
A Review of Document Binarization: Main Techniques, New Challenges, and Trends
Abstract
:1. Introduction
2. Traditional Binarization Techniques
2.1. Global Threshold Method
2.2. Local Threshold Method
2.3. Mixed Threshold Method
2.4. Image Feature Method
3. Deep Learning Binarization Techniques
3.1. Based on Convolutional Neural Networks (CNNs)
3.2. Based on Generative Adversarial Networks (GANs)
3.3. Based on Attention Mechanism
4. Results
4.1. Performance Measures
4.1.1. PSNR
4.1.2. F-Measure
4.1.3. Pseudo F-Measure
4.1.4. DRD
4.2. Experimental Result
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gatos, B.; Pratikakis, I.; Kepene, K.; Perantonis, S.J. Text Detection in Indoor/Outdoor Scene Images. 2005. Available online: https://www.researchgate.net/publication/253135219_Text_Detection_in_IndoorOutdoor_Scene_Images (accessed on 26 March 2024).
- Pan, Y.F.; Hou, X.; Liu, C.L. Text Localization in Natural Scene Images Based on Conditional Random Field. In Proceedings of the 2009 10th International Conference on Document Analysis and Recognition, Barcelona, Spain, 26–29 July 2009; pp. 6–10. [Google Scholar]
- Liao, M.; Wan, Z.; Yao, C.; Chen, K.; Bai, X. Real-time Scene Text Detection with Differentiable Binarization. arXiv 2019, arXiv:1911.08947. [Google Scholar] [CrossRef]
- Kamnitsas, K.; Ledig, C.; Newcombe, V.F.J.; Simpson, J.P.; Kane, A.D.; Menon, D.K.; Rueckert, D.; Glocker, B. Efficient multi-scale 3D CNN with fully connected CRF for accurate brain lesion segmentation. Med. Image Anal. 2016, 36, 61–78. [Google Scholar] [CrossRef] [PubMed]
- Atia, N.; Benzaoui, A.; Jacques, S.; Hamiane, M.; Kourd, K.E.; Bouakaz, A.; Ouahabi, A. Particle Swarm Optimization and Two-Way Fixed-Effects Analysis of Variance for Efficient Brain Tumor Segmentation. Cancers 2022, 14, 4399. [Google Scholar] [CrossRef] [PubMed]
- Gupta, M.R.; Jacobson, N.P.; Garcia, E.K. OCR binarization and image pre-processing for searching historical documents. Pattern Recognit. 2007, 40, 389–397. [Google Scholar] [CrossRef]
- Murdock, M.; Reid, S.; Hamilton, B.; Reese, J.W. ICDAR 2015 competition on text line detection in historical documents. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 1171–1175. [Google Scholar]
- Kumar, G.; Bhatia, P.K. A Detailed Review of Feature Extraction in Image Processing Systems. In Proceedings of the 2014 Fourth International Conference on Advanced Computing & Communication Technologies, Rohtak, India, 8–9 February 2014; pp. 5–12. [Google Scholar]
- Marques, O. Morphological Image Processing. 2011. Available online: https://onlinelibrary.wiley.com/doi/abs/10.1002/9781118093467.ch13 (accessed on 26 March 2024).
- Weszka, J.S.; Rosenfeld, A. Threshold Evaluation Techniques. IEEE Trans. Syst. Man Cybern. 1978, 8, 622–629. [Google Scholar] [CrossRef]
- Weszka, J.S. A survey of threshold selection techniques. Comput. Graph. Image Process. 1978, 7, 259–265. [Google Scholar] [CrossRef]
- Sahoo, P.K.; Soltani, S.; Wong, A.K.C. A survey of thresholding techniques. Comput. Vis. Graph. Image Process. 1988, 41, 233–260. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2015; pp. 770–778. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Gatos, B.; Ntirogiannis, K.; Pratikakis, I. DIBCO 2009: Document image binarization contest. Int. J. Doc. Anal. Recognit. (IJDAR) 2011, 14, 35–44. [Google Scholar] [CrossRef]
- Pratikakis, I.; Gatos, B.; Ntirogiannis, K. ICDAR 2011 Document Image Binarization Contest (DIBCO 2011). In Proceedings of the 2011 International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; pp. 1506–1510. [Google Scholar]
- Pratikakis, I.; Gatos, B.; Ntirogiannis, K. ICDAR 2013 Document Image Binarization Contest (DIBCO 2013). In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 1471–1476. [Google Scholar]
- Pratikakis, I.; Zagoris, K.; Barlas, G.; Gatos, B. ICFHR2016 Handwritten Document Image Binarization Contest (H-DIBCO 2016). In Proceedings of the 2016 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016; pp. 619–623. [Google Scholar]
- Pratikakis, I.; Zagoris, K.; Barlas, G.; Gatos, B. ICDAR2017 Competition on Document Image Binarization (DIBCO 2017). In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japa, 9–15 November 2017; pp. 1395–1403. [Google Scholar]
- Bhowmik, S. Document Image Binarization. In Document Layout Analysis; Springer Nature Singapore: Singapore, 2023; Available online: https://link.springer.com/chapter/10.1007/978-981-99-4277-0_2 (accessed on 26 March 2024).
- Mustafa, W.A.; Kader, M.M.M.A. Binarization of Document Image Using Optimum Threshold Modification. J. Phys. Conf. Ser. 2018, 1019, 012022. [Google Scholar] [CrossRef]
- Patil, P. Survey on document image binarization. Int. J. Adv. Res. Ideas Innov. Technol. 2019, 5, 273–275. [Google Scholar]
- Sezgin, M.; Sankur, B. Survey over image thresholding techniques and quantitative performance evaluation. J. Electron. Imaging 2004, 13, 146–168. [Google Scholar]
- Ismail, S.M.; Abdullah, S.N.H.S.; Fauzi, F. Statistical Binarization Techniques for Document Image Analysis. J. Comput. Sci. 2018, 14, 23–36. [Google Scholar] [CrossRef]
- Saxena, L.P. Niblack’s binarization method and its modifications to real-time applications: A review. Artif. Intell. Rev. 2019, 51, 673–705. [Google Scholar] [CrossRef]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Niblack, W. An Introduction to Digital Image Processing; Prentice-Hall International: Englewood Cliffs, NJ, USA, 1986; Available online: https://archive.org/details/introductiontodi0000nibl (accessed on 26 March 2024).
- Trier, Ø.D.; Jain, A.K. Goal-Directed Evaluation of Binarization Methods. IEEE Trans. Pattern Anal. Mach. Intell. 1995, 17, 1191–1201. [Google Scholar] [CrossRef]
- Sauvola, J.J.; Seppänen, T.; Haapakoski, S.; Pietikäinen, M. Adaptive document binarization. In Proceedings of the Fourth International Conference on Document Analysis and Recognition, Ulm, Germany, 18–20 August 1997; Voume 1, pp. 147–152. [Google Scholar]
- Lazzara, G.; Géraud, T. Efficient Multiscale Sauvola’s Binarization. Int. J. Doc. Anal. Recognit. (IJDAR) 2014, 17, 105–123. [Google Scholar] [CrossRef]
- Khurshid, K.; Siddiqi, I.; Faure, C.; Vincent, N. Comparison of Niblack inspired binarization methods for ancient documents. In Document Recognition and Retrieval XVI; SPIE: Bellingham, WA, USA, 2009. [Google Scholar]
- Bataineh, B.; Abdullah, S.N.H.S.; Omar, K.B. An adaptive local binarization method for document images based on a novel thresholding method and dynamic windows. Pattern Recognit. Lett. 2011, 32, 1805–1813. [Google Scholar] [CrossRef]
- Singh, T.R.; Roy, S.; Singh, O.I.; Sinam, T.; Singh, K.M. A New Local Adaptive Thresholding Technique in Binarization. arXiv 2012, arXiv:1201.5227. [Google Scholar]
- Chaki, N.; Shaikh, S.H.; Saeed, K. A Comprehensive Survey on Image Binarization Techniques. In Exploring Image Binarization Techniques; Springer: New Delhi, India, 2014. [Google Scholar] [CrossRef]
- He, J.; Do, Q.; Downton, A.C.; Kim, J.H. A comparison of binarization methods for historical archive documents. In Proceedings of the Eighth International Conference on Document Analysis and Recognition (ICDAR’05), Seoul, Republic of Korea, 31 August 31–1 September 2005; Volume 1, pp. 538–542. [Google Scholar]
- Hadjadj, Z.; Meziane, A.; Cherfa, Y.; Cheriet, M.; Setitra, I. ISauvola: Improved Sauvola’s Algorithm for Document Image Binarization. In Proceedings of the International Conference on Image Analysis and Recognition, Niagara Falls, ON, Canada, 22–24 July 2015. [Google Scholar]
- Lu, S.; Su, B.; Tan, C.L. Document image binarization using background estimation and stroke edges. Int. J. Doc. Anal. Recognit. (IJDAR) 2010, 13, 303–314. [Google Scholar] [CrossRef]
- Mieloch, K.; Mihăilescu, P.; Munk, A. Dynamic threshold using polynomial surface regression with application to the binarization of fingerprints. In SPIE Defense + Commercial Sensing; SPIE: Bellingham, WA, USA, 2005. [Google Scholar]
- Moghaddam, R.F.; Cheriet, M. RSLDI: Restoration of single-sided low-quality document images. Pattern Recognit. 2009, 42, 3355–3364. [Google Scholar] [CrossRef]
- Gatos, B.; Pratikakis, I.; Perantonis, S.J. Adaptive degraded document image binarization. Pattern Recognit. 2006, 39, 317–327. [Google Scholar] [CrossRef]
- Su, B.; Lu, S.; Tan, C.L. Binarization of historical document images using the local maximum and minimum. In Proceedings of the International Workshop on Document Analysis Systems, Boston, MA, USA, 9–11 June 2010. [Google Scholar]
- Su, B.; Lu, S.; Tan, C.L. Robust Document Image Binarization Technique for Degraded Document Images. IEEE Trans. Image Process. 2013, 22, 1408–1417. [Google Scholar]
- Bernsen, J. Dynamic thresholding of grey-level images. In Proceedings of the Eighth International Conference on Pattern Recognition, Paris, France, 27–31 October 1986. [Google Scholar]
- Wolf, C.; Jolion, J.M. Extraction and recognition of artificial text in multimedia documents. Form. Pattern Anal. Appl. 2003, 6, 309–326. [Google Scholar] [CrossRef]
- Yang, Y. OCR Oriented Binarization Method of Document Image. In Proceedings of the 2008 Congress on Image and Signal Processing, Sanya, China, 27–30 May 2008; Volume 4, pp. 622–625. [Google Scholar]
- Zemouri, E.T.; Chibani, Y.; Brik, Y. Enhancement of Historical Document Images by Combining Global and Local Binarization Technique. Int. J. Inf. Eng. Electron. Bus. 2014, 4, 1. [Google Scholar] [CrossRef]
- Chaudhary, P.; Ambedkar, B. An effective and robust technique for the binarization of degraded document images. Int. J. Res. Eng. Technol. 2014, 03, 140–145. [Google Scholar]
- Ntirogiannis, K.; Gatos, B.; Pratikakis, I. A combined approach for the binarization of handwritten document images. Pattern Recognit. Lett. 2014, 35, 3–15. [Google Scholar] [CrossRef]
- Liang, Y.; Lin, Z.; Sun, L.; Cao, J. Document image binarization via optimized hybrid thresholding. In Proceedings of the 2017 IEEE International Symposium on Circuits and Systems (ISCAS), Baltimore, MD, USA, 28–31 May 2017; pp. 1–4. [Google Scholar]
- Xiao, H.; Lin, L.; Rong, L.; Chengshen, X.; Ye, M. Binarization of degraded document images with global-local U-Nets. Optik 2020, 203, 164025. [Google Scholar]
- Saddami, K.; Arnia, F.; Away, Y.; Munadi, K. Kombinasi Metode Nilai Ambang Lokal dan Global untuk Restorasi Dokumen Jawi Kuno. J. Teknol. Inf. Dan Ilmu Komput. 2020, 7, 163–170. [Google Scholar] [CrossRef]
- Ranjitha, P.; Shreelakshmi, T.D. A Hybrid Ostu based Niblack Binarization for Degraded Image Documents. In Proceedings of the 2021 2nd International Conference for Emerging Technology (INCET), Belagavi, India, 21–23 May 2021; pp. 1–7. [Google Scholar]
- Santhanaprabhu, G.; Karthick, B.; Srinivasan, P.; Vignesh, R.K.; Sureka, K. Extraction and Document Image Binarization Using Sobel Edge Detection. J. Eng. Res. Appl. 2014, 4, 15–21. [Google Scholar]
- Lelore, T.; Bouchara, F. FAIR: A Fast Algorithm for Document Image Restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2039–2048. [Google Scholar] [CrossRef] [PubMed]
- Holambe, S.N.; Shinde, U.B.; Choudhari, B.S. Image Binarization for Degraded Document Images. Int. J. Comput. Appl. 2015, 128, 38–43. [Google Scholar]
- Jia, F.; Shi, C.; He, K.; Wang, C.; Xiao, B. Document Image Binarization Using Structural Symmetry of Strokes. In Proceedings of the 2016 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016; pp. 411–416. [Google Scholar]
- Hadjadj, Z.; Cheriet, M.; Meziane, A.; Cherfa, Y. A new efficient binarization method: Application to degraded historical document images. Signal Image Video Process. 2017, 11, 1155–1162. [Google Scholar] [CrossRef]
- Xiong, W.; Xu, J.; Zijie, X.; Juan, W.L.; Min, L. Degraded historical document image binarization using local features and support vector machine (SVM). Optik 2018, 164, 218–223. [Google Scholar] [CrossRef]
- Lai, A.N.; Lee, G. Binarization by Local K-means Clustering for Korean Text Extraction. In Proceedings of the 2008 IEEE International Symposium on Signal Processing and Information Technology, Vancouver, BC, Canada, 27–30 August 2006; IEEE: New York, NY, USA, 2008; pp. 117–122. [Google Scholar]
- Soua, M.; Kachouri, R.; Akil, M. GPU parallel implementation of the new hybrid binarization based on Kmeans method (HBK). J. Real-Time Image Process. 2018, 14, 363–377. [Google Scholar] [CrossRef]
- Pal, N.R.; Pal, K.; Keller, J.M.; Bezdek, J.C. A possibilistic fuzzy c-means clustering algorithm. IEEE Trans. Fuzzy Syst. 2005, 13, 517–530. [Google Scholar] [CrossRef]
- Farahmand, A.; Sarrafzadeh, H.; Shanbehzadeh, J. Noise removal and binarization of scanned document images using clustering of features. In Proceedings of the International MultiConference of Engineers and Computer Scientists 2017 Vol I, IMECS 2017, Hong Kong, China, 15–17 March 2017. [Google Scholar]
- Tong, L.; Chen, K.; Zhang, Y.; Fu, X.L.; Duan, J. Document Image Binarization Based on NFCM. In Proceedings of the 2009 2nd International Congress on Image and Signal Processing, Tianjin, China, 17–19 October 2009; pp. 1–5. [Google Scholar]
- Biswas, B.; Bhattacharya, U.; Chaudhuri, B.B. A Global-to-Local Approach to Binarization of Degraded Document Images. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 3008–3013. [Google Scholar]
- Annabestani, M.; Saadatmand-Tarzjan, M. A New Threshold Selection Method Based on Fuzzy Expert Systems for Separating Text from the Background of Document Images. Iran. J. Sci. Technol. Trans. Electr. Eng. 2018, 43, 219–231. [Google Scholar] [CrossRef]
- Gatos, B.; Pratikakis, I.; Perantonis, S.J. Improved document image binarization by using a combination of multiple binarization techniques and adapted edge information. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- Rosenfeld, A.; de la Torre, P. Histogram concavity analysis as an aid in threshold selection. IEEE Trans. Syst. Man Cybern. 1983; SMC-13, 231–235. [Google Scholar]
- Sezan, M.I. A Peak Detection Algorithm and its Application to Histogram-Based Image Data Reduction. Comput. Vis. Graph. Image Process. 1990, 49, 36–51. [Google Scholar] [CrossRef]
- Pavlidis, T. Threshold selection using second derivatives of the gray scale image. In Proceedings of the 2nd International Conference on Document Analysis and Recognition (ICDAR ’93), Tsukuba Science City, Japan, 20–22 October 1993; pp. 274–277. [Google Scholar]
- Kapur, J.N.; Sahoo, P.K.; Wong, A.K.C. A new method for gray-level picture thresholding using the entropy of the histogram. Comput. Vis. Graph. Image Process. 1985, 29, 273–285. [Google Scholar] [CrossRef]
- Abutableb, A.S. Automatic thresholding of gray-level pictures using two-dimensional entropy. Comput. Vis. Graph. Image Process. 1989, 47, 22–32. [Google Scholar] [CrossRef]
- Hertz, L.; Schafer, R.W. Multilevel thresholding using edge matching. Comput. Vis. Graph. Image Process. 1988, 44, 279–295. [Google Scholar] [CrossRef]
- Badekas, E.; Papamarkos, N. Optimal combination of document binarization techniques using a self-organizing map neural network. Eng. Appl. Artif. Intell. 2007, 20, 11–24. [Google Scholar] [CrossRef]
- Su, B.; Lu, S.; Tan, C.L. Combination of Document Image Binarization Techniques. In Proceedings of the 2011 International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; pp. 22–26. [Google Scholar]
- Pastor-Pellicer, J.; Boquera, S.E.; Zamora-Martínez, F.; Afzal, M.Z.; Bleda, M.J.C. Insights on the Use of Convolutional Neural Networks for Document Image Binarization. In Proceedings of the International Work-Conference on Artificial and Natural Neural Networks, Palma de Mallorca, Spain, 10–12 June 2015. [Google Scholar]
- Pratikakis, I.; Gatos, B.; Ntirogiannis, K. H-DIBCO 2010—Handwritten Document Image Binarization Competition. In Proceedings of the 2010 12th International Conference on Frontiers in Handwriting Recognition, Kolkata, India, 16–18 November 2010; pp. 727–732. [Google Scholar]
- Pratikakis, I.; Gatos, B.; Ntirogiannis, K. ICFHR 2012 Competition on Handwritten Document Image Binarization (H-DIBCO 2012). In Proceedings of the 2012 International Conference on Frontiers in Handwriting Recognition, Bari, Italy, 18–20 September 2012; pp. 817–822. [Google Scholar]
- Fischer, A.; Indermühle, E.; Bunke, H.; Viehhauser, G.; Stolz, M. Ground truth creation for handwriting recognition in historical documents. In Proceedings of the International Workshop on Document Analysis Systems, Boston, MA, USA, 9–11 June 2010. [Google Scholar]
- Fischer, A.; Frinken, V.; Fornés, A.; Bunke, H. Transcription alignment of Latin manuscripts using hidden Markov models. In Proceedings of the 2011 Workshop on Historical Document Imaging and Processing, Beijing, China, 16–17 September 2011. [Google Scholar]
- Saddami, K.; Munadi, K.; Arnia, F. Degradation Classification on Ancient Document Image Based on Deep Neural Networks. In Proceedings of the 2020 3rd International Conference on Information and Communications Technology (ICOIACT), Yogyakarta, Indonesia, 24–25 November 2020; pp. 405–410. [Google Scholar]
- Sandler, M.; Howard, A.G.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- He, S.; Schomaker, L. DeepOtsu: Document Enhancement and Binarization using Iterative Deep Learning. Pattern Recognit. 2019, 91, 379–390. [Google Scholar] [CrossRef]
- Vo, Q.N.; Kim, S.; Yang, H.J.; Lee, G. Binarization of degraded document images based on hierarchical deep supervised network. Pattern Recognit. 2018, 74, 568–586. [Google Scholar] [CrossRef]
- Meng, G.; Yuan, K.; Wu, Y.; Xiang, S.; Pan, C. Deep Networks for Degraded Document Image Binarization through Pyramid Reconstruction. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 01, pp. 727–732. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Tensmeyer, C.; Martinez, T.R. Document Image Binarization with Fully Convolutional Neural Networks. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 01, pp. 99–104. [Google Scholar]
- Ayyalasomayajula, K.R.; Malmberg, F.; Brun, A. PDNet: Semantic Segmentation integrated with a Primal-Dual Network for Document binarization. Pattern Recognit. Lett. 2018, 121, 52–60. [Google Scholar] [CrossRef]
- Riegler, G.; Ferstl, D.; Rüther, M.; Bischof, H. A Deep Primal-Dual Network for Guided Depth Super-Resolution. arXiv 2016, arXiv:1607.08569. [Google Scholar]
- Dumpala, V.; Kurupathi, S.R.; Bukhari, S.S.; Dengel, A.R. Removal of Historical Document Degradations using Conditional GANs. In Proceedings of the International Conference on Pattern Recognition Applications and Methods, Prague, Czech Republic, 19–21 February 2019. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–19 October 2017; pp. 2242–2251. [Google Scholar]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to Discover Cross-Domain Relations with Generative Adversarial Networks. Int. Conf. Mach. Learn. 2017, 70, 1857–1865. [Google Scholar]
- Suh, S.; Kim, J.; Lukowicz, P.; Lee, Y.O. Two-Stage Generative Adversarial Networks for Document Image Binarization with Color Noise and Background Removal. arXiv 2020, arXiv:2010.10103. [Google Scholar]
- Bhunia, A.K.; Bhunia, A.K.; Sain, A.; Roy, P.P. Improving Document Binarization Via Adversarial Noise-Texture Augmentation. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 2721–2725. [Google Scholar]
- Bhowmik, S.; Sarkar, R.; Das, B.; Doermann, D.S. GiB: A Game Theory Inspired Binarization Technique for Degraded Document Images. IEEE Trans. Image Process. 2019, 28, 1443–1455. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.; Ghose, S.; Chowdhury, P.N.; Roy, P.P.; Pal, U. UDBNET: Unsupervised Document Binarization Network via Adversarial Game. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 7817–7824. [Google Scholar]
- Konwer, A.; Bhunia, A.K.; Bhowmick, A.; Bhunia, A.K.; Banerjee, P.; Roy, P.P.; Pal, U. Staff line Removal using Generative Adversarial Networks. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 1103–1108. [Google Scholar]
- Zhao, J.; Shi, C.; Jia, F.; Wang, Y.; Xiao, B. Document image binarization with cascaded generators of conditional generative adversarial networks. Pattern Recognit. 2019, 96, 106968. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Souibgui, M.A.; Kessentini, Y. DE-GAN: A Conditional Generative Adversarial Network for Document Enhancement. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1180–1191. [Google Scholar] [CrossRef] [PubMed]
- De, R.; Chakraborty, A.; Sarkar, R. Document Image Binarization Using Dual Discriminator Generative Adversarial Networks. IEEE Signal Process. Lett. 2020, 27, 1090–1094. [Google Scholar] [CrossRef]
- Rajesh, B.; Agrawal, M.; Bhuva, M.; Kishore, K.; Javed, M. Document Image Binarization in JPEG Compressed Domain using Dual Discriminator Generative Adversarial Networks. In Computer Vision and Machine Intelligence: Proceedings of CVMI 2022; Springer: Singapore, 2022. [Google Scholar]
- Lin, Y.S.; Ju, R.; Chen, C.C.; Lin, T.Y.; Chiang, J.S. Three-stage binarization of color document images based on discrete wavelet transform and generative adversarial networks. arXiv 2022, arXiv:2211.16098. [Google Scholar]
- Fathallah, A.; El-Yacoubi, M.A.; Amara, N.E.B. EHDI: Enhancement of Historical Document Images via Generative Adversarial Network. In Proceedings of the 18th International Conference on Computer Vision Theory and Applications, Lisbon, Portugal, 19–21 February 2023. [Google Scholar]
- Guo, Y.; Ji, C.; Zheng, X.; Wang, Q.; Luo, X. Multi-scale Multi-attention Network for Moiré Document Image Binarization. Signal Process. Image Commun. 2021, 90, 116046. [Google Scholar] [CrossRef]
- Peng, X.; Wang, C.; Cao, H. Document Binarization via Multi-resolutional Attention Model with DRD Loss. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 45–50. [Google Scholar]
- Bezmaternykh, P.V.; Ilin, D.; Nikolaev, D.P. U-Net-bin: Hacking the document image binarization contest. Comput. Opt. 2019, 43, 825–882. [Google Scholar] [CrossRef]
- Zhao, P.; Wang, W.; Zhang, G.; Lu, Y. Alleviating pseudo-touching in attention U-Net-based binarization approach for the historical Tibetan document images. Neural Comput. Appl. 2021, 35, 13791–13802. [Google Scholar] [CrossRef]
- Ma, K.; Shu, Z.; Bai, X.; Wang, J.; Samaras, D. DocUNet: Document Image Unwarping via a Stacked U-Net. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4700–4709. [Google Scholar]
- Peng, X.; Cao, H.; Natarajan, P. Using Convolutional Encoder-Decoder for Document Image Binarization. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 708–713. [Google Scholar]
- Souibgui, M.A.; Biswas, S.; Jemni, S.K.; Kessentini, Y.; Forn’es, A.; Llad’os, J.; Pal, U. DocEnTr: An End-to-End Document Image Enhancement Transformer. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 1699–1705. [Google Scholar]
- Chaurasia, A.; Culurciello, E. LinkNet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Xiong, W.; Jia, X.; Yang, D.; Ai, M.; Li, L.; Wang, S. DP-LinkNet: A convolutional network for historical document image binarization. KSII Trans. Internet Inf. Syst. 2021, 15, 1778–1797. [Google Scholar]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extraction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 192–1924. [Google Scholar]
- Trier, Ø.D.; Taxt, T. Evaluation of Binarization Methods for Document Images. IEEE Trans. Pattern Anal. Mach. Intell. 1995, 17, 312–315. [Google Scholar] [CrossRef]
- Ramírez-Ortegón, M.A.; Tapia, E.; Ramírez-Ramírez, L.L.; Rojas, R.; Jiménez, E.V.C. Transition pixel: A concept for binarization based on edge detection and gray-intensity histograms. Pattern Recognit. 2010, 43, 1233–1243. [Google Scholar] [CrossRef]
- Ntirogiannis, K.; Gatos, B.; Pratikakis, I. Performance Evaluation Methodology for Historical Document Image Binarization. IEEE Trans. Image Process. 2013, 22, 595–609. [Google Scholar] [CrossRef]
- Ntirogiannis, K.; Gatos, B.; Pratikakis, I. ICFHR2014 Competition on Handwritten Document Image Binarization (H-DIBCO 2014). In Proceedings of the 2014 14th International Conference on Frontiers in Handwriting Recognition, Crete Island, Greece, 1–4 September 2014; pp. 809–813. [Google Scholar]








{kind=link}
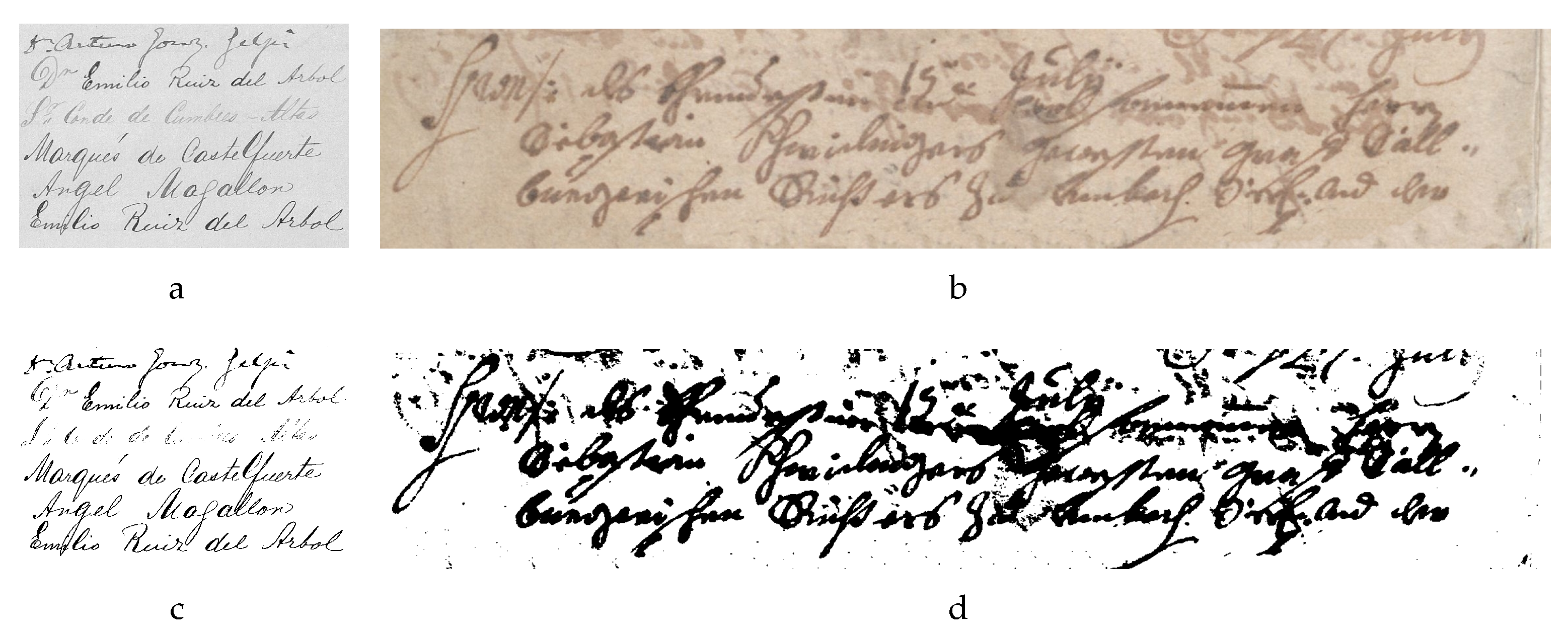{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification | Algorithm | Description | Performance |
|---|---|---|---|
| Global Threshold | Otsu [31] | The gray level corresponding to the maximum inter-class variance is selected as the global threshold. | Low complexity and fast operation. However, it cannot handle complex degraded images and is suitable for processing high-quality document images. |
| Local Threshold | Niblack [32] | It calculates the mean and standard deviation of the pixel within a local window of an image, laying the foundation for local binarization methods. | The processing time has increased, and obvious noise can be seen in the output binarization image, which greatly increases the foreground region. |
| Bernsen [48] | Compute a separate threshold for each pixel by estimating and utilizing the local contrast before classification. | When dealing with complex backgrounds in document images, pseudo-shadow artifacts may occur. | |
| Sauvola [34] | It improves the Niblack method by modifying the threshold calculation. | High complexity. Performance degrades in high contrast regions, but it can eliminate dark areas in the background. | |
| Wolf [49] | Global statistical normalization based on Sauvola for automatic detection of text regions. | It can mitigate the impact of background noise but degradation in performance occurs when there is a sharp change in background gray values across the image. | |
| Gatos [45] | Local adaptive-based approach to enhance degraded image binarization documents. | It performs well on degraded document images with issues such as shadows, uneven lighting, and smear, but leaves a slight amount of noise. | |
| NICK [36] | In order to solve the black noise problem in Niblack, an improved method of threshold calculations was used. | It lowers the threshold and performs better in low-intensity images. | |
| Su [46] | Image contrast technique defined using local image maxima and minima. | This method can handle general document images but performs poorly in specific cases such as the ink-bleeding. | |
| Bataineh [37] | Dynamic segmentation of the image into windows based on image features, determining the threshold value for each window. | It can address specific challenges, such as thin pen strokes and low-contrast images. However, it unavoidably retains excess background. | |
| T.R.Singh [38] | Local adaptive threshold segmentation uses the local mean and mean difference to remove the background. | Unable to recognize faint text, it loses some fine details but exhibits a certain degree of recovery for unevenly lit backgrounds. | |
| Su [47] | Combination method based on local image contrast and local image gradient. | Compared to several classical thresholding methods, it exhibits superior visual quality. However, there is still a small amount of noise present. | |
| Hadjadj [41] | An improved Sauvola’s Algorithm technique for document images is presented. | It improves the quality of binarization results without adjusting manually the user-defined parameters to the document content. | |
| WAN [26] | Improving lost detail strokes by increasing the binarization threshold based on Sauvola. | Performs well on a clean background without pollution. |
| Classification | Algorithm | Description | Performance |
|---|---|---|---|
| Mixed threshold | Yang [50] | A combined Otsu and Bernsen method for processing printed document images. | It can repair broken strokes and eliminate minor ghost artifacts, but with increased processing time. |
| Zemouri [51] | Apply the global threshold to the whole document, and use the Sauvola method on the intermediate image. | Its recognition effect is better than that of a single threshold, but the effect of degraded document images is not good. | |
| Chaudhary [52] | Otsu’s method separates background pixels from the foreground. Sauvola’s method is then applied to eliminate pixels erroneously estimated as foreground. | Thin or weak strokes can be easily confused with the background, making them difficult to identify. Suitable for high-contrast document images. | |
| K.Ntirogiannis [53] | Combining the results of both Otsu and Niblack, incorporating post-processing in intermediate and final steps. | It cannot simultaneously consider text information and large noise, making it unsuitable for document images with folds or page splits. | |
| Liang [54] | Combining the Otsu and Sauvola methods to determine thresholds. | It can reach the general level in document image binarization. | |
| Saddami [56] | It combines the Niblack and Wolf methods. The Otsu method and standard deviation are combined. | It retains a significant amount of noise and degrades the performance in images with low contrast. |
| Classification | Algorithm | Description | Performance |
|---|---|---|---|
| Lu [42] | It detects the text stroke edges based on the local image variation. Combining L1 parametric image gradient and local threshold segmentation. | Suitable for scanned documents with uniform color and texture. Unable to handle situations where the document is skewed or folded. | |
| T.Lelore [59] | The improved Canny method for edge detection is employed to achieve rough text localization. | This method has relatively low computational costs and can be applied in real-time applications. | |
| Edge detection | Santhanaprabhu [58] | This method first constructs an adaptive contrast map, and then combines the Sobel edge map to detect the edges of text strokes. | This method has few parameters and can adapt to various degradation types such as uneven illumination and document smear. |
| Holambe [60] | Adaptive image contrast combined with Canny’s edge map to Edge detection identify stroke-edge pixels. | The approach is low complexity, convenient, and involves fewer parameters. | |
| Jia [61] | By deforming the Sobel operator to compute the image gradient map. Then, a voting framework is employed to compensate for inaccurate structural symmetry pixels (SSPs). | Due to its adaptive stroke width estimation, this method performs slightly better on printed document images compared to handwritten images. | |
| Lai [64] | Binarization is performed on images captured by mobile devices using the K-means clustering approach to address degradation issues. | It can reasonably restore Korean text, but the effectiveness of binarized images with fine strokes needs further investigation. | |
| Tong [68] | Niblack and Fuzzy C-Means (FCM) were used for clustering and to calculate the local thresholds, respectively. | It can effectively preserve strokes and alleviate ghost artifacts. But its performance is unsatisfactory in handling weak strokes. | |
| Fuzzy Logic | Biswas [69] | Blurring of the input degraded file image with Gaussian filter. | Effective for images with a simple background, but may lead to stroke fragmentation when dealing with faint strokes. |
| Soua [65] | A method based on hybrid binarization and implemented processing of the parallel binarization based on Kmeans method in an optical character recognition (OCR) system. | Suitable for high-quality printed document images and can be applied in real-time scenarios. | |
| Annabestani [70] | A global threshold selection method based on fuzzy expert systems (FESs). | It falls within the category of global threshold methods and may require manual adjustment of local threshold for degraded documents. It is more suitable for uniform background. |
| Algorithm | Description | Performance |
|---|---|---|
| Pastor-Pellicer [80] | Describes a practical application of Convolutional Neural Networks (CNNs) in document image binarization tasks. | The method still lags behind advanced approaches, but their work validates the superiority of CNN over Multilayer Perceptrons (MLPs). |
| Meng [90] | Deep Convolutional Neural Network (DCNN)-based framework. Binarization is employed based on the characteristics or patterns of characters. | It performs well on degraded document images. However, defects may appear in the middle of wide color strokes, and deep stains may not be completely removed. |
| Vo [89] | A new supervised binarization method based on Deep Supervised Networks (DSNs). | The results retained only a small amount of noise, with few thin or weak strokes missing. Plus, its processing time needs improvement. |
| He [88] | Combining the Otsu algorithm and CNN results in a method named DeepOtsu. | Enhancing degraded document images before binarization leads to clear and uniform text. |
| Tensmeyer [92] | Fully Convolutional Network (FCN) based binarization algorithm for low-quality document images. | FCN has certain limitations, and there might be effective features that it cannot learn. |
| Ayyalasoma-yajula [93] | Combining a FCN and a Primal-Dual Network (PD-Net). | It is suitable for historical document images and transfer learning scenarios. |
| Algorithm | Description | Performance |
|---|---|---|
| Bhunia [100] | A texture enhancement network is constructed by introducing an adversarial learning approach. | It can provide better visual quality but might compromise stroke edge details, resulting in noise within thick strokes. |
| Zhao [104] | The conditional GANs (cGANs) are introduced to solve the multi-scale information combination problem in binarization tasks. | It performs well under various degradation scenarios, but there are minor noise dots in the middle of the strokes. |
| Bhowmik [101] | They proposed a document image binarization method based on game theory, using the K-means clustering algorithm for pixel classification. | It effectively eliminates artifacts while preserving some boundary pixels of stamps and stains. |
| Kumar [102] | The joint discriminator combines the Texture Augmentation Network (TANet) and unsupervised document binarization network (UDBNet) to address the issue of dataset bias. | In handwritten document images, stroke omissions and background noise may occur. |
| Suh [99] | A two-stage color document image enhancement and binarization method using GANs. The study focuses on the issue of multi-color degradation. | It can solve the problem of document degradation, including postmarks, bleed-through, uneven contrast, and so on. |
| Souibgui [106] | A conditional generative adversarial network for document enhancement named DE-GAN. | It removes most background imprints, but the method also preserves some noise, as well as traces like paper creases. |
| R.De [107] | A Dual Discriminator GAN (DD-GAN) is proposed. It utilizes both global and local information about pixel distribution. | The overall performance is good, but the performance in HDIBCO2018 is poor, mainly due to the inability to distinguish background pixels that do not belong to the manuscript. |
| Rajesh [108] | The proposed model directly binarizes document images in their compressed form without the need for decompression. | The most important point of this method is its ability to significantly enhance computing efficiency and save storage space. |
| Fathallah [110] | A historical document image enhancement model is proposed based on GANs. | Some stains, such as watermarks, can be removed, but the resulting text strokes will be thinner, which may lead to the loss of some details. |
| Algorithm | Description | Performance |
|---|---|---|
| Peng [116] | The probabilities of text regions are inferred from a multi-resolution attention model, which is then fed into a ConvCRF. | It performs well in document images with contrast variations and exhibits good generalization capability. |
| Ke Ma [115] | A hybrid model based on U-Net and Transformer for flattening and correcting distorted deformations in document images. | It significantly restores distorted document images, which is highly beneficial for the binarization of degraded documents. |
| Peng [112] | It extrapolates the probability of the text region using a multi-resolution attention model and feeds it into ConvCRF to obtain the final binarized document image. | It can effectively remove degraded stain marks, but it is easy to identify the page boundary. |
| Bezmaternykh [113] | It uses U-Net architecture to achieve more accurate historical document images binarization. | It can exhibit excellent results for document images, and this method secured the first position in the DIBCO ’17 competition. |
| Xiao [55] | It utilizes a combination of global and local branches, adopting U-Net as its architecture, and finally produces the ultimate binarization result through logical operator fusion. | Comparative experiments indicate that the combined approach can enhance the discriminative performance between text and background. |
| Guo [111] | A Multiscale Multi-Attention Network (MsMa-Net). | It can eliminate the majority of background noise, but it has some limitations as the edges of strokes may not be smooth enough. |
| Zhao [114] | A U-Net-based binarization method provides a solution to the degradation issues in historical Tibetan document images, particularly pseudo-touching strokes. | This method achieves the best results in enlarged Tibetan images, but it may produce holes in the strokes of faint characters. |
| Xiong [119] | Based on the LinkNet architecture, the model integrates the Hybrid Dilated Convolution (HDC) and Spatial Pyramid Pooling (SPP) modules between the encoder and the decoder. | It can effectively remove background stains, restore text information, and is much faster than most CNN-based methods. |
| Classification | Algorithm | F-Measure | PSNR | DRD | |
|---|---|---|---|---|---|
| Otsu [31] | 86.59 | 89.92 | 17.79 | 6.89 | |
| Niblack [32] | 63.10 | 63.64 | 12.47 | 31.48 | |
| Bernsen [48] | 71.73 | 75.87 | 13.66 | 25.41 | |
| Sauvola [34] | 81.27 | 83.91 | 15.36 | 17.92 | |
| Wolf [49] | 86.36 | 90.46 | 17.11 | 9.01 | |
| Traditional | Gatos [45] | 86.59 | 89.09 | 17.47 | 7.01 |
| based | NICK [36] | 80.86 | 82.65 | 15.15 | 19.24 |
| Su [46] | 74.41 | 87.03 | 15.52 | 12.55 | |
| Hadjadj [41] | 83.68 | 87.03 | 16.20 | 13.05 | |
| T.R.Singh [38] | 84.47 | 87.56 | 16.99 | 9.73 | |
| Bataineh [37] | 83.27 | 84.43 | 16.02 | 15.61 | |
| WAN [26] | 75.14 | 76.06 | 13.61 | 30.33 | |
| Vo [89] | 90.10 | 93.57 | 19.01 | 3.58 | |
| Tensmeyer [92] | 89.52 | 93.76 | 18.67 | 3.76 | |
| He [88] | 91.4 | 94.3 | 19.60 | 2.9 | |
| Meng [90] | 89.90 ± 4.55 | - | 18.79 ± 3.36 | - | |
| Ayyalasomayajula [93] | 90.18 | - | 18.99 | 3.61 | |
| Deep learning | Zhao [104] | 91.66 | 94.58 | 19.64 | 2.82 |
| based | Bhowmik [101] | 91.15 | - | 19.18 | 3.20 |
| Kumar [102] | 93.4 | 96.2 | 20.1 | 2.2 | |
| Lin [109] | 91.46 | 96.32 | 19.66 | 2.94 | |
| R.De [107] | 89.98 | 95.23 | 18.83 | 3.61 | |
| Xiao [55] | 90.77 | 94.21 | 19.33 | 3.11 | |
| Peng [112] | 91.68 | - | 19.59 | 2.93 | |
| Peng [116] | 88.07 ± 4.86 | - | 18.13 ± 3.13 | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Z.; Zuo, S.; Zhou, Y.; He, J.; Shi, J. A Review of Document Binarization: Main Techniques, New Challenges, and Trends. Electronics 2024, 13, 1394. https://doi.org/10.3390/electronics13071394
Yang Z, Zuo S, Zhou Y, He J, Shi J. A Review of Document Binarization: Main Techniques, New Challenges, and Trends. Electronics. 2024; 13(7):1394. https://doi.org/10.3390/electronics13071394
Chicago/Turabian StyleYang, Zhengxian, Shikai Zuo, Yanxi Zhou, Jinlong He, and Jianwen Shi. 2024. "A Review of Document Binarization: Main Techniques, New Challenges, and Trends" Electronics 13, no. 7: 1394. https://doi.org/10.3390/electronics13071394