
A Software Testing Workflow Analysis Tool Based on the ADCV Method

 ,
,
Abstract
:1. Introduction
2. Related Work
2.1. Petri Nets and Software Testing Workflow
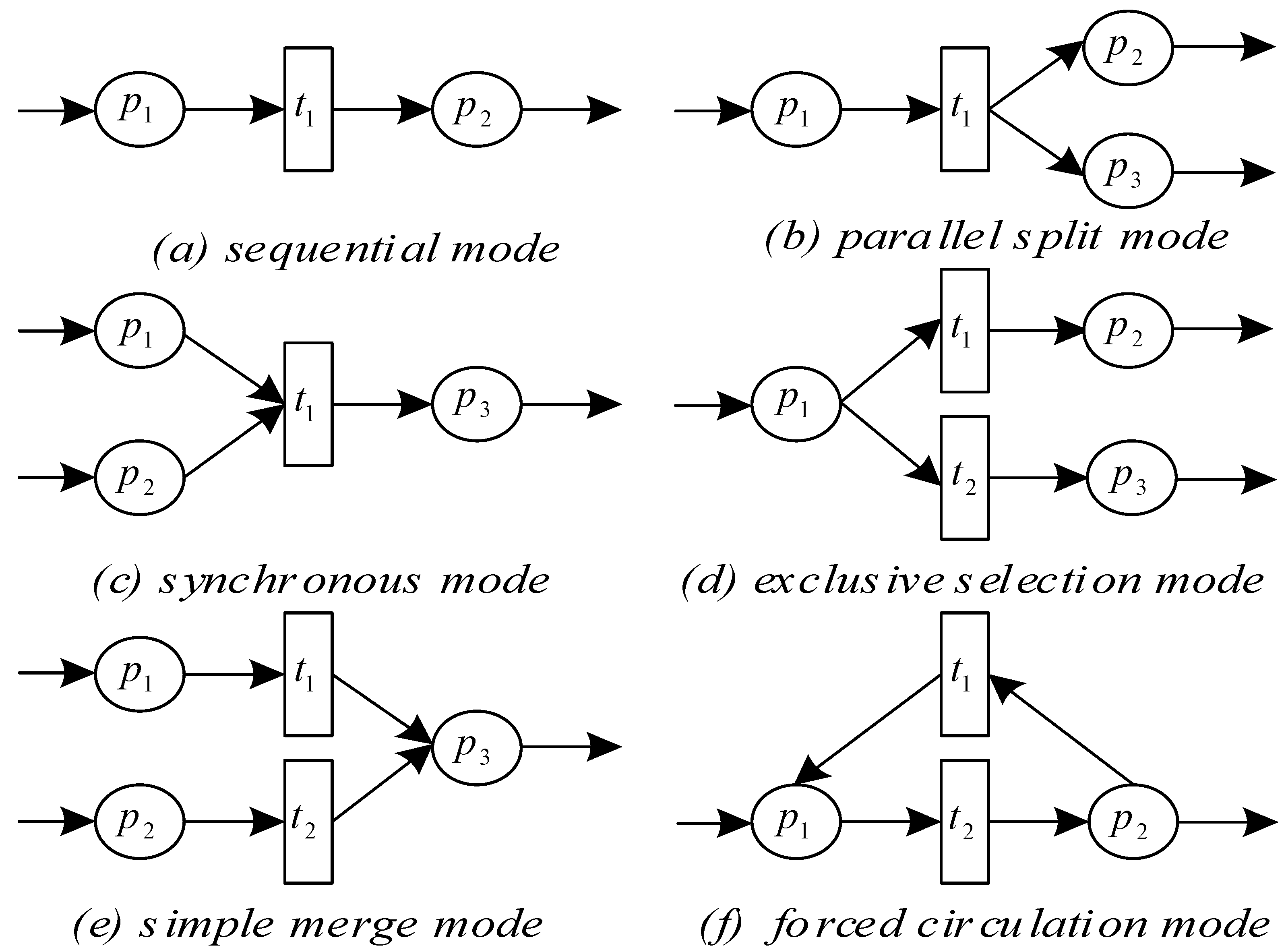
2.2. Petri Nets Model of the Fundamental Workflow Mode
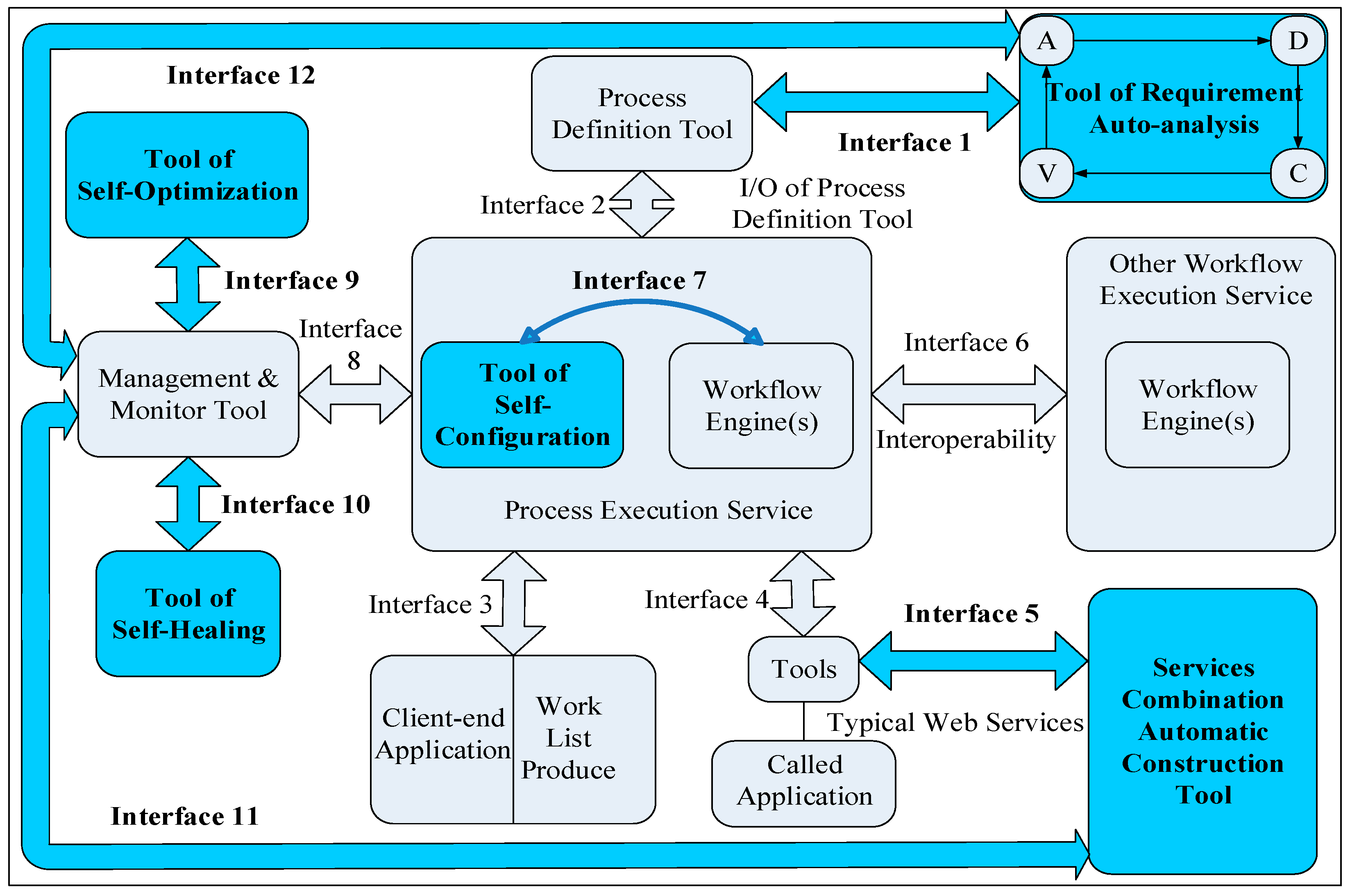
2.3. Architecture and Functions of Tool Based on ADCV Method
- A: Firstly, the process acquisition component generates the corresponding process model by mining the event logs, thus obtaining the structured business process. Here, we adopt a formal method suitable for describing concurrent systems to model, such as Petri nets.
- D: Secondly, the process decomposition component analyzes the established simulation model and extracts the relatively stable subsystem structure, i.e., it can identify and decompose the subprocesses of structured business processes. For example, the obtained model is decomposed into multiple subnets according to the T-invariants of the Petri nets, thus forming multiple nonintersecting subprocesses represented by each subnet.
- C: Thirdly, with the participation of users, it is inevitable that business processes will be recombined due to the changes in requirements, that is, process combination. Generally, the processes involved in the recombination are the subprocesses identified and decomposed in the second stage above, which ensures that the recombined process can better reflect the new requirements.
- V: Finally, the process verification component performs formal verification on the recombined process model to determine whether it meets the new requirements. Regarding the processes that proved to be unable to meet the new requirements after verification, we need to feed back the requirements analysis reports to the first stage, that is, the modeling stage, to participate in the process acquisition again and enter a new round of the iterative cycle of BPM.
3. Business Process Analysis Based on the ADCV Method
3.1. Overview of the ADCV Method
3.2. Business Process Acquisition
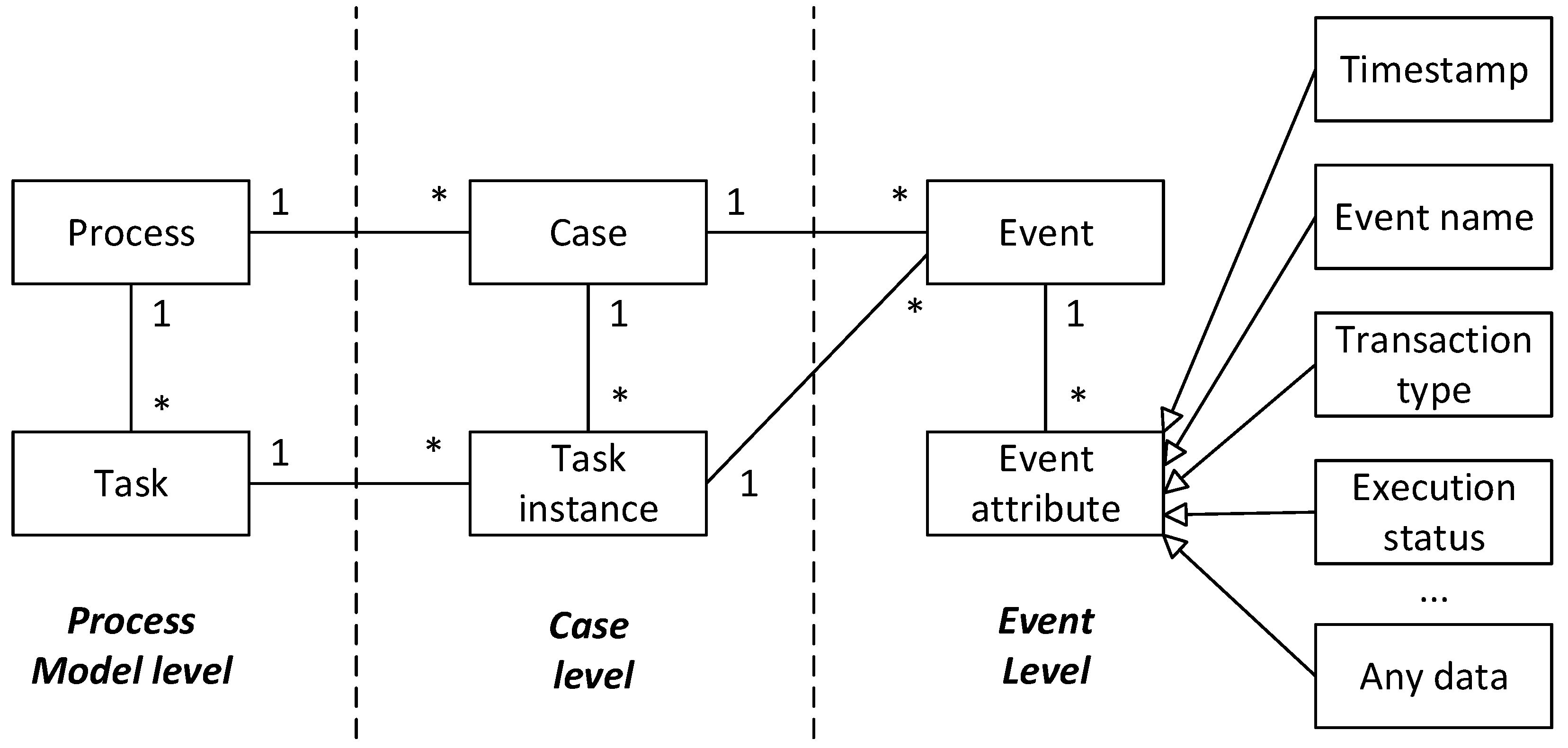
3.2.1. Log Definition Based on Event Status
- (i)
- If, and only if, events have occurred in a trace and satisfy (i.e., has been completed before starts), that is, if there is at least one trace in the log, and no complete task occurs between its two tasks and , then is directly succeeded by , which is represented by .
- (ii)
- If, and only if, events have occurred in a trace and satisfy or , that is, if there is at least one trace in the log, and its two tasks and overlap and intersect, then intersects with , which is represented by .
- (i)
- Causal relation: iff ;
- (ii)
- Indirect relation: iff ;
- (iii)
- Parallel relation: iff .
3.2.2. αS Algorithm Based on Event Status
3.3. Business Process Decomposition
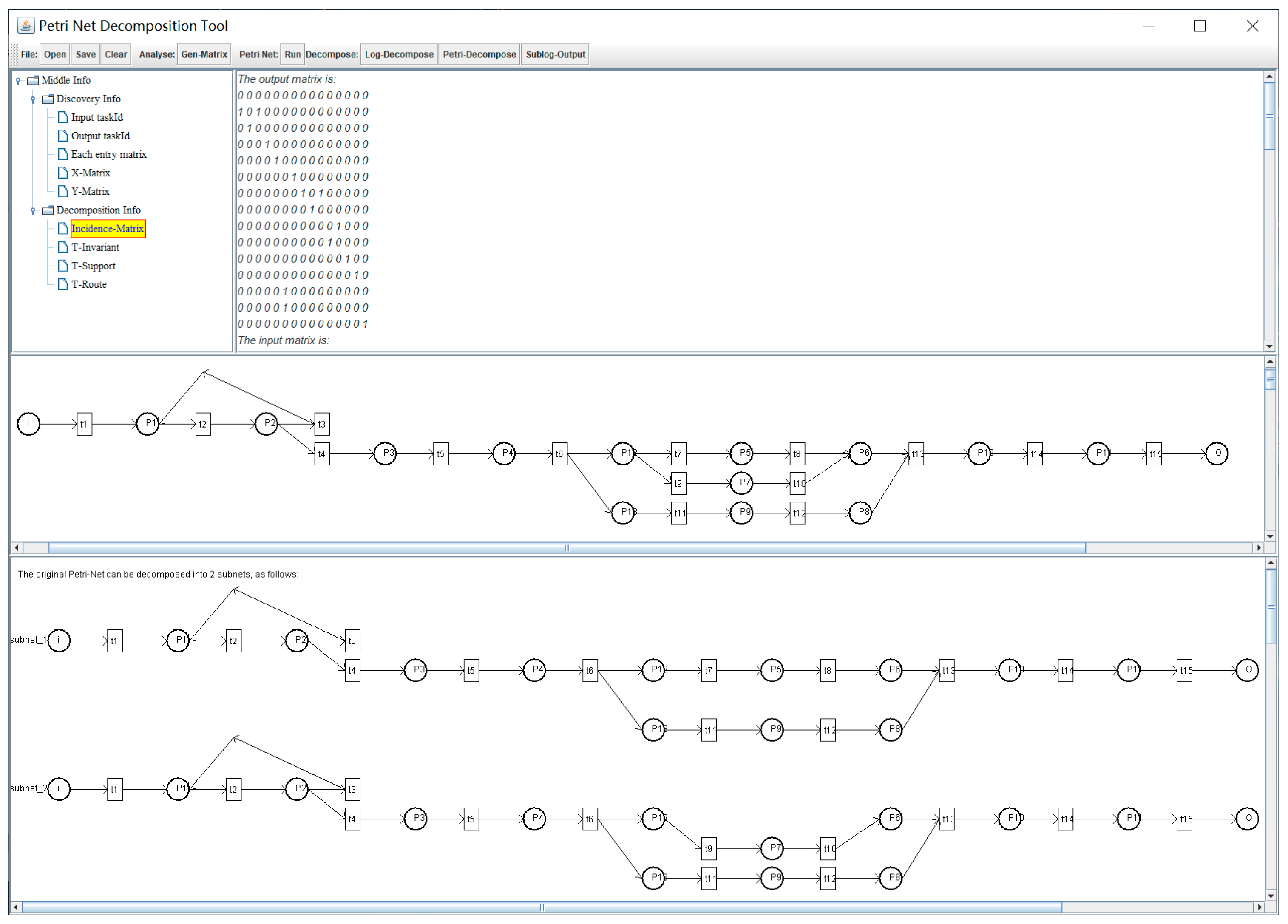
3.3.1. Principle of Process Decomposition
3.3.2. Process Decomposition Algorithm Based on T-Invariant
3.4. Business Process Combination
3.4.1. Workflow Modeling Based on Time Petri Nets
3.4.2. Improved Coverage Tree Algorithm
- (i)
- .
- (ii)
- ,
3.4.3. Place Difference Verification Algorithm
3.5. Business Process Verification
4. Software Testing Workflow Management Oriented to SRGM
4.1. Instantiation Analysis of Process Acquisition
4.2. Instantiation Analysis of Process Decomposition
4.3. Instantiation Analysis of Process Combination and Verification
4.4. Modeling and Analysis for BPMN
4.5. SRGM Modeling of Software Testing Workflow
5. Experimental Analysis
5.1. Application of Tool
5.2. Evaluation and Analysis of Tool
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Han, Q.; Yang, D. Hierarchical Information Entropy System Model for TWfMS. Entropy 2018, 20, 732. [Google Scholar] [CrossRef] [PubMed]
- Sakr, S.; Maamar, Z.; Awad, A.; Benatallah, B.; Aalst, W. Business Process Analytics and Big Data Systems: A Roadmap to Bridge the Gap. IEEE Access 2018, 6, 77308–77320. [Google Scholar] [CrossRef]
- Cinque, M.; Cotroneo, D.; Pecchia, A.; Pietrantuono, R.; Russo, S. Debugging-Workflow-Aware Software Reliability Growth Analysis. Softw. Test. Verif. Reliab. 2017, 27, e1638. [Google Scholar] [CrossRef]
- Kaid, H.; Al-Ahmari, A.; Li, Z.; Davidrajuh, R. Intelligent Colored Token Petri Nets for Modeling, Control, and Validation of Dynamic Changes in Reconfigurable Manufacturing Systems. Processes 2020, 8, 358. [Google Scholar] [CrossRef]
- Cong, X.; Fanti, M.P.; Mangini, A.M.; Li, Z. Critical Observability of Discrete-Event Systems in a Petri Net Framework. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 2789–2799. [Google Scholar] [CrossRef]
- Zhang, C.; Cui, G.; Liu, H.; Meng, F. Component-Based Software Reliability Process Technologies. Chin. J. Comput. 2014, 37, 2586–2612. [Google Scholar]
- Zhang, C.; Meng, F.; Kao, Y.; Lv, W.; Liu, H.; Wan, K.; Jiang, J. Survey of Software Reliability Growth Model. J. Softw. 2017, 28, 2402–2430. [Google Scholar]
- Inoue, S.; Yamada, S. Markovian Software Reliability Modeling with Change-Point. Int. J. Reliab. Qual. Saf. Eng. 2018, 25, 1850009. [Google Scholar] [CrossRef]
- Xu, J.; Pei, Z.; Guo, L.; Zhang, R.; Wang, F. Reliability Analysis of Cloud Service-Based Applications Through SRGM and NMSPN. J. Shanghai Jiaotong Univ. (Sci.) 2020, 25, 57–64. [Google Scholar] [CrossRef]
- Aalst, W.; Weijters, A.; Măruşter, L. Workflow Mining: Discovering Process Models from Event Logs. IEEE Trans. Knowl. Data Eng. 2004, 16, 1128–1142. [Google Scholar] [CrossRef]
- Liu, G.; Reisig, W.; Jiang, C.; Zhou, M. A Branching-Process-Based Method to Check Soundness of Workflow Systems. IEEE Access 2016, 4, 4104–4118. [Google Scholar] [CrossRef]
- He, Y.; Liu, G.; Xiang, D.; Sun, J.; Yan, C.; Jiang, C. Verifying the Correctness of Workflow Systems Based on Workflow Net With Data Constraints. IEEE Access 2018, 6, 11412–11423. [Google Scholar] [CrossRef]
- He, Y.; Liu, G.; Yan, C.; Jiang, C.; Wang, J. Locating and Controlling Unsound Transitions in Workflow Systems Based on Workflow Net With Data Constraints. IEEE Access 2018, 6, 62622–62637. [Google Scholar] [CrossRef]
- Han, Q. Trustworthiness Measurement Algorithm for TWfMS Based on Software Behaviour Entropy. Entropy 2018, 20, 195. [Google Scholar] [CrossRef] [PubMed]
- Han, Q.; Yuan, Y. Research on Trustworthiness Measurement Approaches of Component Based BPRAS. J. Commun. 2014, 35, 47–57. [Google Scholar]
- Gokhale, S.S. Architecture-Based Software Reliability Analysis: Overview and Limitations. IEEE Trans. Dependable Secur. Comput. 2007, 4, 32–40. [Google Scholar] [CrossRef]
- Martins, J.; Branco, F.; Au-Yong-Oliveira, M.; Gonçalves, R.; Moreira, F. Higher Education Students Perspective on Education Management Information Systems: An Initial Success Model Proposal. Int. J. Technol. Hum. Interact. 2019, 15, 1–10. [Google Scholar] [CrossRef]
- Rivest, R.L.; Shamir, A.; Adleman, L.M. A method for obtaining digital signatures and public-key cryptosystems. Commun. ACM 1978, 21, 120–126. [Google Scholar] [CrossRef]
- Kocher, P.C. Timing Attacks on Implementations of Diffie-Hellman, RSA, DSS, and Other Systems. In Proceedings of the 16th Annual International Cryptology Conference on Advances in Cryptology, Santa Barbara, CA, USA, 18–22 August 1996; pp. 104–113. [Google Scholar]
- Pei, J.; Wen, L.; Yang, H.; Wang, J.; Ye, X. Estimating Global Completeness of Event Logs: A Comparative Study. IEEE Trans. Serv. Comput. 2021, 14, 441–457. [Google Scholar] [CrossRef]
- Martin, N.; Solti, A.; Mendling, J.; Depaire, B.; An, C. Mining Batch Activation Rules from Event Logs. IEEE Trans. Serv. Comput. 2021, 14, 1908–1919. [Google Scholar] [CrossRef]
- Pourbafrani, M.; Aalst, W. Discovering System Dynamics Simulation Models Using Process Mining. IEEE Access 2022, 10, 78527–78547. [Google Scholar] [CrossRef]
- Rogge-Solti, A.; Senderovich, A.; Weidlich, M.; Mendling, J.; Gal, A. In Log and Model We Trust? A Generalized Conformance Checking Framework. Lect. Notes Comput. Sci. 2016, 9850, 179–196. [Google Scholar]
- Matthias, G.; Simon, H.; Jörg, L.; Guido, W. BPMN 2.0: The State of Support and Implementation. Future Gener. Comput. Syst. 2018, 80, 250–262. [Google Scholar]
- Lanouar, L.; Rekik, M.; Bouchaala, O.; Krichen, L. An Optimal Power Supervising Strategy for A Smart Home Assessed Based on BPMN Framework. In Proceedings of the 2022 IEEE 21st international Ccnference on Sciences and Techniques of Automatic Control and Computer Engineering (STA), Sousse, Tunisia, 19–21 December 2022; pp. 406–411. [Google Scholar]
- Al-Ali, H.; Cuzzocrea, A.; Damiani, E.; Mizouni, R.; Tello, G. A Composite Machine-Learning-Based Framework for Supporting Low-Level Event Logs to High-Level Business Process Model Activities Mappings Enhanced by Flexible BPMN Model Translation. Soft Comput. 2020, 24, 7557–7578. [Google Scholar] [CrossRef]
- Li, N.; Han, Q.; Zhang, Y.; Li, C.; He, Y.; Liu, H.; Mao, Z. Standardization Workflow Technology of Software Testing Processes and its Application to SRGM on RSA Timing Attack Tasks. IEEE Access 2022, 10, 82540–82559. [Google Scholar] [CrossRef]
- ISO/IEC/IEEE 29119-2:2021(E); ISO/IEC/IEEE International Standard-Software and Systems Engineering-Software Testing—Part 2: Test Processes. IEEE: New York, NY, USA, 28 October 2021; pp. 1–64. [CrossRef]
- Tao, J.; Wang, J.; Wen, L.; Zou, G. Computing Refined Ordering Relations with Uncertainty for Acyclic Process Models. IEEE Trans. Serv. Comput. 2014, 7, 415–426. [Google Scholar]
- Kalenkova, A.; Aalst, W.; Lomazova, I.; Rubin, V. Process Mining Using BPMN: Relating Event Logs and Process Models. Softw. Syst. Model. 2017, 16, 1019–1048. [Google Scholar] [CrossRef]
- Pegoraro, M.; Uysal, M.; Aalst, W. Efficient Time and Space Representation of Uncertain Event Data. Algorithms 2020, 13, 285. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, H.; Bai, R.; Wang, K.; Wang, J.; Lv, W.; Meng, F. Review on Fault Detection Rate in Reliability Model. J. Softw. 2020, 31, 2802–2825. [Google Scholar]
- Lee, D.; Chang, I.; Pham, H. Software Reliability Model with Dependent Failures and SPRT. Mathematics 2020, 8, 1366. [Google Scholar] [CrossRef]
- Tripathi, M.; Singh, L.K.; Singh, S.; Singh, P. A Comparative Study on Reliability Analysis Methods for Safety Critical Systems Using Petri-Nets and Dynamic Flowgraph Methodology: A Case Study of Nuclear Power Plant. IEEE Trans. Reliab. 2022, 71, 564–578. [Google Scholar] [CrossRef]
- Goel, A.L.; Okumoto, K. Time-Dependent Error-Detection Rate Model for Software Reliability and Other Performance Measures. IEEE Trans. Reliab. 1979, R-28, 206–211. [Google Scholar] [CrossRef]
- Nagaraj, V. Software Reliability Assessment: Modeling and Algorithms. In Proceedings of the 2018 IEEE International Symposium on Software Reliability Engineering Workshops (ISSREW), Memphis, TN, USA, 15–18 October 2018; pp. 166–169. [Google Scholar]
- Li, S.; Dohi, T.; Okamura, H. A Comprehensive Evaluation for Burr-Type NHPP-based Software Reliability Models. In Proceedings of the 2021 8th International Conference on Dependable Systems and Their Applications (DSA), Yinchuan, China, 5–6 August 2021; pp. 1–11. [Google Scholar]
- Garg, R.; Raheja, S.; Garg, R.K. Decision Support System for Optimal Selection of Software Reliability Growth Models Using a Hybrid Approach. IEEE Trans. Reliab. 2022, 71, 149–161. [Google Scholar] [CrossRef]
- Song, L.; Minku, L.L. A Procedure to Continuously Evaluate Predictive Performance of Just-In-Time Software Defect Prediction Models during Software Development. IEEE Trans. Softw. Eng. 2023, 49, 646–666. [Google Scholar] [CrossRef]
- Jagtap, M.; Katragadda, P.; Satelkar, P. Software Reliability: Development of Software Defect Prediction Models Using Advanced Techniques. In Proceedings of the 2022 Annual Reliability and Maintainability Symposium (RAMS), Tucson, AZ, USA, 24–27 January 2022; pp. 1–7. [Google Scholar]
- Galanti, R.; Leoni, M.D.; Navarin, N.; Marazzi, A. Object-centric Process Predictive Analytics. Expert Syst. Appl. 2023, 213, 119173. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CaseId | Event | CaseId | Event | CaseId | Event | CaseId | Event | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Name | Status | Name | Status | Name | Status | Name | Status | ||||
| 1 | T1 | Start | 1 | T14 | Start | 2 | T10 | Complete | 3 | T6 | Start |
| 1 | T1 | Complete | 1 | T14 | Complete | 2 | T12 | Complete | 3 | T6 | Complete |
| 1 | T2 | Start | 1 | T15 | Start | 2 | T13 | Start | 3 | T11 | Start |
| 1 | T2 | Complete | 1 | T15 | Complete | 2 | T13 | Complete | 3 | T7 | Start |
| 1 | T4 | Start | 2 | T1 | Start | 2 | T14 | Start | 3 | T11 | Complete |
| 1 | T4 | Complete | 2 | T1 | Complete | 2 | T14 | Complete | 3 | T12 | Start |
| 1 | T5 | Start | 2 | T2 | Start | 2 | T15 | Start | 3 | T7 | Complete |
| 1 | T5 | Complete | 2 | T2 | Complete | 2 | T15 | Complete | 3 | T8 | Start |
| 1 | T6 | Start | 2 | T4 | Start | 3 | T1 | Start | 3 | T8 | Complete |
| 1 | T6 | Complete | 2 | T4 | Complete | 3 | T1 | Complete | 3 | T12 | Complete |
| 1 | T11 | Start | 2 | T5 | Start | 3 | T2 | Start | 3 | T13 | Start |
| 1 | T7 | Start | 2 | T5 | Complete | 3 | T2 | Complete | 3 | T13 | Complete |
| 1 | T7 | Complete | 2 | T6 | Start | 3 | T3 | Start | 3 | T14 | Start |
| 1 | T8 | Start | 2 | T6 | Complete | 3 | T3 | Complete | 3 | T14 | Complete |
| 1 | T11 | Complete | 2 | T11 | Start | 3 | T2 | Start | 3 | T15 | Start |
| 1 | T12 | Start | 2 | T9 | Start | 3 | T2 | Complete | 3 | T15 | Complete |
| 1 | T8 | Complete | 2 | T9 | Complete | 3 | T4 | Start | 4 | T1 | Start |
| 1 | T12 | Complete | 2 | T10 | Start | 3 | T4 | Complete | 4 | T1 | Complete |
| 1 | T13 | Start | 2 | T11 | Complete | 3 | T5 | Start | 4 | T2 | Start |
| 1 | T13 | Complete | 2 | T12 | Start | 3 | T5 | Complete | ... | ... | ... |
| Fault Datasets/ Assessment Indexes | MSE | SAE | Variation | RMSPE | R2 |
|---|---|---|---|---|---|
| DS2 | 0.53174 | 4.95724 | 0.60524 | 0.75995 | 0.89872 |
| DS3 | 0.51658 | 7.74876 | 0.48669 | 0.73130 | 0.96310 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mao, Z.; Han, Q.; He, Y.; Li, N.; Li, C.; Shan, Z.; Han, S. A Software Testing Workflow Analysis Tool Based on the ADCV Method. Electronics 2023, 12, 4464. https://doi.org/10.3390/electronics12214464
Mao Z, Han Q, He Y, Li N, Li C, Shan Z, Han S. A Software Testing Workflow Analysis Tool Based on the ADCV Method. Electronics. 2023; 12(21):4464. https://doi.org/10.3390/electronics12214464
Chicago/Turabian StyleMao, Zijian, Qiang Han, Yu He, Nan Li, Cong Li, Zhihui Shan, and Sheng Han. 2023. "A Software Testing Workflow Analysis Tool Based on the ADCV Method" Electronics 12, no. 21: 4464. https://doi.org/10.3390/electronics12214464