
Self-Supervised Skill Learning for Semi-Supervised Long-Horizon Instruction Following

Abstract
:1. Introduction
- We propose a self-supervised latent skill space with reusable and general task-related skills that can be effectively applied to a wide range of instruction following tasks.
- We propose an annotation-efficient method for the learning of the LLP.
- We propose an efficient grounding method that aligns instructions and learned skills in a latent space.
2. Related Work
2.1. Utilizing External Knowledge
2.2. Utilizing Unannotated Data
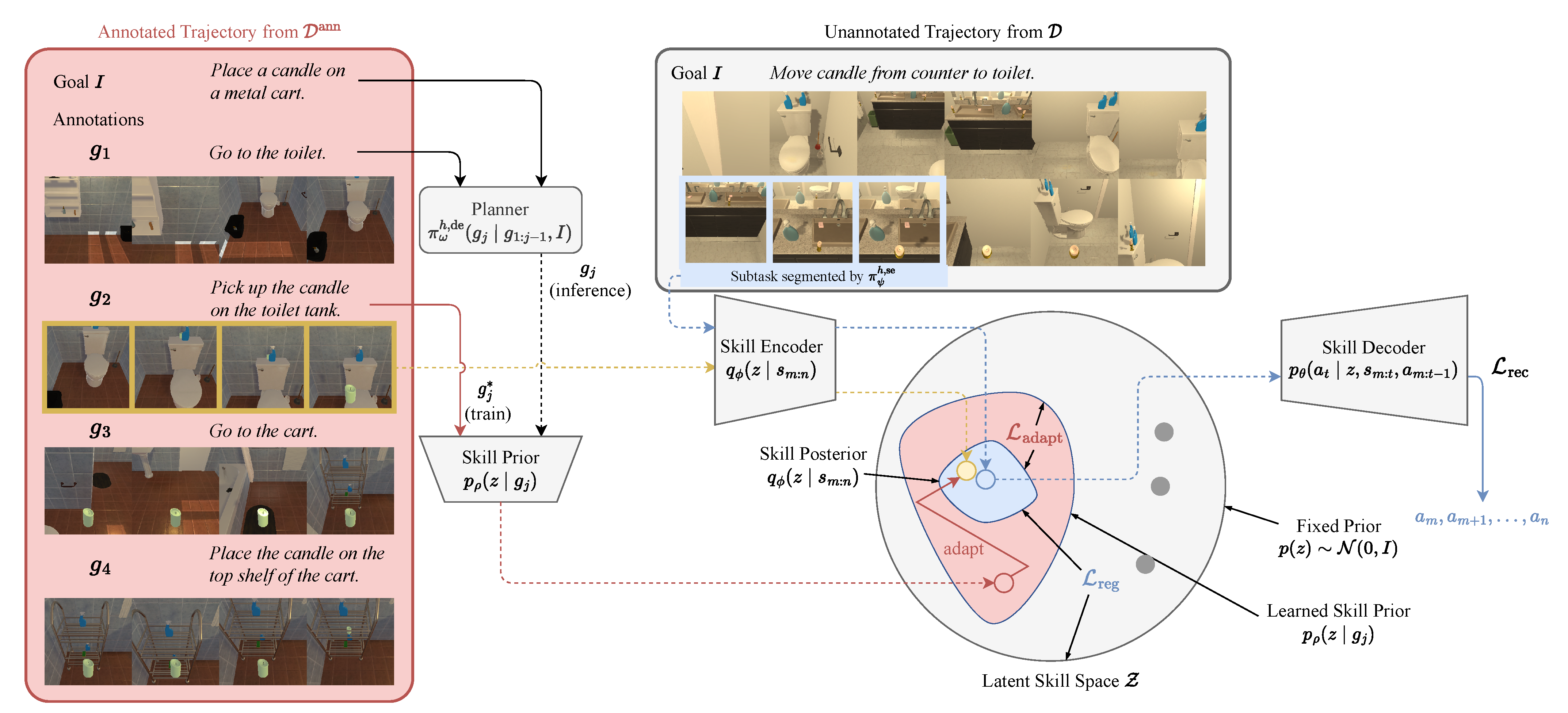
3. Method
3.1. Problem Formulation
3.2. Reusable Skill Extraction
| Algorithm 1: Latent Skill Space Learning |
 |
3.3. Skill Prior Adaptation
| Algorithm 2: Skill Prior Adaptation |
 |
3.4. Planning via Natural Language
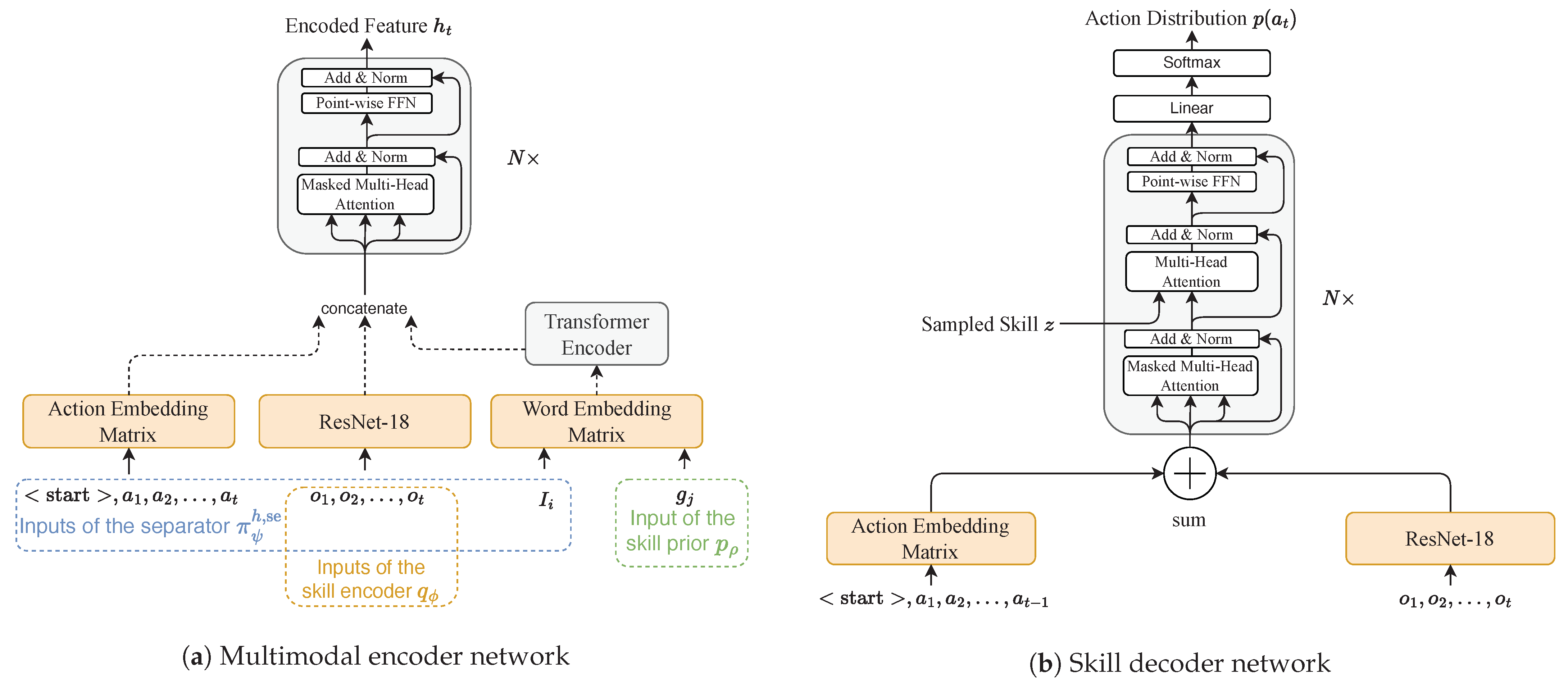
3.5. Network Architectures
4. Experiment
4.1. Dataset
4.2. Baselines
4.3. Model Variants
4.4. Implementation Details
4.5. Evaluation Metrics
5. Results
5.1. Overall Performance
5.2. Data Efficiency
5.3. Latent Skill Space
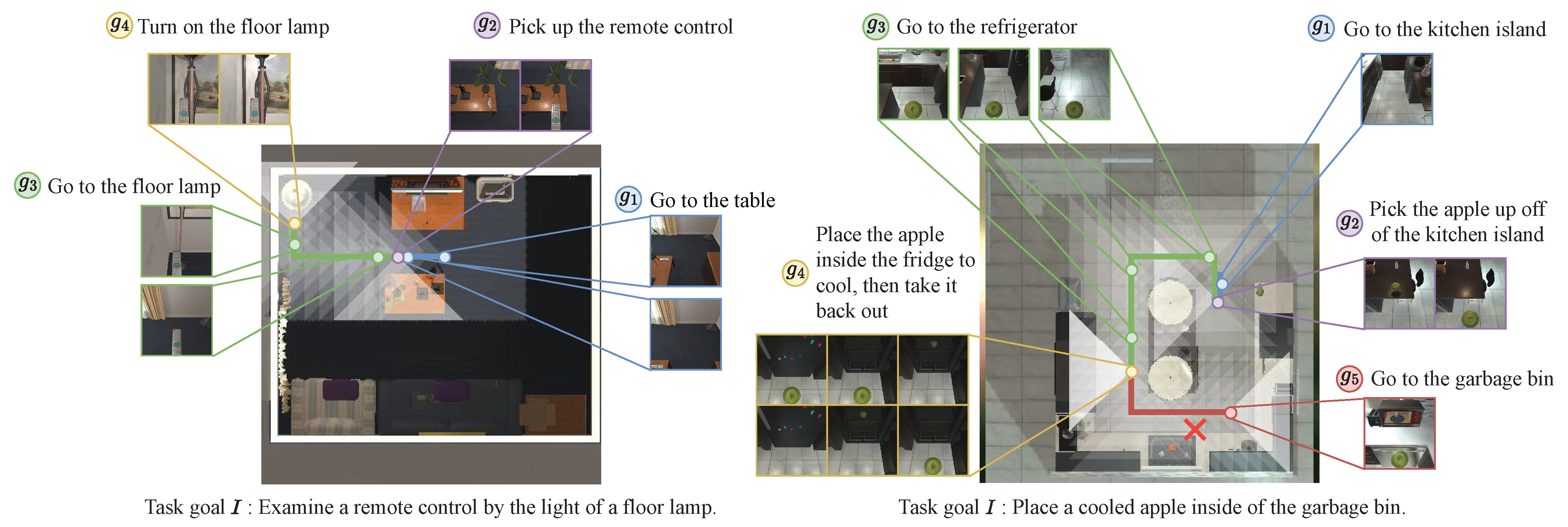
5.4. Case Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Andreas, J.; Klein, D.; Levine, S. Learning with Latent Language. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; pp. 2166–2179. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Y.; Gu, S.; Murphy, K.; Finn, C. Language as an Abstraction for Hierarchical Deep Reinforcement Learning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 9414–9426. [Google Scholar]
- Blukis, V.; Paxton, C.; Fox, D.; Garg, A.; Artzi, Y. A Persistent Spatial Semantic Representation for High-level Natural Language Instruction Execution. In Proceedings of the Conference on Robot Learning, London, UK, 8–11 November 2021; Volume 164, pp. 706–717. [Google Scholar]
- Zhang, Y.; Chai, J. Hierarchical Task Learning from Language Instructions with Unified Transformers and Self-Monitoring. In Proceedings of the International Joint Conference on Natural Language Processing, Virtual, 1–6 August 2021; pp. 4202–4213. [Google Scholar] [CrossRef]
- Suglia, A.; Gao, Q.; Thomason, J.; Thattai, G.; Sukhatme, G.S. Embodied BERT: A Transformer Model for Embodied, Language-guided Visual Task Completion. arXiv 2021, arXiv:2108.04927. [Google Scholar]
- Min, S.Y.; Chaplot, D.S.; Ravikumar, P.K.; Bisk, Y.; Salakhutdinov, R. FILM: Following Instructions in Language with Modular Methods. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2022. [Google Scholar]
- Huang, W.; Abbeel, P.; Pathak, D.; Mordatch, I. Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; Volume 162, pp. 9118–9147. [Google Scholar]
- Li, S.; Puig, X.; Paxton, C.; Du, Y.; Wang, C.; Fan, L.; Chen, T.; Huang, D.; Akyürek, E.; Anandkumar, A.; et al. Pre-Trained Language Models for Interactive Decision-Making. arXiv 2022, arXiv:2202.01771. [Google Scholar]
- Huang, W.; Xia, F.; Xiao, T.; Chan, H.; Liang, J.; Florence, P.; Zeng, A.; Tompson, J.; Mordatch, I.; Chebotar, Y.; et al. Inner Monologue: Embodied Reasoning through Planning with Language Models. arXiv 2022, arXiv:2207.05608. [Google Scholar]
- Ahn, M.; Brohan, A.; Brown, N.; Chebotar, Y.; Cortes, O.; David, B.; Finn, C.; Gopalakrishnan, K.; Hausman, K.; Herzog, A.; et al. Do As I Can, Not As I Say: Grounding Language in Robotic Affordances. arXiv 2022, arXiv:2204.01691. [Google Scholar]
- Vaezipoor, P.; Li, A.C.; Icarte, R.T.; McIlraith, S.A. LTL2Action: Generalizing LTL Instructions for Multi-Task RL. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; Volume 139, pp. 10497–10508. [Google Scholar]
- Sharma, P.; Torralba, A.; Andreas, J. Skill Induction and Planning with Latent Language. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; pp. 1713–1726. [Google Scholar] [CrossRef]
- Xiao, T.; Chan, H.; Sermanet, P.; Wahid, A.; Brohan, A.; Hausman, K.; Levine, S.; Tompson, J. Robotic Skill Acquisition via Instruction Augmentation with Vision-Language Models. arXiv 2022, arXiv:2211.11736. [Google Scholar]
- Cideron, G.; Seurin, M.; Strub, F.; Pietquin, O. HIGhER: Improving instruction following with Hindsight Generation for Experience Replay. In Proceedings of the IEEE Symposium Series on Computational Intelligence, Canberra, Australia, 1–4 December 2020; pp. 225–232. [Google Scholar] [CrossRef]
- Röder, F.; Eppe, M.; Wermter, S. Grounding Hindsight Instructions in Multi-Goal Reinforcement Learning for Robotics. arXiv 2022, arXiv:2204.04308. [Google Scholar]
- Lee, D.H. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Proceedings of the Workshop on Challenges in Representation Learning, ICML, Atlanta, GA, USA, 16–21 June 2013; Voume 3, p. 896. [Google Scholar]
- Arazo, E.; Ortego, D.; Albert, P.; O’Connor, N.E.; McGuinness, K. Pseudo-Labeling and Confirmation Bias in Deep Semi-Supervised Learning. In Proceedings of the International Joint Conference on Neural Networks, Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Shridhar, M.; Thomason, J.; Gordon, D.; Bisk, Y.; Han, W.; Mottaghi, R.; Zettlemoyer, L.; Fox, D. ALFRED: A Benchmark for Interpreting Grounded Instructions for Everyday Tasks. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10737–10746. [Google Scholar] [CrossRef]
- Singh, K.P.; Bhambri, S.; Kim, B.; Mottaghi, R.; Choi, J. Factorizing Perception and Policy for Interactive Instruction Following. In Proceedings of the International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1868–1877. [Google Scholar] [CrossRef]
- Corona, R.; Fried, D.; Devin, C.; Klein, D.; Darrell, T. Modular Networks for Compositional Instruction Following. In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 1033–1040. [Google Scholar] [CrossRef]
- Nguyen, V.; Suganuma, M.; Okatani, T. Look Wide and Interpret Twice: Improving Performance on Interactive Instruction-following Tasks. In Proceedings of the International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 19–27 August 2021; pp. 923–930. [Google Scholar] [CrossRef]
- Jansen, P.A. Visually-Grounded Planning without Vision: Language Models Infer Detailed Plans from High-level Instructions. In Proceedings of the Empirical Methods in Natural Language Processing, Online, 16–20 November 2020; pp. 4412–4417. [Google Scholar] [CrossRef]
- Artzi, Y.; Zettlemoyer, L. Weakly Supervised Learning of Semantic Parsers for Mapping Instructions to Actions. Trans. Assoc. Comput. Linguist. 2013, 1, 49–62. [Google Scholar] [CrossRef]
- Patel, R.; Pavlick, E.; Tellex, S. Grounding Language to Non-Markovian Tasks with No Supervision of Task Specifications. In Proceedings of the Robotics: Science and Systems, Pittsburgh, PA, USA, 26–30 June 2020. [Google Scholar] [CrossRef]
- Nair, S.; Mitchell, E.; Chen, K.; Ichter, B.; Savarese, S.; Finn, C. Learning Language-Conditioned Robot Behavior from Offline Data and Crowd-Sourced Annotation. In Proceedings of the Conference on Robot Learning, London, UK, 8–11 November 2021; Volume 164, pp. 1303–1315. [Google Scholar]
- Mees, O.; Hermann, L.; Burgard, W. What Matters in Language Conditioned Robotic Imitation Learning Over Unstructured Data. IEEE Robot. Autom. Lett. 2022, 7, 11205–11212. [Google Scholar] [CrossRef]
- Andrychowicz, M.; Crow, D.; Ray, A.; Schneider, J.; Fong, R.; Welinder, P.; McGrew, B.; Tobin, J.; Abbeel, P.; Zaremba, W. Hindsight Experience Replay. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5048–5058. [Google Scholar]
- Akakzia, A.; Colas, C.; Oudeyer, P.; Chetouani, M.; Sigaud, O. Grounding Language to Autonomously-Acquired Skills via Goal Generation. In Proceedings of the International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Carta, T.; Lamprier, S.; Oudeyer, P.; Sigaud, O. EAGER: Asking and Answering Questions for Automatic Reward Shaping in Language-guided RL. arXiv 2022, arXiv:2206.09674. [Google Scholar]
- Lynch, C.; Sermanet, P. Grounding Language in Play. arXiv 2020, arXiv:2005.07648. [Google Scholar]
- Pertsch, K.; Lee, Y.; Lim, J.J. Accelerating Reinforcement Learning with Learned Skill Priors. In Proceedings of the Conference on Robot Learning, Cambridge, MA, USA, 16–18 November 2020; Volume 155, pp. 188–204. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Higgins, I.; Matthey, L.; Pal, A.; Burgess, C.P.; Glorot, X.; Botvinick, M.M.; Mohamed, S.; Lerchner, A. beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 140:1–140:67. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Pashevich, A.; Schmid, C.; Sun, C. Episodic Transformer for Vision-and-Language Navigation. In Proceedings of the International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15922–15932. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Fixing Weight Decay Regularization in Adam. arXiv 2017, arXiv:1711.05101. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | During Training | During Inference | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Goals | Instructions | Segmentations | Multi-View | Depth | Goals | Instructions | Multi-View | Depth | |
| SLHSP (ours) | ✓ | ✓ (10%) | ✓ (10%) | ✕ | ✕ | ✓ | ✕ | ✕ | ✕ |
| [12] | ✓ | ✓ (10%) | ✕ | ✕ | ✕ | ✓ | ✕ | ✕ | ✕ |
| seq2seq [12] | ✓ | ✕ | ✕ | ✕ | ✕ | ✓ | ✕ | ✕ | ✕ |
| seq2seq2seq [12] | ✓ | ✓ | ✕ | ✕ | ✕ | ✓ | ✕ | ✕ | ✕ |
| E.T. [37] | ✓ | ✓ | ✓ | ✕ | ✕ | ✓ | ✓ | ✕ | ✕ |
| MOCA [19] | ✓ | ✓ | ✓ | ✕ | ✕ | ✓ | ✓ | ✕ | ✕ |
| LWIT (Multi view) [21] | ✓ | ✓ | ✓ | ✓ | ✕ | ✓ | ✓ | ✓ | ✕ |
| LWIT (Single view) [21] | ✓ | ✓ | ✓ | ✕ | ✕ | ✓ | ✓ | ✕ | ✕ |
| HiTUT [4] | ✓ | ✕ | ✓ | ✕ | ✓ | ✓ | ✕ | ✕ | ✓ |
| HLSM [3] | ✓ | ✕ | ✓ | ✕ | ✓ | ✓ | ✕ | ✕ | ✓ |
| FILM [6] | ✓ | ✕ | ✓ | ✕ | ✓ | ✓ | ✕ | ✕ | ✓ |
| EmBERT [5] | ✓ | ✓ | ✓ | ✓ | ✕ | ✓ | ✓ | ✓ | ✕ |
| (a) Sparse Annotation | ||
|---|---|---|
| Model | Unseen | Seen |
| SLHSP (10%) (ours) | 1.2 (0.5) | 1.7 (0.7) |
| (10%) [12] | 0.0 (-) | - |
| seq2seq [12] | 0.0 (-) | - |
| seq2seq2seq [12] | 0.0 (-) | - |
| (b) Additional Inputs | ||
| Model | Unseen | Seen |
| SLHSP + nav (10%) (ours) | 23.7(18.5) | 30.9 (24.9) |
| + planner (10%) [12] | 40.4 (-) | - |
| + HLSM (10%) [12] | 15.5 (-) | - |
| HLSM [3] | 18.3 (-) | 29.6 (-) |
| FILM [6] | 20.1 (-) | 24.6 (-) |
| EmBERT [5] | 5.7 (3.1) | 37.4 (28.8) |
| LWIT (Multi view) [21] | 9.7 (7.3) | 33.7 (28.4) |
| E.T. [37] | 7.3 (3.3) | 46.6 (32.3) |
| HiTUT [4] | 12.4 (6.9) | 25.2 (12.2) |
| MOCA [19] | 5.4 (3.2) | 25.9 (19.0) |
| Model | Goto | Pickup | Put | Cool | Heat | Clean | Slice | Toggle | Avg. |
|---|---|---|---|---|---|---|---|---|---|
| Sparse annotation | |||||||||
| SLHSP (10%) (ours) | 40 | 63 | 45 | 95 | 98 | 43 | 42 | 20 | 56 |
| (10%) [12] | 13 | 50 | 48 | 75 | 74 | 56 | 54 | 32 | 50 |
| seq2seq2seq [12] | 15 | 29 | 42 | 69 | 58 | 15 | 50 | 32 | 39 |
| seq2seq [12] | 14 | 20 | 15 | 33 | 64 | 16 | 25 | 13 | 25 |
| Additional inputs | |||||||||
| SLHSP (100%) (ours) | 40 | 66 | 46 | 99 | 100 | 42 | 48 | 31 | 59 |
| (100%) [12] | 15 | 50 | 45 | 82 | 75 | 68 | 55 | 32 | 53 |
| LWIT (Multi view) [21] | 39 | 79 | 66 | 94 | 95 | 68 | 85 | 66 | 74 |
| HiTUT [4] | - | 71 | 69 | 100 | 97 | 91 | 78 | 58 | - |
| MOCA [19] | 32 | 44 | 39 | 38 | 86 | 71 | 55 | 11 | 47 |
| E.T. [37] | 45 | 67 | 66 | 100 | 97 | 91 | 53 | 72 | 74 |
| Annotation Settings | Average Success Rate |
|---|---|
| 10% seg + 1% ann | 70.2 |
| 10% seg + 5% ann | 75.0 |
| 10% seg + 10% ann | 76.7 |
| 100% seg + 10% ann | 77.0 |
| 10% seg + 100% ann | 78.1 |
| 100% seg + 100% ann | 78.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhuang, B.; Zhang, C.; Hu, Z. Self-Supervised Skill Learning for Semi-Supervised Long-Horizon Instruction Following. Electronics 2023, 12, 1587. https://doi.org/10.3390/electronics12071587
Zhuang B, Zhang C, Hu Z. Self-Supervised Skill Learning for Semi-Supervised Long-Horizon Instruction Following. Electronics. 2023; 12(7):1587. https://doi.org/10.3390/electronics12071587
Chicago/Turabian StyleZhuang, Benhui, Chunhong Zhang, and Zheng Hu. 2023. "Self-Supervised Skill Learning for Semi-Supervised Long-Horizon Instruction Following" Electronics 12, no. 7: 1587. https://doi.org/10.3390/electronics12071587