
Bidirectional Temporal Pose Matching for Tracking
Abstract
:1. Introduction
- We propose a Bidirectional Temporal Pose-Matching module as a new online pose-tracking framework, applicable to top–down human pose estimation methods. The novelty of this module lies in the reverse propagation of information. Unlike traditional forward propagation of temporal information, we introduce backward propagation of current frame pose information. This places the comparison of pose similarity in the previous frame, overcoming the challenge of drastic pose changes between adjacent frames.
- We propose a novel identity Re-id method called the AAMF module. Differing from the previous difficulty in reidentifying poses occluded for an extended period by relying solely on matching poses between consecutive frames, this module utilizes the temporal relationships provided by frames with a larger span to supplement the lost pose information. This is the novelty of the AAMF Module.
- We demonstrate the effectiveness of our approach through extensive experiments. Our approach outperforms the baseline method by 2.1 mAP and 1.1 MOTA on the widely used PoseTrack 2018 [16] benchmark dataset.
2. Related Work
2.1. Multi-Person Pose Estimation
2.2. Multi-Person Pose Tracking
2.3. Association of Identities
3. Method
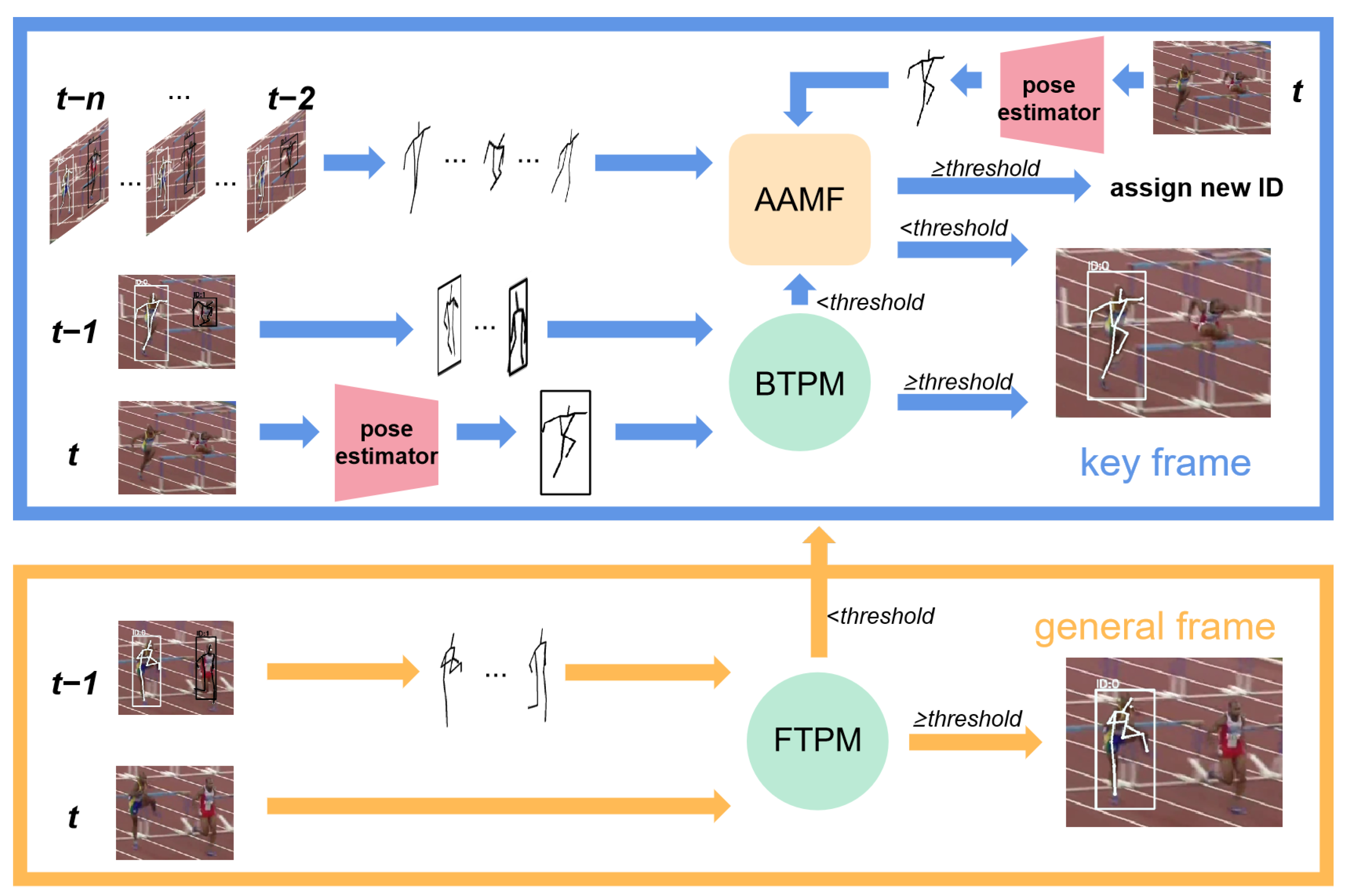
3.1. Overview of Our Approach
3.2. Bidirectional Temporal Pose Matching
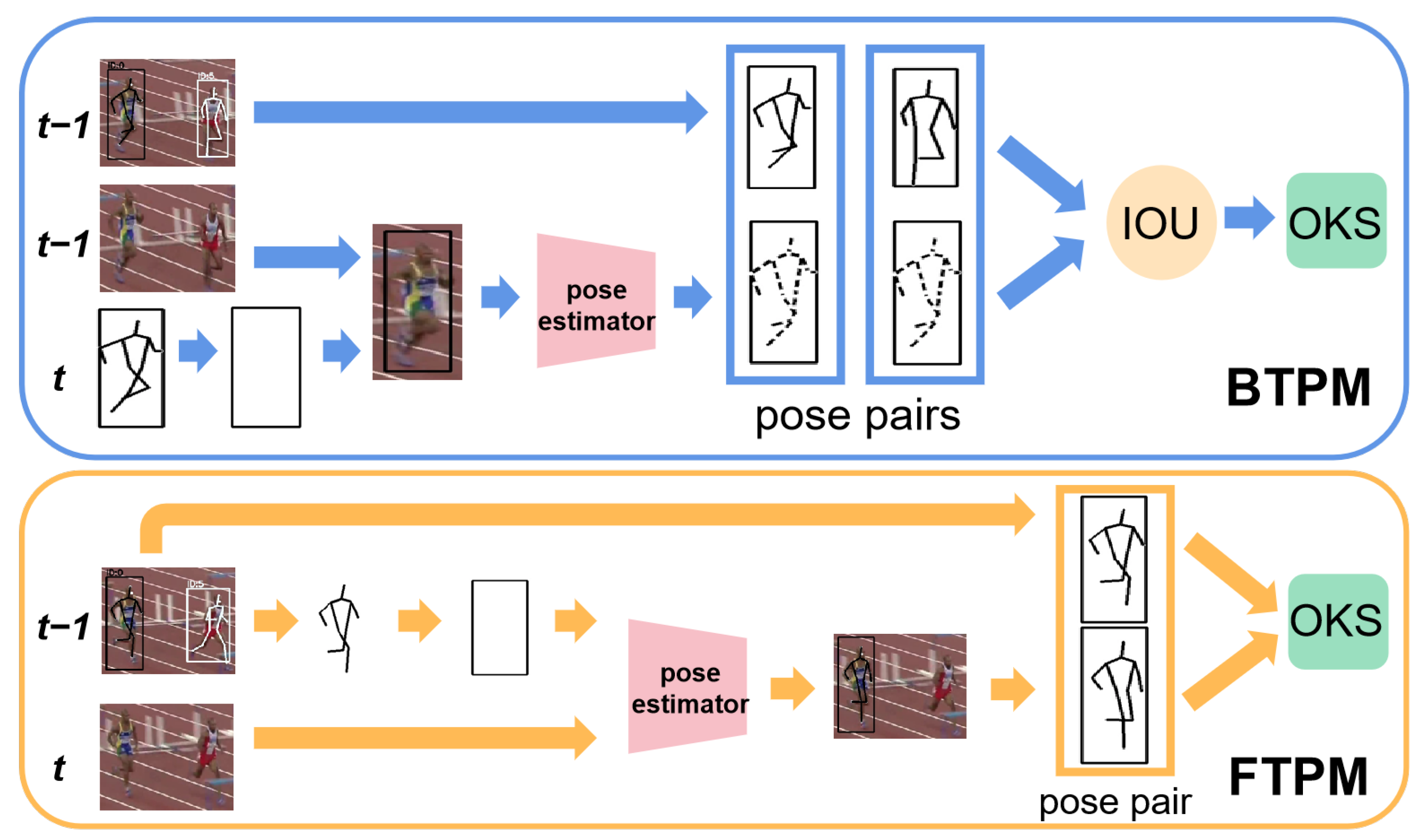
3.2.1. BTPM Module
3.2.2. FTPM Module
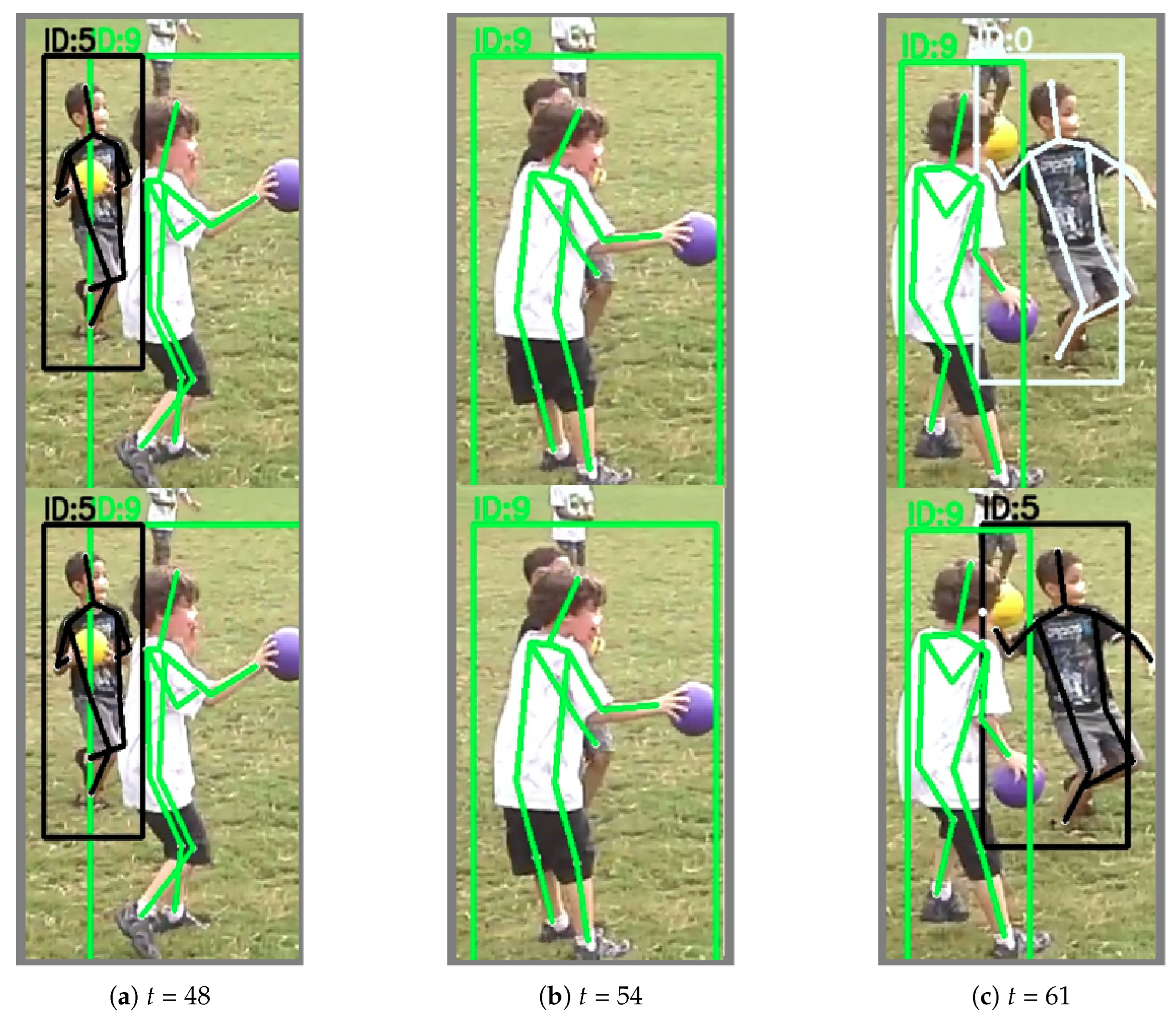
- and belong to the same person, but due to the large motion magnitude or sudden heavy occlusion during the short time period between the two frames, the difference between the two poses is too large.
- Due to the camera movement or sudden image zooming, the position offset of the same target in the two frames is too large to match the poses.
- The target person disappears in the current frame.
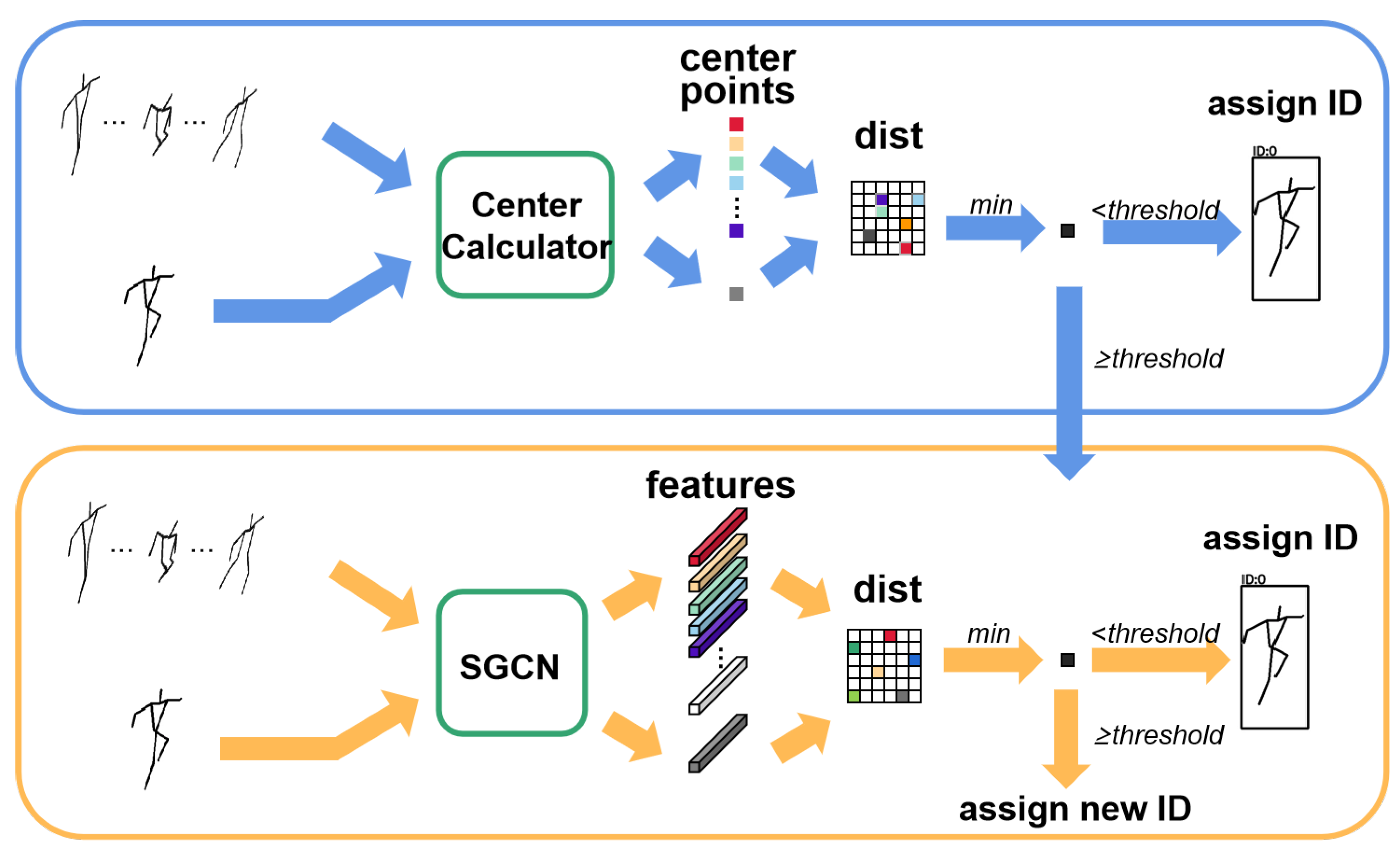
3.3. Association Across Multiple Frames
4. Experiments
4.1. Datasets
4.2. Evaluation Metrics
4.3. Implementation Details
4.4. Comparison with Other Methods of Identity Association
4.4.1. Quantitative Results
4.4.2. Qualitative Results
4.5. Ablation Study
4.5.1. Performance of Different Pose Estimators
4.5.2. Performance of Different Modules
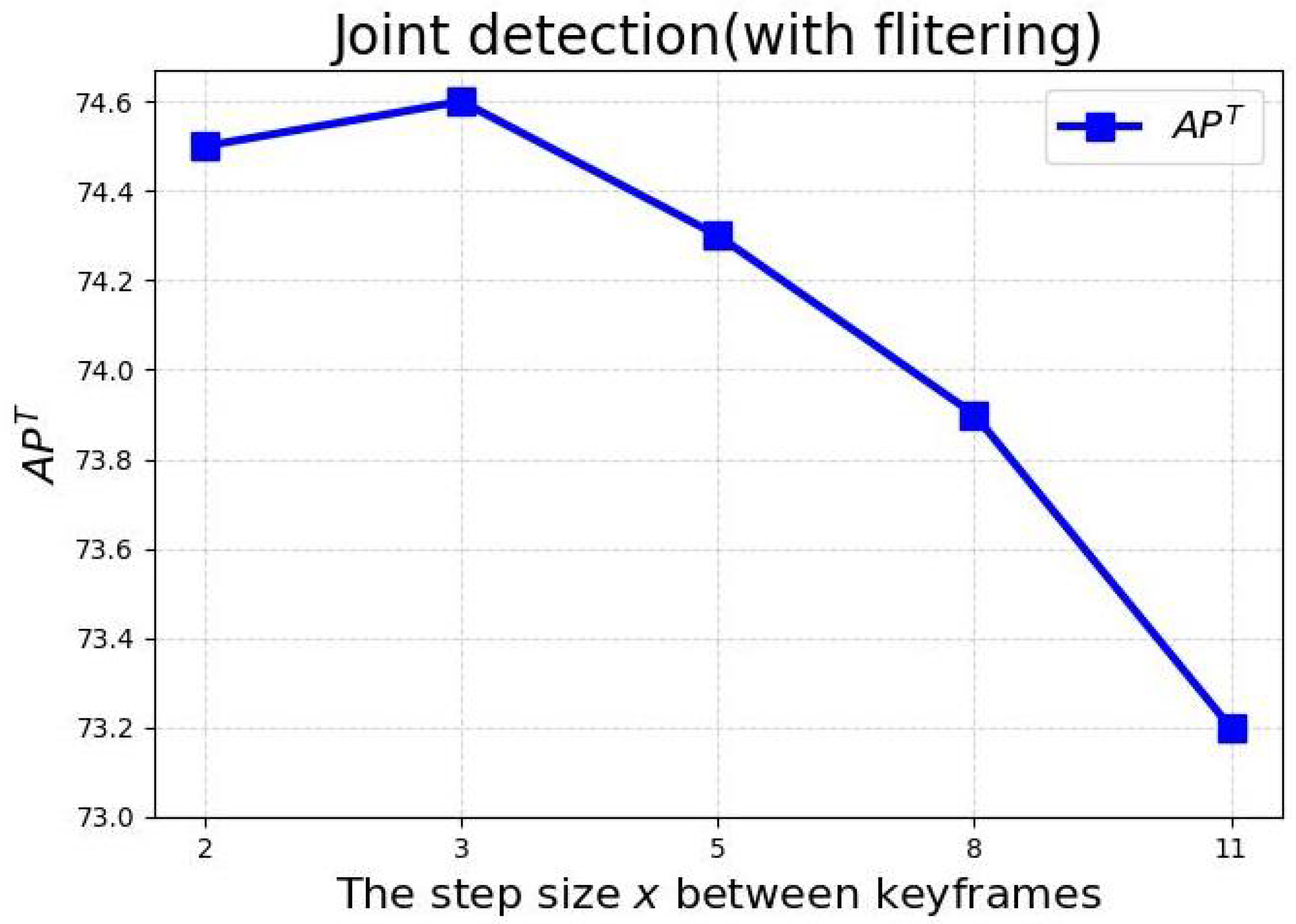
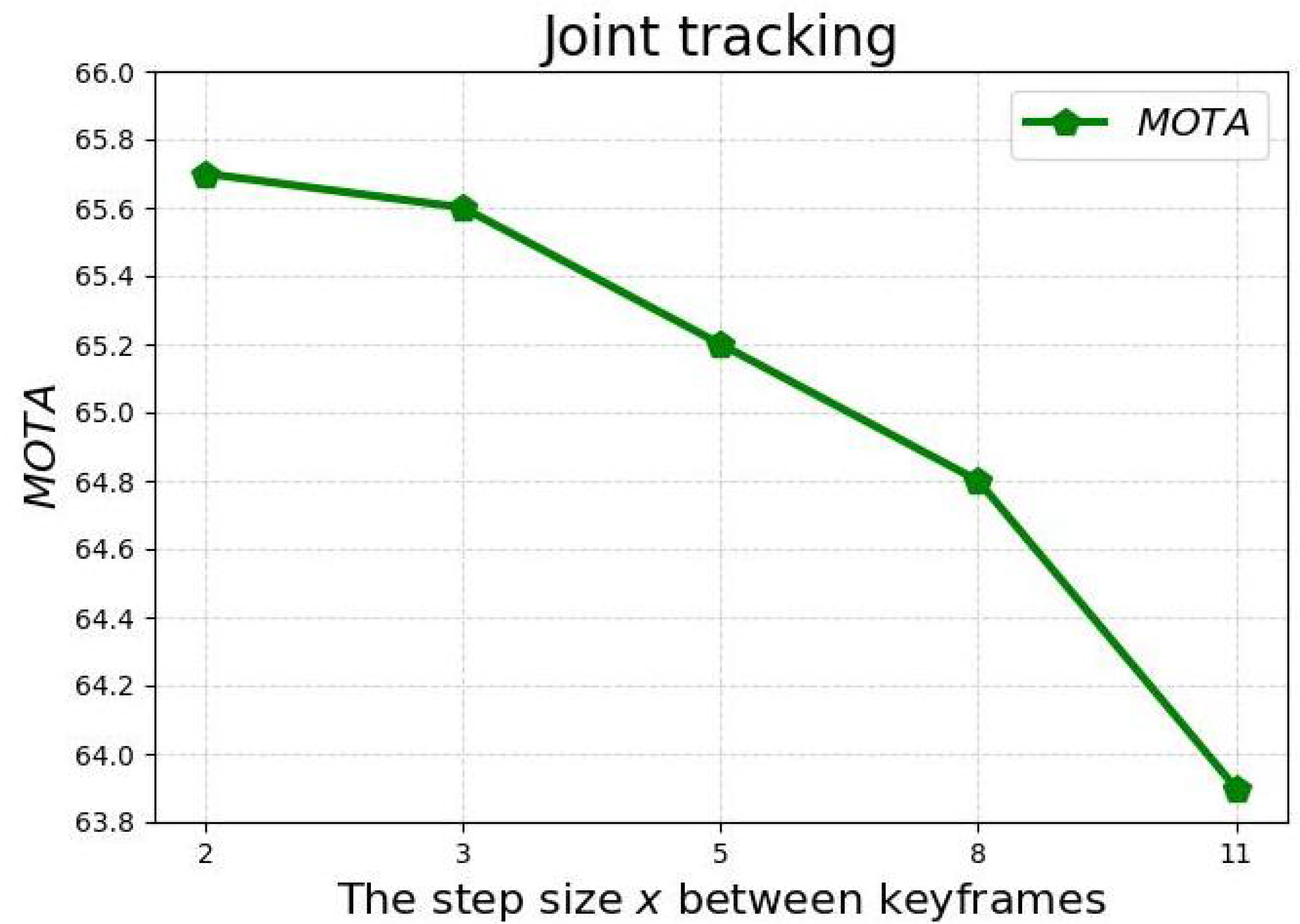
4.5.3. Performance of Different Step Sizes between Keyframes
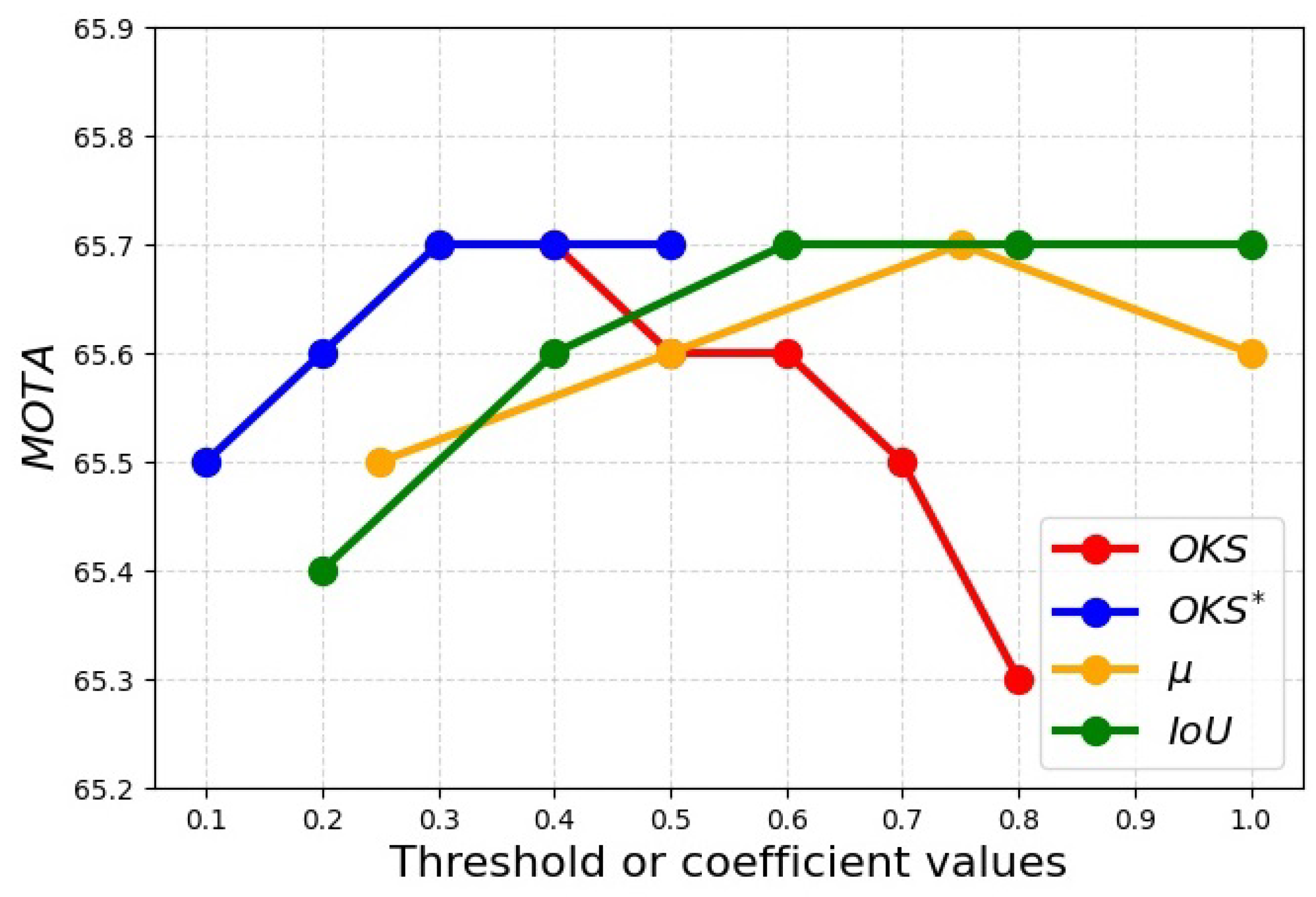
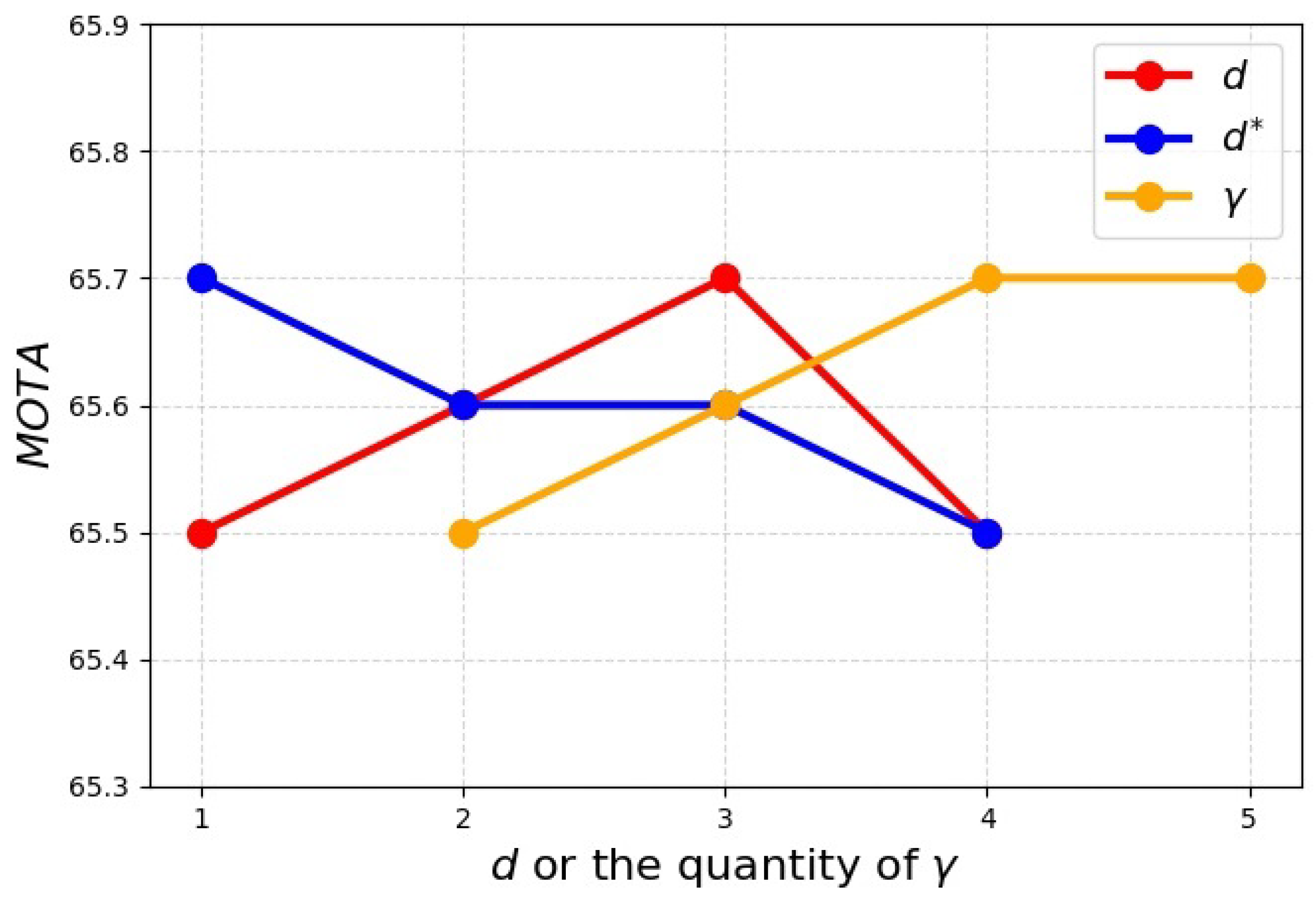
4.5.4. The Setting of Threshold and Coefficient Values
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wei, S.E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional pose machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4724–4732. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part VIII 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 483–499. [Google Scholar]
- Yang, W.; Li, S.; Ouyang, W.; Li, H.; Wang, X. Learning feature pyramids for human pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1281–1290. [Google Scholar]
- Ke, L.; Chang, M.C.; Qi, H.; Lyu, S. Multi-scale structure-aware network for human pose estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 713–728. [Google Scholar]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2d human pose estimation: New benchmark and state of the art analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3686–3693. [Google Scholar]
- Johnson, S.; Everingham, M. Clustered pose and nonlinear appearance models for human pose estimation. In Proceedings of the BMVC, Aberystwyth, UK, 31 August–3 September 2010; Volume 2, p. 5. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014. Part V 13. pp. 740–755. [Google Scholar]
- Andriluka, M.; Roth, S.; Schiele, B. Monocular 3d pose estimation and tracking by detection. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, IEEE, San Francisco, CA, 13–18 June 2010; pp. 623–630. [Google Scholar]
- Pishchulin, L.; Andriluka, M.; Gehler, P.; Schiele, B. Poselet conditioned pictorial structures. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 588–595. [Google Scholar]
- Zhang, W.; Zhu, M.; Derpanis, K.G. From actemes to action: A strongly-supervised representation for detailed action understanding. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2248–2255. [Google Scholar]
- Fang, H.S.; Li, J.; Tang, H.; Xu, C.; Zhu, H.; Xiu, Y.; Li, Y.L.; Lu, C. Alphapose: Whole-body regional multi-person pose estimation and tracking in real-time. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 7157–7173. [Google Scholar] [CrossRef] [PubMed]
- Buizza, C.; Fischer, T.; Demiris, Y. Real-time multi-person pose tracking using data assimilation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 449–458. [Google Scholar]
- Ning, G.; Pei, J.; Huang, H. Lighttrack: A generic framework for online top-down human pose tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 1034–1035. [Google Scholar]
- Snower, M.; Kadav, A.; Lai, F.; Graf, H.P. 15 keypoints is all you need. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6738–6748. [Google Scholar]
- Iqbal, U.; Milan, A.; Gall, J. Posetrack: Joint multi-person pose estimation and tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2011–2020. [Google Scholar]
- Andriluka, M.; Iqbal, U.; Insafutdinov, E.; Pishchulin, L.; Milan, A.; Gall, J.; Schiele, B. Posetrack: A benchmark for human pose estimation and tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5167–5176. [Google Scholar]
- Xiao, B.; Wu, H.; Wei, Y. Simple baselines for human pose estimation and tracking. In Proceedings of the European conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 466–481. [Google Scholar]
- Raaj, Y.; Idrees, H.; Hidalgo, G.; Sheikh, Y. Efficient online multi-person 2d pose tracking with recurrent spatio-temporal affinity fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4620–4628. [Google Scholar]
- Jin, S.; Ma, X.; Han, Z.; Wu, Y.; Yang, W.; Liu, W.; Qian, C.; Ouyang, W. Towards Multi-Person Pose Tracking: Bottom-Up and Top-Down Methods. 2017. Available online: https://jin-s13.github.io/papers/BUTD.pdf (accessed on 1 January 2024).
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Li, Z.; Xue, M.; Cui, Y.; Liu, B.; Fu, R.; Chen, H.; Ju, F. Lightweight 2D Human Pose Estimation Based on Joint Channel Coordinate Attention Mechanism. Electronics 2023, 13, 143. [Google Scholar] [CrossRef]
- Zheng, C.; Wu, W.; Chen, C.; Yang, T.; Zhu, S.; Shen, J.; Kehtarnavaz, N.; Shah, M. Deep learning-based human pose estimation: A survey. ACM Comput. Surv. 2023, 56, 1–37. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Huang, J.; Zhu, Z.; Guo, F.; Huang, G. The devil is in the details: Delving into unbiased data processing for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5700–5709. [Google Scholar]
- Yang, S.; Quan, Z.; Nie, M.; Yang, W. Transpose: Keypoint localization via transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11802–11812. [Google Scholar]
- Zhou, M.; Stoffl, L.; Mathis, M.; Mathis, A. Rethinking pose estimation in crowds: Overcoming the detection information-bottleneck and ambiguity. arXiv 2023, arXiv:2306.07879. [Google Scholar]
- Li, Y.; Zhang, S.; Wang, Z.; Yang, S.; Yang, W.; Xia, S.T.; Zhou, E. Tokenpose: Learning keypoint tokens for human pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11313–11322. [Google Scholar]
- Yuan, Y.; Fu, R.; Huang, L.; Lin, W.; Zhang, C.; Chen, X.; Wang, J. Hrformer: High-resolution transformer for dense prediction. arXiv 2021, arXiv:2110.09408. [Google Scholar]
- Xu, Y.; Zhang, J.; Zhang, Q.; Tao, D. Vitpose: Simple vision transformer baselines for human pose estimation. Adv. Neural Inf. Process. Syst. 2022, 35, 38571–38584. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1440–1448. [Google Scholar] [CrossRef]
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W.; et al. Hybrid task cascade for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4974–4983. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9308–9316. [Google Scholar]
- Cheng, B.; Xiao, B.; Wang, J.; Shi, H.; Huang, T.S.; Zhang, L. Higherhrnet: Scale-aware representation learning for bottom-up human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5386–5395. [Google Scholar]
- Cheng, Y.; Ai, Y.; Wang, B.; Wang, X.; Tan, R.T. Bottom-up 2D pose estimation via dual anatomical centers for small-scale persons. Pattern Recognit. 2023, 139, 109403. [Google Scholar] [CrossRef]
- Qu, H.; Cai, Y.; Foo, L.G.; Kumar, A.; Liu, J. A Characteristic Function-Based Method for Bottom-Up Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 13009–13018. [Google Scholar]
- Jin, S.; Liu, W.; Xie, E.; Wang, W.; Qian, C.; Ouyang, W.; Luo, P. Differentiable hierarchical graph grouping for multi-person pose estimation. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 718–734. [Google Scholar]
- Li, J.; Wang, Y.; Zhang, S. PolarPose: Single-stage multi-person pose estimation in polar coordinates. IEEE Trans. Image Process. 2023, 32, 1108–1119. [Google Scholar] [CrossRef] [PubMed]
- Geng, Z.; Sun, K.; Xiao, B.; Zhang, Z.; Wang, J. Bottom-up human pose estimation via disentangled keypoint regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14676–14686. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Jin, S.; Liu, W.; Ouyang, W.; Qian, C. Multi-person articulated tracking with spatial and temporal embeddings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5664–5673. [Google Scholar]
- Newell, A.; Huang, Z.; Deng, J. Associative Embedding: End-to-End Learning for Joint Detection and Grouping. Adv. Neural Inf. Process. Syst. 2017. Available online: https://patrick-llgc.github.io/Learning-Deep-Learning/paper_notes/associative_embedding.html (accessed on 1 January 2024).
- Girdhar, R.; Gkioxari, G.; Torresani, L.; Paluri, M.; Tran, D. Detect-and-track: Efficient pose estimation in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 350–359. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Algabri, R.; Choi, M.T. Online Boosting-Based Target Identification among Similar Appearance for Person-Following Robots. Sensors 2022, 22, 8422. [Google Scholar] [CrossRef] [PubMed]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Ruggero Ronchi, M.; Perona, P. Benchmarking and error diagnosis in multi-instance pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 369–378. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Hoiem, D.; Divvala, S.K.; Hays, J.H. Pascal VOC 2008 Challenge. 2009. Available online: https://www.researchgate.net/publication/228388312_Pascal_VOC_2008_Challenge (accessed on 1 January 2024).
- Milan, A.; Leal-Taixé, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A benchmark for multi-object tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Yu, D.; Su, K.; Sun, J.; Wang, C. Multi-person pose estimation for pose tracking with enhanced cascaded pyramid network. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Guo, H.; Tang, T.; Luo, G.; Chen, R.; Lu, Y.; Wen, L. Multi-domain pose network for multi-person pose estimation and tracking. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded pyramid network for multi-person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7103–7112. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| mAP | AP | |||
|---|---|---|---|---|
| Method | Wri. | Ank. | Total | Total |
| STAF [18] | 64.7 | 62.0 | - | 70.4 |
| Alphapose-UNI [11] | - | - | - | 74.0 |
| Keytrack [14] | 79.2 | 76.5 | 81.6 | 74.3 |
| MDPN [52] | 74.1 | 69.9 | 75.0 | 71.7 |
| Baseline [13] | 73.3 | 70.9 | 77.2 | 72.4 |
| ours | 75.3 | 71.7 | 79.0 | 74.5 |
| Method | Wri. | Ank. | Total | fps |
|---|---|---|---|---|
| STAF [18] | - | - | 60.9 | 3 |
| Alphapose-UNI [11] | - | - | 64.4 | 10.9 |
| Keytrack [14] | - | - | 66.6 | 1.0 |
| MDPN [52] | 49.0 | 45.1 | 50.6 | - |
| Baseline [13] | - | - | 64.6 | 0.7 |
| Ours | 59.2 | 58.3 | 65.7 | 0.5 |
| Method | Wri. | Ank. | Total |
|---|---|---|---|
| Keytrack [14] | 0.8 | 0.8 | 0.8 |
| Optical Flow [17] | 1.1 | 1.1 | 1.1 |
| Ours | 0.6 | 0.7 | 0.7 |
| Estimation (AP) | Tracking (MOTA) | |||||
|---|---|---|---|---|---|---|
| Pose Estimator | Wri. | Ank. | Total | Wri. | Ank. | Total |
| CPN101 | 67.6 | 65.3 | 71.8 | 56.7 | 53.3 | 62.2 |
| HRNet | 72.4 | 66.1 | 74.7 | 59.2 | 54.7 | 64.4 |
| MSRA152 | 68.9 | 67.3 | 74.5 | 59.2 | 58.3 | 65.7 |
| Method | Wri. | Ank. | Total |
|---|---|---|---|
| SC | 23.2 | 22.5 | 26.8 |
| SC + BTPM | 58.2 | 56.6 | 64.3 |
| SC + BTPM + CPM | 59.2 | 57.7 | 65.4 |
| SC + BTPM + CPM + SGCN | 59.2 | 58.3 | 65.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, Y.; Shi, Q.; Yang, Z. Bidirectional Temporal Pose Matching for Tracking. Electronics 2024, 13, 442. https://doi.org/10.3390/electronics13020442
Fang Y, Shi Q, Yang Z. Bidirectional Temporal Pose Matching for Tracking. Electronics. 2024; 13(2):442. https://doi.org/10.3390/electronics13020442
Chicago/Turabian StyleFang, Yichuan, Qingxuan Shi, and Zhen Yang. 2024. "Bidirectional Temporal Pose Matching for Tracking" Electronics 13, no. 2: 442. https://doi.org/10.3390/electronics13020442