
Detection of Underground Dangerous Area Based on Improving YOLOV8
Abstract
:1. Introduction
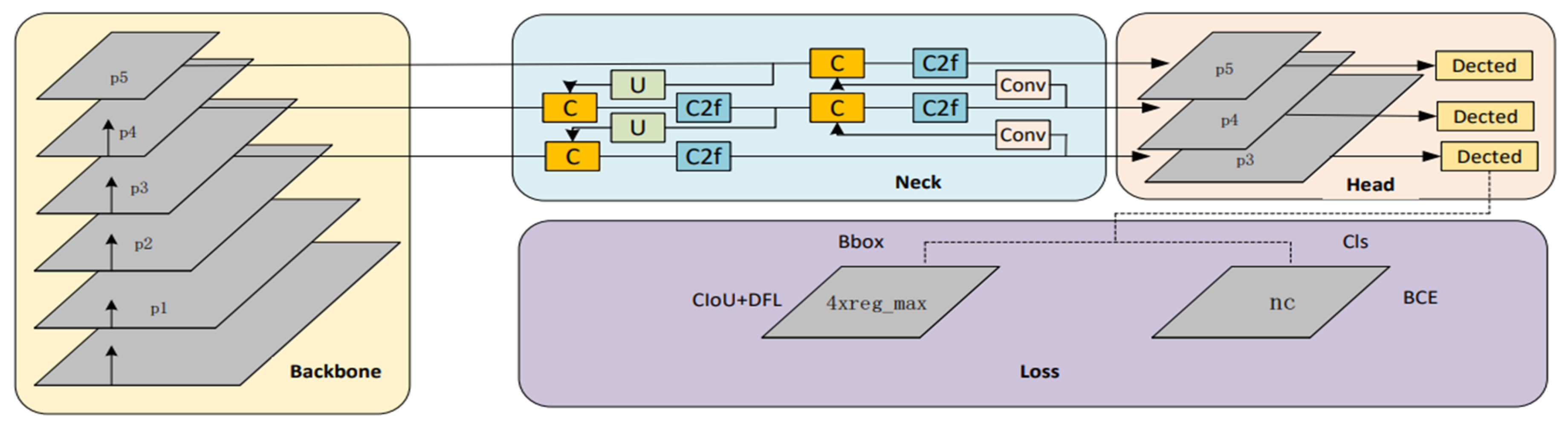
2. YOLOV8 Algorithm Principle
3. Improvement Model
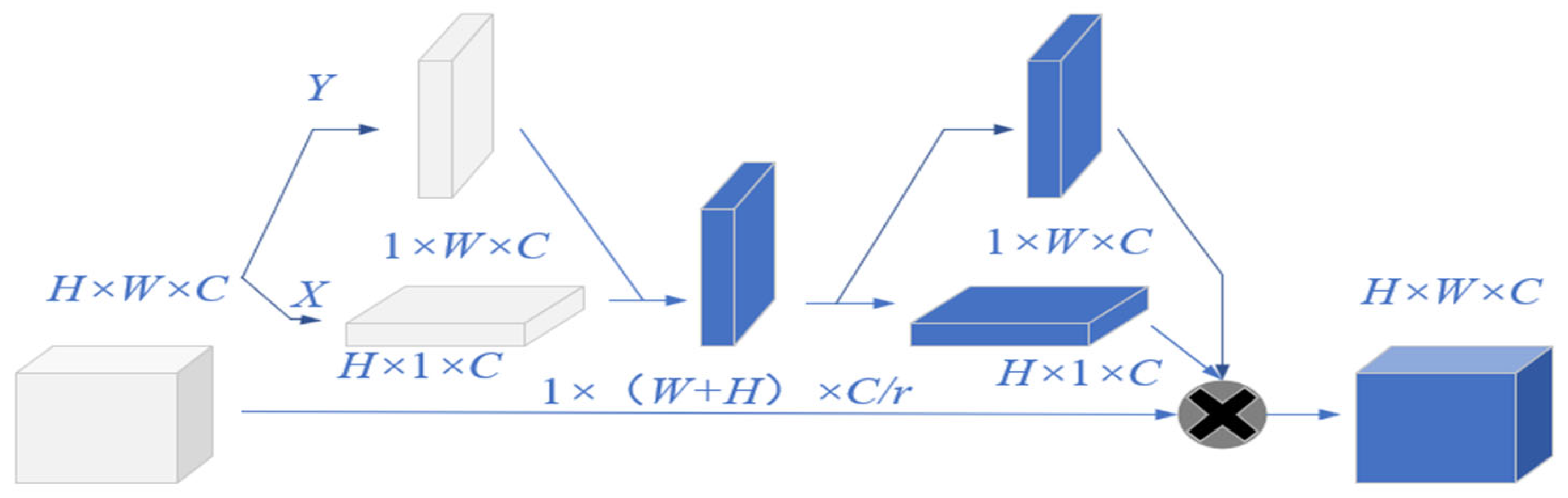
3.1. Introduce CA Attention Mechanism
3.2. Improve Non-Maximum Suppression
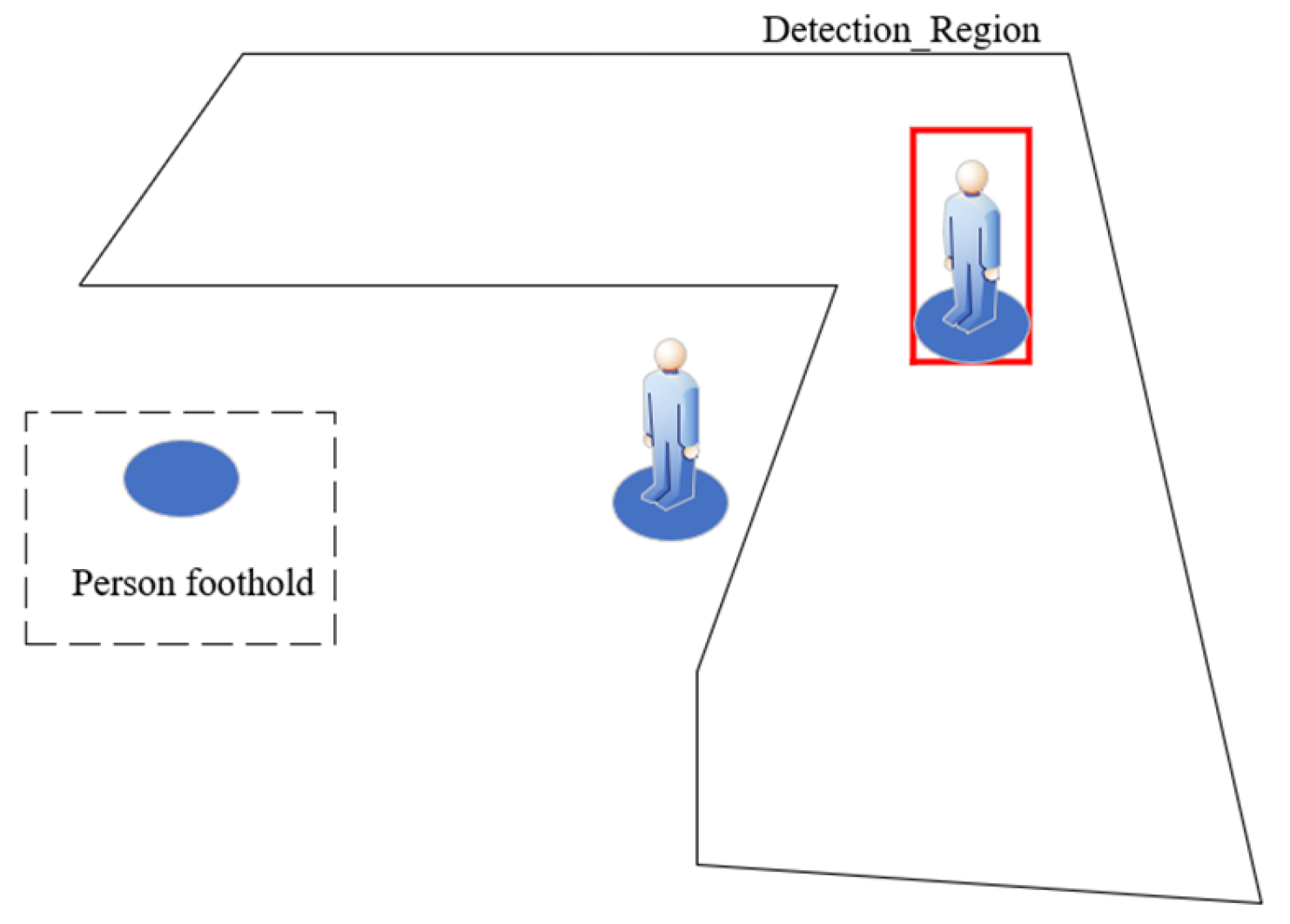
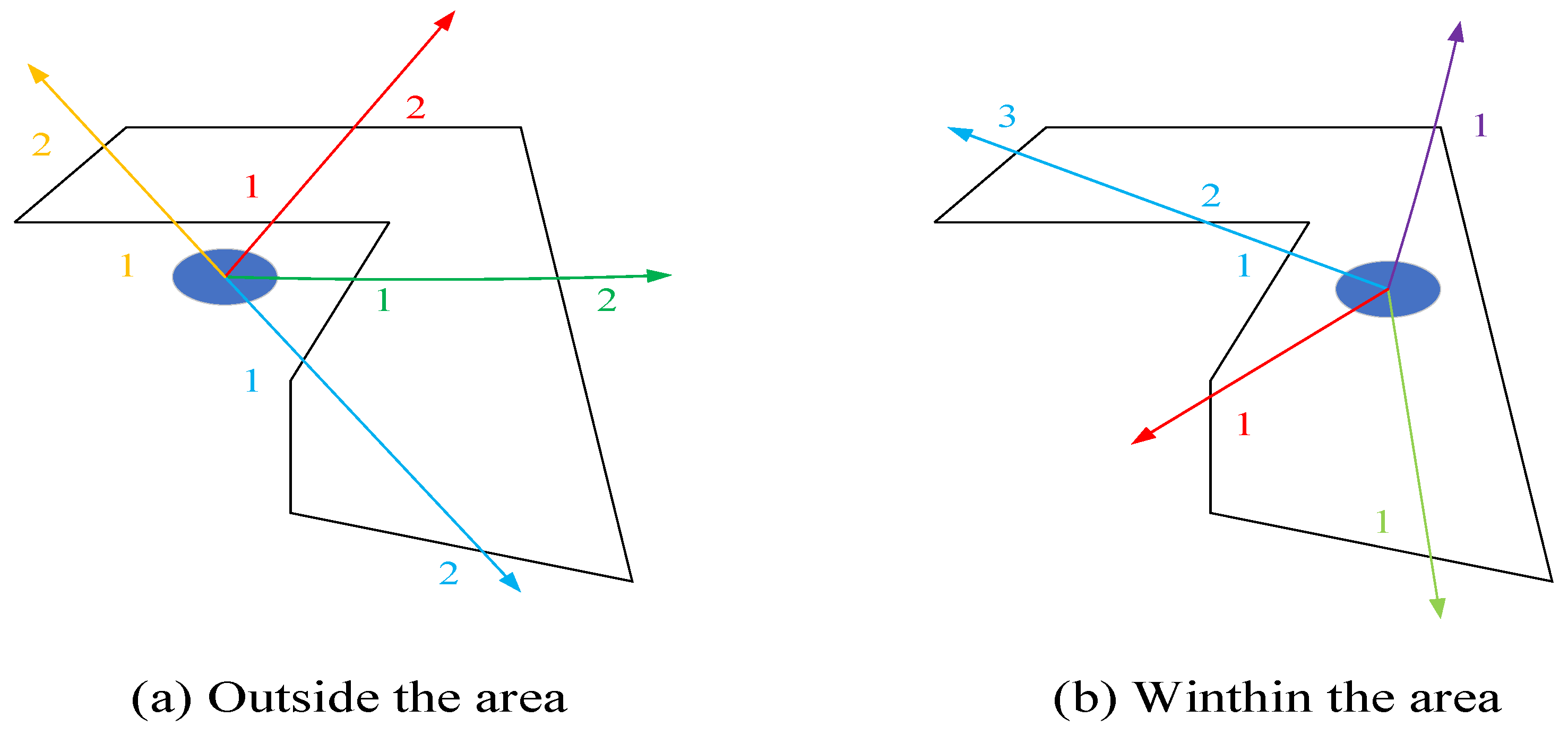
3.3. Invasion in Dangerous Areas
4. Experiments
4.1. Experiment Environment
4.2. Datasets and Preprocessing
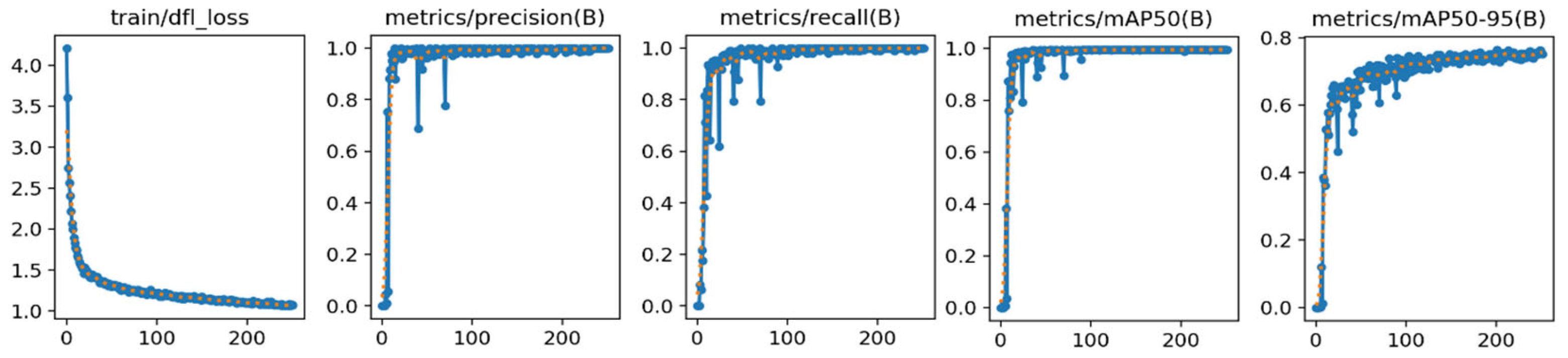
4.3. Training Model
5. Results and Analysis
5.1. Evaluation Index
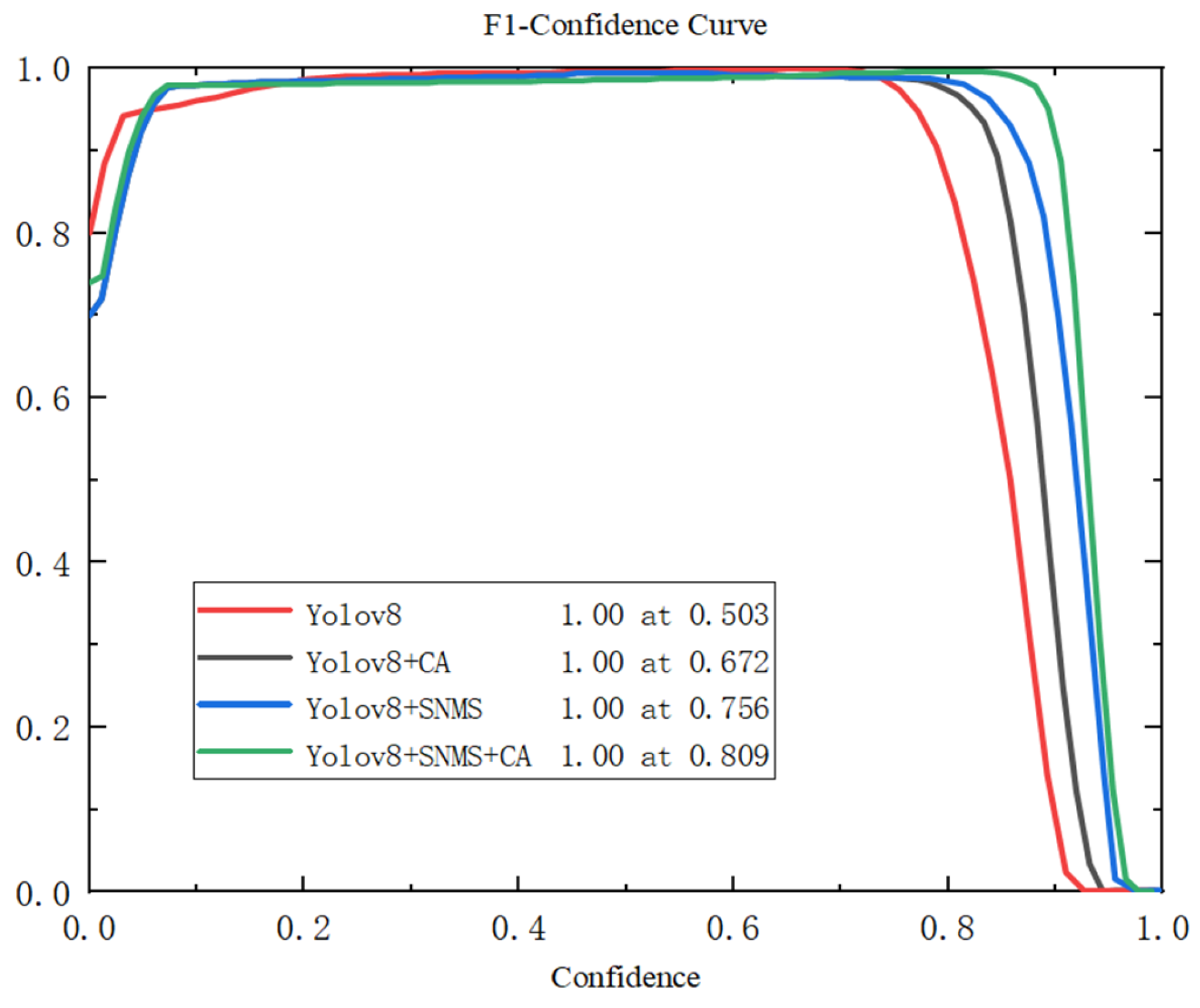
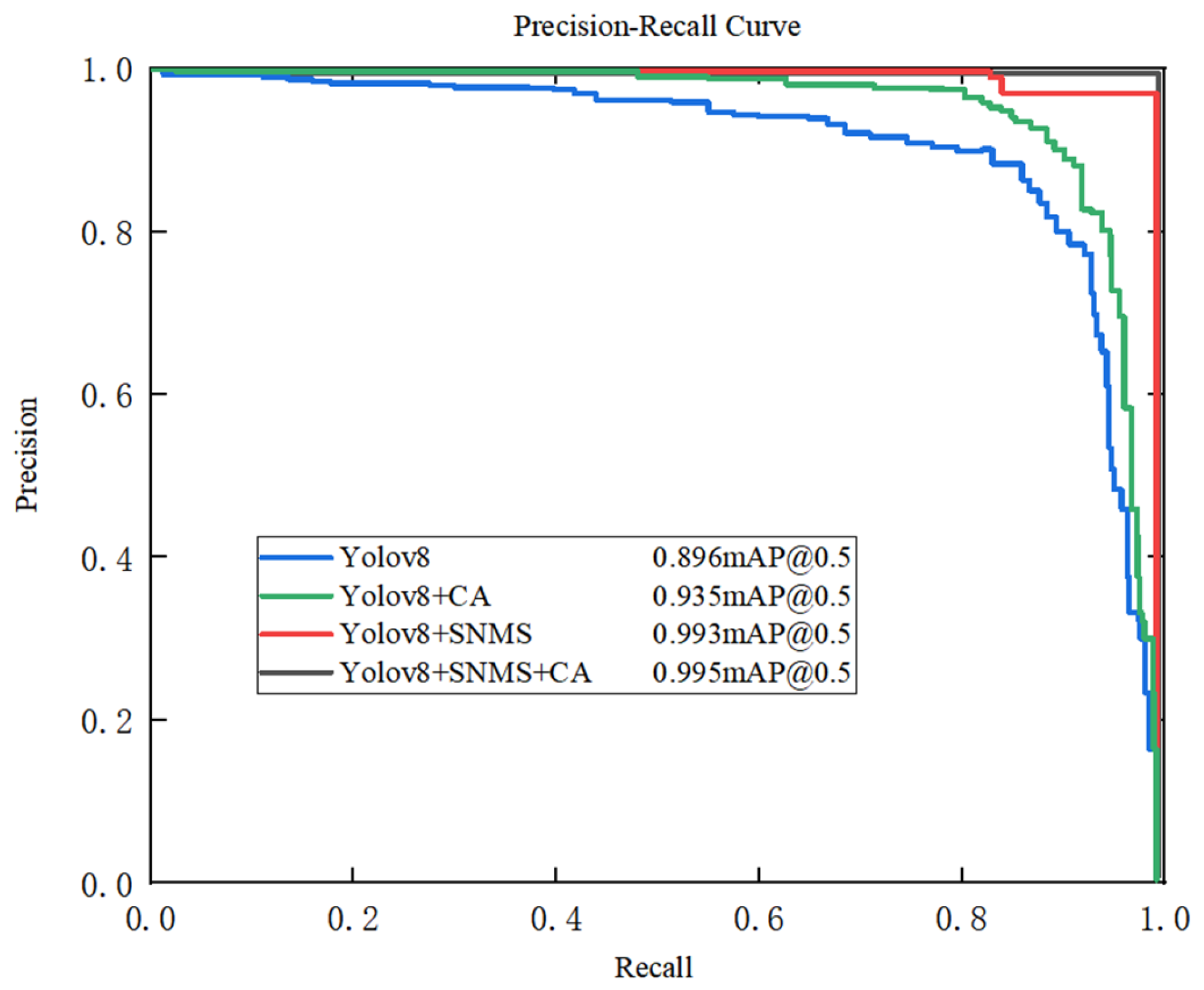
5.2. Ablation Experiment
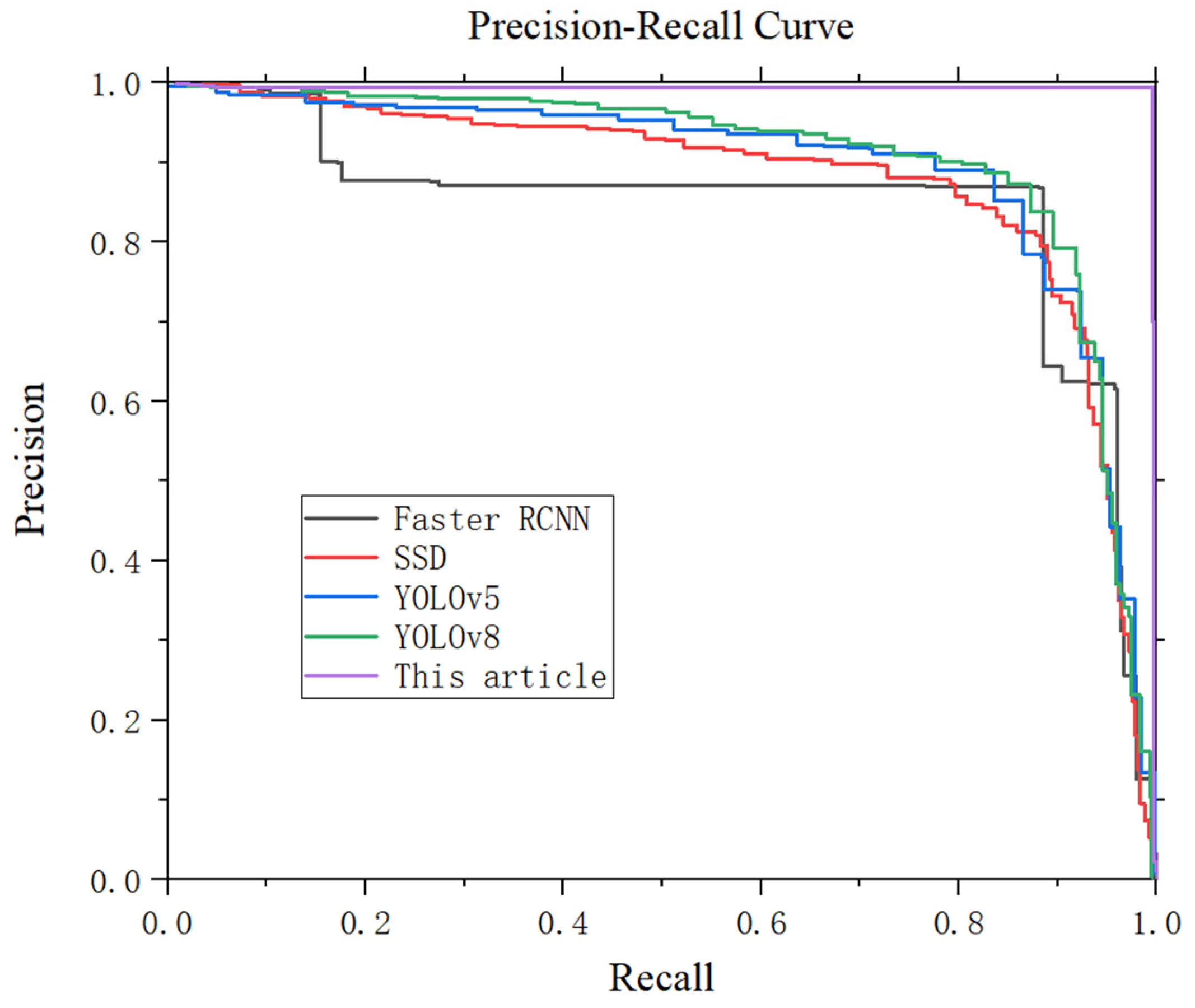
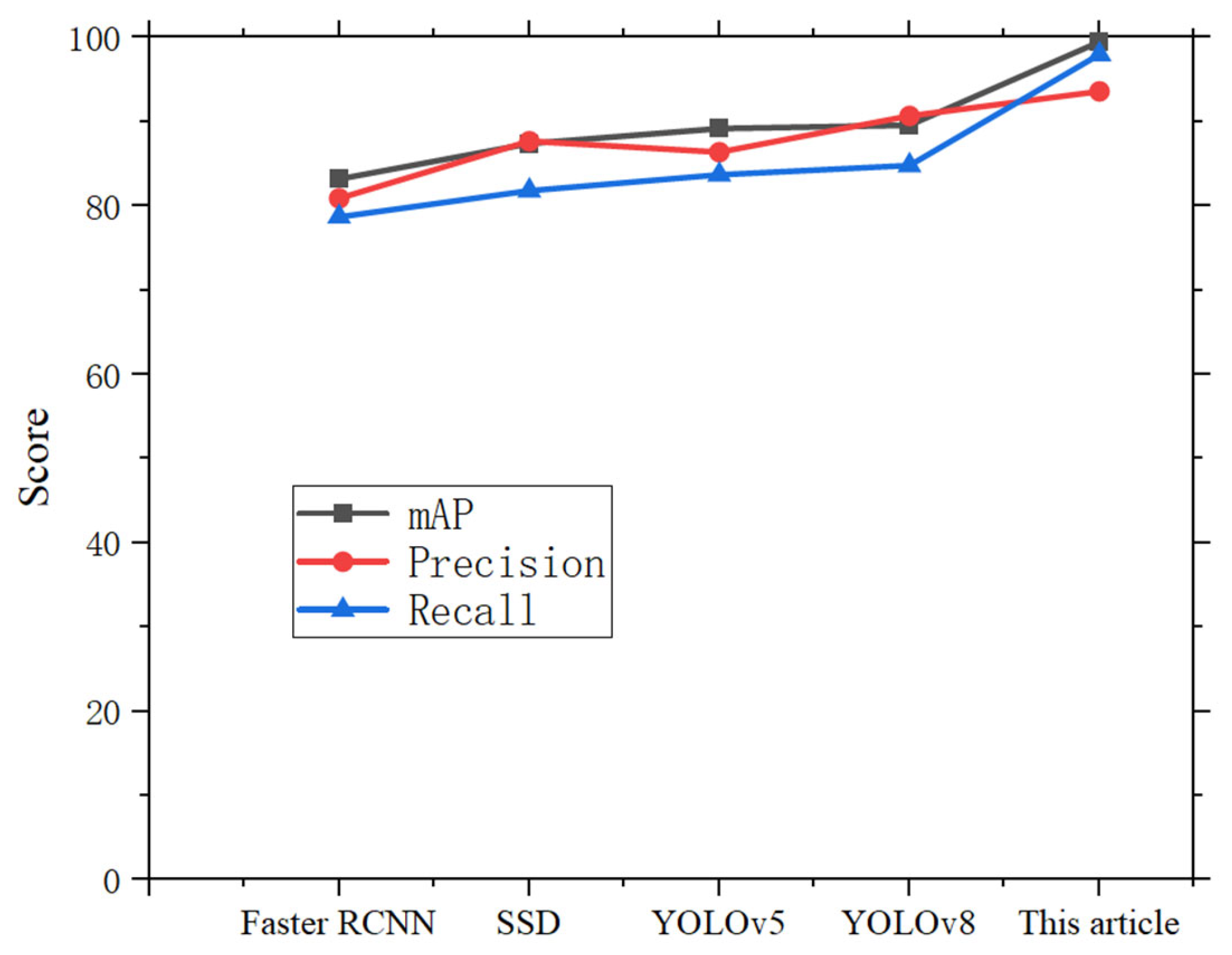
5.3. Comparison of Experimental Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zou, C.; Wu, S.; Yang, Z.; Pan, S.; Wang, G.; Jiang, X.; Guan, M.; Yu, C.; Yu, Z.; Shen, Y. Progress, challenge and significance of building a carbon industry system in the context of carbon neutrality strategy. Pet. Explor. Dev. 2023, 50, 210–228. [Google Scholar] [CrossRef]
- Zeeshan, M.; Chavda, M.; Ehshan, K.M.; Nayek, R.; Malik, S. A Review on Non-RF Underground Positioning Techniques for Mining Applications. IEEE Trans. Instrum. Meas. 2023, 72, 9510217. [Google Scholar] [CrossRef]
- Imam, M.; Baïna, K.; Tabii, Y.; Ressami, E.M.; Adlaoui, Y.; Benzakour, I.; Abdelwahed, E.H. The Future of Mine Safety: A Comprehensive Review of Anti-Collision Systems Based on Computer Vision in Underground Mines. Sensors 2023, 23, 4294. [Google Scholar] [CrossRef]
- El-gayar, M.M.; Soliman, H.; Meky, N. A comparative study of image low level feature extraction algorithms. Egypt. Inform. J. 2013, 14, 175–181. [Google Scholar] [CrossRef]
- Huang, S.Y.; An, W.J.; Zhang, D.S.; Zhou, N.R. Image classification and adversarial robustness analysis based on hybrid quantum–classical convolutional neural network. Opt. Commun. 2023, 533, 129287. [Google Scholar] [CrossRef]
- Tian, Y. Artificial intelligence image recognition method based on convolutional neural network algorithm. IEEE Access 2020, 8, 125731–125744. [Google Scholar] [CrossRef]
- Zhou, D.X. Deep distributed convolutional neural networks: Universality. Anal. Appl. 2018, 16, 895–919. [Google Scholar] [CrossRef]
- Gaba, S.; Budhiraja, I.; Kumar, V.; Garg, S.; Kaddoum, G.; Hassan, M.M. A federated calibration scheme for convolutional neural networks: Models, applications and challenges. Comput. Commun. 2022, 192, 144–162. [Google Scholar] [CrossRef]
- Wang, J.; Zeng, X.; Duan, S.; Zhou, Q.; Peng, H. Image Target Recognition Based on Improved Convolutional Neural Network. Math. Probl. Eng. 2022, 2022, 2213295. [Google Scholar] [CrossRef]
- Zhang, J.; Meng, Y.; Chen, Z. A small target detection method based on deep learning with considerate feature and effectively expanded sample size. IEEE Access 2021, 9, 96559–96572. [Google Scholar] [CrossRef]
- Cao, W. A wheat spike detection method in UAV images based on improved YOLOv5. Remote Sens. 2021, 13, 3095. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Zhuo, S.; Zhang, X.; Chen, Z.; Wei, W.; Wang, F.; Li, Q.; Guan, Y. DAMP-YOLO: A Lightweight Network Based on Deformable Features and Aggregation for Meter Reading Recognition. Appl. Sci. 2023, 13, 11493. [Google Scholar] [CrossRef]
- Wang, X.; Gao, H.; Jia, Z.; Li, Z. BL-YOLOv8: An Improved Road Defect Detection Model Based on YOLOv8. Sensors 2023, 23, 8361. [Google Scholar] [CrossRef] [PubMed]
- Kumar, D.; Muhammad, N. Object Detection in Adverse Weather for Autonomous Driving through Data Merging and YOLOv8. Sensors 2023, 23, 8471. [Google Scholar] [CrossRef] [PubMed]
- Szrek, J.; Zimroz, R.; Wodecki, J.; Michalak, A.; Góralczyk, M.; Worsa-Kozak, M. Application of the Infrared Thermography and Unmanned Ground Vehicle for Rescue Action Support in Underground Mine—The AMICOS Project. Remote Sens. 2021, 13, 69. [Google Scholar] [CrossRef]
- Li, X.; Wang, S.; Liu, B.; Chen, W.; Fan, W.; Tian, Z. Improved YOLOv4 network using infrared images for personnel detection in coal mines. J. Electron. Imaging 2022, 31, 013017. [Google Scholar] [CrossRef]
- Wang, W.; Wang, S.; Guo, Y.; Zhao, Y. Obstacle detection method of unmanned electric locomotive in coal mine based on YOLOv3-4L. J. Electron. Imaging 2022, 31, 023032. [Google Scholar]
- Biao, L.; Tian, B.; Qiao, J. Mine Track Obstacle Detection Method Based on Information Fusion. J. Phys. Conf. Ser. 2022, 2229, 012023. [Google Scholar]
- Imam, M.; Baïna, K.; Tabii, Y.; Benzakour, I.; Adlaoui, Y.; Ressami, E.M.; Abdelwahed, E.H. Anti-Collision System for Accident Prevention in Underground Mines using Computer Vision. In Proceedings of the 6th International Conference on Advances in Artificial Intelligence (ICAAI’22), Brimingham, UK, 21–23 October 2023; Association for Computing Machinery: New York, NY, USA, 2023; pp. 94–101. [Google Scholar]
- Wang, L.; Li, W.; Zhang, Y.; Wei, C. Pedestrian Detection Based on YOLOv2 with Skip Structure in Underground Coal Mine. In Proceedings of the 2017 IEEE 3rd Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 3–5 October 2017. [Google Scholar]
- Fengbo, W.; Liu, W.; Wang, S.; Zhang, G. Improved Mine Pedestrian Detection Algorithm Based on YOLOv4-Tiny. In Proceedings of the Third International Symposium on Computer Engineering and Intelligent Communications (ISCEIC 2022), Xi’an, China, 16–18 September 2023. [Google Scholar]
- Tumas, P.; Serackis, A.; Nowosielski, A. Augmentation of Severe Weather Impact to Far-Infrared Sensor Images to Improve Pedestrian Detection System. Electronics 2021, 10, 934. [Google Scholar] [CrossRef]
- Hou, Y.; Yao, L.; Jia, Z.; Su, D.; Wang, X.; Guo, K. Analysis method for identifying unsafe behaviors in coal mines based on video data. Coal 2023, 32, 33–36+91. [Google Scholar]
- Yang, D.; Guo, Y.; Wang, S.; Ma, X. Obstacle identification of unmanned electric rail locomotives in coal mines. J. Zhejiang Univ. (Eng. Ed.) 2024, 58, 29–39. [Google Scholar]
- Fu, C.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar] [CrossRef]
- Jeong, J.; Park, H.; Kwak, N. Enhancement of SSD by concatenating feature maps for object detection. arXiv 2017, arXiv:1705.09587. [Google Scholar] [CrossRef]
- Guo, C.; He, J. Improved single shot multiboxdetector based on the transposed convolution. J. Comput. Appl. 2018, 38, 2833–2838. [Google Scholar]
- Li, Z.; Zhou, F. FSSD: Feature fusion singleshot Multibox detector. arXiv 2017, arXiv:1712.00960. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Su, J.; Yi, H.; Ling, L.; Shu, A.; Lu, E.; Jiao, Y.; Wang, S. Multi-object surface roughness grade detection based on Faster R-CNN. Meas. Sci. Technol. 2022, 34, 015012. [Google Scholar] [CrossRef]
- Mansouri, S.S.; Karvelis, P.; Kanellakis, C.; Kominiak, D.; Niko-lakopoulos, G. Vision-Based MAV Navigation in Underground Mine Using Convolutional Neural Network. In Proceedings of the IECON 2019—45th Annual Conference of the IEEE Industrial Electronics Society, Lisbon, Portugal, 14–17 October 2019. [Google Scholar]
- Li, C.; Song, D.; Tong, R.; Tang, M. Illumination-aware faster R-CNN for robust multi-spectral pedestrian detection. Pattern Recognit. 2019, 85, 161–171. [Google Scholar] [CrossRef]
- Cui, L.; Zhang, Q.; Guo, Q.; Ma, B. Underground personnel behavior pattern recognition model based on CNN-LSTM. Radio Eng. 2023, 53, 1375–1381. [Google Scholar]
- Ren, H. Recognition of Abnormal Human Behavior Based on Underground Coal Mine Surveillance Videos. Master’s Thesis, Taiyuan University of Science and Technology, Taiyuan, China, 2023. [Google Scholar]
- Wang, Q.; Zhang, L.; Li, Y.; Kpalma, K. Overview ofdeep-learning based methods for salient object detection in videos. Pattern Recognit. 2020, 104, 107340. [Google Scholar] [CrossRef]
- Van den Broeck, W.A.J.; Goedemé, T. Combining Deep Semantic Edge and Object Segmentation for Large-Scale Roof-Part Polygon Extraction from Ultrahigh-Resolution Aerial Imagery. Remote Sens. 2022, 14, 4722. [Google Scholar] [CrossRef]
- Wang, X.; Gao, J.; Hou, B.; Wang, Z.; Ding, H.; Wang, J. A lightweight modified YOLOX network using coordinate attention mechanism for PCB surface defect detection. IEEE Sens. J. 2022, 22, 20910–20920. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CA | SNMS | P/% | Map/% | F1/% |
|---|---|---|---|---|
| — | — | 81.2 | 89.6 | 50.3 |
| √ | — | 87.4 | 93.5 | 67.2 |
| — | √ | 89.3 | 99.3 | 75.6 |
| √ | √ | 88.0 | 99.5 | 80.9 |
| Algorithm | Map/% | Model Size/MB | FPS/s |
|---|---|---|---|
| Faster RCNN | 83.2 | 528 | 28 |
| SSD | 87.4 | 110 | 51 |
| YOLOv5l | 89.2 | 101 | 39 |
| YOLOv8l | 89.6 | 82 | 46 |
| This article | 99.5 | 86 | 45 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ni, Y.; Huo, J.; Hou, Y.; Wang, J.; Guo, P. Detection of Underground Dangerous Area Based on Improving YOLOV8. Electronics 2024, 13, 623. https://doi.org/10.3390/electronics13030623
Ni Y, Huo J, Hou Y, Wang J, Guo P. Detection of Underground Dangerous Area Based on Improving YOLOV8. Electronics. 2024; 13(3):623. https://doi.org/10.3390/electronics13030623
Chicago/Turabian StyleNi, Yunfeng, Jie Huo, Ying Hou, Jing Wang, and Ping Guo. 2024. "Detection of Underground Dangerous Area Based on Improving YOLOV8" Electronics 13, no. 3: 623. https://doi.org/10.3390/electronics13030623