
Research on Algorithm for Improving Infrared Image Defect Segmentation of Power Equipment
Abstract
:1. Introduction
2. Countermeasure Datasets for Learning Attack Strategies
3. CS_DeeplabV3+ Model
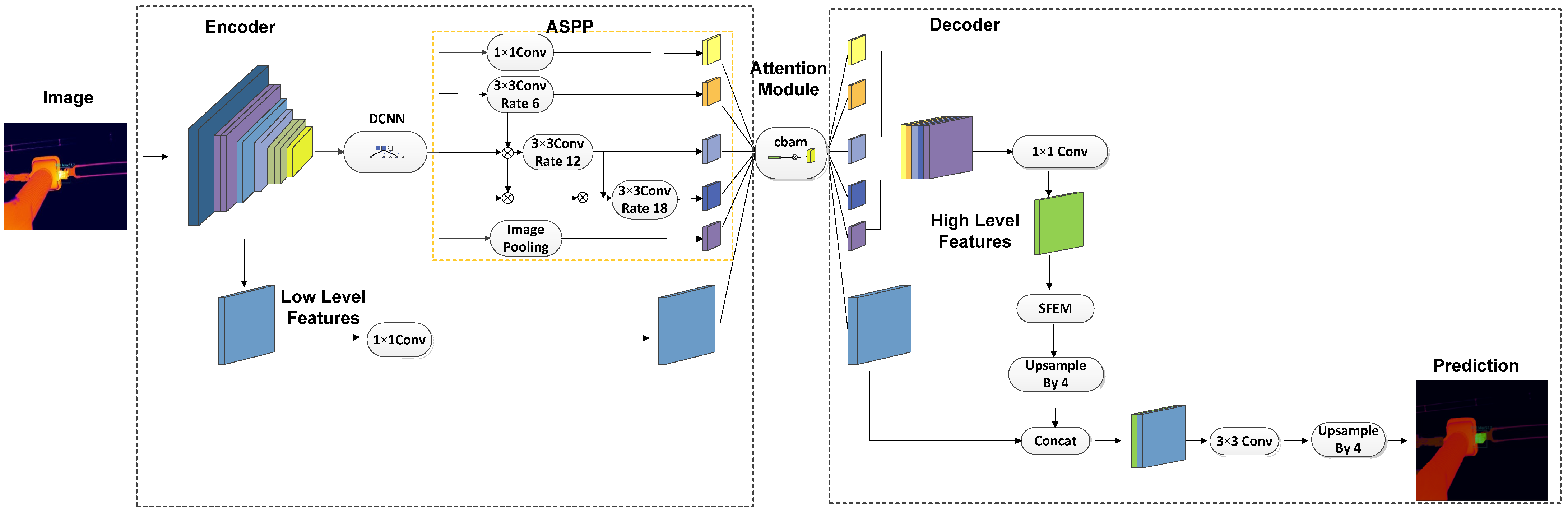
3.1. Deeplab V3+ Model
3.2. CS_DeeplabV3+Model
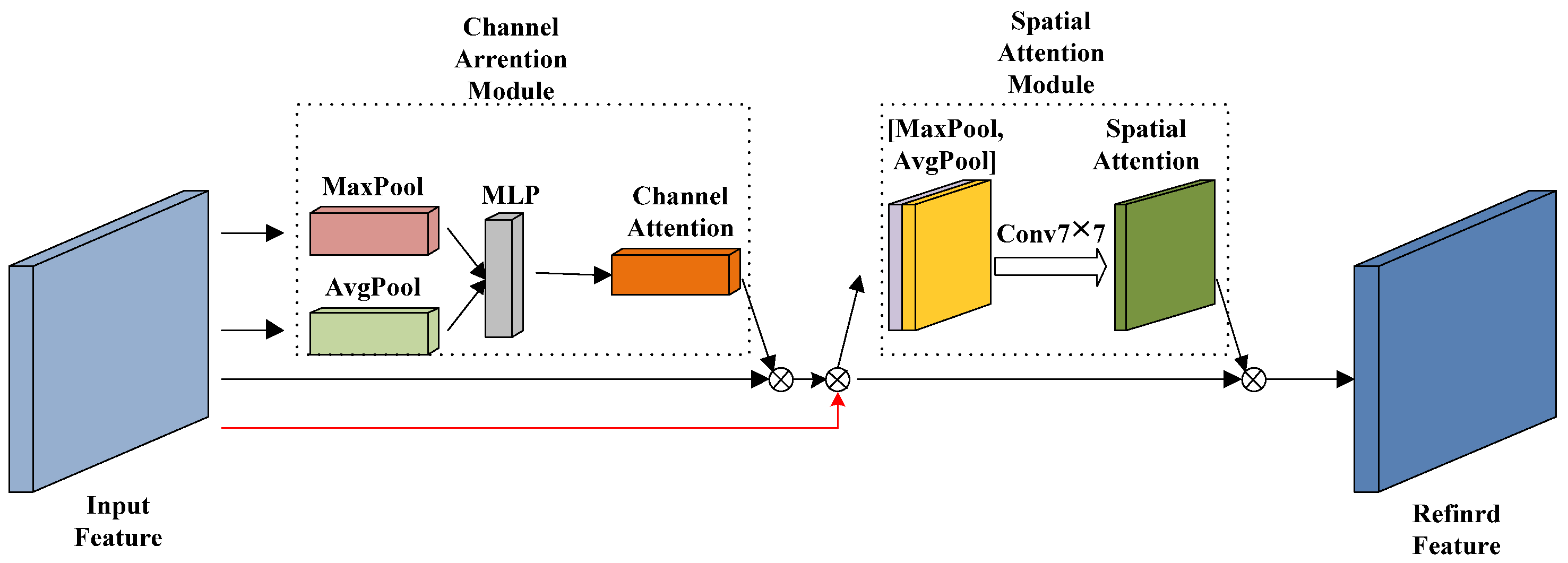
3.3. Improving Attention Mechanism Module
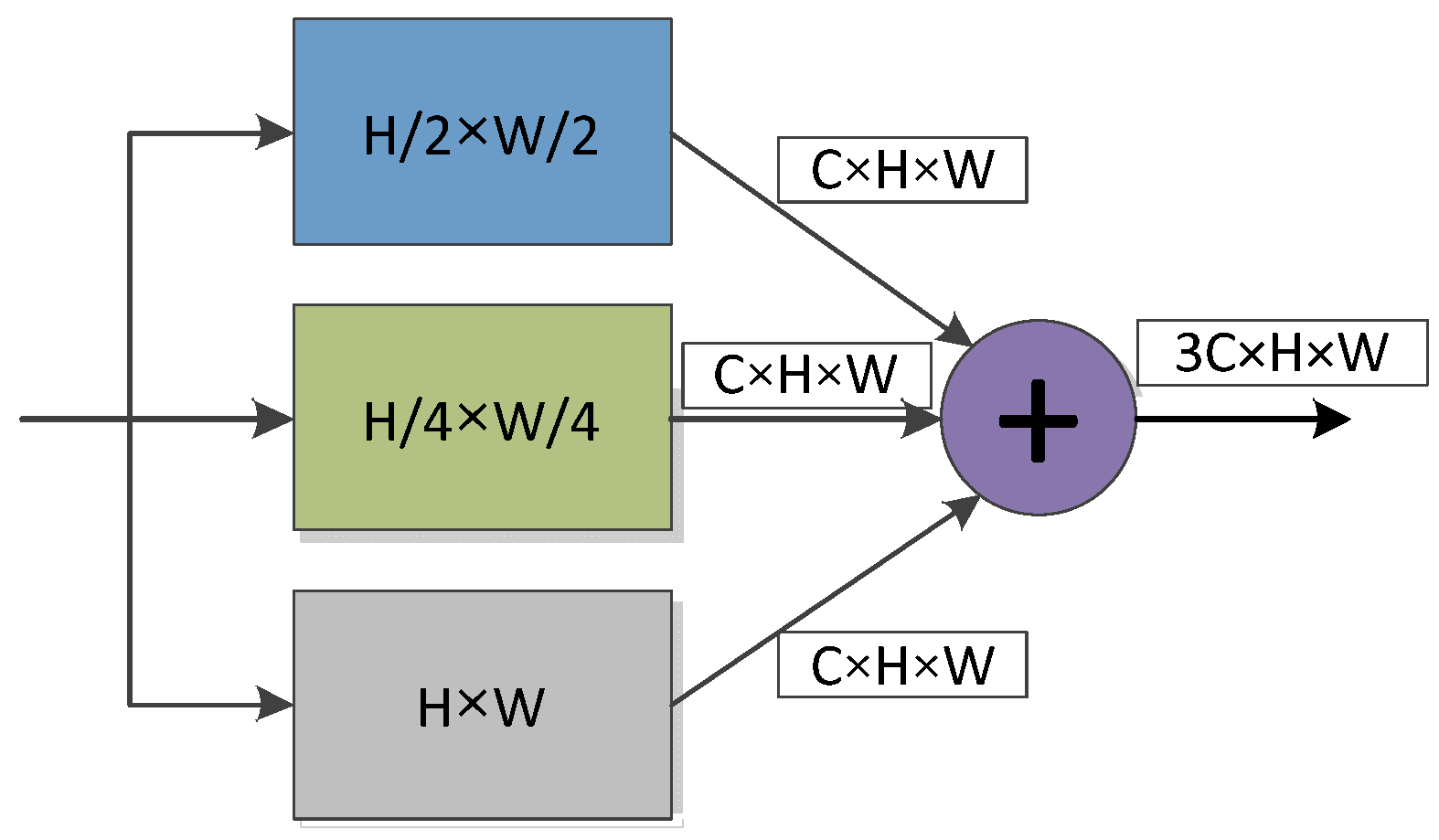
3.4. Semantic Segmentation Feature Enhancement Module
3.5. Improved Loss Function
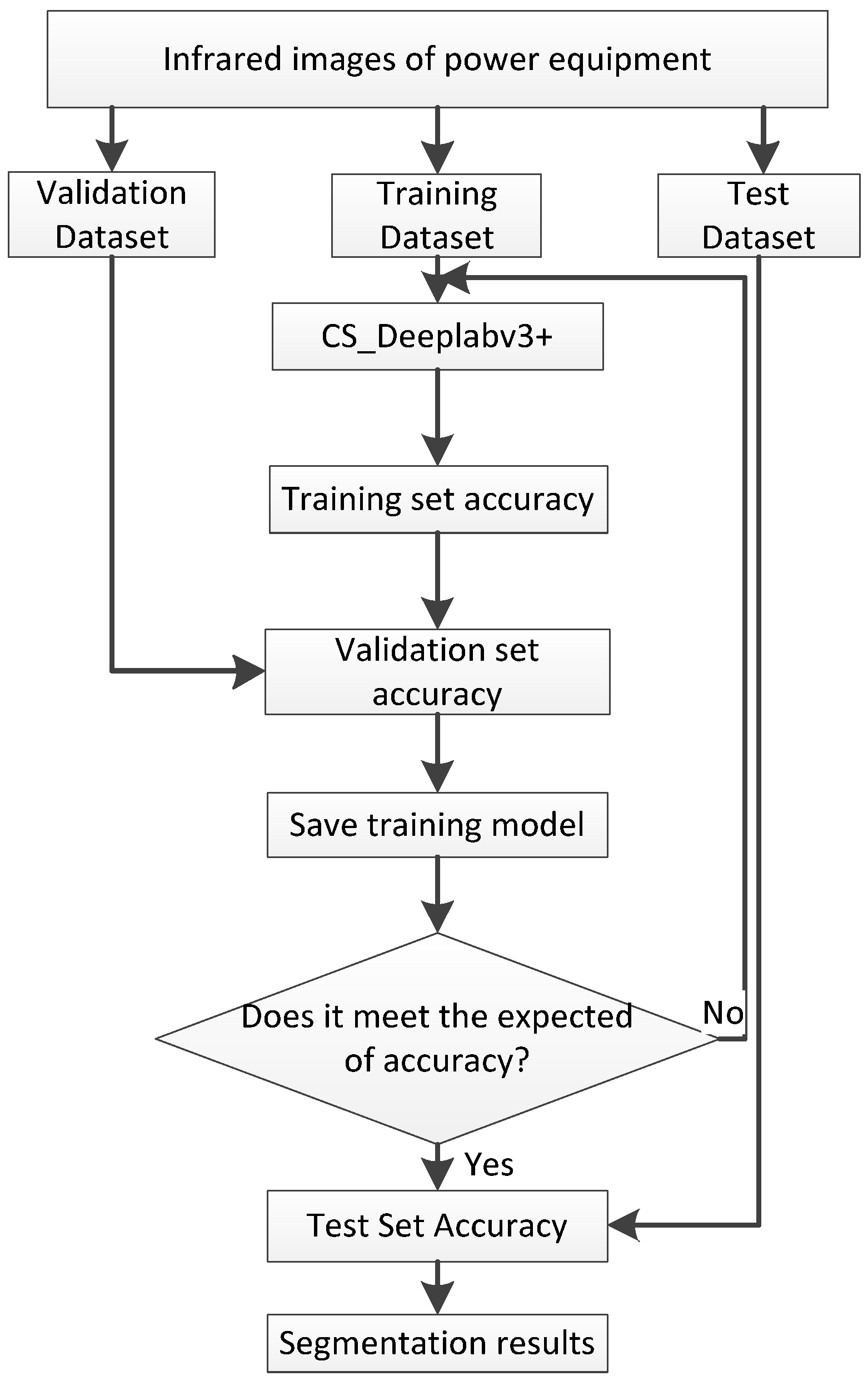
4. Experimental Evaluation and Discussion
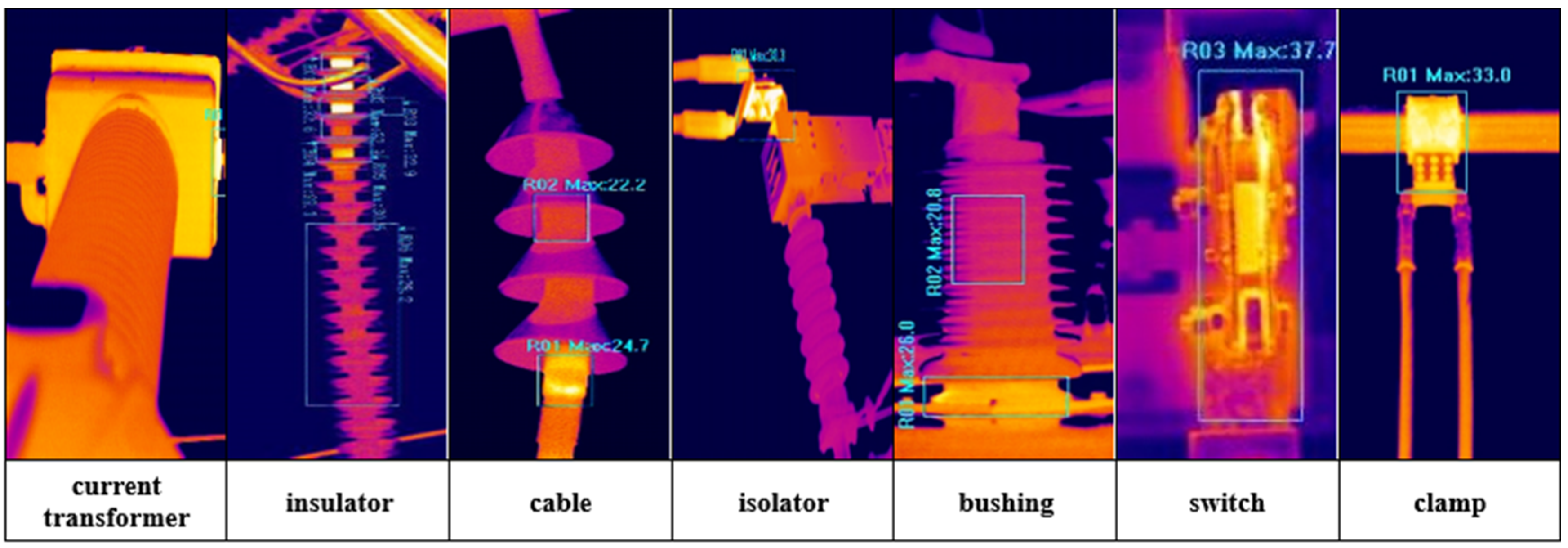
4.1. Dataset
4.2. Experimental Evaluation Indicators
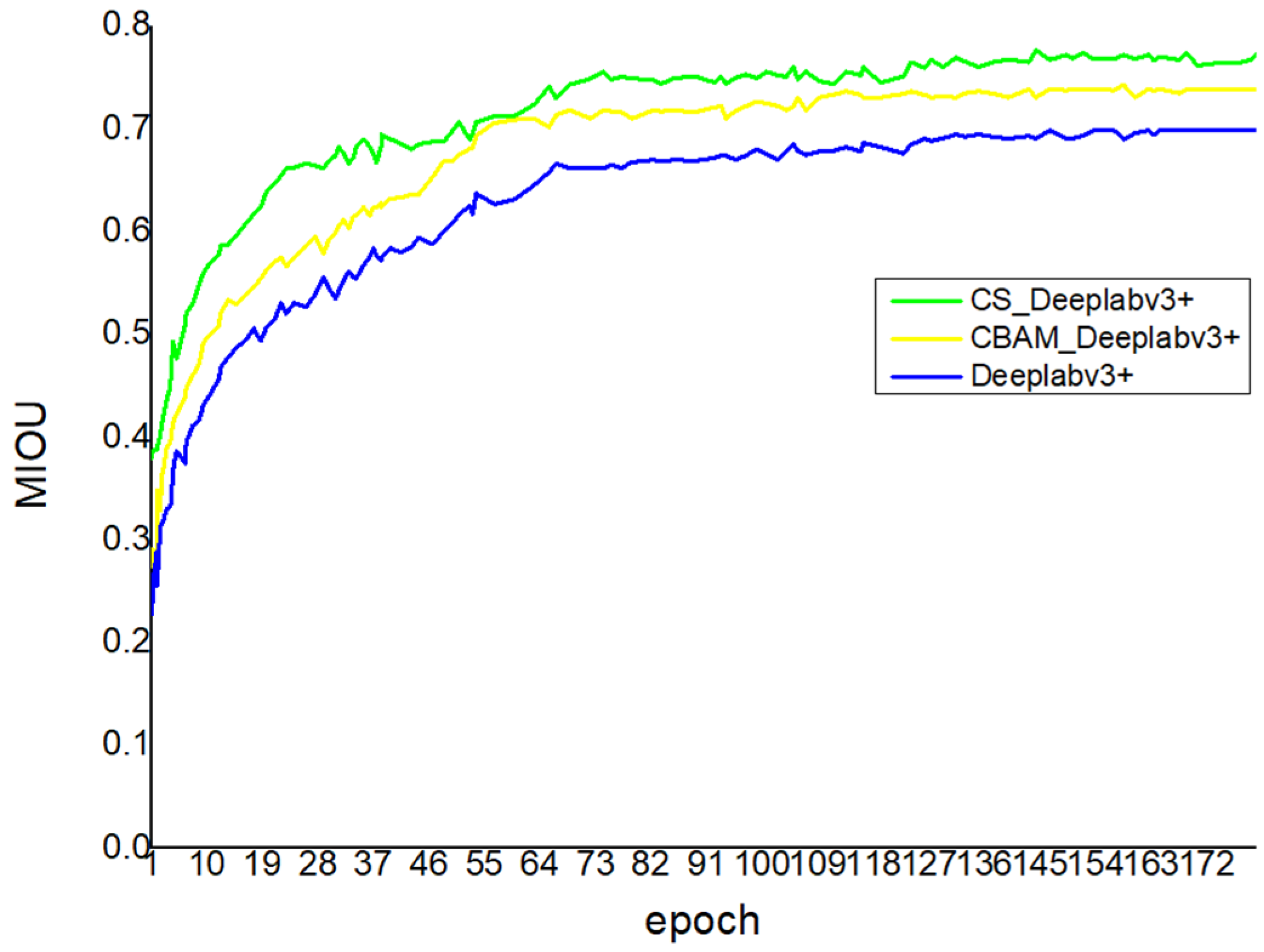
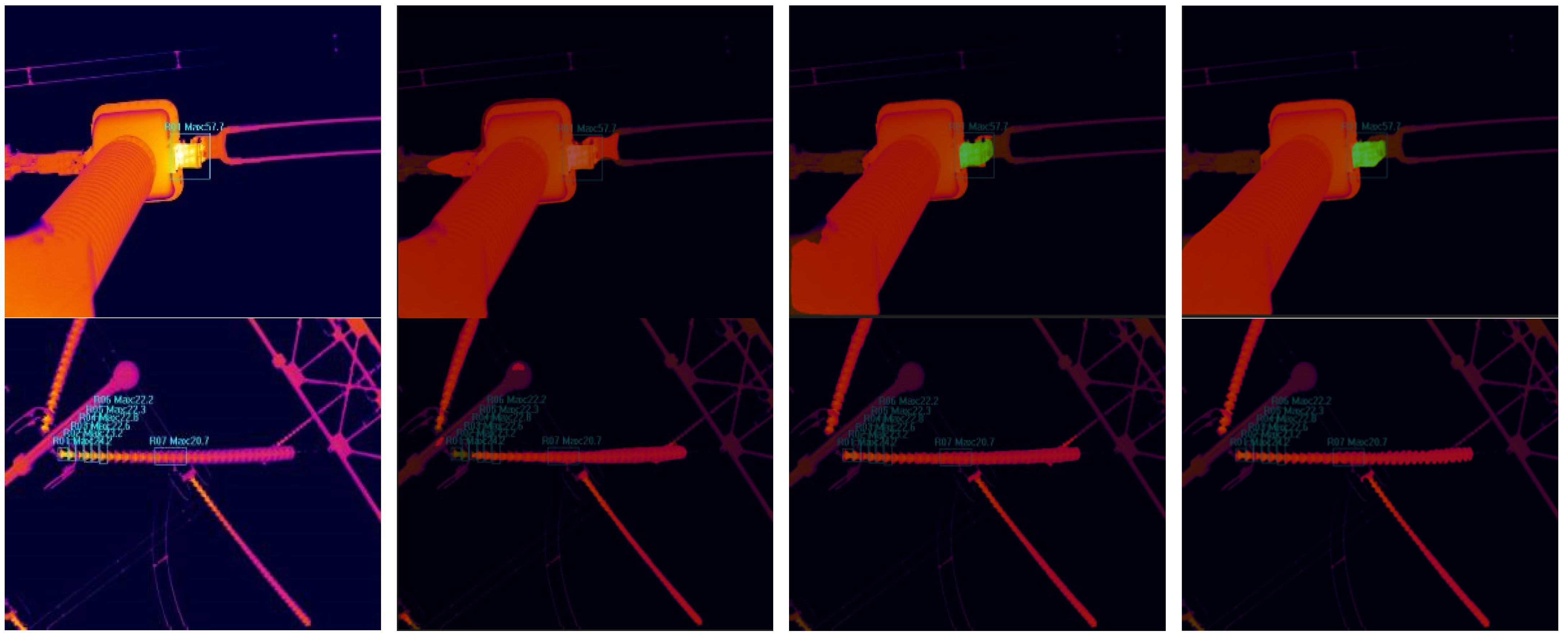
4.3. Comparison Experiment and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cao, H.; Zhang, Y.; Zhu, Q.; Zhao, Q. On-line detection and diagnosis of transformer thermal fault based on infrared imaging technology. Lab. Res. Explor. 2012, 31, 30–32+40. [Google Scholar]
- Li, T. Application of accurate infrared temperature measurement in condition maintenance of power equipment. High Volt. Appar. 2022, 56, 246–251. [Google Scholar] [CrossRef]
- Liu, X.; Ma, J. The Application of the ubiquitous power Internet of Things in the state monitoring of power equipment. Power Syst. Prot. Control 2020, 48, 69–75. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, K.; Liu, J.; Jia, B.; Wang, P.; Geng, J. Live detection technology of deteriorated insulator based on UAV inspection platform. Sci. Technol. Eng. 2020, 20, 8616–8621. [Google Scholar] [CrossRef]
- Jin, L.; Tian, Z.; Gao, K.; Xiao, R. Insulator contamination level recognition based on infrared and visible light image information fusion. Proc. CSEE 2016, 36, 3682–3691. [Google Scholar] [CrossRef]
- Peng, Z.; Chen, Y.; Pu, T.; Wang, Y.; He, Y. Review of image denoising methods based on sparse representation and regular constraints. Data Acquis. Process. 2018, 33, 1–11. [Google Scholar] [CrossRef]
- Zhang, N.; Zhang, Y.; Ding, W. A Review of Classical Image Denoising Methods. Chem. Autom. Instrum. 2021, 48, 409–412, 423. [Google Scholar] [CrossRef]
- Tang, C.; Tao, Q.; Huang, M. Discussion on the application of infrared temperature measurement technology in substation operation and maintenance. Shi He Zi Sci. Technol. 2020, 06, 14–15. [Google Scholar] [CrossRef]
- Chen, D.; Tang, W.; Niu, Z. Fault diagnosis method of infrared image of power equipment based on deep learning. Guangdong Electr. Power 2021, 34, 97–105. [Google Scholar] [CrossRef]
- Liu, H.; Yu, C.; Wu, H.; Duan, Z.; Yan, G. A new hybrid ensemble deep reinforcement learning model for wind speed short term forecasting. Energy 2020, 202, 117794. [Google Scholar] [CrossRef]
- Shao, Z.; Zhang, Z.; Wei, W.; Wang, F.; Xu, Y.; Cao, X.; Jensen, C.S. Decoupled dynamic spatial-temporal graph neural network for traffic forecasting. arXiv 2022, arXiv:2206.09112. [Google Scholar] [CrossRef]
- Qi, C.; Li, Q.; Liu, Y.; Ni, J.; Ma, R.; Xu, Z. Infrared image segmentation based on multi-information fused fuzzy clustering method for electrical equipment. Int. J. Adv. Robot. Syst. 2020, 17, 1–18. [Google Scholar] [CrossRef]
- Shu, J.; He, J.; Li, L. MSIS: Multispectral Instance Segmentation Method for Power Equipment. Comput. Intell. Neurosci. 2022, 2022, 2864717. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI, Munich, Germany, 5–9 October 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Usamentiaga, R.; Lema, D.G.; Pedrayes, O.D.; Garcia, D.F. Automated surface defect detection in metals: A comparative review of object detection and semantic segmentation using deep learning. IEEE Trans. Ind. Appl. 2022, 58, 4203–4213. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the Computer Vision—ECCV, Munich, Germany, 8–14 September 2018; Volume 11211, pp. 833–851. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Yin, F. Image segmentation method based on graph secsion and its new progress. Acta Autom. Sin. 2012, 38, 911–922. [Google Scholar] [CrossRef]
- Zeng, J.; Huang, S. Comparison and analysis of typical image edge detection operators. J. Hebei Norm. Univ. (Nat. Sci. Ed.) 2020, 44, 295–301. [Google Scholar] [CrossRef]
- Dang, W. Research and application of image region segmentation algorithm. Anhui Univ. Sci. Technol. 2018, 12, 76. [Google Scholar] [CrossRef]
- Jia, X.; Zhang, Y.; Wu, B.; Ma, K.; Wang, J.; Cao, X. LAS-AT: Adversarial training with learnable attack strategy. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13398–13408. [Google Scholar]
- Meng, L.; Xu, L.; Guo, J. A Semantic Segmentation Algorithm for MobileNetV2 Network Based on Improvement. Chin. J. Electron. 2020, 48, 1769–1776. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Guo, L.; Zhang, T.; Sun, W.; Guo, J. Pictorial Semantic Description Algorithm for Fusion Spatial Attention Mechanism. Adv. Laser Optoelectron. 2021, 58, 313–322. [Google Scholar] [CrossRef]
- Hou, T.; Zhao, J.; Qiang, Y.; Sanhu, W.; Pan, W. The CRF 3D-UNet lung nodule segmentation network. Comput. Eng. Des. 2020, 41, 1663–1669. [Google Scholar] [CrossRef]
- Li, K.; Han, B.; Zhang, J. Detection and Recognition of Traffic Signs Based on Conditional Random Airport and Multi-scale Convolutional Neural Network. Comput. Appl. 2020, 41, 1663–1669. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | MPA | MIOU |
|---|---|---|
| DeeplabV3+ | 0.794 | 0.699 |
| CBAM_DeeplabV3+ | 0.824 | 0.738 |
| CS_DeeplabV3+ | 0.850 | 0.772 |
| Module | MPA | MIOU |
|---|---|---|
| U-Net | 0.714 | 0.615 |
| DeeplabV3+ | 0.794 | 0.699 |
| CS_DeeplabV3+ | 0.850 | 0.772 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Zhu, W. Research on Algorithm for Improving Infrared Image Defect Segmentation of Power Equipment. Electronics 2023, 12, 1588. https://doi.org/10.3390/electronics12071588
Zhang J, Zhu W. Research on Algorithm for Improving Infrared Image Defect Segmentation of Power Equipment. Electronics. 2023; 12(7):1588. https://doi.org/10.3390/electronics12071588
Chicago/Turabian StyleZhang, Jingwen, and Wu Zhu. 2023. "Research on Algorithm for Improving Infrared Image Defect Segmentation of Power Equipment" Electronics 12, no. 7: 1588. https://doi.org/10.3390/electronics12071588