
BFE-Net: Object Detection with Bidirectional Feature Enhancement

Abstract
:1. Introduction
- (1)
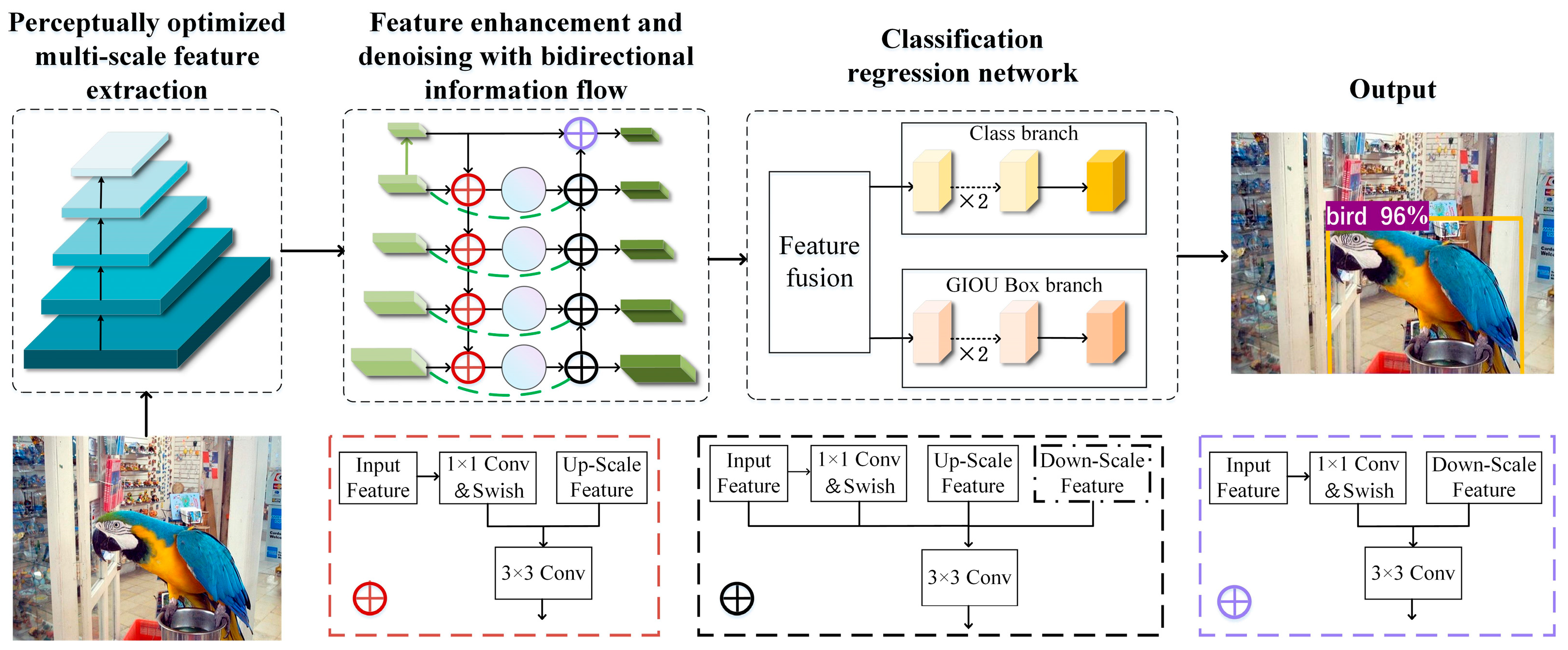
- In order to effectively improve the detection capability for small objects and anti-interference, we propose an object detection algorithm named BFE-Net based on bidirectional feature enhancement, which consists of a perceptually optimized multi-scale feature extraction module, feature enhancement and denoising module with bidirectional information flow, and a classification regression network.
- (2)
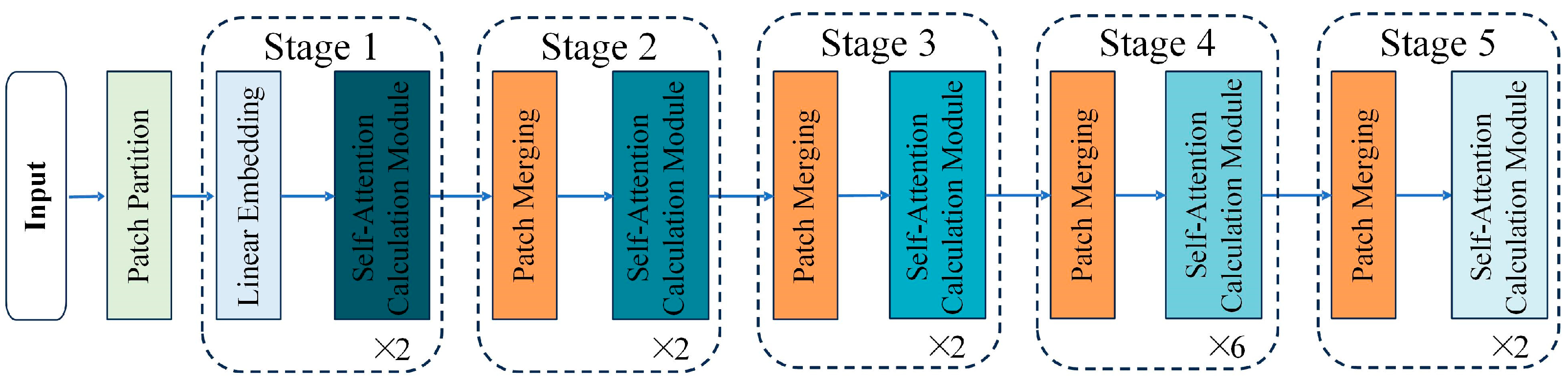
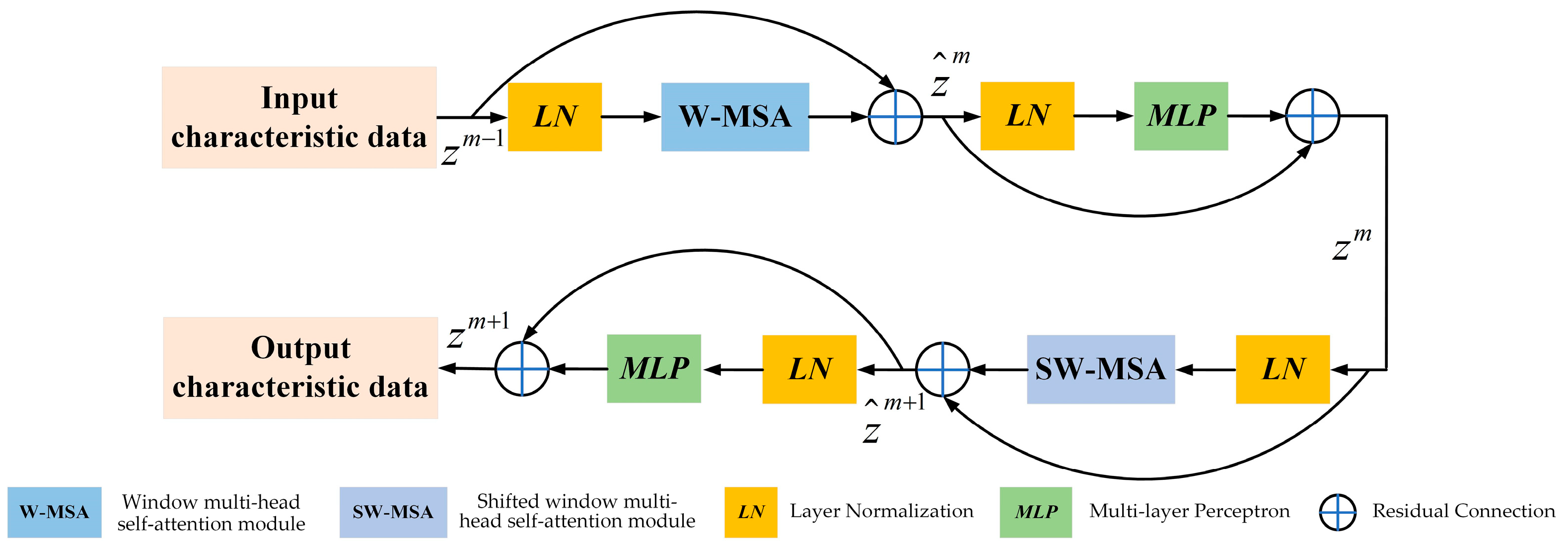
- To enhance multi-scale feature extraction and improve the overall performance of BFE-Net, the perceptually optimized multi-scale feature extraction module utilizes a pyramid hierarchical self-attention mechanism, which can capture global information and long-range dependencies between pixels, thereby facilitating the optimization and extraction of multi-scale features from the input image.
- (3)
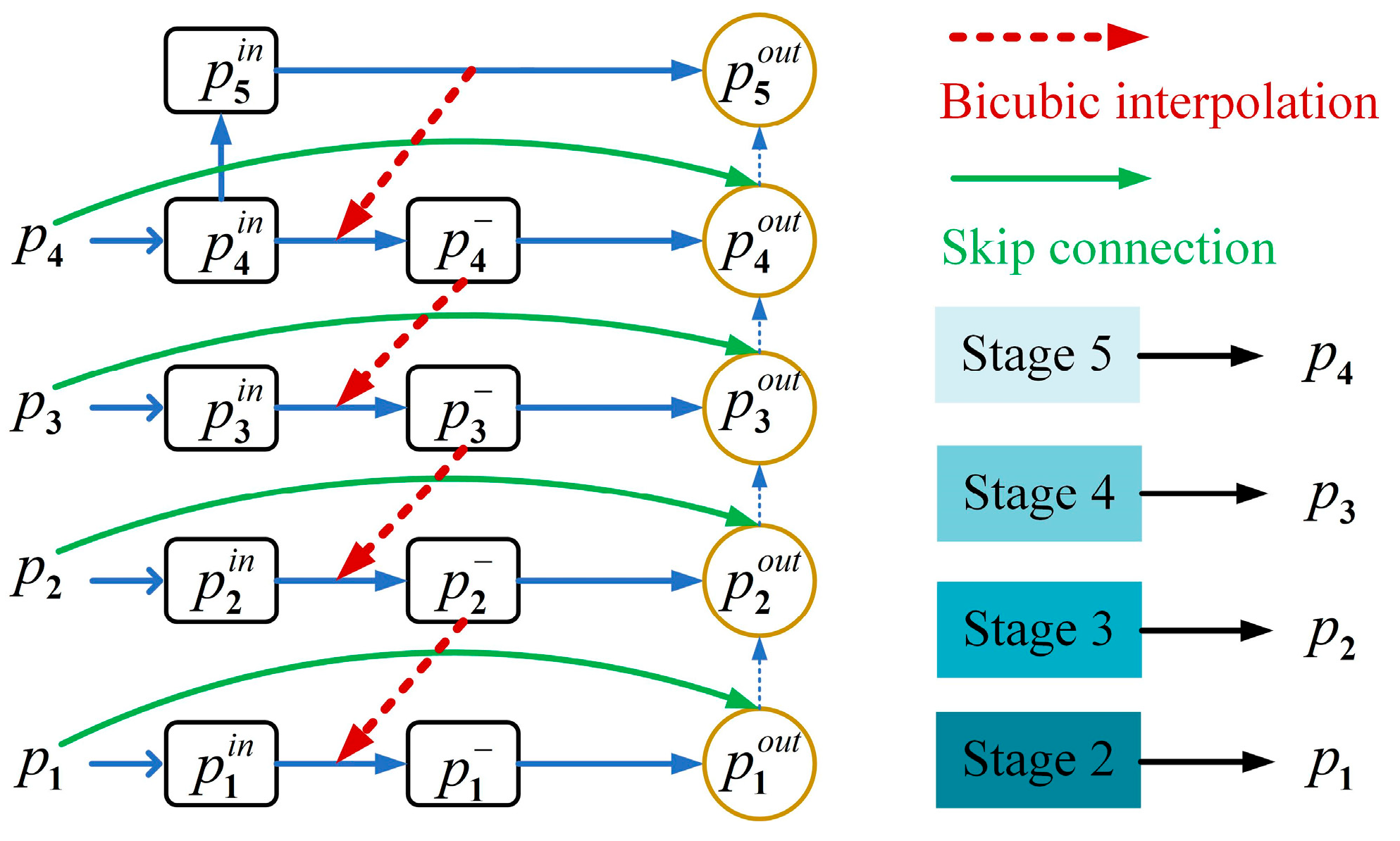
- To mitigate the influence of noise on various objects, particularly small objects, we design a feature pyramid structure with bidirectional information flow and gradually obtain high-resolution images through bicubic interpolation up-sampling, which maintains the details and smoothness of the images. This approach is beneficial to reduce the impact of noise on the feature extraction across different-scale objects, thereby enhancing the detection capability, especially for small-scale objects.
2. BFE-Net
2.1. Perceptually Optimized Multi-Scale Feature Extraction
2.2. Feature Enhancement and Denoising with Bidirectional Information Flow
2.3. Classification Regression Network
3. Results and Analysis
3.1. Experimental Datasets and Environment Settings
3.2. Comparison of Experimental Results
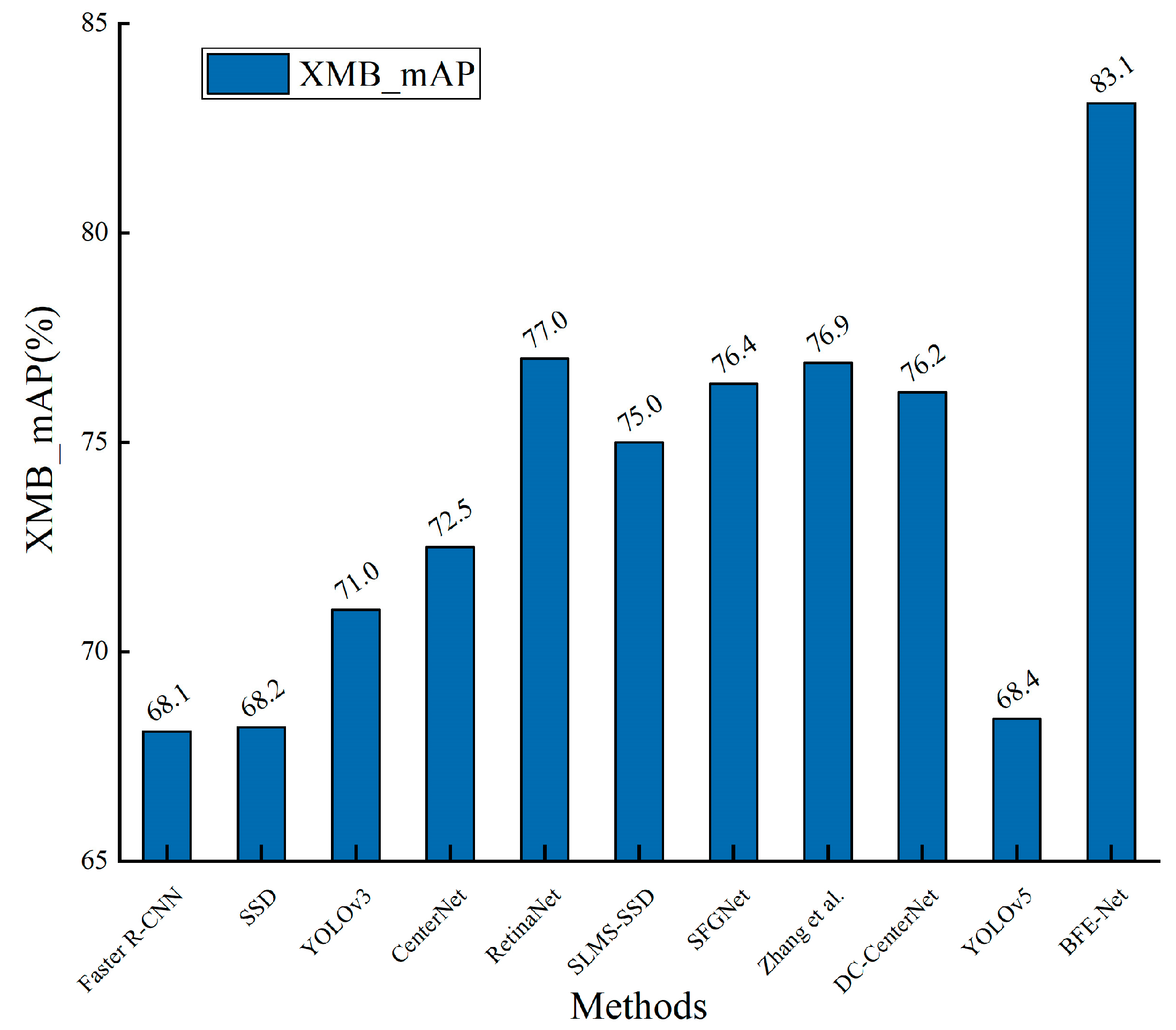
3.2.1. Overall Performance Analysis
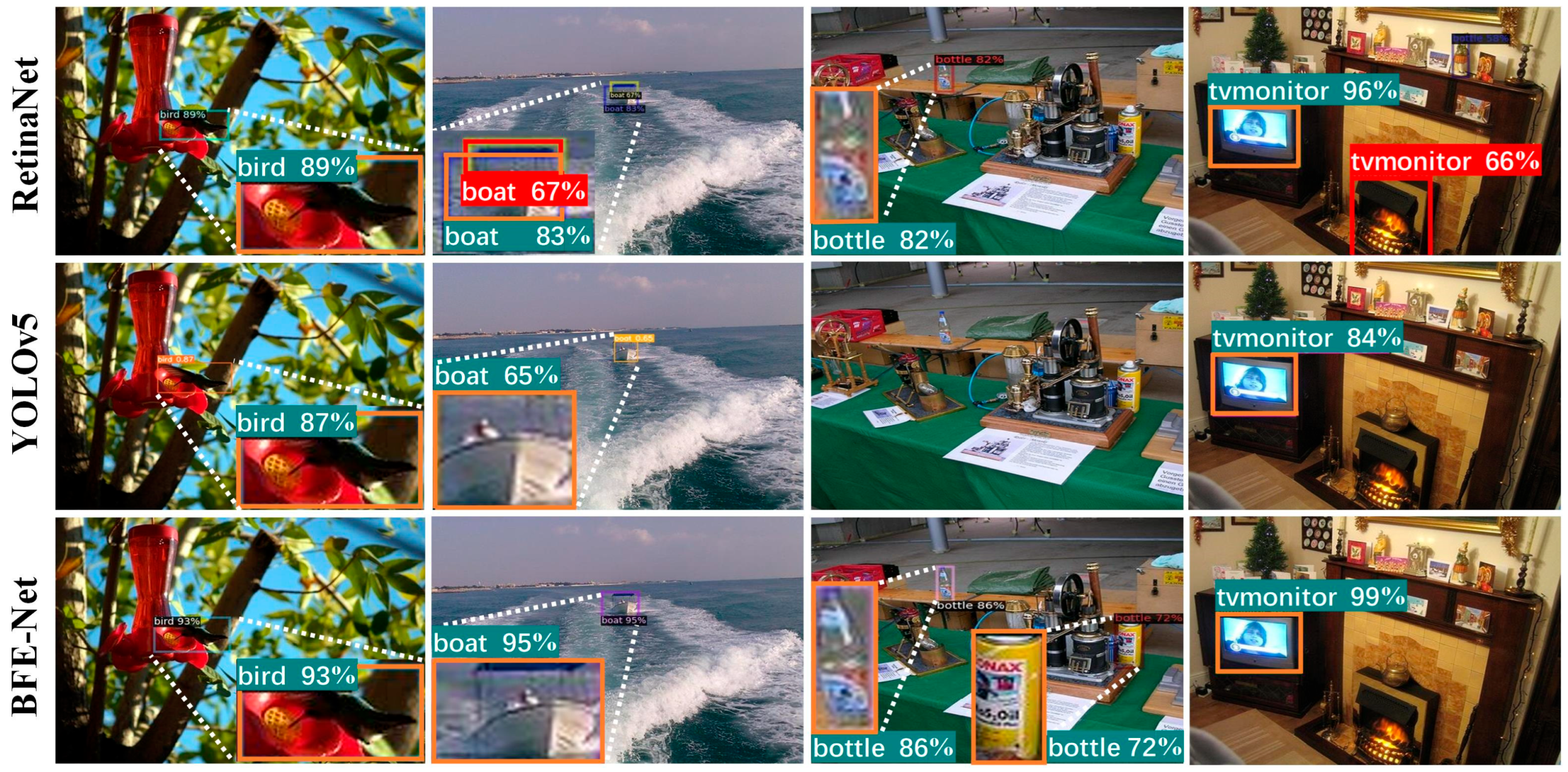
3.2.2. Performance Analysis of Small Object Detection
3.2.3. Analysis of Anti-Interference Performance
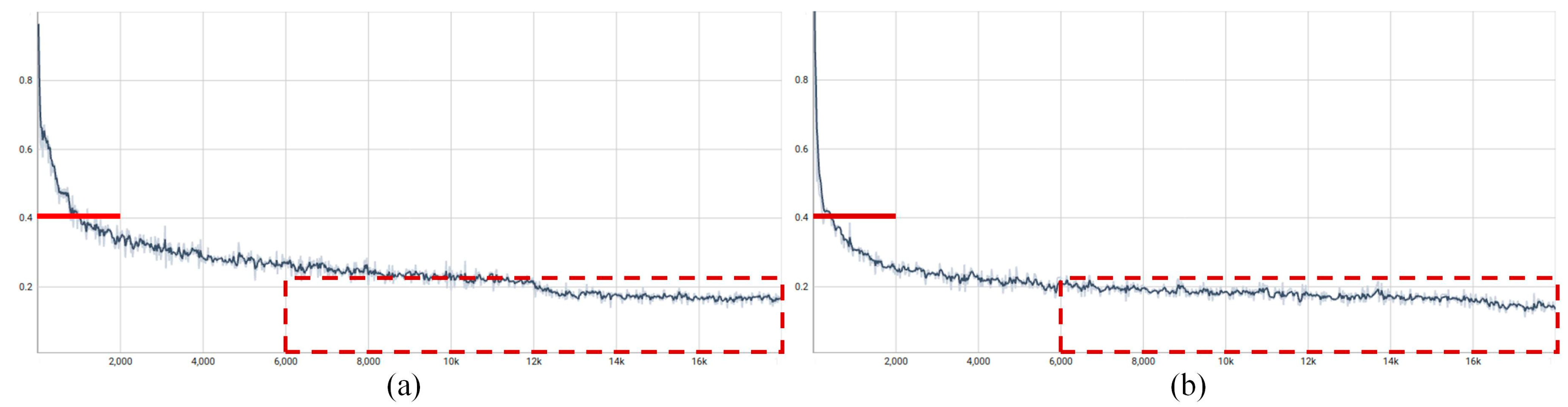
3.2.4. Analysis of Regression Loss Function
3.3. Ablation Experiment
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jiang, S.; Hong, Z. Unexpected Dynamic Obstacle Monocular Detection in the Driver View. IEEE Intell. Transp. Syst. Mag. 2023, 15, 68–81. [Google Scholar] [CrossRef]
- Jiang, S.; Yao, W.; Wong, M.S.; Li, G.; Hong, Z.; Kuc, T.; Tong, X. An Optimized Deep Neural Network Detecting Small and Narrow Rectangular Objects in Google Earth Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1068–1081. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Wang, Y.; Cheng, S.; Liu, J.; Kang, J.; Yang, W. SFGNet detecting objects via spatial fine-grained feature and enhanced RPN with spatial context. Syst. Sci. Control Eng. 2022, 10, 388–406. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhang, M.; Xu, S.; Song, W.; He, Q.; Wei, Q. Lightweight underwater object detection based on yolo v4 and multi-scale attentional feature fusion. Remote Sens. 2021, 13, 4706. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Deng, X.; Li, S. An Improved SSD Object Detection Algorithm Based on Attention Mechanism and Feature Fusion. J. Phys. Conf. Ser. 2023, 2450, 012088. [Google Scholar] [CrossRef]
- Xia, Y.; Kou, X.; Jia, W.; Lu, S.; Wang, L.; Li, L. CenterNet Based on Diagonal Half-length and Center Angle Regression for Object Detection. KSII Trans. Internet Inf. Syst. 2023, 17, 1841–1857. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Saeed, F.; Ahmed, M.J.; Gul, M.J.; Hong, K.J.; Paul, A.; Kavitha, M.S. A robust approach for industrial small-object detection using an improved faster regional convolutional neural network. Sci. Rep. 2021, 11, 23390. [Google Scholar] [CrossRef] [PubMed]
- Han, G.; Chen, Y.; Wu, T.; Li, H.; Luo, J. Adaptive AFM imaging based on object detection using compressive sensing. Micron 2022, 154, 103197. [Google Scholar] [CrossRef] [PubMed]
- Everingham, M.; Eslami, S.M.; Gool, L.V.; Williams, C.K.; Winn, J.M.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2014, 111, 98–136. [Google Scholar] [CrossRef]
- Wang, K.; Wang, Y.; Zhang, S.; Tian, Y.; Li, D. SLMS-SSD: Improving the balance of semantic and spatial information in object detection. Expert Syst. Appl. 2022, 206, 117682. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | mAP | Aero | Bike | Bird | Boat | Bottle | Bus | Car | Cat | Chair | Cow |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Faster R-CNN [4] | 76.4 | 79.8 | 80.7 | 76.2 | 68.3 | 55.9 | 85.1 | 85.3 | 89.8 | 56.7 | 87.8 |
| SSD [7] | 77.3 | 78.8 | 85.3 | 75.7 | 71.5 | 49.1 | 85.7 | 86.4 | 87.8 | 60.6 | 82.7 |
| YOLOv3 [9] | 78.3 | 79.0 | 85.6 | 77.2 | 72.3 | 55.6 | 86.8 | 87.3 | 88.0 | 62.3 | 84.2 |
| CenterNet [8] | 80.3 | 82.1 | 89.8 | 80.6 | 66.7 | 58.7 | 90.5 | 91.2 | 90.7 | 65.0 | 83.8 |
| RetinaNet [12] | 80.8 | 87.4 | 85.4 | 83.4 | 71.3 | 72.5 | 86.4 | 88.6 | 87.8 | 65.9 | 85.4 |
| SLMS-SSD [21] | 81.2 | 88.5 | 87.1 | 83.2 | 76.4 | 59.2 | 88.3 | 88.4 | 89.0 | 66.6 | 86.9 |
| SFGNet [5] | 81.3 | 82.2 | 83.9 | 80.3 | 71.5 | 78.2 | 89.6 | 86.9 | 90.0 | 65.7 | 87.9 |
| Zhang et al. [11] | 81.6 | 88.5 | 87.5 | 83.1 | 75.2 | 67.1 | 85.3 | 90.2 | 88.9 | 60.9 | 89.7 |
| DC-CenterNet [14] | 81.6 | 84.8 | 90.9 | 83.5 | 70.6 | 64.9 | 90.8 | 91.3 | 91.3 | 64.9 | 80.6 |
| YOLOv5 | 82.7 | 95.2 | 85.6 | 65.7 | 50.5 | 89.0 | 65.4 | 92.6 | 92.0 | 82.3 | 78.6 |
| BFE-Net | 85.0 | 89.6 | 89.0 | 86.6 | 80.0 | 78.5 | 88.8 | 89.6 | 89.0 | 73.5 | 88.6 |
| Methods | mAP | Table | Dog | Horse | Mbike | Person | Plant | Sheep | Sofa | Train | TV |
| Faster R-CNN [4] | 76.4 | 69.4 | 88.3 | 88.9 | 80.9 | 78.4 | 41.7 | 78.6 | 79.8 | 85.3 | 72.0 |
| SSD [7] | 77.3 | 76.5 | 84.9 | 86.7 | 84.0 | 79.2 | 51.3 | 77.5 | 78.7 | 86.7 | 76.3 |
| YOLOv3 [9] | 78.3 | 76.4 | 85.0 | 87.2 | 84.3 | 80.3 | 51.9 | 77.2 | 78.9 | 86.7 | 78.9 |
| CenterNet [8] | 80.3 | 75.1 | 88.5 | 89.9 | 89.9 | 86.5 | 42.0 | 82.0 | 80.2 | 89.4 | 83.8 |
| RetinaNet [12] | 80.8 | 75.5 | 86.6 | 87.0 | 86.0 | 85.3 | 57.0 | 82.8 | 75.7 | 85.7 | 80.6 |
| SLMS-SSD [21] | 81.2 | 74.6 | 87.3 | 88.6 | 86.5 | 82.2 | 54.8 | 85.5 | 80.9 | 87.9 | 81.0 |
| SFGNet [5] | 81.3 | 72.4 | 90.3 | 89.9 | 83.5 | 82.5 | 67.8 | 79.0 | 81.6 | 86.7 | 75.7 |
| Zhang et al. [11] | 81.6 | 78.4 | 89.5 | 89.5 | 84.9 | 84.8 | 55.1 | 86.9 | 74.3 | 90.8 | 82.0 |
| DC-CenterNet [14] | 81.6 | 73.8 | 87.5 | 90.6 | 90.8 | 86.4 | 53.3 | 82.9 | 79.0 | 87.7 | 85.6 |
| YOLOv5 | 82.7 | 81.7 | 88.2 | 66.3 | 99.5 | 91.9 | 83.8 | 87.5 | 89.8 | 99.5 | 68.3 |
| BFE-Net | 85.0 | 81.0 | 89.0 | 90.0 | 89.4 | 87.1 | 66.6 | 88.6 | 80.5 | 88.3 | 87.1 |
| Methods | mAP | ||||
|---|---|---|---|---|---|
| VOC2007test | +GN | +GB | +MB | +ED | |
| RetinaNet | 80.80 | 71.89 | 78.25 | 74.39 | 75.55 |
| YOLOv5 | 82.70 | 71.50 | 78.30 | 76.20 | 77.30 |
| BFE-Net | 85.00 | 80.24 | 83.88 | 82.06 | 82.35 |
| / | ResNet-50 | FPN | Perceptually Optimized Multi-Scale Feature Extraction | Feature Enhancement and Denoising with Bidirectional Information Flow | mAP | |
|---|---|---|---|---|---|---|
| 1 | √ | √ | × | × | × | 80.8 |
| 2 | × | √ | √ | × | × | 82.3 |
| 3 | √ | × | × | √ | × | 83.6 |
| 4 | × | × | √ | √ | × | 84.5 |
| 5 | × | × | √ | √ | √ | 85.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, R.; Zhu, Z.; Li, L.; Bai, Y.; Shi, J. BFE-Net: Object Detection with Bidirectional Feature Enhancement. Electronics 2023, 12, 4531. https://doi.org/10.3390/electronics12214531
Zhang R, Zhu Z, Li L, Bai Y, Shi J. BFE-Net: Object Detection with Bidirectional Feature Enhancement. Electronics. 2023; 12(21):4531. https://doi.org/10.3390/electronics12214531
Chicago/Turabian StyleZhang, Rong, Zhongjie Zhu, Long Li, Yongqiang Bai, and Jiong Shi. 2023. "BFE-Net: Object Detection with Bidirectional Feature Enhancement" Electronics 12, no. 21: 4531. https://doi.org/10.3390/electronics12214531