

Siamese Visual Tracking with Spatial-Channel Attention and Ranking Head Network

Abstract
:1. Introduction
- (1)
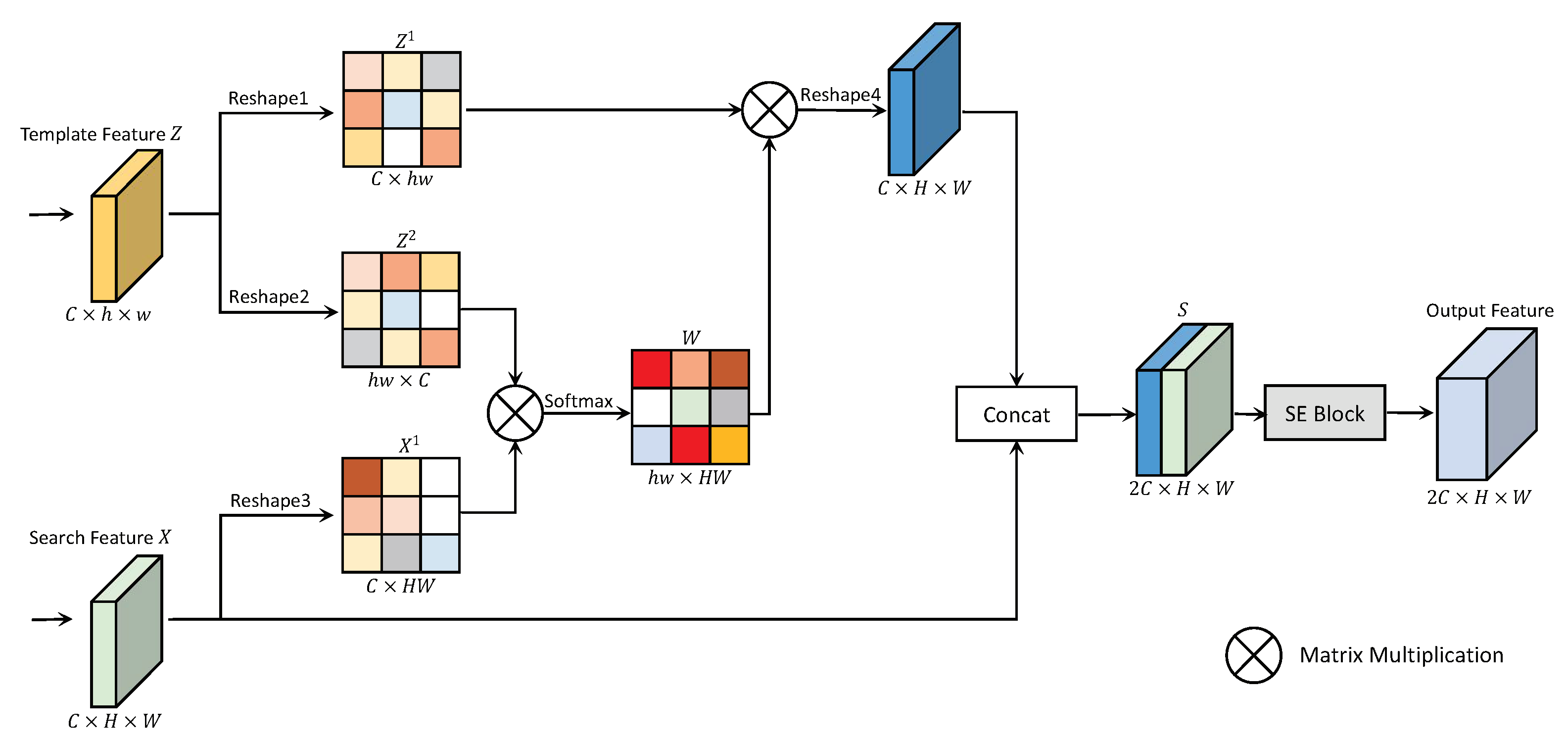
- We propose SCAM. Specifically, we first calculate the spatial similarity matrix between two feature maps, and then we use this similarity matrix to filter the information in the search region’s feature. We concatenate the filtered and original search region’s features, and send it to the channel attention module. This approach is used to achieve spatial channel attention. This enhances the representation of fusion features and makes them more discriminative.
- (2)
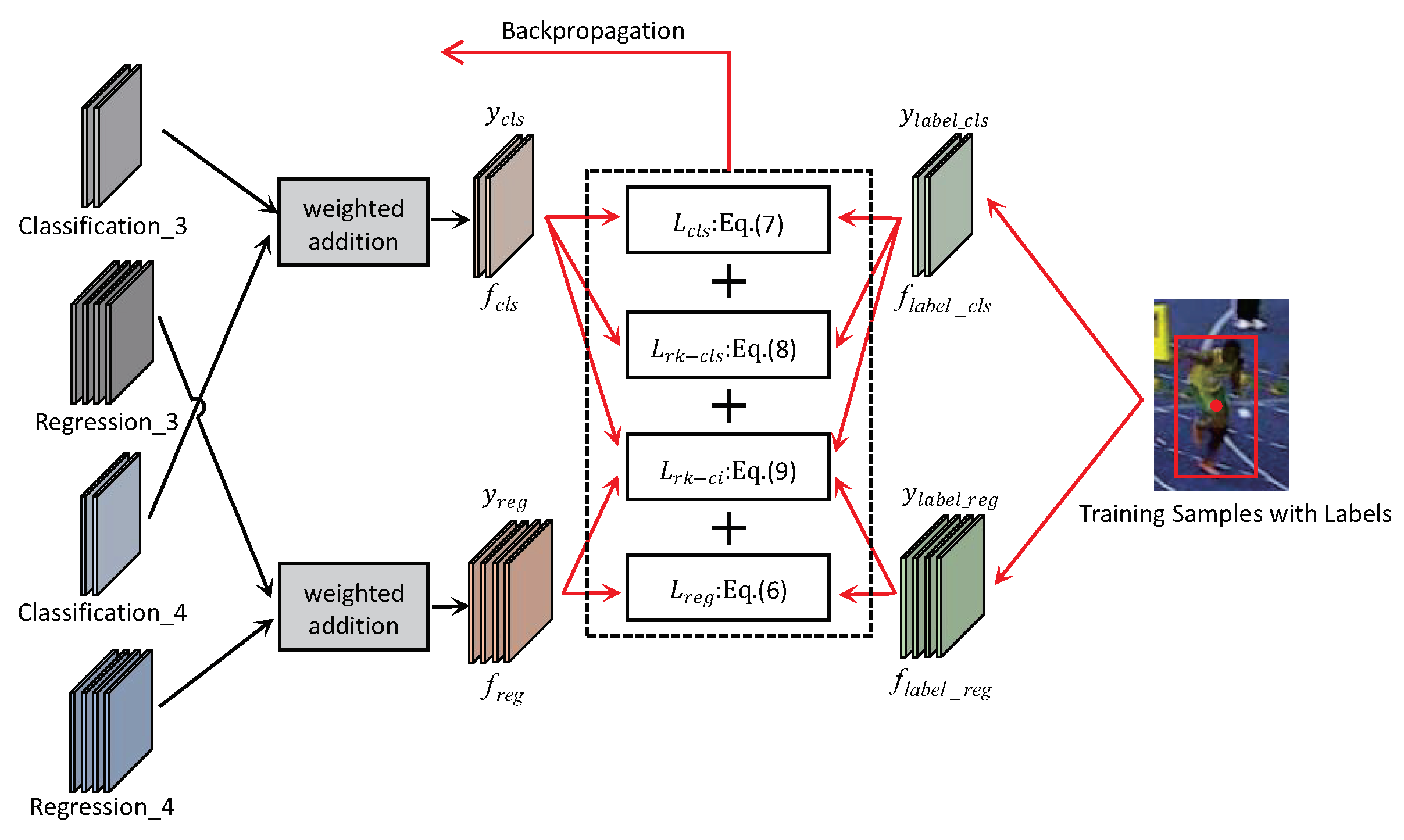
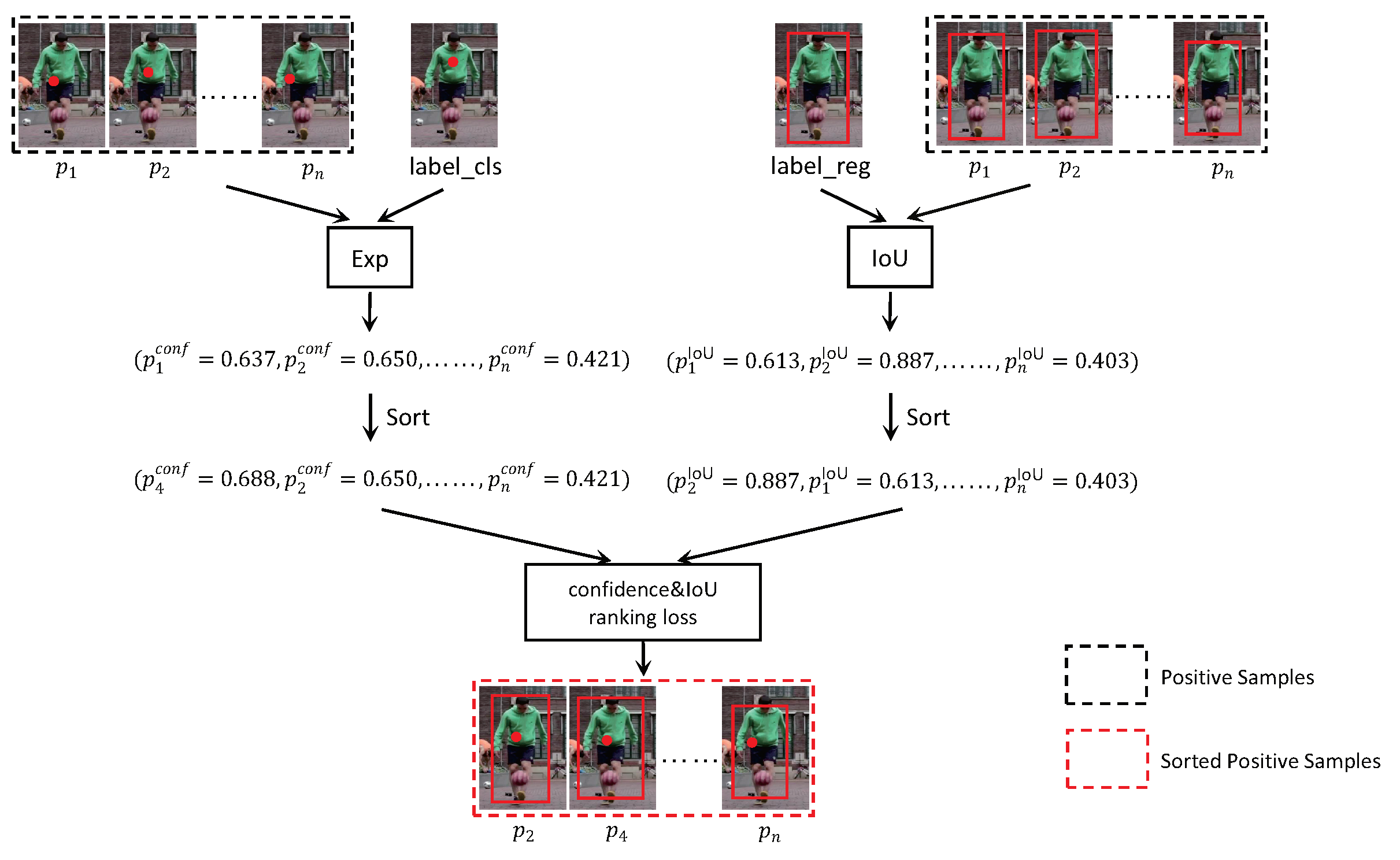
- We design a ranking head network. Specifically, we introduce joint ranking loss terms into our approach. We use the mutual guidance of classification confidence score and IoU to select the final result, which can solve the problem of mismatch between the predicted values of the classification branch and the regression branch. Through the ranking head network, we can obtain more precise results and achieve a more robust tracking performance.
- (3)
- We train our tracker on ImageNet DET [12], ImageNet VID [12], COCO [13], YouTube-BB [14], and GOT-10k training set [15]. Excellent results have been achieved on five challenging datasets, including the GOT-10k testing set, UAV123 [16], OTB100 [17], VOT2016 [18], and VOT2018 [19]. Our code and data are available at https://github.com/csust7zhangjm/lyf2021 (accessed on 9 October 2023).
2. Related Work
2.1. Single Object Siamese Tracking
2.2. Attention Mechanism
2.3. Head Network
3. Methods
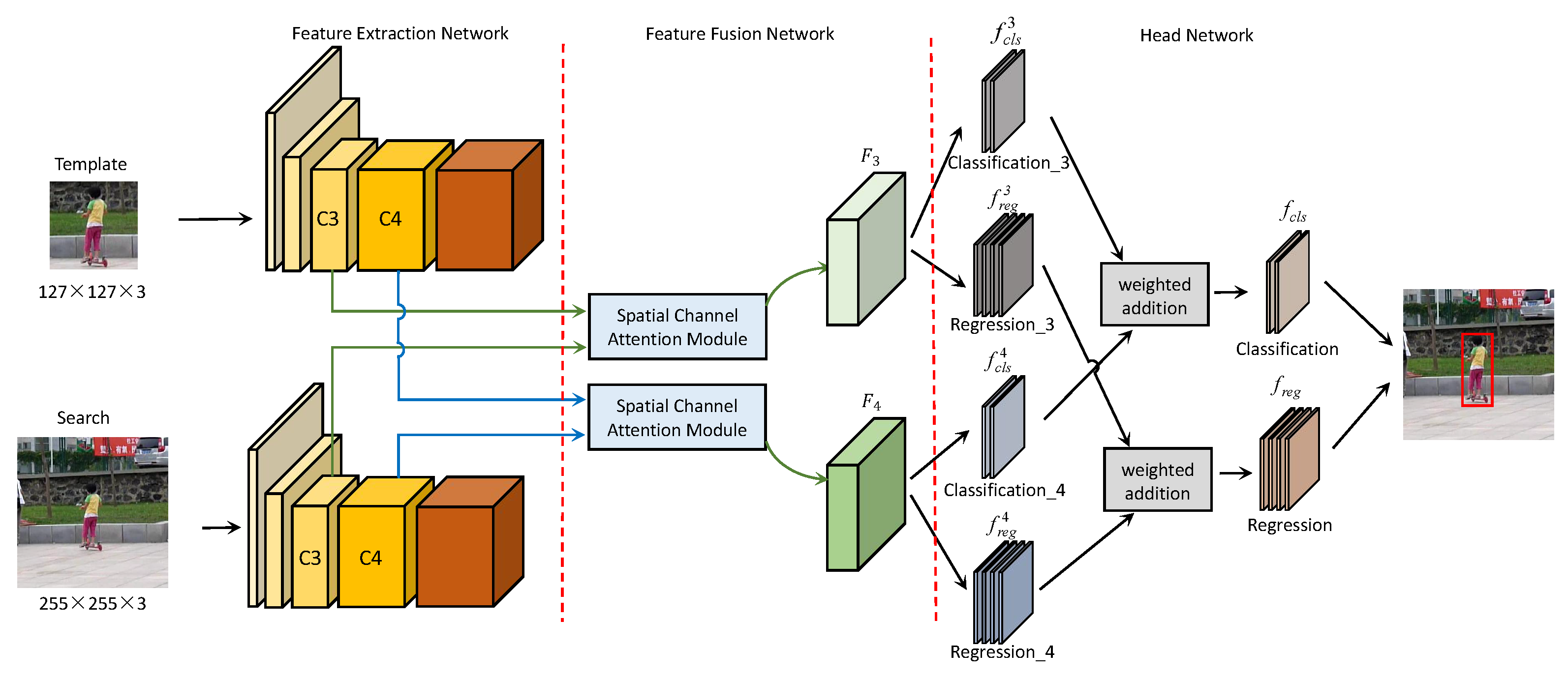
3.1. Overview
3.2. Spatial Channel Attention Module
3.3. Ranking Head Network
4. Experiments
4.1. Implementation Details
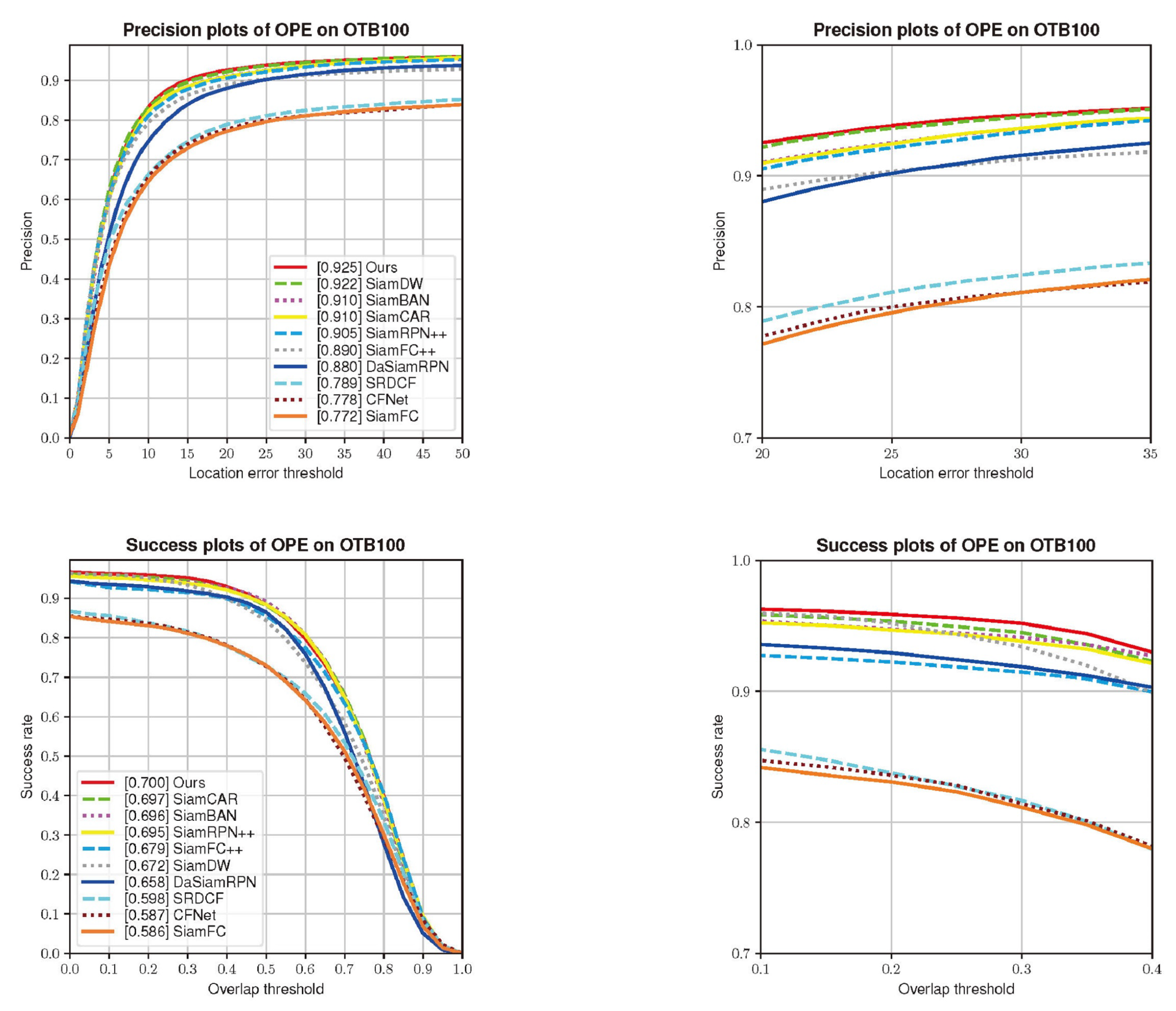
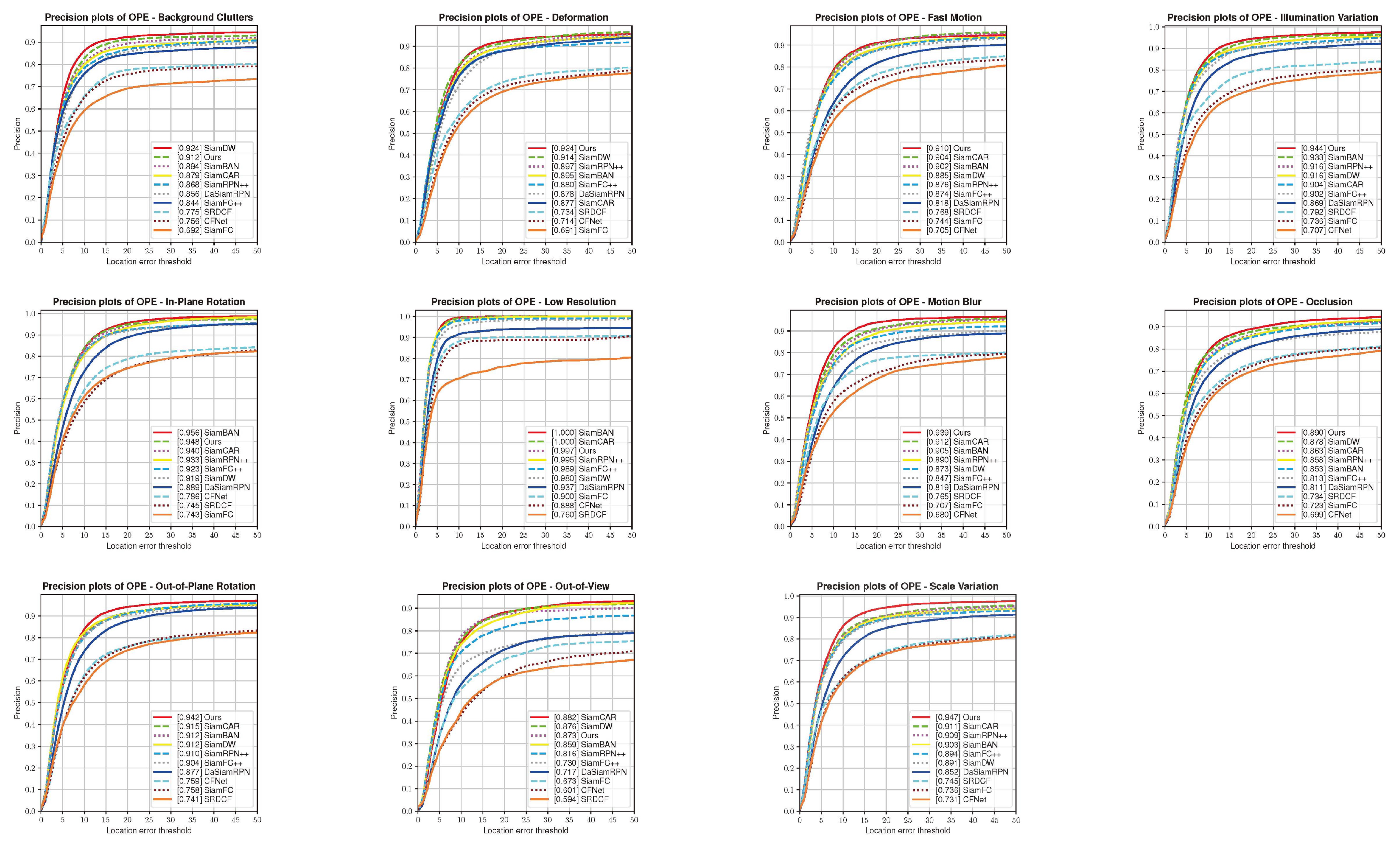
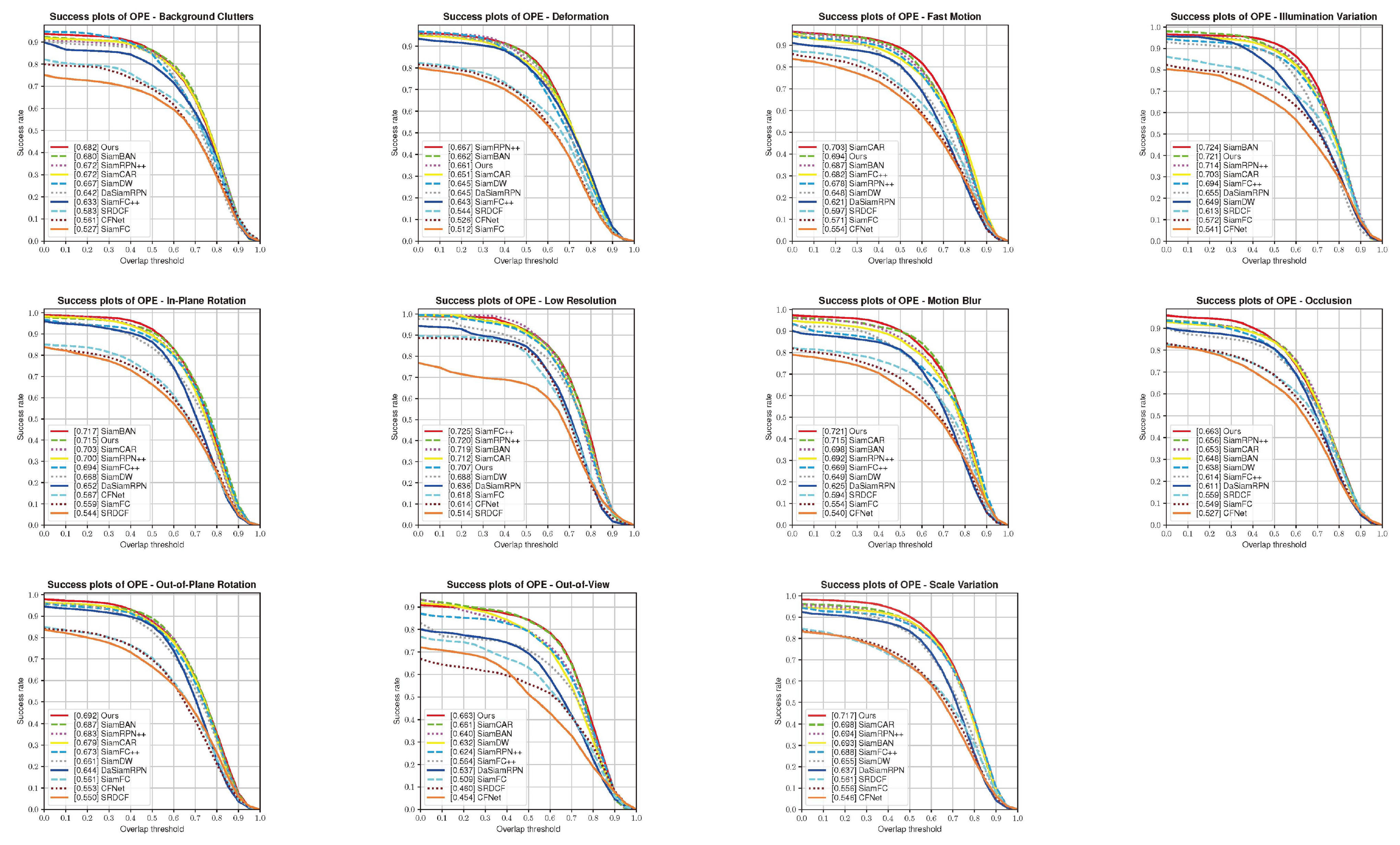
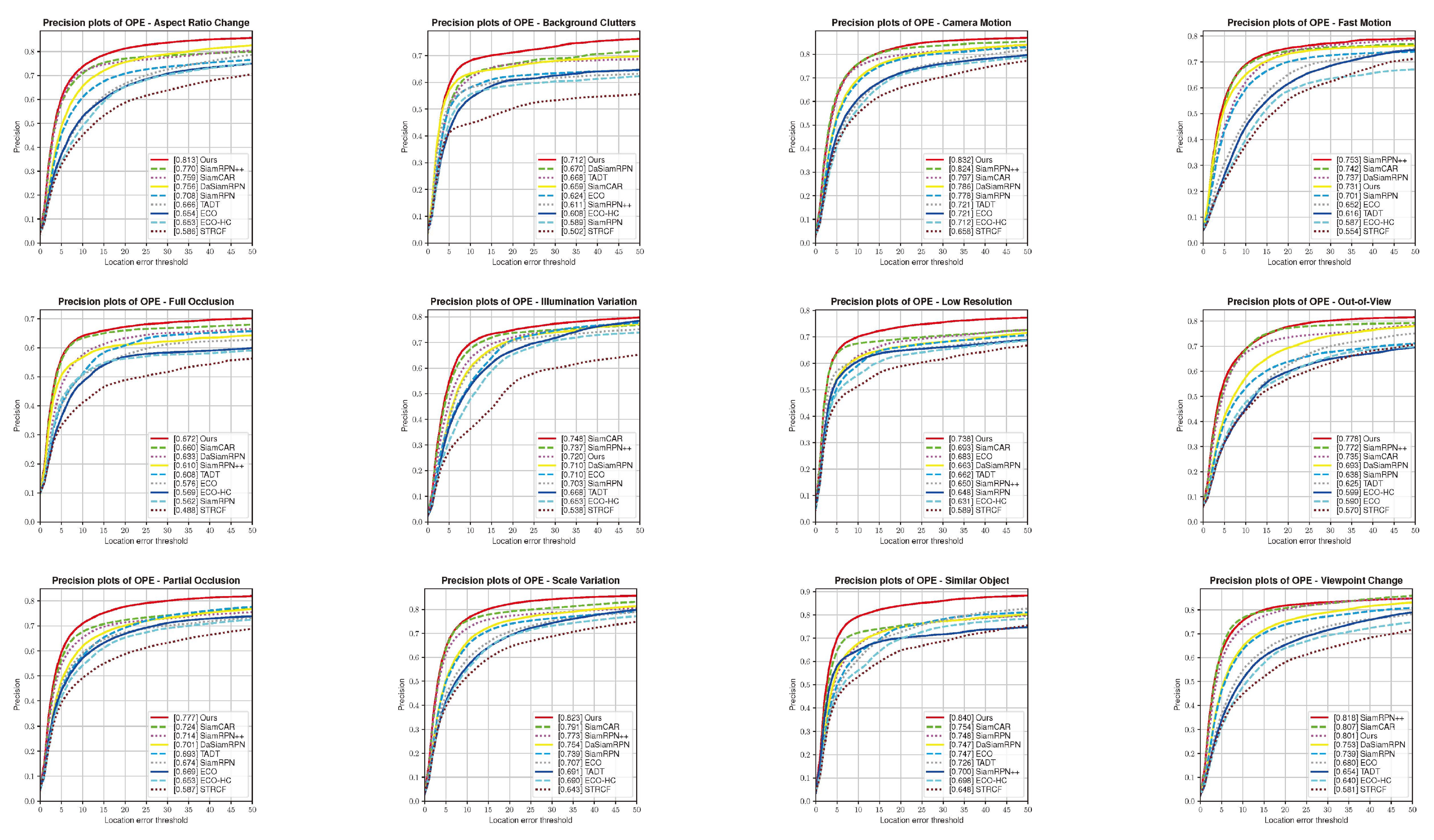
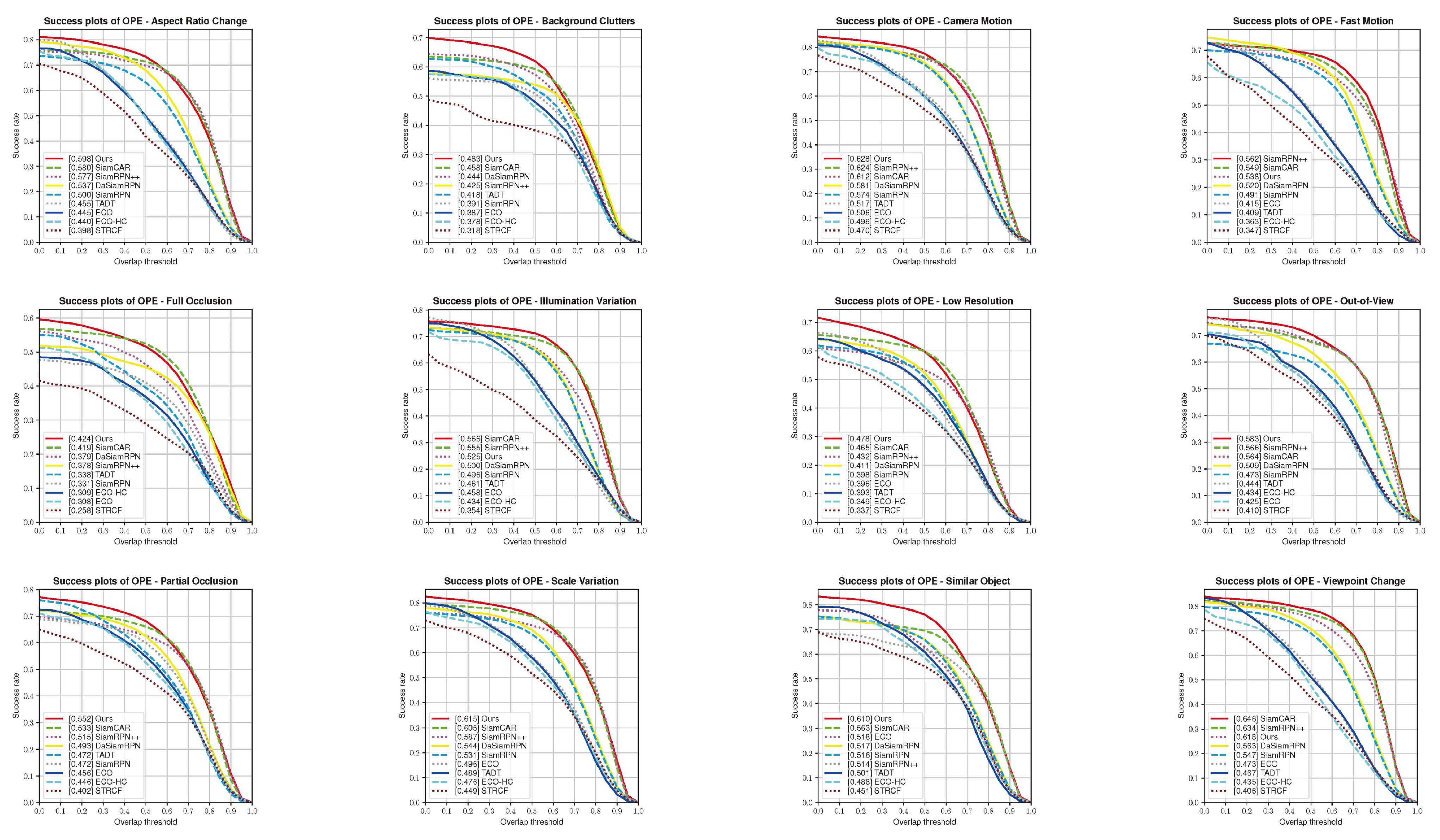
4.2. Results on OTB100 Benchmark
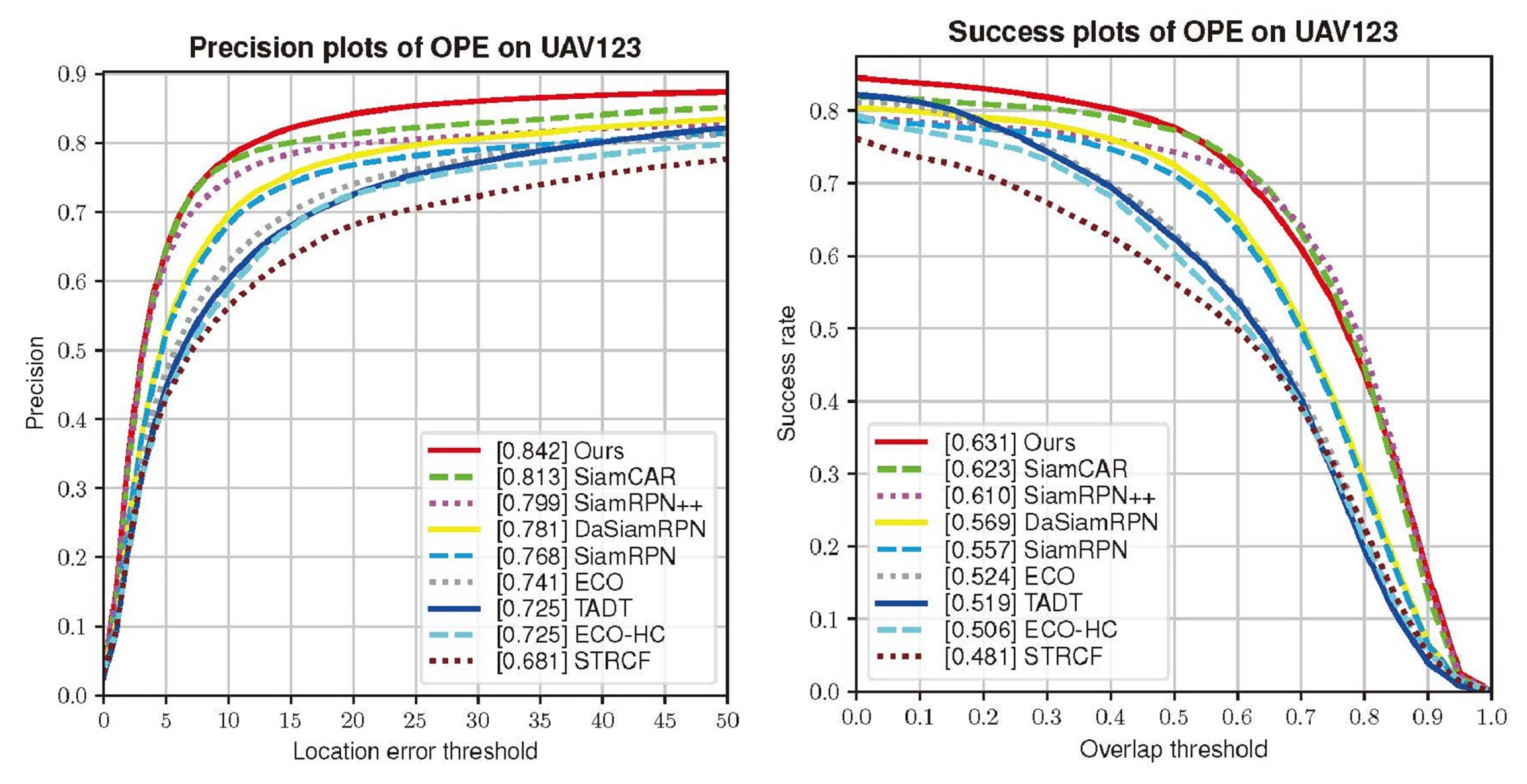
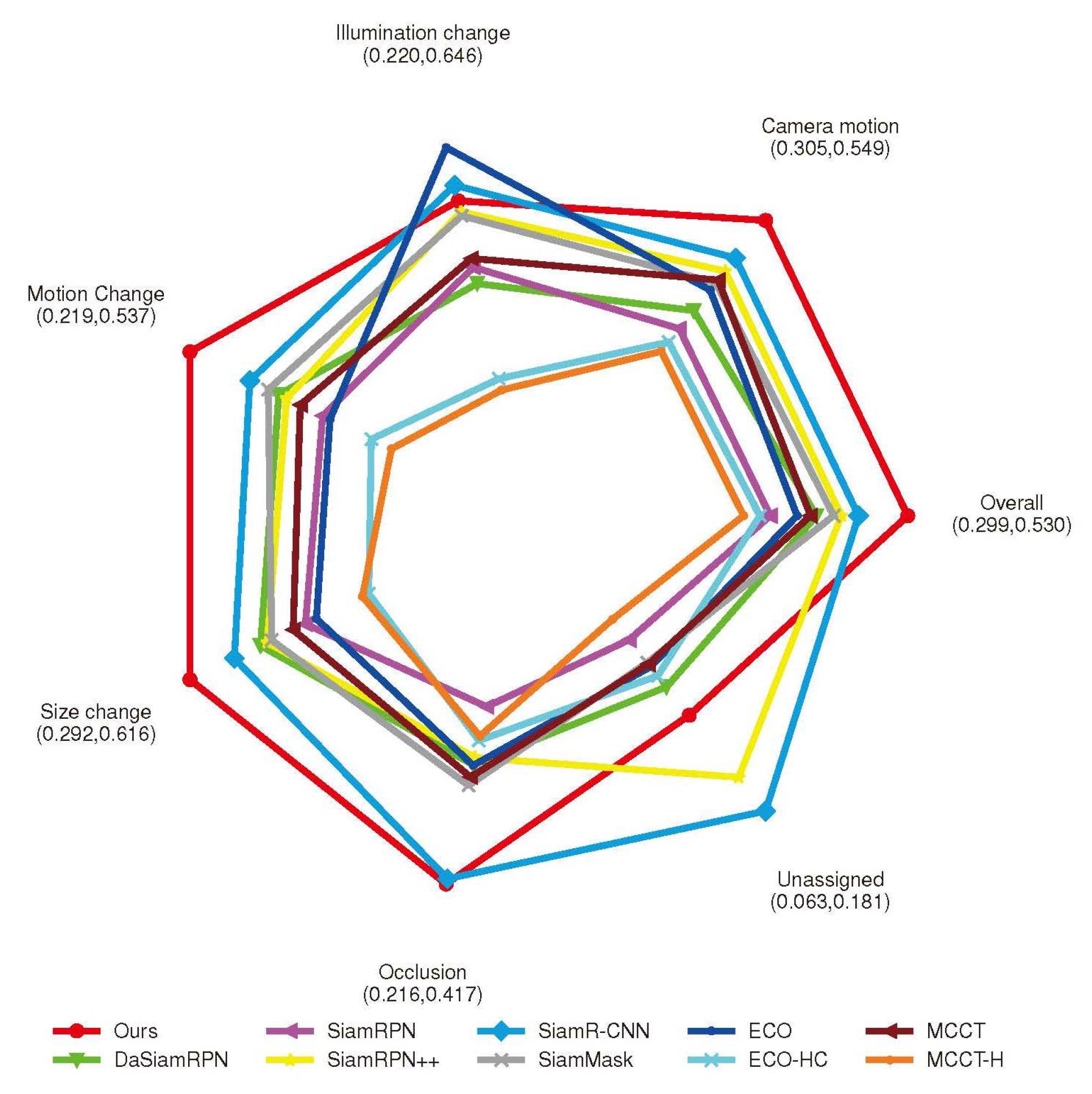
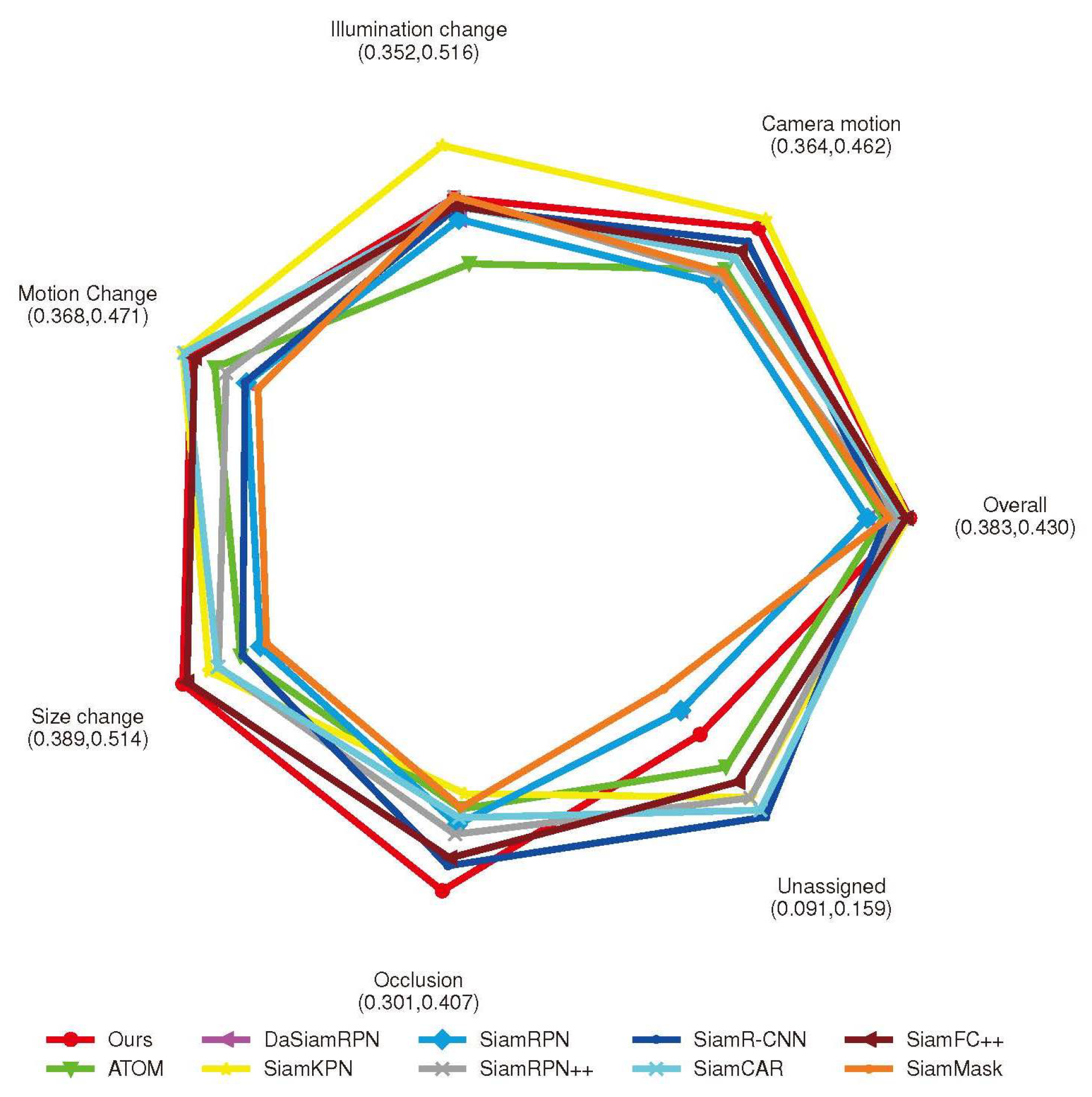
4.3. Results on UAV123 Benchmark
4.4. Results on VOT2016 Benchmark
4.5. Results on VOT2018 Benchmark
4.6. Results on GOT-10k Benchmark
4.7. Ablation Experiment
4.8. Real-Time Analysis
4.9. Experimental Summary
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
- Terminology
- Algorithm
References
- Zhang, J.; Feng, W.; Yuan, T.; Wang, J.; Sangaiah, A.K. SCSTCF: Spatial-channel selection and temporal regularized correlation filters for visual tracking. Appl. Soft Comput. 2022, 118, 108485. [Google Scholar] [CrossRef]
- Zhang, J.; Jin, X.; Sun, J.; Wang, J.; Sangaiah, A.K. Spatial and semantic convolutional features for robust visual object tracking. Multimed. Tools Appl. 2020, 79, 15095–15115. [Google Scholar] [CrossRef]
- Zhang, J.; Sun, J.; Wang, J.; Li, Z.; Chen, X. An object tracking framework with recapture based on correlation filters and Siamese networks. Comput. Electr. Eng. 2022, 98, 107730. [Google Scholar] [CrossRef]
- Zhang, J.; Xie, X.; Zheng, Z.; Kuang, L.D.; Zhang, Y. SiamOA: Siamese offset-aware object tracking. Neural Comput. Appl. 2022, 34, 22223–22239. [Google Scholar] [CrossRef]
- Zhang, J.; Sun, J.; Wang, J.; Yue, X.G. Visual object tracking based on residual network and cascaded correlation filters. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 8427–8440. [Google Scholar] [CrossRef]
- Sidenmark, L.; Parent, M.; Wu, C.H.; Chan, J.; Glueck, M.; Wigdor, D.; Grossman, T.; Giordano, M. Weighted Pointer: Error-aware Gaze-based Interaction through Fallback Modalities. IEEE Trans. Vis. Comput. Graph. 2022, 28, 3585–3595. [Google Scholar] [CrossRef] [PubMed]
- de Curtò, J.; de Zarzà, I.; Calafate, C.T. Semantic scene understanding with large language models on unmanned aerial vehicles. Drones 2023, 7, 114. [Google Scholar] [CrossRef]
- de Curtò, J.; de Zarzà, I.; Roig, G.; Calafate, C.T. Summarization of Videos with the Signature Transform. Electronics 2023, 12, 1735. [Google Scholar] [CrossRef]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Yi-de, M.; Qing, L.; Zhi-Bai, Q. Automated image segmentation using improved PCNN model based on cross-entropy. In Proceedings of the 2004 International Symposium on Intelligent Multimedia, Video and Speech Processing, IEEE, Hong Kong, China, 20–22 October 2004; pp. 743–746. [Google Scholar]
- Tang, F.; Ling, Q. Ranking-based Siamese visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8741–8750. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Real, E.; Shlens, J.; Mazzocchi, S.; Pan, X.; Vanhoucke, V. Youtube-boundingboxes: A large high-precision human-annotated data set for object detection in video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5296–5305. [Google Scholar]
- Huang, L.; Zhao, X.; Huang, K. GOT-10k: A Large High-Diversity Benchmark for Generic Object Tracking in the Wild. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1562–1577. [Google Scholar] [CrossRef] [PubMed]
- Mueller, M.; Smith, N.; Ghanem, B. A Benchmark and Simulator for UAV Tracking. In Proceedings of the Computer Vision–ECCV, Amsterdam, The Netherlands, 11–14 October 2016; pp. 445–461. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Object tracking benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [PubMed]
- Kristan, M.; Leonardis, A.; Matas, J.; Felsberg, M.; Pflugfelder, R.; Čehovin, L.; Vojir, T.; Häger, G.; Lukežič, A.; Fernández, G.; et al. The Visual Object Tracking VOT2016 Challenge Results. In Proceedings of the Computer Vision—ECCV 2016 Workshops, Amsterdam, The Netherlands, 11–14 October 2016; pp. 777–823. [Google Scholar]
- Kristan, M.; Leonardis, A.; Matas, J.; Felsberg, M.; Pflugfelder, R.; Čehovin Zajc, L.; Vojir, T.; Bhat, G.; Lukezic, A.; Eldesokey, A.; et al. The sixth visual object tracking vot2018 challenge results. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018; pp. 3–53. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In Proceedings of the Computer Vision—ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10 October 2016; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 850–865. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High performance visual tracking with siamese region proposal network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Zhu, Z.; Wang, Q.; Li, B.; Wu, W.; Yan, J.; Hu, W. Distractor-aware siamese networks for visual object tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 101–117. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. Siamrpn++: Evolution of siamese visual tracking with very deep networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4282–4291. [Google Scholar]
- Chen, Z.; Zhong, B.; Li, G.; Zhang, S.; Ji, R. Siamese box adaptive network for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6668–6677. [Google Scholar]
- Guo, D.; Wang, J.; Cui, Y.; Wang, Z.; Chen, S. SiamCAR: Siamese fully convolutional classification and regression for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6269–6277. [Google Scholar]
- Zhang, J.; Huang, H.; Jin, X.; Kuang, L.D.; Zhang, J. Siamese visual tracking based on criss-cross attention and improved head network. Multimed. Tools Appl. 2023. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Fu, Z.; Liu, Q.; Fu, Z.; Wang, Y. Stmtrack: Template-free visual tracking with space-time memory networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13774–13783. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 8–14 September 2018; pp. 7794–7803. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Zhou, X.; Zhuo, J.; Krahenbuhl, P. Bottom-up object detection by grouping extreme and center points. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 850–859. [Google Scholar]
- Xu, Y.; Wang, Z.; Li, Z.; Yuan, Y.; Yu, G. Siamfc++: Towards robust and accurate visual tracking with target estimation guidelines. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12549–12556. [Google Scholar]
- Danelljan, M.; Gool, L.V.; Timofte, R. Probabilistic regression for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7183–7192. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Learning spatially regularized correlation filters for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 4310–4318. [Google Scholar]
- Valmadre, J.; Bertinetto, L.; Henriques, J.; Vedaldi, A.; Torr, P.H. End-to-end representation learning for correlation filter based tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2805–2813. [Google Scholar]
- Zhang, Z.; Peng, H. Deeper and wider siamese networks for real-time visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4591–4600. [Google Scholar]
- Danelljan, M.; Bhat, G.; Shahbaz Khan, F.; Felsberg, M. Eco: Efficient convolution operators for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6638–6646. [Google Scholar]
- Li, F.; Tian, C.; Zuo, W.; Zhang, L.; Yang, M.H. Learning spatial-temporal regularized correlation filters for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4904–4913. [Google Scholar]
- Li, X.; Ma, C.; Wu, B.; He, Z.; Yang, M.H. Target-aware deep tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1369–1378. [Google Scholar]
- Wang, N.; Zhou, W.; Tian, Q.; Hong, R.; Wang, M.; Li, H. Multi-cue correlation filters for robust visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4844–4853. [Google Scholar]
- Wang, Q.; Zhang, L.; Bertinetto, L.; Hu, W.; Torr, P.H. Fast online object tracking and segmentation: A unifying approach. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1328–1338. [Google Scholar]
- Voigtlaender, P.; Luiten, J.; Torr, P.H.; Leibe, B. Siam r-cnn: Visual tracking by re-detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6578–6588. [Google Scholar]
- Li, Q.; Qin, Z.; Zhang, W.; Zheng, W. Siamese keypoint prediction network for visual object tracking. arXiv 2020, arXiv:2006.04078. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. Atom: Accurate tracking by overlap maximization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4660–4669. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
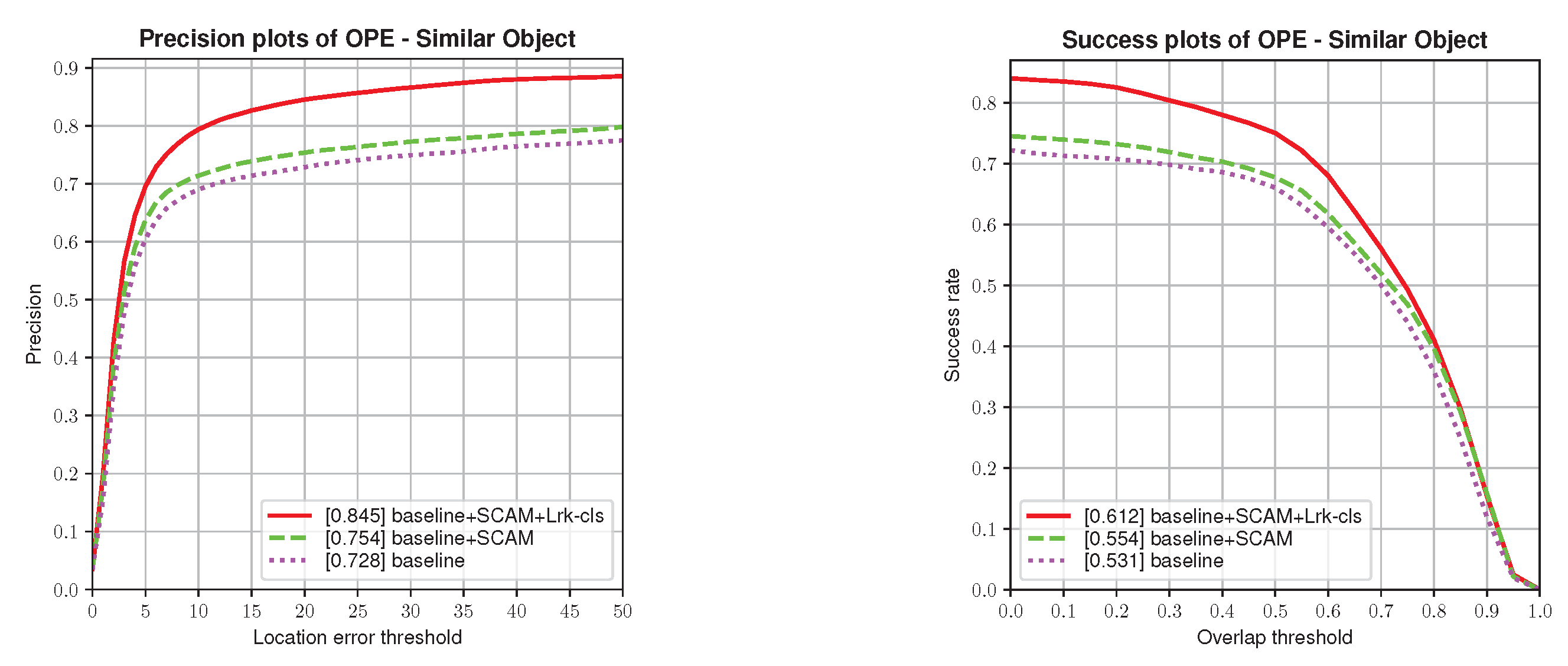{kind=link}
{kind=link}
| MCCT-H | ECO-HC | SiamRPN | ECO | MCCT | DaSiam-RPN | SiamMask | SiamRPN++ | SiamR-CNN | Ours | |
|---|---|---|---|---|---|---|---|---|---|---|
| E↑ | 0.299 | 0.322 | 0.337 | 0.374 | 0.393 | 0.401 | 0.425 | 0.437 | 0.460 | 0.530 |
| A↑ | 0.570 | 0.542 | 0.578 | 0.555 | 0.579 | 0.609 | 0.634 | 0.644 | 0.645 | 0.634 |
| R↓ | 0.331 | 0.303 | 0.312 | 0.200 | 0.186 | 0.224 | 0.214 | 0.219 | 0.172 | 0.084 |
| DaSiam-RPN | ATOM | SiamR-CNN | SiamMask | Siam-RPN++ | SiamCAR | SiamFC++ | SiamKPN | SiamRPN | Ours | |
|---|---|---|---|---|---|---|---|---|---|---|
| E↑ | 0.383 | 0.400 | 0.405 | 0.406 | 0.415 | 0.423 | 0.426 | 0.428 | 0.383 | 0.430 |
| A↑ | 0.586 | 0.590 | 0.612 | 0.598 | 0.601 | 0.578 | 0.583 | 0.596 | 0.586 | 0.587 |
| R↓ | 0.276 | 0.203 | 0.220 | 0.248 | 0.234 | 0.197 | 0.173 | 0.187 | 0.276 | 0.164 |
| SiamDW | DaSiamRPN | SiamRPN++ | SiamCAR | ATOM | SiamRPN | SiamMask | Ours | |
|---|---|---|---|---|---|---|---|---|
| AO↑ | 0.416 | 0.444 | 0.517 | 0.569 | 0.556 | 0.483 | 0.453 | 0.618 |
| ↑ | 0.475 | 0.536 | 0.616 | 0.670 | 0.634 | 0.581 | 0.550 | 0.722 |
| ↑ | 0.144 | 0.220 | 0.325 | 0.415 | 0.402 | 0.270 | 0.248 | 0.491 |
| FPS↑ | 66.67 | 134.40 | 3.18 | 17.21 | 20.71 | 97.55 | 15.37 | 50.91 |
| Method | Success | s | Precision | p |
|---|---|---|---|---|
| baseline | 0.608 | − | 0.805 | − |
| baseline + SCAM | 0.620 | 0.817 | ||
| baseline + SCAM + | 0.624 | 0.823 | ||
| baseline + SCAM + | 0.622 | 0.827 | ||
| baseline + SCAM + + | 0.631 | 0.842 |
| OTB100 | UAV123 | VOT2016 | VOT2018 | GOT-10k | |
|---|---|---|---|---|---|
| FPS↑ | 51.1 | 63.1 | 48.5 | 59.4 | 50.91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Liang, Y.; Huang, X.; Kuang, L.-D.; Zheng, B. Siamese Visual Tracking with Spatial-Channel Attention and Ranking Head Network. Electronics 2023, 12, 4351. https://doi.org/10.3390/electronics12204351
Zhang J, Liang Y, Huang X, Kuang L-D, Zheng B. Siamese Visual Tracking with Spatial-Channel Attention and Ranking Head Network. Electronics. 2023; 12(20):4351. https://doi.org/10.3390/electronics12204351
Chicago/Turabian StyleZhang, Jianming, Yifei Liang, Xiaoyi Huang, Li-Dan Kuang, and Bin Zheng. 2023. "Siamese Visual Tracking with Spatial-Channel Attention and Ranking Head Network" Electronics 12, no. 20: 4351. https://doi.org/10.3390/electronics12204351