
Cervical Intervertebral Disc Segmentation Based on Multi-Scale Information Fusion and Its Application
 and
and
Abstract
:1. Introduction
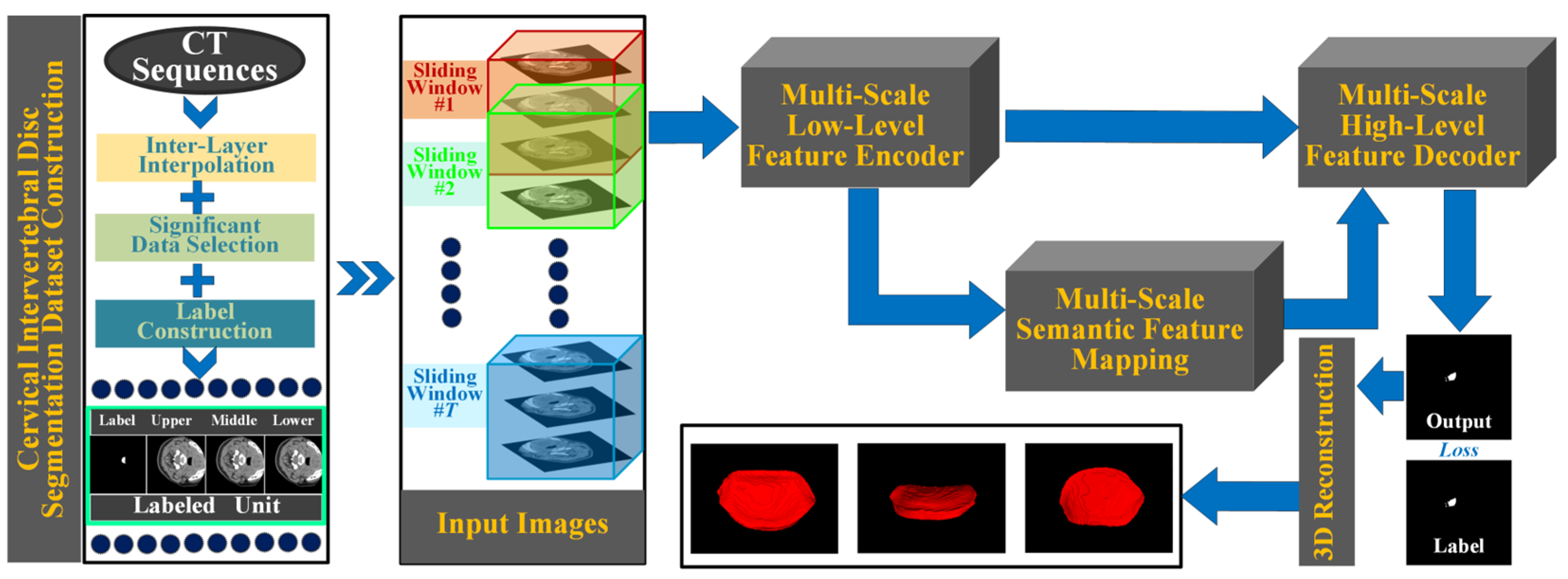
- A multi-scale information fusion framework for segmentation is proposed. This framework consists of multi-scale low–high level feature encoding–decoding fusion module and multi-scale semantic fusion module, with the use of adjacent layer information assisted segmentation strategy. Building upon the conventional hierarchical encoding–decoding framework, it further merges mid-layer semantic information at multiple scales, achieving progressive precision extraction of segmentation features. This framework demonstrates exceptional performance in intervertebral disc segmentation tasks and is effectively applicable to 3D reconstruction and 3D printing.
- An effective multi-scale semantic fusion module is introduced, which can be further divided into two stages: scale interaction based on convolution and scale interaction based on pooling. This two-stage high-precision fusion method significantly enhances the final segmentation performance.
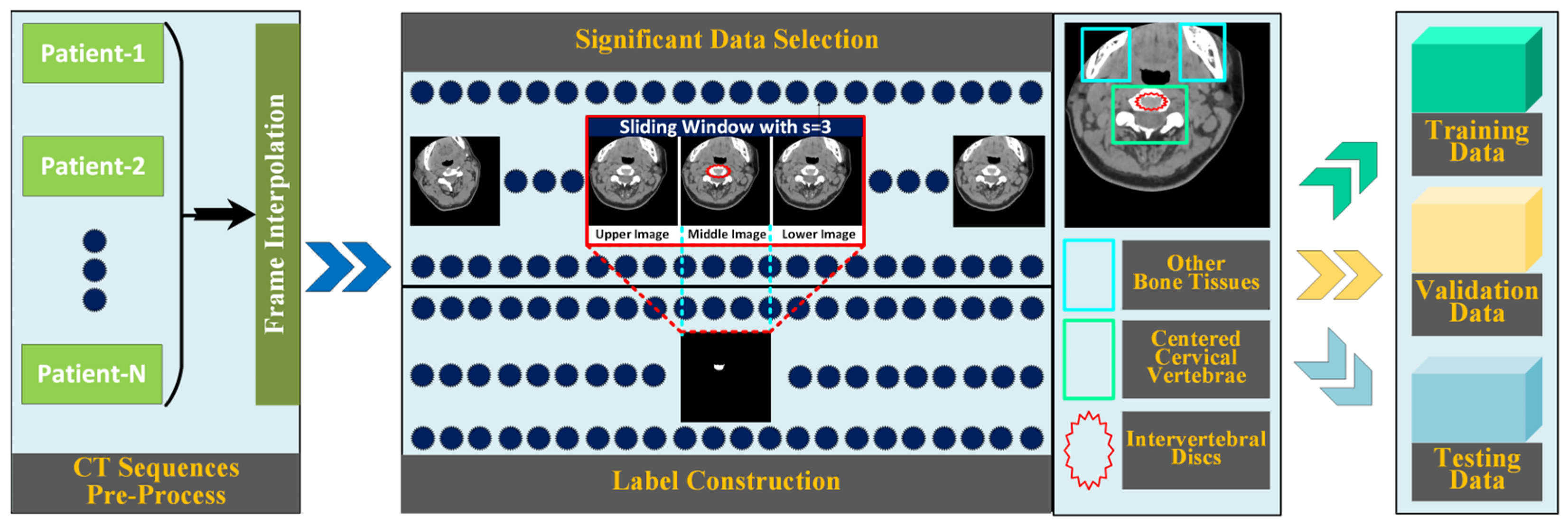
- Datasets specifically aimed at cervical intervertebral disc segmentation are developed. The proposed datasets incorporate inter-layer interpolation to address the inconsistency in longitudinal and transverse pixel spacing in CT sequence images. By selecting frames with prominent intervertebral disc regions through data significance selection and then constructing data groups where three consecutive layer images correspond to one label via manual annotation, the datasets provide important support for research in cervical disc segmentation.
2. Related Work
3. Proposed Method
3.1. Overview of Proposed Method
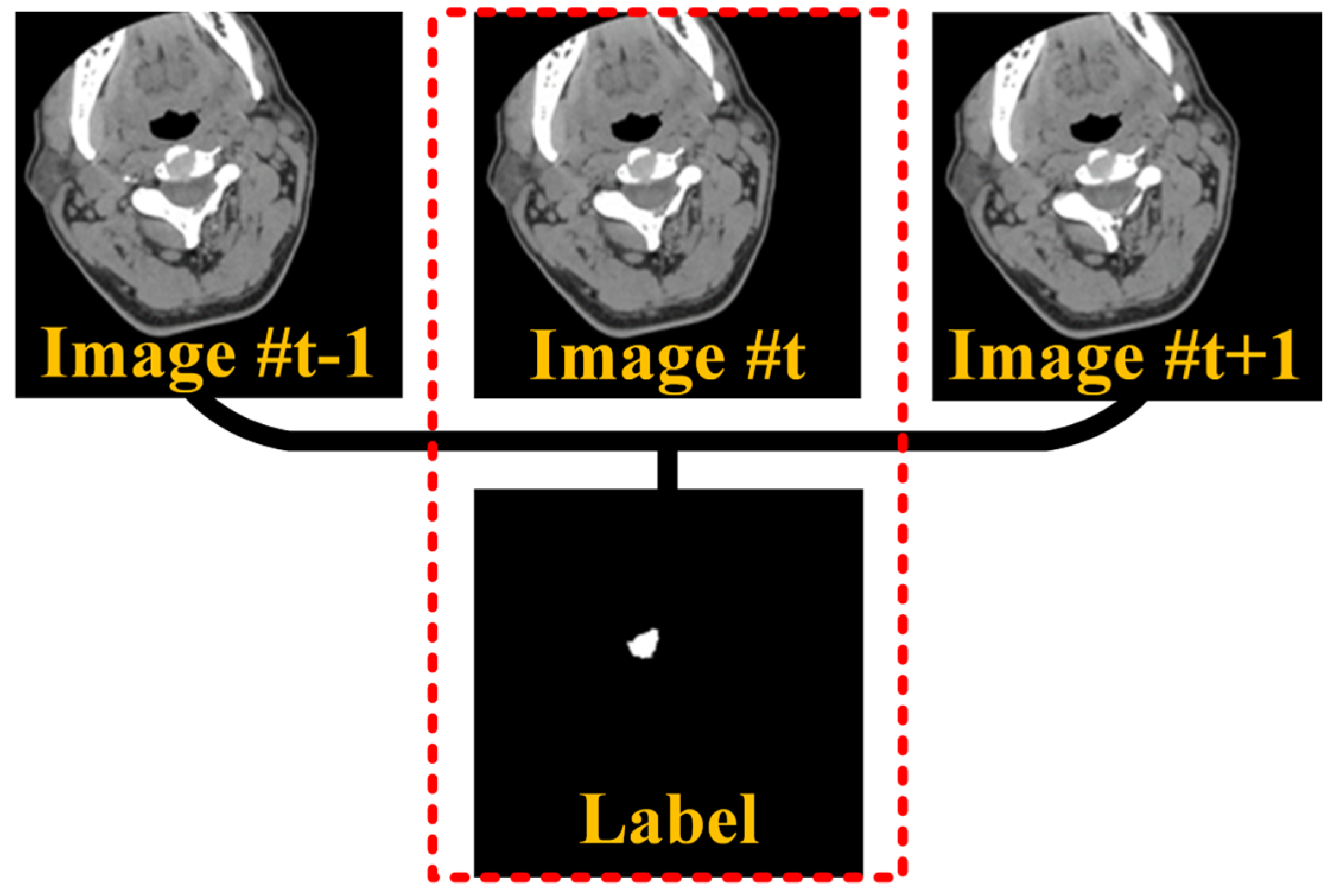
3.2. Adjacent Layer Information Assisted Segmentation
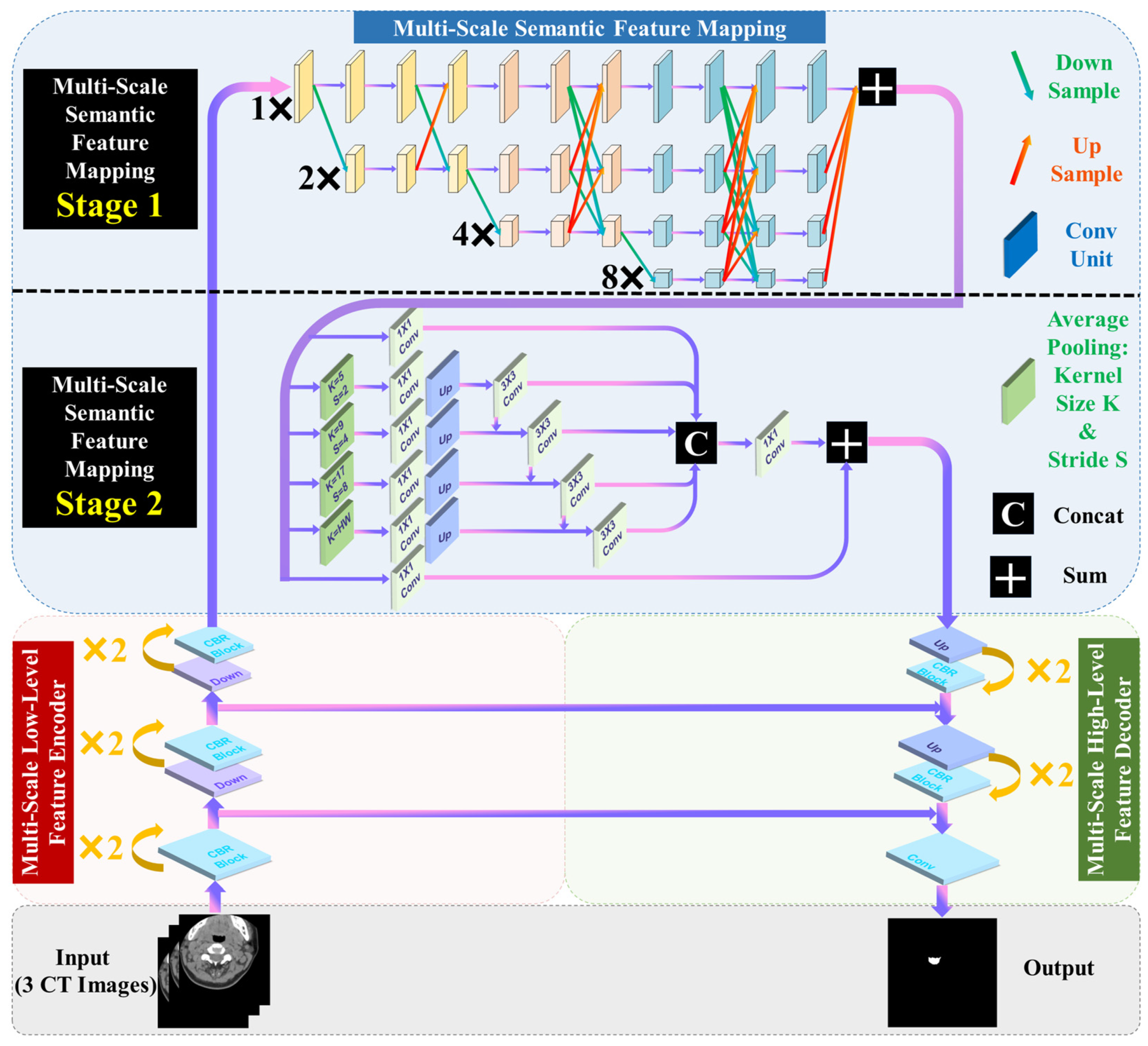
3.3. Multi-Scale Low–High Level Feature Encoding–Decoding Module
3.4. Multi-Scale Semantic Feature Mapping Module
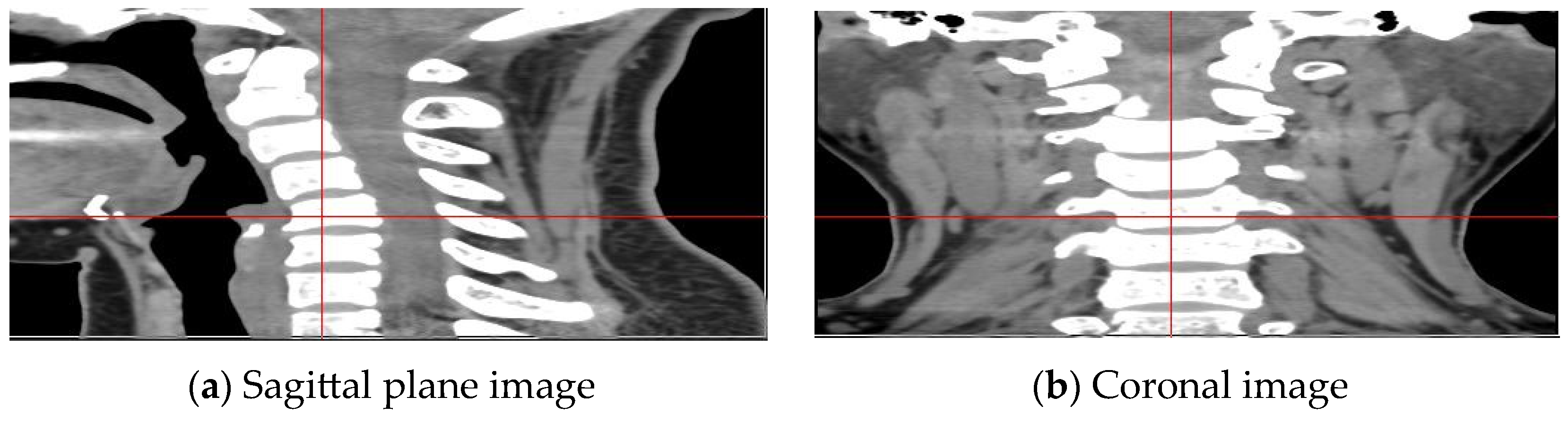
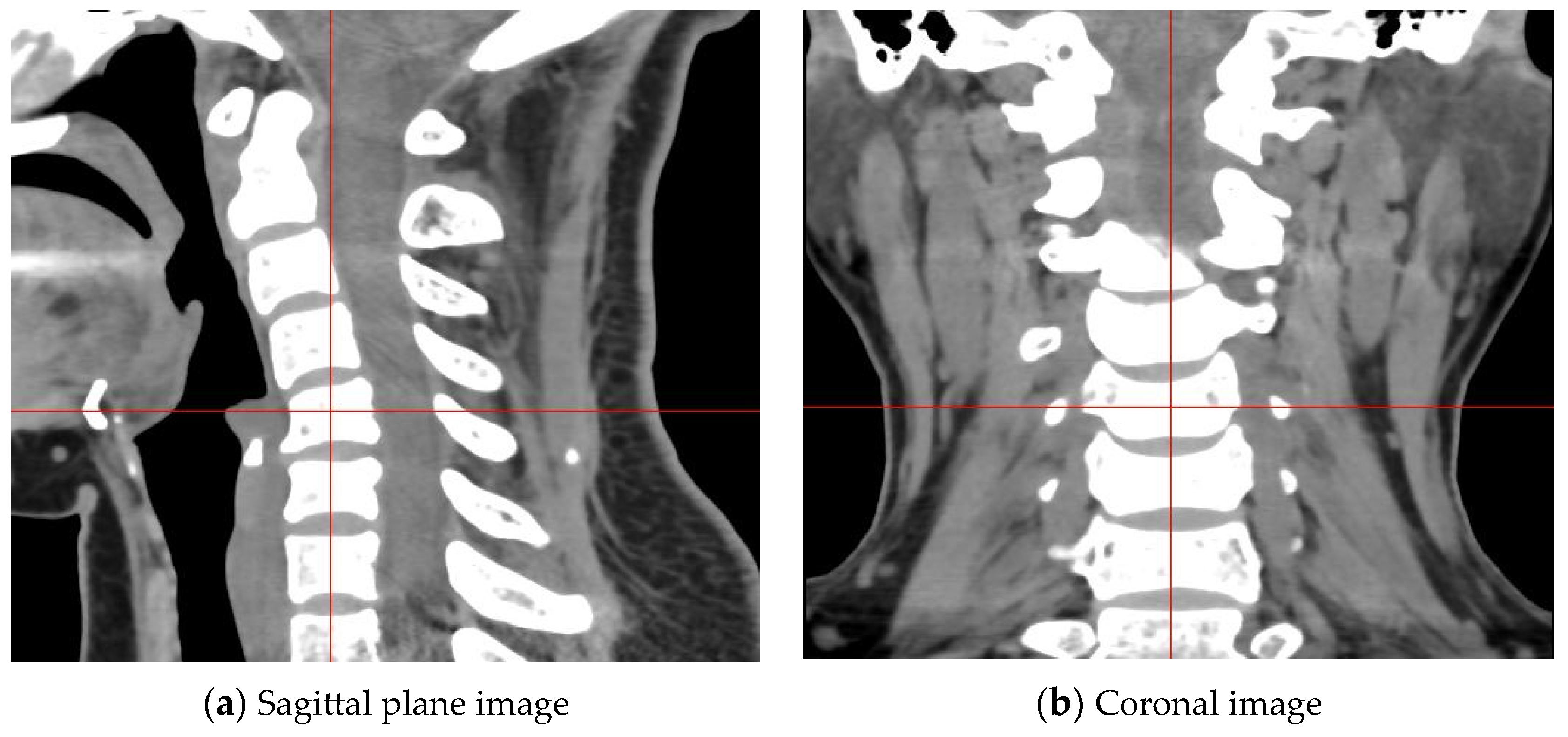
3.5. Construction of Cervical Intervertebral Discs Segmentation Datasets
4. Experiments
4.1. Experimental Settings
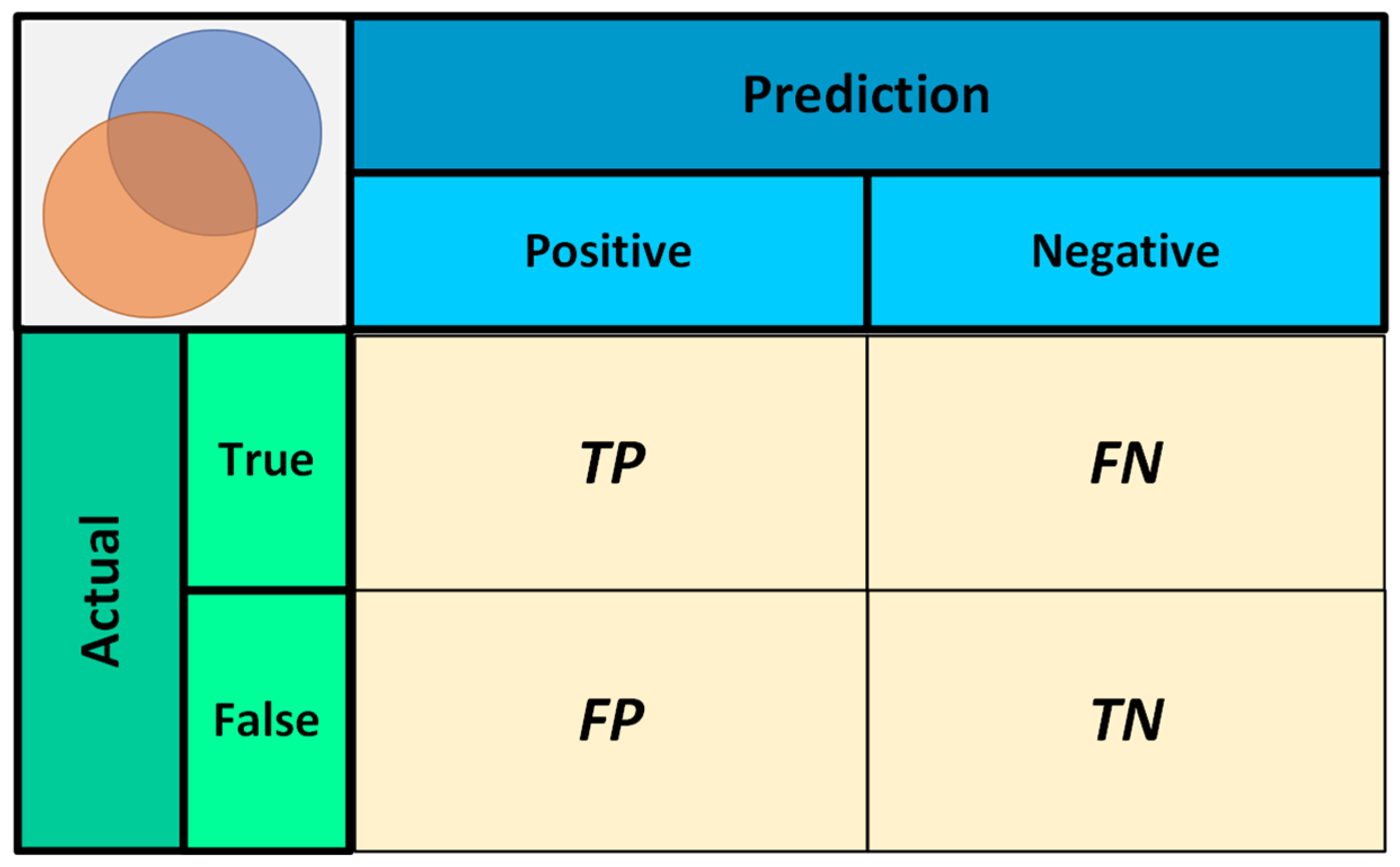
4.2. Evaluation Indicators
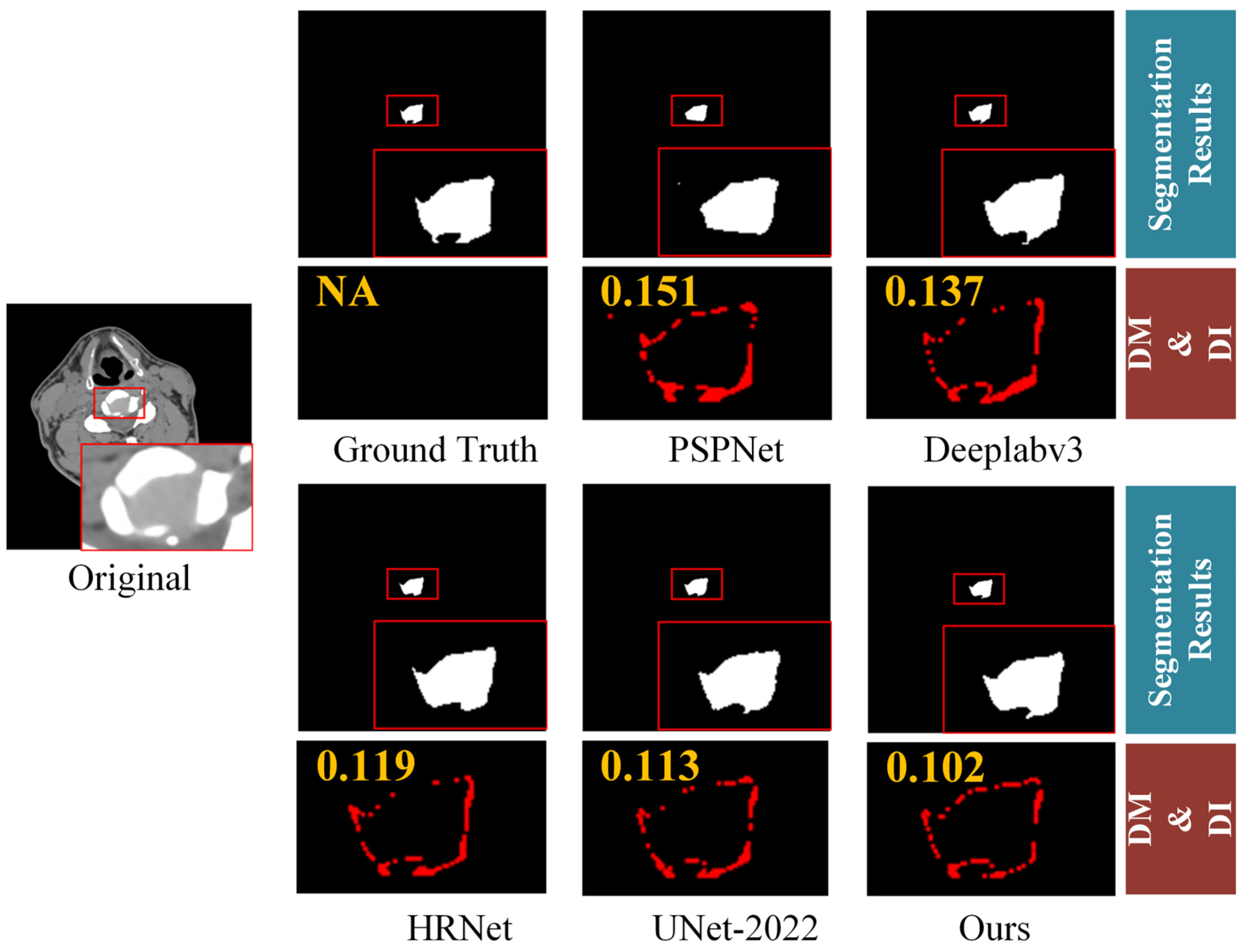
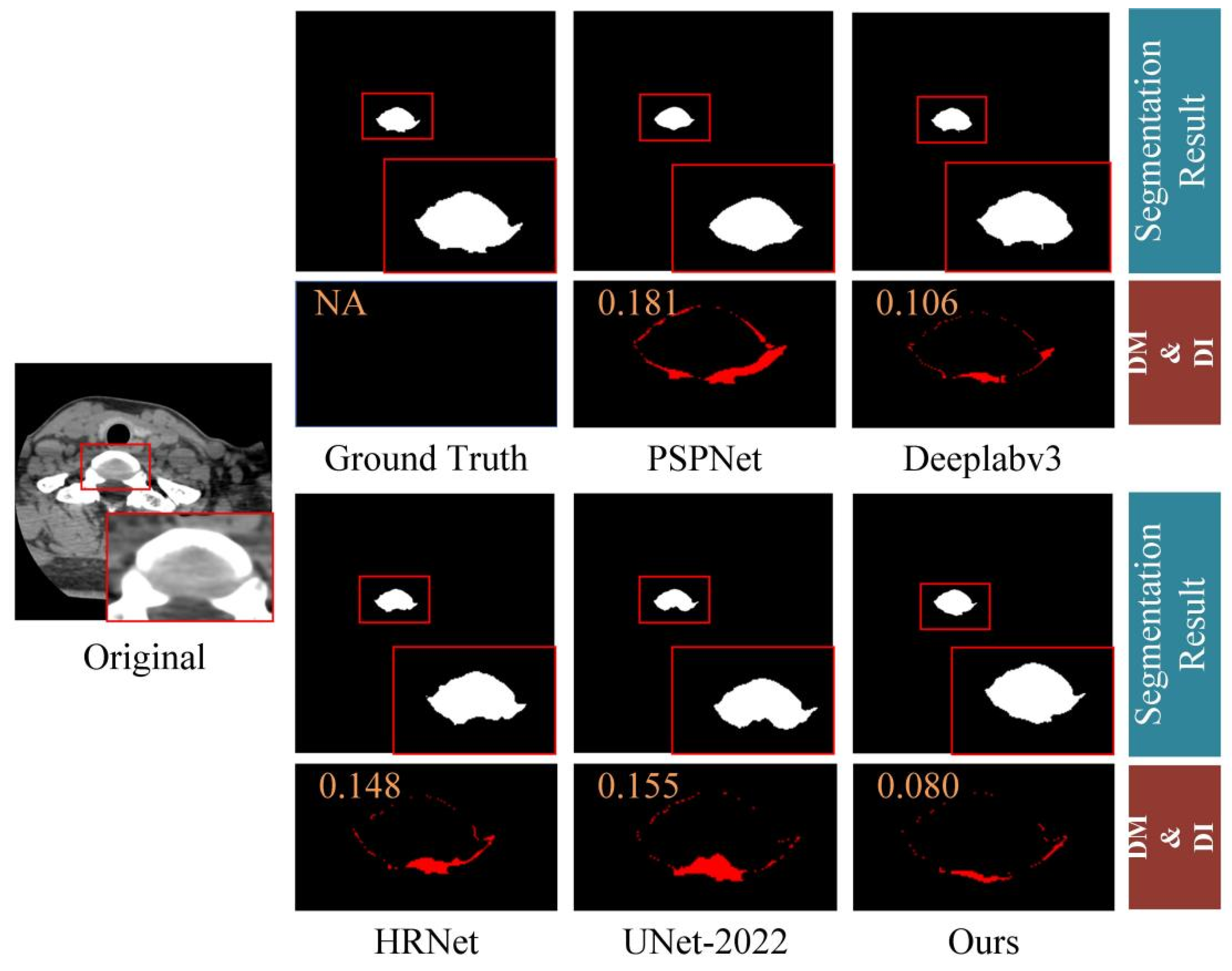
4.3. Comparison with Other Methods
4.4. Generalization to Other Dataset
4.5. Ablation Experiments
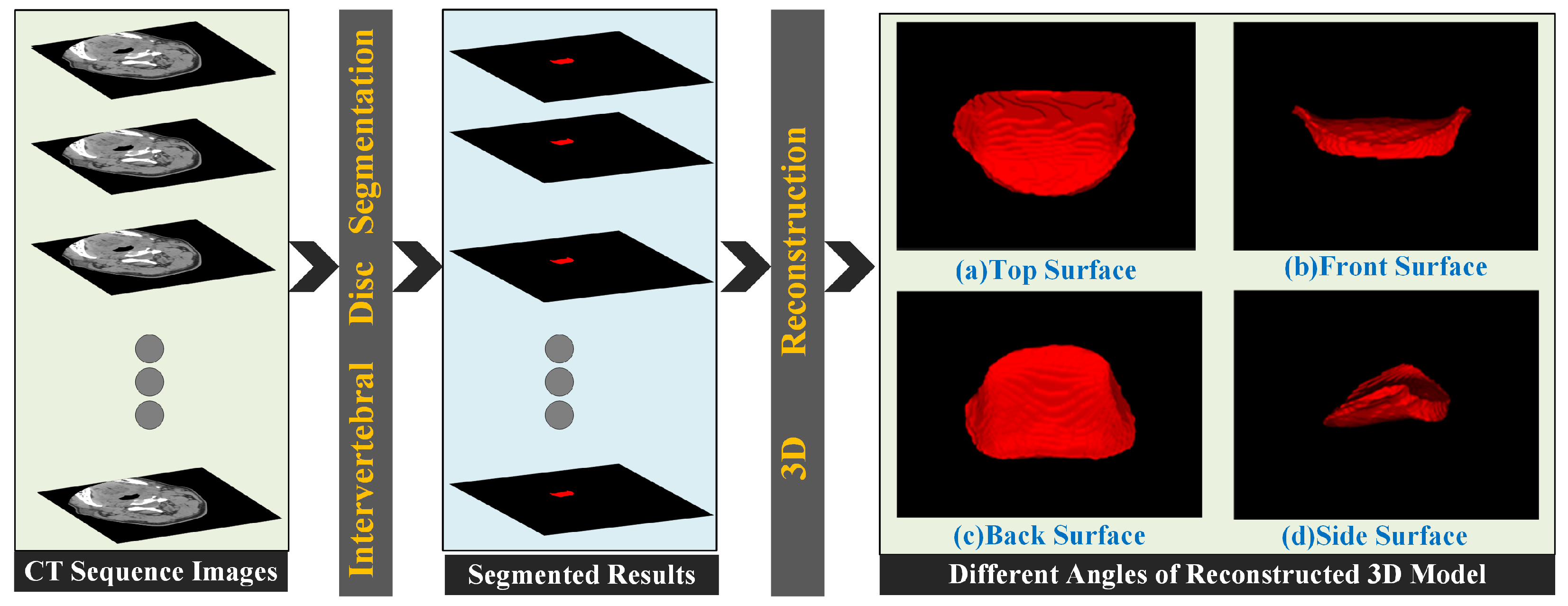
4.6. Application to 3D Reconstruction and 3D Printing
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Epstein Nancy, E. A Review of Complication Rates for Anterior Cervical Diskectomy and Fusion (ACDF). Surg. Neurol. Int. 2019, 10, 100. [Google Scholar] [CrossRef] [PubMed]
- Ramesh, K.K.D.; Kumar, G.K.; Swapna, K. A review of medical image segmentation algorithms. EAI Endorsed Trans. Pervasive Health Technol. 2021, 7, e6. [Google Scholar] [CrossRef]
- Abdellahoum, H.; Mokhtari, N.; Brahimi, A. CSFCM: An improved fuzzy C-Means image segmentation algorithm using a cooperative approach. Expert Syst. Appl. 2021, 166, 114063. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016: 4th International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; IEEE: New York, NY, USA, 2016; pp. 565–571. [Google Scholar]
- He, K.; Zhang, X.; Ren, S. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27 June 2016; pp. 770–778. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Kokkinos, I. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Lin, G.; Milan, A.; Shen, C. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G. Large kernel matters--improve semantic segmentation by global convolutional network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4353–4361. [Google Scholar]
- Zhang, H.; Dana, K.; Shi, J. Context encoding for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7151–7160. [Google Scholar]
- Yang, M.; Yu, K.; Zhang, C. Denseaspp for semantic segmentation in street scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3684–3692. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. arXiv 2017, arXiv:1610.02357. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 5693–5703. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Wang, W.; Xie, E.; Li, X. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y. Swin transformer v2: Scaling up capacity and resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12009–12019. [Google Scholar]
- Ren, S.; Zhou, D.; He, S. Shunted self-attention via multi-scale token aggregation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10853–10862. [Google Scholar]
- Strudel, R.; Garcia, R.; Laptev, I. Segmenter: Transformer for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 7262–7272. [Google Scholar]
- Cheng, B.; Schwing, A.; Kirillov, A. Per-pixel classification is not all you need for semantic segmentation. Adv. Neural Inf. Process. Syst. 2021, 34, 17864–17875. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z. SegFormer: Simple and efficient design for semantic segmentation with transformers. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 6–14 December 2021; Volume 34, pp. 12077–12090. [Google Scholar]
- Guo, J.; Zhou, H.Y.; Wang, L. UNet-2022: Exploring Dynamics in Non-isomorphic Architecture. arXiv 2022, arXiv:2210.15566. [Google Scholar]
- Wan, Q.; Huang, Z.; Lu, J. Seaformer: Squeeze-enhanced axial transformer for mobile semantic segmentation. arXiv 2023, arXiv:2301.13156. [Google Scholar] [CrossRef]
- Jiao, R.; Zhang, Y.; Ding, L. Learning with limited annotations: A survey on deep semi-supervised learning for medical image segmentation. Comput. Biol. Med. 2023, 169, 107840. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, T.; Wang, S. Input augmentation with sam: Boosting medical image segmentation with segmentation foundation model. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Vancouver, BC, Canada, 8–12 October 2023; Springer Nature: Cham, Switzerland, 2023; pp. 129–139. [Google Scholar]
- Tragakis, A.; Kaul, C.; Murray-Smith, R. The fully convolutional transformer for medical image segmentation. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 3660–3669. [Google Scholar]
- Yuan, F.; Zhang, Z.; Fang, Z. An effective CNN and Transformer complementary network for medical image segmentation. Pattern Recognit. 2023, 136, 109228. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023; pp. 4015–4026. [Google Scholar]
- Ali, M.; Jabreel, M.; Valls, A. LezioSeg: Multi-Scale Attention Affine-Based CNN for Segmenting Diabetic Retinopathy Lesions in Images. Electronics 2023, 12, 4940. [Google Scholar] [CrossRef]
- You, Z.; Yu, H.; Xiao, Z. CAS-UNet: A Retinal Segmentation Method Based on Attention. Electronics 2023, 12, 3359. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Index | ||
|---|---|---|---|
| IOU (%) | Dice (%) | Params (M) | |
| PSPNet [16] | 59.22 | 79.61 | 46.70 |
| Deeplabv3 [18] | 70.00 | 78.99 | 54.71 |
| HRNet [20] | 70.93 | 79.61 | 63.59 |
| UNet-2022 [31] | 69.06 | 79.16 | 41.90 |
| Ours | 73.63 | 82.98 | 63.83 |
| Network | Index | ||
|---|---|---|---|
| IOU (%) | Dice (%) | Params (M) | |
| PSPNet [16] | 58.77 | 67.30 | 46.70 |
| Deeplabv3 [18] | 69.94 | 77.53 | 54.71 |
| HRNet [20] | 72.39 | 80.11 | 63.59 |
| UNet-2022 [31] | 68.93 | 76.95 | 41.90 |
| Ours | 73.67 | 81.07 | 63.83 |
| Module | Index | |
|---|---|---|
| IOU (%) | Dice (%) | |
| Baseline (Model0) | 70.93 | 79.61 |
| Model1 | 72.58 | 82.27 |
| Model2 | 73.35 | 82.66 |
| Model3 | 73.63 | 82.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Wang, M.; Ma, L.; Zhang, X.; Zhang, K.; Zhao, X.; Teng, Q.; Liu, H. Cervical Intervertebral Disc Segmentation Based on Multi-Scale Information Fusion and Its Application. Electronics 2024, 13, 432. https://doi.org/10.3390/electronics13020432
Yang Y, Wang M, Ma L, Zhang X, Zhang K, Zhao X, Teng Q, Liu H. Cervical Intervertebral Disc Segmentation Based on Multi-Scale Information Fusion and Its Application. Electronics. 2024; 13(2):432. https://doi.org/10.3390/electronics13020432
Chicago/Turabian StyleYang, Yi, Ming Wang, Litai Ma, Xiang Zhang, Kerui Zhang, Xiaoyao Zhao, Qizhi Teng, and Hao Liu. 2024. "Cervical Intervertebral Disc Segmentation Based on Multi-Scale Information Fusion and Its Application" Electronics 13, no. 2: 432. https://doi.org/10.3390/electronics13020432