1. Introduction
Reachability queries processing is a fundamental graph operation that has been extensively studied in the literature. When given a directed graph, a reachability query
inquires whether there exists a directed path from node
u to
v. It could be used for the Semantic Web, online social networks, biological networks, ontology, transportation networks, etc., to answer whether two nodes have a certain connection. It could also be used as a building block for answering structured queries, such as XQuery (
https://www.w3.org/TR/2017/REC-xquery-31-20170321, accessed on 1 January 2020) or SPARQL (
https://www.w3.org/TR/rdf-sparql-query, accessed on 1 January 2020). For applications where answering reachability queries is intensively involved, any substantial progress in query time could significantly affect the performance of all applications using it. Over the past decades, researchers have proposed many efficient labeling schemes to facilitate processing reachability queries. According to [
1,
2], the existing approaches could be classified into two categories:
Label-Only and
Label+G.
Label-Only means that the index conveys the complete reachability information, and the given query
could be answered by comparing the labels of
u and
v, without graph traversal.
Label+G means that the index covers partial reachability information, and we may need to perform graph traversal to answer a query.
For
Label-Only, the state-of-the-art approaches in [
3,
4,
5] were based on 2-hop labeling schemes [
6], and they generated 2-hop labels based on all the nodes to maintain the whole transitive closure (
TC). The problem of
Label-Only approaches has been that the index size cannot be bounded with respect to the size of the input graph and minimizing the size of the 2-hop labels as NP-hard [
6], which makes the index construction a difficult task in practice for dense graphs. For example, it was shown in [
2] that when the number of nodes was 10 million and the average degree of the input graph was greater than 6, the state-of-the-art
Label-Only approaches, such as
TF [
5],
DL [
3], and
TOL [
4], could not construct the index successfully due to exceeding the memory limit. As compared to
Label-Only, the main advantage of
Label+G approaches has been that the index could be easily constructed, which meant that
Label+G approaches were
indispensable when
Label-Only approaches were not appropriate for the given graph. Due to that, the index could not cover all the reachability information, and the
Label+G approaches usually used two types of labels for pruning in order to terminate the graph traversal in advance. The first was
No-Label, which was used to determine whether a query was an unreachable query. The second was
Yes-Label, which was used to determine whether a query was a reachable query, including the tree interval [
7,
8,
9] and p2HLs, which were constructed based on a portion of, rather than all of, the nodes. In this paper, we referred to nodes that were used to construct p2HLs as hop-nodes. It was shown in [
2] that the state-of-the-art
No-Label could correctly answer more than 95% of unreachable queries. However, this was not enough. Although a workload with completely random queries would be heavily skewed towards unreachable queries [
9,
10], in real scenarios, it would be highly unlikely that most queries would be unreachable, as the node pair in a query would tend to have a certain connection [
11]. For
Label+G approaches, therefore, processing reachable queries has been regarded as a worst-case scenario due to the need of graph traversal [
7], and the query performance has been dominated by the pruning power of
Yes-Label when the number of reachable queries increased.
The pruning power of
Yes-Label depends on reachability ratio (RR), i.e., the ratio of the number of reachable queries that can be answered by
Yes-Label based on the size of the
TC. The higher the RR, the larger the probability that the given reachable query can be answered using
Yes-Label without graph traversal. Our statistics showed that even using five randomly generated tree intervals, as performed in [
10], the RR was less than 10% for most graphs, resulting in poor query performance when the number of reachable queries increased [
7]. As a comparison, it was shown in [
7] that p2HLs could improve the query performance significantly for many graphs. For example,
Figure 1 shows the RR of p2HLs on three graphs, from which we found that even if we constructed p2HLs using 1 hop-node, the RR was greater than 95% on web-uk, meaning the probability that a given reachable query
q could be answered by p2HLs was greater than 95% without graph traversal. In practice, however, the RR of p2HLs changed dynamically for different graphs, and the query performance was not as efficient as expected [
7]. In shown in
Figure 1, the RR was close to 0 on patent, meaning the probability that
q could be answered by p2HLs was close to 0. In this case, using p2HLs resulted in only additional costs.
Considering that
Label+G approaches are indispensable and its query performance is mainly affected by the pruning power of the most important
Yes-Label, i.e., p2HLs, the key problem that needed to be solved was the following: whether we should use p2HLs for a given graph. The answer depended on the RR. For example, given the RR in
Figure 1, we could decide to use p2HLs on web-uk but not on patent, as by using the same number of hop-nodes, the RR would be greater than 95% on web-uk and close to 0 on patent. Furthermore, once RR were determined, we could further determine how many hop-nodes should be chosen to construct the p2HLs. For example, according to
Figure 1, we could decide to use four hop-nodes for a human, but for web-uk, one hop-node would be sufficient due to its larger RR and smaller index size.
To the best of our knowledge, this was the first work to address RR-aware p2HLs. Computing RR for given p2HLs was not a simple task and, thus, involved two operations. One was computing the size of
TC, and the other was computing the exact number of reachable queries that could be answered by p2HLs, which we referred to as the coverage size. Considering that the
TC size computation could be efficiently solved by existing methods in [
12], the difficulty of RR computation was related to efficiently computing the coverage size. The naive way was by first generating p2HLs based on the selected
k-hop-nodes and then obtaining the coverage size by reviewing all the node pairs using p2HLs. In this way, the cost of coverage size computation was
and could not be scaled for larger graphs, where
V was the set of nodes in the input graph. Furthermore, if the RR was too small to fulfill the requirement, we may need to increase
k-value and repeat the above operation, which would then make the RR computation more difficult to solve.
We proposed the computation of the coverage size incrementally, so that when the value of k changed, we could avoid the costly coverage size re-computation to support a more efficient RR computation. The basic concept was, given the coverage size with respect to the k nodes, when we computed the coverage size with respect to hop-nodes, we would not compute it from scratch but only compute the increased coverage size. However, the increased coverage size could not be easily computed. To obtain the increased coverage size with respect to the th hop-node u, we had to firstly traverse from u to obtain a set of nodes that u could reach, then traverse from u in reverse to obtain the second set of nodes that could reach u. Given and , we needed to determine for each pair of nodes , whether a could reach d and whether that could be determined by the current p2HLs without u, where . If this was possible, we could affirm that a could reach d and whether that could be determined by p2HLs without u and, therefore, should not be considered when computing the increased coverage size with respect to u. The cost of processing one hop-node u was as high as . Obviously, with an increase in the number of hop-nodes for p2HLs construction, the cost could become unaffordable. For this problem, we proposed dividing both and into a set of disjointed subsets based on an equivalence relationship (as defined later), so that for each pair of subsets and , we only needed to test one reachability query, rather than queries. The cost of the RR computation was, therefore, reduced significantly even when processing large graphs. We made the following contributions.
To the best of our knowledge, this was the first work to focus on RR-aware p2HLs.
We proposed a set of algorithms for RR computation. We showed that according to the properties of 2-hop labels, the two sets of nodes that could reach, and be reached by, a certain hop-node could be divided into a set of disjointed subsets, so that the computation cost could be reduced significantly. We proved the correctness and efficiency of our approach.
We conducted rich experiments on real datasets. The experimental results showed that when compared with the baseline approach, our algorithm operated much more efficiently on RR computations. We also showed the overall query performance was affected by p2HLs with different numbers of hop-nodes, based on which we provided our findings as to whether and how to use p2HLs for a given graph for processing reachability queries.
The remainder of the paper is organized as follows. We discuss the preliminaries and the related work in
Section 2. In
Section 3, we provide the baseline algorithm for RR computations and propose the first incremental algorithm in
Section 4. After that, we propose the optimized incremental algorithm in
Section 5. We report our experimental results in
Section 6 and conclude our paper in
Section 7.
3. The Baseline Algorithm
In this section, we first analyze the construction of 2-hop labels and then discuss the RR computation and the baseline algorithm.
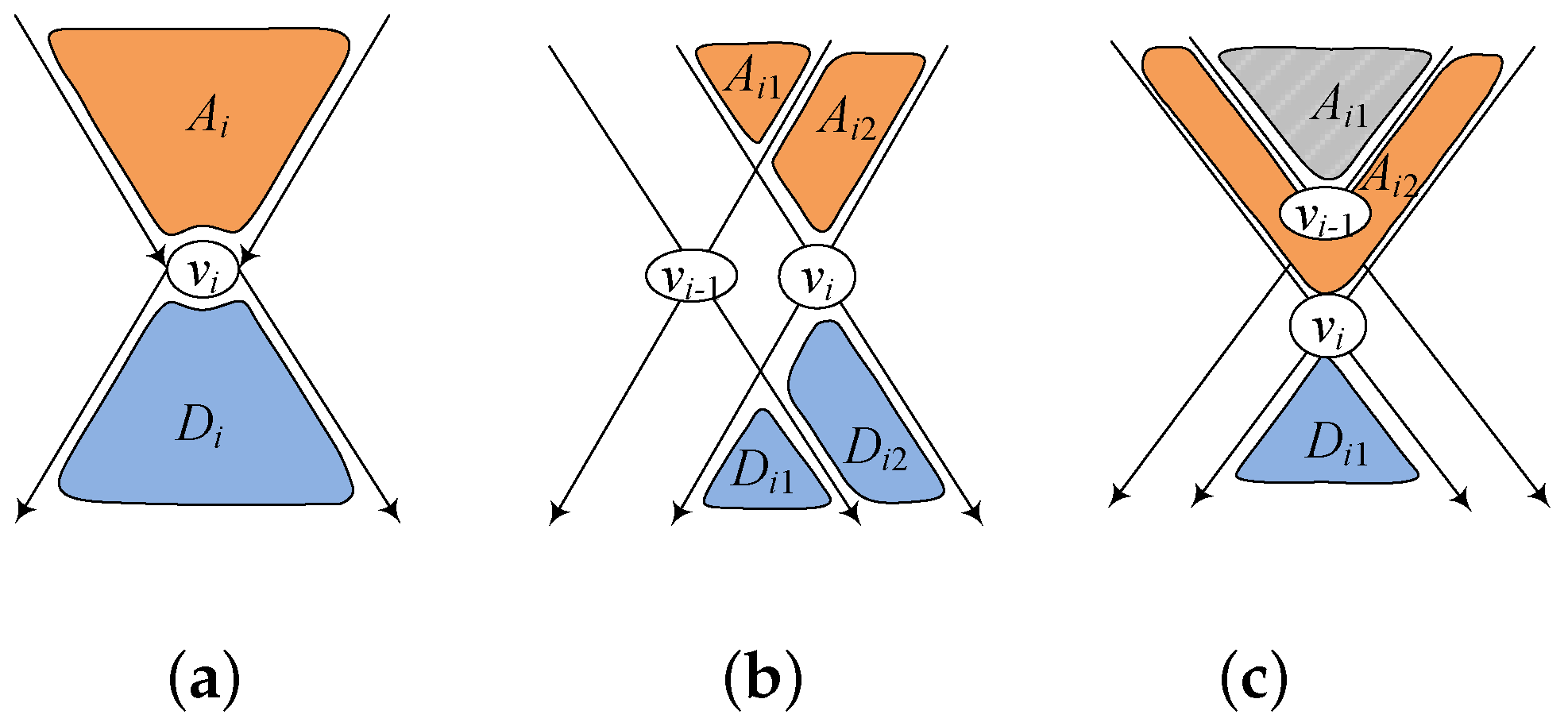
Step-1: 2-hop Label Construction. To construct 2-hop labels, we followed [
3,
14] and sorted all nodes by
. The sorting result was
, where the first node has the largest rank value. We selected the first
k nodes to obtain the hop-node set
. We had the following result: (Equations (
2) and (
3)).
Given
, the p2HL
could be generated by processing
, based on
, according to Equations (
2) and (
3). Specifically, we performed forward (backward)
BFS from
to obtain a set
of nodes that
could reach (could be reached by
),as denoted by
Figure 2a. For each node
, we added
to
a’s out-label, i.e.,
, denoting that
a could reach
. For each node
, we added
to
d’s in-label, i.e.,
, denoting that
could reach
d. After processing
, we obtained 2-hop labels
. The superscript
i in
denotes that both 2-hop labels
and
, with respect to node
a, are subsets of
. Here, we could use
to reduce the size of both
and
. For example, in
Figure 2c, when processing
, the backward
BFS traversal from
could be terminated at
, because
reaching
could be determined by
, and
reaching
through
could also be answered by
.Therefore, in practice,
.
Example 1. Consider G in Figure 3. Assume that the sorting result is . To obtain , we first performed bidirectional BFS of to obtain and . After that, we added 1 to the out-label of nodes in and the in-label of nodes in , in order to obtain . The next processed node was . Similarly, we obtained and . Note that all nodes in could reach , but some of them were not in , because for nodes that were in but not in , whether they could reach could be answered by . Then, we added 2 to the out- and in-labels of nodes in and , as shown by Table 1. Step-2: RR Computation. Given
with respect to
, the baseline approach computed the RR, as follows. First, it obtained the set of nodes that could reach either one of the set of hop-nodes, as shown by Equation (
4). Second, it obtained the set of nodes that could be reached by either one of the set of hop-nodes, as shown by Equation (
5). It computed the number of reachable queries that could be answered by
, as shown by Equation (
6). Finally, we returned the RR of
based on Equation (
1).
Example 2. Continued example of 1. To compute the RR of , we first computed , , according to Equations (4) and (5), respectively. Then, we review each pair of nodes and as to whether a reaching d could be answered by . Furthermore, we computed the number of answered reachable queries according to Equation (6), which was 42 for G in Figure 3 and in Table 1. Given , we knew that the RR of was . The Algorithm: The baseline algorithm (Algorithm 1) computed RR in two steps. Step-1 (lines 1–18) first calls the
buTC algorithm [
12] to compute
TC size in line 1, and then constructs 2-hop labels
and obtained the two sets of nodes,
and
. Specifically, it first sorts all nodes in certain order in line 3 and then selects
k hop-nodes in line 4. In lines 5–16, it performs forward and backward
BFS for each hop-node
to construct 2-hop labels
. During the process, only if the reachability relationship between
and the visited node
v cannot be answered by 2-hop labels
, then it adds
to
v’s in-label (line 9) or out-label (line 14), and adds
v to
(line 10) or
(line 15); otherwise, it terminates the process because the reachability relationship has already been covered by
. In lines 17–18, it obtains the two sets
and
according to Equations (
4) and (
5). Step-2 (lines 19–21) computes the number of covered reachable queries by
according to Equation (
6). Finally, it returns the RR in line 22.
| Algorithm 1: blRR |
1 compute by the buTC algorithm [ 12] 2 3 rank all nodes v in G by 4 put the first k nodes into as hop-nodes 5 foreach do 6 ; 7 perform forward BFS from , and for each visited v 8 if then /**/ 9 /*compute */ 10 11 else stop expansion from v 12 perform backward BFS from , for each visited v 13 if then /**/ 14 /*compute */ 15 16 else stop expansion from v 17 18 19 foreach do 20 if then /**/ 21 22 return as RR of |
Analysis: The time cost of line 1 was
(details are in from
Section 2.2) and was
for line 3 by counting sort. The time cost of
BFS from each hop-node
was
(lines 6–16). During the two
BFS traversals, the cost of processing each visited node
v was
(lines 8 and 13). Therefore, the time cost of processing
k hop-nodes was
. As a result, the time cost of Step-1 was
. For Step-2, the time cost of computing
was
. Therefore, the time complexity of Algorithm 1 was
.
During the processing, we did not need to actually maintain every and ; instead, we only needed to maintain and . Furthermore, we needed to maintain the 2-hop labels with respect to k hop-nodes, so the space cost was . As , and were bounded by V, the space complexity of Algorithm 1 was .
In practice, if the RR was too low to meet the requirement, then we needed to use additional hop-nodes. Therefore, Algorithm 1 would be called once more to compute the new RR, for which all reachability relationships tested for would be tested again for the new hop-node set.
Example 3. Continue Example 2. Given , and , we needed to test 56 queries in lines 19–21, due to and . By line 22, we knew the RR was 60%. If the RR was required to be equal or greater than 80%, we would need to enlarge the hop-node set and re-compute the RR from scratch. As a result, the 56 queries tested for would be tested again for the new hop-node set.
4. The Incremental Approach
Considering that Algorithm 1 would be called again when the hop-node set was enlarged, a natural question was: Could we compute the RR incrementally? That is, given the RR with respect to , when we decided to compute it with respect to , we did not start from scratch; instead, we only computed the number of reachable queries that could not be covered by but could be covered by .
However, the increased RR could not be easily computed. On the one hand, by constructing 2-hop labels using hop-node , we captured 3 types of reachability relationships: (1) that could reach every node in could be determined by 2-hop labels with respect to , and the number of covered reachable queries was ; (2) Every node in that could reach could be determined by 2-hop labels with respect to , and the number of covered reachable queries was ; and (3) each node in that could reach every node in could be determined by 2-hop labels with respect to , and the number of covered reachable queries was . Therefore, the number of covered queries by 2-hop labels with respect to was .
On the other hand, 2-hop labels with respect to different hop-nodes could cover the same reachable queries. For example, consider
Figure 2b. After processing
, every node
that could reach every node
could be covered by 2-hop labels with respect to
, because
. After processing
, we knew that
could reach
, which could also be covered by 2-hop labels with respect to
, because
. Then, the increased number of reachable queries with respect to
could be computed as Equations (
7) and (
8), and the total number of reachable queries
covered by
could be computed as Equation (
9).
Therefore, the intuitive approach was to first obtain the two sets of nodes, and , and then testing for each pair of nodes and , whether a could reach d could be answered by . If the answer was true, then it indicated that had already been covered by ; otherwise, it was a new covered query and needed to be considered, as shown by Algorithm 2.
In Algorithm 2, we computed the RR for each
when
had been added into
. In lines 15–18, we computed the number of queries that could be covered by
. We obtained the increased number of queries in line 19 according to Equation (
7). Then, we obtained the RR of
in line 21. We computed
based on
in lines 22–25. Finally, we returned the RR of
in line 26.
Analysis: Algorithm 2 computed the two sets and in lines 2–14, and then it computed in lines 22–25. The overall cost of Step-1 was same as that of Algorithm 1, i.e., . The cost of Step-2 for each hop-node was . For k hop-node, the cost was . Therefore, the time complexity of Algorithm 2 was . Similar to Algorithm 1, the space complexity of Algorithm 2 was .
Example 4. Consider G in Figure 3. Assume that we want to construct p2HLs . The first processed node is . As , , and then we know . The second processed node is . The p2HLs are shown in Table 1 and , . Then, in lines 16–18, we need to test queries. As , , and . The third processed node is and , . Then, in lines 16–18, we need to test queries. As , , and . After processing , we had , as shown in Table 1, and the RR was % by testing queries in Algorithm 2. As a comparison, for Algorithm 1, , , and we needed to test 80 queries to obtain the RR.
| Algorithm 2: incRR |
1 compute by the buTC algorithm [ 12] 2 3 rank all nodes v in G by 4 put the first k nodes into as hop-nodes 5 foreach do 6 7 perform forward BFS from , and for each visited v 8 if then /**/ 9 10 else stop expansion from v 11 perform backward BFS from , for each visited v 12 if then /**/ 13 14 else stop expansion from v 15 16 foreach do 17 if then /**/ 18 19 20 21 /*RR of */ 22 foreach do /*compute */ 23 24 foreach do /*compute */ 25 26 return as RR of |
5. The Incremental-Partition Approach
5.1. The Equivalence Relationship
Though Algorithm 2 did not need to compute RR from scratch when the hop-node set became large, it still needed to test queries in line 16 with cost . Given a large hop-node set, the cost could still become unaffordable.
Definition 1. [Equivalence Relationship]Given a hop-node , its ancestor set was , and its descendant set was . We assumed the two nodes of were forward-equivalent to each other, denoted as , if they had the same out-labels, i.e., . Similarly, the two nodes of were backward-equivalent to each other, denoted as , if they had the same in-label, i.e., .
By Definition 1, we could determine that for , a partition , which consists of a set of m disjointed subsets satisfying that (1) and ; and (2) belonging to the same subset, . For , we also had a partition satisfying that (1) and ; and (2) belonging to the same subset, . We had the following result.
Theorem 1. Given a hop-node , its ancestor set , and its descendant set , the number of tested queries for RR computation was , which was bounded by .
Proof. Let be the partition of based on the equivalence relationship and the partition of V with respect to hop-node set and the forward (backward) equivalence relationship. Initially, , .
On the one hand, for each subset , the result of testing all the reachability relationships from nodes of to any other node was equivalent to each other; thus, we only needed to randomly select a node and let it be the representative node of to perform the testing of reachability relationship. Similarly, for each subset , we could also randomly select a node and let it be the representative node of to test the reachability relationships from any node to the nodes of . As a result, the number of tested queries from the nodes of to the nodes of was . Since was the partition of , we knew that .
On the other hand, given the partition of V, the size of was, at most, twice the size of , and all nodes in each subset of could be further divided into, at most, two disjointed subsets. One consisted of nodes that could reach (and be reached by) , and the other contained nodes that could reach (or be reached by) . Then, the size of was bounded by , and the size of was bounded by . Therefore, the the number of tested reachability queries was bounded by .
Hence, the number of tested queries for RR with respect to hop-node was bounded by . □
According to Theorem 1, we could reduce the number of tested reachability queries when processing hop-node
. As shown by Equation (
10), for each pair of subsets
, we only needed to review the reachability relationship between their representative nodes
and
. To accomplish this, we first determined the partitions of both
and
, according to their equivalence relationship.
5.2. Partitions Computation
To obtain the partitions of and , the intuitive approach was to sort all nodes in by comparing their out-labels (in-labels) in lexicographic order. After the sorting operation, all equivalent nodes were clustered together. As the size of each label was bounded by i, the cost of computing the partition of was .
Let be the partition of V with respect to hop-node set and the forward equivalence relationship, the partition of V with respect to and backward equivalence relationship. We obtained the following result.
Theorem 2. Assume the hop-node and its ancestor (descendant) set for , , if they belong to the same subset of .
Proof. We proved this result from two aspects. First, we proved the correctness when both and belonged to (Case-1), and then we proved the correctness when both and belonged to (Case-2).
Case-1 where and .
On the one hand, if , it indicated that according to Definition 1. Hence, , i.e., they belonged to the same subset of .
On the other hand, if both and belonged to the same subset of , it indicated that before processing hop-node , , according to the definition of . As , we knew that after processing , and still held. According to Definition 1, .
Therefore, we determined that , if they belonged to the same subset of .
Case-2 where and .
Similar to the proof of Case-1, we knew that , if they belonged to the same subset of .
Therefore, for , , if they belonged to the same subset of . □
According to Theorem 2, we assigned each node v two set IDs, denoted as and , which were used to determine which subset it belonged to in and , respectively. Then, given the ancestor (descendant) set of , we only needed to scan all nodes of once to know immediately that for two nodes and : If in , then , and definitely belonged to the same subset of . Therefore, was a refinement of , i.e., each element of was a subset of a unique element of .
Recall that when processing the hop-node
, we first had its ancestor (descendant) set
and then obtained the partition
of
, based on the equivalence relationship. Since
was the partition of
V with respect to the equivalence relationship, we knew that
, and the relationship between
,
and
was shown as Equations (
11) and (
12).
When processing hop-node , we used a hash table to achieve linear-time complexity. Each element of was a tuple , denoting a subset of , where was, for all nodes of , their old set ID in , and was a triple denoting the new set ID for all nodes of , the representative node of , and the size of , respectively.
Example 5. Consider G in Figure 3. Before processing , , , and for all nodes v, . For the first node , we have , . Since all nodes in have the same , we know that and . , and . In Table 2, the two columns under denote and , where each 1 in the second (third) column correspond to a node in . Figure 4a shows the two hash tables denoting and , respectively. For , there is one (key, value) pair, denoting that contains one subset , and for all nodes in , their set ID is 0 in . Therefore, they all belong to the same subset in , i.e., . By in Figure 4a, we know that all nodes in now have the new set ID 1, the representative node of is , and . For the second processed node , , . As all nodes in have the same set ID 0 in , . As shown by Figure 4b, the key is 0, and the triple denotes that the new set ID for all nodes in is 2, the representative node is , and . Similarly, all nodes in have the same set ID 1 in , , which is denoted as in Figure 4b. For the third processed node , , . As and have the same set ID 2 in , they form the subset in . Furthermore, have the same set ID 1 in , they form the second subset in . Therefore . Similarly, . Both and are denoted by and in Figure 4c, respectively. The Algorithm: As shown by Algorithm 3, for each hop-node
, we first performed forward and backward
BFS to obtain
(lines 6–15) and
(lines 16–25). At the same time, we generated their partitions
and
, for which each subset was recorded in
and
, respectively. In lines 26–29, we computed
according to Equation (
10), which was the number of reachable queries that were covered by
. In line 30, we obtained the number of reachable queries that could be covered by
but not by
. After that, we had the total number of covered reachable queries in line 31 and the RR in line 33. Finally, we generated
in lines 34–37 and returned the RR of
in line 38.
It was worth noting that for Algorithm 3, the improvements was related to not only the coverage size computation, but also the
TC size computation. In line 32, we obtained an estimated
TC size by the approach in [
23], which operated in linear time
and was more efficient than the exact approach in [
12]. Since the denominator in Equation (
1) did not change for
, we could achieve the same effect using an approximate
TC size for the RR computation.
| Algorithm 3: incRR |
1 ; ; ; 2 rank all nodes v in G by 3 put the first k nodes into as hop-nodes 4 foreach do 5 ; ; ; 6 perform forward BFS from , and for each visited v 7 if then /**/ 8 if then 9 10 11 else 12 13 14 15 else stop expansion from v 16 perform backward BFS from , for each visited v 17 if then /**/ 18 if then 19 20 21 else 22 23 24 25 else stop expansion from v 26 27 foreach do 28 if then /**/ 29 30 31 32 estimate the TC size by Formula 3 in [ 23] 33 /*RR of */ 34 foreach do /*compute */ 35 36 foreach do /*compute */ 37 38 return as RR of |
Example 6. Consider G in Figure 3. Assume that we want to compute the RR of . For , as there is no covered reachability relationship, we do not need to test any queries in lines 28. As , , in line 30 of Algorithm 3.
For , as both , we only need to test one reachable query, i.e., whether can be answered by . As , we know that in line 30 of Algorithm 3.
For , as shown by Figure 4c, we know that and . In line 28, we only need to test reachable queries. As whether can reach can be answered by , we know that whether all nodes in can reach every node in can be answered by ; thus, for . In line 30, we know that . Then, we know , and the RR is %. During the process, the total number of tested reachability queries by Algorithm 3 was.
As a comparison, the total number of tested queries for Algorithm 2 was 41, and is 80 for Algorithm 1 to obtain the RR.
Analysis: As Algorithm 3 computed the approximate TC size in linear time, the time cost of Step-1 was . The difference was found in Step-2. The cost of Step-2 for each hop-node was . For k hop-nodes, the cost was for coverage computation. The time complexity of Algorithm 3 was, therefore, . The space complexity of Algorithm 3 was .
6. Experiment
In this section, we show the experimental results of the RR computation. The baseline algorithms included
blRR,
incRR, and
incRR. Moreover, we show the impacts of p2HLs on processing reachability queries based on the state-of-the-art algorithm
FL [
8] and
BFL [
2], in terms of index size, index construction time, and query time. We implemented all algorithms using C++ and compiled them using G++ 6.2.0. All experiments were conducted on a desktop computer with an Intel(R) Core(TM) i5-1135G7 @ 2.4 GHz CPU, 16 GB memory, and Ubuntu 18.04.1 Linux OS. For algorithms that processed
h or exceed the memory limit (16GB), we indicated their results as “–” in the tables.
Datasets: Table 3 shows the statistics of 18 real datasets, where the first 6 were small datasets (|
V| ≤ 100,000) downloaded from the same web page (
https://code.google.com/archive/p/grail/downloads, accessed on 1 January 2020). The following 12 datasets were large (|
V| > 100,000). These datasets have usually been used in the recent works for processing reachability queries [
1,
2,
3,
4,
5,
7,
8,
9,
14,
23]. Among these datasets, human, anthra, agrocyc, ecoo, and vchocyc were graphs describing the genome and biochemical machinery of E. coli K-12 MG1655. The site (
http://snap.stanford.edu/data/index.html, accessed on 1 January 2020) is an email network. LJ is an online social network soc-LiveJournal1 (
http://snap.stanford.edu/data/index.html, accessed on 1 January 2020). The source web is a web graph web-Google (
https://code.google.com/p/ferrari-index/downloads/list, accessed on). In addition, arxiv, 10cit-Patent (
http://pan.baidu.com/s/1bpHkFJx, accessed on 1 January 2020), 10citeseerx (
http://pan.baidu.com/s/1bpHkFJx, accessed on 1 January 2020), 05cit-Patent (
http://pan.baidu.com/s/1bpHkFJx, accessed on 1 January 2020), 05citeseerx (
http://pan.baidu.com/s/1bpHkFJx, accessed on 1 January 2020), citeseerx (
https://code.google.com/archive/p/grail/downloads, accessed on 1 January 2020), and patent (
https://code.google.com/archive/p/grail/downloads, accessed on 1 January 2020) (cit-Patents) are all citation networks. The source dbpedia (
http://pan.baidu.com/s/1c00Jq5E, accessed on 1 January 2020) is a knowledge graph Dbpedia. The sourcetwitter (
https://code.google.com/p/ferrari-index/downloads/list, accessed on 1 January 2020) is a
DAG transformed from a large-scale social network with 55 million users and 1.96 billion edges [
25]. The source web-uk (
https://code.google.com/p/ferrari-index/downloads/list, accessed on 1 January 2020) is a
DAG transformed from a web graph dataset with 133 million nodes and 5.5 billion edges. The statistics in
Table 3 are that of the
DAGs.
6.1. RR Computation
RR and Index Size: We show RR and the index size ratio (ISR) of these datasets in
Figure 5, where ISR denotes the ratio of the size of p2HLs over the size of the 2-hop labels, with respect to all nodes. From
Figure 5, we observed the following.
First, all datasets could be classified into three categories according to their RRs. The first (D1) included email, LJ, web, citeseerx, dbpedia, twitter, and web-uk, for which the RR was more than 99%, even when , and both the RR and ISR do not significantly change with the increase in k. The second type (D2) included human, anthra, agrocyc, ecoo, vchocyc, and arxiv, for which both the RR and ISR increased with the increase in k. The third type (D3) included 10cit-Patent, 10citeseerx, 05cit-Patent, 05citeseerx, and patent, for which both the RR and ISR were very small or even approach zero, and with the increase in k, both RR and ISR did not significantly change.The value of k, therefore, only affected the second type of dataset, and the RR was more than 80% when for all datasets of the second type, which indicated that this approach could benefit from using p2HLs on datasets of both the first and second types.
Second, the storage space used to maintain p2HLs was small, when compared with the RR value. For example, for the first type of dataset, we used about of the available storage space (ISR %) to maintain more than 99% (RR %) of the reachability information.
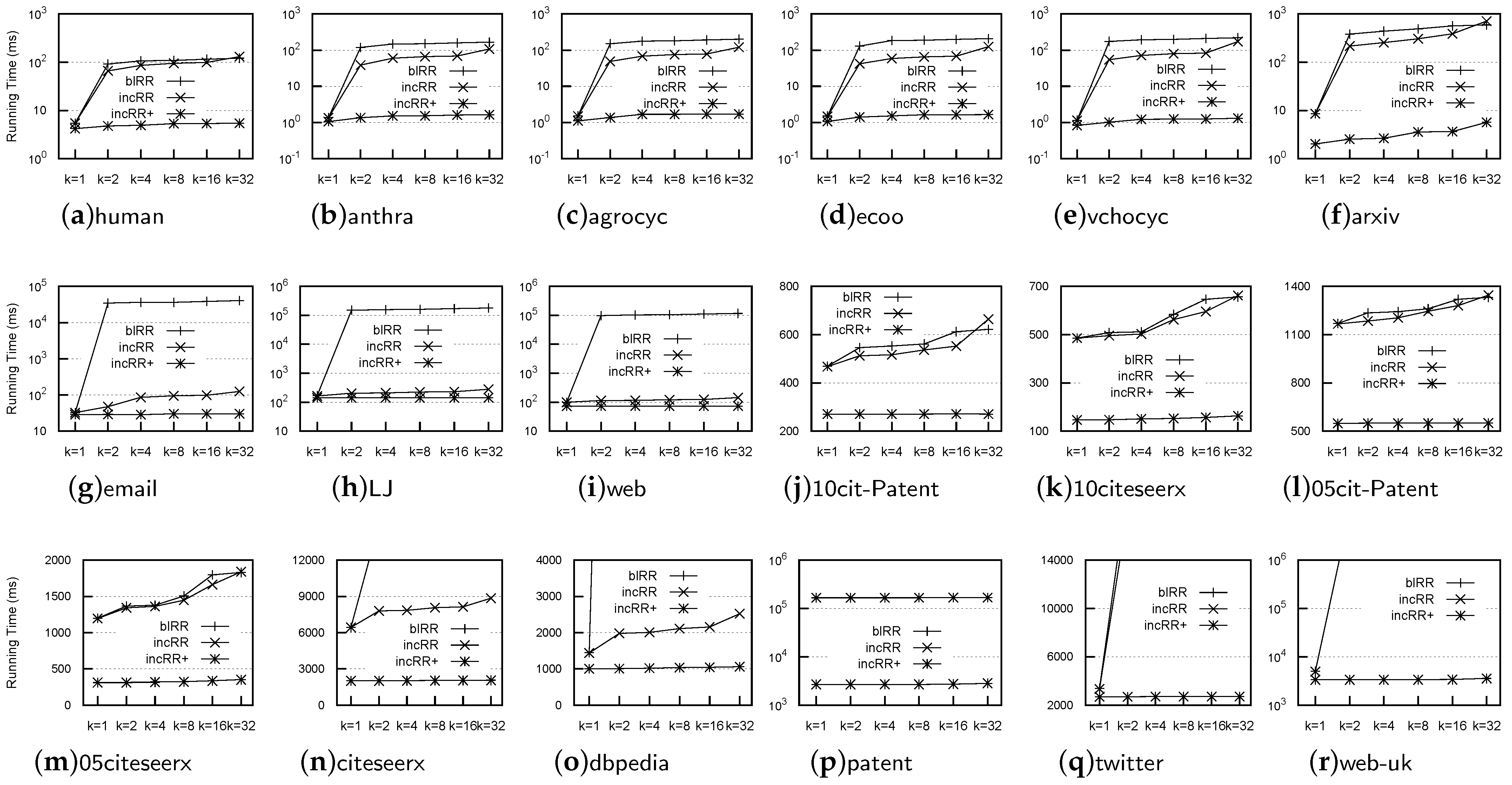
Operational Time: Figure 6 shows the comparison of the operational time for the RR computation, from which we knew that
incRR was much faster than both
blRR and
incRR, on all datasets, and
incRR operated faster than
blRR on most datasets. For example,
incRR was faster than
blRR by more than two or three orders of magnitude on most datasets, and
incRR was ten-times faster than
blRR on email, LJ, web, citeseerx, and dbpedia. According to the last to the second column of
Table 3, the average number of reachable nodes was usually high. Therefore, the number of tested reachability queries by
blRR was significantly high. Although
incRR could reduce the number of tested reachability queries, it still needed to test significantly more reachability queries than
incRR. Neither
blRR nor
incRR could obtain the value of the RR on both twitter and web-uk for
in a limited time frame (3 h), due to testing too many reachability queries.
Based on the above results, we knew that our incRR algorithm could be used to efficiently compute the RR for a given dataset, which allowed us to determine whether we could use p2HLs to facilitate processing reachability queries.
6.2. Processing Reachability Queries
We combined p2HLs with
FELINE [
8] (abbr.
FL) and
BFL [
2] to show the impact of p2HLs on processing reachability queries in
Table 4,
Table 5 and
Table 6, where
FL-
k (
BFL-
k) denotes the
FL (
BFL) algorithm combined with the p2HLs generated using
k hop-nodes by Algorithm 3. Note that we did not set
, because when
, we only needed to use one integer as a bit-vector for each node
v to represent both
and
.
Index Size: Table 4 shows the impact of
k on index size, from which we found that with an increase in
k, the index size increased accordingly. For example, for the web-uk dataset, the index size of
FL-128 was more than two times the size of
FL-0 on all datasets. The reason was that the larger the value of
k, the more space required to maintain p2HLs.
Index Construction Time: Figure 5 shows the impact of
k on the index construction time, from which we found that with an increase in
k, we required more time for index construction. The time for generating p2HLs was usually much less than the index construction time for
FL, i.e.,
FL-0, and the increased time for index construction could be omitted. As a comparison, the index of
BFL, i.e.,
BFL-0, could be constructed very efficiently, as the time used for p2HLs construction was usually one-to-two times longer than the index construction time of
BFL. However, the whole index construction was still less than 5 s for all the tested graphs.
Query Time: We reported the query time was about equal workload, which contained 1,000,000 reachability queries for each dataset. The equal workload consisted of 50% reachable queries and 50% unreachable queries. The reason that we used equal workloads was that using completely random queries would be heavily skewed towards unreachable queries [
9,
10], which was highly unlikely for the real workload as the node pair in a query tended to have a certain connection [
11]. Here, unreachable queries were generated by sampling node pairs with the same probability until we reached the required number of unreachable queries by testing each query using the
FL algorithm. For reachable queries, we could not choose them randomly by sampling the
TC because the
TC computation was not similar to the
TC size computation, and it suffered from high processing times and space complexity. We could not obtain it within the limited time frame and available memory size for large graphs. To address this problem, we randomly selected a node
u in each iteration, and then randomly selected an out-neighbor
v recursively until
v had no out-neighbors available. Then, we had a path
p from
u. Finally, we randomly selected a node
from
p to obtain a reachable query
. This operation was continued until we reached the required number of reachable queries.
We show the comparison of query time from
FL-0 to
FL-128 and from
BFL-0 to
BFL-128 in
Table 6, from which we observed the following.
First, FL-16 (BFL-16) and FL-32 (BFL-32) usually required the least amount of time on the first type of datasets D1, including email, LJ, web, citeseerx, dbpedia, twitter, and web-uk, where the RR was more than 99% even when . For these datasets, although the index size increased along with the index construction time, as compared to FL-0 (BFL-0), we used the least amount of resources to achieve significant improvements.For example, when compared with FL-0, FL-16 used about 1.2-times the index size and 1.4-times the index construction time to achieve a more than 30-fold improvement in query time on the citeseerx dataset. Furthermore, when compared with BFL-0, BFL-16 consumed 1.1-times the index size and 2.3-times index construction time to achieve a more than 15-fold improvement on the amount of query time on the citeseerx dataset.
Second,
FL-128 (
BFL-128) suffered from the largest index size (about 2–3-times larger than
FL-0 (
BFL-0)) and longest index construction time (about 1–3-times longer than
FL-0 (
BFL-0)), but it usually achieved a better query performance on the second type of datasets
D2, including human, anthra, agrocyc, ecoo, vchocyc, and arxiv. On these datasets, the RR increased along with the increase in
k. From
Figure 5, we found that for human, anthra, agrocyc, ecoo, and vchocyc, the RR was greater than 95% when
, and thus, both
BFL-16 and
BFL-32 usually performed better. For arxiv, when
, the RR was still less than 90%, indicating that
FL-128 and
BFL-128 performed the best.
Third, for the third type of datasets D3, including 10cit-Patent, 10citeseerx, 05cit-Patent, 05citeseerx, and patent, the RR was very small or even approached zero, and it did not significantly change with an increase in k. For these datasets, FL-0 and BFL-0 usually performed better, and the use of p2HLs did not yield positive results. For example, the index size of FL-128 (BFL-128) was 2.6 (2.1)-times larger than that of FL-0 (BFL-0) on 10cit-Patent, and the index construction time of FL-128 (BFL-128) was 1.3 (2.5)-times longer than that of FL-0 (BFL-0) on 10cit-Patent. Such cost, however, resulted in more query time. The query time of FL-128 (BFL-128) was 1.3 (5.5)-times longer than that of FL-0 (BFL-0) on 10cit-Patent.
Finally, we selected one dataset from each type and showed the trends of their query times, with respect to
k in
Figure 7. Based on these results, we provide the following suggestions for applying p2HLs: (1) For the first type of datasets
D1, we highly recommend using p2HLs with
to process reachability queries, because this could increase the speed of reachability queries significantly with a minimal increase in index size and index construction time. (2) For the second type of datasets
D2, we also recommend using p2HLs, because could increase the speed of reachability queries. However, for balancing the value of
k, this depends on the resources available for the increases in index size and index construction time. In general, the larger the value of
k, the less the query time, but the longer the index construction time and the larger the index size. (3) For the third type of datasets
D3, we do not recommend using p2HLs to process reachability queries.










{kind=link}
{kind=link}
{kind=link}
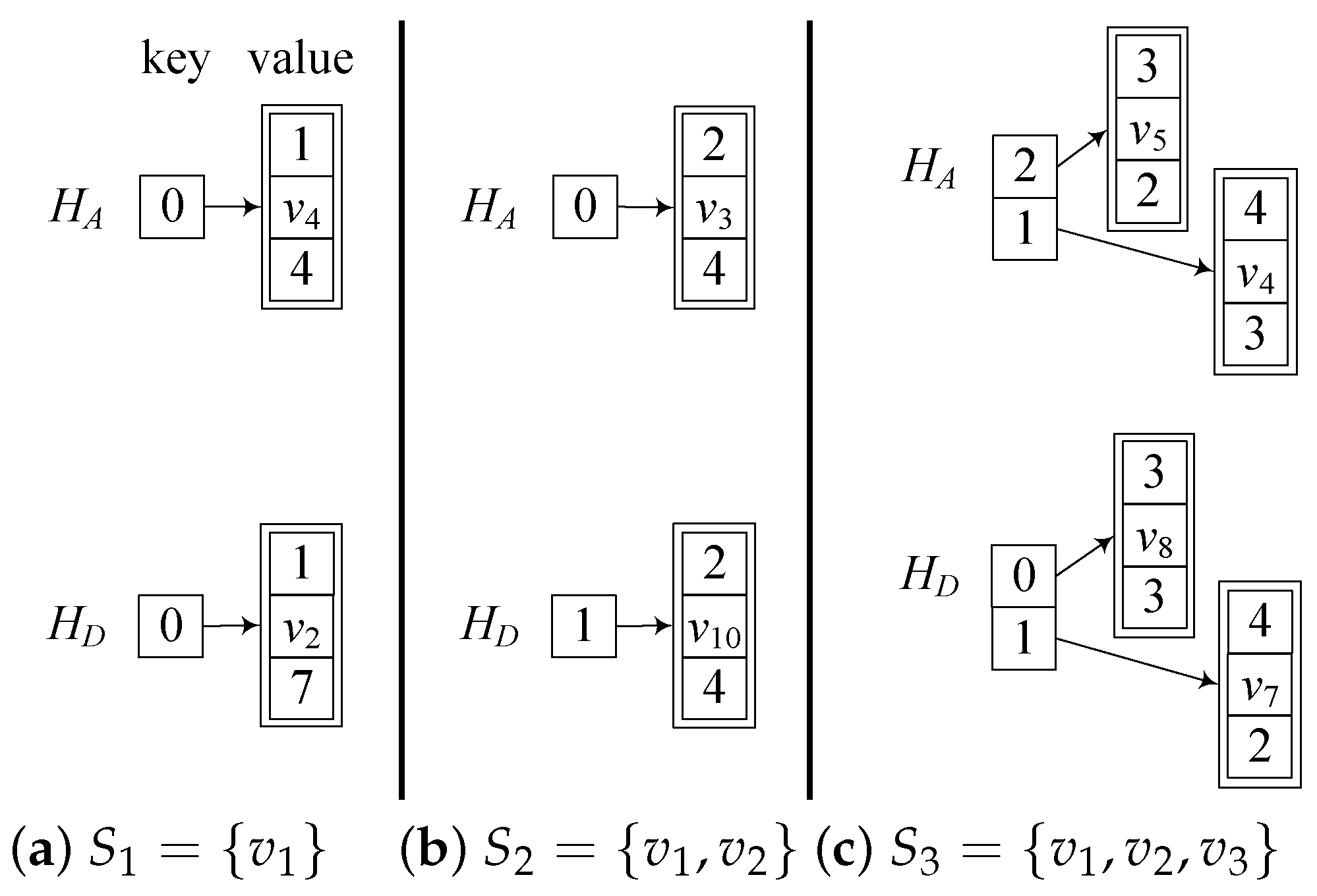{kind=link}
{kind=link}
{kind=link}
{kind=link}