
FLRAM: Robust Aggregation Technique for Defense against Byzantine Poisoning Attacks in Federated Learning

Abstract
:1. Introduction
- This paper proposes a federated learning robust aggregation method, FLRAM, designed to counter byzantine poisoning attacks. FLRAM employs anomaly gradient detection to filter out abnormal clients and selectively aggregates models from clients with higher credibility scores, enhancing model aggregation robustness.
- This paper introduces an improved DBSCAN algorithm for clustering gradient signs to enhance the accuracy of abnormal gradient identification. Additionally, by constructing a credibility matrix, we effectively assess the trustworthiness of each client, further bolstering the model’s robustness.
- We theoretically prove the convergence properties of the proposed method and conduct experimental validations. The experimental results demonstrate that the proposed approach not only ensures model accuracy, but also exhibits outstanding defense performance, effectively enhancing the robustness of the federated learning system.
2. Related Work
3. Basic Theory
3.1. Federated Learning Aggregation Mechanism
3.2. Isolated Forest
3.3. DBSCAN
4. Problem Description
4.1. Problem Definition
4.2. Attack Model
4.3. Defensive Target
- (1)
- Fidelity: Ensure that the accuracy of the globally aggregated model after aggregation remains close to the accuracy of the model obtained through FedAvg in the absence of attacks.
- (2)
- Robustness: The globally aggregated model should maintain a high level of accuracy even when multiple malicious clients engage in poisoning attacks simultaneously, or when certain malicious clients conduct strong poisoning attacks.
- (3)
- Reliability: The defense performance against different datasets and various poisoning attacks should exhibit stability. The aggregation method should apply to a general attack model and not be susceptible to a specific type of attack that causes a rapid deterioration in model performance.
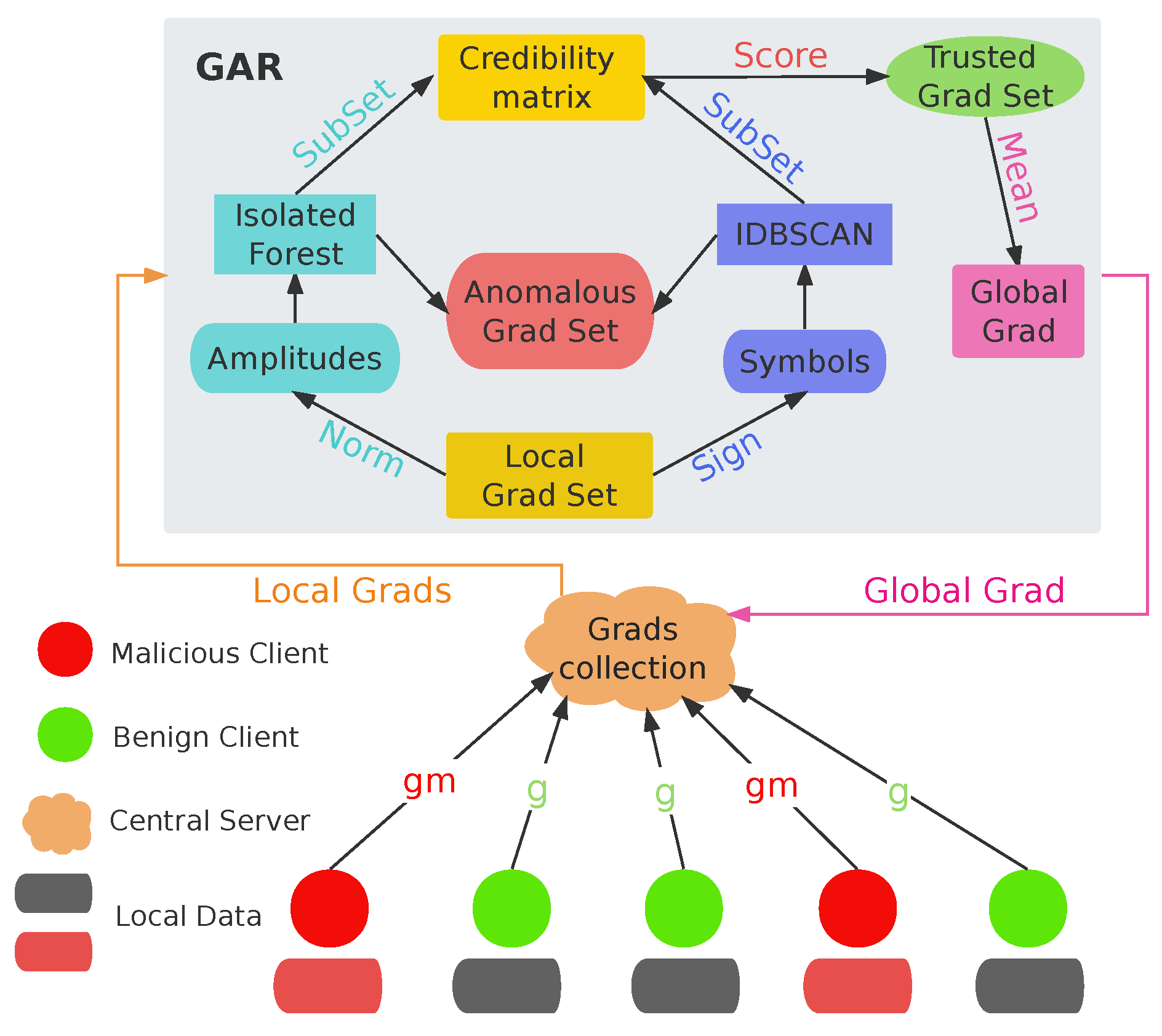
5. FLRAM Frame
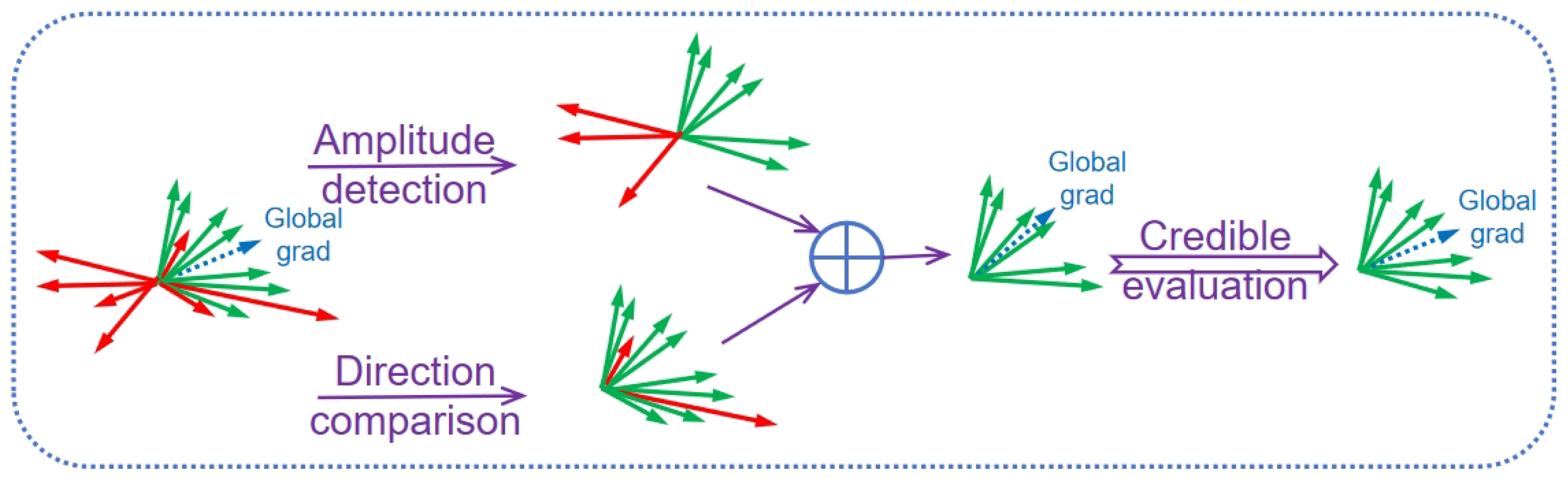
5.1. Method Overview
5.2. Method Design
5.2.1. Anomaly Gradient Detection
- (1)
- Compute the norm of the local gradient uploaded by each client, then input it into the isolation forest model. Calculate the anomaly score for each local gradient norm based on the average path length of the trees as follows:where can be obtained from Equation (2). The range of is (0,1), where approaching one indicates a higher degree of gradient anomaly, and approaching zero indicates a lower degree of gradient anomaly.
- (2)
- Calculate the dynamic anomaly score threshold . Compute the anomaly scores for all local gradients, and then use the percentile rank of sorted anomaly score values as the anomaly score threshold. It can be expressed aswhere C represents the estimated number of anomalous clients, and K denotes the total number of clients. Under the assumptions we made, the valid range for C is in the interval . At the outset of model training, we collect all local gradients and initialize the value of C to . Subsequently, during the training process, the value of C is dynamically adjusted to ensure the effective identification of gradients with significant size deviations by the isolation forest detection.
- (3)
- Determine the degree of anomaly for each gradient based on the anomaly score threshold . When , the gradient is labeled as normal, and when , label it as an anomalous gradient. Subsequently, collect all the benign gradients and store them in a candidate subset .
- (1)
- For each gradient sign feature , obtain the k-nearest neighbors using the k-nearest neighbor algorithm to form a set:Calculate locally based on the k-nearest neighbors of each gradient sign feature , setting it equal to the maximum distance to the k neighbors,where represents the Euclidean distance.
- (2)
- Calculate the density similarity between every two adjacent gradient symbol features (the ratio of the local densities of two gradient symbol features). Define the local density of each gradient symbol feature as the sum of lengths to its MinPts nearest neighbors as follows:Calculate density similarity based on local density
- (3)
- Calculate the number of similar neighbors to the gradient symbol feature (count the number of density similarities greater than the similarity threshold):where is the similarity threshold, which, in this paper, is taken as the mean of all density similarities of gradient symbol features.
| Algorithm 1 IDBSCAN |
|
5.2.2. Credit Evaluation
- (1)
- Labeling Gradients as Normal/Anomalous. We collect the filtered candidate gradient subsets and after anomaly gradient detection. Then, we introduce instance labels and assign a label of 1 to the gradients selected in the intersection, while gradients not included in either gradient subset or are labeled as −1, and all other gradients are labeled as 0. It is represented as
- (2)
- Building the credibility matrix. At the initial stage of model training, we initialize a matrix consisting of all-zero elements, with the indices corresponding to the gradients from different clients. In this matrix, the first row holds counting values . During each iteration, if a gradient is labeled as normal, represented as 1, the counting value for the respective client increases by 1. If the gradient is labeled as abnormal, denoted as −1, the corresponding counting value decreases by 1. Another row in the matrix records the credibility of gradients, denoted as . It represents the average frequency with which a gradient is selected and participates in training. The calculation formula for is , where E represents the number of iterations.
- (3)
- Compute Credibility Scores. We adjust the credibility using a sigmoid function to constrain the values between [−1, 1], expressed as
- (4)
- Selecting the Set of Benign Gradients. Given that the number of malicious clients is less than half of the total clients, the TopK algorithm can be employed to select the top 50% of clients based on their credibility scores. This helps reduce the risk of benign clients being excluded due to misclassification.
5.2.3. Aggregation Strategy
| Algorithm 2 FLRAM |
|
5.3. Convergence Analysis
6. Experimental Evaluation
6.1. Experimental Setup
6.1.1. Baseline and Parameter Settings
6.1.2. Attack Mode
6.1.3. Evaluation Metrics
6.2. Experimental Results and Analysis
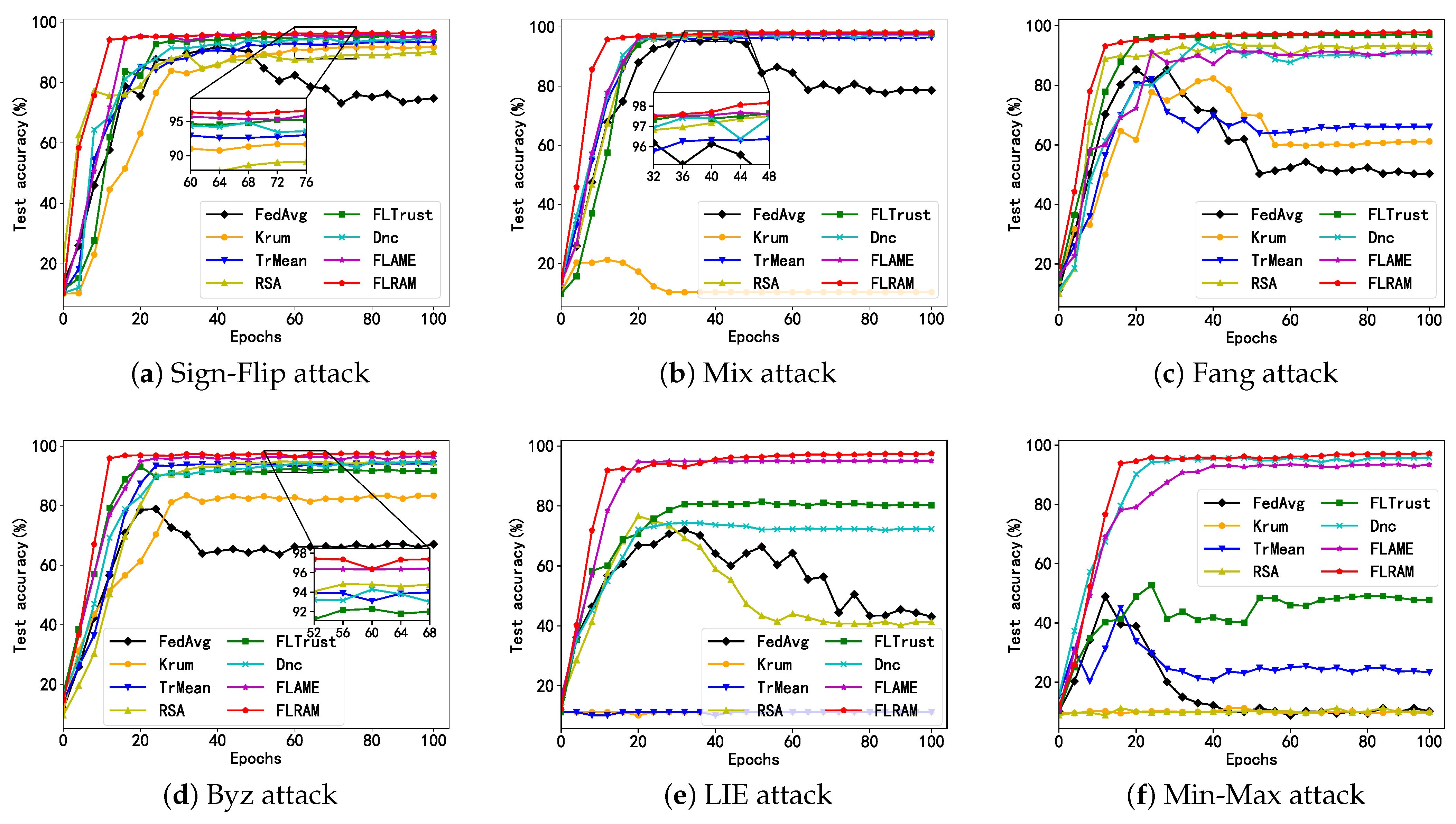
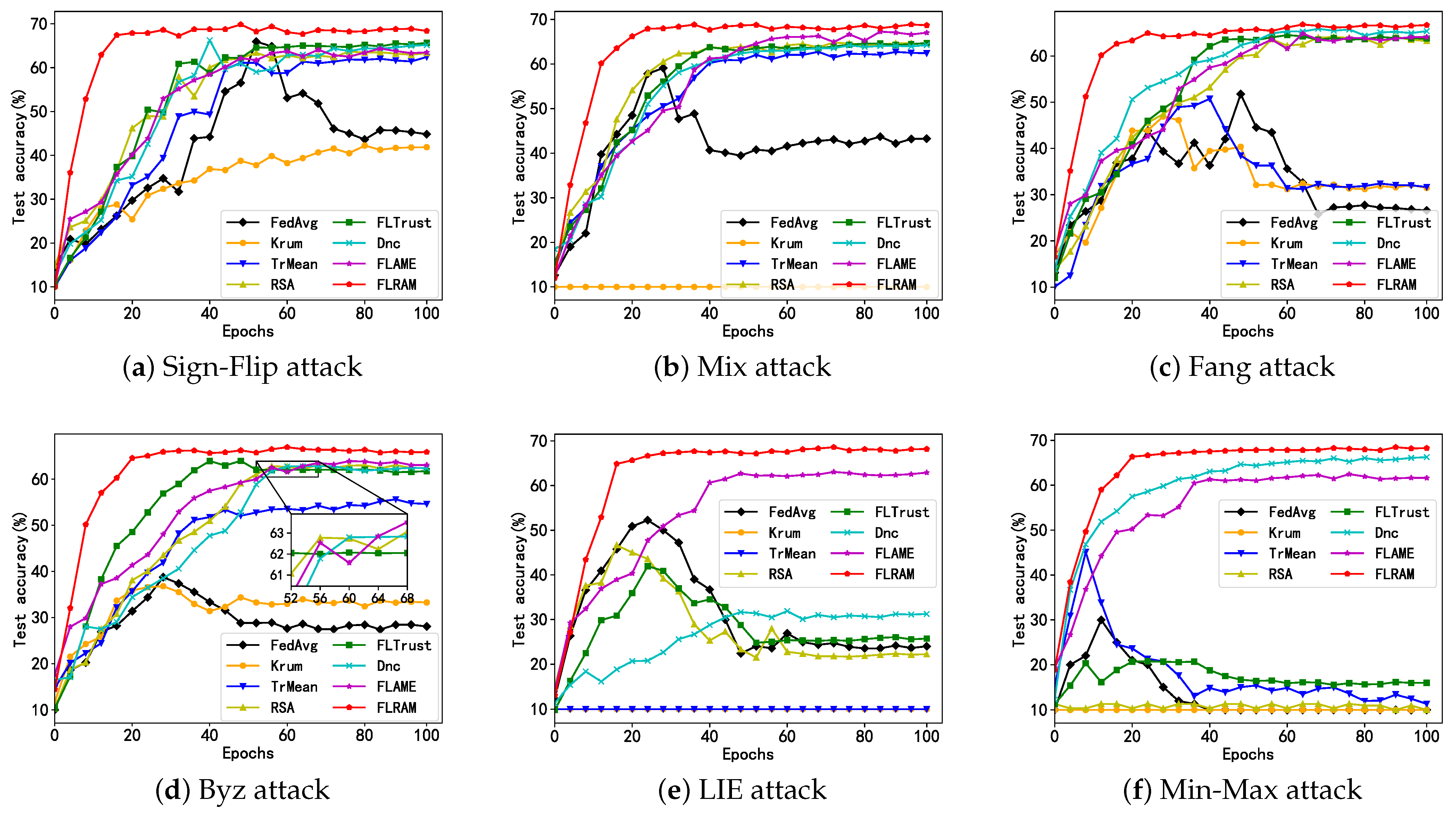
6.2.1. Comparison of Defensive Performance among Different Aggregation Methods
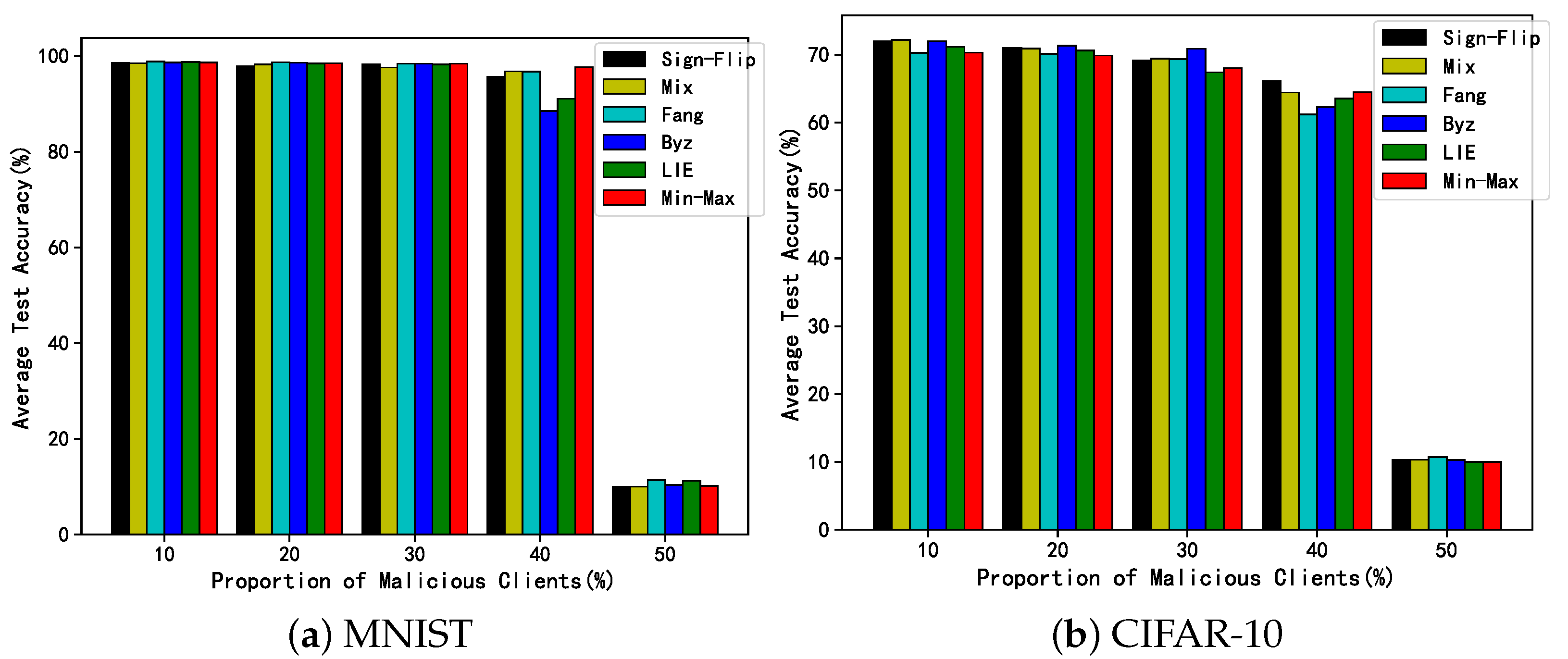
6.2.2. Comparison of Robustness among Different Aggregation Methods
6.2.3. Reliability Verification of FLRAM
6.2.4. Validity under Non-IID
6.2.5. Efficiency Analysis of FLRAM
6.3. Extended Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| FLRAM | Federated Learning Robust Aggregation Methods |
| GAR | Gradient-based Aggregation Rules |
| DBSCAN | Density-Based Spatial Clustering of Applications with Noise |
| IDBSCA | Improved DBSCAN |
| TrMean | Trimmed Mean |
| IID | Identically Distributed Data |
| Non-IID | Non-independent Identically Distributed Data |
References
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A.Y. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 22–27 April 2017; pp. 1273–1282. [Google Scholar]
- Wu, N.; Farokhi, F.; Smith, D.; Kaafar, M.A. The value of collaboration in convex machine learning with differential privacy. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 18–21 May 2020; pp. 304–317. [Google Scholar]
- Lee, Y.; Park, S.; Kang, J. Security-Preserving Federated Learning via Byzantine-Sensitive Triplet Distance. arXiv 2022, arXiv:2210.16519. [Google Scholar]
- Hong, S.; Chandrasekaran, V.; Kaya, Y.; Dumitraş, T.; Papernot, N. On the effectiveness of mitigating data poisoning attacks with gradient shaping. arXiv 2020, arXiv:2002.11497. [Google Scholar]
- Gosselin, R.; Vieu, L.; Loukil, F.; Benoit, A. Privacy and security in federated learning: A survey. Appl. Sci. 2022, 12, 9901. [Google Scholar] [CrossRef]
- Li, H.; Li, C.; Wang, J.; Yang, A.; Ma, Z.; Zhang, Z.; Hua, D. Review on security of federated learning and its application in healthcare. Future Gener. Comput. Syst. 2023, 144, 271–290. [Google Scholar] [CrossRef]
- Lyu, L.; Yu, H.; Yang, Q. Threats to federated learning: A survey. arXiv 2020, arXiv:2003.02133. [Google Scholar]
- Chen, Y.; Gui, Y.; Lin, H.; Gan, W.; Wu, Y. Federated learning attacks and defenses: A survey. In Proceedings of the 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, 18–20 December 2022; pp. 4256–4265. [Google Scholar]
- Yin, D.; Chen, Y.; Kannan, R.; Bartlett, P. Byzantine-robust distributed learning: Towards optimal statistical rates. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 5650–5659. [Google Scholar]
- Blanchard, P.; El Mhamdi, E.M.; Guerraoui, R.; Stainer, J. Machine learning with adversaries: Byzantine tolerant gradient descent. Adv. Neural Inf. Process. Syst. 2017, 30, 10. [Google Scholar]
- Guerraoui, R.; Rouault, S. The hidden vulnerability of distributed learning in byzantium. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 3521–3530. [Google Scholar]
- Muñoz-González, L.; Co, K.T.; Lupu, E.C. Byzantine-robust federated machine learning through adaptive model averaging. arXiv 2019, arXiv:1909.05125. [Google Scholar]
- Tolpegin, V.; Truex, S.; Gursoy, M.E.; Liu, L. Data poisoning attacks against federated learning systems. In Proceedings of the Computer Security–ESORICS 2020: 25th European Symposium on Research in Computer Security, ESORICS 2020, Guildford, UK, 14–18 September 2020; pp. 480–501. [Google Scholar]
- Bilgin, Z. Anomaly Localization in Model Gradients Under Backdoor Attacks against Federated Learning. arXiv 2021, arXiv:2111.14683. [Google Scholar]
- Liu, Y.; Li, Z.; Pan, S.; Gong, C.; Zhou, C.; Karypis, G. Anomaly detection on attributed networks via contrastive self-supervised learning. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 2378–2392. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Cao, X.; Jia, J.; Gong, N.Z. FLDetector: Defending federated learning against model poisoning attacks via detecting malicious clients. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 2545–2555. [Google Scholar]
- Zhao, Y.; Chen, J.; Zhang, J.; Wu, D.; Blumenstein, M.; Yu, S. Detecting and mitigating poisoning attacks in federated learning using generative adversarial networks. Concurr. Comput. Pract. Exp. 2022, 34, e5906. [Google Scholar] [CrossRef]
- Zhu, W.; Zhao, B.Z.H.; Luo, S.; Deng, K. MANDERA: Malicious Node Detection in Federated Learning via Ranking. arXiv 2021, arXiv:2110.11736. [Google Scholar]
- Li, L.; Xu, W.; Chen, T.; Giannakis, G.B.; Ling, Q. RSA: Byzantine-robust stochastic aggregation methods for distributed learning from heterogeneous datasets. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2019; pp. 1544–1551. [Google Scholar]
- Cao, X.; Fang, M.; Liu, J.; Gong, N.Z. Fltrust: Byzantine-robust federated learning via trust bootstrapping. arXiv 2020, arXiv:2012.13995. [Google Scholar]
- Lesouple, J.; Baudoin, C.; Spigai, M.; Tourneret, J.Y. Generalized isolation forest for anomaly detection. Pattern Recognit. Lett. 2021, 149, 109–119. [Google Scholar] [CrossRef]
- Chen, H.; Liang, M.; Liu, W.; Wang, W.; Liu, P.X. An approach to boundary detection for 3D point clouds based on DBSCAN clustering. Pattern Recognit. 2022, 124, 108431. [Google Scholar] [CrossRef]
- Xie, C.; Chen, M.; Chen, P.Y.; Li, B. Crfl: Certifiably robust federated learning against backdoor attacks. In Proceedings of the International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 11372–11382. [Google Scholar]
- Panda, A.; Mahloujifar, S.; Bhagoji, A.N.; Chakraborty, S.; Mittal, P. Sparsefed: Mitigating model poisoning attacks in federated learning with sparsification. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Virtual Event, 28–30 March 2022; pp. 7587–7624. [Google Scholar]
- Nguyen, T.D.; Rieger, P.; De Viti, R.; Chen, H.; Brandenburg, B.B.; Yalame, H.; Möllering, H.; Fereidooni, H.; Marchal, S.; Miettinen, M.; et al. {FLAME}: Taming backdoors in federated learning. In Proceedings of the 31st USENIX Security Symposium (USENIX Security 22), Boston, MA, USA, 22–26 May 2022; pp. 1415–1432. [Google Scholar]
- Yu, S.; Chen, Z.; Chen, Z.; Liu, S. DAGUARD: Distributed backdoor attack defense scheme under federated learning. J. Commun. 2023, 44, 110–122. [Google Scholar]
- Shejwalkar, V.; Houmansadr, A. Manipulating the byzantine: Optimizing model poisoning attacks and defenses for federated learning. In Proceedings of the NDSS, Virtual Event, 21–25 February 2021. [Google Scholar]
- Xu, J.; Huang, S.L.; Song, L.; Lan, T. Byzantine-robust federated learning through collaborative malicious gradient filtering. In Proceedings of the 2022 IEEE 42nd International Conference on Distributed Computing Systems (ICDCS), Bologna, Italy, 10–13 July 2022; pp. 1223–1235. [Google Scholar]
- Karimireddy, S.P.; He, L.; Jaggi, M. Learning from history for byzantine robust optimization. In Proceedings of the International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 5311–5319. [Google Scholar]
- Yu, H.; Yang, S.; Zhu, S. Parallel restarted SGD with faster convergence and less communication: Demystifying why model averaging works for deep learning. AAAI Conf. Artif. Intell. 2019, 33, 5693–5700. [Google Scholar] [CrossRef]
- Li, X.; Huang, K.; Yang, W.; Wang, S.; Zhang, Z. On the convergence of fedavg on non-iid data. arXiv 2019, arXiv:1907.02189. [Google Scholar]
- Che, C.; Li, X.; Chen, C.; He, X.; Zheng, Z. A decentralized federated learning framework via committee mechanism with convergence guarantee. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 4783–4800. [Google Scholar] [CrossRef]
- Yu, H.; Jin, R.; Yang, S. On the linear speedup analysis of communication efficient momentum SGD for distributed non-convex optimization. In Proceedings of the International Conference on Machine Learning, Boca Raton, FL, USA, 16–19 December 2019; pp. 7184–7193. [Google Scholar]
- Alkhunaizi, N.; Kamzolov, D.; Takáč, M.; Nandakumar, K. Suppressing Poisoning Attacks on Federated Learning for Medical Imaging. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Singapore, 18–22 September 2022; pp. 673–683. [Google Scholar]
- Fang, M.; Cao, X.; Jia, J.; Gong, N. Local model poisoning attacks to {Byzantine-Robust} federated learning. In Proceedings of the 29th USENIX security symposium (USENIX Security 20), Boston, MA, USA, 18–22 September 2020; pp. 1605–1622. [Google Scholar]
- Isik-Polat, E.; Polat, G.; Kocyigit, A. ARFED: Attack-Resistant Federated averaging based on outlier elimination. Future Gener. Comput. Syst. 2023, 141, 626–650. [Google Scholar] [CrossRef]
- Baruch, G.; Baruch, M.; Goldberg, Y. A little is enough: Circumventing defenses for distributed learning. Adv. Neural Inf. Process. Syst. 2019, 32, 37. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aggregation | FedAvg | Krum | TrMean | RSA | FLTrust | Dnc | FLAME | FLRAM |
|---|---|---|---|---|---|---|---|---|
| No-Attack | 99.01 | 95.15 | 98.48 | 98.92 | 98.38 | 98.89 | 98.79 | 98.94 |
| Sign-Flip | 97.28 | 91.88 | 98.06 | 97.64 | 98.23 | 98.31 | 98.21 | 98.53 |
| Mix | 96.37 | 89.16 | 97.94 | 97.61 | 98.19 | 98.35 | 98.01 | 98.43 |
| Fang | 85.35 | 84.92 | 85.58 | 95.02 | 94.79 | 96.67 | 97.95 | 98.40 |
| Byz | 79.21 | 87.71 | 95.86 | 95.62 | 92.51 | 96.41 | 97.47 | 98.39 |
| LIE | 74.28 | 56.35 | 73.94 | 74.12 | 81.31 | 75.69 | 95.75 | 98.05 |
| Min-Max | 49.72 | 41.37 | 55.36 | * 1 | 55.15 | 97.41 | 93.42 | 97.82 |
| Aggregation | FedAvg | Krum | TrMean | RSA | FLTrust | Dnc | FLAME | FLRAM |
|---|---|---|---|---|---|---|---|---|
| No-Attack | 75.92 | 52.05 | 69.63 | 73.08 | 73.55 | 74.87 | 69.53 | 73.75 |
| Sign-Flip | 69.80 | 48.70 | 66.17 | 67.88 | 69.85 | 70.58 | 68.58 | 71.75 |
| Mix | 69.65 | 51.98 | 68.78 | 67.52 | 69.05 | 69.79 | 68.47 | 70.92 |
| Fang | 61.20 | 47.58 | 59.02 | 65.83 | 66.03 | 68.49 | 67.18 | 70.67 |
| Byz | 57.13 | 51.25 | 67.18 | 66.68 | 64.72 | 68.05 | 67.76 | 70.31 |
| LIE | 52.08 | 23.54 | 47.21 | 53.44 | 58.72 | 45.66 | 66.78 | 69.62 |
| Min-Max | 26.23 | * 1 | 21.79 | * 1 | 25.69 | 67.89 | 63.73 | 69.22 |
| Heterogeneity(s) | 0 | 0.2 | 0.5 | 0.8 |
|---|---|---|---|---|
| Sign-flip | 97.59 | 97.91 | 98.02 | 98.34 |
| Mix | 97.19 | 97.82 | 97.93 | 98.24 |
| Fang | 96.98 | 97.28 | 97.96 | 98.23 |
| Byz | 96.96 | 97.57 | 97.92 | 98.19 |
| LIE | 96.59 | 97.18 | 97.72 | 98.03 |
| Min-Max | 94.89 | 96.13 | 96.95 | 97.79 |
| Heterogeneity(s) | 0 | 0.2 | 0.5 | 0.8 |
|---|---|---|---|---|
| Sign-flip | 60.14 | 63.26 | 66.79 | 69.37 |
| Mix | 61.45 | 63.50 | 68.71 | 69.60 |
| Fang | 60.59 | 63.42 | 65.38 | 69.32 |
| Byz | 60.89 | 65.65 | 67.43 | 69.21 |
| LIE | 59.98 | 62.82 | 65.49 | 69.43 |
| Min-Max | 58.48 | 61.35 | 64.82 | 68.56 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Chen, X.; Peng, L.; Ma, R. FLRAM: Robust Aggregation Technique for Defense against Byzantine Poisoning Attacks in Federated Learning. Electronics 2023, 12, 4463. https://doi.org/10.3390/electronics12214463
Chen H, Chen X, Peng L, Ma R. FLRAM: Robust Aggregation Technique for Defense against Byzantine Poisoning Attacks in Federated Learning. Electronics. 2023; 12(21):4463. https://doi.org/10.3390/electronics12214463
Chicago/Turabian StyleChen, Haitian, Xuebin Chen, Lulu Peng, and Ruikui Ma. 2023. "FLRAM: Robust Aggregation Technique for Defense against Byzantine Poisoning Attacks in Federated Learning" Electronics 12, no. 21: 4463. https://doi.org/10.3390/electronics12214463