
Evaluating Explainable Artificial Intelligence Methods Based on Feature Elimination: A Functionality-Grounded Approach


Abstract
:1. Introduction
1.1. Problem Statement
1.2. Contributions
- Analysis of the dataset to identify a set of features, that are considered indispensable for the prediction process (ground truth extraction).
- Extracting the features that are actually used by the ML model, based on the explanations proposed by different XAI methods.
- Computing the consistency value for the feature set suggested by each XAI method.
- Comparing different XAI methods based on their ratios according to the model selection metrics we propose.
- We develop an approach to extract a representation of the most influencing features in a given dataset. We denote these features as indispensable ones.
- We introduce a consistency value that measures knowledge shared between the feature set obtained with XAI methods and the computed indispensable features.
- We customize two well-known model selection metrics to incorporate three dimensions of the problem space; namely, the feature set highlighted by an XAI method, its relevant consistency value, and the sample size. This sample is the one used in training the ML model and for which explanations are generated by the XAI method under analysis.
2. Backgrounds
2.1. Explainable Artificial Intelligence
- Robustness, meaning that an explanation can withstand small perturbations of the input that do not change the output prediction [12]. Consequently, robustness expresses a low sensitivity of the XAI method to changes in inputs.
- Fidelity, meaning that the XAI method should preserve the internal concepts and original behavior of the black box ML model whenever there is a need to mimic that model.
- Causality, meaning that the XAI method should maintain causal relationships between inputs and outputs. Note that an ML model is perceived as being more human-like whenever it provides such causal explanations. Therefore, causality is fundamental to achieving a human understanding of the ML model.
- Trust, meaning that the outcomes of an XAI method enable gaining confidence that the ML model acts as intended.
- Fairness, meaning that an explanation has to enable humans to ensure unbiased decisions of the employed ML models.
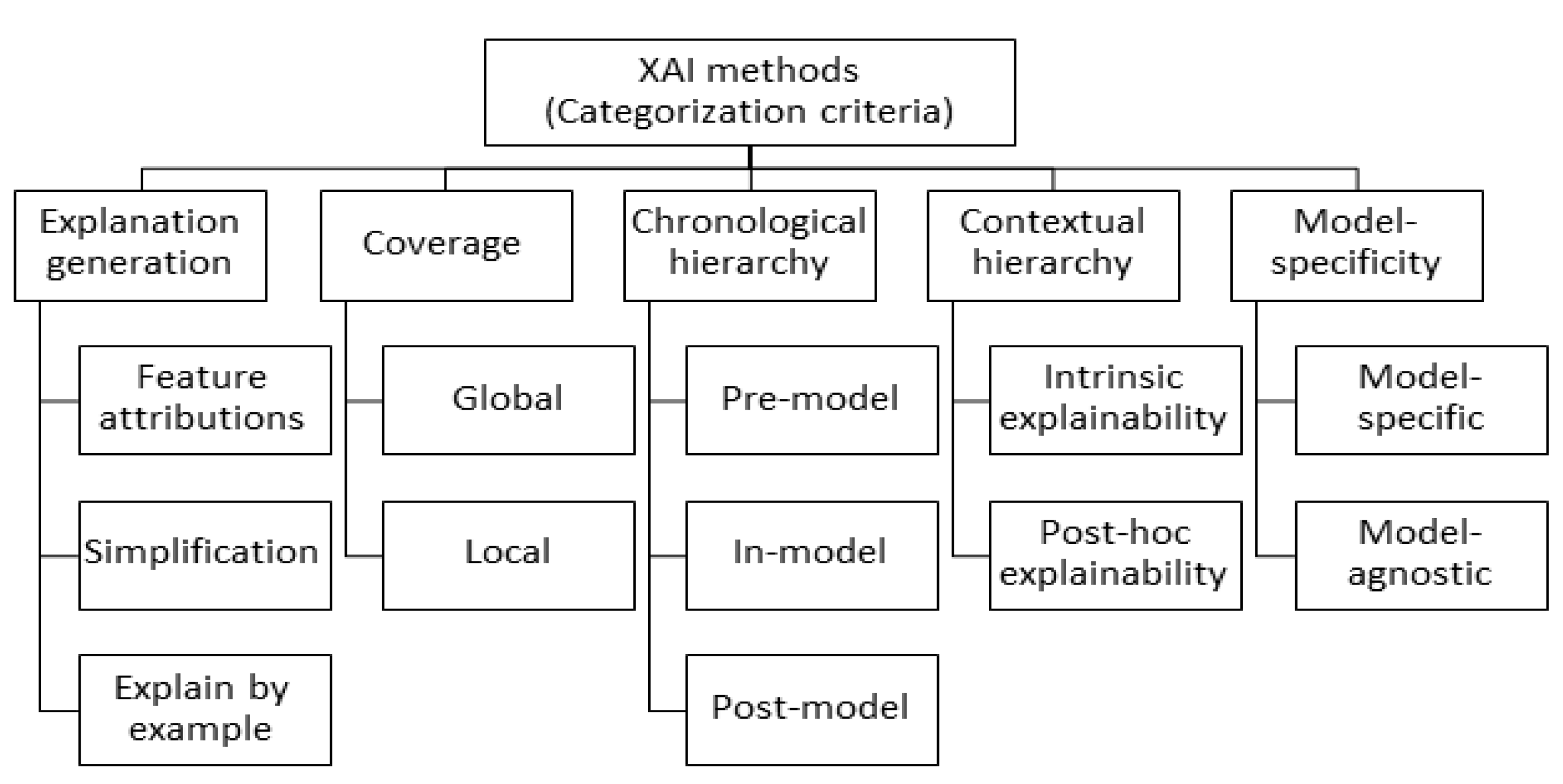
- Explanation generation. The explanation generation approach represents a crucial categorization dimension of XAI methods. The selection of a specific explanation form depends on the level of complexity of the explanation to be conveyed as well as the expertise level of the end user. Refs. [14,15] refer to certain explanation forms. First, feature attributions represents a commonly used explanation form where the relevance or the explanatory power of the features is computed with respect to predictions generated by the original model. Second, Simplification uses an interpretable simpler model to mimic and explain the behavior of the original model. Finally, explain-by-example constitutes another form of explanation where a prediction corresponding to a sample is explained by finding a similar sample with a counterpart prediction or a different sample with a similar prediction.
- Coverage. XAI methods are either global or local. Global explainability methods generate explanations that summarize patterns learned by an ML model over a large number of samples. These methods tend to understand the distribution of the prediction output space in terms of the input features [10]. In turn, local explainability methods study the interactions between patterns to better understand how a specific input led to a certain output in a given sample [16]. Consequently, local explainability methods generate explanations for a single sample or a group of similar samples.
- Chronological hierarchy. [10] groups XAI methods with respect to the point in time an XAI method is applied with respect to the modeling step. First, Pre-Model Explainability means that the XAI method is applied to the dataset itself regardless of the modeling step. Methods falling into this category tend to adopt exploratory and presentation perspectives of the input data. Second, In-Model Explainability means producing explanations as part of the model training process. Finally, Post-Model Explainability means producing explanations for predictions of an ML model as a post-momentum step after training the model on historical data.
- Contextual hierarchy. Another criterion is concerned with the ability of an ML model to provide explanations of the predictions by itself or a separate XAI method is applied. In this context, intrinsic explainability means having models that are interpretable by nature, i.e., models that show a high degree of transparency in terms of being simulatable, algorithmically transparent, and decomposable [14]. Linear models and simple decision trees provide common examples of ML models with inherent explainability. Post-hoc explainability targets complex models, which are not interpretable by design. XAI methods in this category are applied to a trained model to reverse engineer the reasoning process of the analyzed ML model.
- Model specificity. The influence of the executed ML model on the choice of an XAI method. Model-specific explanation methods are limited to specific models, as the XAI methods have been tailored towards specific model internals [10]. For example, Layer-wise Relevance Propagation (LRP) [1] and Saliency Maps [5] are specific XAI methods used in the context of models based on neural networks. In turn, model-agnostic methods are applicable to any ML model independent from its internals [16]. Model-agnostic methods incorporate predictors which untied to a particular type of black box, explanation, or data type [11]. LIME [2] and SHAP [3] are examples of the latter subcategory.
2.2. Evaluation of Explainability Methods
- Application-grounded evaluations imply the use of the ML-based solution in a real-life application, generate explanations for the users of this application, and evaluate the quality of an explanation in the context of real-life tasks.
- Human-grounded evaluations aim to evaluate general criteria with respect to explanation quality. Corresponding evaluations create simplified tasks that resemble the real-life application subject of the ML system. Humans involved in these experiments are less experienced than the ones involved in application-grounded evaluations.
- Functionally-grounded evaluations. In this category, no humans are involved. Instead, some formal definitions of interpretability are considered to form a proxy of explanation quality. Corresponding evaluations are objective (unlike the former categories) and depend on quantitative metrics [15]. These evaluations are suitable if the cost and time budgets for human-based experiments are limited or the explainability technique to be evaluated is not mature enough and still under iterative development.
2.3. Feature Selection
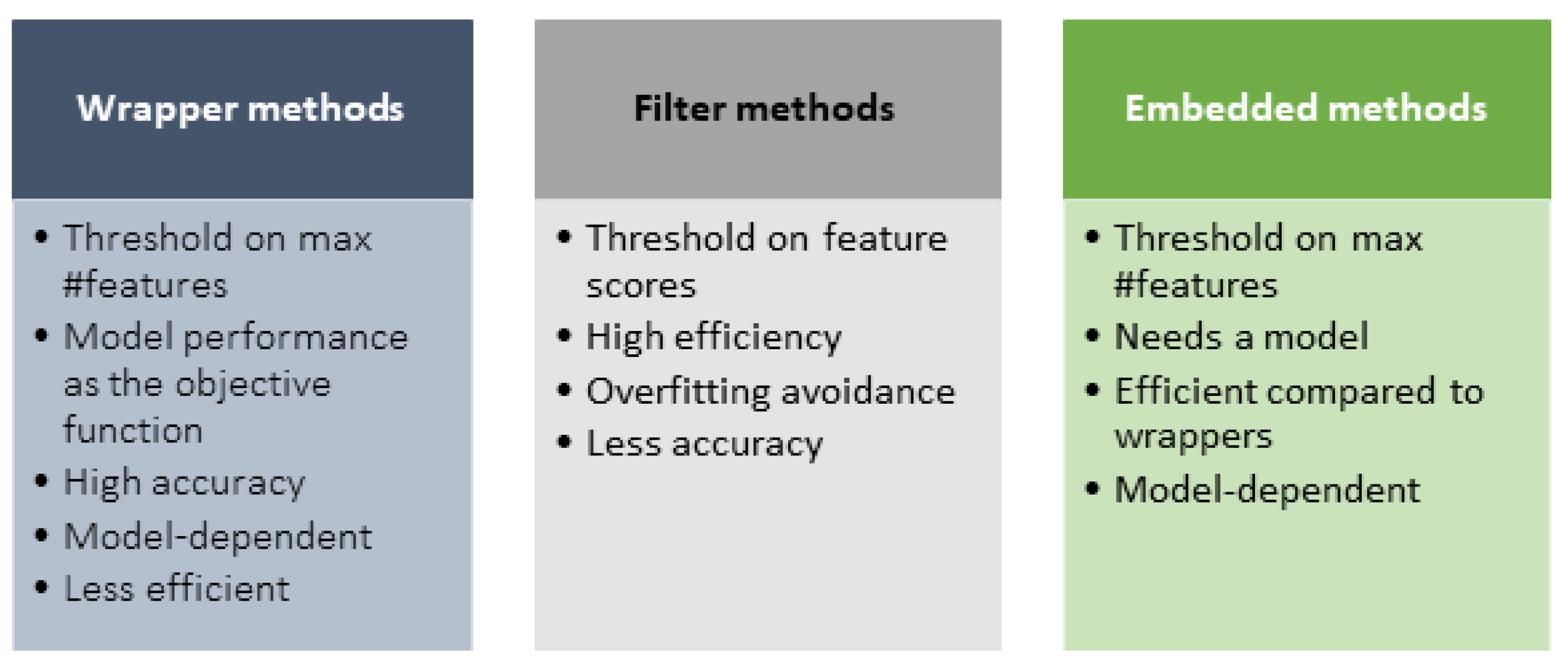
- Wrapper methods. A prediction model is wrapped into the optimal feature subset search step. The selected feature subset is the one that maximizes the performance of the used prediction model [20]. These methods apply a greedy approach for selecting a feature as they consider all possible features with respect to an evaluation criterion [21]. There is one category of methods in this family for which the method begins with an empty feature subset and proceeds forward by adding more features one by one until meeting a stopping criterion. There is another category in which the methods start with the entire feature set and remove features one by one till the predetermined stopping criterion is met. At each step, a new model is trained. Due to the slow computations associated with these methods, wrapper methods have proven to be less efficient despite being more accurate [18].
- Filter methods [20]. Each method belonging to this category utilizes a ranking criterion for ordering the feature set. A selection threshold is used to determine the relevance of a certain feature to the dependent variable. Dependencies between features are not essential to determine whether a particular feature is relevant, i.e., these methods do not take feature interactions into account. However, to be relevant, a feature has to be strongly related to the dependent variable [20]. Note that methods of this category do not rely on any underlying ML model [21].
- Embedded methods. The selection step is an inherent part of the training process when the model assigns some weights or ranks to the features. Common embedded methods include decision tree methods (e.g., CART) and linear models (e.g., linear regression).
3. Research Questions
- RQ1: Given an ML model, how can we identify a feature subset that has the potential to influence the prediction process of this model?
- RQ2: How to use the discovered ground truth as a basis to differentiate global XAI methods?
4. Proposed Approach
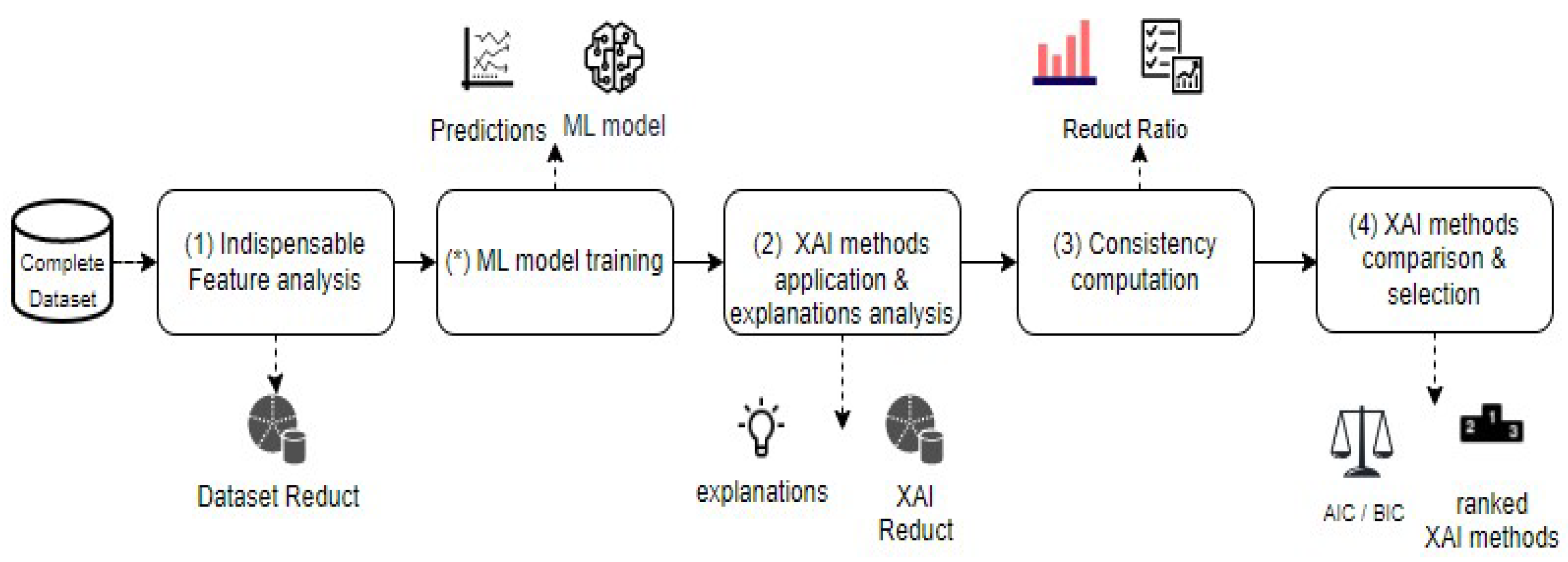
4.1. Stage 1: Indispensable Features Analysis
| Algorithm 1: Compute Dataset Reduct |
 |
4.2. Stage 2: Explainability Methods Application and Explanations Analysis
4.3. Stage 3: Consistency Computation
| Algorithm 2: Calculate Reduct Ratio | ||
| Input: | ||
| Output: | ||
| ▷ common features between reduct of the dataset and XAI method | ||
| ▷ scores of intersection sets as calculated by XAI method | ||
| ▷ each feature in the reduct of the dataset scores 1 | ||
4.4. Stage 4: Explainability Methods Comparison and Selection
5. Experimental Setup
5.1. Datasets
5.2. ML Predictive Models
5.3. Feature Selection Methods
- The feature selection method provides the feature subset together with a score indicating the rank of each feature. Therefore, we excluded the wrapper-based methods (cf. Section 2.3), as their available implementations only return a subset without any means to order the features or any kind of relevance scores.
- The feature selection method must not be biased towards any ML model. This criterion provides another reason to exclude wrapper-based methods. The latter tend to produce feature subsets that are biased towards the characteristics of the wrapped ML model. The same criterion may affect the results of embedded methods. To remedy this, we used two embedded methods that rely on different underlying ML models.
- The implementation of the feature selection method shall facilitate setting the selection threshold to the minimum or the number of selected features to the maximum. In this way, we can obtain an overview of the importance of the entire feature set or relevance scores.
- Whenever an ML model is an input to a feature selection method, it should be possible to input the model that was trained on the same dataset. Using the same model prevents fitting a new one as part of the feature selection process. Based on this, we try to ensure that the selection conditions are the same as the training conditions in our pipeline.
5.4. XAI Methods
6. Analysis and Lessons Learned
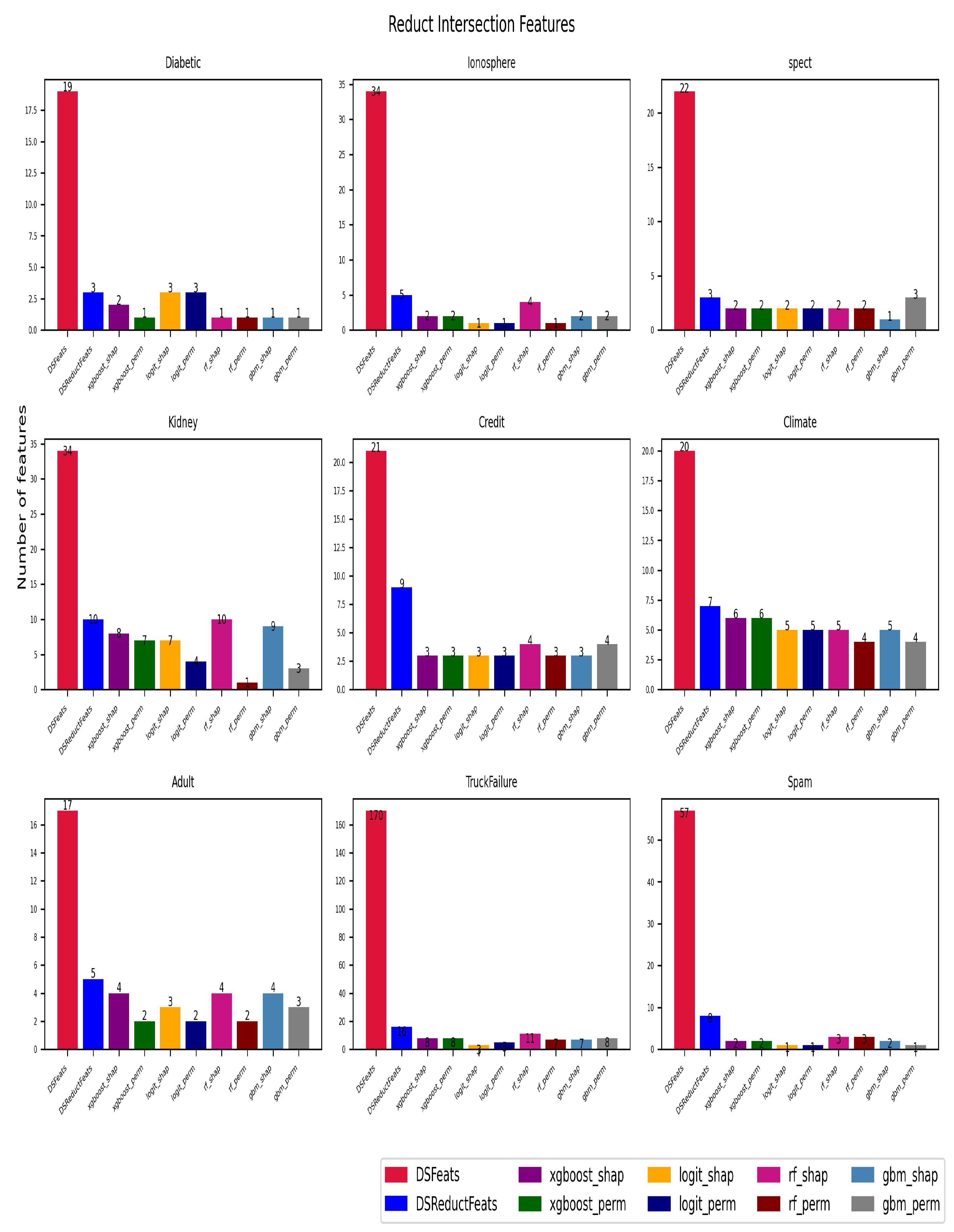
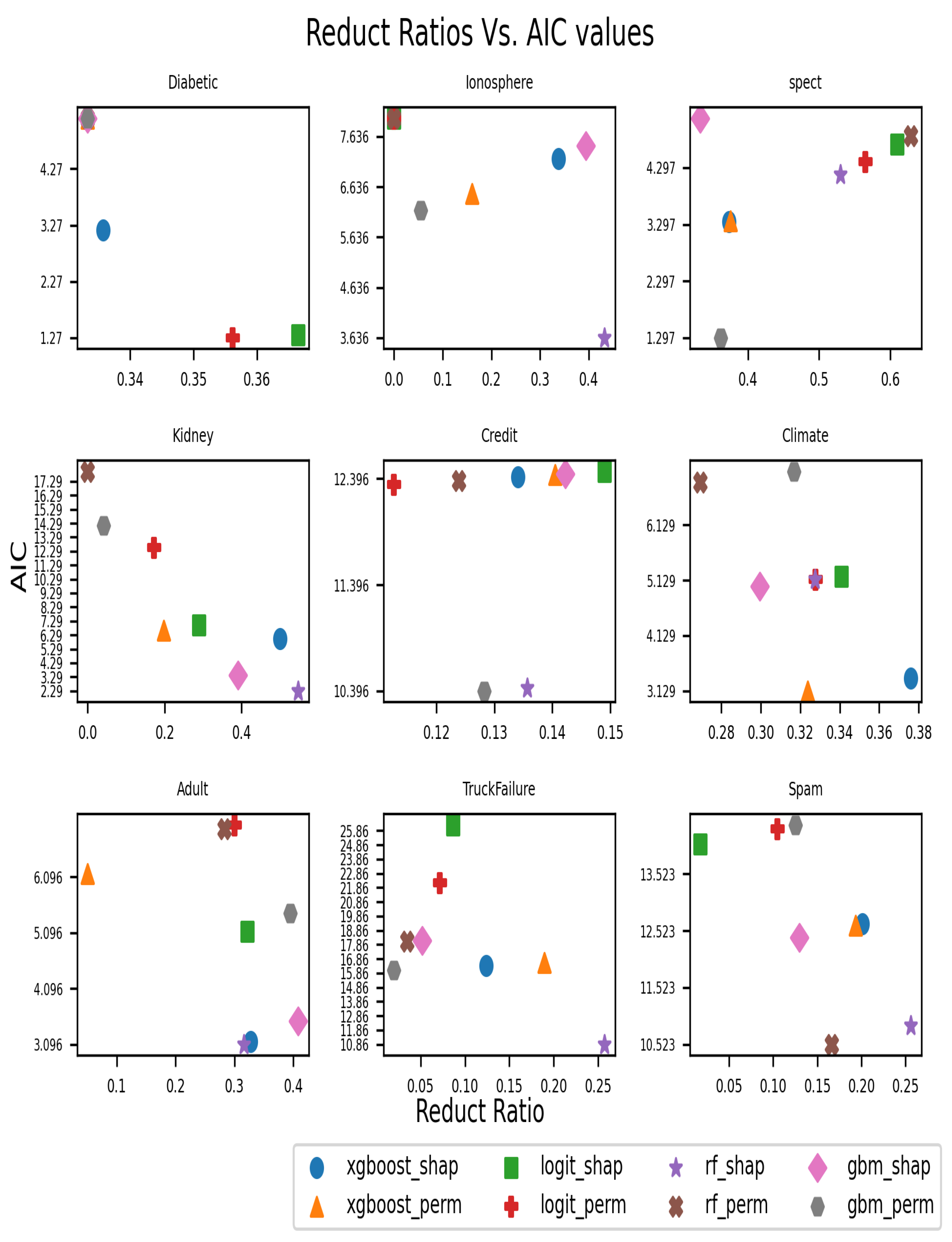
6.1. Experimental Results
6.2. Discussion
7. Related Work
8. Summary and Outlook
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| XAI | eXplainable Artificial Intelligence |
| ML | Machine Learning |
| LRP | Layer-wise Relevance Propagation |
| AIC | e Akaike Information Criterion |
| BIC | Bayesian Information Criterion |
| Logit | Logistic Regression |
| GBM | Gradient Boosting Machine |
| XGBoost | eXtreme Gradient Boosting |
| RF | Random Forest |
References
- Binder, A.; Montavon, G.; Lapuschkin, S.; Müller, K.R.; Samek, W. Layer-Wise Relevance Propagation for Neural Networks with Local Renormalization Layers. In Proceedings of the Artificial Neural Networks and Machine Learning—ICANN 2016, Barcelona, Spain, 6–9 September 2016; Lecture Notes in Computer Science; Villa, A.E., Masulli, P., Pons Rivero, A.J., Eds.; Springer International Publishing: Cham, Switzerland, 2016; Volume 9887, pp. 63–71. [Google Scholar] [CrossRef] [Green Version]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Why Should I Trust You? In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Krishnapuram, B., Shah, M., Smola, A., Aggarwal, C., Shen, D., Rastogi, R., Eds.; ACM: New York, NY, USA, 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Lundberg, S.; Lee, S. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: New York, NY, USA, 2017; pp. 4768–4777. [Google Scholar]
- Apley, D.; Zhu, J. Visualizing the effects of predictor variables in black box supervised learning models. J. R. Stat. Soc. B 2020, 82, 1059–1086. [Google Scholar] [CrossRef]
- Kindermans, P.J.; Hooker, S.; Adebayo, J.; Alber, M.; Schütt, K.T.; Dähne, S.; Erhan, D.; Kim, B. The (Un)reliability of Saliency Methods. In Explainable AI: Interpreting, Explaining and Visualizing Deep Learning; Lecture Notes in Computer Science; Samek, W., Montavon, G., Vedaldi, A., Hansen, L.K., Müller, K.R., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 11700, pp. 267–280. [Google Scholar] [CrossRef] [Green Version]
- Visani, G.; Bagli, E.; Chesani, F.; Poluzzi, A.; Capuzzo, D. Statistical stability indices for LIME: Obtaining reliable explanations for machine learning models. J. Oper. Res. Soc. 2021, 2, 91–101. [Google Scholar] [CrossRef]
- Velmurugan, M.; Ouyang, C.; Moreira, C.; Sindhgatta, R. Evaluating Fidelity of Explainable Methods for Predictive Process Analytics. In Intelligent Information Systems; Lecture Notes in Business Information Processing; Nurcan, S., Korthaus, A., Eds.; Springer International Publishing: Cham, Switzerland, 2021; Volume 424, pp. 64–72. [Google Scholar] [CrossRef]
- Yeh, C.K.; Hsieh, C.Y.; Suggala, A.; Inouye, D.I.; Ravikumar, P.K. On the (In)fidelity and Sensitivity of Explanations. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Hsieh, C.; Yeh, C.K.; Liu, X.; Ravikumar, P.; Kim, S.; Kumar, S.; Hsieh, C. Evaluations and Methods for Explanation through Robustness Analysis. In Proceedings of the 9th International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine Learning Interpretability: A Survey on Methods and Metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef] [Green Version]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A Survey of Methods for Explaining Black Box Models. ACM Comput. Surv. 2019, 51, 1–42. [Google Scholar] [CrossRef] [Green Version]
- Vilone, G.; Longo, L. Notions of explainability and evaluation approaches for explainable artificial intelligence. Inf. Fusion 2021, 76, 89–106. [Google Scholar] [CrossRef]
- Jesus, S.; Belém, C.; Balayan, V.; Bento, J.; Saleiro, P.; Bizarro, P.; Gama, J. How can I choose an explainer? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, Virtual, 3–10 March 2021; ACM: New York, NY, USA, 2021; pp. 805–815. [Google Scholar] [CrossRef]
- Barredo Arrieta, A.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- Zhou, J.; Gandomi, A.H.; Chen, F.; Holzinger, A. Evaluating the Quality of Machine Learning Explanations: A Survey on Methods and Metrics. Electronics 2021, 10, 593. [Google Scholar] [CrossRef]
- Belle, V.; Papantonis, I. Principles and Practice of Explainable Machine Learning. Front. Big Data 2021, 4, 688969. [Google Scholar] [CrossRef]
- Doshi-Velez, F.; Kim, B. Towards A Rigorous Science of Interpretable Machine Learning. arXiv 2017, arXiv:1702.08608. [Google Scholar] [CrossRef]
- Bolón-Canedo, V.; Sánchez-Maroño, N.; Alonso-Betanzos, A. A review of feature selection methods on synthetic data. Knowl. Inf. Syst. 2013, 34, 483–519. [Google Scholar] [CrossRef]
- Jovic, A.; Brkic, K.; Bogunovic, N. A review of feature selection methods with applications. In Proceedings of the 2015 38th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 25–29 May 2015; pp. 1200–1205. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Balogun, A.O.; Basri, S.; Mahamad, S.; Abdulkadir, S.J.; Almomani, M.A.; Adeyemo, V.E.; Al-Tashi, Q.; Mojeed, H.A.; Imam, A.A.; Bajeh, A.O. Impact of Feature Selection Methods on the Predictive Performance of Software Defect Prediction Models: An Extensive Empirical Study. Symmetry 2020, 12, 1147. [Google Scholar] [CrossRef]
- Pawlak, Z. Rough Sets: Theoretical Aspects of Reasoning about Data; Theory and Decision Library D; Springer: Dordrecht, The Netherlands, 1991; Volume v.9. [Google Scholar]
- Molnar, C. Interpretable Machine Learning: A Guide for Making Black Box Models Explainable. 2020. Available online: https://christophm.github.io/interpretable-ml-book/ (accessed on 27 February 2023).
- Elkhawaga, G.; Abuelkheir, M.; Reichert, M. XAI in the Context of Predictive Process Monitoring: An Empirical Analysis Framework. Algorithms 2022, 15, 199. [Google Scholar] [CrossRef]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Vrieze, S.I. Model selection and psychological theory: A discussion of the differences between the Akaike information criterion (AIC) and the Bayesian information criterion (BIC). Psychol. Methods 2012, 17, 228–243. [Google Scholar] [CrossRef] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2019. Available online: http://archive.ics.uci.edu/ml (accessed on 27 February 2023).
- Maalouf, M. Logistic regression in data analysis: An overview. Int. J. Data Anal. Tech. Strateg. 2011, 3, 281–299. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Raileanu, L.E.; Stoffel, K. Theoretical Comparison between the Gini Index and Information Gain Criteria. Ann. Math. Artif. Intell. 2004, 41, 77–93. [Google Scholar] [CrossRef]
- Urbanowicz, R.J.; Meeker, M.; La Cava, W.; Olson, R.S.; Moore, J.H. Relief-based feature selection: Introduction and review. J. Biomed. Inform. 2018, 85, 189–203. [Google Scholar] [CrossRef] [PubMed]
- Zdravevski, E.; Lameski, P.; Kulakov, A. Weight of evidence as a tool for attribute transformation in the preprocessing stage of supervised learning algorithms. In Proceedings of the 2011 International Joint Conference on Neural Networks, San Jose, CA, USA, 31 July–5 August 2011; pp. 181–188. [Google Scholar] [CrossRef]
- Cao, R.; González Manteiga, W.; Romo, J. Nonparametric Statistics; Springer International Publishing: Cham, Switzerland, 2016; Volume 175. [Google Scholar] [CrossRef] [Green Version]
- Lindman, H.R. Analysis of Variance in Experimental Design; Springer Texts in Statistics; Springer: New York, NY, USA, 1992. [Google Scholar] [CrossRef]
- Molnar, C.; Casalicchio, G.; Bischl, B. Quantifying Model Complexity via Functional Decomposition for Better Post-hoc Interpretability. In Communications in Computer and Information Science. Machine Learning and Knowledge Discovery in Databases; Cellier, P., Driessens, K., Eds.; Springer: Cham, Switzerland, 2020; Volume 1167, pp. 193–204. [Google Scholar] [CrossRef] [Green Version]
- Rosenfeld, A. Better Metrics for Evaluating Explainable Artificial Intelligence. In Proceedings of the AAMAS ’21: Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems, Online, 3–7 May 2021; pp. 45–50. [Google Scholar]
- Alvarez-Melis, D.; Jaakkola, T.S. On the Robustness of Interpretability Methods. arXiv 2018, arXiv:1806.08049. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | #Samples | #Features | % Pos Class | Attributes |
|---|---|---|---|---|
| Diabetic | 1151 | 19 | 0.52 | Numerical |
| Ionosphere | 430 | 34 | 0.5 | Numerical |
| Spect | 227 | 22 | 0.55 | Numerical |
| Kidney disease | 400 | 34 | 0.61 | Categorical & Numerical |
| Credit | 689 | 21 | 0.55 | Categorical & Numerical |
| Climate | 180 | 20 | 0.5 | Numerical |
| Adult | 28,533 | 17 | 0.5 | Categorical & Numerical |
| Truck failures | 17,352 | 170 | 0.5 | Numerical |
| Spam | 4938 | 57 | 0.5 | Numerical |
| ML Model | Hyperparameter | Search Space |
|---|---|---|
| Logit | Regularization (c) | |
| XGBoost | Learning rate | |
| Min child weight | ||
| Subsample | ||
| Max tree depth | ||
| Colsample by tree | ||
| n estimators | 500 | |
| GBM | Learning rate | |
| n estimators | 500 | |
| RF | Max features | |
| n estimators | 500 |
| Dataset | Testing Shape | Logit | XGBoost | GBM | RF | ||||
|---|---|---|---|---|---|---|---|---|---|
| F1_score | AUC | F1_score | AUC | F1_score | AUC | F1_score | AUC | ||
| Diabetic | (231,19) | 0.76395 | 0.76287 | 0.74286 | 0.72978 | 0.71429 | 0.6917 | 0.69828 | 0.69774 |
| Ionosphere | (84,34) | 0.88889 | 0.87896 | 0.95238 | 0.93665 | 0.96078 | 0.95645 | 0.95146 | 0.94174 |
| Spect | (46,22) | 0.69767 | 0.71739 | 0.66667 | 0.67391 | 0.625 | 0.60869 | 0.625 | 0.60869 |
| Kidney disease | (80,34) | 1.0 | 1.0 | 1.0 | 1.0 | 0.9836 | 0.99 | 0.98305 | 0.98333 |
| Credit | (138,21) | 0.86667 | 0.85833 | 0.8961 | 0.88397 | 0.84768 | 0.83526 | 0.87898 | 0.85897 |
| Climate | (36,20) | 0.88889 | 0.76154 | 0.94545 | 0.85 | 0.86792 | 0.7423 | 0.90566 | 0.81154 |
| Adult | (5707,17) | 0.7116 | 0.759 | 0.79306 | 0.82322 | 0.77386 | 0.80759 | 0.75693 | 0.79337 |
| Truck failures | (3471,170) | 0.82264 | 0.89058 | 0.89681 | 0.93157 | 0.8784 | 0.93468 | 0.88117 | 0.93333 |
| Spam | (696,57) | 0.91515 | 0.92134 | 0.95149 | 0.95505 | 0.8826 | 0.88777 | 0.89813 | 0.90396 |
| Dataset | #Features at Dataset Reduct | XGBoost | Logit | RF | GBM | ||||
|---|---|---|---|---|---|---|---|---|---|
| SHAP | Perm | SHAP | Perm | SHAP | Perm | SHAP | Perm | ||
| Diabetic | 3 | 2 | 1 | 3 | 3 | 1 | 1 | 1 | 1 |
| Ionosphere | 5 | 2 | 2 | 1 | 1 | 4 | 1 | 2 | 2 |
| Spect | 3 | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 3 |
| Kidney | 10 | 8 | 7 | 7 | 4 | 10 | 1 | 9 | 3 |
| Credit | 9 | 3 | 3 | 3 | 3 | 4 | 3 | 3 | 4 |
| Climate | 7 | 6 | 6 | 5 | 5 | 5 | 4 | 5 | 4 |
| Adult | 5 | 4 | 2 | 3 | 2 | 4 | 2 | 4 | 3 |
| Truck Failures | 16 | 8 | 8 | 3 | 5 | 11 | 7 | 7 | 8 |
| Spam | 8 | 2 | 2 | 1 | 1 | 3 | 3 | 2 | 1 |
| Dataset | XGBoost | Logit | RF | GBM | ||||
|---|---|---|---|---|---|---|---|---|
| SHAP | Perm | SHAP | Perm | SHAP | Perm | SHAP | Perm | |
| Diabetic | 0.3358 | 0.3333 | 0.3665 | 0.3562 | 0.3333 | 0.3333 | 0.3333 | 0.3333 |
| Ionosphere | 0.3382 | 0.1599 | 0.0 | 0.0 | 0.4329 | 0.0 | 0.3945 | 0.0552 |
| Spect | 0.3736 | 0.3756 | 0.6099 | 0.5652 | 0.5297 | 0.6291 | 0.3333 | 0.362 |
| Kidney | 0.4995 | 0.1983 | 0.2889 | 0.1724 | 0.5473 | 0.0 | 0.3905 | 0.04149 |
| Credit | 0.1341 | 0.1405 | 0.149 | 0.113 | 0.1357 | 0.1239 | 0.1423 | 0.1283 |
| Climate | 0.3761 | 0.3237 | 0.3408 | 0.3278 | 0.3276 | 0.2695 | 0.2995 | 0.3169 |
| Adult | 0.3272 | 0.0508 | 0.3217 | 0.2999 | 0.3159 | 0.2831 | 0.4084 | 0.3949 |
| Truck Failures | 0.1237 | 0.1896 | 0.0865 | 0.0718 | 0.2572 | 0.0348 | 0.0517 | 0.0202 |
| Spam | 0.2012 | 0.1931 | 0.0175 | 0.1047 | 0.2562 | 0.1659 | 0.1294 | 0.1249 |
| Dataset | XGBoost | Logit | RF | GBM | ||||
|---|---|---|---|---|---|---|---|---|
| SHAP | Perm | SHAP | Perm | SHAP | Perm | SHAP | Perm | |
| Diabetic | 3.1804 | 5.1699 | 1.3173 | 1.2706 | 5.1699 | 5.1699 | 5.1699 | 5.1699 |
| Ionosphere | 7.1912 | 6.5031 | 8.0 | 8.0 | 3.6365 | 8.0 | 7.4475 | 6.1638 |
| Spect | 3.3498 | 3.3587 | 4.7162 | 4.4033 | 4.1767 | 4.8619 | 5.1699 | 1.2969 |
| Kidney | 5.9973 | 6.6378 | 6.984 | 12.5459 | 2.2866 | 18.0 | 3.4284 | 14.1223 |
| Credit | 12.4154 | 12.4368 | 12.4656 | 12.345 | 10.4208 | 12.381 | 12.4427 | 10.3962 |
| Climate | 3.3613 | 3.1287 | 5.2023 | 5.1459 | 5.1452 | 6.9059 | 5.0272 | 7.0998 |
| Adult | 3.1435 | 6.1503 | 5.1199 | 7.0289 | 3.0958 | 6.9604 | 3.5144 | 5.4496 |
| Truck Failures | 16.3809 | 16.6064 | 26.2609 | 22.2149 | 10.8579 | 18.1023 | 18.1531 | 16.0588 |
| Spam | 12.6483 | 12.6191 | 14.0508 | 14.3191 | 10.8541 | 10.523 | 12.3999 | 14.3853 |
| Dataset | XGBoost | Logit | RF | GBM | ||||
|---|---|---|---|---|---|---|---|---|
| SHAP | Perm | SHAP | Perm | SHAP | Perm | SHAP | Perm | |
| Diabetic | 11.0259 | 20.8609 | 1.3173 | 1.2706 | 20.8609 | 20.8609 | 20.8609 | 20.8609 |
| Ionosphere | 26.4699 | 25.7819 | 33.7051 | 33.7051 | 10.0627 | 33.7051 | 26.7263 | 25.4426 |
| Spect | 8.8497 | 8.8586 | 10.216 | 9.9031 | 9.6765 | 10.362 | 16.1696 | 1.2969 |
| Kidney | 18.6411 | 25.6035 | 25.9499 | 50.4775 | 2.2866 | 74.8974 | 9.7504 | 58.3758 |
| Credit | 55.0508 | 55.0723 | 55.101 | 54.9805 | 45.9503 | 55.0169 | 55.0782 | 45.9257 |
| Climate | 8.5312 | 8.2986 | 15.5421 | 15.4858 | 15.4851 | 22.4157 | 15.367 | 22.6096 |
| Adult | 15.6218 | 43.5855 | 30.0767 | 44.4641 | 15.5742 | 44.3956 | 15.9928 | 30.4064 |
| Truck Failures | 110.4675 | 110.6929 | 179.1517 | 151.584 | 69.662 | 123.9498 | 124.0 | 110.1454 |
| Spam | 68.3225 | 68.2933 | 79.004 | 79.2723 | 57.2492 | 56.9189 | 68.0741 | 79.3385 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elkhawaga, G.; Elzeki, O.; Abuelkheir, M.; Reichert, M. Evaluating Explainable Artificial Intelligence Methods Based on Feature Elimination: A Functionality-Grounded Approach. Electronics 2023, 12, 1670. https://doi.org/10.3390/electronics12071670
Elkhawaga G, Elzeki O, Abuelkheir M, Reichert M. Evaluating Explainable Artificial Intelligence Methods Based on Feature Elimination: A Functionality-Grounded Approach. Electronics. 2023; 12(7):1670. https://doi.org/10.3390/electronics12071670
Chicago/Turabian StyleElkhawaga, Ghada, Omar Elzeki, Mervat Abuelkheir, and Manfred Reichert. 2023. "Evaluating Explainable Artificial Intelligence Methods Based on Feature Elimination: A Functionality-Grounded Approach" Electronics 12, no. 7: 1670. https://doi.org/10.3390/electronics12071670