
The Synergy between a Humanoid Robot and Whisper: Bridging a Gap in Education

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
2.1. Experimental Setup
2.2. Complexity of Statements
- Flesh reading ease: This refers to easiness of reading the text [33];
- Flesh Kincaid grade: This is mostly used in the education field. It indicates the necessary level of education to comprehend a text [34];
- Gunning fog: This is a test utilized for readability in English writing [35];
- SMOG: This is a readability index that determines the required year of education to comprehend the text [36];
- Automated Readability Index: This is used to determine whether or not a text is comprehended [34];
- LIX: This denotes the challenges related to text reading [37]:
- Dale–Chall Readability: This is related to understanding problems that the user faces during text reading [38].
2.3. Pepper Robot Function
2.4. Paramiko Function
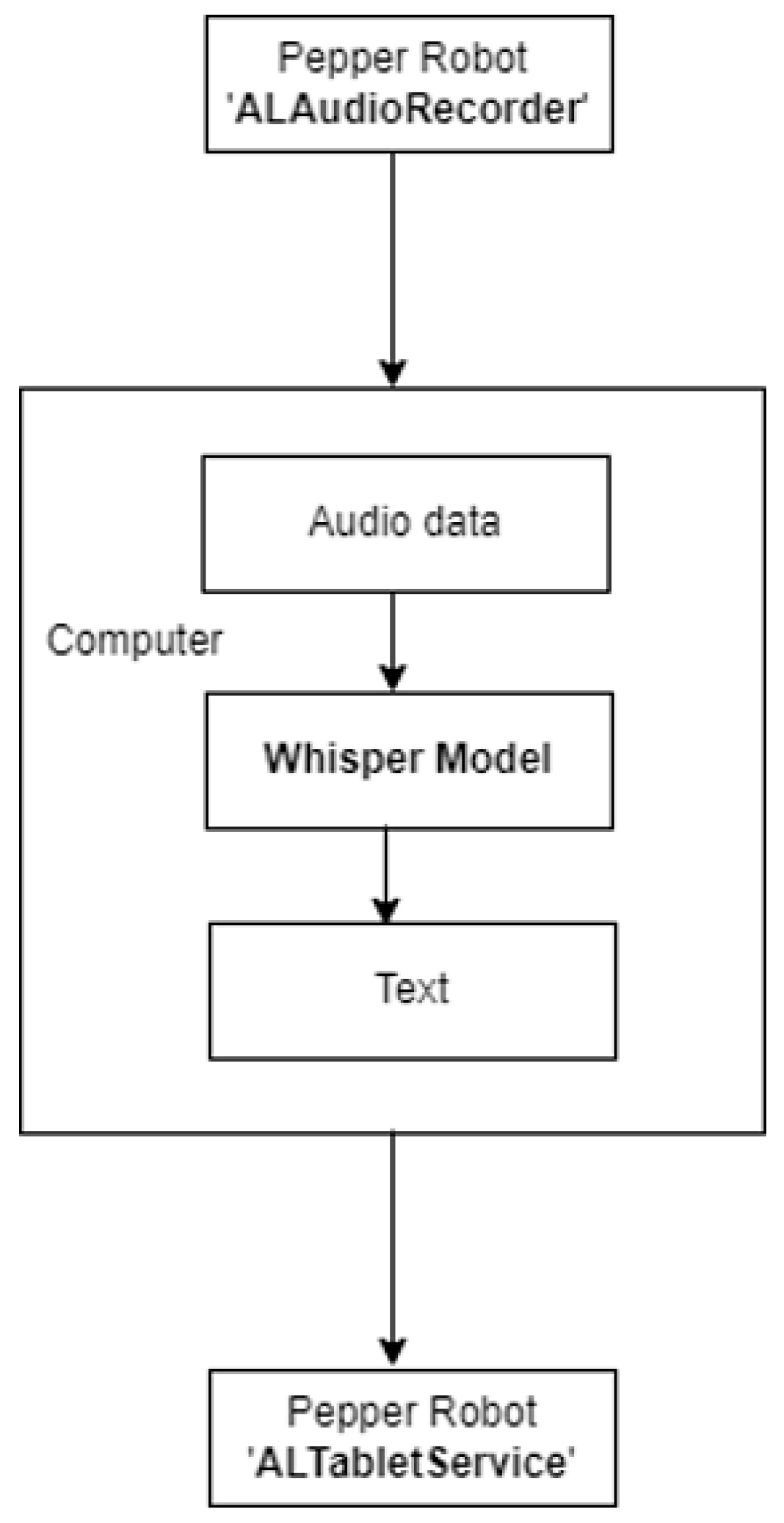
2.5. Whisper Function
3. Results
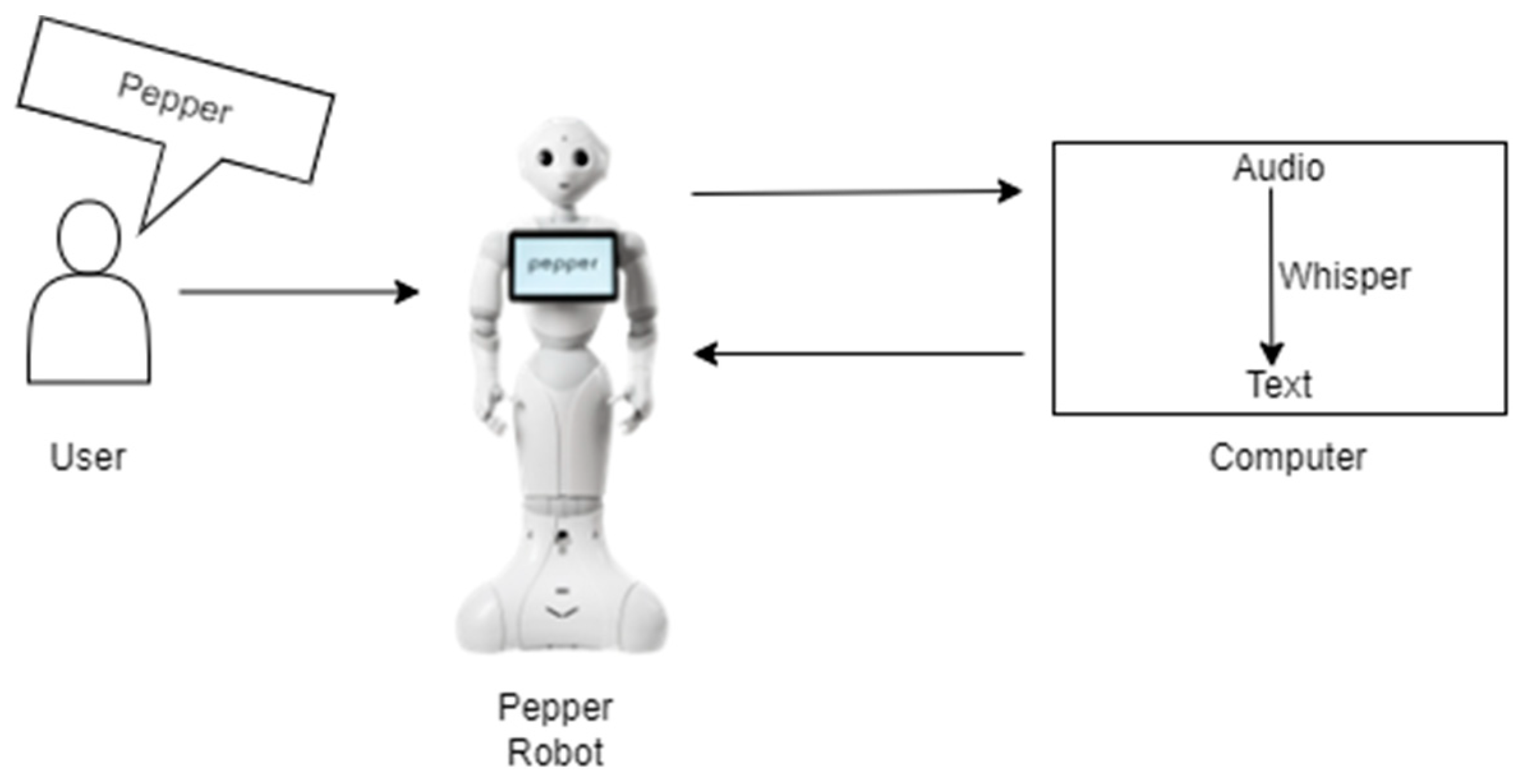
3.1. Integration of Pepper with Speech-to-Text Recognition Tool Whisper
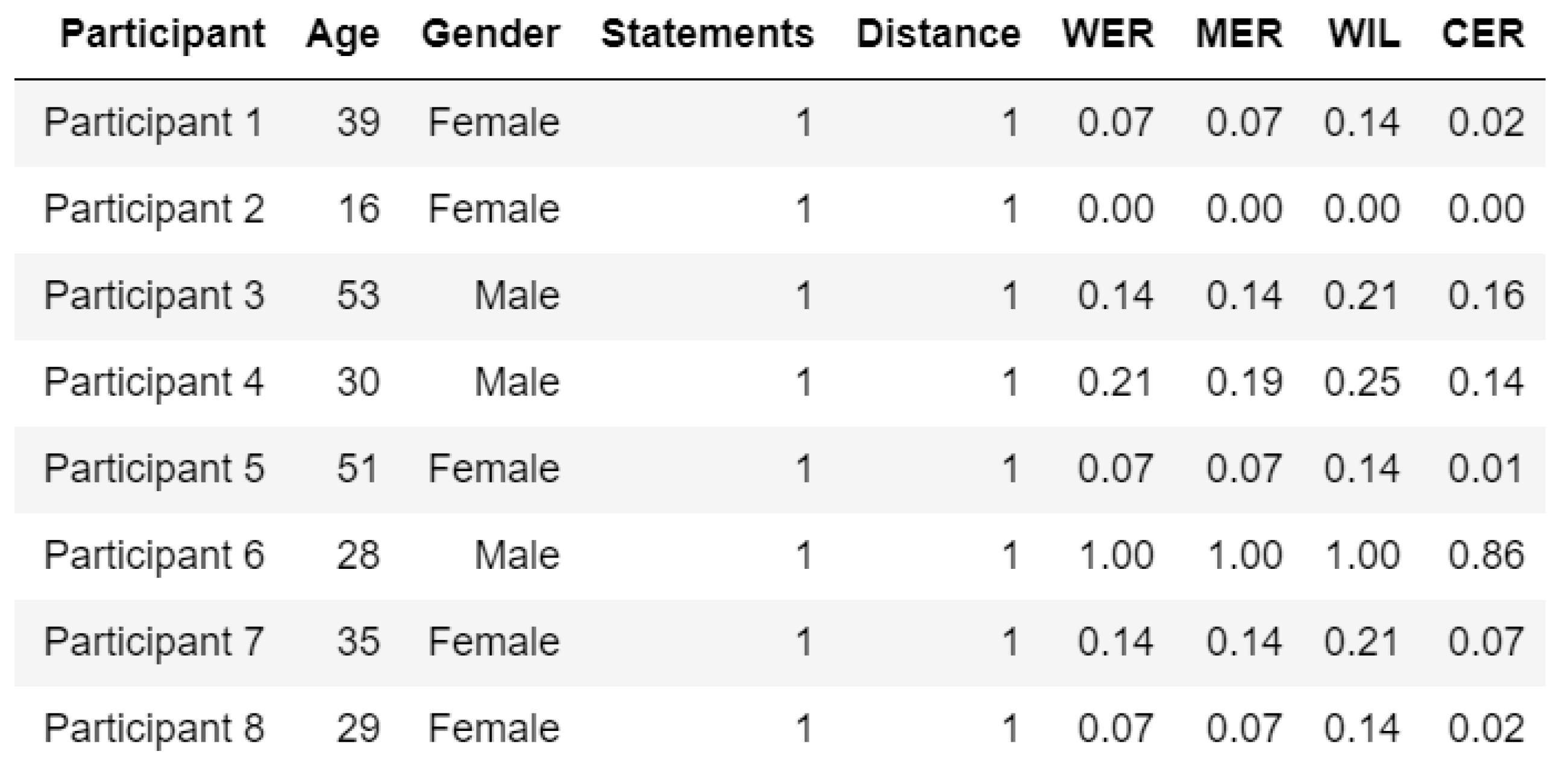
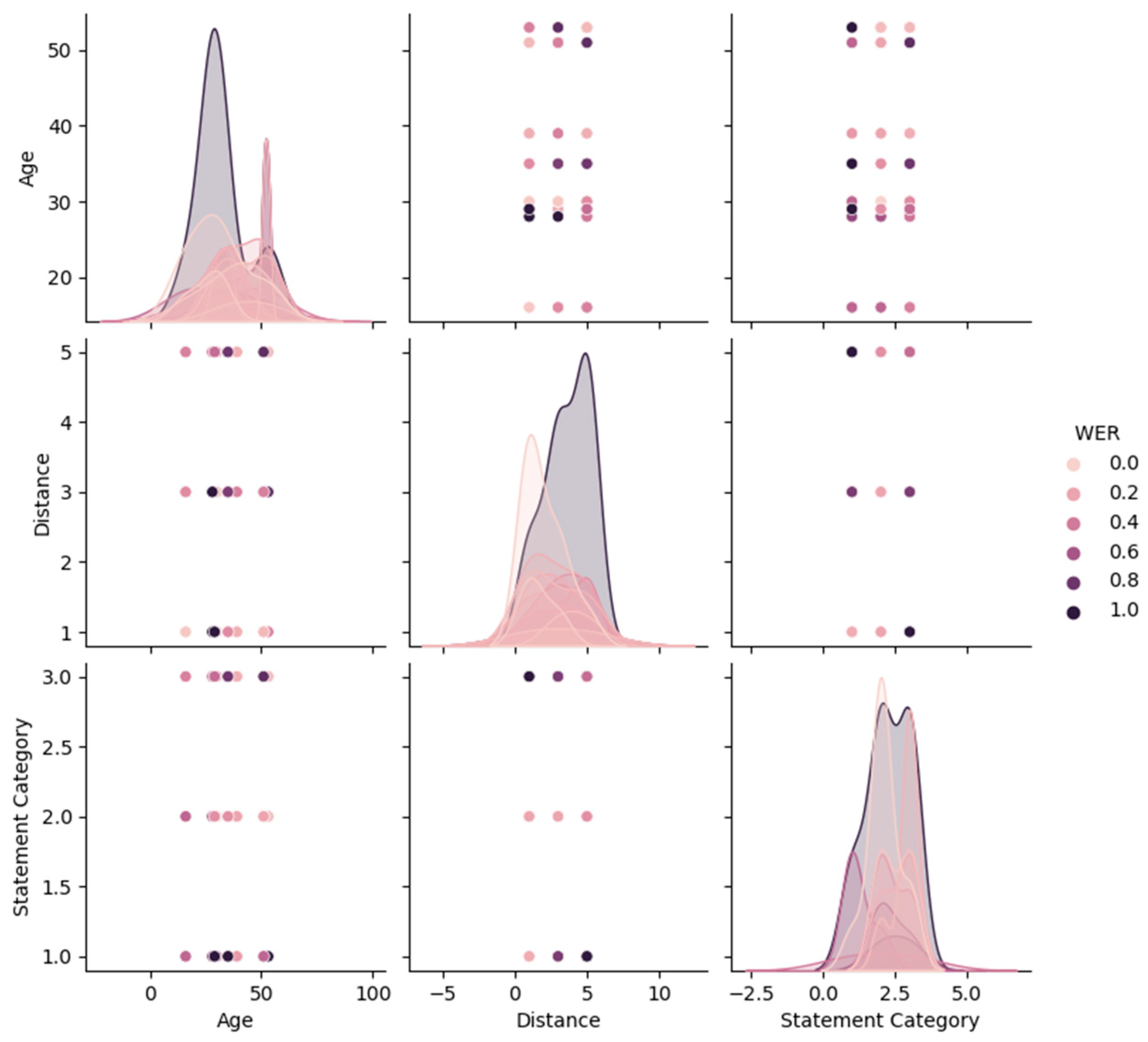
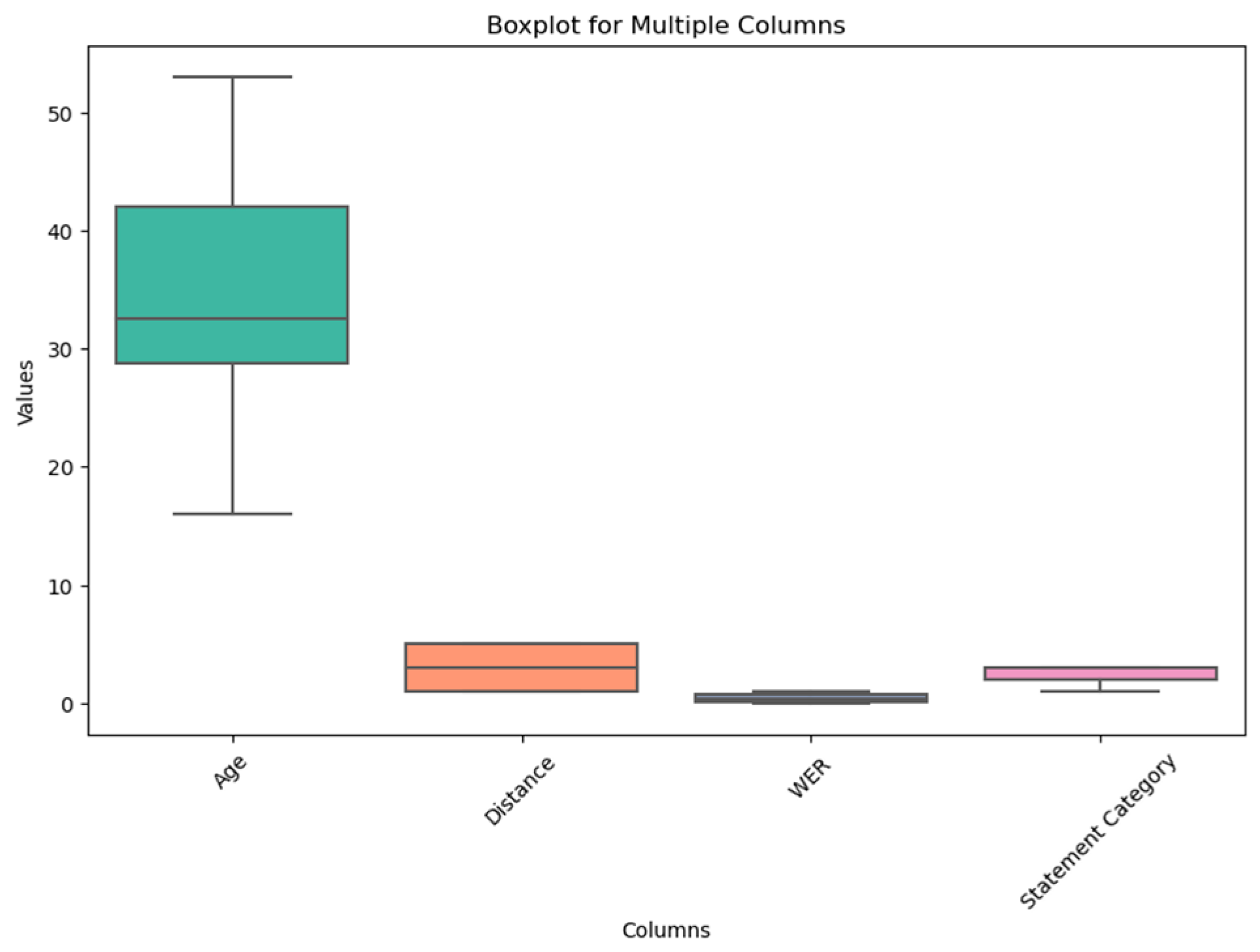
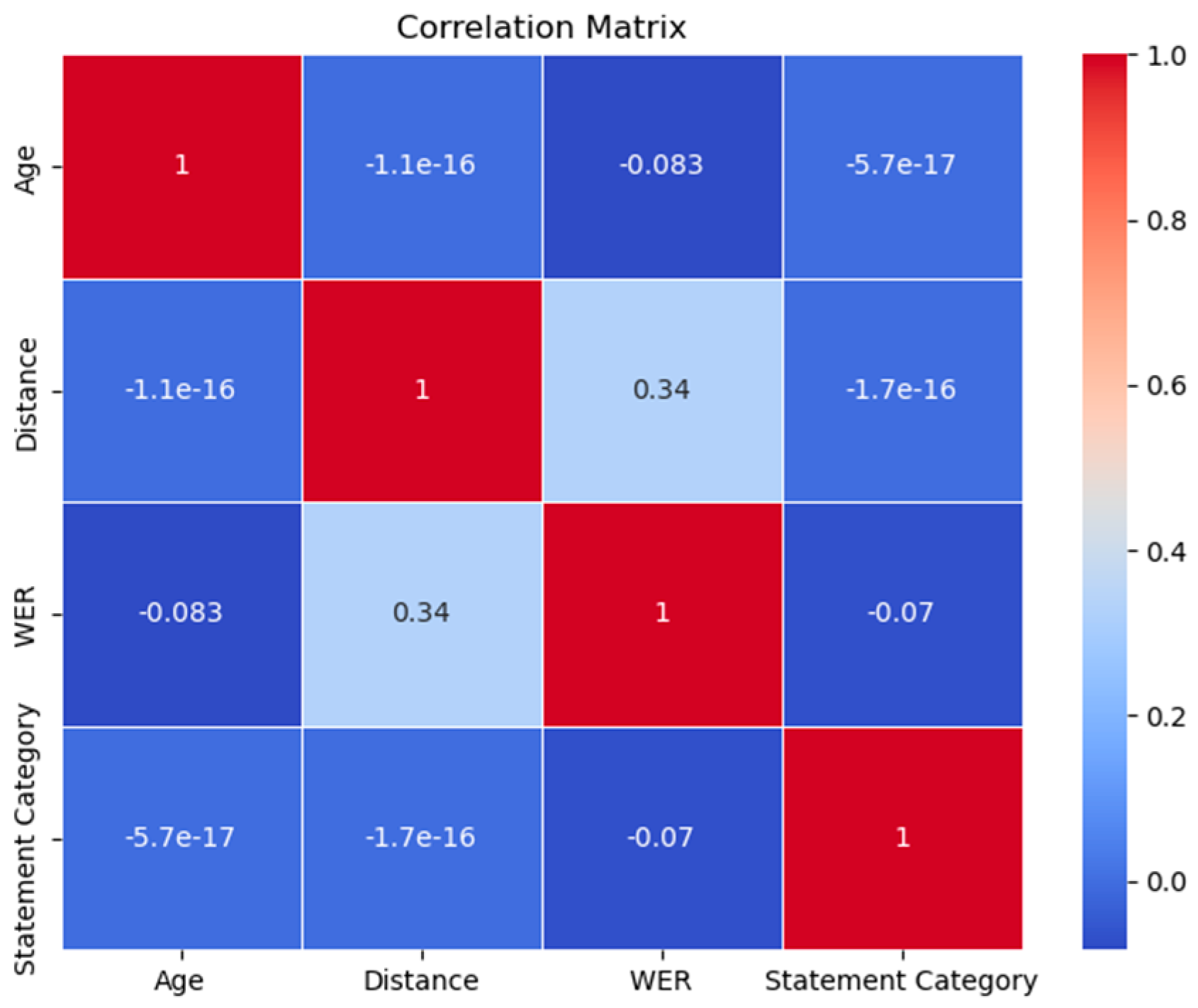
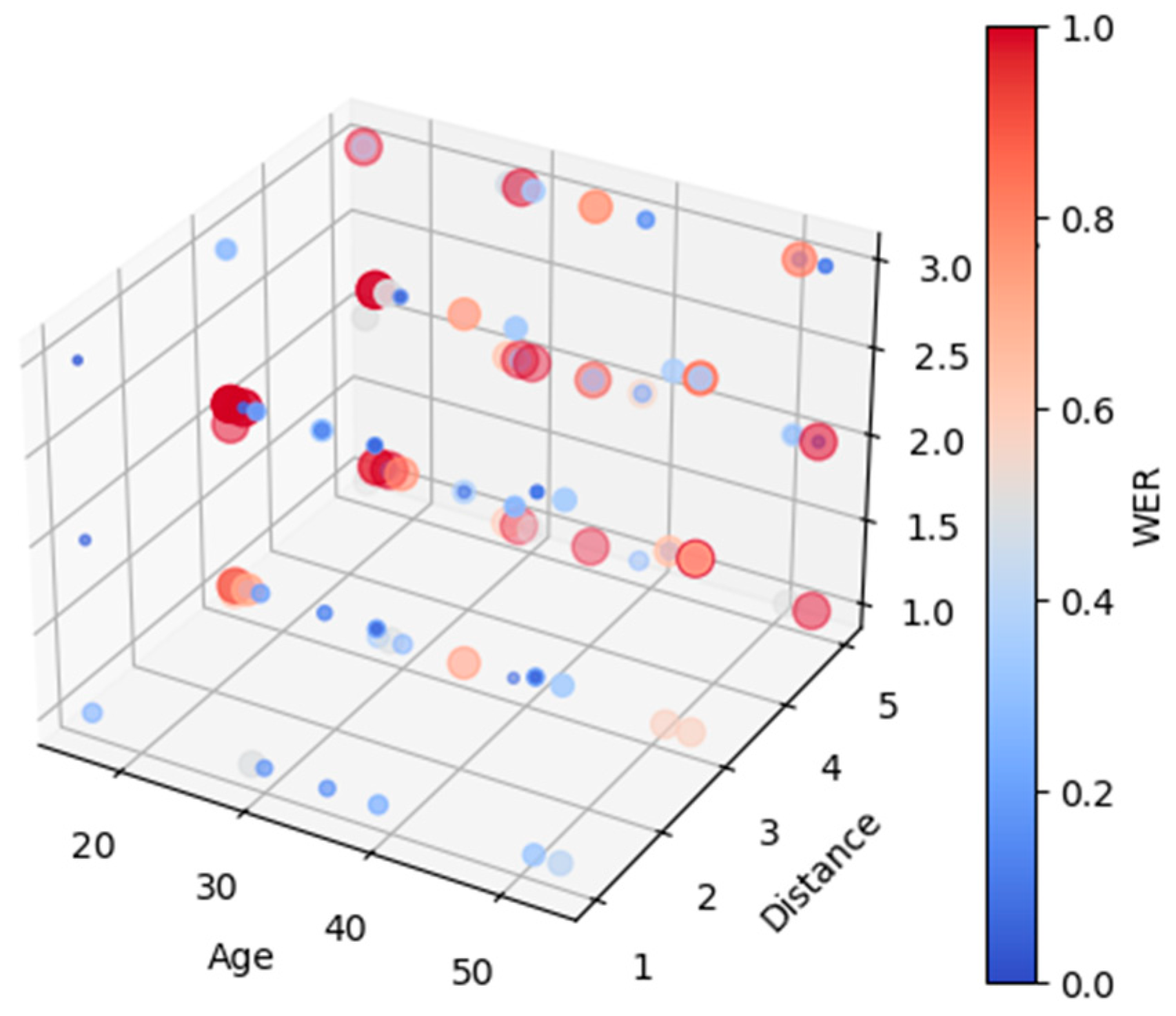
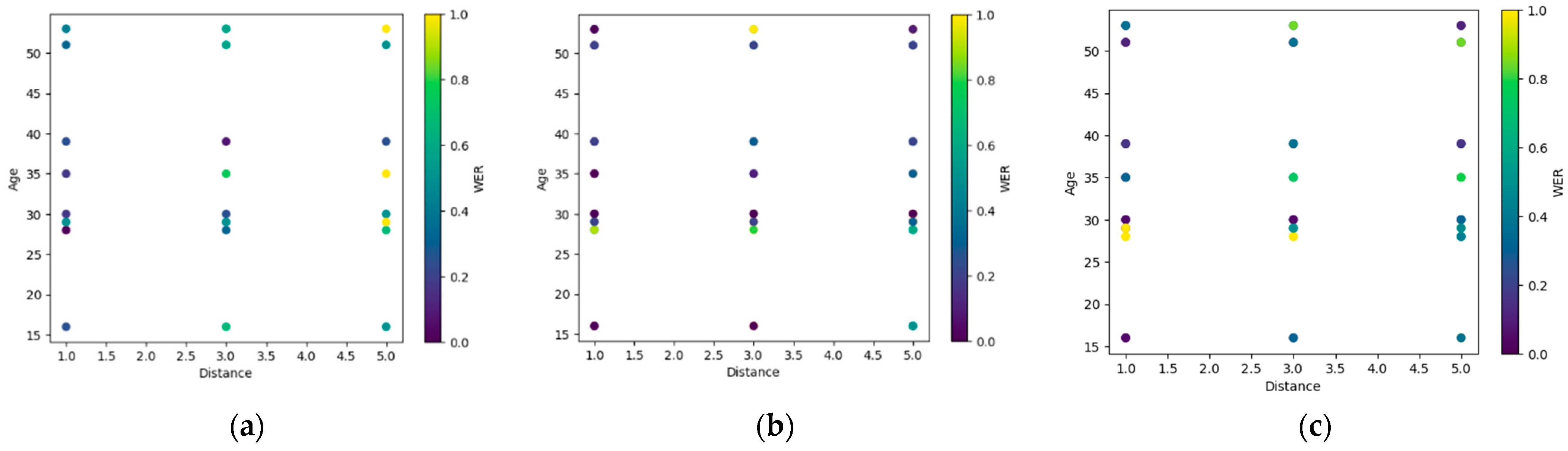
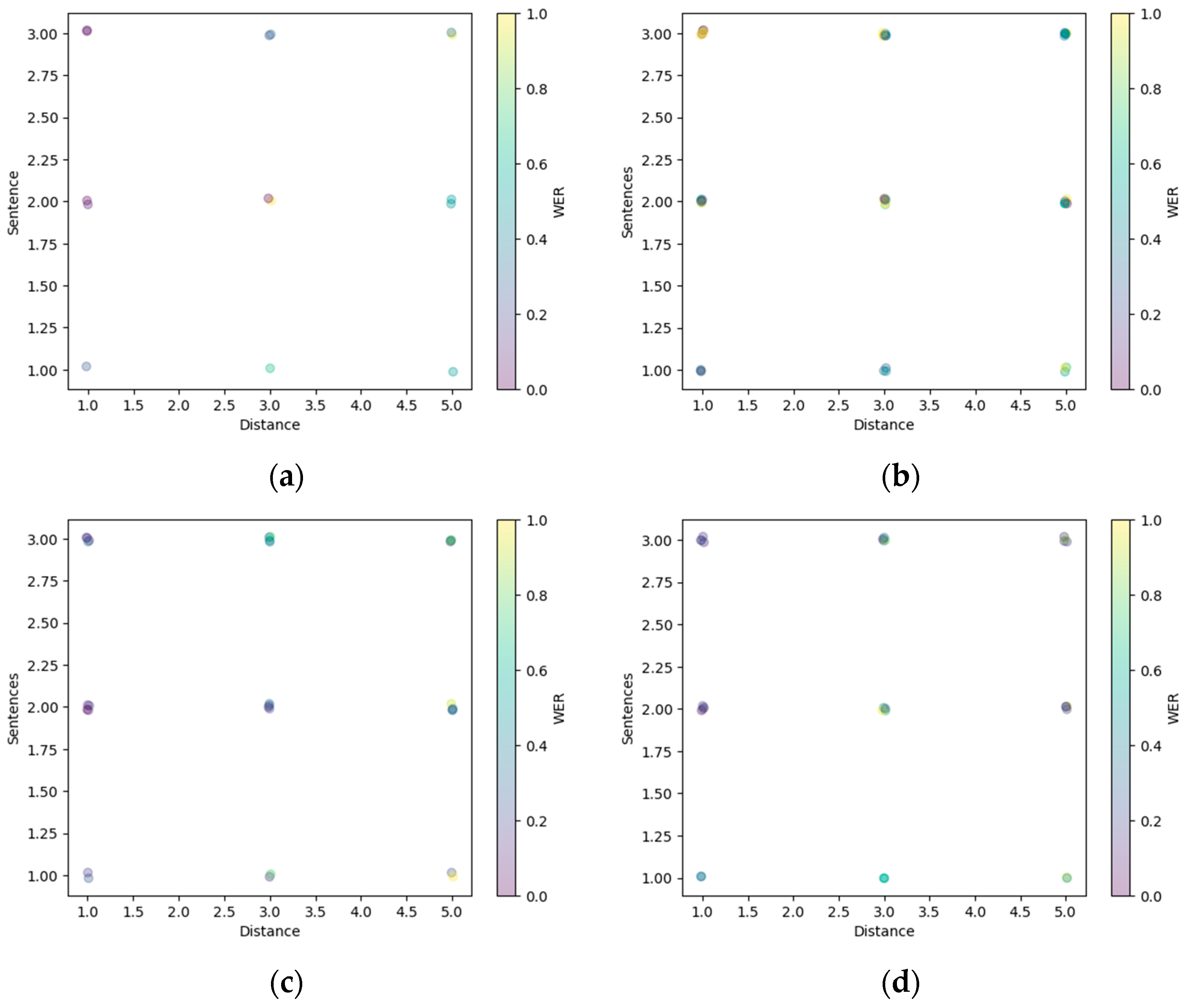
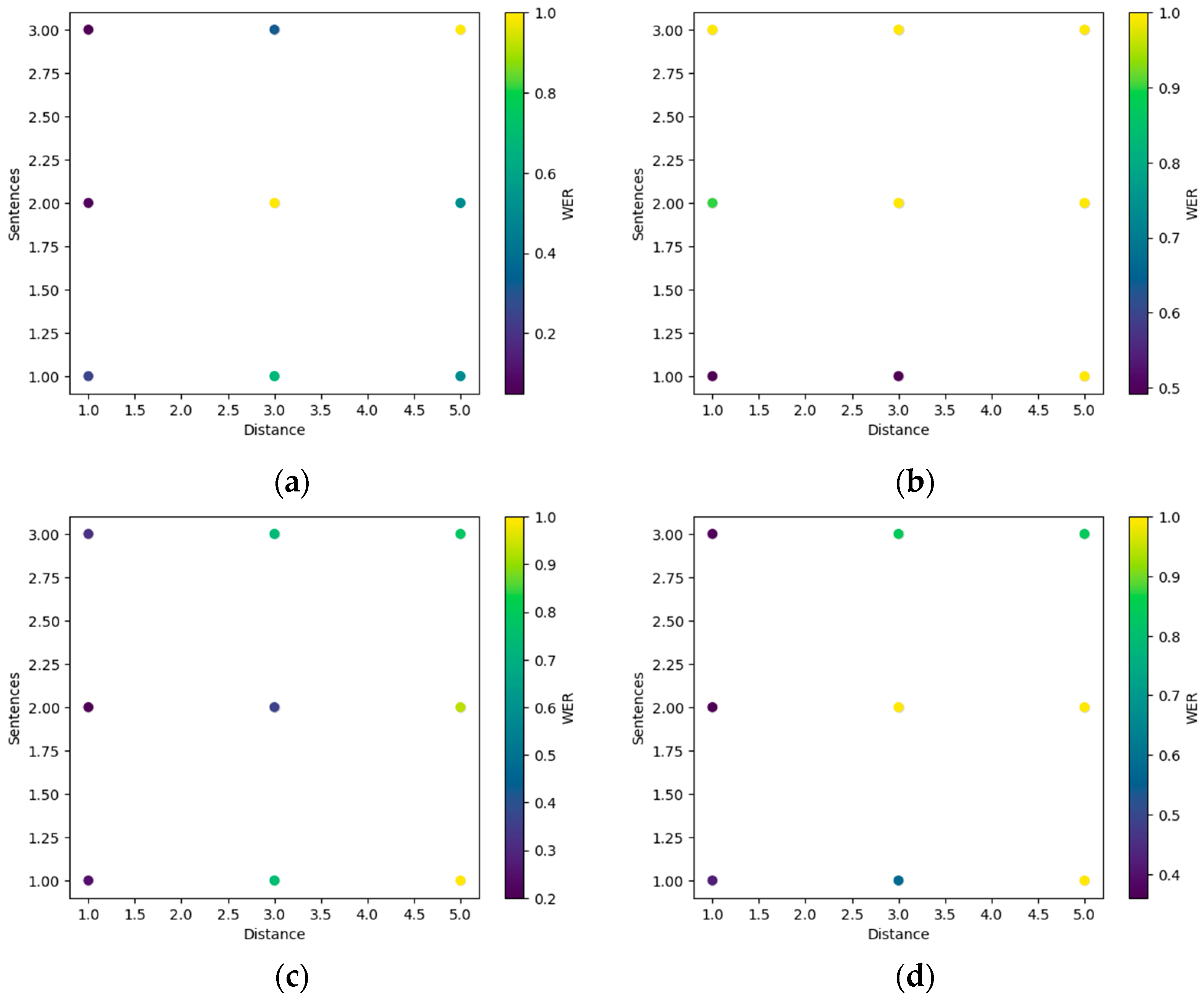
3.2. Exploring the Effectiveness of the Speech Recognition System based on Various Factors
4. Discussions
5. Conclusions, Limitations, Implications, and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dautenhahn, K. Socially intelligent robots: Dimensions of human–robot interaction. Philos. Trans. R. Soc. B Biol. Sci. 2007, 362, 679–704. [Google Scholar] [CrossRef]
- Engwall, O.; Lopes, J. Interaction and collaboration in robot-assisted language learning for adults. Comput. Assist. Lang. Learn. 2022, 35, 1273–1309. [Google Scholar] [CrossRef]
- Lytridis, C.; Bazinas, C.; Papakostas, G.A.; Kaburlasos, V. On measuring engagement level during child-robot interaction in education. In Robotics in Education: Current Research and Innovations 10; Springer: Berlin/Heidelberg, Germany, 2020; pp. 3–13. [Google Scholar]
- Christodoulou, P.; Reid, A.A.M.; Pnevmatikos, D.; del Rio, C.R.; Fachantidis, N. Students participate and evaluate the design and development of a social robot. In Proceedings of the 2020 29th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), Naples, Italy, 31 August–4 September 2020. [Google Scholar]
- Wang, K.; Sang, G.-Y.; Huang, L.-Z.; Li, S.-H.; Guo, J.-W. The Effectiveness of Educational Robots in Improving Learning Outcomes: A Meta-Analysis. Sustainability 2023, 15, 4637. [Google Scholar] [CrossRef]
- Alemi, M.; Meghdari, A.; Ghazisaedy, M. Employing humanoid robots for teaching English language in Iranian junior high-schools. Int. J. Humanoid Robot. 2014, 11, 1450022. [Google Scholar] [CrossRef]
- Kennedy, J.; Baxter, P.; Senft, E.; Belpaeme, T. Higher Nonverbal Immediacy Leads to Greater Learning Gains in Child-Robot Tutoring Interactions. In Social Robotics; Springer International Publishing: Cham, Switzerland, 2015. [Google Scholar]
- Mishra, D.; Inal, Y.; Parish, K.; Romero, G.A.; Rajbhandari, R. Exploring Active and Critical Engagement in Human-Robot Interaction to Develop Programming Skills: A Pilot Study. In Design, User Experience, and Usability; Springer Nature: Cham, Switzerland, 2023. [Google Scholar]
- Alemi, M.; Meghdari, A.; Ghazisaedy, M. The effect of employing humanoid robots for teaching English on students’ anxiety and attitude. In Proceedings of the 2014 Second RSI/ISM International Conference on Robotics and Mechatronics (ICRoM), Tehran, Iran, 15–17 October 2014. [Google Scholar]
- Belpaeme, T.; Kennedy, J.; Ramachandran, A.; Scassellati, B.; Tanaka, F. Social robots for education: A review. Sci. Robot. 2018, 3, eaat5954. [Google Scholar] [CrossRef] [PubMed]
- Movellan, J.; Eckhardt, M.; Virnes, M.; Rodriguez, A. Sociable robot improves toddler vocabulary skills. In Proceedings of the 4th ACM/IEEE International Conference on Human Robot Interaction, La Jolla, CA, USA, 9–13 March 2009. [Google Scholar]
- Rani, A.; Pande, A.; Parish, K.; Mishra, D. Teachers’ Perspective on Robots Inclusion in Education–A Case Study in Norway. In Proceedings of the International Conference on Human-Computer Interaction, Copenhagen, Denmark, 23–28 July 2023. [Google Scholar]
- Tsang, A. Why English accents and pronunciation ‘still’matter for teachers nowadays: A mixed-methods study on learners’ perceptions. J. Multiling. Multicult. Dev. 2020, 41, 140–156. [Google Scholar] [CrossRef]
- Pepper Robot Homepage. Available online: https://www.aldebaran.com/en/pepper (accessed on 7 May 2023).
- Shezi, M.; Ade-Ibijola, A. Deaf chat: A speech-to-text communication aid for hearing deficiency. Adv. Sci. Technol. Eng. Syst. J. 2020, 5, 826–833. [Google Scholar] [CrossRef]
- Shadiev, R.; Hwang, W.-Y.; Chen, N.-S.; Huang, Y.-M. Review of speech-to-text recognition technology for enhancing learning. J. Educ. Technol. Soc. 2014, 17, 65–84. [Google Scholar]
- Debnath, S.; Roy, P.; Namasudra, S.; Crespo, R.G. Audio-Visual Automatic Speech Recognition Towards Education for Disabilities. J. Autism Dev. Disord. 2022, 53, 3581–3594. [Google Scholar] [CrossRef]
- Goss, F.R.; Blackley, S.V.; Ortega, C.A.; Kowalski, L.T.; Landman, A.B.; Lin, C.-T.; Meteer, M.; Bakes, S.; Gradwohl, S.C.; Bates, D.W. A clinician survey of using speech recognition for clinical documentation in the electronic health record. Int. J. Med. Inform. 2019, 130, 103938. [Google Scholar] [CrossRef]
- Pande, A.; Shrestha, B.; Rani, A.; Mishra, D. A Comparative Analysis of Real Time Open-Source Speech Recognition Tools for Social Robots. In Proceedings of the International Conference on Human-Computer Interaction, Copenhagen, Denmark, 23–28 July 2023. [Google Scholar]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust speech recognition via large-scale weak supervision. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023. [Google Scholar]
- Vásquez-Correa, J.C.; Arzelus, H.; Martin-Doñas, J.M.; Arellano, J.; Gonzalez-Docasal, A.; Álvarez, A. When Whisper Meets TTS: Domain Adaptation Using only Synthetic Speech Data. In Proceedings of the International Conference on Text, Speech, and Dialogue, Pilsen, Czech Republic, 4–6 September 2023. [Google Scholar]
- Macháček, D.; Dabre, R.; Bojar, O. Turning Whisper into Real-Time Transcription System. arXiv 2023, arXiv:2307.14743. [Google Scholar]
- Spiller, T.R.; Ben-Zion, Z.; Korem, N.; Harpaz-Rotem, I.; Duek, O. Efficient and Accurate Transcription in Mental Health Research—A Tutorial on Using Whisper AI for Sound File Transcription. 2023. Available online: https://osf.io/9fue8/ (accessed on 7 May 2023). [CrossRef]
- Fujii, A.; Kristiina, J. Open source system integration towards natural interaction with robots. In Proceedings of the 2022 17th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Sapporo, Japan, 7–10 March 2022. [Google Scholar]
- Deuerlein, C.; Langer, M.; Sessner, J.; Heß, P.; Franke, J. Human-robot-interaction using cloud-based speech recognition systems. Procedia CIRP 2021, 97, 130–135. [Google Scholar] [CrossRef]
- Grasse, L.; Boutros, S.J.; Tata, M.S. Speech interaction to control a hands-free delivery robot for high-risk health care scenarios. Front. Robot. AI 2021, 8, 612750. [Google Scholar] [CrossRef]
- Mitsea, E.; Drigas, A. A journey into metacognitive learning strategies. Int. J. Online Biomed. Eng. 2019, 15, 4–22. [Google Scholar] [CrossRef]
- Mitsea, E.; Drigas, A.; Skianis, C. Metacognition in Autism Spectrum Disorder: Digital Technologies in Metacognitive Skills Training. Tech. Soc. Sci. J. 2022, 31, 153. [Google Scholar] [CrossRef]
- Naoqi API Documentation-ALAudioRecorder. Available online: https://doc.aldebaran.com/2-5/naoqi/audio/alaudiorecorder.html (accessed on 7 May 2023).
- Naoqi API Documentation ALTabletService. Available online: https://doc.aldebaran.com/2-5/naoqi/core/altabletservice.html (accessed on 7 May 2023).
- Natural Language Toolkit. Available online: https://www.nltk.org/ (accessed on 19 June 2023).
- Textstat. Available online: https://pypi.org/project/textstat/ (accessed on 19 June 2023).
- Farr, J.N.; Jenkins, J.J.; Paterson, D.G. Simplification of Flesch reading ease formula. J. Appl. Psychol. 1951, 35, 333. [Google Scholar] [CrossRef]
- Kincaid, J.P.; Fishburne, R.P., Jr.; Rogers, R.L.; Chissom, B.S. Derivation of New Readability Formulas (Automated Readability Index, Fog Count and Flesch Reading Ease Formula) for Navy Enlisted Personnel; Institute for Simulation and Training, University of Central Florida: Orlando, FL, USA, 1975. [Google Scholar]
- Gunning, R. Technique of Clear Writing; McGraw-Hill: New York, NY, USA, 1952. [Google Scholar]
- McLaughlin, G. SMOG grading—A new readability formula. J. Read. 1969, 12, 639–646. [Google Scholar]
- Björnsson, C.-H. Readability of newspapers in 11 languages. Read. Res. Q. 1983, 18, 480–497. [Google Scholar] [CrossRef]
- Dale, E.; Chall, J.S. A formula for predicting readability: Instructions. Educ. Res. Bull. 1948, 27, 37–54. [Google Scholar]
- Paramiko Documentation. Available online: https://www.paramiko.org/ (accessed on 7 May 2023).
- OpenAI Whisper. Available online: https://openai.com/research/whisper (accessed on 7 May 2023).
- Wikipedia Page Word Error Rate. Available online: https://en.wikipedia.org/wiki/Word_error_rate (accessed on 7 May 2023).
- Match Error Rate Documentation. Available online: https://torchmetrics.readthedocs.io/en/stable/text/match_error_rate.html (accessed on 7 May 2023).
- Word Information Lost Documentation. Available online: https://torchmetrics.readthedocs.io/en/stable/text/word_info_lost.html (accessed on 7 May 2023).
- Character Error Rate Documentation. Available online: https://torchmetrics.readthedocs.io/en/stable/text/char_error_rate.html#:~:text=character%20error%20rate%20is%20a,0%20being%20a%20perfect%20score (accessed on 7 May 2023).
- Lhoussain, A.S.; Hicham, G.; Abdellah, Y. Adaptating the levenshtein distance to contextual spelling correction. Int. J. Comput. Sci. Appl. 2015, 12, 127–133. [Google Scholar]
- Li, Q.; Russell, M.J. An analysis of the causes of increased error rates in children’s speech recognition. In Proceedings of the Seventh International Conference on Spoken Language Processing, Denver, CO, USA, 16–20 September 2002. [Google Scholar]
- Kennedy, J.; Lemaignan, S.; Montassier, C.; Lavalade, P.; Irfan, B.; Papadopoulos, F.; Senft, E.; Belpaeme, T. Child speech recognition in human-robot interaction: Evaluations and recommendations. In Proceedings of the 2017 ACM/IEEE International Conference on Human-Robot Interaction, Vienna, Austria, 6–9 March 2017. [Google Scholar]
- Diaz-Asper, C.; Chandler, C.; Turner, R.S.; Reynolds, B.; Elvevåg, B. Acceptability of collecting speech samples from the elderly via the telephone. Digit. Health 2021, 7, 20552076211002103. [Google Scholar] [CrossRef] [PubMed]
- Errattahi, R.; El Hannani, A.; Ouahmane, H. Automatic speech recognition errors detection and correction: A review. Procedia Comput. Sci. 2018, 128, 32–37. [Google Scholar] [CrossRef]
- Horton, W.S.; Spieler, D.H.; Shriberg, E. A corpus analysis of patterns of age-related change in conversational speech. Psychol. Aging 2010, 25, 708. [Google Scholar] [CrossRef] [PubMed]
- Young, V.; Mihailidis, A. Difficulties in automatic speech recognition of dysarthric speakers and implications for speech-based applications used by the elderly: A literature review. Assist. Technol. 2010, 22, 99–112. [Google Scholar] [CrossRef] [PubMed]
- Aman, F.; Vacher, M.; Rossato, S.; Portet, F. Analysing the performance of automatic speech recognition for ageing voice: Does it correlate with dependency level? In Proceedings of the 4th Workshop on Speech and Language Processing for Assistive Technologies, Grenoble, France, 21–22 August 2013. [Google Scholar]
- Pépiot, E. Voice, Speech and Gender: Male-female acoustic differences and cross-language variation in english and french speakers. In Proceedings of the XVèmes Rencontres Jeunes Chercheurs de l’ED 268, Paris, France, June 2012; (à paraître), ffhalshs-00764811f. Available online: https://shs.hal.science/halshs-00764811/document (accessed on 7 May 2023).
- Tsantani, M.S.; Belin, P.; Paterson, H.M.; McAleer, P. Low vocal pitch preference drives first impressions irrespective of context in male voices but not in female voices. Perception 2016, 45, 946–963. [Google Scholar] [CrossRef] [PubMed]
- Adda-Decker, M.; Lamel, L. Do speech recognizers prefer female speakers? In Proceedings of the Ninth European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005. [Google Scholar]
- Garnerin, M.; Rossato, S.; Besacier, L. Gender representation in French broadcast corpora and its impact on ASR performance. In Proceedings of the 1st International Workshop on AI for Smart TV Content Production, Access and Delivery, Nice, France, 21 October 2019. [Google Scholar]
- Rodrigues, A.; Santos, R.; Abreu, J.; Beça, P.; Almeida, P.; Fernandes, S. Analyzing the performance of ASR systems: The effects of noise, distance to the device, age and gender. In Proceedings of the XX International Conference on Human Computer Interaction, Donostia, Spain, 25–28 June 2019. [Google Scholar]
- Nematollahi, M.A.; Al-Haddad, S.A.R. Distant speaker recognition: An overview. Int. J. Humanoid Robot. 2016, 13, 1550032. [Google Scholar] [CrossRef]
- Braber, N.; Smith, H.; Wright, D.; Hardy, A.; Robson, J. Assessing the Specificity and Accuracy of Accent Judgments by Lay Listeners. Lang. Speech 2023, 66, 267–290. [Google Scholar] [CrossRef]
- Attawibulkul, S.; Kaewkamnerdpong, B.; Miyanaga, Y. Noisy speech training in MFCC-based speech recognition with noise suppression toward robot assisted autism therapy. In Proceedings of the 2017 10th Biomedical Engineering International Conference (BMEiCON), Hokkaido, Japan, 31 August–2 September 2017. [Google Scholar]
- Gnanamanickam, J.; Natarajan, Y.; KR, S.P. A Hybrid Speech Enhancement Algorithm for Voice Assistance Application. Sensors 2021, 21, 7025. [Google Scholar] [CrossRef]












Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pande, A.; Mishra, D. The Synergy between a Humanoid Robot and Whisper: Bridging a Gap in Education. Electronics 2023, 12, 3995. https://doi.org/10.3390/electronics12193995
Pande A, Mishra D. The Synergy between a Humanoid Robot and Whisper: Bridging a Gap in Education. Electronics. 2023; 12(19):3995. https://doi.org/10.3390/electronics12193995
Chicago/Turabian StylePande, Akshara, and Deepti Mishra. 2023. "The Synergy between a Humanoid Robot and Whisper: Bridging a Gap in Education" Electronics 12, no. 19: 3995. https://doi.org/10.3390/electronics12193995