1. Introduction
Big data is a term that describes a significant amount of complicated and massive data sets that cannot be examined using typical computer approaches where the data might be structured, unstructured, or semi-structured [
1]. The exact definition of the term “Big Data” is continuously evolving, where a data collection is considered “Big” if it has a size ranging from a few terabytes to several petabytes [
2]. On the other hand, even though the data can be apportioned into three categories as above mentioned, the main focus is on unstructured big data [
2]. When the data becomes unstructured and complex, they cannot be maintained and handled by traditional relational databases, which necessitates novel mechanisms to analyze this large volume of complex data [
3,
4,
5]. In simple terms, big data refers to the ever-changing nature of our world [
4,
6], as everything changes around us in every second we spend. For instance, according to the latest statistics, during one single day, more than five hundred terabytes of data become ingested into the databases of Facebook, a social media networking company, owing to the billions of user transactions that are happening daily (audio and video uploads, content creations, message exchanges, and user comments) [
4,
6]. Moreover, the New York Stock Exchange is another example, which generates one terabyte of trade data per single day [
4,
5,
6]. Modern businesses/organizations use the insights from this big data to discover consumer shopping habits/patterns, for targeted marketing and advertising, to offer personalized medical plans for patients, to monitor the health condition from wearable devices, and for real-time monitoring of networks for cyber security attacks [
7]. One of the most significant things is every industry nowadays uses big data for their future planning of businesses, to predict what will happen next, and to identify their customer behavior by inferring insights from past data [
4,
5,
6]. Healthcare, telecommunication, and financial services are some domains that highly reap the benefits of this big data [
5]. According to recent estimates [
5,
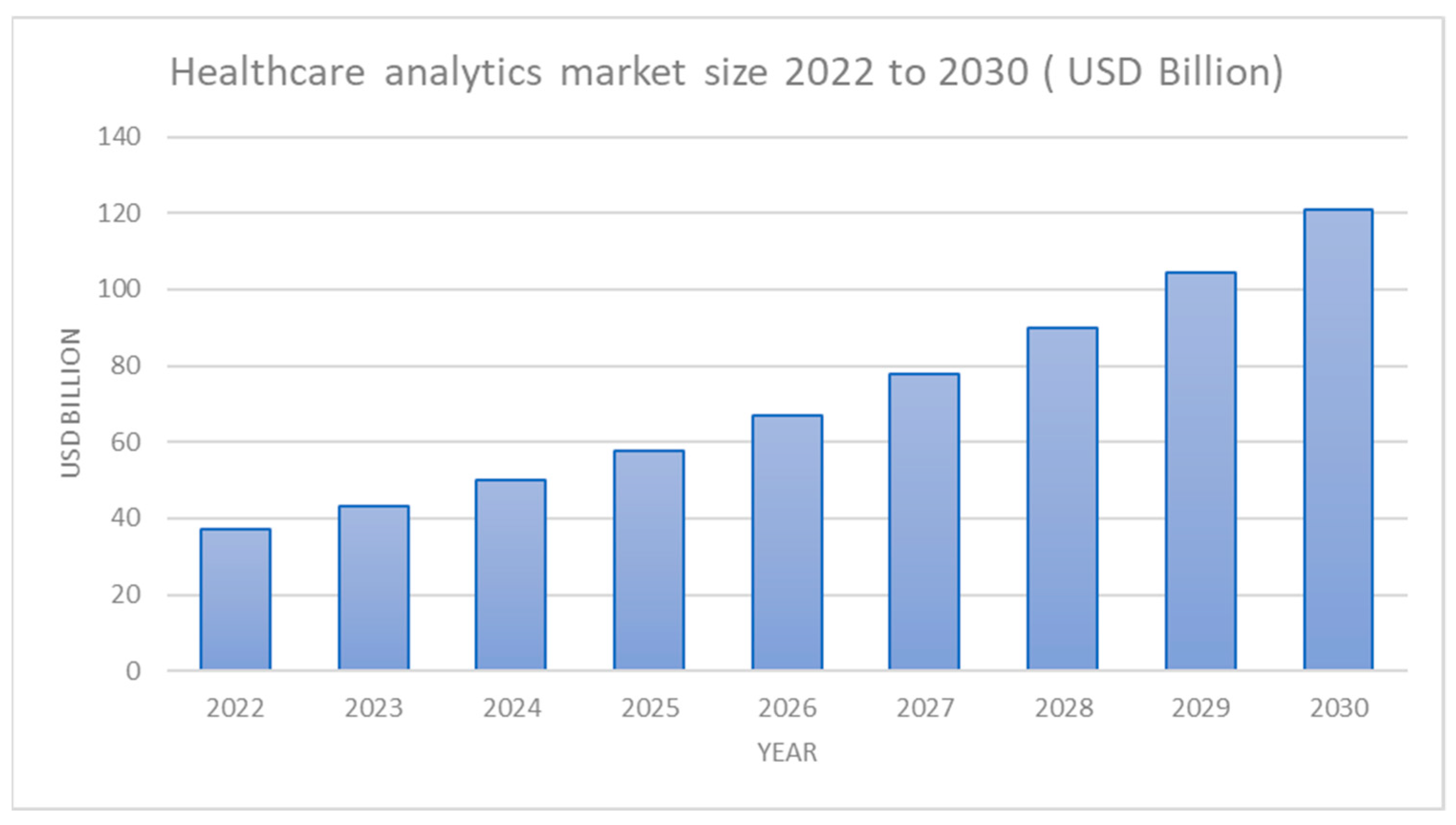
7], the healthcare big data analytics market size could reach more than
$120 billion by 2030, as shown in
Figure 1 [
4,
5,
6,
7], which showcases that big data is becoming a high necessity asset for healthcare.
Big data in the healthcare context is a complex collation of digital medical data acquired from several sources that are challenging to handle with standard technology and Software owing to its large volume and complexity [
1]. According to [
1,
2], this medical big data can also interchangeably be referred to as Multimedia Medical Big Data (MBD), as the data is acquired from a variety of sources. This medical big data mainly consist of patient data in the form of digital health records or Electronic Health Records (EHRs), data from written notes and prescriptions of physicians, medical imaging, insurance, laboratory, medical journals, pharmacy, and other administrative and medical environmental data, and data collected from machines and sensors which form what is referred to as the Internet of Things (IoT) and social media data, for instance, data from social networking sites and blog entries [
7,
8,
9,
10,
11,
12,
13,
14,
15]. All these massive amounts of data have enormous potential in improving the efficiency and quality of healthcare, detecting health hazards before they are onset, predicting outbreaks of epidemics [
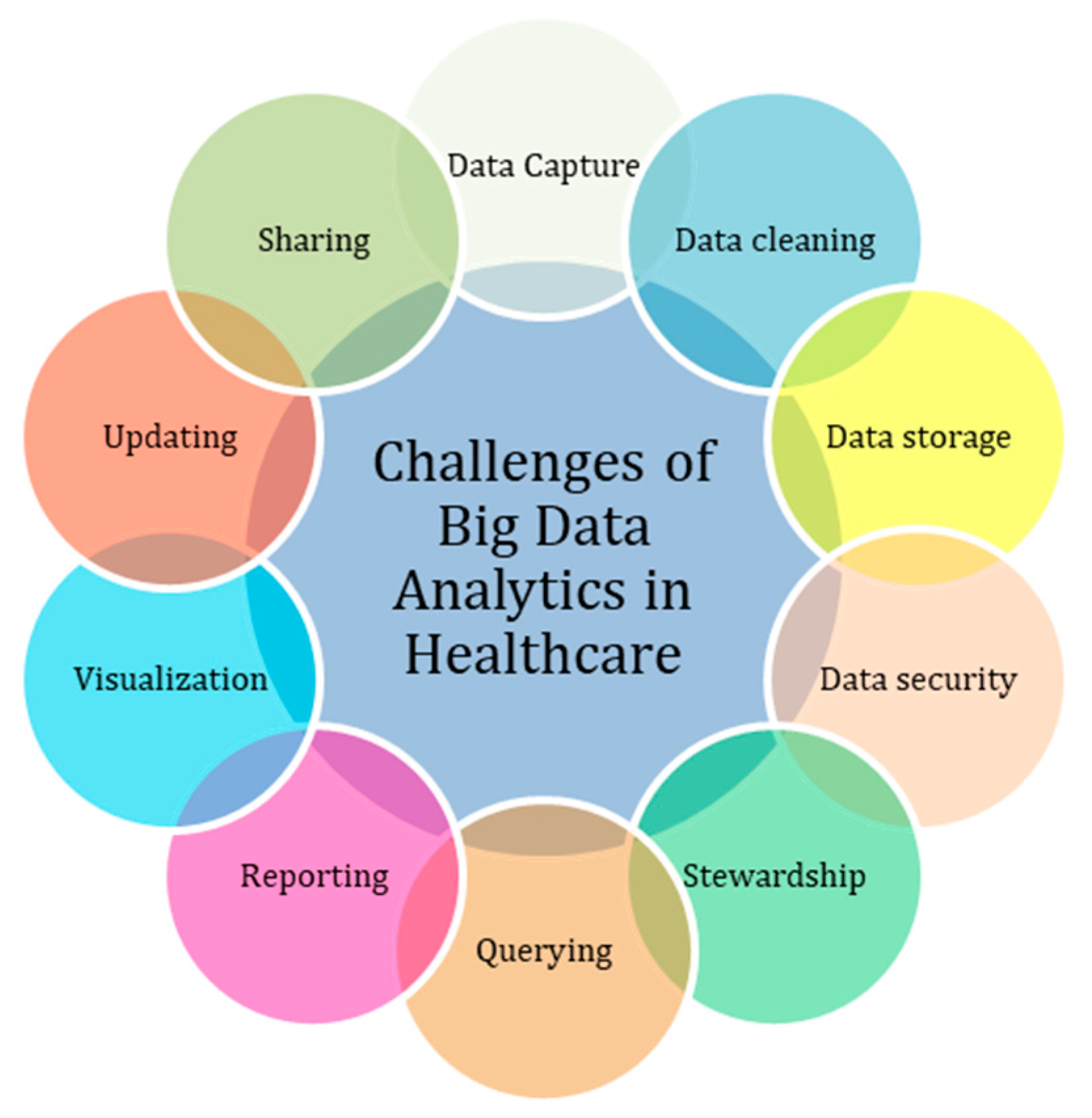
4], controlling human health by diagnosing diseases at an early stage, and aiding in improved decision-making. Even though medical big data offer greater benefits for the goodness of mankind, there are a variety of challenges that hinder the optimal growth of technology, in which the key challenges are data storage, data capture, data cleaning, and data security and privacy, as depicted in
Figure 2 [
1,
2].
According to [
1,
2,
3,
4,
5,
6], the majority of researchers that used artificial intelligence (AI) and big data analytics in medical diagnosis did not place priority on data privacy and security, which could eventually jeopardize the lives of patients. Even though collecting data in healthcare may be highly beneficial for diagnosing the patient’s condition and for further research, we must also consider the adverse consequences that technology brings, which could eventually endanger the lives of innocents. Digitalization in the medical industry is reaching a tipping point where the rapid use of new technologies such as IoT, mobile computing, and cloud computing has posed new difficulties to big data in healthcare. As a result, it is essential to address cyber security concerns throughout the generation, collection, storage, sharing, exchange, and use of medical big data [
1,
2]. Medical big data, on the other hand, is comprised of three types of physical states [
2], that is, files and images, video and data flow, and text and language, which indicate the unstructured nature of all these medical data. As medical big data often consist of patient pathological information and Personal Identification Information (PII), protecting the privacy of medical big data is deemed essential thing. Otherwise, if the patient’s personal information is revealed by any means, it will affect the patient’s reputation and life, as well as pose severe moral and ethical issues [
2,
3,
4,
5,
6].
As previously said, medical big data has many advantages and has a lot of potential for revolutionizing healthcare, but it also has a lot of drawbacks and problems, of which security and privacy are of utmost concern, among many other challenges. The security and privacy concerns that target medical big data are being increased annually, posing doubt in the mind of researchers and medical organizations about the reliability and safety of medical care. Nevertheless, healthcare organizations have discovered that current security and privacy measures are not adequate for safeguarding their big data repositories and pervasive environment [
3,
5,
7,
8]. Thus, it is essential to recognize the limitations of present security and privacy solutions and envisage future research paths to maintain a safe and trustworthy medical big data environment, which was our main motivation behind this research work. Thus, motivated by the fact of designing safe and trustworthy medical environments, in the study, we have provided a comprehensive review of medical big data and present a novel access control model for improving the security and privacy of medical big data. In this regard, the main contributions of the study are highlighted in
Section 1.1.
1.1. Contributions of the Study
Big data and related analytical tools are continually aiding in the administration, measurement, and control of massive amounts of data generated in the healthcare industry [
1,
2,
3,
4,
5,
6,
7], posing a variety of security and privacy issues. In this aspect, this research provides a brief overview of security and privacy problems, as well as the current state of security and privacy solution deployment for medical big data. Nonetheless, toward improving the security and privacy of medical big data, we have proposed a novel access control model that can be used to secure medical big data environments.
The significant contributions of our study are indicated below.
A comprehensive overview of the role of big data in medical care is presented.
An overview of privacy and security implications of medical big data is presented.
A comprehensive examination of strategies and techniques for addressing security and privacy challenges in medical big data, along with key components based on the available literature, is provided.
A comparison of similar research is highlighted.
Designed a novel access control model for improving the security and privacy of medical big data, which can be used as a primary base to build safe medical big data solutions.
1.2. Outline of the Study
The remainder of the research is structured into six sections. Following the introduction, the
Section 2 provides a brief explanation of big data, highlighting major aspects and offering significant information about medical big data. Following that, we give a brief discussion on the privacy and security of medical big data in
Section 3, along with protective methods, with a brief description of these preventative measures and a comparison of associated studies. Our proposed access control model is highlighted in
Section 5, with the analytical results obtained and evaluations of it. Finally, we conclude our research in the
Section 6 with the conclusions we derived.
3. Preamble on Security and Privacy of Big Data
In terms of medical big data, many studies, whitepapers, and business reports [
1,
15], suggested if properly applied, big data can be used to determine the correct treatments plans based on the patient’s condition, assurance of public and community health, improve the diagnosis process and improve the accuracy of clinical decisions, ensure proper management within medial organizations and ensure long term sustainability of the medical industry. However, several researchers have pointed out that this would be somewhat difficult owing to the security and privacy challenges, among many other challenges, such as needed expertise and technological skills, heterogeneity, and complexity pertained to medical big data [
11,
12,
13,
14].
According to [
2], security and privacy risks related to big data in the medical industry may be seen in four stages:
Security of medical big data often involves having protection against unauthorized access while ensuring fundamental information security concepts that are confidentiality, integrity, and availability, which focus totally on protecting the data from a variety of cyber-attacks. On the other hand, privacy is defined as protecting sensitive information from unauthorized disclosure, such as PII included with medical data. Further privacy is mainly focused on developing appropriate policies and authentication and authorization procedures towards guaranteeing that patient private data are collected, shared, and used appropriately [
20,
21,
22,
23,
45].
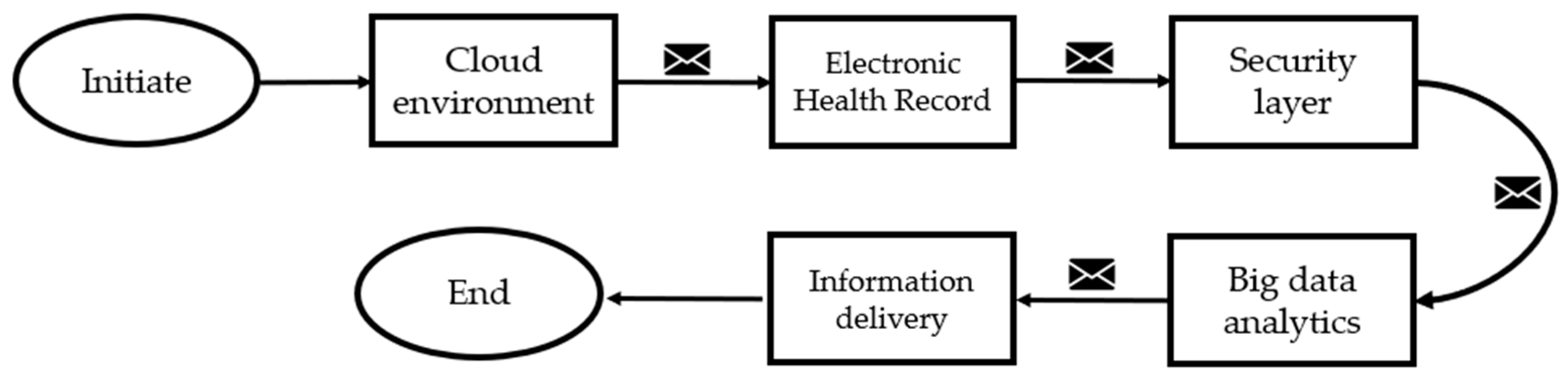
In [
10], the researchers proposed a secure big data analytics framework for the Health Information System (HIS), which is made up of five components that may be used to manage medical big data in a typical healthcare setting, as shown in
Figure 4.
The suggested HIS framework’s initial component is a cloud environment that offers a variety of user services and permits data exchange. In a typical medical context, the second component is the Electronic Health Record (EHR), which is used to collect and integrate patient data from numerous data sources. The security layer is the third component, and it is used to manage different security and privacy problems related to the underlying medical big data, such as authentication, authorization, data confidentiality, and availability. To provide such medical services, the security layer is comprised of cryptographic encryption algorithms such as RSA, RC4, AES and authentication techniques such as Two Factor Authentication (2FA), and One Time Password (OTP) for allowing access only to authorized users. Further, it also comprises access control mechanisms for authorizing users to execute tasks based on the granted access control privileges. The fourth layer comprises big data analytics tools to obtain insights from the raw medical data collated. Finally, the fifth component, which is the information delivery layer, takes care of delivering this medical information to relevant destinations and providing information services [
9]. With this, what we have understood is that security and privacy protection mechanisms should be an integral part of the medical big data life cycle from the point of data generation to the data processing and information dissemination stage, where we can provide optimal protection to underlying medical big data [
46,
47].
In this regard, we plan to present a quick review of what actions may be performed to preserve the security of medical big data in the next part, followed by our proposed access control framework.
3.1. Big Data: Privacy and Security Protection Mechanisms
The main goal of this section is to provide a quick overview of available privacy and security protective strategies for protecting medical big data [
47,
48,
49,
50,
51,
52,
53,
54].
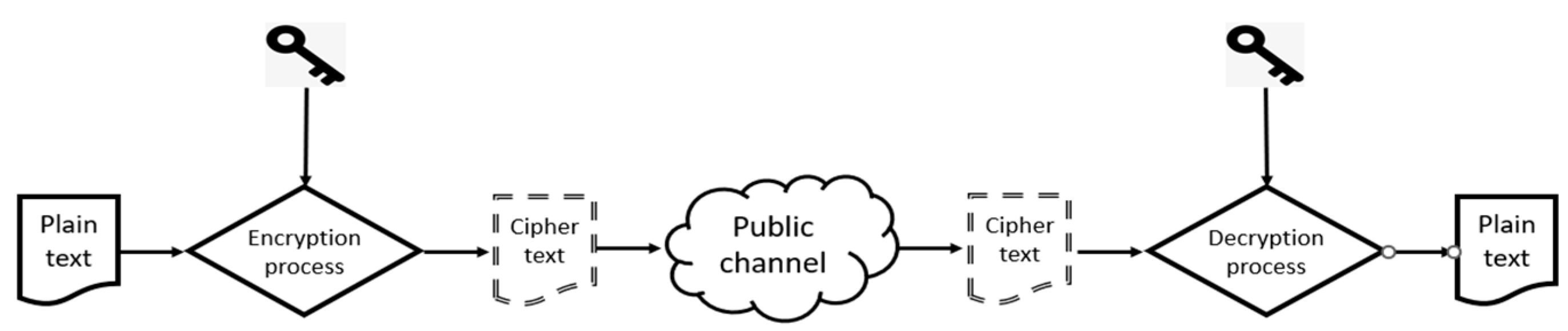
Encryption involves transforming original data from the readable form into an encoded form which is known as cipher text, to prevent unauthorized access to the original data. The encryption method is the most commonly used to protect the confidentiality and integrity of data at storage or during the transfer process. Once the data is encrypted using an appropriate encryption algorithm, using decryption, the cipher text can be transferred back to the original data, as depicted in
Figure 5. This encryption can be performed at different levels, such as database level, protocol level, disk-level, and file level, to protect the underlying data. In this regard, in a typical medical setting, a variety of private key cryptographic algorithms and public key algorithms are used to encrypt medical records [
23,
46,
47,
55,
56,
57,
58].
Even though encryption appears to be the most common solution for protecting the confidentiality and integrity of data, when they are deployed in a resource-constrained environment, particularly in the resource-constrained medical IoT environment, these algorithms may place an additional load on these resource-constrained IoT devices, which may sometimes affect data communication and proper device functioning. As previously said, these cryptographic algorithms may be divided into two categories based on the algorithm and the number of keys and private and public key cryptography. In private key cryptography or symmetric key cryptography, one key is used wherein the public key cryptography or asymmetric key cryptography two keys known as public and private are used [
53], where it is believed that public-key cryptographic algorithms are more secure than private ones.
Table 4 depicts the commonly used encryption algorithms that are already available for protecting medical big data in the resource-constrained medical IoT environment.
Based on these common encryption algorithms, it is evident that there are already algorithms capable of effectively working on resources constrained medical applications, such as Twofish and ECC algorithms.
Users can manage their data thanks to access control, which determines their identity based on preset regulations that prohibit unauthorized users from accessing resources. Medical servers, as well as important medical equipment and data, are only accessible to permitted devices and people, thanks to access control systems [
1,
5]. Access control may be utilized with a variety of encryption schemes, including symmetric and asymmetric encryption, as well as attribute-based encryption [
11,
12,
13,
14].
Personal Health Information (PHI) comprises a variety of pathological facts about patients, such as mental health, medical history, and medical test findings, which might be used for profit by attackers [
3]. As a result of the high value of this data, a simple data breach might threaten consumers’ privacy. As a result, any action that includes the creation or processing of this medical data, as well as its receiving, storage, or transfer, is required to be audited regularly to detect any security flaws [
13,
16,
17,
18].
Most medical networks are now constructed on a restricted domain with a network defensive perimeter to guard the internal network against cyber security attacks that may come through the public Internet [
7]. This outer medical network layer protects the healthcare institution by preventing outside cyber security attacks from breaching the internal network. In this regard, the network has built up with network defensive techniques and devices such as intrusion prevention systems, intrusion detection systems, firewalls, honeypots, web application firewalls and denial of service protection mechanisms, etc. [
18,
20,
21].
The practice of appropriately controlling and managing medical data is referred to as data governance in healthcare. The objective is to provide a consistent data format that integrates industry standards as well as local and regional norms, allowing for successful data management across all sorts of medical organizations [
46,
47,
50,
51,
52,
53,
54,
67].
The process of authenticating a user’s identification is known as authentication. Insufficient authentication protection schemas might allow intruders to breach internal medical networks and obtain access to sensitive medical data residing in the medical organization. Thus, it is necessary for the frequent authenticating of all users and devices who are accessing medical resources. On the other hand, this user and device authentication is critical for medical systems because it guarantees that data is properly ascribed and that information in the system is only available to authorized parties [
23,
46,
47,
51,
52,
53,
54].
Data minimization techniques advise limiting the collection of PHI, however, only to the medical data that is highly essential, as well as the retaining/archiving of sensitive medical data only for as long as the users request [
2,
3,
4]. This data minimization technique may also lead to reducing the overall archiving and storage cost [
48,
49,
50,
51,
52,
53].
Because of the increasing threats, analyzing security and privacy threats and forecasting threat sources in real-time is critical in the healthcare industry. The healthcare business is currently dealing with a slew of sophisticated threats, including ransomware, Distributed Denial of Service (DDoS), and all sorts of malware [
10,
13,
45]. Furthermore, social engineering attacks are becoming more common, and the hazards associated with them are difficult to forecast without taking human cognitive behavior into account. As the healthcare industry embraces developing big data technologies to make better decisions, real-time security analytics should be a major component of any security solution for detecting security and privacy breaches before they occur [
52].
3.2. Related Work and Discussion
Following an overview of medical big data, privacy and security of medical big data, and protection mechanisms, we provide a summary of related work conducted by other researchers, as shown in
Table 5, to emphasize the significance of our study.
According to the summarized literature, it is evident that most of the research that has been conducted in recent years employed AI, cloud computing, fog computing, mobile computing, cryptography, and blockchain for developing security solutions for protecting medical big data.
4. System Design and Implementation
Having provided a brief overview of medical big data and its security and privacy implications along with protection mechanisms, the main intention of this section is to highlight our proposed novel access control model for improving the security and privacy of medical big data. Overall, access control determines the user’s identity and prohibits unauthorized users from accessing resources. Based on that, we intended to design a novel access control model that prevents unauthorized users from accessing into medical big data stored in the cloud environment. In general, access control models can be divided into three main categories as Discretionary Access Control (DAC), Mandatory Access Control (MAC), and Role Based Access Control (RBAC). For a better understanding, a brief comparison of the above-mentioned access control models is listed on the following
Table 6.
According to the reviewed literature, the RBAC model is more advantageous than the MAC and DAC models, but it also has certain problems that must be fixed before it can be deployed. On the other hand, according to the literature, a typical RBAC model can be further improved by including different cryptographic schemes. Thus, the goal of our proposed model is to offer reliable and strong security for medical big data stored in the cloud by utilizing a hybrid cloud architecture and a hybrid cryptographic schema.
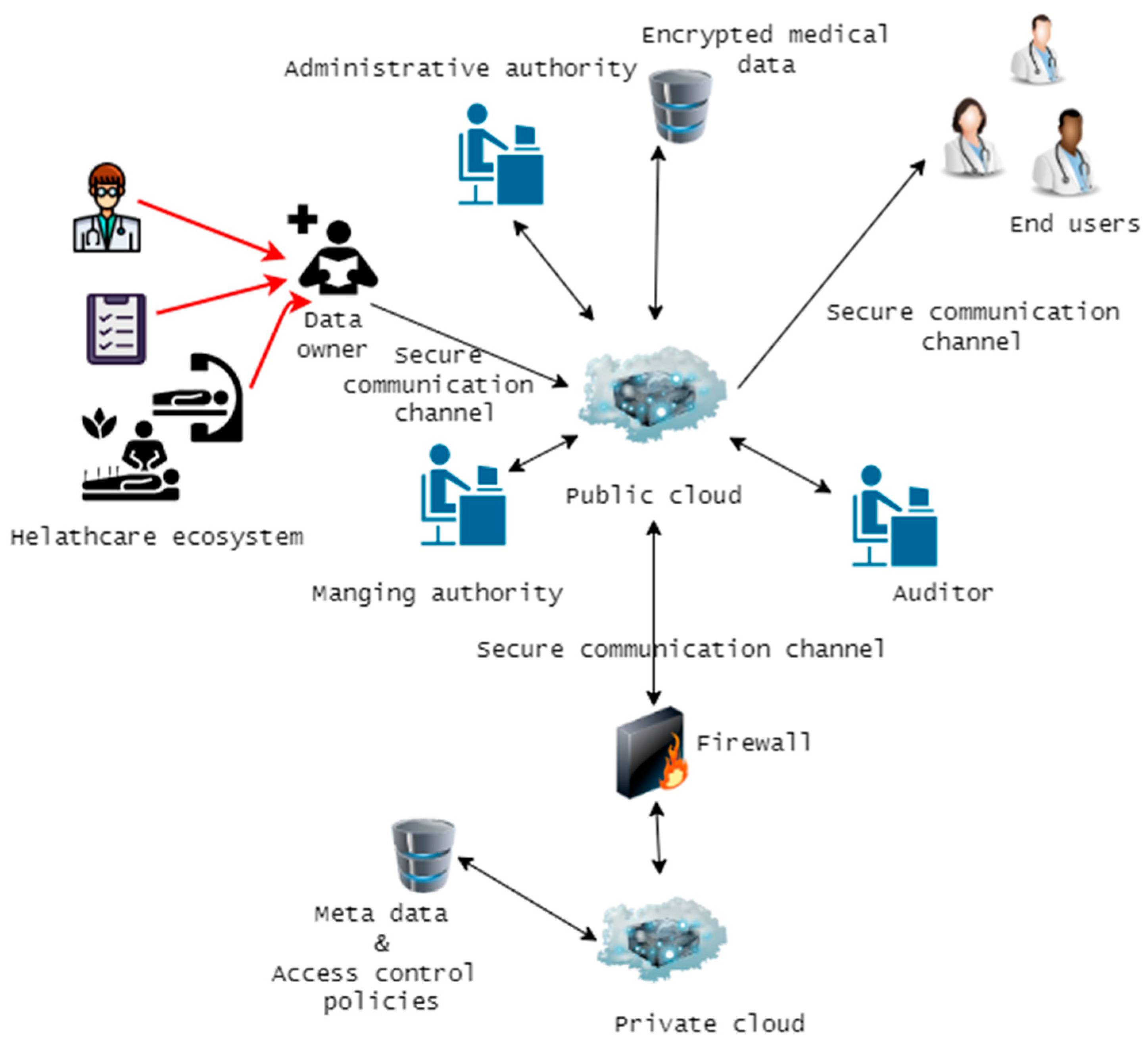
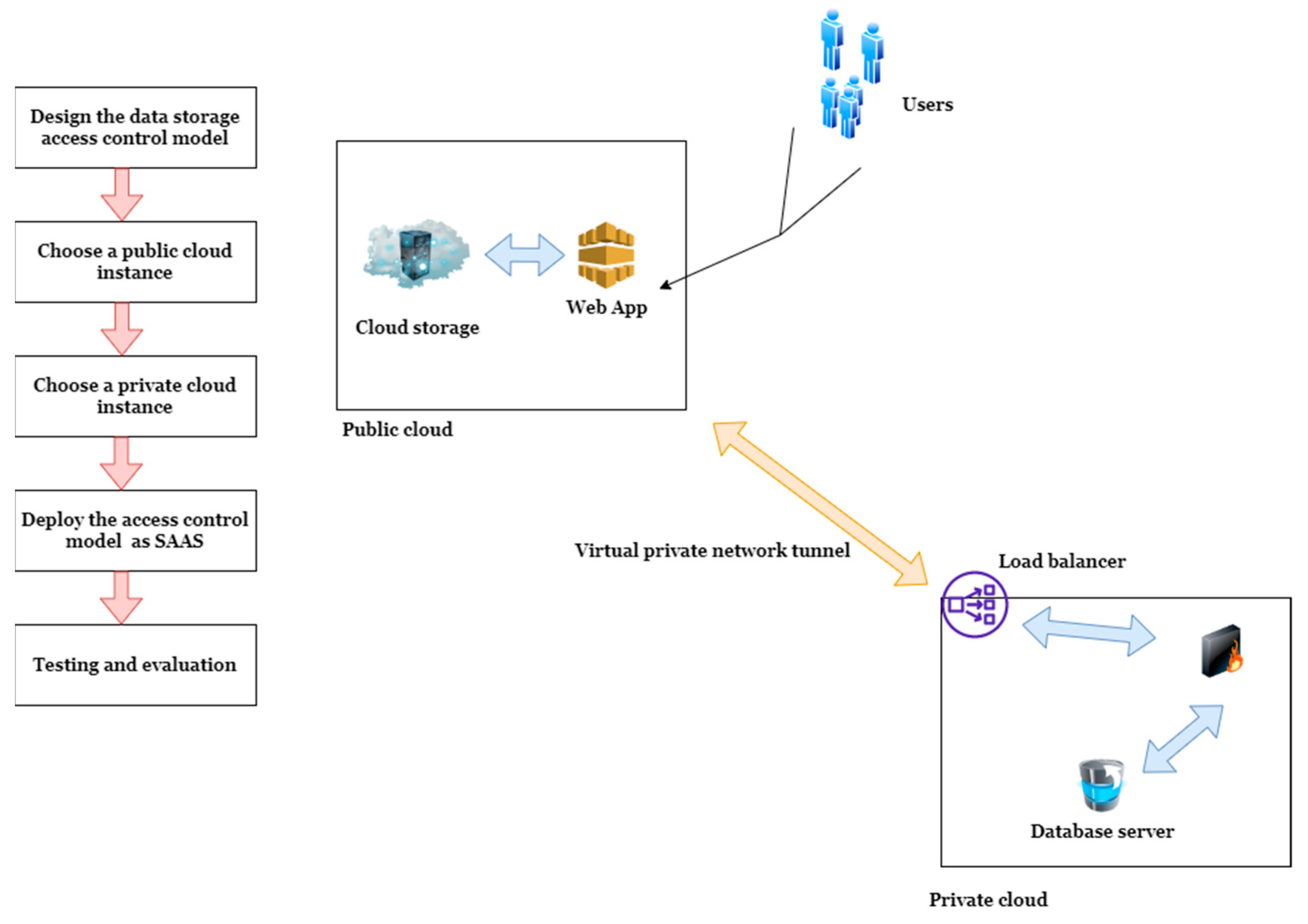
Our analysis of the relevant literature has allowed us to weigh the merits and drawbacks of various access control schemes and previous research in this area. Afterward, we decided to adopt a hierarchical RBAC model in our planned architecture since it appears to be effective at delivering the granular security, we need for our access permissions. Our model will be distinguished from all other existing or proposed models by its use of a hybrid cloud architecture (a combination of private and public cloud) and a hybrid encryption schema (RAS 1024-bit and AES 128-bit algorithm) to provide a high level of security. We have employed the AES algorithm to encrypt and decode medical big data stored in the public cloud and the RSA to encrypt the secret key created by the AES and other associated metadata. Our suggested access control system is primarily composed of the entities: a private cloud, public cloud, super user, data owner, management authority, overriding user and end users. The overview of our proposed model is depicted in
Figure 6.
As depicted, all the pertinent medical data that has to be accessible by relevant stakeholders will be kept on the public cloud. Data owners, in this scenario, relevant hospital employees such as physicians, radiologists, and so on, would upload all the data obtained from various medical devices to the public cloud. This data will be encrypted using the AES encryption technique when uploaded to the public cloud. The medical organization uses a private cloud to store essential data and metadata, such as encryption keys. A private cloud typically consists of a single server or data center located within the healthcare organization.
Access to this data residing in the public cloud must be permitted by administrative authorities in the healthcare organization before end users or any other users can access it. In this context, the end users might be thought of as the medical personnel, insurance providers, and caregivers who need access to the data housed in the public cloud. Nevertheless, end users are not permitted to make any changes to the public cloud’s data or to have any sort of direct communication with the private cloud. Anything having to do with the public cloud falls under the purview of the administrative authority, which also oversees the management of the role hierarchy. When end users seek access to data stored in the cloud, the managing authority will be present to manage their roles accordingly. Data in the cloud is made available to users based on the roles they have been given and the permissions they have been granted by the governing body. For a better understanding, each of the components of the access control model is explained further as follows.
The public cloud is responsible for keeping all aggregated medical data, and it is generic storage that is outside of the medical organization’s authority. (e.g., Azure, Amazon), thus only encrypted bulky data will be saved. End users and data owners in the medical organization connect directly with this.
A private cloud can be thought of as an internal data center or server that is situated within a healthcare facility. The private cloud is used solely for the storage of sensitive and confidential data, such as encryption keys and access permissions, among other things. Because the amount of data that is stored in a private cloud is significantly less than that which is retained in a public cloud, using a private cloud takes significantly less processing power and hence has lower expenses. As a result of the fact that this private cloud is an integral component of the organizational infrastructure, medical organizations have the ability to impose their very own security regulations. (For example, using firewalls and honeypots to maximize private cloud security). Thus, this will add an additional layer of protection.
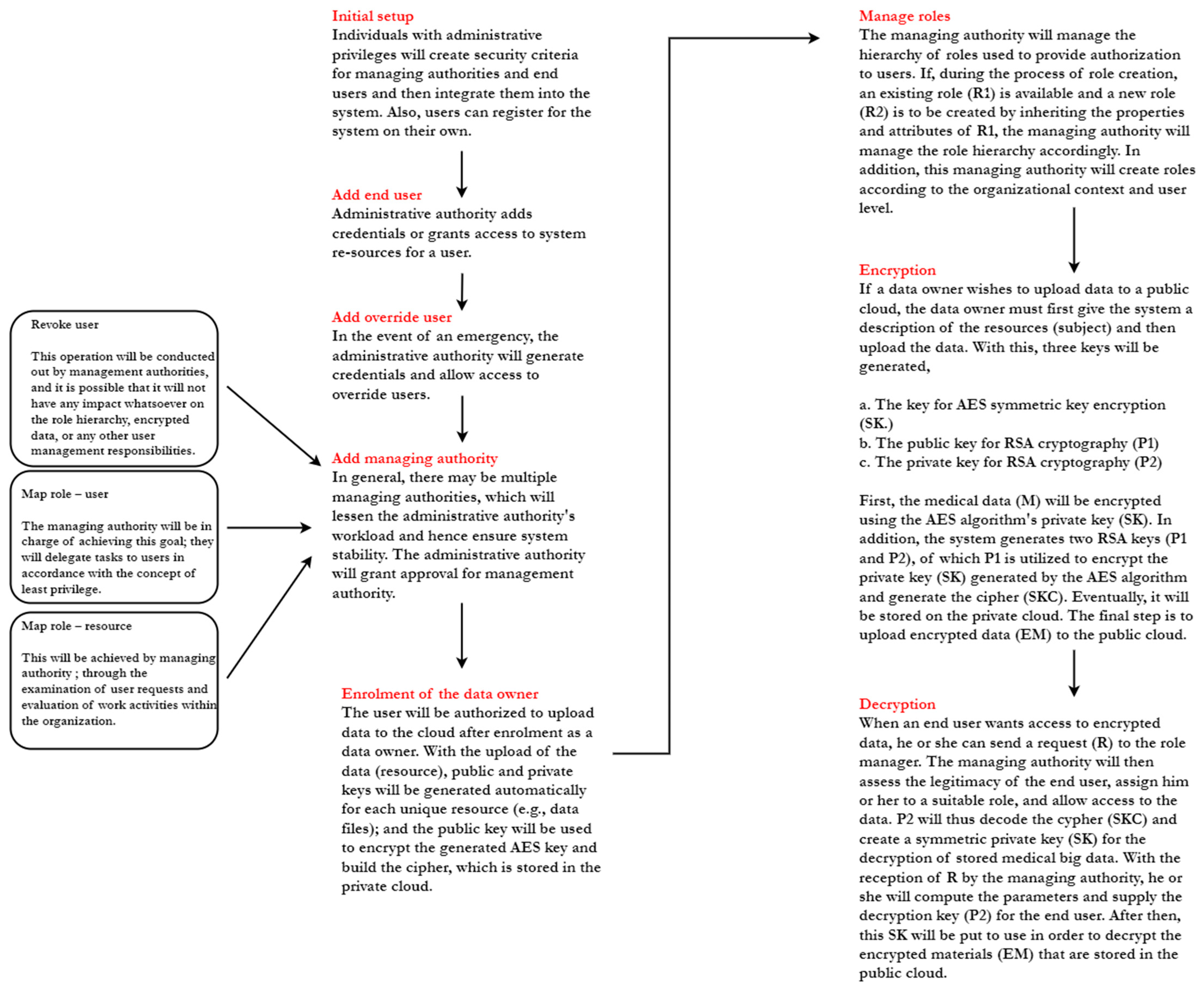
A trusted authority within the organization that can authorize role managers and end users to do specific actions. In the event that some users within the organization have an urgent need to access data, the administrative authority can specify settings for such users as override users, thereby providing entire access to the encrypted medical data that has been stored.
Managing authority oversees role-user relations (role hierarchy). In general, managing authority create roles and categorize encrypted data based on end-user requests, organizational context, and user level. Using the principle of least privilege, the managing authority will grant roles to permitted end users so that these users can access the required data. Managing authority allows for the creation of new roles, which can improve our role-based access schema. These new roles can inherit properties and attributes from higher-level roles. Further, management authority also has the ability to revoke users and restrict the creation of daily roles.
Data owners in medical organizations upload data to the public cloud. He/she can define the relationship between roles and permissions for uploaded resources, ensuring that only authorized users with adequate permission can access encrypted data.
Any authorized party, whether internal or external, wishes to access the data stored in the cloud.
An auditor will keep an eye on system transactions, how users act, and any strange things that happen in the system.
In certain circumstances, users within an organization may need immediate access to data in an emergency. Thus, the administrative authority is able to generate parameters for override users and add them to the system in real-time, with the override user subsequently having complete access to stored big data.
Role Based Encryption (RBE)
In general, in the role-based access control model we employed, access rules and users are both mapped to a particular role. Relevant and authorized users are given and assigned roles based on their functionalities and responsibilities within the medical organization. Permissions are given and assigned for the roles instead of users. Thus, users who have been assigned to a particular role only can access the data. Overall, the RBE schema is used to develop and enforce the RBAC system. In the RBE schema, roles are arranged in a hierarchy such as a tree structure where one role can inherit the properties from other roles.
As aforementioned RBE scheme is able to handle role hierarchies where one role can inherit the properties from another role. In general, users can be added at any time into the role even after the owner has encrypted the data, and the owner does not have to re-encrypt the data if they want to add a new user to any of the roles. Also, a user can be revoked at any time from the role, and after revoking, they will not be authorized anymore to access any of the encrypted data. Revoking the users does not affect role hierarchy and user management as well.
In our model, RBE helps to enforce the RBAC policies on encrypted data stored on the cloud, which act as the foundation for our proposed access control model.
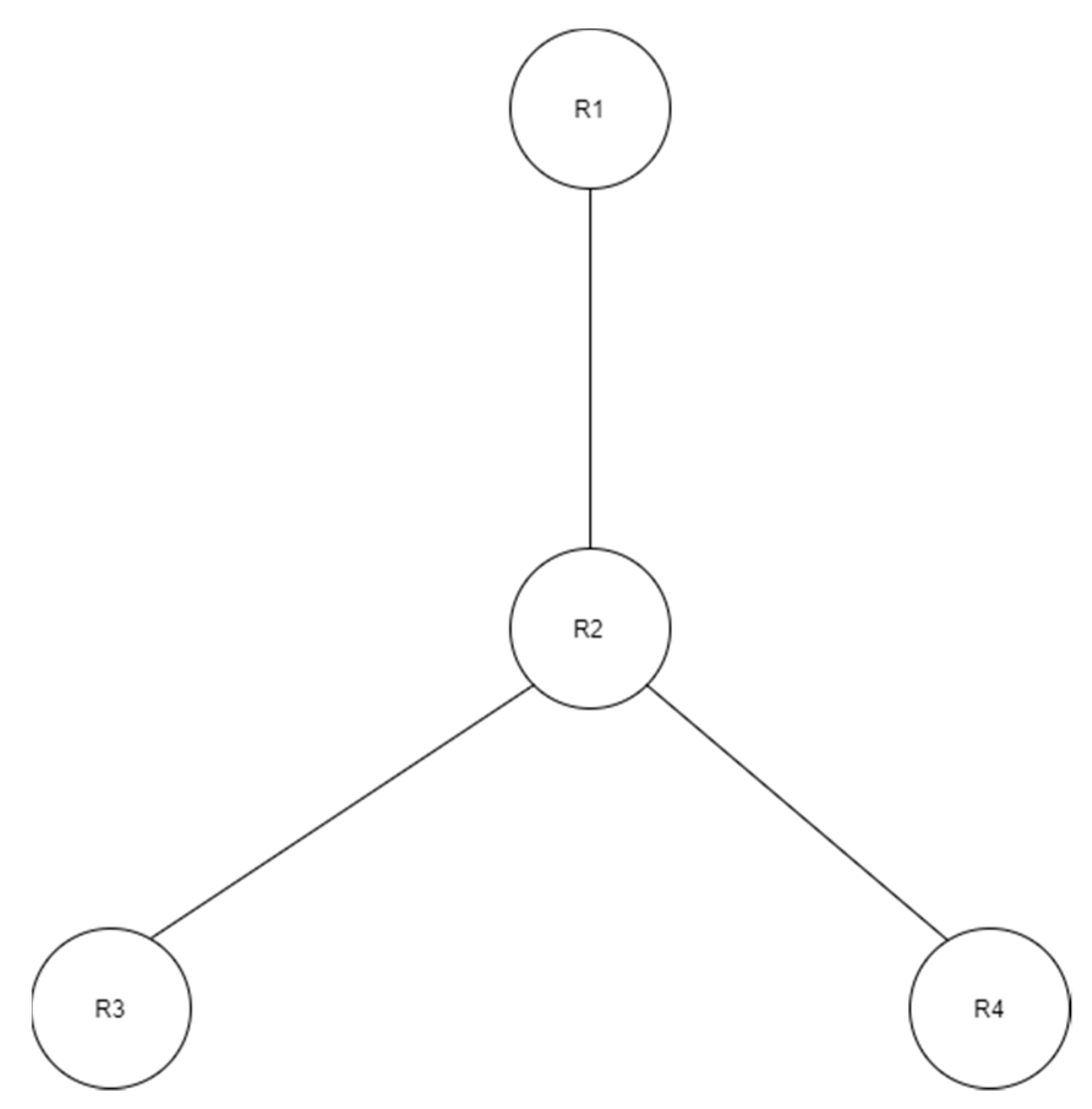
Figure 7 shows an example of RBE. It consists of four roles created in a hierarchical structure. According to
Figure 7, role R2 inherits the properties from roles R4 and R3, and role R1 inherits from role R2.
As an example, suppose the data owner runs an encryption logic and encrypts the Message M using role R3. Assume that role R1 has a set of user members U1, U2, U3
R1 = {U1, U2, U3}
User U1 wants to decrypt the data encrypted by an owner. Now because role R1 is inherited from R2, and R2 is inherited from R3, user U1 from role R1 is authorized to access and decrypt the message M. Then user U1 can successfully decrypt the message M by performing decryption logic.
After reviewing the key aspects of our model in the previous part, we will now examine the model’s workflow as depicted in
Figure 8.
5. Implementation Results and Discussion
To demonstrate the validity of our proposed model, we deployed it in a real cloud environment with Microsoft Azure. We utilized Visual Studio 2019 integrated development environment with C# and the ASP.NET web development framework to design our data storage access control model. For the deployment, we utilized a Microsoft Azure cloud instance comprised of a single core, 50 GB of storage, and 4 GB of RAM. In order to depict a private cloud, we utilized an Azure SQL server instance with an integrated firewall and 2 GB of storage, as doing this in a real-world setting would be more expensive and takes time. A virtual private network tunnel has been created between the public and private cloud, and we assumed that all medical data would be sent to this public cloud, where our access control model has been implemented as a Software as a service (SAAS) on the cloud.
Figure 9 showcases the steps involved in the design of our access control model. The first step involves designing the data storage access control mode using C# and ASP.NET programming languages. The second and third steps involve choosing a public cloud instance and choosing a private cloud. Upon successful selection, the design model was deployed as SAAS in the public cloud.
Figure 10 and
Figure 11 demonstrate the implemented model in the cloud.
As we have used the AES symmetric key algorithm for the encryption and decryption of the input data, the AES symmetric key encryption algorithm uses the key generated by the cryptographic Random Number Generator (RNG) using the implementation provided by the cryptographic service provider (CSP) in. NET software development framework. On the other hand, public key encryption performs using the implementation of the RSA algorithm provided by CSP. Further, using AesManaged Class in the. NET framework, the AES algorithm was also implemented.
Table 7 presents the tools/components we used for the design/testing and evaluation of our access control model with their purpose.
Upon the successful deployment, we tested our model for performance, data integrity, security implications, and functional requirements, which are discussed in detail in forthcoming sections.
5.1. Performance Testing
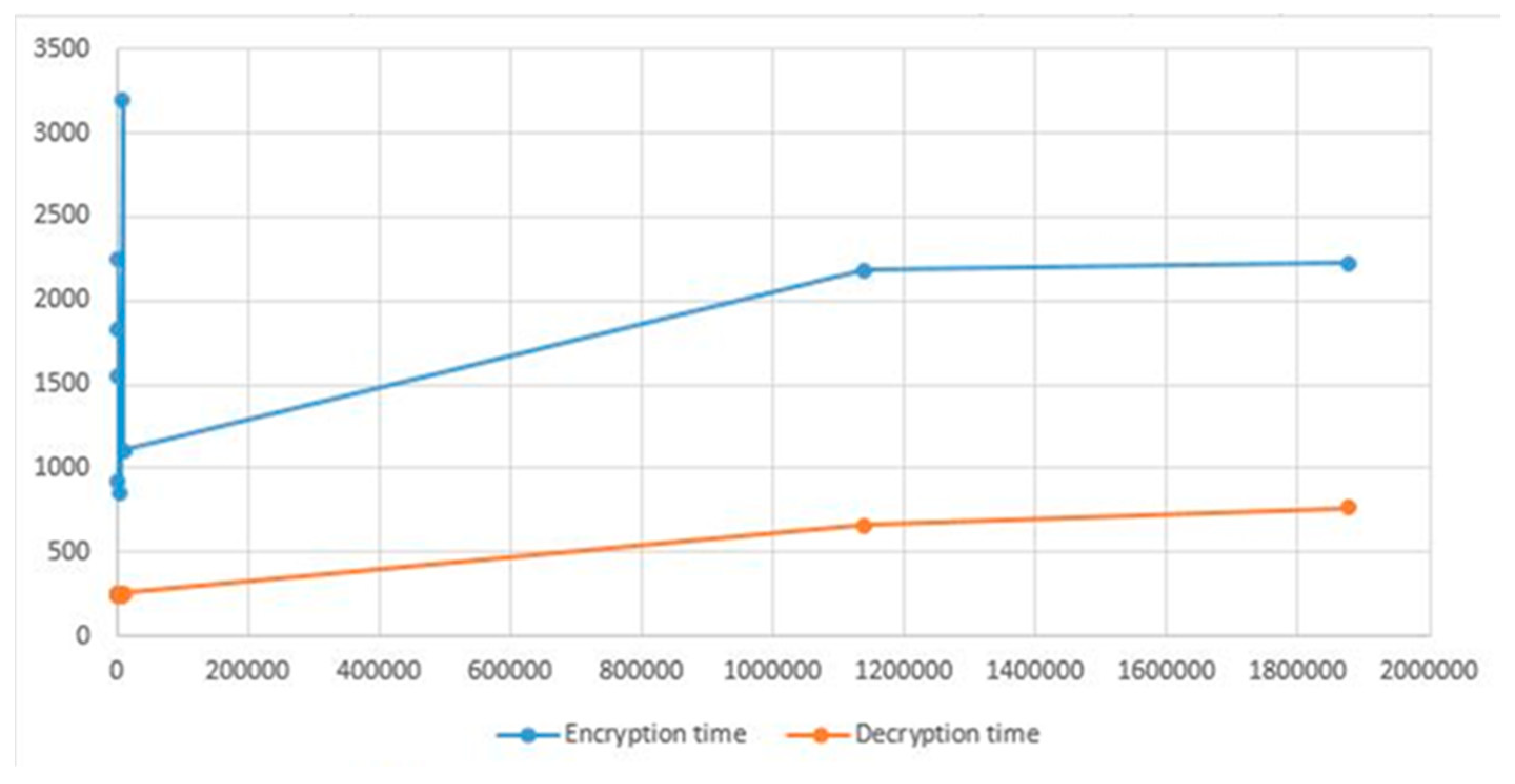
In order to determine how well the implemented model works, we experimented with it using files of different sizes and assessed how long it took to encrypt and decrypt data while maintaining the same connection bandwidth.
Figure 12 illustrates the amount of time required for encryption as well as for decryption, for the same file under the same connection bandwidth.
The y-axis shows time in milliseconds, and the X-axis represents the size in bytes.
Based on the results, we were able to extrapolate that the encryption time required more time than the decryption time, and we can see that the amount of time required for both encryption and decryption progressively increases as the size increases.
5.2. Data Integrity Testing
In order to ensure that the data stored in cloud resources are accurate, data integrity testing has been carried out, as depicted in
Figure 13. We were able to do this by comparing and verifying the SHA-512. SHA-1, SHA-256 and MD5 values of the original cloud resources as well as the decrypted cloud resources that were downloaded. It provided the same value for the integrity of the data for both the original resources and the ones that were downloaded. As a result, we came to the conclusion that the integrity of the files containing the resources was maintained throughout the process of encryption and decryption. This demonstrated that our approach was both reliable and trustworthy.
5.3. Security Implication Testing
To verify the security implications against cyber-attacks, three vulnerability assessment activities has conducted in a cloud environment, which are discussed in detail in the following.
Initial reconnaissance was carried out with the assistance of the programs DNSenum and DMitry. After that, we carried out a Nmap scan in order to locate ports that were left open and collect further data. The tools SPARTA, VEGA, and OWASP Zed Attack Proxy were then utilized in order to do the vulnerability analysis.
Upon the successful deployment of our model into the cloud, first, we used DNSenum and DMitry (Deepmagic Information Gathering Tool) for reconnaissance of our target host, as shown in
Figure 14 and
Figure 15. DNSenum is a tool that is designed for the purpose of enumerating DNS information about a domain. Dmitry is a UNIX/(GNU) Linux Command Line Application coded in C. It has the ability to gather as much information as possible about a host. Base functionality is able to gather possible subdomains, email addresses, uptime information, TCP port scan, WHOIS lookups, and more.
Afterward, in an attempt to identify the potential attack surface, we examined the name servers associated with the domain name (Hosted URL), where we were able to gather the host IP address and DNS information about our host.
Upon gathering the required information (IP address and DNS information), we then performed a Nmap scan to find out about open ports and gather more information about our host, as shown in
Figure 16.
Upon completing the scanning process, we managed to gather all open ports of our target host, SSL certificate information, and server information, outlined in the following.
Open ports: Port 80 (TCP) and Port 443 (TCP)
Server information: Microsoft IIS server 8.0
SSL certificate information: Public key encrypted SSL connection that uses 2048 bits key.
As there were two open ports and it is protected by a public load balancer and a firewall built into the Azure public cloud, we then analyzed our target host using SPARTA and VEGA vulnerability analysis tools to check if any vulnerabilities are there to exploit. The acquired findings demonstrated that our model could resist the majority of the cyberattacks because the test results did not display any common vulnerabilities and exposures (CVE). Hence, with that, we have proven that our access control model can withstand the latest cyber-attacks as no vulnerabilities are present.
5.4. Functional Requirement Analysis
In order to verify the functional needs of our model, we compared it to standard access control models available for cloud computing that are available in the literature. Our comparison was focused on the similarities and differences in the functions and features that all these types of models provide, as shown in
Table 8. From the comparison, it is evident that our access control model features all the criteria outlined in
Table 8 as opposed to other sorts of access control models. In
Table 8, Yes, will be denoted as Y, and No will be denoted as N.
Whenever a user requests to access a resource, the role manager will look for available roles to grant the least access privileges for the user, or else the role manager will create a new role and assign access permissions and resources and assign for the user. In simple terms, this is all about granting only needed permissions for the users to access resources.
- 2.
Separation of duties
Separation of duties is a principle that is supported by the least privilege principle, and it aims to partition tasks and duties associated with roles in order to prevent granting too much authority to a single user.
- 3.
Scalability
Our model is mainly introduced for an organizational level and but it can be scalable as per the environment. If there are a large number of users, there should have serval role managers and system administrators to handle the user requests and role management as per our designed model.
- 4.
Auditing
Our model provides a convenient way of auditing the underlying transactions in the access control system. Those auditing and log information would be collected by the role auditor and check the underlying transactions and user behavior.
- 5.
Policy management
Our model supports policy management (Add, Revoke, Add constraints), and it would help to organize relations between users, administrators, and data owners.
- 6.
Flexibility of configuration
Our model is flexible enough to be configured in the cloud computing environment both as a SAAS and Platform as a Service (PAAS).
- 7.
Delegation of capabilities
To make our model more flexible and allows for flexible role management, a delegation of capabilities is essential between all the stakeholders, which has already been demonstrated through this research.
- 8.
Hybrid cloud architecture
Our model uses employs a hybrid cloud architecture (public cloud and private cloud) to enhance the security of our model.
- 9.
Role hierarchy management
Role manager manages the role hierarchy; hence, newly created roles can inherit the access permission and assigned resources from the existing roles in our model, and it will help to provide hierarchical role-based access control.
5.5. Discussion
In the research, we employed a cryptographic role-based access control system with a hybrid cloud architecture, with the aim of demonstrating a novel role-based access control model for medical organizations to upload their medical big data in the cost-effective public cloud while storing mission-critical access control-related data in the private cloud. Overall, we believe, apart from healthcare, that the proposed system can be adopted in various other domains as it implements the hierarchical cryptographic role-based access control policies based on the job function and user requests in an organization for providing secure data storage in a real cloud environment. Even though there are underlying security mechanisms employed by public cloud services, such as Microsoft Azure, AWS, and Google Cloud, if the hosted web services are vulnerable enough to exploit, it may lead any attackers to compromise the system endangering the lives of patients. However, in our research, we have relied totally on the public cloud and employed a hybrid cloud architecture to deploy our software-based access control model and proved it could withstand cyber-attacks and offer many convenient facilities compared to other models. On the other hand, in light of the cost, as we relied mostly on the public cloud, only a low cost would be spent to design the access control model compared to other available solutions outlined in
Table 5.
On the whole, big data has undeniable benefits for the healthcare industry, without any doubt. Security and privacy, on the other hand, are key issues that big data in healthcare faces as of now, according to the literature we have reviewed. Based on the summarization (see
Table 5), it is evident that many researchers have contributed to this subject, where many have conducted surveys/reviews and research towards security and privacy aspects of medical big data. Further, medical information is always vulnerable to security concerns such as inappropriate patient information disclosure, unauthorized use of patient information, unauthorized data loss, and many more, as we discussed earlier. As a result, the relevant stakeholders in healthcare should take appropriate actions toward the protection of this medical data so that the data can be protected. On the other hand, when designing/setting up the medical environment and designing and deployment of security solutions, the relevant stakeholders should think that security and privacy protection should be an essential and integral part of the big data life cycle, which is data generation [
75,
76,
77,
78,
79], data processing and data storage where optimal protection can be guaranteed to the underlying big data. For the healthcare system to profit from the use of big data in healthcare, the following resolves should be made for the effective utilization of big data so that maximum protection can be guaranteed:
Healthcare data should be sufficiently safeguarded and secured as security and privacy risks are imminent.
When studying big data in healthcare, tools that assure maximum protection for underlying big data need to be employed.
Healthcare data should be protected throughout its life cycle by adopting the above-mentioned and discussed security mechanisms.
The adoption of an audit trail system should be an added advantage, as all the transactions can be traced.
6. Conclusions
The use of big data has the potential to transform healthcare to new levels. However, challenges such as security and privacy impede the success of the technology, which must be addressed urgently. In this study, the security and privacy aspects associated with medical big data were examined, and the need for security and privacy preventive mechanisms was also discussed. Further, a novel cloud-enabled hybrid access control model was proposed that can be used to construct safe medical big data solutions. The review we have performed emphasized that security and privacy preventive mechanisms should be an integral part of the medical big data lifecycle, from data generation to processing and storage. The study also collated knowledge and proposed that secure patient data management is an essential part of global healthcare. The proposed novel access control model for medical big data was evaluated, and related work was summarized. Overall, the proposed access control model can be utilized for organizations, both for commercial and non-commercial purposes, where access control can be categorized according to job functions in the organization. By doing so, the proposed model enables relevant stakeholders to store and access medical big data in a secure way. We have experimented role-based encryption and used it for implementing role-based access control for public cloud storage using hybrid cryptographic schema and hybrid cloud architecture, as the architecture itself provided more security and reliability. Even though there are underlying security mechanisms used by public cloud services such as Microsoft Azure, AWS, Google Cloud, and Alibaba Cloud, if the web applications or hosted services are vulnerable enough to exploit, it may lead any of the attacker to compromise the entire ecosystem. When the time goes by and as technology evolves, all our data will be in the cloud, including big data, rather than having them on physical data storage. Eventually, storage and hosting costs for the cloud may go down, and attacks for the cloud may increase to compromise confidential data on the cloud. Hence the proposed access control model can be improved by better encryption schema and empowered by rigid efficient authentication schema as per the future work. On the other hand, the proposed model can be integrated with artificial intelligence-enabled solutions for designing more robust, secure access control models for real-time threat detection and prevention. The contributions of this study aim to pave the way for future researchers to work in this area, recognizing that security and privacy are paramount concerns for researchers in this field.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}