
YOLO-CID: Improved YOLOv7 for X-ray Contraband Image Detection

Abstract
:1. Introduction
- 1.
- Compared with common scenes, most targets in X-ray images are placed arbitrarily and have directional characteristics. However, the YOLOv7 network’s positioning of key information is relatively vague, making it easy to lose key feature information about the directionality of the target. This further increases the difficulty of contraband detection.
- 2.
- The objects in X-ray images form a complex background due to overlapping and occlusion. However, there is no corresponding attention mechanism to deal with this complex background, resulting in the inaccurate detection of contraband under such conditions.
- 3.
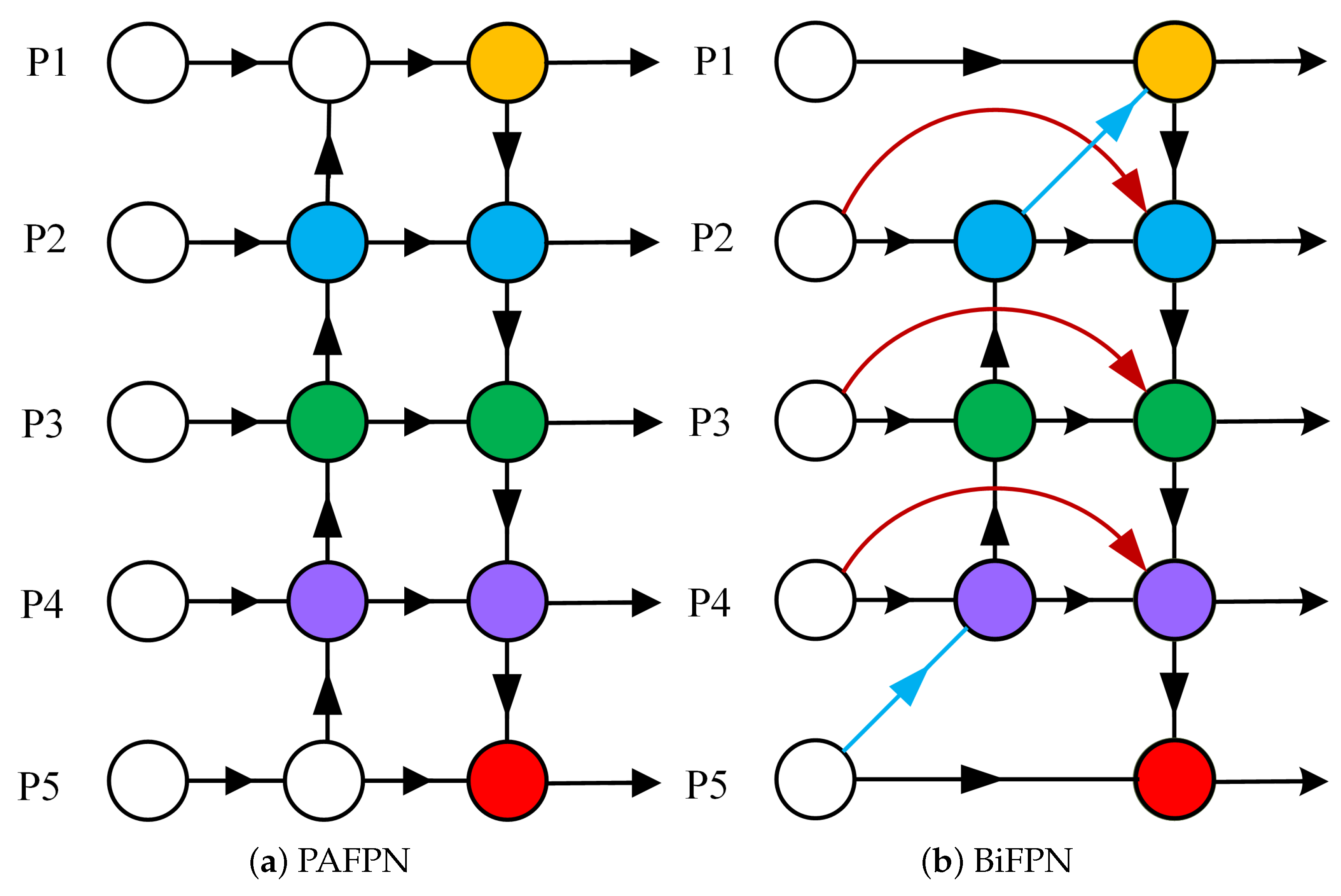
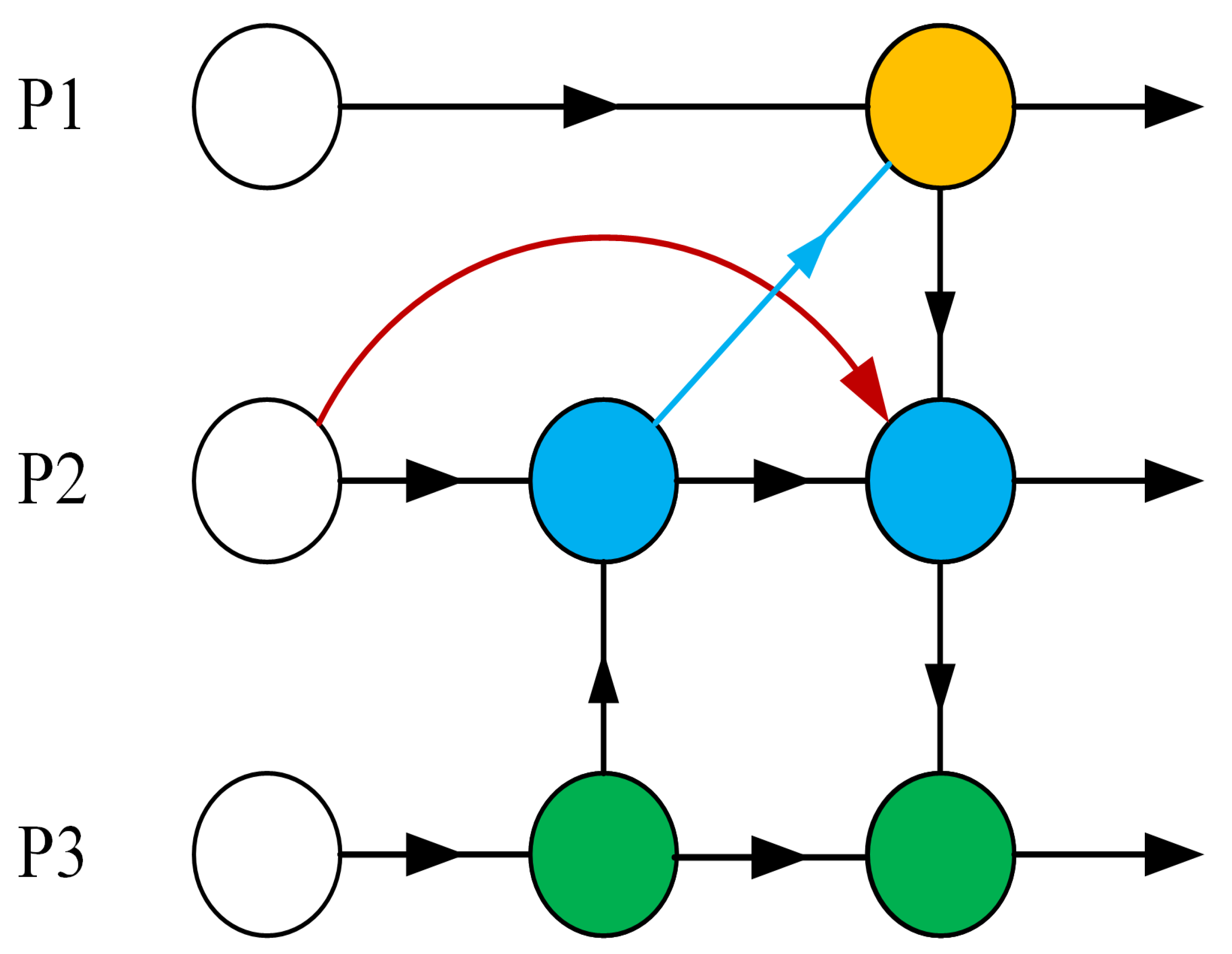
- Although the PAFPN structure in the feature fusion module can enhance the network’s representation ability, it does not make full use of the feature map output of each node and does not take into account the different fusion capabilities of each module for features. In response to these challenges, this article targets improvements on the basis of YOLOv7.
- 1.
- This paper proposes the YOLO-CID algorithm for X-ray contraband detection. We conducted ablation and comparative experiments of YOLO-CID on the PIDray [12] dataset and CLCXray [13] dataset. The experimental results show that, compared with current mainstream algorithms, our algorithm has significantly improved detection accuracy and speeds.
- 2.
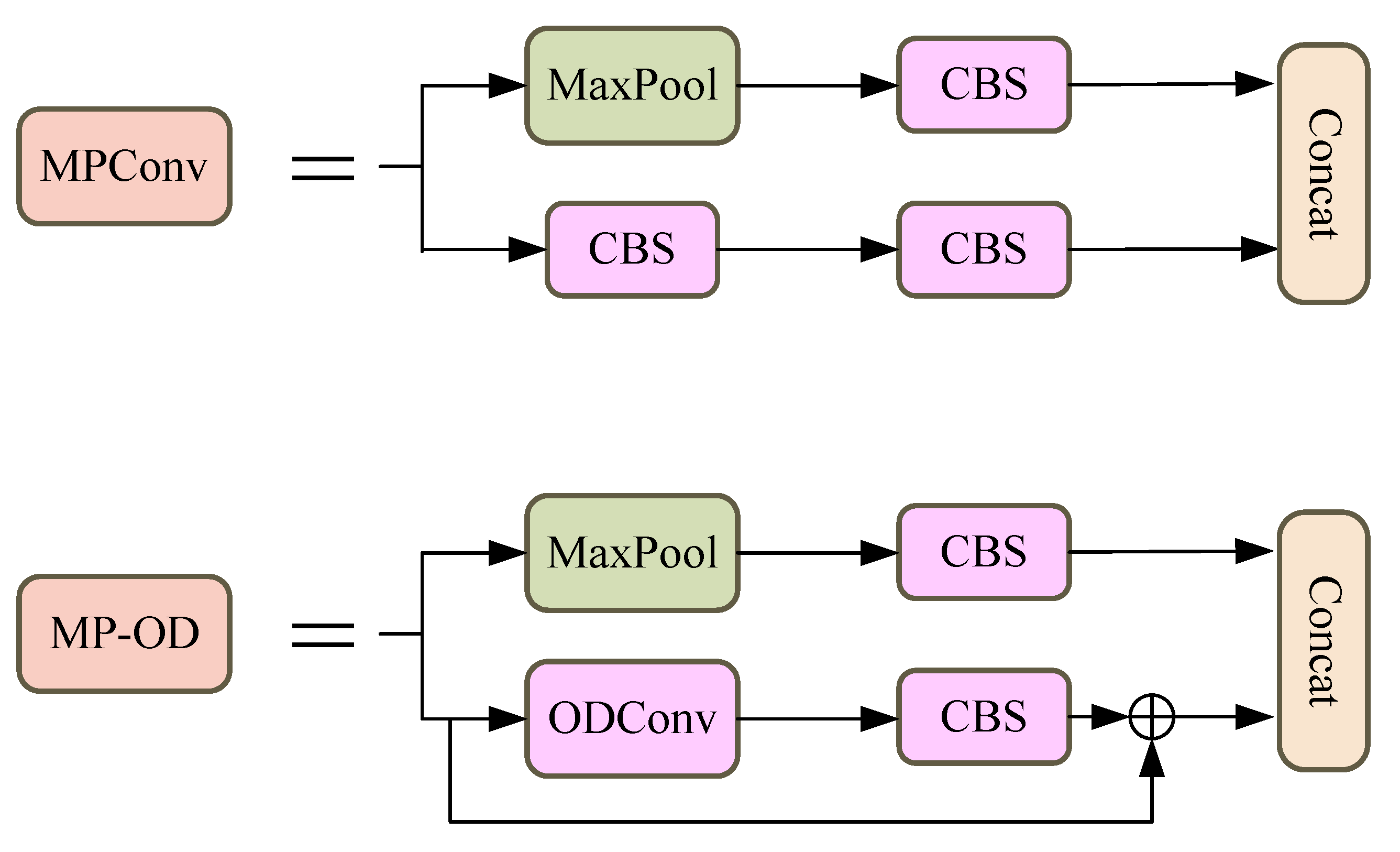
- We implemented a robust new architecture and an enhanced MP-OD model, which builds upon and extends the original MPConv model. We added skip connections between the models and completed the second part (ODConv [14]). This results in a more accurate model with less redundant feature information, greater resilience against background X-ray images, and a faster feature localization speed.
- 3.
- 4.
- We introduced the shuffle attention mechanism [17], an efficient spatial channel dual attention mechanism, in the neck to improve the network’s focus on tiny features.
2. Related Works
2.1. Traditional Machine Learning Methods for Contraband Detection in X-ray Images
2.2. Deep Learning for Contraband X-ray Image Detection
3. YOLO-CID
3.1. Network Architecture
3.2. MP-OD Module
3.3. BiFPN-P3 Module
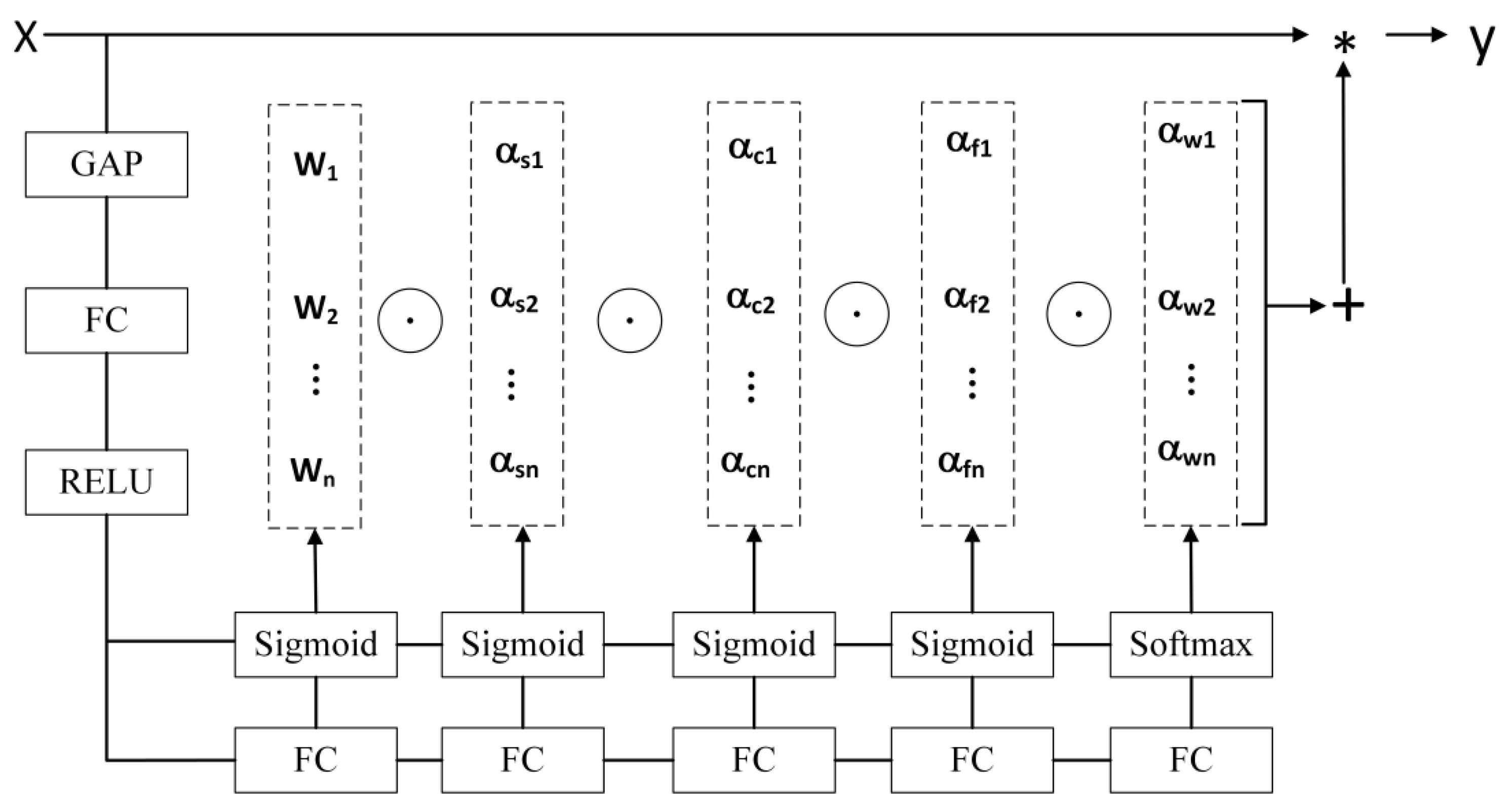
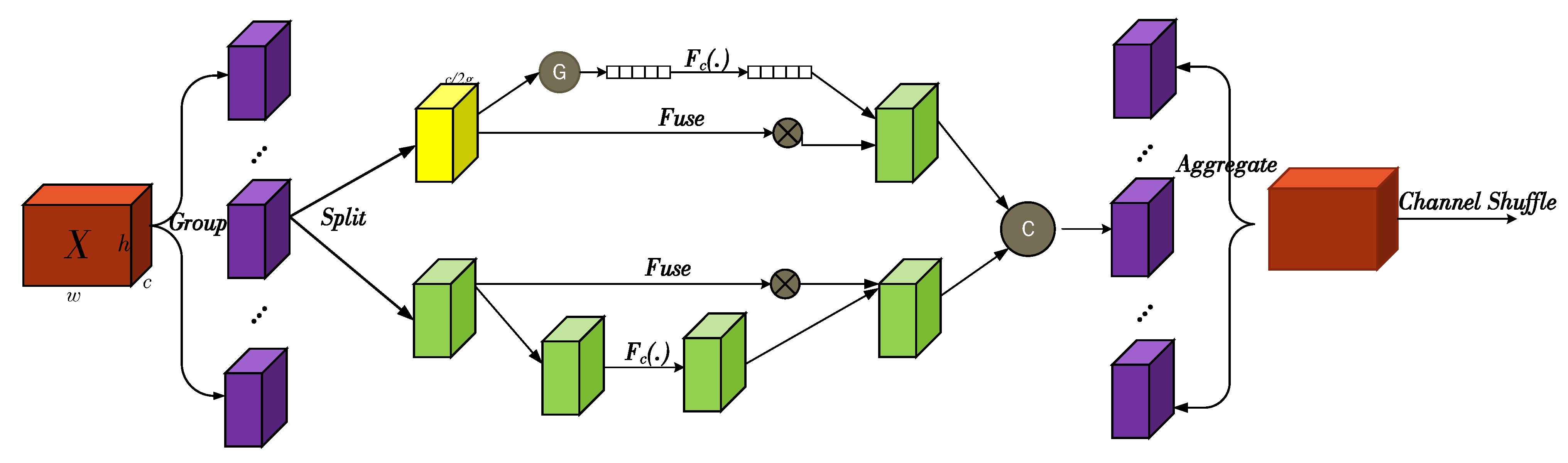
3.4. SA Module
- 1.
- Feature grouping: The feature map S ∈ of a given length, width, and channel number W, H, and C is divided into G groups along the channel dimension, denoted as X = [,…,], ∈. Each sub-feature will gradually capture specific semantic information with training. This part corresponds to the section marked as Group on the leftmost side of the figure above.
- 2.
- Attention mixing: The generated feature is divided into two branches along the channel dimension. The two sub-features are denoted as , ∈, as shown in the section marked as Split in the middle of the figure. During the processing of feature , a group normalization operation is used to accelerate convergence and avoid excessive differences in the values of different features, which can lead to confusion in the learning of lower layer networks. The representation of the enhanced input is then transformed through . The specific formula is as follows:In the equation, GN represents group normalization; and denote the scaling and shifting of the processed feature map. The enhanced feature representation is obtained through the sigmoid activation function.For feature , the channel attention mechanism is employed. To reduce the complexity of the module and improve the processing efficiency, a fast and effective single-layer transformation mode consisting of global average pooling (GAP), scaling, and sigmoid activation is utilized for feature processing. First, channel statistics are generated through GAP to produce channel-level statistics. The specific formula is as follows:In the equation, denotes the contraction calculation of along the spatial dimension . The generated S is then screened to obtain the final feature map . The specific formula is as follows:Finally, the results of the two types of attention are combined through a concatenation layer to obtain = [,].
- 3.
- Feature aggregation: Similar to ShuffleNetv2, a channel shuffle operation is employed to aggregate all features and facilitate cross-group information exchange along the channel dimension, resulting in the final output feature map.
4. Experimental Results and Analysis
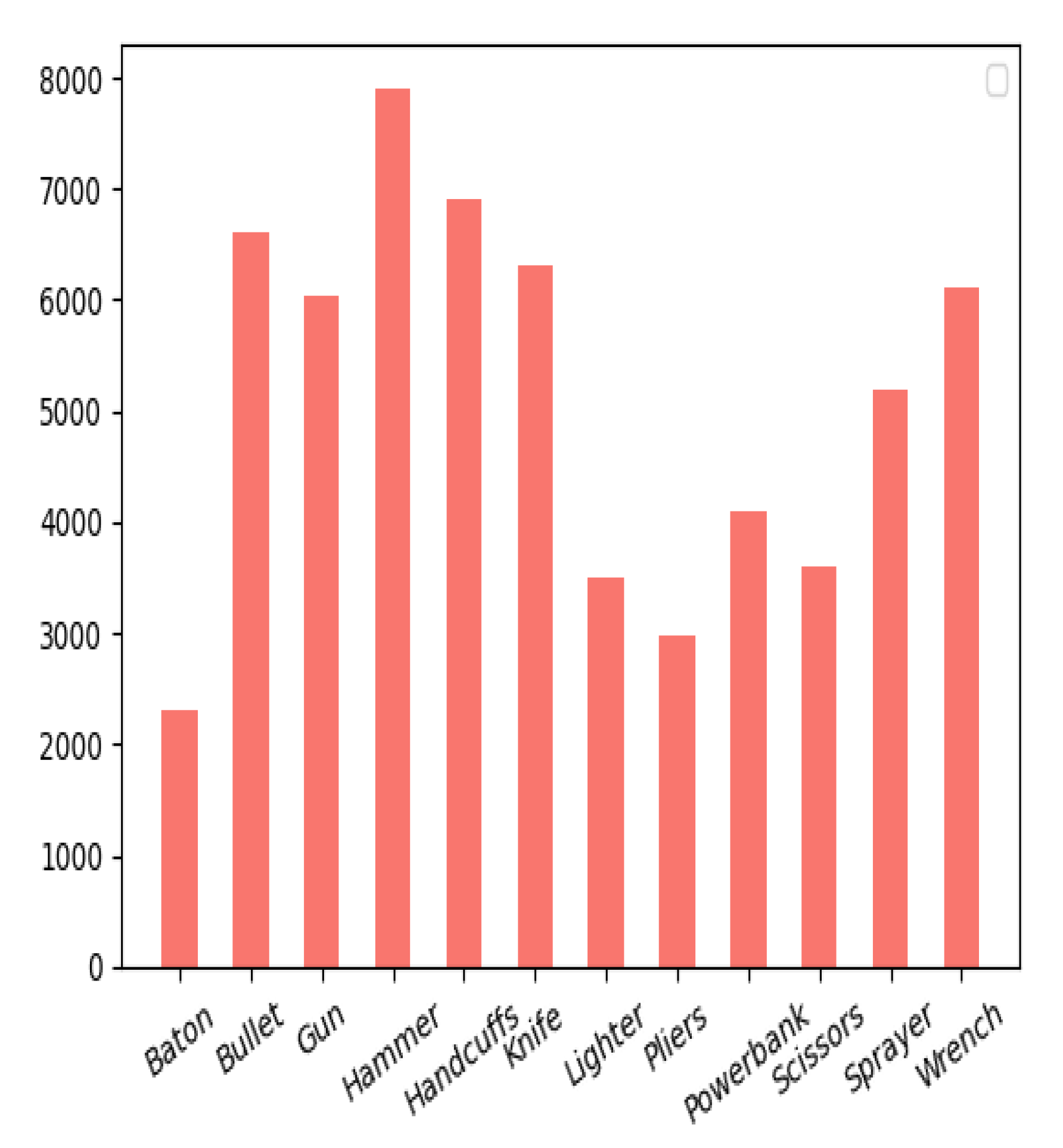
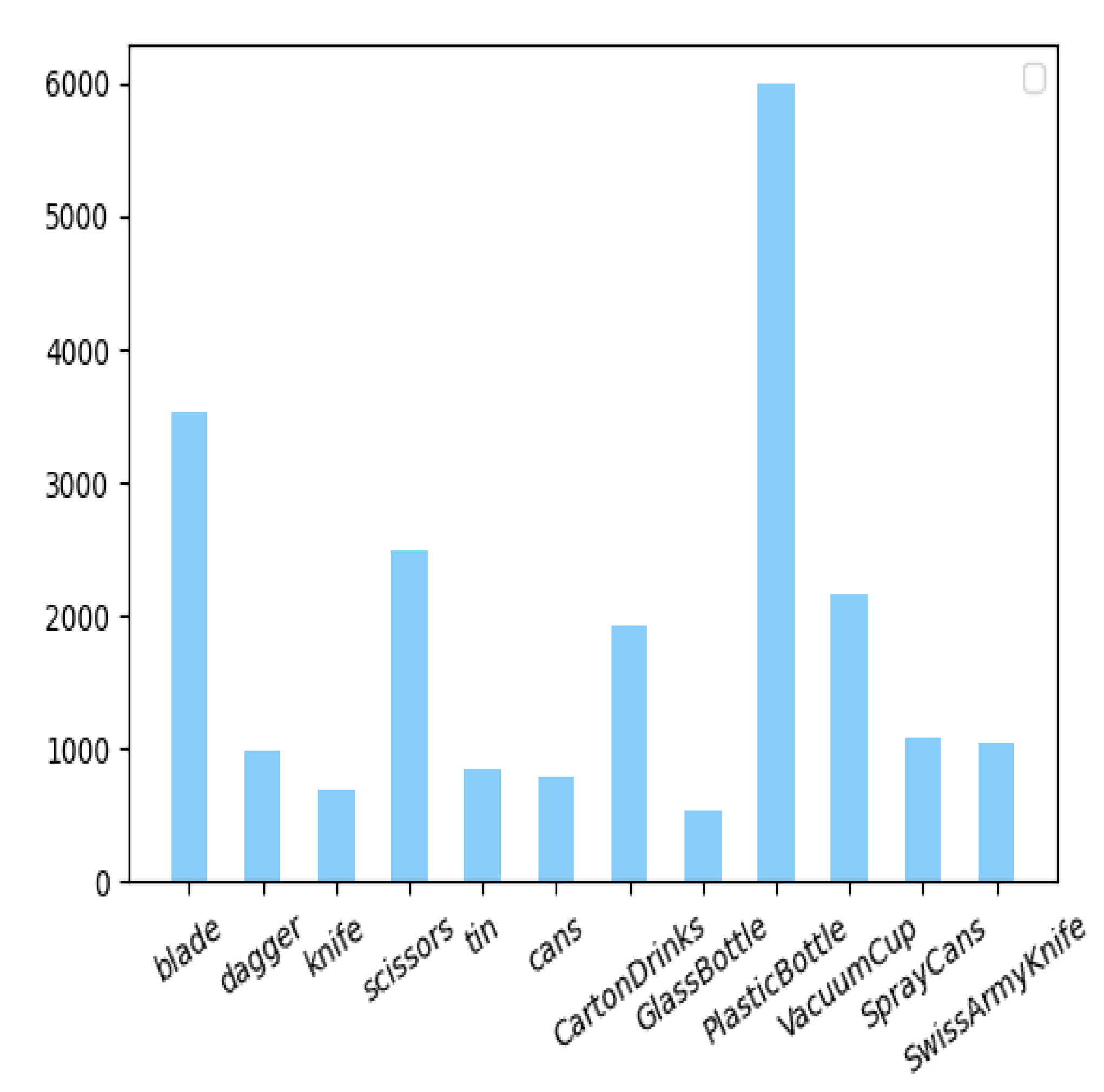
4.1. Dataset
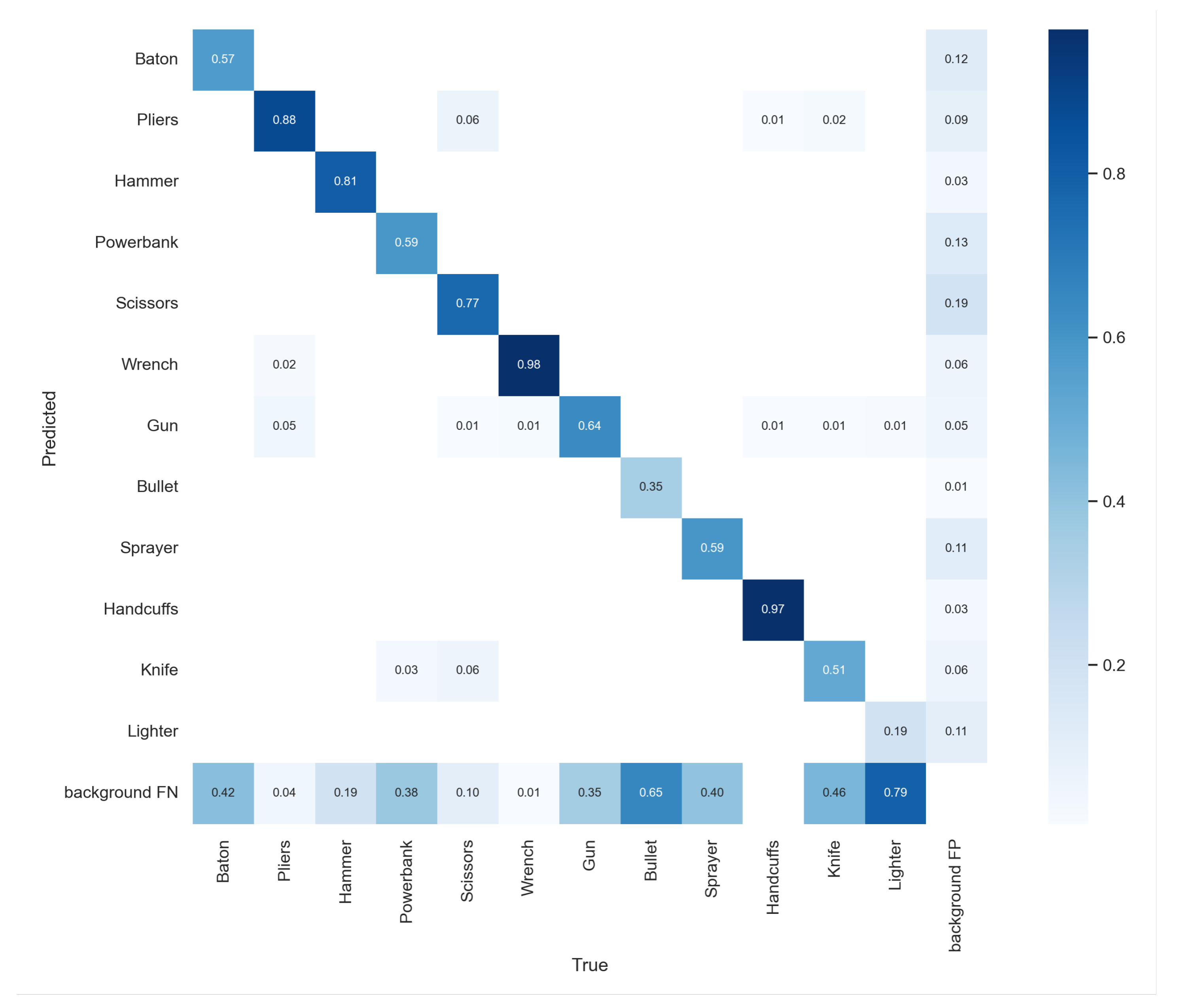
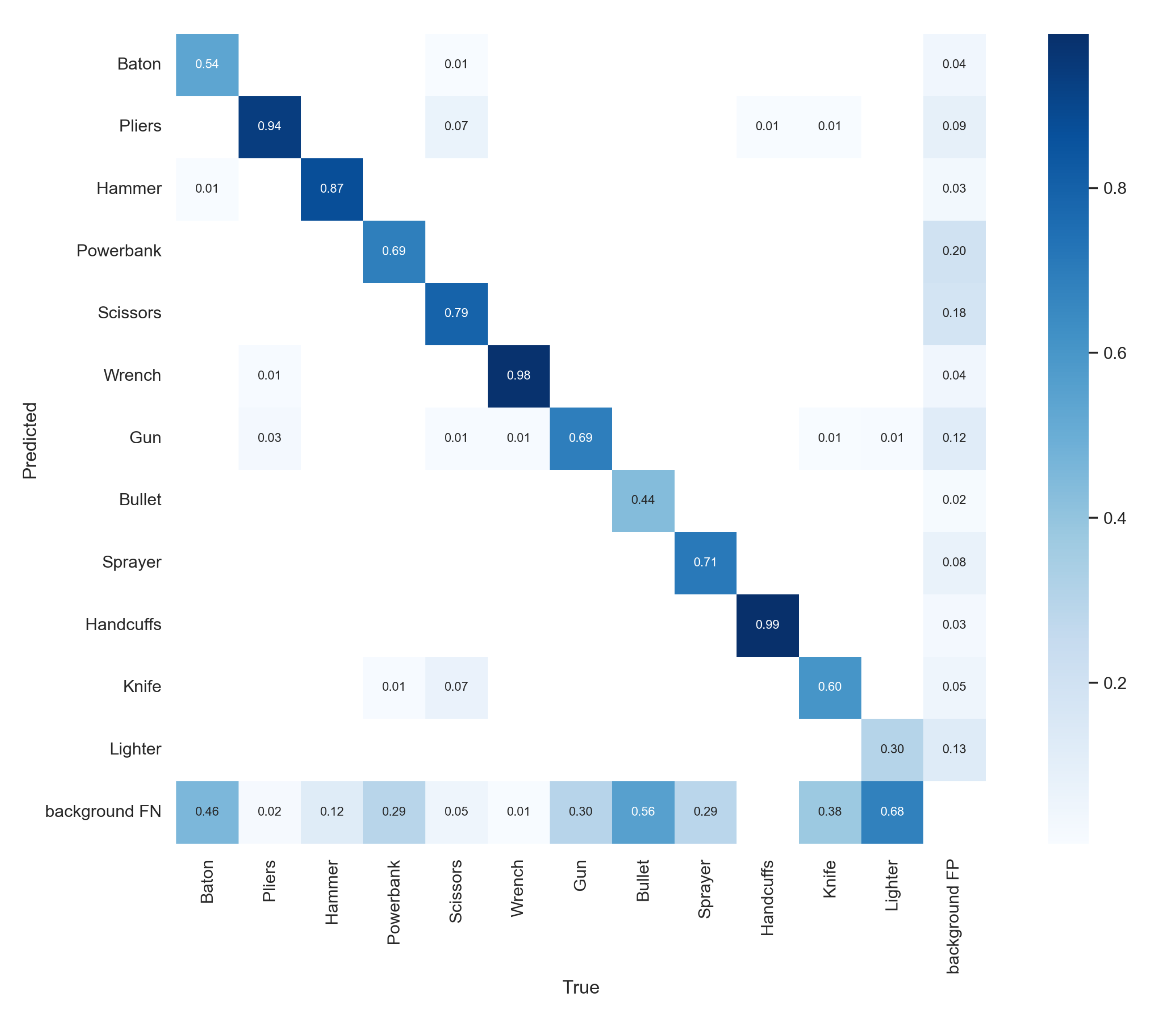
4.2. Analysis of Ablation Experiments
4.3. Algorithm Performance Analysis
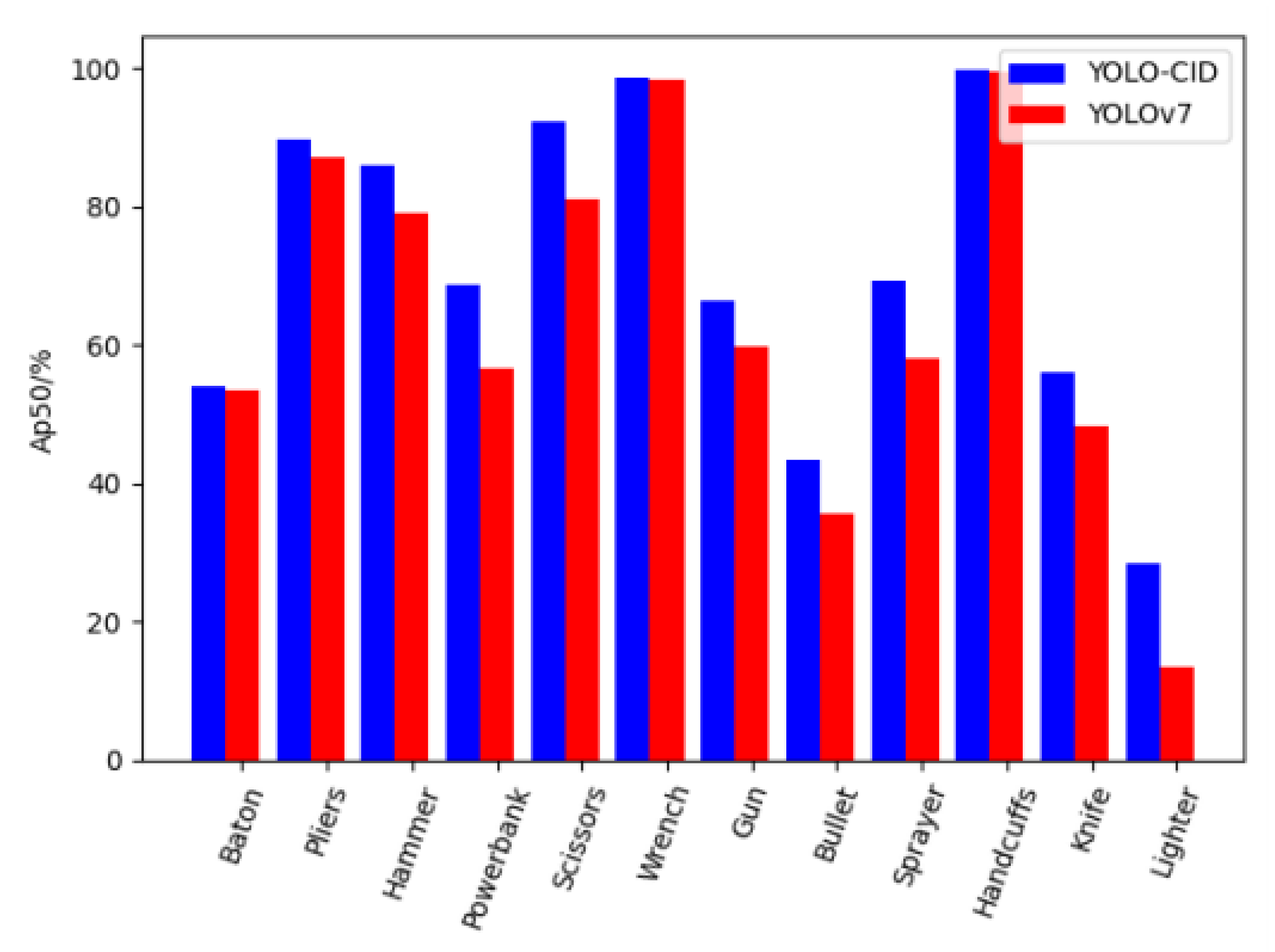
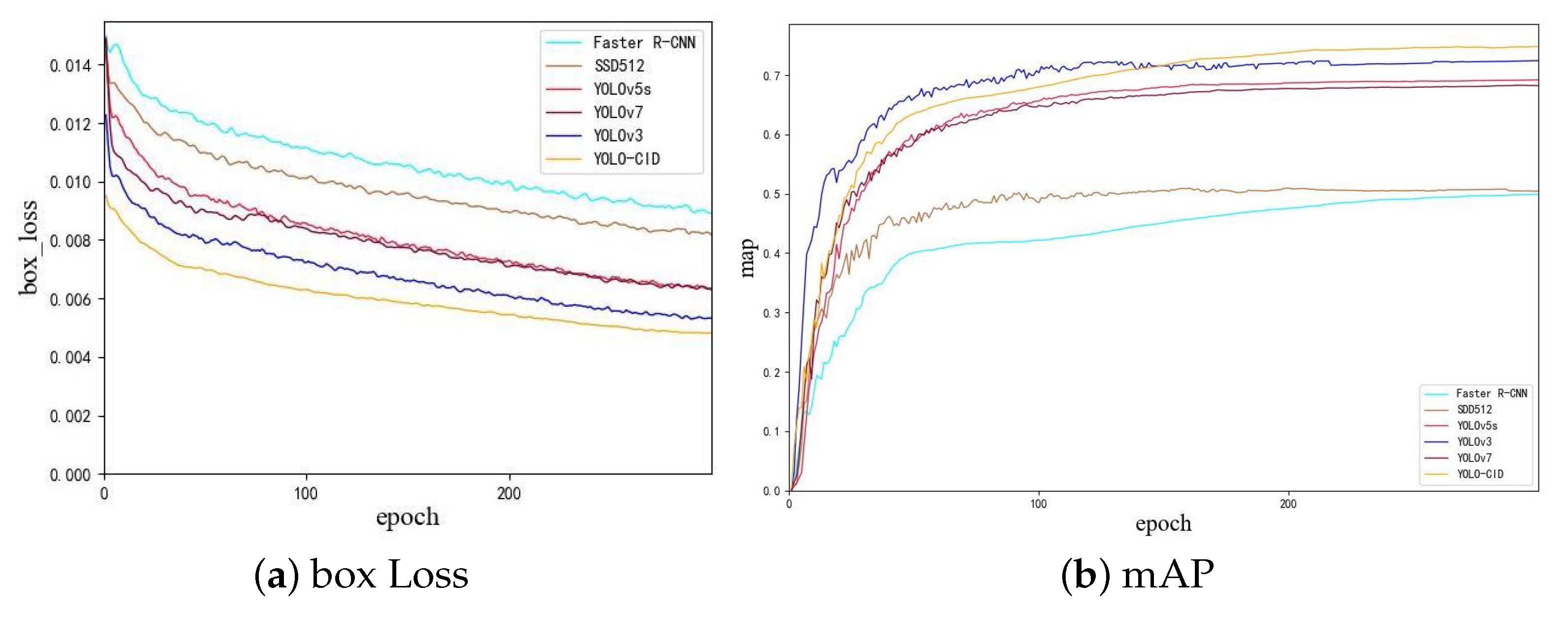
4.4. Comparative Experimental Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, H.; Luo, C.; Wang, Q.; Kitchin, M.; Parmley, A.; Monge-Alvarez, J.; Casaseca-De-La-Higuera, P. A novel infrared video surveillance system using deep learning based techniques. Multimed. Tools Appl. 2018, 77, 26657–26676. [Google Scholar] [CrossRef]
- Cazzato, D.; Cimarelli, C.; Sanchez-Lopez, J.L.; Voos, H.; Leo, M. A survey of computer vision methods for 2d object detection from unmanned aerial vehicles. J. Imaging 2020, 6, 78. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.Y.; Cho, S.J.; Baek, S.J.; Jung, S.W.; Ko, S.J. Learning-based image synthesis for hazardous object detection in X-ray security applications. IEEE Access 2021, 9, 135256–135265. [Google Scholar] [CrossRef]
- Giełczyk, A.; Marciniak, A.; Tarczewska, M.; Lutowski, Z. Pre-processing methods in chest X-ray image classification. PLoS ONE 2022, 17, e0265949. [Google Scholar] [CrossRef]
- Larhmam, M.A.; Mahmoudi, S.; Benjelloun, M. Semi-automatic detection of cervical vertebrae in X-ray images using generalized Hough transform. In Proceedings of the 2012 3rd International Conference on Image Processing Theory, Tools and Applications (IPTA), Istanbul, Turkey, 15–18 October 2012; pp. 396–401. [Google Scholar]
- Dong, H.; Zhao, L.; Shu, Y.; Xiong, N.N. X-ray image denoising based on wavelet transform and median filter. Appl. Math. Nonlinear Sci. 2020, 5, 435–442. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Santosh, K.; Dhar, M.K.; Rajbhandari, R.; Neupane, A. Deep neural network for foreign object detection in chest X-rays. In Proceedings of the 2020 IEEE 33rd International Symposium on Computer-Based Medical Systems (CBMS), Rochester, MN, USA, 28–30 July 2020; pp. 538–541. [Google Scholar]
- Santosh, K.; Roy, S.; Allu, S. Generic Foreign Object Detection in Chest X-rays. In Proceedings of the International Conference on Recent Trends in Image Processing and Pattern Recognition, Kingsville, TX, USA, 1–2 December 2021; pp. 93–104. [Google Scholar]
- Xue, Z.; Candemir, S.; Antani, S.; Long, L.R.; Jaeger, S.; Demner-Fushman, D.; Thoma, G.R. Foreign object detection in chest X-rays. In Proceedings of the 2015 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Washington, DC, USA, 9–12 November 2015; pp. 956–961. [Google Scholar]
- Xie, J.; Miao, Q.; Liu, R.; Xin, W.; Tang, L.; Zhong, S.; Gao, X. Attention adjacency matrix based graph convolutional networks for skeleton-based action recognition. Neurocomputing 2021, 440, 230–239. [Google Scholar] [CrossRef]
- Zhang, L.; Jiang, L.; Ji, R.; Fan, H. PIDray: A Large-scale X-ray Benchmark for Real-World Prohibited Item Detection. arXiv 2022, arXiv:2211.10763. [Google Scholar] [CrossRef]
- Zhao, C.; Zhu, L.; Dou, S.; Deng, W.; Wang, L. Detecting overlapped objects in X-ray security imagery by a label-aware mechanism. IEEE Trans. Inf. Forensics Secur. 2022, 17, 998–1009. [Google Scholar] [CrossRef]
- Li, C.; Zhou, A.; Yao, A. Omni-dimensional dynamic convolution. arXiv 2022, arXiv:2209.07947. [Google Scholar]
- Chen, C.P.; Li, H.; Wei, Y.; Xia, T.; Tang, Y.Y. A local contrast method for small infrared target detection. IEEE Trans. Geosci. Remote Sens. 2013, 52, 574–581. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Zhang, Q.L.; Yang, Y.B. Sa-net: Shuffle attention for deep convolutional neural networks. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2235–2239. [Google Scholar]
- Turcsany, D.; Mouton, A.; Breckon, T.P. Improving feature-based object recognition for X-ray baggage security screening using primed visualwords. In Proceedings of the 2013 IEEE International conference on industrial technology (ICIT), Cape Town, South Africa, 25–28 February 2013; pp. 1140–1145. [Google Scholar]
- Riffo, V.; Mery, D. Automated detection of threat objects using adapted implicit shape model. IEEE Trans. Syst. Man Cybern. Syst. 2015, 46, 472–482. [Google Scholar] [CrossRef]
- Kundegorski, M.E.; Akçay, S.; Devereux, M.; Mouton, A.; Breckon, T.P. On using feature descriptors as visual words for object detection within X-ray baggage security screening. In Proceedings of the 7th International Conference on Imaging for Crime Detection and Prevention (ICDP 2016), Madrid, Spain, 23–25 November 2016. [Google Scholar]
- Franzel, T.; Schmidt, U.; Roth, S. Object detection in multi-view X-ray images. In Proceedings of the Pattern Recognition: Joint 34th DAGM and 36th OAGM Symposium, Graz, Austria, 28–31 August 2012; pp. 144–154. [Google Scholar]
- Bastan, M.; Byeon, W.; Breuel, T.M. Object Recognition in Multi-View Dual Energy X-ray Images. In Proceedings of the BMVC, Bristol, UK, 9–13 September 2013; Volume 1, p. 11. [Google Scholar]
- Mery, D.; Riffo, V.; Zscherpel, U.; Mondragón, G.; Lillo, I.; Zuccar, I.; Lobel, H.; Carrasco, M. GDXray: The database of X-ray images for nondestructive testing. J. Nondestruct. Eval. 2015, 34, 1–12. [Google Scholar] [CrossRef]
- Miao, C.; Xie, L.; Wan, F.; Su, C.; Liu, H.; Jiao, J.; Ye, Q. Sixray: A large-scale security inspection x-ray benchmark for prohibited item discovery in overlapping images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2119–2128. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, Y.; Xu, W.; Yang, S.; Xu, Y.; Yu, X. Improved YOLOX detection algorithm for contraband in X-ray images. Appl. Opt. 2022, 61, 6297–6310. [Google Scholar] [CrossRef] [PubMed]
- Song, B.; Li, R.; Pan, X.; Liu, X.; Xu, Y. Improved YOLOv5 Detection Algorithm of Contraband in X-ray Security Inspection Image. In Proceedings of the 2022 5th International Conference on Pattern Recognition and Artificial Intelligence (PRAI), Xiamen, China, 23–25 September 2022; pp. 169–174. [Google Scholar]
- Akçay, S.; Kundegorski, M.E.; Devereux, M.; Breckon, T.P. Transfer learning using convolutional neural networks for object classification within X-ray baggage security imagery. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 1057–1061. [Google Scholar]
- Mery, D.; Svec, E.; Arias, M.; Riffo, V.; Saavedra, J.M.; Banerjee, S. Modern computer vision techniques for x-ray testing in baggage inspection. IEEE Trans. Syst. Man Cybern. Syst. 2016, 47, 682–692. [Google Scholar] [CrossRef]
- Xu, M.; Zhang, H.; Yang, J. Prohibited item detection in airport X-ray security images via attention mechanism based CNN. In Proceedings of the Pattern Recognition and Computer Vision: First Chinese Conference, PRCV 2018, Guangzhou, China, 23–26 November 2018; pp. 429–439. [Google Scholar]
- Liu, J.; Leng, X.; Liu, Y. Deep convolutional neural network based object detector for X-ray baggage security imagery. In Proceedings of the 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; pp. 1757–1761. [Google Scholar]
- Li, S.; Li, Y.; Li, Y.; Li, M.; Xu, X. Yolo-firi: Improved yolov5 for infrared image object detection. IEEE Access 2021, 9, 141861–141875. [Google Scholar] [CrossRef]
- Xiang, N.; Gong, Z.; Xu, Y.; Xiong, L. Material-Aware Path Aggregation Network and Shape Decoupled SIoU for X-ray Contraband Detection. Electronics 2023, 12, 1179. [Google Scholar] [CrossRef]
- Yang, B.; Bender, G.; Le, Q.V.; Ngiam, J. Condconv: Conditionally parameterized convolutions for efficient inference. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; Liu, Z. Dynamic convolution: Attention over convolution kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11030–11039. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Settings |
|---|---|
| Weights | Yolov7.pt |
| Epochs | 300 |
| Batch size | 16 |
| Hyperparameter file | hyp.scratch.p5.yaml |
| Group | MP-OD | BiFPN-P3 | SA | mAP (%) | Score (%) | ||
|---|---|---|---|---|---|---|---|
| PIDray | CLCXray | PIDray | CLCXray | ||||
| G1 | 64.2 | 75.2 | 72.7 | 78.5 | |||
| G2 | √ | 66.1 | 77.8 | 73.4 | 80.4 | ||
| G3 | √ | √ | 69.3 | 78.7 | 75.3 | 81.9 | |
| G4 | √ | √ | √ | 70.3 | 80.2 | 77.4 | 82.5 |
| Model | AP50 (50%) | FPS |
|---|---|---|
| Faster R-CNN [40] | 42.1 | 13.9 |
| SSD512 [41] | 43.8 | 16.1 |
| YOLOv3 [42] | 69.0 | 34.9 |
| YOLOv5s [30] | 65.5 | 39.2 |
| YOLOv7 | 64.2 | 39.0 |
| Ours | 70.3 | 40.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gan, N.; Wan, F.; Lei, G.; Xu, L.; Xu, C.; Xiong, Y.; Zhou, W. YOLO-CID: Improved YOLOv7 for X-ray Contraband Image Detection. Electronics 2023, 12, 3636. https://doi.org/10.3390/electronics12173636
Gan N, Wan F, Lei G, Xu L, Xu C, Xiong Y, Zhou W. YOLO-CID: Improved YOLOv7 for X-ray Contraband Image Detection. Electronics. 2023; 12(17):3636. https://doi.org/10.3390/electronics12173636
Chicago/Turabian StyleGan, Ning, Fang Wan, Guangbo Lei, Li Xu, Chengzhi Xu, Ying Xiong, and Wen Zhou. 2023. "YOLO-CID: Improved YOLOv7 for X-ray Contraband Image Detection" Electronics 12, no. 17: 3636. https://doi.org/10.3390/electronics12173636