
Sequence Segmentation Attention Network for Skeleton-Based Action Recognition
Abstract
:1. Introduction
- In this paper, we propose a segmentation and encoding strategy for a skeleton sequence, which links joints in consecutive frames into a series of sequences and inserts a position-coding module to obtain spatio-temporal features.
- We suggest using an internal self-attention block to record pertinent information between various joints in adjacent frames and an external segment attention block to merge all actions.
- The validity of each module was established by ablation experiments. On two large datasets, NTU RGB+D and NTU RGB+D 120, our model performs superbly.
2. Related Work
2.1. Skeleton-Based Action Recognition
2.2. Attention Mechanism
3. Methods
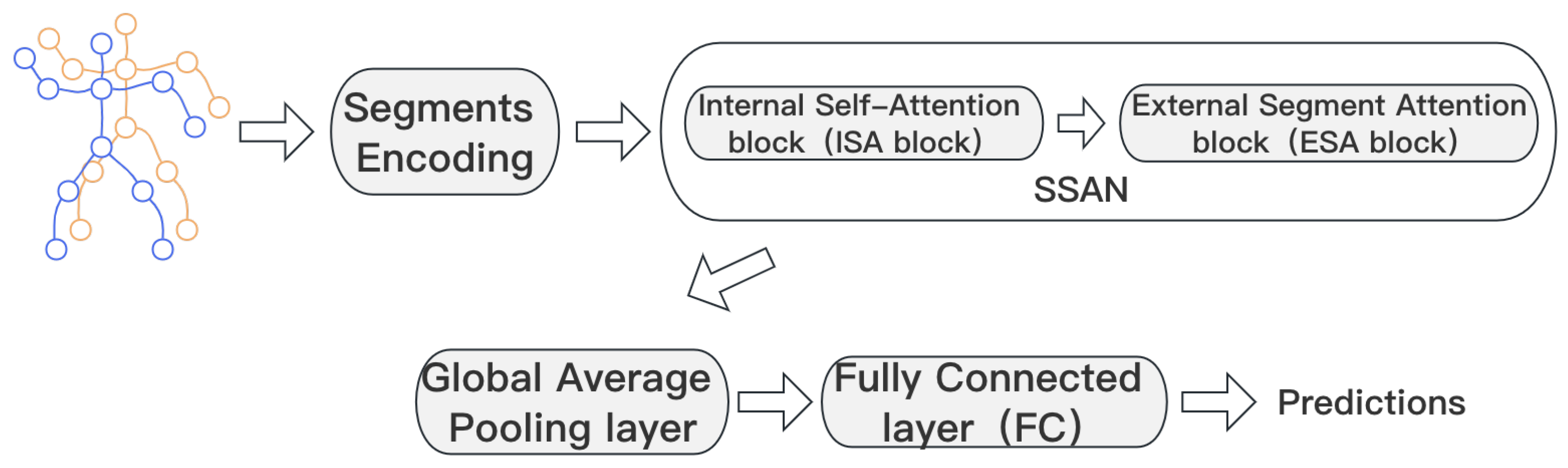
3.1. Overall Architecture
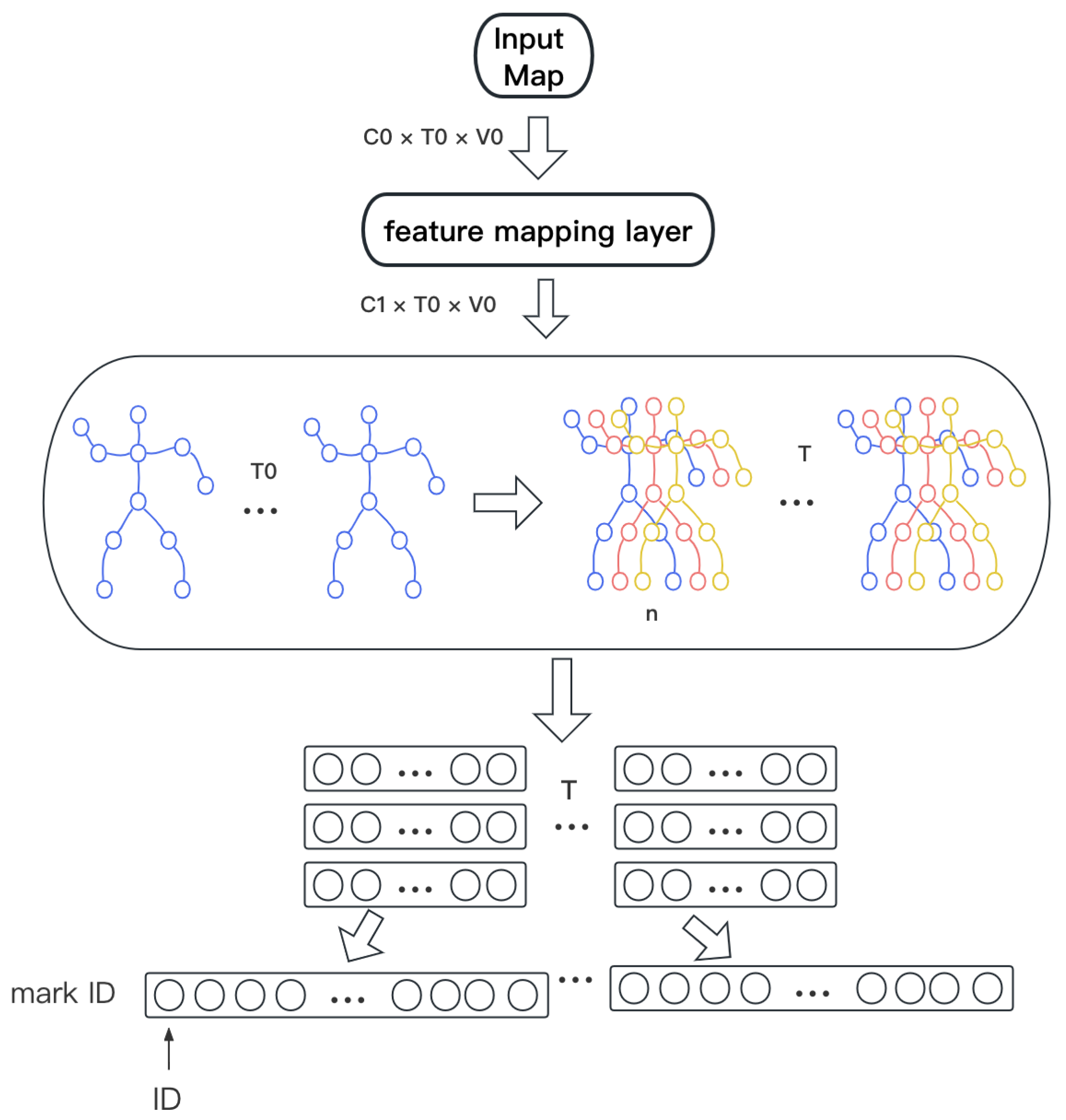
3.2. Segments Encoding
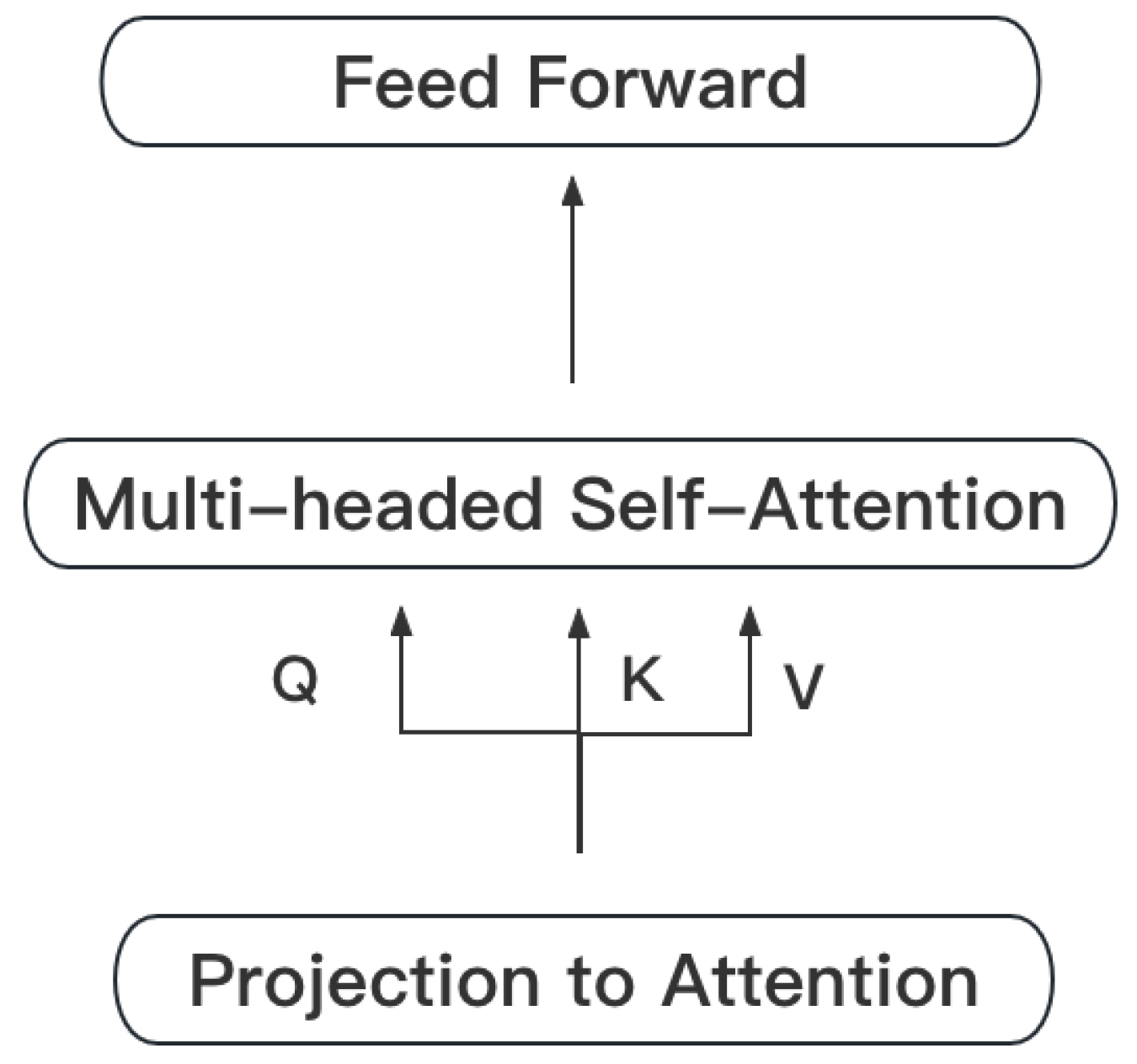
3.3. Internal Self-Attention
3.4. External Segment Attention
4. Experimental Results and Discussion
4.1. Datasets
4.2. Experimental Setting
4.3. Ablation Study
4.3.1. Ablation Study for SSAN
4.3.2. Impact of the Variable n
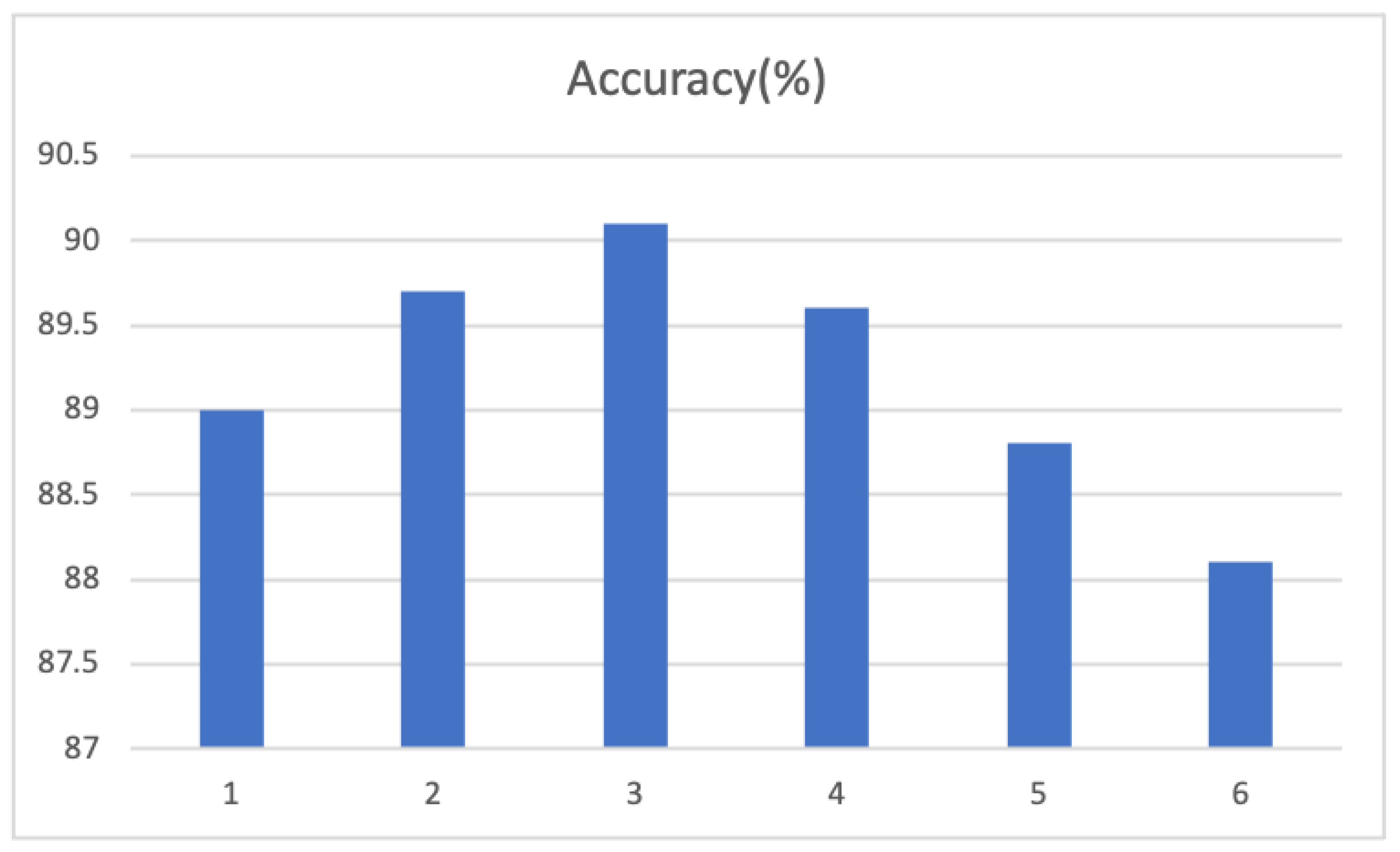
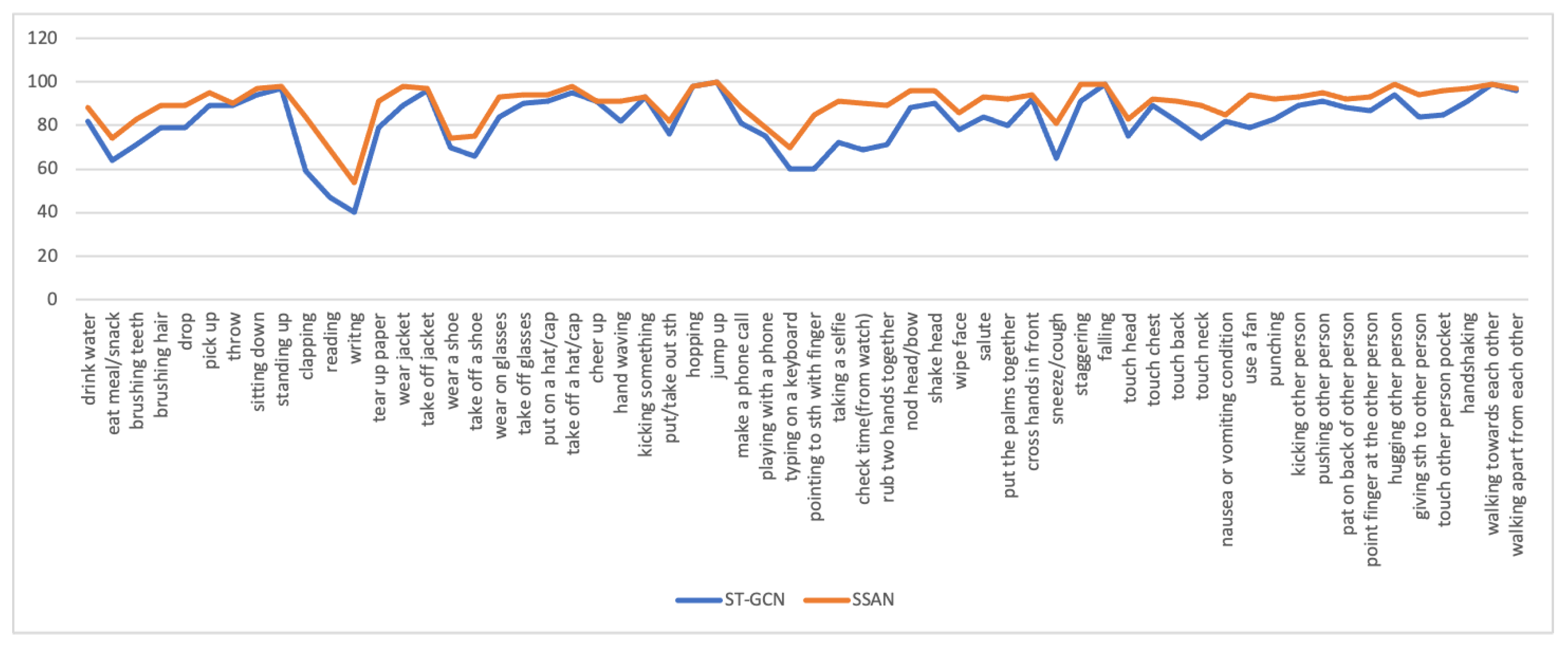
4.3.3. Accuracy of Each Class
4.4. Comparison with the Most Advanced Methods
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 172–186. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hussein, M.E.; Torki, M.; Gowayyed, M.A.; El-Saban, M. Human Action Recognition Using a Temporal Hierarchy of Covariance Descriptors on 3D Joint Locations. In Proceedings of the IJCAI 2013, 23rd International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; Rossi, F., Ed.; IJCAI/AAAI: Palo Alto, CA, USA, 2013; pp. 2466–2472. [Google Scholar]
- Vemulapalli, R.; Arrate, F.; Chellappa, R. Human Action Recognition by Representing 3D Skeletons as Points in a Lie Group. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2014, Columbus, OH, USA, 23–28 June 2014; IEEE Computer Society: Washington, DC, USA, 2014; pp. 588–595. [Google Scholar] [CrossRef]
- Fernando, B.; Gavves, E.; Oramas, J.M.; Ghodrati, A.; Tuytelaars, T. Modeling video evolution for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, 7–12 June 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 5378–5387. [Google Scholar] [CrossRef]
- Du, Y.; Fu, Y.; Wang, L. Skeleton based action recognition with convolutional neural network. In Proceedings of the 3rd IAPR Asian Conference on Pattern Recognition, ACPR 2015, Kuala Lumpur, Malaysia, 3–6 November 2015; IEEE: New York, NY, USA, 2015; pp. 579–583. [Google Scholar] [CrossRef]
- Liu, H.; Tu, J.; Liu, M. Two-Stream 3D Convolutional Neural Network for Skeleton-Based Action Recognition. arXiv 2017, arXiv:1705.08106. [Google Scholar]
- Li, B.; Dai, Y.; Cheng, X.; Chen, H.; Lin, Y.; He, M. Skeleton based action recognition using translation-scale invariant image mapping and multi-scale deep CNN. In Proceedings of the 2017 IEEE International Conference on Multimedia & Expo Workshops, ICME Workshops, Hong Kong, China, 10–14 July 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 601–604. [Google Scholar] [CrossRef]
- Du, Y.; Wang, W.; Wang, L. Hierarchical recurrent neural network for skeleton based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, 7–12 June 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 1110–1118. [Google Scholar] [CrossRef] [Green Version]
- Shahroudy, A.; Liu, J.; Ng, T.; Wang, G. NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 1010–1019. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Shahroudy, A.; Xu, D.; Wang, G. Spatio-Temporal LSTM with Trust Gates for 3D Human Action Recognition. In Proceedings of the Computer Vision—ECCV 2016—14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part III; Lecture Notes in Computer Science. Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9907, pp. 816–833. [Google Scholar] [CrossRef] [Green Version]
- Yan, S.; Xiong, Y.; Lin, D. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition. In Proceedings of the Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th Innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, Louisiana, USA, 2–7 February 2018; McIlraith, S.A., Weinberger, K.Q., Eds.; AAAI Press: Menlo Park, CA, USA, 2018; pp. 7444–7452. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-Stream Adaptive Graph Convolutional Networks for Skeleton-Based Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; Computer Vision Foundation/IEEE: New York, NY, USA, 2019; pp. 12026–12035. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z. Microsoft Kinect Sensor and Its Effect. IEEE Multim. 2012, 19, 4–10. [Google Scholar] [CrossRef] [Green Version]
- Toshev, A.; Szegedy, C. DeepPose: Human Pose Estimation via Deep Neural Networks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2014, Columbus, OH, USA, 23–28 June 2014; IEEE Computer Society: Washington, DC, USA, 2014; pp. 1653–1660. [Google Scholar] [CrossRef] [Green Version]
- Evangelidis, G.D.; Singh, G.; Horaud, R. Skeletal Quads: Human Action Recognition Using Joint Quadruples. In Proceedings of the 22nd International Conference on Pattern Recognition, ICPR 2014, Stockholm, Sweden, 24–28 August 2014; IEEE Computer Society: Washington, DC, USA, 2014; pp. 4513–4518. [Google Scholar] [CrossRef] [Green Version]
- Luo, J.; Wang, W.; Qi, H. Group Sparsity and Geometry Constrained Dictionary Learning for Action Recognition from Depth Maps. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2013, Sydney, Australia, 1–8 December 2013; IEEE Computer Society: Washington, DC, USA, 2013; pp. 1809–1816. [Google Scholar] [CrossRef]
- Rahmani, H.; Mian, A.S. Learning a non-linear knowledge transfer model for cross-view action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, 7–12 June 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 2458–2466. [Google Scholar] [CrossRef]
- Hu, J.; Zheng, W.; Lai, J.; Zhang, J. Jointly Learning Heterogeneous Features for RGB-D Activity Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2186–2200. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rahmani, H.; Mahmood, A.; Huynh, D.Q.; Mian, A.S. Real time action recognition using histograms of depth gradients and random decision forests. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Steamboat Springs, CO, USA, 24–26 March 2014; IEEE Computer Society: Washington, DC, USA, 2014; pp. 626–633. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Liu, Z.; Wu, Y.; Yuan, J. Learning Actionlet Ensemble for 3D Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 914–927. [Google Scholar] [CrossRef] [PubMed]
- Song, S.; Lan, C.; Xing, J.; Zeng, W.; Liu, J. An End-to-End Spatio-Temporal Attention Model for Human Action Recognition from Skeleton Data. In Proceedings of the Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Singh, S., Markovitch, S., Eds.; AAAI Press: Menlo Park, CA, USA, 2017; pp. 4263–4270. [Google Scholar]
- Zhang, P.; Lan, C.; Xing, J.; Zeng, W.; Xue, J.; Zheng, N. View Adaptive Recurrent Neural Networks for High Performance Human Action Recognition from Skeleton Data. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, 22–29 October 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 2136–2145. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Li, W.; Cook, C.; Zhu, C.; Gao, Y. Independently Recurrent Neural Network (IndRNN): Building a Longer and Deeper RNN. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; Computer Vision Foundation/IEEE Computer Society: Washington, DC, USA, 2018; pp. 5457–5466. [Google Scholar] [CrossRef] [Green Version]
- Perez, M.; Liu, J.; Kot, A.C. Interaction Relational Network for Mutual Action Recognition. IEEE Trans. Multim. 2022, 24, 366–376. [Google Scholar] [CrossRef]
- Ke, Q.; Bennamoun, M.; An, S.; Sohel, F.A.; Boussaïd, F. A New Representation of Skeleton Sequences for 3D Action Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 4570–4579. [Google Scholar] [CrossRef] [Green Version]
- Liu, M.; Liu, H.; Chen, C. Enhanced skeleton visualization for view invariant human action recognition. Pattern Recognit. 2017, 68, 346–362. [Google Scholar] [CrossRef]
- Zhao, R.; Ali, H.; van der Smagt, P. Two-stream RNN/CNN for action recognition in 3D videos. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2017, Vancouver, BC, Canada, 24–28 September 2017; IEEE: New York, NY, USA, 2017; pp. 4260–4267. [Google Scholar] [CrossRef] [Green Version]
- Zhou, T.; Wang, W.; Liu, S.; Yang, Y.; Gool, L.V. Differentiable Multi-Granularity Human Representation Learning for Instance-Aware Human Semantic Parsing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Nashville, TN, USA, 19–25 June 2021; Computer Vision Foundation/IEEE: New York, NY, USA, 2021; pp. 1622–1631. [Google Scholar] [CrossRef]
- Obinata, Y.; Yamamoto, T. Temporal Extension Module for Skeleton-Based Action Recognition. In Proceedings of the 25th International Conference on Pattern Recognition, ICPR 2020, Milan, Italy, 10–15 January 2021; IEEE: New York, NY, USA, 2020; pp. 534–540. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, H.; Chen, Z.; Wang, Z.; Ouyang, W. Disentangling and Unifying Graph Convolutions for Skeleton-Based Action Recognition. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; Computer Vision Foundation/IEEE: New York, NY, USA, 2020; pp. 140–149. [Google Scholar] [CrossRef]
- Li, B.; Li, X.; Zhang, Z.; Wu, F. Spatio-Temporal Graph Routing for Skeleton-Based Action Recognition. In Proceedings of the The Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, The Thirty-First Innovative Applications of Artificial Intelligence Conference, IAAI 2019, The Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2019, Honolulu, HI, USA, 27 January–1 February; AAAI Press: Menlo Park, CA, USA, 2019; pp. 8561–8568. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Xu, C.; Tao, D. Context Aware Graph Convolution for Skeleton-Based Action Recognition. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; Computer Vision Foundation/IEEE: New York, NY, USA, 2020; pp. 14321–14330. [Google Scholar] [CrossRef]
- Ye, F.; Pu, S.; Zhong, Q.; Li, C.; Xie, D.; Tang, H. Dynamic GCN: Context-enriched Topology Learning for Skeleton-based Action Recognition. In Proceedings of the MM ’20: The 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; Chen, C.W., Cucchiara, R., Hua, X., Qi, G., Ricci, E., Zhang, Z., Zimmermann, R., Eds.; ACM: New York, NY, USA, 2020; pp. 55–63. [Google Scholar] [CrossRef]
- Cheng, K.; Zhang, Y.; He, X.; Chen, W.; Cheng, J.; Lu, H. Skeleton-Based Action Recognition with Shift Graph Convolutional Network. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; Computer Vision Foundation/IEEE: New York, NY, USA, 2020; pp. 180–189. [Google Scholar] [CrossRef]
- Lin, Z.; Feng, M.; dos Santos, C.N.; Yu, M.; Xiang, B.; Zhou, B.; Bengio, Y. A Structured Self-Attentive Sentence Embedding. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Zhou, T.; Li, J.; Wang, S.; Tao, R.; Shen, J. MATNet: Motion-Attentive Transition Network for Zero-Shot Video Object Segmentation. IEEE Trans. Image Process. 2020, 29, 8326–8338. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.B.; Rossi, R.A.; Kong, X. Graph Classification using Structural Attention. In Proceedings of the Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2018, London, UK, 19–23 August 2018; Guo, Y., Farooq, F., Eds.; ACM: New York, NY, USA, 2018; pp. 1666–1674. [Google Scholar] [CrossRef]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zhang, J.; Shi, X.; Xie, J.; Ma, H.; King, I.; Yeung, D. GaAN: Gated Attention Networks for Learning on Large and Spatiotemporal Graphs. In Proceedings of the Thirty-Fourth Conference on Uncertainty in Artificial Intelligence, UAI 2018, Monterey, CA, USA, 6–10 August 2018; Globerson, A., Silva, R., Eds.; AUAI Press: Arlington, VA, USA, 2018; pp. 339–349. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Decoupled Spatial-Temporal Attention Network for Skeleton-Based Action-Gesture Recognition. In Proceedings of the Computer Vision—ACCV 2020—15th Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020; Revised Selected Papers, Part V. Ishikawa, H., Liu, C., Pajdla, T., Shi, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2020. Lecture Notes in Computer Science. Volume 12626, pp. 38–53. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Liu, J.; Shahroudy, A.; Perez, M.; Wang, G.; Duan, L.; Kot, A.C. NTU RGB+D 120: A Large-Scale Benchmark for 3D Human Activity Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2684–2701. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, L.; Wang, M.; Ni, B.; Wang, H.; Yang, J.; Zhang, W. 3D Human Action Representation Learning via Cross-View Consistency Pursuit. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Nashville, TN, USA, 19–25 June 2021; Computer Vision Foundation/IEEE: New York, NY, USA, 2021; pp. 4741–4750. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, Z.; Yuan, C.; Li, B.; Deng, Y.; Hu, W. Channel-wise Topology Refinement Graph Convolution for Skeleton-Based Action Recognition. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10–17 October 2021; IEEE: New York, NY, USA, 2021; pp. 13339–13348. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SA | n = 1 | n = 3 | PE | ESA | X-Sub (%) | X-View (%) |
|---|---|---|---|---|---|---|
| yes | yes | - | - | - | 89.7 | 94.6 |
| - | yes | - | yes | yes | 90.1 | 94.9 |
| - | - | yes | - | yes | 90.0 | 95.1 |
| - | - | yes | yes | - | 90.1 | 95.2 |
| - | - | yes | yes | yes | 92.9 | 96.7 |
| Methods | Param (×10) | X-Sub (%) | X-View (%) | X-Sub120 (%) | X-Set120 (%) |
|---|---|---|---|---|---|
| 3s-CrossSCLR [43] | - | 86.2 | 92.5 | 80.5 | 80.4 |
| ST-LSTM [10] | - | 69.2 | 77.7 | - | - |
| ST-GCN [11] | 3.1 | 81.5 | 88.3 | - | - |
| 2s-AGCN [12] | 6.9 | 88.5 | 95.1 | 82.9 | 84.9 |
| Shift-GCN [34] | - | 90.7 | 96.5 | 85.9 | 87.6 |
| Dynamic-GCN [33] | 14.4 | 91.5 | 96.0 | 85.9 | 87.6 |
| CTR-GCN [44] | 5.8 | 92.4 | 96.8 | 88.9 | 90.6 |
| SSAN(Ours) | 5.7 | 92.9 | 96.7 | 88.9 | 90.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Cai, H. Sequence Segmentation Attention Network for Skeleton-Based Action Recognition. Electronics 2023, 12, 1549. https://doi.org/10.3390/electronics12071549
Zhang Y, Cai H. Sequence Segmentation Attention Network for Skeleton-Based Action Recognition. Electronics. 2023; 12(7):1549. https://doi.org/10.3390/electronics12071549
Chicago/Turabian StyleZhang, Yujie, and Haibin Cai. 2023. "Sequence Segmentation Attention Network for Skeleton-Based Action Recognition" Electronics 12, no. 7: 1549. https://doi.org/10.3390/electronics12071549