1.1. Technology Application
Infrared and visible image fusion technology has a variety of application scenarios in real life, including military, medical, remote sensing, etc.
In the military field [
3], infrared and visible image fusion technology plays a crucial role, especially when dealing with complex backgrounds and harsh environments. It significantly improves target visibility and accuracy. For instance, in applications like drone reconnaissance and security surveillance, this fusion strategy maintains image clarity when there is ample ambient light. It captures heat source information imperceptible to conventional vision. This greatly enhances the safety and accuracy of surveillance. In low-light situations, the fusion images produced by this technology provide powerful support for night missions. It offers pilots a more comprehensive view of their surroundings, leading to better-informed flight decisions.
In the medical field [
4,
5,
6], fusion technology can depict the temperature distribution of biological tissues more accurately. It assists doctors in more easily determining disease status and enhances the precision of surgical operations. Compared to solely relying on infrared thermal imaging for pinpointing disease sites in organisms, images from fusion technology align more closely with human intuitive perception. The technology integrates external morphology with internal details, rendering a doctor’s disease diagnosis more comprehensive.
In the remote sensing domain [
7,
8], this technology notably enhances land cover classification under intricate surface conditions, improving accuracy. For disaster monitoring and assessment, particularly in forest fire detection, infrared images can precisely pinpoint the fire’s origin. In contrast, visible images provide a detailed overview of the burning area. Fusion technology delves deeper into extracting crucial information about ignition sources from either infrared or visible images, offering invaluable insights for subsequent rescue efforts and fire control.
1.2. Related Work
In the field of infrared and visible image fusion, there are various technical classifications, including traditional fusion techniques and deep learning-based fusion methods [
9].
Traditional fusion techniques mainly use mathematical transformations to transform source images into spatial or transformation domains, measure the activity level in these domains, and design fusion rules to achieve image fusion. Typical methods include methods based on multiscale transformations [
10,
11], methods based on sparse representations [
12], and subspace-based methods [
13,
14].
The method based on multiscale transformation plays an important role in the field of infrared and visible image fusion. Its core idea is to decompose the image into sub-images of different scales and then fuse them, comprising three steps: scale decomposition, fusion strategy, and fusion reconstruction. Multiscale transformation technology helps to capture image details and global information at different scales while effectively suppressing noise and enhancing target information. Recently, various multiscale transformation techniques, such as Laplacian pyramid transform [
15], discrete wavelet transform [
16,
17], curved wave transform [
18], and multiscale pixel-level image fusion, have been successfully applied in image fusion.
The fusion method based on sparse representation aims to use an overcomplete dictionary to represent signals as linear combinations of a small number of basis vectors. First, sparse representation is used to represent the infrared and visible source images. Then, for each pixel in the sparse representation, the basis vectors from different source images are merged into a new base vector. Finally, the new basis vectors are reconstructed into a fused image according to certain rules. The fusion method for infrared and visible images, based on sparse representation technology, can effectively leverage the characteristics of both image types. It extracts useful information from both visible and infrared images and combines them to produce richer and clearer fused images.
Compared to the sparse representation-based fusion method, the subspace-based fusion method treats the visible and infrared images as two separate datasets. Then, the samples in each dataset are projected separately from the high-dimensional source image into different low-dimensional subspaces, each of which describes different local characteristics of the samples. This method allows the relationships between samples to be efficiently compared in subspace, facilitating the analysis and processing of the data.
However, traditional methods can lead to information loss during fusion, especially in subtle features such as edges, textures, and details. In addition, these methods often require manual selection and design of features, which can result in poor performance across different data and scenarios with limited generalization capabilities.
With the rapid development of deep learning technology in computer vision, many infrared and visible image fusion methods based on deep learning have emerged. In the process of infrared and visible image fusion, the deep learning method can automatically learn the features of the input data more effectively. Furthermore, it can capture the complex relationship between different band images, improving the image fusion quality and model adaptive ability, and having a more vital adaptive ability and generalization ability. Mainstream deep learning-based fusion methods are mainly divided into image fusion technology based on autoencoders (AE) [
19,
20]; image fusion technology based on convolution neural networks (CNN); and image fusion technology based on generative adversarial networks (GAN) [
21].
AE-based image fusion technology achieves feature extraction and reconstruction through training an autoencoder. First, the autoencoder extracts features from different images. Then, it fuses this feature information based on specific rules. Finally, the fusion image is generated by a reverse reconstruction process. DenseFuse [
19] is one of the best-known autoencoder-based methods. As a supervised model, it trains encoders and decoders on the MS-COCO [
22] dataset. It employs a pre-trained autoencoder to decompose and reconstruct images. This approach moves away from the image decomposition method typical of traditional image fusion. Instead, it leverages the potent feature extraction capabilities of convolutional neural networks. These networks offer superior adaptability to various images compared to traditional methods. However, since DenseFuse employs only visible images during autoencoder training, it might become insensitive to certain concealed information in infrared images during feature extraction and reconstruction. This can also result in shortcomings in extracting complementary information between infrared and visible feature maps in the fusion process.
CNN-based image fusion techniques include end-to-end fusion methods [
23] and fusion methods that combine CNNs with traditional methods [
24]. In IFCNN [
25], Zhang et al. propose an end-to-end CNN-based method that uses two convolutional layers to extract image features and then uses appropriate fusion rules for the convolution features of multiple input images, and finally performs two-layer convolution reconstruction of the fused features to obtain the final fusion image. It proposes a proportional retention loss of gradient and intensity to guide the network to directly generate fused images. In U2Fusion [
26], Xu et al. propose an unsupervised end-to-end fusion network that can be applied to different types of images, automatically learning the relationships between images and implementing image fusion without the need for additional labeled data to solve different fusion problems in image fusion. Furthermore, in a fusion approach that combines CNNs with traditional methods, Liu et al. [
27] use convolutional networks to generate weight maps. They then employ multiscale image decomposition and reconstruction through image pyramids to produce medical images that align more with human visual perception. Wang et al. [
24] use a contrast pyramid to decompose the source images and fuse the source image in the trained CNN according to different spatial frequency bands and weighted fusion operators. However, some CNN-based fusion methods rely solely on the results of the last layer for image features, potentially resulting in the loss of valuable information from intermediate layers.
GAN-based image fusion technology relies on the adversarial game between the generator and the discriminator to estimate the probability density of the target to generate the fusion image implicitly. In FusionGAN [
21], as pioneers of GAN-based image fusion, Ma et al. further enrich significant target and texture details in fused images by establishing adversarial generative rules between fused images and infrared (visible) images. However, a single discriminator can cause patterns in the fused image to be biased towards either visible or infrared images, which inevitably forces the fused image to be similar to something of little interest in the infrared (visible) image, making it difficult for the fused image to weigh the retention of information such as significant targets and texture detail between the infrared and visible images. Drawing upon GAN frameworks, Ma et al. [
28] introduced an advanced dual-discriminator conditional generative adversarial network to enhance robustness. This approach also aimed to strike a balance between infrared and visible images. Nonetheless, the inherent rivalry between the generator and the discriminator complicates the fine-tuning and control of the resultant fusion images.
1.3. Contribution
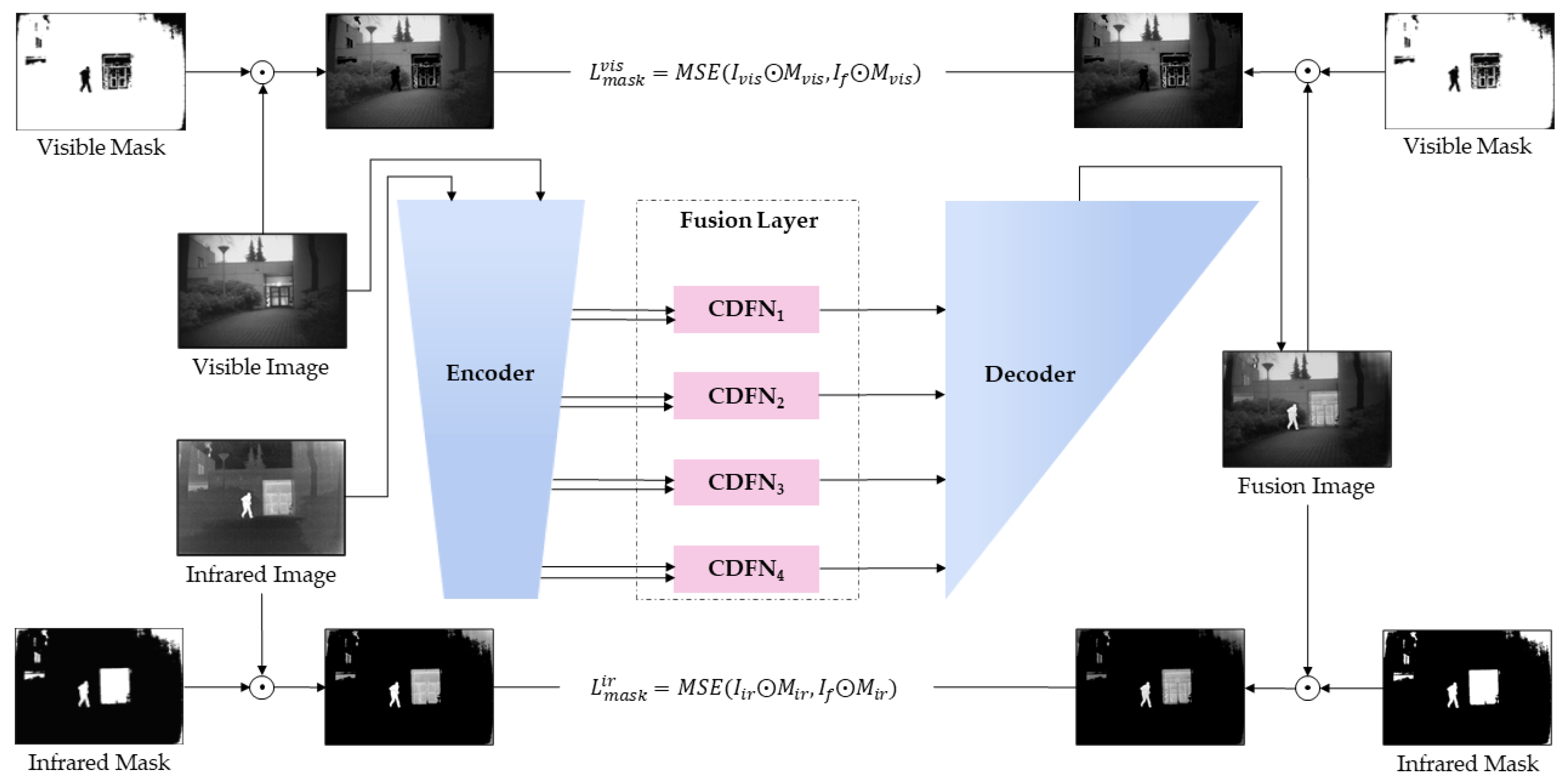
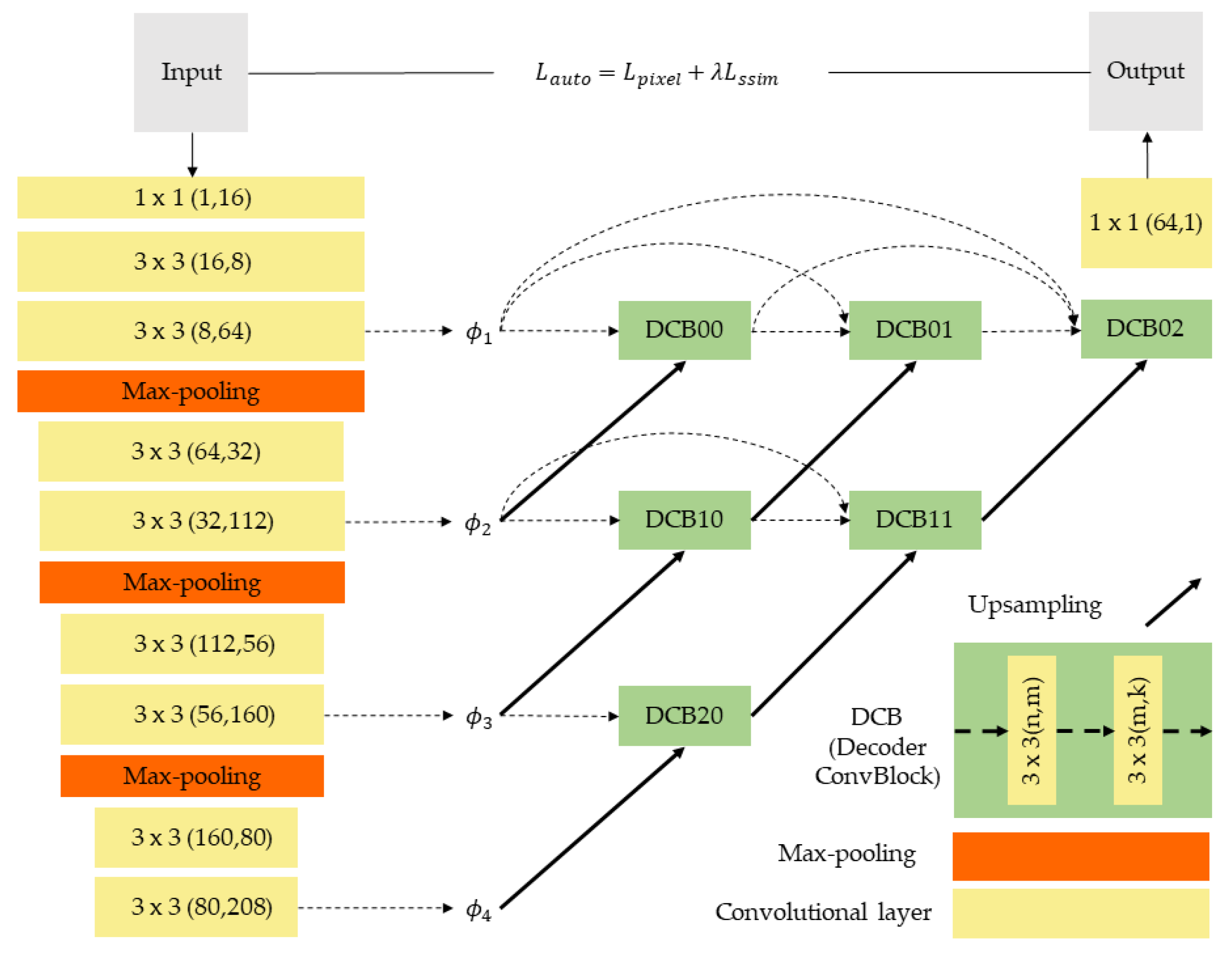
To solve some of the abovementioned problems, this study is based on the Nestfuse [
20] network and is further improved to construct an end-to-end multiscale autoencoder network. At the same time, we propose an efficient fusion strategy based on mask and cross-dynamic fusion methods. This strategy enhances the infrared salient features in the image and injects richer texture detail and edge information into the image. The main contributions of this paper are as follows:
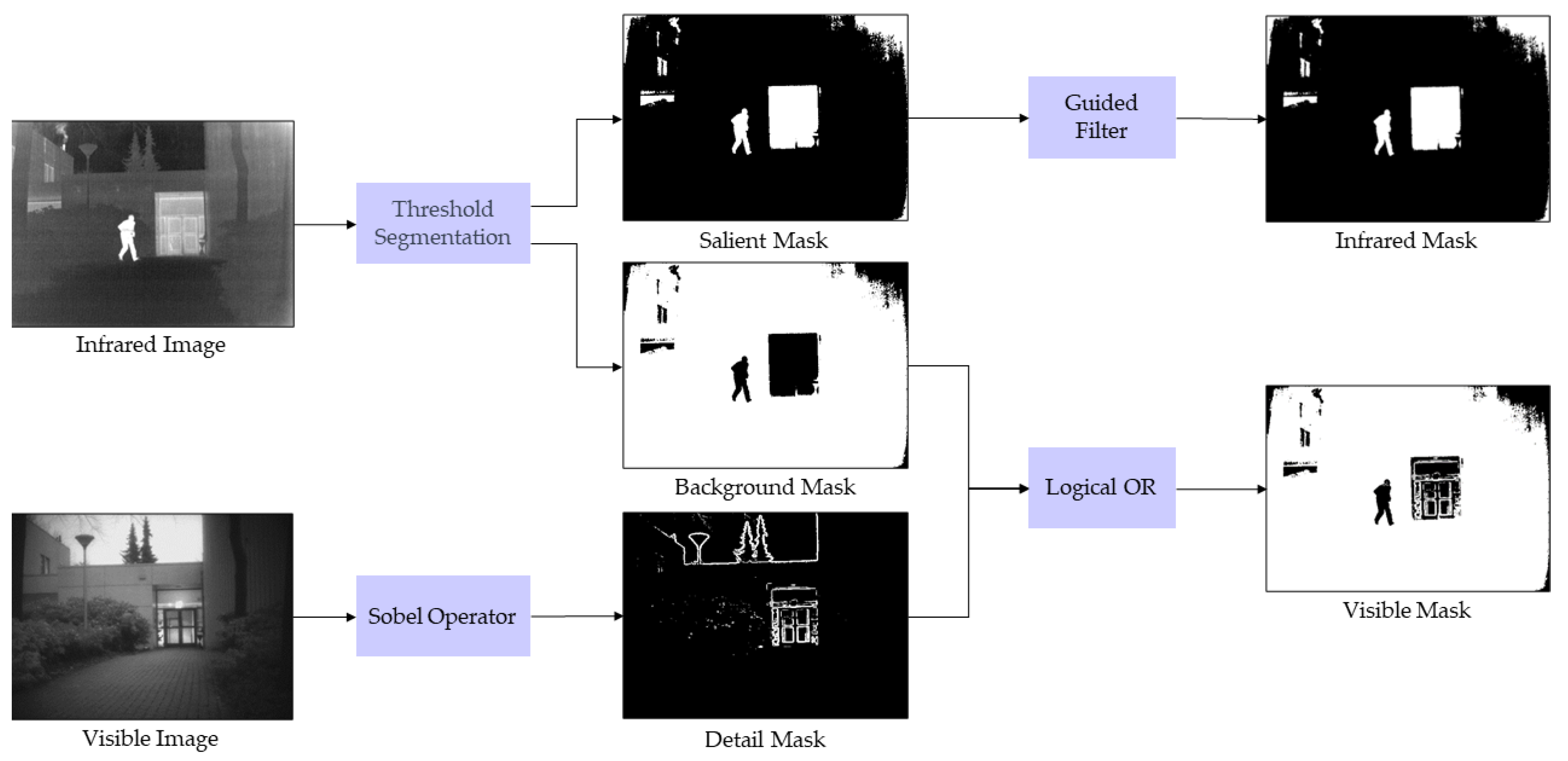
(1) We integrate a novel mask generation strategy in the training stage. The resulting fused image retains the more prominent area features and clearer edge texture information of the source image.
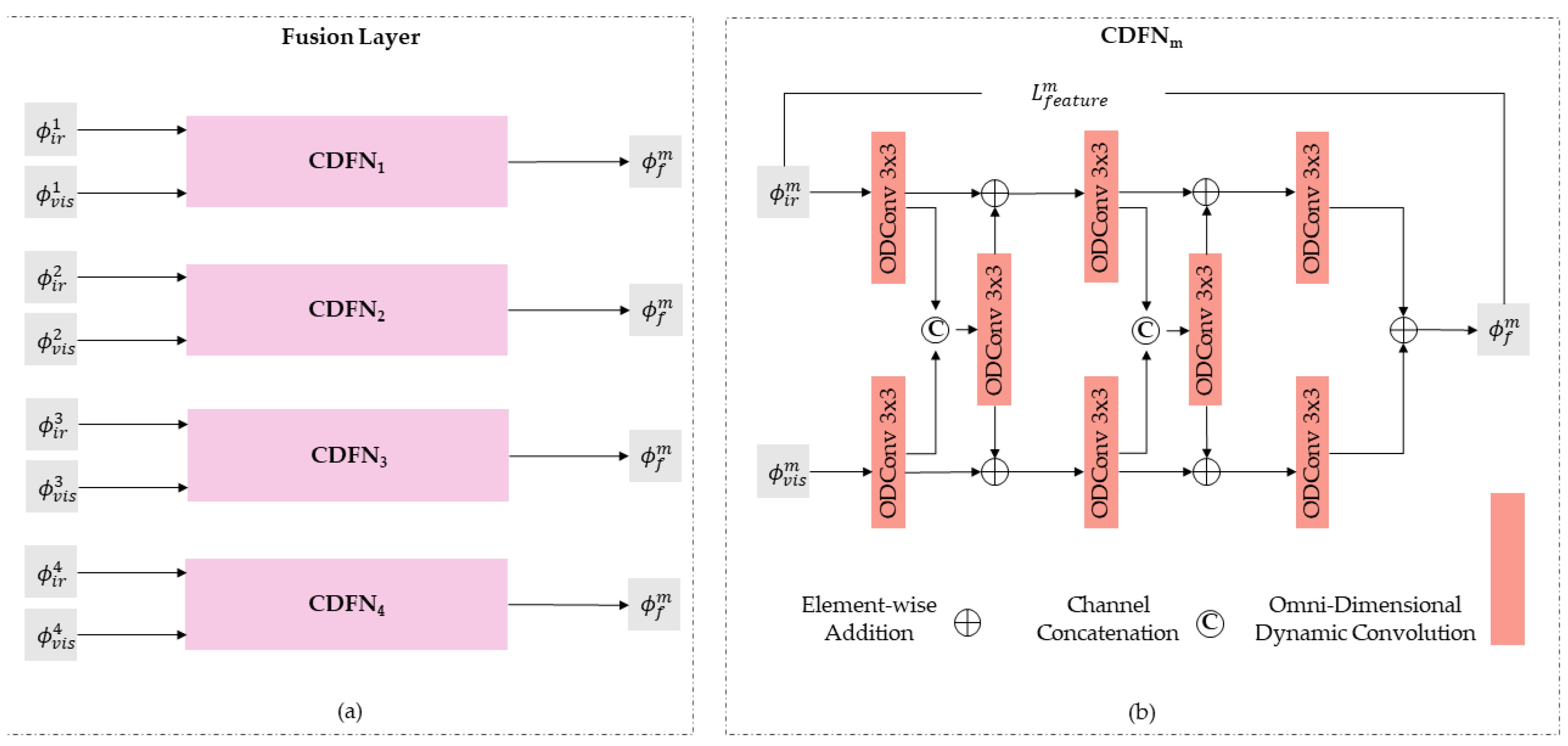
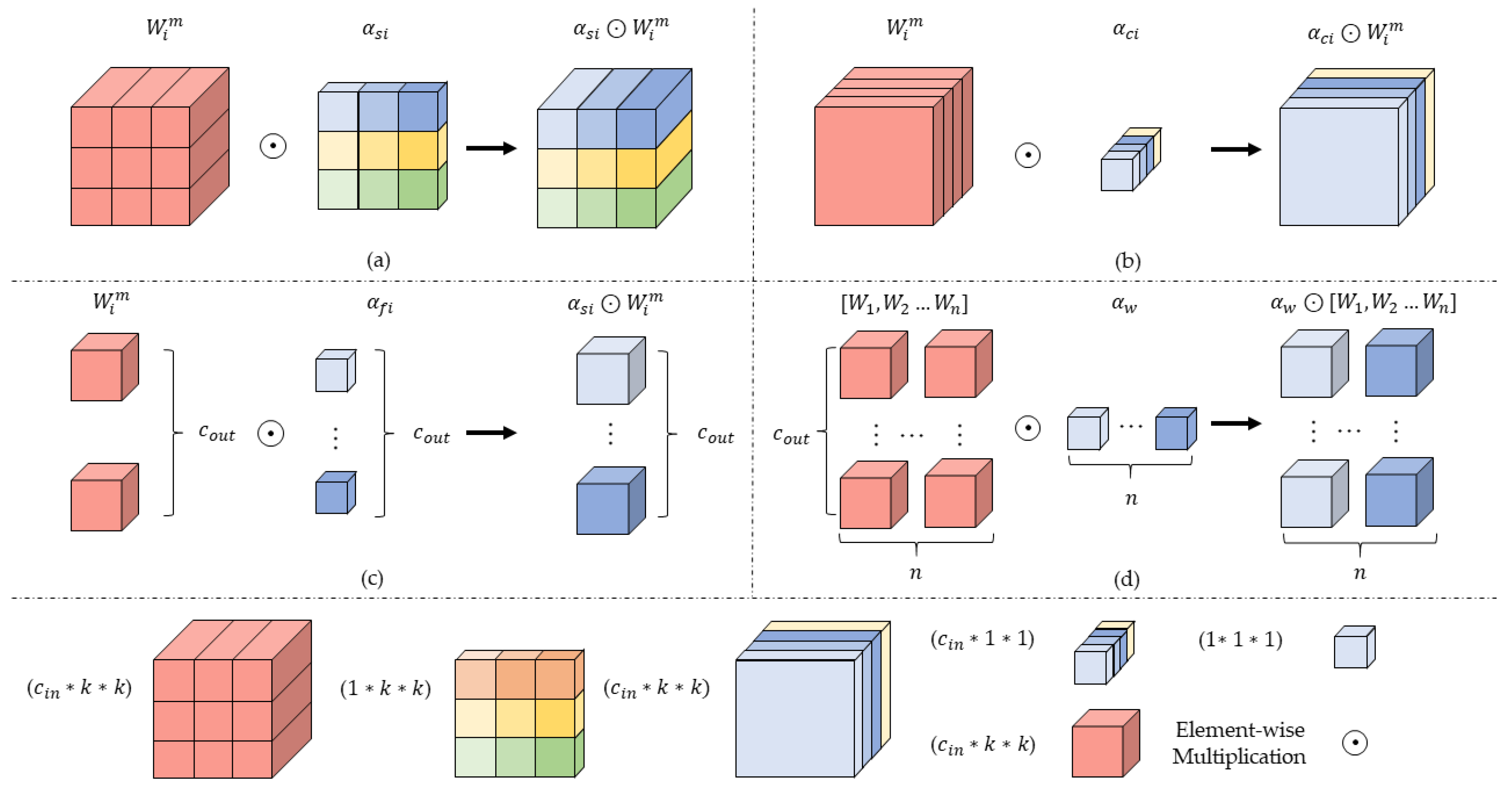
(2) We adopt a cross-dynamic fusion method regarding the fusion layer. In this way, different features in the source images can adaptively fuse in multiple dimensions, further improving the overall fusion effect.
(3) To ensure that the fusion image maintains a mutual balance between retaining rich texture detail and salient features of thermal imaging, we design a blending loss strategy in the fusion stage.
The rest of this article is organized below.
Section 2 details the overall framework of MCDFN and training strategies, mask generation strategies, hybrid loss functions, etc. In
Section 3, we conduct experiments on the proposed method and evaluate the experimental results to demonstrate the effectiveness and generalization of the proposed method. Finally,
Section 4 gives some discussion and conclusions.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}