
A Method for Unseen Object Six Degrees of Freedom Pose Estimation Based on Segment Anything Model and Hybrid Distance Optimization

Abstract
:
1. Introduction
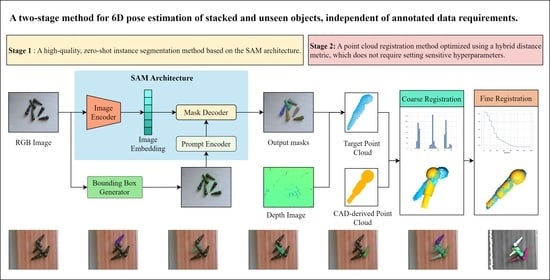
- A two-stage method for 6-DoF pose estimation of stacked and unknown objects, independent of annotated data requirements.
- A high-quality, zero-shot instance segmentation method based on the SAM architecture.
- A point cloud registration method optimized using a hybrid distance metric, which does not require setting sensitive hyperparameters.
2. Related Work
2.1. Pose Estimation with RGB-D Data
2.2. Unseen Object Instance Segmentation
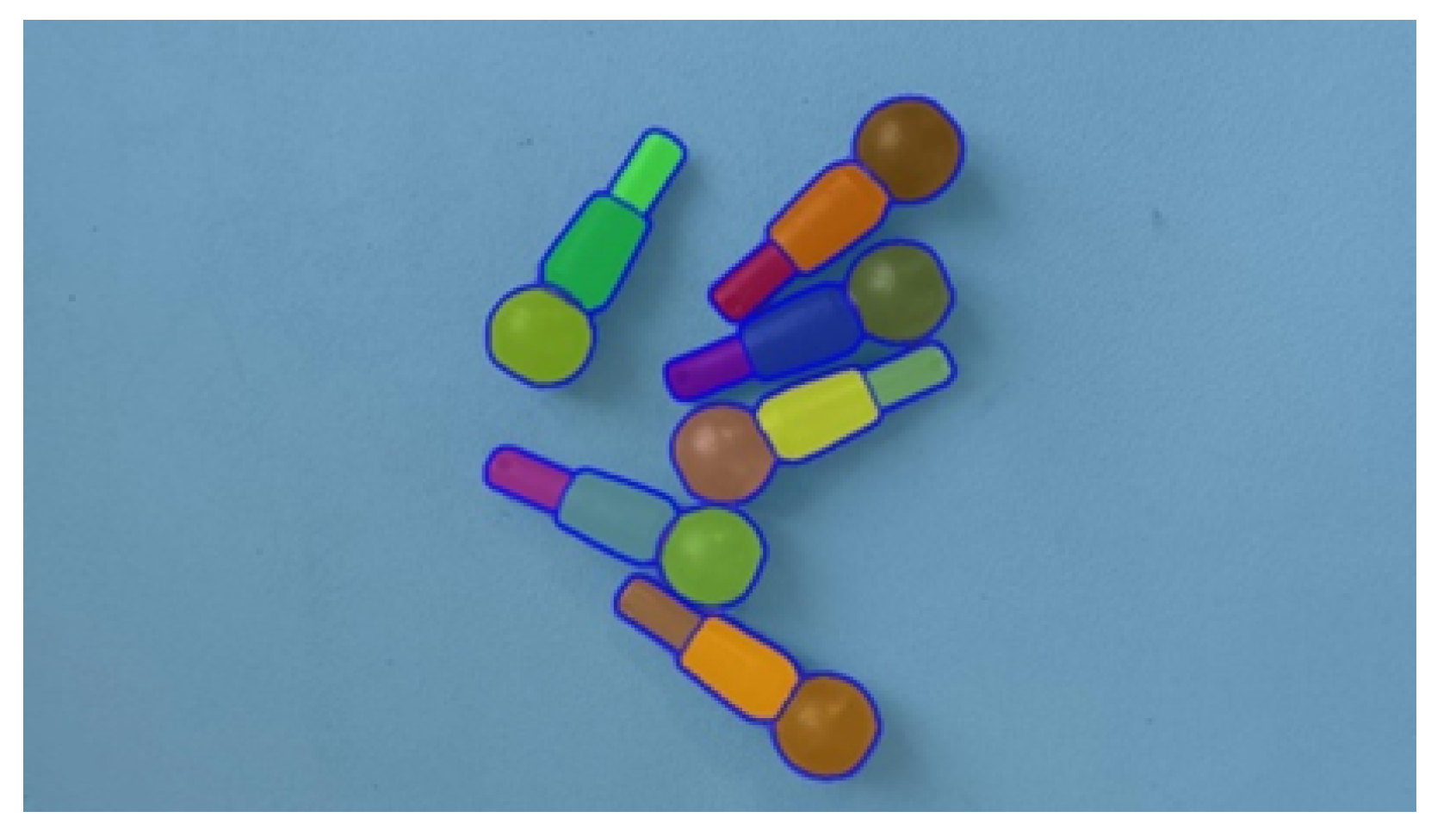
3. Materials and Methods
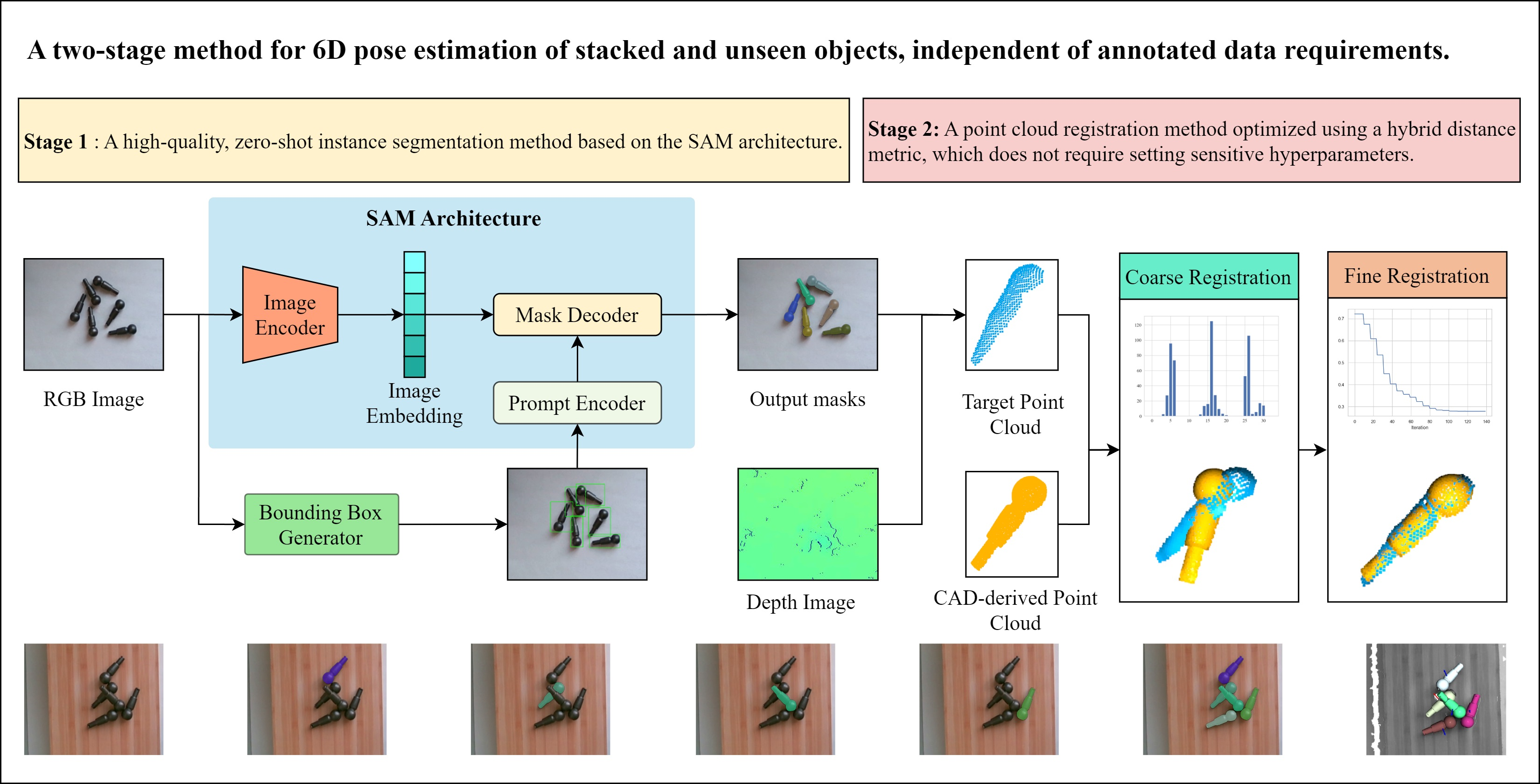
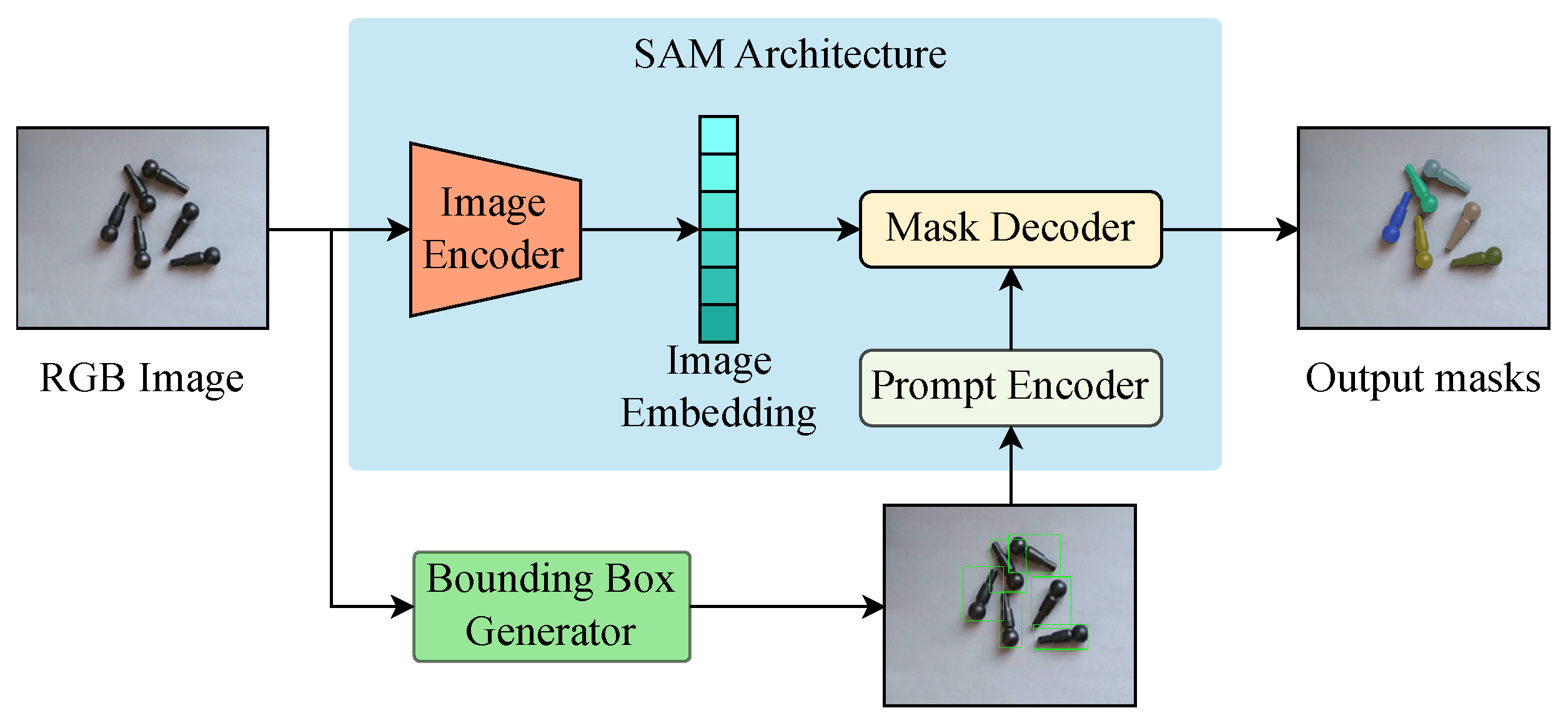
3.1. Context-Aware Enhanced SAM
3.1.1. Image Encoder
3.1.2. Global Context Token
3.1.3. Bounding Box Generator
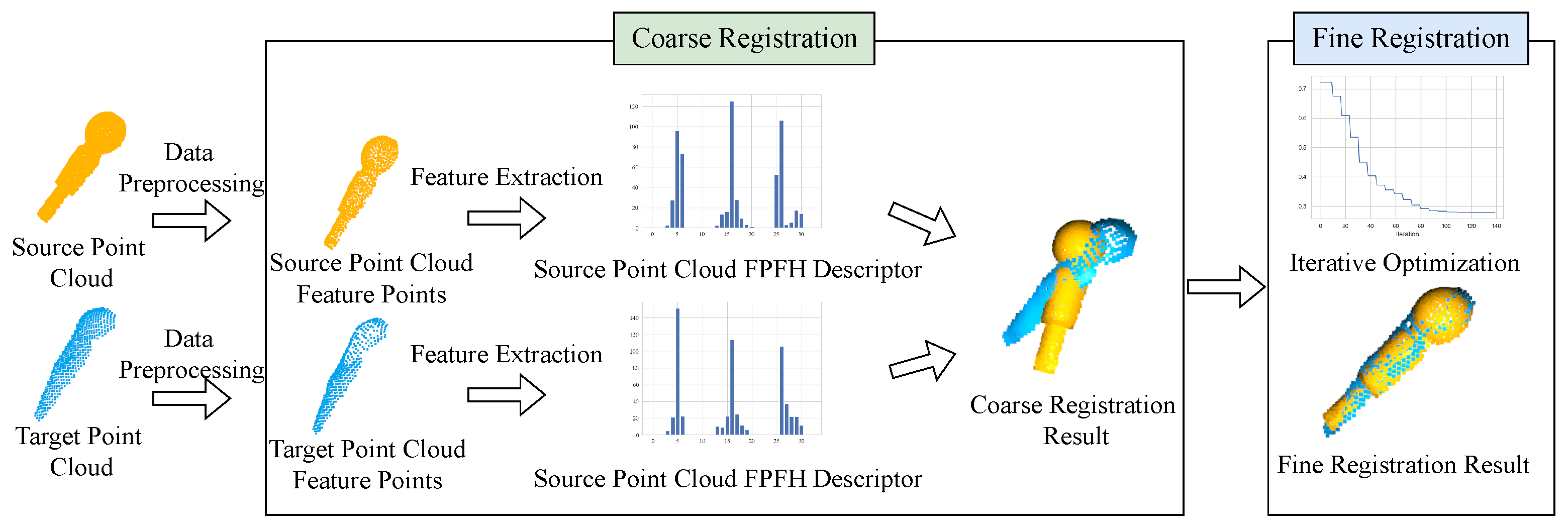
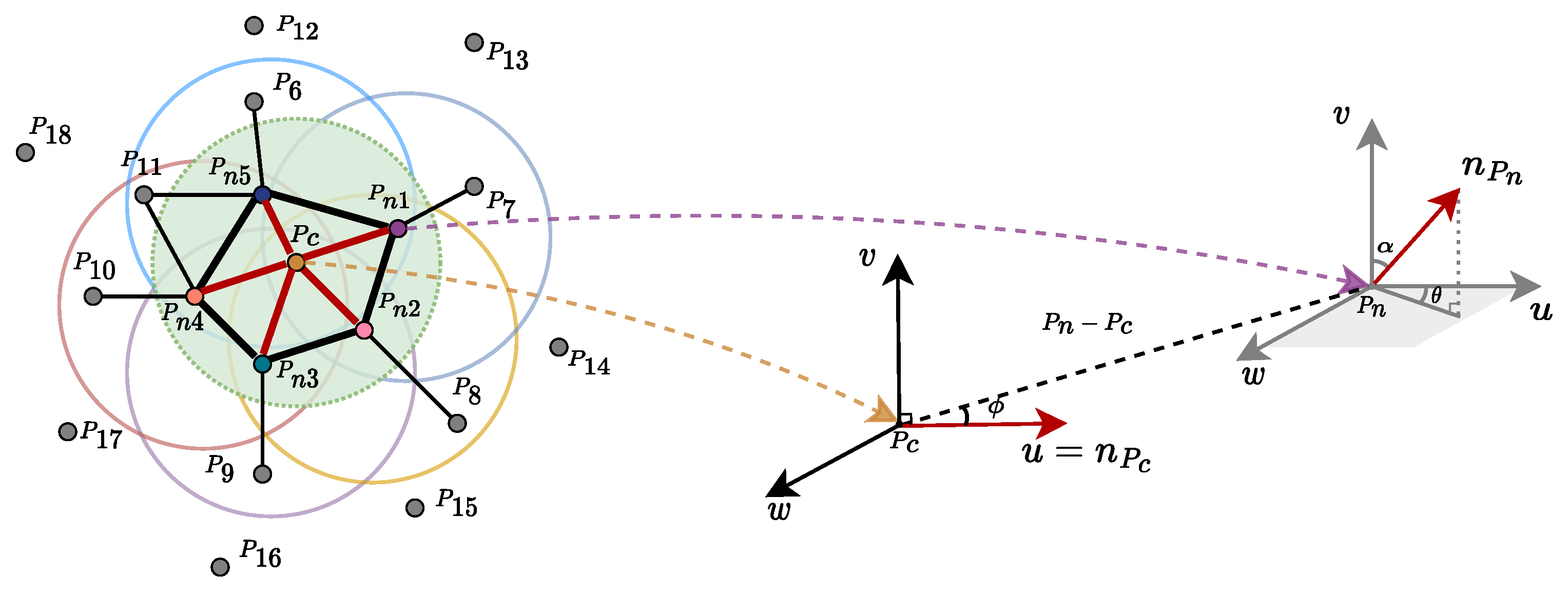
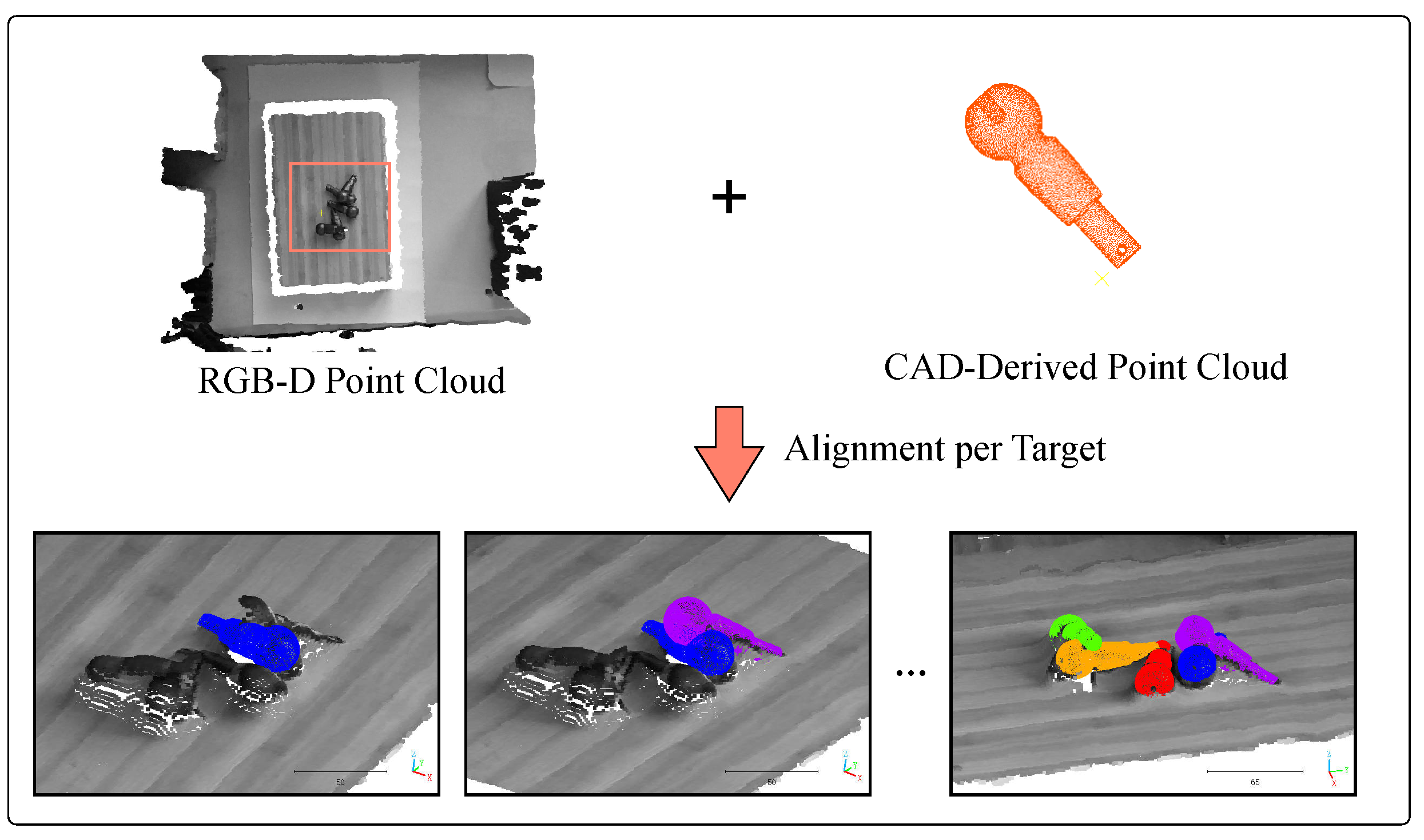
3.2. Point Cloud Registration
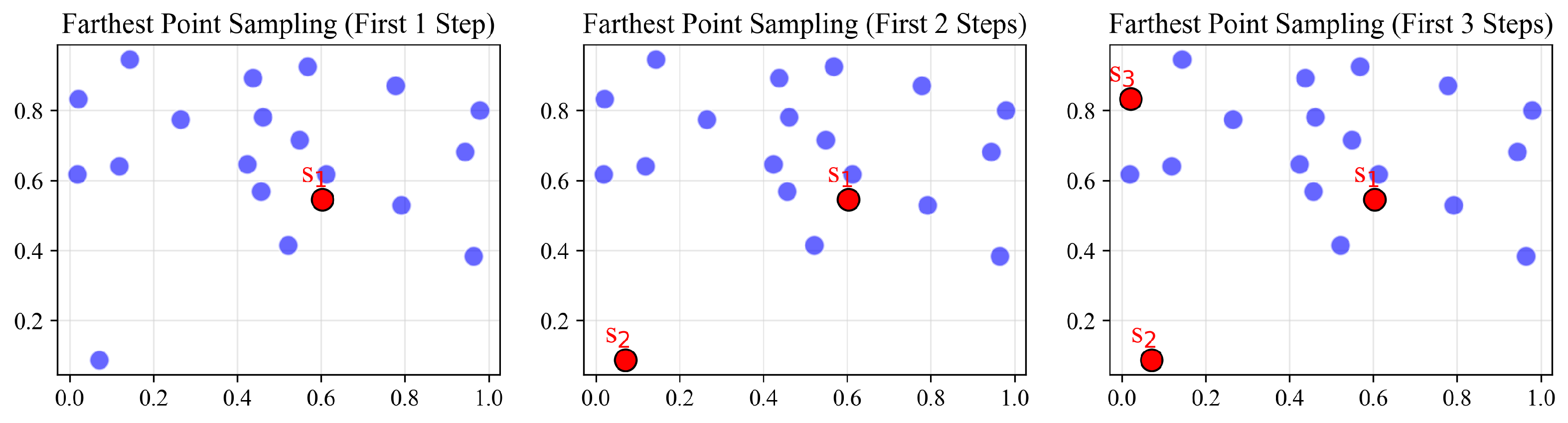
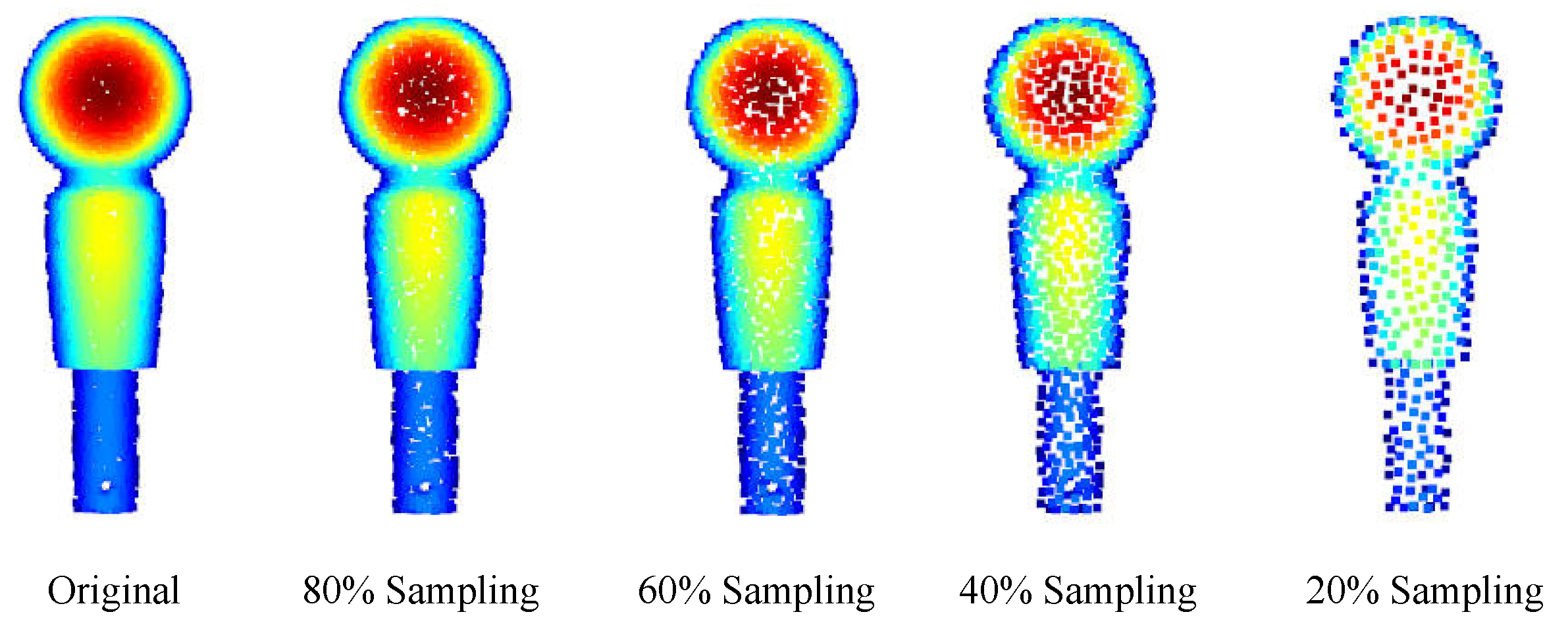
3.2.1. Data Preprocessing
- Randomly select an initial point from the dataset as the first sample point.
- Compute the Euclidean distance from each point in the dataset to the already selected sample points, providing necessary distance information for selecting the next sample point.
- In each iteration round, select the point with the maximum distance to the nearest point in the current sample point set as the new sample point. This selection process is based on the farthest point criterion, aimed at maximizing the distance between the new sample point and the existing sample point set.
- After each new sample point selection, update the shortest distance from each point in the dataset to the nearest sample point, ensuring that the most representative point relative to the current sample point set is chosen in each iteration.
- Repeat the above iteration process until the predetermined number of sample points is reached or other stopping criteria are met.
3.2.2. Point Cloud Feature Extraction
3.2.3. Point Cloud Coarse Registration
3.2.4. Point Cloud Fine Registration
4. Results
4.1. CAE-SAM Experimental Results and Analysis
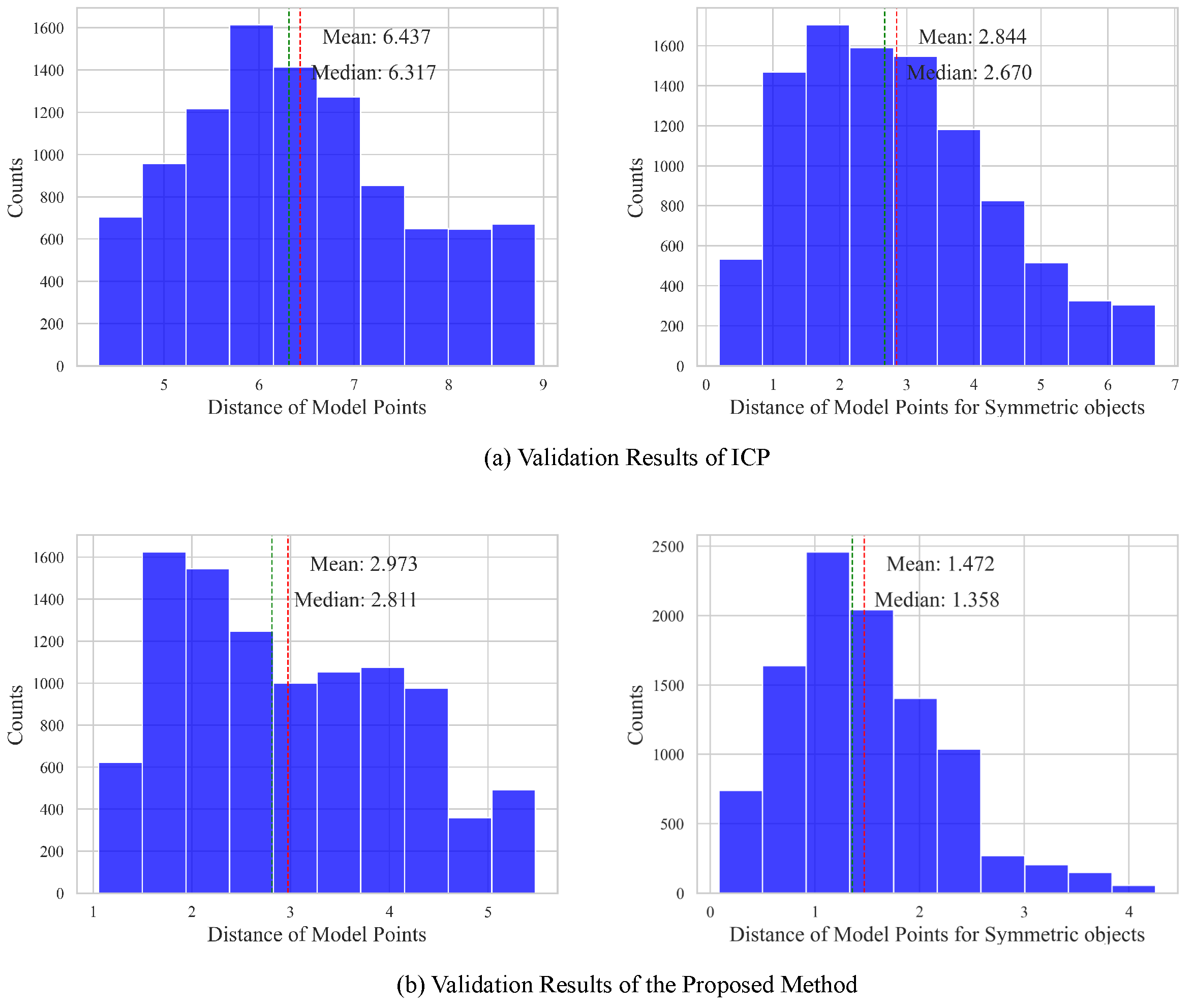
4.2. Pose Estimation Experimental Results and Analysis
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ye, Y.; Park, H. FusionNet: An End-to-End Hybrid Model for 6D Object Pose Estimation. Electronics 2023, 12, 4162. [Google Scholar] [CrossRef]
- Abdelaal, M.; Farag, R.M.; Saad, M.S.; Bahgat, A.; Emara, H.M.; El-Dessouki, A. Uncalibrated stereo vision with deep learning for 6-DOF pose estimation for a robot arm system. Robot. Auton. Syst. 2021, 145, 103847. [Google Scholar] [CrossRef]
- Deng, Y.; Chen, G.; Liu, X.; Sun, C.; Huang, Z.; Lin, S. 3D Pose Recognition of Small Special-Shaped Sheet Metal with Multi-Objective Overlapping. Electronics 2023, 12, 2613. [Google Scholar] [CrossRef]
- Liu, H.; Fang, S.; Zhang, Z.; Li, D.; Lin, K.; Wang, J. MFDNet: Collaborative poses perception and matrix Fisher distribution for head pose estimation. IEEE Trans. Multimed. 2021, 24, 2449–2460. [Google Scholar] [CrossRef]
- Du, G.; Wang, K.; Lian, S.; Zhao, K. Vision-based robotic grasping from object localization, object pose estimation to grasp estimation for parallel grippers: A review. Artif. Intell. Rev. 2021, 54, 1677–1734. [Google Scholar] [CrossRef]
- Yang, J.; Xue, W.; Ghavidel, S.; Waslander, S.L. 6d pose estimation for textureless objects on rgb frames using multi-view optimization. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 2905–2912. [Google Scholar]
- Geng, X.; Shi, F.; Cheng, X.; Jia, C.; Wang, M.; Chen, S.; Dai, H. SANet: A novel segmented attention mechanism and multi-level information fusion network for 6D object pose estimation. Comput. Commun. 2023, 207, 19–26. [Google Scholar] [CrossRef]
- Lee, T.; Lee, B.U.; Kim, M.; Kweon, I.S. Category-level metric scale object shape and pose estimation. IEEE Robot. Autom. Lett. 2021, 6, 8575–8582. [Google Scholar] [CrossRef]
- Zou, W.; Wu, D.; Tian, S.; Xiang, C.; Li, X.; Zhang, L. End-to-End 6DoF Pose Estimation From Monocular RGB Images. IEEE Trans. Consum. Electron. 2021, 67, 87–96. [Google Scholar] [CrossRef]
- Cheng, J.; Liu, P.; Zhang, Q.; Ma, H.; Wang, F.; Zhang, J. Real-Time and Efficient 6-D Pose Estimation from a Single RGB Image. IEEE Trans. Instrum. Meas. 2021, 70, 2515014. [Google Scholar] [CrossRef]
- Jantos, T.G.; Hamdad, M.A.; Granig, W.; Weiss, S.; Steinbrener, J. PoET: Pose Estimation Transformer for Single-View, Multi-Object 6D Pose Estimation. In Conference on Robot Learning; Proceedings of Machine Learning Research; Liu, K., Kulic, D., Ichnowski, J., Eds.; PMLR: London, UK, 2023; Volume 205, pp. 1060–1070. [Google Scholar]
- Li, F.; Vutukur, S.R.; Yu, H.; Shugurov, I.; Busam, B.; Yang, S.; Ilic, S. Nerf-pose: A first-reconstruct-then-regress approach for weakly-supervised 6d object pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 2123–2133. [Google Scholar]
- Guo, S.; Hu, Y.; Alvarez, J.M.; Salzmann, M. Knowledge Distillation for 6D Pose Estimation by Aligning Distributions of Local Predictions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 18633–18642. [Google Scholar]
- Li, Z.; Stamos, I. Depth-based 6DoF Object Pose Estimation using Swin Transformer. arXiv 2023, arXiv:2303.02133. [Google Scholar]
- Cai, D.; Heikkilä, J.; Rahtu, E. Ove6d: Object viewpoint encoding for depth-based 6d object pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6803–6813. [Google Scholar]
- Bruns, L.; Jensfelt, P. RGB-D-Based Categorical Object Pose and Shape Estimation: Methods, Datasets, and Evaluation. arXiv 2023, arXiv:2301.08147. [Google Scholar] [CrossRef]
- Wen, B.; Tremblay, J.; Blukis, V.; Tyree, S.; Müller, T.; Evans, A.; Fox, D.; Kautz, J.; Birchfield, S. BundleSDF: Neural 6-DoF Tracking and 3D Reconstruction of Unknown Objects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 606–617. [Google Scholar]
- He, Y.; Huang, H.; Fan, H.; Chen, Q.; Sun, J. Ffb6d: A full flow bidirectional fusion network for 6d pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3003–3013. [Google Scholar]
- He, Y.; Wang, Y.; Fan, H.; Sun, J.; Chen, Q. FS6D: Few-Shot 6D Pose Estimation of Novel Objects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 6814–6824. [Google Scholar]
- Wu, C.; Chen, L.; Wang, S.; Yang, H.; Jiang, J. Geometric-aware dense matching network for 6D pose estimation of objects from RGB-D images. Pattern Recognit. 2023, 137, 109293. [Google Scholar] [CrossRef]
- Petitjean, T.; Wu, Z.; Demonceaux, C.; Laligant, O. OLF: RGB-D adaptive late fusion for robust 6D pose estimation. In Proceedings of the Sixteenth International Conference on Quality Control by Artificial Vision, Albi, France, 6–8 June 2023; Volume 12749, pp. 132–140. [Google Scholar]
- Rekavandi, A.M.; Boussaid, F.; Seghouane, A.K.; Bennamoun, M. B-Pose: Bayesian Deep Network for Camera 6-DoF Pose Estimation from RGB Images. IEEE Robot. Autom. Lett. 2023, 8, 6747–6754. [Google Scholar] [CrossRef]
- Liu, X.; Wang, G.; Li, Y.; Ji, X. Catre: Iterative point clouds alignment for category-level object pose refinement. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 499–516. [Google Scholar]
- Gao, G.; Lauri, M.; Hu, X.; Zhang, J.; Frintrop, S. Cloudaae: Learning 6d object pose regression with on-line data synthesis on point clouds. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 11081–11087. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Zhang, J.; Yao, Y.; Deng, B. Fast and robust iterative closest point. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3450–3466. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment Anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Wang, C.; Xu, D.; Zhu, Y.; Martín-Martín, R.; Lu, C.; Fei-Fei, L.; Savarese, S. Densefusion: 6d object pose estimation by iterative dense fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3343–3352. [Google Scholar]
- He, Y.; Sun, W.; Huang, H.; Liu, J.; Fan, H.; Sun, J. Pvn3d: A deep point-wise 3d keypoints voting network for 6dof pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11632–11641. [Google Scholar]
- Wang, J.; Chen, K.; Dou, Q. Category-level 6D object pose estimation via cascaded relation and recurrent reconstruction networks. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 4807–4814. [Google Scholar]
- Lin, J.; Wei, Z.; Ding, C.; Jia, K. Category-level 6D object pose and size estimation using self-supervised deep prior deformation networks. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 19–34. [Google Scholar]
- Cao, H.; Dirnberger, L.; Bernardini, D.; Piazza, C.; Caccamo, M. 6IMPOSE: Bridging the reality gap in 6D pose estimation for robotic grasping. Front. Robot. AI 2023, 10, 1176492. [Google Scholar] [CrossRef]
- Zhou, J.; Chen, K.; Xu, L.; Dou, Q.; Qin, J. Deep fusion transformer network with weighted vector-wise keypoints voting for robust 6d object pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 13967–13977. [Google Scholar]
- Back, S.; Kim, J.; Kang, R.; Choi, S.; Lee, K. Segmenting unseen industrial components in a heavy clutter using rgb-d fusion and synthetic data. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 828–832. [Google Scholar]
- Back, S.; Lee, J.; Kim, T.; Noh, S.; Kang, R.; Bak, S.; Lee, K. Unseen object amodal instance segmentation via hierarchical occlusion modeling. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 5085–5092. [Google Scholar]
- Lu, Y.; Khargonkar, N.; Xu, Z.; Averill, C.; Palanisamy, K.; Hang, K.; Guo, Y.; Ruozzi, N.; Xiang, Y. Self-Supervised Unseen Object Instance Segmentation via Long-Term Robot Interaction. arXiv 2023, arXiv:2302.03793. [Google Scholar]
- Xu, M.; Zhang, Z.; Wei, F.; Hu, H.; Bai, X. Side adapter network for open-vocabulary semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 2945–2954. [Google Scholar]
- Xiang, Y.; Xie, C.; Mousavian, A.; Fox, D. Learning rgb-d feature embeddings for unseen object instance segmentation. In Proceedings of the Conference on Robot Learning, PMLR, London, UK, 8–11 November 2021; pp. 461–470. [Google Scholar]
- Xie, C.; Xiang, Y.; Mousavian, A.; Fox, D. Unseen object instance segmentation for robotic environments. IEEE Trans. Robot. 2021, 37, 1343–1359. [Google Scholar] [CrossRef]
- Zhao, X.; Ding, W.; An, Y.; Du, Y.; Yu, T.; Li, M.; Tang, M.; Wang, J. Fast Segment Anything. arXiv 2023, arXiv:2306.12156. [Google Scholar]
- Zhang, C.; Han, D.; Qiao, Y.; Kim, J.U.; Bae, S.H.; Lee, S.; Hong, C.S. Faster Segment Anything: Towards Lightweight SAM for Mobile Applications. arXiv 2023, arXiv:2306.14289. [Google Scholar]
- Ke, L.; Ye, M.; Danelljan, M.; Liu, Y.; Tai, Y.W.; Tang, C.K.; Yu, F. Segment Anything in High Quality. arXiv 2023, arXiv:2306.01567. [Google Scholar]
- Liu, S.; Zeng, Z.; Ren, T.; Li, F.; Zhang, H.; Yang, J.; Li, C.; Yang, J.; Su, H.; Zhu, J.; et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv 2023, arXiv:2303.05499. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Xie, Y.; Zhang, J.; Shen, C.; Xia, Y. Cotr: Efficiently bridging cnn and transformer for 3d medical image segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Proceedings, Part III 24. Springer: Berlin/Heidelberg, Germany, 2021; pp. 171–180. [Google Scholar]
- Liu, M.; Chai, Z.; Deng, H.; Liu, R. A CNN-transformer network with multiscale context aggregation for fine-grained cropland change detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4297–4306. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Li, J.; Zhou, J.; Xiong, Y.; Chen, X.; Chakrabarti, C. An adjustable farthest point sampling method for approximately-sorted point cloud data. In Proceedings of the 2022 IEEE Workshop on Signal Processing Systems (SiPS), Rennes, France, 2–4 November 2022; pp. 1–6. [Google Scholar]
- Wu, L.s.; Wang, G.l.; Hu, Y. Iterative closest point registration for fast point feature histogram features of a volume density optimization algorithm. Meas. Control 2020, 53, 29–39. [Google Scholar] [CrossRef]
- Zhou, Q.Y.; Park, J.; Koltun, V. Fast global registration. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 766–782. [Google Scholar]
- Cheng, B.; Girshick, R.; Dollár, P.; Berg, A.C.; Kirillov, A. Boundary IoU: Improving object-centric image segmentation evaluation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15334–15342. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | DIS | COIFT | HRSOD | ThinObject | Average | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| mIoU | mBIoU | mIoU | mBIoU | mIoU | mBIoU | mIoU | mBIoU | mIoU | mBIoU | |
| SAM | 0.620 | 0.528 | 0.921 | 0.865 | 0.902 | 0.831 | 0.736 | 0.618 | 0.795 | 0.711 |
| HQ-SAM | 0.786 | 0.704 | 0.948 | 0.901 | 0.936 | 0.869 | 0.895 | 0.799 | 0.891 | 0.818 |
| CAE-SAM | 0.813 | 0.733 | 0.956 | 0.913 | 0.946 | 0.891 | 0.934 | 0.845 | 0.912 | 0.846 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xin, L.; Lin, H.; Liu, X.; Wang, S. A Method for Unseen Object Six Degrees of Freedom Pose Estimation Based on Segment Anything Model and Hybrid Distance Optimization. Electronics 2024, 13, 774. https://doi.org/10.3390/electronics13040774
Xin L, Lin H, Liu X, Wang S. A Method for Unseen Object Six Degrees of Freedom Pose Estimation Based on Segment Anything Model and Hybrid Distance Optimization. Electronics. 2024; 13(4):774. https://doi.org/10.3390/electronics13040774
Chicago/Turabian StyleXin, Li, Hu Lin, Xinjun Liu, and Shiyu Wang. 2024. "A Method for Unseen Object Six Degrees of Freedom Pose Estimation Based on Segment Anything Model and Hybrid Distance Optimization" Electronics 13, no. 4: 774. https://doi.org/10.3390/electronics13040774