

Efficient CU Decision Algorithm for VVC 3D Video Depth Map Using GLCM and Extra Trees
Abstract
:1. Introduction
2. Related Works
2.1. Fast Algorithm Based on Heuristic
2.2. Fast Algorithm Based on Machine Learning
2.3. Fast Algorithm Based on Deep Learning
3. Proposed Algorithm
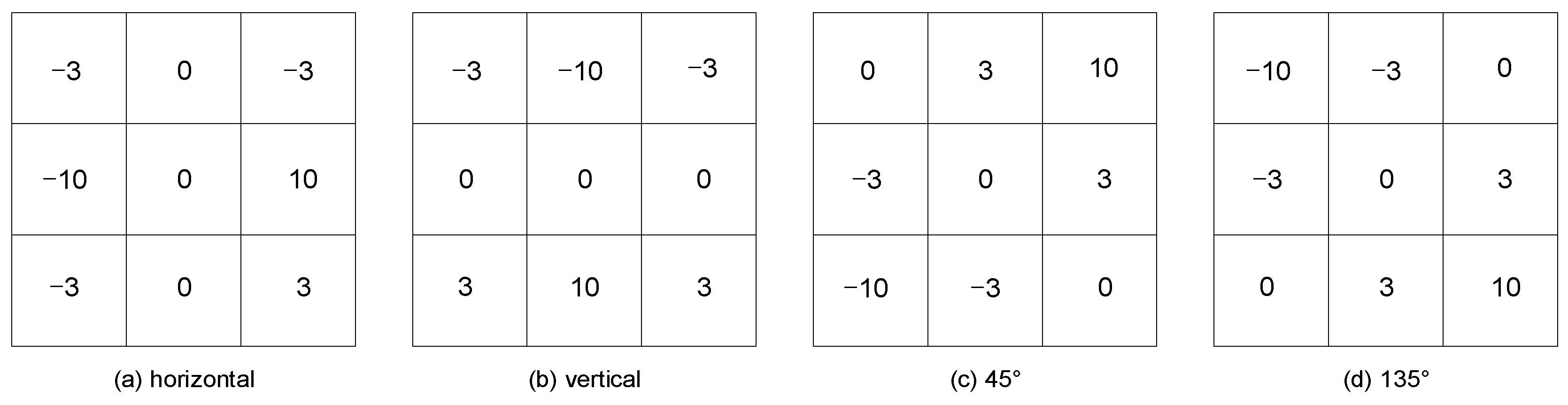
3.1. Edge Complexity Detection Algorithm Based on GLCM
3.2. CU Fast Decision Algorithm Based on Extra Trees
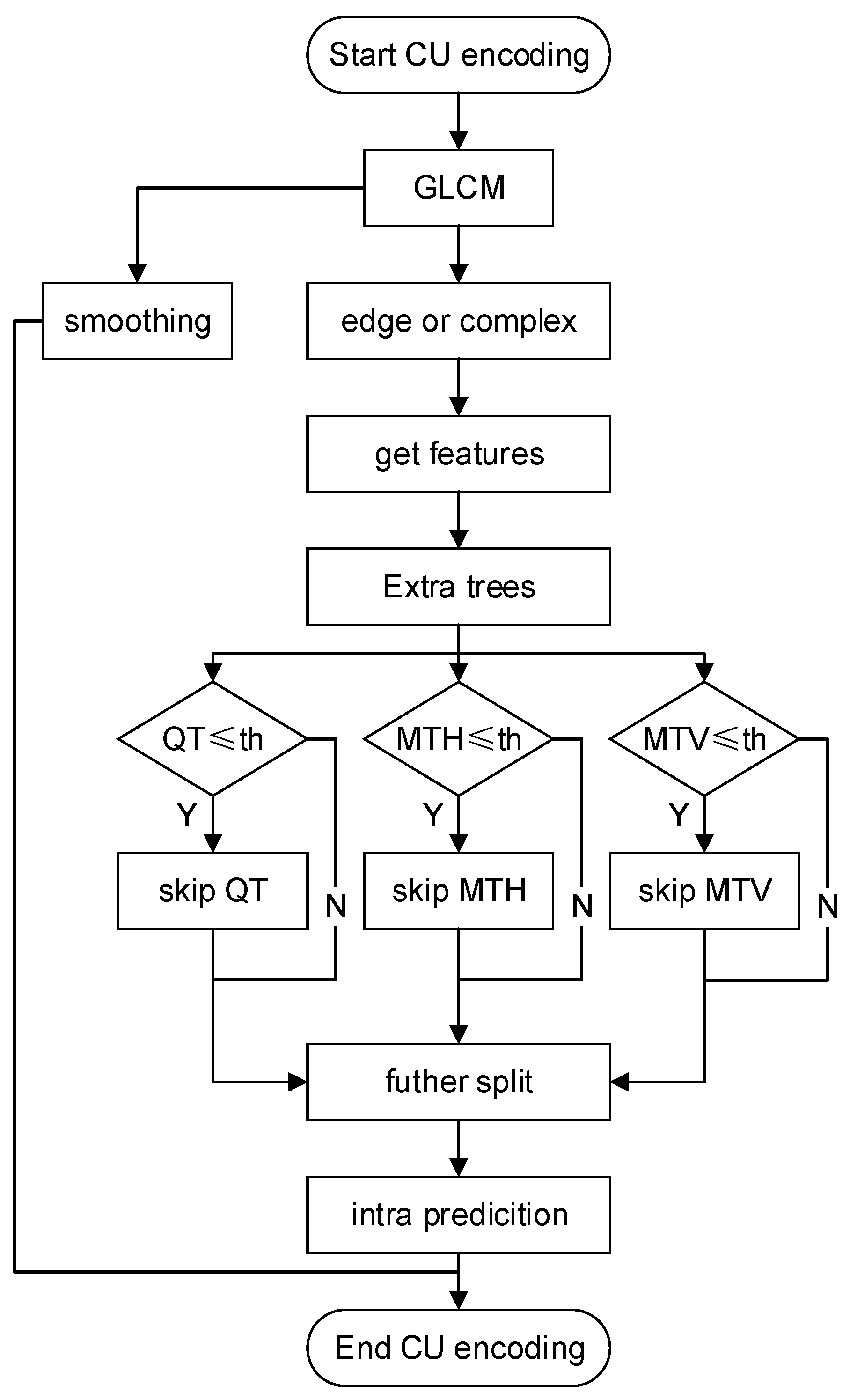
3.3. Framework of the Overall Algorithm
| Algorithm 1 The proposed fast decision algorithm for VVC 3D video CU split. |
| Require: Validity of neighboring frames; the size of the CU input into the Extra trees model is 32 × 32 or 16 × 16 or 8 × 8 or 4 × 4 Ensure: CU is classified into smooth blocks and complex edge blocks; CU skips unnecessary partitioning types 1: Input: current coding unit 2: Calculate the gradient of the current CU by Equation (10); 3: Calculate the feature vector by Equation (12). 4: if () = (0,1,0) and < Th then CU is classified as a smooth block and terminate the CU partition; else if () ≠ (0,1,0) or > Th then CU is classified as a complex or edge block; 5: if CU == 32 × 32 or 16 × 16 or 8 × 8 or 4 × 4 then 6: Compute the block shape ratio, variance, texture trend in the partition direction, the difference between the predicted partition depth and the true depth of the current CU, and QP; 7: Obtain the probabilities of QT, MTH, and MTV through the Extra trees model. 8: if probabilities of QT ≤ th then skip QT; if probabilities of MTH ≤ th then skip MTH; if probabilities of MTV ≤ th then skip MTV; 9: End. |
4. Experimental Results
4.1. Performance Analysis of Individual Algorithm
4.2. Comparison with Other Algorithms
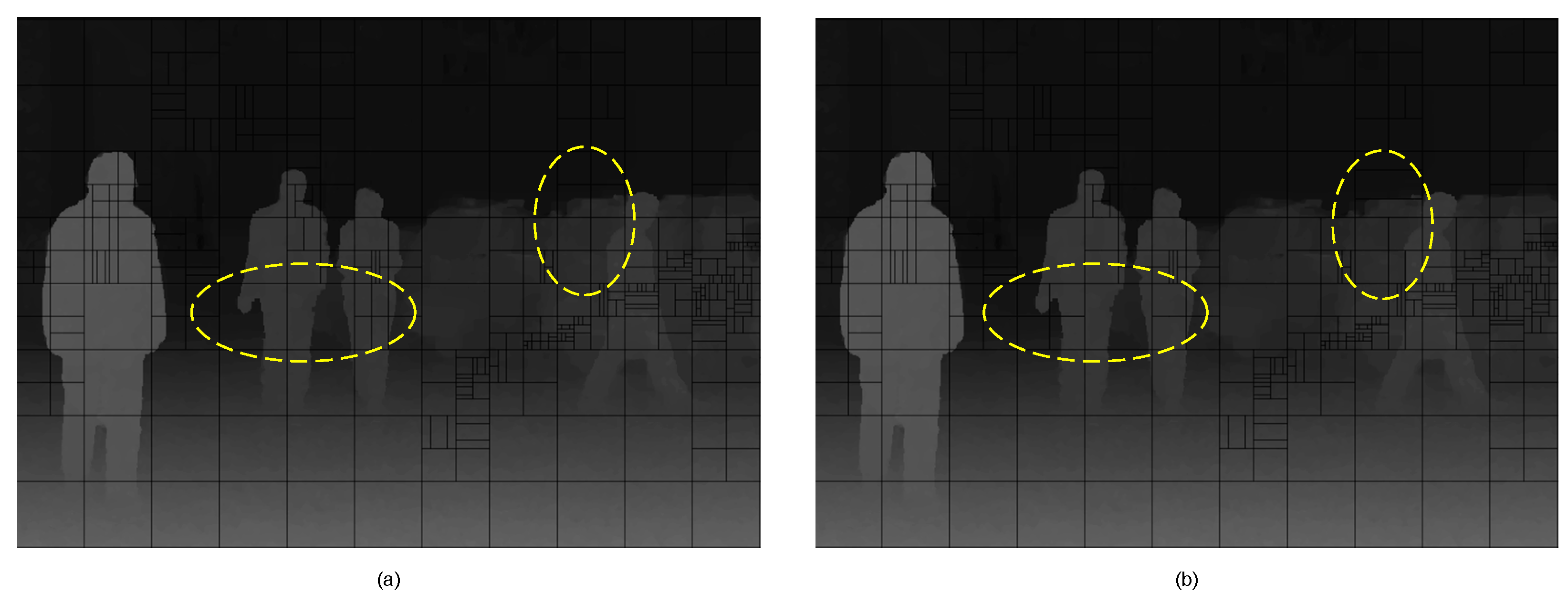
4.3. Additional Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| VVC | Versatile Video Coding |
| QTMT | Quad-tree with Nested Multi-type Tree |
| CU | Coding Unit |
| GLCM | Gray Level Co-occurrence Matrix |
| BDBR | Bjøntegaard Delta Bit Rate |
| HDR | High Dynamic Range |
| VR | Virtual Reality |
| AR | Augmented Reality |
| MPEG | Moving Picture Experts Group |
| VCEG | Video Coding Expert Group |
| HEVC | High Efficiency Video Coding |
| JVET | Joint Video Experts Team |
| RDO | Rate Distortion Optimization |
| DMM | Depth Modeling Modes |
| CNN | Convolutional Neural Network |
| FNN | Feedforward neural network |
| VGGNet | Visual Geometry Group Network |
| QT | Quad Tree |
| BTH | Horizontal Binary Tree |
| BTV | Vertical Binary Tree |
| TTH | Horizontal Trinomial Tree |
| TTV | Vertical Trinomial Tree |
| ASM | Angle-Second Matrix |
| CON | Contrast |
| COR | Correlation |
| MTT | Multi-Type Tree |
| QP | Quantization Parameter |
| VTM | VVC Test Model |
References
- Cheon, M.; Lee, J.-S. Subjective and Objective Quality Assessment of Compressed 4K UHD Videos for Immersive Experience. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 1467–1480. [Google Scholar] [CrossRef]
- Muller, K.; Merkle, P.; Wiegand, T. 3-D Video Representation Using Depth Maps. Proc. IEEE 2011, 99, 643–656. [Google Scholar] [CrossRef]
- Boyce, J.M.; Dore, R.; Dziembowski, A.; Fleureau, J.; Jung, J.; Kroon, B.; Salahieh, B.; Vadakital, V.K.M.; Yu, L. MPEG Immersive Video Coding Standard. Proc. IEEE 2021, 109, 1521–1536. [Google Scholar] [CrossRef]
- Aggoun, A.; Tsekleves, E.; Swash, M.R.; Zarpalas, D.; Dimou, A.; Daras, P.; Nunes, P.; Soares, L.D. Immersive 3D Holoscopic Video System. IEEE MultiMed. 2013, 20, 28–37. [Google Scholar] [CrossRef]
- Chen, Y.; Vetro, A. Next-Generation 3D Formats with Depth Map Support. IEEE MultiMed. 2014, 21, 90–94. [Google Scholar] [CrossRef]
- Lei, J.; Shi, Y.; Pan, Z.; Liu, D.; Jin, D.; Chen, Y.; Ling, N. Deep Multi-Domain Prediction for 3D Video Coding. IEEE Trans. Broadcast. 2021, 67, 813–823. [Google Scholar] [CrossRef]
- Liu, C.; Jia, K.; Liu, P. Fast Depth Intra Coding Based on Depth Edge Classification Network in 3D-HEVC. IEEE Trans. Broadcast. 2022, 68, 97–109. [Google Scholar] [CrossRef]
- Tech, G.; Chen, Y.; Muller, K.; Ohm, J.-R.; Vetro, A.; Wang, Y.-K. Overview of the Multiview and 3D Extensions of High Efficiency Video Coding. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 35–49. [Google Scholar] [CrossRef]
- Tissier, A.; Mercat, A.; Amestoy, T.; Hamidouche, W.; Vanne, J.; Menard, D. Complexity reduction opportunities in the future VVC intra encoder. In Proceedings of the 21th International Workshop Multimedia Signal Process (MMSP), Kuala Lumpur, Malaysia, 27–29 September 2019; pp. 1–6. [Google Scholar]
- Saldanha, M.; Sanchez, G.; Marcon, C.; Agostini, L. Complexity Analysis of VVC Intra Coding. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 3119–3123. [Google Scholar]
- Park, C.-S. Edge-Based Intramode Selection for Depth-Map Coding in 3D-HEVC. IEEE Trans. Image Process. 2015, 24, 155–162. [Google Scholar] [CrossRef]
- Sanchez, G.; Silveira, J.; Agostini, L.V.; Marcon, C. Performance Analysis of Depth Intra-Coding in 3D-HEVC. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 2509–2520. [Google Scholar] [CrossRef]
- Zhang, Y.; Lu, C. Efficient algorithm adaptations and fully parallel hardware architecture of H. 265/HEVC intra encoder. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 3415–3429. [Google Scholar] [CrossRef]
- Li, Y.; Li, L.; Fang, Y.; Peng, H.; Ling, N. Bagged tree and ResNet-based joint end-to-end fast CTU partition decision algorithm for video intra coding. Electronics 2022, 11, 1264. [Google Scholar] [CrossRef]
- Li, H.; Zhang, P.; Jin, B.; Zhang, Q. Fast CU Decision Algorithm Based on CNN and Decision Trees for VVC. Electronics 2023, 12, 3053. [Google Scholar] [CrossRef]
- Li, T.; Wang, H.; Chen, Y.; Yu, L. Fast depth intra coding based on spatial correlation and rate distortion cost in 3D-HEVC. Signal Process. Image Commun. 2020, 80, 115668. [Google Scholar] [CrossRef]
- Zuo, J.; Chen, J.; Zeng, H.; Cai, C.; Ma, K.-K. Bi-Layer Texture Discriminant Fast Depth Intra Coding for 3D-HEVC. IEEE Access. 2019, 7, 34265–34274. [Google Scholar] [CrossRef]
- Fu, C.-H.; Chan, Y.-L.; Zhang, H.-B.; Tsang, S.H.; Xu, M.-T. Efficient Depth Intra Frame Coding in 3D-HEVC by Corner Points. IEEE Trans. Image Process. 2021, 30, 1608–1622. [Google Scholar] [CrossRef]
- Li, T.; Yu, L.; Wang, H.; Chen, Y. Fast depth intra coding based on texture feature and spatio-temporal correlation in 3D-HEVC. IET Image Process. 2021, 15, 206–217. [Google Scholar] [CrossRef]
- Hamout, H.; Elyousfi, A. An efficient edge detection algorithm for fast intra-coding for 3D video extension of HEVC. J. Real-Time Image Proc. 2019, 16, 2093–2105. [Google Scholar] [CrossRef]
- Li, Y.; Yang, G.; Qu, A.; Zhu, Y. Tunable early CU size decision for depth map intra coding in 3D-HEVC using unsupervised learning. Digit. Signal Process. 2022, 123, 103448. [Google Scholar] [CrossRef]
- Zhang, Z.; Yu, L.; Qian, J.; Wang, H. Learning-Based Fast Depth Inter Coding for 3D-HEVC via XGBoost. In Proceedings of the 2022 Data Compression Conference (DCC), Snowbird, UT, USA, 22–25 March 2022; pp. 43–52. [Google Scholar]
- Saldanha, M.; Sanchez, G.; Marcon, C.; Agostini, L. Fast 3D-HEVC Depth Map Encoding Using Machine Learning. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 850–861. [Google Scholar] [CrossRef]
- Zhang, R.; Jia, K.; Liu, P. Fast CU Size Decision Using Machine Learning for Depth Map Coding in 3D-HEVC. In Proceedings of the 2020 Data Compression Conference (DCC), Snowbird, UT, USA, 24–27 March 2020; p. 405. [Google Scholar]
- Fu, C.-H.; Chen, H.; Chan, Y.-L.; Tsang, S.-H.; Hong, H.; Zhu, X. Fast Depth Intra Coding Based on Decision Tree in 3D-HEVC. IEEE Access 2019, 7, 173138–173147. [Google Scholar] [CrossRef]
- Peng, B.; Chang, R.; Pan, Z.; Li, G.; Ling, N.; Lei, J. Deep In-Loop Filtering via Multi-Domain Correlation Learning and Partition Constraint for Multiview Video Coding. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 1911–1921. [Google Scholar] [CrossRef]
- Liu, C.; Jia, K.; Liu, P.; Sun, Z. Fast Depth Intra Coding Based on Layer-Classification and CNN for 3D-HEVC. In Proceedings of the 2020 Data Compression Conference (DCC), Snowbird, UT, USA, 24–27 March 2020; p. 381. [Google Scholar]
- Zhang, J.; Hou, Y.; Zhang, Z.; Jin, D.; Zhang, P.; Li, G. Deep region segmentation-based intra prediction for depth video coding. Multimed. Tools Appl. 2022, 81, 35953–35964. [Google Scholar] [CrossRef]
- Xie, S.; Tu, Z. Holistically-Nested Edge Detection. Int. J. Comput. Vis. 2017, 125, 3–18. [Google Scholar] [CrossRef]
- Guo, L.; Tian, X.; Chen, Y. Simplified depth intra coding for 3D-HEVC based on gray-level co-occurrence matrix. In Proceedings of the 2016 IEEE International Conference on Signal and Image Processing (ICSIP), Beijing, China, 13–15 August 2016; pp. 328–332. [Google Scholar]
- Chen, J.; Liao, J.; Zuo, J.; Zeng, H.; Cai, C.; Ma, K.-K. Fast Depth Intra-Coding for 3D-HEVC based on Gray-Level Co-occurrence Matrix. J. Imaging Sci. Technol. 2019, 63, 30406. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural Features for Image Classification. IEEE Trans. Syst. 1973, 6, 610–621. [Google Scholar]
- Chen, J.; Sun, H.; Katto, J.; Zeng, X.; Fan, Y. Fast QTMT Partition Decision Algorithm in VVC Intra Coding based on Variance and Gradient. In Proceedings of the 2019 IEEE Visual Communications and Image Processing (VCIP), Sydney, Australia, 1–4 December 2019; pp. 1–4. [Google Scholar]
- Qian, X.; Zeng, Y.; Wang, W.; Zhang, Q. Co-Saliency Detection Guided by Group Weakly Supervised Learning. IEEE Trans. Multimed. 2023, 25, 1810–1818. [Google Scholar] [CrossRef]
- Otroshi-Shahreza, H.; Amini, A.; Behroozi, H. Feature-based no-reference video quality assessment using Extra Trees. IET Image Process. 2022, 16, 1531–1543. [Google Scholar] [CrossRef]
- Park, S.; Kang, J.-W. Fast Multi-Type Tree Partitioning for Versatile Video Coding Using a Lightweight Neural Network. IEEE Trans. Multimed. 2021, 23, 4388–4399. [Google Scholar] [CrossRef]
- Li, Q.; Meng, H.; Li, Y. Texture-based fast QTMT partition algorithm in VVC intra coding. Signal Image Video Process. 2023, 17, 1581–1589. [Google Scholar] [CrossRef]
- Bjontegaard, G. Calculation of Average PSNR Differences Between RD Curves. In Proceedings of the ITU SG16 Doc. VCEG-M33, Austin, TX, USA, 2–4 April 2001. [Google Scholar]
- Huo, J.; Zhou, X.; Yuan, H.; Wan, S.; Yang, F. Fast Rate-Distortion Optimization for Depth Maps in 3-D Video Coding. IEEE Trans. Broadcast. 2023, 69, 21–32. [Google Scholar] [CrossRef]
- Zhang, H.; Yao, W.; Huang, H.; Wu, Y.; Dai, G. Adaptive coding unit size convolutional neural network for fast 3D-HEVC depth map intracoding. J. Electron. Imag. 2021, 30, 4. [Google Scholar] [CrossRef]
- Hamout, H.; Elyousfi, A. A Computation Complexity Reduction of the Size Decision Algorithm in 3D-HEVC Depth Map Intracoding. Adv. Multimed. 2022, 2022, 3507201. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video Sequences | Resolution | 3-Views Input | Frame Rate | Frames to Be Encoded |
|---|---|---|---|---|
| Undo_Dancer | 1920 × 1088 | 1-5-9 | 25 | 250 |
| Poznan_Hall2 | 7-6-5 | 25 | 200 | |
| Poznan_Street | 5-4-3 | 25 | 250 | |
| Shark | 1-5-9 | 30 | 300 | |
| GT-Fly | 9-5-1 | 25 | 250 | |
| Kendo | 1024 × 768 | 1-3-5 | 30 | 300 |
| Balloons | 1-3-5 | 30 | 300 | |
| Newspaper | 2-4-6 | 30 | 300 |
| Parameter Name | Model Setting |
|---|---|
| Number of features | 5 |
| Min_samples_of leaf | 10 |
| Max depth | 10 |
| Number of labels | 3 |
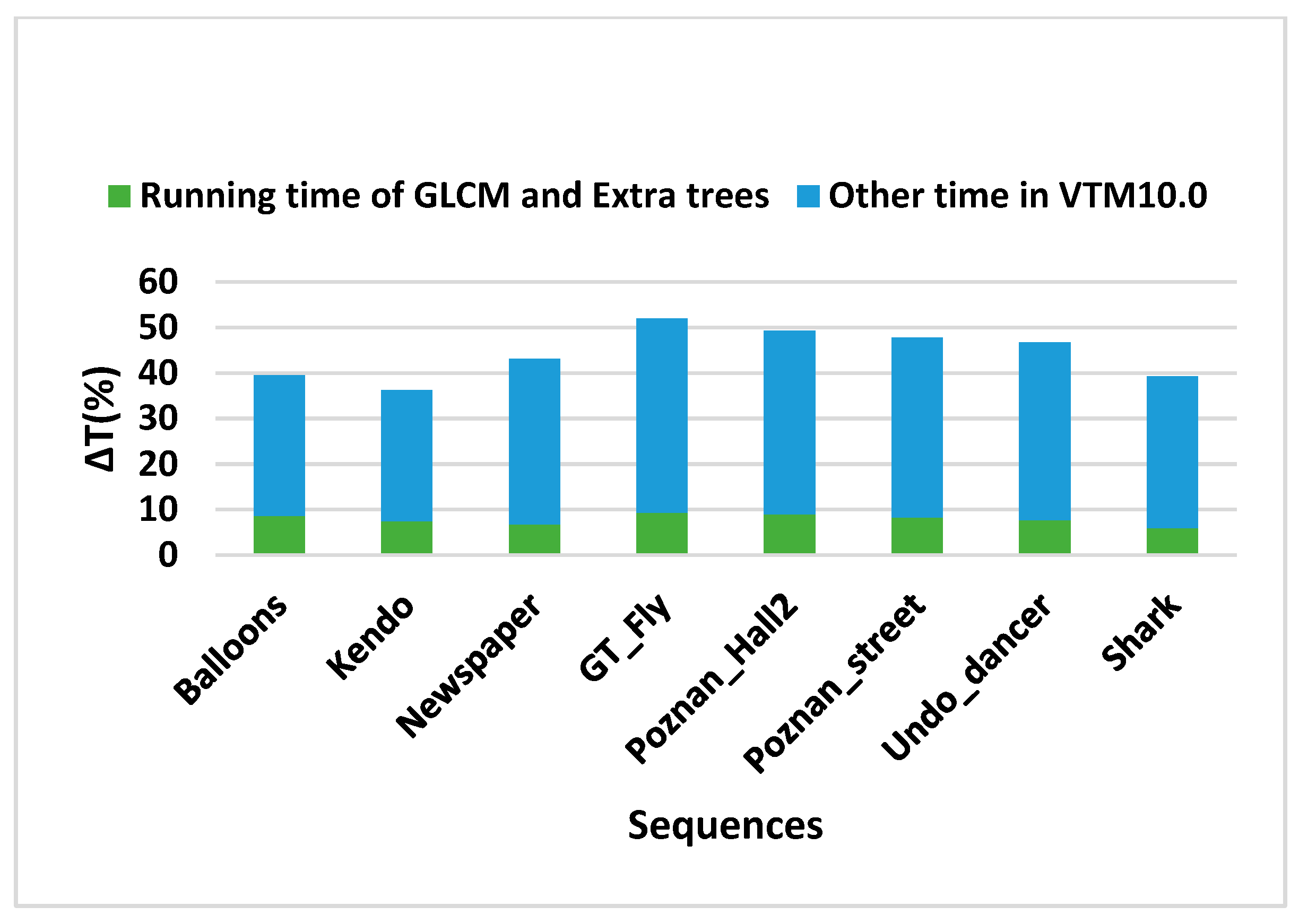
| Sequence | GLCM | Extra Trees | Overall | |||
|---|---|---|---|---|---|---|
| BDBR (%) | (%) | BDBR (%) | (%) | BDBR (%) | (%) | |
| Balloons | 0.25 | 23.09 | 0.24 | 33.21 | 0.18 | 39.45 |
| Kendo | 0.12 | 31.25 | 0.21 | 31.04 | 0.16 | 36.27 |
| Newspaper | 0.24 | 26.41 | 0.35 | 34.72 | 0.39 | 43.09 |
| GT_Fly | 0.19 | 51.18 | 0.28 | 40.71 | 0.31 | 51.98 |
| Poznan_Hall2 | 0.38 | 41.77 | 0.31 | 36.24 | 0.32 | 49.33 |
| Poznan_street | 0.21 | 38.35 | 0.16 | 39.83 | 0.18 | 47.81 |
| Undo_dancer | 0.29 | 37.49 | 0.37 | 35.69 | 0.29 | 46.74 |
| Shark | 0.16 | 36.57 | 0.17 | 37.02 | 0.14 | 39.27 |
| 1024 × 768 | 0.2 | 26.92 | 0.27 | 32.99 | 0.24 | 39.6 |
| 1920 × 1088 | 0.25 | 41.07 | 0.26 | 37.9 | 0.25 | 47.03 |
| Average | 0.23 | 35.76 | 0.26 | 36.06 | 0.25 | 44.24 |
| Sequence | Huo [39] | Zhang [40] | Hamout [41] | Proposed | ||||
|---|---|---|---|---|---|---|---|---|
| BDBR (%) | (%) | BDBR (%) | (%) | BDBR (%) | (%) | BDBR (%) | (%) | |
| Balloons | 0.14 | 27.9 | 0.30 | 22.3 | 0.12 | 32.9 | 0.18 | 39.45 |
| Kendo | 0.11 | 28.2 | 0.50 | 32.4 | 0.17 | 35.2 | 0.16 | 36.27 |
| Newspaper | 0.10 | 24.1 | 0.70 | 25.6 | 0.08 | 32.3 | 0.39 | 43.09 |
| GT_Fly | 0.05 | 23.5 | 0.80 | 51.7 | 0.08 | 35.0 | 0.31 | 51.98 |
| Poznan_Hall2 | 0.06 | 27.6 | 0.40 | 42.7 | 0.39 | 51.6 | 0.32 | 49.33 |
| Poznan_street | 0.05 | 23.1 | 0.50 | 38.4 | 0.26 | 41.6 | 0.18 | 47.81 |
| Undo_dancer | 0.01 | 20.3 | 1.00 | 36.4 | 0.29 | 49.3 | 0.29 | 46.74 |
| Shark | 0.03 | 23.4 | 0.30 | 36.0 | 0.26 | 44.0 | 0.14 | 39.27 |
| Average | 0.07 | 24.8 | 0.55 | 35.7 | 0.21 | 40.2 | 0.24 | 44.24 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, F.; Wang, Z.; Zhang, Q. Efficient CU Decision Algorithm for VVC 3D Video Depth Map Using GLCM and Extra Trees. Electronics 2023, 12, 3914. https://doi.org/10.3390/electronics12183914
Wang F, Wang Z, Zhang Q. Efficient CU Decision Algorithm for VVC 3D Video Depth Map Using GLCM and Extra Trees. Electronics. 2023; 12(18):3914. https://doi.org/10.3390/electronics12183914
Chicago/Turabian StyleWang, Fengqin, Zhiying Wang, and Qiuwen Zhang. 2023. "Efficient CU Decision Algorithm for VVC 3D Video Depth Map Using GLCM and Extra Trees" Electronics 12, no. 18: 3914. https://doi.org/10.3390/electronics12183914