
Application of Improved YOLOv5 Algorithm in Lightweight Transmission Line Small Target Defect Detection
Abstract
:1. Introduction
2. Algorithm Principle
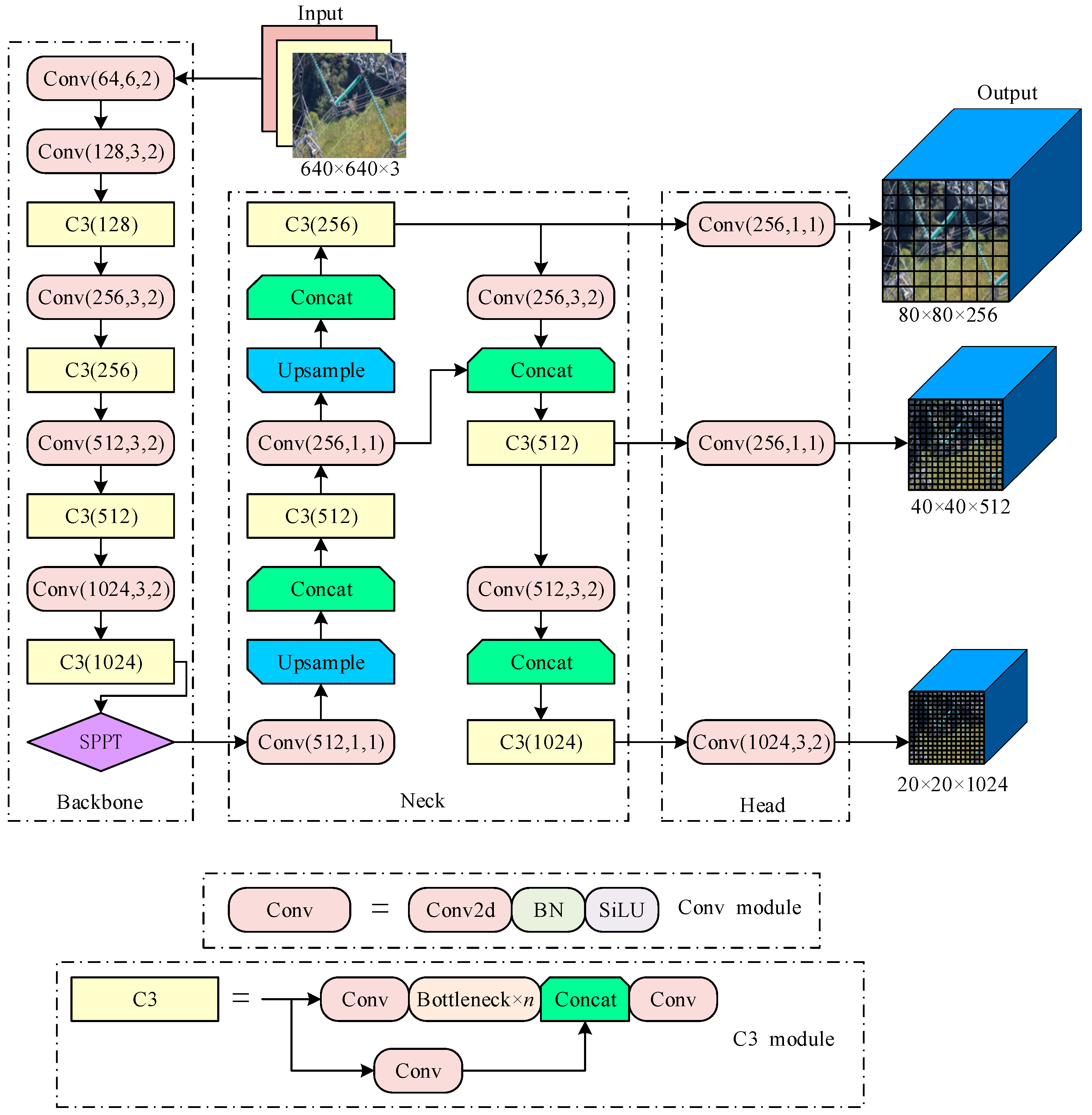
2.1. YOLOv5 Algorithm
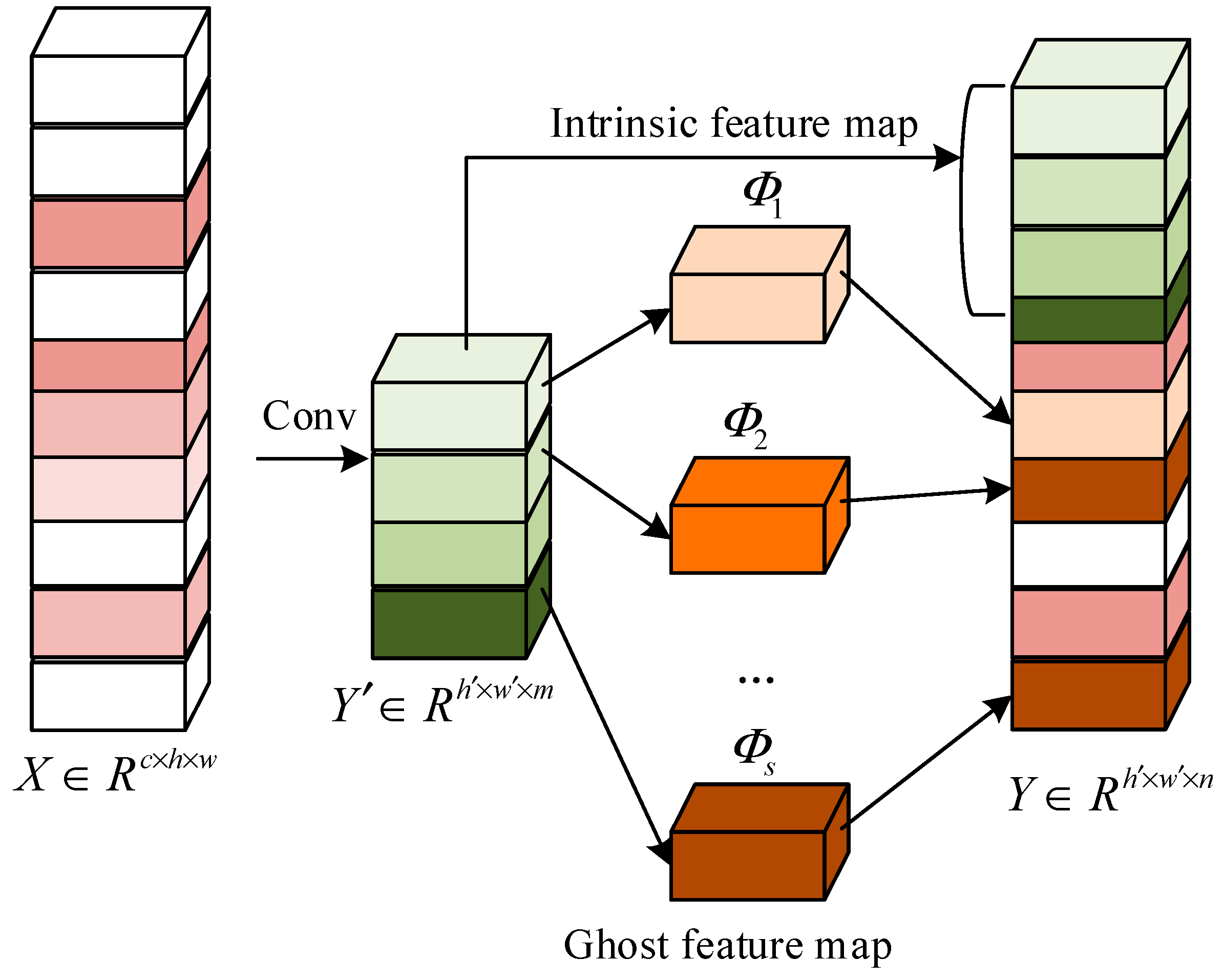
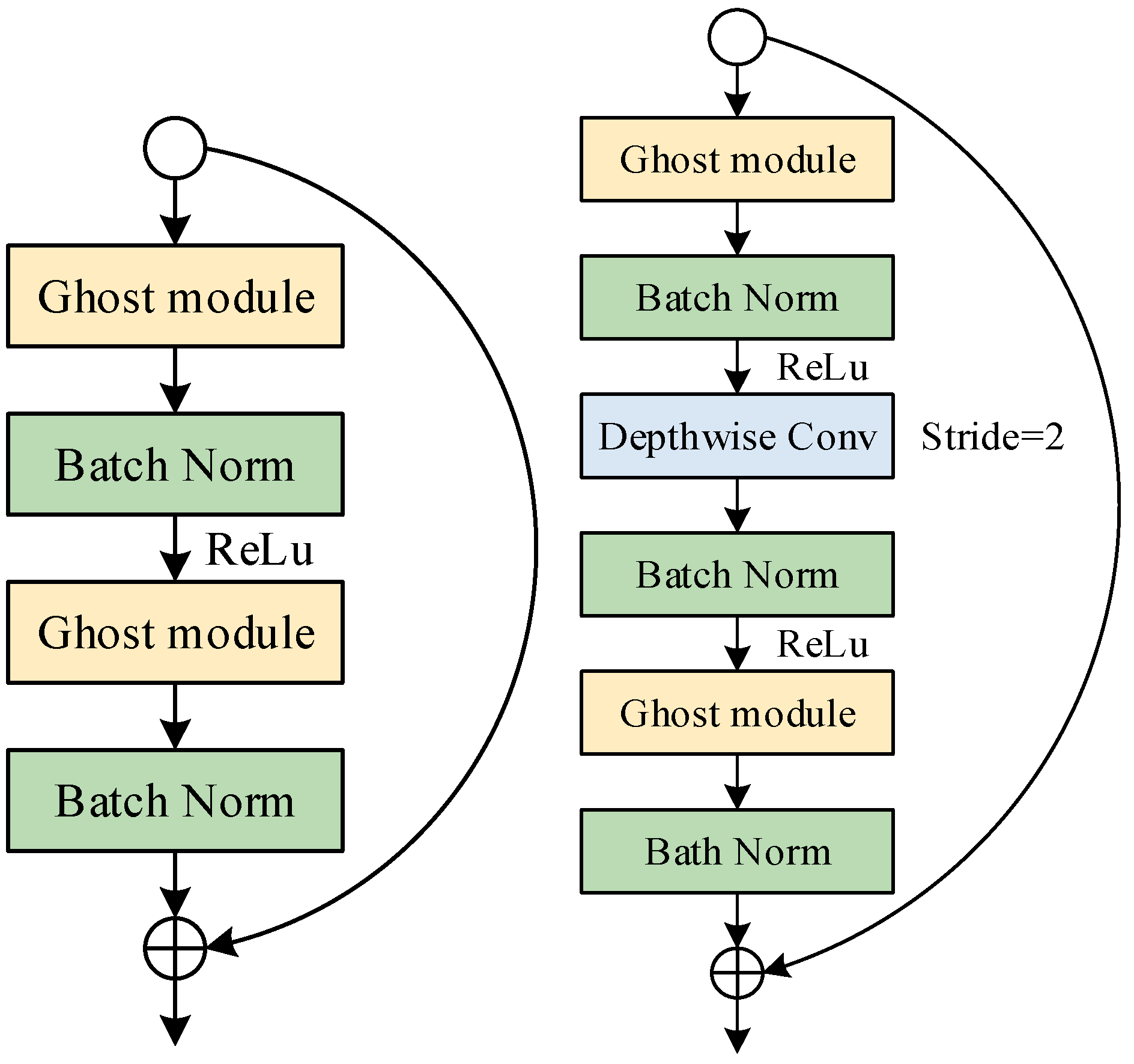
2.2. Lightweight Backbone GhostNet
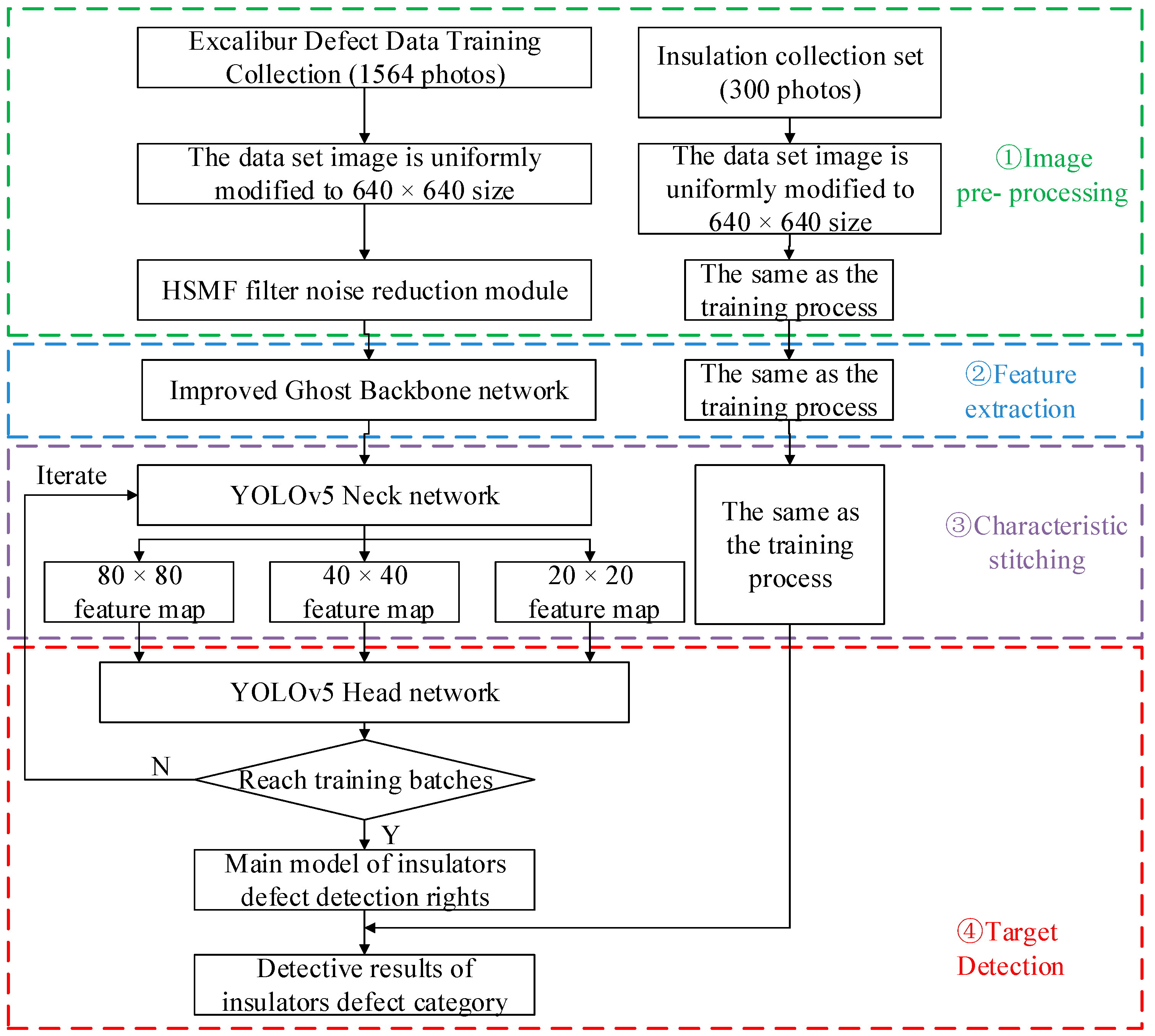
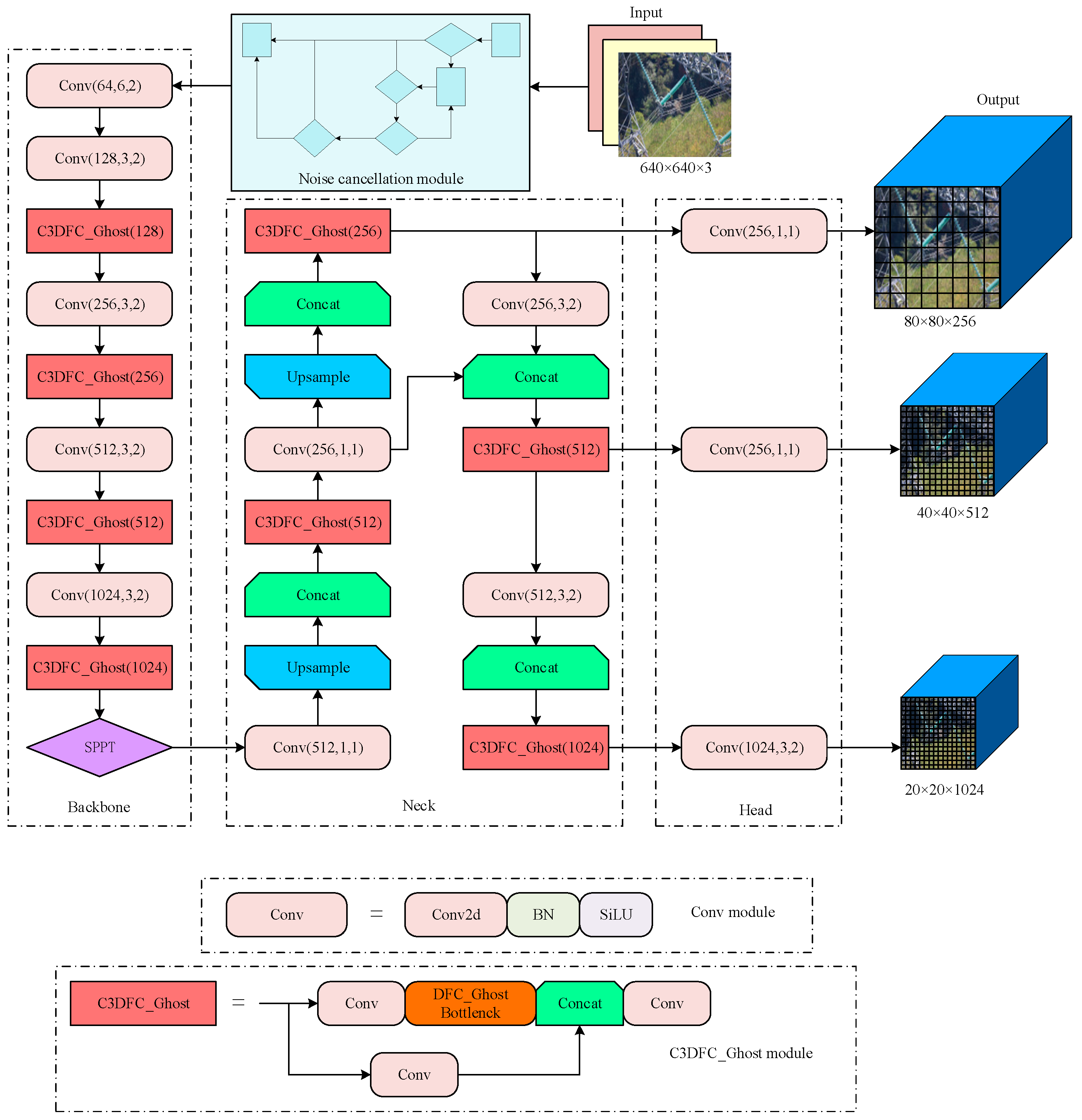
3. DFCG_YOLOv5
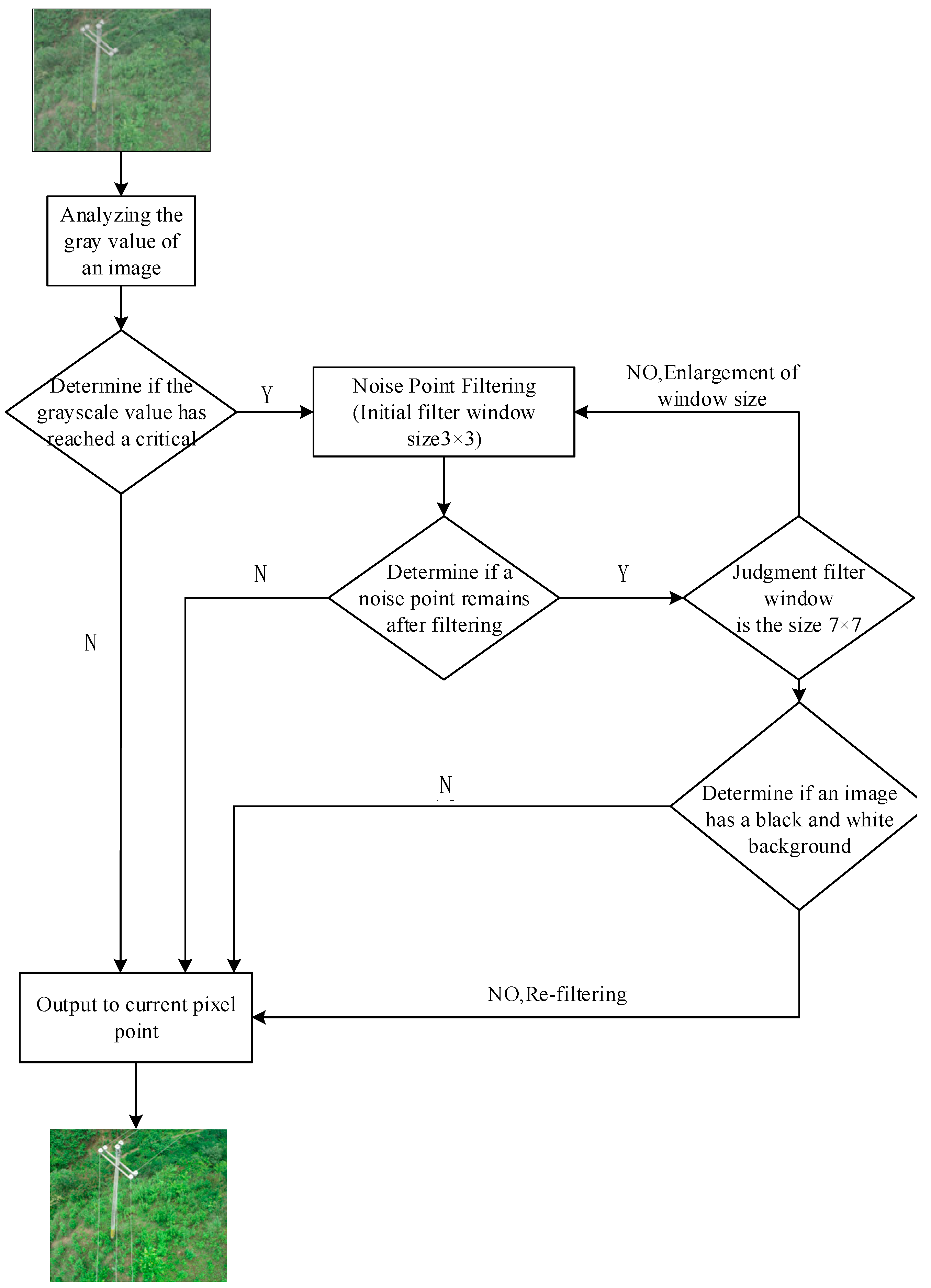
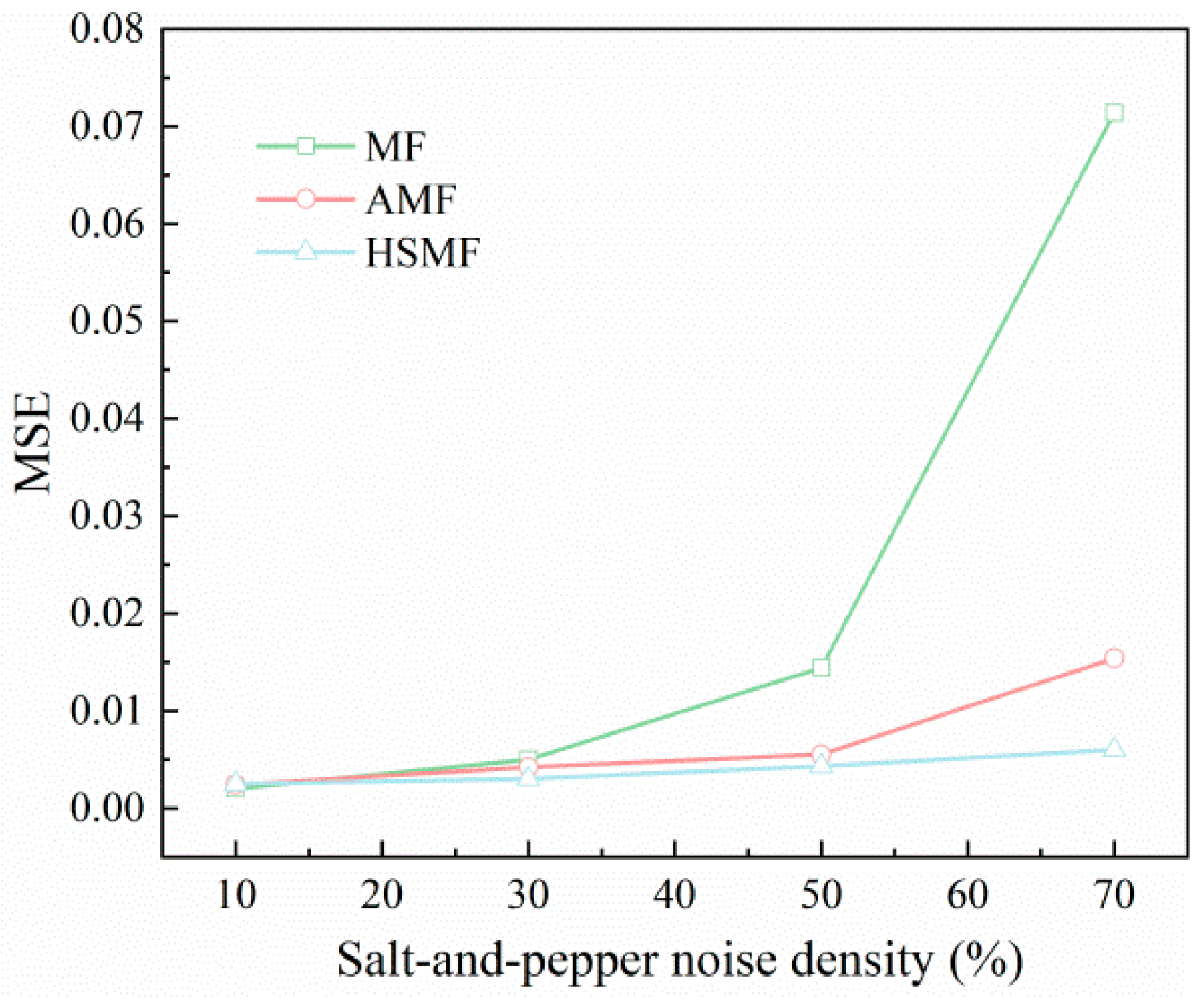
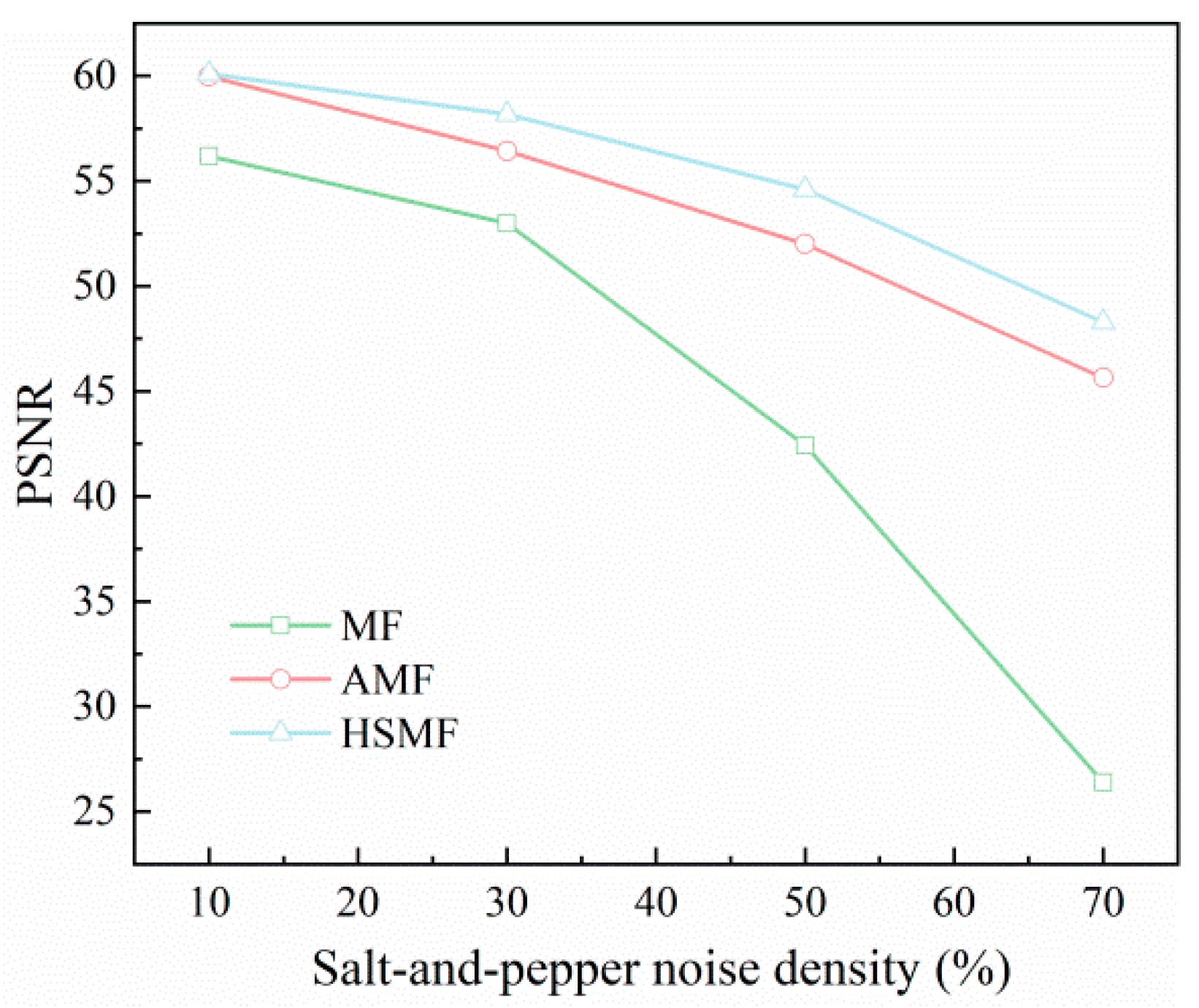
3.1. High-Speed Adaptive Median Filtering Algorithm HSMF
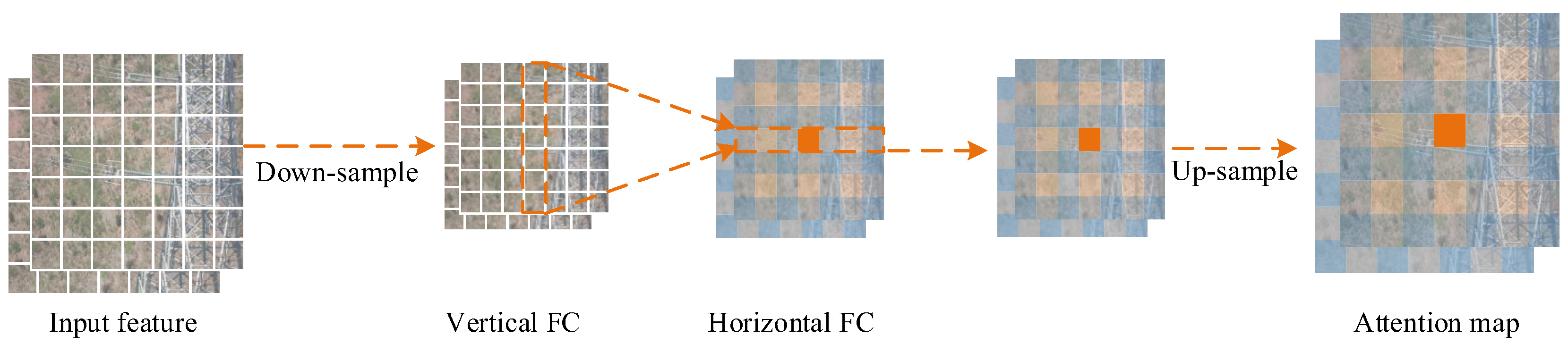
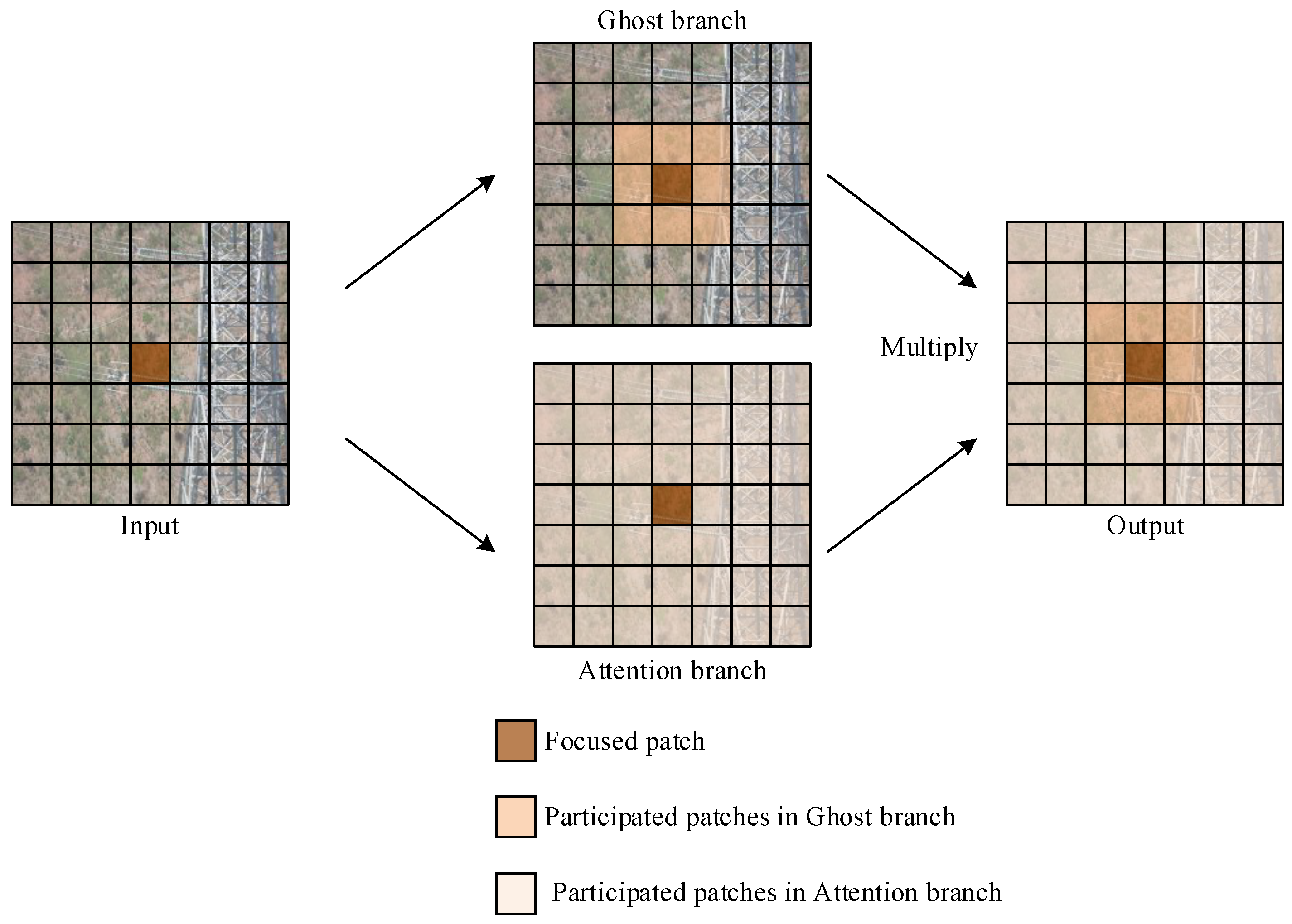
3.2. Decoupling the Fully Connected Attention Mechanism
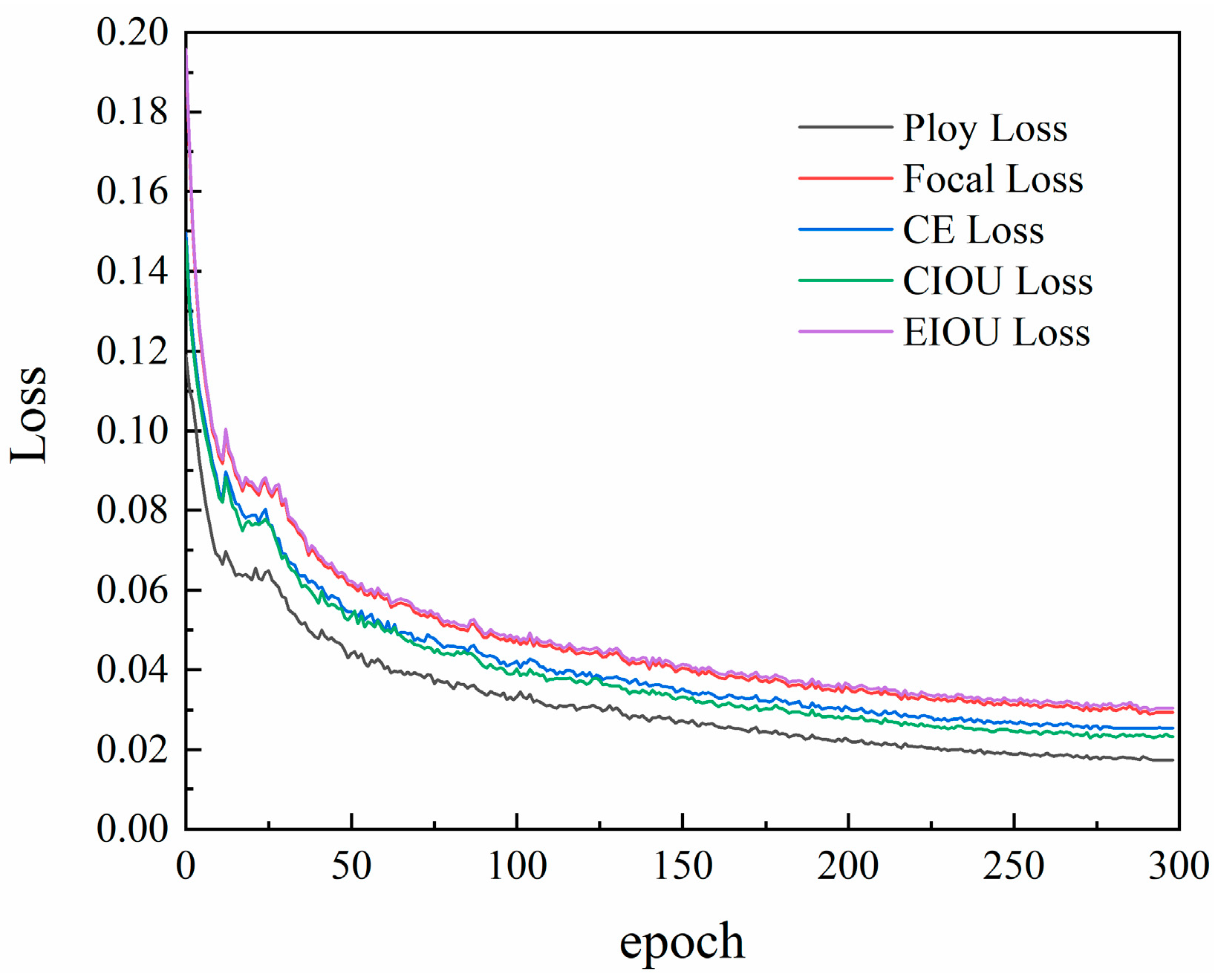
3.3. Loss Function Improvement
4. Experimental Results and Analysis
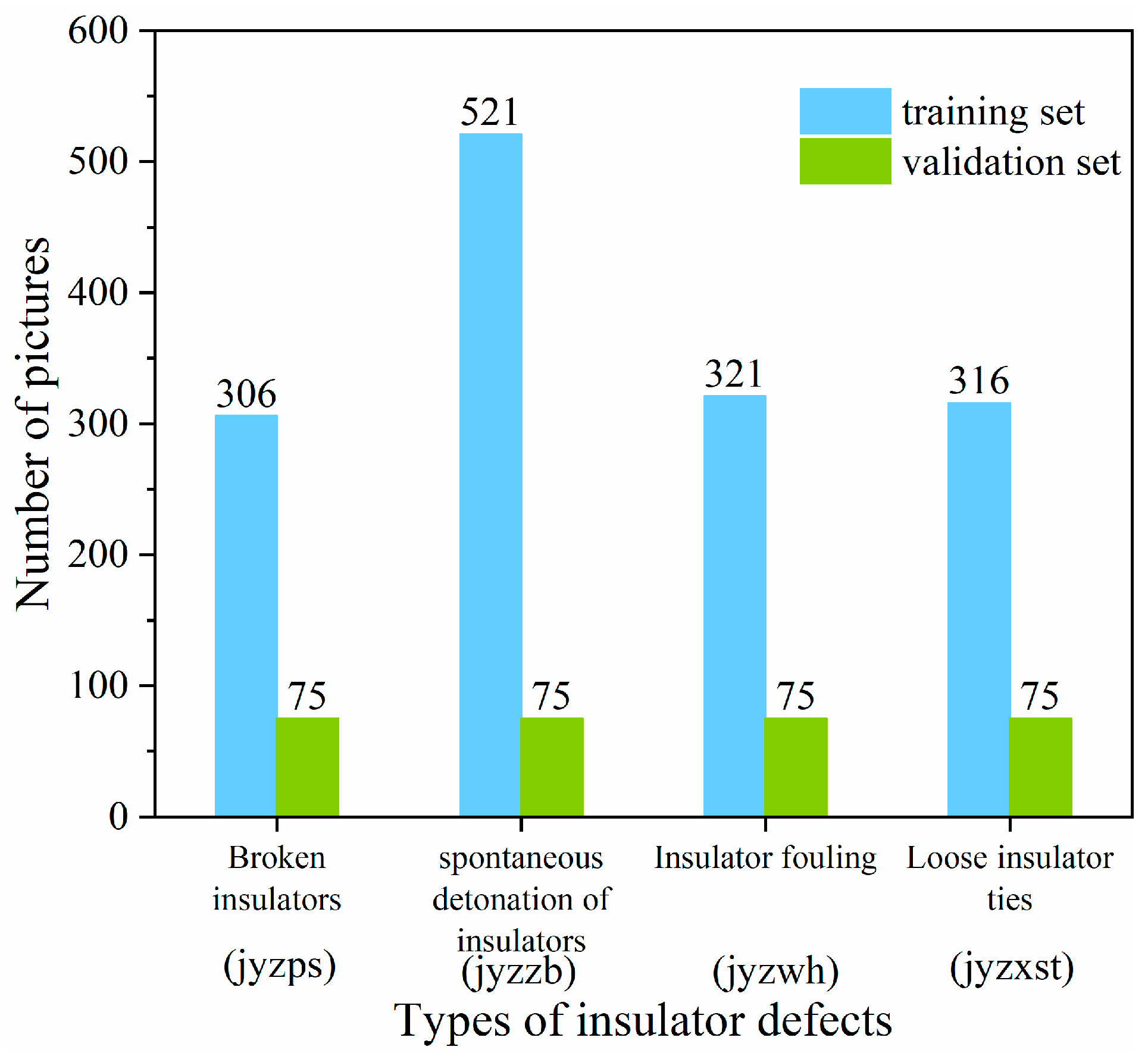
4.1. Experimental Environment and Evaluation Indicators
4.1.1. Experimental Environment
4.1.2. Evaluation Index
4.2. Comparison of Ablation Experiments
4.2.1. Input Section to Add HSMF Noise Reduction Network Effect
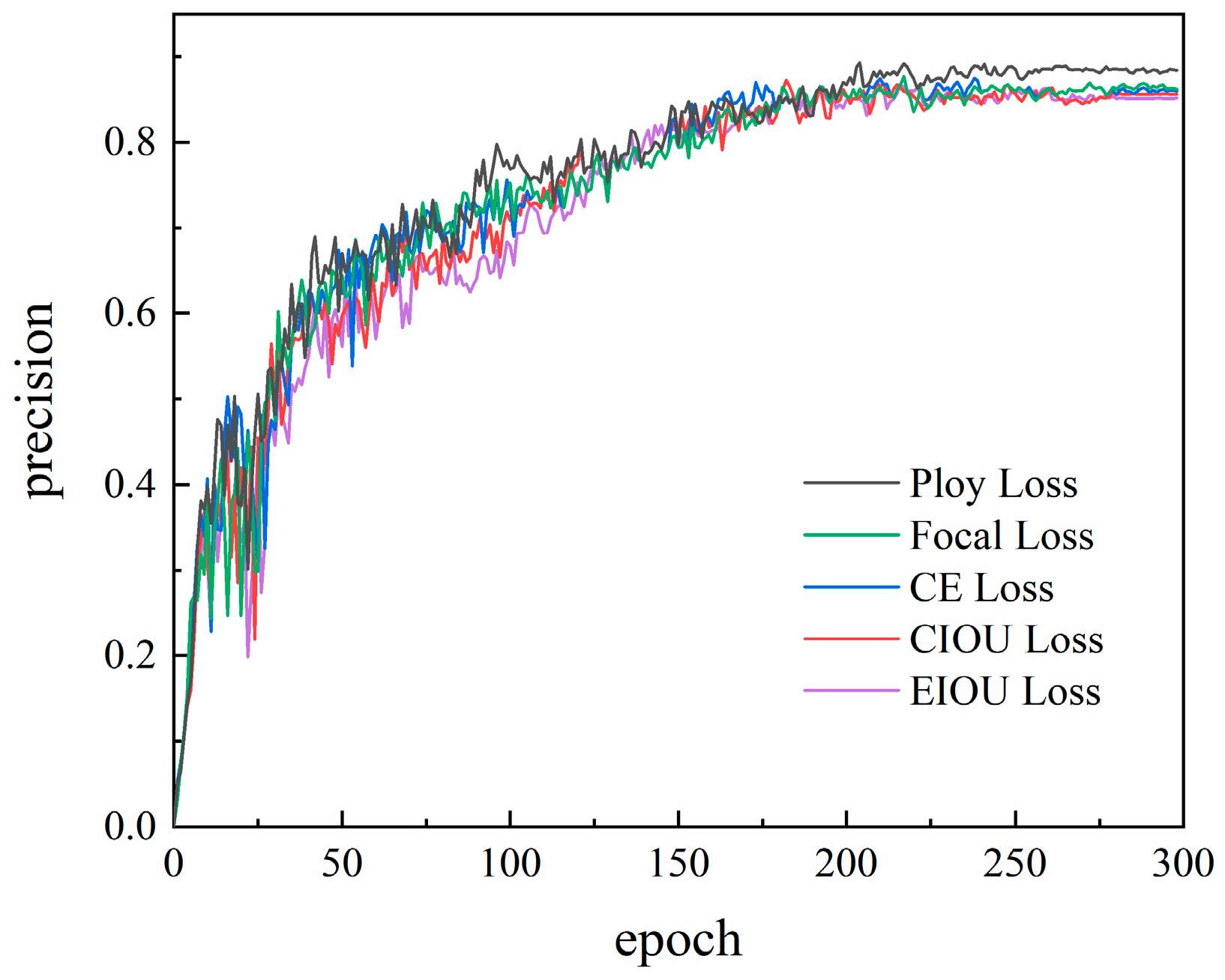
4.2.2. Improvement of the Loss Function
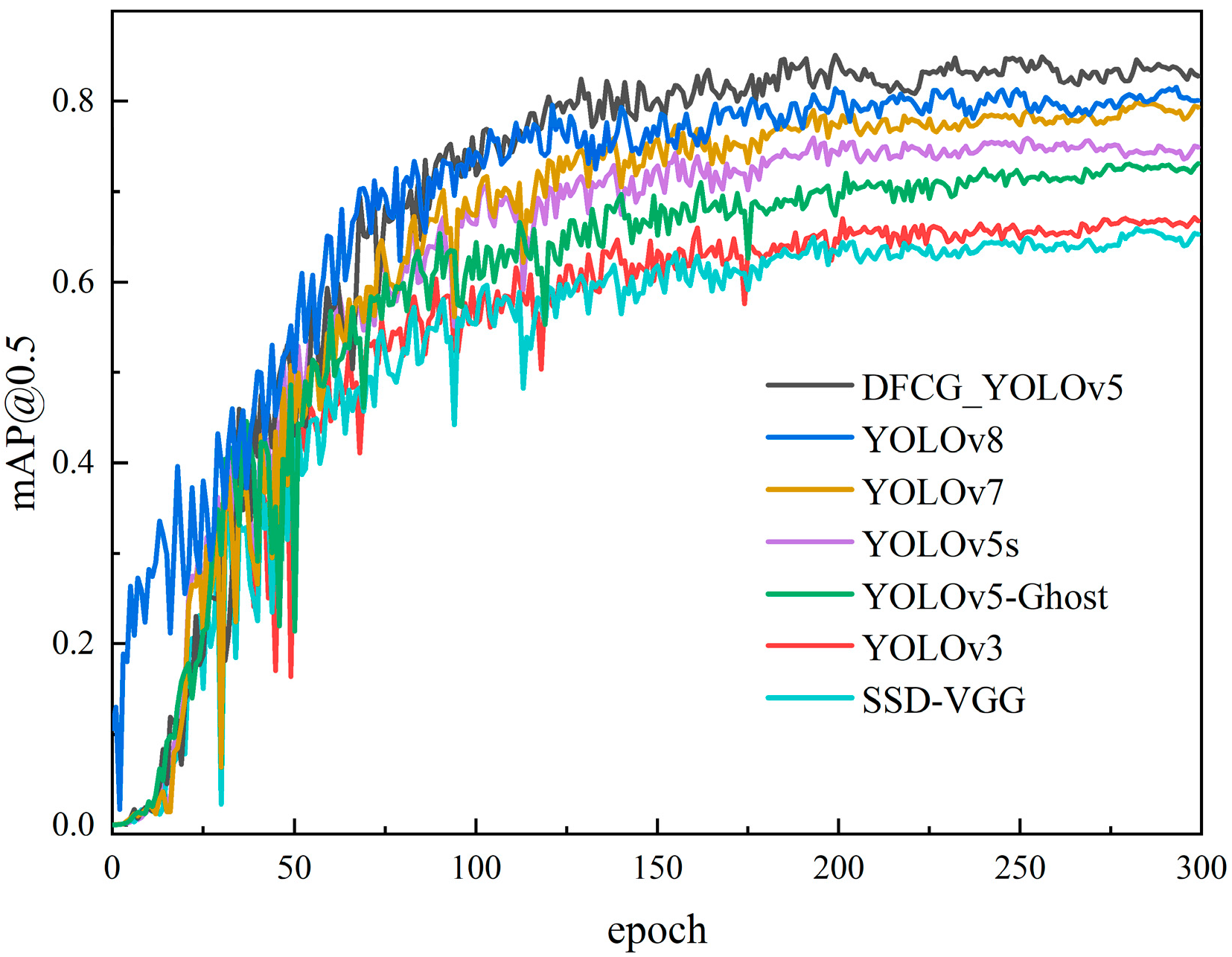
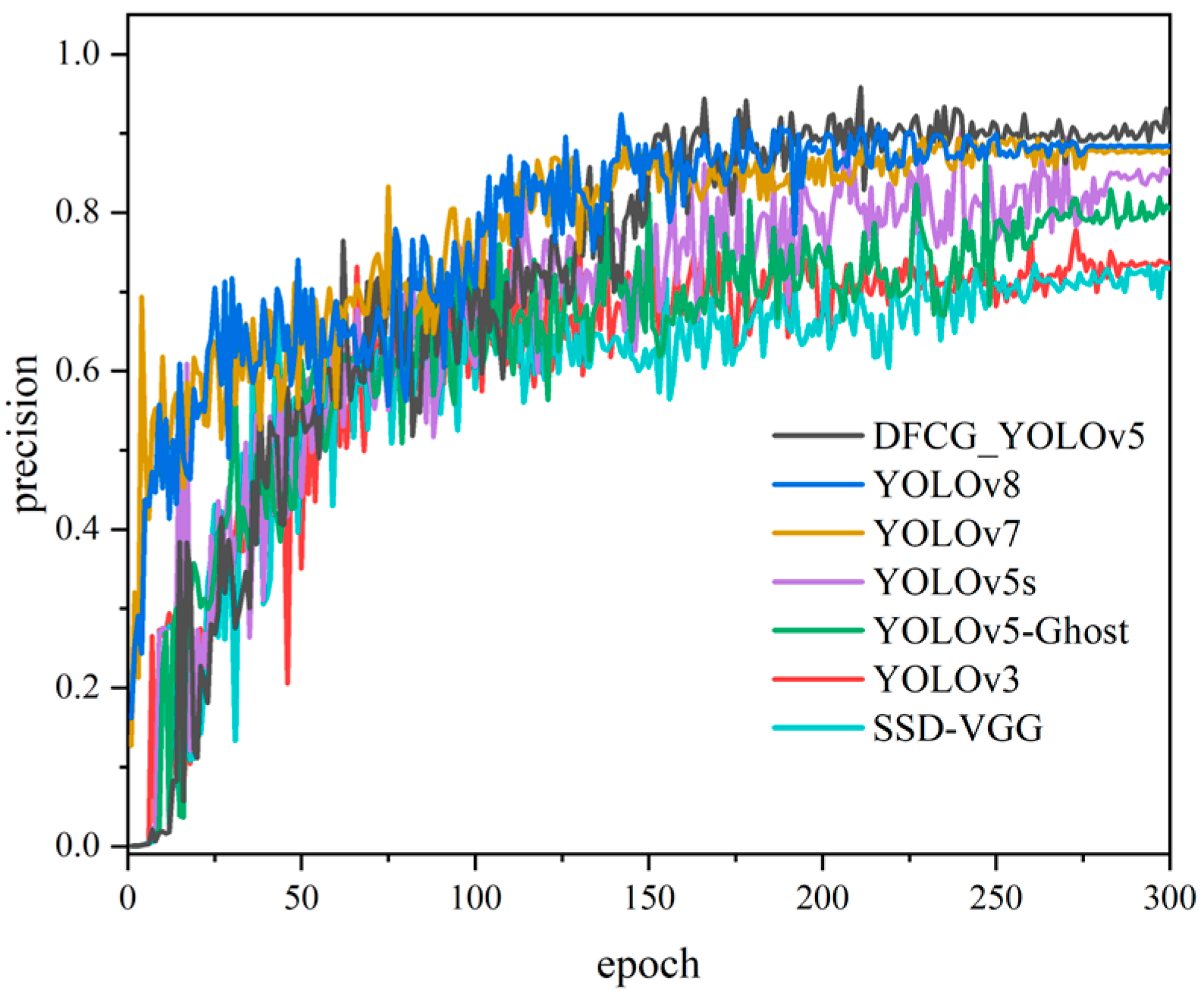
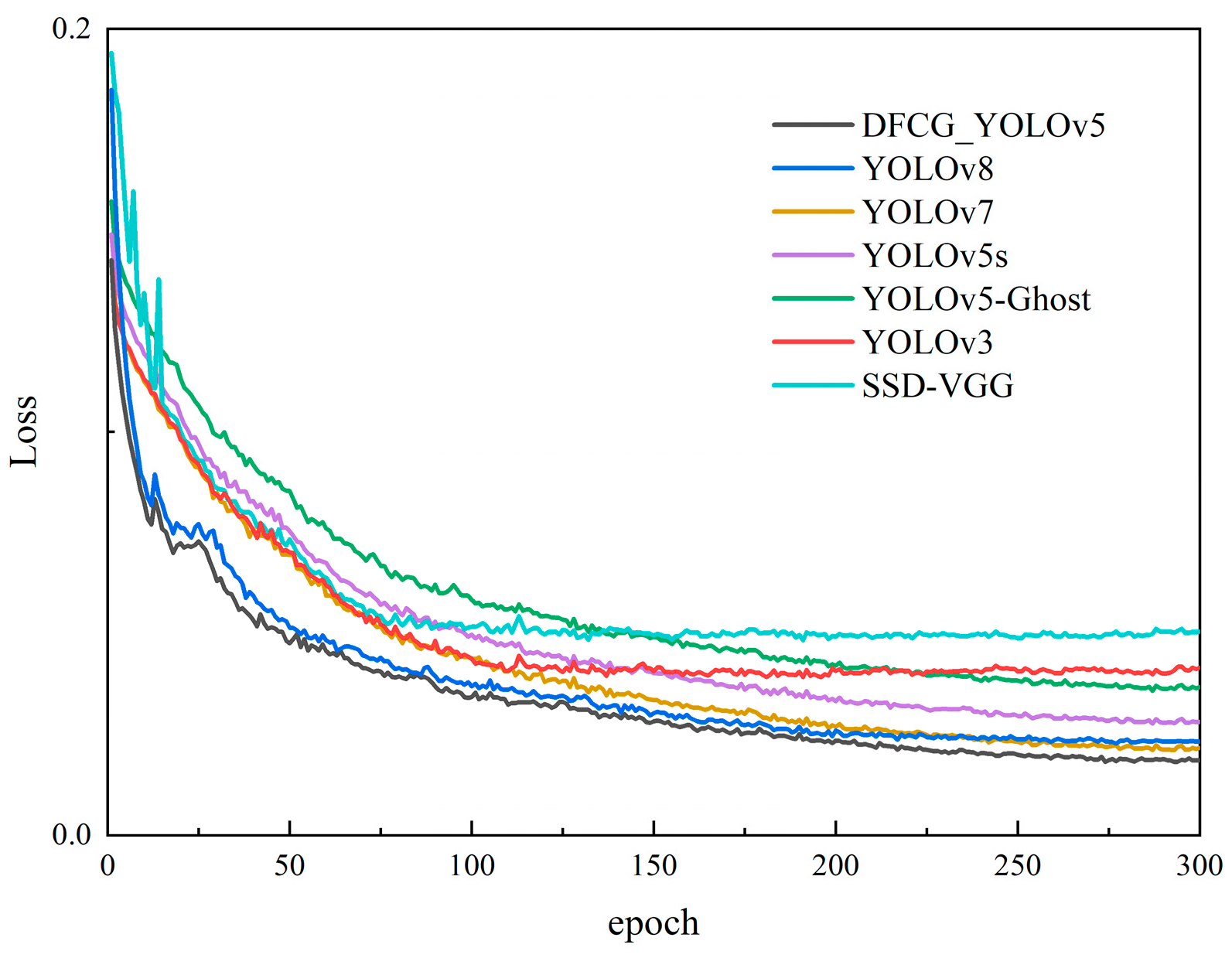
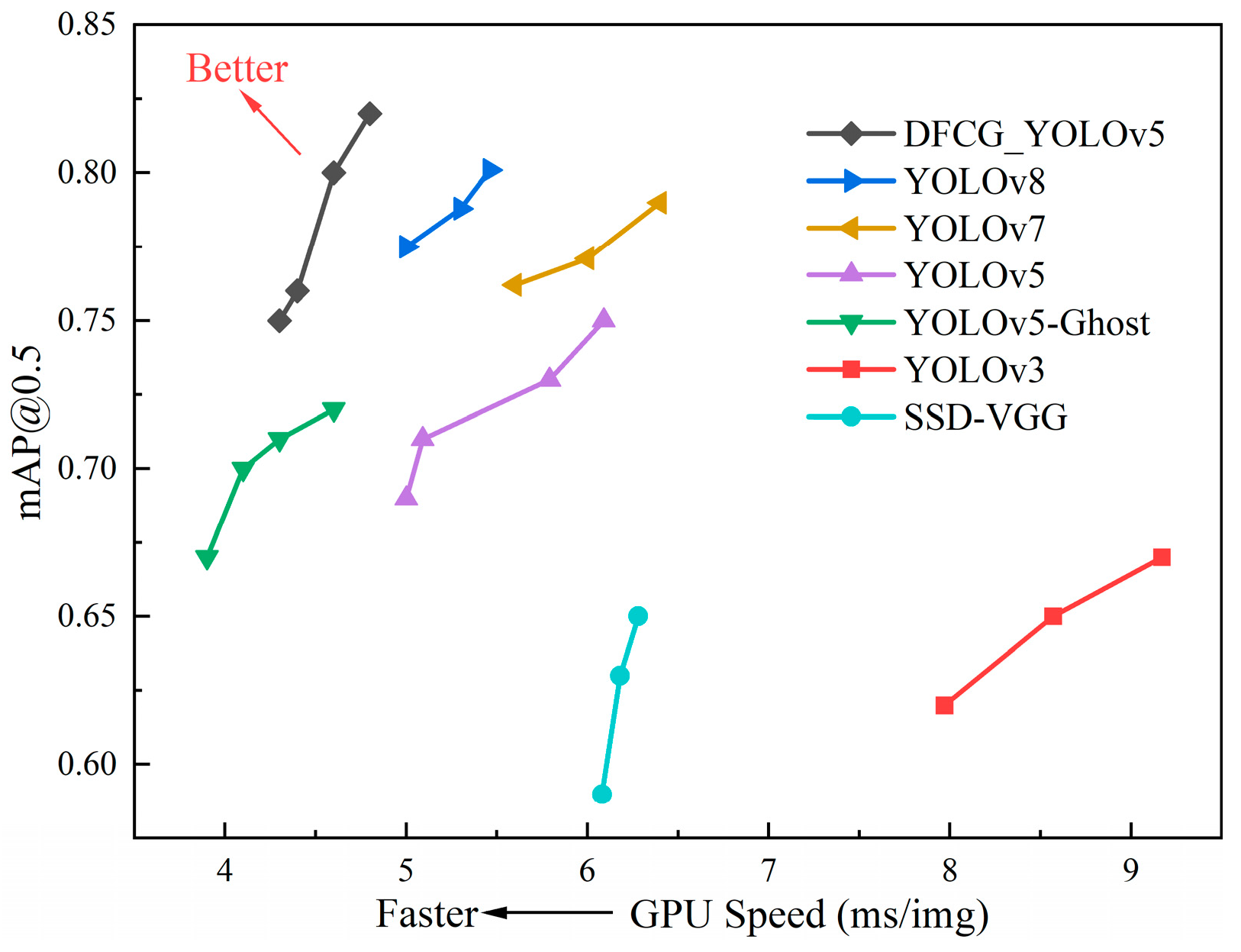
4.2.3. DFCG_YOLOv5 Overall Detection Effect
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
| Algorithm A1: DFCG_YOLOv5 |
| Input: input_size = (640, 640) num_classes = 80 # Define the size and number of anchor boxes anchors = [(10, 13), (16, 30), (33, 23), (30, 61), (62, 45), (59, 119), (116, 90), (156, 198), (373, 326)] num_anchors = len(anchors) # Defining the network structure def yolov5(input): // Backbone x = Conv(input, 32, 3, stride = 2) |
| 1: x = DFC_GhostBottleneck (x, 64, 3, n = 1) 2: x = DFC_GhostBottleneck (x, 128, 3, n = 3) 3: x = DFC_GhostBottleneck (x, 256, 3, n = 15) 4: out1 = x x = DFC_GhostBottleneck (x, 512, 3, n = 15) 5: out2 = x x = DFC_GhostBottleneck (x, 1024, 3, n = 7) 6: out3 = x // Head x = Conv(x, 512, 1) x = SPP(x) x = Conv(x, 1024, 1) out4 = x 7: # Output multi-scale feature map after DFC_Ghost network processing 8: output1 = Conv(out1, num_anchors * (num_classes + 5), 1) 9: output2 = Conv(out2, num_anchors * (num_classes + 5), 1) output3 = Conv(out3, num_anchors * (num_classes + 5), 1) 10: output4 = Conv(out4, num_anchors * (num_classes + 5), 1) return output1, output2, output3, output4 def poly1_cross_entropy_torch(logits, labels, class_number = 3, epsilon = 1.0): 11: # The predicted probability is calculated using softmax and multiplied with the one-hot coded true labels and summed to obtain the predicted probability of the correct category for each sample. 12: poly1 = torch.sum(F.one_hot(labels, class_number).float() * F.softmax(logits), dim = −1) 13: # Calculate the cross-entropy loss for each sample 14: ce_loss = F.cross_entropy(logits, labels, reduction = ‘none’) 15: # Adding a Poly1 term to the cross-entropy loss to increase the penalty for incorrect predictions 16: poly1_ce_loss = ce_loss + epsilon * (1-poly1) 17: return poly1_ce_loss |
References
- Taqi, A.; Beryozkina, S. Overhead transmission line thermographic inspection using a drone. In Proceedings of the 2019 IEEE 10th GCC Conference & Exhibition (GCC), Kuwait, Kuwait, 19–23 April 2019; pp. 1–6. [Google Scholar]
- Hao, J.; Zhou, Y.; Zhang, G. A review of target tracking algorithm based on UAV. In Proceedings of the 2018 IEEE International Conference on Cyborg and Bionic Systems (CBS), Shenzhen, China, 25–27 October 2018; pp. 328–333. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Zhao, M.; Shi, P.; Ren, R.; He, X.; Wei, X.; Yang, H. Crack detection and comparison study based on faster R-CNN and mask R-CNN. Sensors 2022, 22, 1215. [Google Scholar] [CrossRef] [PubMed]
- Yao, L.; Zhang, N.; Gao, A.; Wan, Y. Research on Fabric Defect Detection Technology Based on EDSR and Improved Faster RCNN. In Proceedings of the International Conference on Knowledge Science, Engineering and Management, Singapore, 6–8 August 2022; Springer International Publishing: Cham, Switzerland, 2022; pp. 477–488. [Google Scholar]
- Ni, H.; Wang, M.; Zhao, L. An improved Faster R-CNN for defect recognition of key components of transmission line. Math. Biosci. Eng. 2021, 18, 4679–4695. [Google Scholar] [CrossRef] [PubMed]
- Huang, Z.; Wang, J.; Fu, X.; Yu, T.; Guo, Y.; Wang, R. DC-SPP-YOLO: Dense connection and spatial pyramid pooling based YOLO for object detection. Inf. Sci. 2020, 522, 241–258. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Zhang, X.; Zhang, L.; Li, D. Transmission line abnormal target detection based on machine learning yolo v3. In Proceedings of the 2019 IEEE International Conference on Advanced Mechatronic Systems (ICAMechS), Shiga, Japan, 26–28 August 2019; pp. 344–348. [Google Scholar]
- Zeng, T.; Li, S.; Song, Q.; Zhong, F.; Wei, X. Lightweight tomato real-time detection method based on improved YOLO and mobile deployment. Comput. Electron. Agric. 2023, 205, 107625. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Li, L.; Wang, Z.; Zhang, T. Gbh-yolov5: Ghost convolution with bottleneckcsp and tiny target prediction head incorporating yolov5 for pv panel defect detection. Electronics 2023, 12, 561. [Google Scholar] [CrossRef]
- Gao, J.; Chen, X.; Lin, D. Insulator defect detection based on improved YOLOv5. In Proceedings of the 2021 5th IEEE Asian Conference on Artificial Intelligence Technology (ACAIT), Haikou, China, 29–31 October 2021; pp. 53–58. [Google Scholar]
- Zhang, T.; Zhang, Y.; Xin, M.; Liao, J.; Xie, Q. A Light-Weight Network for Small Insulator and Defect Detection Using UAV Imaging Based on Improved YOLOv5. Sensors 2023, 23, 5249. [Google Scholar] [CrossRef]
- Hao, K.; Chen, G.; Zhao, L.; Li, Z.; Liu, Y.; Wang, C. An insulator defect detection model in aerial images based on multiscale feature pyramid network. IEEE Trans. Instrum. Meas. 2022, 71, 3522412. [Google Scholar] [CrossRef]
- Cao, Z.; Mei, F.; Zhang, D.; Liu, B.; Wang, Y.; Hou, W. Recognition and Detection of Persimmon in a Natural Environment Based on an Improved YOLOv5 Model. Electronics 2023, 12, 785. [Google Scholar] [CrossRef]
- Li, Y.; Huang, H.; Xie, Q.; Yao, L.; Chen, Q. Research on a surface defect detection algorithm based on MobileNet-SSD. Appl. Sci. 2018, 8, 1678. [Google Scholar] [CrossRef]
- Jian, P.; Guo, F.; Pan, C.; Wang, Y.; Yang, Y.; Li, Y. Interpretable Geometry Problem Solving Using Improved RetinaNet and Graph Convolutional Network. Electronics 2023, 12, 4578. [Google Scholar] [CrossRef]
- Tian, R.; Jia, M. DCC-CenterNet: A rapid detection method for steel surface defects. Measurement 2022, 187, 110211. [Google Scholar] [CrossRef]
- Han, G.; Yuan, Q.; Zhao, F.; Wang, R.; Zhao, L.; Li, S.; Qin, L. An Improved Algorithm for Insulator and Defect Detection Based on YOLOv4. Electronics 2023, 12, 933. [Google Scholar] [CrossRef]
- Cao, M.; Fu, H.; Zhu, J.; Cai, C. Lightweight tea bud recognition network integrating GhostNet and YOLOv5. Math. Biosci. Eng. MBE 2022, 19, 12897–12914. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 390–391. [Google Scholar]
- Tang, J.; Liu, S.; Zheng, B.; Zhang, J.; Wang, B.; Yang, M. Smoking behavior detection based on improved YOLOv5s algorithm. In Proceedings of the 2021 9th IEEE International Symposium on Next Generation Electronics (ISNE), Changsha, China, 9–11 July 2021; pp. 1–4. [Google Scholar]
- Huang, Y.; Zhou, Y.; Lan, J.; Deng, Y.; Gao, Q.; Tong, T. Ghost Feature Network for Super-Resolution. In Proceedings of the 2020 IEEE Cross Strait Radio Science & Wireless Technology Conference (CSRSWTC), Fuzhou, China, 13–16 December 2020; pp. 1–3. [Google Scholar]
- Nodes, T.; Gallagher, N. Median filters: Some modifications and their properties. IEEE Trans. Acoust. Speech Signal Process. 1982, 30, 739–746. [Google Scholar] [CrossRef]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2021, 52, 8574–8586. [Google Scholar] [CrossRef] [PubMed]
- Li, R.; Huang, W.; Liu, C.; Chen, P. Remote Sensing Image Detection Algorithm Based on GhostNetv2 Improved YOLOv5s Algorithm. In Proceedings of the 2023 8th IEEE International Conference on Information Systems Engineering (ICISE), Dalian, China, 23–25 June 2023; pp. 193–196. [Google Scholar]
- Cao, J.; Bao, W.; Shang, H.; Yuan, M.; Cheng, Q. GCL-YOLO: A GhostConv-Based Lightweight YOLO Network for UAV Small Object Detection. Remote Sens. 2023, 15, 4932. [Google Scholar] [CrossRef]
- Zheng, Q.; Xu, S.; Liu, C.; Li, Y.; He, Q. Real-time Lightweight Target Detection Network under Autonomous Driving. J. Phys. Conf. Ser. 2023, 2644, 012003. [Google Scholar] [CrossRef]
- Peng, H.; Yu, S. A systematic IOU-related method: Beyond simplified regression for better localization. IEEE Trans. Image Process. 2021, 30, 5032–5044. [Google Scholar] [CrossRef]
- Zhang, Y.F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Zhang, Z.; Sabuncu, M. Generalized cross entropy loss for training deep neural networks with noisy labels. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Wei, X. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, G.; Chen, Y.; An, P.; Hong, H.; Hu, J.; Huang, T. UAV-YOLOv8: A Small-Object-Detection Model Based on Improved YOLOv8 for UAV Aerial Photography Scenarios. Sensors 2023, 23, 7190. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environmental Configuration | Parameter |
|---|---|
| operating system | Window10 |
| GPU | NVIDIA Quadro P4000(8 G) |
| CPU | Intel(R) Core (TM)i9-9900K |
| deep learning model framework | Pytorch 1.7.1 |
| GPU acceleration environment | CUDA 11.0.2 |
| programming language | Python3.8 |
| Noise Density | (all) P | (all) R | (all) mAp@0.5 | (all) mAp@0.5:0.95 |
|---|---|---|---|---|
| 0 | 0.856 | 0.743 | 0.805 | 0.596 |
| 0.1 | 0.821 | 0.740 | 0.759 | 0.571 |
| 0.3 | 0.814 | 0.732 | 0.747 | 0.570 |
| 0.5 | 0.803 | 0.721 | 0.736 | 0.567 |
| 0.7 | 0.801 | 0.703 | 0.729 | 0.561 |
| Noise Reduction Rating | (all) P | (all) R | (all) mAp@0.5 | (all) mAp@0.5:0.95 |
|---|---|---|---|---|
| 0.1 | 0.849 | 0.742 | 0.789 | 0.589 |
| 0.3 | 0.840 | 0.730 | 0.778 | 0.584 |
| 0.5 | 0.836 | 0.732 | 0.769 | 0.583 |
| 0.7 | 0.825 | 0.726 | 0.760 | 0.581 |
| Parameter Value | (all) P | (all) R | (all) mAp@0.5 | (all) mAp@0.5:0.95 |
|---|---|---|---|---|
| 1 | 0.862 | 0.772 | 0.749 | 0.605 |
| 3 | 0.874 | 0.765 | 0.754 | 0.609 |
| 5 | 0.883 | 0.756 | 0.769 | 0.612 |
| 7 | 0.877 | 0.739 | 0.762 | 0.607 |
| 9 | 0.869 | 0.755 | 0.754 | 0.604 |
| Type of Loss Function | (all) P | (all) R | (all) mAp@0.5 | (all) mAp@0.5:0.95 |
|---|---|---|---|---|
| CIOU Loss | 0.856 | 0.743 | 0.751 | 0.596 |
| EIOU Loss | 0.851 | 0.731 | 0.742 | 0.592 |
| CE Loss | 0.862 | 0.736 | 0.759 | 0.599 |
| Focal Loss | 0.859 | 0.742 | 0.752 | 0.592 |
| Ploy Loss | 0.883 | 0.756 | 0.769 | 0.612 |
| Method | (all) P | (all) R | (all) mAp@0.5 | FPS (Hz) |
|---|---|---|---|---|
| YOLOv3 | 0.734 | 0.628 | 0.666 | 109 |
| SSD-VGG | 0.728 | 0.636 | 0.651 | 159 |
| YOLOv5s | 0.856 | 0.743 | 0.751 | 139 |
| YOLOv5m | 0.863 | 0.721 | 0.779 | 102 |
| YOLOv5-Ghost | 0.803 | 0.692 | 0.727 | 218 |
| YOLOv6m | 0.871 | 0.716 | 0.791 | 112 |
| YOLOv7 | 0.879 | 0.738 | 0.792 | 155 |
| YOLOv8 | 0.885 | 0.741 | 0.801 | 183 |
| DFCG_YOLOv5 | 0.899 | 0.748 | 0.822 | 207 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, Z.; Lei, Y.; Shen, F.; Zhou, S. Application of Improved YOLOv5 Algorithm in Lightweight Transmission Line Small Target Defect Detection. Electronics 2024, 13, 305. https://doi.org/10.3390/electronics13020305
Yu Z, Lei Y, Shen F, Zhou S. Application of Improved YOLOv5 Algorithm in Lightweight Transmission Line Small Target Defect Detection. Electronics. 2024; 13(2):305. https://doi.org/10.3390/electronics13020305
Chicago/Turabian StyleYu, Zhilong, Yanqiao Lei, Feng Shen, and Shuai Zhou. 2024. "Application of Improved YOLOv5 Algorithm in Lightweight Transmission Line Small Target Defect Detection" Electronics 13, no. 2: 305. https://doi.org/10.3390/electronics13020305