
A Multi-Channel Parallel Keypoint Fusion Framework for Human Pose Estimation


Abstract
:1. Introduction
2. Related Work
2.1. Vision Transformer
2.2. 2D Human Pose Estimation
2.3. Convolution Enhanced Attention
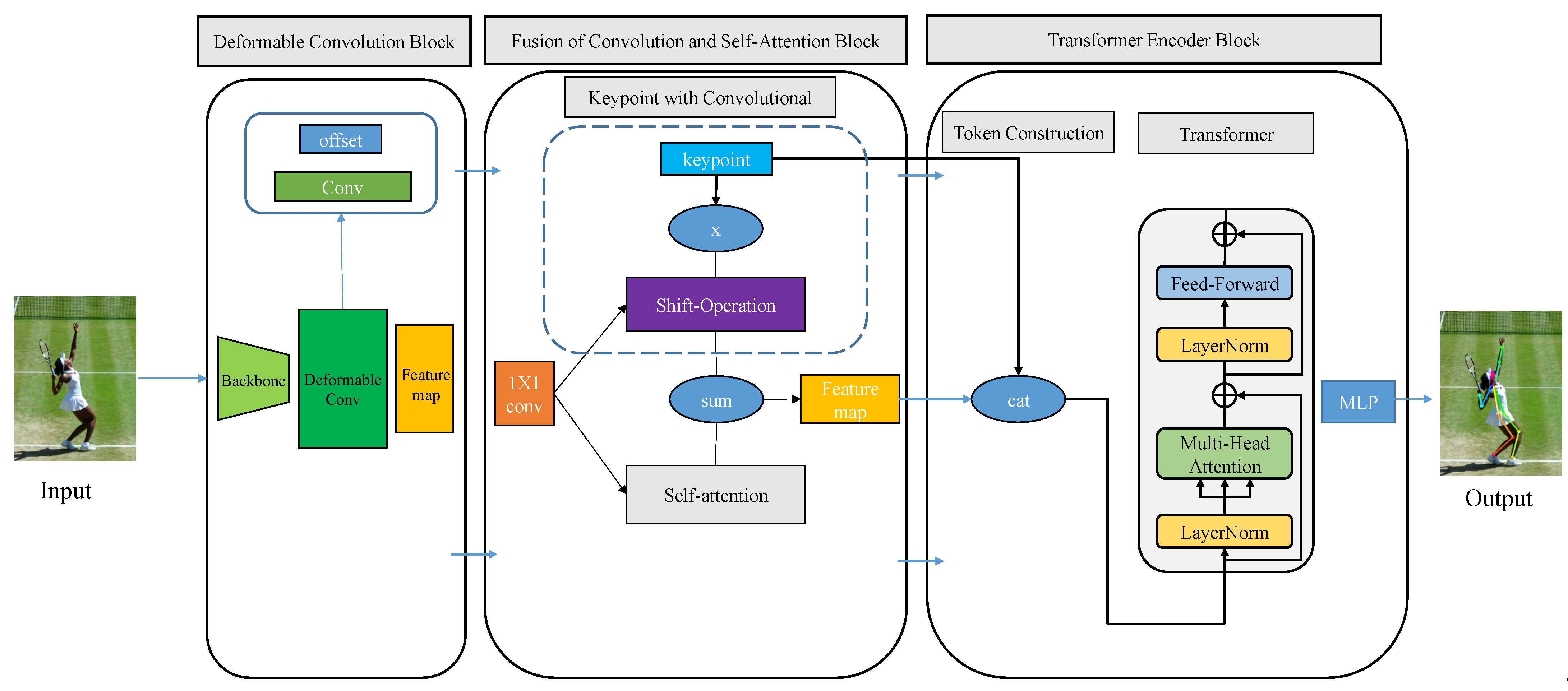
3. Materials and Methods
3.1. Deformable Convolution
3.2. Fusion of Convolution and Self-Attention
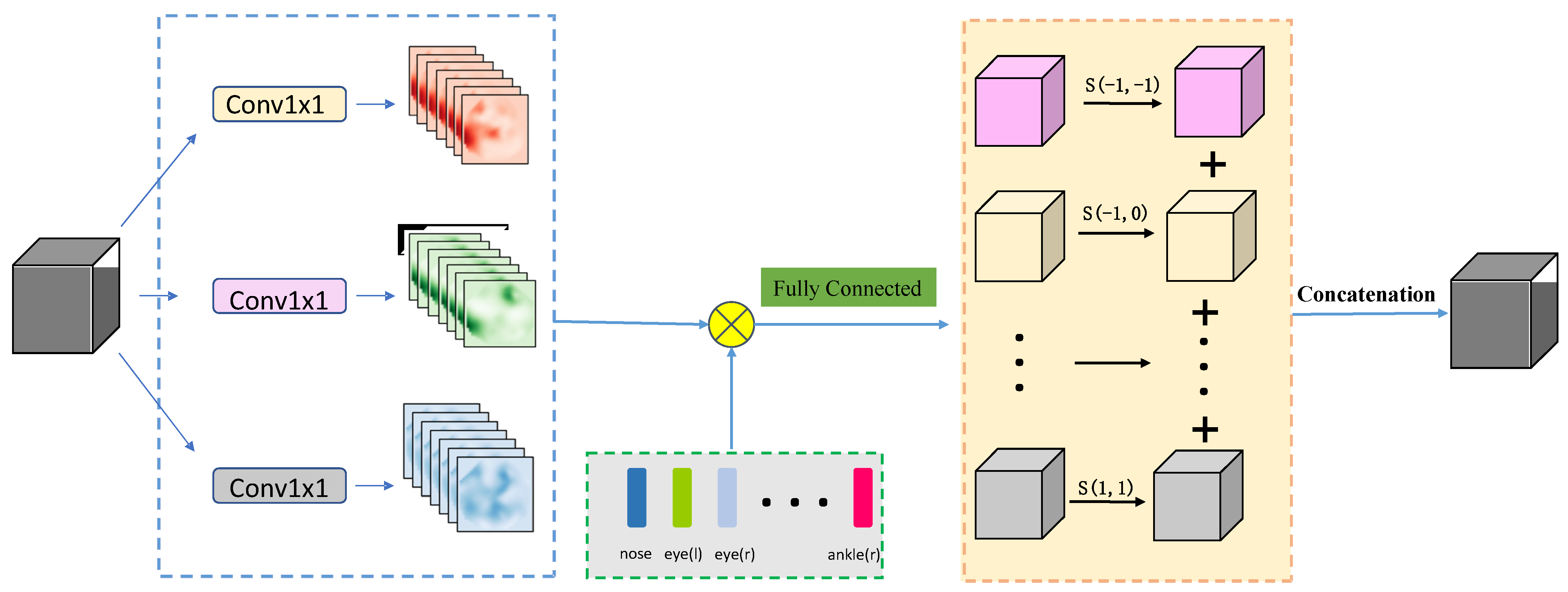
3.2.1. Keypoint with Convolution
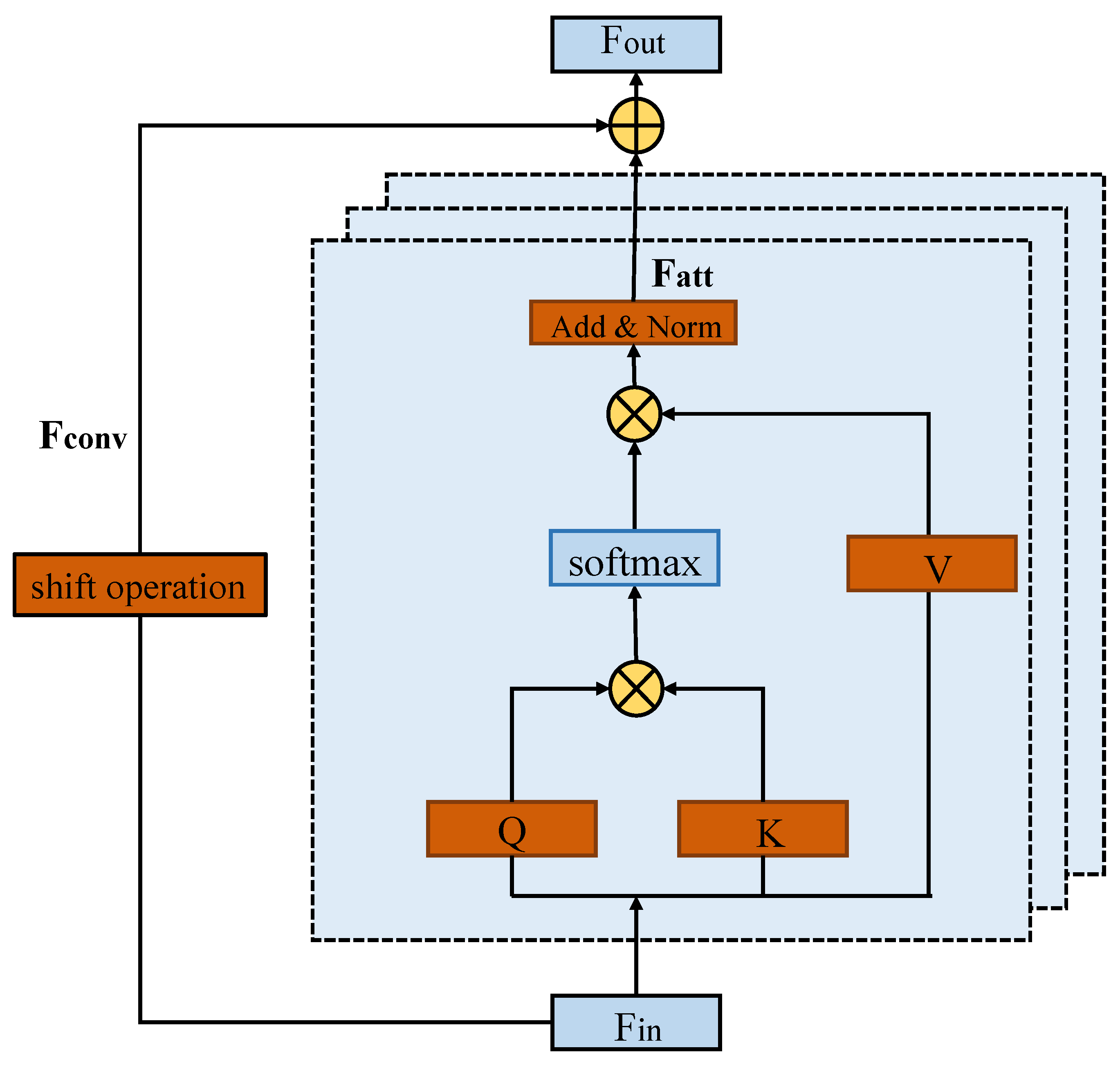
3.2.2. Fusion of Self-Attention Mechanism
3.3. Transformer Module
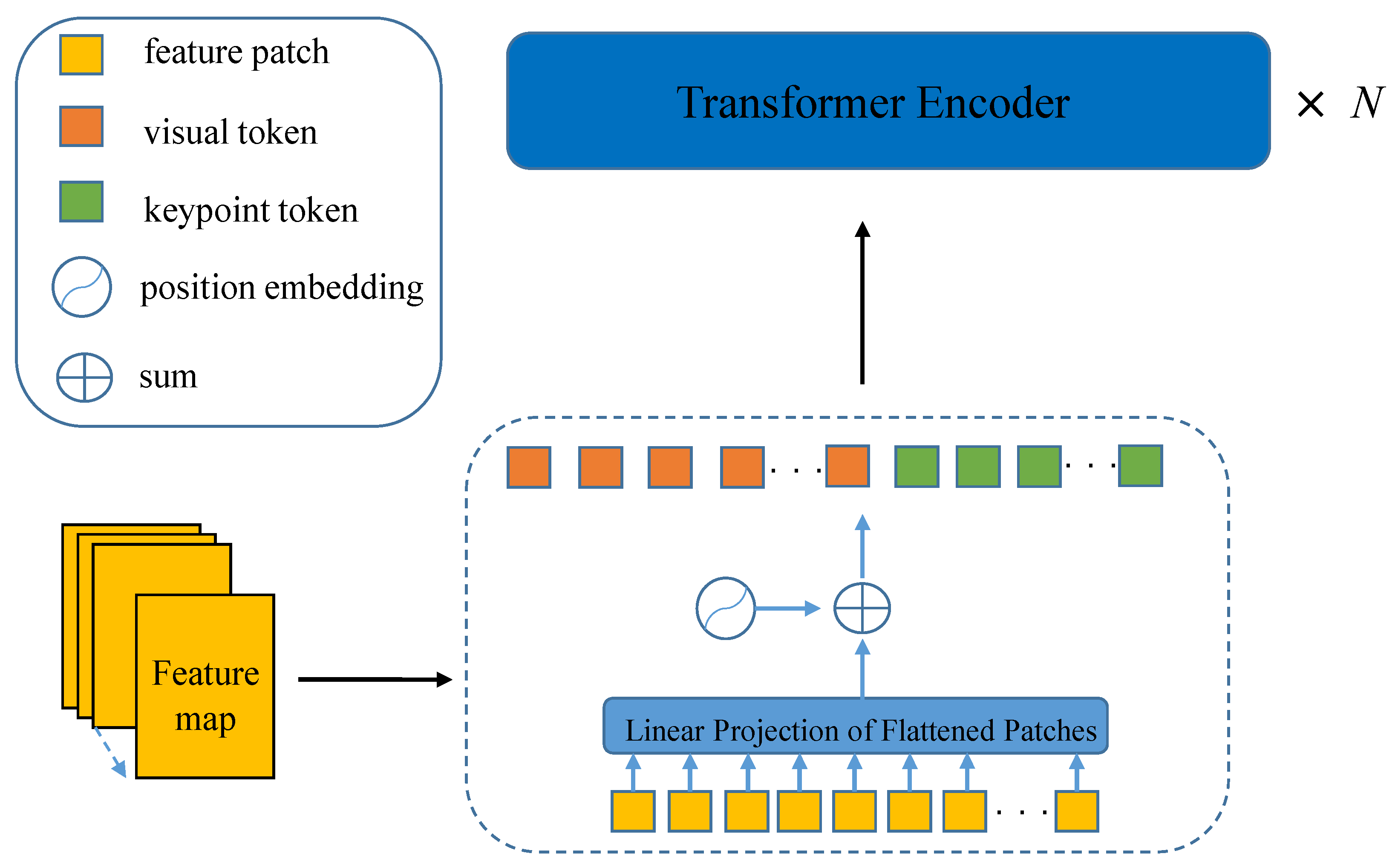
3.3.1. Construction of Token
3.3.2. Transformer Encoder
4. Experiments
4.1. Experimental Details
4.1.1. Dataset
4.1.2. Evaluation Metrics
4.1.3. Implementation Details
4.2. Comparison with State-of-the-Art Methods
4.3. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Adama, D.A.; Lotfi, A.; Ranson, R. A Survey of Vision-Based Transfer Learning in Human Activity Recognition. Electronics 2021, 10, 2412. [Google Scholar] [CrossRef]
- Mavrogiannis, P.; Maglogiannis, I. Amateur football analytics using computer vision. Neural Comput. Appl. 2022, 34, 19639–19654. [Google Scholar] [CrossRef]
- Zhao, L.; Yang, F.; Bu, L.; Han, S.; Zhang, G.; Luo, Y. Driver behavior detection via adaptive spatial attention mechanism. Adv. Eng. Inform. 2021, 48, 101280. [Google Scholar] [CrossRef]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VIII 14. pp. 483–499. [Google Scholar] [CrossRef]
- Xiao, B.; Wu, H.P.; Wei, Y.C. Simple Baselines for Human Pose Estimation and Tracking. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 472–487. [Google Scholar] [CrossRef]
- Cheng, B.W.; Xiao, B.; Wang, J.D.; Shi, H.H.; Huang, T.S.; Zhang, L. HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 5385–5394. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar] [CrossRef]
- Yang, S.; Quan, Z.B.; Nie, M.; Yang, W.K. TransPose: Keypoint Localization via Transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision Electr Network, Montreal, BC, Canada, 11–17 October 2021; pp. 11782–11792. [Google Scholar] [CrossRef]
- Li, Y.J.; Zhang, S.K.; Wang, Z.C.; Yang, S.; Yang, W.K.; Xia, S.T.; Zhou, E.J. TokenPose: Learning Keypoint Tokens for Human Pose Estimation. In Proceedings of the 18th IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 11293–11302. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, J.; Zhang, Q.; Tao, D. Vitpose: Simple vision transformer baselines for human pose estimation. Adv. Neural Inf. Process. Syst. 2022, 35, 38571–38584. [Google Scholar] [CrossRef]
- Yuan, Y.; Fu, R.; Huang, L.; Lin, W.; Zhang, C.; Chen, X.; Wang, J. Hrformer: High-resolution vision transformer for dense predict. Adv. Neural Inf. Process. Syst. 2021, 34, 7281–7293. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.T.; Cao, Y.; Hu, H.; Wei, Y.X.; Zhang, Z.; Lin, S.; Guo, B.N. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 18th IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jegou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning (ICML), Electr Network, Virtual Event, 18–24 July 2021; pp. 7358–7367. [Google Scholar] [CrossRef]
- Rao, Y.M.; Zhao, W.L.; Liu, B.L.; Lu, J.W.; Zhou, J.; Hsieh, C.J. DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification. In Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS), Electr Network, Virtual Event, 6–14 December 2021. [Google Scholar] [CrossRef]
- Jiang, M.X.; Yu, Z.L.; Li, C.H.; Lei, Y.Q. SDM3d: Shape decomposition of multiple geometric priors for 3D pose estimation. Neural Comput. Appl. 2021, 33, 2165–2181. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J.D.; Soc, I.C. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 5686–5696. [Google Scholar] [CrossRef]
- Wu, C.; Wei, X.; Li, S.; Zhan, A. MSTPose: Learning-Enriched Visual Information with Multi-Scale Transformers for Human Pose Estimation. Electronics 2023, 12, 3244. [Google Scholar] [CrossRef]
- Wu, H.P.; Xiao, B.; Codella, N.; Liu, M.C.; Dai, X.Y.; Yuan, L.; Zhang, L. CvT: Introducing Convolutions to Vision Transformers. In Proceedings of the 18th IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 22–31. [Google Scholar] [CrossRef]
- Dong, X.Y.; Bao, J.M.; Chen, D.D.; Zhang, W.M.; Yu, N.H.; Yuan, L.; Chen, D.; Guo, B.N.; Ieee Comp, S.O.C. CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 12114–12124. [Google Scholar] [CrossRef]
- Peng, Z.L.; Huang, W.; Gu, S.Z.; Xie, L.X.; Wang, Y.W.; Jiao, J.B.; Ye, Q.X. Conformer: Local Features Coupling Global Representations for Visual Recognition. In Proceedings of the 18th IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 357–366. [Google Scholar] [CrossRef]
- Dai, J.F.; Qi, H.Z.; Xiong, Y.W.; Li, Y.; Zhang, G.D.; Hu, H.; Wei, Y.C. Deformable Convolutional Networks. In Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar] [CrossRef]
- Zhu, X.Z.; Hu, H.; Lin, S.; Dai, J.F.; Soc, I.C. Deformable ConvNets v2: More Deformable, Better Results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9300–9308. [Google Scholar] [CrossRef]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Muller, K.R.; Samek, W. On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation. PLoS ONE 2015, 10, 46. [Google Scholar] [CrossRef] [PubMed]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv 2013, arXiv:1312.6034. [Google Scholar] [CrossRef]
- Pan, X.R.; Ge, C.J.; Lu, R.; Song, S.J.; Chen, G.F.; Huang, Z.Y.; Huang, G.; Ieee Comp, S.O.C. On the Integration of Self-Attention and Convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 805–815. [Google Scholar] [CrossRef]
- Ba, J.L.; Kiros, J.R.; Hinton, G. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar] [CrossRef]
- Yang, W.; Ouyang, W.L.; Li, H.S.; Wang, X.G. End-to-End Learning of Deformable Mixture of Parts and Deep Convolutional Neural Networks for Human Pose Estimation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3073–3082. [Google Scholar] [CrossRef]
- Chu, X.; Yang, W.; Ouyang, W.L.; Ma, C.; Yuille, A.L.; Wang, X.G. Multi-Context Attention for Human Pose Estimation. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5669–5678. [Google Scholar] [CrossRef]
- Chu, X.; Ouyang, W.L.; Li, H.S.; Wang, X.G. Structured Feature Learning for Pose Estimation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4715–4723. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the 13th European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Chen, Y.L.; Wang, Z.C.; Peng, Y.X.; Zhang, Z.Q.; Yu, G.; Sun, J. Cascaded Pyramid Network for Multi-Person Pose Estimation. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7103–7112. [Google Scholar] [CrossRef]
- Papandreou, G.; Zhu, T.; Kanazawa, N.; Toshev, A.; Tompson, J.; Bregler, C.; Murphy, K. Towards Accurate Multi-person Pose Estimation in the Wild. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3711–3719. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Wang, D.; Xie, W.J.; Cai, Y.C.; Liu, X.P. A Fast and Effective Transformer for Human Pose Estimation. IEEE Signal Process. Lett. 2022, 29, 992–996. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Pretrain | Input Size | #Params | GFLOPs | AP | AP50 | AP75 | AP M | AP L | AR |
|---|---|---|---|---|---|---|---|---|---|---|
| SimpleBaseline-Res50 | Y | 256 × 192 | 34.0 M | 8.9 | 70.4 | 88.6 | 78.3 | 67.1 | 77.2 | 76.3 |
| HRNet-W32 | N | 256 × 192 | 28.5 M | 7.1 | 74.4 | 90.5 | 81.9 | 70.8 | 81.0 | 79.8 |
| TokenPose-S-v1 | N | 256 × 192 | 6.6 M | 2.2 | 72.5 | 89.3 | 79.7 | 68.8 | 79.6 | 78.0 |
| TransPose-R-A4 | Y | 256 × 192 | 6.0 M | 8.9 | 72.6 | - | - | - | - | 78.0 |
| FET | N | 256 × 192 | 8.2 M | 5.9 | 72.9 | - | - | - | - | 78.1 |
| VITPose-B | Y | 256 × 192 | 86 M | 17.1 | 75.8 | 90.7 | 83.2 | - | - | 81.1 |
| DatPose | N | 256 × 192 | 6.9 M | 3.3 | 74.8 | 91.4 | 80.3 | 69.2 | 77.5 | 80.3 |
| Model | AP/% | AP50/% | AP75/% | APM/% | APL/% | AR/% | Params/M | GFlops |
|---|---|---|---|---|---|---|---|---|
| CPN [2] | 72.1 | 91.4 | 80.0 | 68.7 | 77.2 | 78.5 | 58.8 | 29.2 |
| HRNet-W48 [3] | 74.2 | 92.4 | 82.4 | 70.9 | 79.7 | 79.5 | 63.6 | 14.6 |
| TransPose-H-A4 [4] | 74.7 | 91.9 | 82.2 | 71.4 | 80.7 | - | 17.3 | 17.5 |
| TransPose-H-A6 [4] | 75.0 | 92.2 | 82.3 | 71.3 | 81.1 | - | 17.5 | 21.8 |
| TokenPose-L/D6 [5] | 74.9 | 92.1 | 82.5 | 71.7 | 81.1 | 80.2 | 27.5 | 11.0 |
| DatPose | 74.7 | 92.3 | 82.3 | 71.8 | 79.4 | 77.3 | 7.2 | 5.6 |
| Model | Head | Shoulder | Elbow | Wrist | Hip | Knee | Ankle | Mean@0.5 |
|---|---|---|---|---|---|---|---|---|
| SHN [6] | 96.5 | 96.0 | 88.4 | 83.5 | 87.1 | 83.5 | 78.3 | 87.5 |
| SimpleBase-Res50 [7] | 96.4 | 95.3 | 89.0 | 83.2 | 88.4 | 84.0 | 79.6 | 88.5 |
| HRNet-W32 [3] | 96.9 | 96.0 | 90.6 | 85.8 | 88.7 | 86.6 | 82.6 | 90.1 |
| HRNet-W48 [3] | 97.3 | 95.3 | 89.9 | 85.5 | 88.1 | 85.0 | 81.8 | 89.4 |
| TokenPose-L/D6 [5] | 97.1 | 95.9 | 91.0 | 85.8 | 89.5 | 86.1 | 82.7 | 90.2 |
| CAPose-s2 [8] | 97.0 | 95.8 | 90.9 | 86.2 | 89.5 | 86.9 | 83.4 | 90.4 |
| DatPose | 97.3 | 95.6 | 90.1 | 85.7 | 89.8 | 86.6 | 82.4 | 90.3 |
| Model | Deformable Convolution | Fusion Module | AP | AR |
|---|---|---|---|---|
| 1 | - | - | 72.1 | 75.0 |
| 2 | ✓ | - | 72.5 | 78.0 |
| 3 | - | ✓ | 73.5 | 77.3 |
| 4 | ✓ | ✓ | 74.8 | 80.3 |
| Method | AP | AR |
|---|---|---|
| Fusion of Convolution and Self-Attention | 74.8 | 78.0 |
| Only Self-Attention | 73.2 | 77.8 |
| Keypoint with convolution | 73.4 | 77.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Shi, N.; Wang, G.; Shao, J.; Zhao, S. A Multi-Channel Parallel Keypoint Fusion Framework for Human Pose Estimation. Electronics 2023, 12, 4019. https://doi.org/10.3390/electronics12194019
Wang X, Shi N, Wang G, Shao J, Zhao S. A Multi-Channel Parallel Keypoint Fusion Framework for Human Pose Estimation. Electronics. 2023; 12(19):4019. https://doi.org/10.3390/electronics12194019
Chicago/Turabian StyleWang, Xilong, Nianfeng Shi, Guoqiang Wang, Jie Shao, and Shuaibo Zhao. 2023. "A Multi-Channel Parallel Keypoint Fusion Framework for Human Pose Estimation" Electronics 12, no. 19: 4019. https://doi.org/10.3390/electronics12194019