
A Generic Approach towards Enhancing Utility and Privacy in Person-Specific Data Publishing Based on Attribute Usefulness and Uncertainty

Abstract
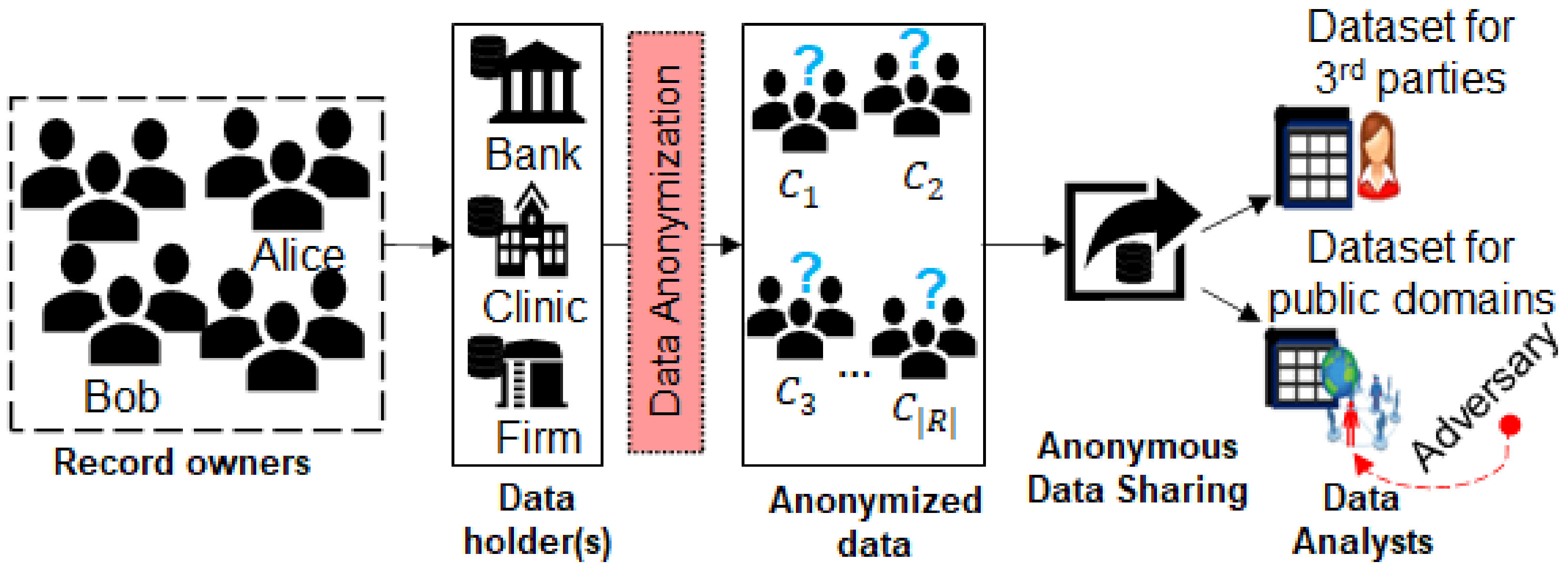
:1. Introduction
- To facilitate the analysis of released data without any constraints that DP and other recent techniques cannot provide.
- To impede higher changes in data during the conversion from their raw forms to anonymized data to enable observation of commonalities among differences, and vice versa.
- To yield consistent performances for both utility and privacy in published data analytics, and remain applicable in diverse domains for similar tasks.
2. Background and Related Work
2.1. Types of Attributes and Their Handling in the Anonymization Process
- In the non-interactive mechanism, the data holder publishes the full D at once in anonymized form (e.g., after introducing some modifications to it).
- In the interactive mechanism, the data holder does not share the whole D in the distorted form. However, the data holder gives an interface (or text box) to data miners, with the help of the interface, data miners can run different queries on the relevant data, and gather (probably noisy) answers. DP [24] and its improved versions are mostly used in this mechanism of PPDP. Although DP provides strong privacy guarantees, the utility of the resulting dataset is often low, especially when a small is used [25,26]. Furthermore, the amount of noise injected by the DP model in less frequent parts of data is very high, leading to poor utility in data-driven applications. The utility issues and difficulty in selecting the optimal value for make DP unsuitable in scenarios where data of higher utility are required [27]. In some cases, more than one-time anonymization of the same D is required if there is some change in data (e.g., the addition and removal of tuples). To this end, the DP model iteratively increases the amount of noise in data, which means that after certain iterations, the data become completely useless [27]. Furthermore, in some cases, the DP assists in releasing aggregate information about the data, which makes knowledge discovery harder from broader perspectives. In contrast, the approach proposed in this paper offers higher utility and assists in releasing whole datasets while preserving both utility and privacy. Furthermore, it maintains utility and privacy even when repetitive anonymization of the same data is needed. The data produced with our approach can greatly contribute to observing commonalities among differences, and vice versa.
2.2. Analysis of the State-of-the-Art Anonymization Methods
2.2.1. Traditional Anonymization Methods
2.2.2. Anonymization Methods for Enhancing Data Utility
- The existing studies enforce constraints (i.e., strict parameters, ℓ, t, , , etc.) with predetermined values on the values of SA in each EC. However, this can lead to inconsistent generalization intervals due to excessive shuffling of records [30,31,32,33]. In skewed data, enforcement of such constraints is not practically possible due to less heterogeneity in some SA values.
- There is a lack of methods that can simultaneously leverage attribute usefulness and uncertainty information to control unnecessary generalization, in order to enhance both utility and privacy in anonymized datasets.
2.3. Major Contributions of This Work
- We devised an RF-based method with a QI value shuffling strategy to identify the useful attributes from original data in an automated way that have minimal impact on individuals’ privacy, instead of manually deciding or assuming that certain attributes might be more useful than others.
- We employed the information theory concept (i.e., entropy) for computing the uncertainty of SA values in ECs to limit privacy breaches in low-uncertainty ECs and to increase utility in high-uncertainty ECs.
- We propose a flexible data generalization method for anonymizing data that takes into account the usefulness weights of the QIs as well as the uncertainty of the SAs, which enhances two competing goals.
- The proposed approach can be used to produce anonymized versions of any dataset, whether balanced (i.e., the SA value distribution is uniform) or imbalanced (i.e., the SA value distribution is skewed).
- This is the first generic approach toward enhancing both utility and privacy by retaining (in the anonymized data) highly useful QI values that are as close as possible to the original values.
3. System Model
3.1. Attack Model
- Already know a part of the released QIs of an individual and attempt to figure out the rest of the QIs. For example, an adversary may know the age and gender value of an individual and try to identify the individual’s zip code.
- Already know the whole record (e.g., all QIs) of the individual and that the respective individual is part of the released data with higher probability. Based on this information, he/she tries to obtain sensitive information from the released data concerning that individual. For example, the released data can encompass sensitive data (e.g., disease contracted, monthly income, etc.) about individuals. If the adversary can somehow identify/link the user’s QIs correctly, he/she can also know the SA related to that user.
3.2. Design Goals
3.3. Problem Formulation
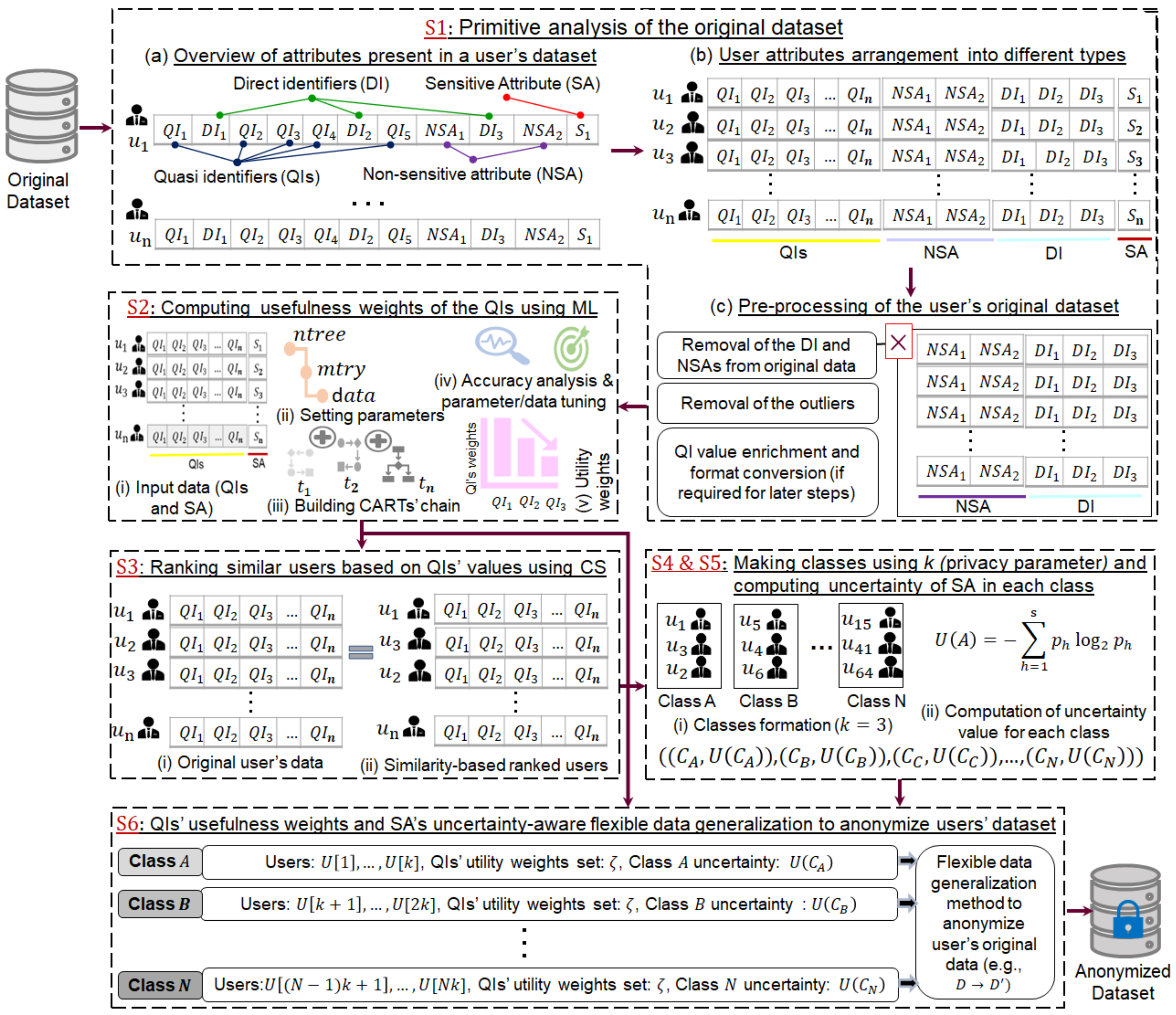
4. Attribute Usefulness and Uncertainty-Aware Anonymization Approach
4.1. Primitive Analysis of the Original Dataset
4.1.1. Analysis of the Attributes Present in a Dataset
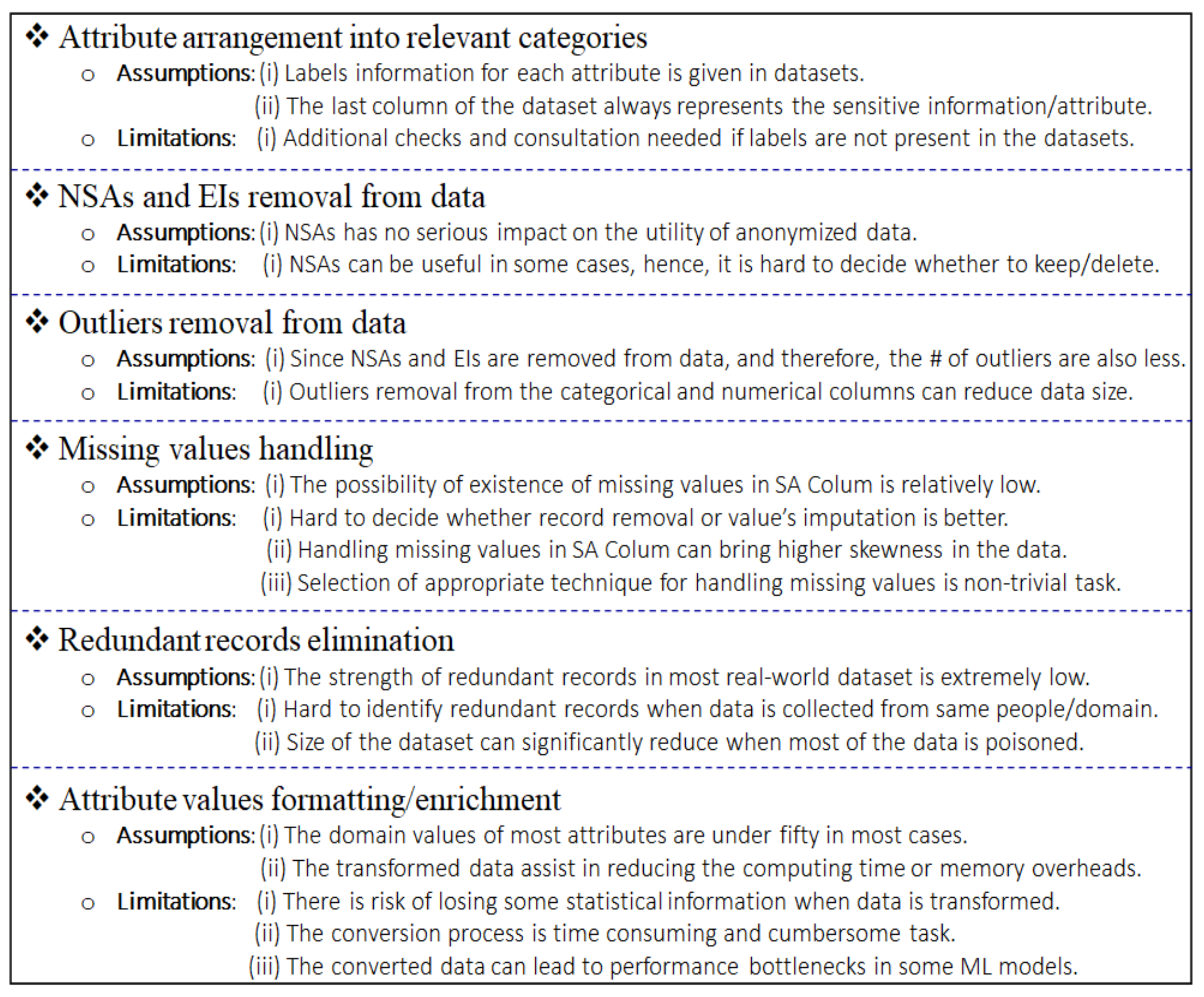
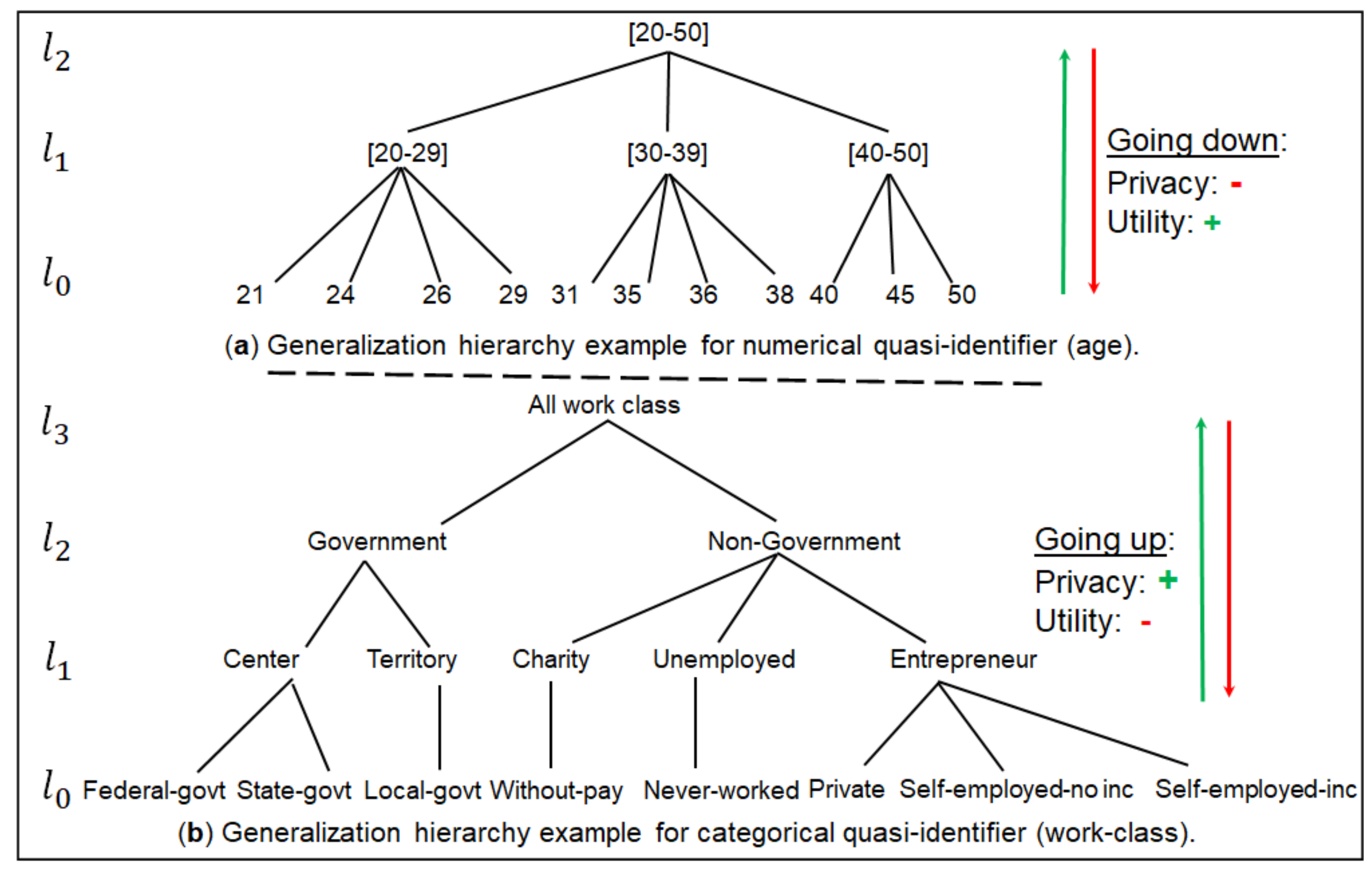
4.1.2. Arrangement of Attributes into Appropriate Categories
4.1.3. Pre-Processing of the D to Yield Informative Analysis
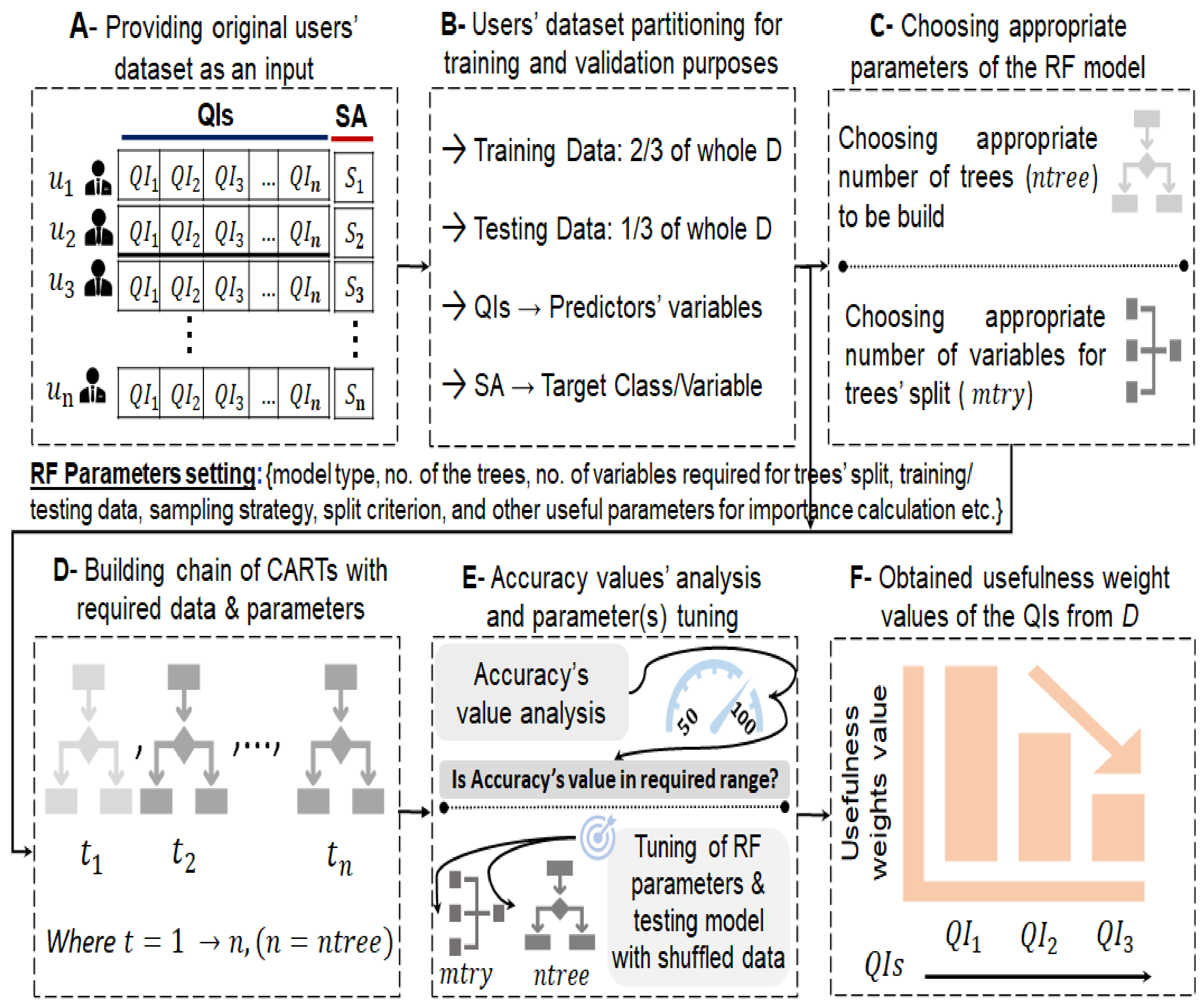
4.2. Computing Usefulness Weights of QIs in a Dataset Using Machine Learning
4.3. Ranking Similar Users to Lower Generalization Intervals
4.4. Making Equivalence Classes from User Matrix X Based on k
| Algorithm 1 Formation of ECs using X and k. |
|
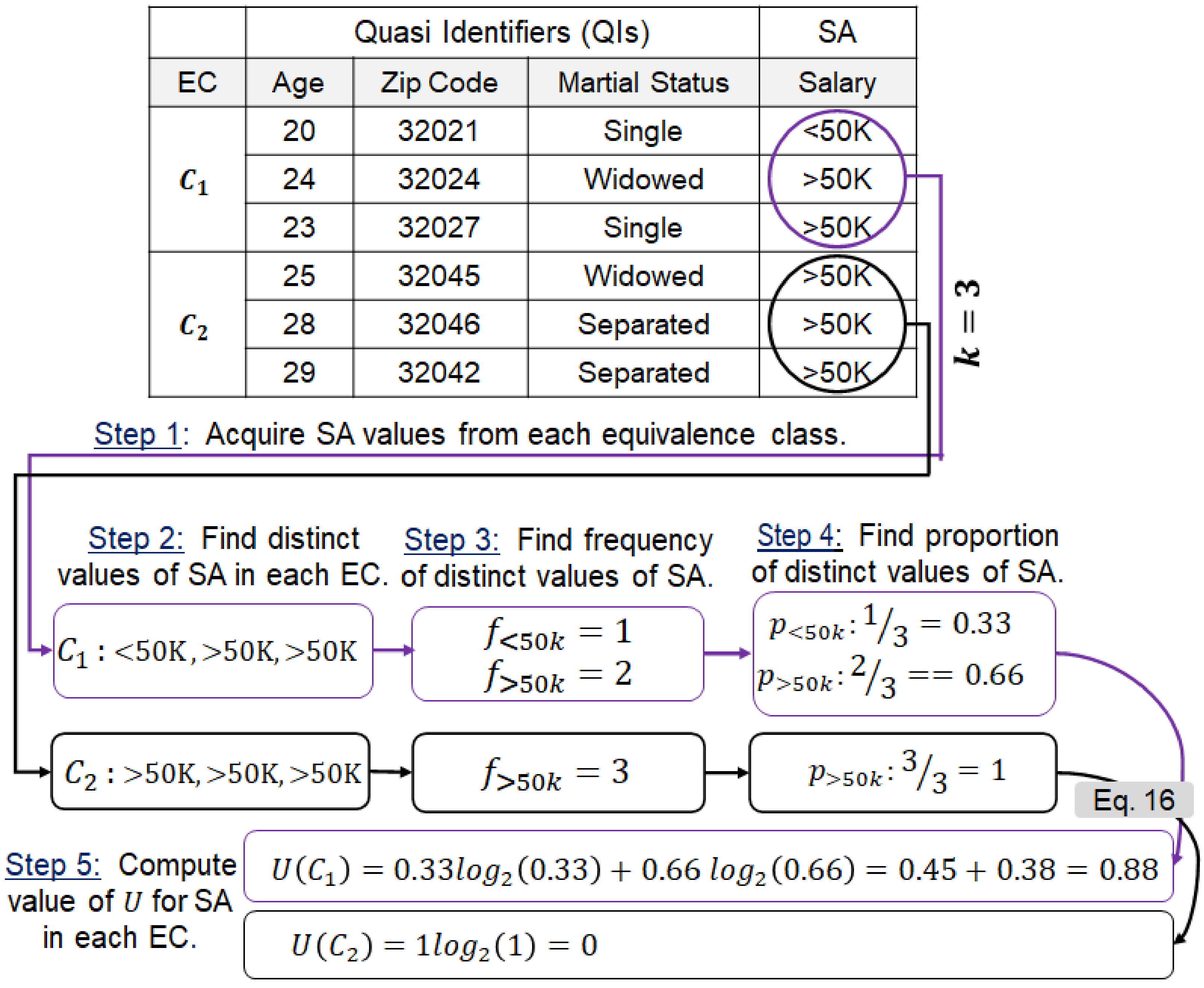
4.5. Computing Uncertainty in Sensitive Attribute Values in ECs
| Algorithm 2 Computing the U values of the SA in ECs. |
|
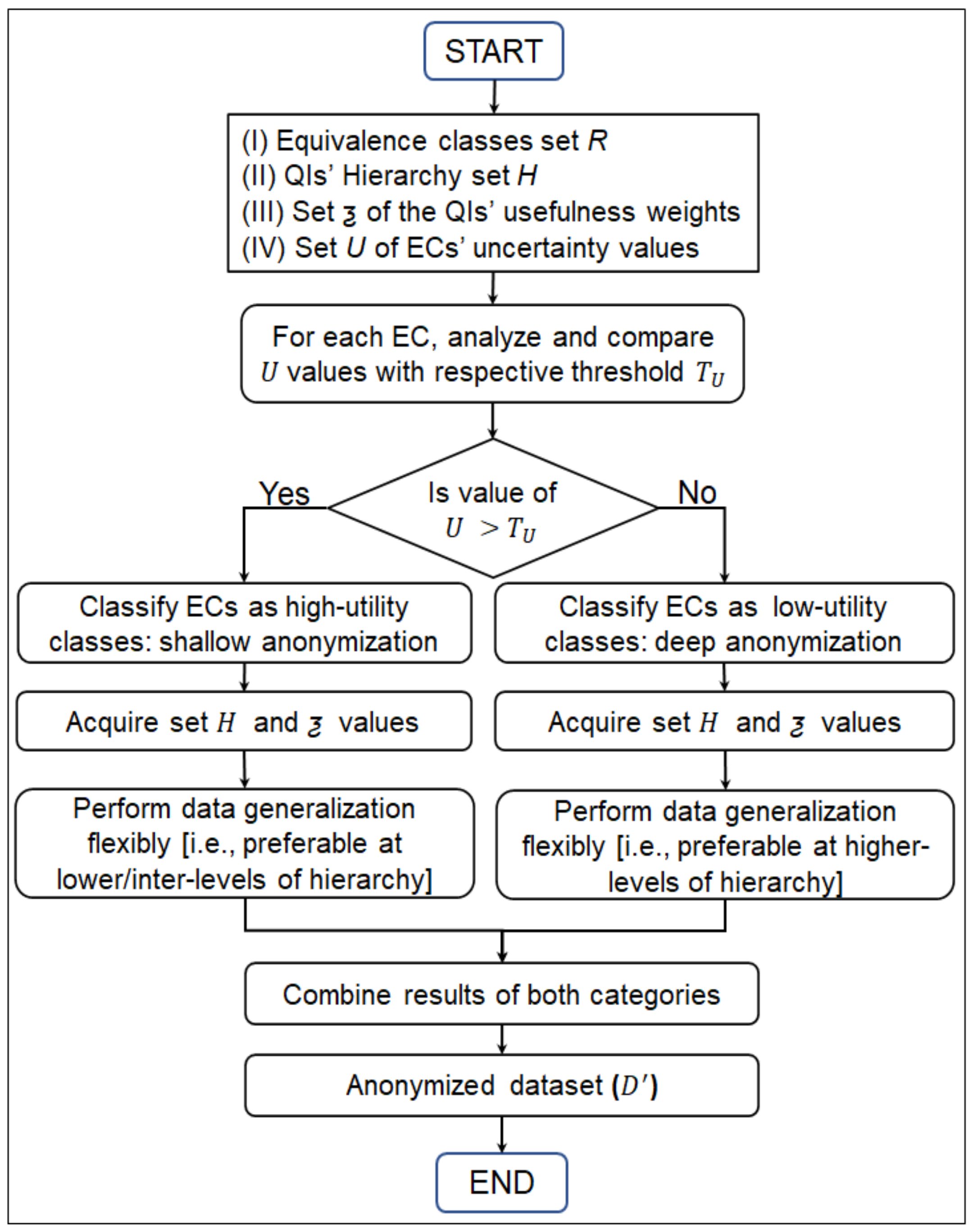
4.6. Flexible Data Generalization Considering the Usefulness Weight of QI and SA Uncertainty
| Algorithm 3 Flexible generalization to produce . |
|
5. Experimental Evaluation
5.1. Descriptions of Datasets
5.2. Descriptions of the Experimental Environments
5.3. Descriptions of Metrics and Evaluation Criteria
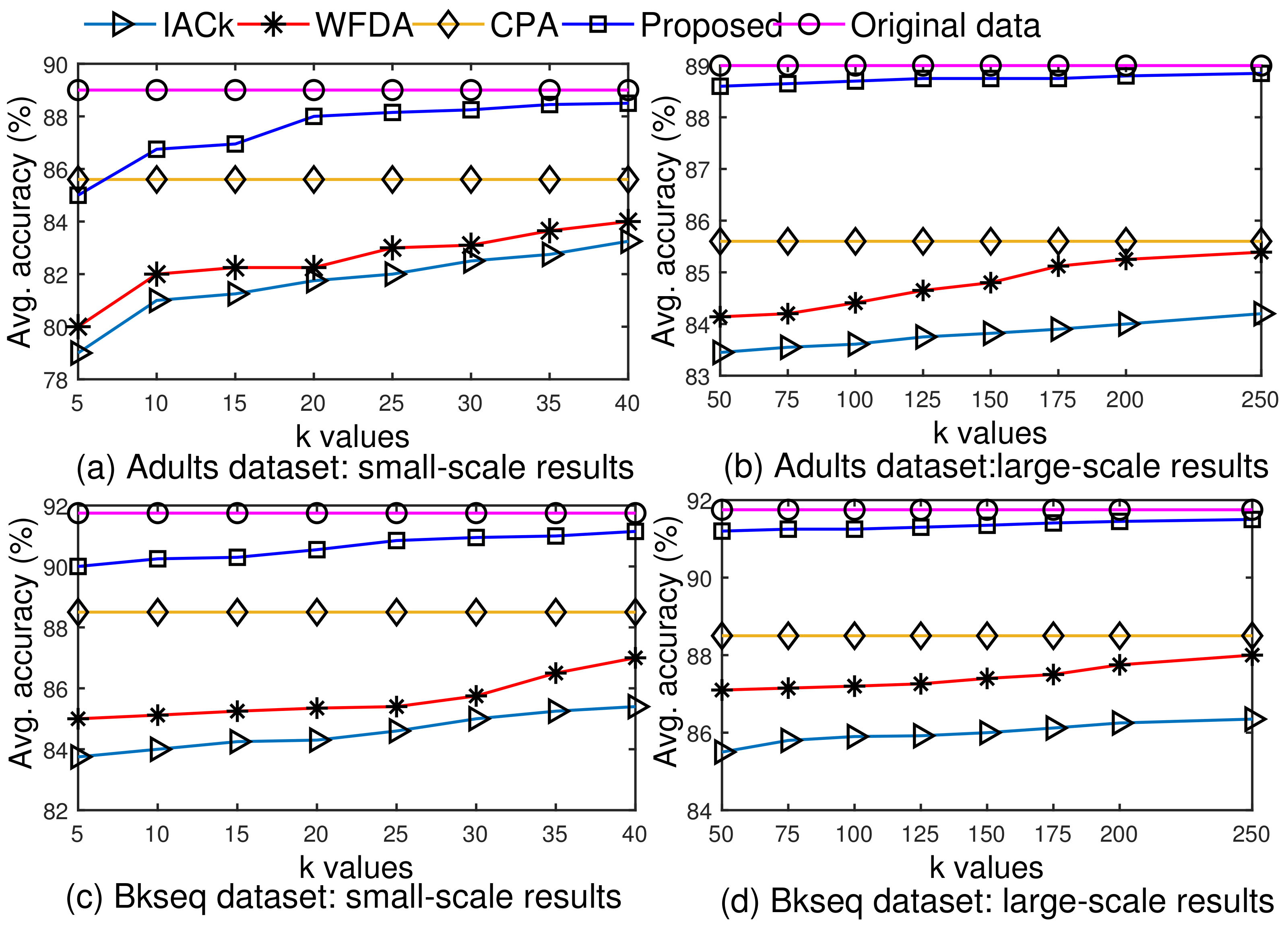
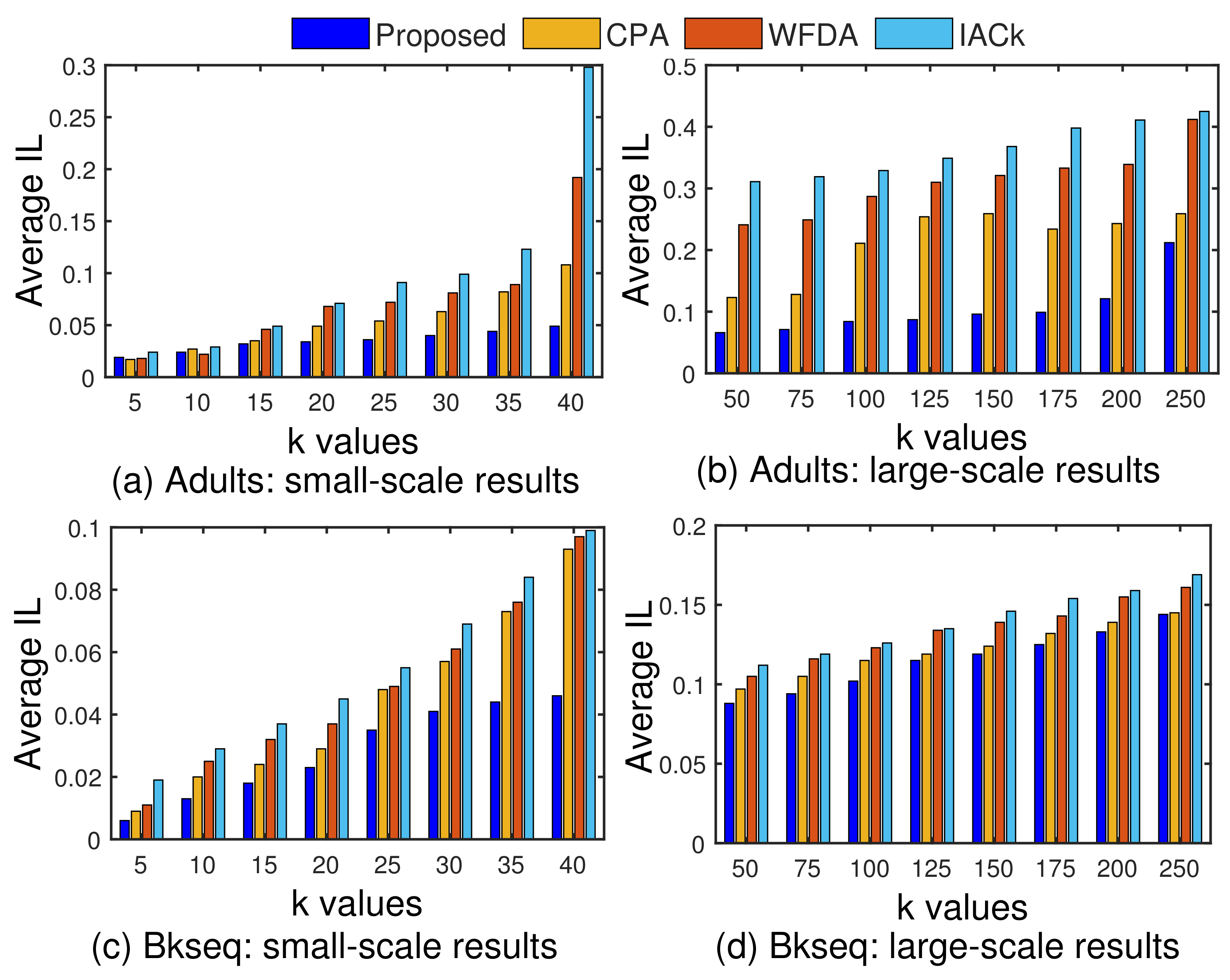
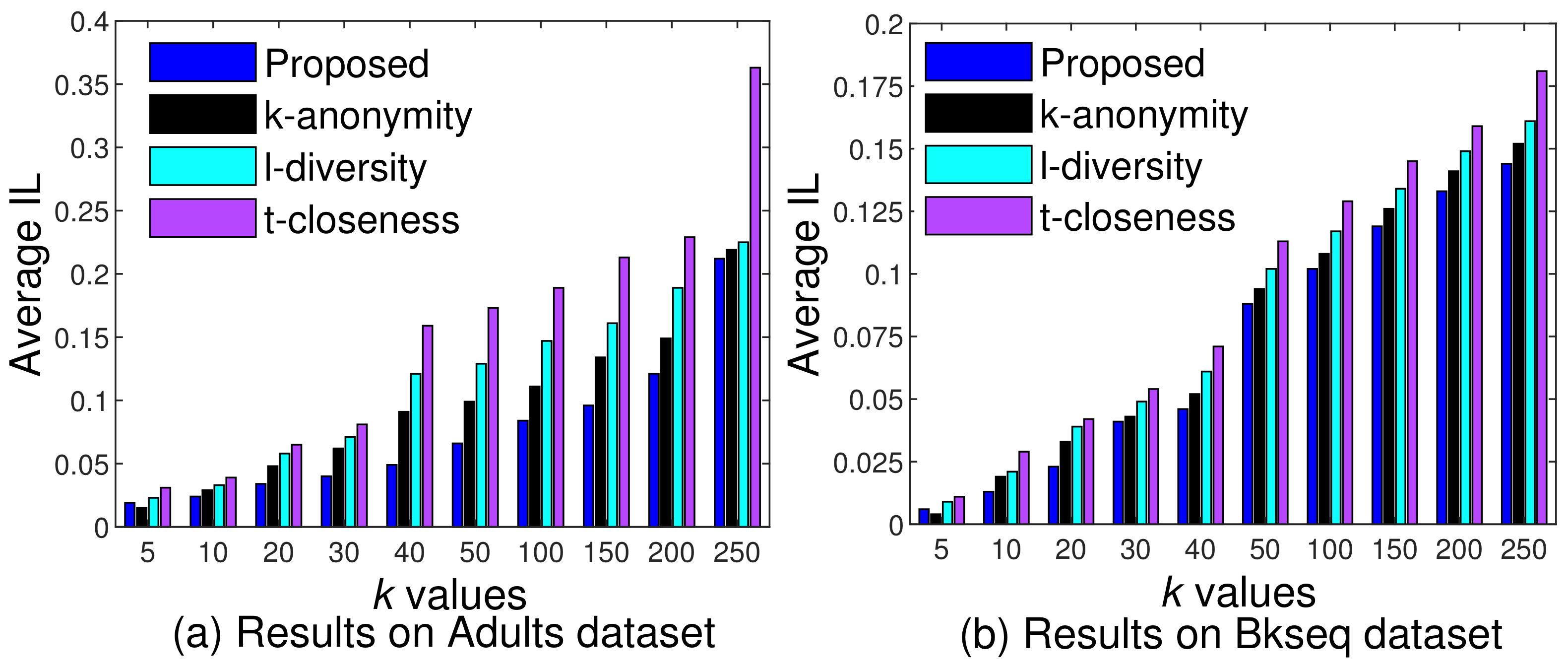
5.4. Performance against Existing Anonymization Algorithms and Models
5.4.1. Comparisons of Anonymous Data Utility/Quality
5.4.2. Comparison of Individual Privacy Preservation
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Parvinen, L.; Alamäki, A.; Hallikainen, H.; Mäki, M. Exploring the challenges of and solutions to sharing personal genomic data for use in healthcare. Health Inform. J. 2023, 29, 14604582231152185. [Google Scholar] [CrossRef] [PubMed]
- O’Leary, J.C. Data sharing: The public’s perspective. In Genomic Data Sharing; Elsevier: Amsterdam, The Netherlands, 2023; pp. 157–170. [Google Scholar]
- Li, F.; Li, H.; Niu, B.; Chen, J. Privacy computing: Concept, computing framework, and future development trends. Engineering 2019, 5, 1179–1192. [Google Scholar] [CrossRef]
- Tran, H.Y.; Hu, J. Privacy-preserving big data analytics a comprehensive survey. J. Parallel Distrib. Comput. 2019, 134, 207–218. [Google Scholar] [CrossRef]
- Majeed, A.; Hwang, S.O. Quantifying the Vulnerability of Attributes for Effective Privacy Preservation Using Machine Learning. IEEE Access 2023, 11, 4400–4411. [Google Scholar] [CrossRef]
- Jayabalan, M.; Rana, M.E. Anonymizing healthcare records: A study of privacy preserving data publishing techniques. Adv. Sci. Lett. 2018, 24, 1694–1697. [Google Scholar] [CrossRef]
- Akinkunmi, O.; Rana, M.E. Privacy preserving data publishing anonymization methods for limiting malicious attacks in healthcare records. J. Comput. Theor. Nanosci. 2019, 16, 3538–3543. [Google Scholar]
- Su, B.; Huang, J.; Miao, K.; Wang, Z.; Zhang, X.; Chen, Y. K-Anonymity Privacy Protection Algorithm for Multi-Dimensional Data against Skewness and Similarity Attacks. Sensors 2023, 23, 1554. [Google Scholar] [CrossRef]
- Yağar, F. Growing Concern During the COVID-19 Pandemic: Data Privacy. Turk. Klin. J. Health Sci. 2021, 6, 387–392. [Google Scholar] [CrossRef]
- Jian, X.; Wang, W.; Pei, J.; Wang, X.; Shi, B.; Fu, A.W.C. Utility-based anonymization using local recoding. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 20–23 August 2006; pp. 785–790. [Google Scholar]
- Xu, J.; Wang, W.; Pei, J.; Wang, X.; Shi, B.; Fu, A.W.C. Utility-based anonymization for privacy preservation with less information loss. ACM Sigkdd Explor. Newsl. 2006, 8, 21–30. [Google Scholar] [CrossRef]
- Onesimu, J.A.; Karthikeyan, J.; Eunice, J.; Pomplun, M.; Dang, H. Privacy Preserving Attribute-Focused Anonymization Scheme for Healthcare Data Publishing. IEEE Access 2022, 10, 86979–86997. [Google Scholar] [CrossRef]
- Lin, C.Y. A reversible privacy-preserving clustering technique based on k-means algorithm. Appl. Soft Comput. 2020, 87, 105995. [Google Scholar] [CrossRef]
- Li, T.; Li, J.; Chen, X.; Liu, Z.; Lou, W.; Hou, T. NPMML: A framework for non-interactive privacy-preserving multi-party machine learning. IEEE Trans. Dependable Secur. Comput. 2020, 18, 2969–2982. [Google Scholar] [CrossRef]
- Wang, R.; Zhu, Y.; Chang, C.C.; Peng, Q. Privacy-preserving high-dimensional data publishing for classification. Comput. Secur. 2020, 93, 101785. [Google Scholar] [CrossRef]
- Eicher, J.; Bild, R.; Spengler, H.; Kuhn, K.A.; Prasser, F. A comprehensive tool for creating and evaluating privacy-preserving biomedical prediction models. BMC Med Inform. Decis. Mak. 2020, 20, 1–14. [Google Scholar] [CrossRef]
- Brough, A.R.; Martin, K.D. Consumer privacy during (and after) the COVID-19 pandemic. J. Public Policy Mark. 2021, 40, 108–110. [Google Scholar] [CrossRef]
- Foraker, R.E.; Lai, A.M.; Kannampallil, T.G.; Woeltje, K.F.; Trolard, A.M.; Payne, P.R. Transmission dynamics: Data sharing in the COVID-19 era. Learn. Health Syst. 2021, 5, e10235. [Google Scholar] [CrossRef]
- Lenert, L.; McSwain, B.Y. Balancing health privacy, health information exchange, and research in the context of the COVID-19 pandemic. J. Am. Med. Inform. Assoc. 2020, 27, 963–966. [Google Scholar] [CrossRef]
- Strobel, M.; Shokri, R. Data Privacy and Trustworthy Machine Learning. IEEE Secur. Priv. 2022, 20, 44–49. [Google Scholar] [CrossRef]
- He, Z.; Cai, Z.; Yu, J. Latent-data privacy preserving with customized data utility for social network data. IEEE Trans. Veh. Technol. 2017, 67, 665–673. [Google Scholar] [CrossRef]
- Majeed, A.; Hwang, S.O. Rectification of Syntactic and Semantic Privacy Mechanisms. IEEE Secur. Priv. 2022, 1, 2–16. [Google Scholar] [CrossRef]
- Mohammed, N.; Chen, R.; Fung, B.C.; Yu, P.S. Differentially private data release for data mining. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 493–501. [Google Scholar]
- Dwork, C. Differential privacy: A survey of results. In Proceedings of the International Conference on Theory and Applications of Models of Computation, Xi’an, China, 25–29 April 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1–19. [Google Scholar]
- Li, Y.; Liu, Y.; Li, B.; Wang, W.; Liu, N. Towards practical differential privacy in data analysis: Understanding the effect of epsilon on utility in private erm. Comput. Secur. 2023, 128, 103147. [Google Scholar] [CrossRef]
- Li, Y.; Li, B.; Wang, W.; Liu, N. An Efficient Epsilon Selection Method for DP-ERM with Expected Accuracy Constraints. In Proceedings of the 2022 IEEE International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Wuhan, China, 9–11 December 2022; pp. 533–540. [Google Scholar]
- Domingo-Ferrer, J.; Sánchez, D.; Blanco-Justicia, A. The limits of differential privacy (and its misuse in data release and machine learning). Commun. ACM 2021, 64, 33–35. [Google Scholar] [CrossRef]
- Singh, R.; Dwivedi, A.D.; Srivastava, G.; Chatterjee, P.; Lin, J.C.W. A Privacy Preserving Internet of Things Smart Healthcare Financial System. IEEE Internet Things J. 2023. [Google Scholar] [CrossRef]
- Sweeney, L. k-anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef]
- Machanavajjhala, A.; Kifer, D.; Gehrke, J.; Venkitasubramaniam, M. l-diversity: Privacy beyond k-anonymity. ACM Trans. Knowl. Discov. Data 2007, 1, 3-es. [Google Scholar] [CrossRef]
- Li, N.; Li, T.; Venkatasubramanian, S. t-closeness: Privacy beyond k-anonymity and l-diversity. In Proceedings of the 2007 IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, 17–20 April 2007; pp. 106–115. [Google Scholar]
- Sun, X.; Sun, L.; Wang, H. Extended k-anonymity models against sensitive attribute disclosure. Comput. Commun. 2011, 34, 526–535. [Google Scholar] [CrossRef]
- Chen, L.; Zhong, S.; Wang, L.e.; Li, X. A Sensitivity-Adaptive ρ-Uncertainty Model for Set-Valued Data. In Proceedings of the International Conference on Financial Cryptography and Data Security, Christ Church, Barbados, 22–26 February 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 460–473. [Google Scholar]
- Wong, R.C.W.; Li, J.; Fu, A.W.C.; Wang, K. (α, k)-anonymity: An enhanced k-anonymity model for privacy preserving data publishing. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 20–23 August 2006; pp. 754–759. [Google Scholar]
- Sun, X.; Li, M.; Wang, H. A family of enhanced (L, α)-diversity models for privacy preserving data publishing. Future Gener. Comput. Syst. 2011, 27, 348–356. [Google Scholar] [CrossRef]
- Soria-Comas, J.; Domingo-Ferrer, J.; Sanchez, D.; Martinez, S. t-closeness through microaggregation: Strict privacy with enhanced utility preservation. IEEE Trans. Knowl. Data Eng. 2015, 27, 3098–3110. [Google Scholar] [CrossRef]
- Ashkouti, F.; Sheikhahmadi, A. DI-Mondrian: Distributed improved Mondrian for satisfaction of the L-diversity privacy model using Apache Spark. Inf. Sci. 2021, 546, 1–24. [Google Scholar] [CrossRef]
- Zigomitros, A.; Casino, F.; Solanas, A.; Patsakis, C. A survey on privacy properties for data publishing of relational data. IEEE Access 2020, 8, 51071–51099. [Google Scholar] [CrossRef]
- Li, J.; Liu, J.; Baig, M.; Wong, R.C.W. Information based data anonymization for classification utility. Data Knowl. Eng. 2011, 70, 1030–1045. [Google Scholar] [CrossRef]
- Cagliero, L.; Garza, P. Improving classification models with taxonomy information. Data Knowl. Eng. 2013, 86, 85–101. [Google Scholar] [CrossRef]
- Zaman, A.; Obimbo, C.; Dara, R.A. A novel differential privacy approach that enhances classification accuracy. In Proceedings of the Ninth International C* Conference on Computer Science & Software Engineering, Porto, Portugal, 20–22 July 2016; pp. 79–84. [Google Scholar]
- Srijayanthi, S.; Sethukarasi, T. Design of privacy preserving model based on clustering involved anonymization along with feature selection. Comput. Secur. 2023, 126, 103027. [Google Scholar] [CrossRef]
- Chen, L.; Zeng, L.; Mu, Y.; Chen, L. Global Combination and Clustering based Differential Privacy Mixed Data Publishing. IEEE Trans. Knowl. Data Eng. 2023. [Google Scholar] [CrossRef]
- Jha, N.; Vassio, L.; Trevisan, M.; Leonardi, E.; Mellia, M. Practical anonymization for data streams: Z-anonymity and relation with k-anonymity. Perform. Eval. 2023, 159, 102329. [Google Scholar] [CrossRef]
- Li, B.; He, K. Local generalization and bucketization technique for personalized privacy preservation. J. King Saud Univ.-Comput. Inf. Sci. 2023, 35, 393–404. [Google Scholar] [CrossRef]
- Chu, Z.; He, J.; Li, J.; Wang, Q.; Zhang, X.; Zhu, N. SSKM_DP: Differential Privacy Data Publishing Method via SFLA-Kohonen Network. Appl. Sci. 2023, 13, 3823. [Google Scholar] [CrossRef]
- Sun, X.; Ye, Q.; Hu, H.; Wang, Y.; Huang, K.; Wo, T.; Xu, J. Synthesizing Realistic Trajectory Data With Differential Privacy. IEEE Trans. Intell. Transp. Syst. 2023. [Google Scholar] [CrossRef]
- Nóbrega, T.; Pires, C.E.S.; Nascimento, D.C.; Marinho, L.B. Towards automatic Privacy-Preserving Record Linkage: A Transfer Learning based classification step. Data Knowl. Eng. 2023, 145, 102180. [Google Scholar] [CrossRef]
- Amiri, F.; Khan, R.; Anjum, A.; Syed, M.H.; Rehman, S. Enhancing Utility in Anonymized Data against the Adversary’s Background Knowledge. Appl. Sci. 2023, 13, 4091. [Google Scholar] [CrossRef]
- Chen, M.; Cang, L.S.; Chang, Z.; Iqbal, M.; Almakhles, D. Data anonymization evaluation against re-identification attacks in edge storage. Wirel. Netw. 2023, 1–15. [Google Scholar] [CrossRef]
- Xia, Y.; Zhao, T.; Lv, Y.; Li, Y.; Yang, R. Hierarchical DP-K Anonymous Data Publishing Model Based on Binary Tree. In Proceedings of the 2023 25th International Conference on Advanced Communication Technology (ICACT), Pyeongchang, Republic of Korea, 19–22 February 2023; pp. 102–110. [Google Scholar]
- Han, J.; Yu, J.; Lu, J.; Peng, H.; Wu, J. An anonymization method to improve data utility for classification. In Proceedings of the International Symposium on Cyberspace Safety and Security, Xi’an China, 23–25 October 2017; Springer: Cham, Switzerland, 2017; pp. 57–71. [Google Scholar]
- Last, M.; Tassa, T.; Zhmudyak, A.; Shmueli, E. Improving accuracy of classification models induced from anonymized datasets. Inf. Sci. 2014, 256, 138–161. [Google Scholar] [CrossRef]
- Fong, P.K.; Weber-Jahnke, J.H. Privacy preserving decision tree learning using unrealized data sets. IEEE Trans. Knowl. Data Eng. 2010, 24, 353–364. [Google Scholar] [CrossRef]
- Lin, K.P.; Chen, M.S. On the design and analysis of the privacy-preserving SVM classifier. IEEE Trans. Knowl. Data Eng. 2010, 23, 1704–1717. [Google Scholar] [CrossRef]
- Park, S.; Byun, J.; Lee, J.; Cheon, J.H.; Lee, J. HE-friendly algorithm for privacy-preserving SVM training. IEEE Access 2020, 8, 57414–57425. [Google Scholar] [CrossRef]
- Eyupoglu, C.; Aydin, M.A.; Zaim, A.H.; Sertbas, A. An efficient big data anonymization algorithm based on chaos and perturbation techniques. Entropy 2018, 20, 373. [Google Scholar] [CrossRef]
- Ye, H.; Chen, E.S. Attribute utility motivated k-anonymization of datasets to support the heterogeneous needs of biomedical researchers. In Proceedings of the AMIA Annual Symposium Proceedings, American Medical Informatics Association, Washington, DC, USA, 22–26 October 2011; Volume 2011, p. 1573. [Google Scholar]
- Kousika, N.; Premalatha, K. An improved privacy-preserving data mining technique using singular value decomposition with three-dimensional rotation data perturbation. J. Supercomput. 2021, 77, 10003–10011. [Google Scholar] [CrossRef]
- Selvi, U.; Pushpa, S. Big Data Feature Selection to Achieve Anonymization. In Proceedings of the International Conference on Communication, Computing and Electronics Systems, Coimbatore, India, 21–22 October 2020; Springer: Singapore, 2020; pp. 59–67. [Google Scholar]
- Zhang, C.; Jiang, H.; Wang, Y.; Hu, Q.; Yu, J.; Cheng, X. User identity De-anonymization based on attributes. In Proceedings of the International Conference on Wireless Algorithms, Systems, and Applications, Honolulu, HI, USA, 24–26 June 2019; Springer: Cham, Switzerland, 2019; pp. 458–469. [Google Scholar]
- Ienca, M.; Vayena, E. On the responsible use of digital data to tackle the COVID-19 pandemic. Nat. Med. 2020, 26, 463–464. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- MacNell, N.; Feinstein, L.; Wilkerson, J.; Salo, P.M.; Molsberry, S.A.; Fessler, M.B.; Thorne, P.S.; Motsinger-Reif, A.A.; Zeldin, D.C. Implementing machine learning methods with complex survey data: Lessons learned on the impacts of accounting sampling weights in gradient boosting. PLoS ONE 2023, 18, e0280387. [Google Scholar] [CrossRef]
- Fernández, J.D.; Kirrane, S.; Polleres, A.; Wenning, R. SPECIAL: Scalable Policy-awarE Linked Data arChitecture for prIvacy, trAnsparency and compLiance. 2018. Available online: https://ceur-ws.org/Vol-2044/paper23/paper23.pdf (accessed on 7 April 2023).
- Gerl, A.; Bennani, N.; Kosch, H.; Brunie, L. LPL, towards a GDPR-compliant privacy language: Formal definition and usage. In Transactions on Large-Scale Data-and Knowledge-Centered Systems XXXVII; Springer: Berlin/Heidelberg, Germany, 2018; pp. 41–80. [Google Scholar]
- Becher, S.; Gerl, A. ConTra Preference Language: Privacy Preference Unification via Privacy Interfaces. Sensors 2022, 22, 5428. [Google Scholar] [CrossRef]
- Ye, J. Cosine similarity measures for intuitionistic fuzzy sets and their applications. Math. Comput. Model. 2011, 53, 91–97. [Google Scholar] [CrossRef]
- Fkih, F. Similarity Measures for Collaborative Filtering-based Recommender Systems: Review and Experimental Comparison. J. King Saud Univ.-Comput. Inf. Sci. 2021, 34, 7645–7669. [Google Scholar] [CrossRef]
- Liu, J.; Xiong, L.; Luo, J. Semantic Security: Privacy Definitions Revisited. Trans. Data Priv. 2013, 6, 185–198. [Google Scholar]
- Newman, D. UCI Repository of Machine Learning Databases, University of California, Irvine. 1998. Available online: http://www.ics.uci.edu/mlearn/MLRepository.html (accessed on 8 January 2023).
- Amiri, F.; Yazdani, N.; Shakery, A.; Chinaei, A.H. Hierarchical anonymization algorithms against background knowledge attack in data releasing. Knowl.-Based Syst. 2016, 101, 71–89. [Google Scholar] [CrossRef]
- Fung, B.C.; Wang, K.; Fu, A.W.C.; Philip, S.Y. Introduction to Privacy-Preserving Data Publishing: Concepts and Techniques; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Main Focus of Study | Possible Attacks | |||||
|---|---|---|---|---|---|---|---|
| P | U | H | S | SS | BK | SAI | |
| Li et al. [39] | × | ✓ | ✓ | ✓ | ✓ | ∘ | ✓ |
| Cagliero et al. [40] | × | ✓ | ✓ | ✓ | × | ✓ | ✓ |
| Zaman et al. [41] | ✓ | ✓ | - | - | - | ✓ | ∘ |
| Srijayanthi et al. [42] | × | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Chen et al. [43] | × | ✓ | × | ∘ | ∘ | ✓ | × |
| Jha et al. [44] | ✓ | × | ✓ | ∘ | ✓ | × | ✓ |
| Li et al. [45] | ✓ | × | ✓ | × | × | ∘ | × |
| Chu et al. [46] | × | × | ✓ | ✓ | × | ∘ | ✓ |
| Sun et al. [47] | × | ✓ | - | ✓ | ✓ | ✓ | ∘ |
| Nóbrega et al. [48] | ✓ | ✓ | × | ✓ | ✓ | × | ✓ |
| Amiri et al. [49] | ✓ | ✓ | × | × | ✓ | × | ✓ |
| Chen et al. [50] | ✓ | × | × | ✓ | ✓ | ✓ | ✓ |
| Xia et al. [51] | ✓ | ✓ | × | ✓ | ✓ | ✓ | ∘ |
| Han et al. [52] | × | ✓ | ✓ | ✓ | ✓ | ∘ | ✓ |
| Last et al. [53] | × | ✓ | ✓ | ∘ | ✓ | ∘ | ✓ |
| Fong et al. [54] | × | ✓ | ✓ | ∘ | ✓ | × | ✓ |
| Lin et al. [55] | × | ✓ | ✓ | ✓ | ✓ | × | ✓ |
| Park et al. [56] | ✓ | × | ∘ | ∘ | ∘ | × | ∘ |
| Eyupoglu et al. [57] | ✓ | ✓ | ✓ | ✓ | ✓ | × | × |
| Ye et al. [58] | ✓ | × | ✓ | ✓ | ✓ | ∘ | ✓ |
| Kousika et al. [59] | × | ✓ | × | ✓ | ✓ | ✓ | ✓ |
| Our approach | ✓ | ✓ | × | × | ∘ | ∘ | × |
| Notation | Description |
|---|---|
| D | Original data (i.e., before anonymization) |
| Anonymized data (i.e., after anonymization) | |
| N | Number (#) of records/tuples in a D, where |
| user in a D | |
| Q | Quasi-identifiers’ set |
| S | Set (a.k.a domain) of SA values |
| Usefulness weight of pth QI | |
| Set of usefulness weights of the QIs | |
| Similarity between two user i and j | |
| k | Privacy parameter |
| Total number of ECs to be made from D | |
| X | Matrix of highly similar users |
| R | Set of EC made based on k |
| ith equivalence class with at least k users | |
| Uncertainty value of the SA in ith EC | |
| Threshold value for analyzing U | |
| U | set of the uncertainty values of ECs |
| Generalization hierarchy of an ith QI |
| Dataset | N | QIs (Distinct Values, # of Levels, Type) | SA (Distinct Values) |
|---|---|---|---|
| Adults [71] | 32,561 | Age (74, 7, Numerical) Race (5, 3, Categorical) Gender (2, 2, Categorical) Country (41, 4, Categorical) | Salary (2) |
| Bkseq [72] | 16,160 | Age (30, 5, Numerical) Weight (30, 3, Numerical) Gender (2, 2, Categorical) | Results of the medical exam (19) |
| Datasets | Parameter Name | Parameter’s Values | |
|---|---|---|---|
| Numerical | Non-Numerical | ||
| Adults [71] | Training data size Testing data size No. of trees () RF model type Variable importance Value of Predictors Target class Keep forest | 21,706 10,855 497 - - 4 - - - | - - - Classification true - All QIs Salary true |
| Bkseq [72] | Training data size Testing data size No. of trees () RF model type Variable importance Value of Predictors Target class Keep forest | 10,773 5,387 267 - - 3 - - - | - - - Classification true - All QIs Medical exam result true |
| Dataset | Quasi-Identifiers and Their Usefulness Weights | ||||
|---|---|---|---|---|---|
| Age | Gender | Race | Country | Weight | |
| Adults [71] | 0.18 | 1.10 | 26.91 | 71.81 | - |
| Bkseq [72] | 47.51 | 38.91 | - | - | 13.58 |
| Dataset | Anonymization Mechanisms (e.g., the Proposed Approach and Existing Privacy Models) | ||||
|---|---|---|---|---|---|
| k-Anonymity [29] | ℓ-Diversity [30] | t-Closeness [31] | Our Approach | Original Data | |
| Adults [71] | 86.46 | 85.71 | 84.09 | 88.71 | 89.01 |
| Bkseq [72] | 88.16 | 87.91 | 86.26 | 91.64 | 91.75 |
| Dataset | Anonymization Mechanism and Original Data | ||
|---|---|---|---|
| SVD3RD [59] | Our Approach | Original Data | |
| Adults [71] | 77.10 | 88.71 | 89.01 |
| Bkseq [72] | 83.89 | 91.64 | 91.75 |
| Dataset | k | PD Comparisons with Existing Studies with Varying k Values | ||
|---|---|---|---|---|
| Existing Algorithms | Existing Models | Proposed Approach | ||
| Adults [71] | 2 | 0.87 | 0.67 | 0.54 |
| 5 | 0.60 | 0.68 | 0.42 | |
| 10 | 0.63 | 0.69 | 0.51 | |
| 15 | 0.75 | 0.74 | 0.64 | |
| 20 | 0.69 | 0.75 | 0.66 | |
| 25 | 0.80 | 0.78 | 0.72 | |
| 30 | 0.78 | 0.79 | 0.67 | |
| 35 | 0.80 | 0.84 | 0.73 | |
| 40 | 0.81 | 0.84 | 0.75 | |
| 50 | 0.83 | 0.85 | 0.76 | |
| 75 | 0.84 | 0.83 | 0.78 | |
| 100 | 0.82 | 0.85 | 0.77 | |
| 125 | 0.86 | 0.86 | 0.79 | |
| 150 | 0.88 | 0.89 | 0.80 | |
| 175 | 0.88 | 0.91 | 0.81 | |
| 200 | 0.89 | 0.92 | 0.82 | |
| 250 | 0.88 | 0.94 | 0.82 | |
| Bkseq [72] | 2 | 0.50 | 0.50 | 0.50 |
| 5 | 0.34 | 0.38 | 0.26 | |
| 10 | 0.39 | 0.41 | 0.33 | |
| 15 | 0.53 | 0.55 | 0.42 | |
| 20 | 0.57 | 0.63 | 0.48 | |
| 25 | 0.65 | 0.69 | 0.53 | |
| 30 | 0.63 | 0.71 | 0.54 | |
| 35 | 0.67 | 0.73 | 0.63 | |
| 40 | 0.69 | 0.74 | 0.64 | |
| 50 | 0.71 | 0.76 | 0.65 | |
| 75 | 0.73 | 0.79 | 0.67 | |
| 100 | 0.75 | 0.81 | 0.69 | |
| 125 | 0.76 | 0.82 | 0.71 | |
| 150 | 0.77 | 0.81 | 0.71 | |
| 175 | 0.79 | 0.84 | 0.73 | |
| 200 | 0.81 | 0.85 | 0.75 | |
| 250 | 0.81 | 0.86 | 0.77 | |
| Dataset | k (# of Classes) | ’s Comparisons with Existing Studies with Varying k Values | ||
|---|---|---|---|---|
| Existing Algorithms | Existing Models | Proposed Approach | ||
| Adults [71] | 2 (16,280) | 4549.56 | 6210.5 | 2779.5 |
| 5 (6512) | 1819.90 | 2484.2 | 1111.8 | |
| 10 (3256) | 909.81 | 1242.10 | 555.81 | |
| 15 (2171) | 606.53 | 828.06 | 370.61 | |
| 20 (1628) | 454.32 | 621.05 | 277.95 | |
| 25 (1302) | 363.92 | 496.84 | 222.36 | |
| 30 (1085) | 303.26 | 414.03 | 185.31 | |
| 35 (930) | 259.94 | 354.82 | 158.82 | |
| 40 (814) | 227.45 | 310.52 | 138.97 | |
| 50 (651) | 181.96 | 248.42 | 111.18 | |
| 75 (434) | 121.30 | 165.61 | 74.12 | |
| 100 (326) | 90.98 | 124.21 | 55.60 | |
| 125 (260) | 72.78 | 99.36 | 44.48 | |
| 150 (217) | 60.65 | 82.80 | 37.06 | |
| 175 (186) | 51.98 | 79.79 | 31.76 | |
| 200 (163) | 45.49 | 62.10 | 27.80 | |
| 250 (130) | 36.39 | 49.64 | 22.36 | |
| Average value | 0.32 | 0.42 | 0.19 | |
| Bkseq [72] | 2 (8080) | 2050.21 | 2600.21 | 1450.32 |
| 5 (3232) | 820.21 | 1040.29 | 580.92 | |
| 10 (1616) | 410.34 | 520.31 | 290.32 | |
| 15 (1077) | 273.33 | 346.67 | 193.21 | |
| 20 (808) | 205.10 | 260.89 | 145.34 | |
| 25 (646) | 164.32 | 208.32 | 116.45 | |
| 30 (539) | 136.66 | 173.33 | 96.67 | |
| 35 (462) | 117.14 | 148.57 | 82.85 | |
| 40 (404) | 102.51 | 130.43 | 72.55 | |
| 50 (323) | 82.32 | 104.65 | 58.98 | |
| 75 (215) | 54.66 | 69.43 | 38.66 | |
| 100 (162) | 41.34 | 52.60 | 29.87 | |
| 125 (129) | 32.81 | 41.67 | 23.24 | |
| 150 (108) | 27.33 | 34.66 | 19.35 | |
| 175 (92) | 23.42 | 29.82 | 16.59 | |
| 200 (81) | 20.51 | 26.69 | 14.43 | |
| 250 (65) | 16.41 | 20.89 | 11.65 | |
| Average value | 0.14 | 0.16 | 0.09 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Majeed, A.; Hwang, S.O. A Generic Approach towards Enhancing Utility and Privacy in Person-Specific Data Publishing Based on Attribute Usefulness and Uncertainty. Electronics 2023, 12, 1978. https://doi.org/10.3390/electronics12091978
Majeed A, Hwang SO. A Generic Approach towards Enhancing Utility and Privacy in Person-Specific Data Publishing Based on Attribute Usefulness and Uncertainty. Electronics. 2023; 12(9):1978. https://doi.org/10.3390/electronics12091978
Chicago/Turabian StyleMajeed, Abdul, and Seong Oun Hwang. 2023. "A Generic Approach towards Enhancing Utility and Privacy in Person-Specific Data Publishing Based on Attribute Usefulness and Uncertainty" Electronics 12, no. 9: 1978. https://doi.org/10.3390/electronics12091978