
Remote Sensing Image Road Extraction Network Based on MSPFE-Net
Abstract
:1. Introduction
- A multi-level strip pooling module (MSPM) was designed to extract global context information to ensure the connectivity and integrity of road extraction.
- A feature enhancement module (FEM) was proposed, which mainly enhanced the clarity and local details of the road
- MSPFE-Net is designed and implemented for road extraction tasks. The effectiveness of MSPFE-Net was verified on the Massachusetts Roads Dataset.
2. Related Works
2.1. Traditional Type
2.2. Type of Deep Learning
3. Methods
3.1. MSPFE-Net Model
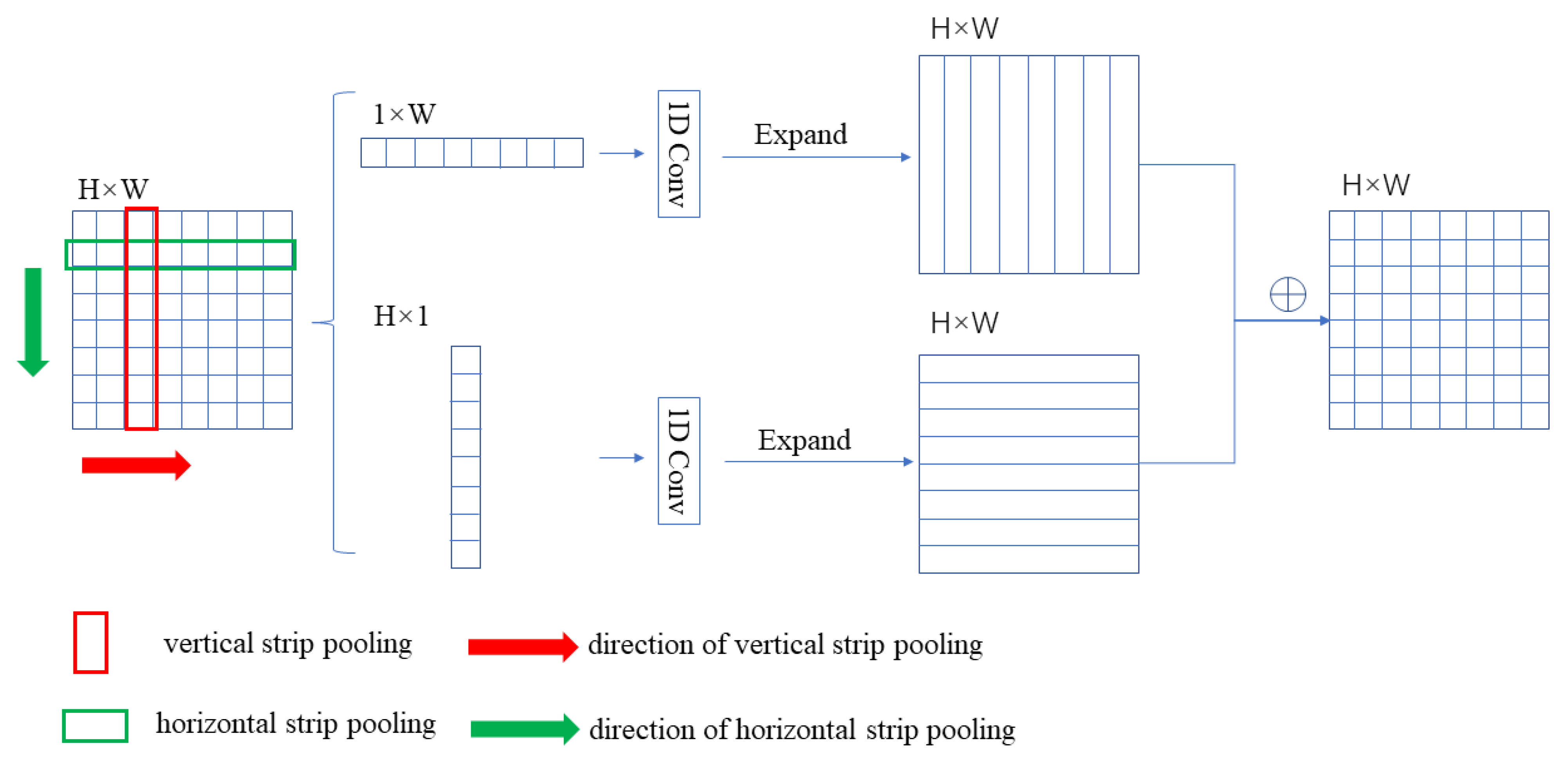
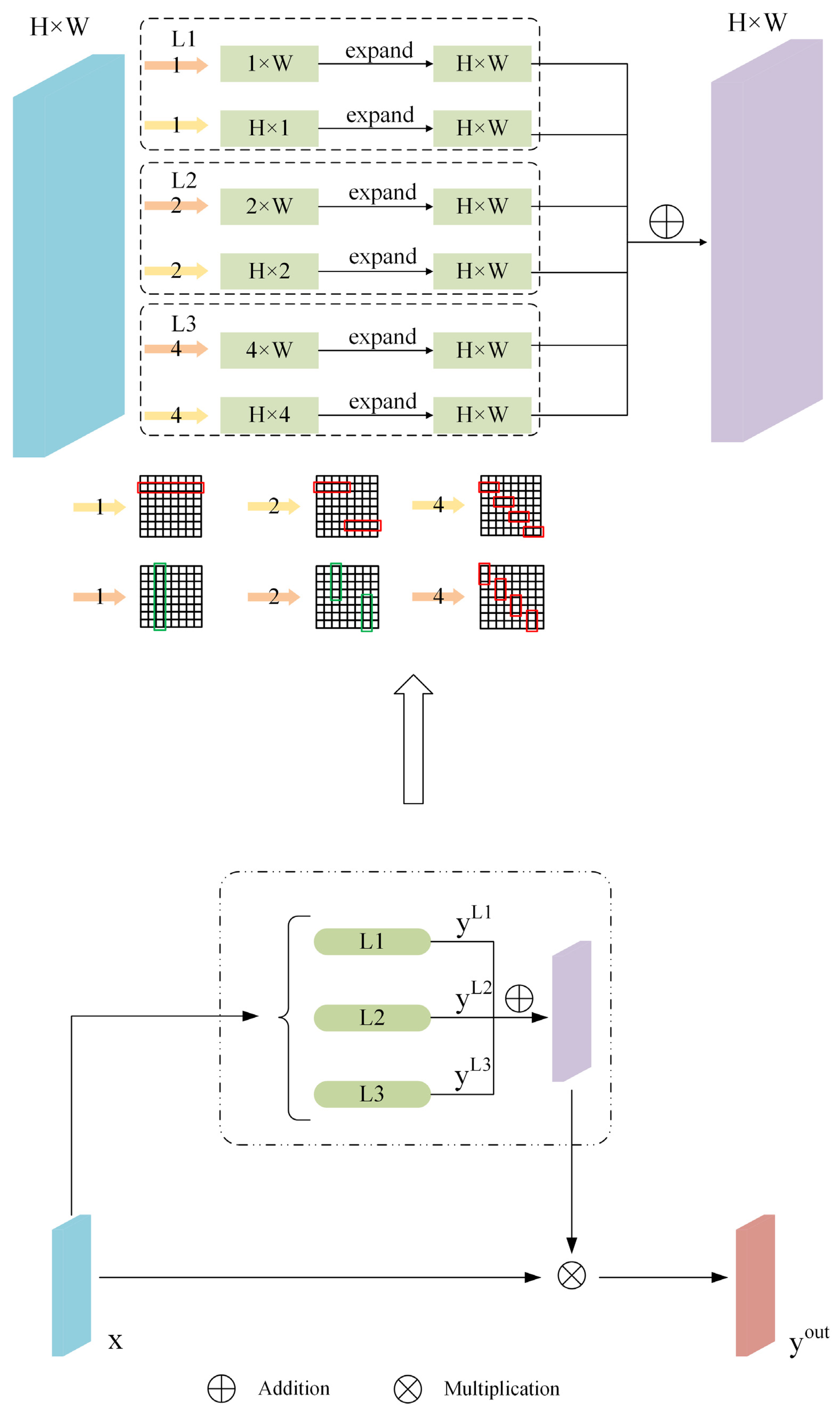
3.2. Multi-Level Strip Pooling Module
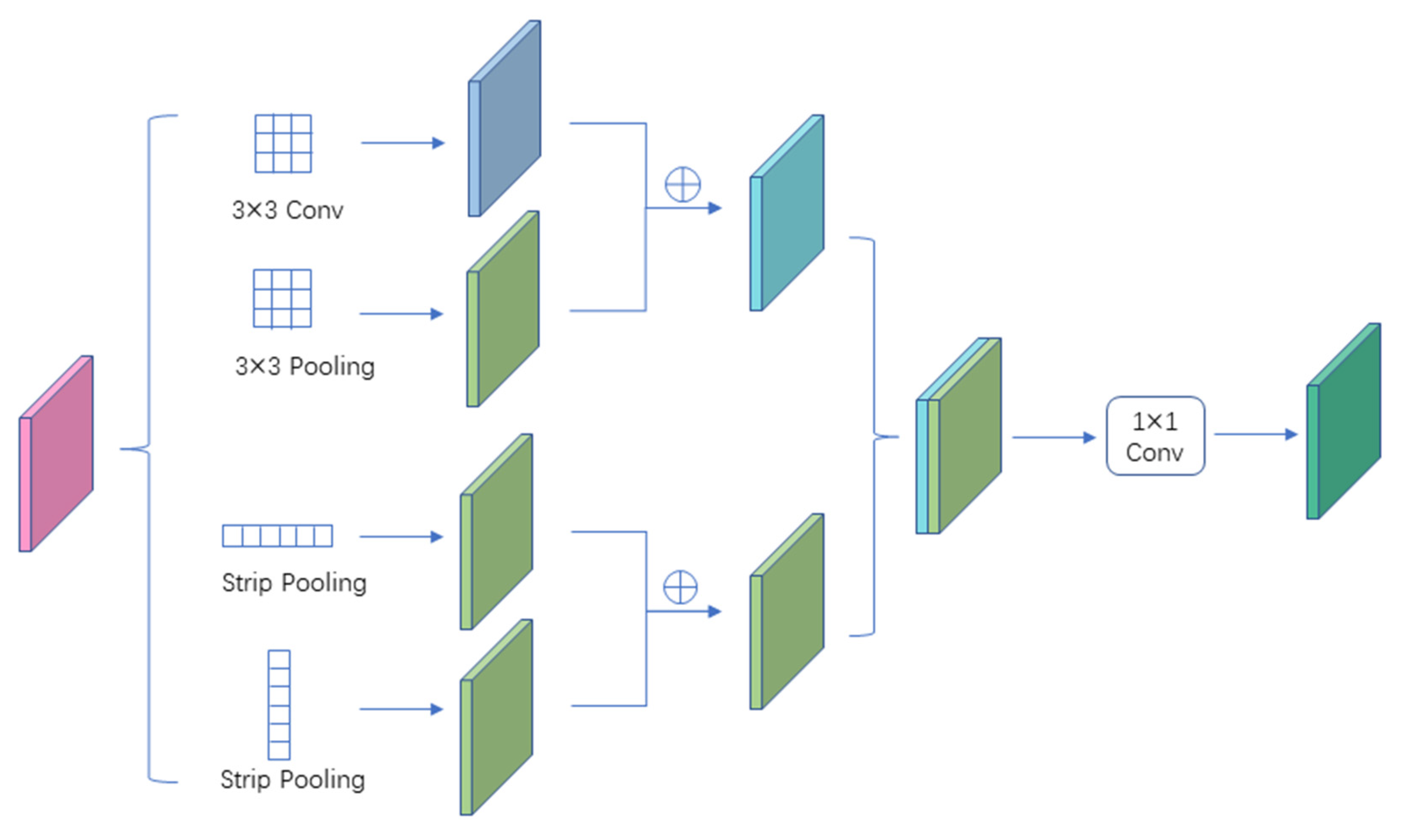
3.3. Feature Enhancement Module
3.4. Loss Function
4. Results
4.1. Dataset
4.2. Evaluation Metrics
4.3. Experimental Settings
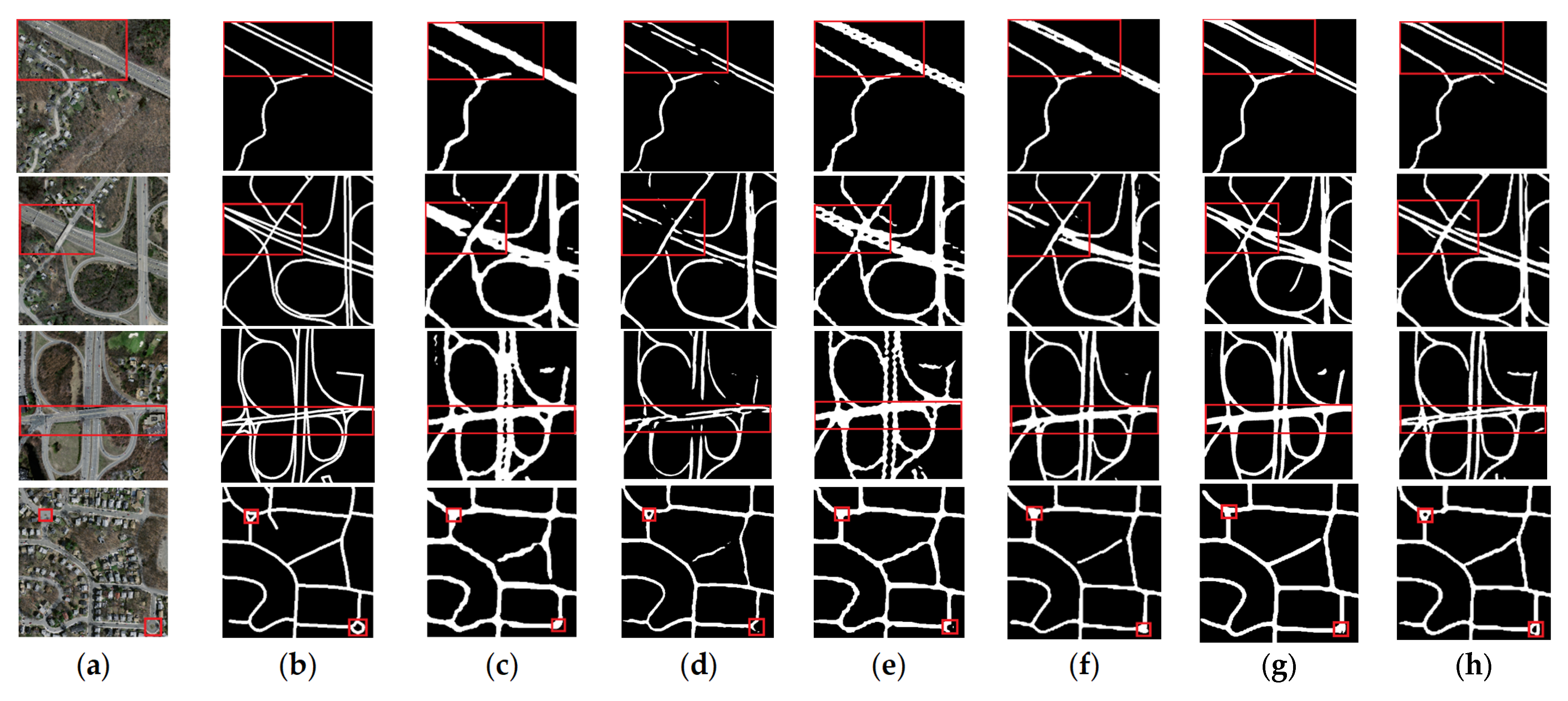
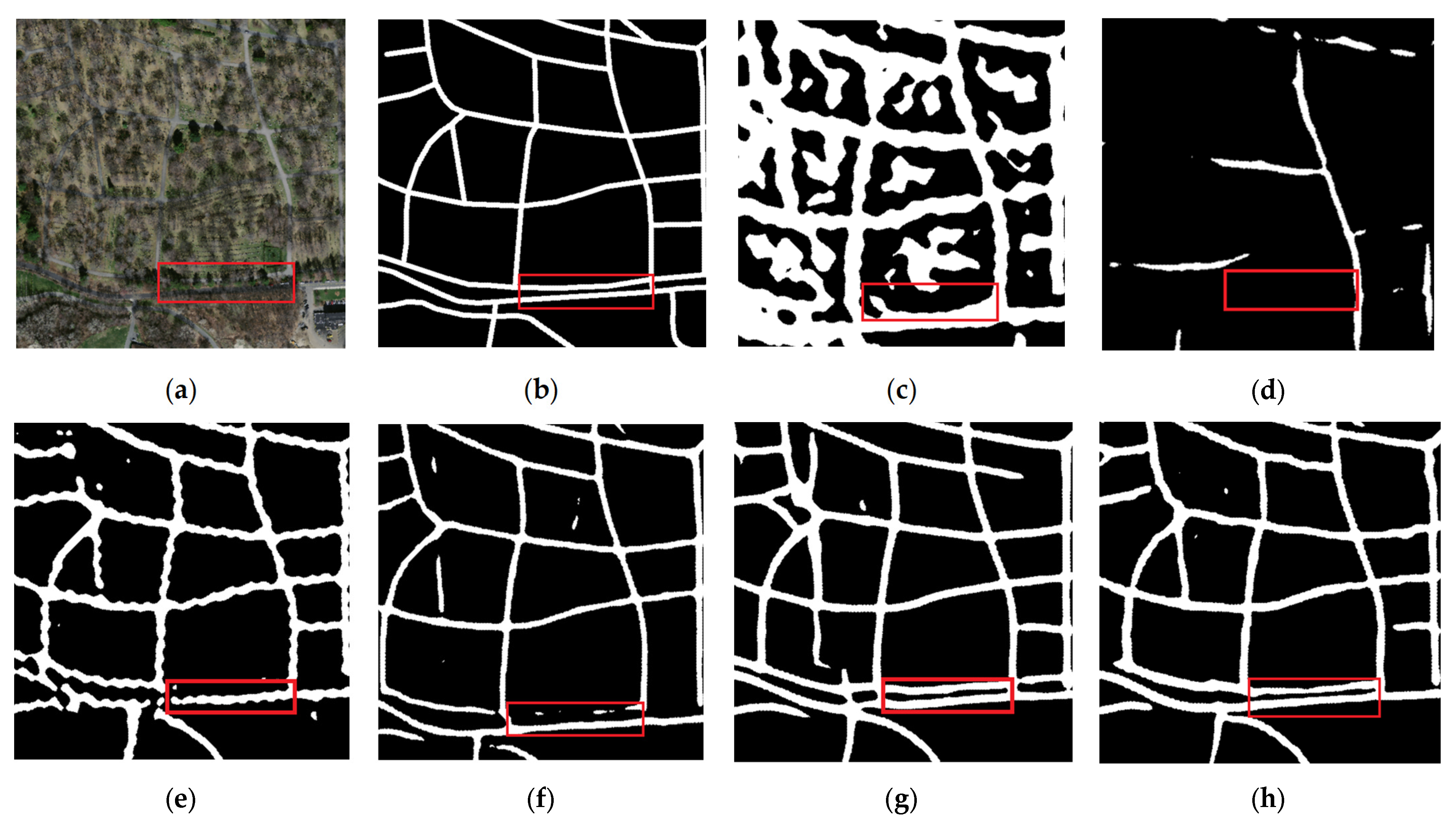
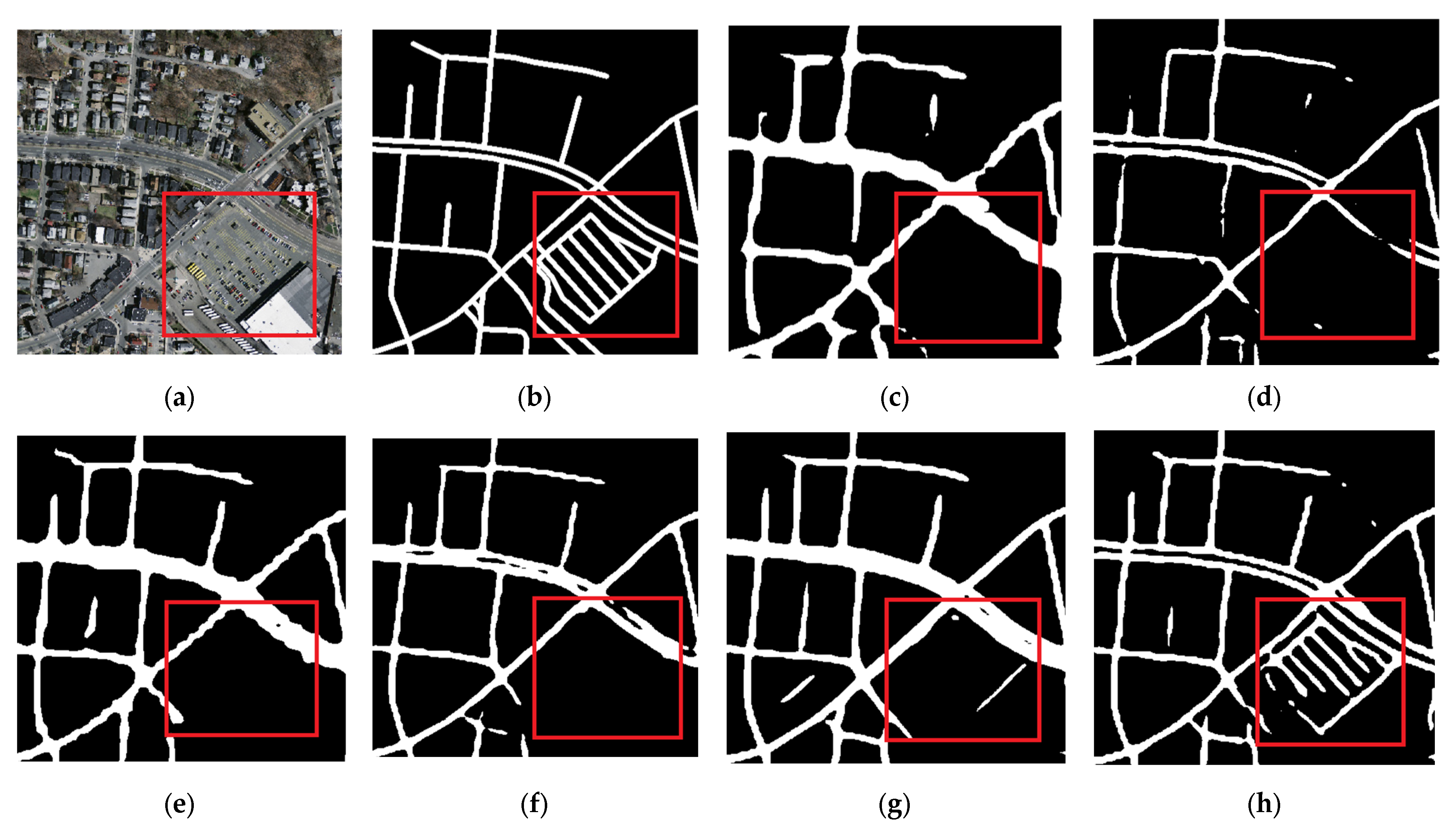
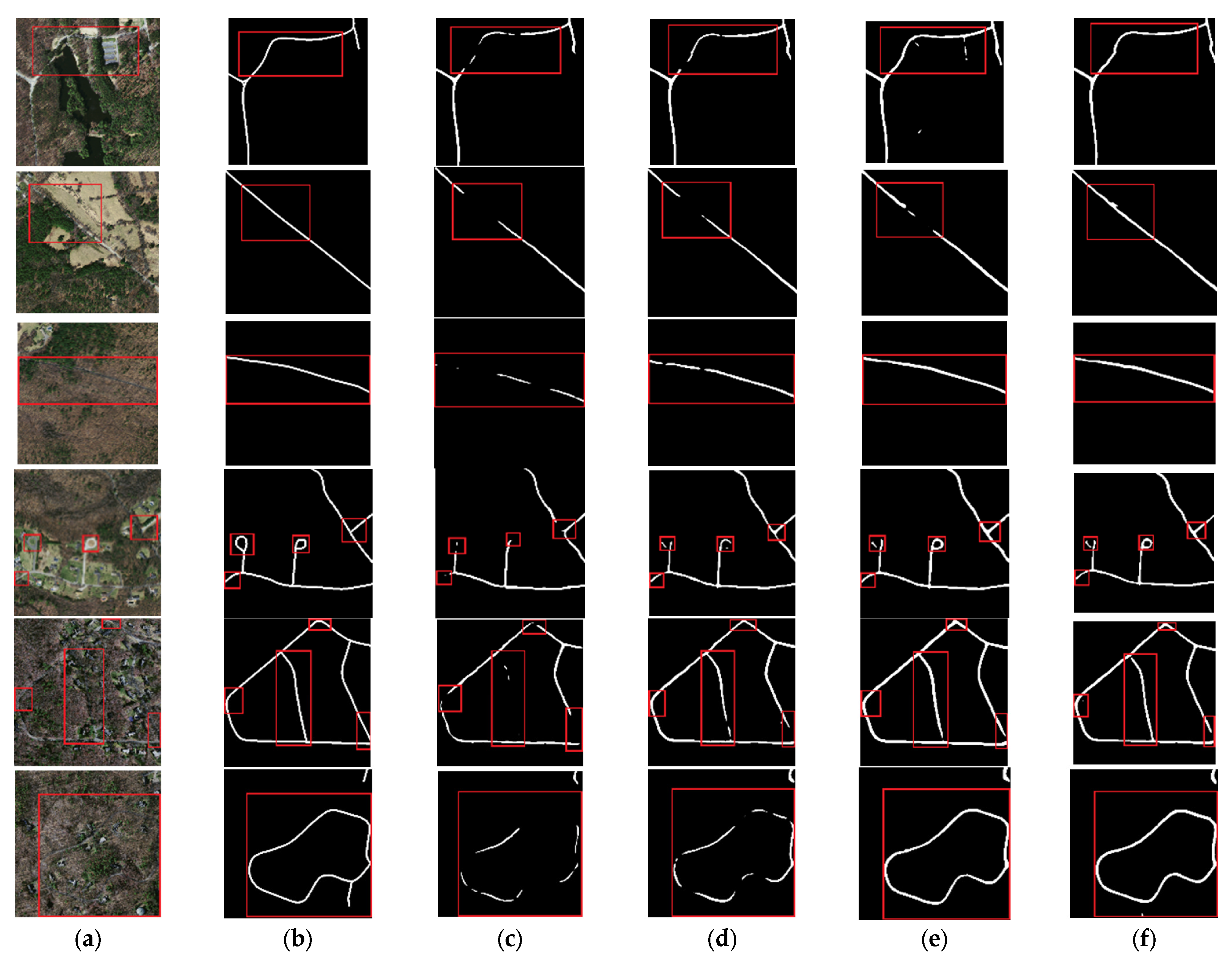
4.4. Experimental Results and Analysis
5. Discussion
5.1. Ablation Experiments
5.1.1. Influence of MSPM and FEM
5.1.2. Comparison of Loss Function
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, Y.; Xie, Z.; Feng, Y.; Chen, Z. Road Extraction from High-Resolution Remote Sensing Imagery Using Deep Learning. Remote Sens. 2018, 10, 1461. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Guo, L.; Rao, J.; Xu, L.; Jin, S. Road Segmentation Based on Hybrid Convolutional Network for High-Resolution Visible Remote Sensing Image. IEEE Geosci. Remote Sens. Lett. 2019, 16, 613–617. [Google Scholar] [CrossRef]
- Bong, D.; Lai, K.C.; Joseph, A. Automatic Road Network Recognition and Extraction for Urban Planning. Int. J. Appl. Sci. Eng. Technol. 2009, 5, 209–215. [Google Scholar]
- Hinz, S.; Baumgartner, A.; Ebner, H. Modeling Contextual Knowledge for Controlling Road Extraction in Urban Areas. In Proceedings of the IEEE/ISPRS Joint Workshop on Remote Sensing and Data Fusion over Urban Areas (Cat. No.01EX482), Rome, Italy, 8–9 November 2001; pp. 40–44. [Google Scholar]
- Ma, H.; Lu, N.; Ge, L.; Li, Q.; You, X.; Li, X. Automatic Road Damage Detection Using High-Resolution Satellite Images and Road Maps. In Proceedings of the 2013 IEEE International Geoscience and Remote Sensing Symposium—IGARSS, Melbourne, VIC, Australia, 21–26 July 2013; pp. 3718–3721. [Google Scholar]
- Li, Q.; Zhang, J.; Wang, N. Damaged Road Extraction from Post-Seismic Remote Sensing Images Based on Gis and Object-Oriented Method. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 4247–4250. [Google Scholar]
- Das, S.; Mirnalinee, T.T.; Varghese, K. Use of Salient Features for the Design of a Multistage Framework to Extract Roads From High-Resolution Multispectral Satellite Images. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3906–3931. [Google Scholar] [CrossRef]
- Lv, X.; Ming, D.; Chen, Y.; Wang, M. Very High Resolution Remote Sensing Image Classification with SEEDS-CNN and Scale Effect Analysis for Superpixel CNN Classification. Int. J. Remote Sens. 2018, 40, 506–531. [Google Scholar] [CrossRef]
- Cheng, G.; Zhu, F.; Xiang, S.; Pan, C. Accurate Urban Road Centerline Extraction from VHR Imagery via Multiscale Segmentatio-n and Tensor Voting. Neurocomputing 2016, 205, 407–420. [Google Scholar] [CrossRef] [Green Version]
- Yang, M.; Yuan, Y.; Liu, G. SDU-Net: Road Extraction via Spatial Enhanced and Densely Connected U-Net. Pattern Recognit. 2022, 126, 108549. [Google Scholar] [CrossRef]
- Xie, Y.; Miao, F.; Zhou, K.; Peng, J. HsgNet: A Road Extraction Network Based on Global Perception of High-Order Spatial Information. ISPRS Int. J. Geo-Inf. 2019, 8, 571. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Ma, W.; Li, C.; Wu, J.; Tang, X.; Jiao, L. Fully Convolutional Network-Based Ensemble Method for Road Extraction From Aerial Images. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1777–1781. [Google Scholar] [CrossRef]
- Chen, Z.; Deng, L.; Luo, Y.; Li, D.; Marcato Junior, J.; Nunes Gonçalves, W.; Awal Md Nurunnabi, A.; Li, J.; Wang, C.; Li, D. Road Extraction in Remote Sensing Data: A Survey. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102833. [Google Scholar] [CrossRef]
- Hou, Q.; Zhang, L.; Cheng, M.-M.; Feng, J. Strip Pooling: Rethinking Spatial Pooling for Scene Parsing. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Raziq, A.; Xu, A.; Li, Y. Automatic Extraction of Urban Road Centerlines from High-Resolution Satellite Imagery Using Automa-tic Thresholding and Morphological Operation Method. J. Geogr. Inf. Syst. 2016, 8, 517–525. [Google Scholar] [CrossRef] [Green Version]
- Haverkamp, D.S. Extracting Straight Road Structure in Urban Environments Using IKONOS Satellite Imagery. Opt. Eng. 2002, 41, 2107–2110. [Google Scholar] [CrossRef]
- Wenfeng, W.; Shuhua, Z.; Yihao, F.; Weili, D. Parallel Edges Detection from Remote Sensing Image Using Local Orientation Co-ding. Acta Opt. Sin. 2012, 32, 0315001. [Google Scholar] [CrossRef]
- Maboudi, M.; Amini, J.; Hahn, M.; Saati, M. Road Network Extraction from VHR Satellite Images Using Context Aware Object Feature Integration and Tensor Voting. Remote Sens. 2016, 8, 637. [Google Scholar] [CrossRef] [Green Version]
- Mnih, V.; Hinton, G.E. Learning to Detect Roads in High-Resolution Aerial Images. In Proceedings of the Computer Vision—ECCV 2010, Heraklion, Greece, 5–11 September 2010; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Springer: Berlin, Heidelberg, 2010; pp. 210–223. [Google Scholar]
- Li, P.; Zang, Y.; Wang, C.; Li, J.; Cheng, M.; Luo, L.; Yu, Y. Road Network Extraction via Deep Learning and Line Integral Convolution. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 1599–1602. [Google Scholar]
- Wei, Y.; Wang, Z.; Xu, M. Road Structure Refined CNN for Road Extraction in Aerial Image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Singh, P.; Dash, R. A Two-Step Deep Convolution Neural Network for Road Extraction from Aerial Images. In Proceedings of the 2019 6th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 7–8 March 2019; pp. 660–664. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef] [Green Version]
- Gao, X.; Sun, X.; Zhang, Y.; Yan, M.; Xu, G.; Sun, H.; Jiao, J.; Fu, K. An End-to-End Neural Network for Road Extraction From Remote Sensing Imagery by Multiple Feature Pyramid Network. IEEE Access 2018, 6, 39401–39414. [Google Scholar] [CrossRef]
- Cheng, G.; Wang, Y.; Xu, S.; Wang, H.; Xiang, S.; Pan, C. Automatic Road Detection and Centerline Extraction via Cascaded End-to-End Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3322–3337. [Google Scholar] [CrossRef]
- Yingxiao, X.; Chen, H.; Du, C.; Li, J. MSACon: Mining Spatial Attention-Based Contextual Information for Road Extraction. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–17. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extraction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), IEEE, Salt Lake City, UT, USA, 18–22 June 2018; pp. 192–1924. [Google Scholar]
- He, H.; Yang, D.; Wang, S.; Wang, S.; Li, Y. Road Extraction by Using Atrous Spatial Pyramid Pooling Integrated Encoder-Decoder Network and Structural Similarity Loss. Remote Sens. 2019, 11, 1015. [Google Scholar] [CrossRef] [Green Version]
- Chen, R.; Hu, Y.; Wu, T.; Peng, L. Spatial Attention Network for Road Extraction. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 1841–1844. [Google Scholar]
- Tao, C.; Qi, J.; Li, Y.; Wang, H.; Li, H. Spatial Information Inference Net: Road Extraction Using Road-Specific Contextual Information. ISPRS J. Photogramm. Remote Sens. 2019, 158, 155–166. [Google Scholar] [CrossRef]
- Zhou, M.; Sui, H.; Chen, S.; Wang, J.; Chen, X. BT-RoadNet: A Boundary and Topologically-Aware Neural Network for Road Extraction from High-Resolution Remote Sensing Imagery. ISPRS J. Photogramm. Remote Sens. 2020, 168, 288–306. [Google Scholar] [CrossRef]
- Lu, X.; Zhong, Y.; Zheng, Z.; Zhang, L. GAMSNet: Globally Aware Road Detection Network with Multi-Scale Residual Learning. ISPRS J. Photogramm. Remote Sens. 2021, 175, 340–352. [Google Scholar] [CrossRef]
- Tan, X.; Xiao, Z.; Wan, Q.; Shao, W. Scale Sensitive Neural Network for Road Segmentation in High-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 533–537. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhang, Y.; Wang, L.; Zhong, Y.; Guan, Q.; Lu, X.; Zhang, L.; Li, D. A Global Context-Aware and Batch-Independent Network for Road Extraction from VHR Satellite Imagery. ISPRS J. Photogramm. Remote Sens. 2021, 175, 353–365. [Google Scholar] [CrossRef]
- Wang, S.; Yang, H.; Wu, Q.; Zheng, Z.; Wu, Y.; Li, J. An Improved Method for Road Extraction from High-Resolution Remote-Sensing Images That Enhances Boundary Information. Sensors 2020, 20, 2064. [Google Scholar] [CrossRef] [Green Version]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Networks | Precision (%) | Recall (%) | F1 (%) | IoU (%) |
|---|---|---|---|---|
| Deeplabv3+ | 54.13% | 73.25% | 62.26% | 45.20% |
| U-Net | 77.41% | 60.17% | 67.71% | 51.18% |
| HRNetV2 | 65.48% | 77.38% | 70.94% | 54.96% |
| D-LinkNet | 71.72% | 72.51% | 72.12% | 56.39% |
| RefineNet | 69.57% | 76.54% | 72.89% | 57.35% |
| MSPFE-Net(ours) | 73.11% | 75.50% | 74.29% | 59.09% |
| Networks | Precision (%) | Recall (%) | F1 (%) | IoU (%) |
|---|---|---|---|---|
| Baseline | 75.92% | 63.28% | 69.02% | 52.70% |
| Baseline + MSPM (L1) | 72.54% | 70.23% | 71.37% | 55.48% |
| Baseline + MSPM (L1 + L2) | 68.87% | 77.95% | 73.13% | 57.64% |
| Baseline + MSPM (L1 + L2 + L3) | 69.87% | 77.65% | 73.55% | 58.17% |
| Baseline + FEM | 68.71% | 71.76% | 70.20% | 54.08% |
| Networks | Precision (%) | Recall (%) | F1 (%) | IoU (%) |
|---|---|---|---|---|
| Baseline + cross entropy loss function | 79.62% | 65.84% | 72.08% | 56.34% |
| Baseline + focal loss function | 77.12% | 68.04% | 72.30% | 56.61% |
| Baseline + dice coefficient loss function | 73.33% | 74.37% | 73.84% | 58.53% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, Z.; Zhang, Z. Remote Sensing Image Road Extraction Network Based on MSPFE-Net. Electronics 2023, 12, 1713. https://doi.org/10.3390/electronics12071713
Wei Z, Zhang Z. Remote Sensing Image Road Extraction Network Based on MSPFE-Net. Electronics. 2023; 12(7):1713. https://doi.org/10.3390/electronics12071713
Chicago/Turabian StyleWei, Zhiheng, and Zhenyu Zhang. 2023. "Remote Sensing Image Road Extraction Network Based on MSPFE-Net" Electronics 12, no. 7: 1713. https://doi.org/10.3390/electronics12071713