1. Introduction
Solar radio spectrum observations are an important tool for studying solar outbursts, which contain important information about solar activity [
1]. The solar radio spectra are divided into various types, corresponding to different physical events [
2,
3]. With the development of radio spectrometers and the massive observational data trend, manual detection and classification of solar radio spectra can no longer meet the needs of research. Therefore, it is important to automatically detect and classify solar radio bursts from this massive information efficiently and rapidly for subsequent scientific research and space weather warning and forecasting.
The solar broadband radio spectrometers (SBRS) at the National Astronomical Observatory of the Chinese Academy of Sciences were put into operation during the 23rd solar activity cycle [
4]. The devices have produced a large number of observations. However, since solar radio bursts are a low-probability event, the observed spectra of solar radio bursts are very small. Additionally, due to the presence of interference, the raw data are not clearly characterized and it is difficult to quickly distinguish between different kinds of data. This creates difficulties for subsequent astronomical studies [
5]. Therefore, it is of great help for solar physics research to classify solar radio spectra accurately, quickly and automatically.
With the rapid development of hardware levels and artificial intelligence, an increasing number of deep learning models and algorithms are used to solve tasks related to natural language processing [
6] and computer vision [
7,
8]. For astronomy problems, many previous works were carried out on solar radio spectrum classification and these works have used image processing algorithms, neural network models and deep learning [
9]. P. J. Zhang et al. designed an event recognition analysis system that can automatically detect solar type III radio bursts. This system used Hough transform to recognize the line segment associated with type III bursts in the dynamic spectra [
10]. However, the computational parameters of this method must be artificially designed and are not universally applicable. In recent years, with the development of convolutional neural networks (CNN) [
11,
12], long short-term memory (LSTM) networks [
13], and deep confidence networks [
14], many of these methods were applied to the classification of solar radio spectra. S. M. J. Jalali introduced LSTM [
15], which was combined with a CNN to propose the CNN–LSTM approach [
16]. This method improves performance with similar time consumption. B. Yan used a feature pyramid network (FPN) as a backbone network [
17] and used ResNet to extract features [
18]. By simply connecting to the structure, FPN fuses features of different scales and different levels of semantics. The performance of detection is improved without affecting the speed of detection. In other related studies, a classification algorithm based on joint convolutional neural networks and transfer learning was proposed by using the inherent correlation between natural datasets and astronomical datasets. In addition, a cost-sensitive multiclassification loss function was proposed to make the network pay more attention to categories with fewer samples during the training process and use the meta-learning method to classify the solar radio spectrum with fewer samples. In addition, H. Salmane et al. proposed automatic identification methods for specific types of solar radio burst structures [
19].
In current research on image classification, a large amount of training data is generally needed. However, since solar radio bursts are low-probability events, there are few samples. To solve the problem of fewer data, some studies have used transfer learning technology and improved loss functions. However, the large difference between natural images and solar radio spectrum images is not conducive to the application of transfer learning.
In natural language processing, self-supervised learning methods have become popular and these methods no longer require large amounts of labeled data in the training step. Researchers can design some rules to let the data supervise their own training [
20]. For example, bidirectional encoder representations from Transformer (BERT) are designed as a kind of fill-in-the-blank method by masking some words in a sentence and then letting the network guess those words. In natural language processing, self-supervised learning is usually based on autoregressive language modeling in generative pre-training (GPT) and mask self-coding in BERT. Their basic principle is to delete some data and let the network learn to predict the deleted content.
In this paper, a solar radio spectrum classification method based on self-supervised learning is proposed. The method uses BERT to train the network to classify solar radio spectrum images by randomly masking a portion of the solar radio spectrum images and letting the network fill in the blank. The main contribution of this paper is that we apply self-supervised learning to classify the solar radio spectrum for the first time. This method is more conducive to using transfer learning. This paper can provide a reference for other small sample data classifications in astronomy.
2. Solar Radio Spectrum Dataset and Its Preprocessing
The solar radio spectra are obtained from the solar broadband radio spectrometer (SBRS) at the National Astronomical Observatory of the Chinese Academy of Sciences. The raw data are stored in binary format and visualized to obtain the solar radio spectrum images. The vertical axis of the solar radio spectrum image represents the frequency of the spectrum, the horizontal axis represents the time, and each pixel value represents the radio flux of the Sun at a certain time and frequency. When displayed as a grayscale image, white indicates high solar radio flux, black indicates low solar radio flux, and the whole image represents the solar radio flux at a frequency over a period of time. The solar radio spectra are divided into three categories: burst, calibration and non-burst, as shown in
Figure 1. The classification tasks in this paper are aimed at these three categories.
The solar radio spectra images show that the original image is noisy and most of the noise is transverse stripe noise. This noise will affect the subsequent classification accuracy. The frequency channel normalization can reduce transverse stripe noise and make its features obvious, and the calculation method is as follows:
where
represents the radio intensity at time
x and frequency
y on the spectrum and
is the radio intensity after channel normalization. The final result is shown in
Figure 2. The noise of the horizontal stripe is significantly reduced and the burst is more obvious. It makes the features of the image more obvious and facilitates the learning of the subsequent network.
3. Method Section
3.1. Self-Supervised Learning
Self-supervised learning (SSL) is the main method used with the Transformer model to learn from large-scale unlabeled datasets [
21]. The basic idea of SSL is to fill in the gaps. It masks or hides some parts of the input and uses observable parts to predict hidden parts [
22]. Another effective method of self-supervised learning is contrastive learning [
23]. In this case, we usually learn the feature representation of samples by creating positive and negative samples and comparing the data with positive samples and negative samples in the feature space. The advantage of contrastive learning is that it does not need to reconstruct pixel-level details to obtain image features but only needs to learn differentiation in the feature space. However, the construction of positive and negative samples is a difficult point in contrastive learning.
SSL provides a promising learning paradigm since it enables learning from a vast amount of readily available nonannotated data. SSL is implemented in two steps. First, a model is trained to learn a meaningful representation of the underlying data by solving a pretext task. The pseudo labels for the pretext task are automatically generated based on data attributes and task definition. Therefore, a critical choice in SSL is the definition of a pretext task. Second, the model trained in the first step is fine-tuned on the downstream tasks using labeled data. The downstream tasks include image classification and object detection [
24,
25].
3.2. Self-Supervised Learning with Self-Masking
Self-supervised learning methods are widely used in natural language processing. However, due to the large difference between the CNN model in computer vision and the Transformer used in natural language processing, the natural language processing method cannot be effectively transferred to computer vision tasks. However, when Vision Transformer (ViT) was proposed [
26], the channel between computer vision and natural language was opened [
27,
28,
29,
30].
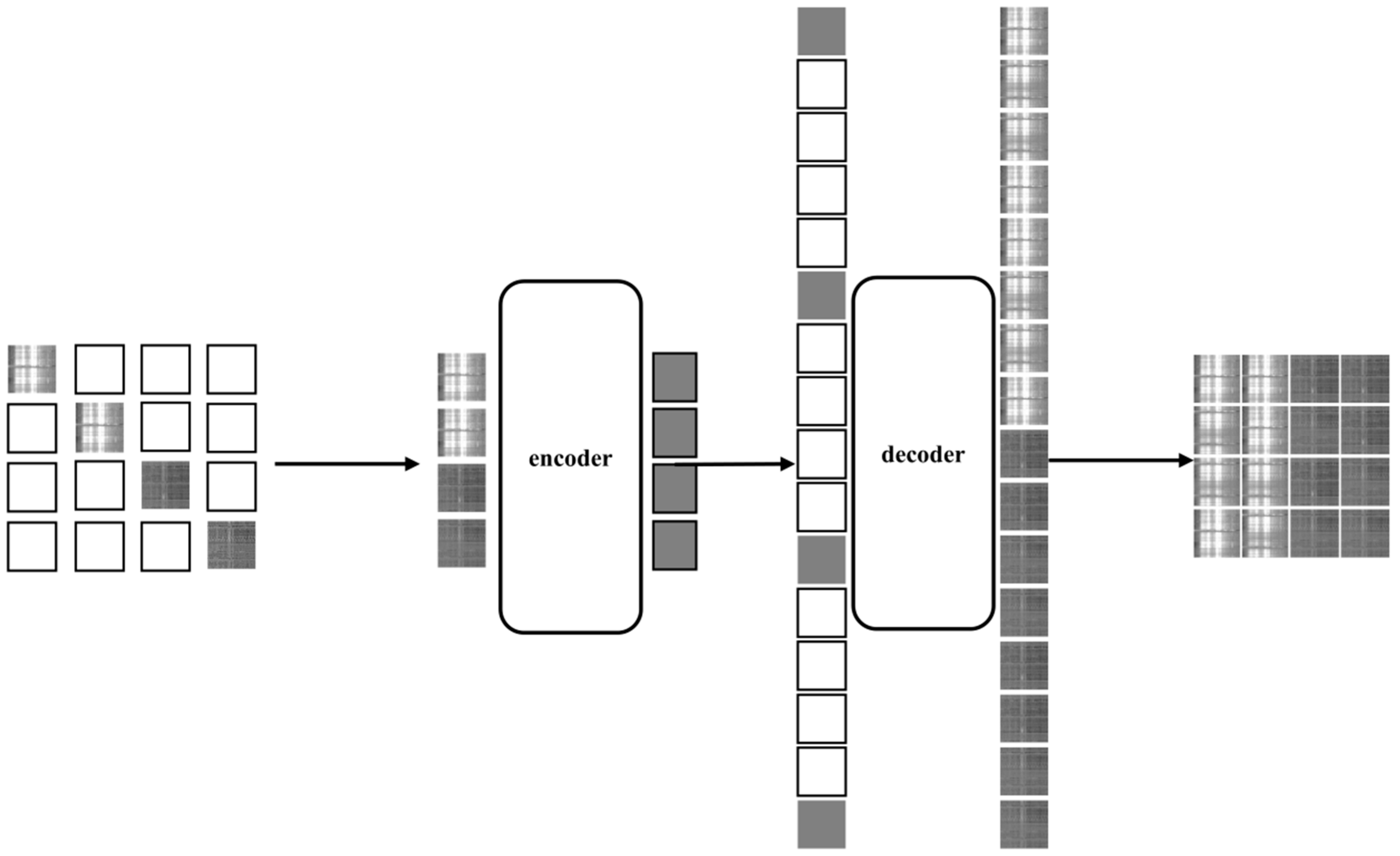
We refer to the mask method used in the BERT and GPT in natural language and let the model learn to restore sentences after covering some words. When the methods are transferred to solar radio spectrum classification, the solar radio spectrum image is first divided into blocks, which are equivalent to a word in a sentence. Then, these blocks are masked randomly and sent to the network. The network is composed of the encoder and decoder of ViT. After the image is restored through model learning, the trained encoder is removed and connected to the fully connected layer for classification. The structure of the self-mask model is shown in
Figure 3.
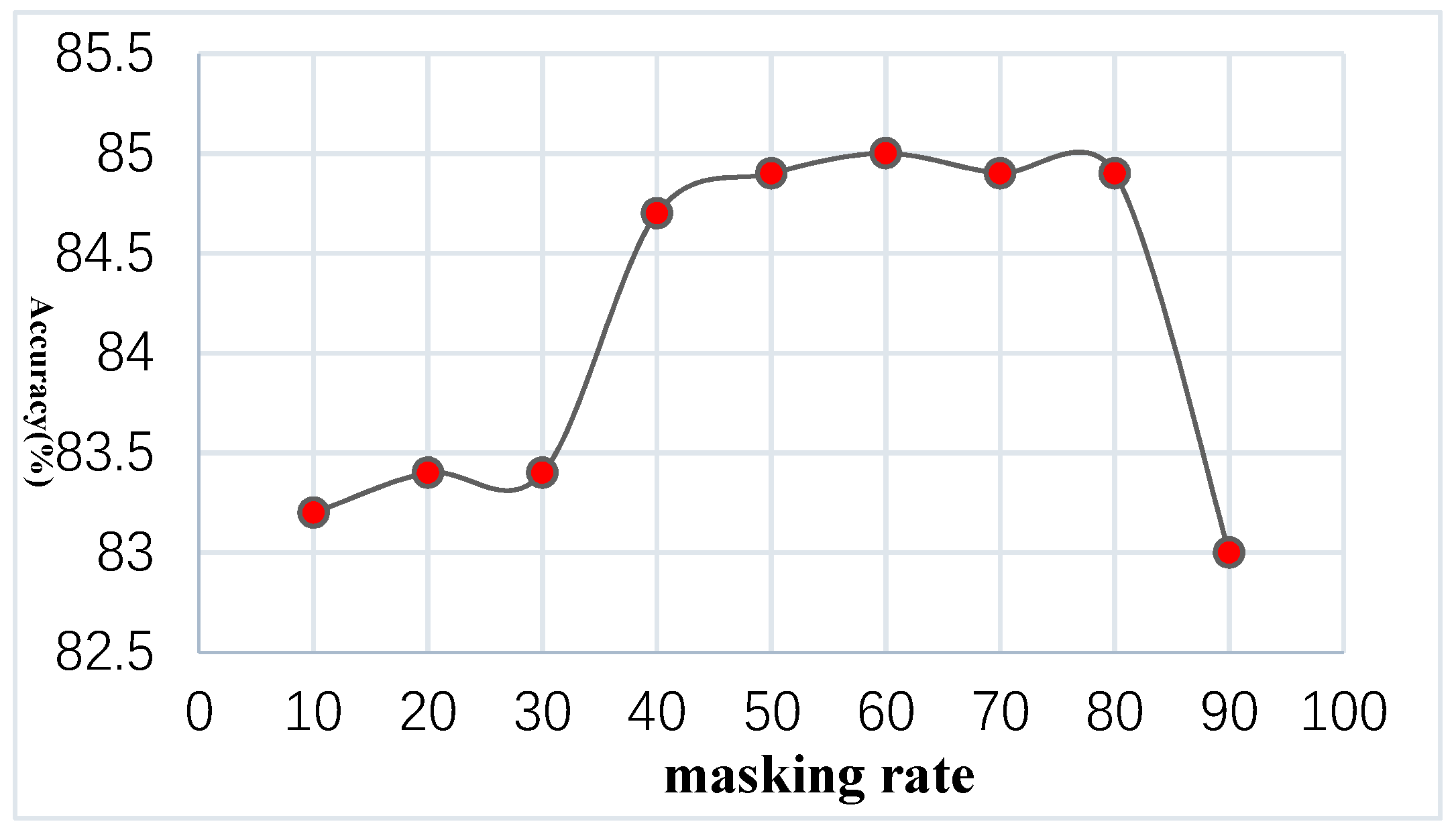
Compared with text, we can cover more parts due to the more redundant information in the image. This not only saves space and improves the model speed but also helps the model learn more information from solar radio spectrum images.
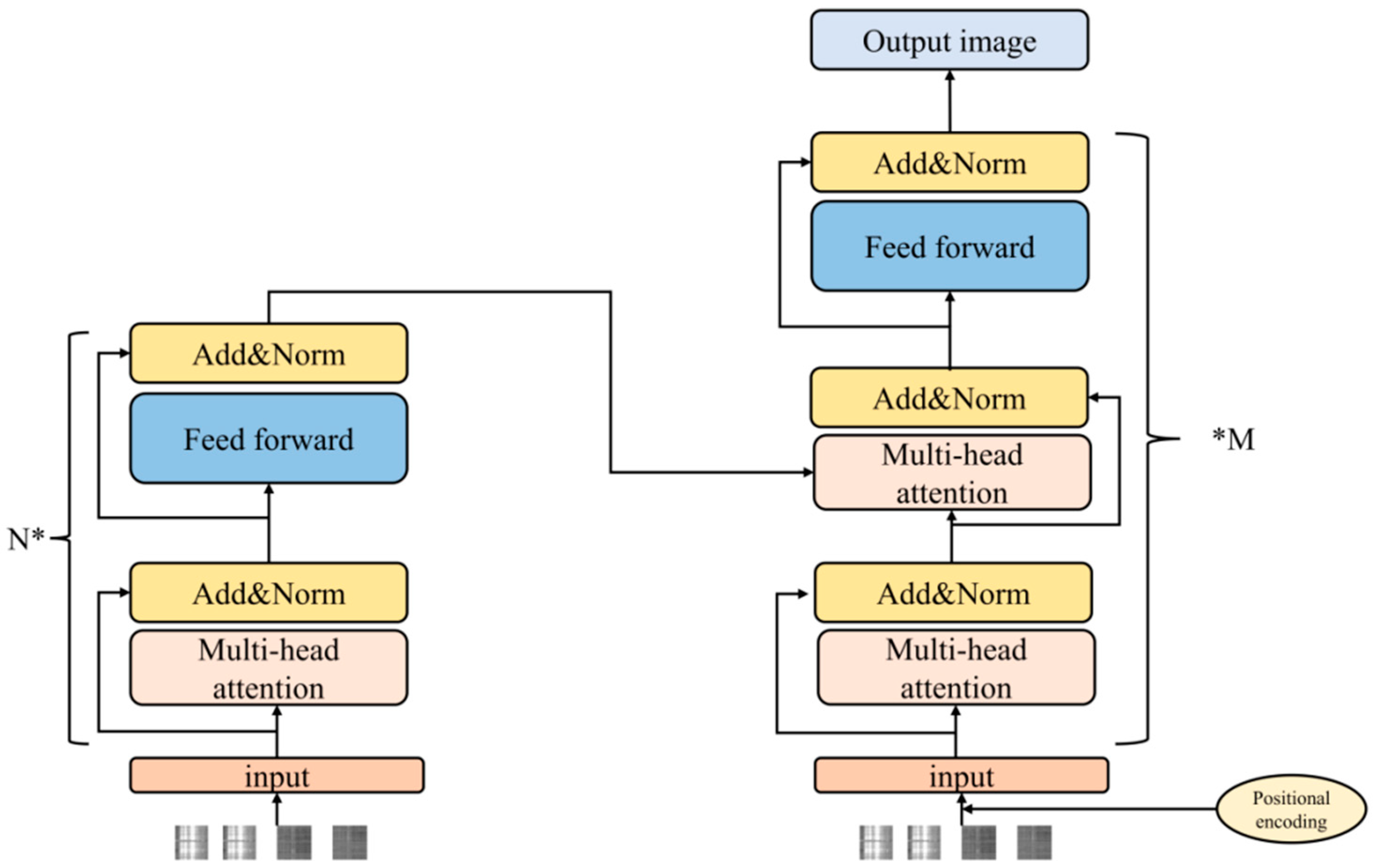
3.3. Encoder and Decoder
Our encoder is only derived from the ViT structure for visible unmasked blocks. Similarly to standard ViT, our encoder embeds patches by adding a linear projection of the positional embedding and then processes the dataset through a series of Transformer blocks. However, our encoder only needs to work on a small subset (e.g., 25%), which allows us to train very large encoders that require only a fraction of the computations and memory. The complete dataset is processed by a lightweight decoder.
The input to the decoder is a complete token set consisting of encoded visible blocks and mask tokens. Each mask token is a shared and learned vector that represents the missing blocks to be predicted. We add a position to all tokens in this complete set. If we do not do this, mask tokens will not have information about their positions in the image. The decoder also has another series of Transformer blocks.
The decoder is only used to perform image reconstruction tasks prior to training. Thus, the decoder architecture can be designed in a flexible way, independent of the encoder design. We experiment with very small decoders that are narrower and shallower than the encoder. For example, our default decoder is 10% smaller in computations per token than the encoder. In this asymmetric design, the complete set of tokens is processed by the lightweight decoder only, which significantly reduces the pre-training time. The encoder and decoder structures are shown in
Figure 4.
3.4. Data Enhancement
Because solar bursts are low-probability events, the solar radio burst spectra observed are not much. To improve the generalization ability and avoid the overfitting of the model, we augment the spectrum of solar radio bursts. We adopt a simple and data-independent augmentation method called mixup. Mixup can be implemented in only a few lines of code. A virtual training sample is constructed with minimal computational overhead. In an extensive evaluation, the results show that mixup improves the generalization error of the most advanced models in ImageNet, CIFAR, voice and tabular datasets. In addition, mixup helps to eliminate the memory of false labels, the sensitivity to confrontation samples and the instability of confrontation training. The formula for mixup data enhancement is as follows:
where
and
are two images randomly selected from the training set and
and
are their corresponding one-hot tags, respectively. Prior knowledge indicates that the linear interpolation of the sample images and the linear interpolation of the corresponding one-hot labels correspond. Mixup constructs a new sample and its one-hot label
based on this prior knowledge. Among them,
is obtained by the data distribution
, and
is a super parameter.
By adjusting the super parameter , we can adjust the proportion of interpolation between images. The research also shows that there is no good method to set at present and the sensitivity to is different in different datasets.
To further improve the generalization ability of the model and avoid overfitting, dropout is also introduced in this model. In deep learning, if the amount of data is small and the model is complex, the trained model will easily overfit. Dropout can alleviate the overfitting problem and achieve a regularization effect to a certain extent.
4. Experimental Dataset and Experimental Configuration
4.1. Experimental Dataset
A solar radio burst corresponds to a certain solar activity event, which is a low-probability event. The calibration data are relatively small and a large number of solar radio spectra are no-burst spectra. Therefore, there is an imbalance between the three types of samples.
Since the solar radio spectrum has two parts, left-handed and right-handed polarization, we separated the two parts so that the burst and calibration data can be expanded. The amount of solar radio data after amplification is shown in
Table 1. The quantity of the three types of spectra is roughly in a balanced state, which alleviates the data imbalance problem. The experiment shows that the separation of these two parts has no effect on the results of solar radio spectrum classification.
After data enhancement, the total number of samples is 5519. We divided these randomly according to a proportion of approximately 8:2; 4415 labeled images were used as the training set and the remaining 1104 were used as the testing set. The specific number of samples in each category of the dataset is shown in
Table 1.
4.2. Experimental Configuration and Evaluation Index
The software environment for our experiments is Windows 10, the programming platform is PyCharm, and the architecture is PyTorch. In the hardware device, the CPU is an Intel Core i7-10700k, the memory is 32 GB, and the GPU is a NVidia GeForce RTX 2080Ti. For pre-training, the batch size is 16, the image size is 224 × 224, the epoch is set to 300, the learning rate is 1.5 × 10−4, the warmup learning rate is 10−6, the warmup is 30 epochs, and the weight decay is set to 0.05. In the fine-tuning stage, the epoch is set to 50, the learning rate is 10−3, the warmup learning rate is 10−6, the warmup is five epochs, and the other parameters are unchanged.
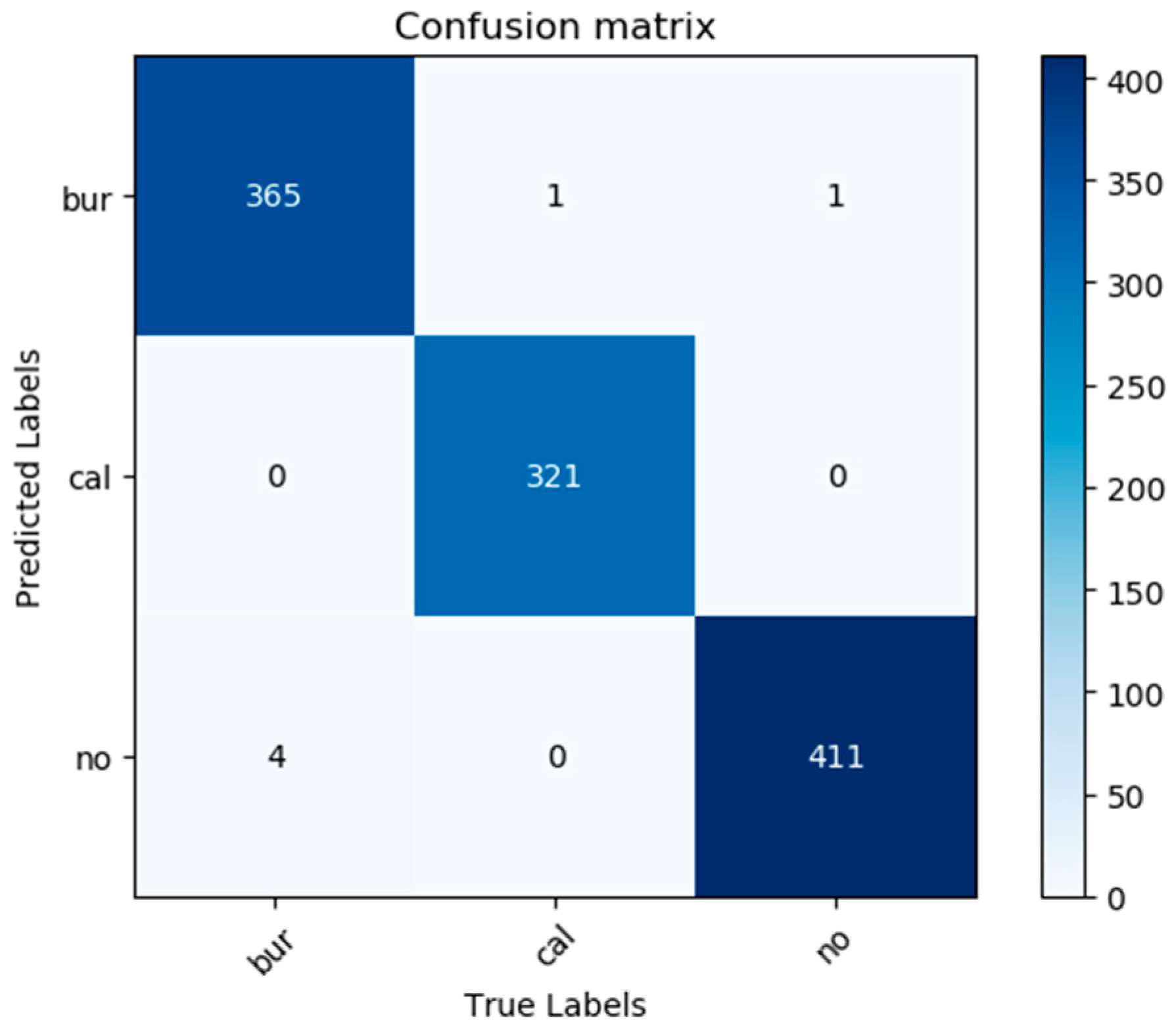
In practice, the burst class has greater research value and greater impact on daily life, so we mainly focus on the burst class. The burst class is defined as a positive class, and the other two classes are defined as negative classes. We define TP as the number of samples that are positive and correctly classified as positive, FP as the number of samples that are negative but wrongly classified as positive, TN as the number of samples that are negative and correctly classified as negative, and FN as the number of samples that are positive but classified as negative. The evaluation metrics used in the experiment are accuracy, precision, recall, specificity, and F-score.
Accuracy refers to the proportion of the number of accurate samples classified by all categories to the total number of samples. It is calculated as follows:
Precision refers to the proportion of the number of correctly predicted positive samples to the total number of predicted positive samples. It is calculated as follows:
Recall refers to the proportion of correctly predicted positive samples relative to all actual positive samples. It is calculated as follows:
Specificity refers to the proportion of correctly predicted negative cases relative to all actual negative cases. It is calculated as follows:
The balanced
F-score is used for the overall evaluation of precision and recall. It is calculated as follows:
6. Conclusions
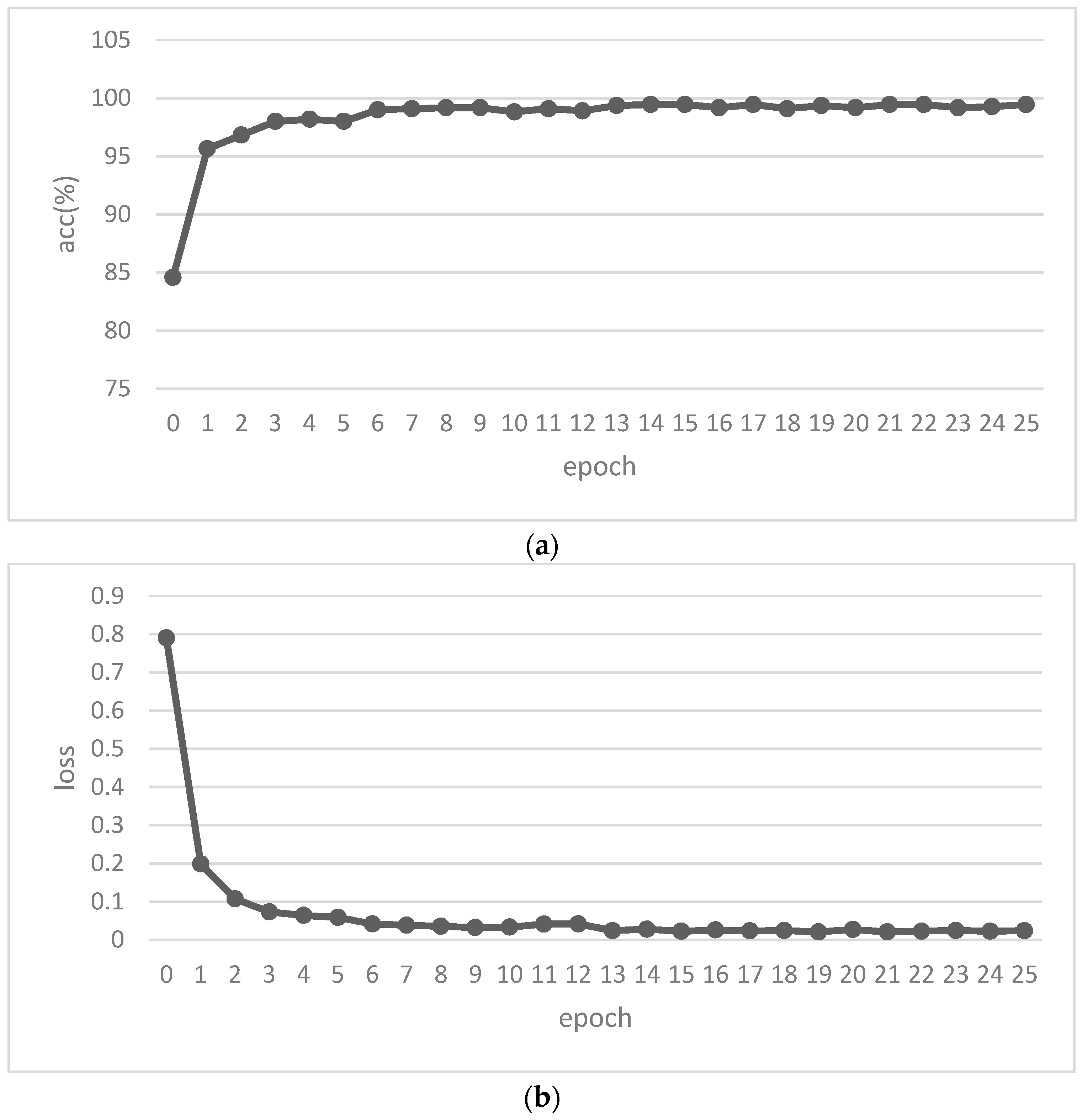
In this paper, we propose a solar radio spectrum classification method based on self-supervised learning. By referring to the BERT method in natural language processing, it is improved for solar radio spectrum classification. After randomly masking the solar radio spectrum image, the method lets the model learn to restore the image to learn the image features. This method uses the image itself as a label to enable the network to learn more information, therefore, it is very suitable for transfer learning, thus addressing the issue of fewer solar radio spectrum image datasets. This method can also obtain a good result on a small dataset. Through experiments, an accuracy of 99.5% was achieved on the solar radio spectrum dataset. Compared with other models, our model achieves better experimental accuracy. However, our model has a larger number of parameters and requires more training time. Therefore, we need to continue to study how to reduce the scale of the model.
According to the spectral morphology of solar radio bursts, they can be divided into type I, II, III, IV, V and their associated fine structures. Different solar radio bursts correspond to different solar physical phenomena. Next, we will further subdivide and label the burst samples and use the fine-grained method to classify type I, II, III, IV, V bursts.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}