1. Introduction
With the development of the transportation industry, transportation security has become a key area of concern, where contraband detection is an important measure to maintain public safety and transportation security. However, the current excessive reliance on the experience and energy of security personnel has decreased the accuracy of manual reviews, and the accuracy rate of contraband detection by security personnel is generally between 80% and 90% [
1]. Therefore, automatically searching for prohibited items in passenger packages from X-ray images is essential for reducing labor costs and improving efficiency and reliability.
Through the analysis of the dual-energy X-ray scanning contraband dataset and operation of related experiments, it is found that they compared with the photographic (optical) object detection dataset, MS-COCO [
2] (Microsoft Common Object in Context), and the dataset PASCAL VOC [
3]. In the past few years, artificial intelligence technology based on the neural network has been applied to X-ray contraband detection [
4,
5,
6]. However, these algorithms have not yielded satisfactory achievements in contraband detection. Contraband security screening remains an open challenge for several key reasons [
7]:
Multi-scale detection in X-ray datasets: Due to the scanning angle of the dual-energy X-ray scanner and the physical characteristics of the contraband, there is a seriously uneven scale, which includes an uneven scale between the different categories, an uneven scale between the same categories, and an uneven scale between the long–short sides, rendering it difficult to detect the contraband.
Extreme clutter and occlusion: Pieces of information obscure each other because of the penetrating nature of the X-ray scanning equipment and the resulting overlap between the deep and shallow high-density image. This has a negative impact on the accuracy of X-ray contraband detection.
To solve the above problems, this paper proposes a material-aware path aggregation network for X-ray object detection and shape-decoupled SIoU (SD-SIoU), which can not only detect items of contraband in common but also detect difficult samples in extreme cases, such as small objects and obscured items. Our model takes the YoloX [
8] object detection network as the baseline and modifies its neck part for the differences between the X-ray images and the natural images in the OPIXray [
9] dataset.
Figure 1 shows the images of the dataset with the above problem.
Our main contributions are listed below:
Constructing a novel material-aware path aggregation network, which includes a smoothed atrous convolution module (SAC) and material-aware coordinate attention mechanism (MCA). The SAC is to handle the multi-scale problem by combining smoothed atrous convolution using separate shared convolutions with a parallel branching structure. The SAC effectively mitigates the grid effect caused by the atrous convolution, while improving the model’s multi-scale detection capability. The MCA is designed to address the clutter and occlusion problem by incorporating a spatial coordinate separation material perception module with a coordinate attention mechanism. The MCA mitigates contraband obstruction by focusing deeply on the contraband material information.
A new shape-decoupled SIoU (SD-SIoU), based on the SIoU, is constructed for the uneven aspect ratio problem. First, we optimize the normalized penalty factor; a centrosymmetric normalization function is constructed. Then, we decouple the predicted bounding box long–short side length information to construct a long–short-shape loss branch. Finally, we introduce the category long–short side coefficient, which is determined by category prior knowledge of the contraband datasets. The category long–short coefficient is embedded in the long–short-shape loss branch to handle the uneven aspect ratio by utilizing the category prior knowledge.
We evaluate our module on the OPIXray [
9] and SIXray [
10] datasets, then compare it to recent high-performing object detection networks and contraband detection networks. The experimental results confirm the superiority of our model over other contraband detection models.
2. Relate Work
X-ray security inspection task. Compared to the traditional photographic imagery generated by light reflection, an X-ray image is based on X-ray properties (penetrating, fluorescent and photographic effects). In X-ray images, the brightness and color of the pictures represent the density and material of the detected items, respectively. Therefore, objects scanned by X-ray lose their texture and original color information.
Traditional feature detection methods. X-ray contraband detection belongs to the category of object detection, and the early object detection feature extractors were mostly designed manually and purposefully. Turcsany et al. [
11] used a Support Vector Machine (SVM) and SURF features (Speeded-UP Robust Features) to build a visual bag-of-words; Zhang et al. [
12] extracted potential features of the image, such as the edges and color, by traditional image processing methods, and obtained a good detection performance improvement.
Deep learning detection methods. Deep learning comprises multiple layers of neural networks that outperform traditional machine learning algorithms. Akcay [
13] et al. first introduced deep learning to luggage classification detection of X-ray images using transfer learning. Li et al. [
14] combined a semantic segmentation network with Mask R-CNN [
15] into a two-stage CNN model, using the semantic segmentation network as Mask R-CNN soft-attention coding to improve the performance degradation caused by overlapping objects in X-ray images. Zhang et al. [
16] used an XMC R-CNN model, consisting of a material classification algorithm and an organic-inorganic separation algorithm, for object detection to mitigate the accuracy degradation caused by the occlusion problem effectively.
Multi-scale problem in contrabands detection. Few research studies focus on X-ray baggage threat detection in complex scenarios, including multi-scale detection. Wang et al. [
17] utilized a dense attention module to contribute to SDANet, and Cascade Mask RCNN is used as the baseline for the extracted multi-scale features. Tao et al. [
18] utilized bidirectional propagation to filter out the impact of the noisy region in the key part by constructing multi-scale features links. Chunjie et al. [
19] proposed EAOD-Net, utilizing the learnable Gabor convolution and deformable convolution. ResNeXt is also used to improve the representative ability of multi-scale features. Nguyen et al. [
20] used a task-specific deep feature extractor to reduce the multi-scale X-ray images to the same aspect ratio in the same size. This can enable a more efficient deep-detection pipeline. Chunjie et al. [
21] constructed a global context feature extraction (GCFE) module and learnable Gabor convolution layer for the high-level and low-level features, which facilitates the detection of bands of different sizes while suppressing background noise.
Obscuration problem in contrabands detection. The obscuration problem has also been widely studied by many scholars. Gas et al. [
22] explored the ability of the traditional CNN model to adapt different properties of the scanner and evaluated the prohibited items predicted result on the Dbf3 and SIXray datasets. Hassan et al. [
23] obtained dual tensors with improved contour information in X-ray baggage images by levering the intensity transit transitions in low- and high-energy scans. Those contour features were then put into an edge suppression model to filter the noise information to a normal level. Li et al. [
24] proposed a method based on GANs with a generator architecture with Res2Net for the natural occurrence problem. Hassan et al. [
25] proposed a tensor pooling strategy to decompose the scans across various scales and then fuse them via a single multi-scale tensor to obtain more salient contour maps for boosting a framework’s capacity for handling the overlap problem. Wei et al. [
9]. proposed the de-occlusion module (DOAM), which combines the edge and material information of the contraband to refine the feature map, which enhances the detection performance.
However, edge information contains too many irrelevant gradients [
26]. Therefore, it has a limited improvement in the model localization and classification; this leads to poor discrimination by the detection model in the case of occlusion and a multi-scale task. In addition, the above model does not take into account the effect of a severely unbalanced aspect ratio on the model predictions, which prevents the model from using the contraband shape information distribution to improve the model’s prediction performance.
3. Method
The anchor-free detection method is able to learn multi-scale features better than the anchor-based method [
27]. Therefore, the YoloX model using the anchor free detection method is chosen as the baseline model in this paper. A new shape-decoupled SIoU loss is also designed for YoloX’s unique decoupling.
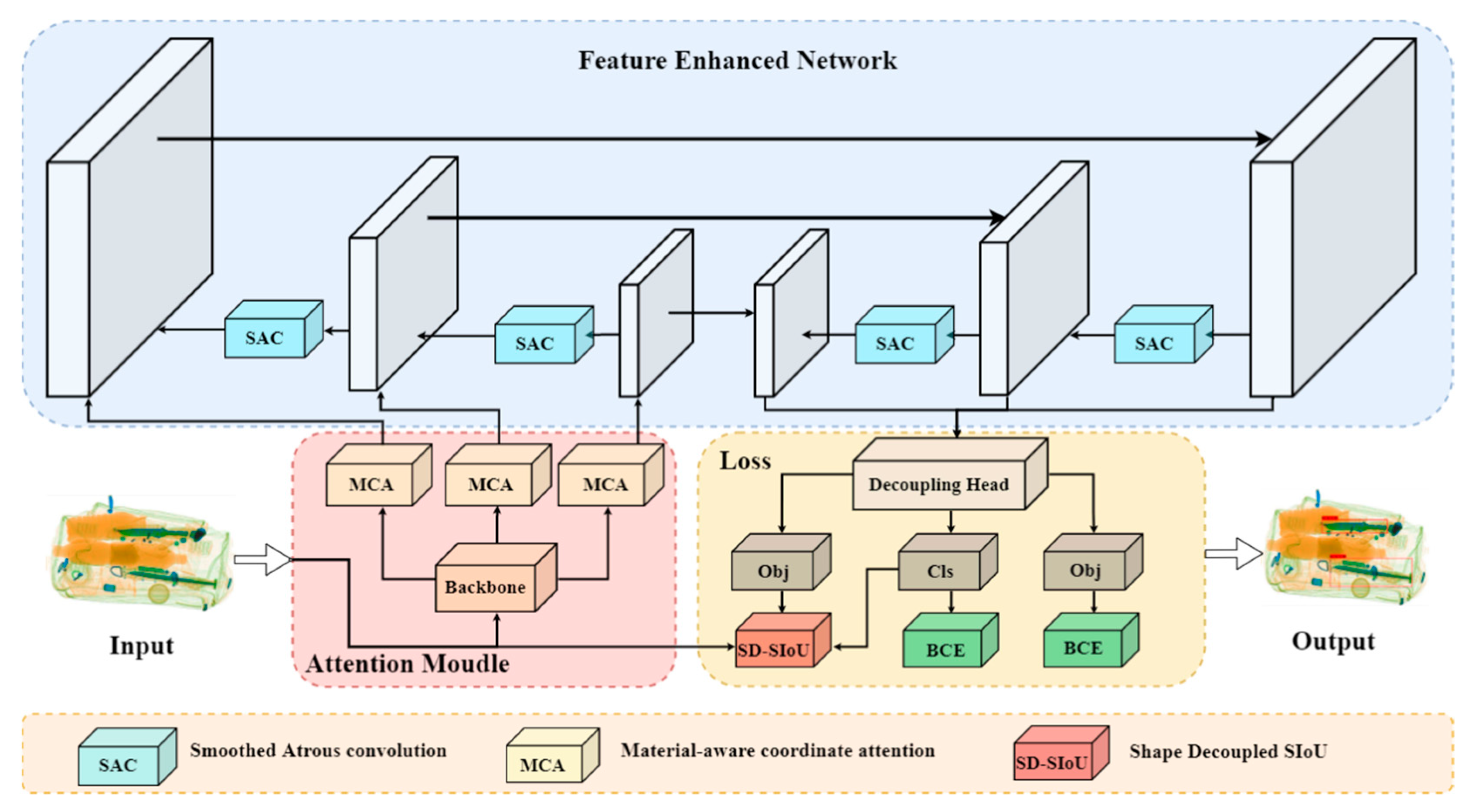
The block diagram of the proposed framework is depicted in
Figure 2. The input origin image is fed into the CSP-DarkNet53 [
28] backbone for multi-scale feature extraction. The extracted multi-scale features are separately fed into the material-aware coordinate attention mechanism (MCA) for recalibration. In the MCA, the material information related to the contraband can be extracted and integrated more accurately by utilizing a spatial coordinate separation material perception module. Afterward, these features containing the aggregated material information are then fed into an improved path aggregation network (PAN) [
29], which is embedded in the multi-scale smoothed atrous convolution module (SAC), with the SAC levering the ability of the smoothed atrous convolution to increase the field of perception for further extraction and fusion of multi-scale object information. Finally, in the training stage, the contraband prediction results are output by the decoupling head. SD-SIoU is used in the bounding box loss calculation, which decouples the shape loss of the prediction box into the long-side and short-side shape loss. The specific details will be described in the following sections.
3.1. Material-Aware Path Aggregation Network
To further address the problem of multi-scale detection and occlusion in contraband images, a Material-aware Path Aggregation network is proposed, which consists of multi-scale smoothing atrous convolution (SAC) and a material-aware coordinate attention mechanism module (MCA).
3.1.1. Multi-Scale Smoothing Atrous Convolution (SAC)
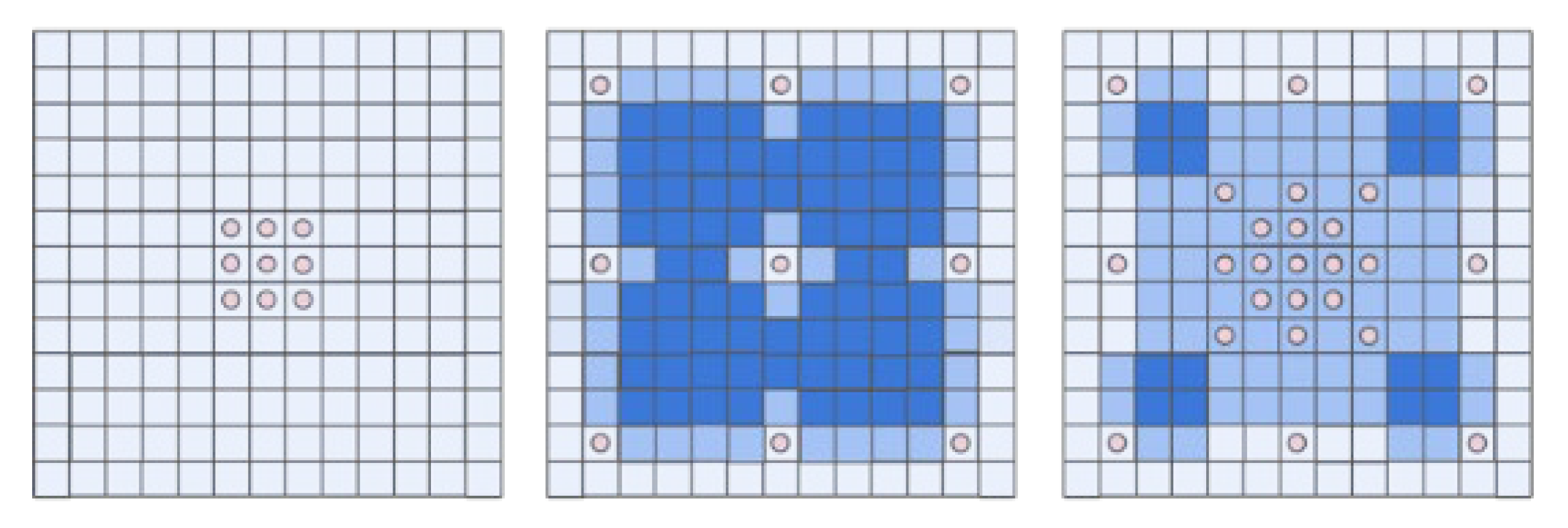
Compared to the traditional convolutional method, atrous convolution increases the receptive field of the convolution kernel while keeping the number of parameters unchanged [
30]. However, atrous convolution faces a serious grid effect, weakening the proximate connections while gaining long-distance dependence. To address this problem, inspired by the smoothed atrous convolution [
31], a multi-scale parallel smoothed atrous convolution structure is designed, which is shown in
Figure 3.
As shown above, to limit the impact of the grid effect, this paper constructs parallel atrous convolution branches; each branch uses a different expansion rate to minimize the grid effect.
Figure 4 shows the visualization of the atrous convolution grid effect rendering.
A smoothed dilated residual block can effectively prevent the grid effect [
31]; it addresses the gridding effect by levering separable and shared convolutions (SS), based on the idea of separable convolutions [
32]. In SS convolutions, sharing means that the filters are the same and shared by all the input and output channel pairs. For both the input and output channels, the SS convolution uses only one filter to obtain all the spatial information and shares that filter over all the channels. Therefore, smoothed dilated convolutions can effectively amplify the receptive field to make this branch pay more attention to style features(e.g. edges and global colors) [
33]. We therefore apply this module to our parallel multi-scale architecture. Finally, inspired by ResNet [
34], the residual information is summed with the fused information in Pixel-Wise and activated by the SiLU activation function.
Although the use of null convolution is effective in reducing the computational effort, the model itself increases some of the parameters and computational effort because of the addition of extra convolution
By using the SAC in the path aggregation network, the weight of the contraband material information can be augmented, which significantly increases the capability of the features to describe the important objects.
3.1.2. Material-Aware Coordinate Attention Mechanism (MCA)
Due to the unique physical characteristics of the X-ray scanner, the material information of the contraband is greatly diminished and is ultimately represented as color information. This means that channel information has a greater contribution to the detection of contraband in X-ray scanned images. The channel attention mechanism can learn different weights of channel dimensions, so that the information from the key channels can be utilized to a greater extent. The coordinate attention (CA) mechanism [
35], as a kind of channel attention module, embeds the spatial location information into the channel attention, which means adding extra information into the channels.
However, due to the weakness of spatial information in X-ray images, the original CA attention mechanism cannot fully extract the comprehensive spatial information of images. For this problem, inspired by SRM [
36], a material-aware coordinate attention mechanism is designed, and the specific structure is shown in
Figure 5.
First, the input feature maps are put into the material-aware extraction module, which is constructed by average pooling and standard pooling in the width and height directions, to obtain four feature maps, respectively. Specifically, given the input X, two special two-dimensional convolution kernels, (H,1) and (1, W), are used to encode the input data, and four different pooling methods are used to obtain the horizontal and vertical coordinate encoding information. The output of the height,
h, at the
c-th channel can be presented as
Similarly, the output of width,
w, at the
c-th channel can be formulated as
The above four branches integrate the information of two spatial dimensions, encoding the spatial information and channel information together. This serves as a summary description of the material information for each example, n, and channel, c.
After that, we enter the coordinate information embedding layer to splice and convolve the channel dimensions of the width and height feature information, which embeds the width and height information with the channel information into one feature map. Two feature maps with scales of H × 1 × C and 1 × W × C are obtained. These two directional feature maps of the width and height of the obtained global receptive field are put together according to the spatial dimension. Then, in the coordinate attention generation part, the two feature maps are fed into a convolution module with a shared convolution kernel of 1 × 1 to scale the dimension to C/r and, finally, to the sigmoid activation function and the BatchNorm operation.
3.2. Shape Decoupling SIoU (SD-SIoU)
In addition to the anchor-free detector, YoloX also introduces a decoupled head. The decoupled head decouples the classification task and the regression localization task into two separate branches for separate outputs. This enables the model to focus on the classification and localization tasks separately and improve the model performance. We further improve the decoupled localization task by introducing the SioU [
37] loss function and improving it for the physical properties of the X-ray scanning object, which include the shape-decoupling module and normalized optimization algorithm
3.2.1. Revisit SIoU Loss Function
Traditional IoU losses, such as DIoU, CioU [
38] and GioU [
39], only consider the distance, overlap area and aspect ratio information, and do not consider the angle and ratio between the shape and the predicted bounding box and the target bounding box, resulting in a slight overlap. However, SIoU redefines the penalty matrix by considering the angle and shape. SIOU regression loss consists of four components: distance loss, IOU loss, angle loss and shape loss. The total loss is defined as:
The angle loss is defined as:
The distance loss is defined as:
where
The shape loss is defined as:
where
and represent the y coordinates of the center point for ground truth and prediction. and represent the width and height of the bounding box.
SIoU has been widely used in recent networks and has proven to be a key component in the implementation of advanced detectors [
40,
41,
42,
43]. However, although SIoU takes shape loss into account, it couples the long- and short-side information of the prediction bounding box together and assigns the same computational weight to them, which ignores the proportional relationship between the long and short sides. In addition, SIoU limits the shape loss to [0, 1] by dividing by the maximum of the predicted and true values, which causes asymmetry in the parameter convergence curve and convergence difficulties due to low proximity gradients.
In the following, we will reconsider the shape loss part for the above problem.
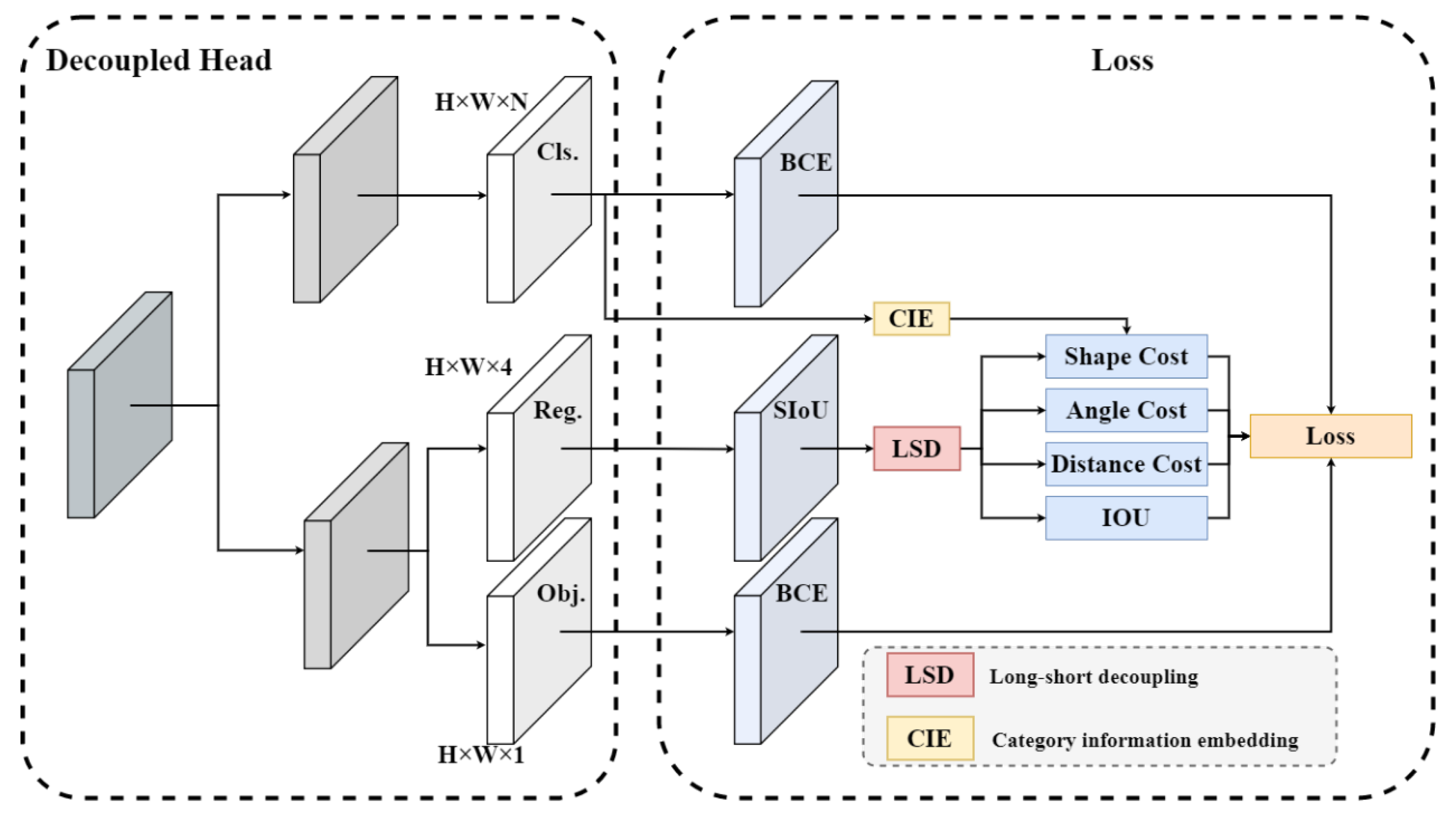
3.2.2. Shape Decoupling Module
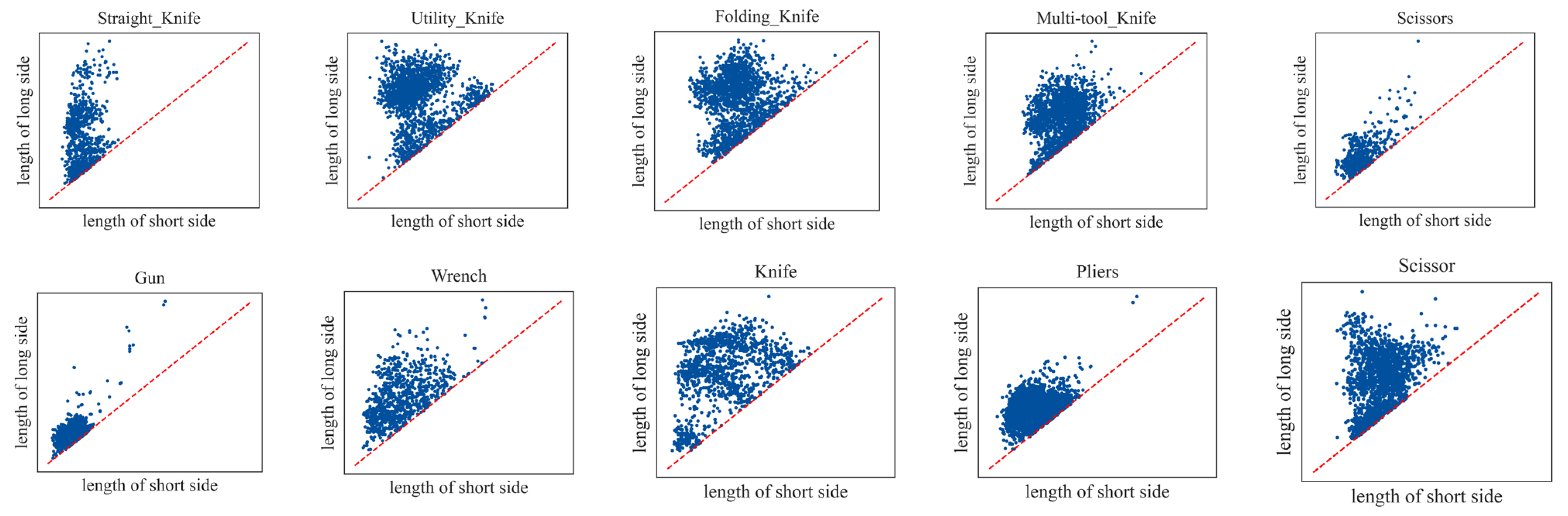
In the X-ray contraband images, the distribution of the long side and short side is always not equal, and the aspect weight of contraband varies greatly among different categories. Giving the same weight to the long side and short side will affect the optimization of the model for the contraband shape information.
Figure 6 shows the scatter plot of the OPIXray dataset consisting of information on the long side and short side of different types of contraband.
As shown in
Figure 6, there is a significant difference between the long–short sides of the target box. To address this problem, we designed the long–short side decoupling module and the category information embedding module, based on the special structure of the YoloX decoupling head. The detailed structure is shown in
Figure 7.
In the long–short side decoupling module, the length and width information of the input prediction bounding box is separated, and the lengths of the long side and the short side are extracted, respectively. Therefore, a new shape loss penalty factor is decoupled for the long length,
l, and short length,
s, as follows.
In the category information embedding module, we collect the long and short side information of the dataset by category and perform a cluster analysis to obtain the gathering point information. Finally, we construct the long–short scale matrix,
, which can be represented as follows.
where
n is the number of categories, and
is the aspect ratio of
i-th category clustered. Then, multiplying the category prediction matrix,
, with the long–short scale matrix,
, yields the category long–short side coefficient matrix,
.
Then, we embed the category information into the shape loss by dividing the long-side penalty factor by the category long–short side coefficient matrix,
. The equation is shown below.
The above formula realizes the decoupling of the shape information and the embedding of the category information, effectively alleviating the impact of the long–short sides on detection accuracy.
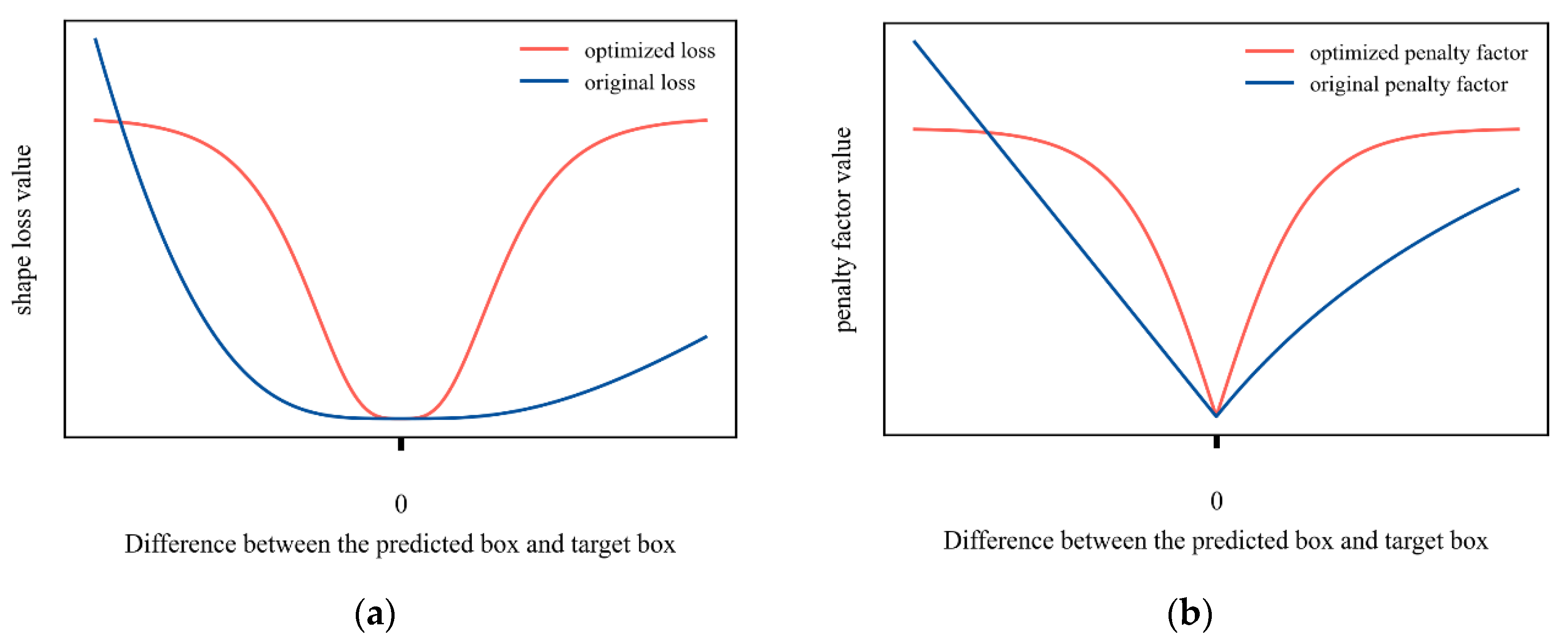
3.2.3. Normalized Optimization Module
As we continue our research, we find that, in shape loss, the range of values is restricted to
by dividing by the maximum value of the ground truth box width and height and the predicted box width and height in Equation (7). However, this method leads to a symmetry problem. It can be seen, in
Figure 8, the maximum normalization does not work consistently for the same distance gap between the target and predicted bounding box sizes in the positive and negative directions, and the optimized gradient is worse as distance between the target and prediction gets closer. Although the function has a very fast convergence speed in the early stage of training, the convergence ability of the model decreases as the prediction results approach.
To address this problem, we designed a symmetric normalization method for the shape loss part of the SIoU. The new shape loss composition is shown below.
where the novel penalty factor is:
As shown above, the improved normalization function solves the left–right asymmetry problem caused by the max function and optimizes the penalty factor regularization algorithm, so that the loss decreases more smoothly during the training process and still has a certain descent gradient in the late training period.
4. Experiment
In this section, we conduct comprehensive experiments on OPIXray and SIXray datasets to evaluate the effectiveness of our method. OPIXray and SIXray are the common datasets for X-ray contraband images.
4.1. Experiment Setting Details
This paper is implemented by a Windows 10 64-bit operating system, 12th Gen Intel Core i9-12900K@3.2 GHz CPU, 32 GB RAM, NVIDIA 3080ti GPU with CUDA Toolkit 11.4 and Torch 1.11 in Python 3.8. As the benchmark of our model, YoloX uses the most primitive parameter settings. The backbone of YoloX uses CSP-Darknet53.
All the experiments of our model and baselines are optimized by an Adam optimizer. The initial learning rate is set to 0.001, and the Cosine Annealing learning rate reduction strategy is used. The momentum and weight decay are set to 0.93 and 0, respectively. The batch size is set to 16. We evaluate the mean Average Precision (mAP) to measure the performance of all the methods. In addition, the IoU threshold measuring the accuracy of the predicted bounding box is set to 0.5.
4.2. Comparing with SOTA Detection Methods
To verify the effectiveness of the proposed methods in this paper, as shown in
Table 1 and
Table 2, we compared the mainstream contraband detection models and object detection models in the last two years on the OPIXray and SIXray datasets, respectively. The method involved included object detection models such as Swin Transformer [
44], RetinaNet [
45], DetectoRS [
46], Yolov5 and baseline YoloX. It also includes the most advanced contraband detection models in the last two years such as CHR [
10], FBS [
47], CFPA-Net [
48], MCIA-FPN [
49] and POD-Y [
21].
As
Table 1 and
Table 2 show, the proposed model can achieve the optimal detection performance on the OPIXray and SIXray datasets; the mAP values are 2.02% and 0.71% higher than those of the state-of-the-art model on the OPIXray and SIXray datasets. Compared with the existing one-stage prohibited items detection network, our model can achieve an optimal detection performance. Especially for the small target category “Straight Knife” in OPIXray, which faces the problem of obscuration and small scale, and its aspect ratio is extremely uneven, our model achieves an 8.88% improvement compared with POD-y. The above experimental results fully demonstrate that our proposed method is effective and efficient.
4.3. Comparing with Different Attention
To verify the effectiveness of the improved attention mechanisms in this paper, we compare the mainstream attention mechanisms, including the SE [
51], GAM [
52], CA [
35] and PSA [
53] attention mechanisms. The specific results are shown in
Table 3, below.
It is obvious that our method performs better on the OPIXray dataset compared to the other methods, with results 2.11%, 1.81%, 2.69%, 1.38%, 1.17% and 0.21% higher than the other attention mechanisms, respectively. We also compare DOAM, an attention mechanism for contraband detection, and see that our model is 0.12% more accurate than DOAM, with a smaller number of computations and parameters than DOAM. It can be seen that our model maintains a high level of detection accuracy and speed without a significant increase in the number of computations and parameters.
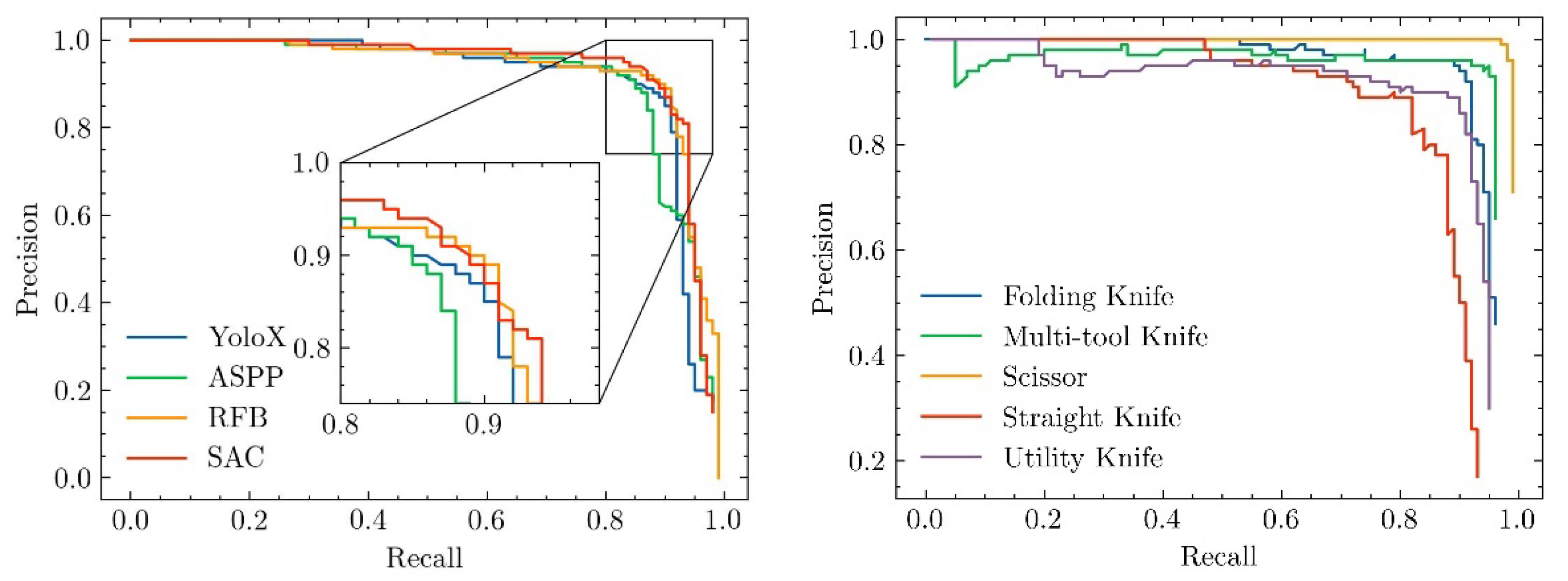
4.4. Comparing with Different Receptive Field Enhancement Module
We further verify the effect of our multi-scale smoothed atrous convolution (SAC). As we can see in
Table 4, we compare different receptive field enhancement modules include ASPP [
54] and RFB [
55]. Our method shows an improvement of 1.80% and 0.34% over the ASPP and RFB modules.
To better show the superiority of our proposed model, we plot the P-R curves for different receptive field modules, as shown in
Figure 9. The P-R curve of our module is closer to the upper right position compared to the other models, which means that our SAC has a better performance.
4.5. Ablation Study
To verify the effect of each module on the model performance, we perform ablation experiments on the OPIXray and SIXray datasets. The results are shown in
Table 5. We compare the mAP of the model with different combinations of components. The same parameters were used for all the experiments performed in the ablation study to ensure the validity of the comparison. The SD-SIoU increases the mAP of the baseline from 89.85% to 91.76% and 89.80% to 90.94% on OPIXray and SIXray, respectively. This result shows that the SD-SIoU has considerably improved the detecting performance. Then, we split the material-aware path aggregation network into SAC and MCA, which represent the Smoothed Atrous Convolution and Material-aware Coordinate Attention. The MCA increases the mAP of the baseline with SD-SIoU by 0.29% on OPIXray and 0.18% on SIXray. SAC increases the mAP of the baseline with SD-SIoU by 0.60% on the OPIXray and 0.33% on the SIXray. The experiments shows that the SAC and MCA modules are helpful for the model to detect contraband accurately. Finally, when all the methods are used together, our model mAP achieves 92.65%and 91.31%. These are 2.80% and 1.51% higher than the YoloX baseline on OPIXray and SIXray, respectively. Each method can improve performance individually, and combining these methods results in the optimal performance. It is worth mentioning that the improvement on the OPIXray dataset is greater than on the SIXray dataset. The main gap is in the SD-SIoU section. It will be further investigated in the following.
To further visualize the effectiveness of our SD-SIoU, we perform detailed ablation experiments on the SD-SIoU part, which we illustrate by two parts of the mAP and loss function curves.
As can be seen in
Table 6, we compared the mAP of the SIoU loss function under different conditions. ON denotes the optimized normalized curve; LSside denotes the long–short side decoupling module. “Decoupling” means the category information embedding module. The optimized normalized curve improves the mAP of the model by 1.38% and 0.95%, which means this normalized method can improve the convergence results of the model. It is worth noting that, when introducing the long–short side decoupling module without the category information embedding module, the accuracy of the model decreases by 0.16% and 0.21%. The reason for this phenomenon is that there is a serious maldistribution after the construction of the long–short side shape loss. The weight of the long-side loss is not balanced with the weight of the short-side loss. Therefore, we continue to add the category length ratio decoupling module. It increases the mAP by 0.69% and 0.50% and achieves higher AP detection performance.
We recorded the shape loss curves and long–short loss curves of the SD-SIoU under different conditions. Since the loss data under different conditions varied widely and had small fluctuations, we normalized and denoised all the curves and indicated their validity by observing the decreasing trend of loss. The specific images are shown in the
Figure 10.
The first figure shows the SD-SIoU loss curves under the ablation experiment. The loss value drops lower after improving the normalization function of the shape loss factor, but the trend is almost the same at the beginning of the training. This is because our new normalization method still has a good gradient in the late training period, while the gradient of the traditional normalization method is not significant in that period. We also find that the downward trend does not change significantly after adding the long–short side decoupling module, but there is a significant improvement after adding the category information embedding module. To address this issue, we conduct more detailed experiments.
Figure 10 splits the long side and short side from the shape loss. This represents the long-side loss and short-side loss before and after adding the category information embedding module. We can see that the addition of this module directly affects the decreasing trend of the long-side loss, while the decreasing trend of the short edge does not change significantly. This means that adding the classification module can effectively improve the convergence of the long side without affecting the short-side loss. In other words, this module alleviates the problem of uneven weights between the long–short sides.
Finally, we use the model proposed in this paper for visual inspection of the OPIXray and SIXray datasets, as shown in
Figure 11 below.
5. Conclusions
In this paper, a new feature extraction network is designed considering the specific physical characteristics of X-ray images. For the X-ray contraband multi-scale problem, a multi-scale smoothing atrous convolution module is designed to capture multi-scale contraband features by acquiring different sizes of the receptive field. For the occlusion and weak textural information in X-ray contraband images, we design a material-aware coordinate attention mechanism to enhance the material features’ extraction ability in obscured X-ray images. In addition, an improved SIoU was designed, named SD-SIoU, which addresses the problem of inconsistent aspect ratios in contraband images. Through a large number of experiments and visualization results, we determine that the feature extraction and enhancement strategies proposed in this paper can effectively strengthen the ability of the model to detect contraband. Its validity is reflected in the evaluation index mAP. Our experimental results, based on the OPIXray and SIXray datasets, show that our method achieves an average accuracy of 92.65% and 91.31%, with a computational volume of 256.86G for 109.46M parameters, respectively. From the quantitative point of view, the proposed method has excellent performance in the field of contraband detection. The comparison results show that the method outperforms other contraband detection methods.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}