
Analysis of Backchannel Inviting Cues in Dyadic Speech Communication



Abstract
:1. Introduction
2. Slovak Dialogue Corpus with Backchannels
2.1. Data Acquisition
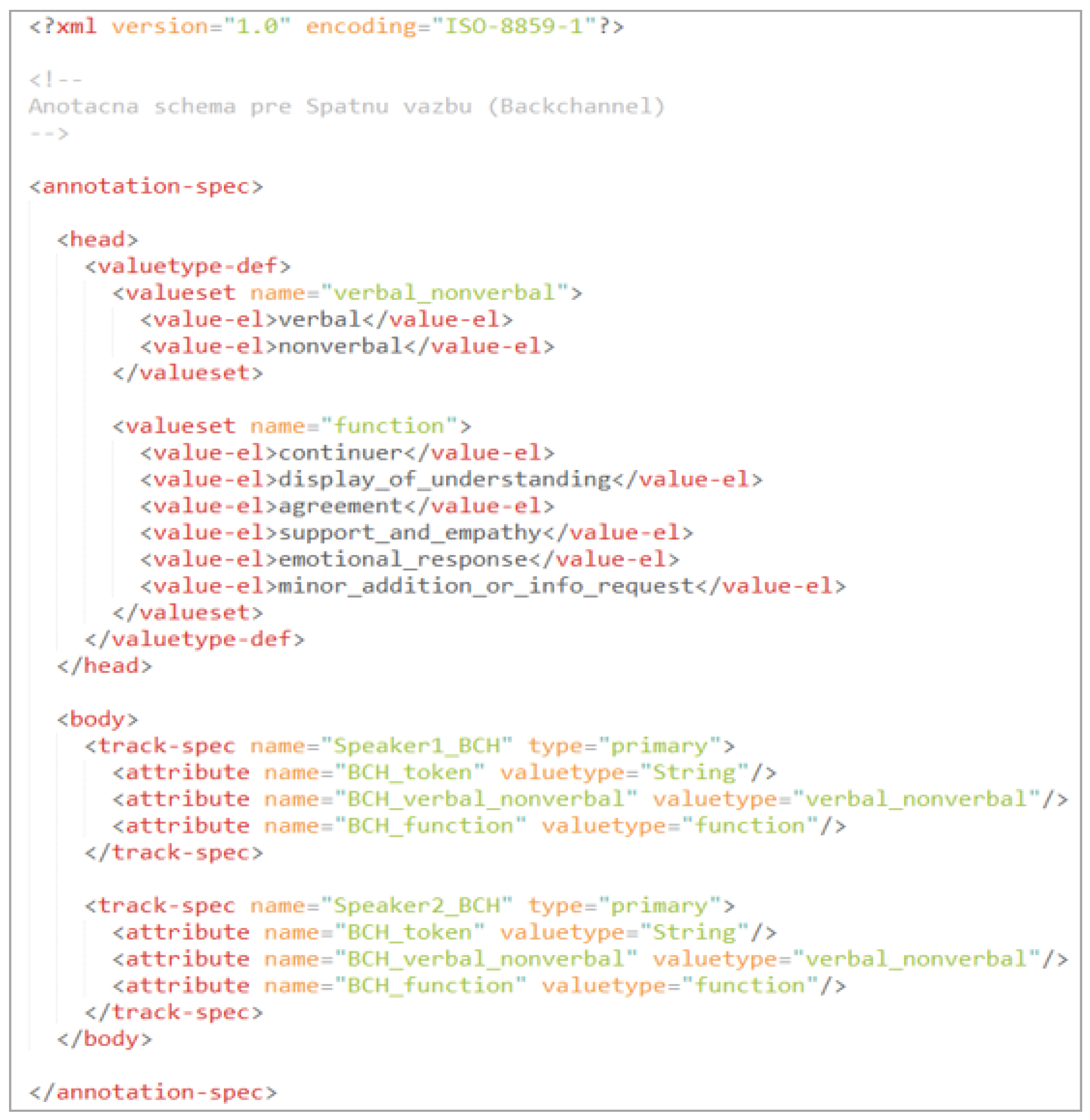
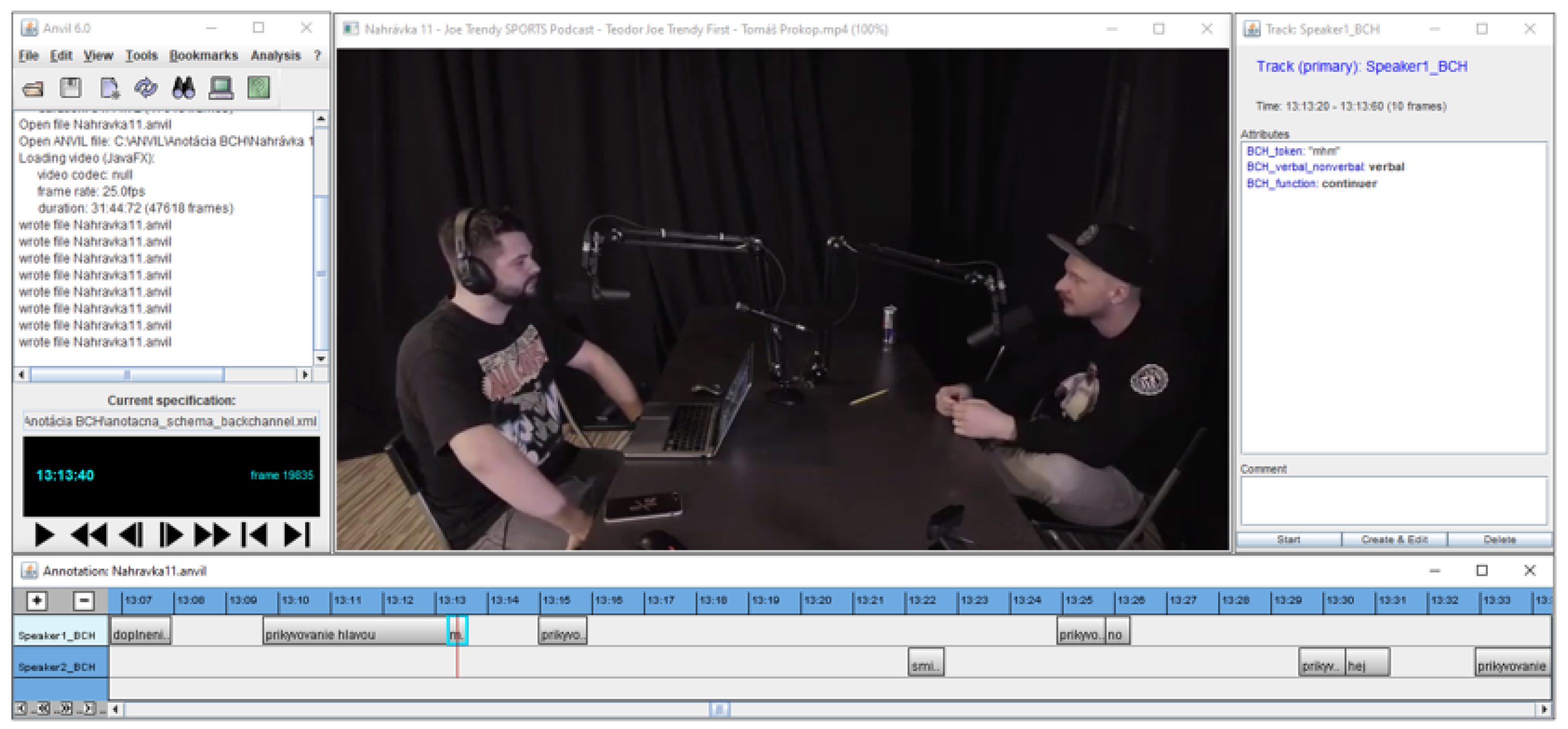
2.2. Backchannel Annotation
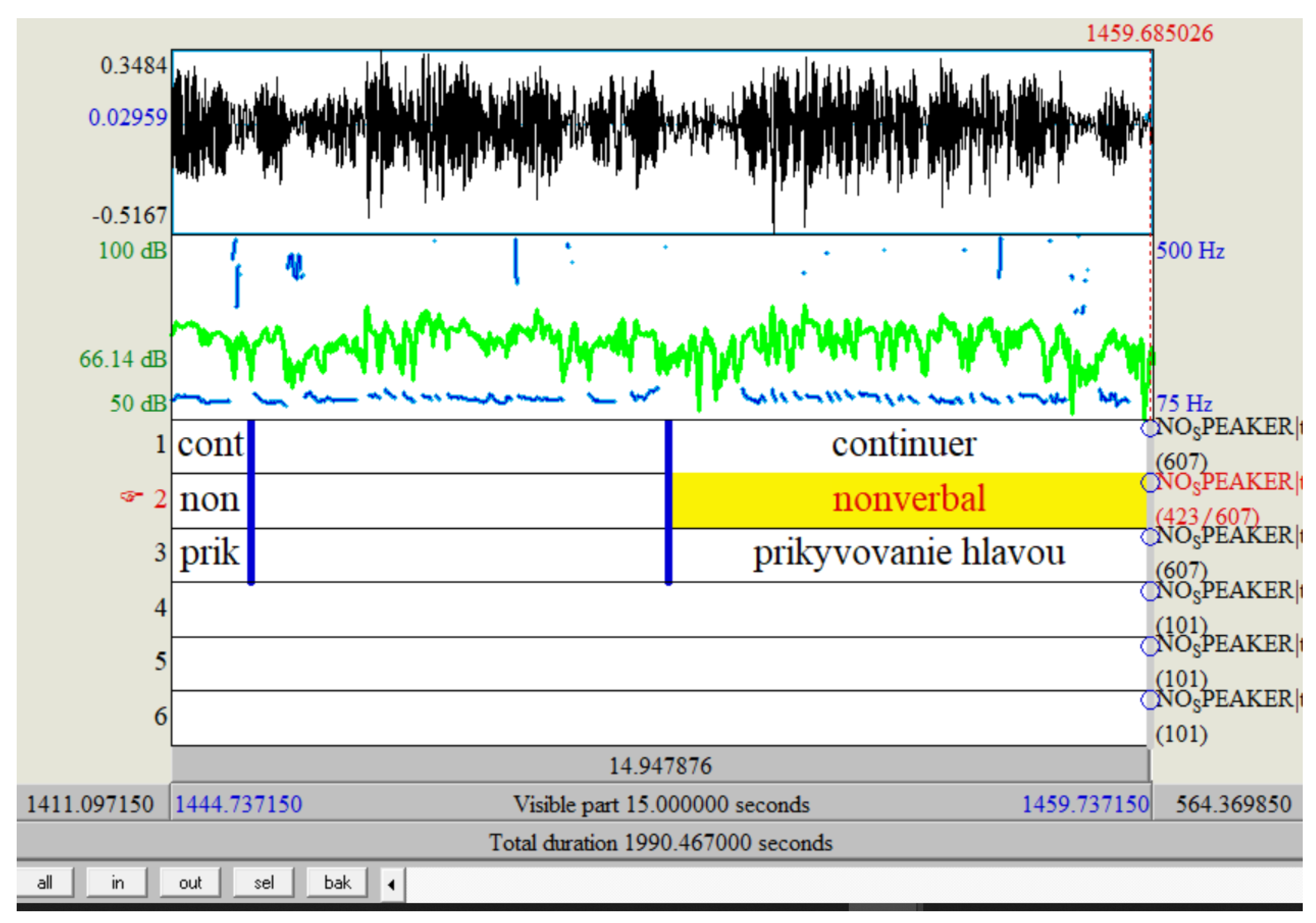
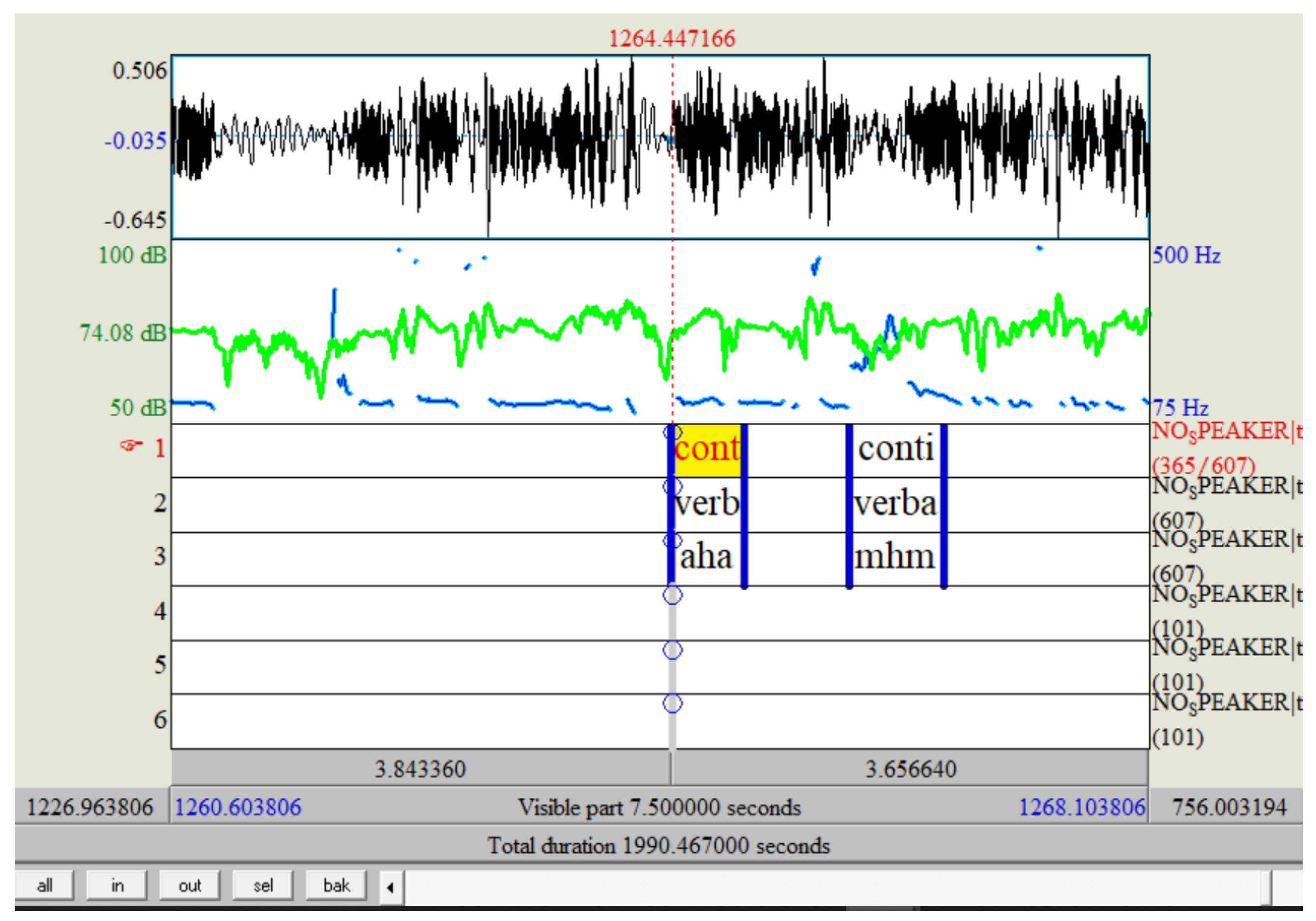
- Token layer.
- Modality layer (verbal/nonverbal).
- Function layer.
- Continuers.
- Displaying understanding.
- Agreement.
- Support and empathy.
- Emotional response.
- Minor addition or information request.
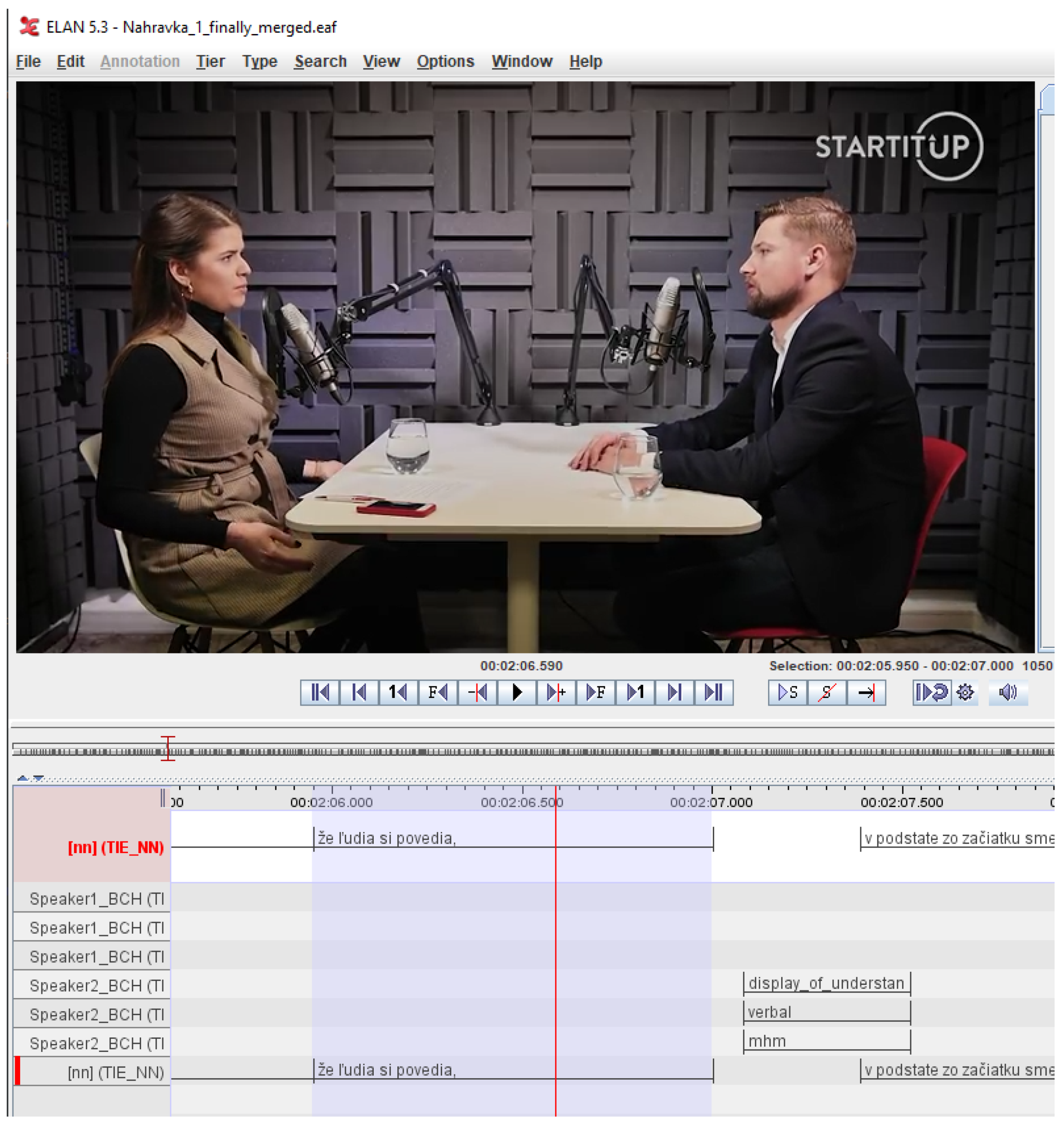
2.3. Text Transcription and Prosody
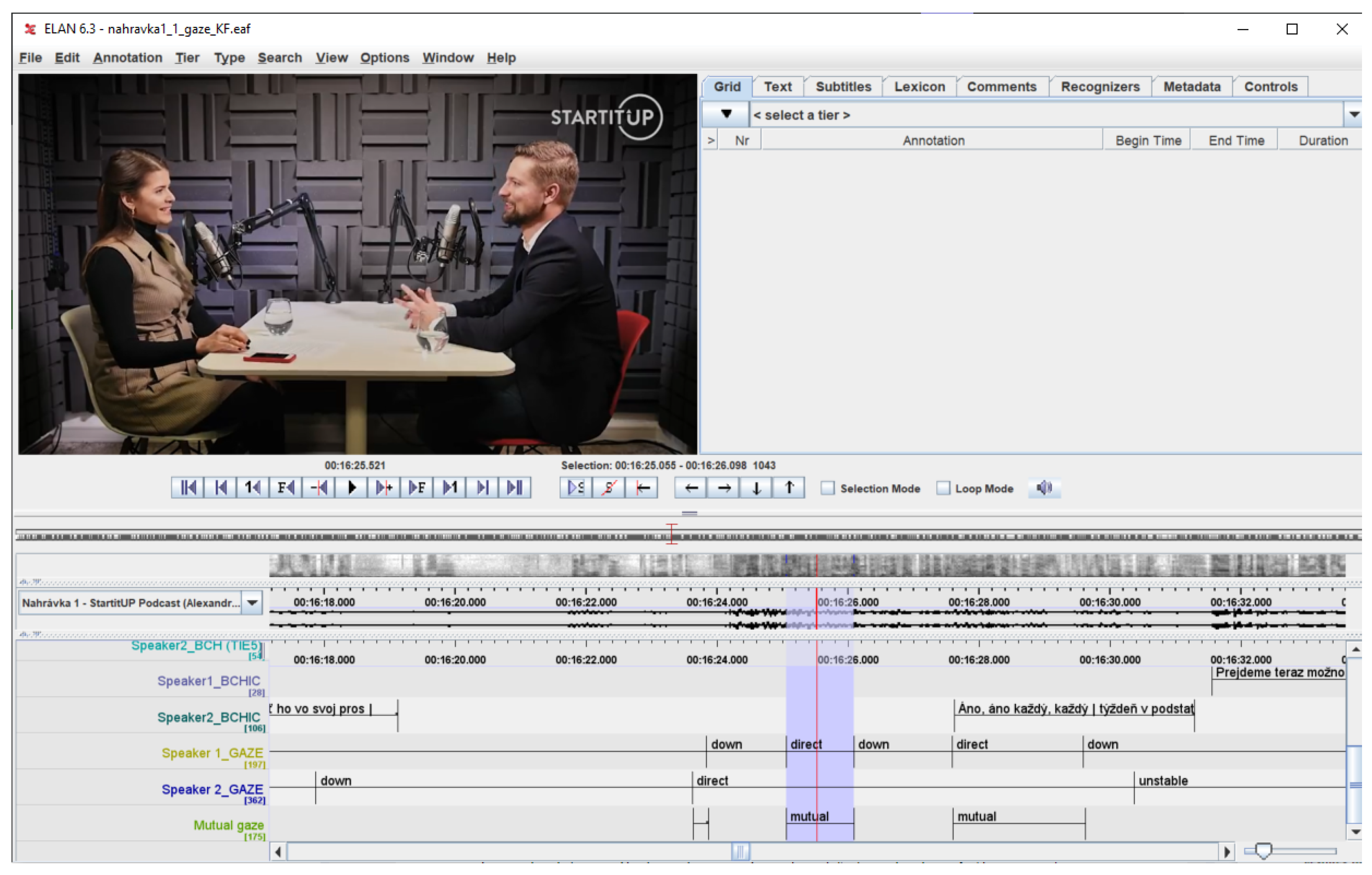
2.4. Gaze Annotation
- Away—the gaze direction into the space (not at the communication partner).
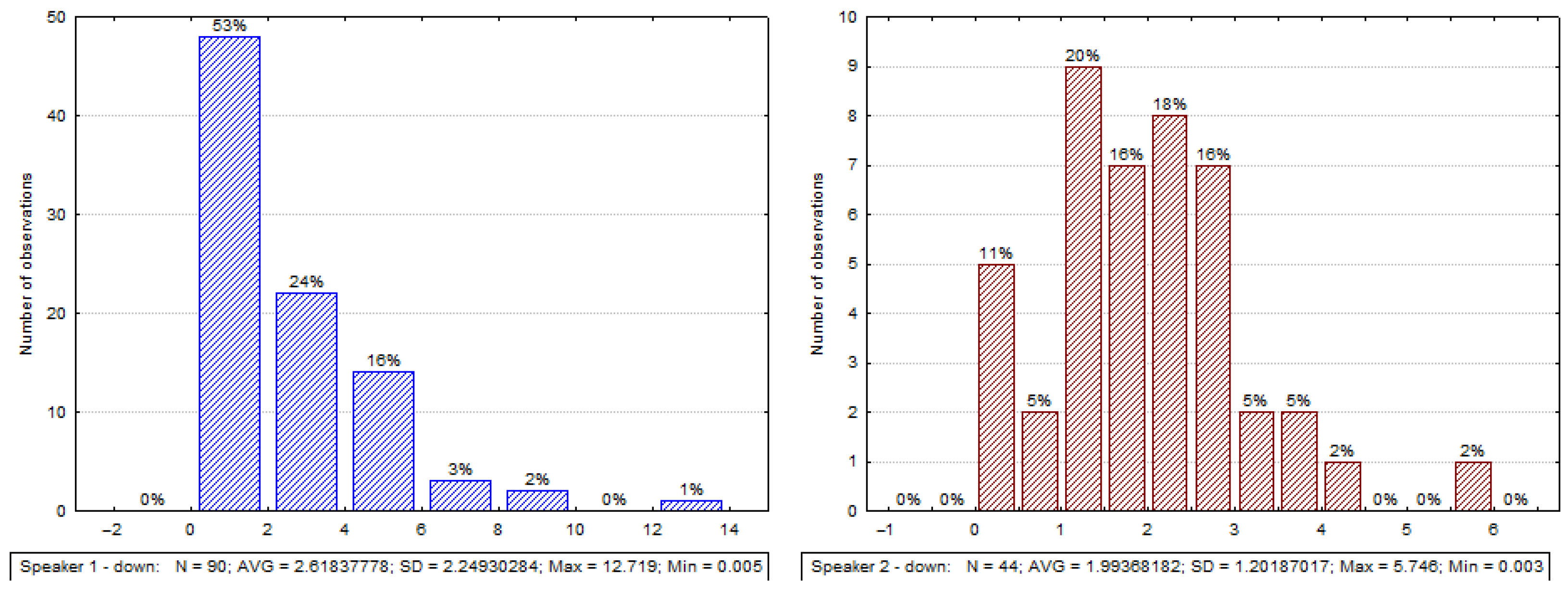
- Down—looking down.
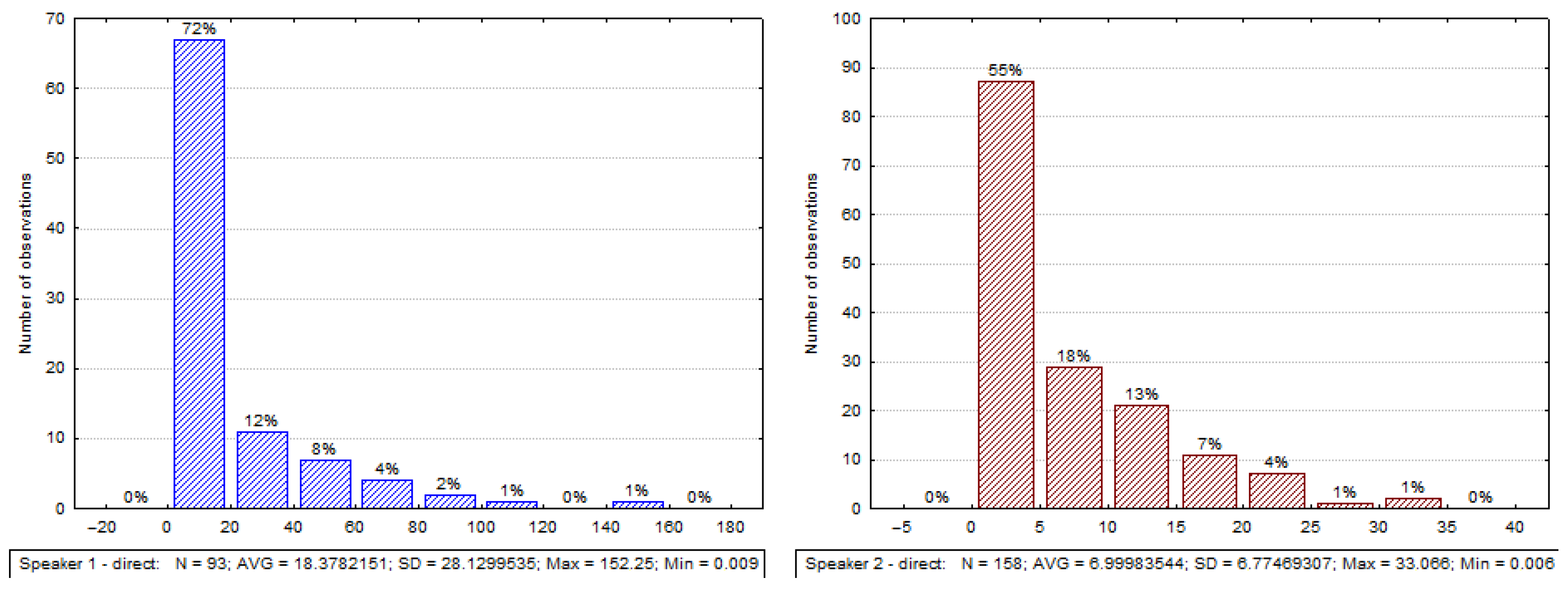
- Direct—direct looking at the communication partner.
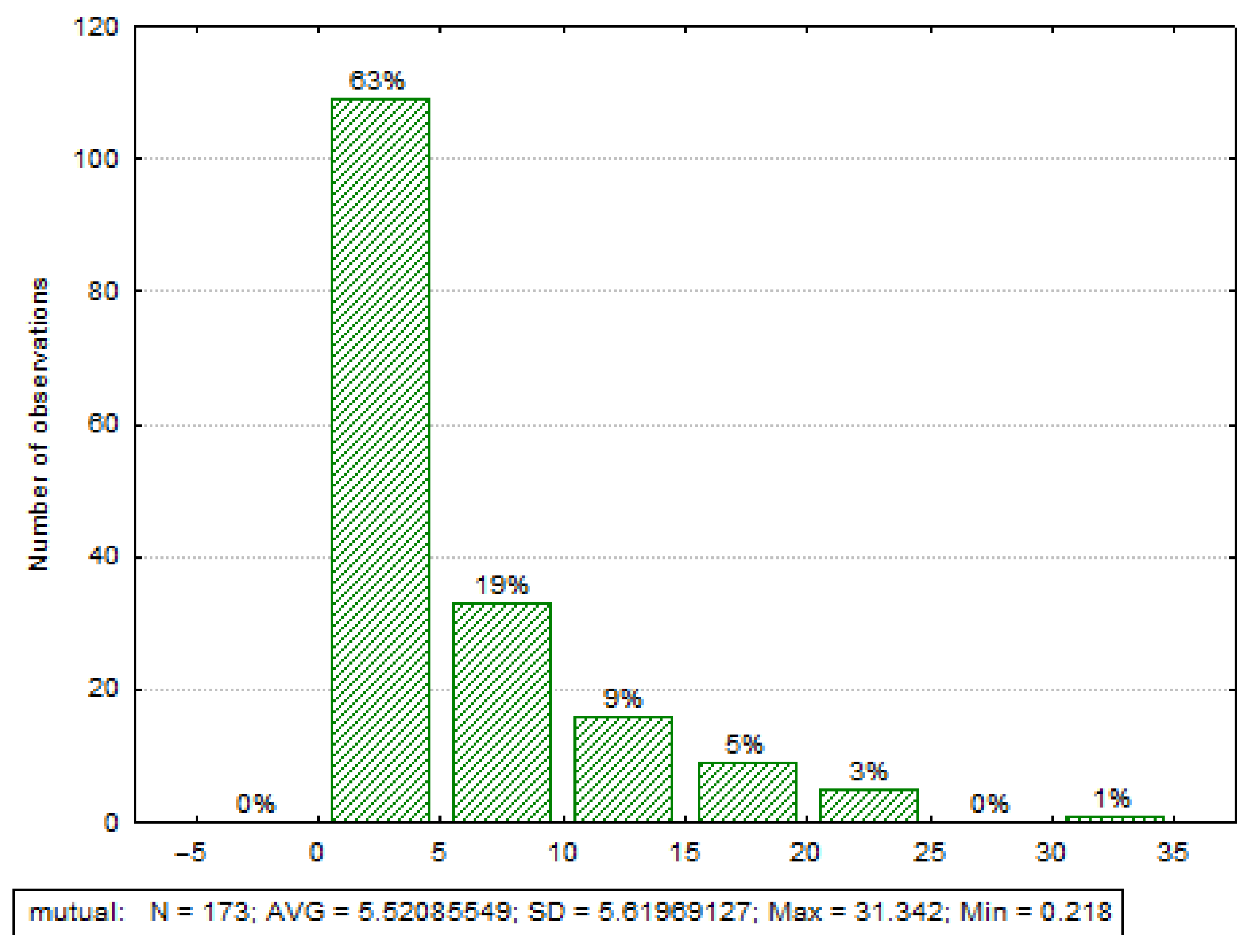
- Mutual—mutual gaze.
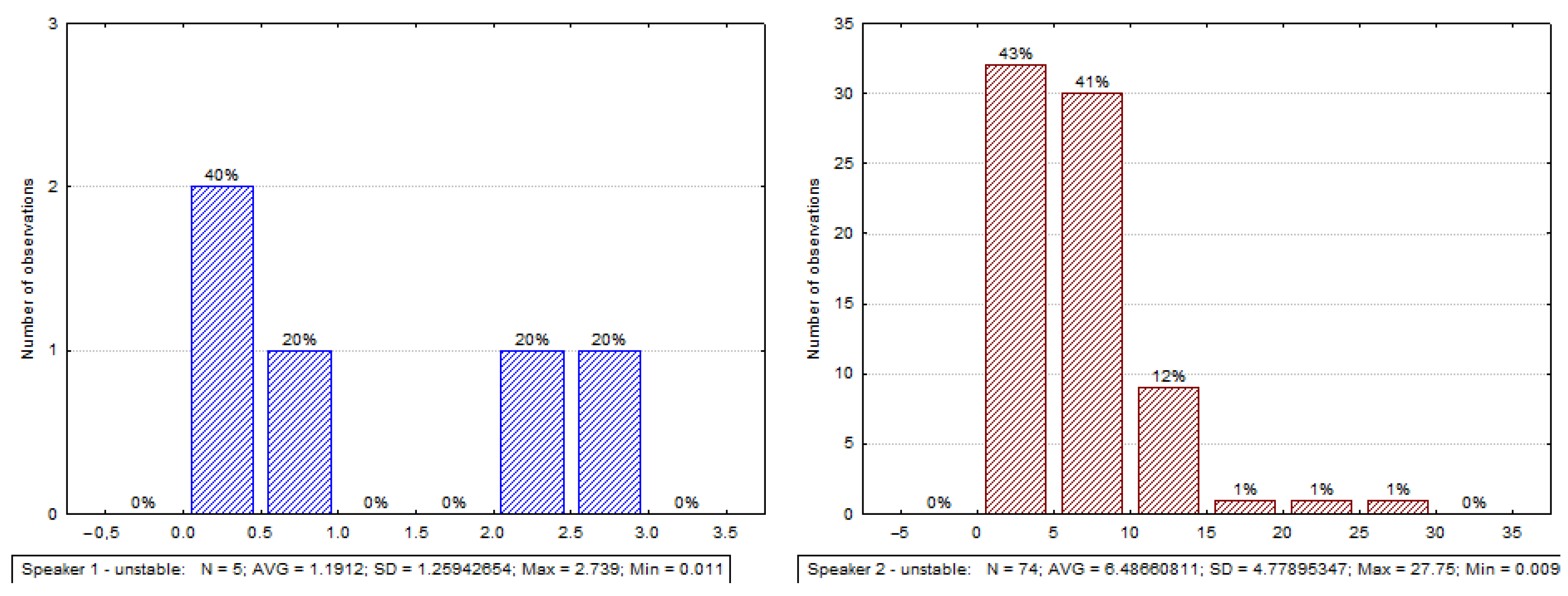
- Unstable—the person often changes the direction of gaze (typical when thinking, avoiding an answer). In this type, the annotation of a specific view direction is irrelevant for its short duration.
3. Results and Discussion
3.1. Backchannels
3.2. Backchannel Inviting Cues
- A final rising intonation.
- A higher intensity level.
- A higher pitch level.
- A final POS bigram equal to ‘DT NN’, ‘JJ NN’, or ‘NN NN’.
- A lower value of noise-to-harmonics ratio (NHR).
- A longer IPU duration.
3.3. The Role of Gaze in BCH and BCH Inviting Cues
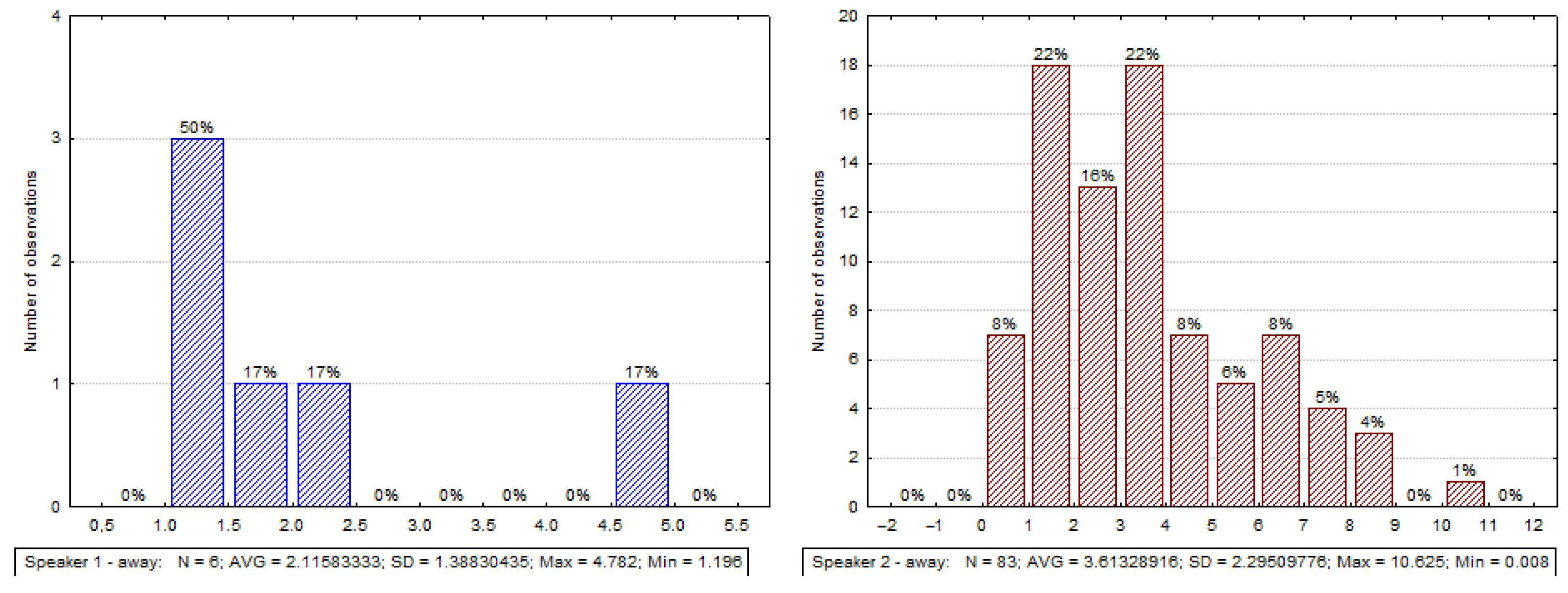
3.3.1. Analysis of Gaze Directions
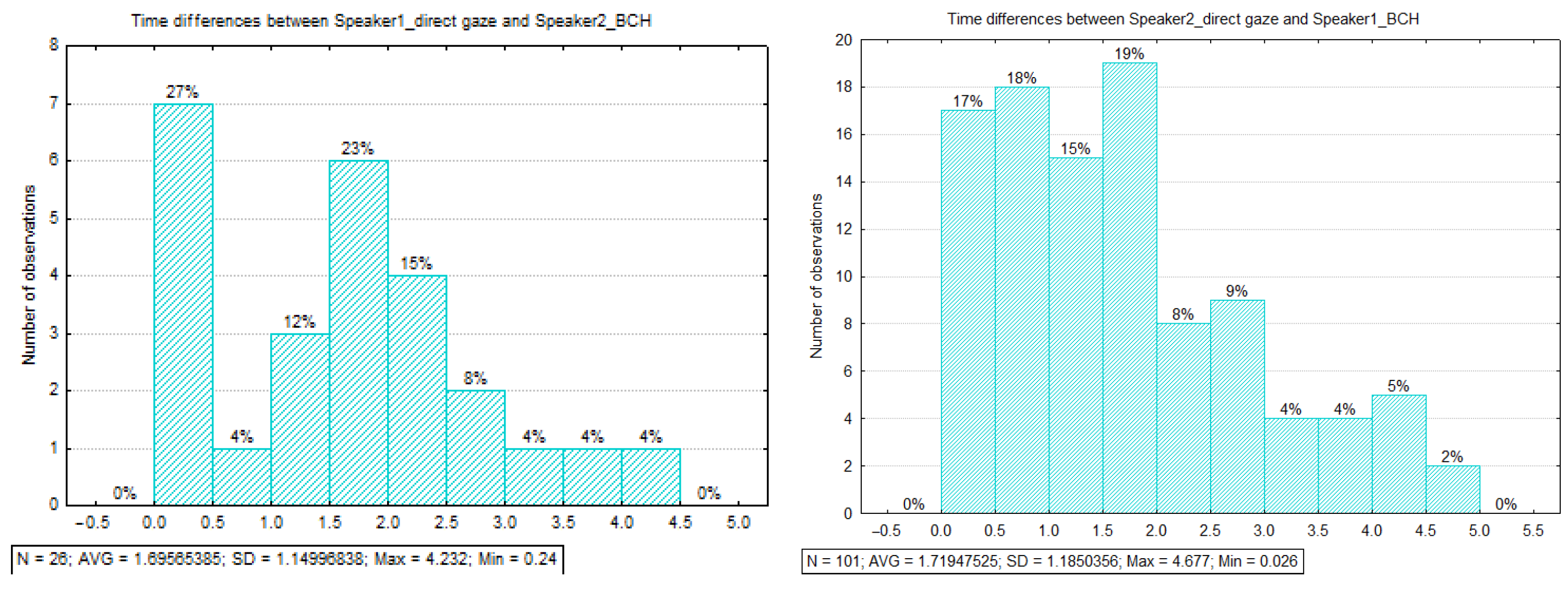
3.3.2. Observed Time Associations between Direct Gaze and BCH
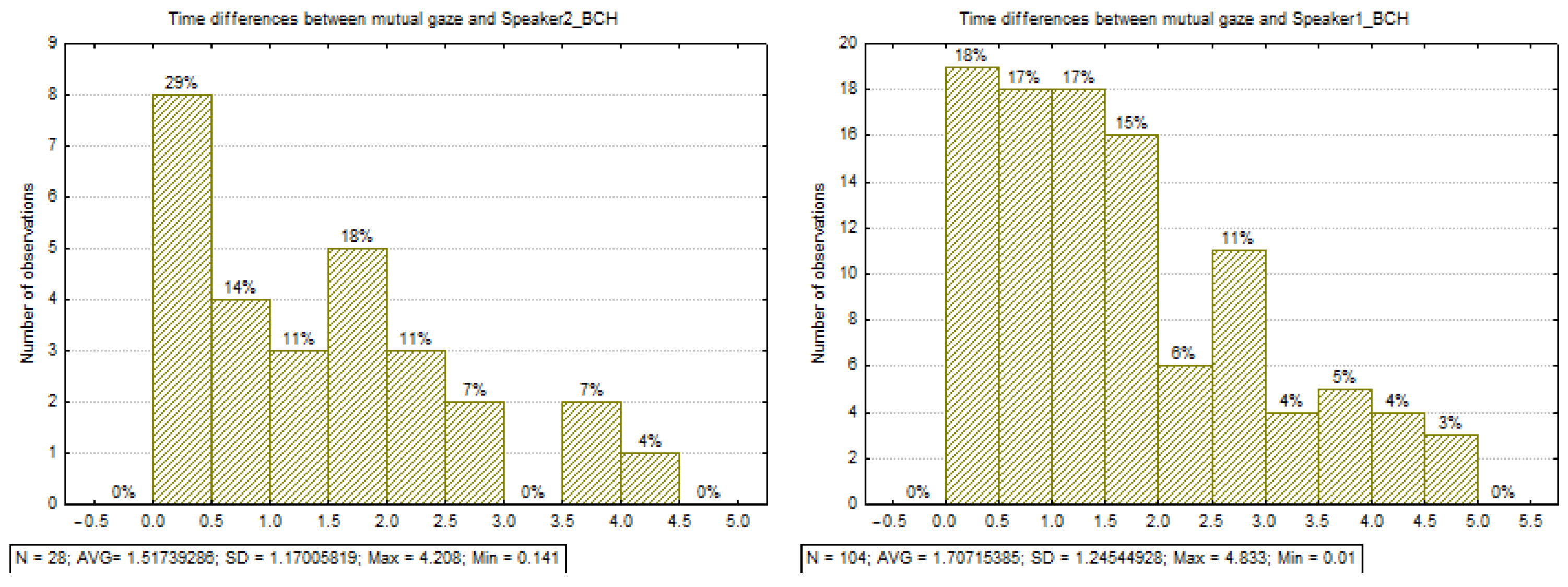
3.3.3. Observed Time Associations between Mutual Gaze and BCH
4. Future Research Challenges
5. Conclusions
- The most frequent BCH has a continuation function (59%) or serves for signaling agreement (17.1%), which is comparable with conclusions in Beňuš’s research [3] on the SK-Games corpus.
- The nonverbal BCHs more frequent than verbal ones (61.1% vs. 38.9%), which is typical for a face-to-face scenario. Nonverbal BCHs do not interrupt the interlocutor’s utterances and can be present for a very short or, on the other side, very long time as well. In our database, there was very often a longer duration of nodding.
- Significant differences were observed between BCH tokens in the analyzed corpus and the SK-Games corpus. The most numerous lexical token “no” in the SK-Games corpus has only 0.7% occurrence in our data. In the case of the fourth ”hej” (”yep” in English) in Beňuš’s data, this lexical unit has only 1.1% occurrence here. Differences between interactions in compared corpora could explain it. Whereas our corpus contains discussions or interviews, the SK-Games corpus consists of task-oriented dialogue. Moreover, the SK-Games corpus does not contain nonverbal BCH annotations. It is focused only on lexical backchannels.
- The comparison of backchannel functions between the above-mentioned corpora brought conclusions that in both studies, displaying the shallow to continue and displaying an agreement are the most frequent backchannel functions.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BCH | Backchannel |
| IoT | Internet of Things |
| IPU | Inter-Pausal Init |
| Web VTT | Web Video Text Tracks |
| POS tags | Part-Of-Speech tags |
| DT NN | Determiner Noun |
| JJ NN | Adjective Noun |
| NN NN | Noun Noun |
| NHR | Noise-to-Harmonics Ratio |
References
- Duncan, S. Some signals and rules for taking speaking turns in conversations. J. Personal. Soc. Psychol. 1972, 23, 283–292. [Google Scholar] [CrossRef]
- Gravano, A.; Hirschberg, J. Backchannel-inviting cues in task-oriented dialogue. In Proceedings of the SigDial, London, UK, 11–12 September 2009; pp. 1019–1022. [Google Scholar] [CrossRef]
- Benus, S. The prosody of backchannels in Slovak. In Proceedings of the 8th International Conference on Speech Prosody, Boston, MA, USA, 31 May–3 June 2016; pp. 75–79. [Google Scholar]
- Hjalmarsson, A.; Oertel, C. Gaze direction as a back-channel inviting cue in dialogue. In Proceedings of the IVA 2012 Workshop on Realtime Conversational Virtual Agents, Santa Cruz, CA, USA, 12–14 September 2012; Volume 9. [Google Scholar]
- Ondáš, S.; Kiktová, E.; Pleva, M. Slovak dialogue corpus with backchannel annotation. In Proceedings of the 2022 32nd International Conference Radioelektronika, Kosice, Slovakia, 21–22 April 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–4. [Google Scholar]
- Vinjamuri, R. (Ed.) Human-Robot Interaction—Perspectives and Applications; IntechOpen: London, UK, 10 May 2023. [Google Scholar] [CrossRef]
- Meyerson, H.; Olikkal, P.; Pei, D.; Vinjamuri, R. ‘Introductory Chapter: Human-Robot Interaction—Advances and Applications’, Human-Robot Interaction—Perspectives and Applications; IntechOpen: London, UK, 10 May 2023. [Google Scholar] [CrossRef]
- Kragic, D.; Gustafson, J.; Karaoguz, H.; Jensfelt, P.; Krug, R. Interactive, collaborative robots: Challenges and opportunities. In Proceedings of the International Joint Conference on Artificial Intelligence IJCAI-18, Stockholm, Sweden, 13–19 July 2018; IJCAI Organization: California City, CA, USA, 2018; pp. 18–25. [Google Scholar] [CrossRef]
- Bodnar, K. Conversational Analysis. Bachelor’s Thesis, Technical University of Kosice, Kosice, Slovakia, 2021. [Google Scholar]
- Kipp, M. Anvil—A Generic Annotation Tool for Multimodal Dialogue. In Proceedings of the 7th European Conference on Speech Communication and Technology (Eurospeech), Aalborg, Denmark, 3–7 September 2001; pp. 1367–1370. [Google Scholar]
- Aghblagh, M.M. Backchannelling in Persian: A Study of Different Types and Frequency of Backchannel. Int. J. Lang. Acad. 2017, 5, 181–189. [Google Scholar]
- Knight, D. A Multi-Modal Corpus Approach to the Analysis of Backchanneling Behaviour. Ph.D. Dissertation, University of Nottingham, Nottingham, UK, 2009. [Google Scholar]
- Najim, Q.N.; Muhammad, K. Cultural Differences in Back-channeling Contents between English and Kurdish Languages. Zanco J. Humanit. Sci. 2020, 24, 289–292. [Google Scholar]
- Wittenburg, P.; Brugman, H.; Russel, A.; Klassmann, A.; Sloetjes, H. ELAN: A Professional Framework for Multimodality Research. In Proceedings of the LREC 2006, Fifth International Conference on Language Resources and Evaluation, ELRA, Genoa, Italy, 22–28 May 2006. [Google Scholar]
- Lojka, M.; Viszlay, P.; Staš, J.; Hládek, D.; Juhár, J. Slovak Broadcast News Speech Recognition and Transcription System. Lect. Notes Data Eng. Commun. Technol. 2019, 22, 385–394. [Google Scholar]
- Barras, C.; Geoffrois, E.; Wu, Z.; Liberman, M. Transcriber: Development and use of a tool for assisting speech corpora production. Speech Commun. Spec. Issue Speech Annot. Corpus Tools 2000, 33, 5–22. [Google Scholar] [CrossRef]
- Boersma, P.; Van Heuven, V. Speak and unSpeak with PRAAT. Glot Int. 2001, 5, 341–347. [Google Scholar]
- Kendon, A. Some functions of gaze direction in social interaction. Acta Psychol. 1967, 26, 22–63. [Google Scholar] [CrossRef] [PubMed]
- Edlund, J.; Beskow, J. MushyPeek—a framework for online investigation of audiovisual dialogue phenomena. Lang. Speech 2009, 52, 351–367. [Google Scholar] [CrossRef] [PubMed]
- Oreström, B. Turn-Taking in English Conversation; Lund University Press: Lund, Sweden, 1983. [Google Scholar]
- Tottie, G. Conversational Style in British and American English: The Case of Backchannels; University of Uppsala: Mimeo, UK, 1990. [Google Scholar]
- Ward, N. Common Backchannels. 2022. Available online: https://www.cs.utep.edu/nigel/bc/common-bcs.html (accessed on 25 July 2023).
- Clancy, P.M.; Thompson, S.A.; Suzuki, R.; Tao, H. The conversational use of reactive tokens in English, Japanese and Mandarin. J. Pragmat. 1996, 26, 355–387. [Google Scholar] [CrossRef]
- Heinz, B. Backchannel responses as strategic responses in bilingual speakers’ conversations, 2003. J. Pragmat. 2003, 35, 1113–1142. [Google Scholar] [CrossRef]
- Ward, N.; Tsukahara, W. Prosodic Features which Cue Back-Channel Feedback in English and Japanese. J. Pragmat. 2000, 32, 1177–1207. [Google Scholar] [CrossRef]
- Young, R.F.; Lee, J. Identifying Units in Interaction: Reactive Tokens in Korean and English Conversations. J. Socioling. 2004, 8, 380–407. [Google Scholar] [CrossRef]
- Tannen, D. That’s Not What I Meant!: How Conversational Style Makes or Breaks Relationships; Ballentine Books: New York, NY, USA, 1986. [Google Scholar]
- Gravano, A.; Hirschberg, J. Turn-taking cues in task-oriented dialogue. Comput. Speech Lang. 2011, 25, 601–634. [Google Scholar] [CrossRef]
- Degutyte, Z.; Astell, A. The Role of Eye Gaze in Regulating Turn Taking in Conversations: A Systematized Review of Methods and Findings. Front. Psychol. 2021, 12, 2021. [Google Scholar] [CrossRef] [PubMed]
- Heldner, M.; Hjalmarsson, A.; Edlund, J. Backchannel relevance spaces. In Nordic Prosody: Proceedings of the XIth Conference, Tartu 2012; Asu, E.L., Lippus, P., Eds.; Peter Lang: Frankfurt, Germany, 2013; pp. 137–146. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Recording | Gender | Description/Topic | Duration |
|---|---|---|---|
| Rec. 1 | F1–M | Gaze—prefect/legal aid | 33 min 44 s |
| Rec. 2 | F1–F | Gaze—good (partial shielding by the one microphone)/Linkedln | 39 min 12 s |
| Rec. 3 | M1–F (young) | Gaze—prefect/the writing style of a young writer (guest) | 40 min 05 s |
| Rec. 4 | M1–M | Gaze—partial/the guest career | 35 min 54 s |
| Rec. 5 | F2–M (young) | Gaze—partial, wearing a mask/traveling | 32 min 45 s |
| Rec. 6 | F2–F | Gaze—partial, wearing a mask/traveling | 40 min 55 s |
| Rec. 7 | F3–F | Gaze—partial, wearing a mask/current life of the singer (guest) | 28 min 55 s |
| Rec. 8 | F4–M | Gaze—partial, wearing a mask/a science in Slovakia | 28 min 52 s |
| Rec. 9 | F4–F | Gaze—partial, wearing a mask/politics, the work of the journalist (guest) | 26 min 58 s |
| Rec. 10 | M2–M | Gaze—partial/the key to success | 30 min 43 s |
| Rec. 11 | M3–M | Gaze—full/sport, the least formal interview | 31 min 44 s |
| Rec. 12 | M4 (old)–M (old) | Gaze—full, different perspective of video/cybersecurity | 38 min 21 s |
| Rec. 13 | M5–M | Gaze—partial/communication, food | 26 min 07 s |
| Rec. 14 | M6–M | Gaze—partial/films, visual effects | 24 min 51 s |
| Rec. 15 | M7–F | Gaze—partial/marketing, the company Zľava dňa | 28 min 25 s |
| Backchannel Function | Frequency of Occurrence | Frequency of Occurrence [%] |
|---|---|---|
| Continuers | 2747 | 59 |
| Displaying understanding | 226 | 4.8 |
| Agreement | 795 | 17.1 |
| Support and empathy | 28 | 0.6 |
| Emotional response | 601 | 12.9 |
| Minor addition or info request | 259 | 5.6 |
| Backchannel Type | Frequency of Occurrence | Frequency of Occurrence [%] |
|---|---|---|
| Verbal | 1812 | 38.9 |
| Nonverbal | 2844 | 61.1 |
| No. | Backchannel | Number of Occurrences | [%] Occurrence |
|---|---|---|---|
| 1 | nodding (prikyvovanie hlavou) | 2217 | 47.6 |
| 2 | mhm (mhm) | 772 | 16.6 |
| 3 | laughter (smiech) | 432 | 9.3 |
| 4 | yes (áno) | 186 | 4.0 |
| 5 | completion (doplnenie vety) | 184 | 4.0 |
| 6 | facial gestures (gestá tváre) | 107 | 2.3 |
| 7 | clear (jasné) | 69 | 1.5 |
| 8 | smiling (usmievanie sa) | 65 | 1.4 |
| 9 | yep (hej) | 53 | 1.1 |
| 10 | mhm_mhm (mhm_mhm) | 44 | 0.9 |
| 11 | mm (mm) | 44 | 0.9 |
| 12 | repetition (opakovanie) | 37 | 0.8 |
| 13 | so clear (no jasné) | 36 | 0.8 |
| 14 | yes_yes (áno_áno) | 31 | 0.7 |
| 15 | so (no) | 31 | 0.7 |
| 16 | aha | 28 | 0.6 |
| 17 | uhuh | 25 | 0.54 |
| 18 | question | 23 | 0.49 |
| 19 | okej | 21 | 0.45 |
| 20 | yes_yes_yes (áno,áno,áno) | 17 | 0.36 |
| - | other | 348 | 7.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ondáš, S.; Kiktová, E.; Pleva, M.; Juhár, J. Analysis of Backchannel Inviting Cues in Dyadic Speech Communication. Electronics 2023, 12, 3705. https://doi.org/10.3390/electronics12173705
Ondáš S, Kiktová E, Pleva M, Juhár J. Analysis of Backchannel Inviting Cues in Dyadic Speech Communication. Electronics. 2023; 12(17):3705. https://doi.org/10.3390/electronics12173705
Chicago/Turabian StyleOndáš, Stanislav, Eva Kiktová, Matúš Pleva, and Jozef Juhár. 2023. "Analysis of Backchannel Inviting Cues in Dyadic Speech Communication" Electronics 12, no. 17: 3705. https://doi.org/10.3390/electronics12173705