
Few-Shot Learning for Misinformation Detection Based on Contrastive Models
 , ,
, ,
Abstract
:1. Introduction
- We have discovered that the baseline approach heavily relies on the pre-trained text embedding model, SBERT, while the image feature is ignored for the out-of-context (OOC) classification task. This reliance on textual features brings about the possibility of bias and distortion in the model’s outcomes.
- We developed a novel model that integrates a contrastive learning component, which offers distinct advantages in capturing image feature representations. This proves particularly beneficial when confronted with limited training data.
- We conducted comprehensive experiments to evaluate our proposed approach, investigating different text encoding methods and examining the impact of varying training data volumes on model performance. We compared our method with baseline approaches. The results of these experiments indicate that our approach is more stable and superior to the baseline methods.
- Rather than an OOC task, we developed a classification model to identify whether a caption corresponds to the image, and it shows promising results.
2. Related Work
2.1. Misinformation Detection
2.2. Contrastive Learning
3. Our Proposed Method
3.1. Text and Image Preprocessing
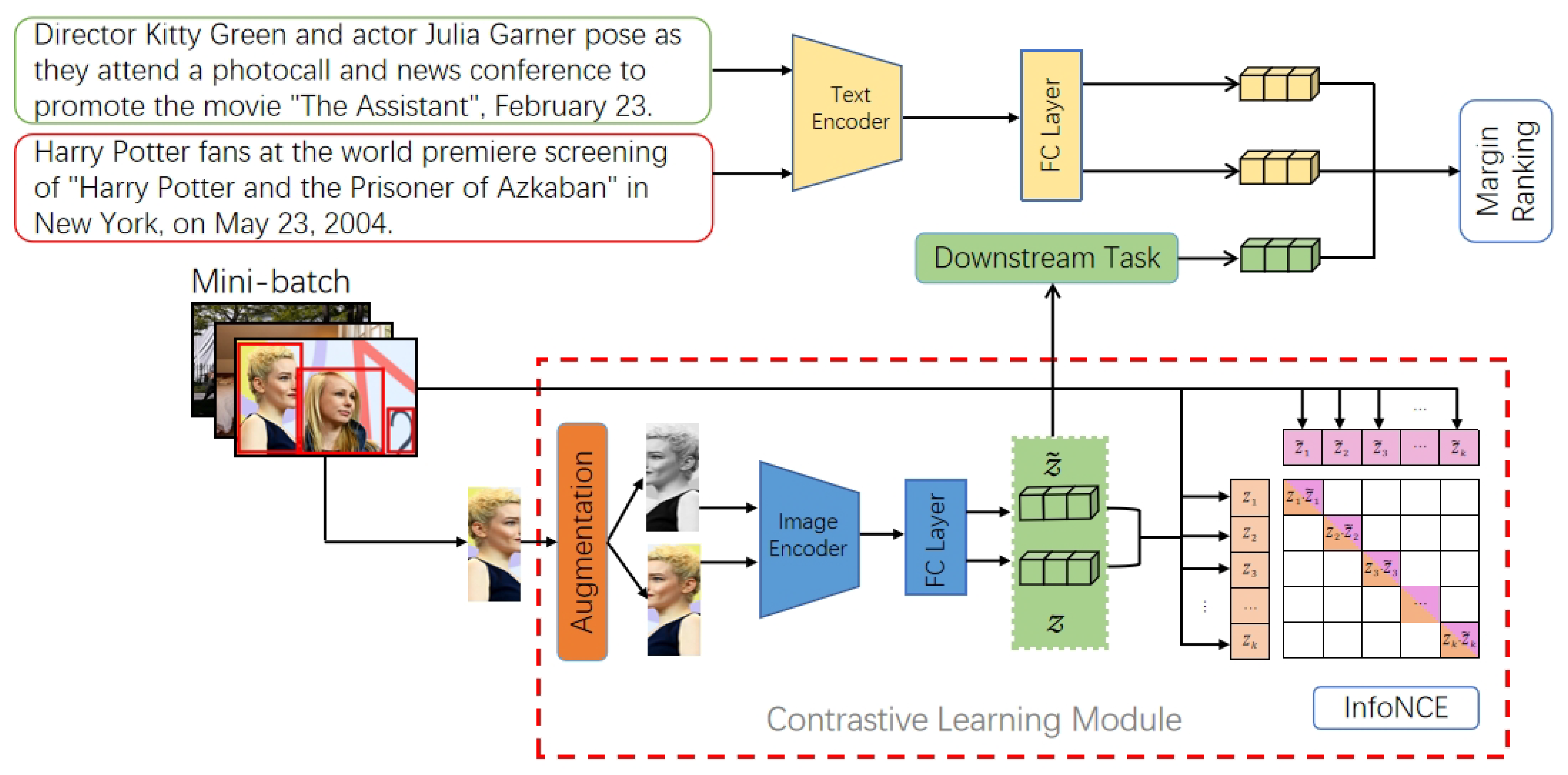
3.2. Contrastive Learning-Guided Image–Text Matching Training
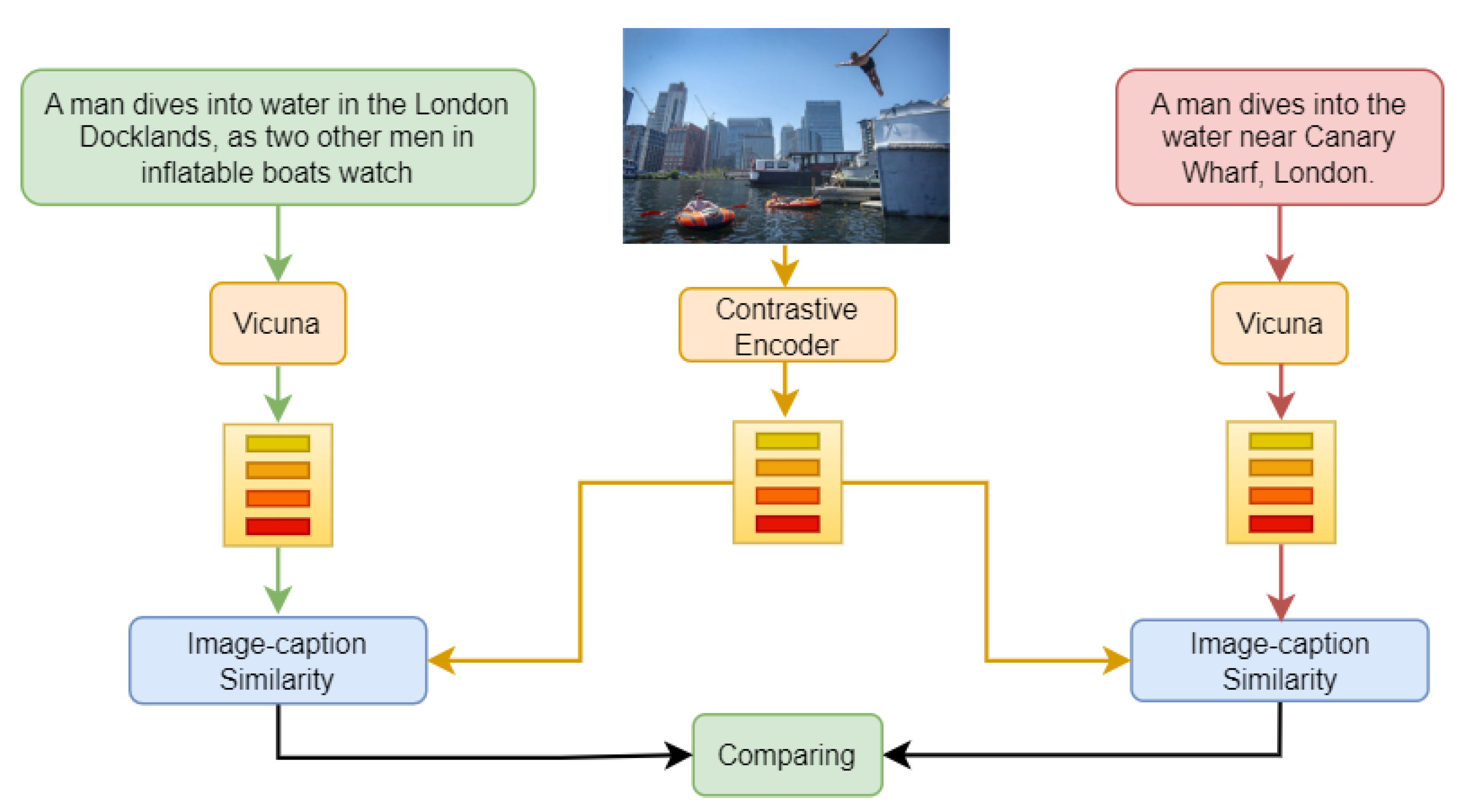
- Image–Text Matching Module. This module aims to match an image with its corresponding text (caption). To achieve this, we employ a pre-trained transformer-based Universal Sentence Encoder (USE, denoted by ) [61], as described in [58]. The USE encodes captions into unified 512-dimensional vectors. These vectors are then passed through an additional text encoder () to convert them into a specific feature space that matches the output dimension (denoted by d) of the image encoder . The text encoder consists of a ReLU activation function followed by a fully connected (FC) layer. As a result, we can represent the final embedded features of the matched caption as and the final embedded features of the random caption as .
| Algorithm 1 Out-of-context matching |
|
- Cross-Training. We first train object encoder E in the contrastive learning module based on (Equation (1)) for all images in the dataset. Then, we fix the contrastive learning module and train text encoder T according to (Equation (3)) on all images. The weights of the whole model are updated iteratively.
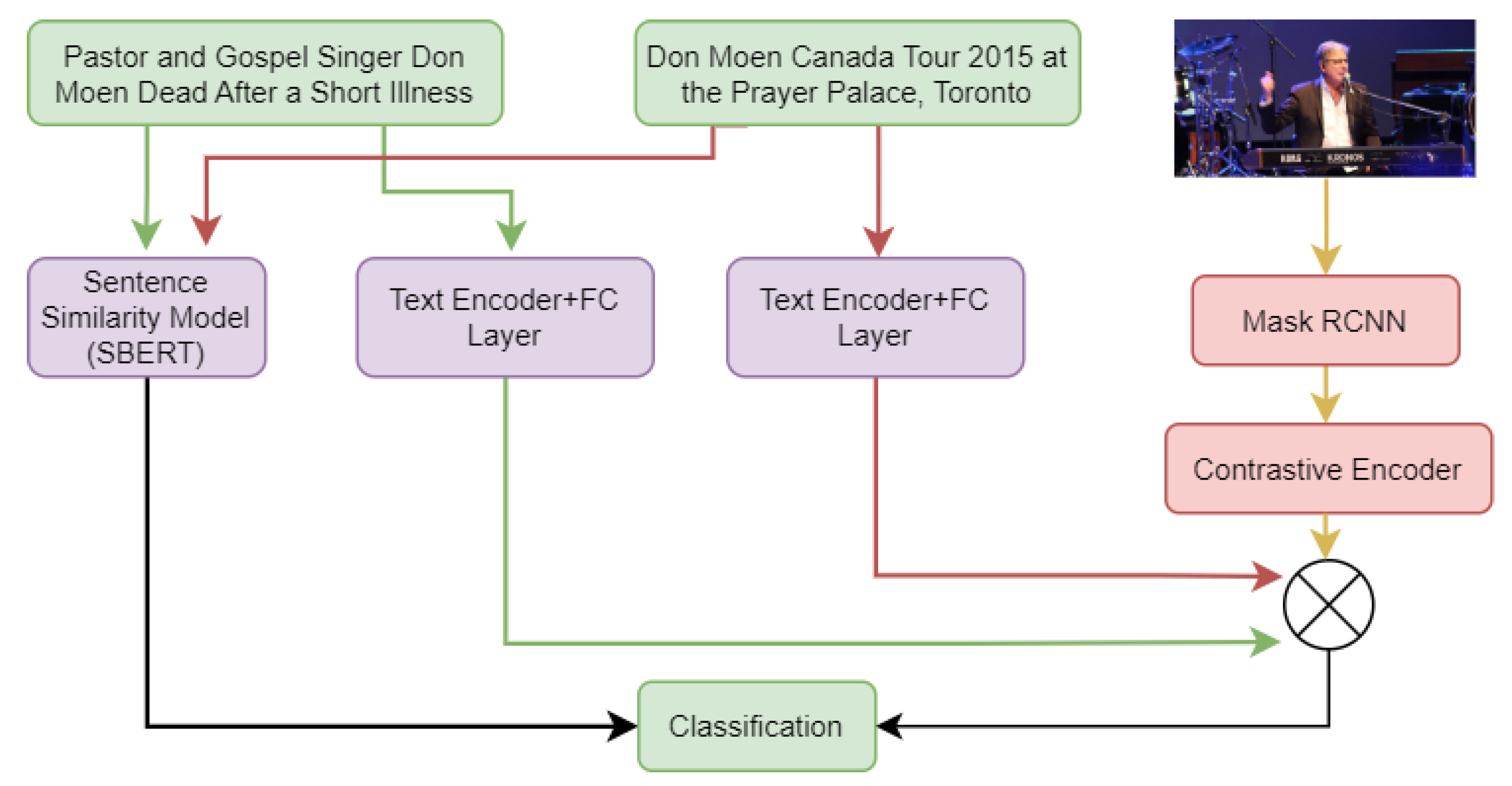
3.3. Image–Text Mismatching Prediction
- Out of context if and ;
- Not out of context otherwise.
4. Experimental Evaluation
4.1. Datasets and Preprocessing
4.2. Experimental Setup
- Baseline: The model originates from [58].
- Cross-training: There are two loss functions—InfoNCE for contrastive learning and MarginRanking for classification. We independently optimize each of the two loss functions to find the optimal match.
- Joint training: As the comparative experiment with alternating training, we simultaneously optimize both loss functions, InfoNCE and MarginRanking, with designed weights.
- Evaluation Metrics. Given that the ultimate goal of this paper is to boost the ability to detect OOC content, we use the standard classification evaluation metrics: (accuracy, precision, recall, and F1-score).
- Implementation Details. Furthermore, we understand that detecting out-of-context (OOC) content involves making a trade-off decision. We must weigh the potential consequences of false negatives, where OOC content is mistakenly classified as non-OOC, against the false positives, where non-OOC content is incorrectly identified as OOC. In a real-world scenario, it is presumed that the failure to identify misinformation and allow its propagation would have a more significant impact on social networks than mistakenly labeling clean content as misinformation. Consequently, our research will expand upon the original study, which solely focuses on accuracy, by placing greater emphasis on recall, also known as the true positive rate.
4.3. Contrastive Learning vs. Baseline
- We detected ten objects using the Mask-RCNN model.
- To introduce variation in the training data, we incorporated augmentation techniques such as rotation, the addition of gray, filtering, resizing, translation, brightness adjustment, and more.
- The ResNet model consists of 18 convolutional layers, with the output being a 512-dimensional feature representation (the text encoder also has a dimension of 512).
- Lastly, the Dense Layer produced a dense vector output of 300 dimensions.
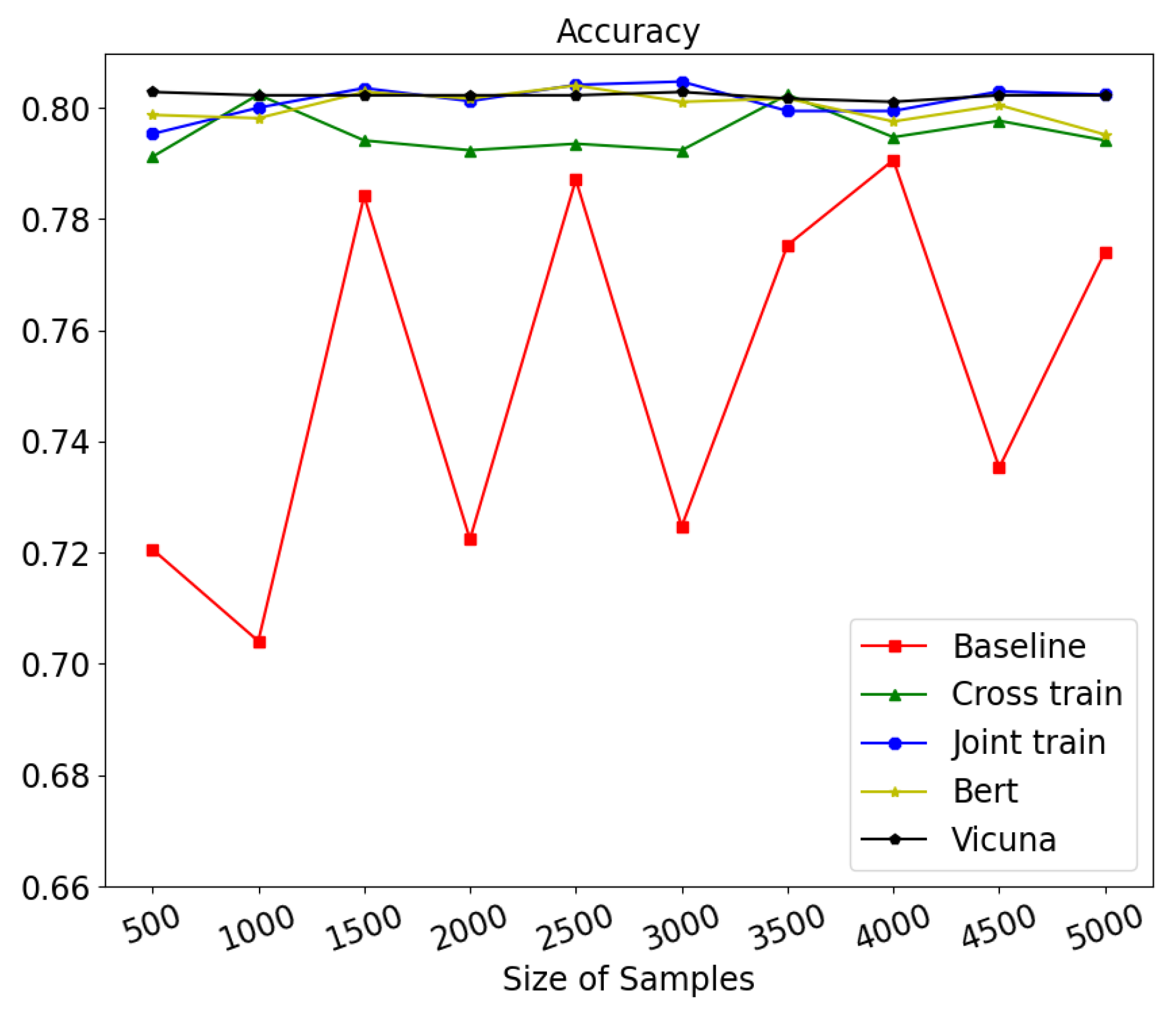
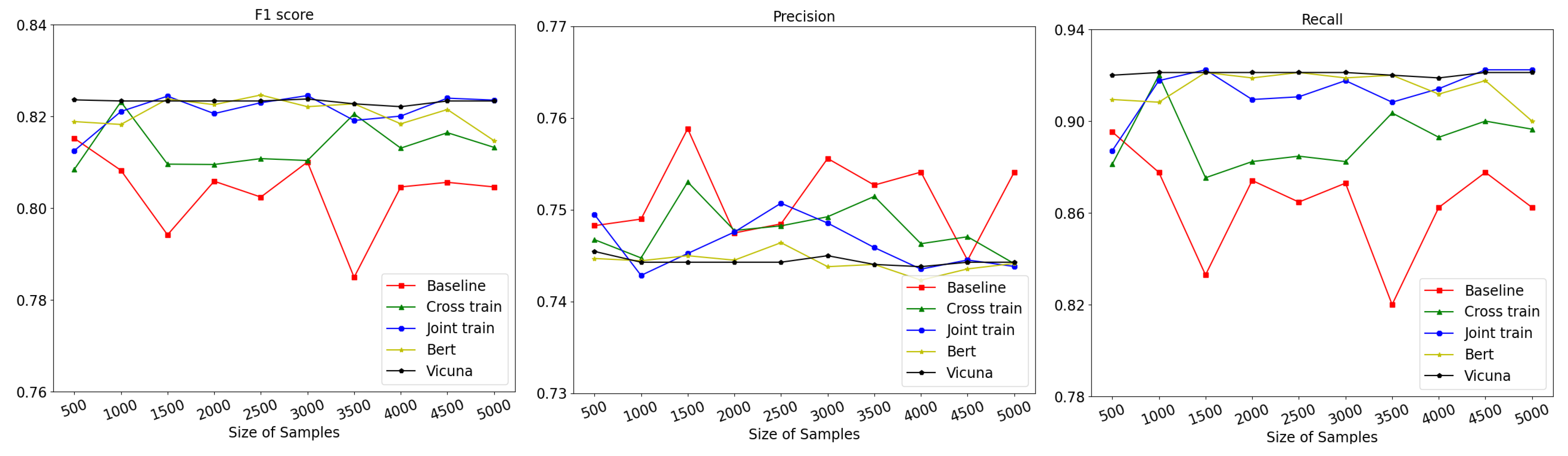
4.4. Comparison on Varying Training Data Sizes
4.5. Contrastive Learning for True Caption Classification
5. Conclusions
- The proposal of an advanced model: We introduced an improved out-of-context (OOC) detection model by leveraging contrastive learning, a self-supervised machine learning technique. Our model incorporates data augmentation during training, resulting in superior performance compared to the benchmark model outlined in the original paper.
- Emphasis on inadequate labeled data: We specifically investigated the scenario where there is a lack of labeled data, a common limitation in many classification tasks. Through our comparisons, we demonstrated that contrastive learning exhibits strong capabilities in learning image features, achieving 94% of the full performance, even with a significant reduction in the training data size.
- A comprehensive analysis of classifiers: We conducted a thorough analysis of different classifiers’ abilities to handle varying training data sizes. The results showcased the stability and consistent performance improvement of the contrastive learning model as more training data were added. In contrast, the baseline model exhibited fluctuating results with ups and downs.
- A comparison of the impact of different text encoders on model performance: The proposed method expands on our previous work [29] in terms of textual content and replaces the text encoding module with the text encoder of a large-scale model, showing better stability.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| COSMOS | Catching Out-of-Context Misinformation |
References
- Geeng, C.; Yee, S.; Roesner, F. Fake news on Facebook and Twitter: Investigating how people (don’t) investigate. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–14. [Google Scholar]
- Fernández-Barrero, Á.; Rivas-de Roca, R.; Pérez-Curiel, C. Disinformation and Local Media in the Iberian Context: How to Protect News Credibility. J. Media 2024, 5, 65–77. [Google Scholar] [CrossRef]
- Grinberg, N.; Joseph, K.; Friedland, L.; Swire-Thompson, B.; Lazer, D. Fake news on Twitter during the 2016 U.S. presidential election. Science 2019, 363, 374–378. [Google Scholar] [CrossRef]
- Skafle, I.; Nordahl-Hansen, A.; Quintana, D.S.; Wynn, R.; Gabarron, E. Misinformation about COVID-19 vaccines on social media: Rapid review. J. Med. Int. Res. 2022, 24, e37367. [Google Scholar] [CrossRef]
- Rocha, Y.M.; de Moura, G.A.; Desidério, G.A.; de Oliveira, C.H.; Lourenço, F.D.; de Figueiredo Nicolete, L.D. The impact of fake news on social media and its influence on health during the COVID-19 pandemic: A systematic review. J. Public Health 2021, 31, 1007–1016. [Google Scholar] [CrossRef]
- Sallam, M.; Dababseh, D.; Yaseen, A.; Al-Haidar, A.; Ababneh, N.A.; Bakri, F.G.; Mahafzah, A. Conspiracy beliefs are associated with lower knowledge and higher anxiety levels regarding COVID-19 among students at the University of Jordan. Int. J. Environ. Res. Public Health 2020, 17, 4915. [Google Scholar] [CrossRef]
- Baptista, J.P.; Gradim, A. Understanding Fake News Consumption: A Review. Soc. Sci. 2020, 9, 185. [Google Scholar] [CrossRef]
- Wang, X.; Guo, H.; Hu, S.; Chang, M.C.; Lyu, S. GAN-Generated Faces Detection: A Survey and New Perspectives. Front. Artif. Intell. Appl. 2022, 372, 2533–2542. [Google Scholar]
- Pu, W.; Hu, J.; Wang, X.; Li, Y.; Hu, S.; Zhu, B.; Song, R.; Song, Q.; Wu, X.; Lyu, S. Learning a deep dual-level network for robust DeepFake detection. Pattern Recognit. 2022, 130, 108832. [Google Scholar] [CrossRef]
- Guo, H.; Hu, S.; Wang, X.; Chang, M.C.; Lyu, S. Open-Eye: An Open Platform to Study Human Performance on Identifying AI-Synthesized Faces. In Proceedings of the 2022 IEEE 5th International Conference on Multimedia Information Processing and Retrieval (MIPR), Online, 2–4 August 2022; pp. 224–227. [Google Scholar]
- Guo, H.; Hu, S.; Wang, X.; Chang, M.C.; Lyu, S. Eyes Tell All: Irregular Pupil Shapes Reveal GAN-generated Faces. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 2904–2908. [Google Scholar]
- Guo, H.; Hu, S.; Wang, X.; Chang, M.C.; Lyu, S. Robust attentive deep neural network for detecting gan-generated faces. IEEE Access 2022, 10, 32574–32583. [Google Scholar] [CrossRef]
- Hu, S.; Li, Y.; Lyu, S. Exposing GAN-generated Faces Using Inconsistent Corneal Specular Highlights. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2500–2504. [Google Scholar]
- Yang, S.; Shu, K.; Wang, S.; Gu, R.; Wu, F.; Liu, H. Unsupervised fake news detection on social media: A generative approach. Proc. AAAI Conf. Artif. Intell. 2019, 33, 5644–5651. [Google Scholar] [CrossRef]
- Pv, S.; Bhanu, S.M.S. UbCadet: Detection of compromised accounts in twitter based on user behavioural profiling. Multimed. Tools Appl. 2020, 79, 19349–19385. [Google Scholar] [CrossRef]
- Konkobo, P.M.; Zhang, R.; Huang, S.; Minoungou, T.T.; Ouedraogo, J.A.; Li, L. A deep learning model for early detection of fake news on social media. In Proceedings of the 2020 7th International Conference on Behavioural and Social Computing (BESC), Bournemouth, UK, 5–7 November 2020; pp. 1–6. [Google Scholar]
- Du, J.; Dou, Y.; Xia, C.; Cui, L.; Ma, J.; Philip, S.Y. Cross-lingual covid-19 fake news detection. In Proceedings of the 2021 International Conference on Data Mining Workshops (ICDMW), Auckland, New Zealand, 7–10 December 2021; pp. 859–862. [Google Scholar]
- Li, X.; Lu, P.; Hu, L.; Wang, X.; Lu, L. A novel self-learning semi-supervised deep learning network to detect fake news on social media. Multimed. Tools Appl. 2022, 81, 19341–19349. [Google Scholar] [CrossRef]
- Guan, L.; Liu, F.; Zhang, R.; Liu, J.; Tang, Y. MCW: A Generalizable Deepfake Detection Method for Few-Shot Learning. Sensors 2023, 23, 8763. [Google Scholar] [CrossRef]
- Alom, M.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; Hasan, M.; Van Essen, B.C.; Awwal, A.A.S.; Asari, V.K. A State-of-the-Art Survey on Deep Learning Theory and Architectures. Electronics 2019, 8, 292. [Google Scholar] [CrossRef]
- Bucos, M.; Drăgulescu, B. Enhancing Fake News Detection in Romanian Using Transformer-Based Back Translation Augmentation. Appl. Sci. 2023, 13, 13207. [Google Scholar] [CrossRef]
- Kozik, R.; Mazurczyk, W.; Cabaj, K.; Pawlicka, A.; Pawlicki, M.; Choraś, M. Deep Learning for Combating Misinformation in Multicategorical Text Contents. Sensors 2023, 23, 9666. [Google Scholar] [CrossRef] [PubMed]
- Cheng, M.; Nazarian, S.; Bogdan, P. Vroc: Variational autoencoder-aided multi-task rumor classifier based on text. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 2892–2898. [Google Scholar]
- Guo, Z.; Zhang, Q.; Ding, F.; Zhu, X.; Yu, K. A novel fake news detection model for context of mixed languages through multiscale transformer. IEEE Trans. Comput. Soc. Syst. 2023, 1–11. [Google Scholar] [CrossRef]
- Pelrine, K.; Danovitch, J.; Rabbany, R. The Surprising Performance of Simple Baselines for Misinformation Detection. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 3432–3441. [Google Scholar]
- Girgis, S.; Amer, E.; Gadallah, M. Deep Learning Algorithms for Detecting Fake News in Online Text. In Proceedings of the 2018 13th International Conference on Computer Engineering and Systems (ICCES), Cairo, Egypt, 18–19 December 2018; pp. 93–97. [Google Scholar]
- Alenezi, M.N.; Alqenaei, Z.M. Machine learning in detecting COVID-19 misinformation on twitter. Future Int. 2021, 13, 244. [Google Scholar] [CrossRef]
- Aneja, S.; Midoglu, C.; Dang-Nguyen, D.T.; Khan, S.A.; Riegler, M.; Halvorsen, P.; Bregler, C.; Adsumilli, B. ACM Multimedia Grand Challenge on Detecting Cheapfakes. arXiv 2022, arXiv:2207.14534. [Google Scholar]
- Chen, H.; Zheng, P.; Wang, X.; Hu, S.; Zhu, B.; Hu, J.; Wu, X.; Lyu, S. Harnessing the Power of Text-image Contrastive Models for Automatic Detection of Online Misinformation. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Vancouver, BC, Canada, 17–24 June 2023; pp. 923–932. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the International Conference on Machine Learning (PMLR), Virtual Event, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Fernandez, M.; Alani, H. Online Misinformation: Challenges and Future Directions. In Proceedings of the Companion Proceedings of the The Web Conference 2018, Lyon, France, 23–27 April 2018; pp. 595–602.
- Bondielli, A.; Marcelloni, F. A survey on fake news and rumour detection techniques. Inf. Sci. 2019, 497, 38–55. [Google Scholar] [CrossRef]
- Guo, B.; Ding, Y.; Yao, L.; Liang, Y.; Yu, Z. The future of misinformation detection: New perspectives and trends. arXiv 2019, arXiv:1909.03654. [Google Scholar]
- Meel, P.; Vishwakarma, D.K. Fake news, rumor, information pollution in social media and web: A contemporary survey of state-of-the-arts, challenges and opportunities. Expert Syst. Appl. 2020, 153, 112986. [Google Scholar] [CrossRef]
- Enayet, O.; El-Beltagy, S.R. NileTMRG at SemEval-2017 Task 8: Determining Rumour and Veracity Support for Rumours on Twitter. In Proceedings of the Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, BC, Canada, 3–4 August 2017; pp. 470–474.
- Giasemidis, G.; Singleton, C.; Agrafiotis, I.; Nurse, J.R.; Pilgrim, A.; Willis, C.; Greetham, D.V. Determining the Veracity of Rumours on Twitter. In Proceedings of the International Conference on Social Informatics; Springer: Berlin/Heidelberg, Germany, 2016; pp. 185–205. [Google Scholar]
- Hu, S.; Wang, X.; Lyu, S. Rank-Based Decomposable Losses in Machine Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 13599–13620. [Google Scholar] [CrossRef] [PubMed]
- Shu, K.; Mahudeswaran, D.; Wang, S.; Lee, D.; Liu, H. Fakenewsnet: A data repository with news content, social context, and spatiotemporal information for studying fake news on social media. Big Data 2020, 8, 171–188. [Google Scholar] [CrossRef]
- Chua, A.Y.; Banerjee, S. Linguistic Predictors of Rumor Veracity on the Internet. In Proceedings of the International MultiConference of Engineers and Computer Scientists, Hong Kong, China, 16–18 March 2016; Nanyang Technological University: Singapore, 2016; Volume 1, p. 387. [Google Scholar]
- Castillo, C.; Mendoza, M.; Poblete, B. Information Credibility on Twitter. In Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 675–684. [Google Scholar]
- Nasir, J.A.; Khan, O.S.; Varlamis, I. Fake news detection: A hybrid CNN-RNN based deep learning approach. Int. J. Inf. Manag. Data Insights 2021, 1, 100007. [Google Scholar] [CrossRef]
- Wani, A.; Joshi, I.; Khandve, S.; Wagh, V.; Joshi, R. Evaluating Deep Learning Approaches for Covid19 Fake News Detection. In Proceedings of the International Workshop on Combating Online Hostile Posts in Regional Languages during Emergency Situation; Springer: Berlin/Heidelberg, Germany, 2021; pp. 153–163. [Google Scholar]
- Sahoo, S.R.; Gupta, B.B. Multiple features based approach for automatic fake news detection on social networks using deep learning. Appl. Soft Comput. 2021, 100, 106983. [Google Scholar] [CrossRef]
- Ma, J.; Gao, W.; Mitra, P.; Kwon, S.; Jansen, B.J.; Wong, K.F.; Cha, M. Detecting Rumors from Microblogs with Recurrent Neural Networks. In Proceedings of the International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016. [Google Scholar]
- Chen, T.; Li, X.; Yin, H.; Zhang, J. Call Attention to Rumors: Deep Attention Based Recurrent Neural Networks for Early Rumor Detection. In Proceedings of the Trends and Applications in Knowledge Discovery and Data Mining: PAKDD 2018 Workshops, BDASC, BDM, ML4Cyber, PAISI, DaMEMO, Melbourne, VIC, Australia, 3 June 2018, Revised Selected Papers 22; Springer: Berlin/Heidelberg, Germany, 2018; pp. 40–52. [Google Scholar]
- Shu, K.; Wang, S.; Liu, H. Beyond News Contents: The Role of Social Context for Fake News Detection. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, VIC, Australia, 11–15 February 2019; pp. 312–320. [Google Scholar]
- Fazio, L. Out-of-context photos are a powerful low-tech form of misinformation. Conversation 2020, 14. [Google Scholar]
- Singhal, S.; Shah, R.R.; Chakraborty, T.; Kumaraguru, P.; Satoh, S. SpotFake: A Multi-modal Framework for Fake News Detection. In Proceedings of the 2019 IEEE Fifth International Conference on Multimedia Big Data (BigMM), Singapore, 11–13 September 2019; pp. 39–47. [Google Scholar]
- Singh, B.; Sharma, D.K. Predicting image credibility in fake news over social media using multi-modal approach. Neural Comput. Appl. 2022, 34, 21503–21517. [Google Scholar] [CrossRef]
- Qian, S.; Wang, J.; Hu, J.; Fang, Q.; Xu, C. Hierarchical Multi-modal Contextual Attention Network for Fake News Detection. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Online, 11–15 July 2021; pp. 153–162. [Google Scholar]
- Munappy, A.; Bosch, J.; Olsson, H.H.; Arpteg, A.; Brinne, B. Data Management Challenges for Deep Learning. In Proceedings of the 2019 45th Euromicro Conference on Software Engineering and Advanced Applications (SEAA), Kallithea, Greece, 28–30 August 2019; pp. 140–147. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Jaiswal, A.; Babu, A.R.; Zadeh, M.Z.; Banerjee, D.; Makedon, F. A Survey on Contrastive Self-Supervised Learning. Technologies 2021, 9, 2. [Google Scholar] [CrossRef]
- Wu, Z.; Xiong, Y.; Yu, S.X.; Lin, D. Unsupervised Feature Learning via Non-parametric Instance Discrimination. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3733–3742. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised learning of visual features by contrasting cluster assignments. Adv. Neural Inf. Process. Syst. 2020, 33, 9912–9924. [Google Scholar]
- Aneja, S.; Bregler, C.; Nießner, M. COSMOS: Catching Out-of-Context Misinformation with Self-Supervised Learning. arXiv 2021, arXiv:2101.06278. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Wang, Y.; Zhang, R.; Zhang, S.; Li, M.; Xia, Y.; Zhang, X.; Liu, S. Domain-specific suppression for adaptive object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9603–9612. [Google Scholar]
- Cer, D.; Yang, Y.; Kong, S.y.; Hua, N.; Limtiaco, N.; St. John, R.; Constant, N.; Guajardo-Cespedes, M.; Yuan, S.; Tar, C.; et al. Universal sentence encoder. arXiv 2018, arXiv:1803.11175. [Google Scholar]
- Wang, B.; Kuo, C.C. Sbert-wk: A sentence embedding method by dissecting bert-based word models. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2146–2157. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar]
- Taori, R.; Gulrajani, I.; Zhang, T.; Dubois, Y.; Li, X.; Guestrin, C.; Liang, P.; Hashimoto, T.B. Stanford Alpaca: An Instruction-Following llaMA Model. 2023. Available online: https://github.com/tatsu-lab/stanford_alpaca (accessed on 10 August 2023).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # of Images | # of Captions | Annotation | |
|---|---|---|---|
| Training Data | 160 k | 360 k | no |
| Validation Data | 40 k | 90 k | no |
| Testing Data | 1700 | 1700 | yes |
| Accuracy | Precision | Recall | F1-Score | |
|---|---|---|---|---|
| Baseline | 73.53 | 75.8 | 87.76 | 80.56 |
| Cross-Training | 80.23 | 75.3 | 90.94 | 82.05 |
| Joint Training | 80.47 | 74.85 | 92.23 | 82.45 |
| BERT | 80.4 | 74.35 | 91.76 | 82.14 |
| Vicuna | 80.28 | 74.54 | 92 | 82.35 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, P.; Chen, H.; Hu, S.; Zhu, B.; Hu, J.; Lin, C.-S.; Wu, X.; Lyu, S.; Huang, G.; Wang, X. Few-Shot Learning for Misinformation Detection Based on Contrastive Models. Electronics 2024, 13, 799. https://doi.org/10.3390/electronics13040799
Zheng P, Chen H, Hu S, Zhu B, Hu J, Lin C-S, Wu X, Lyu S, Huang G, Wang X. Few-Shot Learning for Misinformation Detection Based on Contrastive Models. Electronics. 2024; 13(4):799. https://doi.org/10.3390/electronics13040799
Chicago/Turabian StyleZheng, Peng, Hao Chen, Shu Hu, Bin Zhu, Jinrong Hu, Ching-Sheng Lin, Xi Wu, Siwei Lyu, Guo Huang, and Xin Wang. 2024. "Few-Shot Learning for Misinformation Detection Based on Contrastive Models" Electronics 13, no. 4: 799. https://doi.org/10.3390/electronics13040799