

Introducing the UWF-ZeekDataFall22 Dataset to Classify Attack Tactics from Zeek Conn Logs Using Spark’s Machine Learning in a Big Data Framework
 , , ,
, , ,
Abstract
:1. Introduction
2. Related Work
3. The Datasets
3.1. Tactics in the UWF-ZeekDataFall22 Dataset
3.2. The Zeek Conn Log Files of the UWF-ZeekDataFall22 Dataset
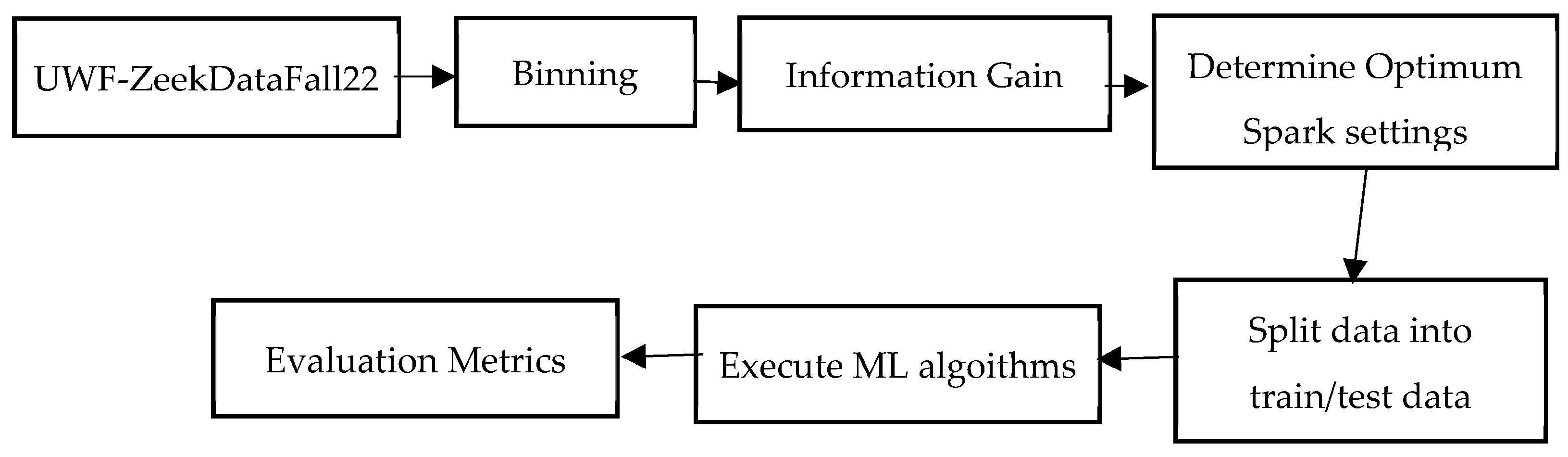
4. Experimentation
4.1. Overview of Processing UWF-ZeekDataFall22
4.2. Preprocessing Using Binning
- dest_ip and src_ip for IP addresses;
- dest_port and src_port for port numbers;
- local_orig and local_resp, which are Boolean data types;
- protocol, conn_state, history, and service, all of which are nominal attributes;
- duration, orig_bytes, orig_pkts, orig_ip_bytes, resp_bytes, resp_pkts, resp_ip_bytes, and missed_bytes, which are all continuous valued attributes.
4.2.1. Binning IP Addresses
4.2.2. Binning Port Numbers
4.2.3. Binning Booleans and Nominal Attributes
4.2.4. Binning Continuous Valued Attributes
| Algorithm 1 Binning Continuous Valued Attributes |
| if min_val >= 0: |
| while mean_val − 2 * stddev_val < 0: |
| mean_val += stddev_val |
| edge0 = float(‘-inf’) |
| edge1 = mean_val − stddev_val * 2 |
| edge2 = mean_val − stddev_val |
| edge3 = mean_val |
| edge4 = mean_val + stddev_val |
| edge5 = mean_val + stddev_val * 2 |
| edge6 = float(‘inf’) |
| edges = [edge0, edge1, edge2, edge3, edge4, edge5, edge6] |
| edges_distinct = [] |
| Algorithm 2 Moving-mean Logic |
| if min_val >= 0: |
| while mean_val – 2 * stddev_val < 0: |
| mean_val += stddev_val |
4.3. Information Gain
- Info(D) is the average amount of information needed to identify the class level of a tuple in D;
- InfoA(D) is the expected information required to classify a tuple from D based on the partitioning from A;
- pi is the non-zero probability that an arbitrary tuple belongs to a class;
- |Dj|/|D| is the weight of the partition.
5. Machine Learning Algorithms
5.1. Decision Trees
5.2. Support Vector Machines
5.3. Random Forest
5.4. Naïve Bayes
5.5. Logistic Regression
5.6. Gradient-Boosting Trees
6. Results
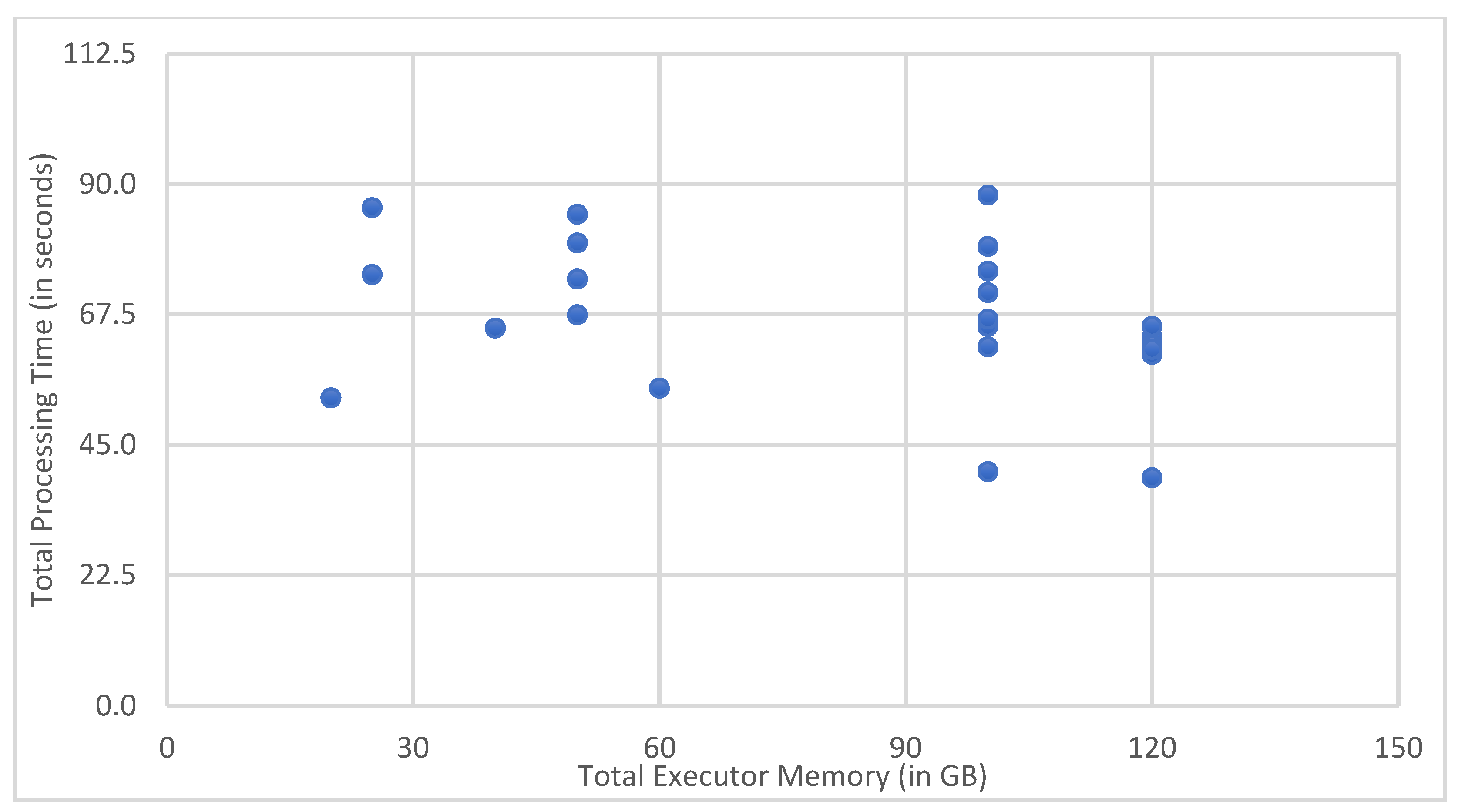
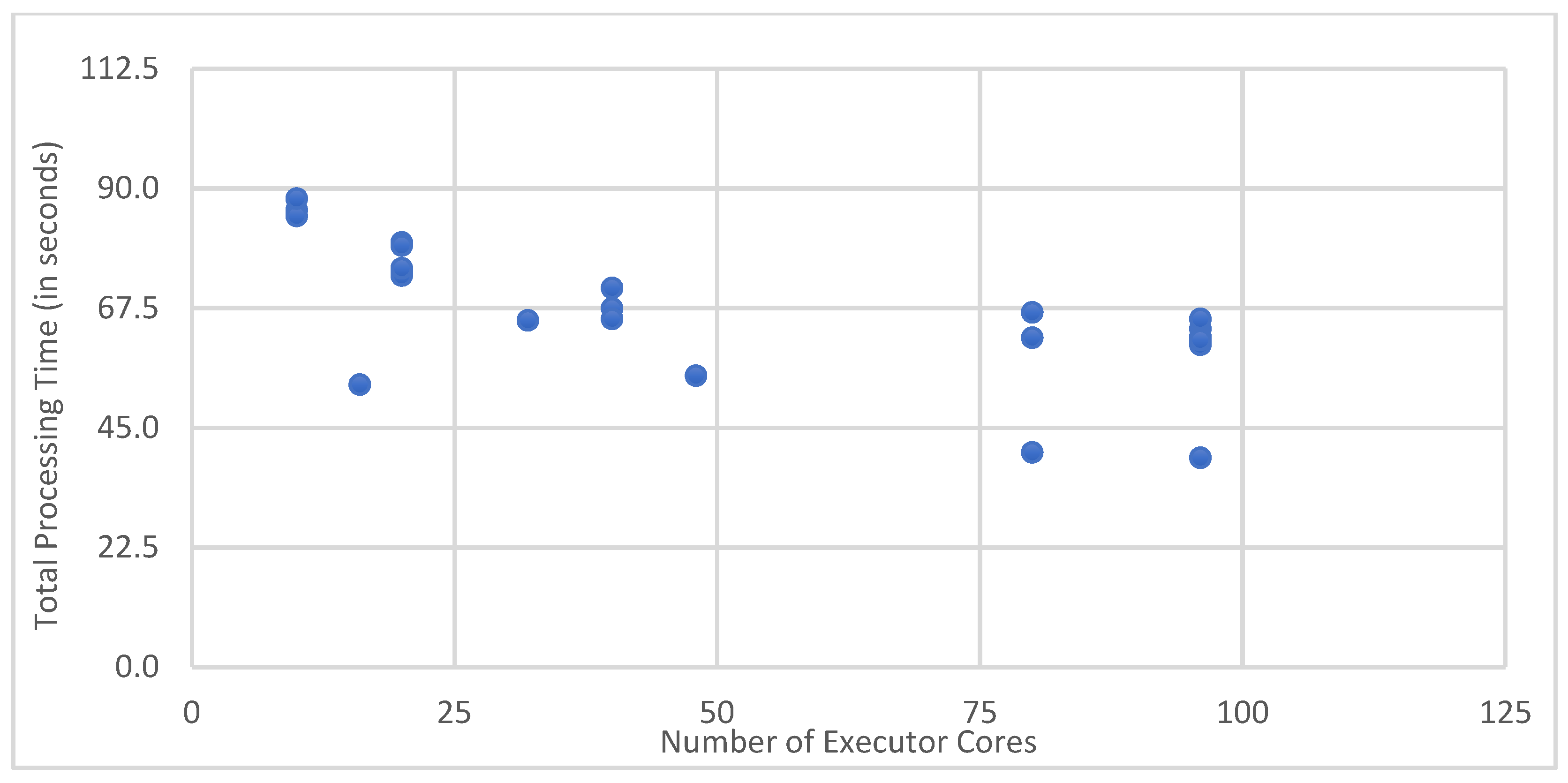
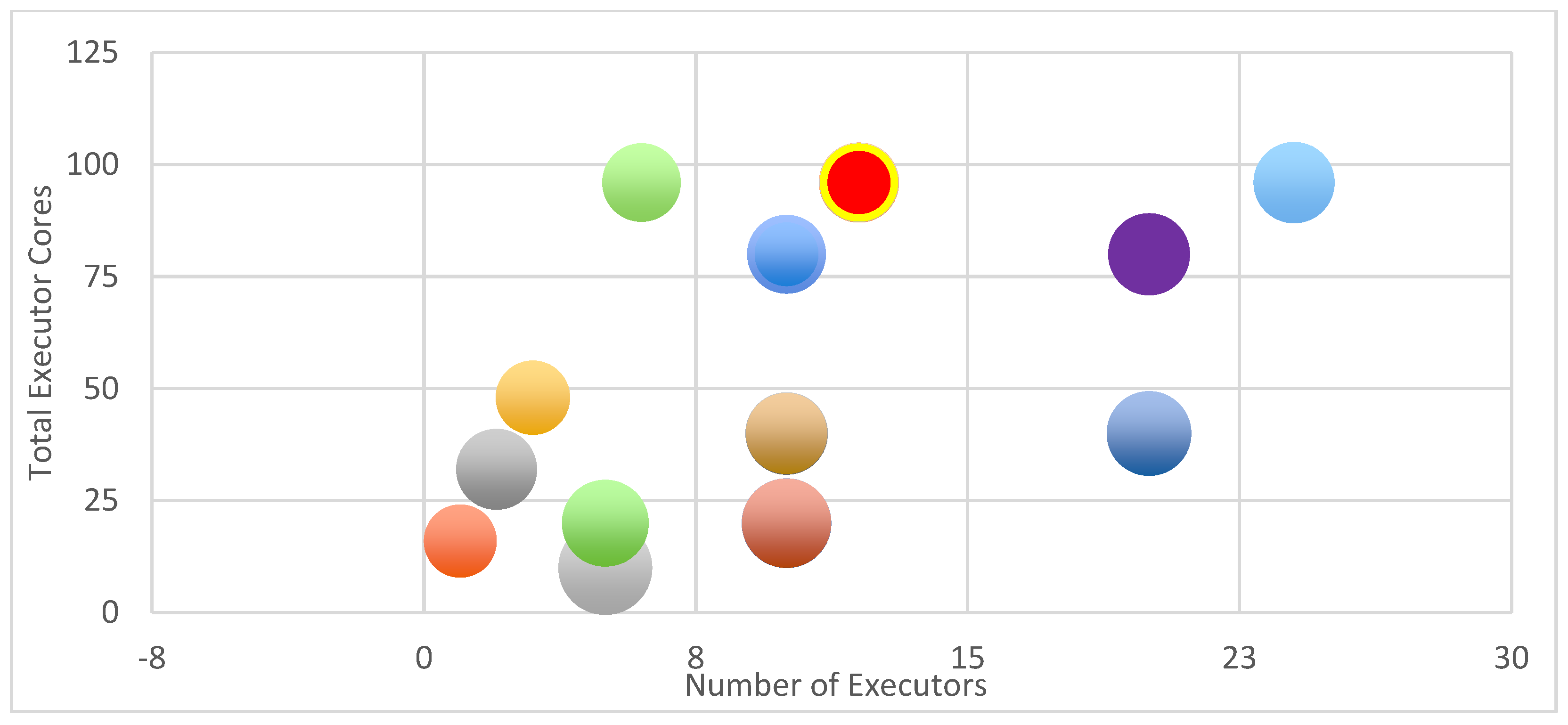
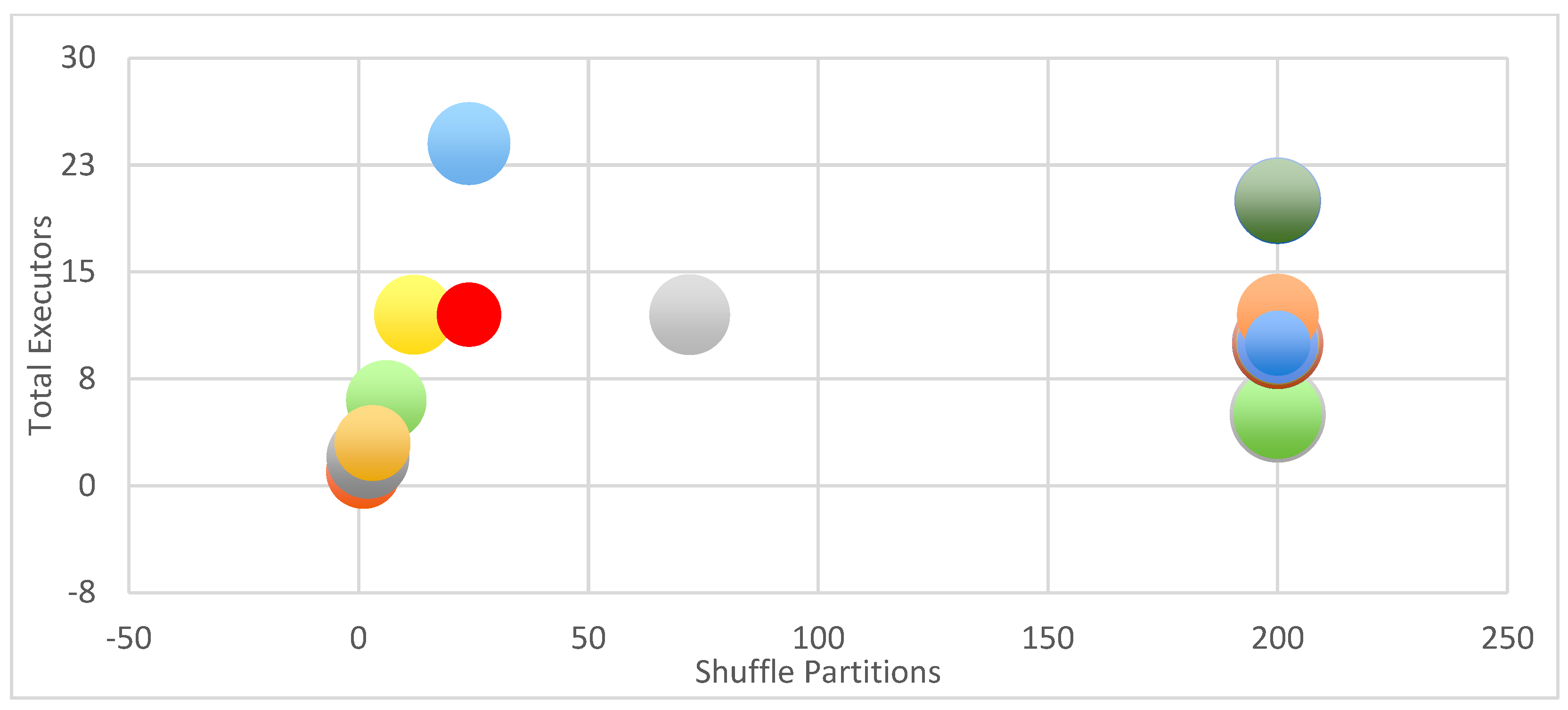
6.1. Determining Spark’s Best Configuration Parameters
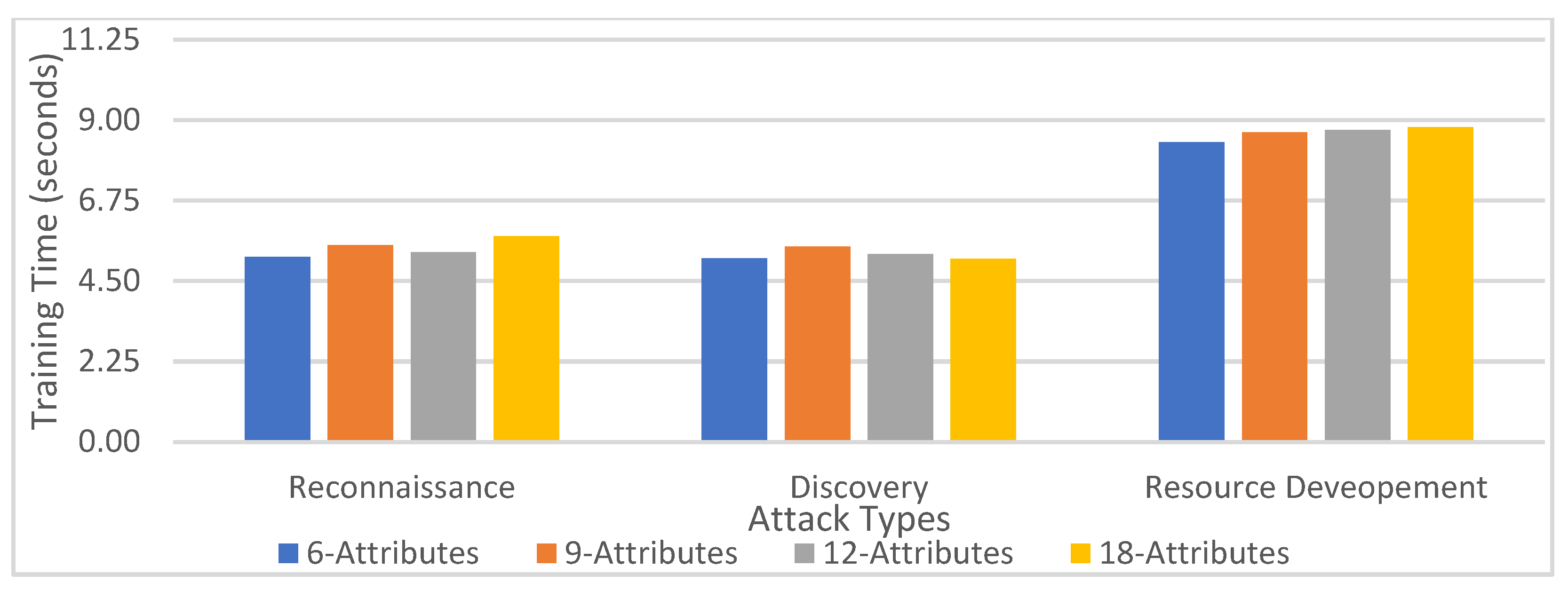
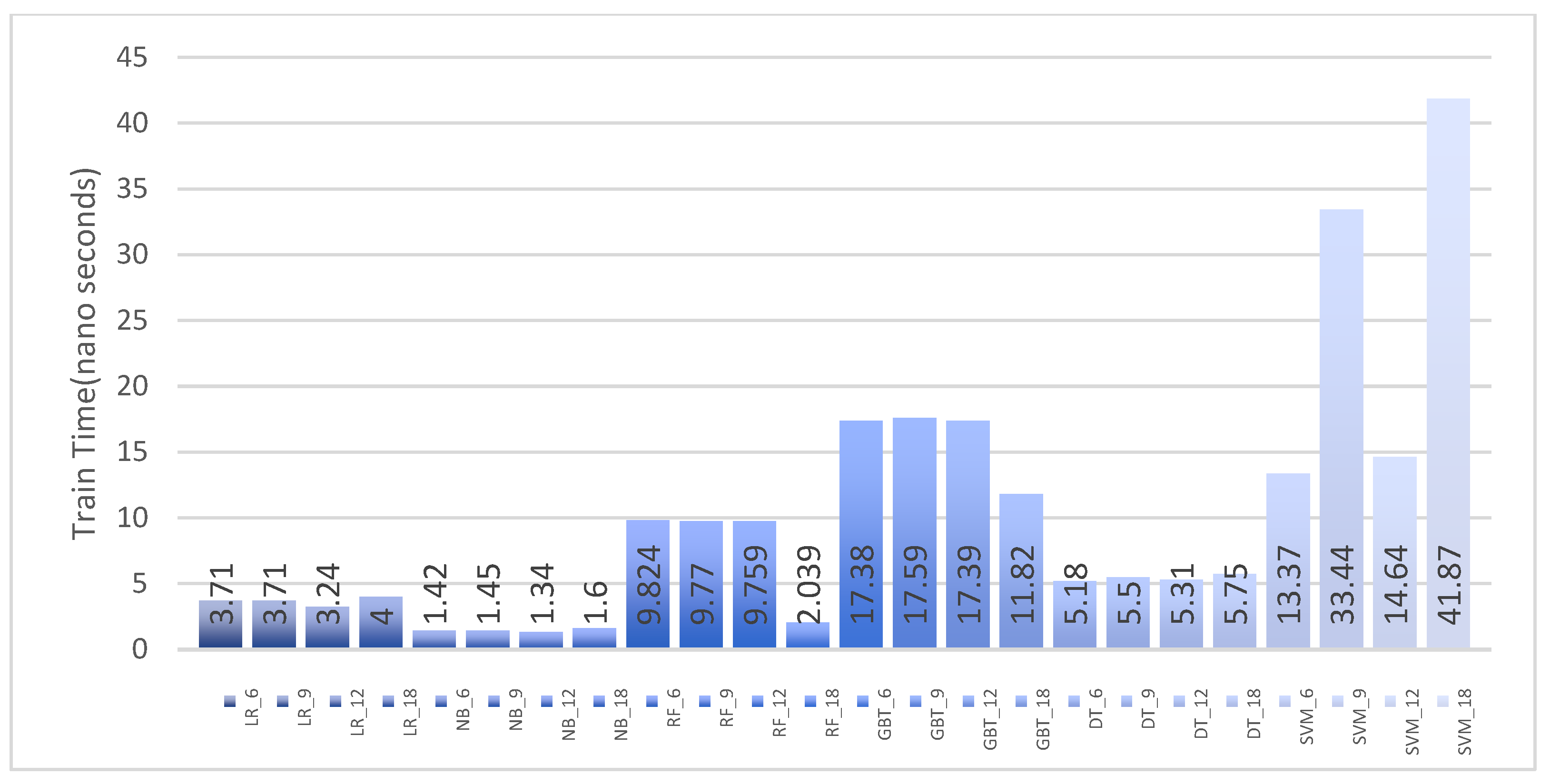
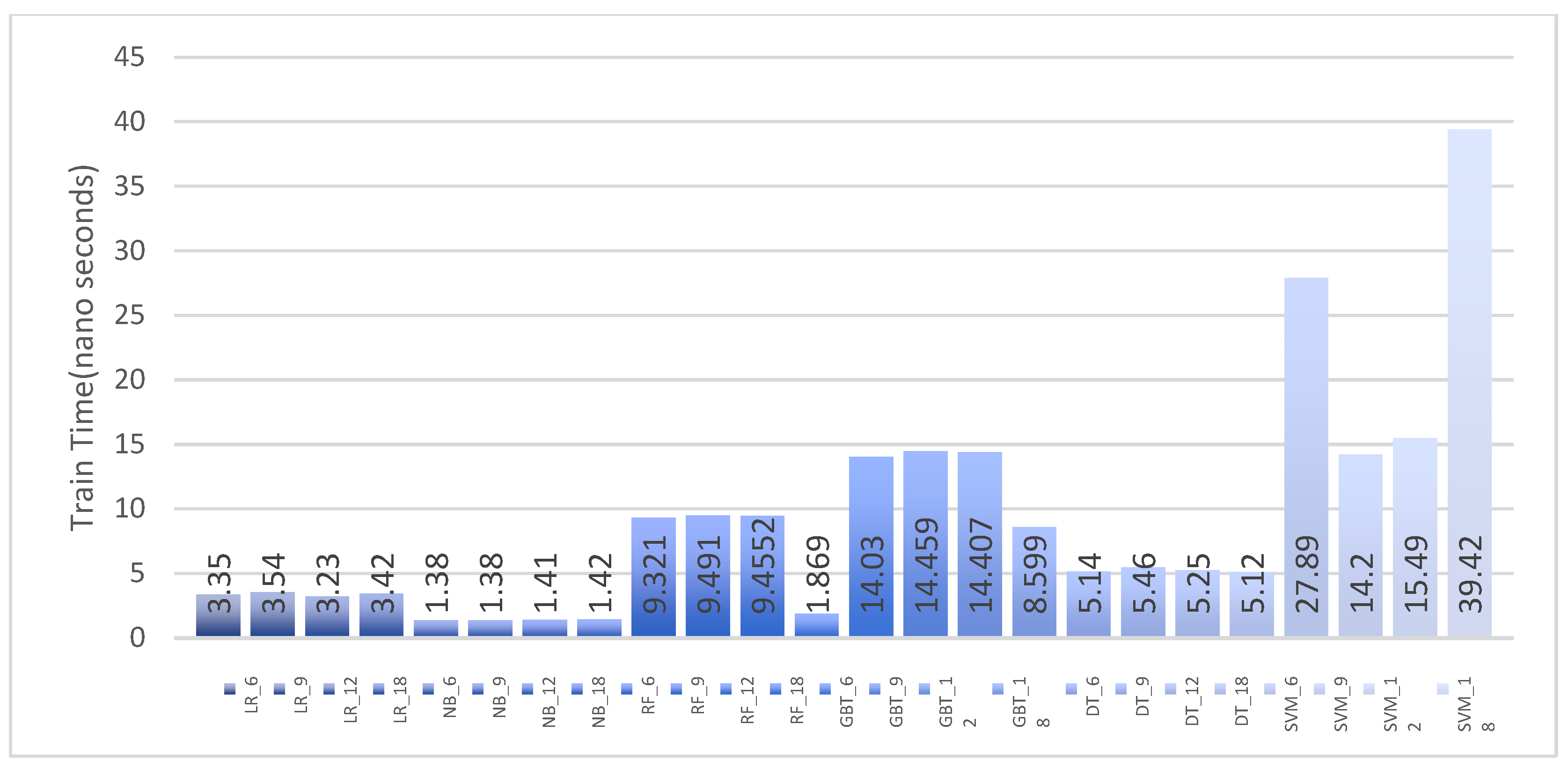
6.2. Analyzing Training Time
6.3. Performance of the Machine Learning Classifiers Using UWF-ZeekDataFall22
6.3.1. Evaluation Metrics
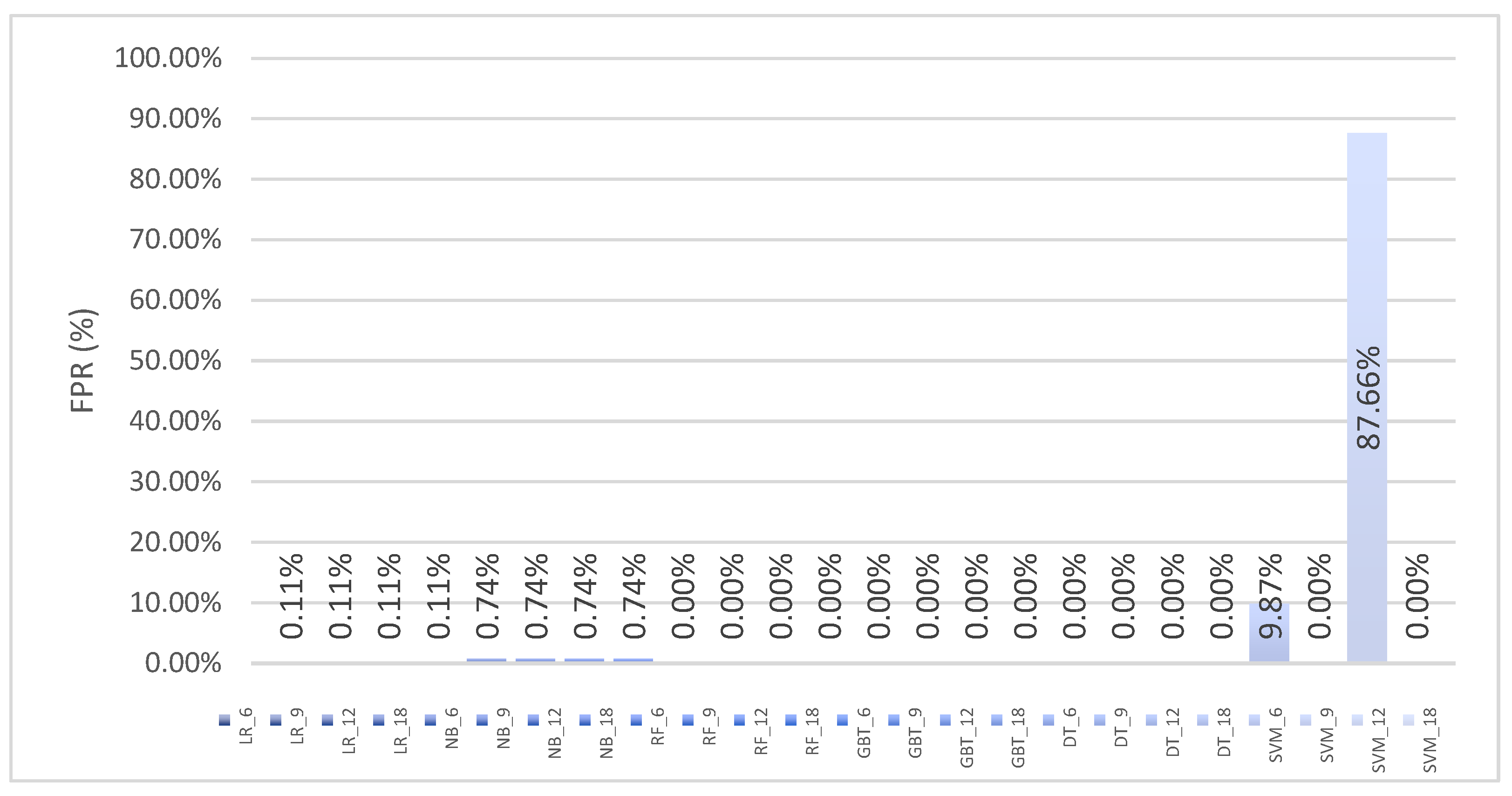
6.3.2. Machine Learning Classifier Results for Binary Classification
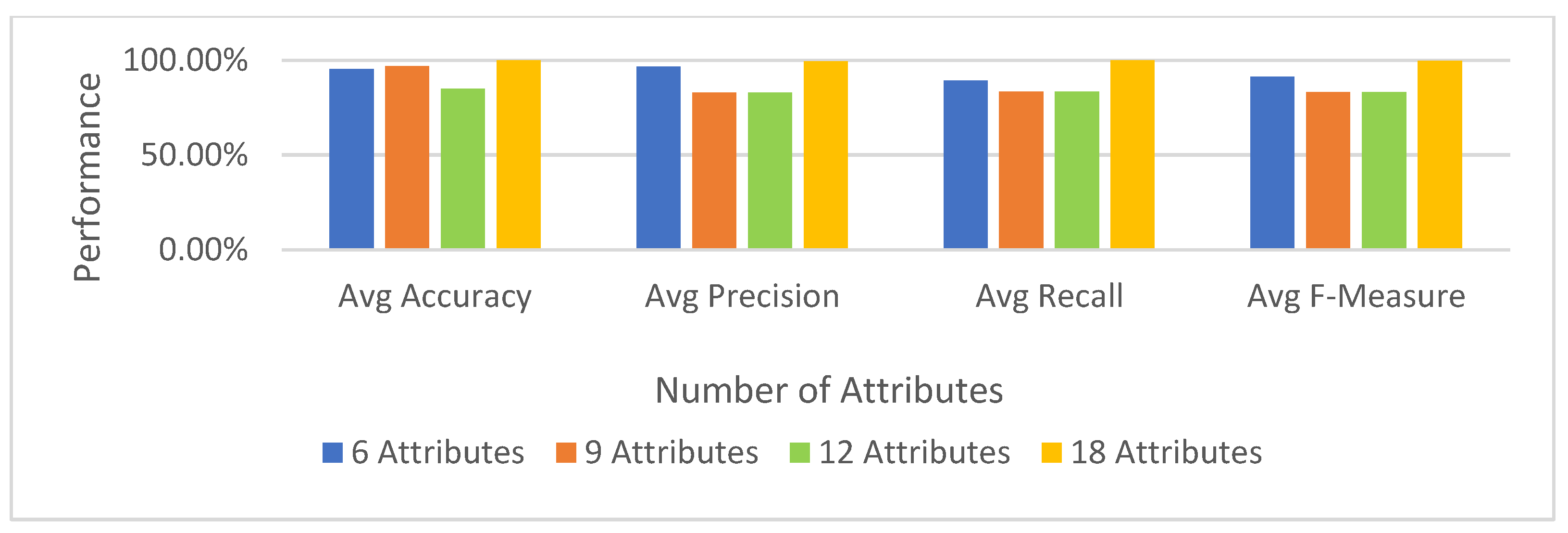
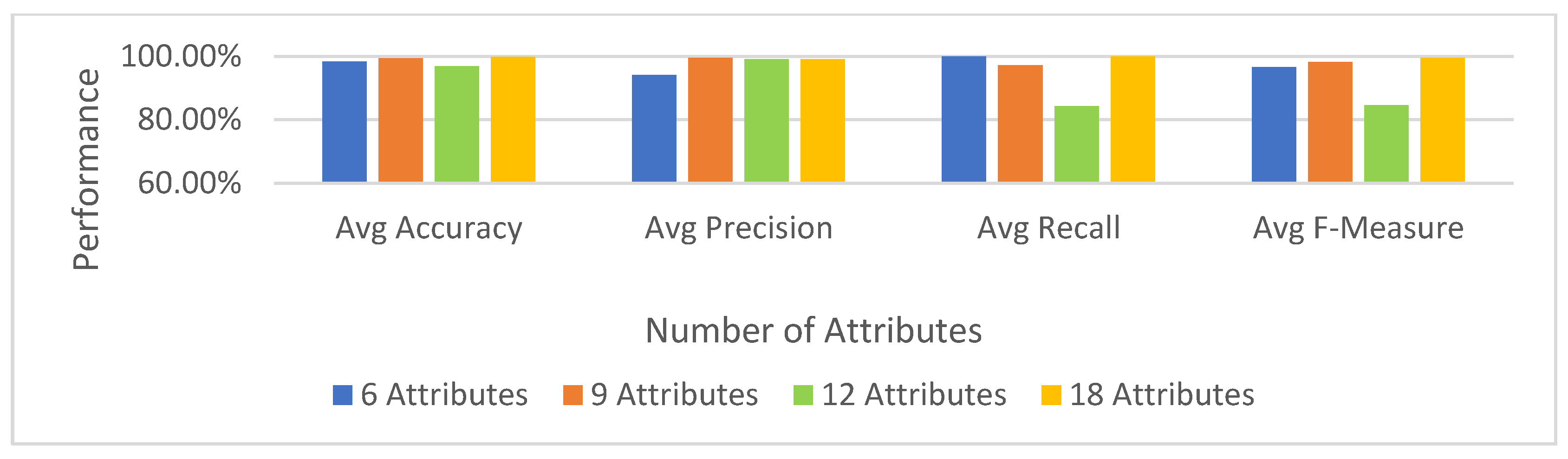
The Reconnaissance Tactic
The Discovery Tactic
The Resource Development Tactic
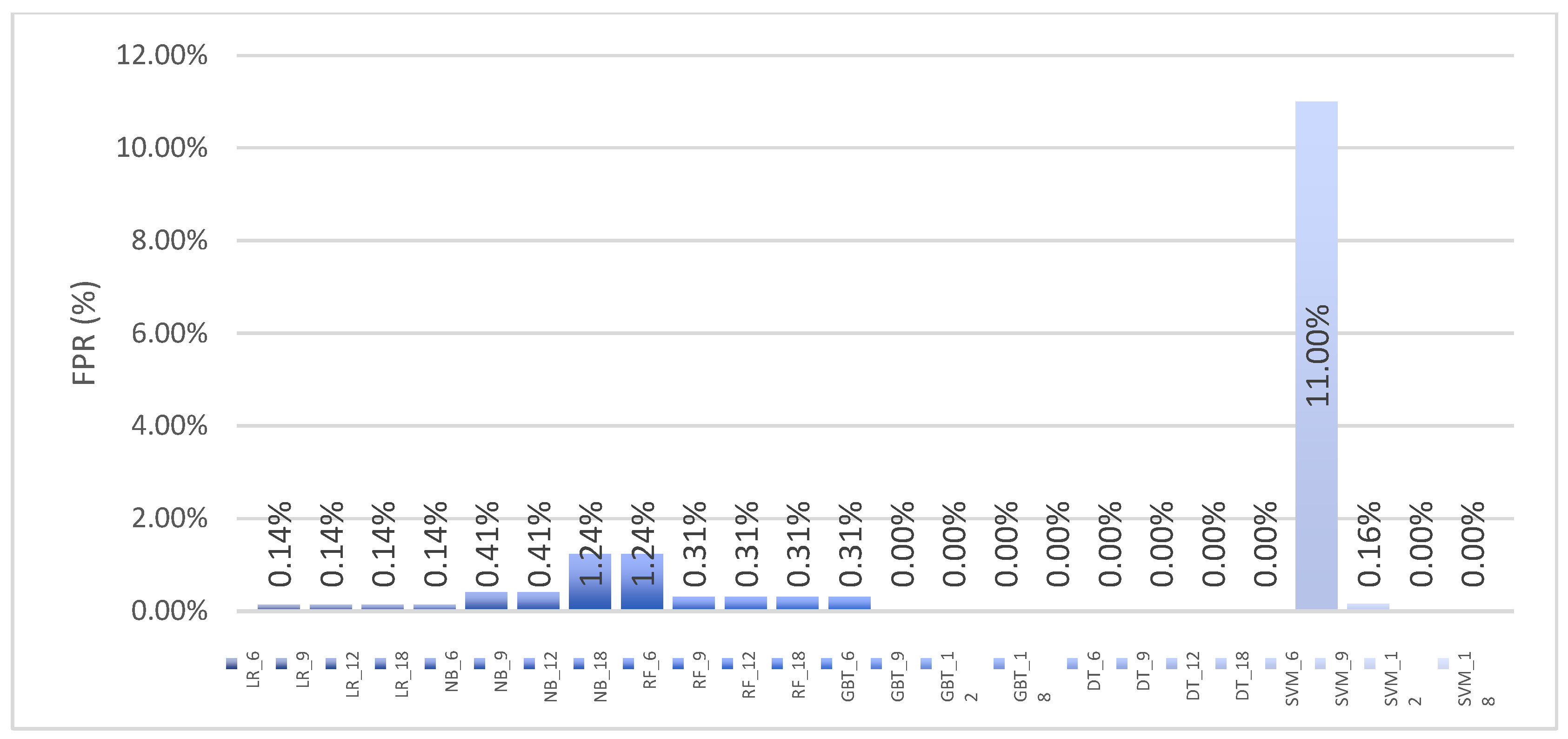
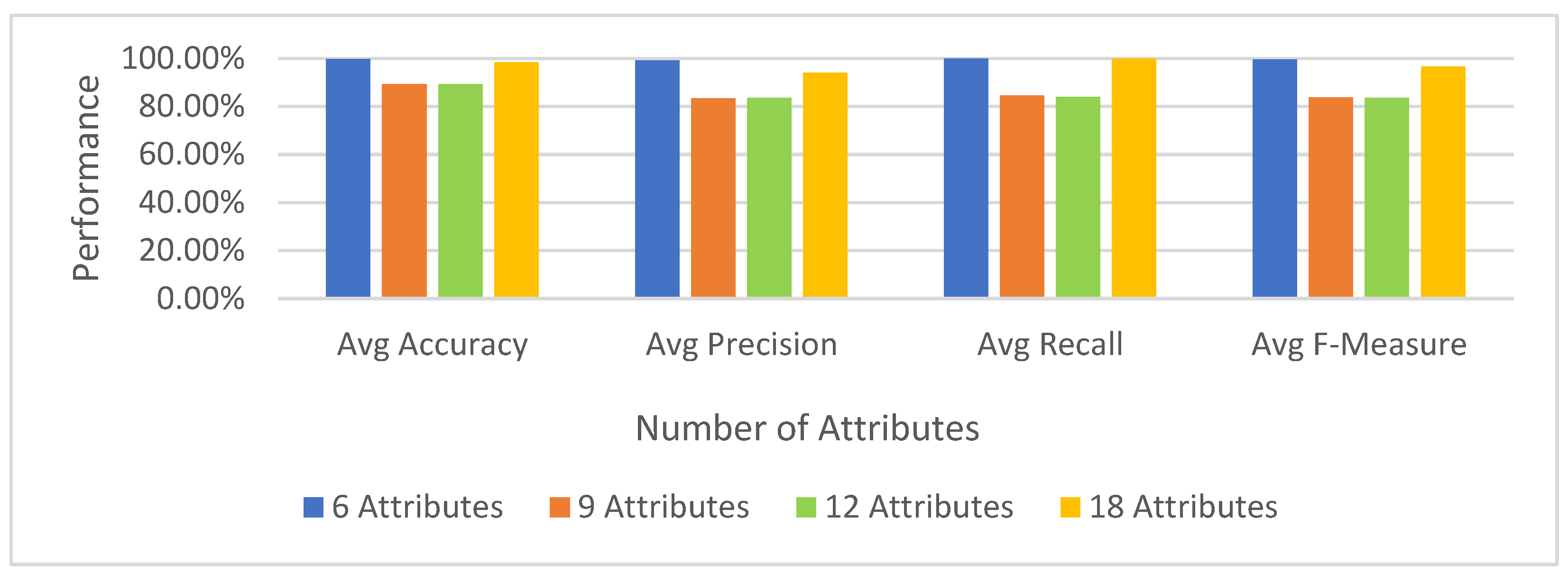
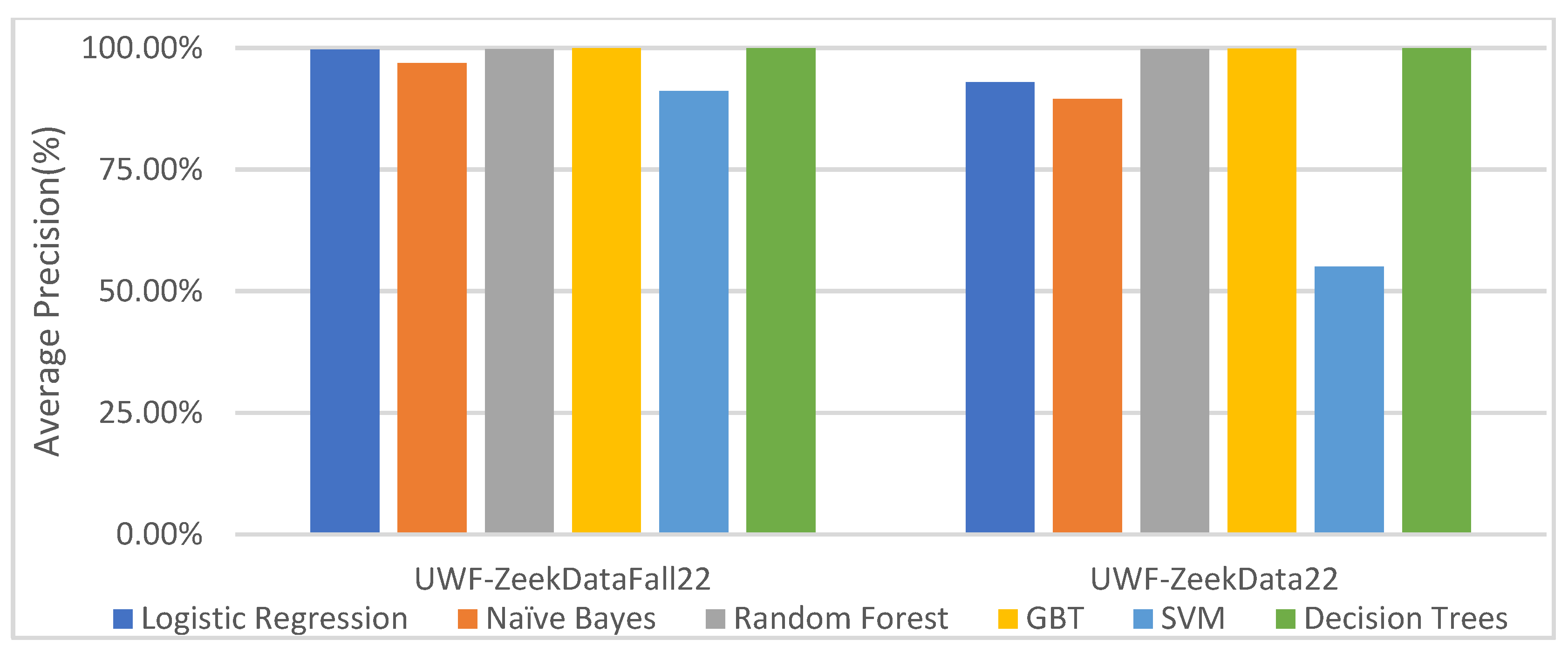
6.3.3. Machine Learning Classifier Results for Multinomial Classification Using the UWF-ZeekDataFall22 Dataset
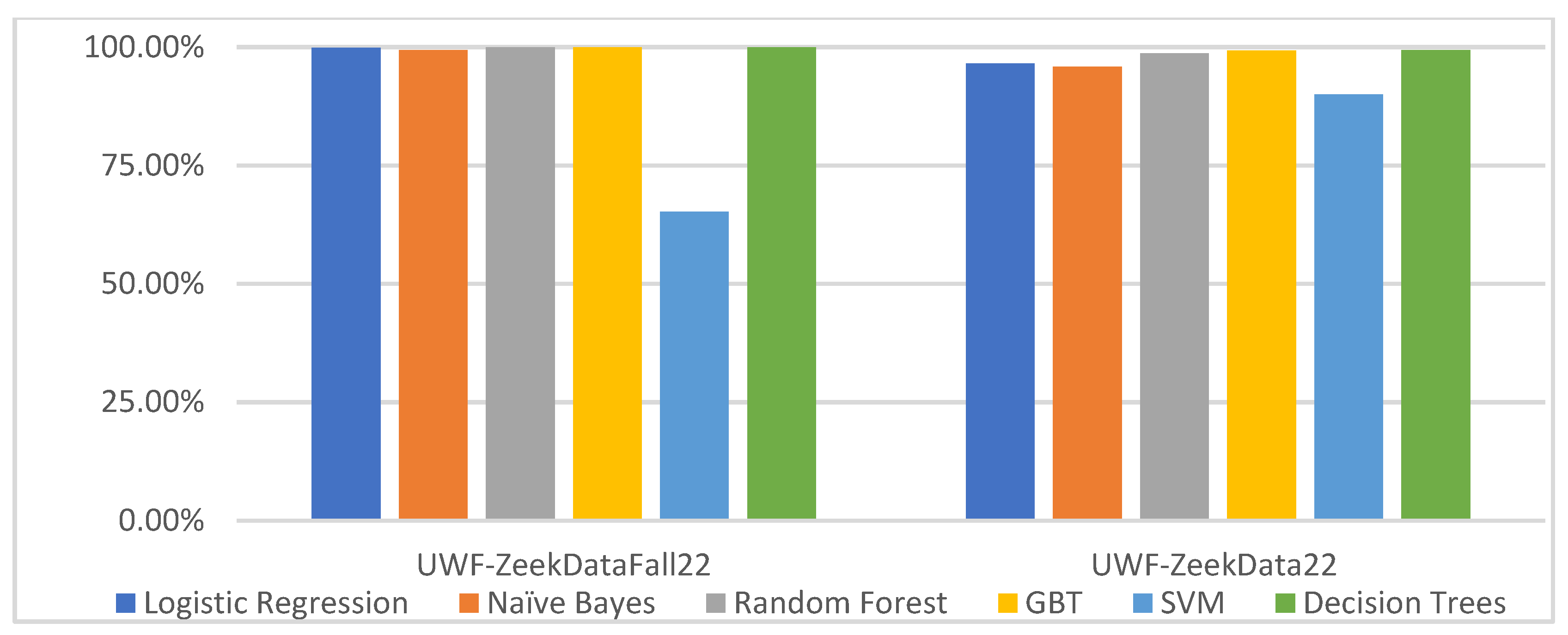
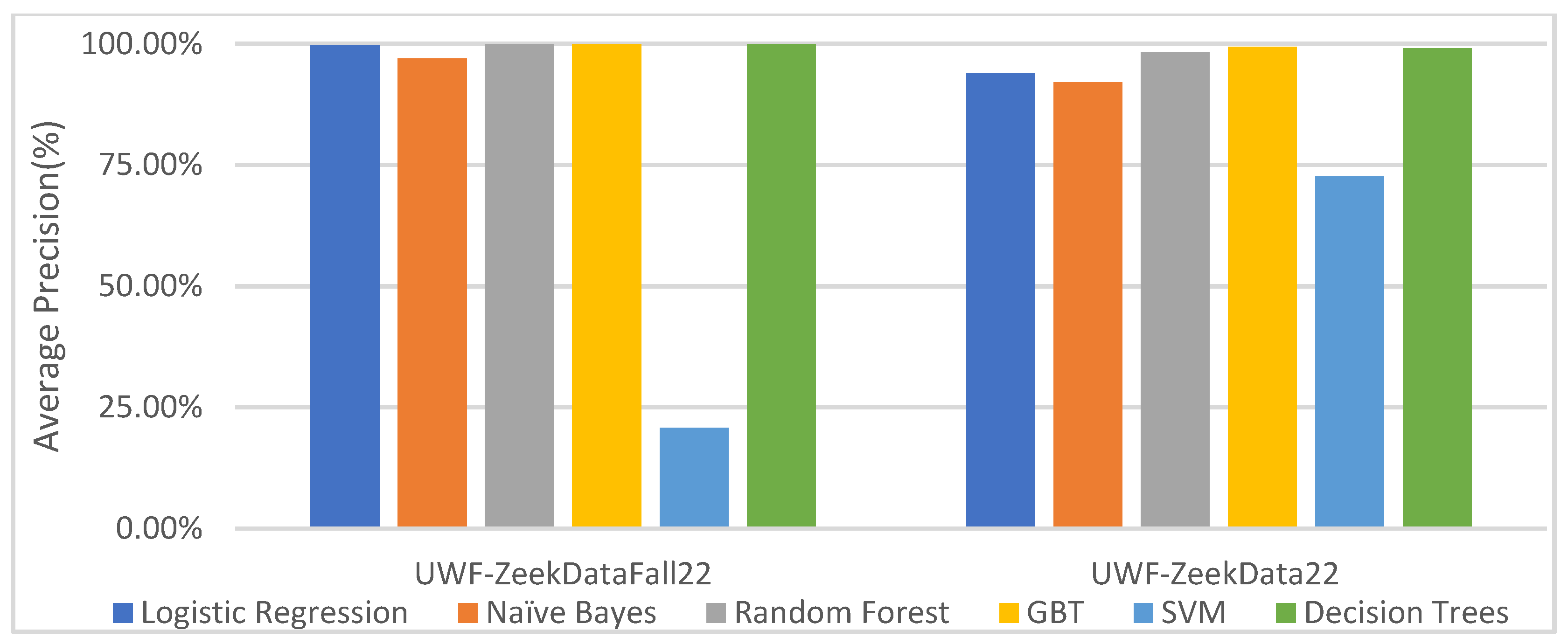
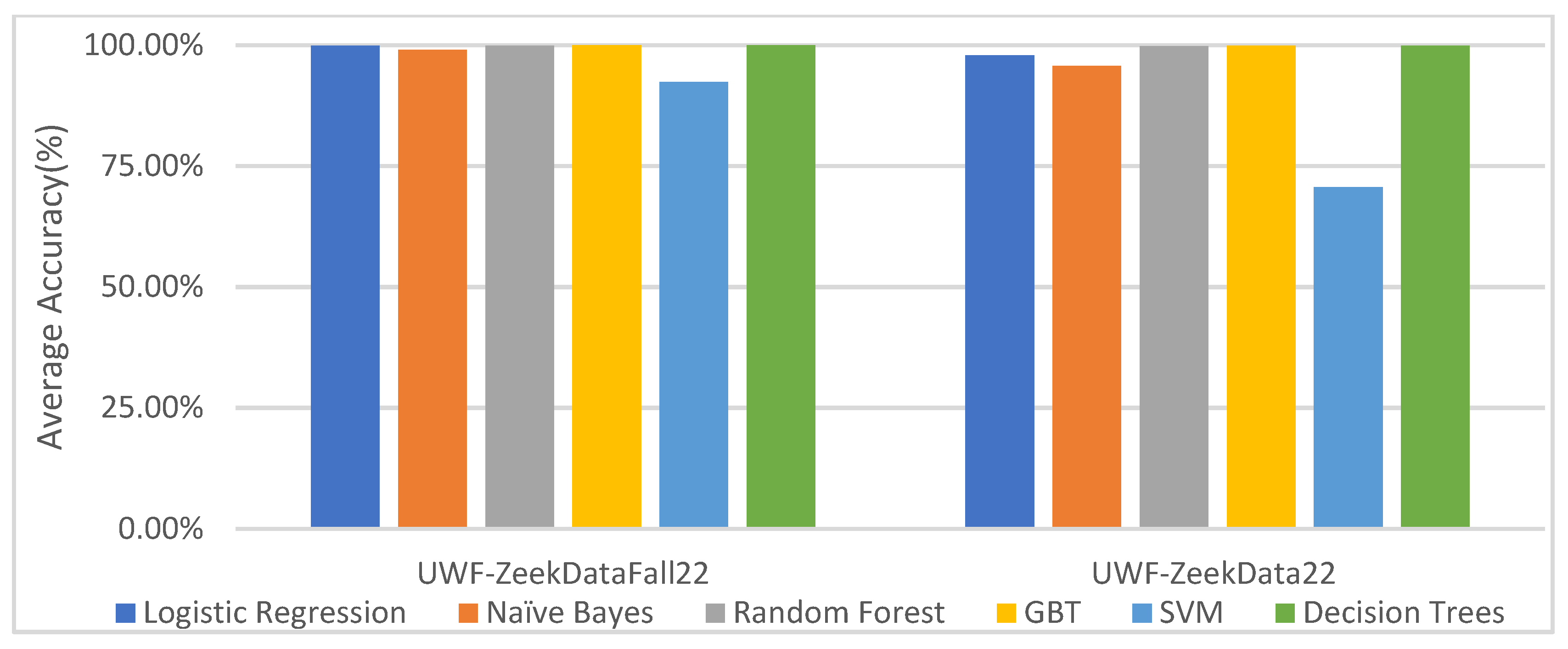
6.3.4. Comparing the UWF-ZeekDataFall22 and UWF-ZeekData22 Datasets
6.4. Limitations of This Study
7. Summary of Key Findings
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- MITRE ATT&CK|MITRE ATT&CK®. Available online: https://attack.mitre.org/# (accessed on 8 August 2023).
- MITRE ATT&CK. Reconnaissance, Tactic TA0043—Enterprise|MITRE ATT&CK®. 2022. Available online: https://attack.mitre.org/tactics/TA0043/ (accessed on 5 September 2023).
- MITRE ATT&CK. Discovery, Tactic TA0007—Enterprise|MITRE ATT&CK®. 2022. Available online: https://attack.mitre.org/tactics/TA0007/ (accessed on 5 September 2023).
- MITRE ATT&CK. Resource Development, Tactic TA0042—Enterprise|MITRE ATT&CK®. 2022. Available online: https://attack.mitre.org/tactics/TA0042/ (accessed on 8 August 2023).
- University of West Florida. 2022. Available online: https://datasets.uwf.edu/ (accessed on 2 September 2023).
- Karun, A.K.; Chitharanjan, K. A review on Hadoop—HDFS infrastructure extensions. In Proceedings of the 2013 IEEE Conference on Information and Communication Technologies, Thuckalay, India, 11–12 April 2013. [Google Scholar] [CrossRef]
- Guller, M. Big Data Analytics with Spark: A Practitioner’s Guide to Using Spark for Large Scale Data Analysis; Apress: New York, NY, USA, 2015. [Google Scholar]
- About Zeek. Available online: https://docs.zeek.org/en/master/about.html (accessed on 2 August 2023).
- Mebawondu, O.J.; Popoọla, O.S.; Ayogu, I.I.; Ugwu, C.C.; Adetunmbi, A.O. Network Intrusion Detection Models based on Naives Bayes and C4.5 Algorithms. In Proceedings of the 2022 IEEE Nigeria 4th International Conference on Disruptive Technologies for Sustainable Development (NIGERCON), Lagos, Nigeria, 5–7 April 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Panda, M.; Patra, M.R. Network Intrusion Detection Using Naïve Bayes. IJCSNS Int. J. Comput. Sci. Netw. Secur. 2007, 7, 258–263. [Google Scholar]
- Tufail, S.; Batool, S.; Sarwat, A.I. A Comparative Study of Binary Class Logistic Regression and Shallow Neural Network for DDoS Attack Prediction. In Proceedings of the SoutheastCon 2022, Mobile, AL, USA, 26 March–3 April 2022; pp. 310–315. [Google Scholar] [CrossRef]
- Kejriwal, S.; Patadia, D.; Dagli, S.; Tawde, P. Machine Learning Based Intrusion Detection. In Proceedings of the 2022 IEEE Fourth International Conference on Advances in Electronics, Computers and Communications (ICAECC), Bengaluru, India, 10–11 January 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Disha, R.A.; Waheed, S. A Comparative study of machine learning models for Network Intrusion Detection System using UNSW-NB 15 dataset. In Proceedings of the 2021 International Conference on Electronics, Communications and Information Technology (ICECIT), Khulna, Bangladesh, 14–16 September 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Swamy, K.V.R.; Lakshmi, K.V. Network Intrusion Detection Using Improved Decision Tree Algorithm. IJCSIT Int. J. Comput. Sci. Inf. Technol. 2012, 3, 4971–4975. [Google Scholar]
- Mulay, S.; Devale, P.R.; Garje, G. Intrusion Detection System Using Support Vector Machine and Decision Tree. Int. J. Comput. Appl. 2010, 3, 10–16. [Google Scholar] [CrossRef]
- Jha, J.; Ragha, L. Intrusion Detection System using Support Vector Machine. In Proceedings of the IJAIS Proceedings on International Conference and Workshop on Advanced Computing (ICWAC), Mumbai, India, 22–23 February 2013; pp. 25–30. [Google Scholar]
- Belouch, M.; El Hadaj, S.; Idhammad, M. Performance evaluation of intrusion detection based on machine learning using Apache Spark. Procedia Comput. Sci. 2018, 127, 1–6. [Google Scholar] [CrossRef]
- Bagui, S.S.; Mink, D.; Bagui, S.C.; Ghosh, T.; Plenkers, R.; McElroy, T.; Dulaney, S.; Shabanali, S. Introducing UWF-ZeekData22: A Comprehensive Network Traffic Dataset Based on the MITRE ATT&CK Framework. Data 2023, 8, 18. [Google Scholar] [CrossRef]
- Bagui, S.S.; Mink, D.; Bagui, S.C.; Ghosh, T.; McElroy, T.; Paredes, E.; Khasnavis, N.; Plenkers, R. Detecting Reconnaissance and Discovery Tactics from the MITRE ATT&CK Framework in Zeek Conn Logs Using Spark’s Machine Learning in the Big Data Framework. Sensors 2022, 22, 7999. [Google Scholar] [CrossRef] [PubMed]
- Deckert, A.C.; Kummerfeld, E. Investigating the Effect of Binning on Casual Discovery. 2022. Available online: https://arxiv.org/pdf/2202.11789.pdf (accessed on 10 September 2023).
- Microsoft. TCP/IP Addressing and Subnetting—Windows Client|Microsoft Docs. 2022. Available online: https://docs.microsoft.com/en-us/troubleshoot/windows-client/networking/tcpip-addressing-and-subnetting (accessed on 5 April 2023).
- IANA. Service Name and Transport Protocol Port Number Registry. 2022. Available online: https://www.iana.org/assignments/service-names-port-numbers/service-names-port-numbers.xhtml (accessed on 5 April 2023).
- Apache Spark Configuration—Spark 3.3.0 Documentation. 2022. Available online: https://spark.apache.org/docs/latest/configuration.html (accessed on 5 September 2023).
- Han, J.; Kamber, M.; Pei, J. Data Mining: Concepts and Techniques; Morgan Kaufmann: Burlington, MA, USA, 2022. [Google Scholar]
- Piryonesi, S.; El-Diraby, T. Data Analytics in Asset Management: Cost-Effective Prediction of the Pavement Condition. J. Infrastruct. Systems. 2020, 26, 04019036. [Google Scholar] [CrossRef]
- Hastie, T.J.; Tibshirani, R.J.; Friedman, J.H. The Elements of Statistical Learning: Data Mining Inference and Prediction, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2009; ISBN 978-0-387-84857-0. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tactic | Count |
|---|---|
| None | 350,339 |
| Resource Development | 275,471 |
| Reconnaissance | 51,492 |
| Discovery | 16,819 |
| Privilege Escalation | 3066 |
| Defense Evasion | 3064 |
| Execution | 30 |
| Initial Access | 19 |
| Command and Control | 17 |
| Lateral Movement | 11 |
| Persistence | 10 |
| Collection | 1 |
| Credential Access | 1 |
| Classification | Octet Values | Bin Number | dest_ip Count | src_ip Count |
|---|---|---|---|---|
| Non-class | Null or NA | 0 | 0 | 0 |
| Class A | 0–127 | 1 | 3,072,966 | 6 |
| Class B | <=191 | 2 | 608,348 | 3,719,960 |
| Class C | <=223 | 3 | 33,482 | 0 |
| Class D | <=239 | 4 | 5168 | 0 |
| Class E | <=254 | 5 | 0 | 0 |
| Other | If none of the above | 6 | 2 | 0 |
| Classification | Port Numbers | Bin Number | dest_port Count | src_port Count |
|---|---|---|---|---|
| Well-known ports | 0–1023 | 1 | 3,505,385 | 73,900 |
| Registered ports | <=49,151 | 2 | 205,615 | 2,095,923 |
| Dynamic/private ports | <=65,535 | 3 | 65,812 | 1,606,989 |
| Other | If none of the above | 4 | 0 | 0 |
| Attributes | Count of Integer Bins |
|---|---|
| local_orig | 1 |
| local_resp | 1 |
| Protocol | 2 |
| conn_state | 9 |
| history | 32 |
| service | 11 |
| Attributes | Count of Integer Bins |
|---|---|
| duration | 6 |
| orig_bytes | 6 |
| orig_pkts | 2 |
| orig_ip_bytes | 6 |
| resp_bytes | 2 |
| resp_pkts | 2 |
| resp_ip_bytes | 2 |
| missed_bytes | 2 |
| Full Dataset | |
|---|---|
| Attribute | Info_Gain |
| history | 0.3769642 |
| protocol | 0.36886144 |
| dest_port | 0.34085092 |
| service | 0.3125681 |
| orig_bytes | 0.29707623 |
| duration | 0.29682565 |
| resp_bytes | 0.29655516 |
| orig_ip_bytes | 0.29552263 |
| orig_pkts | 0.29124352 |
| dest_ip | 0.20953701 |
| local_resp | 0.19356702 |
| conn_state | 0.022014592 |
| src_port | 0.003268247 |
| src_ip | 0.001607323 |
| local_orig | 5.02 × 10−4 |
| missed_bytes | 0 |
| resp_ip_bytes | 0 |
| resp_pkts | 0 |
| Resource Development | |
|---|---|
| Attribute | Info_Gain |
| history | 0.8810788 |
| protocol | 0.8810783 |
| dest_port | 0.8239399 |
| orig_ip_bytes | 0.823516 |
| service | 0.81280994 |
| orig_bytes | 0.7881991 |
| duration | 0.7871984 |
| resp_bytes | 0.7861375 |
| orig_pkts | 0.778875 |
| dest_ip | 0.6267121 |
| local_resp | 0.59013766 |
| conn_state | 0.032609735 |
| src_port | 0.010610466 |
| src_ip | 0.005892113 |
| local_orig | 0.001804289 |
| missed_bytes | 0 |
| resp_ip_bytes | 0 |
| resp_pkts | 0 |
| Discovery | |
|---|---|
| Attribute | Info_Gain |
| history | 0.88164663 |
| protocol | 0.8805963 |
| conn_state | 0.8794843 |
| orig_ip_bytes | 0.8471305 |
| service | 0.7876045 |
| orig_bytes | 0.7738234 |
| duration | 0.773805 |
| resp_bytes | 0.7718542 |
| orig_pkts | 0.76303893 |
| dest_ip | 0.623519 |
| dest_port | 0.60750306 |
| local_resp | 0.57914233 |
| src_port | 0.19649306 |
| src_ip | 0.00906063 |
| local_orig | 0.0017338 |
| missed_bytes | 0 |
| resp_ip_bytes | 0 |
| resp_pkts | 0 |
| Reconnaissance | |
|---|---|
| Attribute | Info_Gain |
| protocol | 0.8821778 |
| history | 0.8709951 |
| conn_state | 0.8681412 |
| orig_ip_bytes | 0.82774657 |
| service | 0.8121441 |
| orig_bytes | 0.7853897 |
| duration | 0.78459907 |
| resp_bytes | 0.78186846 |
| orig_pkts | 0.7734535 |
| dest_ip | 0.6330686 |
| dest_port | 0.61232007 |
| local_resp | 0.59225047 |
| src_port | 0.011235193 |
| src_ip | 0.006443019 |
| local_orig | 0.001454109 |
| resp_ip_bytes | 0 |
| resp_pkts | 0 |
| missed_bytes | 0 |
| Test ID | Executor Count | Executor Core Count | Total Executor Cores | Executor Memory | Total Executor Memory (GB) | Binning Time (s) | Training Time (s) | Testing Time (s) |
|---|---|---|---|---|---|---|---|---|
| 1 | 5 | 2 | 10 | 5 | 25 | 69.5 | 16.4 | 0.091 |
| 2 | 5 | 2 | 10 | 10 | 50 | 69.1 | 15.6 | 0.088 |
| 3 | 5 | 2 | 10 | 20 | 100 | 71.7 | 16.2 | 0.107 |
| 4 | 5 | 4 | 20 | 5 | 25 | 59.11 | 15.13 | 0.151 |
| 5 | 5 | 4 | 20 | 10 | 50 | 58.33 | 15.16 | 0.113 |
| 6 | 5 | 4 | 20 | 20 | 100 | 59.9 | 14.91 | 0.126 |
| 7 | 10 | 2 | 20 | 5 | 50 | 63.96 | 15.77 | 0.109 |
| 8 | 10 | 2 | 20 | 10 | 100 | 63.18 | 15.94 | 0.105 |
| 9 | 10 | 4 | 40 | 5 | 50 | 54.15 | 13.15 | 0.121 |
| 10 | 10 | 4 | 40 | 10 | 100 | 52.56 | 12.788 | 0.125 |
| 11 | 20 | 2 | 40 | 5 | 100 | 57.3 | 13.84 | 0.134 |
| 12 | 20 | 4 | 80 | 5 | 100 | 51.9 | 14.7 | 0.123 |
| 13 | 10 | 8 | 80 | 10 | 100 | 49.68 | 12.09 | 0.129 |
| 14 | 12 | 8 | 96 | 10 | 120 | 50.96 | 12.54 | 0.122 |
| 15 | 12 | 8 | 96 | 10 | 120 | 49.47 | 12.54 | 0.144 |
| 16 | 12 | 8 | 96 | 10 | 120 | 47.8 | 12.6 | 0.15 |
| 17 | 24 | 4 | 96 | 5 | 120 | 50.7 | 14.5 | 0.134 |
| 18 | 6 | 16 | 96 | 20 | 120 | 46.45 | 14.87 | 0.133 |
| 19 | 12 | 8 | 96 | 10 | 120 | 28.52 | 7.94 | 0.083 |
| 20 | 1 | 16 | 16 | 20 | 20 | 44.77 | 18.25 | 0.131 |
| 21 | 2 | 16 | 32 | 20 | 40 | 46.98 | 16.57 | 0.172 |
| 22 | 3 | 16 | 48 | 20 | 60 | 38.48 | 16.7 | 0.134 |
| Test ID | Executor Count | Cores Per Executor | Memory per Executor | Total Exec. Cores | Total Executor Memory (GB) | Total Time (s) | Shuffle Partitions | Driver Cores | Driver Memory (GB) |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 5 | 2 | 5 | 10 | 25 | 85.93 | 200 | 2 | 10 |
| 2 | 5 | 2 | 10 | 10 | 50 | 84.8 | 200 | 2 | 10 |
| 3 | 5 | 2 | 20 | 10 | 100 | 88.09 | 200 | 2 | 10 |
| 4 | 5 | 4 | 5 | 20 | 25 | 74.41 | 200 | 2 | 10 |
| 5 | 5 | 4 | 10 | 20 | 50 | 73.61 | 200 | 2 | 10 |
| 6 | 5 | 4 | 20 | 20 | 100 | 74.98 | 200 | 2 | 10 |
| 7 | 10 | 2 | 5 | 20 | 50 | 79.84 | 200 | 2 | 10 |
| 8 | 10 | 2 | 10 | 20 | 100 | 79.24 | 200 | 2 | 10 |
| 9 | 10 | 4 | 5 | 40 | 50 | 67.43 | 200 | 2 | 10 |
| 10 | 10 | 4 | 10 | 40 | 100 | 65.44 | 200 | 2 | 10 |
| 11 | 20 | 2 | 5 | 40 | 100 | 71.29 | 200 | 2 | 10 |
| 12 | 20 | 4 | 5 | 80 | 100 | 66.7 | 200 | 2 | 10 |
| 13 | 10 | 8 | 10 | 80 | 100 | 61.91 | 200 | 2 | 10 |
| 14 | 12 | 8 | 10 | 96 | 120 | 63.62 | 200 | 2 | 10 |
| 15 | 12 | 8 | 10 | 96 | 120 | 62.16 | 72 | 2 | 10 |
| 16 | 12 | 8 | 10 | 96 | 120 | 60.6 | 12 | 2 | 10 |
| 17 | 24 | 4 | 5 | 96 | 120 | 65.47 | 24 | 2 | 10 |
| 18 | 6 | 16 | 20 | 96 | 120 | 61.46 | 6 | 2 | 10 |
| 19 | 12 | 8 | 10 | 96 | 120 | 39.33 | 24 | 2 | 10 |
| 20 | 1 | 16 | 20 | 16 | 20 | 53.1 | 1 | 2 | 10 |
| 21 | 2 | 16 | 20 | 32 | 40 | 65.17 | 2 | 2 | 10 |
| 22 | 3 | 16 | 20 | 48 | 60 | 54.79 | 3 | 2 | 10 |
| 23 | 10 | 8 | 10 | 80 | 100 | 40.37 | 200 | 2 | 10 |
| ML Algo | # of Attrs. | Accuracy (%) | Precision (%) | Recall (%) | F-Measure (%) | FPR (%) | Training Time (s) | Testing Time(s) |
|---|---|---|---|---|---|---|---|---|
| LR | 6 | 99.89 | 99.74 | 99.91 | 99.82 | 0.11 | 3.71 | 0.1 |
| LR | 9 | 99.89 | 99.74 | 99.91 | 99.82 | 0.11 | 3.71 | 0.1 |
| LR | 12 | 99.89 | 99.74 | 99.91 | 99.82 | 0.11 | 3.24 | 0.055 |
| LR | 18 | 99.77 | 99.73 | 99.47 | 99.60 | 0.11 | 4 | 0.098 |
| NB | 6 | 99.33 | 96.93 | 99.65 | 98.27 | 0.74 | 1.42 | 0.044 |
| NB | 9 | 99.33 | 96.93 | 99.65 | 98.27 | 0.74 | 1.45 | 0.09 |
| NB | 12 | 99.33 | 96.93 | 99.65 | 98.27 | 0.74 | 1.34 | 0.086 |
| NB | 18 | 99.33 | 96.93 | 99.65 | 98.27 | 0.74 | 1.6 | 0.089 |
| RF | 6 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 9.824 | 0.103 |
| RF | 9 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 9.77 | 0.087 |
| RF | 12 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 9.759 | 0.099 |
| RF | 18 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 2.039 | 0.08651 |
| GBT | 6 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 17.38 | 0.1101 |
| GBT | 9 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 17.59 | 0.113 |
| GBT | 12 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 17.39 | 0.108 |
| GBT | 18 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 11.82 | 0.112 |
| DT | 6 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 5.18 | 0.13 |
| DT | 9 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 5.5 | 0.09 |
| DT | 12 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 5.31 | 0.14 |
| DT | 18 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 5.75 | 0.14 |
| SVM | 6 | 72.96 | 82.98 | 34.96 | 49.20 | 9.87 | 13.37 | 0.059 |
| SVM | 9 | 80.88 | 0.00 | 0.00 | 0.00 | 0.00 | 33.44 | 0.059 |
| SVM | 12 | 9.97 | 0.00 | 0.00 | 0.00 | 87.66 | 14.64 | 0.069 |
| SVM | 18 | 99.99 | 100.00 | 99.91 | 99.95 | 0.00 | 41.87 | 0.111 |
| ML Algo. | # of Attrs. | Accuracy (%) | Precision (%) | Recall (%) | F-Measure (%) | FPR (%) | Training Time (s) | Testing Time (s) |
|---|---|---|---|---|---|---|---|---|
| LR | 6 | 99.90 | 99.64 | 100.00 | 99.82 | 0.14 | 3.35 | 0.093 |
| LR | 9 | 99.90 | 99.64 | 100.00 | 99.82 | 0.14 | 3.54 | 0.092 |
| LR | 12 | 99.90 | 99.64 | 100.00 | 99.82 | 0.14 | 3.23 | 0.048 |
| LR | 18 | 99.90 | 99.64 | 100.00 | 99.82 | 0.14 | 3.42 | 0.093 |
| NB | 6 | 99.66 | 96 | 100.00 | 99.12 | 0.41 | 1.38 | 0.061 |
| NB | 9 | 99.66 | 98.26 | 100.00 | 99.12 | 0.41 | 1.38 | 0.089 |
| NB | 12 | 98.90 | 94.99 | 100.00 | 97.42 | 1.24 | 1.41 | 0.093 |
| NB | 18 | 98.99 | 94.96 | 100.00 | 97.42 | 1.24 | 1.42 | 0.0875 |
| RF | 6 | 99.90 | 99.80 | 100.00 | 99.90 | 0.31 | 9.321 | 0.099 |
| RF | 9 | 99.90 | 99.80 | 100.00 | 99.90 | 0.31 | 9.491 | 0.1 |
| RF | 12 | 99.90 | 99.80 | 100.00 | 99.90 | 0.31 | 9.4552 | 0.102 |
| RF | 18 | 99.90 | 99.80 | 100.00 | 99.90 | 0.31 | 1.869 | 0.0985 |
| GBT | 6 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 14.03 | 0.1066 |
| GBT | 9 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 14.459 | 0.1016 |
| GBT | 12 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 14.407 | 0.103 |
| GBT | 18 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 8.599 | 0.107 |
| DT | 6 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 5.14 | 0.12 |
| DT | 9 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 5.46 | 0.13 |
| DT | 12 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 5.25 | 0.09 |
| DT | 18 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 5.12 | 0.07 |
| SVM | 6 | 90.87 | 67.54 | 100.00 | 80.62 | 11.00 | 27.89 | 0.06 |
| SVM | 9 | 96.64 | 99.15 | 83.03 | 90.38 | 0.16 | 14.2 | 0.06 |
| SVM | 12 | 82.09 | 100.00 | 5.65 | 10.70 | 0.00 | 15.49 | 0.067 |
| SVM | 18 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 39.42 | 0.08 |
| ML Algo. | # of Attrs. | Accuracy (%) | Precision (%) | Recall (%) | F-Measure (%) | FPR (%) | Training Time | Testing Time |
|---|---|---|---|---|---|---|---|---|
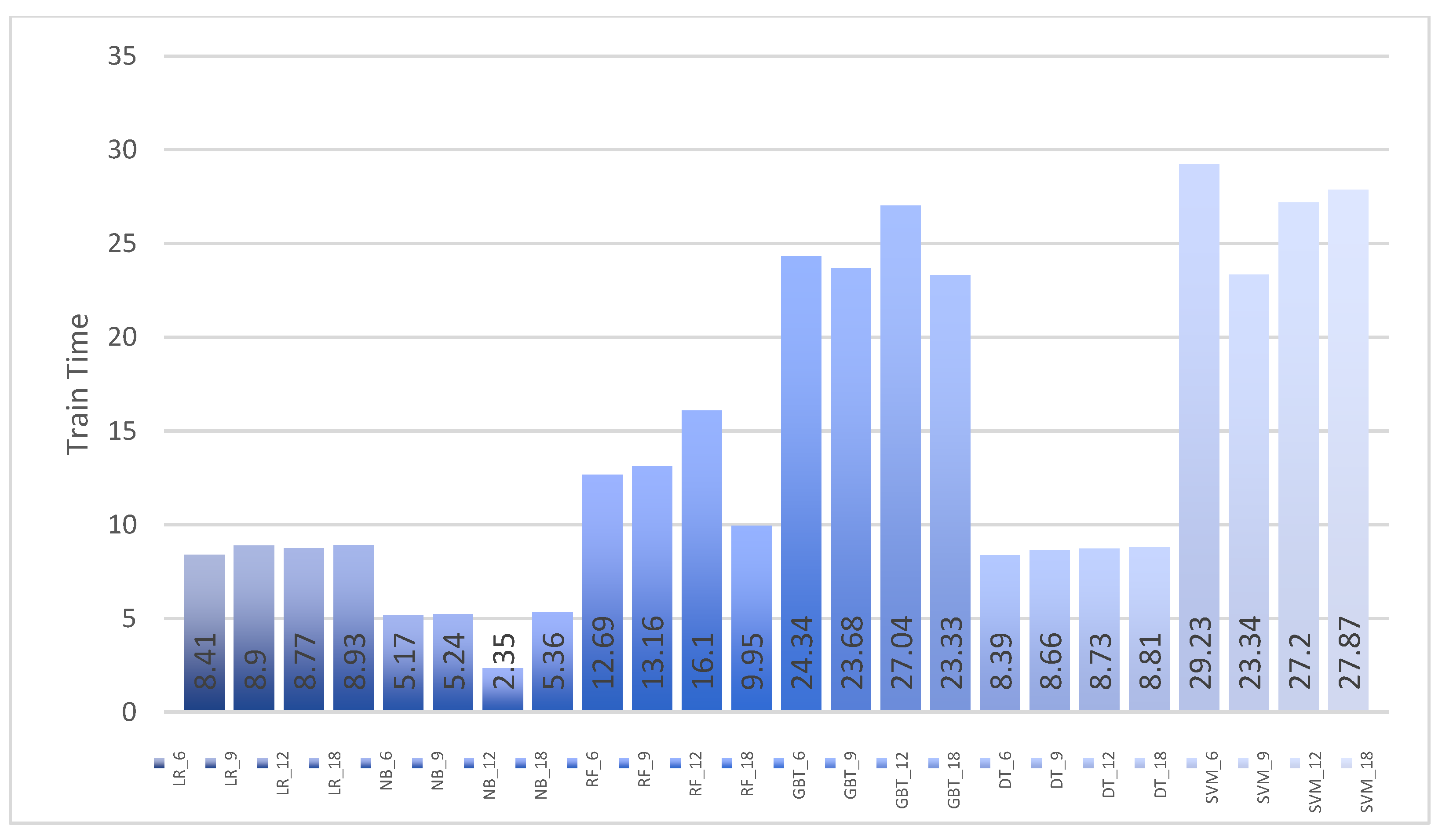
| LR | 6 | 99.87 | 99.61 | 99.96 | 99.78 | 0.17 | 8.41 | 0.118 |
| LR | 9 | 99.87 | 99.61 | 99.96 | 99.78 | 0.17 | 8.9 | 0.118 |
| LR | 12 | 99.87 | 99.61 | 99.96 | 99.78 | 0.17 | 8.77 | 0.068 |
| LR | 18 | 99.85 | 99.61 | 99.90 | 99.75 | 0.17 | 8.93 | 0.136 |
| NB | 6 | 99.33 | 96.78 | 99.97 | 98.35 | 0.83 | 5.17 | 0.053 |
| NB | 9 | 99.33 | 96.78 | 99.96 | 98.35 | 0.83 | 5.24 | 0.096 |
| NB | 12 | 99.34 | 99.91 | 99.90 | 99.38 | 0.80 | 2.35 | 0.089 |
| NB | 18 | 98.55 | 93.36 | 99.90 | 96.52 | 1.78 | 5.36 | 0.104 |
| RF | 6 | 99.99 | 99.99 | 100.00 | 99.99 | 0.00 | 12.69 | 0.17 |
| RF | 9 | 99.99 | 99.99 | 100.00 | 99.99 | 0.00 | 13.16 | 0.12 |
| RF | 12 | 99.99 | 99.99 | 100.00 | 99.99 | 0.00 | 16.1 | 0.0921 |
| RF | 18 | 99.99 | 99.99 | 100.00 | 99.99 | 0.00 | 9.95 | 0.108 |
| GBT | 6 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 24.34 | 0.114 |
| GBT | 9 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 23.68 | 0.113 |
| GBT | 12 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 27.04 | 0.125 |
| GBT | 18 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 23.33 | 0.13 |
| DT | 6 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 8.39 | 0.12 |
| DT | 9 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 8.66 | 0.12 |
| DT | 12 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 8.73 | 0.078 |
| DT | 18 | 100.00 | 100.00 | 100.00 | 100.00 | 0.00 | 8.81 | 0.08 |
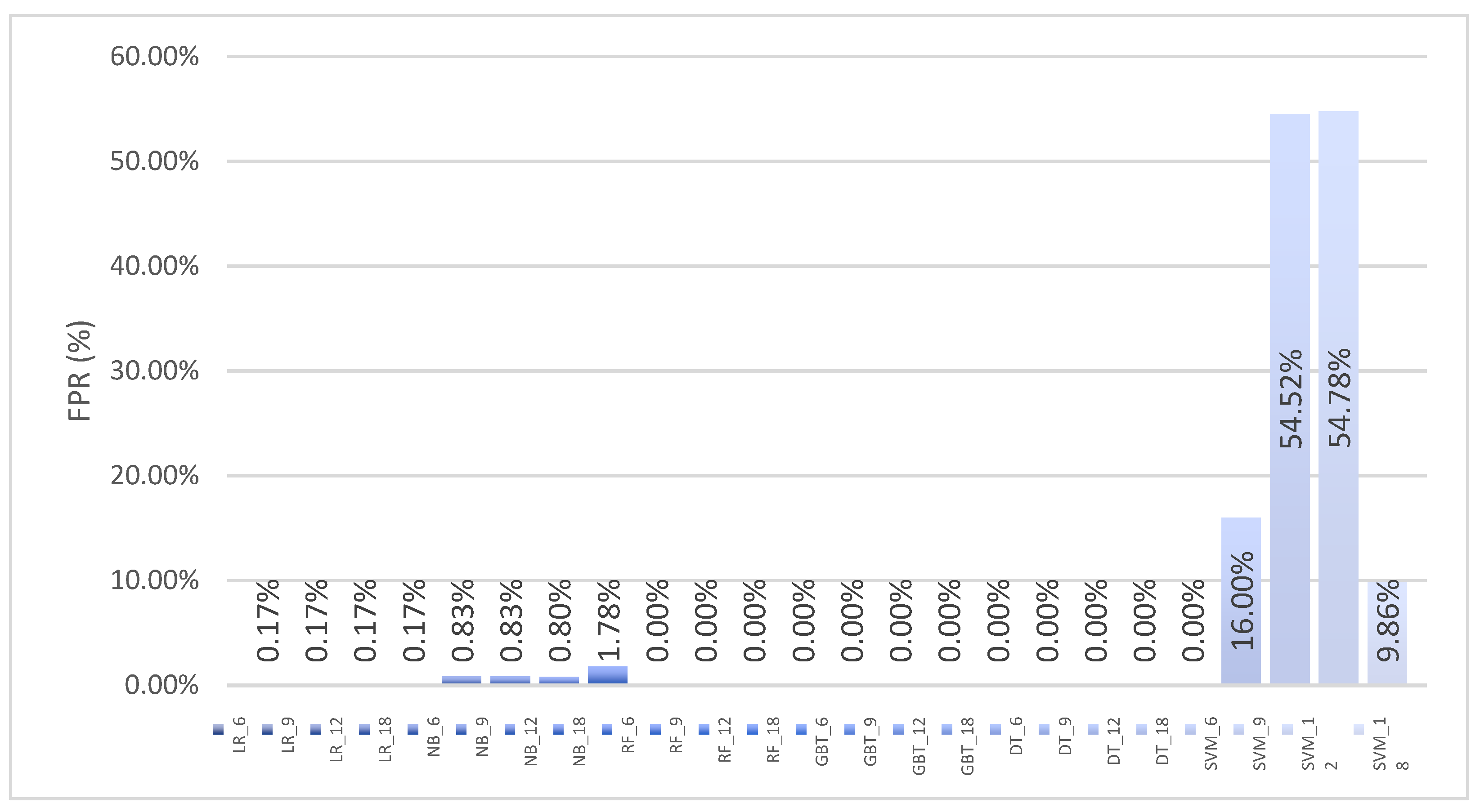
| SVM | 6 | 99.87 | 99.36 | 99.99 | 99.68 | 16.00 | 29.23 | 0.06 |
| SVM | 9 | 36.36 | 3.40 | 7.00 | 4.00 | 54.52 | 23.34 | 0.035 |
| SVM | 12 | 36.16 | 1.70 | 3.79 | 2.30 | 54.78 | 27.2 | 0.035 |
| SVM | 18 | 92.12 | 71.79 | 99.99 | 83.57 | 9.86 | 27.87 | 0.034 |
| ML Algo. | No. of Attrs. | Weighted Precision (%) | Weighted Recall (%) | Weighted F-Measure (%) | Weighted Accuracy (%) | FPR (%) | Training Time | Testing Time |
|---|---|---|---|---|---|---|---|---|
| LR | 6 | 86.36 | 92.93 | 89.52 | 92.95 | 92.93 | 15.8 | 0.11 |
| LR | 9 | 86.36 | 92.93 | 89.52 | 92.95 | 92.93 | 15.95 | 0.1 |
| LR | 12 | 86.36 | 92.93 | 89.52 | 92.95 | 92.93 | 16.3 | 0.11 |
| LR | 18 | 86.36 | 92.93 | 89.52 | 92.95 | 92.93 | 16.55 | 0.1 |
| NB | 6 | 7.62 | 0.6235 | 1.152 | 8.82 | 92.18 | 9.02 | 0.12 |
| NB | 9 | 7.58 | 0.622 | 1.15 | 8.82 | 92.18 | 11.11 | 0.144 |
| NB | 12 | 7.72 | 0.672 | 1.2 | 9.8 | 91.1 | 11.27 | 0.13 |
| NB | 18 | 7.72 | 0.672 | 1.2 | 9.706 | 91.1 | 11.16 | 0.136 |
| RF | 6 | 99.94 | 99.97 | 99.95 | 99.99 | 0.0012 | 35.9 | 0.099 |
| RF | 9 | 99.94 | 99.97 | 99.95 | 99.99 | 0.0012 | 36.6 | 0.101 |
| RF | 12 | 99.94 | 99.97 | 99.95 | 99.99 | 0.0012 | 37 | 0.1012 |
| RF | 18 | 99.94 | 99.97 | 99.95 | 99.99 | 0.0012 | 22.937 | 0.1 |
| DT | 6 | 99.95 | 99.97 | 99.96 | 99.99 | 0.0804 | 13.45 | 0.104 |
| DT | 9 | 99.95 | 99.97 | 99.96 | 99.99 | 0.0672 | 13.91 | 0.12 |
| DT | 12 | 99.95 | 99.97 | 99.96 | 99.99 | 0.0737 | 12.29 | 0.143 |
| DT | 18 | 99.95 | 99.97 | 99.96 | 99.99 | 0.0738 | 13.61 | 0.128 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bagui, S.S.; Mink, D.; Bagui, S.C.; Madhyala, P.; Uppal, N.; McElroy, T.; Plenkers, R.; Elam, M.; Prayaga, S. Introducing the UWF-ZeekDataFall22 Dataset to Classify Attack Tactics from Zeek Conn Logs Using Spark’s Machine Learning in a Big Data Framework. Electronics 2023, 12, 5039. https://doi.org/10.3390/electronics12245039
Bagui SS, Mink D, Bagui SC, Madhyala P, Uppal N, McElroy T, Plenkers R, Elam M, Prayaga S. Introducing the UWF-ZeekDataFall22 Dataset to Classify Attack Tactics from Zeek Conn Logs Using Spark’s Machine Learning in a Big Data Framework. Electronics. 2023; 12(24):5039. https://doi.org/10.3390/electronics12245039
Chicago/Turabian StyleBagui, Sikha S., Dustin Mink, Subhash C. Bagui, Pooja Madhyala, Neha Uppal, Tom McElroy, Russell Plenkers, Marshall Elam, and Swathi Prayaga. 2023. "Introducing the UWF-ZeekDataFall22 Dataset to Classify Attack Tactics from Zeek Conn Logs Using Spark’s Machine Learning in a Big Data Framework" Electronics 12, no. 24: 5039. https://doi.org/10.3390/electronics12245039