
Attention-Mechanism-Based Models for Unconstrained Face Recognition with Mask Occlusion

Abstract
:1. Introduction
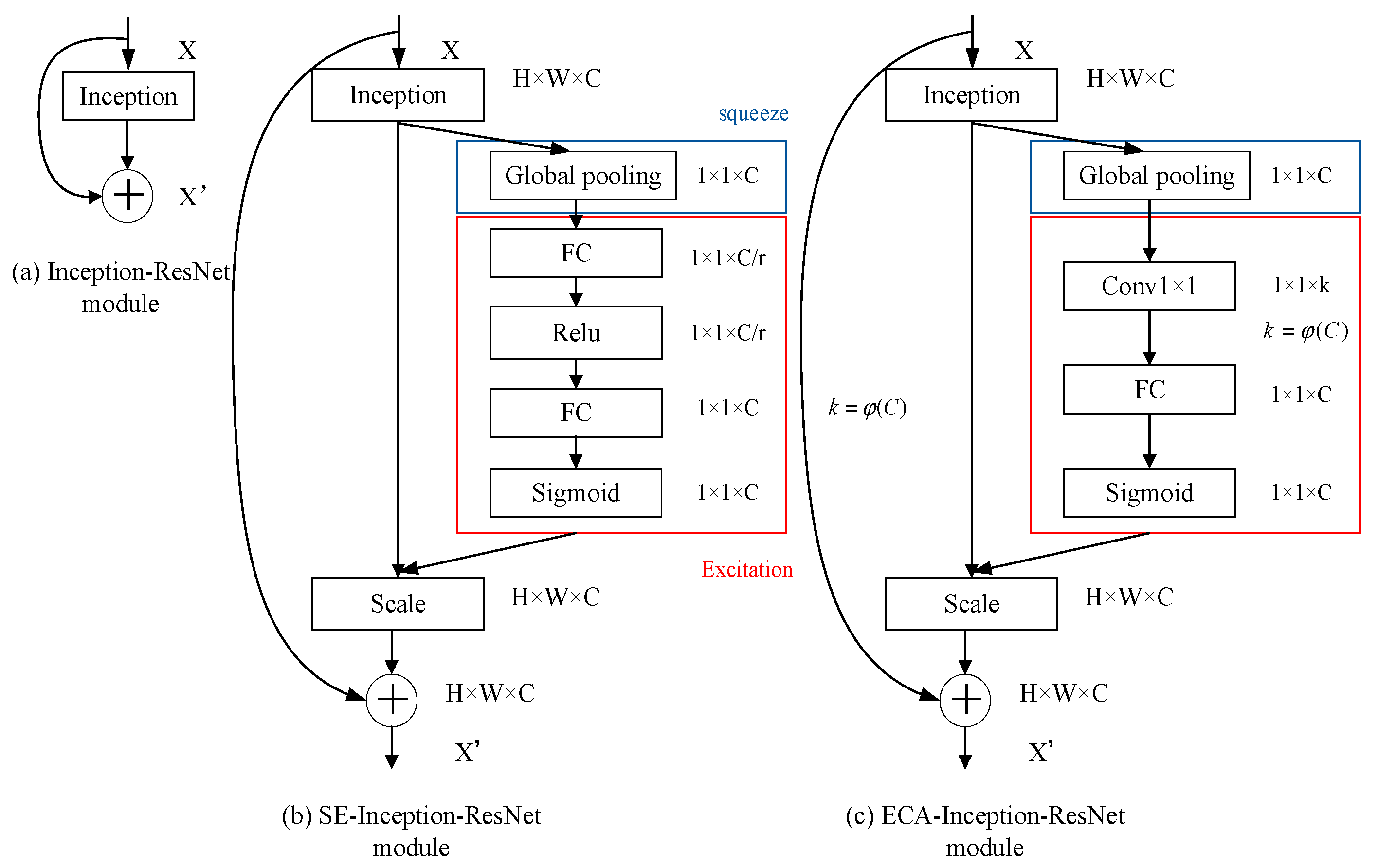
- We propose incorporating the SE attention module into the Inception-Resnet-v1 network structure to obtain more discriminative deep face features. This is achieved by changing the network structure, increasing the weights of non-occluded regions and decreasing the weights of occluded regions.
- In order to increase the attention of non-occluded face areas, we propose the embedding of the ECA module into Inception-Resnet-v1. The ECA module helps capture key information from the input and improves the generalization capability of the model.
- By taking advantage of both the CNN and capsule network, we propose the ECA-Inception-Resnet-Caps framework to further enhance the performance and generalization of mask-occluded face recognition. Experimental results on different loss settings show the effectiveness of the proposed ECA-Inception-Resnet-Caps.
2. Related Work
2.1. Inception-Resnet-v1 Network
2.2. Attention Mechanism
2.2.1. SE Attention Mechanism
2.2.2. ECA Attention Mechanism
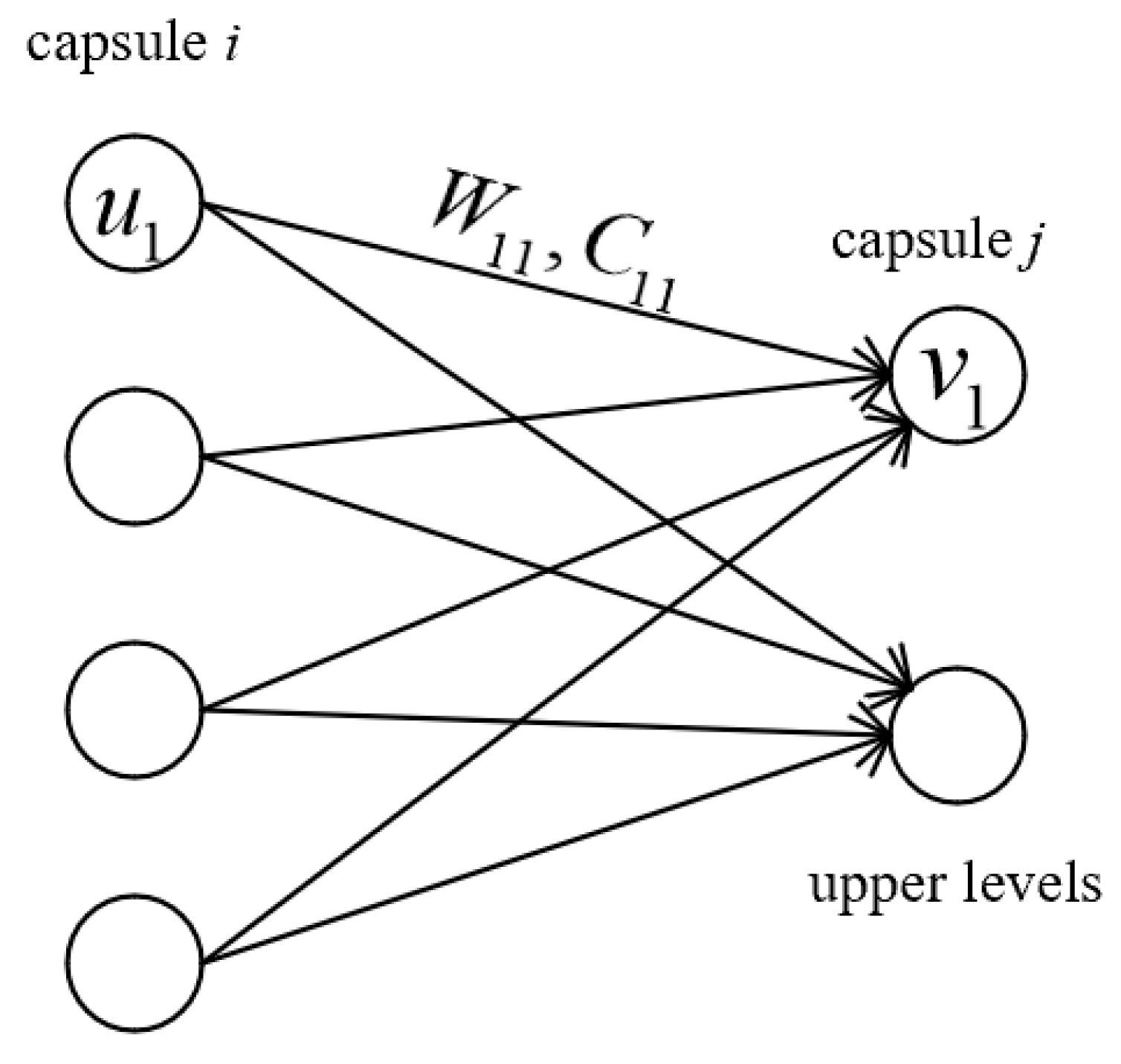
2.2.3. Capsule Network
3. Proposed Models and Methods
3.1. SE-Based Attention Network
3.2. ECA-Based Attention Network
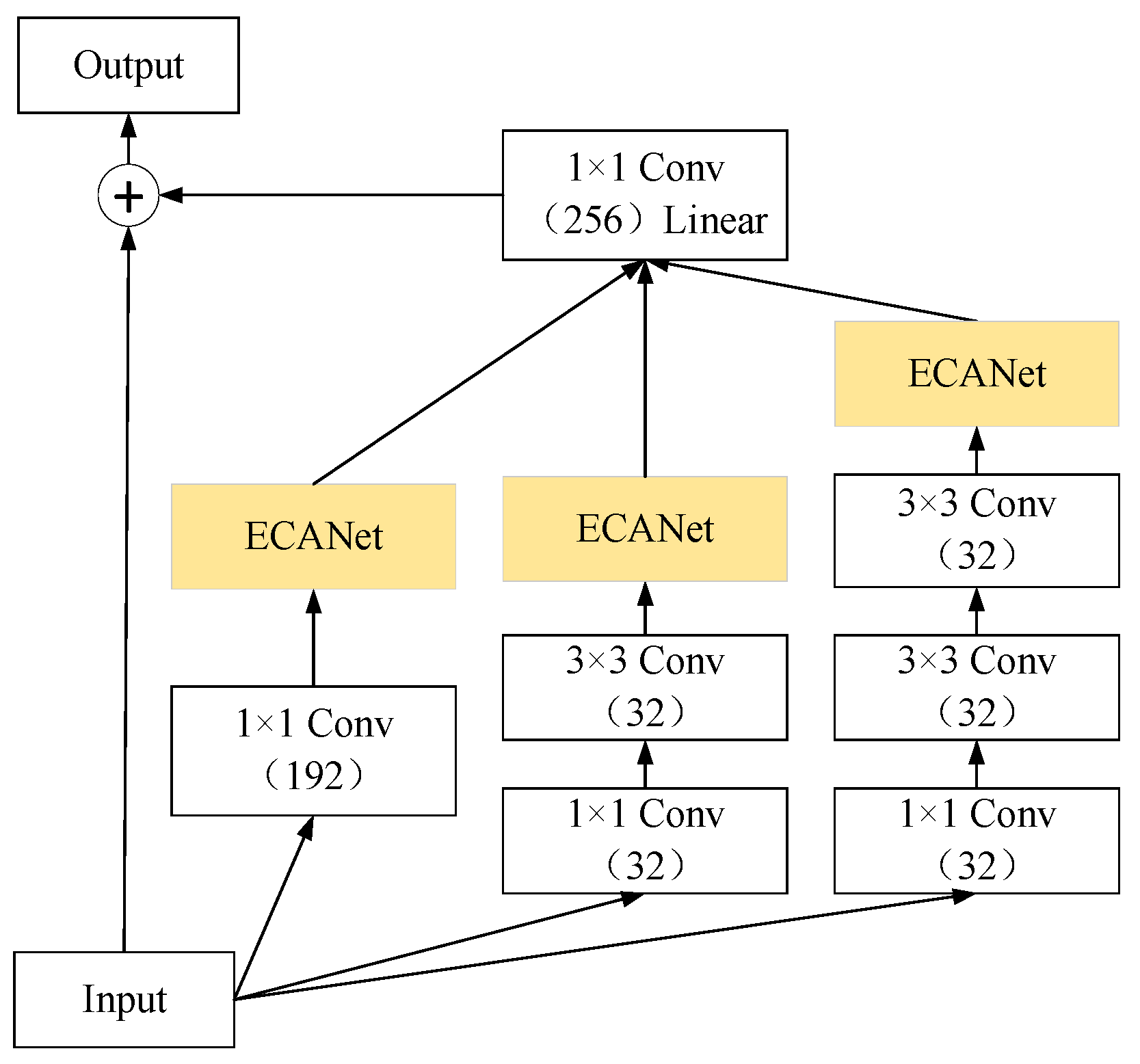
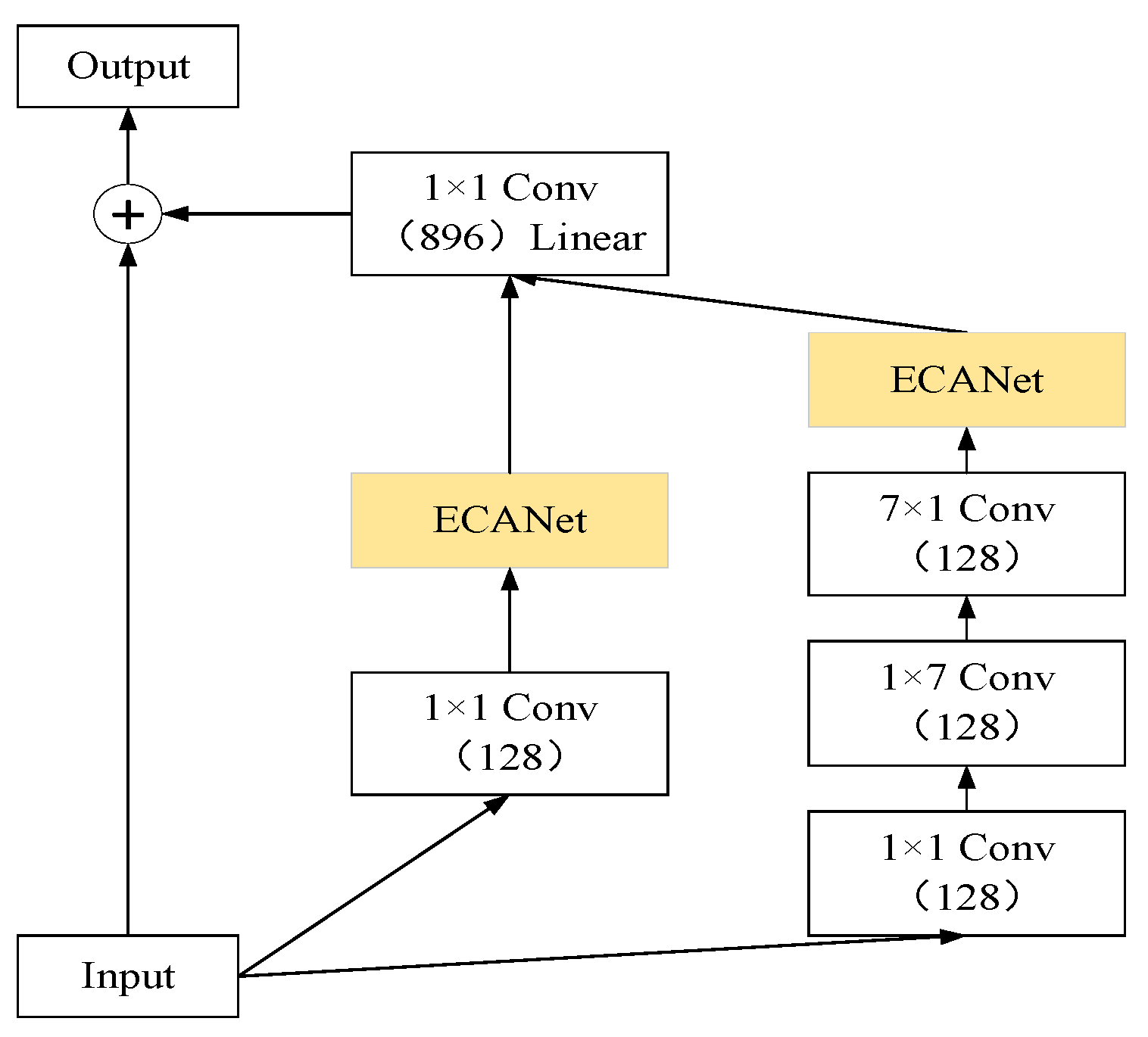
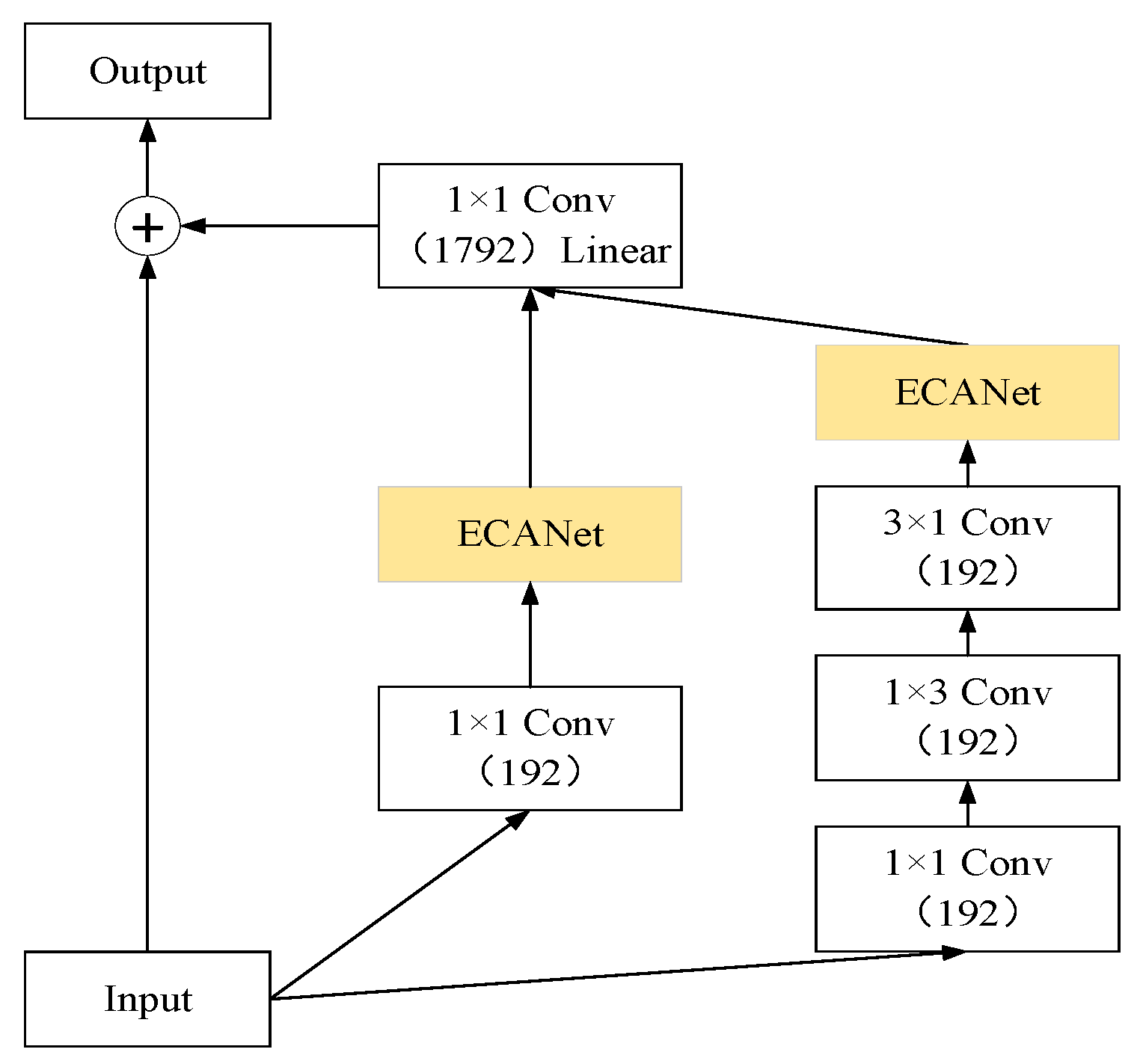
3.3. EIRC Network
4. Experiments
4.1. Experimental Setup
4.2. Employed Datasets
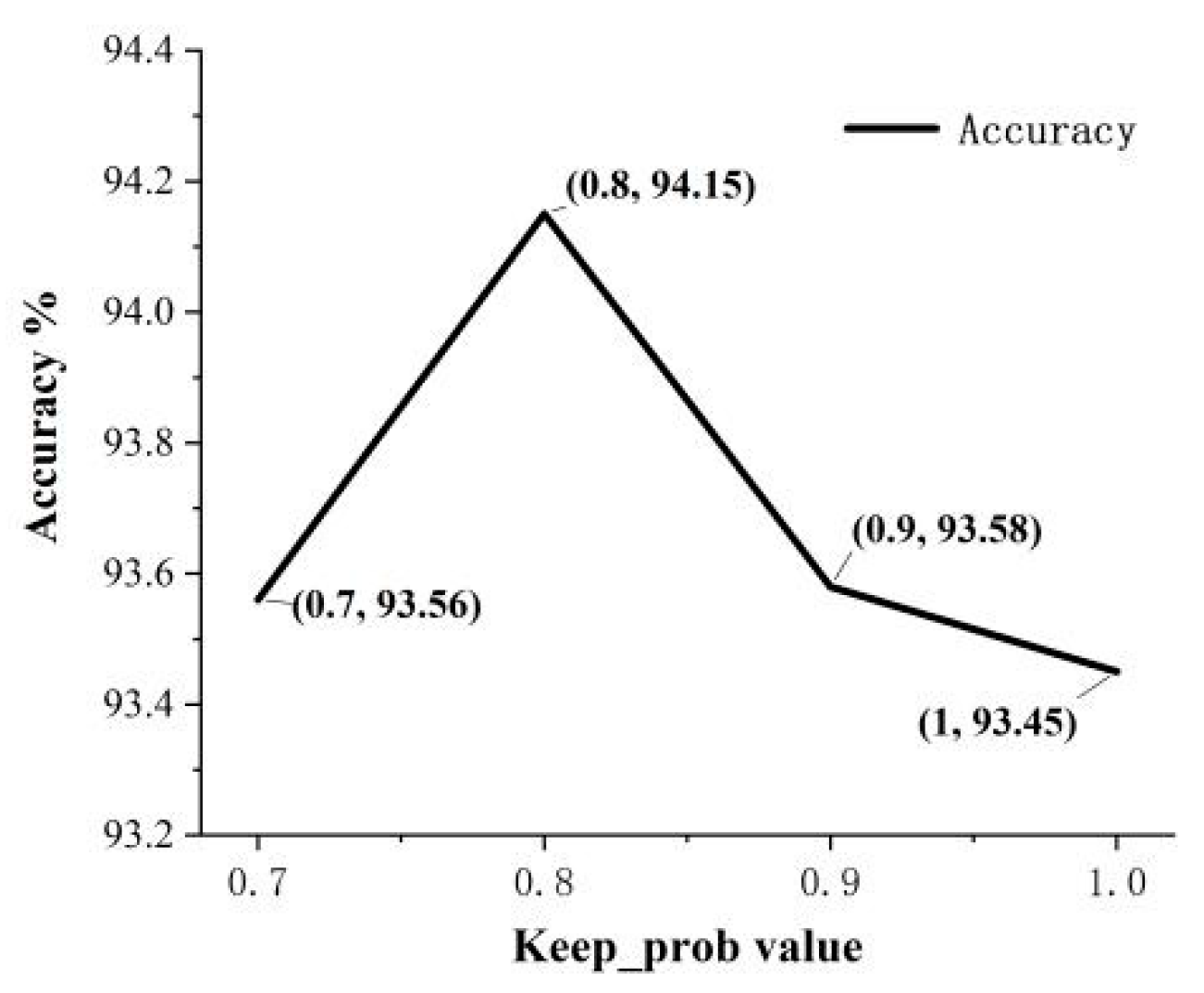
4.3. Evaluation Criteria and Parameters
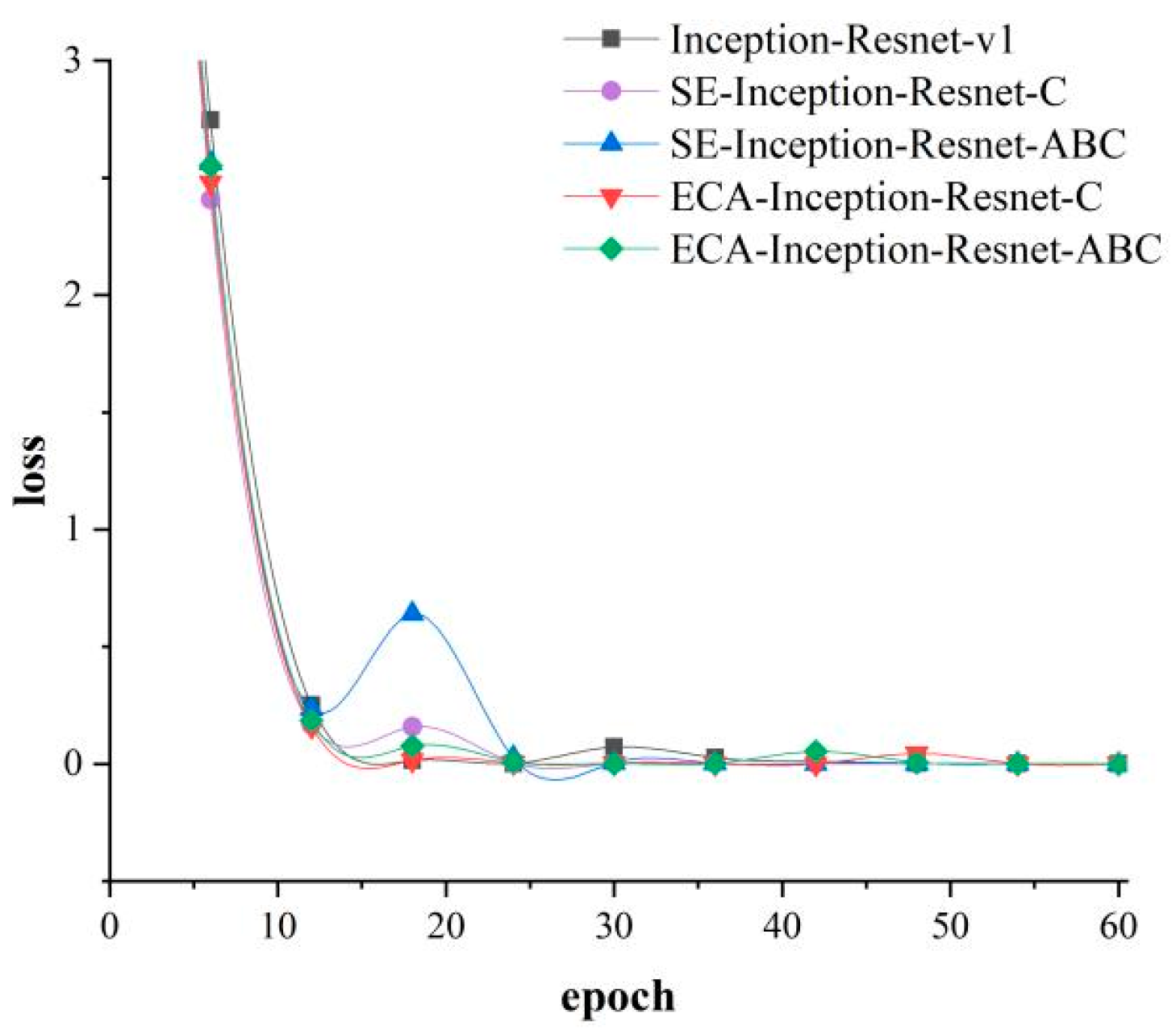
4.4. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Damer, N.; Grebe, J.H.; Chen, C.; Boutros, F.; Kirchbuchner, F.; Kuijper, A. The effect of wearing a mask on face recognition performance: An exploratory study. In Proceedings of the 2020 International Conference of the Biometrics Special Interest Group, Darmstadt, Germany, 16–18 September 2020; pp. 1–6. [Google Scholar]
- Chen, C.; Sixiang, W.; Wenfeng, W. Research on face recognition system and standards for epidemic prevention and control. Inf. Technol. Stand. 2020, 6, 11–13. [Google Scholar]
- Yaoling, X.; Tao, L.; Guohui, T.; Wenjuan, Y.; Dajun, X.; Shapeng, L. Overview of face recognition methods in occlusive environments. Comput. Eng. Appl. 2021, 57, 46–60. [Google Scholar]
- Hemathilaka, S.; Aponso, A. A comprehensive study on occlusion invariant face recognition under face mask occlusion. arXiv 2022, arXiv:2201.09089. [Google Scholar] [CrossRef]
- Zhang, J.; Yan, X.; Cheng, Z.; Shen, X. A face recognition algorithm based on feature fusion. Concurr. Comput. Pract. Exp. 2022, 34, e5748. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, S. Deep partial occlusion facial expression recognition via improved cnn. In Proceedings of the International Symposium on Visual Computing, San Diego, CA, USA, 5–7 October 2020; Springer: Cham, Switzerland, 2020; pp. 451–462. [Google Scholar]
- Hariri, W. Efficient masked face recognition method during the COVID-19 pandemic. Signal Image Video Process. 2022, 16, 605–612. [Google Scholar] [CrossRef] [PubMed]
- Mandal, B.; Okeukwu, A.; Theis, Y. Masked face recognition using resnet-50. arXiv 2021, arXiv:2104.08997. [Google Scholar]
- Song, L.; Gong, D.; Li, Z.; Liu, C.; Liu, W. Occlusion robust face recognition based on mask learning with pairwise differential siamese network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Repbulic of Korea, 27 October–2 November 2019; pp. 773–782. [Google Scholar]
- Li, Y.; Guo, K.; Lu, Y.; Liu, L. Cropping and attention based approach for masked face recognition. Appl. Intell. 2021, 51, 3012–3025. [Google Scholar] [CrossRef] [PubMed]
- Deng, H.; Feng, Z.; Qina, G.; Lv, X.; Li, H.; Li, G. MFCosface: A masked-face recognition algorithm based on large margin cosine loss. Appl. Sci. 2021, 11, 7310. [Google Scholar] [CrossRef]
- Zeng, D.; Veldhuis, R.; Spreeuwers, L. A survey of face recognition techniques under occlusion. IET Biom. 2021, 10, 581–606. [Google Scholar] [CrossRef]
- Li, C.; Ge, S.; Zhang, D.; Li, J. Look through masks: Towards masked face recognition with de-occlusion distillation. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 3016–3024. [Google Scholar]
- Din, N.U.; Javed, K.; Bae, S.; Yi, J. A novel gan-based network for unmasking of masked face. IEEE Access 2020, 8, 44276–44287. [Google Scholar] [CrossRef]
- Deng, J.; Guo, J.; An, X.; Zhu, Z.; Zafeiriou, S. Masked face recognition challenge: The insightface track report. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1437–1444. [Google Scholar]
- Qi, D.; Hu, K.; Tan, W.; Yao, Q.; Liu, J. Balanced masked and standard face recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1497–1502. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; p. 31. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECANet: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Huang, G.B.; Mattar, M.; Berg, T.; Learned-Miller, E. Labeled faces in the wild: A database forstudying face recognition in unconstrained environments. In Proceedings of the Workshop on faces in’Real-Life’Images: Detection, Alignment, and Recognition, Marseille, France, 16 September 2008. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Patrick, M.K.; Adekoya, A.F.; Mighty, A.; Edward, B.Y. Capsule networks–A survey. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 1295–1310. [Google Scholar]
- Zhang, Z.; Ye, S.; Liao, P.; Liu, Y.; Su, G.; Sun, Y. Enhanced capsule network for medical image classification. In Proceedings of the 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society, Montreal, QC, Canada, 20–24 July 2020; pp. 1544–1547. [Google Scholar]
- Srivastava, S.; Khurana, P.; Tewari, V. Identifying aggression and toxicity in comments using capsule network. In Proceedings of the First Workshop on Trolling, Aggression and Cyberbullying, Santa Fe, NM, USA, 25 August 2018; pp. 98–105. [Google Scholar]
- Yi, D.; Lei, Z.; Liao, S.; Li, S.Z. Learning face representation from scratch. arXiv 2014, arXiv:1411.7923. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Anwar, A.; Raychowdhury, A. Masked face recognition for secure authentication. arXiv 2020, arXiv:2008.11104. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyper-Parameters | Setting |
|---|---|
| Optimizer | Adam |
| Learning rate | 0.0005 |
| Batch size | 128 |
| Epoch | 60 |
| Logits_margin | 0.5 |
| Logits_scale | 64 |
| Loss_method | Cross-entropy |
| weight decay | 0.0005 |
| Embed_length | 128 |
| Shuffle | 10,000/20,000 |
| Input shape | (112,112,3) |
| Method | Precision | Recall | F1 |
|---|---|---|---|
| Inception-Resnet-v1 | 92.09% | 90.03% | 91.02% |
| SE-Inception-Resnet-C | 93.49% | 92.00% | 92.79% |
| SE-Inception-Resnet-ABC | 93.07% | 91.01% | 92.01% |
| ECA-Inception-Resnet-C | 94.00% | 92.11% | 92.97% |
| ECA-Inception-Resnet-ABC | 93.28% | 91.88% | 92.55% |
| Method | Test Accuracy |
|---|---|
| Inception-Resnet-v1 | 92.9% |
| SE-Inception-Resnet-C | 93.82% |
| SE-Inception-Resnet-ABC | 93.63% |
| ECA-Inception-Resnet-C | 94.15% |
| ECA-Inception-Resnet-ABC | 94.03% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Zhang, Y.; Zhang, Q. Attention-Mechanism-Based Models for Unconstrained Face Recognition with Mask Occlusion. Electronics 2023, 12, 3916. https://doi.org/10.3390/electronics12183916
Zhang M, Zhang Y, Zhang Q. Attention-Mechanism-Based Models for Unconstrained Face Recognition with Mask Occlusion. Electronics. 2023; 12(18):3916. https://doi.org/10.3390/electronics12183916
Chicago/Turabian StyleZhang, Mengya, Yuan Zhang, and Qinghui Zhang. 2023. "Attention-Mechanism-Based Models for Unconstrained Face Recognition with Mask Occlusion" Electronics 12, no. 18: 3916. https://doi.org/10.3390/electronics12183916