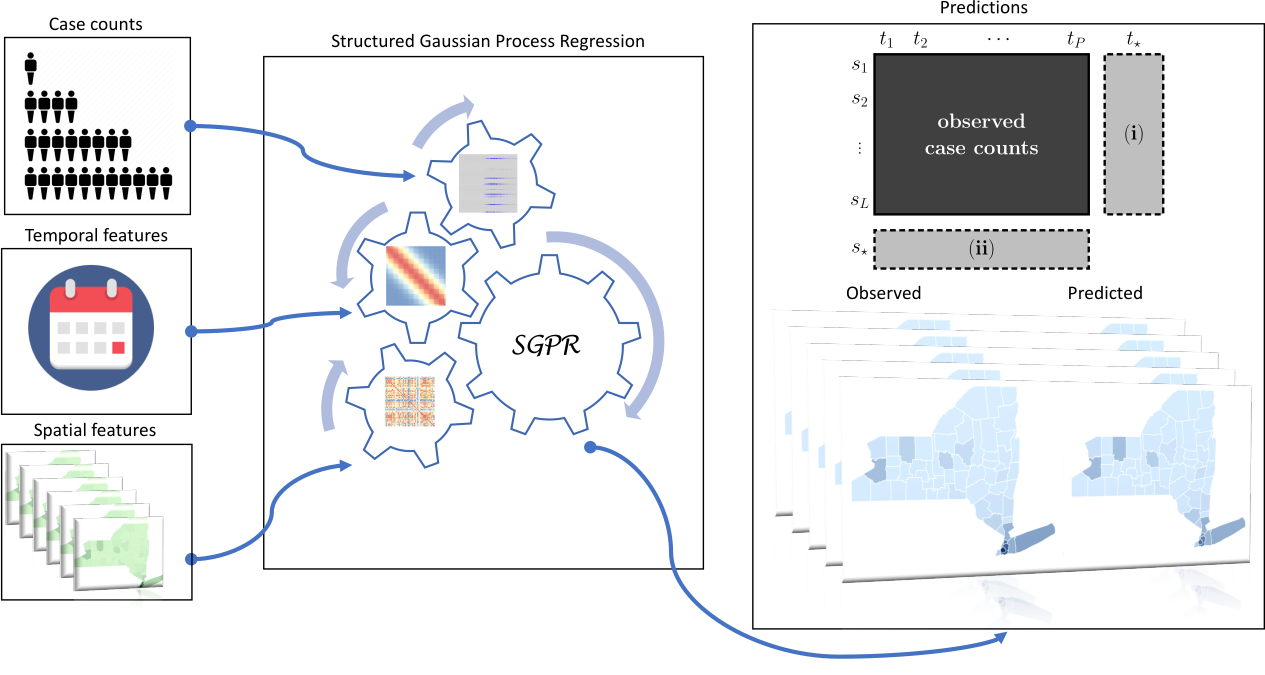
2.1. Supervised Prediction Algorithm: Gaussian Process Regression
2.2. Unsupervised Prediction Algorithm: Topic Modeling
- For a given county d, the topic distribution, is drawn.
- For the spatial feature in the county,
- (a)
- A topic assignment is drawn,
- (b)
- and a spatial feature is drawn and observed.
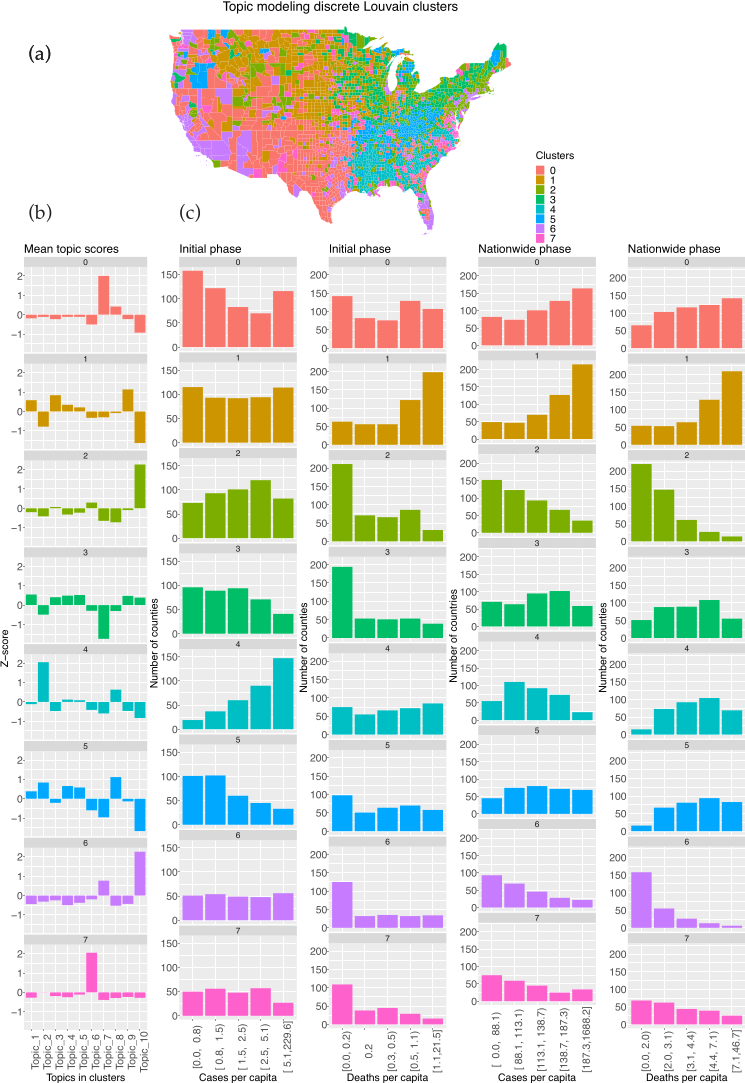
2.3. Clustering Counties
3. Results
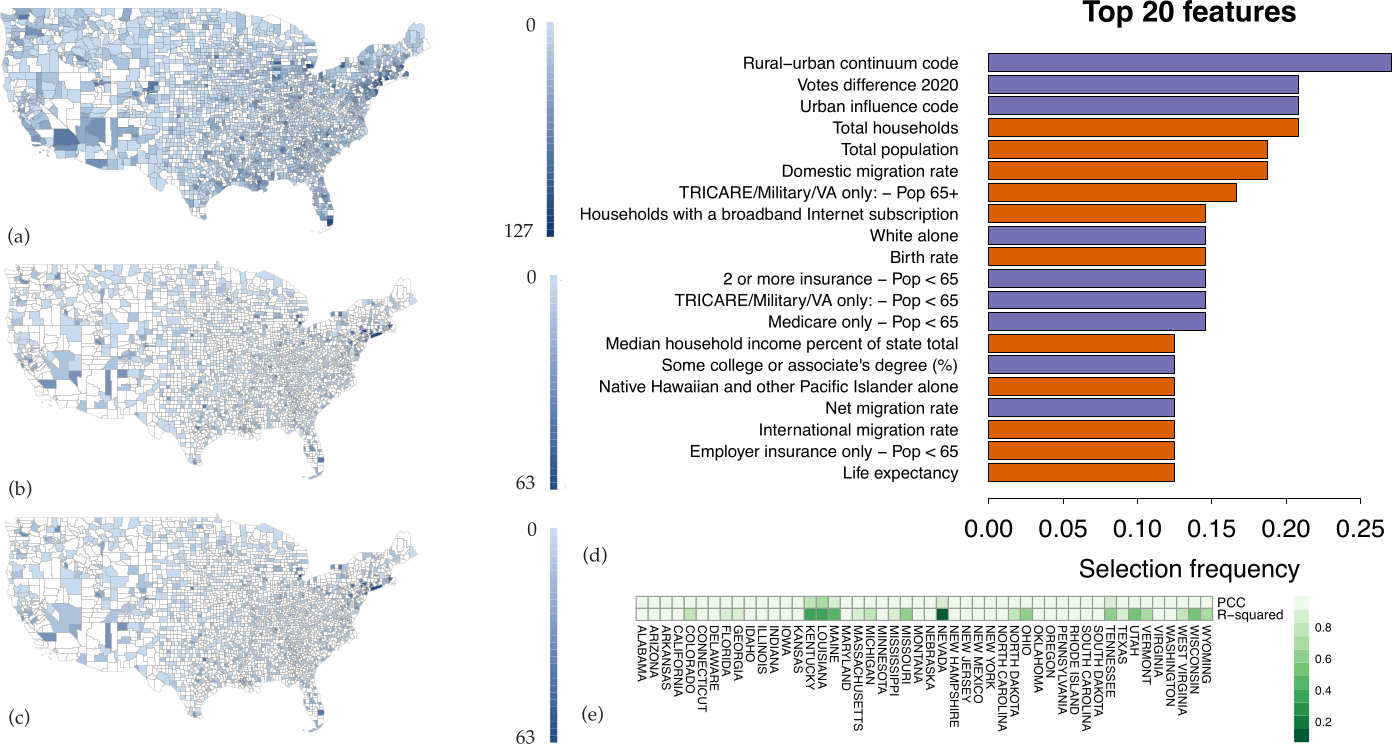
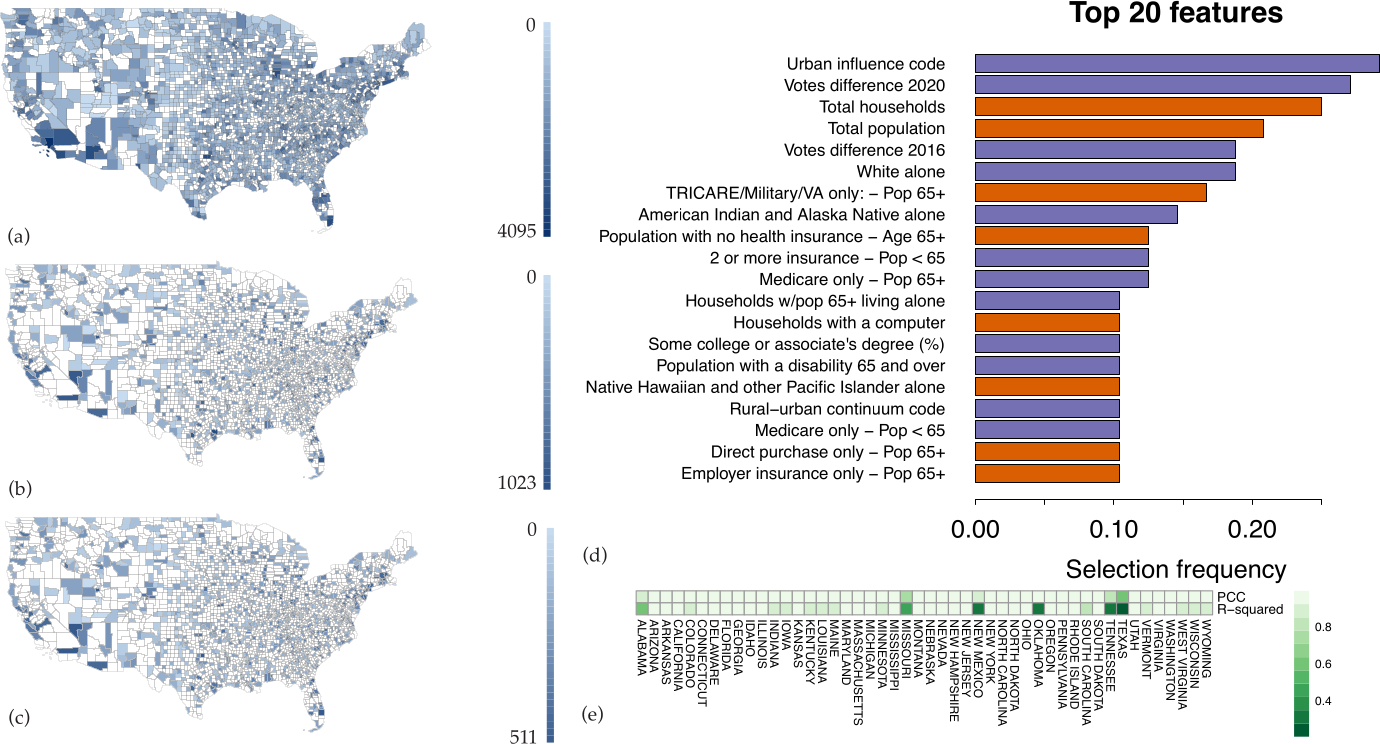
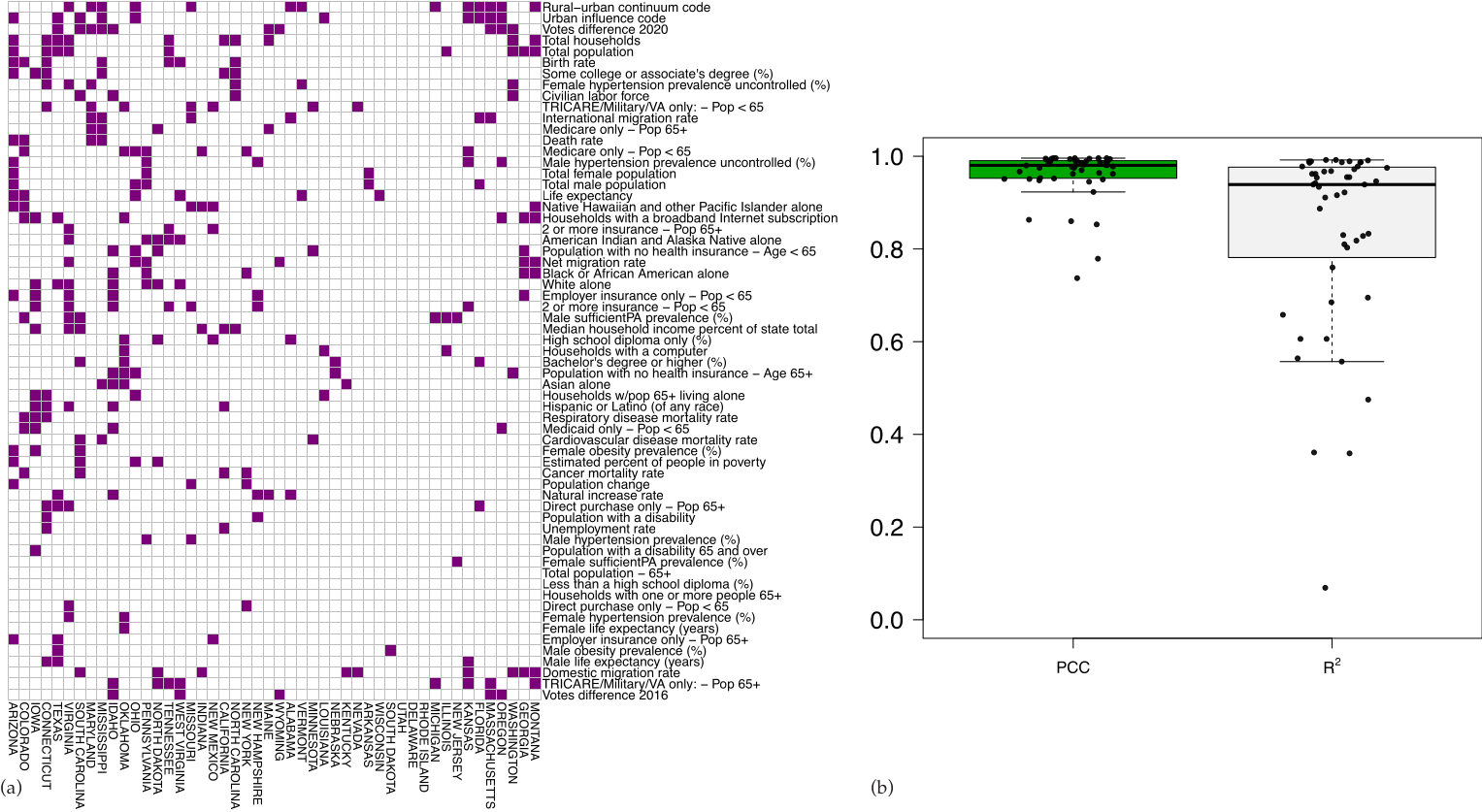
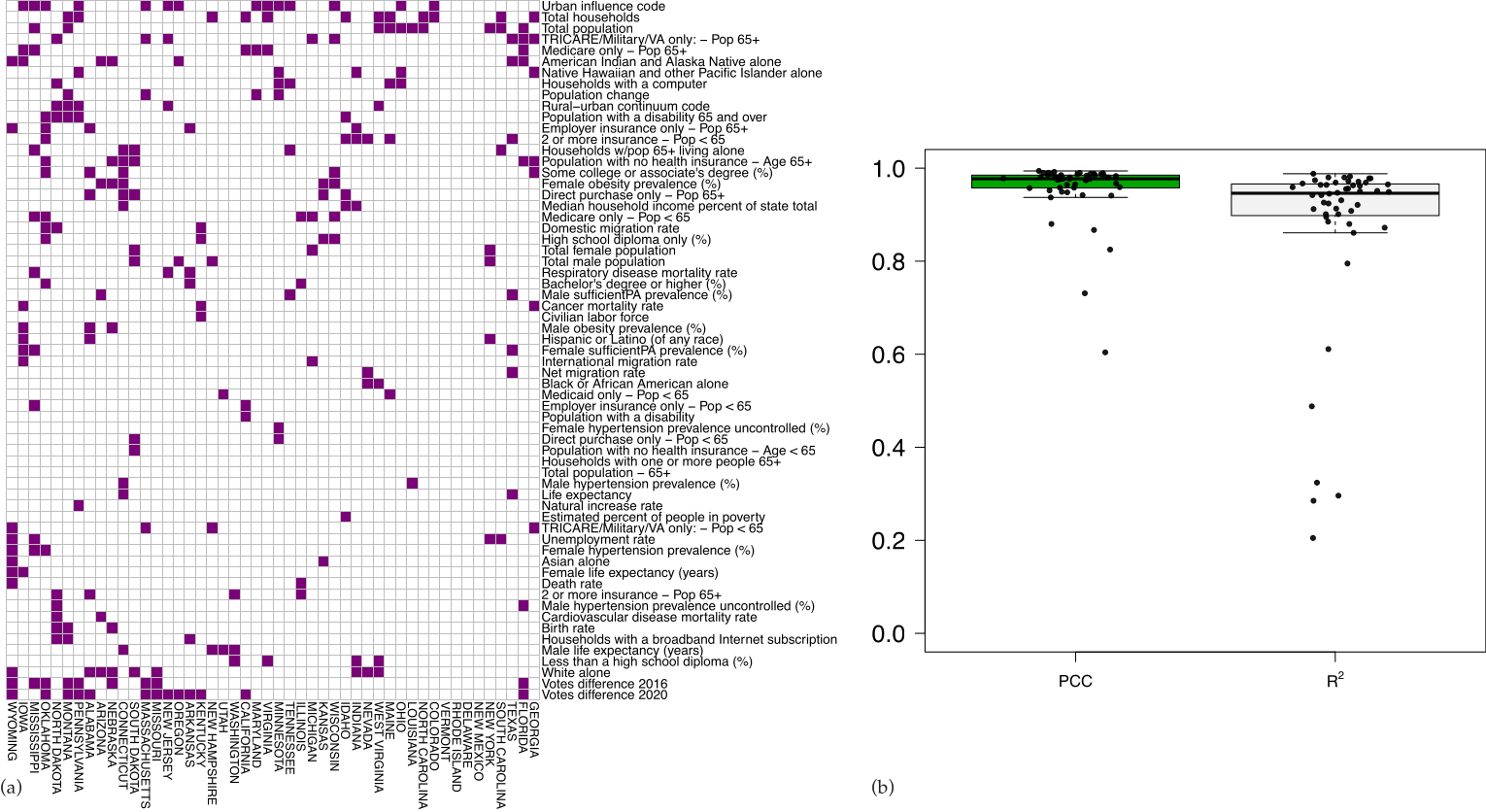
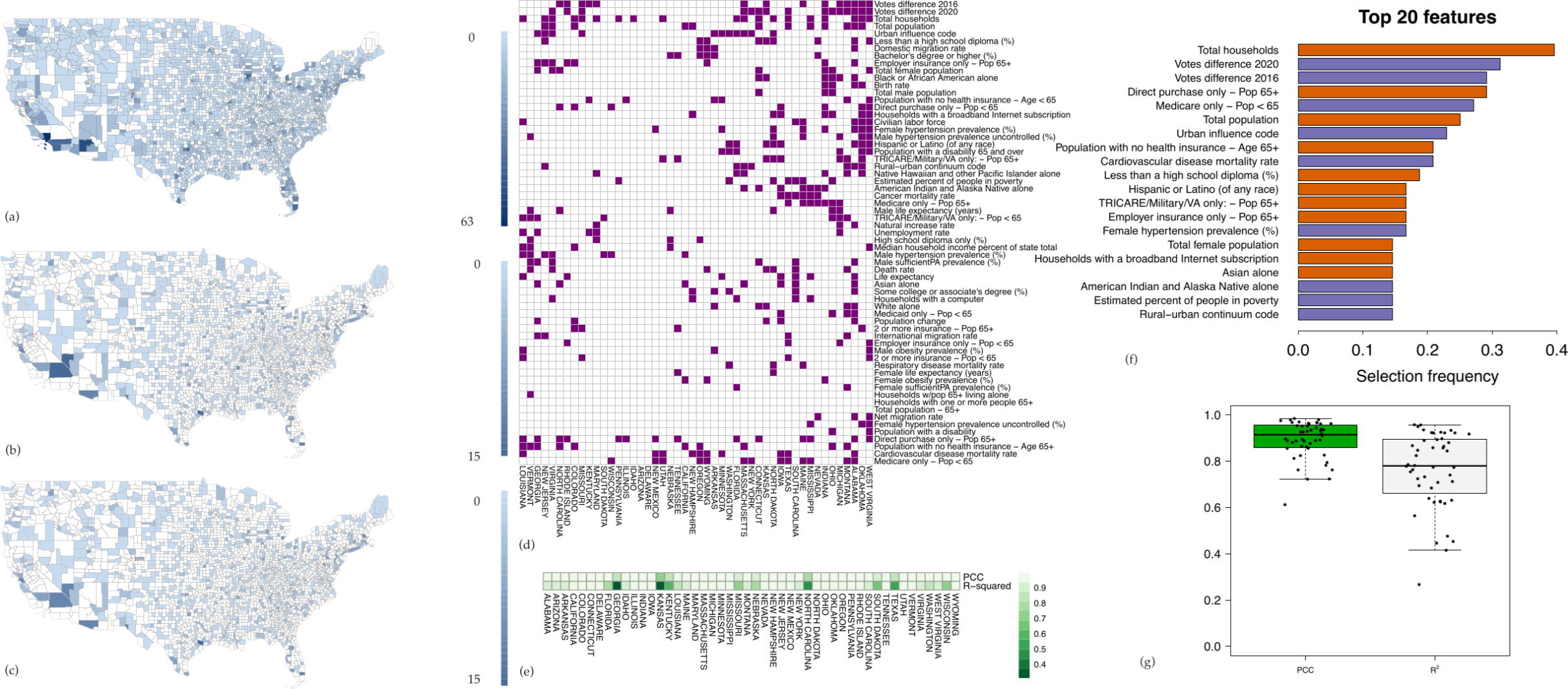
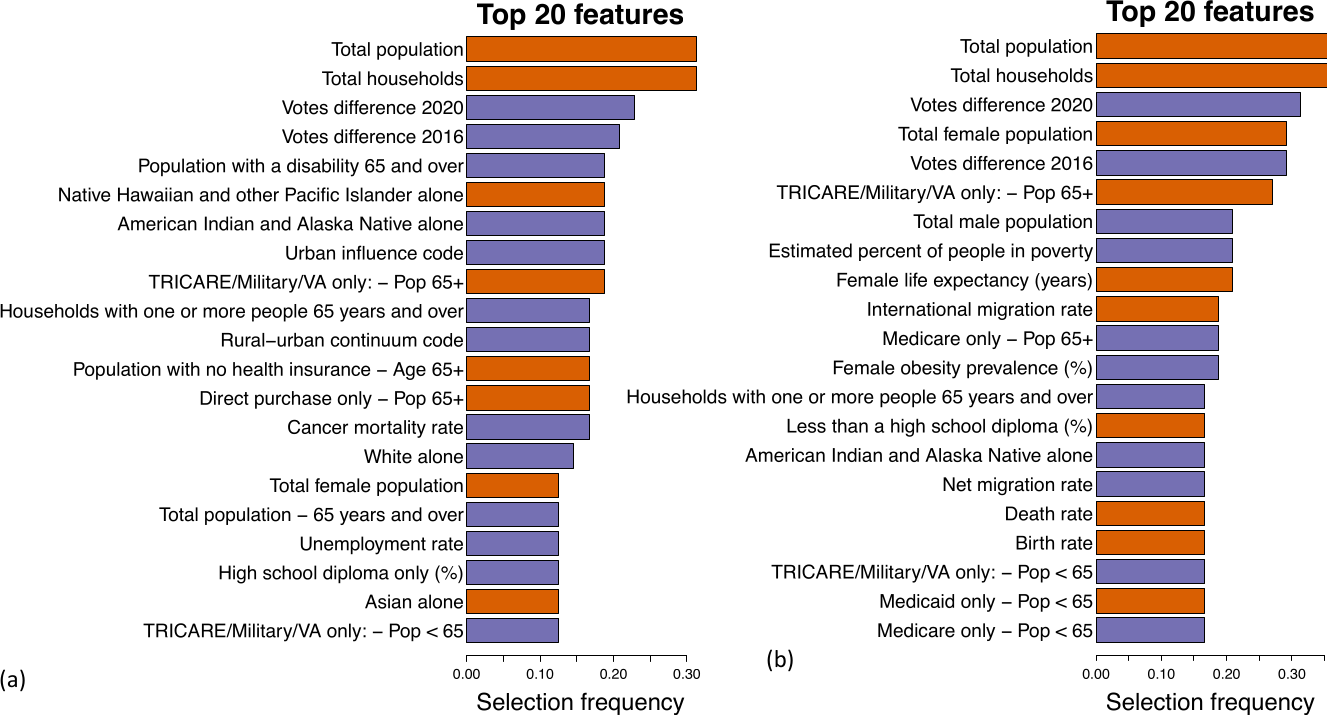
3.1. Defining Spatial Features
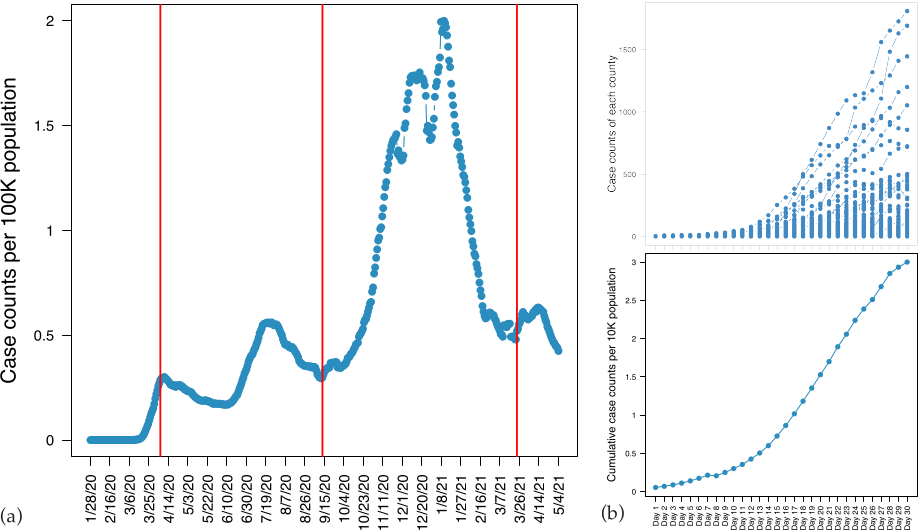
3.2. Analysis of the Nationwide Phase Dynamics
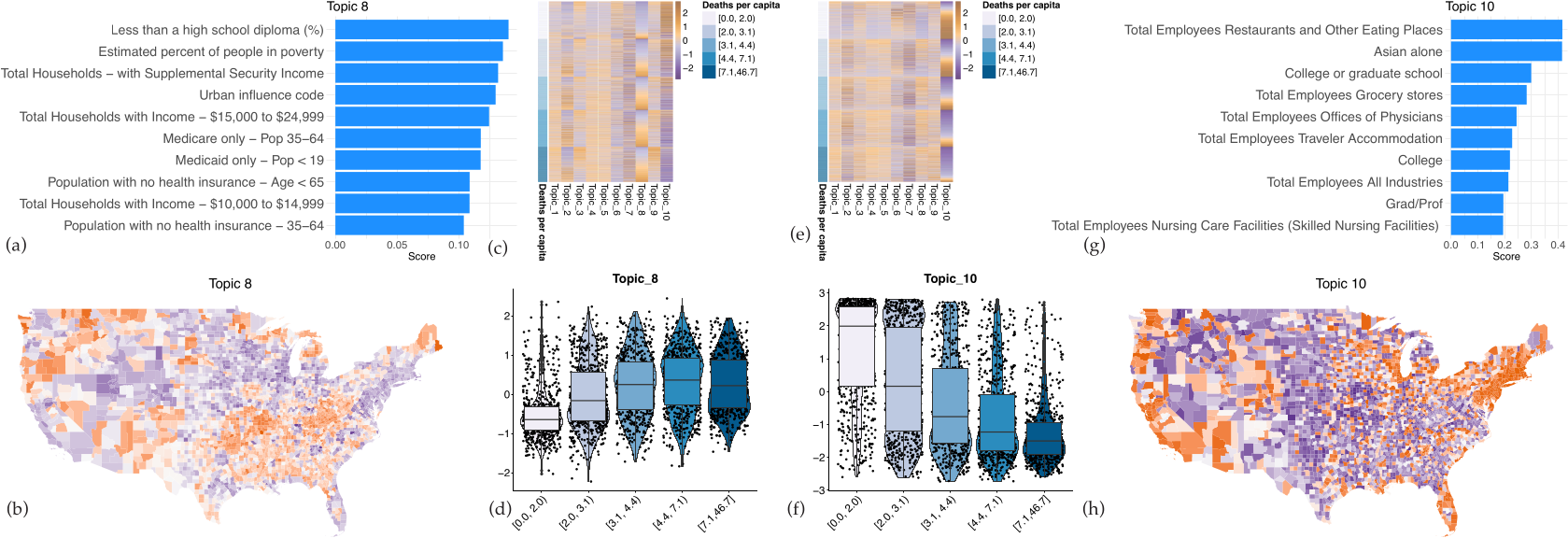
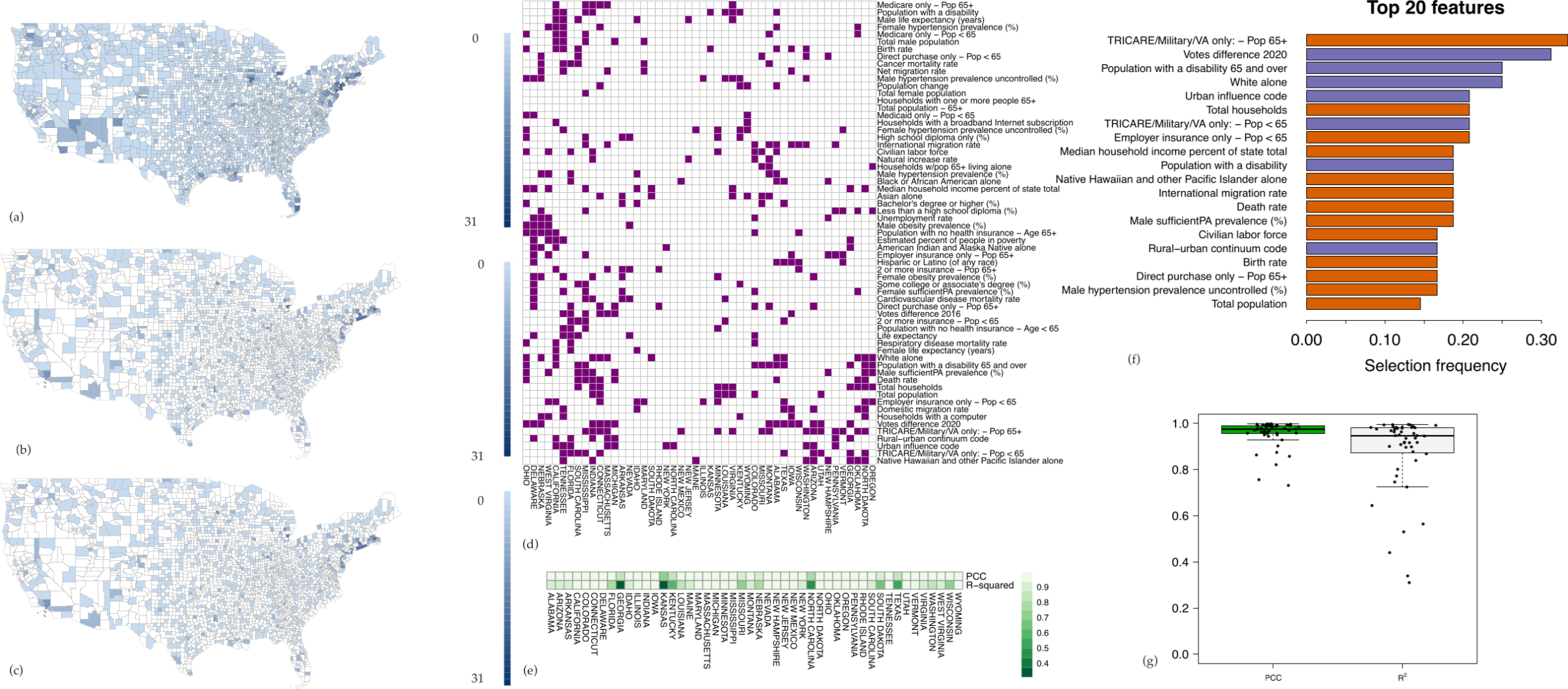
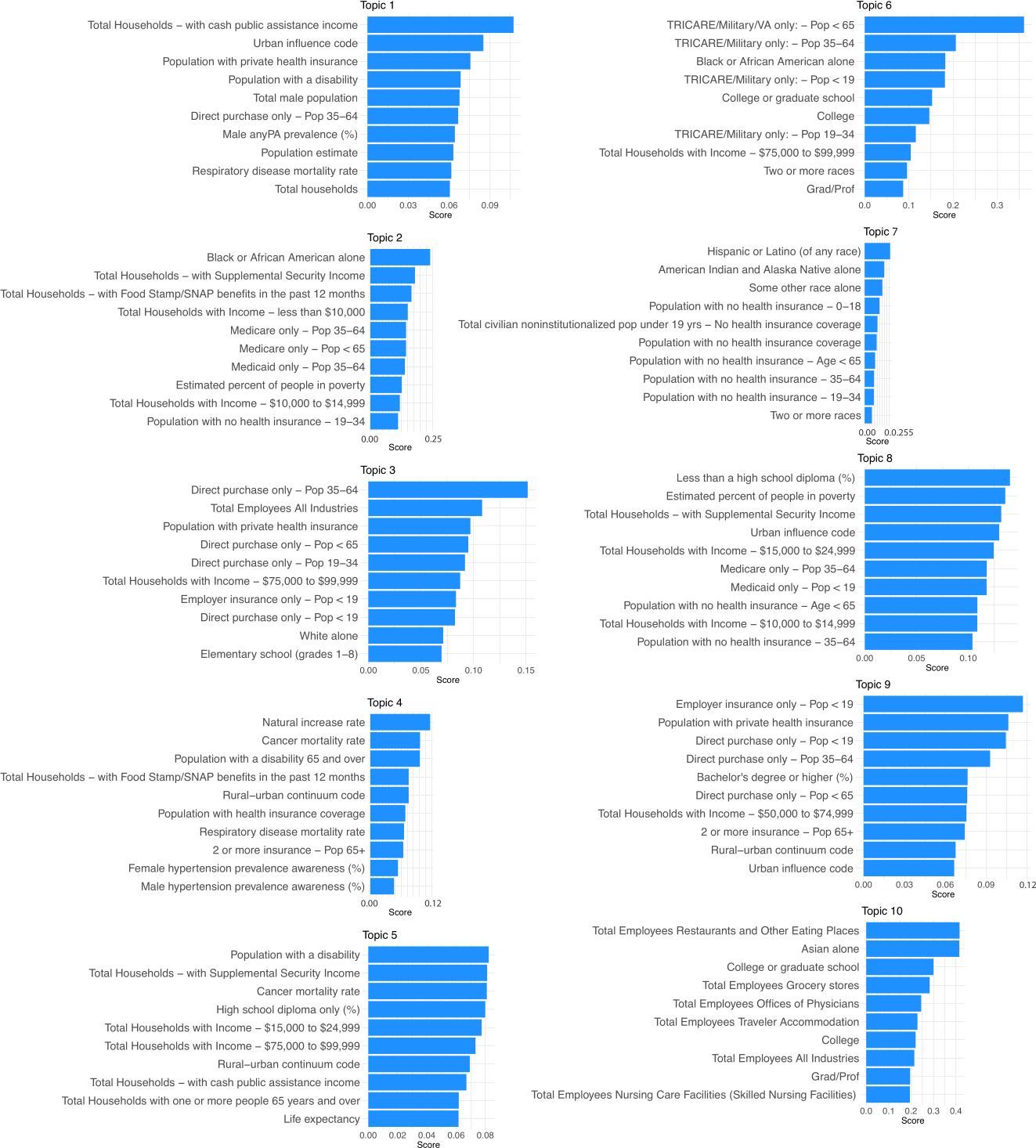
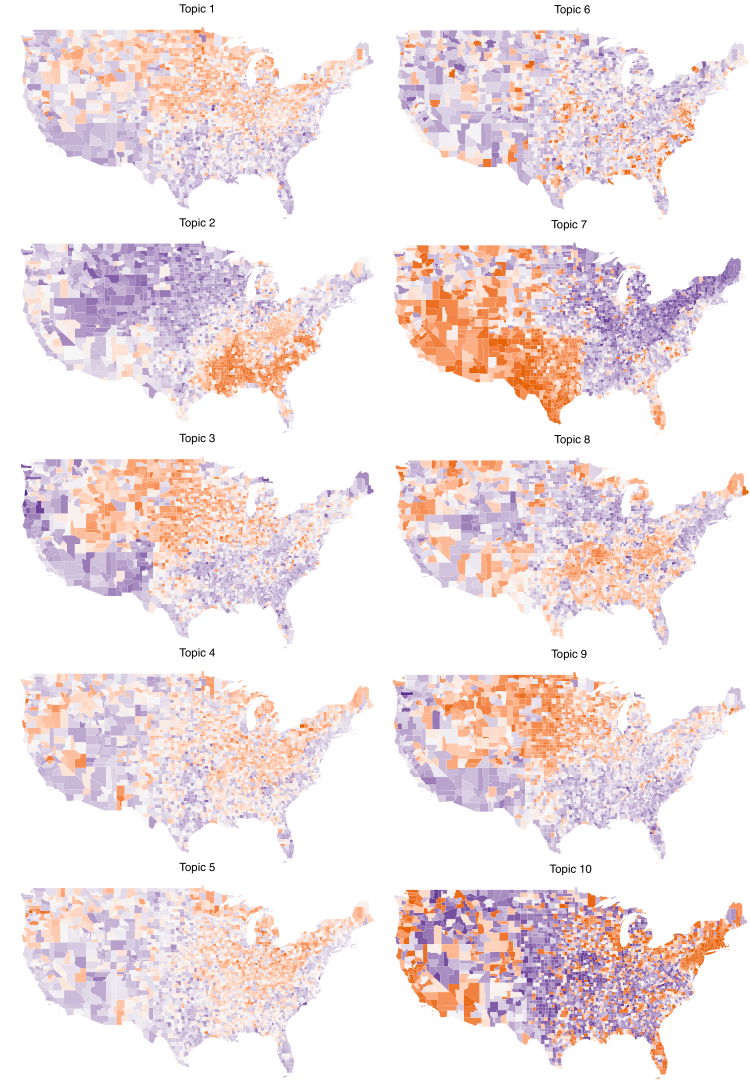
3.3. Topic Modeling and Unsupervised Cluster Analysis Reveals High Risk Counties
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A









References
- WHO. World Health Organization Coronavirus (COVID-19) Dashboard. Available online: https://covid19.who.int/ (accessed on 14 May 2022).
- Blanco-Melo, D.; Nilsson-Payant, B.E.; Liu, W.C.; Uhl, S.; Hoagland, D.; Moller, R.; Jordan, T.X.; Oishi, K.; Panis, M.; Sachs, D.; et al. Imbalanced Host Response to SARS-CoV-2 Drives Development of COVID-19. Cell 2020, 181, 1036–1045. [Google Scholar] [CrossRef] [PubMed]
- Karmakar, M.; Lantz, P.M.; Tipirneni, R. Association of Social and Demographic Factors With COVID-19 Incidence and Death Rates in the US. JAMA Netw. Open 2021, 4, e2036462. [Google Scholar] [CrossRef] [PubMed]
- Upshaw, T.L.; Brown, C.; Smith, R.; Perri, M.; Ziegler, C.; Pinto, A.D. Social determinants of COVID-19 incidence and outcomes: A rapid review. PLoS ONE 2021, 16, e0248336. [Google Scholar] [CrossRef] [PubMed]
- Andersen, L.M.; Harden, S.R.; Sugg, M.M.P.D.; Runkle, J.D.P.D.; Lundquist, T.E. Analyzing the spatial determinants of local COVID-19 transmission in the United States. Sci. Total Environ. 2021, 754, 142396. [Google Scholar] [CrossRef]
- Garcia, E.; Eckel, S.P.; Chen, Z.; Li, K.; Gilliland, F.D. COVID-19 mortality in California based on death certificates: Disproportionate impacts across racial/ethnic groups and nativity. Ann. Epidemiol. 2021, 58, 69–75. [Google Scholar] [CrossRef]
- Mollalo, A.; Vahedi, B.; Rivera, K.M. GIS-based spatial modeling of COVID-19 incidence rate in the continental United States. Sci. Total Environ. 2020, 728, 138884. [Google Scholar] [CrossRef]
- Sung, B. A spatial analysis of the effect of neighborhood contexts on cumulative number of confirmed cases of COVID-19 in U.S. Counties through October 20 2020. Prev. Med. 2021, 147, 106457. [Google Scholar] [CrossRef]
- Sun, Y.; Hu, X.; Xie, J. Spatial inequalities of COVID-19 mortality rate in relation to socioeconomic and environmental factors across England. Sci. Total Environ. 2021, 758, 143595. [Google Scholar] [CrossRef]
- McCloskey, J.K.; Ellis, J.L.; Uratsu, C.S.; Drace, M.L.; Ralston, J.D.; Bayliss, E.A.; Grant, R.W. Accounting for Social Risk Does not Eliminate Race/Ethnic Disparities in COVID-19 Infection Among Insured Adults: A Cohort Study. J. Gen. Intern. Med. 2022, 37, 1183–1190. [Google Scholar] [CrossRef]
- Zamani, M.; Schwartz, H.A.; Eichstaedt, J.; Guntuku, S.C.; Ganesan, A.V.; Clouston, S.; Giorgi, S. Understanding Weekly COVID-19 Concerns through Dynamic Content-Specific LDA Topic Modeling. Proc. Conf. Empir. Methods Nat. Lang. Process. 2020, 2020, 193–198. [Google Scholar] [CrossRef]
- Pasquini, G.; Ferguson, G.; Bouklas, I.; Vu, H.; Zamani, M.; Zhaoyang, R.; Harrington, K.D.; Roque, N.A.; Mogle, J.; Schwartz, H.A.; et al. The where and when of COVID-19: Using ecological and Twitter-based assessments to examine impacts in a temporal and community context. PLoS ONE 2022, 17, e0264280. [Google Scholar] [CrossRef] [PubMed]
- Ak, C.; Ergonul, O.; Sencan, I.; Torunoglu, M.A.; Gonen, M. Spatiotemporal prediction of infectious diseases using structured Gaussian processes with application to Crimean-Congo hemorrhagic fever. PLoS Negl. Trop. Dis. 2018, 12, e0006737. [Google Scholar] [CrossRef]
- Ak, C.; Ergonul, O.; Gonen, M. A prospective prediction tool for understanding Crimean-Congo haemorrhagic fever dynamics in Turkey. Clin. Microbiol. Infect. 2020, 26, e121–e123. [Google Scholar] [CrossRef]
- Ak, Ç.; Ergönül, Ö.; Gönen, M. Structured Gaussian Processes with Twin Multiple Kernel Learning. In Proceedings of the 10th Asian Conference on Machine Learning, Beijing, China, 14–16 November 2018; pp. 65–80. [Google Scholar]
- Roberts, D.R.; Bahn, V.; Ciuti, S.; Boyce, M.S.; Elith, J.; Guillera-Arroita, G.; Hauenstein, S.; Lahoz-Monfort, J.J.; Schröder, B.; Thuiller, W.; et al. Cross-validation strategies for data with temporal, spatial, hierarchical, or phylogenetic structure. Ecography 2017, 40, 913–929. [Google Scholar] [CrossRef]
- Ploton, P.; Mortier, F.; Rejou-Mechain, M.; Barbier, N.; Picard, N.; Rossi, V.; Dormann, C.; Cornu, G.; Viennois, G.; Bayol, N.; et al. Spatial validation reveals poor predictive performance of large-scale ecological mapping models. Nat. Commun. 2020, 11, 4540. [Google Scholar] [CrossRef]
- Valavi, R.; Elith, J.; Lahoz-Monfort, J.J.; Guillera-Arroita, G. blockCV: An r package for generating spatially or environmentally separated folds for k-fold cross-validation of species distribution models. Methods Ecol. Evolut. 2019, 10, 225–232. [Google Scholar] [CrossRef]
- Brenning, A. Spatial machine-learning model diagnostics: A model-agnostic distance-based approach. arXiv 2021, v1, 1–16. [Google Scholar] [CrossRef]
- Zhao, W.; Chen, J.J.; Perkins, R.; Liu, Z.; Ge, W.; Ding, Y.; Zou, W. A heuristic approach to determine an appropriate number of topics in topic modeling. BMC Bioinform. 2015, 16 (Suppl. 13), S8. [Google Scholar] [CrossRef]
- Rubin, D.; Huang, J.; Fisher, B.T.; Gasparrini, A.; Tam, V.; Song, L.; Wang, X.; Kaufman, J.; Fitzpatrick, K.; Jain, A.; et al. Association of Social Distancing, Population Density, and Temperature With the Instantaneous Reproduction Number of SARS-CoV-2 in Counties Across the United States. JAMA Netw. Open 2020, 3, e2016099. [Google Scholar] [CrossRef]
- Sy, K.T.L.; White, L.F.; Nichols, B.E. Population density and basic reproductive number of COVID-19 across United States counties. PLoS ONE 2021, 16, e0249271. [Google Scholar] [CrossRef]
- Lawton, R.; Zheng, K.; Zheng, D.; Huang, E. A longitudinal study of convergence between Black and White COVID-19 mortality: A county fixed effects approach. Lancet Reg. Health Am. 2021, 1, 100011. [Google Scholar] [CrossRef]
- Cheng, K.J.G.; Sun, Y.; Monnat, S.M. COVID-19 Death Rates Are Higher in Rural Counties With Larger Shares of Blacks and Hispanics. J. Rural Health 2020, 36, 602–608. [Google Scholar] [CrossRef] [PubMed]
- Golestaneh, L.; Neugarten, J.; Fisher, M.; Billett, H.H.; Gil, M.R.; Johns, T.; Yunes, M.; Mokrzycki, M.H.; Coco, M.; Norris, K.C.; et al. The association of race and COVID-19 mortality. EClinicalMedicine 2020, 25, 100455. [Google Scholar] [CrossRef]
- Gold, J.A.W.; Rossen, L.M.; Ahmad, F.B.; Sutton, P.; Li, Z.; Salvatore, P.P.; Coyle, J.P.; DeCuir, J.; Baack, B.N.; Durant, T.M.; et al. Race, Ethnicity, and Age Trends in Persons Who Died from COVID-19—United States, May–August 2020. MMWR Morb. Mortal. Wkly. Rep. 2020, 69, 1517–1521. [Google Scholar] [CrossRef]
- Price-Haywood, E.G.; Burton, J.; Fort, D.; Seoane, L. Hospitalization and Mortality among Black Patients and White Patients with COVID-19. N. Engl. J. Med. 2020, 382, 2534–2543. [Google Scholar] [CrossRef]
- Luo, Y.; Yan, J.; McClure, S. Distribution of the environmental and socioeconomic risk factors on COVID-19 death rate across continental USA: A spatial nonlinear analysis. Environ. Sci. Pollut. Res. Int. 2021, 28, 6587–6599. [Google Scholar] [CrossRef]
- Hawkins, R.B.; Charles, E.J.; Mehaffey, J.H. Socio-economic status and COVID-19-related cases and fatalities. Public Health 2020, 189, 129–134. [Google Scholar] [CrossRef]
- Jin, J.; Agarwala, N.; Kundu, P.; Harvey, B.; Zhang, Y.; Wallace, E.; Chatterjee, N. Individual and community-level risk for COVID-19 mortality in the United States. Nat. Med. 2021, 27, 264–269. [Google Scholar] [CrossRef]
- Woolf, S.H.; Chapman, D.A.; Lee, J.H. COVID-19 as the Leading Cause of Death in the United States. JAMA 2021, 325, 123–124. [Google Scholar] [CrossRef]
- McCright, A.M.; Dentzman, K.; Charters, M.; Dietz, T. The influence of political ideology on trust in science. Environ. Res. Lett. 2013, 8, 044029. [Google Scholar] [CrossRef]
- Gonsalves, G.; Yamey, G. Political interference in public health science during COVID-19. BMJ 2020, 371, m3878. [Google Scholar] [CrossRef] [PubMed]
- Allcott, H.; Boxell, L.; Conway, J.; Gentzkow, M.; Thaler, M.; Yang, D. Polarization and public health: Partisan differences in social distancing during the coronavirus pandemic. J. Public Econ. 2020, 191, 104254. [Google Scholar] [CrossRef] [PubMed]
- Bruine de Bruin, W.; Saw, H.W.; Goldman, D.P. Political polarization in US residents’ COVID-19 risk perceptions, policy preferences, and protective behaviors. J. Risk Uncertain. 2020, 61, 177–194. [Google Scholar] [CrossRef]
- Clinton, J.; Cohen, J.; Lapinski, J.; Trussler, M. Partisan pandemic: How partisanship and public health concerns affect individuals’ social mobility during COVID-19. Sci. Adv. 2021, 7, eabd7204. [Google Scholar] [CrossRef] [PubMed]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ak, Ç.; Chitsazan, A.D.; Gönen, M.; Etzioni, R.; Grossberg, A.J. Spatial Prediction of COVID-19 Pandemic Dynamics in the United States. ISPRS Int. J. Geo-Inf. 2022, 11, 470. https://doi.org/10.3390/ijgi11090470
Ak Ç, Chitsazan AD, Gönen M, Etzioni R, Grossberg AJ. Spatial Prediction of COVID-19 Pandemic Dynamics in the United States. ISPRS International Journal of Geo-Information. 2022; 11(9):470. https://doi.org/10.3390/ijgi11090470
Chicago/Turabian StyleAk, Çiğdem, Alex D. Chitsazan, Mehmet Gönen, Ruth Etzioni, and Aaron J. Grossberg. 2022. "Spatial Prediction of COVID-19 Pandemic Dynamics in the United States" ISPRS International Journal of Geo-Information 11, no. 9: 470. https://doi.org/10.3390/ijgi11090470