
Cross-Perspective Human Behavior Recognition Based on a Joint Sparse Representation and Distributed Adaptation Algorithm Combined with Wireless Optical Transmission


Abstract
:1. Introduction
2. Cross Perspective Human Behavior Recognition Method Design in Wireless Communication Optical Technology
2.1. Human Behavior Recognition
2.2. Design of Cross Perspective Human Behavior Recognition Method
2.2.1. Joint Sparse Representation
2.2.2. Joint Distribution Adaptation
3. Experimental on Cross Perspective Human Behavior Recognition
3.1. Methods of Optical Wireless Communication
3.2. Comparison of Algorithms
3.2.1. Recall and Precision
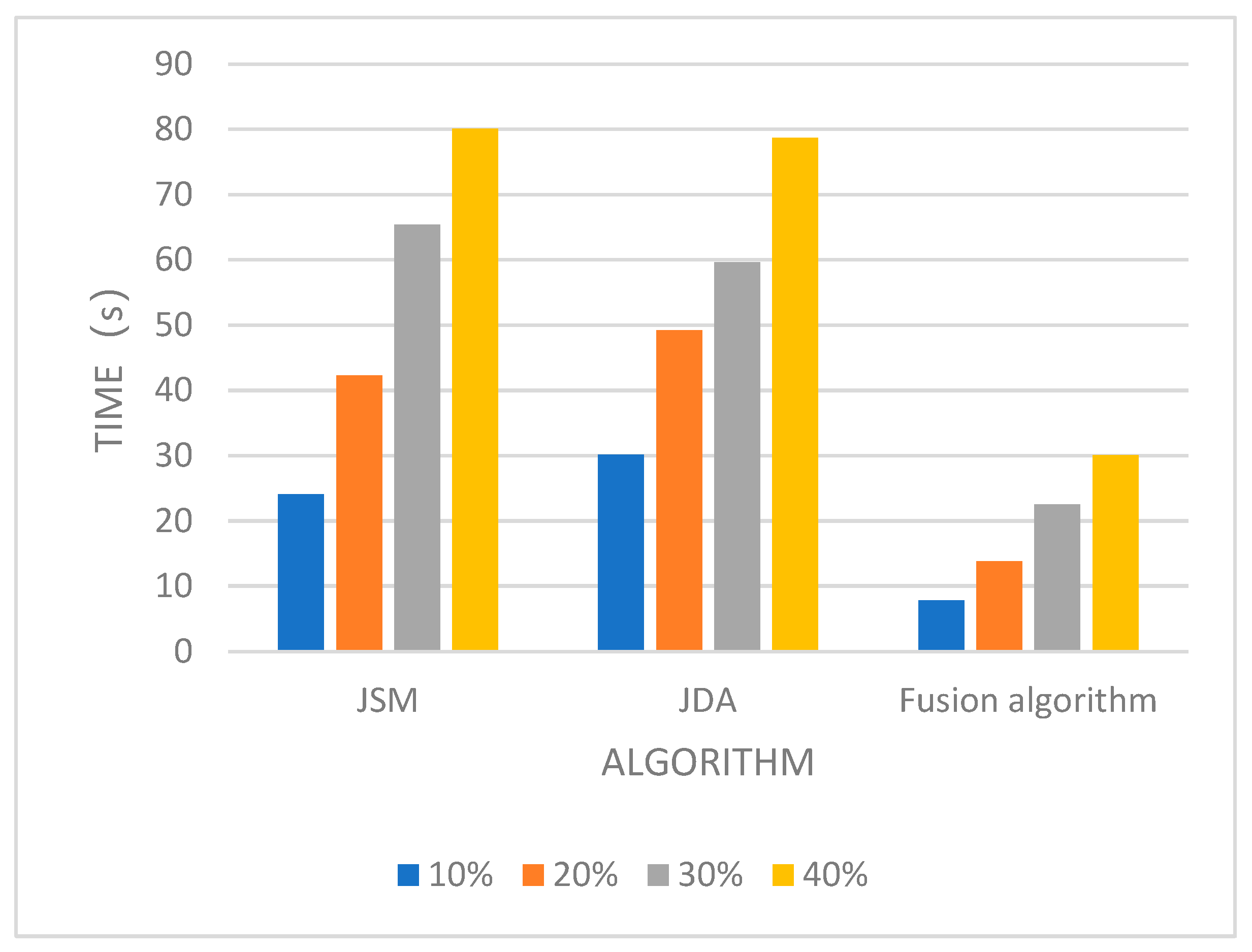
3.2.2. Running Time
3.2.3. Training Speed
3.2.4. Recognition Accuracy of Different Actions
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yücel, M.; Açikgöz, M. Optical Communication Infrastructure in New Generation Mobile Networks. Fiber Integr. Opt. 2023, 42, 53–92. [Google Scholar] [CrossRef]
- Chen, L.; Chen, X.; Ni, L.; Peng, Y.; Fang, D. Human Behavior Recognition Using Wi-Fi CSI: Challenges and Opportunities. IEEE Commun. Mag. 2017, 55, 112–117. [Google Scholar] [CrossRef]
- Yousefi, S.; Narui, H.; Dayal, S.; Ermon, S.; Valaee, S. A Survey on Behavior Recognition Using WiFi Channel State Information. IEEE Commun. Mag. 2017, 55, 98–104. [Google Scholar] [CrossRef]
- Wang, Z.; Guo, B.; Yu, Z.; Zhou, X. Wi-Fi CSI-Based Behavior Recognition: From Signals and Actions to Activities. IEEE Commun. Mag. 2018, 56, 109–115. [Google Scholar] [CrossRef]
- Sajjad, M.; Zahir, S.; Ullah, A.; Akhtar, Z.; Muhammad, K. Human Behavior Understanding in Big Multimedia Data Using CNN based Facial Expression Recognition. Mob. Netw. Appl. 2020, 25, 1611–1621. [Google Scholar] [CrossRef]
- Tian, Y.; Kong, Y.; Ruan, Q.; An, G.; Fu, Y. Hierarchical and Spatio-Temporal Sparse Representation for Human Action Recognition. IEEE Trans. Image Process. 2017, 27, 1748–1762. [Google Scholar] [CrossRef]
- Zhang, J.; Shum, H.P.H.; Han, J.; Shao, L. Action Recognition From Arbitrary Views Using Transferable Dictionary Learning. IEEE Trans. Image Process. 2018, 27, 4709–4723. [Google Scholar] [CrossRef]
- Shahroudy, A.; Ng, T.-T.; Gong, Y.; Wang, G. Deep Multimodal Feature Analysis for Action Recognition in RGB+D Videos. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1045–1058. [Google Scholar] [CrossRef]
- Liu, Y.; Lu, Z.; Li, J.; Yang, T. Hierarchically Learned View-Invariant Representations for Cross-View Action Recognition. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 2416–2430. [Google Scholar] [CrossRef]
- Qu, J.; Qiao, N.; Shi, H.; Su, C.; Razi, A. Convolutional neural network for human behavior recognition based on smart bracelet. J. Intell. Fuzzy Syst. 2020, 38, 5615–5626. [Google Scholar] [CrossRef]
- Gao, Z.; Xuan, H.-Z.; Zhang, H.; Wan, S.; Choo, K.-K.R. Adaptive Fusion and Category-Level Dictionary Learning Model for Multiview Human Action Recognition. IEEE Internet Things J. 2019, 6, 9280–9293. [Google Scholar] [CrossRef]
- Dai, C.; Liu, X.; Lai, J.; Li, P.; Chao, H.-C. Human Behavior Deep Recognition Architecture for Smart City Applications in the 5G Environment. IEEE Netw. 2019, 33, 206–211. [Google Scholar] [CrossRef]
- Wang, L. Three-dimensional convolutional restricted Boltzmann machine for human behavior recognition from RGB-D video. EURASIP J. Image Video Process. 2018, 2018, 120. [Google Scholar] [CrossRef]
- Zheng, B.; Yun, D.; Liang, Y. Research on behavior recognition based on feature fusion of automatic coder and recurrent neural network. J. Intell. Fuzzy Syst. 2020, 39, 8927–8935. [Google Scholar] [CrossRef]
- Saleem, G.; Bajwa, U.I.; Raza, R.H. Toward human activity recognition: A survey. Neural Comput. Appl. 2023, 35, 4145–4182. [Google Scholar] [CrossRef]
- Kamel, A.; Sheng, B.; Yang, P.; Li, P.; Shen, R.; Feng, D.D. Deep Convolutional Neural Networks for Human Action Recognition Using Depth Maps and Postures. IEEE Trans. Syst. Man Cybern. Syst. 2018, 49, 1806–1819. [Google Scholar] [CrossRef]
- Al-Kinani, A.; Wang, C.-X.; Zhou, L.; Zhang, W. Optical Wireless Communication Channel Measurements and Models. IEEE Commun. Surv. Tutor. 2018, 20, 1939–1962. [Google Scholar] [CrossRef]
- Menaka, D.; Gauni, S.; Manimegalai, C.T.; Kalimuthu, K. Vision of IoUT: Advances and future trends in optical wireless communication. J. Opt. 2021, 50, 439–452. [Google Scholar] [CrossRef]
- Maier, A.; Syben, C.; Lasser, T.; Riess, C. A gentle introduction to deep learning in medical image processing. Z. Für Med. Phys. 2019, 29, 86–101. [Google Scholar] [CrossRef]
- Wiley, V.; Lucas, T. Computer vision and image processing: A paper review. Int. J. Artif. Intell. Res. 2018, 2, 29–36. [Google Scholar] [CrossRef]
- Peng, J.; Sun, W.; Du, Q. Self-Paced Joint Sparse Representation for the Classification of Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1183–1194. [Google Scholar] [CrossRef]
- Vishwakarma, R.; Monani, R.; Hedayatipour, A.; Rezaei, A. Reliable and Secure Memristor-based Chaotic Communication Against Eavesdroppers and Untrusted Foundries. Discov. Internet Things 2023, 3, 2. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Conventional Receiver | 2D Image Sensor Receiving Terminal | Compound Eye Structure Receiving Terminal | |
|---|---|---|---|
| Field angle | 60° | 90° | 180° |
| Gain | 13 | 20 | 19 |
| Communication distance | 31.6 m | 189.5 m | 45 m |
| Detection range | directional | directional | omnidirectional |
| Field Mirror | Immersion Lens | Light Cone | |
|---|---|---|---|
| Optical efficiency | 92% | 87% | 83% |
| Gain | 22.1 | 12.5 | 11.4 |
| Coefficient | 7.8 | 8.0 | 7.1 |
| Optical signal-to-noise ratio | 44.2 | 38.6 | 35.4 |
| Uniformity | good | common | poor |
| JSM Algorithm | JDA Algorithm | Fusion Algorithm | |
|---|---|---|---|
| having dinner | 90.4% | 89.2% | 95.2% |
| applause | 93.1% | 90.7% | 96.2% |
| nodding | 100% | 100% | 100% |
| phoning | 95.7% | 92.1% | 99.8% |
| shaking head | 100% | 100% | 100% |
| waving | 98.2% | 95.2% | 100% |
| embracing | 96.2% | 93.1% | 99.6% |
| falling | 93.5% | 89.5% | 96.8% |
| standing up | 100% | 100% | 100% |
| running | 92.1% | 89.0% | 95.2% |
| average accuracy | 95.92% | 93.88% | 98.28% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, X.; Long, L.; Ou, Y.; Zhou, X. Cross-Perspective Human Behavior Recognition Based on a Joint Sparse Representation and Distributed Adaptation Algorithm Combined with Wireless Optical Transmission. Electronics 2023, 12, 1980. https://doi.org/10.3390/electronics12091980
Yu X, Long L, Ou Y, Zhou X. Cross-Perspective Human Behavior Recognition Based on a Joint Sparse Representation and Distributed Adaptation Algorithm Combined with Wireless Optical Transmission. Electronics. 2023; 12(9):1980. https://doi.org/10.3390/electronics12091980
Chicago/Turabian StyleYu, Xiaomo, Long Long, Yang Ou, and Xiaomeng Zhou. 2023. "Cross-Perspective Human Behavior Recognition Based on a Joint Sparse Representation and Distributed Adaptation Algorithm Combined with Wireless Optical Transmission" Electronics 12, no. 9: 1980. https://doi.org/10.3390/electronics12091980