1. Introduction
Exercise is essential in daily life. With the acceleration of the pace of life, people tend to exercise at home and evaluate their exercise effectiveness by themselves. However, ordinary self-study methods lack professional guidance, and incorrect or improper body movements can lead to a decrease in exercise effectiveness and even cause physical harm. Therefore, it is necessary to analyze and evaluate exercise and provide feedback for achieving better results.
Currently, most exercise analysis relies on specialized sensor devices [
1]. For example, Albert et al. [
2] developed a home exercise system based on inertial measurement components, which allows users to practice kicking exercises at home by wearing sensors. Gupta et al. [
3] designed a yoga-assisted exercise system that helps amateur enthusiasts learn correct yoga movements without the supervision of a coach. The motion sensors used in this system mainly include accelerometers and gyroscopes. Although these wearable sensors have good data acquisition and analysis capabilities, they require exercisers to wear related devices, which causes inconvenience to exercise and also has certain invasiveness and safety risks to the human body.
With the development and popularization of computers and image technology, visual-based action recognition has gradually attracted people’s attention [
4]. The idea of visual-based recognition is that there is action information hidden in human skeletal data, and action recognition can be achieved through methods such as feature extraction and information mining. For example, the authors of [
5] proposed a machine learning-based shooting action recognition method. This method can extract multidimensional motion posture features and use those features to recognize actions. In addition, Xu et al. [
6] designed an end-to-end network to improve the efficiency of optical flow feature extraction, and combined spatiotemporal features to achieve human action recognition. These methods have brought convenience and achieved certain performance. However, it requires a large amount of annotated data and a long training time if directly extracting video features based on deep learning.
In this paper, we propose a visual-based motion recognition algorithm and apply it to the fitness exercise “BaDuanJin”, an exercise that focuses on a mind–body integration [
7]. The proposed method does not require a large amount of annotated data and it has low computational complexity, making it suitable for motion videos with varying lengths. In addition, we propose a feedback method for trainers to evaluate their training effectiveness and obtain recommendations accordingly. In this feedback method, label sequence and pose vector are used to evaluate the video motion similarity, which assists practitioners in correcting their actions and obtaining suggestions.
The main contribution of this paper includes the following.
This paper proposes a lightweight backbone network called Oct-MobileNet to address the problem of high parameter volume in the traditional OpenPose algorithm’s VGG19 backbone network. The proposed method utilizes the attention mechanism and octave convolution to enhance the network’s ability to extract high-frequency features of human body contours while reducing the model’s computational complexity.
A motion recognition method based on skeleton information and multi-feature fusion is proposed in this paper. Multiple features are extracted from the spatial geometry and temporal characteristics, and a sliding window algorithm is used to fuse them.
A multimodal information-based motion evaluation method is proposed for the fitness exercise. The method uses a pose detector to obtain the label sequence of standard motions and represents the coordinates of each frame’s key points as a pose vector. The method extracts motion similarity from multiple modal information, such as label sequence and pose vector, and performs a quantitative evaluation for exercisers.
The rest of the paper is organized as follows. In
Section 2, the related work is introduced.
Section 3 introduces the Oct-OpenPose and Coordinates Preprocess. In
Section 4, we elaborate on the Action Recognition Model.
Section 5 presents the Evaluation Methods for BaDuanJin Movements. Concluding remarks are drawn in
Section 6.
2. Related Work
Human action recognition is one of the fundamental ways to achieve human–computer interaction aiming at describing human behavior in images or videos. From the perspective of information acquisition, the methods can be broadly classified into two categories [
8]: sensor-based action recognition and vision-based action recognition.
Sensor-based action recognition has emerged as a promising field of research with numerous applications in fields such as healthcare, sports analysis, and human–computer interactions [
9]. In particular, wearable sensors are placed on important joint positions of the human body to collect motion data in real time and transmit it to the upper computer. The upper computer then analyzes and processes the data, thus achieving human motion recognition. Pansiot et al. [
10] designed a head-mounted inertial sensor for swimming motion analysis. By recording features such as pitch angle and rotation angle, they analyzed the movement details of swimmers and developed a swimming monitoring system for training guidance. Ma et al. [
11] designed a wireless network module based on MEMS inertial sensors [
12] and Zigbee [
13] used the SVM classification algorithm [
14] for human motion recognition. This work showed desirable performance in detecting abnormal behaviors such as falls. Authors of [
15] developed a wearable system using an accelerometer, an analog-to-digital converter, and a WiFi module to acquire and transmit human motion data. They used the KNN algorithm [
16] to recognize four types of daily behaviors: lying down, sitting, standing, and walking, achieving an accuracy of 93%. Authors of [
17] used a smartphone on the waist of subjects to measure linear acceleration and angular velocity along three axes using the built-in accelerometer and gyroscope of the phone. The LightGBM [
18] algorithm was used to recognize and classify six types of movements, including going up and down stairs, sitting, and standing.
While sensor-based action recognition has shown promising results in various applications, it also has limitations that need to be considered. The biggest limitation is that it relies on the availability and proper placement of sensors on the body to capture motion data. Compared to sensor-based action recognition, vision-based action recognition does not use any extra sensors, which makes it a preferred choice in many scenarios. Recently, there has been some research in this field. For example, Sun et al. [
19] proposed a method for extracting key frames from video streams, and combined it with a posture estimation algorithm to extract skeleton information for golf action comparison recognition.
In addition to action recognition, human action evaluation is also an important branch of motion analysis. By measuring the difference or similarity between two actions, the consistency of the practice action and the standard action can be judged. For example, Xu et al. [
20] designed two complementary long short-term memory networks to extract information from figure skating videos and used aggregate feature information to predict scores. The proposed model achieved desirable performance on their self-built data set. Another work is provided by authors of [
21], who proposed a method for evaluating the similarity of etiquette actions. First, the video keyframes were extracted using the frame difference method, and then the evaluation criteria were set based on standard actions. Action scoring was carried out by calculating the similarity of limb vector angles and foot distance in keyframes. The above-mentioned methods generally require a substantial quantity of annotated data and lengthy training times, which results in relatively limited model generalization capabilities.
Based on the above discussion, it is evident that sensor-based action assessment approaches heavily depend on hardware devices, which presents challenges in terms of widespread adoption. On the other hand, deep learning methods that directly extract video features necessitate a substantial volume of annotated data and entail lengthy training durations. Therefore, there is a need for an alternative approach that eliminates the requirement for extensive annotated data, possesses low computational complexity, and proves suitable for fitness routines of varying durations.
3. Oct-OpenPose and Coordinates Preprocess
In this section, we analyze the current popular human pose estimation methods and then propose a method that meets the requirements of body movement recognition discussed in the related work section. In particular, we focus on fitness exercises in normal scenarios, and a lightweight model is needed for human pose estimation.
Visual-based human pose estimation methods can be divided into two categories: the top-down approach and the bottom-up approach. The top-down approach detects each person in the image first and then performs key point detection for each individual. The typical top-down approach algorithms include RMPE [
22] and CPN [
23]. In contrast, the bottom-up approach detects all the key points of all people in the image first and then assigns key points to each individual. The typical bottom-up approach algorithms include OpenPose [
24] and HigherHRNet [
25].
The bottom-up approach is relatively faster and more robust, so in this paper, we use the bottom-up approach for keypoint detection and multi-body pose estimations. We have two options: HigherHRNet and OpenPose. The HigherHRNet network is complex and usually focuses on solving the pose estimation problem for dense, small-sized people, which does not meet the scenario of fitness exercise. Therefore, we choose OpenPose in this paper. The traditional OpenPose uses VGG19 as the backbone network to extract features from input images. The VGG19 network, due to its extensive parameter count, is not considered a lightweight backbone network. Consequently, the traditional OpenPose model utilizing VGG19 fails to fulfill the real-time performance demanded by the scenario discussed in this paper.
Natural images can be decomposed into low-frequency components and high-frequency components. Octave convolution divides the convolutional feature map into low-frequency components and high-frequency components. Information interactions between the two frequency groups are achieved through up-sampling and down-sampling, and ultimately, the original feature map can be reassembled. We can achieve the following advantages by replacing traditional convolutions with Octave convolutions. (1) Reduced storage and computational load. The size of the low-frequency feature map can be halved, effectively reducing storage and computational resources. This enhancement contributes to improving the speed of detecting human key points. (2) Enhanced receptive field. With the feature map size reduced while keeping the convolutional kernel size constant, the receptive field increases. This expansion enables better capture of contextual information in scenarios like the “BaDuanJin” movement, ultimately enhancing recognition performance. (3) Preserved high-frequency information. Octave convolution fully retains high-frequency information, and since the human body outline constitutes critical high-frequency information for action recognition, this preservation is important.
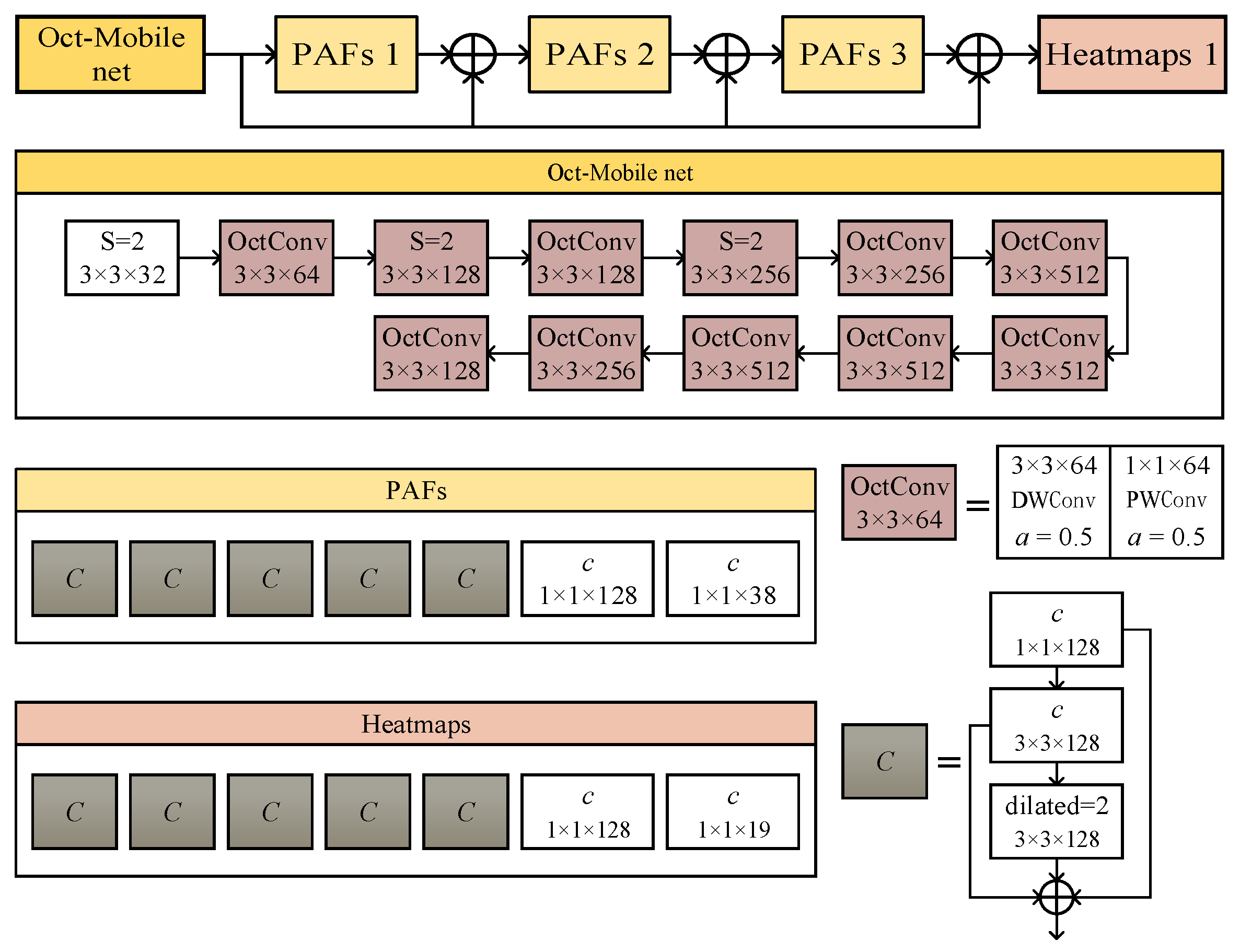
Based on the structure design of OpenPose and the above discussion, we propose an improved model named Oct-OpenPose in this paper. The network structure of the Oct-OpenPose is shown in
Figure 1. The Predicted Affinity Fields (PAFs) prediction part of the network is reduced from the original four stages to three stages, and the Heatmaps prediction part is reduced to one stage. The first convolution kernel size of the three inside concatenated convolutions is changed to
. The final convolution kernel is designed as a dilated convolution with a dilation factor of two to reduce the redundancy of the network. The new backbone network Oct-MobileNet using the Oct-OpenPose has greatly reduced the parameter quantity of the MobileNet. It also reduces low-frequency information redundancy and focuses more on high-frequency information so that the extracted deep features contain more effective information.
In order to evaluate the performance of the proposed model, we used the Common Objects in the Context (COCO2017) data set to test the MobileNet and Oct-MobileNet networks. Specifically, we used the adaptive momentum method to train and optimize the models. The training was conducted for
iterations, with an initial learning rate of
, and a batch size of 24.
Figure 2 compares the feature visualization results. It can be seen that the Oct-MobileNet places more emphasis on high-frequency feature components such as the human body contour when extracting deep features and suppresses other low-frequency components, which makes the PAFs of human key points more clear.
We also compared the accuracy of the proposed model as well as the network in
Table 1. As can be seen from
Table 1, the number of stages for PAFs and Heatmaps has been reduced from 4 + 2 to 3 + 1, with negligible loss in accuracy. When using a regular MobileNet as the backbone network, the model’s accuracy decreased by 7.1% compared to the original network. However, Oct-MobileNet, which integrates the improved Octave convolution, places more emphasis on high-frequency features such as the human body outline and suppresses other low-frequency features when extracting features, resulting in a 6% increase in model accuracy compared to regular MobileNet. The accuracy of the improved model is only reduced by 1.2% compared to the original model. The detection speed of the improved model can reach 31 fps, which is 300% faster than the original model.
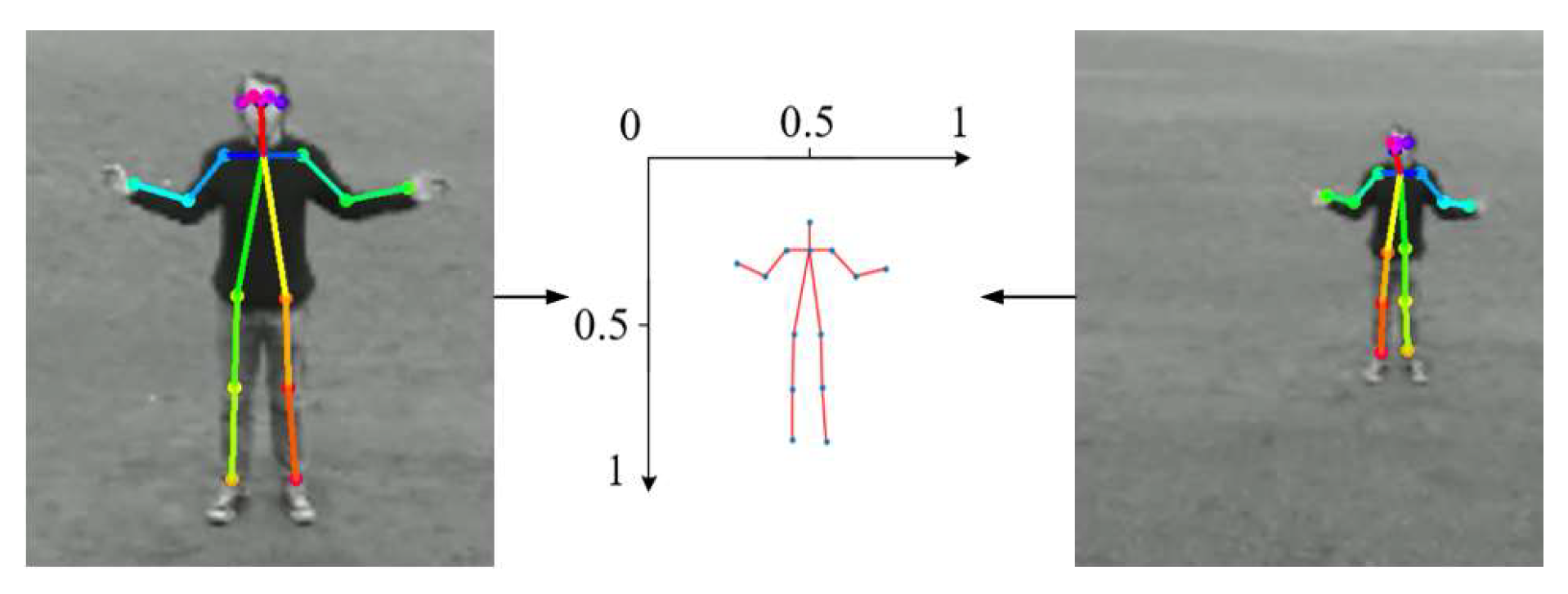
Besides feature extraction, we also normalize the coordinates of key points. The coordinates are normalized in order to solve the problem of non-uniformity caused by image size or lens distance variation. First, the input image is scaled so that an image with width and height (w, h) is first scaled to (1, h/w). The center position
of the human body is then calculated based on the coordinates of 18 points according to Equation (
1). Second, we calculate the height H between the neck and the hip. Note that the height H does not change for different actions. Finally, each keypoint is subtracted from the central coordinate and divided by H according to Equation (
2) to obtain the normalized coordinates (Xnew, Ynew), as shown in
Figure 3.
4. Action Recognition Model
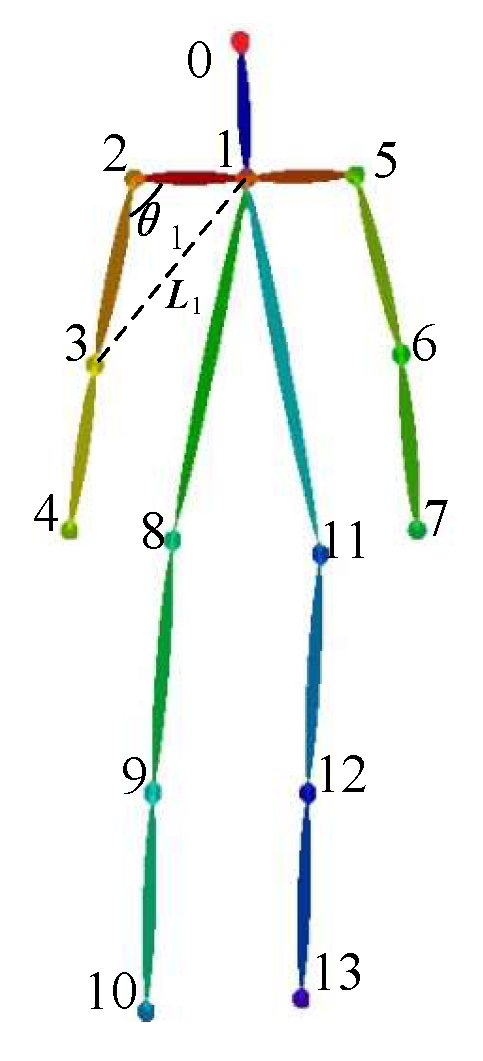
During human movement, the main movements are in the limbs and torso, which are not related to the face. Therefore, eye and ear coordinates are excluded, and the position information of the head is abstracted using the nose to represent the head position, reducing the total number of key points from 18 to 14. The diagram of geometric features is depicted in
Figure 4, where the numbers represent the key joints of human body.
The spatial position of the human skeleton and its geometric relationship can be used to model human motion. In order for the classifier to better distinguish between different movements in the BaDuanJin, spatial geometry and temporal motion features are extracted from the skeletal coordinate information. Taking
and
as an example,
Table 2 shows that d(1–3) represents the pixel distance between the neck and right elbow, while
represents the angle formed by the neck, right shoulder, and right elbow, as shown in
Figure 4. The calculation formulas are shown in Equations (
3) and (
4), where (
,
) and (
,
) represent the coordinates of key points 1 and 3, and
a,
b, and
c represent the three sides of the triangle formed by the neck, right shoulder, and right elbow, respectively.
The motion feature reflects the changes in the human body over consecutive moments, such as the swing speed of certain joints or limbs. The calculation method for key point velocity is to divide the displacement into the
x and
y directions between adjacent frames
and
by the interval time
t, as shown in Equation (
5). The value of
t is related to the video frame rate F. For example, when F is 25 fps,
t = 0.04 s (1/25 = 0.04 s).
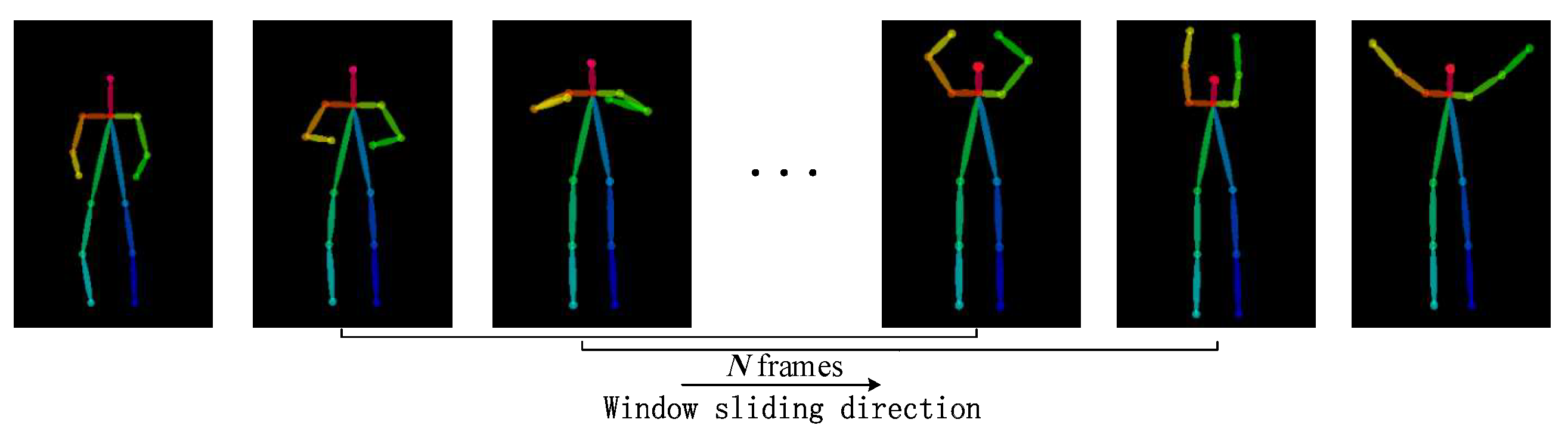
To achieve sequence-based feature extraction, new features need to be constantly extracted from the video sequence and old features need to be removed in real time. We use a sliding window algorithm to deal with the feature extraction, as shown in
Figure 5. A window of size N is used to store data based on the time series. As time progresses, the window moves directionally, with new data added to the head of the window and old data pushed out from the tail. This process continues until the window has traversed through all the data. In this paper, the sliding window size N is set to 10 frames, and spatial geometry features and temporal motion features are calculated accordingly. The final aggregated feature vector is shown in
Table 3, where the dimension of the fused feature reaches 772. In order to reduce the computational complexity during model training, the classical feature extraction and data representation technique Principal Component Analysis (PCA) [
26] is used to compress the features to 100 dimensions.
In this paper, since the scenario is action recognition based on time series, an LSTM-based classifier is proposed to deal with the classification. In particular, the input to the model is the 100-dimensional features that are aggregated and reduced by the sliding window with a time step T of 30. Two layers of LSTM units are designed in the LSTM block, and each layer has 128 neurons. After that, a fully connected layer (FC) with a size of 64 is used to further integrate the features. Finally, the softmax activation function is used to classify the movements.
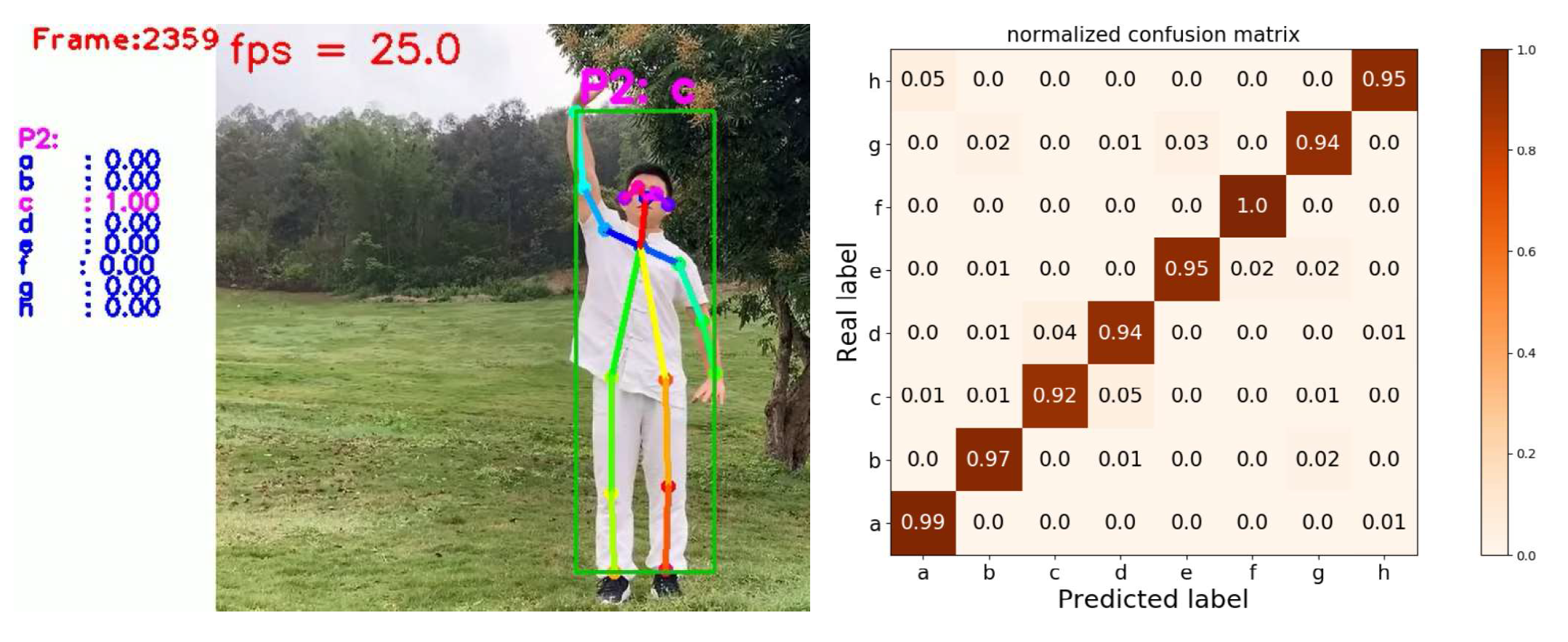
Figure 6 shows the classification results and confusion matrix of the recognition results. It can be seen that the average recognition accuracy of each movement reaches 95.7%, and the frame rate of video detection can be maintained above 25 fps.
5. The Evaluation Methods for BaDuanJin Movements
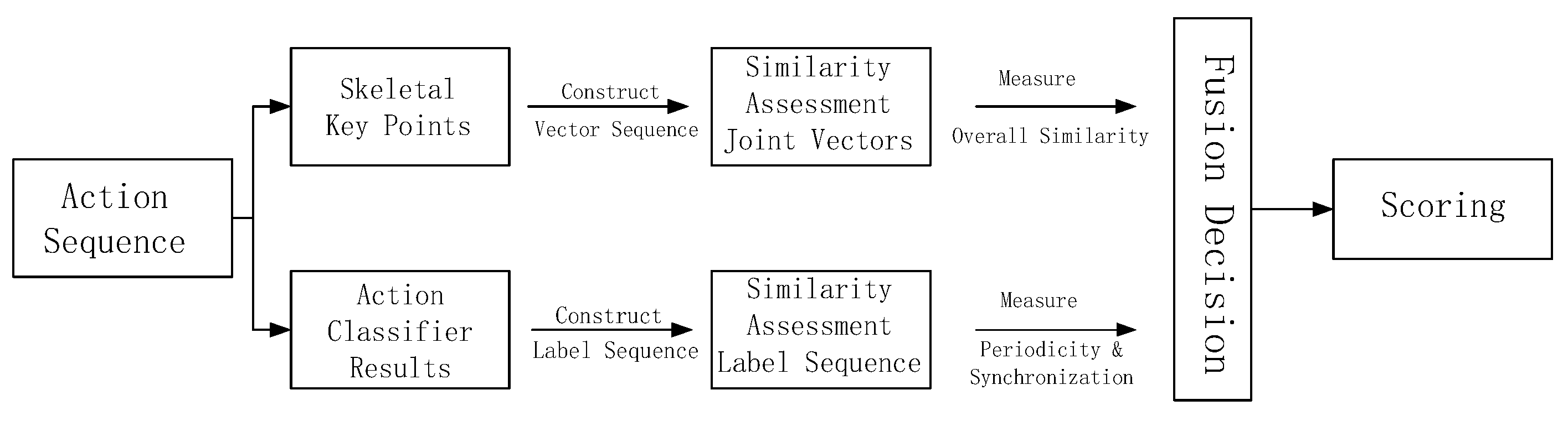
In the context of BaDuanJin movements, the mere recognition of the actions holds limited significance. The primary objective is to thoroughly analyze the disparities between the practitioner’s movement sequences and the standard ones, facilitating a quantitative evaluation. This evaluation aims to assist the practitioner in rectifying individual movements, ultimately enhancing the overall effectiveness and benefits of the exercise routine. This section proposes a multi-modal information-based movement evaluation method, as shown in
Figure 7. The first modality information is joint vector information extracted from each frame of the video, and the overall similarity between the test movement and the standard movement is measured by evaluating the similarity of joint vectors. The second modality information is the action label detected by the pose detection model for each frame, and the periodicity and synchronization of the two movements are evaluated by analyzing the similarity of the label sequence.
5.1. Similarity Evaluation Based on Joint Vectors
By improving OpenPose to detect BaDuanJin movements in videos, the coordinates of key points for each frame of the human body can be extracted. These coordinates can be further organized into vectors to characterize the movement of the human body in each frame, and similarity can be analyzed through the cosine distance. At the same time, the length of the BaDuanJin movement sequence varies, making it suitable for dynamic time warping (DTW) algorithm processing. Inspired by this, this section proposes a similarity evaluation method based on joint vectors that combines cosine similarity and the DTW algorithm to calculate the similarity of movement sequences.
Let A =
and B =
be two time series with lengths
n and
m, respectively, where
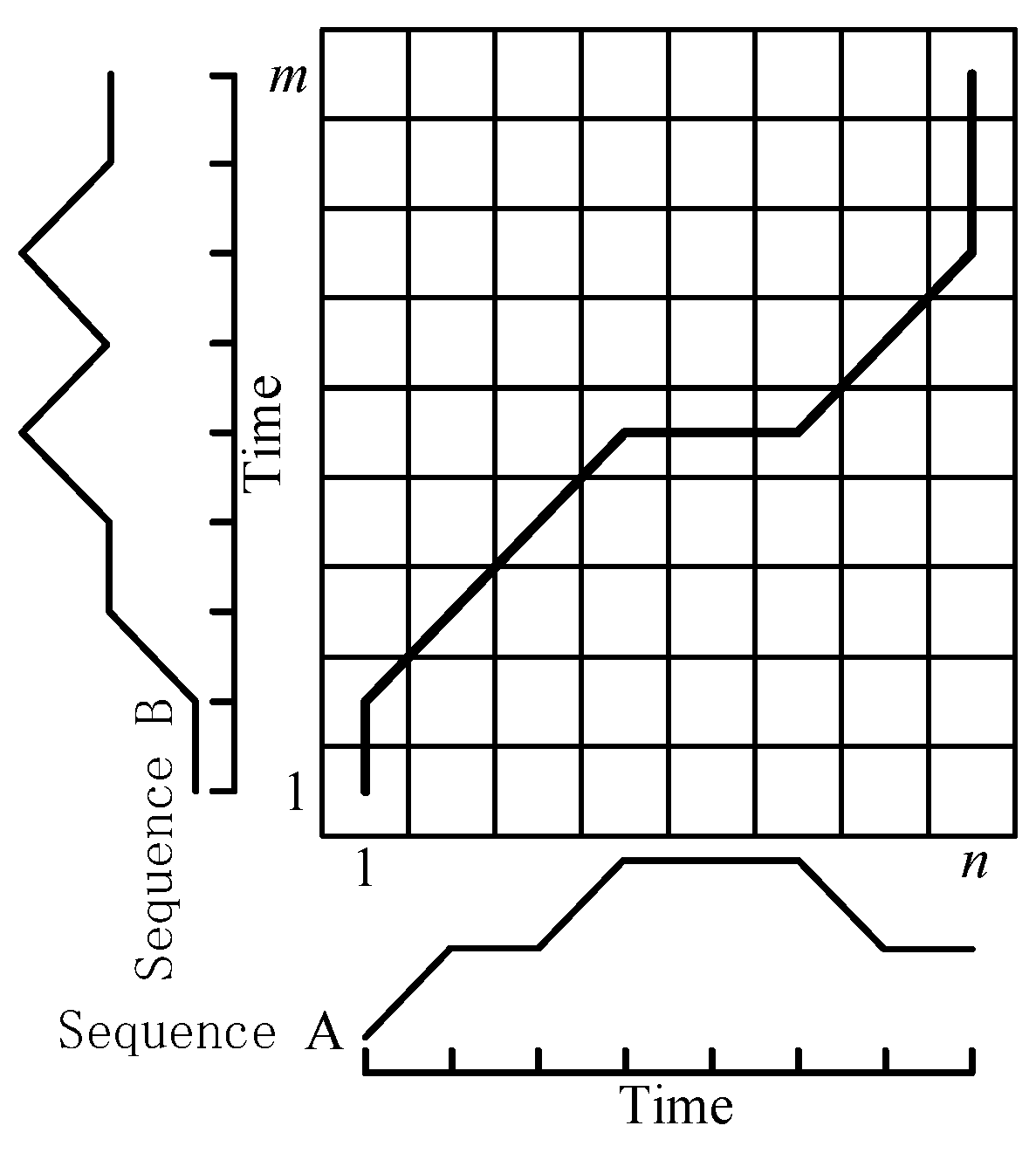
. To align the two sequences on the time axis, a matrix grid with m rows and n columns is constructed as shown in
Figure 8. The value in the
i-th row and
j-th column of the grid represents the distance between
and
, denoted as
. Then, the DTW distance calculation method for the time series A and B is shown in Equation (
6). Equation (
6) can characterize the similarity between the two sequences, where a smaller distance indicates a higher similarity.
In order to facilitate analysis and calculation, a minimum bounding box is created around the human in the image using the coordinates
of the 18 key points outputted by the model, where
. Then, we create a new coordinate system, and the position of the key points in the new coordinate system is calculated according to Equation (
7), where
and
represent the position of the lower-left endpoint of the bounding box.
For the movement A in a certain frame of the video, the preprocessed key point coordinates are represented as a high-dimensional vector in order, i.e., A = [
], where
are the position coordinates of 14 key points. Then, the similarity between two frames of movements A and B can be transformed into the similarity between vectors A and B. Suppose that the number of frames in video M and N is m and n, respectively, during a time interval t, and the human body movements in the two videos can be characterized as sequences
and
, where
and
are vectors composed of key point coordinates in a certain frame. By substituting Equation (
8) into Equation (
6), the distance between the two sequences can be calculated.
The
in Equation (
8) represents the cosine distance between
and
, and the similarity score between the two sequences is finally calculated using Equation (
9), which represents the overall similarity between the two sequences.
D represents the DTW distance
between the sequences
M and
N.
is the distance when the sequence similarity reaches its minimum, and at this time, the cosine distance of each element reaches its maximum. The pseudo-code of the algorithm is given in Algorithm 1.
| Algorithm 1 Similarity evaluation based on joint vectors |
- 1:
Input: - 2:
Template Sequence - 3:
State Test sequence - 4:
Output: - 5:
Similarity Score - 6:
- 7:
for () do - 8:
for () do - 9:
- 10:
- 11:
end for - 12:
end for - 13:
Calculate for template sequence M - 14:
Similarity Score
|
5.2. Similarity Evaluation Based on Label Sequence
The BaDuanJin movements exhibit robust regularity, characterized by their periodic nature. Each movement follows a specific pattern, commencing from the preparatory position, progressing through several essential postures, and concluding by returning to the preparatory position. For example, as depicted in
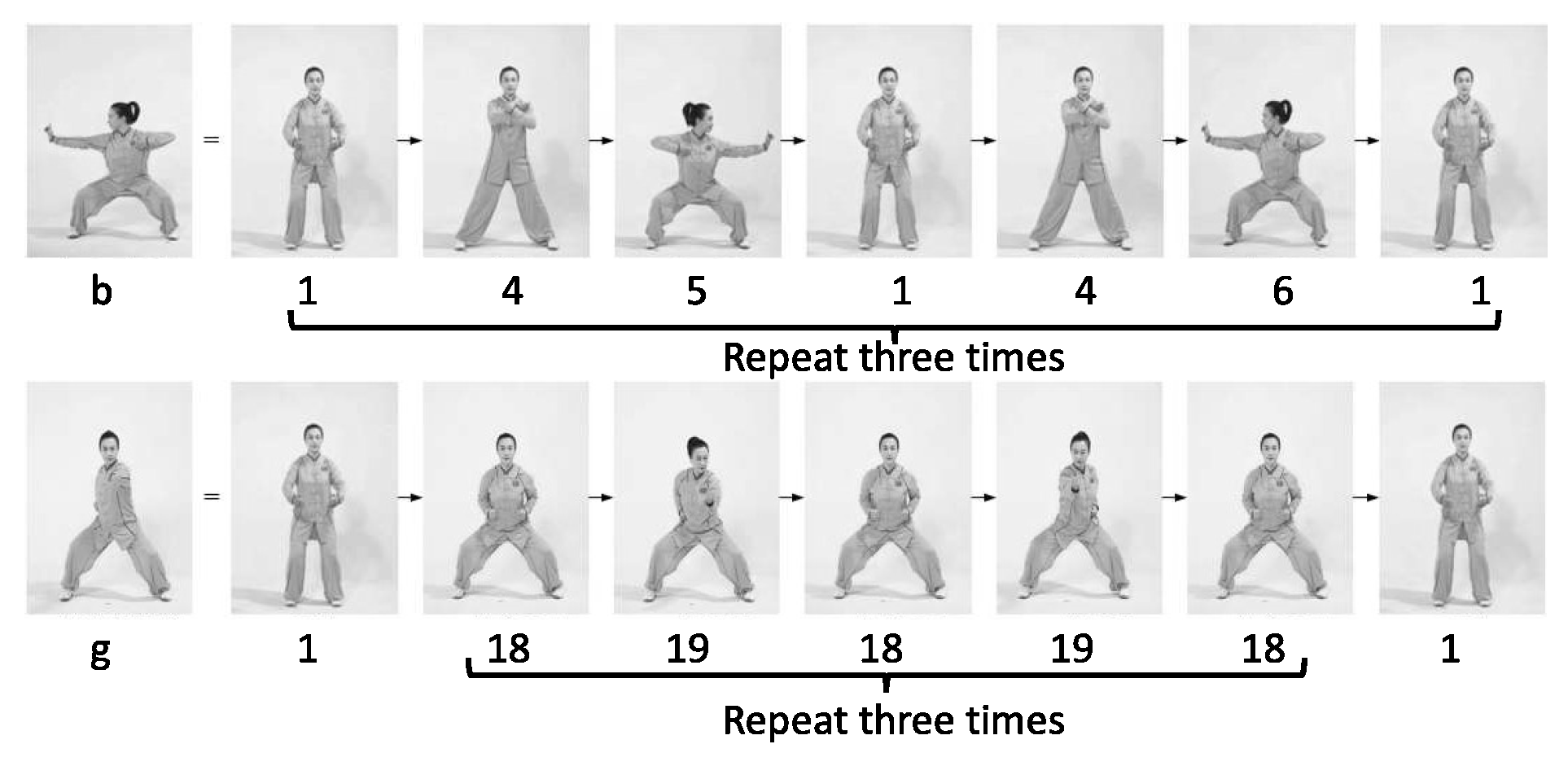
Figure 9, movement b is decomposed into posture combinations of 1-4-5-1-4-6-1, and a complete cycle is repeated three times. Similarly, other movements can also be decomposed in a similar way. The eight movements (
) are divided into 21 key postures, which will be used as labels for similarity evaluation.
For a video of BaDuanJin movements, we first use a movement classifier to recognize the corresponding movement, and then use the pose detection model to detect the posture results for each frame, i.e., continuous posture labels. The sequence formed by these labels contains the period and speed of the movement, from which information on the synchronization and periodicity of different practitioners performing the same movement can be extracted.
During video processing, some frames may be missed or detected incorrectly, resulting in noise in the generated label sequence, which is not conducive to subsequent analysis and judgment. Therefore, it is necessary to conduct denoising. Since video frames are continuous, they do not suddenly change into another movement in the middle of a continuous movement. Based on this, noise can be filtered out. For example, if a few frames of movement 2 appear in a series of continuous movement labels 1, movement 2 is considered noise and will be removed.
Both the template movements and the test movements contain a certain regularity after processing and becoming label sequences. Either a template movement or a test movement is a periodic sequence. The difference lies in the length of the interval from one posture to the next one, which corresponds to different sequences and represents the difference in speed when different practitioners perform the same movement. To compare the similarity of label sequences, we propose a sequence pattern mining method based on sequence intervals.
The sequence pattern mining method is shown in
Figure 10, where the template sequence and the test sequence are divided into multiple corresponding intervals. The associate pseudo-code of the algorithm is given in Algorithm 2. The elements in each interval are the same but they may have different lengths, representing the same movement state but with different durations. The formula for calculating the similarity between the test sequence and the template sequence is shown in Equation (
10), where
represents the deviation of each corresponding interval.
| Algorithm 2 Periodic similarity evaluation based on label sequence |
Input: Template label sequence: A Test label sequence: B Output: Cycle Score Divide template label sequence A into n intervals Count the length of subsequence Divide test label sequence B into n intervals Count the length of subsequence for () do end for Cycle Score
|
5.3. Decisions and Suggestions
We tested different exercisers, and associated suggestions were given to them. For example, one of the tests included two coaches and one beginner. By using Equation (
10), it was calculated that the periodic similarity score between the beginner and the coach was 65.7. The periodic similarity score between coach one and coach two was 90.4. Since the overall speed of the beginner was too fast, it resulted in a lower periodic similarity score. The movement of both coach one and coach two had a similar speed, resulting in a higher periodic similarity score.
The scoring system was designed to have two perspectives: the similarity of movements and the periodicity of movements. Users can change their perspectives by adjusting a factor and obtaining suggestions accordingly. If they want to check whether their movements are performed correctly while periodicity is not particularly important, they can increase the weight of similarity. In this test, the weight factor is set to 0.4, which means the proportion of movement label similarity assessment counts 40%, and the proportion of joint vector similarity assessment counts the rest 60%.
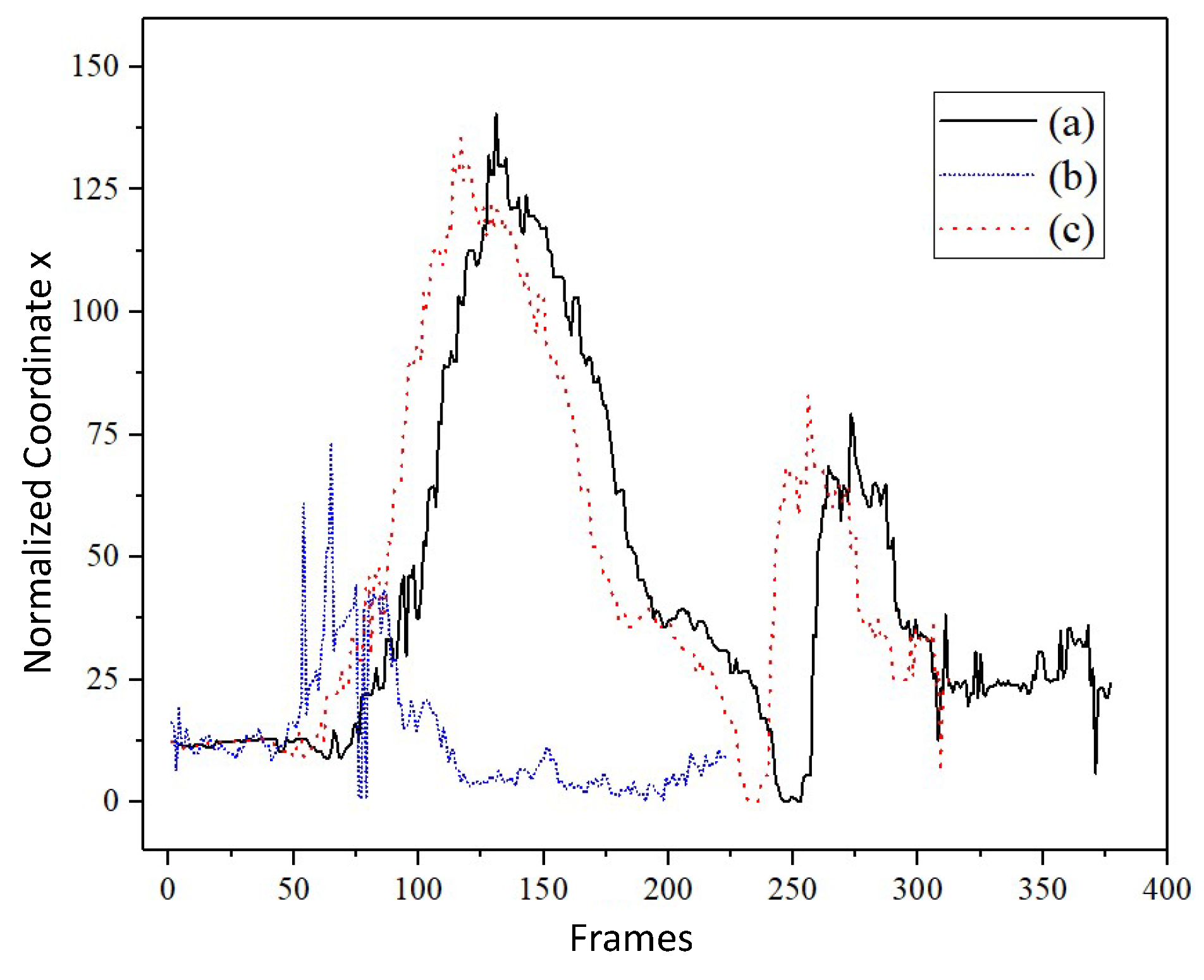
The displacement trajectories of key points in the human body can also be visualized.
Figure 11 depicts the changes in the right knee’s x-coordinate of three testers. The trends of curves (a) and (c) are the same, indicating a higher similarity in movements. Curve (b) also has a similar pattern to curve (a), but the movement amplitude of curve (b) is very low, which results in a poor similarity of the curve. Those curves can be used to give suggestions to the exercisers.
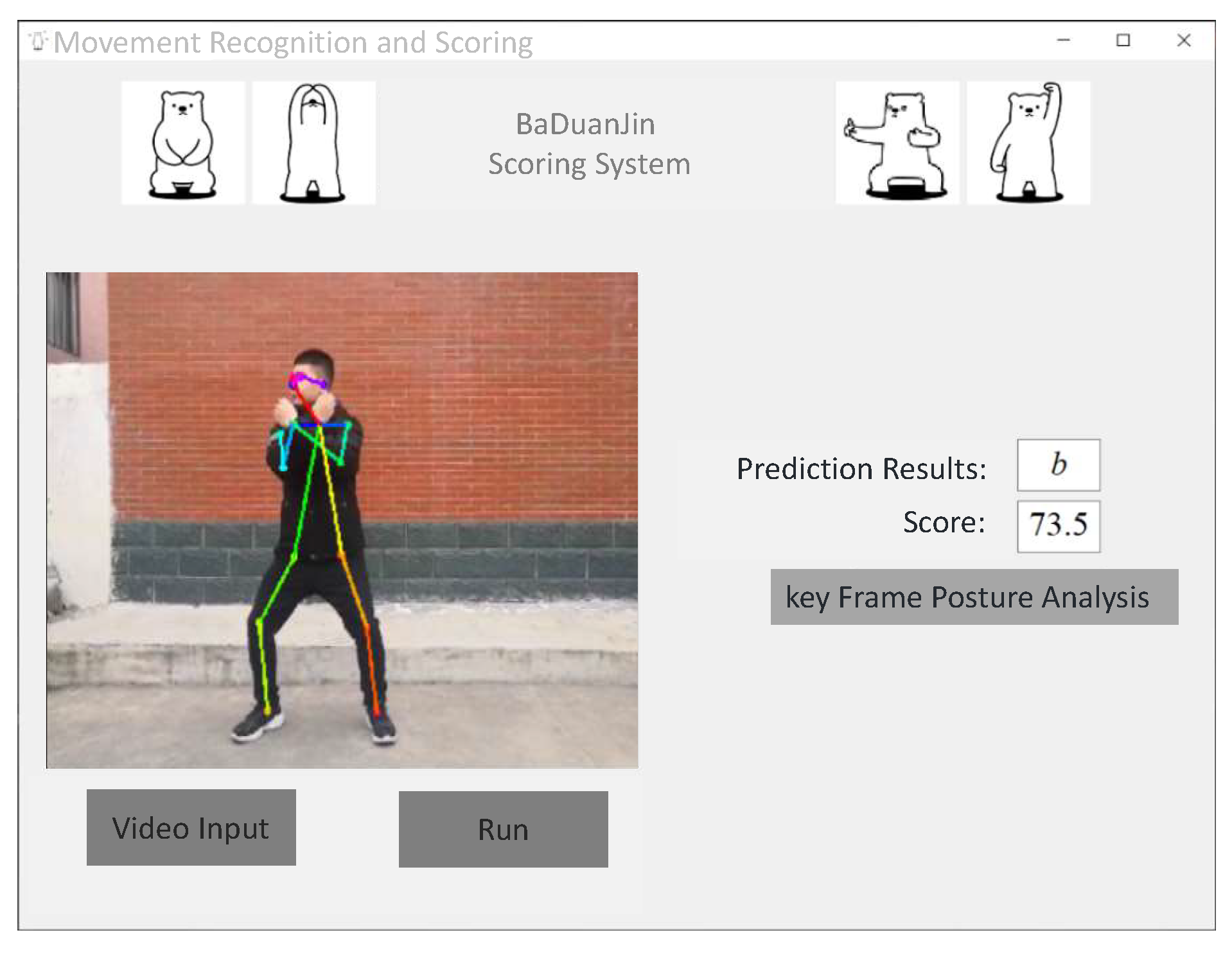
In order to present the system detection results more clearly and directly, we designed a visual interface using QT. This interface can help practitioners compare and correct their movements by displaying the predicted results of action techniques and analyzing joint angles, thereby assisting in their training. The movement recognition and scoring interface is shown in
Figure 12.
Practitioners can upload a video of the BaDuanJin exercise by clicking the “Video Input” button. Then, by clicking the “Run” button, the system calls the trained action classification model to perform the detection and display the results in the window. Finally, on the right side, the category of the exercise video and the similarity score with the standard video are displayed. Based on this score, practitioners can have a preliminary understanding of their own level and enhance their interest in exercise.
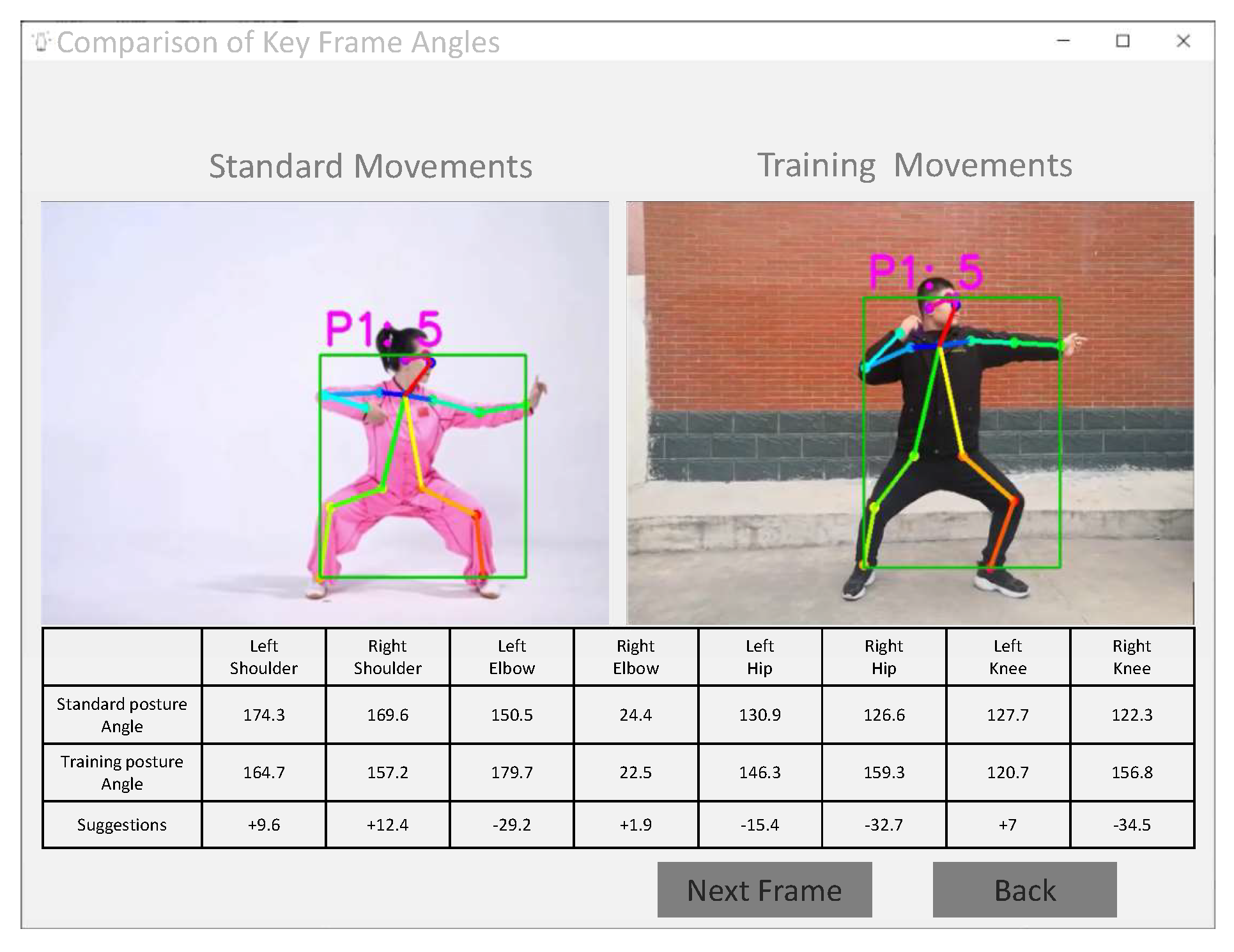
After obtaining the action results from the action classifier and the similarity score of the movements, practitioners can click on the key frame posture analysis results to view the key movement details of the corresponding technique. The evaluation interface is shown in
Figure 13. The left window displays the posture frames of the standard action, and the right window displays the key frames of the input test video.
The scoring method for the BaDuanJin fitness movements designed in this paper measures the similarity of the practitioners’ movements from two perspectives: overall movement similarity and the periodicity of the movements. This method achieves a quantitative assessment of the similarity when practitioners perform the BaDuanJin movements.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
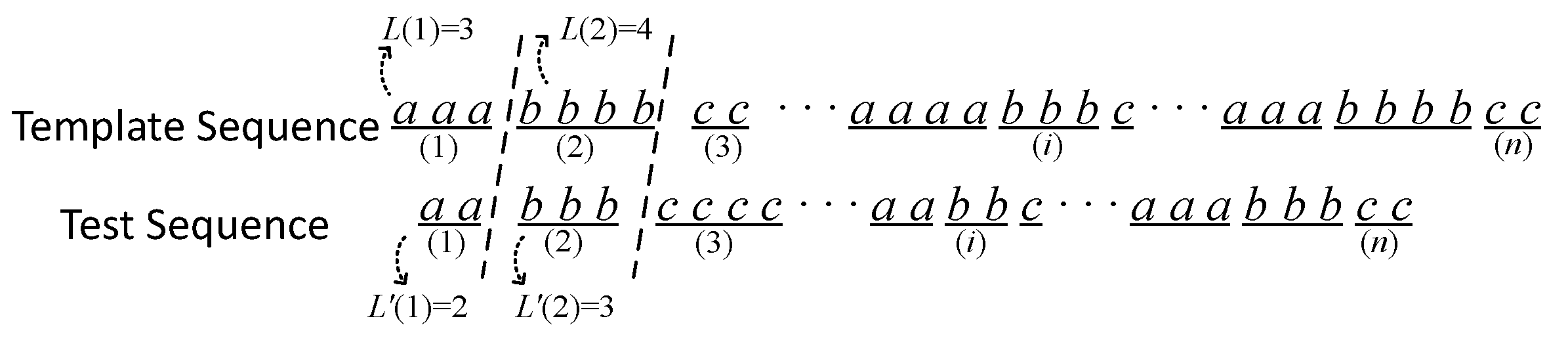{kind=link}
{kind=link}
{kind=link}
{kind=link}