In recent years, video coding technology has advanced rapidly, resulting in a significant increase in video resolution. This progress has also led to increasingly detailed image textures. Only the QT partition structure is included in HEVC, but the QTMT partition structure is included in VVC. At the same time, the diversity of QTMT partition structures has led to a significant increase in coding complexity. This significant increase in coding complexity poses a significant barrier to the generalization of practical applications. In order to effectively reduce the coding complexity, efforts are being made to optimize the coding complexity without compromising the coding efficiency. This section analyses the partition structure characteristics of the QTMT using relevant experimental data and proposes an efficient framework for fast CU partitioning within VVC frames. This section consists of four parts.
Section 3.1 discusses decision analysis,
Section 3.2 discusses texture feature analysis and selection,
Section 3.3 discusses model construction and training, and finally
Section 3.4 gives the overall algorithm framework.
3.1. Decision Analysis
Table 1 provides the distribution of CU sizes in VTM-10.0 [
25].
Table 1 clearly indicates that no segmentation (NS) is the preferred option for the majority of CU sizes. TT_H and TT_V partitioning only account for a small proportion, whereas horizontal and vertical partitioning together account for a larger proportion.
It is well known that early termination of the partitioning of partial CUs can effectively reduce coding complexity. Therefore, this section describes the classifiers and features used in the proposed framework for intra-VVC fast CU partitioning. The algorithm uses DT as a classifier and uses the classifier to predict the CU partition. This algorithm significantly reduces the complexity of encoding. Next, we propose several frameworks for classic VVC fast CU partition decision algorithms. The advantages and disadvantages of each are analyzed. Finally, we propose a cascaded partition decision framework that can effectively balance predictive accuracy and practicality.
In study [
30], a classical VVC fast CU decision early termination framework is proposed. The framework first performs an in-frame prediction of the CU at the current depth and subsequently uses coding information such as RD cost and coding mode to decide whether to terminate the division process. If the division is terminated, all division patterns are skipped; if the division continues, all candidate division methods are traversed in turn. The framework treats the division judgement as a binary classification problem. Sufficient classification information is obtained through intra-frame prediction to improve the results. Although the algorithm does not affect the encoding result, this approach has very limited ability to reduce complexity. Firstly, intra-frame prediction is required for each decision layer. However, for intermediate decision layers that require further segmentation, intra-frame prediction becomes redundant at this stage. Secondly, intermediate nodes that continue to divide must evaluate all remaining division patterns, even though the encoder will ultimately choose only one option. Thus, redundancy persists in the process.
The framework proposed in study [
31] builds on the work of [
30], introducing a partitioning pattern selection framework for multi-class classifiers. Before performing in-frame prediction, the framework determines whether the CU needs to be further subdivided into sub-CUs. If no partitioning is required, it pre-evaluates the current CU to the optimal size, terminates all partitioning, and continues with in-frame pattern prediction for the current CU. When partitioning is required, multiple classifiers are used to select one of the various partitioning candidate patterns, effectively bypassing the remaining partitioning methods and intra-pattern prediction for the current CU layer. The framework’s fast algorithm significantly reduces redundancy in the coding unit selection process at the cost of a large loss in coding performance. The main factor contributing to this is the expansion of the division patterns in QTMT, which greatly complicates the decision process. The selection of a single pattern often leads to relatively low prediction accuracy and ultimately to higher coding losses.
To strike a balance between decision accuracy and complexity reduction, a parallel decision framework was introduced in the literature [
32]. This framework constructs parallel decision models for both QT division and MT division. The division termination judgement is first made for both QT and MT. If the judgment confirms termination, the intra-frame pattern prediction of the current CU is not skipped. When the MT segmentation process is not terminated, a multi-class classifier is used to select the type of MT segmentation. In this framework, QT is considered as a different division method from MT and is determined independently. Furthermore, the parallel structure implemented in this approach helps to reduce the risk of prediction errors. However, the parallel structure still falls short in terms of optimization complexity, leaving room for further improvements.
We next discuss our proposed fast CU partition decision framework. First, the framework judges whether the current CU needs to be divided after extracting features. If not, the CU immediately terminates the division and bypasses all partition types. If dividing, it continues to determine whether QT dividing is required. In the case of a QT division, all MT divisions are ignored. Otherwise, QT partition is skipped and MT partition is performed. In summary, this framework effectively solves the multi-classification problem in QTMT, allowing the model to focus on evaluating specific patterns and improving prediction accuracy. By selecting appropriate classifiers, the VVC fast CU early termination framework achieves greater complexity reduction while maintaining the small loss of coding performance.
3.2. Analysis and Selection of Texture Features
The algorithm in this paper uses a decision framework based on decision tree classifiers to create a partitioned decision model by decomposing the QTMT decision process into multiple binary classification problems. During the encoding process, the classifier can accurately determine the CU partition type and the complexity reduction of the classifiers is critical for partitioning decisions. Choosing an appropriate classifier is crucial. After careful analysis, a decision tree was finally chosen as the classifier for this algorithm. Decision trees as classifiers have the following advantages:
Can handle non-linear classification problems well;
Have a built-in mechanism for handling missing values and outliers;
Provide feature importance ranking;
Can handle large datasets efficiently.
Our data come from a wide range of video sequences; some of these features can be extracted directly during the encoding process, whereas other features are integrated into the VTM encoder. These features contain three main categories of information: local texture information, global texture information, and encoding information.
The global texture is characterized by the variance (var) of the current CU, as well as the horizontal gradient (Gx) and vertical gradient (Gy) calculated using the Sobel operator. In addition, the ratio of Gx to Gy (ratioGxGy) and the normalized gradients obtained by dividing Gx and Gy by the sum of the block areas (normGradient) are also considered.
The decision on MT partitioning is influenced by local texture features, which emphasizes the importance of overall and local texture descriptions within the CU. We introduced two local texture features: The absolute variance between the upper and lower regions of the CU is referred to as “diffVarHor”, whereas the absolute difference between the left and right regions of the CU is denoted as “diffVarVer”.
As the evaluation of NS takes precedence over the evaluation of QT and MT segmentations, we prioritize multiple encoding attributes derived from the current CU to determine the appropriate segmentation type. As the segmentation types are performed sequentially, each subsequent segmentation can make use of the information computed from the previous segmentation. The coding information consists of RD cost (currCost) and distortion (currDistortion).
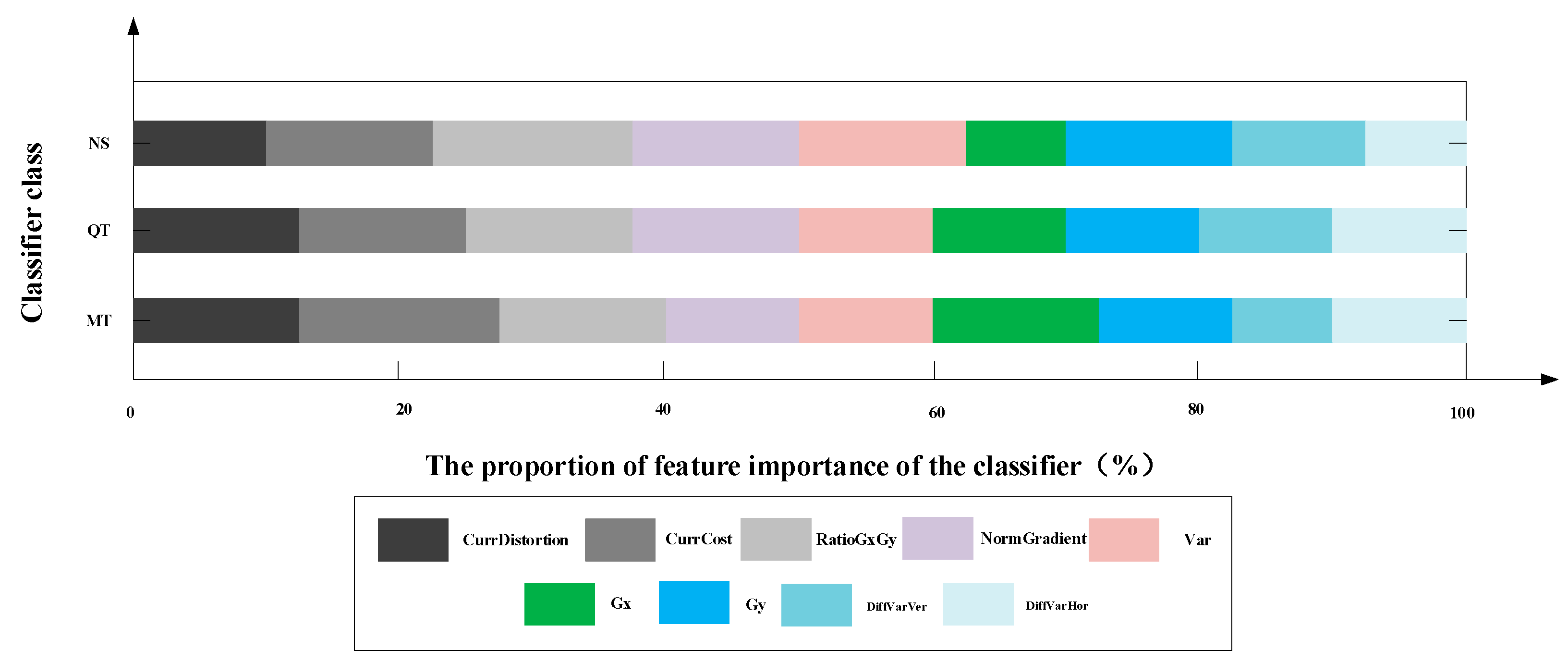
Figure 2 illustrates the importance of each classifier feature.
Figure 2 demonstrates that the features related to RD cost (CurrCost and CurrDistortion) are of utmost importance, followed by the texture information.
3.3. Model Building and Training
In order to improve accuracy and to solve over- and under-fitting problems, several hyperparameters were introduced to be combined into the classifier to be optimized. Hyperparameter optimization can improve the performance of a classifier. When optimizing the hyperparameters, manual adjustment of the parameters is a tedious process. Therefore, automatic parameter tuning tools were utilized to simplify the process and provide approximate results at an early stage. These tools are designed to determine the appropriate parameter intervals for effective optimization. Optuna is a tool that automatically searches for the most balanced combination of parameters within a predefined parameter grid. By utilizing Optuna, the optimal parameter settings can be determined more easily.
The key parameters for classifier optimization are as follows:
max_depth: This hyperparameter determines the maximum depth of the decision tree. By setting a suitable max_depth value, the complexity of the tree can be controlled and over-fitting can be prevented;
min_samples_split: This hyperparameter sets the minimum number of samples required to further split the internal nodes. Adding min_samples_split regularizes the tree and prevents overfitting by ensuring that a minimum number of samples are present when the split occurs;
min_samples_leaf: The minimum number of samples required for internal node subdivision. Adjusting min_samples_leaf can affect the generalization ability of the tree;
The maximum number of features to consider for each split (max_features): The maximum number of features when looking for the best split in an internal node. By limiting the number of features, the risk of overfitting can be reduced;
Criterion: This hyperparameter determines the metric used to split the nodes in the decision tree.
In video coding, the partitioning of CUs is treated as several binary classification problems. In order to solve such problems, we adopt the CART algorithm as the basic decision tool of the decision tree classifier. This enables us to build a model that predicts the outcome of CU partitioning. CART constructs a binary tree by generating features and thresholds corresponding to the minimum Gini coefficient for each node. Assuming that there are
k categories in total, the probability that the sample point belongs to the kth category is expressed as
. In this case, the Gini index of the probability distribution is defined by the following formula:
represents the probability that the selected sample belongs to category k, and the probability that the sample is misclassified is .
We will select the attribute with the smallest Gini coefficient from the candidate attribute set A as the optimal partition attribute. When we divide a dataset
D using a specific possible value a of attribute
A, we can calculate the Gini coefficients of the sets
D1 and
D2 divided under the conditions of feature
A. Under the conditions of feature
A, the definition formula of the Gini coefficient of set
D is as follows:
Next, we describe the process of classifier offline training, which involves the following steps:
Step 1: Select 40 frames from each video sequence and encode them with a full intra-frame profile. We split them into a sample set of the first 20 frames and a test set of the last 20 frames.
Step 2: For the current node, the training dataset is recorded as D and we continue to calculate the Gini index corresponding to the dataset. We consider each feature A, and for each possible value a, we divide D into two subsets, D1 and D2, according to whether the test at the sample point A = a yields a “yes” or “no” response. Then, we use formula 2 to calculate the Gini coefficient when A = a.
Step 3: From all possible features A and their potential segmentation points a, find the feature with the smallest Gini coefficient and its corresponding optimal segmentation point. With the optimal features and split points, we generate two child nodes from the current node and assign the training dataset to each child node according to their respective features.
Step 4: Call step 1 and step 2 recursively on the two child nodes and continue to repeat the above steps until the training of N decision trees is completed.
Step 5: Use the classifier to classify the current sample; each tree evaluates the classification results individually. The final classification result is determined by the prediction with the most number of identical judgments in the tree. This process yields an optimal partitioning pattern for the CU.
Table 2 illustrates the training parameters of the decision tree classifier. The training set comes from some video sequences for the JVET official standard test sequence set, including “ParkScene”, “RaceHorses”, “BQMall”, and “Johnny”.
After training the classifier, the next step involves evaluating the accuracy of the classifier. We adopt the AUC-ROC curve as the visual performance metric because it provides a comprehensive measure of classification performance at different threshold settings. It quantifies the effectiveness of the model in distinguishing between different classes.
Figure 3 demonstrates the superior performance of our NS and QT classifiers on the test set. The AUC-ROC curves further confirm the accuracy of our predictions, showing a strong agreement between the test and predicted values. These results demonstrate that our classifier excels in accurately predicting the CU partition types, providing high-performance results.
Figure 4 depicts the training and implementation process of the decision tree classifier within the VTM encoder, as illustrated in the framework. After feature extraction, it is used for classifier training. The VTM encoder was modified to collect multiple statistics containing information related to CU partitioning decisions. This process generates a dataset specific to each partition type. The dataset comprises encoder properties, video encoding sequences, and relevant features for partitioning decisions. In the preprocessing step, the dataset is first balanced and then key features are selected. These selected features serve as the input for training the classifiers. The training process of the model consists of the hyperparameter optimization and separate training of the classifier. Finally, the improved VTM encoder is evaluated for encoding time and efficiency savings. The encoder incorporates a decision tree classifier for QTMT partition determination but does not perform a full RDO process.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}