
2s-GATCN: Two-Stream Graph Attentional Convolutional Networks for Skeleton-Based Action Recognition

Abstract
:1. Introduction
- We propose a graph attention convolutional network (GATCN) to adaptively learn the topology of the graph. By combining physical, semantic, and temporal features of the graph, our approach is able to learn and fuse features in a powerful and flexible manner.
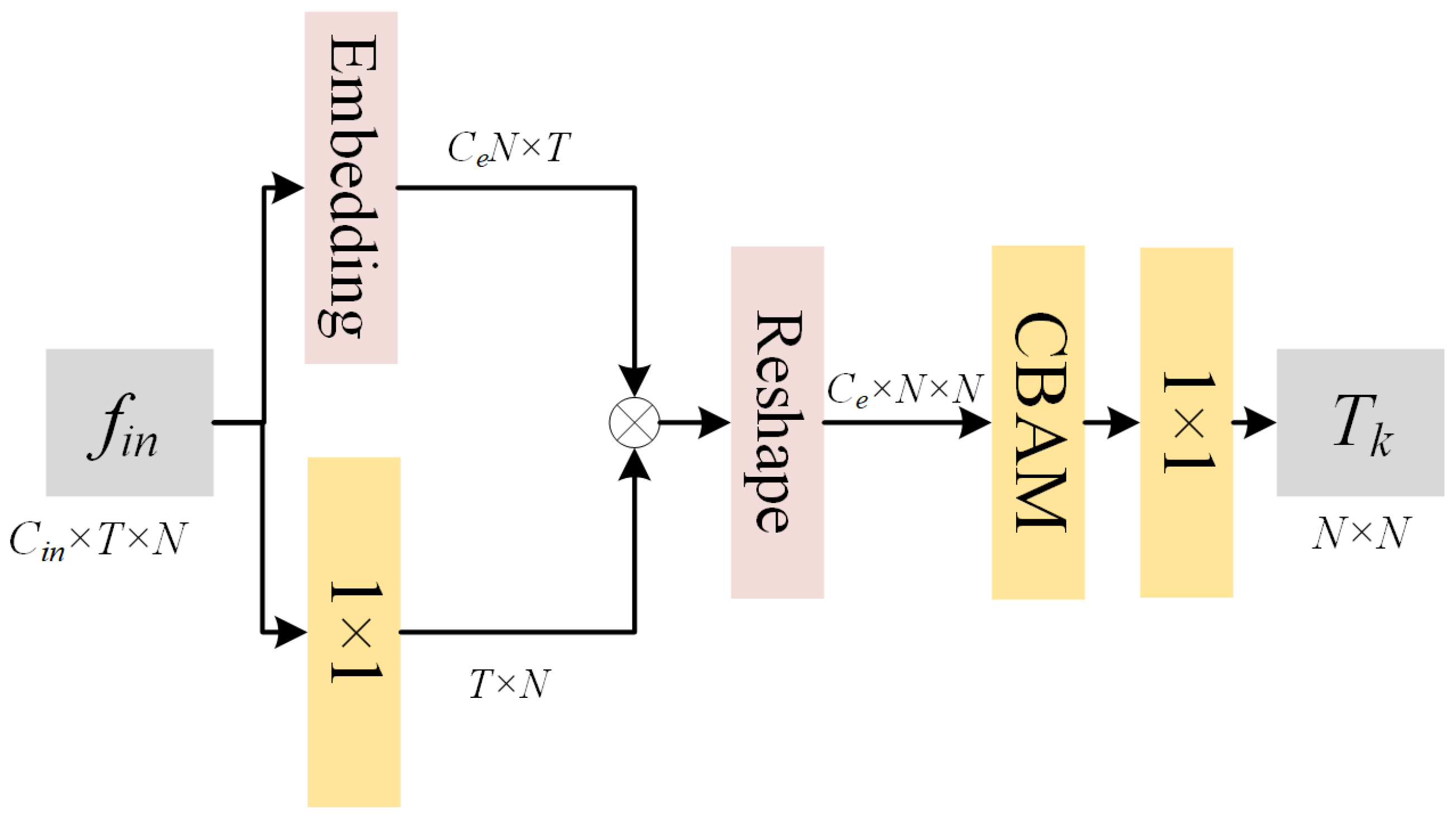
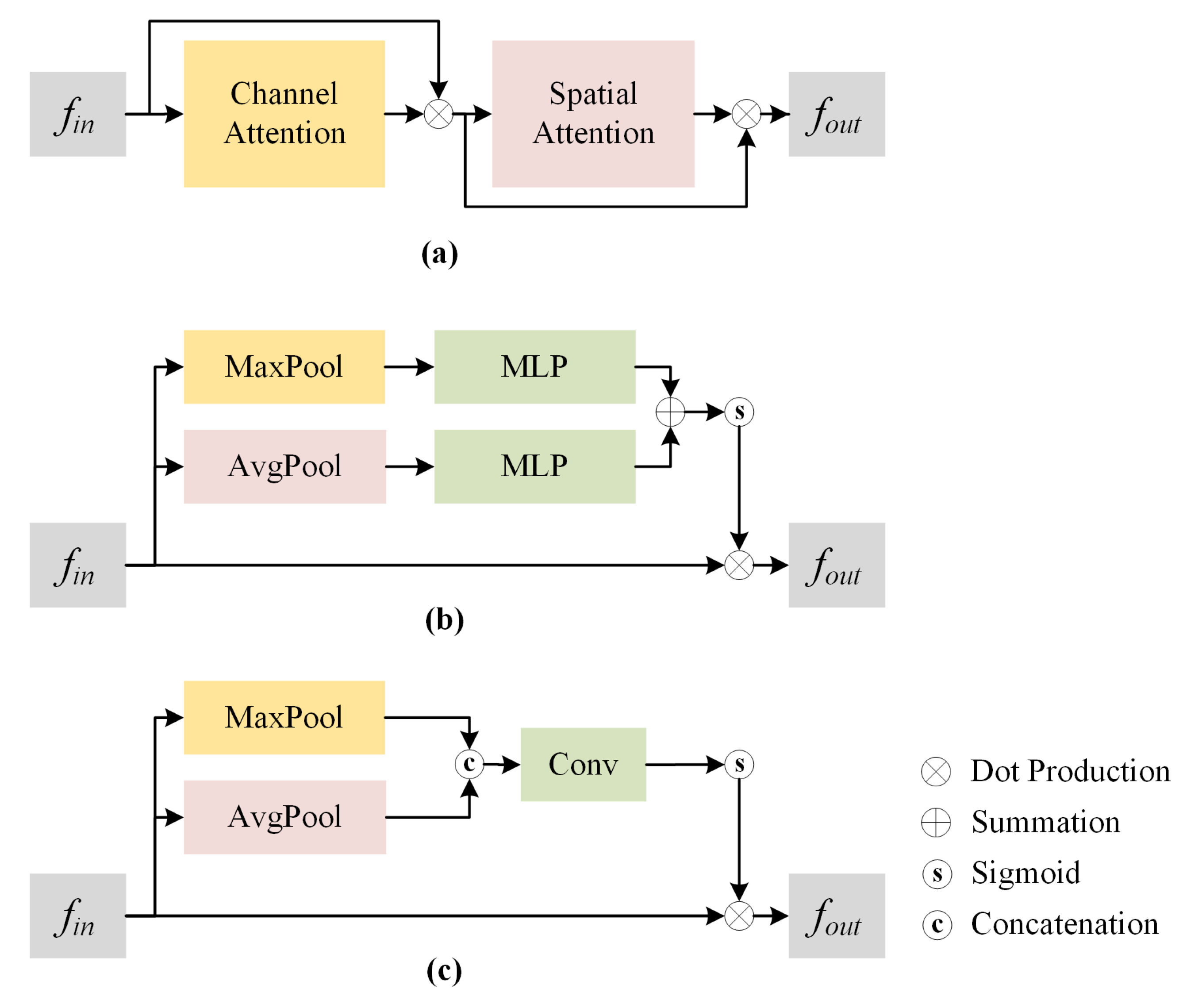
- We present a novel approach for estimating semantic correlations by designing a graph attention block (GAB), which can highlight the most discriminative vertex connections relating to the corresponding actions. The GAB incorporates a data embedding method, to obtain a multi-channel semantic correlation strength tensor, and a CBAM-based attention module, to obtain the semantic correlation strength matrix, By considering the semantic connections between vertices, the action recognition accuracy is significantly improved.
- Extensive experiments on NTU-RGB+D 60 and Kinetics-Skeleton datasets demonstrate that the proposed network obtains superior performance compared to state-of-the-art methods.
2. Related Work
2.1. Graph Covolutional Networks for Skeleton-Based Action Recognition
2.2. Attention Mechanisms in Skeleton-Based Action Recognition
3. Background
3.1. Graph-Based Skeleton Sequence Representation
3.2. Spatial and Temporal Graph Convolutions
4. Methodology
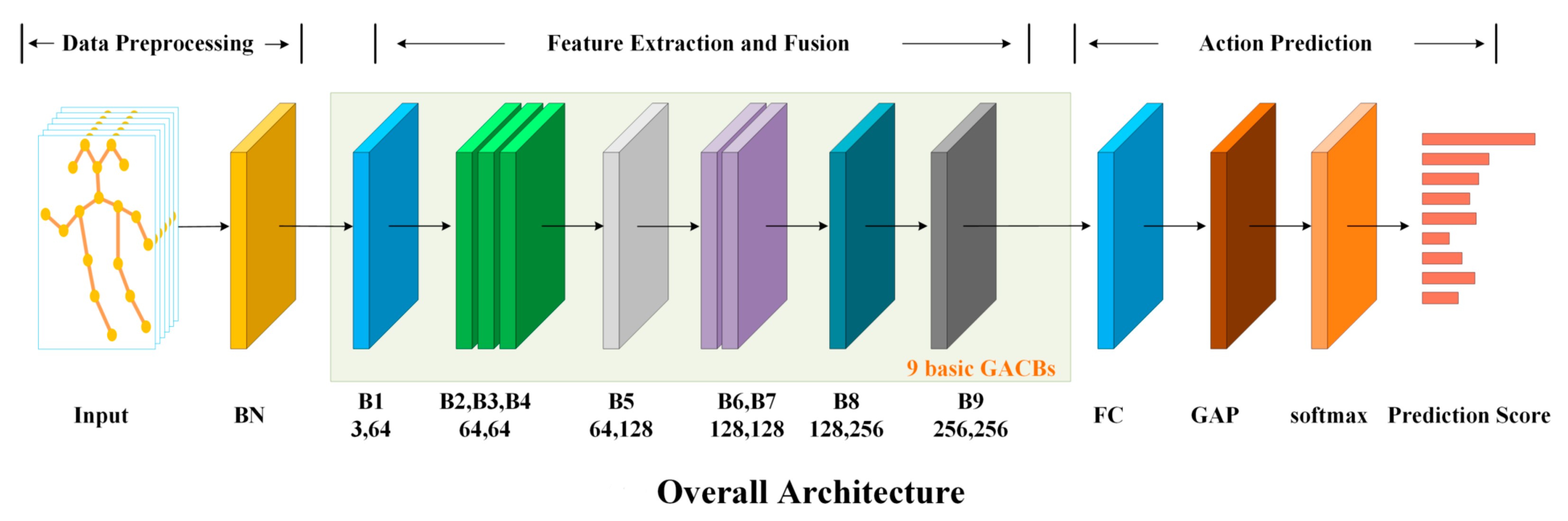
4.1. Overall Network
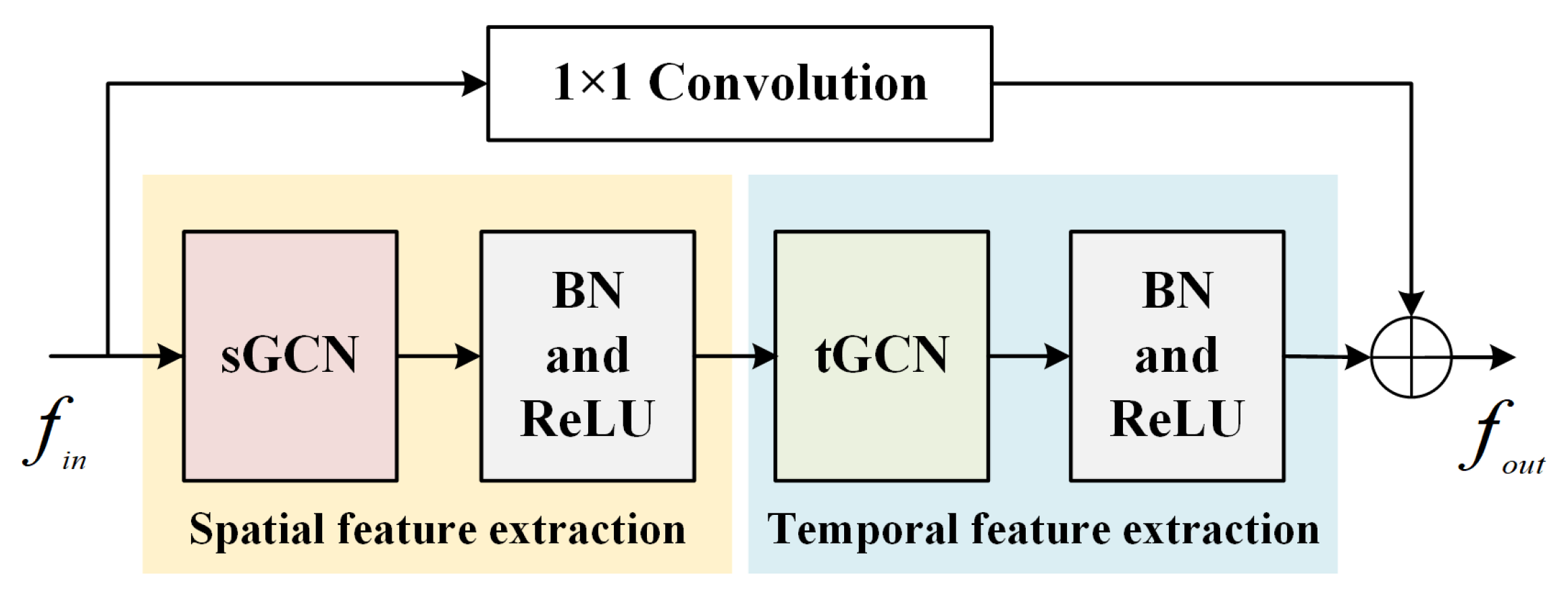
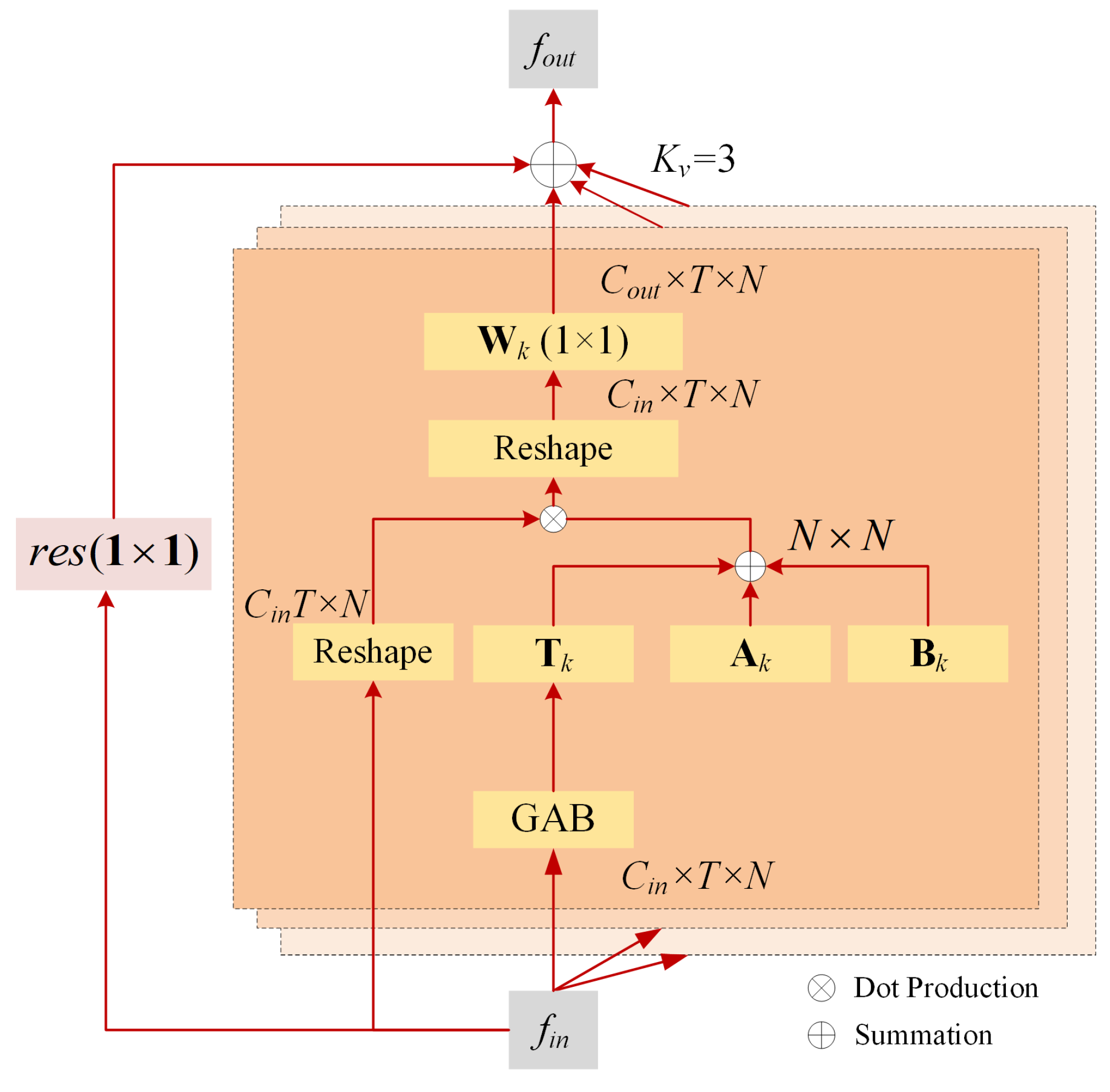
4.2. GACB
4.3. GAB
5. Experiments
5.1. Datasets and Implementing Details
5.2. Ablation Study
5.2.1. Optimal Attention Heads Number Determination
5.2.2. Effectiveness Validation of the Matrix
5.3. Comparison with State-of-the-Art Methods
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, H.B.; Zhang, Y.X.; Zhong, B.; Lei, Q.; Yang, L.; Du, J.X.; Chen, D.S. A comprehensive survey of vision-based human action recognition methods. Sensors 2019, 19, 1005. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ushapreethi, P.; Jeyakumar, B.; BalaKrishnan, P. Action recongnition in video survillance using hipi and map reducing model. Int. J. Mech. Eng. Technol. 2017, 8, 368–375. [Google Scholar]
- Ren, B.; Liu, M.; Ding, R.; Liu, H. A survey on 3d skeleton-based action recognition using learning method. arXiv 2020, arXiv:2002.05907. [Google Scholar]
- Ma, Z.; Liu, S. A review of 3D reconstruction techniques in civil engineering and their applications. Adv. Eng. Inform. 2018, 37, 163–174. [Google Scholar] [CrossRef]
- Tian, F.; Gao, Y.; Fang, Z.; Fang, Y.; Gu, J.; Fujita, H.; Hwang, J.N. Depth estimation using a self-supervised network based on cross-layer feature fusion and the quadtree constraint. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1751–1766. [Google Scholar] [CrossRef]
- Poppe, R. A survey on vision-based human action recognition. Image Vis. Comput. 2010, 28, 976–990. [Google Scholar] [CrossRef]
- Jegham, I.; Khalifa, A.B.; Alouani, I.; Mahjoub, M.A. Vision-based human action recognition: An overview and real world challenges. Forensic Sci. Int. Digit. Investig. 2020, 32, 200901. [Google Scholar] [CrossRef]
- Song, S.; Lan, C.; Xing, J.; Zeng, W.; Liu, J. An end-to-end spatio-temporal attention model for human action recognition from skeleton data. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Voume 31. [Google Scholar]
- Peng, W.; Shi, J.; Zhao, G. Spatial temporal graph deconvolutional network for skeleton-based human action recognition. IEEE Signal Process. Lett. 2021, 28, 244–248. [Google Scholar] [CrossRef]
- Du, Y.; Wang, W.; Wang, L. Hierarchical recurrent neural network for skeleton based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1110–1118. [Google Scholar]
- Zhang, S.; Yang, Y.; Xiao, J.; Liu, X.; Yang, Y.; Xie, D.; Zhuang, Y. Fusing geometric features for skeleton-based action recognition using multilayer LSTM networks. IEEE Trans. Multimed. 2018, 20, 2330–2343. [Google Scholar] [CrossRef]
- Du, Y.; Fu, Y.; Wang, L. Skeleton based action recognition with convolutional neural network. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 579–583. [Google Scholar]
- Zheng, W.; Li, L.; Zhang, Z.; Huang, Y.; Wang, L. Relational network for skeleton-based action recognition. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 826–831. [Google Scholar]
- Ding, W.; Ding, C.; Li, G.; Liu, K. Skeleton-Based Square Grid for Human Action Recognition With 3D Convolutional Neural Network. IEEE Access 2021, 9, 54078–54089. [Google Scholar] [CrossRef]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 12026–12035. [Google Scholar]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-structural graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 3595–3603. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Skeleton-based action recognition with directed graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2021; pp. 7912–7921. [Google Scholar]
- Liu, Z.; Zhang, H.; Chen, Z.; Wang, Z.; Ouyang, W. Disentangling and unifying graph convolutions for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 143–152. [Google Scholar]
- Peng, W.; Hong, X.; Chen, H.; Zhao, G. Learning graph convolutional network for skeleton-based human action recognition by neural searching. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Voume 34, pp. 2669–2676. [Google Scholar]
- Chen, Y.; Zhang, Z.; Yuan, C.; Li, B.; Deng, Y.; Hu, W. Channel-wise topology refinement graph convolution for skeleton-based action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 13359–13368. [Google Scholar]
- Zhao, M.; Dai, S.; Zhu, Y.; Tang, H.; Xie, P.; Li, Y.; Liu, C.; Zhang, B. PB-GCN: Progressive binary graph convolutional networks for skeleton-based action recognition. Neurocomputing 2022, 501, 640–649. [Google Scholar] [CrossRef]
- Zhang, J.; Ye, G.; Tu, Z.; Qin, Y.; Qin, Q.; Zhang, J.; Liu, J. A spatial attentive and temporal dilated (SATD) GCN for skeleton-based action recognition. CAAI Trans. Intell. Technol. 2022, 7, 46–55. [Google Scholar] [CrossRef]
- Yang, W.; Zhang, J.; Cai, J.; Xu, Z. HybridNet: Integrating GCN and CNN for skeleton-based action recognition. Appl. Intell. 2023, 53, 574–585. [Google Scholar] [CrossRef]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, X.; Huang, F.; Zhang, B.; Li, Z. Cross-attentional spatio-temporal semantic graph networks for video question answering. IEEE Trans. Image Process. 2022, 31, 1684–1696. [Google Scholar] [CrossRef]
- Gong, J.; Wang, S.; Wang, J.; Feng, W.; Peng, H.; Tang, J.; Yu, P.S. Attentional graph convolutional networks for knowledge concept recommendation in moocs in a heterogeneous view. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 25–30 July 2020; pp. 79–88. [Google Scholar]
- Zhang, G.; Zhang, X. Multi-heads attention graph convolutional networks for skeleton-based action recognition. In Proceedings of the 2019 IEEE Visual Communications and Image Processing (VCIP), Sydney, Australia, 1–4 December 2019; pp. 1–4. [Google Scholar]
- Si, C.; Chen, W.; Wang, W.; Wang, L.; Tan, T. An attention enhanced graph convolutional lstm network for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1227–1236. [Google Scholar]
- Cho, S.; Maqbool, M.; Liu, F.; Foroosh, H. Self-attention network for skeleton-based human action recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 635–644. [Google Scholar]
- Li, C.; Xie, C.; Zhang, B.; Han, J.; Zhen, X.; Chen, J. Memory attention networks for skeleton-based action recognition. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 4800–4814. [Google Scholar] [CrossRef]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. Stat 2017, 1050, 10–48550. [Google Scholar]
- Yang, H.; Yan, D.; Zhang, L.; Sun, Y.; Li, D.; Maybank, S.J. Feedback graph convolutional network for skeleton-based action recognition. IEEE Trans. Image Process. 2021, 31, 164–175. [Google Scholar] [CrossRef]
- Heidari, N.; Iosifidis, A. Temporal attention-augmented graph convolutional network for efficient skeleton-based human action recognition. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), MiCo Milano Congress Center, Milan, Italy, 10–15 January 2021; pp. 7907–7914. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Liu, J.; Shahroudy, A.; Xu, D.; Wang, G. Spatio-temporal lstm with trust gates for 3d human action recognition. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part III 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 816–833. [Google Scholar]
- Liu, H.; Tu, J.; Liu, M. Two-stream 3d convolutional neural network for skeleton-based action recognition. arXiv 2017, arXiv:1705.08106. [Google Scholar]
- Soo Kim, T.; Reiter, A. Interpretable 3d human action analysis with temporal convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 20–28. [Google Scholar]
- Song, Y.F.; Zhang, Z.; Wang, L. Richly activated graph convolutional network for action recognition with incomplete skeletons. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1–5. [Google Scholar]
- Zhang, P.; Lan, C.; Zeng, W.; Xing, J.; Xue, J.; Zheng, N. Semantics-guided neural networks for efficient skeleton-based human action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1112–1121. [Google Scholar]
- Huang, L.; Huang, Y.; Ouyang, W.; Wang, L. Part-level graph convolutional network for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Voume 34, pp. 11045–11052. [Google Scholar]
- Fu, Z.; Liu, F.; Zhang, J.; Wang, H.; Yang, C.; Xu, Q.; Qi, J.; Fu, X.; Zhou, A. SAGN: Semantic adaptive graph network for skeleton-based human action recognition. In Proceedings of the 2021 International Conference on Multimedia Retrieval, Taipei, Taiwan, 21–24 August 2021; pp. 110–117. [Google Scholar]
- Alsarhan, T.; Ali, U.; Lu, H. Enhanced discriminative graph convolutional network with adaptive temporal modelling for skeleton-based action recognition. Comput. Vis. Image Underst. 2022, 216, 103348. [Google Scholar] [CrossRef]
- Zhang, J.; Xie, W.; Wang, C.; Tu, R.; Tu, Z. Graph-aware transformer for skeleton-based action recognition. Vis. Comput. 2022, 1–12. [Google Scholar] [CrossRef]
- Zhu, Q.; Deng, H.; Wang, K. Skeleton Action Recognition Based on Temporal Gated Unit and Adaptive Graph Convolution. Electronics 2022, 11, 2973. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| nheads | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| accuracy (%) | 94.43 | 94.45 | 94.61 | 94.53 | 94.55 | 94.60 |
| Method | Accuracy (%) | Method | Accuracy (%) |
|---|---|---|---|
| Js-GATCN | 93.5 | Bs-GATCN | 93.3 |
| Js-GATCN | 93.8 | Bs-GATCN | 93.5 |
| Js-GATCN | 94.6 | Bs-GATCN | 94.5 |
| Methods | Year | Cross-Subject | Cross-View |
|---|---|---|---|
| HBRNN [10] | 2015 | 50.1 | 82.8 |
| ST-LSTM [37] | 2016 | 69.2 | 77.7 |
| Two-Stream 3DCNN [38] | 2017 | 66.8 | 72.6 |
| TCN [39] | 2017 | 74.3 | 83.1 |
| ST-GCN [15] | 2018 | 81.5 | 88.3 |
| AS-GCN [17] | 2018 | 86.8 | 94.2 |
| RA-GCN [40] | 2019 | 85.9 | 93.5 |
| 2s-AGCN [16] | 2019 | 88.5 | 95.1 |
| AGC-LSTM [29] | 2019 | 89.2 | 95.0 |
| SGN [41] | 2020 | 89.0 | 94.5 |
| PL-GCN [42] | 2020 | 89.2 | 90.5 |
| SAGN [43] | 2021 | 89.2 | 94.2 |
| ED-GCN [44] | 2022 | 88.7 | 95.2 |
| GAT [45] | 2022 | 89.0 | 95.2 |
| Zhu [46] | 2022 | 89.6 | 94.9 |
| Js-GATCN | - | 87.9 | 94.6 |
| Bs-GATCN | - | 87.4 | 94.5 |
| 2s-GATCN | - | 89.6 | 95.9 |
| Method | Year | Top-1(%) | Top-5(%) |
|---|---|---|---|
| TCN [39] | 2017 | 20.3 | 40.0 |
| ST-GCN [15] | 2018 | 30.7 | 52.8 |
| AS-GCN [17] | 2018 | 34.8 | 56.5 |
| 2s-AGCN [16] | 2019 | 36.1 | 58.7 |
| GAT [45] | 2022 | 36.1 | 58.9 |
| Zhu [46] | 2022 | 34.0 | 57.5 |
| Js-GATCN | - | 34.1 | 57.2 |
| Bs-GATCN | - | 34.7 | 56.6 |
| 2s-GATCN | - | 36.7 | 59.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, S.-B.; Chen, R.-R.; Jiang, X.-Q.; Pan, F. 2s-GATCN: Two-Stream Graph Attentional Convolutional Networks for Skeleton-Based Action Recognition. Electronics 2023, 12, 1711. https://doi.org/10.3390/electronics12071711
Zhou S-B, Chen R-R, Jiang X-Q, Pan F. 2s-GATCN: Two-Stream Graph Attentional Convolutional Networks for Skeleton-Based Action Recognition. Electronics. 2023; 12(7):1711. https://doi.org/10.3390/electronics12071711
Chicago/Turabian StyleZhou, Shu-Bo, Ran-Ran Chen, Xue-Qin Jiang, and Feng Pan. 2023. "2s-GATCN: Two-Stream Graph Attentional Convolutional Networks for Skeleton-Based Action Recognition" Electronics 12, no. 7: 1711. https://doi.org/10.3390/electronics12071711