
ESTUGAN: Enhanced Swin Transformer with U-Net Discriminator for Remote Sensing Image Super-Resolution


Abstract
:1. Introduction
- (1)
- We propose a promising framework, ESTUGAN, which adopts the Enhanced Swin Transformer as the generator backbone and a U-Net discriminator. The Enhanced Swin Transformer is capable of mobilizing more input information to model local content, benefiting from united channel attention and self-attention. In addition, it employs an overlapping cross-attention mechanism to further aggregate cross-window information with stronger representational capabilities. Extensive experiments demonstrate that our proposed network outperforms other methods when targeting remote sensing image SR.
- (2)
- We propose a U-Net discriminator with the region-aware learning strategy to reconstruct highly detailed remote sensing images. The region-aware learning strategy can effectively suppress artifacts by masking flat regions and feeding only texture-rich regions to the discriminator for adversarial training. Moreover, the U-shaped network is designed with jumping connections that allows for the connection of shallow detailed content with deep semantic information, providing intensive feedback for each pixel’s authenticity.
- (3)
- The BB loss and BP loss are employed to further enhance the visual quality of the image. Multiple supervised signals that are similar to the ground truth are utilized to flexibly guide the image reconstruction; this reduces the training difficulty and helps to generate high-frequency information.
2. Related Works
2.1. Swin Transformer
2.2. Generative Adversarial Network
2.3. Loss Function on Deep Learning
2.4. Deep Learning Based SISR for Remote Sensing Images
2.5. Image Super Resolution Quality Assessment
3. Methods
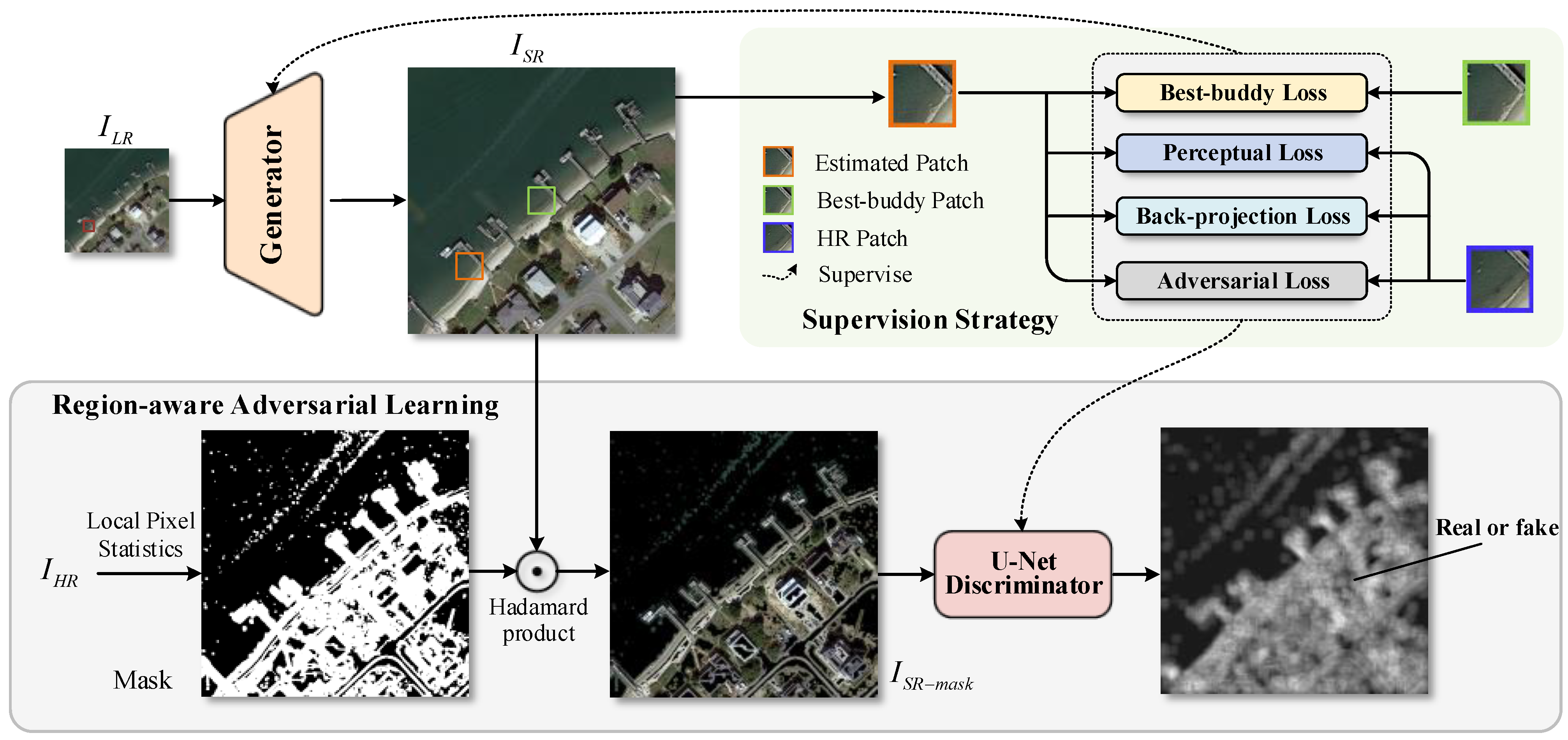
3.1. Overview of ESTUGAN
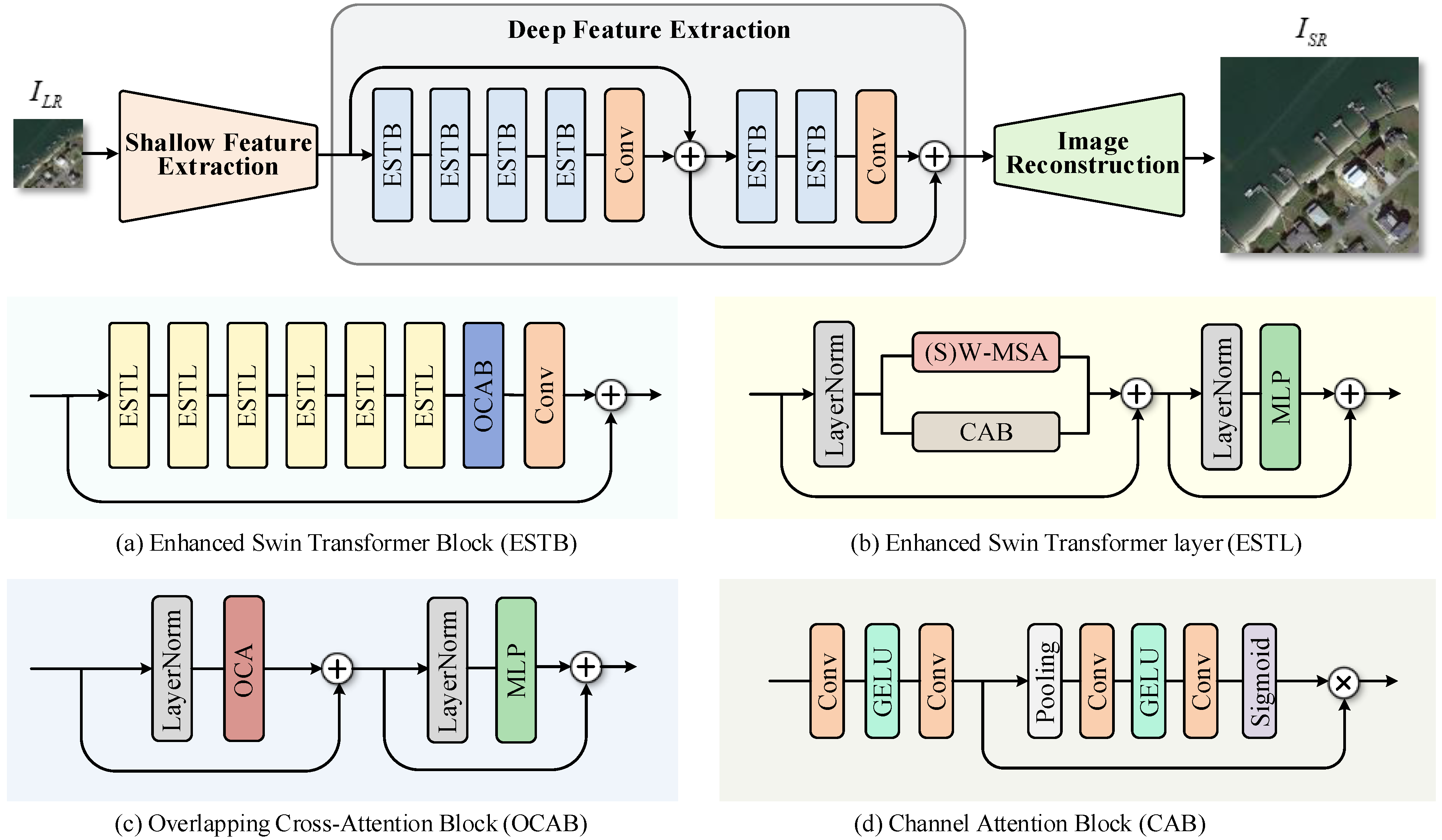
3.2. The Architecture of the Generator
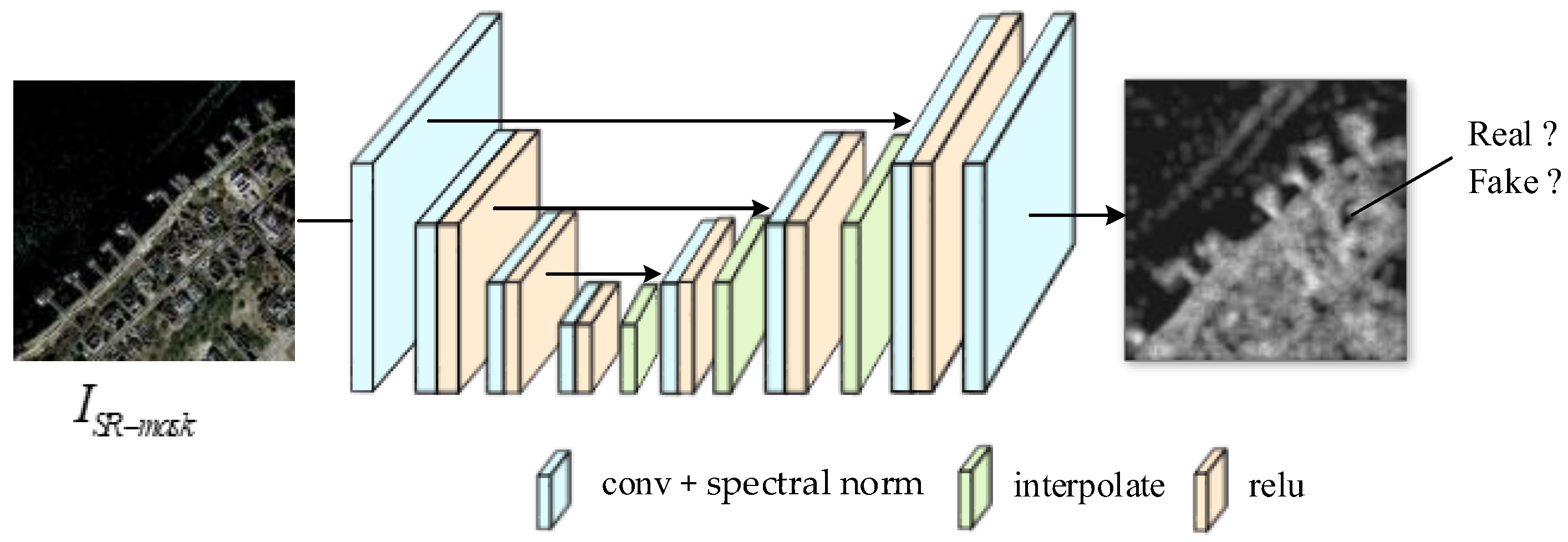
3.3. U-Net Discriminator with Region-Aware Learning Strategy
3.4. Loss Function
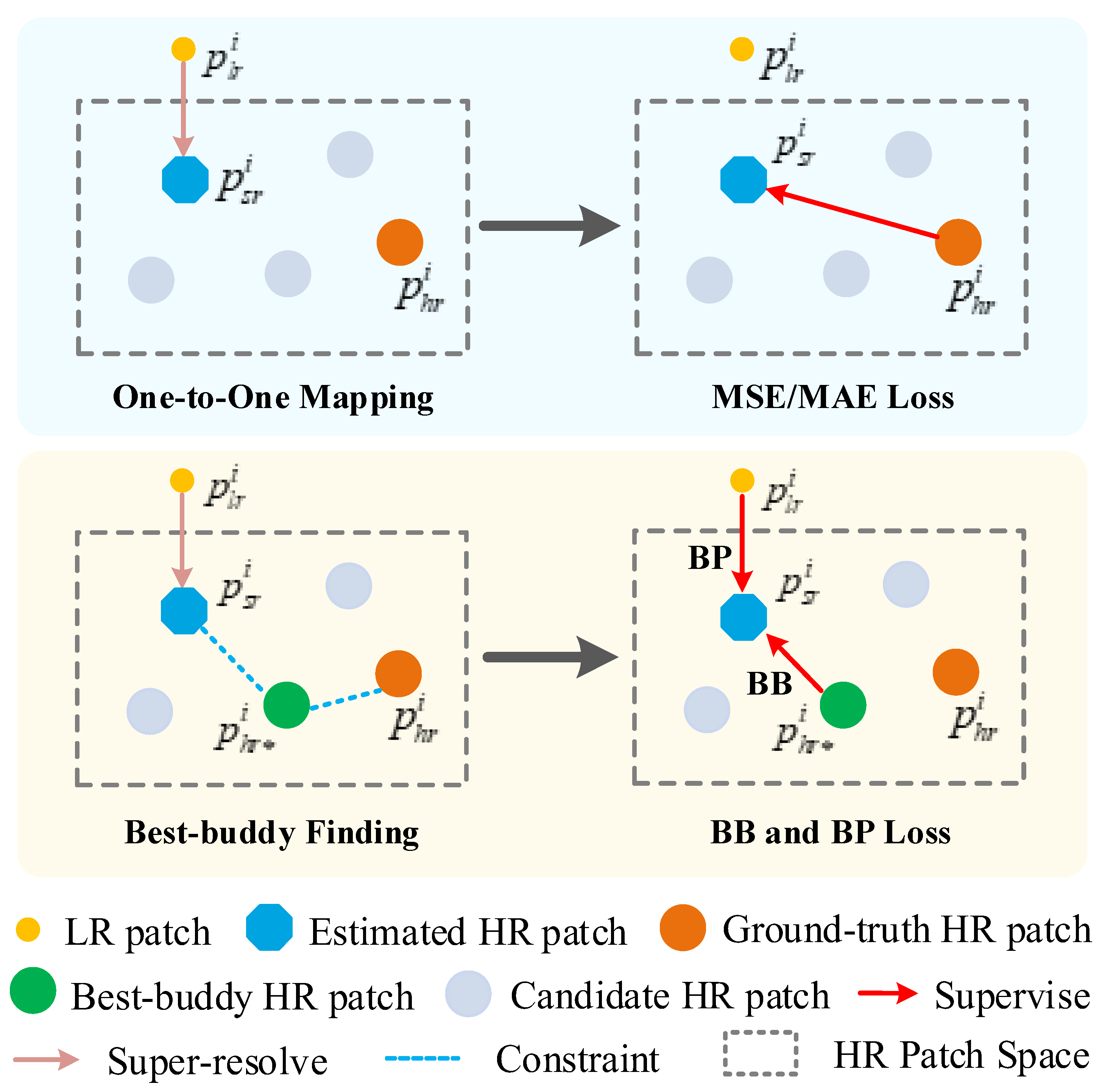
3.4.1. Best-Buddy Loss
3.4.2. Adversarial Loss
3.4.3. Perceptual Loss
3.4.4. Back-Projection Loss
4. Experiments and Analysis
4.1. Datasets in Experiments
4.1.1. NWPU-RESISC45 Dataset
4.1.2. UCMerced Dataset
4.1.3. RSCNN7 Dataset
4.1.4. DOTA Dataset
4.2. Quantitative Evaluation Metrics
4.2.1. PSNR
4.2.2. SSIM
4.2.3. LPIPS
4.3. Experimental Details
4.4. Comparison with State-of-the-Art Methods
4.4.1. Quantitative Comparison
4.4.2. Qualitative Comparison
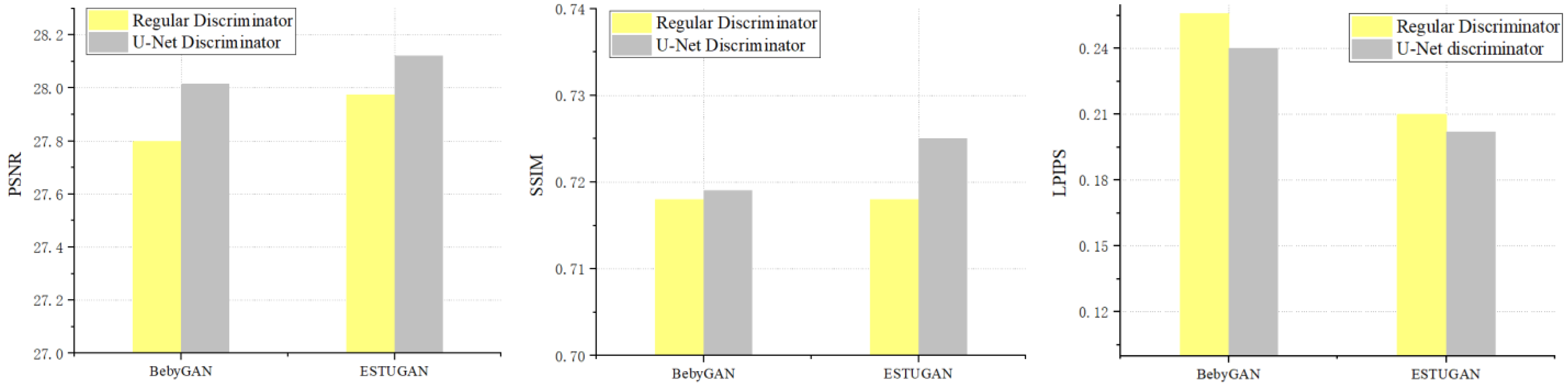
4.5. Ablation Study
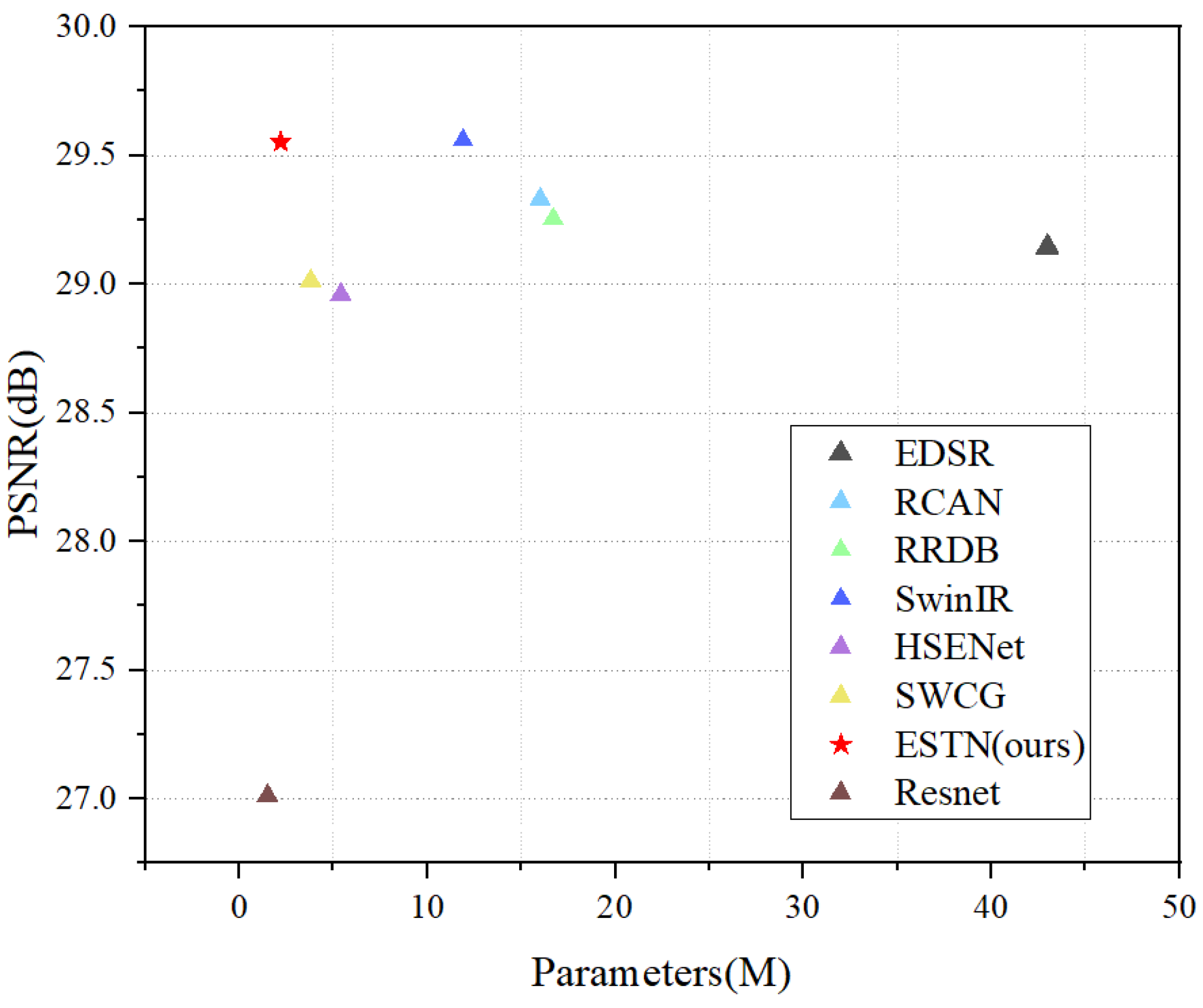
4.6. Model Complexity Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a Deep Convolutional Network for Image Super-Resolution. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; pp. 184–199. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1646–1654. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-Recursive Convolutional Network for Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1637–1645. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 26 June–21 July 2017; pp. 624–632. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image Super-Resolution Using Very Deep Residual Channel Attention Networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All You Need. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Vaswani, A.; Ramachandran, P.; Srinivas, A.; Parmar, N.; Hechtman, B.; Shlens, J. Scaling Local Self-Attention for Parameter Efficient Visual Backbones. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Kuala Lumpur, Malaysia, 18–20 December 2021; pp. 1637–1645. [Google Scholar]
- Wang, Z.; Cun, X.; Bao, J.; Zhou, W.; Liu, J.; Li, H.U. A general u-shaped transformer for image restoration. arXiv 2021, arXiv:2106.03106. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Gool, L.V.; Timofte, R. Swinir: Image Restoration Using Swin Transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 1833–1844. [Google Scholar]
- Chen, X.; Wang, X.; Zhou, J.; Qiao, Y.; Dong, C. Activating More Pixels in Image Super-Resolution Transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Vancouver, BC, Canada, 18–22 June 2023; pp. 22367–22377. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2014, 63, 139–144. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Loy, C.C. Esrgan: Enhanced Super-Resolution Generative Adversarial Networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhang, W.; Liu, Y.; Dong, C.; Qiao, Y. Ranksrgan: Generative Adversarial Networks with Ranker for Image Super-Resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3096–3105. [Google Scholar]
- Li, W.; Zhou, K.; Qi, L.; Lu, L.; Lu, J. Best-Buddy Gans for Highly Detailed Image Super-Resolution. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 22 February–1 March 2022; pp. 1412–1420. [Google Scholar]
- Lei, S.; Shi, Z.; Zou, Z. Super-resolution for remote sensing images via local–global combined network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1243–1247. [Google Scholar] [CrossRef]
- Jiang, K.; Wang, Z.; Yi, P.; Wang, G.; Lu, T.; Jiang, J. Edge-enhanced GAN for remote sensing image superresolution. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5799–5812. [Google Scholar] [CrossRef]
- Pan, Z.; Ma, W.; Guo, J.; Lei, B. Super-resolution of single remote sensing image based on residual dense backprojection networks. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7918–7933. [Google Scholar] [CrossRef]
- Ma, W.; Pan, Z.; Guo, J.; Lei, B. Achieving super-resolution remote sensing images via the wavelet transform combined with the recursive resnet. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3512–3527. [Google Scholar] [CrossRef]
- Jiang, W.; Zhao, L.; Wang, Y.J.; Liu, W.; Liu, B.D. U-shaped attention connection network for remote-sensing image super-resolution. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Wu, H.; Zhang, L.; Ma, J. Remote sensing image super-resolution via saliency-guided feedback GANs. IEEE Trans. Geosci. Remote Sens. 2020, 60, 1–16. [Google Scholar] [CrossRef]
- Lei, S.; Shi, Z. Hybrid-scale self-similarity exploitation for remote sensing image super-resolution. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–10. [Google Scholar] [CrossRef]
- Liu, Z.; Feng, R.; Wang, L.; Han, W.; Zeng, T. Dual learning-based graph neural network for remote sensing image super-resolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Yu, Y.; Li, X.; Liu, F. E-DBPN: Enhanced deep back-projection networks for remote sensing scene image super-resolution. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5503–5515. [Google Scholar] [CrossRef]
- Jia, S.; Wang, Z.; Li, Q.; Jia, X.; Xu, M. Multiattention generative adversarial network for remote sensing image super-resolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Guo, B. Swin Transformer v2: Scaling up Capacity and Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 12009–12019. [Google Scholar]
- Choi, H.; Lee, J.; Yang, J. N-Gram in Swin Transformers for Efficient Lightweight Image Super-Resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Vancouver, BC, Canada, 18–22 June 2023; pp. 2071–2081. [Google Scholar]
- Hassani, A.; Shi, H. Dilated neighborhood attention transformer. arXiv 2022, arXiv:2209.15001. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and Improving the Image Quality of Stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–20 June 2020; pp. 8110–8119. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large scale GAN training for high fidelity natural image synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4401–4410. [Google Scholar]
- Yang, M.; Sowmya, A. New image quality evaluation metric for underwater video. IEEE Signal Process. Lett. 2014, 21, 1215–1219. [Google Scholar] [CrossRef]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Fuoli, D.; Van Gool, L.; Timofte, R. Fourier Space Losses for Efficient Perceptual Image Super-Resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 2360–2369. [Google Scholar]
- Liang, J.; Zeng, H.; Zhang, L. Details or Artifacts: A Locally Discriminative Learning Approach to Realistic Image Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 5657–5666. [Google Scholar]
- Jiang, K.; Wang, Z.; Yi, P.; Jiang, J.; Xiao, J.; Yao, Y. Deep distillation recursive network for remote sensing imagery super-resolution. Remote Sens. 2018, 10, 1700. [Google Scholar] [CrossRef]
- Zhang, D.; Shao, J.; Li, X.; Shen, H.T. Remote sensing image super-resolution via mixed high-order attention network. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5183–5196. [Google Scholar] [CrossRef]
- Zhang, S.; Yuan, Q.; Li, J.; Sun, J.; Zhang, X. Scene-adaptive remote sensing image super-resolution using a multiscale attention network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4764–4779. [Google Scholar] [CrossRef]
- Li, Y.; Mavromatis, S.; Zhang, F.; Du, Z.; Sequeira, J.; Wang, Z.; Zhao, X.; Liu, R. Single-image super-resolution for remote sensing images using a deep generative adversarial network with local and global attention mechanisms. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–24. [Google Scholar] [CrossRef]
- Huynh-Thu, Q.; Ghanbari, M. Scope of validity of PSNR in image/video quality assessment. Electron. Lett. 2008, 44, 800–801. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. FSIM: A feature similarity index for image quality assessment. IEEE Trans. Image Process. 2011, 20, 2378–2386. [Google Scholar] [CrossRef]
- Zhou, W.; Wang, Z.; Chen, Z. Image Super-Resolution Quality Assessment: Structural Fidelity versus Statistical Naturalness. In Proceedings of the IEEE International Conference on Quality of Multimedia Experience (QoMEX), Virtual, 14–17 June 2021; pp. 61–64. [Google Scholar]
- Zhou, W.; Wang, Z. Quality Assessment of Image Super-Resolution: Balancing Deterministic and Statistical Fidelity. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 934–942. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 586–595. [Google Scholar]
- Zhou, W.; Jiang, Q.; Wang, Y.; Chen, Z.; Li, W. Blind quality assessment for image superresolution using deep two-stream convolutional networks. Inf. Sci. 2020, 528, 205–218. [Google Scholar] [CrossRef]
- Chen, T.; Liu, H.; Ma, Z.; Shen, Q.; Cao, X.; Wang, Y. End-to-end learnt image compression via non-local attention optimization and improved context modeling. IEEE Trans. Image Process. 2021, 30, 3179–3191. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, K.; Li, K.; Zhong, B.; Fu, Y. Residual non-local attention networks for image restoration. arXiv 2019, arXiv:1903.10082. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1874–1883. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Schonfeld, E.; Schiele, B.; Khoreva, A. A U-Net Based Discriminator for Generative Adversarial Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8207–8216. [Google Scholar]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral normalization for generative adversarial networks. arXiv 2018, arXiv:1802.05957. [Google Scholar]
- Kindermann, S.; Osher, S.; Jones, P.W. Deblurring and denoising of images by nonlocal functionals. Multiscale Model. Simul. 2005, 4, 1091–1115. [Google Scholar] [CrossRef]
- Protter, M.; Elad, M.; Takeda, H.; Milanfar, P. Generalizing the nonlocal-means to super-resolution reconstruction. IEEE Trans. Image Process. 2008, 18, 36–51. [Google Scholar] [CrossRef]
- Pan, T.; Zhang, L.; Song, Y.; Liu, Y. Hybrid Attention Compression Network with Light Graph Attention Module for Remote Sensing images. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Glasner, D.; Bagon, S.; Irani, M. Super-resolution from a single image. In Proceedings of the IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; pp. 349–356. [Google Scholar]
- Huang, J.B.; Singh, A.; Ahuja, N. Single Image Super-Resolution from Transformed Self-Exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–12 June 2015; pp. 5197–5206. [Google Scholar]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-Visual-Words and Spatial Extensions for Land-Use Classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep learning-based feature selection for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 26 June–21 July 2017; pp. 136–144. [Google Scholar]
- Tu, J.; Mei, G.; Ma, Z.; Piccialli, F. SWCGAN: Generative adversarial network combining swin transformer and CNN for remote sensing image super-resolution. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 5662–5673. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | NWPU-RESISC45 | UCMerced | ||||
| PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | |
| Bicubic | 27.61 | 0.697 | 0.528 | 26.96 | 0.698 | 0.492 |
| RCAN | 29.23 | 0.772 | 0.346 | 28.86 | 0.776 | 0.318 |
| RRDB | 29.20 | 0.770 | 0.362 | 28.86 | 0.775 | 0.338 |
| SwinIR | 29.42 | 0.779 | 0.340 | 29.17 | 0.787 | 0.312 |
| ESTN (ours) | 29.39 | 0.777 | 0.341 | 29.11 | 0.785 | 0.312 |
| SRGAN | 25.26 | 0.644 | 0.233 | 24.13 | 0.645 | 0.258 |
| ESRGAN | 26.18 | 0.711 | 0.263 | 25.24 | 0.717 | 0.259 |
| BebyGAN | 27.80 | 0.718 | 0.261 | 27.28 | 0.724 | 0.257 |
| ESTUGAN (ours) | 28.12 | 0.725 | 0.204 | 27.81 | 0.739 | 0.208 |
| Method | RSCNN7 | DOTA | ||||
| PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | |
| Bicubic | 27.99 | 0.684 | 0.592 | 30.89 | 0.809 | 0.431 |
| RCAN | 29.17 | 0.744 | 0.441 | 33.66 | 0.868 | 0.267 |
| RRDB | 29.16 | 0.744 | 0.449 | 33.65 | 0.868 | 0.273 |
| SwinIR | 29.33 | 0.751 | 0.436 | 33.98 | 0.873 | 0.264 |
| ESTN (ours) | 29.30 | 0.749 | 0.438 | 33.95 | 0.872 | 0.266 |
| SRGAN | 25.23 | 0.608 | 0.284 | 26.31 | 0.732 | 0.272 |
| ESRGAN | 26.24 | 0.692 | 0.331 | 28.19 | 0.824 | 0.246 |
| BebyGAN | 28.07 | 0.698 | 0.318 | 31.06 | 0.829 | 0.233 |
| ESTUGAN (ours) | 28.15 | 0.699 | 0.271 | 32.17 | 0.829 | 0.179 |
| Scene Class | Bicubic PSNR/LPIPS | RCAN PSNR/LPIPS | SwinIR PSNR/LPIPS | SRGAN PSNR/LPIPS | ESRGAN PSNR/LPIPS | BebyGAN PSNR/LPIPS | ESTN (Ours) PSNR/LPIPS | ESTGAN (Ours) PSNR/LPIPS |
|---|---|---|---|---|---|---|---|---|
| Airplane | 28.57/0.434 | 31.05/0.229 | 31.42/0.225 | 26.84/0.168 | 26.15/0.207 | 29.24/0.207 | 31.32/0.224 | 29.99/0.153 |
| Airport | 27.83/0.551 | 29.13/0.394 | 29.26/0.393 | 25.63/0.244 | 25.90/0.284 | 28.01/0.287 | 29.22/0.395 | 28.17/0.242 |
| Baseball diamond | 27.69/0.520 | 29.69/0.314 | 29.88/0.312 | 26.23/0.201 | 26.81/0.226 | 28.44/0.238 | 29.85/0.312 | 28.40/0.175 |
| Basketball court | 26.53/0.510 | 28.74/0.276 | 29.06/0.265 | 25.75/0.205 | 26.18/0.253 | 27.40/0.249 | 29.01/0.264 | 27.37/0.176 |
| Beach | 30.05/0.485 | 31.30/0.350 | 31.36/0.346 | 27.13/0.205 | 26.13/0.281 | 29.23/0.275 | 31.36/0.347 | 30.26/0.227 |
| Bridge | 29.04/0.450 | 31.05/0.265 | 31.23/0.258 | 28.18/0.169 | 28.23/0.212 | 29.56/0.224 | 31.21/0.259 | 29.81/0.166 |
| Chaparral | 25.54/0.533 | 27.14/0.324 | 27.31/0.327 | 20.74/0.329 | 24.59/0.233 | 25.82/0.247 | 27.31/0.324 | 25.74/0.158 |
| Church | 24.49/0.568 | 26.39/0.321 | 26.60/0.315 | 23.50/0.207 | 24.43/0.264 | 25.28/0.276 | 26.57/0.318 | 25.25/0.194 |
| Circular farmland | 31.21/0.448 | 33.26/0.246 | 33.43/0.242 | 29.99/0.150 | 28.32/0.197 | 31.52/0.202 | 33.41/0.241 | 32.12/0.153 |
| Cloud | 34.81/0.362 | 36.21/0.267 | 36.38/0.275 | 29.07/0.168 | 27.92/0.159 | 32.37/0.164 | 36.35/0.274 | 34.73/0.153 |
| Commercial area | 25.98/0.576 | 27.53/0.341 | 27.67/0.334 | 24.45/0.239 | 25.38/0.275 | 26.50/0.282 | 27.66/0.333 | 26.51/0.207 |
| Dense residential | 22.43/0.660 | 23.84/0.411 | 24.01/0.391 | 20.20/0.257 | 22.56/0.286 | 23.02/0.294 | 24.00/0.391 | 22.87/0.206 |
| Desert | 32.17/0.472 | 33.13/0.361 | 33.23/0.361 | 27.03/0.214 | 25.05/0.289 | 30.76/0.270 | 33.26/0.359 | 32.08/0.230 |
| Forest | 28.47/0.653 | 29.00/0.553 | 29.03/0.547 | 22.33/0.392 | 27.79/0.358 | 28.11/0.319 | 29.04/0.546 | 27.64/0.288 |
| Freeway | 27.34/0.544 | 28.79/0.350 | 29.16/0.333 | 25.71/0.235 | 26.81/0.266 | 27.78/0.266 | 29.06/0.335 | 27.84/0.198 |
| Golf course | 29.26/0.531 | 31.11/0.340 | 31.20/0.342 | 27.53/0.188 | 28.56/0.243 | 29.81/0.259 | 31.20/0.340 | 29.83/0.188 |
| Ground track field | 27.22/0.520 | 28.89/0.327 | 29.19/0.318 | 24.99/0.203 | 26.55/0.230 | 27.64/0.239 | 29.10/0.321 | 27.75/0.168 |
| Harbor | 21.44/0.534 | 22.91/0.309 | 23.33/0.273 | 20.25/0.177 | 21.83/0.224 | 22.14/0.228 | 23.22/0.281 | 22.04/0.171 |
| Industrial area | 27.04/0.509 | 28.88/0.315 | 29.09/0.316 | 24.77/0.198 | 25.75/0.237 | 27.35/0.246 | 29.04/0.315 | 27.77/0.188 |
| Intersection | 23.44/0.587 | 25.19/0.340 | 25.38/0.323 | 22.50/0.269 | 23.19/0.306 | 24.02/0.308 | 25.43/0.327 | 24.29/0.226 |
| Island | 36.18/0.283 | 37.43/0.189 | 37.64/0.187 | 33.43/0.124 | 29.52/0.158 | 32.35/0.160 | 37.67/0.187 | 35.94/0.124 |
| Lake | 30.65/0.495 | 31.78/0.377 | 31.84/0.377 | 26.27/0.262 | 28.62/0.265 | 30.19/0.259 | 31.84/0.378 | 30.65/0.233 |
| Meadow | 29.36/0.675 | 29.61/0.610 | 29.63/0.608 | 24.80/0.357 | 28.43/0.480 | 28.92/0.366 | 29.63/0.605 | 28.62/0.363 |
| Medium residential | 27.45/0.639 | 28.67/0.442 | 28.77/0.436 | 24.97/0.267 | 26.95/0.310 | 27.73/0.341 | 28.74/0.435 | 27.53/0.242 |
| Mobile home park | 22.76/0.660 | 24.62/0.407 | 24.84/0.395 | 21.56/0.236 | 23.18/0.313 | 23.69/0.340 | 24.81/0.393 | 23.60/0.235 |
| Mountain | 29.70/0.555 | 30.55/0.444 | 30.60/0.444 | 26.74/0.268 | 27.23/0.290 | 29.45/0.293 | 30.60/0.443 | 29.54/0.257 |
| Overpass | 27.71/0.515 | 29.66/0.329 | 29.83/0.321 | 27.18/0.199 | 27.16/0.247 | 28.48/0.260 | 29.82/0.325 | 28.61/0.188 |
| Palace | 26.34/0.533 | 28.11/0.338 | 28.31/0.333 | 23.38/0.255 | 25.75/0.237 | 26.94/0.237 | 28.29/0.337 | 27.03/0.185 |
| Parking lot | 21.36/0.579 | 23.08/0.326 | 23.46/0.301 | 20.13/0.229 | 21.57/0.271 | 21.93/0.271 | 23.35/0.301 | 22.30/0.215 |
| Railway | 26.98/0.569 | 28.37/0.376 | 28.57/0.366 | 25.76/0.219 | 26.51/0.286 | 27.42/0.289 | 28.48/0.372 | 27.35/0.209 |
| Railway station | 25.95/0.547 | 27.65/0.367 | 27.93/0.360 | 24.76/0.212 | 25.13/0.258 | 26.49/0.253 | 27.91/0.361 | 26.82/0.203 |
| Rectangular farmland | 31.36/0.542 | 32.78/0.361 | 32.93/0.356 | 30.50/0.214 | 28.86/0.296 | 31.16/0.291 | 32.92/0.358 | 31.72/0.241 |
| River | 29.20/0.482 | 30.98/0.302 | 31.13/0.297 | 27.97/0.176 | 27.65/0.210 | 29.53/0.214 | 31.12/0.298 | 29.78/0.177 |
| Roundabout | 24.97/0.572 | 26.41/0.385 | 26.57/0.382 | 23.75/0.244 | 24.41/0.283 | 25.58/0.293 | 26.56/0.381 | 25.51/0.226 |
| Runway | 29.35/0.437 | 33.07/0.240 | 33.87/0.234 | 29.01/0.171 | 27.63/0.216 | 30.71/0.218 | 33.63/0.235 | 31.95/0.157 |
| Sea ice | 29.60/0.447 | 31.38/0.303 | 31.49/0.298 | 22.89/0.378 | 27.94/0.221 | 29.65/0.221 | 31.47/0.302 | 30.14/0.182 |
| Ship | 27.67/0.494 | 29.58/0.292 | 29.79/0.281 | 26.34/0.203 | 26.56/0.266 | 28.25/0.261 | 29.72/0.286 | 28.44/0.187 |
| Snowberg | 23.89/0.550 | 25.10/0.408 | 25.22/0.400 | 19.42/0.383 | 23.05/0.272 | 24.19/0.280 | 25.22/0.398 | 24.06/0.225 |
| Sparse residential | 26.94/0.657 | 27.95/0.506 | 28.08/0.505 | 24.57/0.319 | 26.10/0.395 | 27.15/0.391 | 28.04/0.503 | 26.98/0.313 |
| Stadium | 26.70/0.506 | 28.49/0.326 | 28.65/0.325 | 24.49/0.223 | 25.32/0.228 | 27.15/0.239 | 28.61/0.324 | 27.44/0.183 |
| Storage tank | 25.72/0.494 | 27.94/0.282 | 28.17/0.278 | 24.98/0.181 | 25.12/0.204 | 26.80/0.219 | 28.12/0.277 | 26.84/0.154 |
| Tennis court | 25.65/0.601 | 27.51/0.373 | 27.63/0.366 | 24.22/0.223 | 25.31/0.281 | 26.27/0.295 | 27.63/0.370 | 26.33/0.207 |
| Terrace | 28.79/0.475 | 30.49/0.287 | 30.66/0.283 | 27.38/0.183 | 26.73/0.242 | 29.00/0.256 | 30.62/0.283 | 29.42/0.186 |
| Thermal power station | 26.60/0.511 | 28.51/0.315 | 28.71/0.312 | 25.13/0.214 | 25.52/0.222 | 27.07/0.234 | 28.66/0.310 | 27.46/0.186 |
| Wetland | 31.14/0.512 | 32.25/0.370 | 32.35/0.368 | 24.51/0.329 | 29.62/0.268 | 30.82/0.284 | 32.36/0.367 | 30.92/0.226 |
| Mean | 27.61/0.528 | 29.23/0.346 | 29.42/0.340 | 25.26/0.233 | 26.18/0.263 | 27.80/0.261 | 29.39/0.341 | 28.12/0.204 |
| Standard deviation | 3.07/0.076 | 3.03/0.078 | 3.02/0.079 | 2.87/0.062 | 1.94/0.055 | 2.50/0.046 | 3.03/0.078 | 2.94/0.044 |
| Dataset | Metrics | Ours | w/o BBL | w/o RA |
|---|---|---|---|---|
| NWPU-RESISC45 | PSNR | 28.12 | 27.95 | 27.98 |
| SSIM | 0.725 | 0.717 | 0.719 | |
| LPIPS | 0.204 | 0.213 | 0.212 | |
| UC-Merced | PSNR | 27.81 | 27.46 | 27.50 |
| SSIM | 0.739 | 0.726 | 0.728 | |
| LPIPS | 0.208 | 0.217 | 0.215 |
| Generator Settings | PSNR | SSIM | LPIPS |
|---|---|---|---|
| Baseline1 | 29.04 | 0.783 | 0.311 |
| Baseline2 | 28.60 | 0.768 | 0.330 |
| ESTN (ours) | 29.11 | 0.785 | 0.312 |
| Model | Parameters | FLOPs | GPU Runtime |
|---|---|---|---|
| RCAN | 16 M | 233.8 G | 0.189 s |
| RRDB | 16.7 M | 257.5 G | 0.101 s |
| HSENet | 5.4 M | 73.3 G | 0.155 s |
| SwinIR | 11.9 M | 202.2 G | 0.288 s |
| ESTN (ours) | 2.2 M | 53.5 G | 0.165 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, C.; Hong, L.; Pan, T.; Li, Y.; Li, T. ESTUGAN: Enhanced Swin Transformer with U-Net Discriminator for Remote Sensing Image Super-Resolution. Electronics 2023, 12, 4235. https://doi.org/10.3390/electronics12204235
Yu C, Hong L, Pan T, Li Y, Li T. ESTUGAN: Enhanced Swin Transformer with U-Net Discriminator for Remote Sensing Image Super-Resolution. Electronics. 2023; 12(20):4235. https://doi.org/10.3390/electronics12204235
Chicago/Turabian StyleYu, Chunhe, Lingyue Hong, Tianpeng Pan, Yufeng Li, and Tingting Li. 2023. "ESTUGAN: Enhanced Swin Transformer with U-Net Discriminator for Remote Sensing Image Super-Resolution" Electronics 12, no. 20: 4235. https://doi.org/10.3390/electronics12204235