
Multi-Branch Spectral Channel Attention Network for Breast Cancer Histopathology Image Classification
Abstract
:1. Introduction
- (1)
- We analyze the characteristics and attention mechanism of pathological tissue images of breast cancer from the perspective of frequencies. Following this view, we design a new channel attention network, the MbsCANet, in the frequency domain.
- (2)
- We propose a multi-branch channel attention structure to fulfill MbsCANet, in which three kinds of frequency components are mined to compress and represent channels.
- (3)
- In comparison to existing well-known spectral-based channel attention techniques (SENet and FcaNet), our model performs well and also achieves competitive or better results against state-of-the-art methods on the breast cancer histopathology image dataset.
2. Methodology
2.1. Discrete Cosine Transform (DCT)
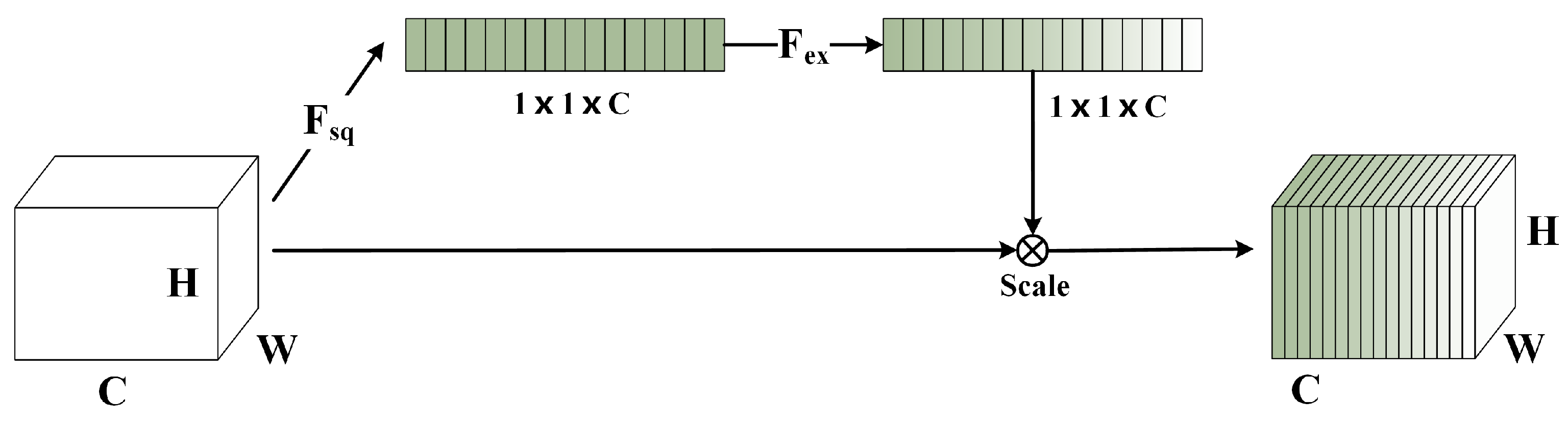
2.2. Spectral-Channel-Attention-Based SENet and FcaNet
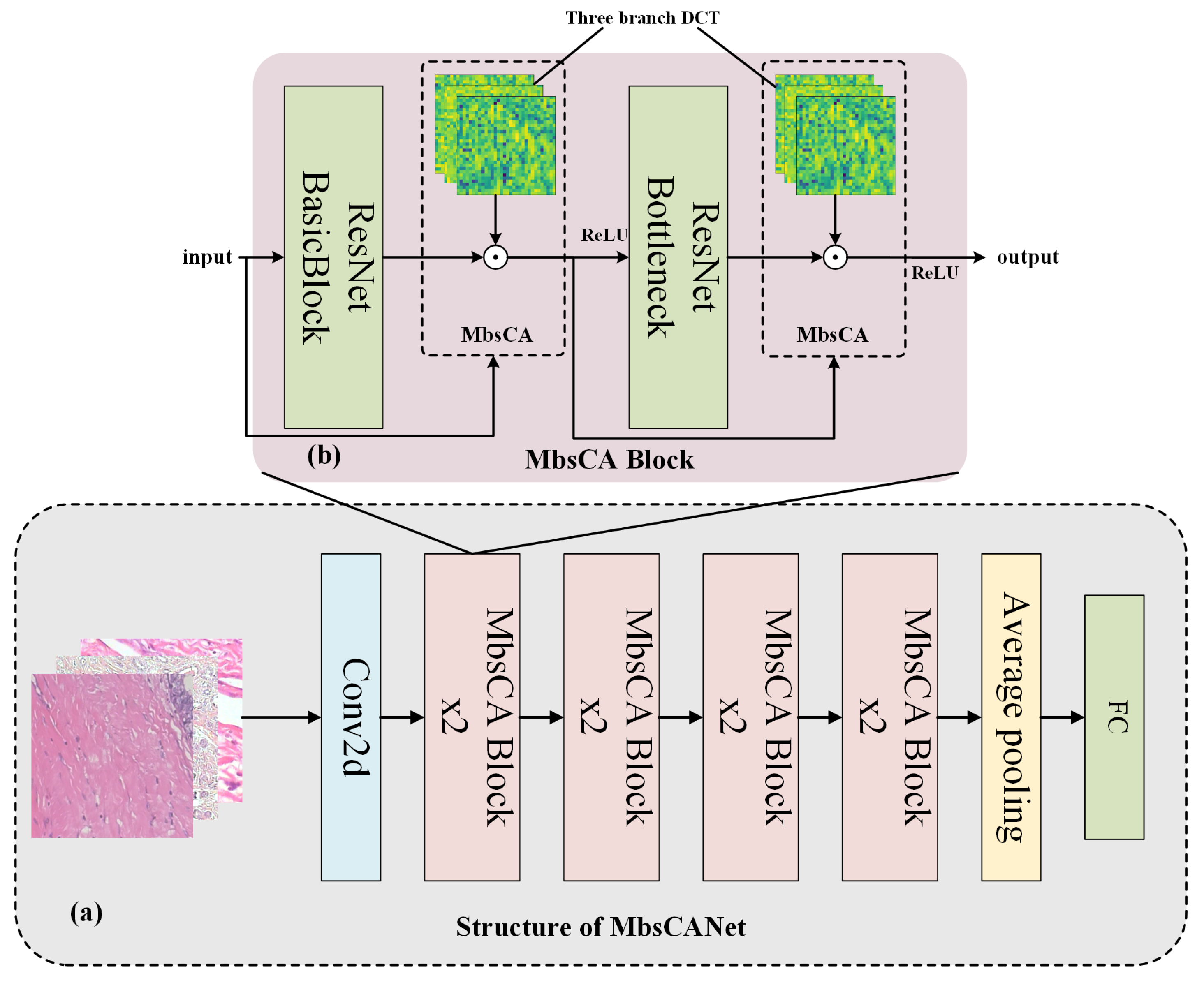
2.3. Multi-Branch Spectral Channel Attention Network (MbsCANet)
2.3.1. General Structure
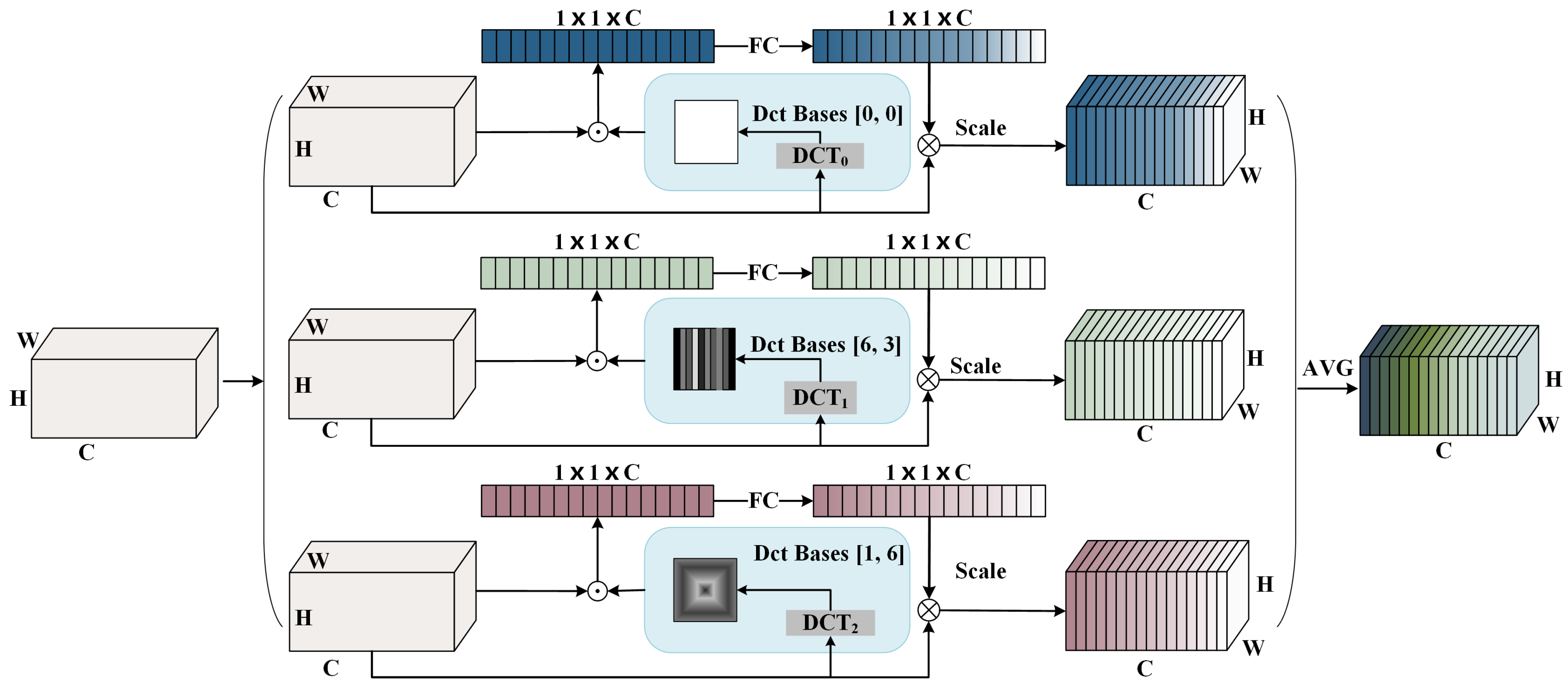
2.3.2. Multi-Branch Spectral Channel Attention Module
3. Experiments
3.1. Implementation Details
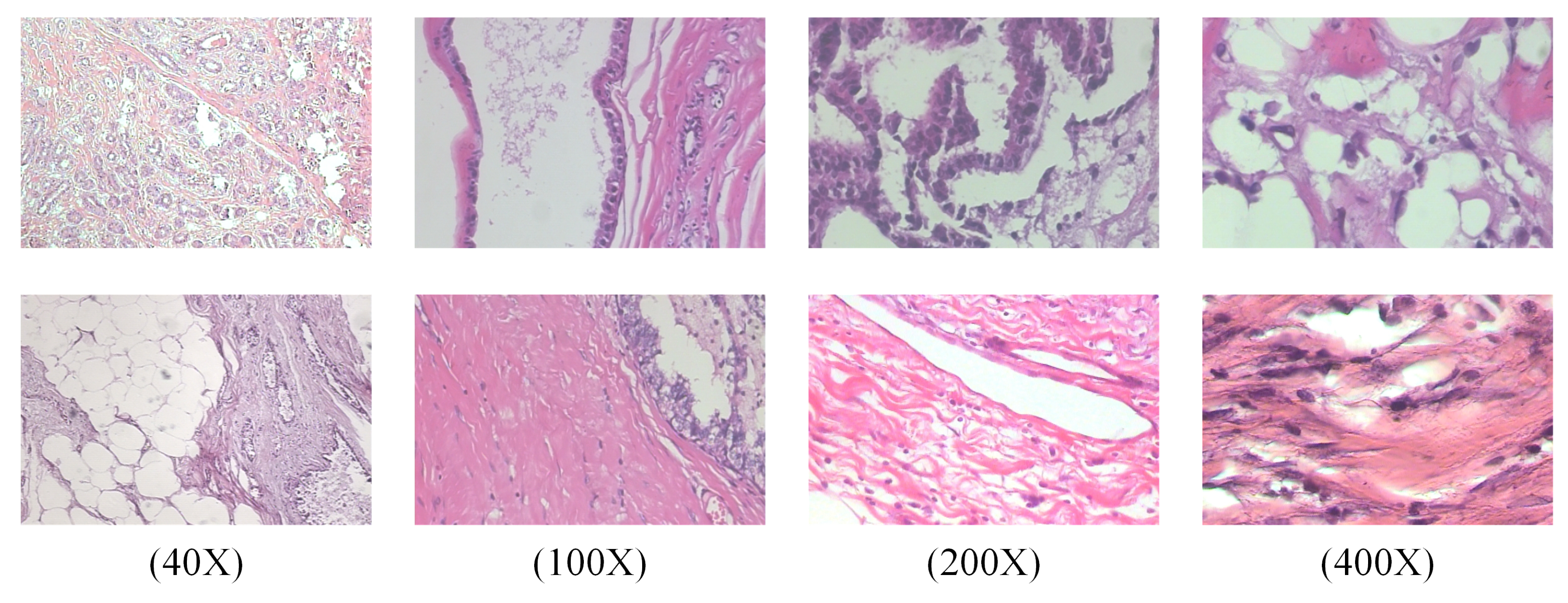
3.1.1. Dataset
3.1.2. Evaluation Metrics and Setting
3.2. Ablation Study
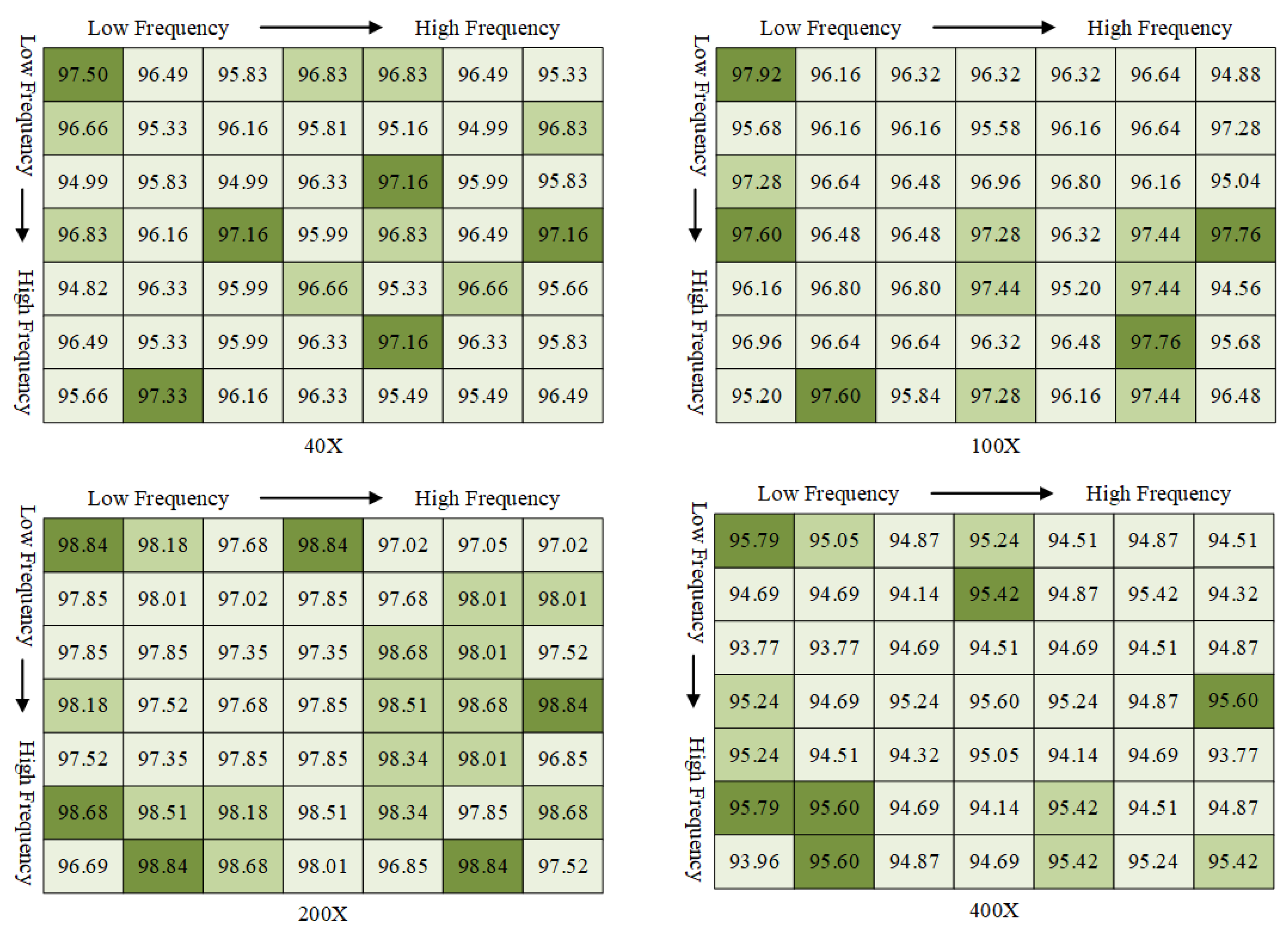
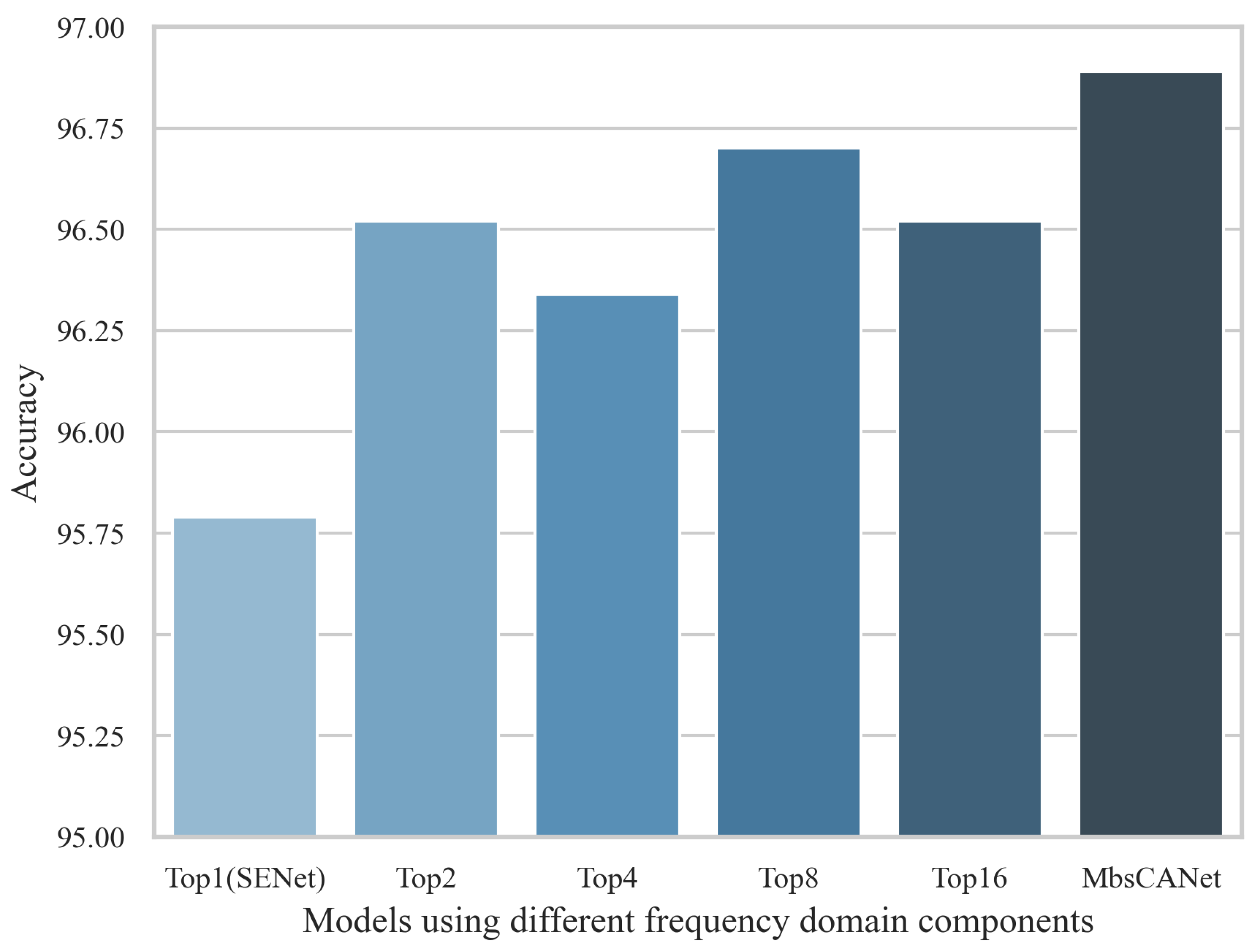
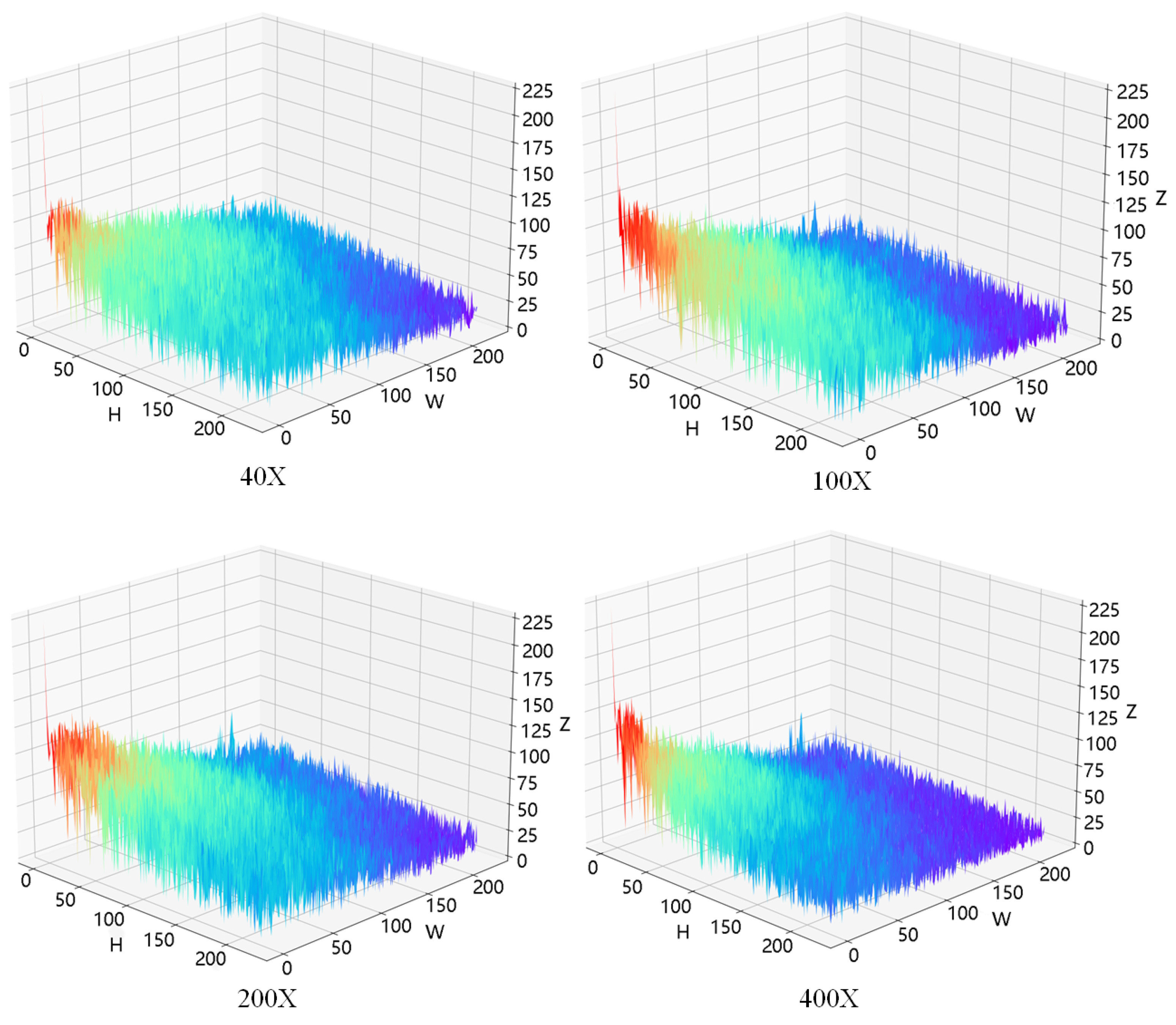
3.2.1. Ablation on Individual Frequency Components
3.2.2. Accuracy, Precision, Recall, and F1-Score Results
3.2.3. Comparisons with Counterparts
3.3. Comparisons with State-of-the-Art Methods

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Year | Method | Images Level | Patient Level | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 40× | 100× | 200× | 400× | 40× | 100× | 200× | 400× | |||
| Benhammou et al. [33] | 2018 | InceptionV3 | 90.20 | 85.60 | 86.10 | 82.50 | 91.50 | 85.10 | 86.80 | 82.90 |
| Alom et al. [34] | 2019 | IRRCNN | 97.16 | 96.84 | 96.61 | 95.78 | 96.69 | 96.37 | 96.27 | 96.37 |
| Sudharshan et al. [35] | 2019 | PFTAS + NPMIL | 87.8 ± 5.6 | 85.6 ± 4.3 | 80.8 ± 2.8 | 82.9 ± 4.1 | 92.1 ± 5.9 | 89.1 ± 5.2 | 87.2 ± 4.3 | 82.7 ± 4.0 |
| Lichtblau et al. [36] | 2019 | DE ensemble | 85.60 | 87.40 | 89.80 | 87.00 | 83.90 | 86.00 | 89.10 | 86.60 |
| Zhang et al. [37] | 2020 | VGG-VD16 | 95.03 | 90.41 | 88.48 | 85.00 | 95.50 | 91.57 | 89.20 | 89.20 |
| Hou [38] | 2020 | 22 layers CNN | 90.89 | 90.99 | 91.00 | 90.97 | 91.00 | 91.00 | 91.00 | 91.00 |
| Man et al. [39] | 2020 | DenseNet121-AnoGAN | 99.13 ± 0.2 | 96.39 ± 0.7 | 86.38 ± 1.2 | 85.20 ± 2.1 | 96.32 ± 1.3 | 95.89 ± 0.9 | 86.91 ± 2.0 | 85.16 ± 1.3 |
| Gour et al. [40] | 2020 | IDSNet | 87.4 ± 3.0 | 87.2 ± 3.5 | 91.1 ± 2.3 | 86.2 ± 2.1 | 87.4 ± 3.3 | 88.1 ± 2.9 | 92.5 ± 2.8 | 87.7 ± 2.4 |
| Togacar et al. [41] | 2020 | BreastNet | 97.99 | 97.84 | 98.51 | 95.88 | n/a | n/a | n/a | n/a |
| Wang et al. [42] | 2021 | FE-BkCapsNet | 92.71 ± 0.16 | 94.52 ± 0.11 | 94.03 ± 0.25 | 93.54 ± 0.24 | n/a | n/a | n/a | n/a |
| Ibraheem et al. [43] | 2021 | 3PC NNB-N et | 92.27 | 93.07 | 97.04 | 92.09 | n/a | n/a | n/a | n/a |
| Li et al. [44] | 2021 | Sliding + Class Balance Random | 87.85 ± 2.69 | 86.68 ± 2.28 | 87.75 ± 2.37 | 85.30 ± 4.41 | 87.93 ± 3.91 | 87.41 ± 3.26 | 88.76 ± 2.50 | 85.55 ± 4.03 |
| Hao et al. [45] | 2021 | APVEC | 92.10 | 90.20 | 95.00 | 92.80 | n/a | n/a | n/a | n/a |
| Zhou et al. [31] | 2022 | RANet+ADSVM | 94.43 ± 0.8 | 98.31 ± 0.3 | 99.14 ± 0.2 | 93.35 ± 0.9 | 96.16 ± 0.9 | 97.91 ± 0.4 | 98.83 ± 0.3 | 92.64 ± 0.9 |
| Chattopadhyay et al. [46] | 2022 | DRDA-Net7 | 95.72 | 94.41 | 97.43 | 96.84 | n/a | n/a | n/a | n/a |
| Djouima et al. [47] | 2022 | DCGAN | 96.00 | 95.00 | 88.00 | 92.00 | n/a | n/a | n/a | n/a |
| AMin et al. [32] | 2023 | FabNet | 99.03 | 89.68 | 98.51 | 97.10 | 99.01 | 89.26 | 98.38 | 96.96 |
| MbsCANet (ours) | - | Mutiple Spectral Channel Attention | 97.66 | 97.92 | 99.01 | 96.89 | 97.17 | 97.98 | 98.87 | 97.06 |
| Method | Accuracy |
|---|---|
| Baseline | 75% |
| MbsCANet | 86% |
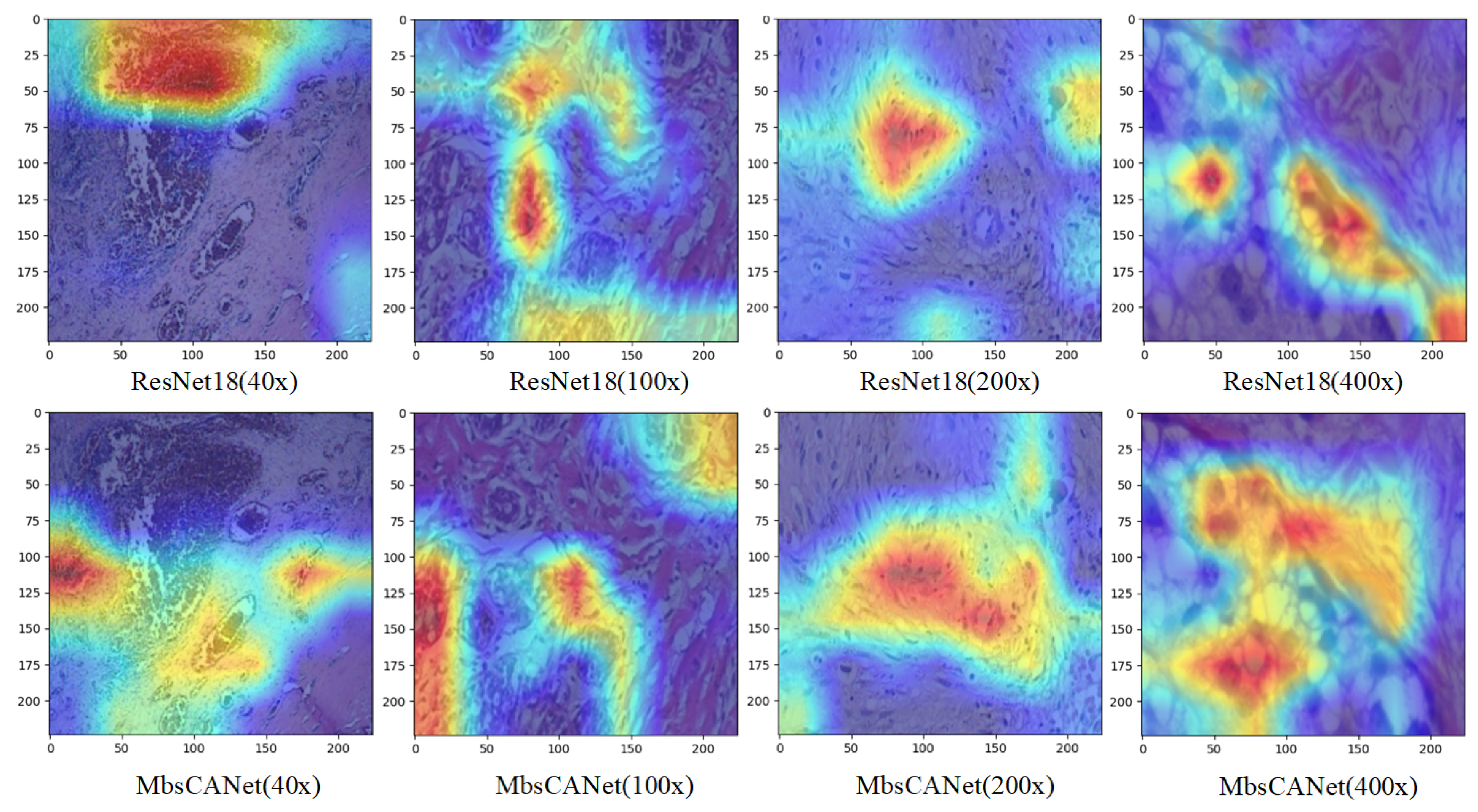
3.4. Visualization Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ferlay, J.; Colombet, M.; Soerjomataram, I.; Parkin, D.M.; Piñeros, M.; Znaor, A.; Bray, F. Cancer statistics for the year 2020: An overview. Int. J. Cancer 2021, 149, 778–789. [Google Scholar] [CrossRef] [PubMed]
- Xue, Y.; Ye, J.; Zhou, Q.; Long, L.R.; Antani, S.; Xue, Z.; Cornwell, C.; Zaino, R.; Cheng, K.C.; Huang, X. Selective synthetic augmentation with HistoGAN for improved histopathology image classification. Med. Image Anal. 2021, 67, 101816. [Google Scholar] [CrossRef] [PubMed]
- Dif, N.; Attaoui, M.O.; Elberrichi, Z.; Lebbah, M.; Azzag, H. Transfer learning from synthetic labels for histopathological images classification. Appl. Intell. 2022, 52, 358–377. [Google Scholar] [CrossRef]
- Burçak, K.C.; Baykan, Ö.K.; Uğuz, H. A new deep convolutional neural network model for classifying breast cancer histopathological images and the hyperparameter optimisation of the proposed model. J. Supercomput. 2021, 77, 973–989. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Los Alamitos, CA, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11534–11542. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 16000–16009. [Google Scholar]
- Tang, J.; Zheng, G.; Shi, C.; Yang, S. Contrastive Grouping with Transformer for Referring Image Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 23570–23580. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Li, Y.; Mao, H.; Girshick, R.; He, K. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Tel-Aviv, Israel, 23–27 October 2022; pp. 280–296. [Google Scholar]
- Li, Y.; Fan, H.; Hu, R.; Feichtenhofer, C.; He, K. Scaling language-image pre-training via masking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 23390–23400. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Elston, C.W.; Ellis, I.O. Pathological prognostic factors in breast cancer. I. The value of histological grade in breast cancer: Experience from a large study with long-term follow-up. Histopathology 1991, 19, 403–410. [Google Scholar] [CrossRef] [PubMed]
- Giannakeas, N.; Tsiplakidou, M.; Tsipouras, M.G.; Manousou, P.; Forlano, R.; Tzallas, A.T. Image Enhancement of Routine Biopsies: A Case for Liver Tissue Detection. In Proceedings of the 2017 IEEE 17th International Conference on Bioinformatics and Bioengineering (BIBE), Washington, DC, USA, 23–25 October 2017; pp. 236–240. [Google Scholar]
- Gueguen, L.; Sergeev, A.; Kadlec, B.; Liu, R.; Yosinski, J. Faster neural networks straight from jpeg. NeurIPS 2018, 31, 3933–3944. [Google Scholar]
- Ehrlich, M.; Davis, L.S. Deep residual learning in the jpeg transform domain. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3484–3493. [Google Scholar]
- Xu, K.; Qin, M.; Sun, F.; Wang, Y.; Chen, Y.K.; Ren, F. Imagenet: Learning in the frequency domain. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1740–1749. [Google Scholar]
- Dziedzic, A.; Paparrizos, J.; Krishnan, S.; Elmore, A.; Franklin, M. Band-limited training and inference for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 1745–1754. [Google Scholar]
- Yang, X.; Zhou, D.; Feng, J.; Wang, X. Diffusion probabilistic model made slim. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 22552–22562. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. FcaNet: Frequency channel attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 783–792. [Google Scholar]
- Lai, Z.; Fu, Y. Mixed Attention Network for Hyperspectral Image Denoising. arXiv 2023, arXiv:2301.11525. [Google Scholar]
- Ahmed, N.; Natarajan, T.; Rao, K.R. Discrete cosine transform. IEEE Trans. Comput. 1974, 100, 90–93. [Google Scholar] [CrossRef]
- Lee, H.J.; Kim, H.; Nam, H. Srm: A style-based recalibration module for convolutional neural networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1854–1862. [Google Scholar]
- Yang, Z.; Zhu, L.; Wu, Y.; Yang, Y. Gated channel transformation for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11794–11803. [Google Scholar]
- Li, M.; Liu, J.; Fu, Y.; Zhang, Y.; Dou, D. Spectral Enhanced Rectangle Transformer for Hyperspectral Image Denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 5805–5814. [Google Scholar]
- Zerouaoui, H.; Idri, A. Reviewing machine learning and image processing based decision-making systems for breast cancer imaging. J. Med. Syst. 2021, 45, 8. [Google Scholar] [CrossRef] [PubMed]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 3933–3944. [Google Scholar]
- Zhou, Y.; Zhang, C.; Gao, S. Breast cancer classification from histopathological images using resolution adaptive network. IEEE Access 2022, 10, 8026–8037. [Google Scholar] [CrossRef]
- Amin, M.S.; Ahn, H. FabNet: A Features Agglomeration-Based Convolutional Neural Network for Multiscale Breast Cancer Histopathology Images Classification. Cancers 2023, 15, 1013. [Google Scholar] [CrossRef] [PubMed]
- Benhammou, Y.; Tabik, S.; Achchab, B.; Herrera, F. A first study exploring the performance of the state-of-the art CNN model in the problem of breast cancer. In Proceedings of the International Conference on Learning and Optimization Algorithms: Theory and Applications, Rabat, Morocco, 2–5 May 2018; pp. 1–6. [Google Scholar]
- Alom, M.Z.; Yakopcic, C.; Nasrin, M.S.; Taha, T.M.; Asari, V.K. Breast cancer classification from histopathological images with inception recurrent residual convolutional neural network. J. Digit. Imaging 2019, 32, 605–617. [Google Scholar] [CrossRef]
- Sudharshan, P.; Petitjean, C.; Spanhol, F.; Oliveira, L.E.; Heutte, L.; Honeine, P. Multiple instance learning for histopathological breast cancer image classification. Expert Syst. Appl. 2019, 117, 103–111. [Google Scholar] [CrossRef]
- Lichtblau, D.; Stoean, C. Cancer diagnosis through a tandem of classifiers for digitized histopathological slides. PLoS ONE 2019, 14, e0209274. [Google Scholar] [CrossRef]
- Zhang, J.; Wei, X.; Dong, J.; Liu, B. Aggregated deep global feature representation for breast cancer histopathology image classification. J. Med. Imaging Health Inform. 2020, 10, 2778–2783. [Google Scholar] [CrossRef]
- Hou, Y. Breast cancer pathological image classification based on deep learning. J. Xray Sci. Technol. 2020, 28, 727–738. [Google Scholar] [CrossRef]
- Man, R.; Yang, P.; Xu, B. Classification of breast cancer histopathological images using discriminative patches screened by generative adversarial networks. IEEE Access 2020, 8, 155362–155377. [Google Scholar] [CrossRef]
- Gour, M.; Jain, S.; Sunil, K.T. Residual learning based CNN for breast cancer histopathological image classification. Int. J. Imaging Syst. Technol. 2020, 30, 621–635. [Google Scholar] [CrossRef]
- Toğaçar, M.; Özkurt, K.B.; Ergen, B.; Cömert, Z. BreastNet: A novel convolutional neural network model through histopathological images for the diagnosis of breast cancer. Physica A 2020, 545, 123592. [Google Scholar] [CrossRef]
- Wang, P.; Wang, J.; Li, Y.; Li, P.; Li, L.; Jiang, M. Automatic classification of breast cancer histopathological images based on deep feature fusion and enhanced routing. Biomed. Signal Process. Control 2021, 102341, 65. [Google Scholar] [CrossRef]
- Ibraheem, A.M.; Rahouma, K.H.; Hamed, H.F. 3PCNNB-net: Three parallel CNN branches for breast cancer classification through histopathological images. J. Med. Biol. Eng. 2021, 41, 494–503. [Google Scholar] [CrossRef]
- Li, X.; Li, H.; Cui, W.; Cai, Z.; Jia, M. Breast cancer pathological image classification based on deep learning. Math. Probl. Eng. 2021, 2021, 1–13. [Google Scholar]
- Hao, Y.; Qiao, S.; Zhang, L.; Xu, T.; Bai, Y.; Hu, H.; Zhang, W.; Zhang, G. Breast cancer histopathological images recognition based on low dimensional three-channel features. Front. Oncol. 2021, 11, 657560. [Google Scholar] [CrossRef]
- Chattopadhyay, S.; Dey, A.; Singh, P.K. Sarkar, R. DRDA-Net: Dense residual dual-shuffle attention network for breast cancer classification using histopathological images. Comput. Biol. Med. 2022, 145, 105437. [Google Scholar] [CrossRef]
- Djouima, H.; Zitouni, A.; Megherbi, A.C.; Sbaa, S. Classification of Breast Cancer Histopathological Images using DensNet201. In Proceedings of the 2022 7th International Conference on Image and Signal Processing and their Applications (ISPA), Mostaganem, Algeria, 8–9 May 2022; pp. 1–6. [Google Scholar]








| Magnification | Accuray | Precision | Recall | F1-Score |
|---|---|---|---|---|
| 40× | 97.66 | 97.79 | 94.65 | 96.19 |
| 100× | 97.92 | 97.35 | 95.83 | 96.58 |
| 200× | 99.01 | 99.40 | 97.08 | 98.22 |
| 400× | 96.89 | 95.24 | 94.67 | 94.95 |
| Method | 40× | 100× | 200× | 400× |
|---|---|---|---|---|
| Baseline | 96.16 | 95.84 | 97.35 | 93.77 |
| SENet | 97.50 | 97.92 | 98.84 | 95.79 |
| FcaNet | 97.49 | 97.12 | 98.18 | 96.70 |
| MbsCANet | 97.66 | 97.92 | 99.01 | 96.89 |
| Method | 40× | 100× | 200× | 400× |
|---|---|---|---|---|
| Baseline | 95.99 | 96.29 | 97.59 | 94.33 |
| SENet | 96.82 | 96.03 | 98.19 | 96.69 |
| FcaNet | 96.76 | 97.47 | 98.46 | 96.17 |
| MbsCANet | 97.17 | 97.98 | 98.87 | 97.06 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, L.; Pan, K.; Ren, Y.; Lu, R.; Zhang, J. Multi-Branch Spectral Channel Attention Network for Breast Cancer Histopathology Image Classification. Electronics 2024, 13, 459. https://doi.org/10.3390/electronics13020459
Cao L, Pan K, Ren Y, Lu R, Zhang J. Multi-Branch Spectral Channel Attention Network for Breast Cancer Histopathology Image Classification. Electronics. 2024; 13(2):459. https://doi.org/10.3390/electronics13020459
Chicago/Turabian StyleCao, Lu, Ke Pan, Yuan Ren, Ruidong Lu, and Jianxin Zhang. 2024. "Multi-Branch Spectral Channel Attention Network for Breast Cancer Histopathology Image Classification" Electronics 13, no. 2: 459. https://doi.org/10.3390/electronics13020459